#sql server replication tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
How to Choose a Database Management System: The Best Tools and Software for 2025
Data is at the core of every modern business. Whether it’s customer information, financial records, or product inventories, managing data efficiently is crucial for smooth operations and decision-making. A database management system (DBMS) helps businesses store, organize, and retrieve data securely and efficiently.
However, with so many database management tools and software available, choosing the right one can be challenging. Businesses need to consider factors like scalability, security, performance, and cost before making a decision.
This article explores how to choose the best database management system (DBMS) for your needs and highlights some of the top tools available in 2025.
1. What is a Database Management System (DBMS)?
A database management system (DBMS) is software that enables users to create, retrieve, update, and manage data efficiently. It acts as an interface between the database and users, ensuring data is stored securely and can be accessed when needed.
Key Functions of a DBMS
Data Storage — Organizes large volumes of structured and unstructured data.
Data Retrieval — Allows users and applications to access specific information quickly.
Data Security — Protects sensitive information from unauthorized access.
Data Integrity — Ensures accuracy and consistency in stored data.
Multi-User Access — Supports multiple users accessing and modifying data simultaneously.
Businesses of all sizes — from startups to enterprises — need a well-structured database to manage operations efficiently.
2. How to Choose a Database Management System?
Selecting the right database management tools and software requires careful consideration. The ideal DBMS should align with your business needs, performance expectations, and budget.
Factors to Consider When Choosing a DBMS
Scalability
Can the database handle growing amounts of data as your business expands? Cloud-based and distributed database solutions offer better scalability than traditional on-premise databases.
Performance
Look for a DBMS that ensures fast query processing and efficient indexing. Performance is crucial for applications handling real-time data processing, such as e-commerce or financial platforms.
Security Features
Data security is critical, especially for businesses handling sensitive information. The DBMS should offer encryption, access control, and regular backups to prevent data breaches.
Compatibility and Integration
Your DBMS should integrate seamlessly with existing software, including ERP systems, business intelligence tools, and cloud applications.
Cost and Licensing
Some database management systems are open-source and free, while others require licensing fees or subscription models. Factor in hosting, maintenance, and upgrade costs before making a choice.
Ease of Use and Administration
If your team lacks database expertise, choose a DBMS with a user-friendly interface and automated management features.
3. Best Database Management Tools and Software in 2025
The database landscape is diverse, with options ranging from relational databases (SQL) to NoSQL and cloud-based solutions. Below are some of the best database management tools and software in 2025.
A) Relational Database Management Systems (RDBMS) (SQL-Based)
Relational databases store data in structured tables, making them ideal for applications that require consistency and complex queries.
1. MySQL
One of the most popular open-source relational databases.
Best for web applications, e-commerce, and content management systems.
Supports high availability and replication.
2. PostgreSQL
Advanced open-source RDBMS with powerful performance and security features.
Great for handling complex queries and large-scale data applications.
Supports JSON and NoSQL-like functionality.
3. Microsoft SQL Server
A high-performance RDBMS designed for enterprises.
Integrates with Microsoft Azure and business intelligence tools.
Strong security features like Transparent Data Encryption (TDE).
4. Oracle Database
Best for large enterprises that need high availability and reliability.
Features AI-powered automation and in-memory data processing.
High licensing costs but offers advanced analytics and security.
B) NoSQL Database Management Systems
NoSQL databases are designed for handling unstructured and semi-structured data, making them ideal for real-time applications, big data, and cloud-based services.
5. MongoDB
A document-based NoSQL database used for flexible data storage.
Ideal for content management systems, mobile applications, and IoT.
Supports horizontal scaling and distributed storage.
6. Cassandra
Best for handling large-scale distributed data across multiple servers.
Used by major tech companies like Netflix and Facebook.
Offers fault tolerance and high availability.
7. Firebase
A cloud-based NoSQL database by Google, built for mobile and web apps.
Offers real-time data synchronization and offline access.
Best suited for startups and small businesses.
C) Cloud-Based Database Management Systems
Cloud databases provide scalability, flexibility, and cost efficiency, making them an excellent choice for businesses that want managed database solutions.
8. Amazon RDS (Relational Database Service)
A fully managed cloud database service by AWS.
Supports MySQL, PostgreSQL, SQL Server, and more.
Automated backups, scaling, and security management.
9. Google Cloud Firestore
A NoSQL document-based database optimized for real-time applications.
Integrates well with Google Cloud services.
Serverless, making it easy to scale applications.
10. Microsoft Azure SQL Database
A cloud-based RDBMS designed for high availability and disaster recovery.
AI-powered performance tuning and security monitoring.
Supports automatic scaling based on workload.
4. Key Trends in Database Management for 2025
As businesses generate more data than ever, database technologies are evolving. Here are some trends shaping the future of database management tools and software in 2025.
AI and Automation in Database Management
AI-powered databases like Oracle Autonomous Database are improving performance, security, and self-healing capabilities without human intervention.
Multi-Cloud and Hybrid Databases
Businesses are increasingly using multi-cloud and hybrid database solutions to avoid vendor lock-in and improve redundancy.
Edge Computing and Distributed Databases
With the rise of IoT and edge computing, distributed databases like Apache Cassandra are becoming more popular for handling real-time data processing at scale.
Graph Databases for Advanced Analytics
Graph databases like Neo4j are being used for applications requiring deep data relationships, such as fraud detection and recommendation engines.
Choosing the right database system depends on your business needs, application type, and data management requirements. If your business requires structured data storage and complex queries, a relational database like MySQL or PostgreSQL is ideal.
For real-time applications, big data, and scalability, a NoSQL solution like MongoDB or Firebase may be the best choice. For businesses looking for fully managed, scalable solutions, cloud databases like Amazon RDS or Microsoft Azure SQL Database provide automated security and maintenance.
0 notes
Text
AI and Automation in Data Analyst: Why You Still Need an "Data Analyst Certification Course" in 2025, 100% Job in MNC, Excel, VBA, SQL, Power BI, Tableau Projects, Alteryx Certification, Data Analyst Training Course in Delhi, 110097 - Free Python Data Science Certification, By SLA Consultants India,
AI and automation are transforming the data analytics profession in 2025, but they are not making the data analyst role obsolete—instead, they are elevating its importance and changing its nature. While AI excels at automating repetitive and time-consuming tasks such as data cleaning, preparation, and even some aspects of predictive modeling, it cannot replace the nuanced judgment, business context, and communication skills that human analysts bring to the table. As a result, the demand for data-literate professionals who can interpret, contextualize, and act on AI-generated insights is only increasing.
A comprehensive Data Analyst Course in Delhi with certification remains essential in this environment because it equips professionals with both foundational and advanced skills that AI cannot replicate. Employers in 2025 are looking for candidates who are not only proficient in tools like Excel, VBA, SQL, Power BI, Tableau, and Alteryx, but who also understand how to leverage AI-driven analytics platforms, automate workflows, and adapt to rapidly evolving technologies. Certification programs, such as those offered by SLA Consultants India in Delhi (110097), ensure that analysts are trained in the latest methodologies, including Python for data science, cloud computing, and data visualization. This comprehensive skill set is critical, as 69.3% of job postings seek domain experts with specialized knowledge, while 30.7% want versatile professionals who can adapt to new tools and business needs.
Data Analyst Training Course in Delhi
AI is shifting the analyst’s focus from manual data wrangling to higher-order responsibilities—interpreting AI outputs, validating models, ensuring ethical compliance, and communicating insights in ways that drive business value. Certification courses emphasize not just technical mastery, but also the soft skills that are increasingly vital: critical thinking, data storytelling, and the ability to translate complex analytics into actionable recommendations for decision-makers. These human-centric skills are irreplaceable, as AI cannot fully understand organizational goals, cultural nuances, or the strategic implications of data-driven decisions.
Data Analytics Training Course Modules Module 1 - Basic and Advanced Excel With Dashboard and Excel Analytics Module 2 - VBA / Macros - Automation Reporting, User Form and Dashboard Module 3 - SQL and MS Access - Data Manipulation, Queries, Scripts and Server Connection - MIS and Data Analytics Module 4 - MS Power BI | Tableau Both BI & Data Visualization Module 5 - Free Python Data Science | Alteryx/ R Programing Module 6 - Python Data Science and Machine Learning - 100% Free in Offer - by IIT/NIT Alumni Trainer
In summary, A Data Analyst Certification Course in Delhi is more valuable than ever in 2025. It future-proofs your career by providing the technical expertise, business acumen, and adaptability required to thrive in a hybrid human-AI workforce. Certified analysts are empowered to work alongside AI, amplifying their impact and ensuring organizations make smarter, more ethical, and more effective decisions. With strong job prospects, rising salaries, and opportunities for advancement, investing in a comprehensive certification is a strategic move for anyone seeking a resilient and rewarding analytics career in the age of AI. For more details Call: +91-8700575874 or Email: [email protected]
0 notes
Text
Common Challenges in Oracle Forms to APEX Migrations—and How to Solve Them
Migrating from Oracle Forms to Oracle APEX is not just a technology shift—it's a transformation of how your business applications work, look, and scale. While Oracle Forms has served enterprises reliably for decades, it's built on a client-server architecture that doesn't align with modern, web-first expectations.
