#sqoop import from mysql to hdfs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Big Data and Data Engineering
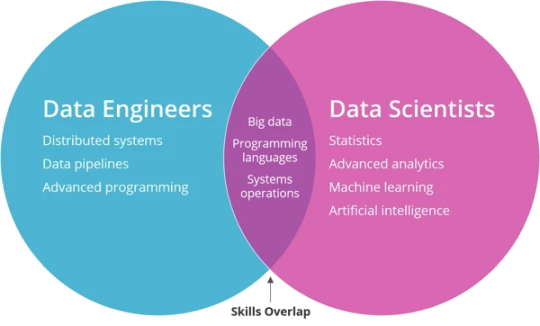
Big Data and Data Engineering are essential concepts in modern data science, analytics, and machine learning.
They focus on the processes and technologies used to manage and process large volumes of data.
Here’s an overview:
What is Big Data? Big Data refers to extremely large datasets that cannot be processed or analyzed using traditional data processing tools or methods.
It typically has the following characteristics:
Volume:
Huge amounts of data (petabytes or more).
Variety:
Data comes in different formats (structured, semi-structured, unstructured). Velocity: The speed at which data is generated and processed.
Veracity: The quality and accuracy of data.
Value: Extracting meaningful insights from data.
Big Data is often associated with technologies and tools that allow organizations to store, process, and analyze data at scale.
2. Data Engineering:
Overview Data Engineering is the process of designing, building, and managing the systems and infrastructure required to collect, store, process, and analyze data.
The goal is to make data easily accessible for analytics and decision-making.
Key areas of Data Engineering:
Data Collection:
Gathering data from various sources (e.g., IoT devices, logs, APIs). Data Storage: Storing data in data lakes, databases, or distributed storage systems. Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Integration:
Combining data from multiple sources to create a unified dataset for analysis.
3. Big Data Technologies and Tools
The following tools and technologies are commonly used in Big Data and Data Engineering to manage and process large datasets:
Data Storage:
Data Lakes: Large storage systems that can handle structured, semi-structured, and unstructured data. Examples include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Distributed File Systems:
Systems that allow data to be stored across multiple machines. Examples include Hadoop HDFS and Apache Cassandra.
Databases:
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra, HBase).
Data Processing:
Batch Processing: Handling large volumes of data in scheduled, discrete chunks.
Common tools:
Apache Hadoop (MapReduce framework). Apache Spark (offers both batch and stream processing).
Stream Processing:
Handling real-time data flows. Common tools: Apache Kafka (message broker). Apache Flink (streaming data processing). Apache Storm (real-time computation).
ETL (Extract, Transform, Load):
Tools like Apache Nifi, Airflow, and AWS Glue are used to automate data extraction, transformation, and loading processes.
Data Orchestration & Workflow Management:
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. Kubernetes and Docker are used to deploy and scale applications in data pipelines.
Data Warehousing & Analytics:
Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse Analytics are popular cloud data warehouses for large-scale data analytics.
Apache Hive is a data warehouse built on top of Hadoop to provide SQL-like querying capabilities.
Data Quality and Governance:
Tools like Great Expectations, Deequ, and AWS Glue DataBrew help ensure data quality by validating, cleaning, and transforming data before it’s analyzed.
4. Data Engineering Lifecycle
The typical lifecycle in Data Engineering involves the following stages: Data Ingestion: Collecting and importing data from various sources into a central storage system.
This could include real-time ingestion using tools like Apache Kafka or batch-based ingestion using Apache Sqoop.
Data Transformation (ETL/ELT): After ingestion, raw data is cleaned and transformed.
This may include:
Data normalization and standardization. Removing duplicates and handling missing data.
Aggregating or merging datasets. Using tools like Apache Spark, AWS Glue, and Talend.
Data Storage:
After transformation, the data is stored in a format that can be easily queried.
This could be in a data warehouse (e.g., Snowflake, Google BigQuery) or a data lake (e.g., Amazon S3).
Data Analytics & Visualization:
After the data is stored, it is ready for analysis. Data scientists and analysts use tools like SQL, Jupyter Notebooks, Tableau, and Power BI to create insights and visualize the data.
Data Deployment & Serving:
In some use cases, data is deployed to serve real-time queries using tools like Apache Druid or Elasticsearch.
5. Challenges in Big Data and Data Engineering
Data Security & Privacy:
Ensuring that data is secure, encrypted, and complies with privacy regulations (e.g., GDPR, CCPA).
Scalability:
As data grows, the infrastructure needs to scale to handle it efficiently.
Data Quality:
Ensuring that the data collected is accurate, complete, and relevant. Data
Integration:
Combining data from multiple systems with differing formats and structures can be complex.
Real-Time Processing:
Managing data that flows continuously and needs to be processed in real-time.
6. Best Practices in Data Engineering Modular Pipelines:
Design data pipelines as modular components that can be reused and updated independently.
Data Versioning: Keep track of versions of datasets and data models to maintain consistency.
Data Lineage: Track how data moves and is transformed across systems.
Automation: Automate repetitive tasks like data collection, transformation, and processing using tools like Apache Airflow or Luigi.
Monitoring: Set up monitoring and alerting to track the health of data pipelines and ensure data accuracy and timeliness.
