#python lambda function explained
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
Top Python Interview Questions and Answers to Crack Your Next Tech Interview

Python is one of the most in-demand programming languages for developers, data scientists, automation engineers, and AI specialists. If you're preparing for a Python-based role, reviewing commonly asked Python interview questions and answers is a smart move.
This blog covers essential questions and sample answers to help you prepare for technical interviews at both beginner and advanced levels.
📘 Looking for the full list of expert-level Q&A? 👉 Visit: Python Interview Questions and Answers – Freshy Blog
🔹 Basic Python Interview Questions and Answers
1. What is Python?
Python is an interpreted, high-level programming language known for its simplicity and readability. It supports multiple programming paradigms including OOP, functional, and procedural styles.
2. What are Python's key features?
Easy-to-read syntax
Large standard library
Open-source and community-driven
Supports object-oriented and functional programming
Platform-independent
3. What are Python lists and tuples?
List: Mutable, allows changes
Tuple: Immutable, used for fixed collections
🔸 Intermediate Python Interview Questions and Answers
4. What is a dictionary in Python?
A dictionary is an unordered collection of key-value pairs. It allows fast lookups.
my_dict = {"name": "Alice", "age": 30}
5. What is a Python decorator?
A decorator is a function that takes another function and extends its behavior without explicitly modifying it.
def decorator(func):
def wrapper():
print("Before")
func()
print("After")
return wrapper
🔹 Advanced Python Interview Questions and Answers
6. What is the difference between deep copy and shallow copy?
Shallow Copy: Copies the outer object; inner objects are still referenced.
Deep Copy: Copies all nested objects recursively.
7. Explain Python's Global Interpreter Lock (GIL).
GIL is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecode simultaneously in CPython.
🔍 More Covered in the Full Guide:
Exception handling and custom exceptions
Lambda functions and map/filter/reduce
File handling in Python
List comprehension vs generator expressions
Python 3.x updates and syntax changes
📘 Read them all in this full-length guide: 👉 https://www.freshyblog.com/python-interview-questions-and-answers/
✅ Tips to Crack Python Interviews
Practice writing code daily
Review OOP, exception handling, file I/O
Solve Python problems on LeetCode or HackerRank
Be prepared to explain your logic step-by-step
Final Thoughts
Whether you're a beginner or aiming for a senior developer position, reviewing these Python interview questions and answers will boost your confidence and interview performance.
🔗 Explore the full list with real-world examples and pro tips: 👉 https://www.freshyblog.com/python-interview-questions-and-answers/
#PythonInterviewQuestionsAndAnswers#PythonForBeginners#TechInterviewPrep#PythonJobs2025#LearnPython#BackendDeveloper#FreshyBlog#PythonTips#CrackTheInterview#CodingInterviewQuestions#pyhon
0 notes
Text
Top Function as a Service (FaaS) Vendors of 2025
Businesses encounter obstacles in implementing effective and scalable development processes. Traditional techniques frequently fail to meet the growing expectations for speed, scalability, and innovation. That's where Function as a Service comes in.
FaaS is more than another addition to the technological stack; it marks a paradigm shift in how applications are created and delivered. It provides a serverless computing approach that abstracts infrastructure issues, freeing organizations to focus on innovation and core product development. As a result, FaaS has received widespread interest and acceptance in multiple industries, including BFSI, IT & Telecom, Public Sector, Healthcare, and others.
So, what makes FaaS so appealing to corporate leaders? Its value offer is based on the capacity to accelerate time-to-market and improve development outcomes. FaaS allows companies to prioritize delivering new goods and services to consumers by reducing server maintenance, allowing for flexible scalability, cost optimization, and automatic high availability.
In this blog, we'll explore the meaning of Function as a Service (FaaS) and explain how it works. We will showcase the best function as a service (FaaS) software that enables businesses to reduce time-to-market and streamline development processes.
Download the sample report of Market Share: https://qksgroup.com/download-sample-form/market-share-function-as-a-service-2023-worldwide-5169
What is Function-as-a-Service (FaaS)?
Function-as-a-Service (FaaS), is a cloud computing service that enables developers to create, execute, and manage discrete units of code as individual functions, without the need to oversee the underlying infrastructure. This approach enables developers to focus solely on writing code for their application's specific functions, abstracting away the complexities of infrastructure management associated with developing and deploying microservices applications. With FaaS, developers can write and update small, modular pieces of code, which are designed to respond to specific events or triggers. FaaS is commonly used for building microservices, real-time data processing, and automating workflows. It decreases much of the infrastructure management complexity, making it easier for developers to focus on writing code and delivering functionality. FaaS can power the backend for mobile applications, handling user authentication, data synchronization, and push notifications, among other functions.
How Does Function-as-a-Service (FaaS) Work?
FaaS provides programmers with a framework for responding to events via web apps without managing servers.PaaS infrastructure frequently requires server tasks to continue in the background at all times. In contrast, FaaS infrastructure is often invoiced on demand by the service provider, using an event-based execution methodology.
FaaS functions should be formed to bring out a task in response to an input. Limit the scope of your code, keeping it concise and lightweight, so that functions load and run rapidly. FaaS adds value at the function separation level. If you have fewer functions, you will pay additional costs while maintaining the benefit of function separation. The efficiency and scalability of a function may be enhanced by utilizing fewer libraries. Features, microservices, and long-running services will be used to create comprehensive apps.
Download the sample report of Market Forecast: https://qksgroup.com/download-sample-form/market-forecast-function-as-a-service-2024-2028-worldwide-4685
Top Function-as-a-Service (FaaS) Vendors
Amazon
Amazon announced AWS Lambda in 2014. Since then, it has developed into one of their most valuable offerings. It serves as a framework for Alexa skill development and provides easy access to many of AWS's monitoring tools. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code.
Alibaba Functions
Alibaba provides a robust platform for serverless computing. You may deploy and run your code using Alibaba Functions without managing infrastructure or servers. To run your code, computational resources are deployed flexibly and reliably. Dispersed clusters exist in a variety of locations. As a result, if one zone becomes unavailable, Alibaba Function Compute will immediately switch to another instance. Using distributed clusters allows any user from anywhere to execute your code faster. It increases productivity.
Microsoft
Microsoft and Azure compete with Microsoft Azure Functions. It is the biggest FaaS provider for designing and delivering event-driven applications. It is part of the Azure ecosystem and supports several programming languages, including C#, JavaScript, F#, Python, Java, PowerShell, and TypeScript.
Azure Functions provides a more complex programming style built around triggers and bindings. An HTTP-triggered function may read a document from Azure Cosmos DB and deliver a queue message using declarative configuration. The platform supports multiple triggers, including online APIs, scheduled tasks, and services such as Azure Storage, Azure Event Hubs, Twilio for SMS, and SendGrid for email.
Vercel
Vercel Functions offers a FaaS platform optimized for static frontends and serverless functions. It hosts webpages and online apps that install rapidly and expand themselves.
The platform stands out for its straightforward and user-friendly design. When running Node.js, Vercel manages dependencies using a single JSON. Developers may also change the runtime version, memory, and execution parameters. Vercel's dashboard provides monitoring logs for tracking functions and requests.
Key Technologies Powering FaaS and Their Strategic Importance
According to QKS Group and insights from the reports “Market Share: Function as a Service, 2023, Worldwide” and “Market Forecast: Function as a Service, 2024-2028, Worldwide”, organizations around the world are increasingly using Function as a Service (FaaS) platforms to streamline their IT operations, reduce infrastructure costs, and improve overall business agility. Businesses that outsource computational work to cloud service providers can focus on their core capabilities, increase profitability, gain a competitive advantage, and reduce time to market for new apps and services.
Using FaaS platforms necessitates sharing sensitive data with third-party cloud providers, including confidential company information and consumer data. As stated in Market Share: Function as a Service, 2023, Worldwide, this raises worries about data privacy and security, as a breach at the service provider's end might result in the disclosure or theft of crucial data. In an era of escalating cyber threats and severe data security rules, enterprises must recognize and mitigate the risks of using FaaS platforms. Implementing strong security measures and performing frequent risk assessments may assist in guaranteeing that the advantages of FaaS are realized without sacrificing data integrity and confidentiality.
Vendors use terms like serverless computing, microservices, and Function as a Service (FaaS) to describe similar underlying technologies. FaaS solutions simplify infrastructure management, enabling rapid application development, deployment, and scalability. Serverless computing and microservices brake systems into small, independent tasks that can be executed on demand, resulting in greater flexibility and efficiency in application development.
Conclusion
Function as a Service (FaaS) is helping businesses build and run applications more efficiently without worrying about server management. It allows companies to scale as needed, reduce costs, and focus on creating better products and services. As more sectors use FaaS, knowing how it works and selecting the right provider will be critical to keeping ahead in a rapidly altering digital landscape.
Related Reports –
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-western-europe-4684
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-western-europe-5168
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-usa-4683
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-usa-5167
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-middle-east-and-africa-4682
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-middle-east-and-africa-5166
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-china-4679
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-china-5163
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-asia-excluding-japan-and-china-4676
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-asia-excluding-japan-and-china-5160
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
Key Python Concepts Every Programmer Should Know
Python has become one of the most popular and versatile programming languages in the world, widely used for web development, data science, automation, and more. Considering the kind support of Learn Python Course in Hyderabad, Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

