#read uncommitted data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
A Deep Dive into NOLOCK's Power and Pitfalls in SQL Server
In the realm of SQL Server management, the NOLOCK hint emerges as a quintessential tool for database administrators, aimed at enhancing query efficiency through the minimization of locking and blocking phenomena. This tool, however, is double-edged, necessitating a nuanced understanding and strategic deployment. This exploration ventures into the practical utilization of NOLOCK, enriched with…
View On WordPress
#database concurrency solutions#NOLOCK SQL Server#read uncommitted data#SQL performance optimization#SQL Server locking issues
0 notes
Text
Dueling primaries in the critical swing state of Michigan added some new data points and, in many ways, built on several preexisting narratives. Here's a basic roundup.
1. Donald Trump underperformed the polling again!
Congrats to Trump on his 42-percentage-point victory over rival Nikki Haley, but the polls still love him more than the people do—a consistent phenomenon this cycle.
With 98% of the vote in, Trump holds a roughly 42-point edge over Haley, nothing close to his predicted margin. The final 538 polling average had Trump winning by 57 points, meaning he underperformed his polls by about 15 points.
Since the GOP primary has become a two-person race, Trump has consistently underperformed his polls. Across the four contests so far (excluding Nevada’s overcomplicated primary/caucus system), he has now underperformed his 538 polling average by 9 points. One way or the other, it can’t be bad for Biden.
2. "Uncommitted" passed their 10,000-vote goal, but President Joe Biden still finished strong
The "uncommitted" vote—an effort to challenge President Joe Biden's pro-Israel stance on the war in Gaza—set a low bar of getting 10,000 votes in this Democratic primary and easily surpassed it, clearing the 100,000 mark.
Hillary Clinton famously lost Michigan to Trump by about 10,000 votes. So Tuesday night's results revealed a meaningful level of concern about Biden's support for Israel in a key swing state with a large number of Arab American voters.
That said, the overall percentage of "uncommitted" voters—a little over 13%—only modestly surpassed the 11% share of uncommitted voters in 2012, the last time a Democratic incumbent president faced a virtually uncontested primary. Later that year, President Barack Obama went on to win the state by nearly 450,000 votes.
The bottom line is that the uncommitted protest vote made a statement, but Biden still finished strong, with more than 80% of the vote in a primary where voters had three other options (uncommitted, author Marianne Williamson, and Rep. Dean Phillips).
3. Marianne Williamson (who wasn't running) bests Rep. Dean Phillips (who was running)
Big night for Williamson, who had suspended her campaign and has now unsuspended it after blowing out Phillips by less than half a point, 3.0% to 2.7%.
Phillips is toast. And Williamson's move to re-enter the race is a laughable over-read of her “victory” over Phillips, who, again, is toast. “Uncommitted” beat both by double digits.
4. The Trump protest vote was far more meaningful than the Biden protest vote
More than 30% of voters in the state’s Republican primary cast what is functionally a protest vote against Trump, who's won every state so far. Haley garnered the majority of those votes and will likely finish with north of 26%.
At the same time, just under 20% of voters in the state’s Democratic primary didn’t vote for Biden.
In other words, Biden will win Michigan’s Democratic primary with more than 80% of the vote, despite a lot of suspense around the uncommitted vote, but Trump will win the Republican primary with under 70% of the vote, despite his diehard supporters surely wanting to make a statement against Haley and all non-MAGA Republicans.
5. Haley isn't done bashing Trump
Despite her loss, Haley vowed to stay in the Republican primary until at least Super Tuesday. She is also on pace to hold at least 10 fundraisers in the 10 days before those contests ensue, according to Andrew Romano of Yahoo News.
Haley also used her spotlight Monday evening to make some astute observations about Trump and the Republican Party.
"What I am saying to my Republican Party family is, we are in a ship with a hole in it," Haley said.
"The RNC is not about winning races up and down the ticket. The RNC is now about Donald Trump," Haley argued, calling the organization Trump's "legal slush fund."
The Biden-Harris rapid-response account helpfully tweeted out the clip.
3 notes
·
View notes
Text
Hey, just one thing: When @bogleechogleech cited the 70 percent number, they were talking about districts and not the state as a whole.
In fact, it took me like 2 seconds to find the source (I presume) they were talking about:

The final vote tally for Uncommitted in Dearborn didn't end up being that high, but it still reached 56 percent.

Now, there can be a conversation about the significance of this, or how much this applies nationwide and whatnot, or whatever else the data from this primary can tell us, but it's another thing to make wild claims of "wild factual untruths" based on lazy misreadings of what other people say.
But hey, I get it: when you're unable to do such arcane, impossible tasks as "scrolling down a webpage" and "using your reading comprehension skills," it's easier to just sling bad-faith attacks.
If you’re living in Michigan, you should vote “uncommitted” in today’s Democratic presidential primary.
10K notes
·
View notes
Text
Understanding the ACID Properties of Databases

In the world of databases, ACID properties are foundational principles that ensure the reliability, consistency, and integrity of data. If you're new to databases or just looking to deepen your understanding, this guide will break down the ACID properties in a way that's easy to grasp. So, let’s dive in and explore what ACID stands for and why it’s so important for database systems.
What Does ACID Stand For?
ACID is an acronym that represents four key properties of a database transaction: Atomicity, Consistency, Isolation, and Durability. These properties ensure that databases operate in a predictable and reliable manner, even in the face of errors, power failures, or other unexpected events. Let’s unpack each of these properties one by one.
1. Atomicity: All or Nothing
Atomicity means that a transaction is an indivisible unit of work. It either completes entirely or doesn’t happen at all. Imagine you’re transferring money from your savings account to your checking account. This operation involves two steps: deducting the amount from your savings and adding it to your checking. With atomicity, if any part of this transaction fails (say, the system crashes after deducting from your savings but before adding to your checking), the database ensures that both steps are either fully completed or not done at all. This prevents partial transactions that could lead to data inconsistencies.
Real-Life Analogy: Think of atomicity like sending a text message. If you lose internet connection while sending, the message doesn’t get sent halfway. It either reaches the recipient completely or not at all.
2. Consistency: Maintaining Integrity
Consistency ensures that a database remains in a valid state before and after a transaction. Every transaction must transition the database from one valid state to another, adhering to all predefined rules and constraints. For instance, if a banking database has a rule that an account balance cannot be negative, consistency ensures this rule is never violated. If a transaction attempts to withdraw more money than is available, the transaction will fail, maintaining the integrity of the database.
Real-Life Analogy: Imagine a vending machine that only accepts exact change. If you try to use a $5 bill for a $2 snack, the machine won’t accept it because it can’t provide change, thus ensuring it operates within its defined rules.
3. Isolation: Transactions in Solitude
Isolation ensures that transactions occur independently without interference. When multiple transactions are executed concurrently, isolation ensures they do not affect each other’s outcome. This is crucial in a multi-user environment where simultaneous transactions are common. For example, if two people are booking the last seat on a flight at the same time, isolation ensures that only one transaction succeeds and the seat isn’t double-booked.
Isolation levels can vary:
Read Uncommitted: Transactions may see uncommitted changes from other transactions.
Read Committed: Transactions only see committed changes.
Repeatable Read: Ensures that if a transaction reads the same data multiple times, it sees the same data each time.
Serializable: Transactions are completely isolated from each other.
Real-Life Analogy: Think of isolation like library study rooms. Each room allows students to study without distractions from others. Even if multiple rooms are occupied, what happens in one room doesn’t affect others.
4. Durability: Permanence of Transactions
Durability guarantees that once a transaction is committed, it is permanently recorded in the database. Even in the event of a system crash or power failure, the committed transaction remains intact. This property ensures that the database can recover to a known good state after any failure. For example, once you’ve completed an online purchase and received a confirmation, durability ensures that the transaction is not lost, even if the website crashes right after.
Real-Life Analogy: Durability is like saving your work on a computer. Once you hit the save button, your work is stored on the disk. Even if your computer shuts down unexpectedly, your saved work is still there when you restart.
Why Are ACID Properties Important?
The ACID properties are crucial for maintaining the reliability and robustness of a database. Here’s why they matter:
Data Integrity: ACID properties ensure that data remains accurate and consistent, preventing corruption and loss.
Error Handling: They provide mechanisms to handle errors gracefully, ensuring partial transactions don’t disrupt the database.
Concurrent Access: They enable safe and reliable access to data in multi-user environments, crucial for applications like online banking and e-commerce.
Recovery: They ensure that databases can recover from failures without losing committed transactions.
ACID in Action: A Simple Example
Let’s consider a simple example to see ACID properties in action. Imagine a scenario where you are transferring $100 from your checking account to your savings account using an online banking app. Here’s how the ACID properties come into play:
Atomicity: The transaction involves two steps—debiting $100 from checking and crediting $100 to savings. If either step fails, the transaction is rolled back, and your accounts remain unchanged.
Consistency: The transaction ensures that the total amount of money in your accounts remains the same. If a rule states that account balances cannot be negative, this rule is enforced throughout the transaction.
Isolation: If another transaction (like your partner transferring money between their accounts) is happening simultaneously, isolation ensures that your transaction does not interfere with theirs.
Durability: Once the transaction is committed, the changes are permanent. Even if the bank’s servers crash immediately after the transaction, your accounts will reflect the updated balances when the system is back up.
Conclusion
Understanding the ACID properties of databases is essential for anyone involved in database management or application development. These properties—Atomicity, Consistency, Isolation, and Durability—ensure that databases function reliably and efficiently, maintaining data integrity and enabling robust error recovery. Whether you’re handling financial transactions, managing inventories, or running any application that relies on accurate data, the principles of ACID will help you ensure your database remains trustworthy and dependable.
So, next time you think about the complex operations happening behind the scenes of your favorite apps and services, remember the ACID properties and appreciate the magic they bring to the world of databases.
for more information visit https://itgurublog.com/acid-properties-of-databases/
1 note
·
View note
Text
The Benefit of Real Estate Analysis Software

Crunching rental property cash flows, rates of return and profitability numbers adequately enough for investors to make prudent real estate investment decisions can be quite labor-intensive. In fact, prior to the advent of computer technology it was very time consuming because it required the analyst to manually compute and format the results manually.
Now with the advance of third-party software solutions, however, it has become common practice for investors and analysts to rely on software to do the number crunching for them. The benefit derived, of course, goes without saying: The time and effort they save by eliminating as many manual tasks as possible frees up time for them to pursue their real estate investing objective. Namely, to locate rental properties they might be able to acquire for profit.
Nonetheless, this benefit is not understood by everyone who works with rental income property and conducts a real estate analysis. Strangely, it's not uncommon to find, despite this age of technology, investors and agents who still compute and format the results manually.
So it seemed needful to address the issue and to make a case about the benefits of using software to those of you that remain uncommitted.
Rest assured, however, that my purpose is not intended to highlight any one particular software product, but rather to get you thinking about the "concept" overall. In other words, hopefully once you consider how we conducted a real estate analysis in the "old days" you will come to more fully appreciate why software evolved, the issues it solves, and how you can benefit as a result.
Origin
The challenge to create a cash flow and rate of return analysis has been around as long as real estate investing. It's difficult to imagine, in fact, that any investor throughout any time in history didn't use some method to determine whether or not a property would result in a profit.
Prior to the advent of computers, of course, that process had to always be performed manually. Even as recently as the early 1990's, for example, I was conducting a real estate analysis with a calculator in one hand and pencil and paper in the other.
Some of you remember the hardships and difficulties those of us working with income property had to resolve manually in those "early days".
The Data
The data associated with investment real estate is the heart and soul of any real estate analysis. This goes without saying. The real estate investor must understand the financial performance of a property in order to discern its particular value.
Before computer programs, however, this presented several problems.
Foremost, especially for novices, knowing what data was required for a meaningful bottom-line was not always understood. What constitutes a rental property's operating expenses, for instance? Or what data is needed to arrive at a property's net operating income, cash flow, or rate of return? What must be included to make revenue projections? And so it was.
Then, of course, there was the issue of the math. Because by the same token the correct data is required, computing the numbers correctly is paramount. As a result, there was always the laborious task of checking and re-checking the numbers to ensure accuracy.
Up until computers and third-party software programs came along that process always took plenty of time and involved a lot of second-guessing.
The Formulas
There are a host of returns real estate investors rely upon to measure the worth of an income-producing property in order for the investor to determine how it compares to their individual investment objectives, and/or how its value stacks up to the values of similar types of property in the local market area.
As a result, investors look at returns such as cap rate, gross rent multiplier, cash-on-cash, internal rate of return, and numerous others. Some of these returns require just simple math that can almost be computed in one's head. But there are also many returns far more complex. For instance, rates of return associated with the elements of tax shelter and time value of money are certainly going to require nothing less than a financial calculator.
The point is that each return constitutes a formula, and up until the availability of software solutions, those formulas needed to be learned.