7. Cloud and Managed Services for Big Data
Many companies are now leveraging cloud-based services to handle Big Data:
AWS:
Offers tools like AWS Glue (ETL), Redshift (data warehousing), S3 (storage), and Kinesis (real-time streaming).
Azure:
Provides Azure Data Lake, Azure Synapse Analytics, and Azure Databricks for Big Data processing.
Google Cloud:
Offers BigQuery, Cloud Storage, and Dataflow for Big Data workloads.
Data Engineering plays a critical role in enabling efficient data processing, analysis, and decision-making in a data-driven world.

0 notes
Text
Hadoop Admin training in Pune, India.

Hadoop Admin Training in Pune
At SevenMentor training institute, we are always striving to achieve value for our applicants. We provide the best Hadoop Admin Training in Pune that pursues latest instruments, technologies, and methods. Any candidate out of IT and Non-IT history or having basic knowledge of networking could register for this program. Freshers or experienced candidates can combine this course to understand Hadoop management, troubleshooting and setup almost. The candidates who are Freshers, Data Analyst, BE/ Bsc Candidate, Any Engineers, Any schooling, Any Post-Graduate, Database Administrators, Working Professional all can join this course and update themselves to improve a career in late technologies. Hadoop Admin classes in Pune is going to be processed by Accredited Trainer from Corporate Industries directly, As we believe in supplying quality live Greatest Hadoop Administration Training in Pune with all the essential practical to perform management and process under training roofing, The coaching comes with Apache spark module, Kafka and Storm for real time occasion processing, You to combine the greater future with SevenMentor.
Proficiency After Training
Can handle and procedures the Big Data, Learn How to Cluster it and manage complex team readily.
Will Have the Ability to manage extra-large amount of Unstructured Data Across various Business Companies
He/She will Have the Ability to apply for various job positions to data process Engineering operate in MNCs
Hadoop Admin Classes in Pune
What we provide for Hadoop Admin Courses before stepping into Hadoop Environment for the very first time, we will need to understand why Hadoop came into existence. What were the drawbacks of traditional RDBMS in and Hadoop is better?
We're going to learn about fundamental networking concepts. Together with media terminologies we're also going understand about AWS Cloud. Why cloud at the very first location? Now businesses are turning to cloud. Baremetals and VM's do not probably have the capacity to put away the number of information that is generated in the present world. Plus it costs business a great deal of money to store the information to the hardware, and also the upkeep of these machines will also be required on timely basis. Cloud offers answer to such issues, where a company can store all of its information which is generated without worrying about the number of information that's created on daily basis. They don't need to care for the upkeep and safety of these machines, cloud sellers appears after all this. Here at SevenMentor we'll provide you hands on exposure to the Amazon Web Services (AWS Cloud) since AWS is market leader within this subject.
We'll offer exposure to Linux surroundings too. Hadoop Administrator understands a great deal of tickets concerning the Hadoop bunch and those tickets need to be resolved in accordance with the priority of these tickets. In business we call it all troubleshooting. Thus, Hadoop Admin must troubleshoot in Linux environment. We've developed our course in this manner that in the event that you don't have any knowledge from Linux Environment we'll provide you sufficient exposure to the technology whilst covering the sessions of Hadoop Admin.
What is Hadoop Admin?
Hadoop is a member level open supply package framework designed for storage and procedure for huge scale type of information on clusters of artifact hardware. The Apache Hadoop software library is a framework which allows the data distributed processing across clusters for calculating using easy programming versions called Map Reduce. It is intended to rescale from single servers to a bunch of machines and each giving native computation and storage in economical means. It functions in a run of map-reduce tasks and each of these tasks is high-latency and depends on each other. So no job can begin until the previous job was completed and successfully finished. Hadoop solutions usually comprise clusters that are tough to manage and maintain. In many cases, it requires integration with other tools like MySQL, mahout, etc.. We have another popular framework which works with Apache Hadoop i.e. Spark. Apache Spark allows software developers to come up with complicated, multi-step data pipeline application routines. It also supports in-memory data sharing across DAG (Directed Acyclic Graph) established applications, so that different jobs can work with the same shared data. Spark runs on top of this Hadoop Distributed File System (HDFS) of Hadoop to improve functionality. Spark does not possess its own storage so it uses storage. With the capacities of in-memory information storage and information processing, the spark program performance is more time quicker than other big data technology or applications. Spark has a lazy evaluation which helps with optimization of the measures in data processing and control. It supplies a higher-level API for enhancing consistency and productivity. Spark is designed to be a fast real-time execution engine which functions both in memory and on disk. Spark is originally written in Scala language plus it runs on the exact same Java Virtual Machine (JVM) environment. It now supports Java, Scala, Clojure, R, Python, SQL for writing applications.
Why Should I take Hadoop Admin Training in Pune?
Apache Hadoop framework allows us to write distributed systems or applications. It's more efficient and it automatically distributes the job and information among machines which lead a parallel programming model. Hadoop works with various sorts of data effectively. In addition, it provides a high fault-tolerant method to prevent data losses. Another big advantage of Hadoop is that it is open source and compatible with all platforms since it's based on java. On the current market, Hadoop is the only remedy to work on large data effectively in a distributed fashion. The Apache Hadoop software library is a framework that makes it possible for the data distributed processing across clusters for computing using simple programming models known as Map Reduce. It's intended to ratio from single servers to the cluster of servers and each giving native computation and storage in a cheap way. It works in a series of map-reduce tasks and every one of these tasks is high-latency and depends upon each other. So no occupation can start until the last job has been finished and successfully finished. Hadoop solutions normally include clusters that are hard to manage and maintain.