If you're looking to master Python, understanding certain fundamental concepts is essential. This guide will walk you through the core ideas that form the backbone of Python programming, helping you to become more efficient and confident in your coding journey.
1. Understanding Python's Structure and Indentation
One of Python's most distinctive features is its reliance on indentation to define blocks of code. Unlike many other programming languages that use braces or keywords, Python uses whitespace to structure code, making it readable and clear. However, this means you need to be meticulous with your indentation to avoid errors.
In addition to indentation, using comments is vital for improving the readability of your code. Comments help explain what your code is doing, making it easier to understand and maintain.
2. Exploring Python’s Core Data Types
A solid understanding of Python’s basic data types is crucial for managing data effectively. You’ll frequently work with integers, floats, strings, and booleans to represent and manipulate different types of data.
In addition, Python offers powerful collection types like lists, tuples, sets, and dictionaries. These data structures allow you to store and organize data efficiently, each serving unique purposes for specific tasks.
3. Controlling Flow with Conditions and Loops
Control flow refers to the order in which your program’s code is executed. Python allows you to manage this through conditional statements, which help your program make decisions and take different actions depending on various conditions.
Another critical part of control flow is loops. Loops allow you to repeat tasks efficiently by iterating over data structures or performing repetitive actions, which is essential in automating tasks or managing large datasets. Enrolling in the Best Python Certification Online can help people realise Python’s full potential and gain a deeper understanding of its complexities.

4. Mastering Functions for Reusable Code
Functions allow you to create reusable sections of code, making your programming more efficient and organized. You can define a function once and then call it multiple times whenever needed, saving time and reducing errors.
In addition, lambda functions offer a more concise way of writing simple, anonymous functions for quick tasks, allowing for more efficient coding in certain scenarios.
5. Leveraging Object-Oriented Programming (OOP)
Python’s Object-Oriented Programming (OOP) paradigm helps structure your code by organizing it into classes and objects. This approach not only enhances the readability of your code but also promotes reusability by allowing you to create new objects and define methods specific to those objects.
Concepts like inheritance and polymorphism are central to OOP, allowing you to build more flexible and scalable programs by reusing existing code in new ways.
6. Expanding Functionality with Modules and Packages
One of the great strengths of Python is its vast ecosystem of modules and packages. By importing these libraries, you can quickly access pre-built functions and tools that expand the functionality of your programs.
Creating your own modules and organizing code into packages is also essential as your projects grow in size and complexity. This ensures your code remains clean, organized, and manageable.
7. Managing Data with File Handling
When developing Python applications, you’ll often need to work with external data. Knowing how to read from and write to files is a core concept that allows you to interact with data stored in various formats.
Mastering file handling ensures you can effectively manage data, whether you’re saving user input or processing external data sources.
8. Handling Errors Gracefully
Errors are inevitable when programming, but Python offers a robust system for error handling. Using exceptions, you can detect and manage errors, allowing your program to continue running smoothly even when issues occur.
Moreover, you can define your own custom exceptions, which enable more tailored error handling for specific scenarios, further enhancing the reliability of your applications.
9. Simplifying Tasks with List Comprehensions
Python offers a unique feature called list comprehensions, which allows you to create lists in a more compact and readable format. This is particularly useful for simplifying tasks that involve creating or modifying lists, making your code cleaner and easier to follow.
10. Enhancing Code with Decorators and Generators
Decorators allow you to modify the behavior of functions without altering the function itself. This powerful feature enables you to extend functionality in a clean and efficient way.
On the other hand, generators are ideal for working with large data sets or streams of data. They allow you to create iterators that yield items one at a time, which conserves memory and improves efficiency in large-scale operations.
11. Managing Dependencies with Virtual Environments
As you begin working on larger Python projects, you’ll likely encounter dependency issues. Understanding how to use virtual environments allows you to isolate dependencies for different projects, ensuring that each project has the required libraries without conflicts.
12. Collaborating with Version Control
While not exclusive to Python, knowledge of version control systems like Git is invaluable for managing your code. It allows you to track changes, collaborate with others, and maintain a history of your project’s evolution, making it easier to manage large codebases and collaborate with teams.
Conclusion
By mastering these key Python concepts, you’ll lay a strong foundation for your programming skills. These fundamental principles are essential for anyone looking to build robust and efficient Python applications. Whether you’re a beginner or an experienced programmer, understanding these concepts will help you take your Python skills to the next level.
#python course#python training#python#technology#tech#python online training#python programming#python online course#python online classes#python certification
0 notes
Text
Python’s filter() function: An Introduction to Iterable Filtering

Introduction

Efficiency and elegance frequently go hand in hand in the world of Python programming. The filter() function is one tool that exemplifies these ideas. Imagine being able to quickly select particular items that fit your requirements from a sizable collection. Thanks to Python’s filter() method, welcome to the world of iterable filtering. We’ll delve further into this crucial function in this complete guide, looking at its uses, how it may be combined with other functional tools and even more Pythonic alternatives.
Get Started With Filter()
You’ll start your trip with the filter() function in this section. We’ll give a clear explanation of filter()’s operation in order to dispel any confusion and demonstrate its usefulness. You will learn how to use filter() in common situations through clear examples, laying the groundwork for a more thorough investigation. This section is your starting point for releasing the potential of iterable filtering, whether you’re new to programming or looking to diversify your arsenal.
Python Filter Iterables (Overview)
In this introduction, we lay the groundwork for our investigation of the filter() function in Python. We’ll start by explaining the idea of filtering and why it’s important in programming. We’ll demonstrate how filtering serves as the foundation for many data manipulation tasks using familiar analogies. You’ll be able to see why knowing filter() is so important in the world of Python programming by the end of this chapter.

Recognize the Principle of Filtering
We examine the idea of filtering in great detail before digging into the details of the filter(). We examine situations, such as sorting emails or cleaning up databases, when filtering is crucial. We establish the significance of this operation in routine programming with accessible examples. With this knowledge, you’ll be able to appreciate the efficiency that filter() offers completely.