Oracle APEX, on the other hand, offers a low-code, browser-based environment with rich UI capabilities, tight PL/SQL integration, and excellent support for modern development practices.
But let’s be honest—Forms to APEX migration isn't a plug-and-play process. It comes with real-world challenges that, if not addressed properly, can lead to delays, frustration, or missed opportunities.
In this post, we'll explore the most common challenges in migrating Oracle Forms to APEX—and, more importantly, how to solve them.
Challenge 1: Understanding the Legacy Code and Business Logic
📌 The Problem:
Many Forms applications have evolved over decades, often with minimal documentation. The logic is tightly bound to the UI, buried in triggers, program units, and PL/SQL blocks.
✅ The Solution:
Perform a full inventory of all Forms modules.
Use tools like Oracle Forms2XML or third-party scanners to extract and analyze code.
Identify reusable business logic and move it to database packages, separating logic from UI.
Document core workflows before rewriting in APEX.
Pro tip: Establish a “Forms-to-APEX Reference Map” to track where each legacy feature is being re-implemented or redesigned.
⚠️ Challenge 2: UI/UX Differences Between Forms and APEX
📌 The Problem:
Forms applications often use canvases, blocks, and modal windows—none of which translate 1:1 into APEX. Users familiar with old-school layouts may resist change.
✅ The Solution:
Focus on functionality parity, not screen-by-screen cloning.
Reimagine the UI with APEX Interactive Reports, Dialogs, and Faceted Search.
Use the Redwood Light theme in APEX to deliver a clean, modern experience.
Conduct end-user workshops to involve them early in the redesign process.
Remember: This is a chance to improve UX, not just replicate the past.
⚠️ Challenge 3: Handling Triggers and Built-in Events
📌 The Problem:
Forms relies heavily on triggers like WHEN-VALIDATE-ITEM, PRE-INSERT, or KEY-NEXT-ITEM. These don't exist in APEX in the same way.
✅ The Solution:
Move data validation logic into database triggers or packages.
Use Dynamic Actions, Process Handlers, and Validations in APEX to simulate similar behaviors.
Create custom JavaScript where necessary for field-level interactions.
Keep business logic in PL/SQL, and use APEX to handle client-side workflows.
⚠️ Challenge 4: List of Values (LOVs) and Pop-Ups
📌 The Problem:
Oracle Forms uses LOVs and pop-up windows extensively. These may not behave the same in APEX without thoughtful redesign.
✅ The Solution:
Replace Forms LOVs with APEX’s popup LOV or select list components.
Use shared LOVs to centralize list management.
For cascading LOVs, use Dynamic Actions to update values based on selections.
APEX provides more flexibility—but you may need to rethink the user flow.
⚠️ Challenge 5: State Management and Navigation
📌 The Problem:
Forms is stateful; APEX is stateless. In Forms, navigation and state retention happen automatically. In APEX, every action reloads a page or region.
✅ The Solution:
Use session state variables and hidden items to manage state across pages.
Apply branching logic and URL parameters for navigation control.
Embrace modal dialogs for maintaining context.
Design with the web in mind—shorter tasks, fewer clicks, intuitive flow.
⚠️ Challenge 6: Training & Developer Mindset Shift
📌 The Problem:
Developers accustomed to Forms development need to shift from procedural to declarative, low-code development in APEX.
✅ The Solution:
Provide hands-on training and access to APEX learning resources.
Create internal sandboxes for experimenting with APEX features.
Promote code reusability, templates, and UI best practices.
APEX is powerful—but it takes time to shift the mindset from "Form triggers" to "Dynamic Actions and page processes."
✅ Conclusion
Oracle Forms to APEX migration is a rewarding journey��but like any transformation, it comes with technical and cultural challenges. The key is to approach it methodically:
Analyze and document before you migrate.
Modernize, don’t just replicate.
Train your team, and embrace the new development model.
Done right, the migration leads to modern, maintainable, and scalable applications that align with today’s business and user expectations.
0 notes
Text
TIBCO Scribe Agents: Enabling Seamless Data Integration
TIBCO Cloud™ Integration – Connect simplifies data integration by using Agents, Connectors, and Apps to establish secure and efficient communication between source and target systems. Whether your data resides on-premises or in the cloud, TIBCO Scribe Agents ensure seamless connectivity.
Types of TIBCO Scribe Agents
🔹 On-Premises Agent – Installed on a local machine, this agent is ideal for integrating with on-premises databases like SQL Server. Multiple On-Premises Agents can be installed on a single system. 🔹 Cloud Agent – Hosted in the cloud, this agent enables integration between cloud-based systems. Only one Cloud Agent can be provisioned per organization.
Understanding TIBCO Connections
A Connection in TIBCO Cloud™ Integration – Connect acts as a bridge between applications, allowing secure data movement via APIs. Connectors, such as the Dynamics Connector, authenticate and facilitate interactions between source and target databases. The Connections Page provides users with access to existing connections, metadata management, and configuration settings.
TIBCO Cloud™ Integration – Connect Apps
TIBCO Connect Apps help users execute data integration tasks with custom configurations. There are three types of apps: ✅ On Schedule Apps – Automate data synchronization between multiple sources using flows, filters, and formulas. ✅ On Event Apps – Trigger integration tasks dynamically based on inbound API calls. ✅ Data Replication Apps – Copy and replicate data across databases, ensuring data consistency and backup.
Why Use TIBCO Cloud™ Integration – Connect?
🔹 Effortless Data Integration – Automate workflows with scheduled and event-driven apps. 🔹 Seamless Connectivity – Supports on-premises and cloud-based data sources. 🔹 Flexible Configuration – Advanced flows, filters, and mapping tools enhance data processing.
0 notes
Text
Building a Scalable Web Application for Long-Term Success
Introduction
In today's fast-paced digital world, web applications must be designed for scalability to ensure long-term success.
A scalable application can efficiently handle increasing user traffic, maintain high performance, and adapt to evolving business needs.
Whether you're developing an e-commerce site, a SaaS platform, or a social media network, adopting the right architecture and best practices is crucial.
This guide outlines the key principles, architectural patterns, and technologies needed to build a web application that scales efficiently over time.
1. Understanding Scalability
What is Scalability?
Scalability refers to a system's ability to handle increased workloads efficiently by leveraging additional resources such as computing power, storage, and network bandwidth. A well-designed scalable web application can support more users and process greater data loads without performance degradation.
Types of Scalability
Vertical Scaling (Scaling Up): Expanding a single server's resources (CPU, RAM, storage) to improve performance.
Horizontal Scaling (Scaling Out): Adding more servers to distribute workloads and enhance reliability.
Horizontal scaling is generally preferred for long-term success due to its resilience and ability to handle traffic spikes effectively.
2. Choosing the Right Architecture
A well-structured architecture is fundamental to scalability. Popular architectural patterns include:
Monolithic vs. Microservices
Monolithic Architecture: A single codebase integrating all components. While easier to develop initially, scaling becomes complex as the application grows.
Microservices Architecture: A modular approach where independent services communicate via APIs, allowing flexible scaling of individual components.
Serverless Architecture
Serverless computing enables developers to focus on code while cloud providers manage infrastructure dynamically, making it highly scalable and cost-effective.
3. Database Design for Scalability
Choosing the Right Database
Selecting a database that aligns with your application’s needs is crucial:
Relational Databases (SQL): MySQL, PostgreSQL – Ideal for structured data and transactional consistency.
NoSQL Databases: MongoDB, Cassandra – Suitable for unstructured data and large-scale applications.
Database Optimization Strategies
Sharding: Distributes data across multiple database instances.
Replication: Creates copies of data for redundancy and load balancing.
Indexing: Enhances query speed.
Caching: Uses tools like Redis or Memcached to store frequently accessed data in memory.
4. Efficient Backend and API Design
REST vs. GraphQL
REST APIs: Stateless architecture, widely used but may lead to over-fetching of data.
GraphQL: Allows clients to request only necessary data, optimizing bandwidth usage.
Asynchronous Processing
Using message queues (RabbitMQ, Kafka) enables background task processing, improving application responsiveness.
5. Frontend Scalability Considerations
Selecting the Right Framework
Popular frontend frameworks such as React, Angular, and Vue.js support scalable development with their component-based structures.
Frontend Performance Optimization
Lazy Loading: Loads only necessary components to enhance performance.