We have another popular framework which works with Apache Hadoop i.e. Spark.
Apache Spark enables software developers to develop complicated, multi-step data pipeline software patterns. It also supports in-memory data sharing across DAG (Directed Acyclic Graph) established applications, so that different tasks can use the exact same shared data. Spark runs on top of this Hadoop Distributed File System (HDFS) of Hadoop to improve functionality. Spark does not possess its own storage so it utilizes storage. With the capabilities of in-memory data storage and data processing, the spark program functionality is more time faster than other large information technologies or applications. Spark includes a lazy evaluation which helps with optimization of the steps in data processing and control. It provides a higher-level API for improving consistency and productivity. Spark is designed to be a fast real-time execution engine which works both in memory and on disk.
Where Hadoop Admin could be utilized?
Machine Learning -- Machine learning is that the scientific research of calculations and applied mathematics versions that computer systems use to execute a specific job whilst not mistreatment specific directions. AI -- Machine intelligence which behaves like a person and takes decisions.
Data Analysis - is an extensive way of scrutinizing and re-transforming data with the objective of discovering useful information, notifying conclusions and supporting decision-making steps.
Graph and data visualization -- Data representation through graphs, graphs, images, etc..
Tools in Hadoop:
HDFS (Hadoop Distributed File System) fundamental storage for Hadoop.
Map scale back might be a programmatic version engine to perform man jobs.
Apache Hive is a Data Warehouse tool used to operate on Ancient data using HQL.
Apache Sqoop is a tool for Import and export data from RDBMS into HDFS and Vice-Versa.
Apache Ooozie is a tool for Job scheduling and similarly control applications over the cluster.
Apache HBase is a NoSQL database based on CAP(Consistency Automaticity Partition) principles.
A flicker could be a framework will in memory computation and works with Hadoop. This framework relies on scala and coffee language.
Why go for Best Hadoop Admin Training in Pune in SevenMentor?
At our renowned institute SevenMentor training, we have got industry-standard Hadoop program designed by IT professionals. The coaching we provide is 100% functional. Together with Hadoop Administrator Certification at Pune, we supply 100+ missions, POC's and real-time jobs. Additionally CV writing, mock tests, interviews are required to earn candidate industry-ready. We offer elaborated notes, interview kit and reference books to each candidate. Hadoop Administration Courses in Pune from Sevenmentor will master you handling and processing considerable quantities of info, unfiltered data with simple. The coaching went beneath bound modules where pupils find out how to install, strategy, configure a Hadoop cluster from planning to monitoring. The pupil can get coaching from live modules and also on a software package to fully optimize their data within the field of information process, the Best Hadoop Admin institute in Pune will allow you to monitor performance and work on information safety concepts in profound.
Hadoop admin is chargeable for the execution and support of this Enterprise Hadoop atmosphere.
Hadoop Administration invloves arising with, capacity arrangement, cluster discovered, performance fine-tuning, observation, structure arising withscaling and management. Hadoop Admins itself might well be a name that covers a heap of different niches within the massive information world: trusting on the size of this corporate they work for, Hadoop administrator may additionally worry liberal arts DBA like jobs with HBase and Hive databases, security administration and cluster management. Our syllabus covers all topics to deploy, manage, monitor, and secure a Hadoop Cluster at the end.
After successful conclusion of Hadoop Administration Classes in Pune in SevenMentor, you can manage and procedures that the Big Data, Learn to Cluster it and manage complex things readily. You will be able to control the extra-large quantity of Unstructured Data Around various small business Companies. You will have the ability to use for various job positions to information process Engineering work in MNCs.
Job Opportunities After Greatest Hadoop Admin Training in Pune.
The present IT job market is shifting about Big information only, 65 percent of their highest paid jobs direct to Big data Hadoop careers. Thus, if you're interested in finding a profession in Substantial data Hadoop admin, then you will be happy to know that existing Hadoop market is growing rapidly not just in IT industry but also in additional domain and sectors such as e-commerce, banking, digital marketing, government, medical, research, and promotion.
Hadoop Administrator -- Responsible for the implementation and ongoing administration of Hadoop infrastructure. Aligning with all the systems engineering team to suggest and deploy new hardware and software bundle environments required for Hadoop and also revamp existing environments.
A Hadoop admin plays a major job role in the company, he or she acts as the core of the business. The best Hadoop Administrator Training at Pune learner is not only responsible to administrate to handle entire Hadoop clusters but also handle all resources, tools, the infrastructure of the Hadoop ecosystem. He is also responsible for handling installation and maintenance of full Hadoop multi-node cluster, and manage overall maintenance and functionality. Hadoop admin is clearly responsible for the implementation and support of the Enterprise Hadoop atmosphere. Hadoop Admins itself might be a title that covers a pile of assorted niches within the huge data world: counting on the grade of the firm they work for, Hadoop administrator could, in addition, be worried performing arts DBA like tasks with HBase and Hive databases, safety administration and cluster administration. It covers matters to deploy, manage, track, and secure a Hadoop Cluster.