Recognize the Filtering Filter Iterables Idea Using filter ()
It’s time to put on our labor gloves and get to work with the show’s star: the filter() function. We walk you step-by-step through the use of a filter(). We cover every angle, from specifying the filtering condition to using it on different iterables. As we demystify filter(), you will be able to use its syntax and parameters without thinking about them.
Here’s a basic example of using filter() with numbers:defis_positive(x): return x > 0numbers = [-3, 7, -12, 15, -6] positive_numbers = list(filter(is_positive, numbers)) print(positive_numbers) # Output: [7, 15]
Get Even Numbers
By concentrating on a practical task—extracting even integers from a list—in this hands-on tutorial, we improve our grasp of filter(). We guide you through the procedure, thoroughly outlining each step. You’ll discover how to create filtering criteria that meet certain needs through code examples and explanations. By the end of this chapter, filtering won’t simply be theoretical; it’ll be a skill you can use immediately.
Extracting even numbers using filter():defis_even(x): return x % 2 == 0numbers = [3, 8, 11, 14, 9, 6] even_numbers = list(filter(is_even, numbers)) print(even_numbers) # Output: [8, 14, 6]
Look for Palindrome Strings
By extending filter(), we turn our attention away from numbers and take on the exciting task of recognizing palindrome strings. This section highlights the function’s adaptability by illustrating how it can be used with various data kinds and circumstances. You’ll learn how to create customized filtering functions that address particular situations, strengthening your command of filters ().
Filtering palindrome strings using filter():defis_palindrome(s): return s == s[::-1]words = [“radar”, “python”, “level”, “programming”] palindromes = list(filter(is_palindrome, words)) print(palindromes) # Output: [‘radar’, ‘level’]
For Functional Programming, use filter().
As we combine the elegance of lambda functions with the filter() concepts, the world of functional programming will open up to you. According to functional programming, developing code that resembles mathematical functions improves readability and reuse. You’ll learn how to use the advantages of filter() and lambda functions together to write concise and expressive code through practical examples. You’ll be able to incorporate functional paradigms into your programming by the time you finish this chapter.
Code With Functional Programming
This section examines how the functional programming paradigm and filter() interact. We describe the idea of functional programming and show how filter() fits in perfectly with its tenets. When lambda functions are integrated with filter(), it becomes possible to create filtering criteria that are clear and expressive. You’ll see how this pairing enables you to create code that is both effective and elegant.
Combining filter() with a lambda function:numbers = [2, 5, 8, 11, 14] filtered_numbers = list(filter(lambda x: x % 3 == 0, numbers)) print(filtered_numbers) # Output: [5, 11, 14]
Learn about Lambda Functions
We devote a section to the study of lambda functions, which occupy center stage. We examine the structure of lambda functions, demonstrating their effectiveness and simplicity. With a solid grasp of lambda functions, you’ll be able to design flexible filtering conditions that effectively express your criteria. This information paves the way for creating more intricate and specific filter() processes.
Creating a lambda function for filtering:numbers = [7, 10, 18, 22, 31] filtered_numbers = list(filter(lambda x: x > 15and x % 2 == 0, numbers)) print(filtered_numbers) # Output: [18, 22]
Map() and filter() together
Prepare for the union of filter() and map, two potent functions (). We provide examples of how these functions work well together to change data. You’ll see via use cases how combining these techniques can result in code that is clear and effective that easily manipulates and extracts data from iterables. You won’t believe the level of data manipulation skill revealed in this part.
Combining filter() and map() for calculations:numbers = [4, 7, 12, 19, 22] result = list(map(lambda x: x * 2, filter(lambda x: x % 2 != 0, numbers))) print(result) # Output: [14, 38, 44]
Combine filter() and reduce()
When we explore intricate data reduction scenarios, the interplay between filter() and reduce() comes into focus. We demonstrate how applying filters and decreasing data at the same time can streamline your code. This part gives you the knowledge you need to handle challenging problems and demonstrates how filter() is used for more complex data processing than just basic extraction.
Using reduce() along with filter() for cumulative multiplication:from functools import reduce
numbers = [2, 3, 4, 5] product = reduce(lambda x, y: x * y, filter(lambda x: x % 2 != 0, numbers)) print(product) # Output: 15
Use filterfalse() to filter iterables.
Each coin has two sides, and filters are no different (). the inverse of filter, filterfalse() (). We discuss situations where you must omit things that satisfy a particular requirement. Knowing when to utilize filterfalse() and how to do so will help you be ready for data manipulation tasks that call for an alternative viewpoint. Once you realize the full power of iterative manipulation, your toolbox grows.
Using filterfalse() to exclude elements:from itertools import filterfalse
numbers = [1, 2, 3, 4, 5] non_even_numbers = list(filterfalse(lambda x: x % 2 == 0, numbers)) print(non_even_numbers) # Output: [1, 3, 5]
Pythonic Coding Style
Join the world of Pythonic aesthetics, where writing and reading code is a pleasure rather than just a means to a goal. Here, we explore the core ideas behind Pythonic programming and how they can improve your codebase. We’ll look at how to align your code with Python’s guiding principles, including the use of Python Environment Variables, by making it simple, readable, and elegant. You’ll learn how to create code using filter() and other coding structures that not only function well but also serve as a showcase for the elegance of the Python language.
List comprehension should be used instead of filter().
As we introduce the idea of list comprehensions as an alternative to filter, get ready to see a metamorphosis (). Here, we show how list comprehensions can streamline your code and improve its expressiveness. List comprehensions are a mechanism for Python to filter iterables by merging iteration with conditionality. You’ll leave with a flexible tool that improves readability and effectiveness.
Using list comprehension to filter even numbers:numbers = [6, 11, 14, 19, 22] even_numbers = [x for x in numbers if x % 2 == 0] print(even_numbers) # Output: [6, 14, 22]
Extract Even Numbers With a Generator
As we investigate the situations where generators can take the role of filter(), the attraction of generators beckons. The advantages of generators are discussed, and a thorough comparison of generator expressions and filters is provided (). We demonstrate how to use generators to extract even numbers, which broadens your toolkit and directs you to the best answer for particular data manipulation problems.
Using a generator expression to filter even numbers:numbers = [5, 8, 12, 15, 18] even_numbers = (x for x in numbers if x % 2 == 0) print(list(even_numbers)) # Output: [8, 12, 18]
Filter Iterables With Python (Summary)
In this final chapter, we pause to consider our experience exploring the world of filters (). We provide an overview of the main ideas, methods, and solutions discussed in the blog. With a thorough understanding of iterable filtering, you’ll be prepared to choose the programming tools that are most appropriate for your needs.
These examples provide practical insights into each section’s topic, illustrating the power and versatility of Python’s filter() function in different contexts.
Conclusion
Python’s filter() function opens up a world of possibilities when it comes to refining and enhancing your code. From isolating specific elements to embracing functional programming paradigms, the applications of filter() are boundless. By the end of this journey, with the expertise of a reputable Python Development Company, you’ll not only be equipped with the knowledge of how to wield filter() effectively but also armed with alternatives that align with the Pythonic philosophy. Let the filtering revolution begin!
Read More Python’s filter() function: An Introduction to Iterable Filtering
#Pythonfilterfunction#Pythonicfiltering#FilteringinPython#IterablefilteringinPython#Pythonfilter#Pythoniterable#Pythonprogramming#PythonDevelopment
0 notes
Text
Continuation-passing style and tail recursion
You know recursion, right? You know how tail recursion is different from non-tail recursion? We say a recursive procedure call is tail recursive if it appears in the tail position, or if there's nothing left to do after the procedure call.
For example, this is how we might implement a function to reverse a list in Haskell:

This function (rev) recursive but not tail recursive, because after the recursive call to reverse, we have to append [x] onto the result. We can re-write this function to be tail recursive by adding another parameter to hold an accumulator:
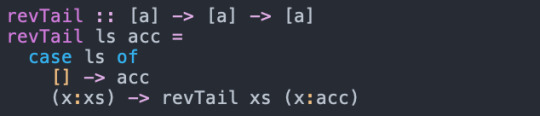
Okay, so what's the big deal? This has some implications for the performance of the program---tail calls can be optimised into goto/jump statements, for example. I'll leave an in-depth discussion of that for a later post. The classic paper on this is Lambda the Ultimate GOTO.
Notice how we had to re-think our algorithm a bit to write it in tail recursive form. By using an accumulator, we essentially wrote out the loop version of list reverse. It's an iterative solution, instead of a recursive one, and we used tail recursion because (unlike other languages like Python or Java) Haskell doesn't have traditional loops.
But, it turns out there's a technique we can use to transform the original recursive function such that all the procedure calls are tail calls. We will re-write it to use continuation-passing style.
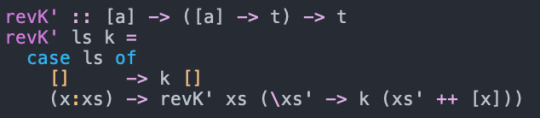
This takes a bit of explaining.
A CPS function takes an additional argument, usually called k, that represents the continuation of the computation. Basically, instead of returning a value from our CPS function, we pass what would be the return value into k. So, for the base case (empty list) we pass the empty list into k.
Additionally, we remove the "nested" computation from before, where we reverse a list and then append an element to the result. Instead, we made the function tail recursive. The continuation for the recursive call is a function that takes the reversed list and appends [x] onto the end.
To make sense of this, think of (reverse xs ++ [x]) as having two parts. One, we reverse xs. Two, we append [x] to the reversed xs. Here, when we perform step one, our "continuation" is step two (that is, it is what we will do next). So, we have our tail call perform step one, and then the continuation function does step two.

We can use our CPS reverse function like this, using the identity function as the initial continuation. This gets us the same type as the original rev function above, but contains no non-tail calls.
It might not come as a surprise to hear that this is a transformation that is often done automatically by compilers for functional languages. This turns out to be a really convenient way to represent programs internally in a compiler.
Another advantage of CPS is that it turns what was a big computation into a series of smaller ones. It is the same amount of overall work, but broken up naturally into pieces. Imagine we had a concurrent system with a (cooperative) scheduler, and we needed computations to regularly pause and yield to the scheduler so another thread could run. A natural way to do this is to use CPS and have every (tail) call be an opportunity for the scheduler to take over. A really excellent, classic paper on this is Continuation-based Multiprocessing.
EDIT: fixed the code in the first function
15 notes
·
View notes
Text
A DATA INTEGRATION APPROACH TO MAXIMIZE YOUR ROI
The data Integration approach adopted by many data integration projects relies on a set of premium tools leading to cash burnout with RoI less than the standard.
To overcome this and to maximize the RoI, we lay down a data integration approach that makes use of open-source tools over the premium to deliver better results and an even more confident return on the investment.

Adopt a two-stage data integration approach:
Part 1 explains the process of setting up technicals and part 2 covers the execution approach involving challenges faced and solutions to the same.
Part 1: Setting Up
The following are the widely relied data sources:
REST API Source with standard NoSQL JSON (with nested datasets)
REST API Source with full data schema in JSON
CSV Files in AWS S3
Relational Tables from Postgres DB
There are 2 different JSON types above in which the former is conventional, and the latter is here
Along with the data movement, it is necessary to facilitate Plug-n-Play architecture, Notifications, Audit data for Reporting, Un-burdened Intelligent scheduling, and setting up all the necessary instances.
The landing Data warehouse chosen was AWS Redshift which is a one-stop for the operational data stores (ODS) as well as facts & dimensions. As said, we completely relied on open-source tools over the tools from tech giants like Oracle, Microsoft, Informatica, Talend, etc.,
The data integration was successful by leveraging Python, SQL, and Apache Airflow to do all the work. Use Python for Extraction; SQL to Load & Transform the data and Airflow to orchestrate the loads via python-based scheduler code. Below is the data flow architecture.
Data Flow Architecture
Part 2: Execution
The above data flow architecture gives a fair idea of how the data was integrated. The execution is explained in parallel with the challenges faced and how they were solved.
Challenges:
Plug-n-Play Model.
Dealing with the nested data in JSON.
Intelligent Scheduling.
Code Maintainability for future enhancements.
1. Plug-n-Play Model
To meet the changing business needs, the addition of columns or a datastore is obvious and if the business is doing great, expansion to different regions is apparent. The following aspects were made sure to ensure a continuous integration process.
A new column will not break the process.
A new data store should be added with minimal work by a non-technical user.
To bring down the time consumed for any new store addition(expansion) integration from days to hours.
The same is achieved by using:
config table which is the heart of the process holding all the jobs needed to be executed, their last extract dates, and parameters for making the REST API call/extract data from RDBMS.
Re-usable python templates which are read-modified-executed based on the parameters from the config table.
Audit table for logging all the crucial events happening whilst integration.
Control table for mailing and Tableau report refreshes after the ELT process
By creating state-of-art DAGs which can generate DAGs(jobs) with configuration decided in the config table for that particular job.
Any new table which is being planned for the extraction or any new store being added as part of business expansion needs its entries into the config table.
The DAG Generator DAG run will build jobs for you in a snap which will be available in Airflow UI on the subsequent refresh within seconds, and the new jobs are executed on the next schedule along with existing jobs.
2. Dealing with the nested data in JSON.
It is a fact that No-SQL JSONS hold a great advantage from a storage and data redundancy perspective but add a lot of pain while reading the nested data out of the inner arrays.
The following approach is adopted to conquer the above problem:
Configured AWS Redshift Spectrum, with IAM Role and IAM Policy as needed to access AWS Glue Catalog and associating the same with AWS Redshift database cluster
Created external database, external schema & external tables in AWS Redshift database
Created AWS Redshift procedures with specific syntax to read data in the inner array
AWS Redshift was leveraged to parse the data directly from JSON residing in AWS S3 onto an external table (no loading is involved) in AWS Redshift which was further transformed to rows and columns as needed by relational tables.
3. Intelligent Scheduling
There were multiple scenarios in orchestration needs:
Time-based – Batch scheduling; MicroELTs ran to time & again within a day for short intervals.
Event-based – File drop in S3
For the batch scheduling, neither the jobs were run all in series (since it is going to be an underutilization of resources and a time-consuming process) nor in parallel as the workers in airflow will be overwhelmed.
A certain number of jobs were automated to keep running asynchronously until all the processes were completed. By using a python routine to do intelligent scheduling. The code reads the set of jobs being executed as part of the current batch into a job execution/job config table and keeps running those four jobs until all the jobs are in a completed/failed state as per the below logical flow diagram.
Logical Flow Diagram
For Event-based triggering, a file would be dropped in S3 by an application, and the integration process will be triggered by reading this event and starts the loading process to a data warehouse.
The configuration is as follows:
CloudWatch event which will trigger a Lambda function which in turn makes an API call to trigger Airflow DAG
4. Code Maintainability for future enhancements
A Data Integration project is always collaborative work and maintaining the correct source code is of dire importance. Also, if a deployment goes wrong, the capability to roll back to the original version is necessary.
For projects which involve programming, it is necessary to have a version control mechanism. To have that version control mechanism, configure the GIT repository to hold the DAG files in Airflow with Kubernetes executor.
Take away:
This data integration approach is successful in completely removing the premium costs while decreasing the course of the project. All because of the reliance on open-source tech and utilizing them to the fullest.
By leveraging any ETL tool in the market, the project duration would be beyond 6 months as it requires building a job for each operational data store. The best-recommended option is using scripting in conjunction with any ETL tool to repetitively build jobs that would more or less fall/overlap with the way it is now executed.
Talk to our Data Integration experts:
Looking for a one-stop location for all your integration needs? Our data integration experts can help you align your strategy or offer you a consultation to draw a roadmap that quickly turns your business data into actionable insights with a robust Data Integration approach and a framework tailored for your specs.
1 note
·
View note
Text
Python Live-1 | Lambda Function & Constructors in Python | Python Tutorial for Beginners | Edureka
Python Live-1 | Lambda Function & Constructors in Python | Python Tutorial for Beginners | #Edureka #Python #Datalytical
🔥Edureka Python Certification Training: https://www.edureka.co/python-programming-certification-training This Edureka session on Lamda Function & Constructors in Python will educate you about the Lambda functions and various constructors available in Python and help you understand how to use them in various scenarios.
———————————————————————————————-
🔴Subscribe to our channel to get video…
View On WordPress
#anonymous function#anonymous function in python#constructors in python#edureka#lambda expresssions#lambda function#lambda function in python#lambda python#python 3 lambda functions#python constructor and destructor#python constructor class#python constructor overloading#python constructor tutorial#python edureka#python functions#python lambda function example#python lambda function explained#python lambda functions#python lambda tutorial#yt:cc=on
0 notes
Photo
I'mma try this again this way and see if it helps. (I was stuck on "pointers are ints but really not ints, and references are pointers but get pronouns and possessive clauses as if they are not pointers" and that wasn't helping, but then, it also sometimes takes me about 8 tries to get my c++ function types to compile also, but the compiler doesn't stare at me awkwardly while I try to remember the pronouns of all my variables.)
(Python is more fun*, everything is They, and if that's not good enough to explain something's behaviour, you can just stuff in some more lambdas and pretend that they are methods.)
*'fun' here means both ridiculously chaotic and gay.
98K notes
·
View notes
Text
Analysis of Life Expectancy across countries
Explaining the cross-national Life Expectancy with respect to Income per person, HIV Rate and other influencing factors.
The codebook which I have chosen for study is GapMinder which states various factors such as social, economic, environmental, etc. related to different countries.
The study will be focused on “Life Expectancy” and the variables chosen are “Income Per Person” and “HIV Rate”. Though I would also like to explore more variables such as “Alcohol Consumption”, “CO2 Emission” and “Urban Rate”.
We have always heard that the wealthier a person is, the longer they can expect to live as they have ease to good healthcare and medical facilities. But, the life expectancy also depends upon various factors such as environmental condition where a person dwell, education status and many more. A person living in an urban area has better access to healthcare facilities but on other hand the increase in pollution and life style has put an adverse effect.
The social and economic conditions of each country will undoubtedly affect its citizens, their lifestyles and decisions. Citizens of wealthier countries have access to modern medicine and medical facilities. Their life expectancy, therefore, naturally should be higher than those of less developed countries.
With the development in medical science and diagnostic techniques, declines in mortality rate is observed in people with HIV overtime. A 2017 study in the journal AIDS found that the additional life expectancy for people with HIV at age 20 during the early monotherapy era was 11.8 years. However, that number rose to 54.9 years for the most recent combination antiretroviral era. Which means that countries with good educational, medical structure and general awareness shows low HIV cases.However, cases increasing cases of HIV can still be seen in developing countries with low economy and less medical amenities.
By examining the variation across countries about the relationship between Life Expectancy and Income Per Person or HIV Rate, we could get to know the association such that
1. Does countries with high Income Per Person has high Life Expectancy
2. Does countries with high HIV Rate has low Life Expectancy
References:
https://www.medicalnewstoday.com/articles/323517.php
https://www.bbc.com/news/world-asia-48348941
https://www.medicalnewstoday.com/articles/324321.php
Python Code for Data Analysis:
#loading the required libraries in python
import pandas as pd
import numpy as np
#using the pandas read_csv method to the read the data
data=pd.read_csv(”gapminder.csv")
#getting the head, shape and columns names to cross check that the data is loaded correctly
data.head()
data.shape
data.columns.values