The Presentations
Another (more subtle) issue facing anyone conducting a rental property analysis concerns the presentation. For in addition to ensuring complete and accurate data, at the same time it must be displayed well. That is, the reports must be constructed so the facts and figures are easy-to-read and easy-to-understand.
Over the years I'm sure there have been real estate deals transacted with numbers presented on a napkin. But that's far from the norm, and would certainly not fair well for presentations made to investors, colleagues, partners or lenders.
Thanks to computers and software, all the efforts we once made to create professional-quality reports are a thing of the past. In today's world, reports are created automatically and look better than ever.
Conclusion
A computer or third-party software program cannot guarantee your real estate investing success. Whether you own the most advanced PC, most recent MS Excel version, or maybe even more than one real estate analysis software solution, you're not off the hook. You still have to do your research and homework.
Nonetheless, there is a benefit to this technology if you wish to employ it. Hopefully this article has shed some light on the advantages. Here's to your success.
3 notes
·
View notes
Text
The Benefit of Real Estate Analysis Software

Crunching rental property cash flows, rates of return plus profitability numbers adequately enough for investors to make recommended real estate investment decisions can be quite labor-intensive. In fact , prior to the advent in computer technology it was very time consuming because it required the actual analyst to manually compute and format the results physically. Now with the advance of third-party software solutions, nevertheless it has become common practice for investors and experts to rely on software to do the number crunching for them. The benefit derived, of course, goes without saying: The time and hard work they save by eliminating as many manual tasks as possible frees up time for them to pursue their real estate investing goal. Namely, to locate rental properties they might be able to acquire just for profit. Nonetheless, this benefit is not understood by all of us who works with rental income property and conducts a really estate analysis. Strangely, it's not uncommon to find, despite this get older of technology, investors and agents who still work out and format the results manually. So it seemed needful to handle the issue and to make a case about the benefits of using programs to those of you that remain uncommitted. Rest assured, however , who my purpose is not intended to highlight any one particular software system product, but rather to get you thinking about the "concept" overall. To explain, hopefully once you consider how we conducted a real estate researching in the "old days" you will come to more fully recognize why software evolved, the issues it solves, and easy methods to benefit as a result. Origin The challenge to create a cash flow and quote of return analysis has been around as long as real estate investing. It will be difficult to imagine, in fact , that any investor throughout while in history didn't use some method to determine whether or not a home would result in a profit. Prior to the advent of computers, keep in mind, that process had to always be performed manually. Even as fairly recently as the early 1990's, for example , I was conducting a genuine estate analysis with a calculator in one hand and pencil and paper in the other. Some of you remember any hardships and difficulties those of us working with income residence had to resolve manually in those "early days". The The data associated with investment real estate is the heart and soul of any specific real estate analysis. This goes without saying. The real residence investor must understand the financial performance of a real estate in order to discern its particular value. Before computer services, however , this presented several problems. Foremost, especially for newcomers, knowing what data was required for a meaningful bottom-line was not always understood. What constitutes a rental property's managing expenses, for instance? Or what data is needed to arrive at the property's net operating income, cash flow, or rate regarding return? What must be included to make revenue projections? Therefore it was. Then, of course, there was the issue of the math. For the reason that by the same token the correct data is required, computing the particular numbers correctly is paramount. As a result, there was always typically the laborious task of checking and re-checking the statistics to ensure accuracy. Up until computers and third-party software programs arrived that process always took plenty of time and involved loads of second-guessing. The Formulas There are a host of returns realty investors rely upon to measure the worth of an income-producing property in order for the investor to determine how it compares to their individual investment objectives, and/or how its worth stacks up to the values of similar types of building in the local market area. As a result, investors look at profits such as cap rate, gross rent multiplier, cash-on-cash, indoor rate of return, and numerous others. Some of these rewards require just simple math that can almost be calculated in one's head. But there are also many returns additional complex. For instance, rates of return associated with the elements of place a burden on shelter and time value of money are most certainly going to require nothing less than a financial calculator. The idea is that each return constitutes a formula, and up until the availability of software program solutions, those formulas needed to be learned. The Presentations A second (more subtle) issue facing anyone conducting a rental place analysis concerns the presentation. For in addition to ensuring carry out and accurate data, at the same time it must be displayed most certainly. That is, the reports must be constructed so the facts as well as figures are easy-to-read and easy-to-understand. Over the years I'm sure we have witnessed real estate deals transacted with numbers presented on a paper napkin. But that's far from the norm, and would certainly not reasonable well for presentations made to investors, colleagues, partners or perhaps lenders. Thanks to computers and software, all the efforts we all once made to create professional-quality reports are a thing of your past. In today's world, reports are created automatically and look better than ever in your life. Conclusion A computer or third-party software program cannot guarantee your own real estate investing success. Whether you own the most advanced HOME PC, most recent MS Excel version, or maybe even more than one real estate studies software solution, you're not off the hook. You still have to do your research and homework. non-etheless, there is a benefit to this technology the employees employ it. Hopefully this article has shed some lgt on the advantages. Here's to your success.
1 note
·
View note
Text
What Is a Favicon?
A favicon which is short for "faves icon", can be taken a faster way icon, sites symbol, icon of the URL, or symbol for the bookmark. It is basic a square icon of the dimension 16 × 16 or 32 × 32 pixels. Microsoft was the initial to present the favicon in Net Explorer 4. In the initial Microsoft standard, a data called favicon was placed in the root directory site. If you want to see the origin, tradition or trivialities of this topic we do guidance you to see Wikipedia for extra info.
Let's see if we cannot beat around the fundamentals concerning favicon creator with couple of questions.
What does a favicon do?
It sits somewhere in your site quietly. A contemporary web browser shows the favicon next to the internet site's LINK which you type in the address bar area.
Just how does a favicon aid?
Typically, a bulk of developers think about favicon as a part of the theme design procedure. Instead of disregarding the favicon as a worthless component, if integrated effectively into the internet site it can just enhances the visibility of the internet site in a mutitabbed browsing setting as well as an individual might quickly differentiate the tabs representing various websites being used at that point of time.

Do I need a favicon?
"A photo is worth a thousand words" and also in this web site we might utilize this quote a 100 times a lot more. Checking out the speed of internet surfing as well as various modern browsers. Many individuals use multi-tab searching where a favicon-based tab might stand apart.
If your site makes use of a specific color theme, a logo or a market specific content ... after that why not make use of a favicon ... might be it will contribute to that professional expectation of your internet site. Well I additionally see a number of the web content writers ignore fundamental color style of the sites as well as additionally a whole bunch of key phrases are dumped on the customer claiming that I uncommitted for images as the internet search engine cannot read photos. However, it is you as well as me as well as a great deal of people who really want to see neatly presented material with images, symbols, clip art as well as ofcourse a favicon. And I duplicate "A picture deserves a thousand words"
Exactly how do I install a favicon?
Typically, a favicon is coupled with websites, it can be mounted in a site by different ways. Although, if a favicon is not incorporated by the design template designer or your website designer if you can access the server, the favicon can be put on the server right into the exact same directory site as the website. There may be some help web pages depending on which software program system or CMS.
1 note
·
View note
Text
Case Study: Limiting The Number Of Joined Customers Using SQL Transaction Isolation Levels

Agenda: In many real-time applications, at times we have to limit the total number of users to a limit. Ex: while booking movie tickets, or gaming events, and so on. The problem at hand is to limit the total number of users registered in such scenarios.
We will consider virtual cricket match application registration for the use case.
Background of the Scenario
Following is a walkthrough of the actions in the picture:
Users register themselves.
Users see a list of different cricket matches that will start within an hour timeframe. The timer is running in the background.
The User clicks on a cricket match from the list. Now the user has to create a virtual team of cricket players to play the match.
The User clicks on a cricket match from the list. Now the user has to create a virtual team of cricket players to play the match.
As soon as the team is created a list of contests appears. Users now have to join any contest. Some amount will be deducted from the wallet depending on the contest the user is joining.
Now there is a limit of users who can join a particular contest.
For example, suppose there are only 2 spots for contest A. When the user clicks Join Contest and the number of slots is filled then he should not be able to join.
The task seems to be unchallenging and effortless. Simply apply an if..else.. condition which checks if the maximum limit is exceeding and terminates the transaction before insertion if it exceeds.
But here comes the catch in this supposititious scenario. There are lakhs of users using the application at the same second. Say a couple of thousand users click on the Join Contest button at the same time. Hence instead of 2 users, 1000 users are able to join the match. Their money from the wallet is also deducted which becomes a huge challenge. This is a serious predicament and a massive technical issue.
Solution: SQL Transaction Isolation Levels
When multiple database transactions are occurring at the same time, transactions have to be isolated from each other so as to complete the transaction properly. The SQL standard defines four levels of isolation.
Now following database anomalies come into the picture:
Dirty read: A transaction reads data written by a concurrent uncommitted transaction.
Non-Repeatable reads: A transaction re-reads data it has previously read and finds that data has been modified by another transaction (that committed since the initial read).
Phantom Reads: A transaction re-executes a query returning a set of rows that satisfy a search condition and finds that the set of rows satisfying the condition has changed due to another recently-committed transaction.
Serialization anomalies: The result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.
To eliminate these anomalies, we use transaction isolation levels.
Choosing the best isolation level based, have a great impact on the database, each level of isolation comes with a trade-off, let’s discuss each of them:
1. Read Uncommitted
Read Uncommitted is the lowest isolation level. In this level, one transaction may read not yet committed changes made by another transaction, thereby allowing dirty reads. At this level, transactions are not isolated from each other.
Syntax: SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
2. Read Committed
This isolation level guarantees that any data read is committed at the moment it is read. Thus it does not allow dirty reads. The transaction holds a read or write lock on the current row, and thus prevents other transactions from reading, updating, or deleting it.
Syntax: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
3. Repeatable Reads
This is the most restrictive isolation level. The transaction holds read locks on all rows it references and writes locks on all rows it inserts, updates, or deletes. Since other transactions cannot read, update or delete these rows, consequently it avoids non-repeatable reads.
Syntax: SET TRANSACTION ISOLATION LEVEL READ REPEATABLE READS
4. Serializable
This is the highest isolation level. A serializable execution is guaranteed to be serializable. Serializable execution is defined to be an execution of operations in which concurrently executing transactions appears to be serially executing.
Syntax: SET TRANSACTION ISOLATION LEVEL READ SERIALIZABLE
The following table describes the various conditions and the applicability of transactions.
Use case: Virtual cricket match application registration Table ‘[dbo][Players]’
NOTE: Following case shows the syntax of the SQL server. For other database platforms, syntax can be modified.
Consider a table ‘Players’ having the following structure:

Database concept: There are Database Hazards That interrupt or corrupt database transactions. Following are the database hazards:
1. Dirty read
2. Update loss
3. Phantom
These hazards are outbreaks that we tackle using Isolation Levels
SQL Transaction Isolation Levels to tackle the hazards. 1. SQL Transaction Isolation level 1: READ UNCOMMITTED
Consider two users, Player 1 and Player 2. Following transactions are made by these users:
PLAYER 1 (Session 1)
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL READ UNCOMMITTED INSERT INTO [dbo].[Players] ([Player_id],[Player_name], [Contest_name], [Maximum_players],[Amount]) VALUES (10005, ‘Vaibhav’, ‘Hot Contests’,8, 1288) -> WAIT FOR DELAY 20s -> ROLLBACK TRANSACTION
PLAYER 2 (Session 2)
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL READ UNCOMMITTED -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 \1 record returned -> WAIT FOR DELAY 20s -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 \0 records returned (dirty read) -> END TRANSACTION
RESULT
Player 1 inserts into the table and waits for the 20s. Meanwhile, Player 2 selects the record just inserted. Player 2 is able to see this uncommitted record. Now after 20s User 1 rollback transaction. When Player 2 selects again no record is fetched. This is a case of Dirty Read.
Hence READ UNCOMMITTED eliminates none of the anomalies and is the lowest stage of Isolation level. DIRTY READ ———-Not removed UPDATE LOSS——–Not removed PHANTOM————–Not removed
2. SQL Transaction Isolation level 2: READ COMMITTED
Consider 2 players Player 1 and Player 2. Following transactions are made:
PLAYER 1 (Session 1)
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL READ COMMITTED INSERT INTO [dbo].Players VALUES (10005, ‘Vaibhav’, ‘Hot Contests’,8, ‘Rs.1288’) -> WAIT FOR DELAY 20s -> ROLLBACK TRANSACTION
PLAYER 2 (Session 2) **Dirty read removed
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL READ COMMITTED -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 \No records are returned as it is not committed. -> WAIT FOR DELAY 20s -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 \ No records returned as the transaction is rolled back. -> END TRANSACTION
RESULT
Player 1 inserts into the table and waits for the 20s. Meanwhile, Player 2 selects the record just inserted. Player 2 is not able to see the record as it is uncommitted. Now after 20s Player 1 commits a transaction. When Player 2 selects again no record is fetched as it is rolled back.