After effective Hadoop administrator training in Pune completion in SevenMentor, you can handle and processes the Big Data, Learn to Cluster it and manage complicated things readily. You will have the ability to control the extra-large quantity of Unstructured Data Across various Business Companies. You'll have the ability to apply for various job positions to information process Engineering operate in MNCs.
Accessible Hadoop Admin Certification Course at Pune
Businesses square measure using Hadoop wide to interrupt down their informational sets. The main reason is Hadoop system mainly depends on a straightforward programming model (MapReduce) and it empowers a figuring arrangement that is flexible, adaptable, blame tolerant and fiscally savvy. Here, the primary concern is to stay up to speed in creating prepared in-depth datasets as so much as holding time up amongst queries and holding up time to conduct the app.
We at Seventmentor understands the need for candidates and most well-liked batch timings. Presently, we've got weekends and weekdays batches for Big data Hadoop Admin Training in Pune. We also give versatile batch timings as per need. The entire duration for the Hadoop Admin class in Pune is 40 Hours. In weekdays batch, Hadoop Administrator Certification at Pune will probably be of 2 hours each day and at the weekend its 3 hours every day.
Nowadays learning of Hadoop is important and essential skills for beginners and seasoned to make a career in IT as well as experience to boost the abilities for better opportunities. It will be helpful for any operational, technical and support adviser.
SevenMentor as Best Hadoop Admin Training in Pune provides a unique Big Data Hadoop Admin class in Pune considering fresher or entry-level engineers to encounter.
0 notes
Text
300+ TOP Apache SQOOP Interview Questions and Answers
SQOOP Interview Questions for freshers experienced :-
1. What is the process to perform an incremental data load in Sqoop? The process to perform incremental data load in Sqoop is to synchronize the modified or updated data (often referred as delta data) from RDBMS to Hadoop. The delta data can be facilitated through the incremental load command in Sqoop. Incremental load can be performed by using Sqoop import command or by loading the data into hive without overwriting it. The different attributes that need to be specified during incremental load in Sqoop are- Mode (incremental) –The mode defines how Sqoop will determine what the new rows are. The mode can have value as Append or Last Modified. Col (Check-column) –This attribute specifies the column that should be examined to find out the rows to be imported. Value (last-value) –This denotes the maximum value of the check column from the previous import operation. 2. How Sqoop can be used in a Java program? The Sqoop jar in classpath should be included in the java code. After this the method Sqoop.runTool () method must be invoked. The necessary parameters should be created to Sqoop programmatically just like for command line. 3. What is the significance of using –compress-codec parameter? To get the out file of a sqoop import in formats other than .gz like .bz2 we use the –compress -code parameter. 4. How are large objects handled in Sqoop? Sqoop provides the capability to store large sized data into a single field based on the type of data. Sqoop supports the ability to store- CLOB ‘s – Character Large Objects BLOB’s –Binary Large Objects Large objects in Sqoop are handled by importing the large objects into a file referred as “LobFile” i.e. Large Object File. The LobFile has the ability to store records of huge size, thus each record in the LobFile is a large object. 5. What is a disadvantage of using –direct parameter for faster data load by sqoop? The native utilities used by databases to support faster load do not work for binary data formats like SequenceFile 6. Is it possible to do an incremental import using Sqoop? Yes, Sqoop supports two types of incremental imports- Append Last Modified To insert only rows Append should be used in import command and for inserting the rows and also updating Last-Modified should be used in the import command. 7. How can you check all the tables present in a single database using Sqoop? The command to check the list of all tables present in a single database using Sqoop is as follows- Sqoop list-tables –connect jdbc: mysql: //localhost/user; 8. How can you control the number of mappers used by the sqoop command? The Parameter –num-mappers is used to control the number of mappers executed by a sqoop command. We should start with choosing a small number of map tasks and then gradually scale up as choosing high number of mappers initially may slow down the performance on the database side. 9. What is the standard location or path for Hadoop Sqoop scripts? /usr/bin/Hadoop Sqoop 10. How can we import a subset of rows from a table without using the where clause? We can run a filtering query on the database and save the result to a temporary table in database. Then use the sqoop import command without using the –where clause

Apache SQOOP Interview Questions 11. When the source data keeps getting updated frequently, what is the approach to keep it in sync with the data in HDFS imported by sqoop? qoop can have 2 approaches. To use the –incremental parameter with append option where value of some columns are checked and only in case of modified values the row is imported as a new row. To use the –incremental parameter with lastmodified option where a date column in the source is checked for records which have been updated after the last import. 12. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. 13. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 14. Tell few import control commands: Append Columns Where These command are most frequently used to import RDBMS Data. 15. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 16. How can you see the list of stored jobs in sqoop metastore? sqoop job –list 17. What type of databases Sqoop can support? MySQL, Oracle, PostgreSQL, IBM, Netezza and Teradata. Every database connects through jdbc driver. 