pd.set_option('display.float_format', lambda x:'%f'%x)
#converting the required variables to numeric
data['lifeexpectancy']=data['lifeexpectancy'].convert_objects(convert_numeric=True)
data['incomeperperson']=data['incomeperperson'].convert_objects(convert_numeric=True)
data['hivrate']=data['hivrate'].convert_objects(convert_numeric=True)
#checking the data types of the converted variables
print(data.dtypes)

#dropping the rows which have null values for the required variables
data=data.dropna(subset=['lifeexpectancy','incomeperperson','hivrate'], how='all')
#For my hypothesis the most significant variable is "lifeexpectancy", but since it is a continuous variable I will create a new categorical variable based on it, so as to study the significance of it on the other variables
#creating a new variable "Life_Expectancy" whcih is categorial into 3 categories as Low"<=65",Average"<=75",High">75"
data['Life_Expectancy']=pd.cut(data['lifeexpectancy'],bins=[0,65,75,np.max(data['lifeexpectancy'])],labels=['Low','Average','High'])
LE = data['Life_Expectancy'].value_counts(sort=False, dropna=False)
# to see the number of observations in all the 3 categories from newly created categorical variable
LE

# grouping the newly created categorical variable using ‘groupby’ function, so as to conduct a category-wise analysis and take further decisions regarding the modelling.
data.groupby('Life_Expectancy')

# instead of splitting the original data the groupby function creates a groupby object that has two attributes, name and group.
grouped=data.groupby('Life_Expectancy')
for names,groups in grouped:
print(names)
print(groups)




#checking the mean for the 2 other variable i.e.'incomeperperson' and 'hivrate' with respect to the grouped categorical variable i.e.,Life_Expectancy
grouped.aggregate({'lifeexpectancy':np.mean,'incomeperperson':np.mean,'hivrate':np.mean})

Now, from the above output we assume that the variables are associated and
Counties with high Life Expectancy has high incomeperperson
Counties with low Life Expectancy has high hivrate
Univariate Analysis:
import matplotlib.pyplot as plt
import seaborn as sns
For univariate analysis I have used the matplotlib.pyplot library. However, we can also use seaborn library to explore the variables
plt.hist(data["lifeexpectancy"])--using matplotlib.pyplot
plt.title("lifeexpectancy")

sns.FacetGrid(data,size=5).map(sns.distplot,"lifeexpectancy") -- using seaborn

From the above figures we can conclude that the maximum Life_Expectancy is 83 years and in most of the countries 75years is the average Life_Expectancy.
plt.hist(data["incomeperperson"])
plt.title("IncomePerPerson")

sns.FacetGrid(data,size=5).map(sns.distplot,"incomeperperson")

From the above figure is right skewed and we can conclude that most of countries falls under low or average incomeperperson.
plt.hist(data["hivrate"])
plt.title("hivrate")

sns.FacetGrid(data,size=5).map(sns.distplot,"hivrate")

The above figure I right skewed as well and we can conclude that most of the countries have low or moderate hivrate.
Bivariate Analysis:
Here, I have used the seaborn and matplotlip.pyplot library to explore the bivariate analysis.
sns.regplot(x="hivrate",y="lifeexpectancy",data=data)
plt.xlabel('incomeperperson')
plt.ylabel('lifeexpectancy')
plt.title('Association between IncomePerPerson and LifeExpectancy')

The above figure shows a positive relation between IncomePerPerson and LifeExpectancy i.e., as income per person increases lifeexpectancy also increases.
sns.regplot(x="hivrate",y="lifeexpectancy",data=data)
plt.xlabel('hivrate')
plt.ylabel('lifeexpectancy')
plt.title('Association between HivRate and LifeExpectancy')