Code Splitting: Reduces initial load time by dividing JavaScript bundles.
CDN (Content Delivery Network): Improves load times by serving assets from distributed locations.
6. Load Balancing and Caching Strategies
Load Balancing
Distributing traffic across multiple servers prevents bottlenecks. Common solutions include Nginx, HAProxy, and AWS Elastic Load Balancer.
Caching Strategies
Client-Side Caching: Stores static files in the user's browser.
Server-Side Caching: Uses Redis or Memcached for frequently requested data.
Edge Caching: CDNs (Cloudflare, AWS CloudFront) serve cached content closer to users.
7. Security and Compliance
Implementing Security Best Practices
HTTPS Everywhere: Encrypts communication with TLS/SSL.
Authentication & Authorization: Uses OAuth, JWT, or OpenID Connect for secure user access.
Data Encryption: Protects sensitive information.
Rate Limiting & DDoS Protection: Prevents abuse using security services like Cloudflare.
Compliance Standards
Ensuring compliance with regulations such as GDPR, HIPAA, and PCI DSS protects user data and meets legal requirements.
8. Automated Testing and Continuous Deployment
Testing Strategies
Unit Testing: Validates individual components (Jest, Mocha, JUnit).
Integration Testing: Ensures smooth service interactions.
Load Testing: Simulates high traffic using JMeter and Locust.
CI/CD Pipelines
Automating deployment with GitHub Actions, Jenkins, and GitLab CI/CD ensures faster and more reliable releases.
9. Monitoring and Logging
Observability Tools
Tracking application health and performance is essential for scalability:
Logging: ELK Stack (Elasticsearch, Logstash, Kibana), Fluentd.
Monitoring: Prometheus, Grafana, New Relic.
Error Tracking: Sentry, Rollbar.
Automated Alerts
Using tools like PagerDuty ensures proactive issue resolution before they impact users.
10. Cloud Infrastructure and Hosting Choices
Cloud Providers
Choosing a scalable cloud platform ensures flexibility. Popular options include:
AWS (Amazon Web Services)
Google Cloud Platform (GCP)
Microsoft Azure
Containerization and Orchestration
Docker: Ensures consistency across development environments.
Kubernetes: Manages containerized applications at scale, providing resilience and efficiency.
Conclusion
Building a scalable web application requires thoughtful planning, robust architecture, and best practices in database management, API design, frontend optimization, and security.
Leveraging cloud infrastructure, automation, and monitoring tools ensures your application remains resilient and adaptable over time.
By following these principles, you can develop a high-performance, future-proof web application capable of handling increasing user demand and evolving business requirements.
0 notes
Text
SQL Server: A Comprehensive Overview
SQL Server, developed by Microsoft, is a powerful relational database management system (RDBMS) used by organizations worldwide to manage and store data efficiently. It provides a robust platform for database operations, including data storage, retrieval, security, and analysis SQL Server is known for its scalability, reliability, and integration with other Microsoft services, making it a preferred choice for businesses of all sizes.
Key Features of SQL Server
1. Scalability and Performance
SQL Server is designed to handle large-scale databases while maintaining high performance. With features like in-memory processing, indexing, and optimized query execution, it ensures fast data retrieval and efficient processing, even with massive datasets.
2. Security and Compliance
Data security is a critical concern, and SQL Server addresses this with advanced security features such as:
Transparent Data Encryption (TDE): Encrypts the database at rest.
Row-Level Security (RLS): Restricts access to specific rows within a table based on user permissions.
Dynamic Data Masking (DDM): Protects sensitive data by masking it during query execution.
Always Encrypted: Ensures data remains encrypted both at rest and in transit.
3. High Availability and Disaster Recovery
SQL Server ensures continuous availability through features such as:
Always On Availability Groups: Provides failover support and high availability for critical databases.
Database Mirroring and Log Shipping: Helps maintain real-time data replication and backup solutions.
Backup and Restore Capabilities: Ensures data recovery in case of system failures.
4. Business Intelligence and Data Analytics
SQL Server includes built-in tools for business intelligence (BI) and analytics, allowing organizations to gain insights from their data. Features include:
SQL Server Analysis Services (SSAS): Enables data mining and multidimensional analysis.
SQL Server Integration Services (SSIS): Facilitates data extraction, transformation, and loading (ETL).
SQL Server Reporting Services (SSRS): Allows for the creation of interactive reports and dashboards.
5. Integration with Cloud and AI
SQL Server seamlessly integrates with Microsoft Azure, enabling hybrid cloud solutions. Additionally, it supports artificial intelligence (AI) and machine learning (ML) capabilities, allowing users to perform predictive analytics and automate decision-making processes.
SQL Server Editions
Microsoft offers SQL Server in different editions to cater to various business needs:
Enterprise Edition: Designed for large-scale applications with high performance and security requirements.
Standard Edition: Suitable for mid-sized businesses with essential database functionalities.
Express Edition: A free version with limited features, ideal for small applications and learning purposes.
Developer Edition: Offers full Enterprise Edition capabilities but is licensed for development and testing only.
SQL Server vs. Other RDBMS
While SQL Server is a leading database management system, it competes with other RDBMS like MySQL, PostgreSQL, and Oracle Database. Here’s how it compares:
Ease of Use: SQL Server has a user-friendly interface, particularly for Windows users.
Security Features: Provides robust security compared to MySQL and PostgreSQL.
Integration with Microsoft Ecosystem: Works seamlessly with tools like Power BI, Azure, and Office 365.
Licensing Costs: SQL Server can be more expensive than open-source databases like MySQL and PostgreSQL.
Conclusion
SQL Server is a powerful and versatile database management system that supports businesses in managing their data efficiently. With features like scalability, security, high availability, and cloud integration, it remains a top choice for enterprises looking for a reliable RDBMS. Whether used for small applications or large-scale enterprise systems, SQL Server continues to evolve with new advancements, making it an essential tool for modern data management.
0 notes
Text
Best Practices for Optimizing ETL Performance on Oracle Cloud

Extract, Transform, Load (ETL) processes are crucial for managing and integrating data in enterprise environments. As businesses increasingly migrate to the cloud, optimizing Oracle Cloud ETL workflows is essential for improving efficiency, reducing costs, and ensuring data accuracy. Oracle Cloud provides a robust ETL ecosystem with tools like Oracle Data Integrator (ODI), Oracle Cloud Infrastructure Data Integration (OCI DI), and Oracle GoldenGate, offering powerful solutions for handling large-scale data integration.
In this article, we’ll explore best practices for optimizing ETL performance on Oracle Cloud to ensure faster data processing, lower latency, and improved scalability.
1. Choose the Right Oracle Cloud ETL Tool
Oracle Cloud offers multiple ETL solutions, each suited for different business needs. Selecting the right tool can significantly impact performance and efficiency.
Oracle Data Integrator (ODI): Best for traditional ETL workloads that require batch processing and complex transformations.
Oracle Cloud Infrastructure Data Integration (OCI DI): A serverless ETL solution ideal for low-code/no-code integrations and real-time data movement.
Oracle GoldenGate: Recommended for real-time data replication and streaming ETL across multiple cloud and on-premise databases.
Tip: If your ETL workload involves large batch processing, ODI is ideal. If you need real-time data replication, GoldenGate is a better choice.
2. Optimize Data Extraction for Faster Processing
Efficient data extraction is the first step in ETL performance optimization. Poor extraction methods can slow down the entire process.
Best Practices for Data Extraction:
Use Incremental Data Extraction: Instead of loading the entire dataset, extract only new or changed data to reduce processing time.
Leverage Parallel Processing: Use multi-threading to extract data from multiple sources simultaneously.
Optimize Source Queries: Use indexed tables, partitioning, and query optimization to speed up data retrieval from databases.
Tip: In Oracle Autonomous Database, use Partition Pruning to retrieve only relevant data, reducing query execution time.
3. Improve Data Transformation Efficiency
The transformation step is where most of the performance bottlenecks occur, especially with complex business logic.
Best Practices for Data Transformation:
Push Transformations to the Database: Oracle Cloud ETL tools allow ELT (Extract, Load, Transform) processing, where transformations run within Oracle Autonomous Database instead of external ETL servers.
Use Bulk Operations Instead of Row-by-Row Processing: Batch processing is faster and reduces database overhead.
Leverage Oracle Cloud Compute Power: Scale up Oracle Cloud Compute Instances to handle heavy transformations efficiently.
Tip: Oracle Data Integrator (ODI) uses Knowledge Modules to execute transformations directly within the database, improving efficiency.
4. Optimize Data Loading for High-Speed Performance
Loading large datasets into Oracle Cloud databases requires optimized strategies to prevent slowdowns and failures.
Best Practices for Data Loading:
Use Direct Path Load: In Oracle Cloud, SQL*Loader Direct Path Load speeds up bulk data insertion.