Hence READ COMMITTED eliminates the first database hazard: DIRTY READS and is the second stage of Isolation level. DIRTY READ ———-Removed UPDATE LOSS——–Not removed PHANTOM————–Not removed
3. SQL Transaction Isolation level 3: REPEATABLE READ
Consider 2 Players: Player 1, Player 2. Following transactions are made by the users:
USER 1 (Session 1)
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL REPEATABLE READ -> UPDATE [dbo].[Players] SET [Amount]=1,20,000 WHERE [Emp_id]=10005 -> WAIT FOR DELAY 20s -> COMMIT TRANSACTION -> END TRANSACTION
USER 2 (Session 2) ** Update loss removed
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL REPEATABLE READ -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 //No records returned as there is a lock on this record. -> WAIT FOR DELAY 20s -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10005 //One record is returned as the lock opens after the 20s. -> END TRANSACTION
RESULT
Player 1 updates one record in the table but has not committed it yet and waits for the 20s. Meanwhile, Player 2 selects the record being updated by User 1. Player 2 is not able to see the record as it is uncommitted. Now after 20s Player 1 commits a transaction. When Player 2 selects the record again and the updated record is returned. Hence Player 2 is able to fetch the record only when the transaction is either ROLLBACK or COMMITTED.
Hence REPEATABLE READ eliminates the second database hazard: UPDATE LOSS and is the third stage of Isolation level. DIRTY READ ———-Removed UPDATE LOSS——–Removed PHANTOM————–Not removed
4. SQL Transaction Isolation level 4: SERIALIZABLE
Consider 2 players Player 1, Player 2. Following transactions are made by the users:
USER 1 (Session 1)
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL SERIALIZABLE -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10006 \10 records are returned and the user makes a report of the number of records for this Player_id. -> WAIT FOR DELAY 20s -> SELECT * FROM [dbo].[Players] WHERE Player_id = 10006 //Fetches 2 more records. Extra records fetched. -> END TRANSACTION
USER 2 (Session 2) ** Phantom removed
-> GO -> BEGIN TRANSACTION -> SET ISOLATION LEVEL SERIALIZABLE -> INSERT INTO [dbo].[Players] ([Player_id],[Player_name], [Contest_name],[Maximum_players],[Amount]) VALUES (10005, ‘Vaibhav’, ‘Head to Head’,8, ‘Rs.774’) \\1 record inserted -> INSERT INTO [dbo].[Players] ([Player_id],[Player_name], [Contest_name],[Maximum_players],[Amount]) VALUES (10005, ‘Vaibhav’, ‘Hot Contests,8, ‘Rs.414’) \\1 record inserted -> COMMIT TRANSACTION -> END TRANSACTION
RESULT
Player 1 selects one record in the table with Player_id=10006. 10 records are returned and Player 1 prepares the report on it. Meanwhile, Player 2 is inserting 2 records in the table for Player_id=10006. After a 20-second delay Player 2 commits a transaction. Now player 1 again selects records for Player_id=10006 and 12 records are returned. A mismatch of data occurs and the report is not correct. This is a massive transactional error called Phantom and database reports also become incorrect.
To tackle this hazard, we use a SERIALIZABLE isolation level which applies a lock on records between a specific range of PLAYER_ID says 10005-10010. Now the Player cannot insert a record within this range before the transaction is committed by Player 1.
Hence SERIALIZABLE eliminates the third database hazard: Phantom and is the fourth stage of Isolation level. DIRTY READ ———-Removed UPDATE LOSS——–Removed PHANTOM————- Removed
Hence SERIALIZATION is the strongest lock as it eliminates all three database hazards.
Hence concluding, understanding the concept of Transactional Isolation Level is crucial to resolve SQL transaction-related glitches and maintaining database integrity and a lot of Database Hazards can be eliminated making the transactions go smoothly.
For More Details And Blogs :Aelum Consulting Blogs
If you want to increase the quality and efficiency of your ServiceNow workflows, Try out our ServiceNow Microassesment
.For ServiceNow Implementations and ServiceNow Consulting Visit our website: https://aelumconsulting.com/servicenow/
0 notes
Text
MySQL 8.0.24: thank you for the contributions
MySQL 8.0.24 has been released today o/ As usual, it’s highly advised to read the release notes to get informed about the changes and bug fixed. MySQL is Open Source and each release contains contributions from our great Community. Let me thanks all the contributors on behalf of the entire MySQL Team: Thank you ! MySQL 8.024 includes contributions from Daniël van Eeden, Kaiwang Chen, Zhai Weixiang, Venkatesh Prasad Venugopal, Jingbo Zhao, Yuxiang Jiang, Brian Yue, Hope Lee, Stanislav Revin, Facebook and a suggestion from Dmitriy Philimonov. Once again, thank you all for your great contributions. Here is the list of the above contributions and related bugs: Optimizer [#96459] Type resolution of DIV operator produces one less precision – Kaiwang Chen[#101256] Regexp_engine::Replace doesn’t reset error code after processing a record – Hope LeeClients / Connectors [#98311] Include port number in client error message – Daniël van Eeden[#101592] Re-open the bug #89850 Throwing exception if access to granted for table – Stanislav Revin[#101914] Add support for VERIFY_CA and VERIFY_IDENTITY SslMode’s – Daniël van EedenInnoDB [#100118] Server doesn’t restart because of too many gaps in the mysql.gtid_executed table – Venkatesh Prasad Venugopal[#100966] select count(*) works very slow for uncommitted data – Brian YuePerformance_Schema [#102115] Fix replica threads not showing in variables_by_thread – FacebookOthers Thank you Jingbo Zhao and Yuxiang Jiang for their contributions on security bugs. If you have patches and you also would like to be part of the MySQL Contributors, you can do so from MySQL’s GitHub repositories (requires signing the Oracle Contributor Agreement). Thank you again to all our contributors ! https://lefred.be/content/mysql-8-0-24-thank-you-for-the-contributions/
0 notes
Text
Spring Digging Road 7 - Advanced use of transactions
####When a transaction method is called by another transaction method, you must specify how the transaction should propagate.
For example, a method may continue to run in an existing transaction, or it may open a new transaction and run in its own transaction.
>The propagation behavior of a transaction can be specified by propagation properties.
###Spring defines seven kinds of communication behaviors:
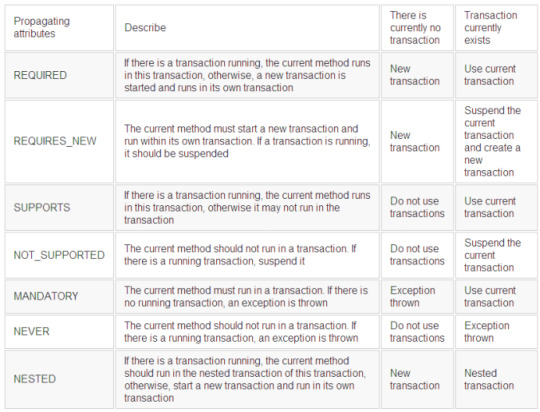
####REQUIRED Communication behavior:
Transaction propagation properties can be defined in the propagation property of the @Transactional annotation
@Transactional(propagation=Propagation.REQUIRED)
In Spring2.x transaction notification, rollback rules can be specified in the <tx:method> element.
<tx:method name="xxx" propagation="REQUIRED" />
####REQUIRES_NEW Communication behavior:
Another common communication behavior is REQUIRES_NEW. It means that the method must start a new transaction and run in its own transaction. If a transaction is running, it should be suspended first.
###Problems caused by concurrent transactions:
When multiple transactions in the same application or different applications are executed concurrently on the same data set, many unexpected problems may occur.
##The problems caused by concurrent transactions can be divided into the following three types:
###Dirty reading:
**One transaction reads uncommitted data in another transaction.**
>For two transactions T1, T2,T1 reads the fields that have been updated by T2 but have not yet been committed. After that, if T2 rolls back, what T1 reads is temporary and invalid.
###Can not be read repeatedly:
**In a transaction, the same data is queried twice, and the results obtained twice are inconsistent because another transaction in the middle submits an update.**
>For two transactions T1 and T2, T2 reads a field, then T2 updates the field, and then T1 reads the same field again, with different values.
###Magic reading:
**A transaction executes two queries, and the second result set contains data that has not been or some rows have been deleted in the first time, resulting in inconsistent results, which is only caused by another transaction inserting or deleting data between the two queries.**
>For two transactions T1 and T2, T1 reads a field from a table, and then T2 inserts some new rows into the table. After that, if T1 reads the same table again, there will be several more rows.
###Isolation level of transaction:
Theoretically, transactions should be completely isolated from each other to avoid the problems caused by concurrent transactions. However, that will have a great impact on performance, because transactions must run in sequence. In actual development, transactions will run at a lower isolation level in order to improve performance. The isolation level of a transaction can be specified by the isolation transaction attribute.
###Transaction isolation level supported by Spring
The isolation level of transactions should be supported by the underlying database engine, not by the application or framework.
```
Oracle supports two transaction isolation levels:READ_COMMITED,SERIALIZABLE
Mysql supports four transaction isolation levels
```

###Set isolation transaction properties
You can set the isolation level in the isolation property of @Transactional when you declaratively manage transactions with the @Transactional annotation
@Transactional(propagation=Propagation.REQUIRED,isolation=Isolation.READ_COMMITTED)
In Spring2.x transaction notification, you can specify the isolation level in the <tx:method> element
<tx:method name="xxx" propagation="REQUIRED"
isolation="READ_COMMITTED">
###Set rollback transaction properties
**By default, only unchecked exceptions (RuntimeException and Error type exceptions) will cause transaction rollback, while checked exceptions will not.**
Rollback rules for transactions can be defined by the rollbackFor and noRollbackFor attributes of the @Transactional annotation.
These two attributes are declared as Class[], so you can specify multiple exception classes for these two attributes
>rollbackFor : You must roll back when you encounter it
>noRollbackFor : A set of exception classes, which must not be rolled back when encountered
@Transactional(propagation=Propagation.REQUIRED,
isolation=Isolation.READ_COMMITTED,
rollbackFor={XXXException.class},
noRollbackFor={xxxException.class})
In the Spring2.x transaction notification, rollback rules can be specified in the <tx:method> element, and if there is more than one exception, they are separated by commas.
<tx:method name="xxx"
propagation="REQUIRED",
isolation="READ_COMMITTED",
rollback-for="java.io.IOException,java.sql.SQLException",
no-rollback-for="java.lang.ArithmeticException/">
###Delay and read-only attributes
Because transactions can obtain locks on rows and tables, long transactions will take up resources and affect the overall performance. If a transaction only reads data but does not modify it, the database engine can optimize the transaction.
>Timeout transaction attribute: How long a transaction can last before forced rollback, so as to prevent long-running transactions from occupying resources.
>Read-only transaction attribute: indicates that this transaction only reads data but does not update data, which can help the database engine optimize transactions.
###Set timeout and read-only transaction properties:
Timeout and read-only transactions can be defined in the @Transactional annotation, and the timeout attribute is calculated in seconds
@Transactional(propagation=Propagation.REQUIRED,isolation=Isolation.READ_COMMITTED,
rollbackFor={XXXException.class},timeout=30,read-only=true)
In Spring2.x transaction notification, timeout and read-only attributes can be specified in the <tx:method> element
<tx:method name="xxx"
propagation="REQUIRED"
isolation="READ_COMMITTED",
rollback-for="java.io.IOException,java.sql.SQLException"
no-rollback-for="java.lang.ArithmeticException
timeout="30"
read-only="true"/">
Now, starting with the code part, the structure and content of the code are the same as those in the previous article.
Last article address:
https://blog.csdn.net/qq_33811662/article/details/80560897
Now explain the changes:
##Example of transaction propagation properties:
###REQUIRED
insertOrder code in OrderService is:
@Transactional(propagation=Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
Code in BookService is:
@Transactional(propagation = Propagation.REQUIRED)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
At this time, the propagation behavior of both annotations is REQUIRED,
Output result of running program is:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
###REQUIRES_NEW
OrderService transaction code:
@Transactional(propagation=Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.REQUIRES_NEW)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Run output:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, although the data of the order table is rolled back normally, there is a problem with the book table, 15 books are missing, and a new transaction has been opened by REQUIRES_NEW, so the BookService was not brought when the OrderService rolled back.
###SUPPORTS
At this time, the database has been changed back to its original state:
OrderService transaction code:
@Transactional(propagation=Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.SUPPORTS)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Run program results:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, BookService and OrderService are the same transaction, so look at another situation, that is, there is no transaction at present.
OrderService transaction code:
@Transactional(propagation=Propagation.SUPPORTS)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Run code output:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
OrderInfo [id=55, customerName=大明, bookName=Java从入门到放弃, orderQuantities=15, payCount=225.0]
At this time, there is actually no transaction in the program, so all rollback failed! ! Actually, SUPPORT is not commonly used, so restore the database again.