18. What is the purpose of sqoop-merge? The merge tool combines two datasets where entries in one dataset should overwrite entries of an older dataset preserving only the newest version of the records between both the data sets. 19. How sqoop can handle large objects? Blog and Clob columns are common large objects. If the object is less than 16MB, it stored inline with the rest of the data. If large objects, temporary stored in_lob subdirectory. Those lobs processes in a streaming fashion. Those data materialized in memory for processing. IT you set LOB to 0, those lobs objects placed in external storage. 20. What is the importance of eval tool? It allows user to run sample SQL queries against Database and preview the results on the console. It can help to know what data can import? The desired data imported or not? 21. What is the default extension of the files produced from a sqoop import using the –compress parameter? .gz 22. Can we import the data with “Where” condition? Yes, Sqoop has a special option to export/import a particular data. 23. What are the limitations of importing RDBMS tables into Hcatalog directly? There is an option to import RDBMS tables into Hcatalog directly by making use of –hcatalog –database option with the –hcatalog –table but the limitation to it is that there are several arguments like –as-avro file , -direct, -as-sequencefile, -target-dir , -export-dir are not supported. 24. what are the majorly used commands in sqoop? In Sqoop Majorly Import and export command are used. But below commands are also useful sometimes. codegen, eval, import-all-tables, job, list-database, list-tables, merge, metastore. 25. What is the usefulness of the options file in sqoop. The options file is used in sqoop to specify the command line values in a file and use it in the sqoop commands. For example the –connect parameter’s value and –user name value scan be stored in a file and used again and again with different sqoop commands. 26. what are the common delimiters and escape character in sqoop? The default delimiters are a comma(,) for fields, a newline(\n) for records Escape characters are \b,\n,\r,\t,\”, \\’,\o etc 27. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 28. while loading table from MySQL into HDFS, if we need to copy tables with maximum possible speed, what can you do? We need to use -direct argument in import command to use direct import fast path and this -direct can be used only with MySQL and PostGreSQL as of now. 29. How can you sync a exported table with HDFS data in which some rows are deleted? Truncate the target table and load it again. 30. Differentiate between Sqoop and distCP. DistCP utility can be used to transfer data between clusters whereas Sqoop can be used to transfer data only between Hadoop and RDBMS. 31. How can you import only a subset of rows form a table? By using the WHERE clause in the sqoop import statement we can import only a subset of rows. 32. How do you clear the data in a staging table before loading it by Sqoop? By specifying the –clear-staging-table option we can clear the staging table before it is loaded. This can be done again and again till we get proper data in staging. 33. What is Sqoop? Sqoop is an open source project that enables data transfer from non-hadoop source to hadoop source. It can be remembered as SQL to Hadoop -> SQOOP. It allows user to specify the source and target location inside the Hadoop. 35. How can you export only a subset of columns to a relational table using sqoop? By using the –column parameter in which we mention the required column names as a comma separated list of values. 36. Which database the sqoop metastore runs on? Running sqoop-metastore launches a shared HSQLDB database instance on the current machine. 37. How will you update the rows that are already exported? The parameter –update-key can be used to update existing rows. In it a comma-separated list of columns is used which uniquely identifies a row. All of these columns is used in the WHERE clause of the generated UPDATE query. All other table columns will be used in the SET part of the query. 38. You have a data in HDFS system, if you want to put some more data to into the same table, will it append the data or overwrite? No it can’t overwrite, one way to do is copy the new file in HDFS. 39. Where can the metastore database be hosted? The metastore database can be hosted anywhere within or outside of the Hadoop cluster. 40. Which is used to import data in Sqoop ? In SQOOP import command is used to import RDBMS data into HDFS. Using import command we can import a particular table into HDFS. – 41. What is the role of JDBC driver in a Sqoop set up? To connect to different relational databases sqoop needs a connector. Almost every DB vendor makes this connecter available as a JDBC driver which is specific to that DB. So Sqoop needs the JDBC driver of each of the database it needs to interact with. 42. How to import only the updated rows form a table into HDFS using sqoop assuming the source has last update timestamp details for each row? By using the lastmodified mode. Rows where the check column holds a timestamp more recent than the timestamp specified with –last-value are imported. 43. What is InputSplit in Hadoop? When a hadoop job is run, it splits input files into chunks and assign each split to a mapper to process. This is called Input Split 44. Hadoop sqoop word came from ? Sql + Hadoop = sqoop 45. What is the work of Export In Hadoop sqoop ? Export the data from HDFS to RDBMS 46. Use of Codegen command in Hadoop sqoop ? Generate code to interact with database records 47. Use of Help command in Hadoop sqoop ? List available commands 48. How can you schedule a sqoop job using Oozie? Oozie has in-built sqoop actions inside which we can mention the sqoop commands to be executed. 49. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 50. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. SQOOP Questions and Answers pdf Download Read the full article
0 notes
Text
Post 3 | HDPCD | Sqoop Import
Post 3 | HDPCD | Sqoop Import

Hi everyone, hope you are finding the tutorials useful. From this tutorial onwards, we are going to perform objectives for HDPCD certification.
In this tutorial, we are going to see the first objective in Data Ingestion category. If you go to Hortonworks’ objective page here, you will find it to be worded as “Import data from a table in a relational database into HDFS.”, shown in below screenshot.