The above figure shows a negative relationship between HivRate and LifeExpectancy i.e., as the hivrate increases the lifeexpectancy decreases.
2 notes
·
View notes
Text
Lasso Regression Coursera
Summary
Lasso regression, also known as L1 regularization, is a type of linear regression that involves adding a penalty term to the loss function to reduce overfitting. The penalty term is the sum of the absolute values of the regression coefficients, multiplied by a tuning parameter lambda.
The purpose of the penalty term is to encourage the model to select a smaller number of predictors that are most important in predicting the outcome variable. This is achieved by shrinking the coefficients of less important predictors towards zero, effectively removing them from the model.
Lasso regression is particularly useful in situations where there are many potential predictors, and it is unclear which ones are most important. It can also help to improve the interpretability of the model, as it identifies the most important predictors and sets the coefficients of unimportant predictors to zero.
One disadvantage of lasso regression is that it can lead to biased estimates of the regression coefficients, particularly in situations where there are strong correlations among the predictors. In these cases, ridge regression, which uses L2 regularization, maybe a better alternative.
Python code for Lasson Regression:
import pandas as pd
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset data = pd.read_csv('marketing.csv')
# Create a dataframe with the predictor variables (marketing channels)
X = data.drop(['Sales'], axis=1)
# Create a series with the outcome variable (sales)
y = data['Sales']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create a Lasso regression object
lasso = Lasso(alpha=0.1)
# Fit the model to the training data
lasso.fit(X_train, y_train)
# Predict the outcome variable for the testing data
y_pred = lasso.predict(X_test)
# Evaluate the performance of the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean squared error:", mse)
print("R-squared score:", r2)
# View the coefficients of the model
coef_df = pd.DataFrame({'Feature': X.columns, 'Coefficient': lasso.coef_})
print(coef_df)
Explanation
In this example, we load a marketing dataset using pandas and create a dataframe with the predictor variables (marketing channels) and a series with the outcome variable (sales). We split the data into training and testing sets using train_test_split.
Next, we create a Lasso regression object with an alpha value of 0.1, which determines the strength of the regularization penalty. We fit the model to the training data using the fit method and predict the outcome variable for the testing data using the predict method.
We evaluate the performance of the model using the mean squared error (MSE) and R-squared score, which measures the proportion of variance in the outcome variable that is explained by the model. Finally, we view the coefficients of the model using a dataframe that shows the feature names and their corresponding coefficients. This information can be used to identify which marketing channels have the most impact on sales.
0 notes
Text
Basic Linear Regression Analysis
Centering:
I have a quantitative explanatory variable called horsepower and I centered it so that the mean = 0 (or really close to 0) by subtracting the mean.
Mean before centering= 104.469
Mean after centering= 1.4E-13 = 0
Regression Model:
The model is testing the relationship between horsepower(hp) and miles per gallon(mpg),
We find that the F-statistic is 599.7 and the P value is infinitesimally small. Considerably less than our alpha level of .05,which tells us that we can reject the null hypothesis and conclude that horsepower is significantly associated with miles per gallon for an automobile.
The R-squared value,which is the proportion of the variance in the response variable that can be explained by the explanatory variable is 0.606. We now know that this model accounts for about 60% of the variability we see in our response variable, mpg.
The coefficient for hp is -0.1578, and the intercept is 23.4459, which gives us the regression equation: mpg=23.4459-0.1578*hp
Python Program:
#Created on Tue,Jan29 2019 #author: Swaraj Mohapatra
import numpy as np import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf
# bug fix for display formats to avoid run time errors pandas.set_option(‘display.float_format’, lambda x:’%.2f’%x)
#call in dataset data = pd.read_excel(“Auto-MPG.xlsx”)
# BASIC LINEAR REGRESSION # convert variables to numeric format using convert_objects function data['hp’] = pd.to_numeric(data['hp’], errors='coerce’)
reg1 = smf.ols(formula='mpg ~ hp’, data=data).fit() print (reg1.summary())
Output:
OLS Regression Results ============================================================================== Dep. Variable: mpg R-squared: 0.606 Model: OLS Adj. R-squared: 0.605 Method: Least Squares F-statistic: 599.7 Date: Wed, 30 Jan 2019 Prob (F-statistic): 7.03e-81 Time: 02:06:24 Log-Likelihood: -1178.7 No. Observations: 392 AIC: 2361. Df Residuals: 390 BIC: 2369. Df Model: 1 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [95.0% Conf. Int.] —————————————————————————— Intercept 23.4459 0.248 94.625 0.000 22.959 23.933 hp -0.1578 0.006 -24.489 0.000 -0.171 -0.145 ============================================================================== Omnibus: 16.432 Durbin-Watson: 1.071 Prob(Omnibus): 0.000 Jarque-Bera (JB): 17.305 Skew: 0.492 Prob(JB): 0.000175 Kurtosis: 3.299 Cond. No. 38.4 ==============================================================================
Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
1 note
·
View note
Text
Top Function as a Service (FaaS) Vendors of 2025
Businesses encounter obstacles in implementing effective and scalable development processes. Traditional techniques frequently fail to meet the growing expectations for speed, scalability, and innovation. That's where Function as a Service comes in.
FaaS is more than another addition to the technological stack; it marks a paradigm shift in how applications are created and delivered. It provides a serverless computing approach that abstracts infrastructure issues, freeing organizations to focus on innovation and core product development. As a result, FaaS has received widespread interest and acceptance in multiple industries, including BFSI, IT & Telecom, Public Sector, Healthcare, and others.
So, what makes FaaS so appealing to corporate leaders? Its value offer is based on the capacity to accelerate time-to-market and improve development outcomes. FaaS allows companies to prioritize delivering new goods and services to consumers by reducing server maintenance, allowing for flexible scalability, cost optimization, and automatic high availability.
In this blog, we'll explore the meaning of Function as a Service (FaaS) and explain how it works. We will showcase the best function as a service (FaaS) software that enables businesses to reduce time-to-market and streamline development processes.
Download the sample report of Market Share: https://qksgroup.com/download-sample-form/market-share-function-as-a-service-2023-worldwide-5169
What is Function-as-a-Service (FaaS)?
Function-as-a-Service (FaaS), is a cloud computing service that enables developers to create, execute, and manage discrete units of code as individual functions, without the need to oversee the underlying infrastructure. This approach enables developers to focus solely on writing code for their application's specific functions, abstracting away the complexities of infrastructure management associated with developing and deploying microservices applications. With FaaS, developers can write and update small, modular pieces of code, which are designed to respond to specific events or triggers. FaaS is commonly used for building microservices, real-time data processing, and automating workflows. It decreases much of the infrastructure management complexity, making it easier for developers to focus on writing code and delivering functionality. FaaS can power the backend for mobile applications, handling user authentication, data synchronization, and push notifications, among other functions.
How Does Function-as-a-Service (FaaS) Work?
FaaS provides programmers with a framework for responding to events via web apps without managing servers.PaaS infrastructure frequently requires server tasks to continue in the background at all times. In contrast, FaaS infrastructure is often invoiced on demand by the service provider, using an event-based execution methodology.
FaaS functions should be formed to bring out a task in response to an input. Limit the scope of your code, keeping it concise and lightweight, so that functions load and run rapidly. FaaS adds value at the function separation level. If you have fewer functions, you will pay additional costs while maintaining the benefit of function separation. The efficiency and scalability of a function may be enhanced by utilizing fewer libraries. Features, microservices, and long-running services will be used to create comprehensive apps.
Download the sample report of Market Forecast: https://qksgroup.com/download-sample-form/market-forecast-function-as-a-service-2024-2028-worldwide-4685
Top Function-as-a-Service (FaaS) Vendors
Amazon
Amazon announced AWS Lambda in 2014. Since then, it has developed into one of their most valuable offerings. It serves as a framework for Alexa skill development and provides easy access to many of AWS's monitoring tools. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code.
Alibaba Functions
Alibaba provides a robust platform for serverless computing. You may deploy and run your code using Alibaba Functions without managing infrastructure or servers. To run your code, computational resources are deployed flexibly and reliably. Dispersed clusters exist in a variety of locations. As a result, if one zone becomes unavailable, Alibaba Function Compute will immediately switch to another instance. Using distributed clusters allows any user from anywhere to execute your code faster. It increases productivity.
Microsoft
Microsoft and Azure compete with Microsoft Azure Functions. It is the biggest FaaS provider for designing and delivering event-driven applications. It is part of the Azure ecosystem and supports several programming languages, including C#, JavaScript, F#, Python, Java, PowerShell, and TypeScript.
Azure Functions provides a more complex programming style built around triggers and bindings. An HTTP-triggered function may read a document from Azure Cosmos DB and deliver a queue message using declarative configuration. The platform supports multiple triggers, including online APIs, scheduled tasks, and services such as Azure Storage, Azure Event Hubs, Twilio for SMS, and SendGrid for email.
Vercel
Vercel Functions offers a FaaS platform optimized for static frontends and serverless functions. It hosts webpages and online apps that install rapidly and expand themselves.
The platform stands out for its straightforward and user-friendly design. When running Node.js, Vercel manages dependencies using a single JSON. Developers may also change the runtime version, memory, and execution parameters. Vercel's dashboard provides monitoring logs for tracking functions and requests.
Key Technologies Powering FaaS and Their Strategic Importance
According to QKS Group and insights from the reports “Market Share: Function as a Service, 2023, Worldwide” and “Market Forecast: Function as a Service, 2024-2028, Worldwide”, organizations around the world are increasingly using Function as a Service (FaaS) platforms to streamline their IT operations, reduce infrastructure costs, and improve overall business agility. Businesses that outsource computational work to cloud service providers can focus on their core capabilities, increase profitability, gain a competitive advantage, and reduce time to market for new apps and services.
Using FaaS platforms necessitates sharing sensitive data with third-party cloud providers, including confidential company information and consumer data. As stated in Market Share: Function as a Service, 2023, Worldwide, this raises worries about data privacy and security, as a breach at the service provider's end might result in the disclosure or theft of crucial data. In an era of escalating cyber threats and severe data security rules, enterprises must recognize and mitigate the risks of using FaaS platforms. Implementing strong security measures and performing frequent risk assessments may assist in guaranteeing that the advantages of FaaS are realized without sacrificing data integrity and confidentiality.
Vendors use terms like serverless computing, microservices, and Function as a Service (FaaS) to describe similar underlying technologies. FaaS solutions simplify infrastructure management, enabling rapid application development, deployment, and scalability. Serverless computing and microservices brake systems into small, independent tasks that can be executed on demand, resulting in greater flexibility and efficiency in application development.
Conclusion
Function as a Service (FaaS) is helping businesses build and run applications more efficiently without worrying about server management. It allows companies to scale as needed, reduce costs, and focus on creating better products and services. As more sectors use FaaS, knowing how it works and selecting the right provider will be critical to keeping ahead in a rapidly altering digital landscape.
Related Reports –
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-western-europe-4684
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-western-europe-5168
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-usa-4683
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-usa-5167
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-middle-east-and-africa-4682
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-middle-east-and-africa-5166
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-china-4679
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-china-5163
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-asia-excluding-japan-and-china-4676 https://qksgroup.com/market-research/market-share-function-as-a-service-2023-asia-excluding-japan-and-china-5160
0 notes
Text
Python comment