###NOT_SUPPORTED
OrderService transaction code:
@Transactional(propagation=Propagation.NOT_SUPPORTED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Output result:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
OrderInfo [id=56, customerName=大明, bookName=Java从入门到放弃, orderQuantities=15, payCount=225.0]
There are no transactions in the code at this time.
Restore the database, plus a transaction:
OrderService transaction code:
@Transactional(propagation = Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Output the following results:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
Actually, in the BookService, the current transaction is suspended, so the data operated by the BookService is not rolled back, and the database restores the original data again.
###MANDATORY
OrderService transaction code:
@Transactional(propagation = Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.MANDATORY)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Running results are:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, BookService uses the transaction brought by OrderService, so the data rollback is normal. But if there is no transaction at present: comment out the annotation of OrderService
Run the program:
org.springframework.transaction.IllegalTransactionStateException: No existing transaction found for transaction marked with propagation 'mandatory'
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
OrderInfo [id=59, customerName=大明, bookName=Java从入门到放弃, orderQuantities=15, payCount=225.0]
IllegalTransactionStateException was thrown. At this time, an error was thrown directly without executing it in the business code of BookService! !
###NEVER
OrderService transaction code:
@Transactional(propagation = Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.NEVER)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Running results:
org.springframework.transaction.IllegalTransactionStateException: Existing transaction found for transaction marked with propagation 'never'
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, an exception is thrown directly, in fact, at this time, an exception is thrown without entering the update method of BookService, which causes OrderService to roll back.
If there is no transaction:
OrderService transaction code:
@Transactional(propagation = Propagation.NEVER)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Execution results:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
OrderInfo [id=63, customerName=大明, bookName=Java从入门到放弃, orderQuantities=15, payCount=225.0]
There is no transaction in the code, and no system exception will be reported, but it will not be rolled back, so it is necessary to reset the contents of the database manually.
###NESTED
OrderService transaction code:
@Transactional(propagation = Propagation.REQUIRED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
@Transactional(propagation = Propagation.NESTED)
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Execution results:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, the transaction is nested and the rollback is normal.
If there are no other transactions in the code:
OrderService transaction code:
@Transactional(propagation = Propagation.NESTED)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
BookService transaction code:
public int updateBookStock(String name, int stock) {
return bookDao.updateBookStock(name, stock);
}
Execution results:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=100]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
At this time, a new transaction is created, but NESTED can only see the effect after more than 3 transactions, which is not obvious here.
##Set rollback transaction properties
OrderService transaction code:
@Transactional(propagation = Propagation.REQUIRED, noRollbackFor = AccountException.class)
public void insertOrder(String customerName, String bookName, int orderQuantities) {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setCustomerName(customerName);
orderInfo.setBookName(bookName);
orderInfo.setOrderQuantities(orderQuantities);
double price = bookService.getPriceByName(bookName);
double payCount = orderQuantities * price;
orderInfo.setPayCount(payCount);
orderDao.insertOrder(orderInfo);
bookService.updateBookStock(bookName, orderQuantities);
customerService.updateCustomer(customerName, payCount);
}
It is specified here that AccountException will not be rolled back, so execute the code:
springtx.exception.AccountException: 金钱不足,购买失败!
BookInfo [id=1, name=Java从入门到放弃, price=15.0, stock=85]
BookInfo [id=2, name=Mysql从删库到跑路, price=22.5, stock=120]
BookInfo [id=3, name=Linux从入门到砸电脑, price=17.0, stock=15]
CustomerInfo [id=1, name=小明, account=40.0]
CustomerInfo [id=2, name=大明, account=70.0]
OrderInfo [id=67, customerName=大明, bookName=Java从入门到放弃, orderQuantities=15, payCount=225.0]
Even if an error is reported, rollback is not controlled!
# End of this article
0 notes
Text
Reading code late at night and realizing that it’s not a good idea
So it's 11:09 PM on a Sunday night. I've been spending the past couple of hours working on implementing a routing table in C for one of my networking classes. It's the last programming assignment of my college career, which makes me feel some type of way (relieved).
Lucky for you, this blog post isn't about routing tables! I figured I'd give myself a mental break and look into something else.
In this blog post, I'll be continuing the series of posts that I've been doing about the internals of Git. Over the past few posts, I've been trying to answer the question: how does Git know that you have uncommitted changes in a repository?
The relevant chunk of code that I was reading through was the following.
int has_uncommitted_changes(int ignore_submodules) { struct rev_info rev_info; int result; if (is_cache_unborn()) return 0; init_revisions(&rev_info, NULL); if (ignore_submodules) rev_info.diffopt.flags.ignore_submodules = 1; rev_info.diffopt.flags.quick = 1; add_head_to_pending(&rev_info); diff_setup_done(&rev_info.diffopt); result = run_diff_index(&rev_info, 1); return diff_result_code(&rev_info.diffopt, result); }
In previous posts, I looked into the rev_info struct and how Git maintains information about the options of a particular repository. Then I started diving into the add_head_to_pending function which looks like this.
void add_head_to_pending(struct rev_info *revs) { struct object_id oid; struct object *obj; if (get_oid("HEAD", &oid)) return; obj = parse_object(&oid); if (!obj) return; add_pending_object(revs, obj, "HEAD"); }
The function above got me looking into objects as they are used in Git. I explored how they are represented in the filesystem. In this blog post, I want to look into how objects are expressed as a data structure in the Git source code. From the code above, I can see that two relevant struct definitions are worth exploring object_id and object.
From the digging into the filesystem representation of objects that I did in my last blog post, I have a little bit of an idea of what these two structs might represent. I think object_id is a representation of the hash associated with an object and object is the metadata associated with the object itself (as defined in previous posts).
But enough hypothesizing, time to investigate! I found the definition of the object_id here.
struct object_id { unsigned char hash[GIT_MAX_RAWSZ]; };
Aha! As I suspected, the object_id struct holds a reference to the hash associated with an object.
OK. The next thing I wanted to look into is the definition of the object struct, which I found here.
struct object { unsigned parsed : 1; unsigned type : TYPE_BITS; unsigned flags : FLAG_BITS; struct object_id oid; };
The oid bit makes sense. Each object should have a reference to its ID. I was curious to figure out what parsed was used for. After some digging, I discovered the following code comment.
/** * Blobs do not contain references to other objects and do not have * structured data that needs parsing. However, code may use the * "parsed" bit in the struct object for a blob to determine whether * its content has been found to actually be available, so * parse_blob_buffer() is used (by object.c) to flag that the object * has been read successfully from the database. **/
OK! So it seems like one case in which the parsed bit can be used is to determine whether or not a blob object has had its file contents properly parsed.
Sidebar: For those who might be unfamiliar with C, the unsigned parsed: 1 syntax means that parsed is an unsigned value that consists of 1 bit. Similarly, the unsigned type : TYPE_BITS means that type is an unsigned value that consists of 3 bits.
From reading the code comments, I deduced that the type field indicates the type of the object (tree, commit, blob, etc.). The flag field was a little more complicated to figure out. It consisted of 27 bits. From the code comment below, I could discern that the flags were used in different parts of the codebase for a variety of use cases.
/* * object flag allocation: * revision.h: 0---------10 26 * fetch-pack.c: 0----5 * walker.c: 0-2 * upload-pack.c: 4 11----------------19 * builtin/blame.c: 12-13 * bisect.c: 16 * bundle.c: 16 * http-push.c: 16-----19 * commit.c: 16-----19 * sha1_name.c: 20 * list-objects-filter.c: 21 * builtin/fsck.c: 0--3 * builtin/index-pack.c: 2021 * builtin/pack-objects.c: 20 * builtin/reflog.c: 10--12 * builtin/unpack-objects.c: 2021 */
Yep! That sure is a lot. It looks like this flags field is used in everything from commits to pushes to bisections.
OK! So now I feel like I have a solid perspective of what an object is from both a filesystem and data structures perspective. It's time to look back at this chunk of code.
void add_head_to_pending(struct rev_info *revs) { struct object_id oid; struct object *obj; if (get_oid("HEAD", &oid)) return; obj = parse_object(&oid); if (!obj) return; add_pending_object(revs, obj, "HEAD"); }
OK! So the get_oid("HEAD", &oid) gets the ID of the object associated with the head commit. It's the equivalent of doing this one the command line.
$ git cat-file -t HEAD commit $ git cat-file -p HEAD tree f9505fb80cdbdb1081735bf9a824c6bc67081447 parent 38eea52e57f993d5c594aa7091cc9377b6063f5c author Safia Abdalla <[email protected]> 1520217895 -0600 committer Safia Abdalla <[email protected]> 1520217895 -0600 Change #1
So essentially, the first couple of lines in the function get the object associated with the current HEAD (or the most recent commit).
Alright, now the next thing I wanna figure out is what the add_pending_object function is doing. It's almost midnight at this point, and I'm debating whether or not I really want to dive into the code read for yet another function. I did find a piece of documentation that explained what the function did.
`add_pending_object`:: This function can be used if you want to add commit objects as revision information. You can use the `UNINTERESTING` object flag to indicate if you want to include or exclude the given commit (and commits reachable from the given commit) from the revision list.
I get what this statement is saying, but I also don't. Ya feel me? I think it might have something to do with the fact that I've been up for 18 hours and 75% of them have been reading/writing C code.
What I'm trying to say is, I'm going to end this blog post here. I did learn a couple of interesting things.
Git objects are uniquely identified by their hashes.
The type (blob, commit, tree, etc.) of a Git object is stored in a 3-bit unsigned integer.
Each object has a flag which is used throughout the code base for function-specific details.
To be honest, I'm starting to lose interest in this line of investigation. I think I might have gotten myself too in the weeds and strayed from my original point of inquiry. I'm gonna try and pose a new question to myself to structure my exploration in a different perspective and hopefully get me curious about it again. Specifically, in future posts, I'd like to figure out how a commit is made.
OK, I gotta get to bed...
1 note
·
View note
Text
Can Republicans Vote In Iowa Caucus
New Post has been published on https://www.patriotsnet.com/can-republicans-vote-in-iowa-caucus/
Can Republicans Vote In Iowa Caucus

Former Massachusetts Governor Takes Narrow Victory In First Republican Party Vote To Determine Who Will Challenge Barack Obama In November
Republican presidential candidate and former Massachusetts Governor Mitt Romney hugs his wife Ann at his Iowa Caucus night rally in Des Moines.
Omar karmi
CEDAR RAPIDS, IOWA // Former Massachusetts governor Mitt Romney may have won the inaugural contest to determine who will be Barack Obama’s main challenger in this year’s US presidential elections.
Iowa vote
Obama campaign warns of ‘extremist’ Republicans. Read article
But his victory in the Iowa caucuses by the narrowest of margins – eight votes out of 122,255 ballots cast – shows that his Republican Party is anything but certain about what kind of candidate it wants to challenge Mr Obama in November.
Mr Romney may consider himself to have the advantage, and the millionaire businessman will certainly try to paint himself as the only candidate with broad enough appeal to mount a serious challenge to Mr Obama.
Nevertheless, his hair-breadth’s victory mirrors a party that is hardly united in passion behind him. His appeal appears to lie in the cold-blooded perception that the economy would be safe in his hands were he president.
Rick Santorum, the former Pennsylvania senator, who took a surprising second place in Iowa, will continue to appeal to America’s religious conservative voters as the campaigns move to other states. His focus on family values helped him in Iowa where the evangelical Christian vote is a significant bloc.
“In many ways, Iowa is about who has to quit,” Mr Muller said.
The Iowa Caucuses Are Separated Out For Democrats And Republicans And They Each Do Things Pretty Differently
The process of “caucusing” on both sides takes roughly an hour or so in the evening.
For the Republicans, the process is generally considered to be simpler. Those in the caucus meetings are called activists, and they gather in groups to make their campaign. This is all in preparation for the final pitch. It can be pretty informal at times with candidates’ names written on pieces of paper, or some opting for a more formal . The votes are counted by chosen representatives and then sent along to Iowa’s GOP headquarters where the final numbers are kept.
For the Democrats, it’s not that simple.
First of all, there are no secret ballots for the Democrats and those attending Iowa caucus gatherings will be asked to physically move to a section of the room devoted to their candidate.
Some end up in uncommitted groups if they can’t make a decision. At this point, groups must have at least 15% of the people that came to that caucus location in their group to remain in the running. This is called being “viable.”
If a group isn’t considered viable at that point, attendees can either move to a group that is or try to convince others to join them. Once all the low-performing candidates have been weeded out and each group accounts for at least 15% of the room, delegates are awarded. The more support a candidate has during a caucus, the more delegates they are allocated.
The Iowa Caucuses Are On: Republicans Say Early Political Trips Reinforce Plans For 2024 Caucus
USA TODAY
Bloomberg
Mike Pompeo rattled off a list of his accomplishments as Secretary of State under former President Donald Trump, touted his Midwest roots and took nearly an hour of questions from a roomful of eager Iowa Republicans.
“We put America first, and we got it right,” he told the group of about 100 people who sipped coffee and finished plates of eggs and toast at the Machine Shed restaurant in Urbandale Friday.
It was part of Pompeo’s two-day swing through Iowa to help support the party in a state where Republicans nearly swept the board in the last election cycle and no major candidates have yet announced their intentions for the next one.
In the lead-up to the 2020 election, all eyes are on Iowa. Get updates of all things Iowa politics delivered to your inbox.
The subtext of his visit, however, is not 2022 but 2024.
Pompeo has hinted at a possible run for president, and his early forays into Iowa are yet another data point signaling the Republican presidential shadow primary has already begun.
“I see a lot of cameras in the back. I think there’s going to be some big announcement,” Pompeo joked, alluding to as much. “We’re in Iowa and all.”
Two other potential contenders — GOP Sens. Rick Scott of Florida and Tim Scott of South Carolina — have also announced trips to Iowa next month. Others, like former U.N. Ambassador Nikki Haley, visited the state to help Republicans campaign late last year.
Iowa Democrats Want To Be Fair To Candidates But Also Have A Clear Winner The Result Is A Mess
The funny or perhaps maddening aspect to all this is that the Iowa caucus results barely matter to the true way Democrats choose their nominee: national convention delegates.
This year, Iowa has 41 of those pledged delegates — about 1 percent of the national total. And since they’re allotted proportionally based on the above results, it’s tough for any candidate to rack up a big lead there.
But the caucuses’ big impact on the race has little to do with delegates anyway. It’s all about the perceptions of the political world. The media, party insiders, donors, activists, the candidates themselves, and even voters elsewhere look at what can be relatively small differences in Iowa results — and come to conclusions about which candidates have “won” or “lost.”
You’ll notice that in our hypothetical precinct results, though, we got three different results for who “won”:
For the pre-realignment total, Sanders had the most votes.
For the final vote total, Biden had the most.
For state delegate equivalents, Sanders and Biden were tied.
Of course, the result didn’t change that much; Biden and Sanders were the top two candidates and are close to each other in all three metrics. But the state delegate equivalent formula means that discrepancies from the vote total may — will — be introduced in each those 1,600-plus precincts. If one candidate ends up being systematically disadvantaged by these discrepancies, a different metric could mean a different “winner.”
Dc Dispatch: Biden Signs Rural Mental Health Bill Republicans Vote Against Jan 6 Commission


The U.S. Capitol.
Ahead of the July 4th holiday, members of Iowa’s congressional delegation led the passage of a veteran’s mental health bill, visited Iowa in a glimpse of what the 2024 caucus cycle might look like and voted on whether to create a commission to investigate the Jan. 6 Capitol attack.
Here’s what you missed in D.C. this week:
Biden signs rural mental health bill named for Iowa veteran
President Joe Biden on Wednesday signed a bill to establish new mental health programs for rural veterans. Rep. Cindy Axne, a Democrat, was the bill’s sponsor. Reps. Ashley Hinson, Randy Feenstra and Mariannette Miller-Meeks, all Republicans, joined her as co-sponsors on the legislation.
The bill is named for Sergeant Brandon Ketchum, an Iowa native and Army veteran who died by suicide in 2016. Ketchum was turned away by the Iowa City Veterans Administration Medical Center when he sought in-patient care.
“Brandon asked for help but was turned away because of a lack of resources,” Axne said in a May speech on the House floor. “We must make sure — in his memory and for the sake of others still serving — that when our soldiers return home, they can get the treatment they need.”
House votes to create select committee on Jan. 6 insurrection
Iowa’s senators attend GOP event in Sioux Center
Grassley also spoke in favor of the 60-vote filibuster rule in the Senate. He argued that the filibuster is the only way to ensure bipartisanship in Washington.
House passes INVEST in America Act
Iowa Caucuses Explained: What They Are Why They Don’t Really Matter And Why We Care Anyway
After months of media hype and TV debates and the ups-and-downs of polling, the long political warmup is over. The race for the presidency will finally get under way Feb. 1 when real voters make real choices in Iowa, the first state on the complicated U.S. election calendar. The Iowa caucuses are quirky, different for each party, and attract international attention. Adrian Morrow and Paul Koring explain what’s going on
Democratic presidential candidate Bernie Sanders speaks at a campaign event in Fort Dodge, Iowa.
JIM YOUNG/REUTERS
The Iowa Caucuses Are More About Gaining Momentum In The Race Than Predicting A Nominee
Did you know that every president since Jimmy Carter has been in the top three at the Iowa caucuses? Yes, it’s true. Well, save for when Tom Harkin of Iowa ran back in 1992. But, this is all to guide you to my point, that the Iowa caucuses are more of a mechanism to sort of speed the race up. It’s a way to gain momentum, rather than a solid predictor of who is going to be the nominee for each party, and go on to win the presidency.
Gop Anger At Barack Obama Washington Hillary Clinton Dc Republicans The Establishment
Iowa’s record-setting Democratic turnout in 2008 has been attributed in part to an unpopular president and a party’s frustration at being locked out of the White House for eight years.
Republican George W. Bush’s job approval was just 34 percent at the end of his term. A GOP groundswell is possible now that the tables are turned, and a Democrat with 44 percent approval occupies the White House.
Except for George H. W. Bush, no party has kept the White House three terms in a row since World War I, Goldford noted. Republicans believe that the “two-terms-and-you’re-out dynamic” points to a GOP victory in the general election, he said.
WHERE IN IOWA?: Track presidential campaign visits across the state
Curl: President Trump First Ever To Win Republican And Democratic Caucuses In Iowa
A perfect storm had rolled in just in time for the state’s first-in-the-nation vote on the 2020 Democratic presidential nomination. A newly, apparently untested app meant to ease communication among precinct chiefs during the caucuses failed completely, with the app designers blaming “coding issues.” A failsafe backstop — having precinct chiefs simply phone in the results to the state party headquarters — also failed, with workers being too busy to answer the calls.
The whole mess was a terrible start for Democrats vying to replace President Trump in the White House. Memes immediately exploded across the internet, with one being repeated often: The Democrats want to run the country, but they can’t even hold a caucus in the cornfields.
For the record, the Republicans also held their caucuses in Iowa on Monday. While they garnered little media coverage, Trump blew out his primary rivals, winning more than 97% of the vote over former Massachusetts Gov. Bill Weld and former Illinois congressman Joe Walsh, who each came in with about 1% each.
In many ways, Trump won both caucuses. And he knew it. He took to Twitter early to needle Democrats for their pathetic efforts in Iowa.
“The Democrat Party in Iowa really messed up, but the Republican Party did not. I had the largest re-election vote in the history of that great state, by far, beating President Obama’s previous record by a lot. Also, 97% Plus of the vote! Thank you Iowa!” Trump wrote first thing in the morning.
Countdown To Iowa: A Caucus Guide For What To Know About America’s First Vote
Caucuses are only the first stage in key voting states’ selection process and provide a litmus test for which party candidates could fare well in the primaries
Explainer: how the confusing Iowa caucuses actually work
Last modified on Wed 26 Feb 2020 18.01 GMT
The Iowa caucuses are a unique political institution that play a crucial role in the American primary process. However, they aren’t particularly intuitive to understand or follow.
What time do the caucuses start?
The caucuses start at 7pm local time on Monday, but campaigns encourage their supporters to show up half an hour early.
How do the caucuses unfold?
Very different rules govern the Democratic and Republican caucuses:
Republicans have a relatively straightforward process, in which they cast secret ballots in their precinct caucuses – church halls, school buildings.
Read more
Can unregistered voters take part?
Any Iowan who will be over the age of 18 at the time of the presidential election can participate. Attendees can register on the night at the caucuses and can switch their party affiliation there as well. This means a Democrat can go to the Republican caucuses and vice versa. Four years ago, 121,503 people showed up to the 2012 Republican caucuses. Democrats have traditionally had higher turnout and, in their last competitive caucus in 2008, 239,872 people attended.
What happens then?
A simple guide to the Hawkeye state caucuses.
How are delegates decided?
Where will the candidates be on the night?
Once The Voting Is Over Its Time To Translate Those Results Into Delegates
Delegates, after all, are the point of presidential primaries and caucuses. It’s delegates, not the sheer number of votes, that political parties count to determine who will be their nominee.
After the alignments, the viable candidates will be allocated what’s called “State Delegate Equivalents,” according to their performance at that site.
These delegates, through a process involving Democratic Party math and the state convention, will eventually correlate to the number of national delegates a candidate gets at the national conventions.
The Iowa Democratic Party doesn’t declare a winner, but historically the person with the most SDEs has been considered the winner. However, with the first- and second-round results being reported out this year, it’s conceivable candidates could have more opportunities to spin the results in their favor.
Registered Republican voters show up at their caucus site, hear some speeches and vote for their preferred candidate. The votes are counted and the delegates are elected to the county convention based on the proportion of support a candidate receives.
Despite several state Republican parties canceling their 2020 primaries because an incumbent is running for reelection, Iowa Republicans will hold their caucus on Feb. 3.
The Difference Between A Republican And Democratic 2020 Caucus Experience
IOWA — Precinct locations throughout Siouxland are geared up to open their doors for caucus-goers Monday night.
The process of caucusing can be confusing since it differs so much from a primary vote.
There are many Democratic candidates to choose from, 11 to be exact, and Democratic caucuses different from Republican.
Democrats have an open vote.
For comparison: during the primaries, you simply vote but in the caucus, you have a discussion and then vote.
You physically vote with your body, and you move to certain parts of the room to show which candidate you support.
So, after each campaign makes its pitch, Democrats split up into “preference groups”, which support a specific candidate. But, unless a “preference group” is made up of at least 15% of the people at that caucus, the group isn’t viable.
Those supporters can choose to re-align and support another candidate that’s still “viable” and what some may not know is that undecided could be one of those viable groups
“If a group of undecided people align together and they are above 15%, then yeah, they have to stay with that group of undecided,” said Theresa Weaber-Basye, Co-Chair for Precinct 10. “And they could make their decision further down the road as to where their vote will go.”
While the Democrats have a large ballot of candidates to choose from, it’s different for the Republicans.
Votes are then counted and winner takes all.
To learn more about how a caucus works,
Iowa Is Not The Only State That Conducts Caucuses Instead Of Primaries

Caucuses are different from primaries for a number of reasons. You do not simply show up, check a box, and leave with an “I voted” sticker.
The process can take hours, as voters gather at a venue to hear out supporters of various candidates, debate issues, and ultimately come to a conclusion about which person will make the best presidential nominee. Voters select delegates who will represent them at the party’s annual convention in the summer.
When voters arrive at the venue, which can be anywhere from a high school gymnasium to a restaurant, supporters of certain candidates break off into groups, including groups for undecided voters. Then voters, who are typically activists and very politically engaged, will plead their case to everyone about why their preferred candidate is the best choice.
With a large field of candidates and a diverse spectrum of ideology in the Democratic race, this could take all night. On Monday night’s Iowa caucuses, the process stretched into the next day due to the errors in reporting the results. By Tuesday afternoon, Iowa’s results still hadn’t been released.
Most caucuses have a threshold to earn delegates, meaning that a candidate might need 15% or more of the votes to be awarded delegates. For instance, Ted Cruz earned eight delegates in the 2017 Iowa caucuses, while Donald Trump and Marco Rubio each earned seven, respectively.
The states with caucuses are:
Iowa
The US territories conducting caucuses are:
What Are The Iowa Caucuses And How Do They Work All You Need To Know
The midwestern state is the first to vote in the presidential primary race. So what are caucuses, and how do they work? Here’s your guide to the night
The Iowa caucuses take place on Monday 3 February, kicking off the long process of nominating a Democratic presidential candidate who will eventually take on Donald Trump in November’s US election.
The primary race is made up of a series of contests called primaries and caucuses that take place in all 50 states plus Washington DC and outlying territories, by which the parties select their presidential nominee from the candidates who are running.
The goal in these contests is for candidates is to amass support from voters that translates into a majority of delegates, whose job it is to nominate a presidential candidate at the party conventions in July and August.
When it comes to choosing a presidential candidate, Iowa traditionally goes first. Though Iowa has relatively few delegates, it is highly influential because it gives Americans their first chance to see what support the candidates have, and a win could provide a vital boost in momentum, as it did for Barack Obama in 2008.
Democratic and Republican caucuses will take place on Monday evening, but because Trump does not face any serious competition from his challengers for the nomination, all eyes will be on the Democratic contenders this year.
County District State Convention And National Convention Delegates
Total pledged delegates 41
A total of 11,402 county convention delegates are elected according to the procedure described above across 1,678 precinct caucuses and 87 satellite caucuses. They will then go to their local county convention on March 21, to choose 2,107 district and state delegates who are pledged to support presidential candidates according to the proportional state delegate equivalents result of the caucuses. These elected districts and state delegates will subsequently go to the district conventions on April 25 and state convention on June 13 . In total, 41 pledged national convention delegates are elected for the 2020 Democratic National Convention with their pledged support being determined proportionally to the presidential candidate’s total number of SDEs won statewide and in each of the state’s four congressional districts; but only for those presidential candidates who manage to qualify by winning at least a 15% share of the SDEs statewide or in the specific district. Meaning that all presidential candidates winning less than a 15% share of SDEs statewide and in CD1, CD2, CD3, CD4, will win 0 pledged national convention delegates.
Why Does Such A Small Homogeneous State Get Such An Oversized Role
Iowa’s first-in-the-nation status is the end result of the 1968 Democratic National Convention, which was marred by conflict in the convention hall, and racial and Vietnam War protests and violence in the streets. Party leaders decided to turn away from a top-down process of selecting nominees and instead move toward a voter-driven process that was viewed as more democratic. Iowa had long held caucuses, but the state’s months-long delegate selection process resulted in it being selected to go first. Republicans soon followed suit.
The caucuses have long drawn criticism. They take place at a set time in the evening, so they preclude the participation of some Iowans, such as night shift workers. The new Democratic satellite caucuses are designed to address this.
The number of participants is dismally low. In 2016 — a contest when both the Democratic and Republican nominations were up for grabs — fewer than 358,000 Iowans caucused, less than 16% of those eligible to vote.
To put that number in perspective, more than 8.5 million Californians voted in the two parties’ 2016 presidential primaries, or 47.7% of the state’s registered voters. Iowa caucus supporters argue that it is critical for candidates to be able to make their case to voters in person, and in states that don’t require massive media buys.
Democrats increasingly worried about the prospect of Bernie Sanders winning their nomination are pushing harder to block him, galvanizing his backers in the process.
Presidential Caucuses Are Complicated Why Do Some States Use Them
Politics
As the 2020 presidential nomination season kicks off in February, it won’t start with a primary — where voters go to their polling place and cast a secret ballot — but with caucuses. While the vast majority of states hold primary elections, a few use these more complicated events to show their preferences for candidates.
In recent years, some states have ditched caucuses for primaries, but Iowa, Nevada and Wyoming are holdouts. So why choose a caucus?
Party caucuses have been used in various forms in the United States since the 1800s to address a range of political topics. In Iowa’s case, caucuses not only allow activists and voters to make a case for their preferred candidate, but also to talk about issues that could be incorporated into the state party platform, said Dennis Goldford, a political science professor with Drake University in Iowa.
They also attract enthusiastic party members. Caucusing requires passion and a strong connection to a particular candidate, in contrast to the simple and private act of marking a ballot in a primary. “ make candidates and potential candidates talk to voters as real, live, individual human beings,” Goldford said. Candidates meet with voters in a more personal way, he added, rather than using them as “campaign props.” Especially in early caucus states, a relatively small group of people wields a lot of power to influence average voters around the country.
Are The Iowa Caucuses Predictive Of Who Will Win The White House
Maybe. But probably not. Among Democrats, the winner of the caucuses has won the nomination in seven out of the 10 contested races since 1972. But only two candidates — Jimmy Carter and Barack Obama — have gone on to win the White House. Among Republicans, the caucus winner has won the nomination in three of eight contested contests, but only won the White House once: George W. Bush in 2000.
The caucuses definitely have had their moments, allowing candidates to prove theirviability. Among the top examples is Obama in 2008. His ability to win the caucuses — beating John Edwards and Hillary Clinton in an overwhelmingly white state — helped dispel doubts that the United States could elect a black president.
Record Turnout Means Big Numbers For Everyone Not Just Trump
More than 180,000 Republicans caucused Monday night, shattering the 2012 record of 121,503 people. According to entrance polling from The New York Times, 45% of those Republican caucusgoers were participating in the process for the first time.
Many predicted record turnout primarily would benefit Trump, suggesting Trump would inspire people who had not previously been engaged in the political process.
And that held true — to a degree.
Thirty percent of those first-time caucusgoers were supporting Trump. But Rubio and Cruz also benefited, earning 22% and 23% of those voters respectively, effectively stopping Trump from running away with it.
“Even though the Trump people were able to bring some new voters to the polls, they just couldn’t overcome a groundswell of Republicans who now have a good reason to go out and vote,” said Bryan English, Cruz’s state director, noting Cruz’s attractiveness to the GOP base.
0 notes
Text
T SQL Advanced Tutorial By Sagar Jaybhay 2020
New Post has been published on https://is.gd/AQSl2U
T SQL Advanced Tutorial By Sagar Jaybhay 2020
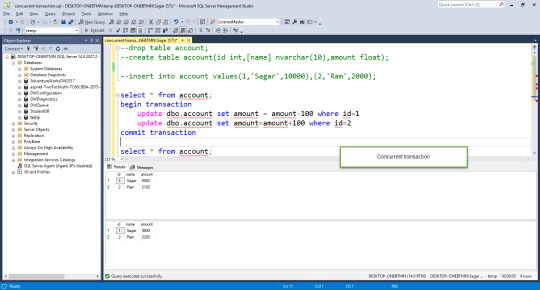
In this article we will understand T SQL Advanced Tutorial means Transaction In SQL and Common Concurrency Problem and SQL server transaction Isolation level by Sagar Jaybhay
What is the Transaction?
A transaction is a group of commands that changed the data stored in a database. A transaction is treated as a single unit.
The transaction ensures that either all commands will succeed or none of them. Means anyone fails then all commands are rolled back and data that might change is reverted back to the original state. A transaction maintains the integrity of data in a database.
begin try begin transaction update dbo.account set amount = amount-100 where id=1 update dbo.account set amount=amount+100 where id=2 commit transaction print 'transaction committed' end try begin catch rollback transaction print 'transaction rolled-back' end catch
In the above example either both statements executed or none of them because it goes in catch block where we rolled-back transactions.
begin try begin transaction update dbo.account set amount = amount-100 where id=1 update dbo.account set amount=amount+100 where id='A' commit transaction print 'transaction commited' end try begin catch rollback transaction print 'tranaction rolledback' end catch
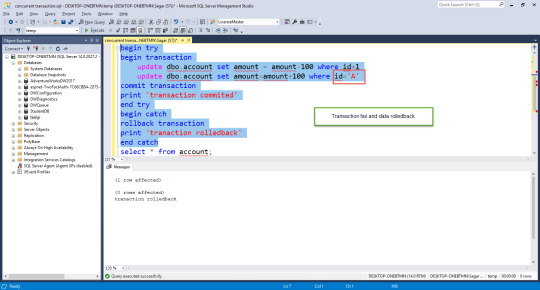
Common Concurrency Problem
Dirty reads
Lost update
Nonrepetable reads
Phantom reads
SQL server transaction Isolation level
Read Uncommitted
Read committed
Repeatable read
Snapshot
Serializable
How to overcome the concurrency issues?
One way to overcome this issue is to allow only one user at the time allowed for the transaction.
Dirty Read Concurrency Problem:
A dirty read happens when one transaction permitted to read data that modified by another transaction but that yet not committed. Most of the time it will not cause any problem because if any case transaction fails then the first transaction rolled back its data and the second transaction not have dirty data that also not exist anymore.
To do 2 transactions on one machine open 2 query editor that is your 2 transaction machine and you do an operation like below
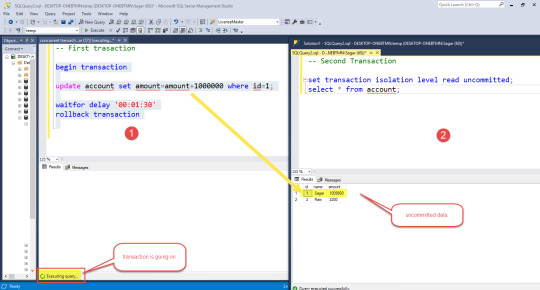
For the first transaction, we update the amount in the account table and then given a delay for 1 min 30 seconds and after this, we rollback the transaction. And in the second window, we select data from a table where we can see uncommitted data and after transaction rollback, we see committed data.
We have default isolation level read committed to set different for reading uncommitted data you can use below command.
set transaction isolation level read uncommitted; -- the First transaction begin transaction update account set amount=amount+1000000 where id=1; waitfor delay '00:01:30' rollback transaction -- Second Transaction set transaction isolation level read uncommitted; select * from account;
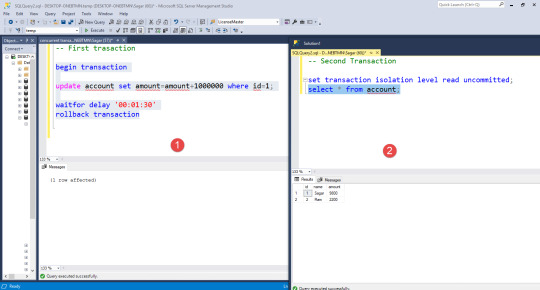
Lost Update
It means that 2 transactions read and update the same data. When one transaction silently overrides the data of another transaction modified this is called a lost update.
Both read committed and read uncommitted have lost update side effects.
Repeatable reads, snapshots, and serialization do not have these side effects.
Repeatable read has an additional locking mechanism that Is applied on a row that read by current transactions and prevents them from updated or deleted from another transaction.
-- first transaction begin transaction declare @amt float select @amt=amount from account where id =1; waitfor delay '00:01:20' set @amt=@amt-1000 update account set amount=@amt where id=1; print @amt commit transaction -- first tarnsaction -- second transaction begin transaction declare @amt float select @amt=amount from account where id =1; waitfor delay '00:00:20' set @amt=@amt-2000 update account set amount=@amt where id=1; print @amt commit transaction
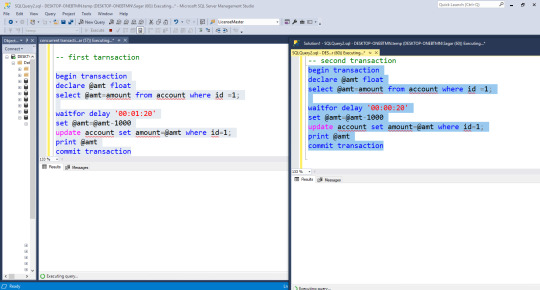
Non-Repeatable read
It was when the first transaction reads the data twice and the second transaction updates the data in between the first and second transactions.
Phantom read
It happens when one transaction executes a query twice and it gets a different number of rows in the result set each time. This happens when a second transaction inserts a new record that matches where the clause of executed by the first query.
To fix phantom read problem we can use serializable and snapshot isolation levels. When we use the serializable isolation level it would apply the range lock. Means whatever range you have given in first transaction lock is applied to that range by doing so second transaction not able to insert data between this range.
Snapshot isolation level
Like a serializable isolation level snapshot also does not have any concurrency side effects.
What is the difference between serializable and Snapshot isolation level?
Serialization isolation level acquires it means during the transaction resources in our case tables acquires a lock for that current transaction. So acquiring the lock it reduces concurrency reduction.
Snapshot doesn’t acquire a lock it maintains versioning in TempDB. Since snapshot does not acquire lock resources it significantly increases the number of concurrent transactions while providing the same level of data consistency as serializable isolation does.
See below the image in that we use a serializable isolation level that acquires a lock so that we are able to see the execution of a query in progress.
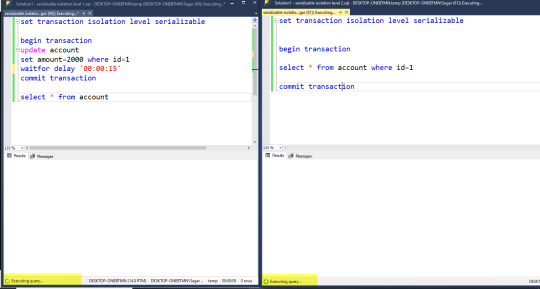
Now in the below example, we set a database for allowing snapshot isolation. For that, we need to execute the below command.
alter database temp set allow_snapshot_isolation on
Doing so our database tempdb is allowed for snapshot transaction than on one window we use serialization isolation level and on the second we use snapshot isolation level. When we run both transactions we are able to see the snapshot isolation level transaction completed while serialization is in progress and after completing both transactions we see one window has updated data and others will have previous data. First

Now after completing both transactions
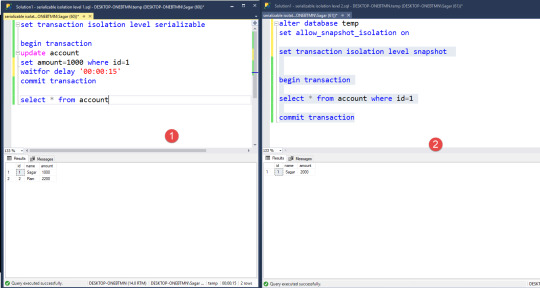
snapshot isolation never blocks the transaction.