Enable Parallel Data Loading: Divide large datasets into smaller partitions and load them in parallel.
Compress Data Before Loading: Reducing file size minimizes data transfer time, improving ETL performance.
Monitor and Tune Network Latency: Ensure low-latency cloud storage and database connectivity for fast data transfer.
Tip: Oracle GoldenGate supports real-time, low-latency data replication, ideal for high-speed data loading.
5. Leverage Oracle Cloud Storage and Compute Resources
Oracle Cloud offers high-performance storage and compute services that enhance ETL processing speeds.
Best Practices for Cloud Resource Optimization:
Use Oracle Cloud Object Storage: Store large files efficiently and process data directly from cloud storage instead of moving it.
Auto-Scale Compute Instances: Oracle Cloud’s Autoscaling feature ensures compute resources adjust based on workload demand.
Enable Oracle Exadata for High-Performance Workloads: If handling petabyte-scale data, Oracle Exadata Cloud Service offers extreme performance for ETL.
Tip: Oracle Autonomous Database automates indexing, partitioning, and caching, reducing ETL overhead.
6. Implement Monitoring and Performance Tuning
Regular monitoring and performance tuning ensure smooth ETL operations without unexpected failures.
Best Practices for ETL Monitoring:
Use Oracle Cloud Monitoring Services: Track ETL execution time, CPU usage, and query performance.
Enable Logging and Alerts: Set up real-time alerts in OCI Logging and Performance Hub to detect failures early.
Optimize Execution Plans: Use EXPLAIN PLAN and SQL Tuning Advisor to identify and improve slow SQL queries.
Tip: Oracle Cloud Autonomous Database provides AI-driven performance tuning, reducing manual optimization efforts.
7. Secure Your ETL Pipelines
Data security is crucial in Oracle Cloud ETL to protect sensitive information and comply with industry regulations.
Best Practices for ETL Security:
Use Encryption: Enable TDE (Transparent Data Encryption) for securing data at rest and SSL/TLS encryption for in-transit data.
Implement Role-Based Access Control (RBAC): Restrict access to ETL jobs, logs, and sensitive data based on user roles.
Enable Data Masking for Compliance: Use Oracle Data Safe to anonymize sensitive data in non-production environments.
Tip: Oracle Cloud automatically encrypts storage and databases, ensuring secure data handling in ETL workflows.
Final Thoughts: Optimize Oracle Cloud ETL for Maximum Efficiency
Optimizing Oracle Cloud ETL is essential for fast, cost-effective, and reliable data integration. By following these best practices, businesses can enhance performance, reduce processing time, and ensure seamless data workflows in Oracle Cloud.
✔️ Choose the right Oracle ETL tool for batch or real-time processing. ✔️ Optimize extraction, transformation, and loading using parallelism and direct path loading. ✔️ Leverage Oracle Cloud’s compute, storage, and database features for efficiency. ✔️ Implement performance monitoring and security best practices to ensure smooth ETL operations.
By adopting these strategies, businesses can fully utilize the power of Oracle Cloud ETL to accelerate data-driven decision-making and innovation.
0 notes
Text
SQL Server 2019 Standard on Windows 2019: A Powerful Combination for Business Needs
SQL Server 2019 Standard on Windows 2019 is a robust and reliable solution designed to meet the growing demands of modern businesses. This combination of Microsoft’s leading database platform and the latest iteration of Windows Server provides a strong foundation for organizations looking to leverage the power of data management and analytics. SQL Server 2019 offers numerous improvements in performance, security, and flexibility, while Windows Server 2019 enhances the infrastructure with advanced capabilities and modern security features.
One of the key advantages of SQL Server 2019 Standard on Windows 2019 is the overall performance optimization. SQL Server 2019 introduces significant performance improvements over previous versions, such as the intelligent query processing feature, which allows for faster query execution and greater resource efficiency. The ability to handle large volumes of data with increased speed is crucial for businesses that rely on real-time analytics and seamless data access. The SQL server 2019 Standard on Windows 2019 enhanced performance in SQL Server 2019 ensures that organizations can run complex queries and analytics workloads with minimal latency.
SQL Server 2019 Standard also includes an integrated big data cluster feature, which supports the management and analysis of large data sets, such as those from IoT devices or social media platforms. This capability allows businesses to manage structured and unstructured data in a unified platform, offering flexibility and scalability for future growth. Additionally, SQL Server 2019 includes enhanced support for machine learning, allowing users to run R and Python scripts directly within the database. This integration enables organizations to harness the power of artificial intelligence and advanced analytics without the need for external tools or platforms.
Security is another critical aspect of SQL Server 2019 Standard on Windows 2019. With an increasing number of cyber threats targeting businesses, it is essential to protect sensitive data and ensure compliance with industry regulations. SQL Server 2019 enhances security by offering features such as Always Encrypted with secure enclaves, which protect data even while it is being processed. This means that data remains encrypted at all stages, minimizing the risk of unauthorized access or data breaches. Additionally, SQL Server 2019 provides enhanced auditing capabilities and data masking, which help organizations monitor and secure sensitive information.
Windows Server 2019 complements SQL Server 2019 by providing a modern, secure, and scalable environment for hosting databases. With improved support for hybrid cloud environments, Windows Server 2019 makes it easier for businesses to migrate to the cloud or manage hybrid infrastructures. Windows Server 2019 introduces advanced networking features such as Software-Defined Networking (SDN), which improves performance and scalability while simplifying network management. It also includes Windows Defender ATP (Advanced Threat Protection), which offers robust protection against malware and other security threats, ensuring that SQL Server 2019 runs in a secure and protected environment.
In addition to security and performance improvements, SQL Server 2019 Standard on Windows 2019 offers advanced data management features that make it an excellent choice for organizations of all sizes. With built-in data virtualization, businesses can access and query data from multiple sources without having to move or replicate it, reducing the complexity of data management. The platform also supports a wide range of applications, from transactional systems to data warehousing, making it suitable for a diverse set of workloads. Whether businesses are running a small database for a local application or managing an enterprise-level data warehouse, SQL Server 2019 Standard on Windows 2019 provides the scalability and flexibility needed to meet the demands of any use case.
One of the standout features of SQL Server 2019 Standard is its ability to integrate with popular business intelligence (BI) and reporting tools. With support for Microsoft Power BI, businesses can easily create interactive dashboards, reports, and visualizations that help stakeholders make data-driven decisions. SQL Server 2019 also integrates seamlessly with SQL Server Reporting Services (SSRS) and SQL Server Integration Services (SSIS), providing a comprehensive suite of tools for data extraction, transformation, and reporting. This makes it easier for organizations to consolidate their data and gain insights that drive business success.
SQL Server 2019 Standard on Windows 2019 also benefits from enhanced scalability, making it suitable for businesses of all sizes. With the ability to scale up or out depending on the workload, SQL Server 2019 can accommodate both small-scale applications and enterprise-level systems. Whether organizations are managing a single server or a multi-node cluster, SQL Server 2019 provides the tools to manage databases efficiently. The high availability and disaster recovery features in SQL Server 2019, such as Always On Availability Groups, ensure that data is always available, even in the event of hardware failures or other disruptions.
Cost-effectiveness is another advantage of SQL Server 2019 Standard. Compared to the more advanced Enterprise edition, the Standard edition offers many of the same core features at a lower price point, making it an attractive option for businesses with budget constraints. SQL Server 2019 Standard provides a balance between functionality and affordability, making it an ideal choice for small to medium-sized businesses that need a reliable and secure database platform without the high costs associated with enterprise-level solutions.
In conclusion SQL server 2019 Standard on Windows 2019 is a powerful combination that offers businesses a comprehensive solution for database management, analytics, and security. With performance improvements, advanced data management features, and tight integration with modern BI tools, it enables organizations to unlock the full potential of their data. The enhanced security features and scalability ensure that businesses can protect their valuable information while growing and evolving with the demands of the modern enterprise. Whether for small businesses or large organizations, SQL Server 2019 Standard on Windows 2019 is a solution that provides reliability, flexibility, and innovation.
0 notes
Text
Firebird to Cassandra Migration
In this article, we delve into the intricacies of migrating from Firebird to Cassandra. We will explore the reasons behind choosing Cassandra over Firebird, highlighting its scalability, high availability, and fault tolerance. We'll discuss key migration steps, such as data schema transformation, data extraction, and data loading processes. Additionally, we'll address common challenges faced during migration and provide best practices to ensure a seamless transition. By the end of this article, you'll be equipped with the knowledge to effectively migrate your database from Firebird to Cassandra.