View On WordPress
#Big Data#big data certification#certification#certified#course objective#exam objective#hadoop#hadoop certification#HDPCD#hdpcd big data#hdpcd certification#Hortonworks#hortonworks big data#hortonworks certification#hortonworks data platform certified developer#hortonworks sandbox#import from mysql into hdfs#mysql to hdfs#Sqoop#sqoop import
0 notes
Link
Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC ##FreeCourse ##UdemyDiscount #Admin #Big #Bootcamp #Class #Data #Hadoop #Hive #NYC #Spark Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC Introduction Hadoop Big Data Course Introduction to the Course Top Ubuntu commands Understand NameNode, DataNode, YARN and Hadoop Infrastructure Hadoop Install Hadoop Installation & HDFS Commands Java based Mapreduce # Hadoop 2.7 / 2.8.4 Learn HDFS commands Setting up Java for mapreduce Intro to Cloudera Hadoop & studying Cloudera Certification SQL and NoSQL SQL, Hive and Pig Installation (RDBMS world and NoSQL world) More Hive and SQOOP (Cloudera – Sqoop and Hive on Cloudera. JDBC drivers. Pig Intro to NoSQL, MongoDB, Hbase Installation Understanding different databases Hive : Hive Partitions and Bucketing Hive External and Internal Tables Spark Scala Python Spark Installations and Commands Spark Scala Scala Sheets Hadoop Streaming Python Map Reduce PySpark – (Python – Basics). RDDs. Running Spark-shell and importing data from csv files PySpark – Running RDD Mid Term Projects Pull data from csv online and move to Hive using hive import Pull data from spark-shell and run map reduce for fox news first page Create Data in MySQL and using SQOOP move it to HDFS Using Jupyter Anaconda and Spark Context run count on file that has Fox news first page Save raw data using delimiter comma, space, tab and pipe and move that into spark-context and spark shell Broadcasting Data – stream of data Kafka Message Broadcasting Who this course is for: Carrier changes who would like to move to Big Data Hadoop Learners who want to learn Hadoop installations 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/hadoop-spark-hive-big-data-admin-class-bootcamp-course-nyc/
0 notes
Text
Apache Sqoop in Hadoop
Rainbow Training Institute provides the best Big Data and Hadoop online training. Enroll for big data Hadoop training in Hyderabad certification, delivered by Certified Big Data Hadoop Experts. Here we are offering big data Hadoop training across global.
What is SQOOP in Hadoop?
Apache Sqoop (SQL-to-Hadoop) is intended to help mass import of data into HDFS from organized data stores, for example, social databases, undertaking data stockrooms, and NoSQL frameworks. Sqoop depends on a connector engineering that underpins modules to give network to new outside frameworks.
A model use instance of Sqoop is an undertaking that runs a daily Sqoop import to stack the day's data from a creation value-based RDBMS into a Hive data distribution center for additional examination.
Sqoop Architecture
All the current Database Management Systems are planned in light of SQL standard. In any case, every DBMS varies as for lingo somewhat. In this way, this distinction presents difficulties with regard to data moves over the frameworks. Sqoop Connectors are segments that help conquer these difficulties.
Data move among Sqoop and outside stockpiling framework is made conceivable with the assistance of Sqoop's connectors.
Sqoop has connectors for working with a scope of mainstream social databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Every one of these connectors realizes how to collaborate with its related DBMS. There is additionally a conventional JDBC connector for interfacing with any database that supports Java's JDBC convention. Moreover, Sqoop gives improved MySQL and PostgreSQL connectors that utilization database-explicit APIs to perform mass exchanges effectively.
What is Sqoop? What is FLUME - Hadoop
Sqoop Architecture
What's more, Sqoop hosts different third-gathering connectors for data stores, going from big business data distribution centers (counting Netezza, Teradata, and Oracle) to NoSQL stores, (for example, Couchbase). Be that as it may, these connectors don't accompany the Sqoop group; those should be downloaded independently and can be added effectively to a current Sqoop establishment.
For what reason do we need Sqoop?
Scientific preparation utilizing Hadoop requires the stacking of gigantic measures of data from assorted sources into Hadoop groups. This procedure of mass data load into Hadoop, from heterogeneous sources and afterward preparing it, accompanies a specific arrangement of difficulties. Keeping up and guaranteeing data consistency and guaranteeing productive use of assets, are a few elements to consider before choosing the correct methodology for data load.
Significant Issues:
1. Data load utilizing Scripts
The conventional methodology of utilizing contents to stack data isn't appropriate for mass data load into Hadoop; this methodology is wasteful and very tedious.
2. Direct access to outer data through Map-Reduce application
Giving direct access to the data living at outer systems(without stacking into Hadoop) for map-lessen applications muddles these applications. Thus, this methodology isn't possible.
3. Notwithstanding being able to work with huge data, Hadoop can work with data in a few distinct structures. Thus, to load such heterogeneous data into Hadoop, various devices have been created. Sqoop and Flume are two such data stacking apparatuses.
0 notes
Photo

Apache Sqoop for Certifications - CCA and HDPCD
As part of this course, we will be Seeing various setup options to explore sqoop Understand how to import data from mysql database to Hadoop HDFS/Hive All the important control arguments while performing import Export data from Hive/HDFS to MySQL After the course, you can confidently execute...
http://texperts.it/deal/apache-sqoop-certifications-cca-hdpcd/
0 notes
Photo

Flume and Sqoop for Ingesting Big Data Import data to HDFS, HBase and Hive from a variety of sources , including Twitter and MySQL…
0 notes
Text
Sqoop Import
SQOOP IMPORT:
The sqoop import tool imports individual tables from RDBMS to HDFS.Sqoop import tool takes data from RDBMS with four mappers by default,to HDFS.In the process of importing sqoop provides java classes and jar file.