It will display that data which is before another transaction processing
It means that snapshot isolation never locks resources and other transaction able read the data
But here one transaction is updating the data another is reading that data so it’s ok
When both transactions updating same data then transaction blocks and this blocks until the first transaction complete and then transaction 2 throws error lost update why because preventing overwriting the data and it fails and error is transaction is aborted you can’t use snapshot isolation level update, delete insert that had been deleted or modified by another transaction.
If you want to complete the second transaction you need to rerun that transaction and data is modified successfully.
Read Committed Snapshot Isolation Level
It is not a different isolation level. It is an only different way of implementing Read committed isolation level. one problem in that if anyone transaction is updating the record while reading the same data by another transaction is blocked.
Difference between Snapshot isolation level and Read Committed Snapshot isolation level.
Snapshot IsolationRead Committed Snapshot isolation levelIt is vulnerable to update conflictsNo update conflicts hereCan not use with a distributed transactionIt can work with a distributed transactionProvides transaction-level read consistencyIt provides statement-level read consistency
My Other Site: https://sagarjaybhay.net
0 notes
Text
300+ TOP Database Architecture Interview Questions and Answers
Database Architecture Interview Questions for freshers experienced :-
1. What is an Oracle Rollback Segment? A Database contains one or more Rollback Segments to temporarily store "undo" information. 2. What are the uses of Oracle Rollback Segment? Rollback Segments are used : To generate read consistent database information during database recovery to rollback uncommitted transactions for users 3. What are Oracle Schema Objects? Schema objects are the logical structures that directly refer to the databases data. Schema objects include tables, views, sequences, synonyms, indexes, clusters, database triggers, procedures, functions packages and database links. 4. What is an Oracle Data Block? ORACLE database's data is stored in data blocks. One data block corresponds to a specific number of bytes of physical database space on disk. Oracle database consists of logical storage place which is called as blocks and the bytes in a block is set through DB_BLOCK parameter in parameter file 5. Can objects of the same Schema reside in different tablespaces? Yes objects of the same Schema reside in different tablespaces 6. What is the use of Oracle Control File? When an instance of an ORACLE database is started, its control file is used to identify the database and redo log files that must be opened for database operation to proceed. It is also used in database recovery. Control files is a binary file. Before database is opened it determines whether database is in valid state or not. If yes then database is opened. 7. Can a View based on another View in Oracle? Yes a View based on another View in Oracle 8. What is the function of Redo Log in Oracle? The Primary function of the redo log is to record all changes made to data 9. Describe the different type of Integrity Constraints supported by ORACLE? NOT NULL Constraint - Disallows Nulls in a table's column. UNIQUE Constraint - Disallows duplicate values in a column or set of columns. PRIMARY KEY Constraint - Disallows duplicate values and Nulls in a column or set of columns. FOREIGN KEY Constrain - Require each value in a column or set of columns match a value in a related table's UNIQUE or PRIMARY KEY. CHECK Constraint - Disallows values that do not satisfy the logical expression of the constraint. 10. What is an Oracle Data Dictionary? The data dictionary of an ORACLE database is a set of tables and views that are used as a read-only reference about the database. It stores information about both the logical and physical structure of the database, the valid users of an ORACLE database, integrity constraints defined for tables in the database and space allocated for a schema object and how much of it is being used.

Database Architecture Interview Questions 11. What is an Oracle SYSTEM tablespace and when is it Created? Every ORACLE database contains a tablespace named SYSTEM, which is automatically created when the database is created. The SYSTEM tablespace always contains the data dictionary tables for the entire database. The SYSTEM tablespace is created automatically for each new Oracle database. It contains all the data dictionary objects for the entire database. 12. Can an Integrity Constraint be enforced on a table if some existing table data does not satisfy the constraint? Yes we can enforce integrity constraint on a table if some existing table does not satisfy the constraint by using "ENABLE NOVALIDATE" 13. How to define Data Block size in Oracle? A data block size is specified for each ORACLE database when the database is created. A database users and allocated free database space in ORACLE datablocks. Block size is specified in INIT.ORA file and can?t be changed latter. A data block size is defined by DB_BLOCK parameter in pfile and there could be non standard block sizes supported by Oracle upto block size of 32bytes Once set the block size could not be changed and the database has to be created again 14. What is an Integrity Constrains in Oracle? An integrity constraint is a declarative way to define a business rule for a column of a table. 15. Can a Tablespace hold objects from different Schemes in Oracle? Yes a Tablespace can hold objects from different Schemes in Oracle 16. What is an oracle database schema? A schema is collection of database objects of a User. A schema is collection of database objects of an user and is used synonym of an user. Schema name = user name 17. What is an Oracle Data Segment? Each Non-clustered table has a data segment. All of the table's data is stored in the extents of its data segment. Each cluster has a data segment. The data of every table in the cluster is stored in the cluster's data segment. Database Architecture Questions and Answers Pdf Download Read the full article
0 notes
Text
Various Types of InnoDB Transaction Isolation Levels Explained Using Terminal
The goal of this blog post is to explain the various types of transaction isolation levels available in MySQL. After reading the blog, you will be able to explain dirty reads, non-repeatable reads, and the concept of phantom rows as well. What is the Isolation Level in MySQL? Isolation (I) is one of the properties from ACID. It defines how each transaction is isolated from other transactions and is a critical component of application design. As per the SQL:1992 standard, InnoDB has four types of Isolation levels. Below, I have listed the types in order, and each transaction isolation level provides better consistency compared to the previous one. READ-UNCOMMITTED READ-COMMITTED REPEATABLE-READ – ( MySQL’s DEFAULT ) SERIALIZABLE You can change the isolation level using the variable “transaction_isolation” at runtime. As transaction isolation changes can impact the result sets of your queries, you most certainly want to test this in a non-production environment in order to evaluate the impact on your application.”mysql> set global transaction_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) READ-UNCOMMITTED: No locks Dirty reads, non-repeatable reads, phantom reads are possible The below example will help to understand the “read-uncommitted” and how the dirty reads are happening. I am using two sessions – S1 and S2. For session S1:mysql> set global transaction_isolation='read-uncommitted'; Query OK, 0 rows affected (0.00 sec) mysql> r Connection id: 16 Current database: percona mysql> select * from ReadUncommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update ReadUncommit set name='ram' where id=3; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0For session S2:mysql> select * from percona.ReadUncommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | ram | +----+------+ 3 rows in set (0.00 sec)At S1, I globally modified the transaction_isolation to read-uncommitted and started the transaction. I executed the UPDATE statement ( name = ram ) at S1 but did not commit the transaction yet. Then I created the S2 and executed the SELECT for the table, and I was able to see the uncommitted modified data. This is called dirty reads. So, with “read-uncommitted”, the transactions from different sessions can view the modification from the different transactions before it commits. READ-COMMITTED: Dirty reads are not possible Non-repeatable reads and phantom reads are possible The below example will help to understand the “read-committed” and how the non-repeatable reads are happening. I am using two sessions – S1 and S2. For session S1:mysql> set global transaction_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) mysql> r Connection id: 18 Current database: percona mysql> select * from ReadCommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update ReadCommit set name='ram' where id=3; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0For session S2:mysql> select * from percona.ReadCommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)At S1, I globally modified the transaction_isolation to “read-committed” and started the transaction. I executed the UPDATE statement ( name = ram ) at S1 but did not commit the transaction. Then I created S2 and executed the SELECT for the table, and I was not able to see the uncommitted modified data. So, with “read-committed”, the transactions from different sessions can’t view the modification from the different transactions until it commits. Only committed modifications can be viewed. Then, what is the drawback with “read-committed”? Non-repeatable read is possible with the “read-committed”. Below, I explain how the non-repeatable read occurred. For session S1:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from ReadCommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)For session S2:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update percona.ReadCommit set name='ram' where id=3; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)For session S1:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from ReadCommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> select * from ReadCommit; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | ram | +----+------+ 3 rows in set (0.00 sec)At S1, I started the transaction and executed the SELECT to view the data. Then at S2, I executed the UPDATE statement ( name = ram where id = 3) to modify the data. I committed the transaction on S2. Again, at S1 I executed the same SELECT to view the data inside the same transaction. But, this time I have a different result. This is called a non-repeatable read. Having a different result for the same query inside the transaction is not fair, and it may lead your transaction to be inconsistent. “REPEATABLE-READ” will help to overcome this. REPEATABLE-READ: Dirty reads and non-repeatable reads are not possible Phantom reads are possible The below example will help to understand the “repeatable-read” and how the phantom reads are happening. I am using two sessions – S1 and S2. For session S1:mysql> set global transaction_isolation='repeatable-read'; Query OK, 0 rows affected (0.00 sec) mysql> r Connection id: 20 Current database: percona mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)For session S2:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update percona.RepeatRead set name='ram' where id=3; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)For session S1:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ |�� 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)At S1, I globally modified the transaction_isolation to “repeatable-read” and started the transaction. I executed the SELECT to view the data. Then I created S2 and executed the UPDATE statement ( name = ram where id = 3) to modify the data. I committed the transaction on S2. Again at S1, I executed the same SELECT to view the data inside the same transaction. There are no changes. So, here we overcome the problem of being read-committed. At repeatable-read, the snapshot of the SELECT will be taken during the first execution of SELECT, and it will be until the transaction ends. Still, we may get the phantom rows with repeatable-read. How Do Phantom Rows Occur? The below example will help to understand how the phantom rows are occurring inside the transaction. For session S1:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)For session S2:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> insert into percona.RepeatRead values (4,'ram'); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec)For session S1:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> select * from RepeatRead; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec) mysql> update percona.RepeatRead set name='sriram' where id=4; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from RepeatRead; +----+--------+ | id | name | +----+--------+ | 1 | jc | | 2 | herc | | 3 | sri | | 4 | sriram | +----+--------+ 4 rows in set (0.00 sec)From the above example, at S1, I have executed the SELECT to read the data. Then, I have inserted the row ( id=4 ) on S2. Again, I executed the SELECT at S1, and there are no changes because we are using repeatable-read isolation. Again at S1, I executed the UPDATE to modify the data which was inserted by S2 ( id = 4 ), then executed the same SELECT at S1. But, this time I have different results, which is called the phantom reads. This can be avoided with “SERIALIZABLE”. SERIALIZABLE: No dirty reads No non-repeatable reads No phantom reads The below example will help to understand the “serializable” isolation. I am using two sessions – S1 and S2. For session S1:mysql> set global transaction_isolation='serializable'; Query OK, 0 rows affected (0.00 sec) mysql> r Connection id: 22 Current database: percona mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from Serialize; +----+------+ | id | name | +----+------+ | 1 | jc | | 2 | herc | | 3 | sri | +----+------+ 3 rows in set (0.00 sec)For session S2:mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> insert into percona.Serialize values (4,'ram'); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction mysql> update percona.Serialize set name='aaa' where id=3; ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionFrom the above example, I globally modified the isolation level to “serializable” and started the transaction at S1. Then I created session 2 and tried to do an INSERT/UPDATE at S2… however, these statements timeout due to pre-existing locks being held. At the isolation level serializable, InnoDB implicitly converts all SELECT statements to SELECT FOR SHARE if autocommit is disabled. The SELECT statement from S1 sets shared locks (LOCK IN SHARE MODE) that permit other transactions to read the examined rows but not to update or delete them. So, the INSERT/UPDATE is failing. Serializable ensures more consistency for the transactions, but you will have to address increased locking conditions in MySQL. https://www.percona.com/blog/2021/02/11/various-types-of-innodb-transaction-isolation-levels-explained-using-terminal/
0 notes
Link
via Politics – FiveThirtyEight
If you’re an electoral politics junkie, you may have already read something about how Iowa could actually produce three different winners (!) on Monday night. What the heck does that actually mean? Let me explain — while also giving you some insight into how our forecast model handles these different versions of the vote count, and which candidates might benefit in one count versus another.
The Iowa caucuses work by voters entering a caucus site such as a high school gymnasium at 7 p.m. and physically forming preference groups — all the Elizabeth Warren supporters stand in one corner of the room, and all the Joe Biden supporters in another, for instance. Voters may also join an uncommitted group.1
This is called the first alignment of voter preferences — and for the first time this year, Iowa Democrats will count and record how voters are aligned at this stage of the process. Thus, the first alignment is the first of the three ways that the caucus vote will be reported. It’s the most straightforward metric of candidate support, and it’s the closest that the Iowa caucuses come to the voting as it will take place in most other states, where voters get just one choice and there are none of the complicated rules that I’ll describe in a moment.2
Iowa’s process doesn’t stop there, however. Voters in candidate groups that fail to meet a viability threshold in the first alignment — typically 15 percent of the vote, but it can be higher in smaller precincts — have one of three choices:
They can join a viable group.
They can try to combine with voters in other nonviable groups to achieve viability. For example, if the Warren group initially has 14 percent of the vote, it’s not necessarily dead in the water. Rather, it could recruit a few Tom Steyer voters, or a Michael Bennet supporter, etc., to get to 15 percent. It can’t recruit voters from groups that already achieved viability, however. Once a group is viable, it can continue to add new voters and grow larger, but it can’t lose them.
Or they could just go home. Nothing forces them to participate in further rounds of caucusing.
The vote count after this stage goes by several names, but I’ll call it the final alignment. It’s the second of the three ways that Iowa will report its vote. And it has a lot of things going for it. Since only candidates who get at least 15 percent of the vote are eligible for delegates to the Democratic National Convention, it makes sense to give voters who initially choose a candidate who can’t get 15 percent a chance to express a preference for a candidate who does. And the realignment process is a highly traditional and distinctive part of the caucuses that the candidates plan around.
Incidentally, the final alignment is the version of the vote count that our model simulates. When we say that Bernie Sanders’s projected share of the vote runs between 13 and 43 percent, that’s a projection of his final alignment vote.
But the model does make a few simplifications. For instance, because the process of simulating realignment is somewhat computationally intensive, we calculate it for 80 hypothetical caucus sites of various sizes — 20 in each congressional district — rather than the full contingent of roughly 1,700 precincts that will caucus on Monday. And to estimate how widely initial preferences might vary from precinct to precinct, we used the precinct-by-precinct vote from the Republican caucuses in 2016 as our guide.3 Incidentally, you should expect there to be quite a bit of variation in the vote from precinct to precinct, especially given that most precincts are fairly small. If Warren is at 15 percent of the vote districtwide, she’ll have some precincts where she’s at 25 percent of the vote or more and others where she has very few votes. There is not necessarily a bright line at 15 percent exactly.
In simulating the process, we assume that voters make decisions in order of the smallest nonviable group to the largest. (Essentially, this is the equivalent of tabulating votes under ranked choice voting.) If Bennet has 1 percent of the vote for example and is the smallest group in a particular precinct, his voters will be assigned to other candidates first. The process continues until all groups either become viable or have their voters reassigned.4
I’ve skipped over a rather important detail, however. How does the model decide which voters realign to which groups? This is based on a combination of three factors:
Larger groups are assumed to be more capable of attracting new supporters, other things being equal.
Whether the group was initially viable matters. If a group was not viable at first, it may be at risk of losing members to other groups at the same time it is trying to recruit its own new members. So the model hedges its bets. In some simulations, supporters of nonviable candidates may be willing to join with other nonviable candidates in an effort to achieve viability. Other times, they’ll resist this.
Finally, we use a proximity rating, which estimates how far apart the candidates are from one another along ideological and other dimensions. For instance, Sanders supporters are assumed to be somewhat more likely to go to Warren than the other major candidates and vice versa. And Biden voters are assumed to be fairly close to Amy Klobuchar voters and to be more likely to prefer one another as a second choice.
None of this ideal — there’s a lot of guesswork involved. Second choices for unconventional candidates such as Andrew Yang aren’t easy to capture under this method, for instance. (All of the data that Iowa publishes this year should hopefully make things easier in 2024.) Nonetheless, our method does a pretty good job of replicating polls that show voters’ second choices. Note that our assumptions aren’t terribly aggressive, either. For instance, if a group of Warren voters is trying to decide between Sanders and Biden, the model would have them going about 3:2 to Sanders, but not in a more lopsided ratio than that.
As you can probably infer from the above, this yields some fairly complicated patterns as far as second choices go:
Sanders isn’t a natural second choice for any of the moderates (Biden, Klobuchar or Pete Buttigieg). But he is a good second choice for Warren voters, and Warren may be under 15 percent in many precincts.
Biden’s case is somewhat parallel to Sanders’s, except with Klobuchar serving in the role of Warren. If Klobuchar stays under 15 percent in most precincts, Biden is an obvious second choice for her voters. But a Klobuchar surge could hurt him.
Buttigieg tends to pick up a lot of second-choice support both in polls and in our model, and to draw it from a fairly wide-ranging group of candidates. This is because he’s sort of in the middle of the spectrum: more progressive than Biden and arguably Klobuchar, but less so than Warren and Sanders.
Warren often polls well as a second choice. However, much of her second-choice support comes from Sanders supporters, and Sanders figures to be above 15 percent in most precincts. So while there’s an upside case for Warren if Sanders underperforms his polls, his recent surge has hurt her. Still, she is also a somewhat logical landing spot for Klobuchar and Buttigieg supporters as all three candidates overperform among college-educated voters.
Klobuchar, like Buttigieg, could theoretically be a logical second choice for supporters of several other candidates. However, she’ll need to beat her polls to do so, as her current position in our Iowa polling average (10 percent) will have her under the viability threshold in many precincts.
Acknowledging that our model has to make a lot of educated guesses about voter behavior, let’s look at some of its predictions. First, here’s a comparison between the first alignment and the final alignment for each candidate, averaged across 10,000 simulations from a model run late Sunday night:
How Iowa’s votes could change from one stage to the next
Average FiveThirtyEight model Iowa caucus first alignment and final alignment projections, as of Feb. 2, 2020
Candidate First Alignment Final Alignment Change Sanders 23.6% 28.1% +4.5 Biden 22.5 26.4 +3.9 Buttigieg 16.5 17.9 +1.4 Warren 15.7 15.9 +0.2 Klobuchar 10.8 8.8 -2.0 Yang 4.0 1.4 -2.6 Steyer 3.8 1.3 -2.5 Bloomberg 1.3 0.1 -1.2 Gabbard 1.2 0.0 -1.2 Bennet 0.5 0.0 -0.5 Patrick 0.2 0.0 -0.2
As you can see, the topline effects of realignment are fairly simple. Candidates comfortably above 15 percent tend to gain votes and see their leads grow — for instance, Sanders’s share of the vote grows from 23.6 percent (first alignment) to 28.1 percent (final alignment) in our projections. Candidates near 15 percent tend to tread water. And candidates well under 15 percent can lose the large majority of their vote, perhaps almost all of it, to other candidates.
With that said, these topline effects conceal a range of possible outcomes. For a taste of this, here is a chart showing how Buttigieg’s final alignment is projected to turn out given various levels of first alignment vote:
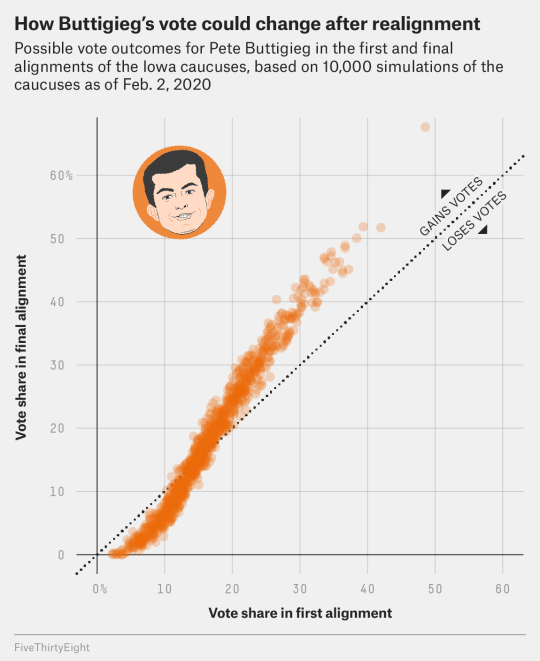
If Buttgiieg’s first alignment vote is in the single digits or the low teens, then realignment will hurt him. But if he gets around 20 percent of the vote in the first alignment, he’s projected to wind up with an average of somewhere around 24 or 25 percent of the vote in the final alignment. That’s actually a fairly big gain. It’s slightly better than Sanders, for instance, who would be projected to get closer to 23 percent of the final alignment vote with 20 percent of the first alignment vote:
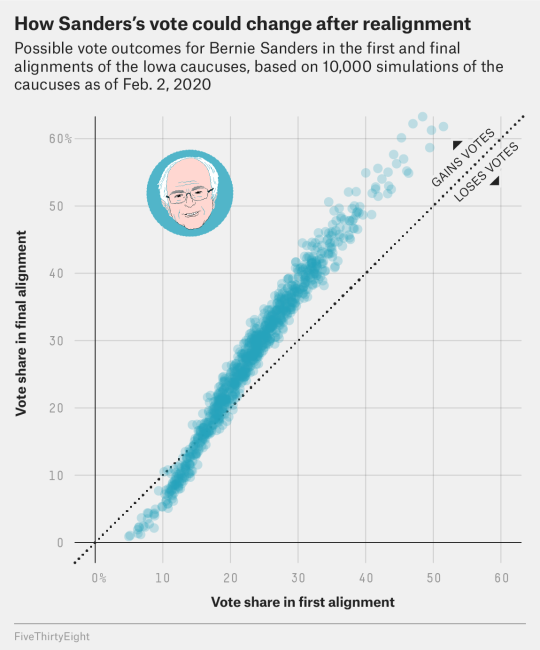
Granted, these are not exactly huge differences — 23 percent as compared with 24 or 25 percent. But an extra percentage point or two added or lost as the result of the realignment process could make the difference in a race where the top four candidates remain fairly closely bunched together. Moreover, our model’s assumptions about who might be helped or hurt by realignment may be too conservative. Having well-trained precinct captains can help a candidate in the realignment process a lot, and there’s also the possibility of strategic alliances between the candidates. Klobuchar and Buttigieg, for example, could agree to try to send their caucusgoers toward one another in precincts where they hadn’t achieved viability. The one thing you probably don’t want to do is enter into an alliance with one of the front-runners.
This isn’t the final stage, though. Instead, the final alignment is translated into something called state delegate equivalents, which is the third way that Iowa counts its vote. Until this year, in fact, this was the only way that Iowa counted its vote. It comes from a now archaic process where the caucuses technically served to elect delegates to county conventions, which in turn elected delegates to district conventions and the state convention, which in turn elected delegates to the Democratic National Convention.
This process is no longer used — delegates to the DNC will be elected based on caucus night results. However, state delegate equivalents are still used to determine essentially how much weight each precinct gets in determining DNC delegates.
The catch is that these weights are based on the number of votes that Hillary Clinton got in the general election in 2016 and that Democratic gubernatorial candidate Fred Hubbell got in the 2018 general election. And this can create some distortions. General election turnout is much higher than caucus turnout; 630,000 Iowans voted for Hubbell in 2018 and 650,000 did for Clinton in the general election in 2016. By comparison, 172,000 Democrats participated in the 2016 caucuses. Additionally, a higher share of caucus turnout tends to come from more liberal, upscale, urban and suburban counties and/or counties with colleges and universities, and proportionately less of it from rural counties.
Essentially, then, rural votes are likely to give candidates more bang for the buck in terms of state delegate equivalents. Candidates whose voters are mostly concentrated in liberal, highly populous counties are liable to underperform, conversely. There are various estimates out there as to who this is liable to help or hurt. But my read on the evidence is that Warren and to a lesser extent Sanders are likely to be hurt by it. Warren’s vote is mostly concentrated in upscale suburbs, and Sanders is hoping for big turnout surges in counties with a lot of young voters. Conversely, Klobuchar and Buttigieg have put a lot of emphasis on covering Iowa’s entire map and could benefit from this process. So could Biden, whose voters should be older, more working-class and more rural. To repeat, none of this is reflected in our model, which stops at the final alignment stage.5
But despite being somewhat convoluted — and do Democrats really want to give more weight to rural areas given the party’s complaints about the non-representativeness of the U.S. Senate and the Electoral College? — state delegate equivalents are likely to get a fair amount of attention on election night. It’s the metric that the various networks and news agencies are used to using to declare winners. And it is technically the measure that is used to determine delegates to the Democratic National Convention, although the importance of Iowa comes from the momentum it produces rather than the number of delegates it has.
As you can probably infer, we personally don’t buy that state delegate equivalents is necessarily a superior measure to the other two. So we intend to refer to all three metrics fairly often in our coverage of the caucuses on Monday night.
We can’t control what the rest of the media does, though, and the media will probably still lean into state delegate equivalents fairly heavily. Knowing how the media covers the race is important to being able to project the bounce that Iowa may be expected to produce for candidates who perform well there.
So in predicting the bounce that each candidate will receive, our model will essentially make a compromise. Bounces are projected based both on the share of the vote each candidate gets, and a binary variable indicating whether he or she won the state. For the vote share part of the calculation in Iowa, the model will use state delegate equivalents. But the winner bonus will be split, if necessary, between the three different measures, reflecting the fact that different candidates may have reasonable competing claims to victory.
In any event, a disputed or ambiguous outcome in Iowa is likely to dampen the bounces that candidates get out of Iowa, especially given that the media’s attention span may be limited by the State of the Union on Tuesday and the conclusion to President Trump’s impeachment trial later this week. So every candidate’s goal in Iowa should be not just to win, but to win clearly enough that they sweep all three metrics.
0 notes