PYTHON COMMENT HOW TO
Our code is more comprehensible when we use comments in it. Single-line comments, multi-line comments, and documentation strings are the 3 types of comments in Python. The Python interpreter overlooks the remarks and solely interprets the script when running a program. Formulas, procedures, and sophisticated business logic are typically explained with comments. We leverage the remarks to accomplish this. We might wish to take notes of why a section of script functions, for instance. We may wish to describe the code we develop. We'll also learn about single-line comments, multi-line comments, documentation strings, and other Python comments.
PYTHON COMMENT HOW TO
We'll study how to write comments in our program in this article. Python Tutorial Python Features Python History Python Applications Python Install Python Example Python Variables Python Data Types Python Keywords Python Literals Python Operators Python Comments Python If else Python Loops Python For Loop Python While Loop Python Break Python Continue Python Pass Python Strings Python Lists Python Tuples Python List Vs Tuple Python Sets Python Dictionary Python Functions Python Built-in Functions Python Lambda Functions Python Files I/O Python Modules Python Exceptions Python Date Python Regex Python Sending Email Read CSV File Write CSV File Read Excel File Write Excel File Python Assert Python List Comprehension Python Collection Module Python Math Module Python OS Module Python Random Module Python Statistics Module Python Sys Module Python IDEs Python Arrays Command Line Arguments Python Magic Method Python Stack & Queue PySpark MLlib Python Decorator Python Generators Web Scraping Using Python Python JSON Python Itertools Python Multiprocessing How to Calculate Distance between Two Points using GEOPY Gmail API in Python How to Plot the Google Map using folium package in Python Grid Search in Python Python High Order Function nsetools in Python Python program to find the nth Fibonacci Number Python OpenCV object detection Python SimpleImputer module Second Largest Number in Python
0 notes
Text
Sixteen Steps To Become a DevOps Professional
The DevOps ecosystem is growing fast since the past few years but I’ve always seen the same question that is somehow hard to answer in some lines: How to become a DevOps engineer?
so, i have decided to write this article which will help you to become a successful DevOps Engineer.So,with out wasting any time go through the blog.

Here are the 16 steps to follow,
1. Start By Learning About Culture
2. Learn A Programming Language
3. Learn How To Manage Servers
4. Learn Networking and Security Basics
5. Learn Scripting
6. Learn How To Install & Configure Middleware’s
7. Learn How To Deploy Software
8. Learn GIT
9. Learn How To Build Software
10. Learn How To Automate Your Software Factory
11. Learn Configuration Management
12. Learn Infrastructure As Code
13. Learn How To Monitor Software & Infrastructure
14. Learn About Containers & Orchestration
15. Learn How To Deploy & Manage Server less Applications.
16. Read Technical Article related to devops stuff from blogs like,
DevOps.com, DzoneDevOps, the XebiaLabs DevOps, DevOps Guys
1. Start By Learning about the Culture:
DevOps is a movement and a culture before being a job this is why cultural aspects are very important.
2. Learn A Programming Language:
In my experience, a good DevOps engineer is someone who has skills in development and operations. Python, Go, Nodejs .you have a large choice! You don’t necessarily need to learn the same main language that your company use but programming skills are really nice to have.
3. Learn How To Manage Servers:
One of the principal tasks that a DevOps professional do, is managing servers. Knowing how servers work is a must-know and to do this, some good knowledge about the hardware (CPU, architecture, memory ...) is needed. The other thing to learn is operating systems and especially Linux. You can start by choosing a distribution like Ubuntu.
If you are really beginning with Linux, you can try it first in your laptop/desktop and start playing with in order to learn.
You can also use DigitalOcean, Amazon Lightsail or Linode to start a cheap server and start learning Linux.
4. Learn Networking & Security Basics
You may probably say that these are skills for network and security engineers. No! Knowing how HTTP, DNS, FTP and other protocols work, securing your deployed software, anticipating security flaws in the code and configuring your infrastructure network are things that you should know. Using Kali Linux could be a good way to learn networking and security.
5. Learn Scripting
Even with the growing number of tools that could be an alternative to creating your own scripts, scripting is a must-know and you will need it for sure. In my experience, Bash is one of the most used scripting languages. Python is also a good scripting language that could be used to go fast while writing less code.
6. Learn How to install & Configure Middleware’s
Apache and Nginx are the most used middleware in the DevOps industry and knowing how to install and configure things like virtual hosts, reverse proxies, domain names and SSL will help you a lot in your daily tasks. Start by deploying Nginx as a web server for a WordPress blog then, as a load balancer for two backend servers.
7. Learn How to Deploy Software
Once you know how to deploy and configure Nginx, you need to know how to deploy applications to a production server.
Create a “hello world” applications using Python, Nodejs and PHP. Deploy these 3 applications. You can use Nginx as a reverse proxy for all of them.
8. Learn GIT
GIT is one of the versioning systems being used in the IT industry. You don’t need to be a GIT expert but this is a technology that will follow you through all of your DevOps experiences.
GIT basics are well explained in the official documentation.
“Pro Git” is the book you really need to read if you want to learn GIT.
9. Learn How to Build Software
Building comes before running. Building software is generally about running a procedure of creating a software release that could run in a production server. A DevOps professional need to know about this important part of the software lifecycle.
Create an application in the language of your choice and check the different ways to install its dependencies and build your code.
10. Learn How to Automate Your Software Factory
DevOps is not about automation, but automation is one of the pillars of the DevOps business transformation. Once you learned how to build software, you can use tools like Jenkins to automate builds and connect your code to the code repository. If you are not familiar with all of this, read about Continuous Integration and Continuous Delivery.
11. Learn Configuration Management
Once things become more complex and once you will need to manage multiple environments and configurations, learning a configuration management tool will make your life easier.
There are a lot of CM tools like Saltstack , Ansible, Chef, Puppet ..Etc. and you can find online resource that compares these tools. In function of what you need, choose a CM tool and start learning it.
12. Learn Infrastructure as Code
IaC is absolutely important to automate your infrastructure and provision your environments with simple scripts or alternative tools. DevOps is about reducing the time to market while keeping a good software quality and IaC will help you on this.
Choose a cloud provider (AWS, GCP ..Etc.) and you will find a lot of free online resources to start your infrastructure. You can also learn how to use “cloud managers” technologies, some CM tools like Saltstack could help you provision infrastructure on AWS or GCP, otherwise, if you need more go for technologies like Terraform.
13. Learn How to Monitor Software & Infrastructure
A software deployed in production and the infrastructure hosting it should be monitored. Monitoring and alerting are one of the important skills you need to know.
Zabbix, Icinga, Sensu, prometheus.. There are a lot of tools you can learn but start by comparing these tools and choose the one that fits your requirements. You can also consider learning how to deploy and use an ELK stack.
14. Learn About Containers & Orchestration
Containers like Docker are becoming a must-know skill! You need to have good skills creating, building, deploying and managing containers in development and production environments.
15. Learn How to Deploy & Manage Serverless Applications
Serverless is one of the most buzzing technologies of 2017 and sooner it will become a requirement in many job descriptions.
AWS Lambda, Azure Functions, Google Cloud Functions, IBM OpenWhisk, or Auth0 WebTask, you have the choice to start learning one of them.
16. Read Technical Article related to devops stuff
from blogs like,
DevOps.com, DzoneDevOps, the XebiaLabs DevOps, DevOps Guys
2 notes
·
View notes
Text
Why should you take the PG Diploma in Data Science using Python?
Believe it or not, the fastest-growing Python usage is for data science. Behind the massive fan following of the Python lies numerous conditions. Python is a very simple language to learn. While on the other hand, Data Science using Python is a nifty tool with a range of benefits. As it is open-source, Python's flexibility and continuous improvements with Data Science have become a genuinely resourceful option.
Other integrated languages, such as Java, can be utilized in this well-established system. It is extremely beneficial for your professional to pursue data science training and have a bright future full of possibilities. It is crucial to get in touch with the best data science training institute in Bangalore for ideal support from the industry trainer in every possible way. Cranes Varsity is the top data science using python training institute where you'll not only learn but explore and build a future that will take you high in life with promising job placements.

Why is Python for Data Science the best?
Data science using python is in high demand across the globe. There are a few grounds to support the statement that Data Science with Python is the best among all to choose as a great career option. There are notable advantages to learning this, which are all listed below;
1: Simplistic Approach :
Python is very popular as a programming language mainly due to its simplicity. The best features are inherited with easy readability, making it a friendly language for beginners or freshers. It is time savvy which allows straightaway to get into the research part without spending most of its time in documentation. It is extensively used in statistical analysis, text processing, data analysis, web development, and much more.
2: One library for every sort of need:
In Data Science using Python, the following is the most assorted library that makes it propelling to Data Science professionals. Python libraries include;
● NumPy is one of the most accessible libraries to find the use case in Data science.
● Pandas are built on the top of the NumPy.
● SciPy is the scientific equivalent of NumPy.
There are some more libraries like SymPy (statistical applications); Shogun, PyLearn2, and PyMC (machine learning); Bokeh, ggplot, Plotly, prettyplotlib, and seaborn (data visualization and plotting), and csvkit, PyTables, SQLite3 (data formatting and storage), to name a few.
3: It’s Multi-paradigm Approach
A great thing about Python is it's not limited to any programming language. The multi-paradigm feature makes it unique, which enables the support of functional, procedural, and objective-oriented programming & aspect-oriented programming style as well. With the data science certification, all this knowledge you'll gain eventually in training.
Who are all eligible for the data science online course?
Once you know about the immense benefits that you'll gather with the learning of Python in Data Science, you must be feeling to find out who is eligible for this? At Cranes Varsity, you can apply for the Data Science using Python training course if you are a working professional from an Engineering background, who is willing to increase your knowledge for better career aspects.
What is included in the data science training?
At Cranes Varsity, Data Science using Python training course syllabus is well-structured in terms of modules that will help the students better understand the subject. It includes:
● Relational Database - MySQL
● NoSQL - Mongo DB
● Web Technology - HTML, CSS, JavaScript
● Python Programming
● Advanced Python & Unit Testing
● Statistics
● Data Analysis & Visualization
● Machine Learning using SKlearn
● Deep Learning using Tenser Flow
● Tableau, Cloud Computing
You'll learn:
● Understand concepts like lambdas and CSV file manipulation.
● Describe standard Python data science functionality and features.
● For cleaning and processing, use DataFrame structures.
● Explain how t-tests, sampling, and distributions work.
About the PG Diploma in Data Science with Python at Cranes Varsity
The PG Diploma in Data Science using Python is a four-month professional program that provides solid knowledge and comprehension of Data Science. The expert teachers/ trainers have been industry leaders for decades. They offer instruction in all necessary disciplines so that engineers may create Java-based applications that satisfy industry standards.
As the best data science training institute in Bangalore, Cranes provides students with an organized framework to help them improve their technical skills and knowledge curve. The lectures are well-planned and delivered using examples to make them more engaging and understandable. The goal is to help students develop more strong knowledge representations in their heads in Data Science using Python.
Choosing Crane s Varsity is ideal for you in many ways:
● Extraordinary faculty who are practically experienced for years and know in and out of the market trends.
● Online and offline assistance from time to time.
● All notes are provided related to the Data Science using Python
● Guaranteed placement to the top companies in the country
● Extensive study and knowledge sharing sessions
● Open discussions are appreciated
● Full-time assistance 24/7 over time
● Timely assessment
How valuable is the data science certification?
Once you have chosen the data science online course from Cranes Varsity, there is no looking back. Your qualifications will be valued at the best ways to the top class management where you can explore more opportunities. The chances of placement are guaranteed from the Cranes campus for those who complete the training successfully. Data Science using Python training course is not just a course. It is a promising way to advance with the trend and demands of employment opportunities for the long run.
The platforms used in the Cranes Varsity for offering Data Science Using Python are;
● Anaconda Distribution (Jupyter Notebook)
● Tableau
● MYSQL
● Mongo DB
● Google Colab
● AWS
Any data science using python training institute won't offer such versatility in the module designing and syllabus that covers so much, apart from Cranes Varsity. The placement opportunities are on a larger scale to the top organizations in the country. Do not wait and skip your chance; apply/register for the course today! With this helpful data science using python certification, you'll surely see a better career for yourself.
0 notes