Sqoop import <——-> either Database(tables) or Mainframe(datasets)
sqoop import
Sqoop tool ‘import’ is used to import table data from the table to the Hadoop file…
View On WordPress
#sqoop import#sqoop import example#sqoop import from mysql to hdfs#sqoop import options-file#sqoop import query example#sqoop import warehouse-dir#sqoop import where
0 notes
Link
Big Data Ingestion Using Sqoop and Flume - CCA and HDPCD ##UdemyFreeCourses #Big #CCA #Data #Flume #HDPCD #Ingestion #Sqoop Big Data Ingestion Using Sqoop and Flume - CCA and HDPCD In this course, you will start by learning what is hadoop distributed file system and most common hadoop commands required to work with Hadoop File system. Then you will be introduced to Sqoop Import Understand lifecycle of sqoop command. Use sqoop import command to migrate data from Mysql to HDFS. Use sqoop import command to migrate data from Mysql to Hive. Use various file formats, compressions, file delimeter,where clause and queries while importing the data. Understand split-by and boundary queries. Use incremental mode to migrate the data from Mysql to HDFS. Further, you will learn Sqoop Export to migrate data. What is sqoop export Using sqoop export, migrate data from HDFS to Mysql. Using sqoop export, migrate data from Hive to Mysql. Finally, we will start with our last section about Apache Flume Understand Flume Architecture. Using flume, Ingest data from Twitter and save to HDFS. Using flume, Ingest data from netcat and save to HDFS. Using flume, Ingest data from exec and show on console. Describe flume interceptors and see examples of using interceptors. Who this course is for: Who want to learn sqoop and flume or who are preparing for CCA and HDPCD certifications 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/big-data-ingestion-using-sqoop-and-flume-cca-and-hdpcd/
0 notes
Text
May 22, 2020 at 10:00PM - Flume & Sqoop for Ingesting Big Data (69% discount) Ashraf
Flume & Sqoop for Ingesting Big Data (69% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Description
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/3cW502R https://ift.tt/eA8V8J via Blogger https://ift.tt/2WUs6kU #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
February 11, 2020 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/37kIn4G #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
January 20, 2020 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/36fNMJC #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
300+ TOP Apache SQOOP Interview Questions and Answers
SQOOP Interview Questions for freshers experienced :-
1. What is the process to perform an incremental data load in Sqoop? The process to perform incremental data load in Sqoop is to synchronize the modified or updated data (often referred as delta data) from RDBMS to Hadoop. The delta data can be facilitated through the incremental load command in Sqoop. Incremental load can be performed by using Sqoop import command or by loading the data into hive without overwriting it. The different attributes that need to be specified during incremental load in Sqoop are- Mode (incremental) –The mode defines how Sqoop will determine what the new rows are. The mode can have value as Append or Last Modified. Col (Check-column) –This attribute specifies the column that should be examined to find out the rows to be imported. Value (last-value) –This denotes the maximum value of the check column from the previous import operation. 2. How Sqoop can be used in a Java program? The Sqoop jar in classpath should be included in the java code. After this the method Sqoop.runTool () method must be invoked. The necessary parameters should be created to Sqoop programmatically just like for command line. 3. What is the significance of using –compress-codec parameter? To get the out file of a sqoop import in formats other than .gz like .bz2 we use the –compress -code parameter. 4. How are large objects handled in Sqoop? Sqoop provides the capability to store large sized data into a single field based on the type of data. Sqoop supports the ability to store- CLOB ‘s – Character Large Objects BLOB’s –Binary Large Objects Large objects in Sqoop are handled by importing the large objects into a file referred as “LobFile” i.e. Large Object File. The LobFile has the ability to store records of huge size, thus each record in the LobFile is a large object. 5. What is a disadvantage of using –direct parameter for faster data load by sqoop? The native utilities used by databases to support faster load do not work for binary data formats like SequenceFile 6. Is it possible to do an incremental import using Sqoop? Yes, Sqoop supports two types of incremental imports- Append Last Modified To insert only rows Append should be used in import command and for inserting the rows and also updating Last-Modified should be used in the import command. 7. How can you check all the tables present in a single database using Sqoop? The command to check the list of all tables present in a single database using Sqoop is as follows- Sqoop list-tables –connect jdbc: mysql: //localhost/user; 8. How can you control the number of mappers used by the sqoop command? The Parameter –num-mappers is used to control the number of mappers executed by a sqoop command. We should start with choosing a small number of map tasks and then gradually scale up as choosing high number of mappers initially may slow down the performance on the database side. 9. What is the standard location or path for Hadoop Sqoop scripts? /usr/bin/Hadoop Sqoop 10. How can we import a subset of rows from a table without using the where clause? We can run a filtering query on the database and save the result to a temporary table in database. Then use the sqoop import command without using the –where clause