What is Firebird
Firebird is a robust, open-source relational database management system renowned for its versatility and efficiency. It offers advanced SQL capabilities and comprehensive ANSI SQL compliance, making it suitable for various applications. Firebird supports multiple platforms, including Windows, Linux, and macOS, and is known for its lightweight architecture. Its strong security features and performance optimizations make it an excellent choice for both embedded and large-scale database applications. With its active community and ongoing development, Firebird continues to be a reliable and popular database solution for developers.
What is Cassandra
Cassandra is a highly scalable, open-source NoSQL database designed to handle large amounts of data across many commodity servers without any single point of failure. Known for its distributed architecture, Cassandra provides high availability and fault tolerance, making it ideal for applications that require constant uptime. It supports dynamic schema design, allowing flexible data modeling, and offers robust read and write performance. With its decentralized approach, Cassandra ensures data replication across multiple nodes, enhancing reliability and resilience. As a result, it is a preferred choice for businesses needing to manage massive datasets efficiently and reliably.
Advantages of Firebird to Cassandra Migration
Scalability: Cassandra’s distributed architecture allows for seamless horizontal scaling as data volume and user demand grow.
High Availability: Built-in replication and fault-tolerance mechanisms ensure continuous availability and data integrity.
Performance: Write-optimized design handles high-velocity data, providing superior read and write performance.
Flexible Data Model: Schema-less support allows agile development and easier management of diverse data types.
Geographical Distribution: Data replication across multiple data centers enhances performance and disaster recovery capabilities.
Method 1: Migrating Data from Firebird to Cassandra Using the Manual Method
Firebird to Cassandra migration manually involves several key steps to ensure accuracy and efficiency:
Data Export: Begin by exporting the data from Firebird, typically using SQL queries or Firebird's export tools to generate CSV or SQL dump files.
Schema Mapping: Map the Firebird database schema to Cassandra’s column-family data model, ensuring proper alignment of data types and structures.
Data Transformation: Transform the exported data to fit Cassandra’s schema, making necessary adjustments to comply with Cassandra’s requirements and best practices.
Data Loading: Use Cassandra’s loading utilities, such as CQLSH COPY command or bulk loading tools, to import the transformed data into the appropriate keyspaces and column families.
Verification and Testing: After loading, verify data integrity and consistency by running validation queries and tests to ensure the migration was successful and accurate.
Disadvantages of Migrating Data from Firebird to Cassandra Using the Manual Method
High Error Risk: Manual efforts significantly increase the risk of errors during the migration process.
Need to do this activity again and again for every table.
Difficulty in Data Transformation: Achieving accurate data transformation can be challenging without automated tools.
Dependency on Technical Resources: The process heavily relies on technical resources, which can strain teams and increase costs.
No Automation: Lack of automation requires repetitive tasks to be done manually, leading to inefficiencies and potential inconsistencies.
Limited Scalability: For every table, the entire process must be repeated, making it difficult to scale the migration.
No Automated Error Handling: There are no automated methods for handling errors, notifications, or rollbacks in case of issues.
Lack of Logging and Monitoring: Manual methods lack direct automated logs and tools to track the amount of data transferred or perform incremental loads (Change Data Capture).
Method 2: Migrating Data from Firebird to Cassandra Using ETL Tools
There are certain advantages in case if you use an ETL tool to migrate the data
Extract Data: Use ETL tools to automate the extraction of data from Firebird, connecting directly to the database to pull the required datasets.
Transform Data: Configure the ETL tool to transform the extracted data to match Cassandra's schema, ensuring proper data type conversion and structure alignment.
Load Data: Use the ETL tool to automate the loading of transformed data into Cassandra, efficiently handling large volumes of data and multiple tables.
Error Handling and Logging: Utilize the ETL tool’s built-in error handling and logging features to monitor the migration process, receive notifications, and ensure data integrity.
Incremental Loads: Leverage the ETL tool's Change Data Capture (CDC) capabilities to perform incremental data loads, migrating only updated or new data to optimize performance.
Testing and Verification: After loading the data, use the ETL tool to verify data accuracy and consistency, running validation checks to ensure the migration was successful.
Scalability: ETL tools support scalable migrations, allowing for easy adjustments and expansions as data volume and complexity increase.
Challenges of Using ETL Tools for Data Migration
Initial Setup Complexity: Configuring ETL tools for data extraction, transformation, and loading can be complex and time-consuming.
Cost: Advanced ETL tools can be expensive, increasing the overall cost of the migration.
Resource Intensive: ETL processes can require significant computational resources, impacting system performance.
Data Mapping Difficulties: Mapping data between different schemas can be challenging and error-prone.
Customization Needs: Standard ETL tools may require custom scripts to meet specific migration needs.
Dependency on Tool Features: The success of migration depends on the capabilities of the ETL tool, which may have limitations.
Maintenance and Support: Ongoing maintenance and vendor support are often needed, adding to long-term operational costs.
Why Ask On Data is the Best Tool for Migrating Data from Firebird to Cassandra
Seamless Data Transformation: Automatically handles data transformations to ensure compatibility between Firebird and Cassandra.
User-Friendly Interface: Simplifies the migration process with an intuitive, easy-to-use interface, making it accessible for both technical and non-technical users.
High Efficiency: Automates repetitive tasks, significantly reducing the time and effort required for migration.
Built-In Error Handling: Offers robust error handling and real-time notifications, ensuring data integrity throughout the migration.
Incremental Load Support: Supports incremental data loading, enabling efficient updates and synchronization without duplicating data.
Usage of Ask On Data : A chat based AI powered Data Engineering Tool
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download from Github and deploy on your own servers, whereas with enterprise version, you can use Ask On Data as a managed service.
Advantages of using Ask On Data
Built using advanced AI and LLM, hence there is no learning curve.
Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
No dependence on technical resources
Super fast to implement (at the speed of typing)
No technical knowledge required to use
Below are the steps to do the data migration activity
Step 1: Connect to Firebird(which acts as source)
Step 2 : Connect to Cassandra (which acts as target)
Step 3: Create a new job. Select your source (Firebird) and select which all tables you would like to migrate.
Step 4 (OPTIONAL): If you would like to do any other tasks like data type conversion, data cleaning, transformations, calculations those also you can instruct to do in natural English. NO knowledge of SQL or python or spark etc required.
Step 5: Orchestrate/schedule this. While scheduling you can run it as one time load, or change data capture or truncate and load etc.
For more advanced users, Ask On Data is also providing options to write SQL, edit YAML, write PySpark code etc.
There are other functionalities like error logging, notifications, monitoring, logs etc which can provide more information like the amount of data transferred, logs, any error information if the job did not run and other kind of monitoring information etc.
Trying Ask On Data
You can reach out to us on mailto:[email protected] for a demo, POC, discussion and further pricing information. You can make use of our managed services or you can also download and install on your own servers our community edition from Github.
0 notes
Text
How to Optimize Your Bustabit Script for Scalability and Performance

The online gaming industry is highly competitive, and platforms built on the Bustabit script are no exception. To stay ahead, optimizing your script for scalability and performance is crucial. A well-optimized script not only ensures smooth gameplay but also handles growing user demands effectively. In this article, we will explore strategies to enhance your script's efficiency while maintaining a seamless user experience.
Understanding the Core of Bustabit Script
Powered by a Bustabit script, online gambling platforms allow users to place bets on a graph that crashes at any given time. This script is the backbone of such platforms, detailing everything, including user interaction and backend computation, which dictates the outcome. Such has served as an inspiration for a Bustabit clone script, available to developers who want to replicate this idea.
These scripts are quite essential for launching your crypto gaming platform. However, the defaults coming with these scripts would most likely not be optimized for high traffic or peak performance. Thus, understanding how to enhance these scripts forms the first step in this journey of scalability and success.
Why Scalability and Performance Matter
Scalability is the ability of your platform to support more and more users and transactions without sacrificing speed or functionality. Performance optimization, on the other hand, ensures that your platform remains responsive and delivers a smooth experience even under high loads.
For example, if your Bustabit clone script is given a hard time during peak hours, players may experience lagging or crashes, which would be frustrating and result in losing users. So, spending on optimization can contribute to the retention of users and operational efficiency.
Important Strategies to Optimize Your Bustabit Script
Optimize Database Performance
Optimization requires effective database management for high performance. Here are some strategies:
Indexing: Speed up data retrieval by creating indexes on frequently queried fields.
Query Optimization: Use tools to analyze and refine your database queries.
Scalable Solutions: Opt for databases like MongoDB or sharded SQL setups that can handle growing data loads effectively.
Implement Efficient Server-Side Code
The server-side code of your Bustabit script must be clean and modular. Here’s how to achieve that:
Caching: Reduce server load by storing frequently accessed data temporarily.
Code Refactoring: Regularly review and rewrite sections of code to eliminate inefficiencies.
Asynchronous Processing: Use asynchronous operations to perform multiple tasks at the same time without causing delays.
Use Content Delivery Networks (CDNs)
CDNs are very important for delivering static assets, such as images or scripts, faster by distributing them across multiple servers worldwide. This reduces the load on your main server, thus improving performance and reliability.
Use Load Balancers
Load balancing distributes incoming user requests across multiple servers, preventing any single server from becoming overloaded. This not only ensures better performance but also enhances the overall reliability of your platform.
Security Enhancements for Your Bustabit Script
While focusing on scalability and performance, don’t overlook security. A secure platform is essential for long-term success. Implement the following measures:
DDoS Protection: Shield your platform from distributed denial-of-service attacks.
Encryption: Encrypt user data and transactions with SSL certificates.
Security Audits: Carry out periodic security audits to determine vulnerabilities and eliminate them.
Testing and Monitoring for Continuous Improvement
Performance Testing
Use Apache JMeter or LoadRunner, for example, to simulate heavy traffic to see how your Bustabit script handles it. Look for bottlenecks and deal with them ahead of time.
Monitoring Tools
Real-time monitoring tools like New Relic or Grafana will enable you to keep track of your key performance indicators. Apply these learnings to your optimization decisions.
Constant Updates
Just like technology changes fast, your Bustabit clone script needs constant updates. Such updates ensure compatibility with the latest technology and optimize general performance.
Working with Experts on Optimization
Proper optimization of the Bustabit script would require much expertise, especially in a scenario where you don't have all the technical knowledge. Hiring experience-rich developers saves your time and ensures that your platform runs efficiently. It's either changing the code, improving the security, or scaling the infrastructure for which you would need the help of experts.
Conclusion
Being ready to scale and optimized for performance for your Bustabit is not only necessary but also a strategic play, through which you guarantee that your product will be more than able to handle growth gracefully while giving every user an amazing experience. Call experts like those at AIS Technolabs—customizing the gaming script by scaling it out helps find the best from the strategies in the list above. If needed, reach us for further consultations.
FAQs
1. What is a Bustabit script, and why is it popular?
A Bustabit script is the central software behind the crash-betting games. It is popular for its engaging gameplay and potential for high returns, especially in the crypto gaming industry.
2. How does scalability impact Bustabit clone scripts?
Scalability will make sure that the Bustabit clone script is ready for an increased level of user activity and data that doesn't interfere with its performance. It's an essential characteristic to maintain retention and satisfaction.
3. Which tools should I use to monitor the performance of my platform?
Excellent monitoring and testing tools are New Relic, Grafana, and Apache JMeter.
Blog Source: https://penzu.com/p/3c6278351c505bc3
0 notes
Text
Scalable Applications with Full Stack Python Development

Scalability is one of the most important considerations when developing applications, especially in the context of Full Stack Python development. As applications grow in terms of users, data, and traffic, ensuring they can scale effectively without compromising on performance or reliability becomes crucial. This blog will guide you through strategies and best practices for building scalable applications using Full Stack Python development
Understanding Scalability in Full Stack Python Development
Scalability refers to the ability of an application to handle increased load — whether that’s more users, more data, or more requests — without sacrificing performance. In Full Stack Python development this means making sure both your frontend and backend are designed to handle growth efficiently.
Scalability is generally classified into two types:
Vertical Scaling (Scaling up): Adding more power (CPU, RAM) to a single server.
Horizontal Scaling (Scaling out): Adding more servers to distribute the load.
In Full Stack Python development, both types of scaling can be employed, but horizontal scaling is usually preferred for web applications that need to serve a large number of concurrent users.
Backend Scalability in Full Stack Python development
Database Optimization:
Sharding: Dividing your database into smaller, more manageable pieces (shards) helps spread the load and improves database performance.
Read/Write Replication: Use replication to separate read-heavy and write-heavy operations. For instance, you can have multiple read replicas and a single master for writes to distribute load more evenly.
NoSQL vs. SQL: Depending on your application’s needs, NoSQL databases like MongoDB might offer more flexibility for scaling horizontally. On the other hand, traditional relational databases like PostgreSQL can be vertically scaled with more advanced configurations.
Caching Layers:
Redis: Implement caching solutions like Redis to store frequently accessed data in memory, reducing database load and improving response times. Caching helps your application serve repeated requests much faster.
Memcached: Another in-memory caching system that can be used in combination with your backend, reducing database hits and improving throughput.
Asynchronous Processing:
Use Celery or RQ for managing background tasks in Python. When scaling your application, background task processing can help offload heavy tasks like email sending, data processing, or image resizing from the main application flow.
AsyncIO in Python allows you to handle multiple I/O-bound operations concurrently without blocking the main application, allowing for better utilization of resources when handling a large number of requests.
Microservices Architecture:
Instead of building a monolithic application, consider breaking your backend into microservices. Each microservice can handle a specific function or domain within your application (e.g., user authentication, payment processing). Microservices can be independently scaled based on demand.
Use tools like Docker and Kubernetes to deploy and manage your microservices. Docker allows you to containerize your microservices, and Kubernetes can automate deployment, scaling, and operations of those containers.
Frontend Scalability in Full Stack Python Development
Load Balancing:
For scalable frontend applications, use load balancers like Nginx or HAProxy to evenly distribute traffic across your servers. Load balancing ensures that no single server gets overwhelmed, even as the number of concurrent users increases.
Frontend Optimization:
Code Splitting: In JavaScript, Webpack or Parcel can help you split your code into smaller, manageable chunks that are only loaded when needed. This reduces the initial page load time and makes the application faster for the user.
Lazy Loading: Lazy loading of images and components ensures that only the essential parts of your application load initially, improving perceived performance. Implement lazy loading using techniques like Intersection Observer API or libraries like React Lazy.
Single Page Application (SPA) Frameworks:
Using a SPA approach with frameworks like React, Vue.js, or Angular allows for more responsive user interfaces and can reduce the amount of server-side rendering required, decreasing the load on your backend.
React, for example, allows the frontend to manage its state independently of the server, which can help reduce server-side requests and improve scalability.
Content Delivery Networks (CDNs):
A CDN like Cloudflare or Amazon CloudFront helps deliver static resources (images, CSS, JavaScript) from servers closest to your users. This reduces load times by serving content faster, improving the user experience as the application scales.
Scaling Full Stack Python Applications
Use of Containers:
Docker allows you to containerize both the frontend and backend of your Full Stack Python development application. Containers can easily be replicated across multiple servers to ensure horizontal scaling.
For orchestration of containers, Kubernetes can automatically scale your application by adjusting the number of containers in response to traffic loads.
Distributed Systems:
RabbitMQ or Kafka can be used for building distributed systems where various parts of the application communicate asynchronously. This is useful when scaling applications that require data to be processed and passed between multiple components of the system.
Auto-Scaling:
Cloud services like AWS or Google Cloud provide auto-scaling options, automatically adjusting your application’s resources based on traffic. This ensures that your application can handle periods of high demand without manual intervention.
APIs and Microservices:
If your application is based on RESTful APIs or GraphQL, ensure your API endpoints are designed to handle scaling efficiently. Use techniques like rate limiting to protect your backend and ensure a smooth experience for users during peak times.
Best Practices for Scalable Full Stack Python Development
Optimize Database Queries: Whether you are using a relational database like PostgreSQL or a NoSQL database like MongoDB, optimizing queries is crucial. Use proper indexing, avoid N+1 queries, and ensure your database is optimized for performance.
Decouple Components: Decouple components in your backend to make it easier to scale. For instance, use message queues (like RabbitMQ or Redis Pub/Sub) to separate your application logic from background tasks.
Automate Testing and Deployment: Implement CI/CD pipelines using tools like GitLab CI, Jenkins, or CircleCI to automate testing and deployment. This ensures that your application is always ready for scaling and reduces the chances of downtime.
Conclusion
Building scalable applications in Full Stack Python development requires careful planning, choosing the right tools, and following best practices to ensure your application can handle increased demand. By optimizing both the backend and frontend, leveraging containerization, and using the right database and caching strategies, you can build applications that scale effectively as your user base grows.
0 notes
Text
AI vs. Analytics: Why Human Expertise Will Still Be in Demand in 2025, 100% Job in MNC, Excel, VBA, SQL, Power BI, Tableau Projects, Data Analyst Course in Delhi, 110009 - Free Python Data Science Certification, By SLA Consultants India,
As we move deeper into the era of automation and artificial intelligence (AI), one pressing question emerges: Will AI replace human professionals in data analytics? The answer is a resounding no—because while AI excels at processing large volumes of data at lightning speed, it lacks the critical thinking, domain knowledge, and contextual understanding that only humans can offer. This is precisely why human expertise in analytics will remain in high demand in 2025 and beyond. A well-structured training program like the Data Analyst Course in Delhi (Pin Code 110009) by SLA Consultants India prepares professionals not only with technical skills but also with the strategic mindset needed to work alongside AI, rather than be replaced by it.
AI tools are designed to assist in data processing, prediction, and automation. However, they rely heavily on the quality of input data and need human oversight to define problems, interpret outcomes, and apply results in real-world business contexts. Human analysts add value by asking the right questions, ensuring ethical use of data, identifying anomalies, and applying industry-specific knowledge that AI simply cannot replicate. This is why employers will continue to seek professionals who are proficient in tools like Excel, VBA, SQL, Power BI, and Tableau, all of which are covered extensively in the best Data Analyst Training Course in Delhi by SLA Consultants India.
One of the most powerful aspects of this course is its inclusion of live projects and case studies, which mimic real corporate challenges. Learners are trained to clean, analyze, and visualize data, providing actionable insights that drive strategic decisions. In addition to technical mastery, the course emphasizes communication skills and business acumen—traits that AI lacks and employers value. Furthermore, the course includes a Free Python Data Science Certification as part of the Summer Offer 2025, giving learners the opportunity to work with Python for automation, advanced analytics, and machine learning fundamentals—skills that enable them to effectively collaborate with AI tools.
Another key advantage of this Data Analyst Certification Course in Delhi program is the 100% Job Assistance in MNCs. SLA Consultants India offers dedicated placement support, from resume development to mock interviews and corporate tie-ups. Graduates of this course are equipped to apply for roles such as Data Analyst, Business Intelligence Analyst, Data Consultant, and Reporting Analyst—positions that require a blend of technical skill and human judgment, which AI alone cannot fulfill. These roles often serve as the bridge between raw data and executive decision-makers, making them indispensable in the modern business environment.
Data Analyst Training Course Modules Module 1 - Basic and Advanced Excel With Dashboard and Excel Analytics Module 2 - VBA / Macros - Automation Reporting, User Form and Dashboard Module 3 - SQL and MS Access - Data Manipulation, Queries, Scripts and Server Connection - MIS and Data Analytics Module 4 - MS Power BI | Tableau Both BI & Data Visualization Module 5 - Free Python Data Science | Alteryx/ R Programing Module 6 - Python Data Science and Machine Learning - 100% Free in Offer - by IIT/NIT Alumni Trainer
In conclusion, while AI is transforming how data is processed, the demand for skilled human analysts is far from fading. In fact, the synergy between human expertise and AI tools is what will define the next generation of data-driven enterprises. By completing the Data Analyst Course in Delhi, 110009, from SLA Consultants India—with hands-on training in Excel, VBA, SQL, Power BI, Tableau, and Python—you position yourself as a critical asset in this hybrid future. This course is not just an educational investment; it's your pathway to a secure, impactful, and future-proof career in analytics. For more details Call: +91-8700575874 or Email: [email protected]
0 notes
Text
Understanding MySQL: Why It's So Popular and Its Core Features

What is MySQL?
MySQL is an open-source relational database management system (RDBMS) that is widely used for managing and storing data. It uses Structured Query Language (SQL) to create, manage, and query databases. MySQL is one of the most popular database systems worldwide due to its ease of use, reliability, and robust performance. It is commonly used in web applications, especially in conjunction with PHP, and powers some of the largest websites and applications on the internet, including Facebook, Twitter, and YouTube.
Why is MySQL So Popular?
There are several reasons why MySQL has gained immense popularity among developers, businesses, and organisations alike:
Open Source and Free: MySQL is open-source, meaning it is free to use and can be modified to suit specific needs. This makes it an attractive option for both small businesses and large enterprises.
Reliability and Stability: MySQL is known for its stability and robustness, making it a reliable choice for applications that require high availability and minimal downtime.
Speed and Efficiency: MySQL offers high-speed data retrieval and processing, which is essential for modern applications that need to handle large volumes of data quickly and efficiently.
Scalability: MySQL can handle large datasets, which allows it to scale seamlessly as an application grows. This scalability makes it suitable for both small websites and large-scale enterprise applications.
Cross-Platform Support: MySQL can run on various platforms, including Windows, Linux, macOS, and others, making it versatile and adaptable to different environments.
Active Community and Support: Being an open-source platform, MySQL benefits from a large, active community that contributes to its development, support, and troubleshooting.
Core Features of MySQL
MySQL comes with a variety of features that make it a powerful and efficient database management system:
Data Security: MySQL provides robust security features, including data encryption and user access controls, to ensure that only authorised users can access sensitive information.
Multi-User Access: MySQL allows multiple users to access and manipulate the database simultaneously, without interfering with each other’s work. This is essential for collaborative environments.
Backup and Recovery: MySQL offers various backup and recovery options, ensuring that data is protected against loss or corruption. Tools such as MySQL Enterprise Backup allow for fast and reliable backups.
Replication: MySQL supports data replication, which allows for data to be copied across multiple servers, ensuring high availability and load balancing. This feature is crucial for large-scale applications that require constant uptime.
Indexes: MySQL supports the use of indexes to improve query performance. Indexes speed up data retrieval operations, making it easier for developers to work with large datasets.
ACID Compliance: MySQL supports ACID (Atomicity, Consistency, Isolation, Durability) properties, which ensures that database transactions are processed reliably.
Full-Text Search: MySQL includes a full-text search engine, allowing developers to search and index text-based data more efficiently.
Stored Procedures and Triggers: MySQL allows the use of stored procedures and triggers to automate tasks and enforce business logic directly within the database.
Conclusion
MySQL is an essential tool for developers and businesses that require a reliable, fast, and secure database management system. Its open-source nature, combined with its powerful features, makes it an ideal choice for projects of all sizes. If you're just starting out with MySQL or looking to improve your knowledge of this versatile platform, check out our complete guide to MySQL to learn more.
0 notes
Text
Best Practices for a Smooth Data Warehouse Migration to Amazon Redshift
In the era of big data, many organizations find themselves outgrowing traditional on-premise data warehouses. Moving to a scalable, cloud-based solution like Amazon Redshift is an attractive solution for companies looking to improve performance, cut costs, and gain flexibility in their data operations. However, data warehouse migration to AWS, particularly to Amazon Redshift, can be complex, involving careful planning and precise execution to ensure a smooth transition. In this article, we’ll explore best practices for a seamless Redshift migration, covering essential steps from planning to optimization.
1. Establish Clear Objectives for Migration
Before diving into the technical process, it’s essential to define clear objectives for your data warehouse migration to AWS. Are you primarily looking to improve performance, reduce operational costs, or increase scalability? Understanding the ‘why’ behind your migration will help guide the entire process, from the tools you select to the migration approach.
For instance, if your main goal is to reduce costs, you’ll want to explore Amazon Redshift’s pay-as-you-go model or even Reserved Instances for predictable workloads. On the other hand, if performance is your focus, configuring the right nodes and optimizing queries will become a priority.
2. Assess and Prepare Your Data
Data assessment is a critical step in ensuring that your Redshift data warehouse can support your needs post-migration. Start by categorizing your data to determine what should be migrated and what can be archived or discarded. AWS provides tools like the AWS Schema Conversion Tool (SCT), which helps assess and convert your existing data schema for compatibility with Amazon Redshift.
For structured data that fits into Redshift’s SQL-based architecture, SCT can automatically convert schema from various sources, including Oracle and SQL Server, into a Redshift-compatible format. However, data with more complex structures might require custom ETL (Extract, Transform, Load) processes to maintain data integrity.
3. Choose the Right Migration Strategy
Amazon Redshift offers several migration strategies, each suited to different scenarios:
Lift and Shift: This approach involves migrating your data with minimal adjustments. It’s quick but may require optimization post-migration to achieve the best performance.
Re-architecting for Redshift: This strategy involves redesigning data models to leverage Redshift’s capabilities, such as columnar storage and distribution keys. Although more complex, it ensures optimal performance and scalability.
Hybrid Migration: In some cases, you may choose to keep certain workloads on-premises while migrating only specific data to Redshift. This strategy can help reduce risk and maintain critical workloads while testing Redshift’s performance.
Each strategy has its pros and cons, and selecting the best one depends on your unique business needs and resources. For a fast-tracked, low-cost migration, lift-and-shift works well, while those seeking high-performance gains should consider re-architecting.
4. Leverage Amazon’s Native Tools
Amazon Redshift provides a suite of tools that streamline and enhance the migration process:
AWS Database Migration Service (DMS): This service facilitates seamless data migration by enabling continuous data replication with minimal downtime. It’s particularly helpful for organizations that need to keep their data warehouse running during migration.
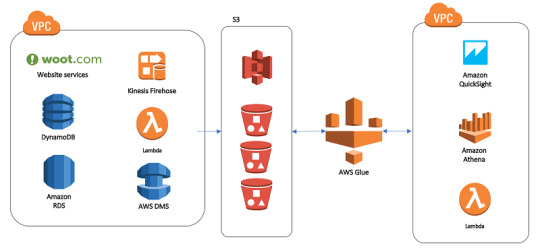
AWS Glue: Glue is a serverless data integration service that can help you prepare, transform, and load data into Redshift. It’s particularly valuable when dealing with unstructured or semi-structured data that needs to be transformed before migrating.
Using these tools allows for a smoother, more efficient migration while reducing the risk of data inconsistencies and downtime.
5. Optimize for Performance on Amazon Redshift
Once the migration is complete, it’s essential to take advantage of Redshift’s optimization features:
Use Sort and Distribution Keys: Redshift relies on distribution keys to define how data is stored across nodes. Selecting the right key can significantly improve query performance. Sort keys, on the other hand, help speed up query execution by reducing disk I/O.
Analyze and Tune Queries: Post-migration, analyze your queries to identify potential bottlenecks. Redshift’s query optimizer can help tune performance based on your specific workloads, reducing processing time for complex queries.
Compression and Encoding: Amazon Redshift offers automatic compression, reducing the size of your data and enhancing performance. Using columnar storage, Redshift efficiently compresses data, so be sure to implement optimal compression settings to save storage costs and boost query speed.
6. Plan for Security and Compliance
Data security and regulatory compliance are top priorities when migrating sensitive data to the cloud. Amazon Redshift includes various security features such as:
Data Encryption: Use encryption options, including encryption at rest using AWS Key Management Service (KMS) and encryption in transit with SSL, to protect your data during migration and beyond.
Access Control: Amazon Redshift supports AWS Identity and Access Management (IAM) roles, allowing you to define user permissions precisely, ensuring that only authorized personnel can access sensitive data.
Audit Logging: Redshift’s logging features provide transparency and traceability, allowing you to monitor all actions taken on your data warehouse. This helps meet compliance requirements and secures sensitive information.
7. Monitor and Adjust Post-Migration
Once the migration is complete, establish a monitoring routine to track the performance and health of your Redshift data warehouse. Amazon Redshift offers built-in monitoring features through Amazon CloudWatch, which can alert you to anomalies and allow for quick adjustments.
Additionally, be prepared to make adjustments as you observe user patterns and workloads. Regularly review your queries, data loads, and performance metrics, fine-tuning configurations as needed to maintain optimal performance.
Final Thoughts: Migrating to Amazon Redshift with Confidence
Migrating your data warehouse to Amazon Redshift can bring substantial advantages, but it requires careful planning, robust tools, and continuous optimization to unlock its full potential. By defining clear objectives, preparing your data, selecting the right migration strategy, and optimizing for performance, you can ensure a seamless transition to Redshift. Leveraging Amazon’s suite of tools and Redshift’s powerful features will empower your team to harness the full potential of a cloud-based data warehouse, boosting scalability, performance, and cost-efficiency.
Whether your goal is improved analytics or lower operating costs, following these best practices will help you make the most of your Amazon Redshift data warehouse, enabling your organization to thrive in a data-driven world.
#data warehouse migration to aws#redshift data warehouse#amazon redshift data warehouse#redshift migration#data warehouse to aws migration#data warehouse#aws migration
0 notes
Text
What is MongoDB? Features & How it Works

Think about managing a library. Traditional libraries place books in organized rows based on subjects or author names. Now imagine a library where books are placed anywhere but a powerful search tool finds them instantly using the title or content. This is what MongoDB does for data storage. It is a modern database that offers flexibility & ease when it comes to storing & retrieving information.
What is MongoDB
MongoDB is a NoSQL database designed to handle large amounts of data efficiently. Unlike traditional relational databases such as MySQL or SQL Server, MongoDB does not rely on tables or fixed structures. Instead it uses a document-oriented approach. The data is stored in documents similar to JSON format which allows for handling complex data without the strict limitations of predefined schemas.
If you think of relational databases like tightly controlled spreadsheets where each row represents a data entry & each column represents a fixed attribute MongoDB works differently. In a relational system adding new information can be challenging because all rows need to follow the same structure. With MongoDB each document or data entry can have its own unique attributes without following a rigid format.
How MongoDB Works
MongoDB is built for flexibility & scalability. It stores data in collections which are similar to tables in traditional databases. Each document within a collection can have different structures. For instance one document might contain a person's name & address while another includes additional details like social media profiles. MongoDB adapts to changing needs without requiring predefined rules for storing data.
This database shines when handling large amounts of unstructured data which makes it popular in industries like social media online retail & IoT systems. It is especially useful for storing real-time analytics logs & customer profiles. By not sticking to rows & columns MongoDB offers more freedom in how data is managed.
Key Features of MongoDB
1. Document-Oriented Storage
MongoDB uses BSON documents which are essentially key-value pairs. This means it can handle complex data structures with ease. A customer document might include their name address & a list of their recent orders all stored in one place. This approach is much more flexible than traditional databases.
2. Scalability
One of the standout qualities of MongoDB is its horizontal scalability. When dealing with massive datasets MongoDB can distribute data across several servers or clusters. This process known as sharding splits the data into smaller pieces allowing it to scale across multiple machines rather than requiring one large server.
3. Flexible Schema
MongoDB does not need a fixed schema so it easily adapts to changing data requirements. For example a company might begin collecting new information about its customers & MongoDB can handle this new data without restructuring the entire system. This ability to evolve without strict rules is a key benefit.
4. Replication
To ensure data availability MongoDB uses replica sets. These sets involve one primary server handling data requests with several secondary servers maintaining copies of the data. In case the primary server fails one of the secondary servers takes over reducing the chance of downtime.
5. High Performance
MongoDB is optimized for high-speed read & write operations. It supports indexing specific fields within documents which allows it to handle high-demand applications like real-time analytics or customer-facing platforms with ease.
6. Rich Query Language
MongoDB's query language is versatile. It allows users to search based on fields or perform text searches. MongoDB supports complex aggregations enabling businesses to pull insights from large datasets without struggling with performance.
MongoDB in Action
Let us visualize MongoDB through a real-world example. Picture an online store selling everything from fashion to electronics. Each product comes with its own set of details—clothing has sizes & colors while electronics have specs like battery life & screen size. With traditional databases storing all this information would require multiple tables & predefined attributes which can become complex over time.
In MongoDB each product is stored as a document that contains only the attributes it needs. A shirt would have fields for size & color while a laptop might include processor speed & storage. This level of flexibility makes MongoDB ideal for businesses that handle evolving & varied data. The database grows & adapts as the business does without needing major changes to its structure.
When to Use MongoDB
MongoDB is a strong fit in any situation where data is complex & grows rapidly. Its structure works well for storing customer data inventory information & real-time interactions. Some use cases include:
E-commerce: Storing customer profiles product data & inventory
Social Media: Managing user profiles posts & comments
IoT Systems: Collecting & analyzing data from smart devices
That said MongoDB may not be the best solution for every situation. In cases where multi-row transactions are crucial such as in banking relational databases may offer better functionality.
Final Comment
MongoDB offers a fresh way to think about data storage. It lets businesses store their data in a flexible document format without being held back by the rigid structures of traditional databases. Whether managing thousands of users or handling large product catalogs MongoDB provides the performance scalability & flexibility needed to keep up with growth.
By storing information in a natural & efficient manner MongoDB training helps businesses innovate quickly. In today’s data-driven world having a database that can scale & adapt as needed is essential for staying competitive.
People A lso Read : Top Automation Anywhere Courses Online
0 notes
Text
Benefits of Snowflake for enterprise database management
The importance of data for businesses cannot be overstated as the world continues to run on data-intensive, hyper-connected and real-time applications.
Businesses of all scale and capabilities rely on data to make future decisions and derive useful insights to create growth.
However, with the rising volume, complexity and dependency on data rich applications and platforms, it has become imperative for companies and enterprises to make use of scalable, flexible and robust tools and technologies.

This is where database management solutions help businesses implement data pipelines for storing, modifying and analysing data in real-time.
Although there are many tools and solutions to make use of real-time data processing and analysis, not all tools are created equal.
While many companies rely on legacy systems like Microsoft SQL server to power a wide range of applications, modern day businesses are increasingly adapting to cloud-based data warehousing platforms.
One such name in the database management sphere is called Snowflake which is a serverless, cloud-native infrastructure as a service platform.
Snowflake supports Microsoft Azure, Google Cloud and Amazon AWS and is fully scalable to meet your computing and data processing needs.
If you are interested in leveraging the power and capabilities of Snowflake’s cloud based data warehousing solution, it’s time to prepare for migrating your existing SQL server to Snowflake with the help of tools like Bryteflow. Bryteflow allows fully automated, no-code replication of SQL server database to a Snowflake data lake or data warehouse.
0 notes