Apache SQOOP Interview Questions 11. When the source data keeps getting updated frequently, what is the approach to keep it in sync with the data in HDFS imported by sqoop? qoop can have 2 approaches. To use the –incremental parameter with append option where value of some columns are checked and only in case of modified values the row is imported as a new row. To use the –incremental parameter with lastmodified option where a date column in the source is checked for records which have been updated after the last import. 12. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. 13. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 14. Tell few import control commands: Append Columns Where These command are most frequently used to import RDBMS Data. 15. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 16. How can you see the list of stored jobs in sqoop metastore? sqoop job –list 17. What type of databases Sqoop can support? MySQL, Oracle, PostgreSQL, IBM, Netezza and Teradata. Every database connects through jdbc driver. 18. What is the purpose of sqoop-merge? The merge tool combines two datasets where entries in one dataset should overwrite entries of an older dataset preserving only the newest version of the records between both the data sets. 19. How sqoop can handle large objects? Blog and Clob columns are common large objects. If the object is less than 16MB, it stored inline with the rest of the data. If large objects, temporary stored in_lob subdirectory. Those lobs processes in a streaming fashion. Those data materialized in memory for processing. IT you set LOB to 0, those lobs objects placed in external storage. 20. What is the importance of eval tool? It allows user to run sample SQL queries against Database and preview the results on the console. It can help to know what data can import? The desired data imported or not? 21. What is the default extension of the files produced from a sqoop import using the –compress parameter? .gz 22. Can we import the data with “Where” condition? Yes, Sqoop has a special option to export/import a particular data. 23. What are the limitations of importing RDBMS tables into Hcatalog directly? There is an option to import RDBMS tables into Hcatalog directly by making use of –hcatalog –database option with the –hcatalog –table but the limitation to it is that there are several arguments like –as-avro file , -direct, -as-sequencefile, -target-dir , -export-dir are not supported. 24. what are the majorly used commands in sqoop? In Sqoop Majorly Import and export command are used. But below commands are also useful sometimes. codegen, eval, import-all-tables, job, list-database, list-tables, merge, metastore. 25. What is the usefulness of the options file in sqoop. The options file is used in sqoop to specify the command line values in a file and use it in the sqoop commands. For example the –connect parameter’s value and –user name value scan be stored in a file and used again and again with different sqoop commands. 26. what are the common delimiters and escape character in sqoop? The default delimiters are a comma(,) for fields, a newline(\n) for records Escape characters are \b,\n,\r,\t,\”, \\’,\o etc 27. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 28. while loading table from MySQL into HDFS, if we need to copy tables with maximum possible speed, what can you do? We need to use -direct argument in import command to use direct import fast path and this -direct can be used only with MySQL and PostGreSQL as of now. 29. How can you sync a exported table with HDFS data in which some rows are deleted? Truncate the target table and load it again. 30. Differentiate between Sqoop and distCP. DistCP utility can be used to transfer data between clusters whereas Sqoop can be used to transfer data only between Hadoop and RDBMS. 31. How can you import only a subset of rows form a table? By using the WHERE clause in the sqoop import statement we can import only a subset of rows. 32. How do you clear the data in a staging table before loading it by Sqoop? By specifying the –clear-staging-table option we can clear the staging table before it is loaded. This can be done again and again till we get proper data in staging. 33. What is Sqoop? Sqoop is an open source project that enables data transfer from non-hadoop source to hadoop source. It can be remembered as SQL to Hadoop -> SQOOP. It allows user to specify the source and target location inside the Hadoop. 35. How can you export only a subset of columns to a relational table using sqoop? By using the –column parameter in which we mention the required column names as a comma separated list of values. 36. Which database the sqoop metastore runs on? Running sqoop-metastore launches a shared HSQLDB database instance on the current machine. 37. How will you update the rows that are already exported? The parameter –update-key can be used to update existing rows. In it a comma-separated list of columns is used which uniquely identifies a row. All of these columns is used in the WHERE clause of the generated UPDATE query. All other table columns will be used in the SET part of the query. 38. You have a data in HDFS system, if you want to put some more data to into the same table, will it append the data or overwrite? No it can’t overwrite, one way to do is copy the new file in HDFS. 39. Where can the metastore database be hosted? The metastore database can be hosted anywhere within or outside of the Hadoop cluster. 40. Which is used to import data in Sqoop ? In SQOOP import command is used to import RDBMS data into HDFS. Using import command we can import a particular table into HDFS. – 41. What is the role of JDBC driver in a Sqoop set up? To connect to different relational databases sqoop needs a connector. Almost every DB vendor makes this connecter available as a JDBC driver which is specific to that DB. So Sqoop needs the JDBC driver of each of the database it needs to interact with. 42. How to import only the updated rows form a table into HDFS using sqoop assuming the source has last update timestamp details for each row? By using the lastmodified mode. Rows where the check column holds a timestamp more recent than the timestamp specified with –last-value are imported. 43. What is InputSplit in Hadoop? When a hadoop job is run, it splits input files into chunks and assign each split to a mapper to process. This is called Input Split 44. Hadoop sqoop word came from ? Sql + Hadoop = sqoop 45. What is the work of Export In Hadoop sqoop ? Export the data from HDFS to RDBMS 46. Use of Codegen command in Hadoop sqoop ? Generate code to interact with database records 47. Use of Help command in Hadoop sqoop ? List available commands 48. How can you schedule a sqoop job using Oozie? Oozie has in-built sqoop actions inside which we can mention the sqoop commands to be executed. 49. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 50. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. SQOOP Questions and Answers pdf Download Read the full article
0 notes
Text
October 12, 2019 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/31cHtUE #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
July 29, 2019 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/2MjWyQG #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes