#the error refers to metadata
Text
in the latest episode of Adobe Premiere is trash:
with the latest update, if your export folder's name has letters that aren't in the latin alphabet, the exported video files turn out broken! Haha!
#peak video editing for professionals#just so you know#the error refers to metadata#but yeah#wasted two hours of my life I'll never get back on this#ääkköset fucks it up#sign up for creative cloud they said#you'll always have the lastest version of the software they said#but in reality all anyone using this shit wants is a working fucking product#continuous updates my ass when you have to fucking keep them disabled#please don't suggest adobe alternatives i use them for work and changing isn't an option right now
5 notes
·
View notes
Text

Welcome to Riverview Reimagined - A complete overhaul/redo of Riverview as you know it!
" Riverview is a flourishing riverfront town with a diverse population nestled in the beautiful rolling countryside. The town was founded by the Harrington family some 200 years ago, and it has since grown significantly and begun to truly flourish, with a great sense of community. This is the ideal small, yet lively town to call home for a variety of reasons, including stunning panoramas from nearly every angle, a wide range of activities to do and sights to see, and interesting individuals to meet. Riverview is undoubtedly a remarkable town! "
WARNING:
The world may be laggy at times and take a while to load, depending on your computer specifications, but then again, The Sims 3 is a rather poorly optimised game.
Here are some general 'stats':
103 lots in total
55 residential lots (7 empty)
48 community lots
150 sims (including NPCs, role sims & animals)
30 households
This world has been PLAYTESTED by 5 other people, so no major issues should occur when playing this world, at least not any issues unheard of when generally playing this game.
REQUIRED:
ALL Expansion Packs

RIVERVIEW (Free)
Since it is somehow not possible to include the bridges and distant terrain in the exported world, that metadata will not show up and you will need to download them and place them in your mods folder to appear in-game. Technically, these are not required, however, without them, parts of the town will not look very good. Luckily simsample on ModTheSims has our backs! Get them HERE
Scroll to the bottom of the page and download the following 2 files:
Bluefunk_Riverview_Bridges_InGame.package.zip
Bluefunk_Riverview_DistantTerrain_InGame.package.zip
Then, simply place them in your packages folder within your mods folder. If you do not have a mods folder, please refer to THIS easy tutorial.
They should show up in your game now.
HIGHLY RECOMMENDED:
NRAAS MODS
NRAAS Mods are essential to a smooth, significantly less buggy game, as they assist in dealing with errors and things that cause performance issues in-game.
- NRAAS Master Controller
- NRAAS Overwatch
- NRAAS Errortrap
- NRAAS Register (optional)
- NRAAS StoryProgression (optional)
HERE is a fantastic, in-depth explanation video of the NRAAS mods and what they do/how they work by the lovely acottonsock
FOR CAMPGROUND
I could not find a way to place functional tents on the campground without them disappearing once the world was exported. There are a few workarounds, though.
1.) Simply type in the cheat "buydebug" and look for the tent/s that come with World Adventures. Purchase it for your sim, have them manually place it in their inventory, and from there you can place the tent/s on the campground for your sims to use. Alternatively, you can use the tents that come with Island Paradise, found in the miscellaneous part of the comfort section in buy mode. Do the same as instructed above and place the tent/s on the campground.
2.) Download this mod that enables the World Adventures tents from buydebug. In Edit Town, edit the campground and navigate to the community objects icon in build mode. From there, click on the infinity sign to load all community objects
and rabbit holes. HERE you'll find the unlocked tents. Place them on the campground and they should be functional once you enter live mode.[I used the first option, "Tents as Community Objects"]
(NB!!! IF YOU INSTALL THIS MOD BEFORE LOADING THE WORLD, FUNCTIONAL TENTS WILL SHOW UP ON THE LOT.)
I'm really sad that I couldn't include the tents already, but I tried several different methods and none of them worked.
The world is populated, with 30 households in total, but there are plenty of houses available for purchase, as well as 7 empty lots.
CHANGES MADE TO THE WORLD ITSELF:
I manually replaced and added trees individually. It's a bit cluttered, but more lush, especially in the area around the campgrounds.
I manually replaced all the roads, intersections, and sidewalks. Credit goes to GrandeLlama
Added a small bay in the lake into which the river flows to add a campground with a pier.
Swapped the bridge near the campground with the green one found in Twinbrook.
Small changes and additions to some sidewalks.
Some lots were added and/or changed.
Some street addresses changed.
Other minor details.
~ I really wanted to add ghosts to the cemetery and some other lots, especially to add to the lore, but unfortunately it is not possible when exporting a world through CAW.
~ Most of the interior tips and tricks I used to make custom furniture/unique decor were my own, but for a few of them, the credit has to go to the wonderful and talented @theplumdot.
DISCLAIMERS/ISSUES:
~ I had several issues with the apartment lots but managed to fix most of them, except this one... The apartments are set to 'EP09 Apartments', which I accidentally set and even if I changed them to regular residential, they reverted back. This means roommates will appear after a while, but BEFORE you move your sims in, you can fix this by going into Edit Town, clicking on the lot, and changing it to 'Regular Lot'. If roommates still show up, you can cancel roommate services by clicking on your sim's phone and going to 'Real Estate and Travel Services'. Also, choosing where to move your sims in, two apartment lots in the central town area will be available for rent that is actually occupied and will add the existing sims as roommates. The only unoccupied apartment in town is the "Midview Apartments".
~ Some female sims have the weird two-tone blue and green lipstick from Into The Future for some outfits, mostly swimwear. I have no idea why this happened, but I tried multiple times to get rid of it but it keeps showing up again.
~ Pretty much all of the sims have gloves for their outerwear. I have this glitch where even if I remove them, they somehow show up again. Hey, Riverview gets cold in the winter!
~ The female butler, Arasha Shreshta's face goes all EA's "pudding face" when she is in her career outfit, but normal/the way I made her in her normal outfits. I have no why idea why this happens.
~ Some role NPCs might get stuck in the apartment buildings, but a simple reset should fix them. I've tried several workarounds to stop this from happening but to no avail. This tends to often occur in Bridgeport and would generate NRAAS "Unroutable Sim" popups.
~ Upon loading the world (no fly-in, unfortunately I'm not that technically inclined), you might notice the household thumbnails taking a while to load and pets showing up pitch black, it's just a simple graphical issue.
~ Most of the big houses are quite expensive, which I apologise for. I'm quite the perfectionist and detail is very important to me, which means it doesn't take much for my builds to become quite pricey.
CREDITS & THANK YOUS
Testers:
ShanFindsPixels YOUTUBE / TWITTER
@cowboysimmer YOUTUBE / TWITTER / TWITCH
@plantyl-m TWITTER / INSTAGRAM
Z_C0SM0 (Zach) TWITTER
MorningDew YOUTUBE / TWITTER
A special thanks to @theplumdot (YOUTUBE / TWITTER) for inspiring me to always try new things with builds and interiors and for the support!
INSTALLATION INSTRUCTIONS
If you want to install the .sims3pack version, simply click on it and install it through the launcher. Alternatively, if you wish to bypass the launcher, you can install the .world file by placing it in the Worlds folder within your root Sims 3 directory, and depending on what platform you play from, it will differ;
For Origin/EA App it will be 'ProgramFiles(x86)/OriginGames/The Sims 3/GameData/Shared/NonPackaged/Worlds'
For a disc/retail installation, it will be 'ProgramFIles(x86)/Electronic Arts/The Sims 3/GameData/Shared/NonPackaged/Worlds'
For Steam, it will be 'ProgramFiles/Steam/steamapps/The Sims 3/GameData/Shared/NonPackaged/Worlds'
If you encounter any issues with the installation, like the world not showing up in-game, please contact me on Twitter.
↓ DOWNLOAD ↓
IF YOU DOWNLOADED THE WORLD BEFORE MAY 24TH 2023, THERE IS AN UPDATED VERSION WITH MULTIPLE FIXES, MAINLY THE ISSUE WHERE EXISTING DOUBLE BEDS WERE UNUSABLE. LINKS ARE UPDATED.
Alternatively, you can fix this issue with the old version by installing the NRAAS SleepFreedom mod, although it does not apply to existing saves with the old version, unfortunately.
- (.sims3pack) SFS
- (.world) SFS
MIRROR:
- (.sims3pack) DRIVE
- (.world) DRIVE
I hope you enjoy it!
My amazing friend ShanFindsPixels made a world overview on his YouTube channel, please go show him some love!

499 notes
·
View notes
Text
Radio Free Monday
Good morning everyone, and welcome to Radio Free Monday!
Just a periodic reminder: I know not everyone has the energy or money to volunteer or give, but I wanted to remind folks that even reblogging helps -- reblogging RFM, yes, but also (or, really, instead) taking a moment to go to a tumblr post and reblog the post helps too. You are also always welcome to crosspost to your social media of choice or post a link from there to here.
Ways to Give:
alirhi linked to a fundraiser to get herself, her mother, and her sister stable housing; they are currently staying in their cars in a a dangerous parking lot. They have a friend who will let them park a camper in her yard, but the camper there currently is unlivable, and they haven't been able to find an affordable replacement. With two of the family on disability it is difficult for them to keep up with bills and also save for housing. You can read more, reblog, and find giving information here.
Anon linked to a fundraiser for West Maui Animal Clinic, a Lahaina-based clinic where one of their vet school classmates works; the clinic burned to the ground in the fires, and many of the staff lost everything. They are raising funds to try and keep paying clinic staff while they figure out how to recover. You can read more and support the fundraiser here. (sorry to credit you as anon, but your username wasn't a tumblr handle and I wasn't confident the username without stops was the right one.)
Beck is raising funds to help cover the vet bill for their tortie cat, Lady Clytemnestra, who had to be treated for an abscess; you can read more and reblog here or support the gofundme here (as a warning, there is a photo of the injury at the fundraiser if you scroll).
Anon linked to a fundraiser for lumierew, to cover the vet bills for her cat's spinal surgery. You can read more and support the fundraiser here.
squidgiepdx and squidge.org are running a fall fundraiser; they are a small fansite that provides image and podfic hosting, site hosting, and a story archive for the fannish community, which runs them about $2K per year. They are now incorporated as a 501c3 (a nonprofit) in the US, and so your donations are tax-deductible. You can read more and support the fundraiser here.
News to Know:
blackestglass is running the fourth annual Chromatic Characters Podfic Anthology, which collects podfics of stories of less than 1500 words and center characters of color. This year's optional theme is "solidarity" and the due date for submissions is September 12th; they are encouraging authors who'd like to write a story for the anthology to team up with a podficcer by commenting at the info post. They are also looking for technical betas who can commit to 2 hours of beta listening the week of Sept. 13, to check for volume issues and other errors in the files and metadata. If you are a person of color who would be willing to lend their services as a contextual content beta (formerly known as cultural sensitivity listeners), they'd love to have you onboard as well. You can read more and comment here to volunteer or ask a question, DM the mods on twitter at ccpamods, or email ccpamods at gmail.com.
Buy Stuff, Help Out:
grumpycakes's coworker made a Tarot deck that they're kickstarting, but they haven't yet reached goal; the deck is "A unique tarot deck that references not only symbols and keywords, but also; flowers, crystals and more with affirmations. [...] The Symbolic Tarot not only draws from the traditional tarot structure but also includes corresponding aspects including simple answers to questions, making each card a collectible piece of resourcefulness." You can read more and reblog here or join in the kickstarter here.
And this has been Radio Free Monday! Thank you for your time. You can post items for my attention at the Radio Free Monday submissions form. If you're new to fundraising, you may want to check out my guide to fundraising here.
66 notes
·
View notes
Text
TikTok, Seriality, and the Algorithmic Gaze
Princeton-Weimar Summer School for Media Studies, 2024
Princeton University
If digital moving image platforms like TikTok differ in meaningful ways from cinema and television, certainly one of the most important differences is the mode by which the viewing experience is composed. We are dealing not only with fixed media nor with live broadcast media, but with an AI recommender system, a serial format that mixes both, generated on the fly and addressed to each individual user. Out of this series emerges something like a subject, or at least an image of one, which is then stored and constantly re-addressed.
TikTok has introduced a potentially dominant design for the delivery of moving images—and, potentially, a default delivery system for information in general. Already, Instagram has adopted this design with its Reels feature, and Twitter, too, has shifted towards a similar emphasis. YouTube has been providing video recommendations since 2008. More than other comparable services, TikTok places its proprietary recommender system at the core of the apparatus. The “For You” page, as TikTok calls it, presents a dynamically generated, infinitely scrollable series of video loops. The For You page is the primary interface and homepage for users. Content is curated and served on the For You page not only according to explicit user interactions (such as liking or following) or social graphs (although these do play some role in the curation). Instead, content is selected on the basis of a wider range of user behavior that seems to be particularly weighted towards viewing time—the time spent watching each video loop. This is automatic montage, personalized montages produced in real time for billions of daily users. To use another transmedial analogy—one perhaps justified by TikTok’s approximation of color convergence errors in its luminous cyan and red branding—this montage has the uncanny rhythm of TV channel surfing. But the “channels” you pass through are not determined by the fixed linear series of numbered broadcast channels. Instead, each “channel” you encounter has been preselected for you; you are shown “channels” that are like the ones you have tended to linger on.
The experience of spectatorship on TikTok, therefore, is also an experience of the responsive modeling of one’s spectatorship—it involves the awareness of such modeling. This is a cybernetic loop, in effect, within which future action is performed on the basis of the past behavior of the recommender system as it operates. Spectatorship is fully integrated into the circuit. Here is how it works: the system starts by recommending a sequence of more or less arbitrary videos. It notes my view time on each, and cross-references the descriptive metadata that underwrites each video. (This involves, to some degree, internal, invisible tags, not just user-generated tags.) The more I view something, the more likely I am to be shown something like it in the future. A series of likenesses unfolds, passing between two addresses: my behavior and the database of videos. It’s a serial process of individuation. As TikTok puts it in a 2020 blog post: these likenesses or recommendations increasingly become “polished,” “tailored,” “refined,” “improved,” and “corrected” apparently as a function of consistent use over time.
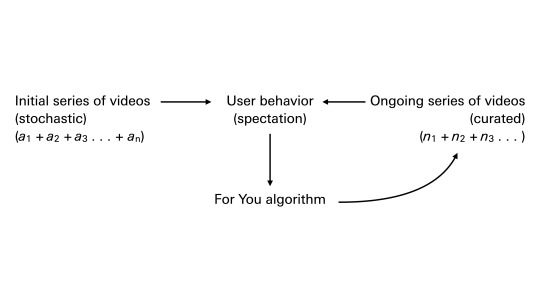
Like many recommender systems—and such systems are to be found everywhere nowadays—the For You algorithm is a black box. It has not been released to the public, although there seem to have been, at some point, promises to do this. In lieu of this, a “TikTok Transparency Center” run by TikTok in Los Angeles (delayed, apparently, by the 2020 COVID-19 pandemic) opened in 2023. TikTok has published informal descriptions of the algorithm, and by all accounts it appears to be rather straightforward. At the same time, the algorithm has engendered all kinds of folk sciences, superstitions, paranoid theories, and magical practices. What is this algorithm that shows me such interesting, bizarre, entertaining, unexpected things? What does it think I want? Why does it think I want this? How does this algorithm sometimes seem to know me so well, to know what I want to see? What is it watching me watch? (From the side of content creators, of course, there is also always the question: what kind of content do I need to produce in order to be recognized and distributed by the algorithm? How can I go viral and how can I maximize engagement? What kinds of things will the algorithm want to see? Why is the algorithm not seeing me?)
These seem to be questions involving an algorithmic gaze. That is to say: there is something or someone watching prior to the actual instance of watching, something or someone which is beyond empirical, human viewers, “watching” them watch. There is something watching me, whether or not I actually make an optical image of myself. I am looked at by the algorithm. There is a structuring gaze. But what is this gaze? How does it address us? Is this the gaze of a cinematic apparatus? Is it the gaze we know from filmtheory, a gaze of mastery with which we are supposed to identify, a gaze which hails or interpellates us, which masters us? Is it a Foucauldian, panoptic gaze, one that disciplines us?
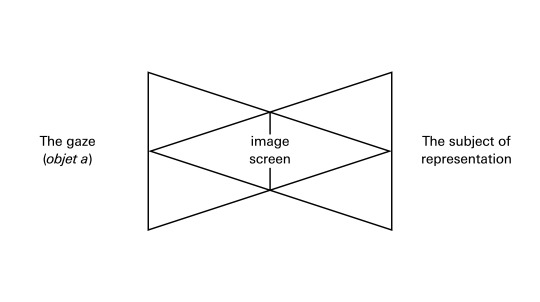
Any one of us who uses the major platforms is familiar with how the gaze of the system feels. It a gaze that looks back—looks at our looking—and inscribes our attention onto a balance sheet. It counts and accounts for our attention. This account appears to be a personalized account, a personalized perspective. People use the phrase “my TikTok algorithm,” referring to the personalized model which they have generated through use. Strictly speaking, of course, it’s not the algorithm that’s individualized or that individuates, but the model that is its product. The model that is generated by the algorithm as I use it and as it learns from my activity is my profile. The profile is “mine” because I am constantly “training” it with my attention as its input, and feel a sense of ownership since it’s associated with my account, but the profile is also “of me” and “for me” because it is constantly subjecting me to my picture, a picture of my history of attention. Incidentally, I think this is precisely something that Jacques Lacan, in his 1973 lecture on the gaze in Seminar XI, refers to as a “bipolar reflexive relation,” the ambiguity of the phrase “my image.” “As soon as I perceive, my representations belong to me.” But, at the same time, something looks back; something pictures me looking. “The picture, certainly, is in my eye. But I am in the picture.”
On TikTok, the picture often seems sort of wrong, malformed. Perhaps more often than not. Things drift around and get stuck in loops. The screen fills with garbage. As spectators, we are constantly being shown things we don’t want any more of, or things we would never admit we want, or things we hate (but cannot avoid watching: this is the pleasurable phenomenon of “cringe”). But we are compelled to watch them all. The apparatus seems to endlessly produce desire. Where does this desire come from? Is it from the addictive charge of the occasional good guess, the moment of brief recognition (the lucky find, the Surrealist trouvaille: “this is for me”)? Is it the promise that further training will yield better results? Is it possible that our desire is constituted and propelled in the failures of the machine, in moments of misrecognition and misidentification in the line of sight of a gaze that evidently cannot really see us?
In the early 1970s, in the British journal Screen, scholars such as Laura Mulvey, Colin MacCabe, and Stephen Heath developed a film-theoretical concept of the gaze. This concept was used to explain how desire is determined, specified, and produced by visual media. In some ways, the theory echoes Lacan’s phenomenological interest in “the pre-existence to the seen of a given-to-be-seen” (Seminar XI, 74). The gaze is what the cinematic apparatus produces as part of its configuration of the given-to-be-seen.
In Screen theory, as it came to be known, the screen becomes a mirror. On it, all representations seem to belong to me, the individual spectator. This is an illusion of mastery, an imaginary relation to real conditions of existence in the terms of the Althusserian formula. It corresponds to the jubilant identification that occurs in a moment in Lacan’s famous 1949 paper “The Mirror Stage as Formative of the I Function as Revealed in Psychoanalytic Experience,” in which the motor-challenged infant, its body fragmented (en morceaux) in reality, discovers the illusion of its wholeness in the mirror. The subject is brought perfectly in line with this ideal-I, with this spectacle, such that what it sees is simply identical to its desire. There is convergence. To slightly oversimplify: for Screen theory, this moment in mirror stage is the essence of cinema and ideology, or cinema as ideology.
Joan Copjec, in her essay “The Orthopsychic Subject,” notes that Screen theory considered a certain relationship of property to be one of its primary discoveries. The “screen as mirror”: the ideological-cinematic apparatus produces representations which are “accepted by the subject as its own.” This is what Lacan calls the “belong to me aspect so reminiscent of property.” “It is this aspect,” says Copjec, speaking for Screen theory, “that allows the subject to see in any representation not only a reflection of itself but a reflection of itself as master of all it surveys. The imaginary relation produces the subject as master of the image. . . . The subject is satisfied that it has been adequately reflected on the screen. The ‘reality effect’ and the ‘subject effect’ both name the same constructed impression: that the image makes the subject fully visible to itself” (21–22).
According to Copjec, “the gaze always remains within film theory the sense of being that point at which sense and being coincide. The subject comes into being by identifying with the image’s signified. Sense founds the subject—that is the ultimate point of the film-theoretical and Foucauldian concepts of the gaze” (22).
But this is not Lacan’s gaze. The gaze that Lacan introduces in Seminar XI is something much less complete, much less satisfying. The gaze concept is not exhausted by the imaginary relation of identification described in Screen theory, where the subject simply appropriates the gaze, assumes the position created for it by the image “without the hint of failure,” as Copjec puts it. In its emphasis on the imaginary, Screen theory neglects the symbolic relation as well as the issue of the real.
In Seminar XI, Lacan explicates the gaze in the midst of a discussion on Sartre and Merleau-Ponty. Again, Lacan’s gaze is something that pre-exists the seeing subject and is encountered as pre-existing it: “we are beings who are looked at, in the spectacle of the world” (75). But—and this is the crucial difference in emphasis—it is impossible to look at ourselves from the position of this all-seeing spectacle. The gaze, as objet a in the field of the visible, is something that in fact cannot be appropriated or inhabited. It is nevertheless the object of the drive, a cause of desire. The gaze “may come to symbolize” the "central lack expressed in the phenomenon of castration” (77). Lacan even says, later in the seminar, that the gaze is “the most characteristic term for apprehending the proper function of the objet a” (270). As objet a, as the object-cause of desire, the gaze is said to be separable and separated off from the subject and has only ever existed as lack. The gaze is just all of those points from which I myself will never see, the views I will never possess or master. I may occasionally imagine that I have the object, that I occupy the gaze, but I am also constantly reminded of the fact that I don’t, by images that show me my partiality, my separation. This is the separation—between eye and gaze—that manifests as the drive in the scopic field.
The gaze is a position that cannot be assumed. It indicates an impossible real. Beyond everything that is shown to the subject, beyond the series of images to which the subject is subjected, the question is asked: “What is being concealed from me? What in this graphic space does not show, does not stop not writing itself?” This missing point is the point of the gaze. “At the moment the gaze is discerned, the image, the entire visual field, takes on a terrifying alterity,” says Copjec. “It loses its ‘belong-to-me aspect’ and suddenly assumes the function of a screen” (35). We get the sense of being cut off from the gaze completely. We get the sense of a blind gaze, a gaze that “is not clear or penetrating, not filled with knowledge or recognition; it is clouded over and turned back on itself, absorbed in its own enjoyment” (36). As Copjec concludes: “the gaze does not see you” (36).
So the holes and stains in the model continuously produced by the TikTok algorithm—those moments in which what we are shown seems to indicate a misreading, a wrong guess—are those moments wherein the gaze can be discerned. The experience is this: I am watching a modeling process and engaging with the serial missed encounters or misrecognitions (meconnaissance—not only misrecognition but mistaken knowledge—mis-knowing) that the modeling process performs. The Lacanian point would simply be the following: the situation is not that the algorithm knows me too well or that it gives me the illusion of mastery that would be provided by such knowledge. The situation is that the algorithm may not know or recognize me at all, even though it seems to respond to my behavior in some limited way, and offers the promise of knowing or recognizing me. And this is perhaps the stain or tuche, the point at which we make contact with the real, where the network of signifiers, the automaton, or the symbolic order starts to break down. It is only available through the series, through the repeated presentation of likenesses.
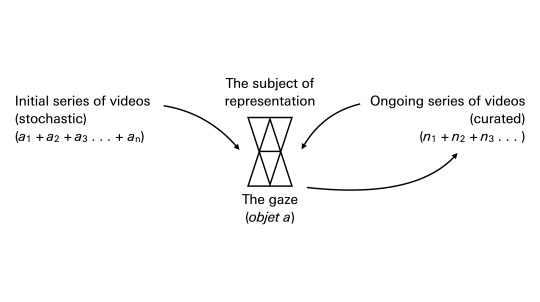
As Friedrich Kittler memorably put it, “the discourse of the other is the discourse of the circuit.” It is not the discourse of cinema or television or literature. Computational recommender systems operating as series of moving image loops seem to correspond strangely closely to the Lacanian models, to the gaze that is responsive yet absent, perceptive yet blind, desired yet impossible, perhaps even to the analytic scene. Lacan and psychoanalysis constantly seemed to suggest that humans carry out the same operations as machines, that the psyche is a camera-like apparatus capable of complicated performance, and that the analyst might be replaced with an optical device. Might we substitute recommender media for either psyche or analyst? In any case, it’s clear that the imaginary register of identification does not provide a sufficient model for subjectivity as it is addressed by computational media. That model, as Kittler points out, is to be found in Lacan’s symbolic register: “the world of the machine.”
8 notes
·
View notes
Text
This Week in Rust 526
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Blog: Launching the 2023 State of Rust Survey Survey
A Call for Proposals for the Rust 2024 Edition
Project/Tooling Updates
ratatui: a Rust library for cooking up terminal user interfaces - v0.25.0
Introducing Gooey: My take on a Rusty GUI framework
Two New Open Source Rust Crates Create Easier Cedar Policy Management
Introducing FireDBG - a Time Travel Visual Debugger for Rust
Fornjot 0.48.0 - open source b-rep CAD kernel written in Rust
Committing to Rust for kernel code
A Rust implementation of Android's Binder
Preventing atomic-context violations in Rust code with klint
Rust for Linux — in space
Observations/Thoughts
Rust is growing
A curiously recurring lifetime issue
The rabbit hole of unsafe Rust bugs
Faster Rust Toolchains for Android
The Most Common Rust Compiler Errors as Encountered in RustRover: Part 1
Nine Rules for SIMD Acceleration of your Rust Code (Part 2): General Lessons from Boosting Data Ingestion in the range-set-blaze Crate by 7x
What I Learned Making an embedded-hal Driver in Rust (for the MAX6675 Thermocouple Digitizer)
Rust Walkthroughs
Rust: Traits
Write a Toy VPN in Rust
Getting Started with Actix Web in Rust
Getting Started with Rocket in Rust
Generic types for function parameters in Rust 🦀
Benchmarking Rust Compiler Settings with Criterion: Controlling Criterion with Scripts and Environment Variables
[series] Multithreading and Memory-Mapping: Refining ANN Performance with Arroy
[series] Getting started with Tiny HTTP building a web application in Rust
Miscellaneous
Embedded Rust Education: 2023 Reflections & 2024 Visions
The Most Common Rust Compiler Errors as Encountered in RustRover: Part 1
Default arguments for functions in Rust using macros
[audio] Rust in Production Ep 1 - InfluxData's Paul Dix
[audio] Episode 160: Rust & Safety at Adobe with Sean Parent
Crate of the Week
This week's crate is constcat, a std::concat!-replacement with support for const variables and expressions.
Thanks to Ross MacArthur for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Ockam - Fix documentation warnings
Ockam - Library - Validate CBOR structs according to the cddl schema for nodes/models/secure_channel
Ockam - Implement events in SqlxDatabase
Hyperswitch - [REFACTOR]: [Nuvei] MCA metadata validation
Hyperswitch - [FEATURE] : [Noon] Sync with Hyperswitch Reference
Hyperswitch - [FEATURE] : [Zen] Sync with Hyperswitch Reference
Hyperswitch - [REFACTOR] : [Authorizedotnet] Sync with Hyperswitch Reference
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
386 pull requests were merged in the last week
enable stack probes on aarch64 for LLVM 18
add new tier 3 aarch64-apple-watchos target
add hexagon support
add the function body span to StableMIR
allow async_fn_in_trait traits with Send variant
cherry-pick "M68k: Fix ODR violation in GISel code (#72797)"
AIX: fix XCOFF metadata
-Ztrait-solver=next to -Znext-solver
actually parse async gen blocks correctly
add a method to StableMIR to check if a type is a CStr
add more suggestions to unexpected cfg names and values
add support for --env on tracked_env::var
add unstable -Zdefault-hidden-visibility cmdline flag for rustc
annotate panic reasons during enum layout
attempt to try to resolve blocking concerns (RFC #3086)
avoid overflow in GVN constant indexing
cache param env canonicalization
check FnPtr/FnDef built-in fn traits correctly with effects
check generic params after sigature for main-fn-ty
collect lang items from AST, get rid of GenericBound::LangItemTrait
coroutine variant fields can be uninitialized
coverage: skip instrumenting a function if no spans were extracted from MIR
deny ~const trait bounds in inherent impl headers
desugar yield in async gen correctly, ensure gen always returns unit
don't merge cfg and doc(cfg) attributes for re-exports
erase late bound regions from Instance::fn_sig() and add a few more details to StableMIR APIs
fix ICE ProjectionKinds Deref and Field were mismatched
fix LLD thread flags in bootstrap on Windows
fix waker_getters tracking issue number
fix alignment passed down to LLVM for simd_masked_load
fix dynamic size/align computation logic for packed types with dyn trait tail
fix overlapping spans in delimited meta-vars
ICE 110453: fixed with errors
llvm-wrapper: adapt for LLVM API changes
make IMPLIED_BOUNDS_ENTAILMENT into a hard error from a lint
make exhaustiveness usable outside of rustc
match lowering: Remove the make_target_blocks hack
more expressions correctly are marked to end with curly braces
nudge the user to kill programs using excessive CPU
opportunistically resolve region var in canonicalizer (instead of resolving root var)
properly reject default on free const items
remove unnecessary constness from ProjectionCandidate
replace some instances of FxHashMap/FxHashSet with stable alternatives (mostly in rustc_hir and rustc_ast_lowering)
resolve: replace visibility table in resolver outputs with query feeding
skip rpit constraint checker if borrowck return type error
some cleanup and improvement for invalid ref casting impl
tweak short_ty_string to reduce number of files
unconditionally register alias-relate in projection goal
update FreeBSD CI image
uplift TypeAndMut and ClosureKind to rustc_type_ir
use if cfg! instead of #[cfg]
use the LLVM option NoTrapAfterNoreturn
miri: visit the AllocIds and BorTags in borrow state FrameExtra
miri run: default to edition 2021
miri: make mmap not use expose semantics
fast path for declared_generic_bounds_from_env
stabilize type_name_of_val
stabilize ptr::{from_ref, from_mut}
add core::intrinsics::simd
add a column number to dbg!()
add more niches to rawvec
add ASCII whitespace trimming functions to &str
fix cases where std accidentally relied on inline(never)
Windows: allow File::create to work on hidden files
std: add xcoff in object's feature list
codegen: panic when trying to compute size/align of extern type
codegen_gcc: simd: implement missing intrinsics from simd/generic-arithmetic-pass.rs
codegen_llvm: set DW_AT_accessibility
cargo: clean up package metadata
cargo: do not allow empty name in package ID spec
cargo: fill in more empty name holes
cargo: hold the mutate exclusive lock when vendoring
rustdoc: use Map instead of Object for source files and search index
rustdoc: allow resizing the sidebar / hiding the top bar
rustdoc-search: fix a race condition in search index loading
rustdoc-search: use set ops for ranking and filtering
bindgen: use \r\n on windows
bindgen: better working destructors on windows
clippy: add new unconditional_recursion lint
clippy: new Lint: result_filter_map / Mirror of option_filter_map
clippy: don't visit nested bodies in is_const_evaluatable
clippy: redundant_pattern_matching: lint if let true, while let true, matches!(.., true)
clippy: do not lint assertions_on_constants for const _: () = assert!(expr)
clippy: doc_markdown Recognize words followed by empty parentheses () for quoting
clippy: fix binder handling in unnecessary_to_owned
rust-analyzer: deduplicate annotations
rust-analyzer: optimizing Performance with Promise.all 🏎
rust-analyzer: desugar doc correctly for mbe
rust-analyzer: dont assume ascii in remove_markdown
rust-analyzer: resolve alias before resolving enum variant
rust-analyzer: add minimal support for the 2024 edition
rust-analyzer: move out WithFixture into dev-dep only crate
rust-analyzer: fix false positive type mismatch in const reference patterns
rust-analyzer: syntax fixup now removes subtrees with fake spans
rust-analyzer: update builtin attrs from rustc
rust-analyzer: fix fragment parser replacing matches with dummies on incomplete parses
rust-analyzer: fix incorrectly replacing references in macro invocation in "Convert to named struct" assist
Rust Compiler Performance Triage
A lot of noise in the results this week; there was an lull in the noise recently, so our auto-inferred noise threshold went down, and thus five PR's were artificially flagged this week (and three supposed improvements were just reverting to the mean). Beyond that, we had three nice improvements: the first to debug builds in #117962 (by ceasing emission of expensive+unused .debug_pubnames and .debug_pubtypes), a second to diesel and serde in #119048 (by avoiding some unnecessary work), and a third to several benchmarks in #117749 (by adding some caching of an internal compiler structure).
Triage done by @pnkfelix. Revision range: 57010939..bf9229a2
6 Regressions, 9 Improvements, 3 Mixed; 5 of them in rollups 67 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: postpone] RFC: Precise Pre-release Deps
Tracking Issues & PRs
[disposition: merge] Support async recursive calls (as long as they have indirection)
[disposition: merge] make soft_unstable show up in future breakage reports
[disposition: merge] Tracking Issue for ip_in_core
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
RFC: patchable-function-entry
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-12-20 - 2024-01-17 🦀
Virtual
2023-12-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Adventures in egui app dev
2023-12-26 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-12-28 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-01-03 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-01-09 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-01-11 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-01-16 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
Europe
2023-12-27 | Copenhagen, DK | Copenhagen Rust Community
Rust hacknight #1: CLIs, TUIs and plushies
2023-12-28 | Vienna, AT | Rust Vienna
Rust Dojo 3: Holiday Edition
2024-01-11 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2024-01-11 | Wrocław, PL | Rust Wrocław
Rust Meetup #36
2024-01-13 | Helsinki, FI | Finland Rust-lang Group
January Meetup
North America
2023-12-20 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-12-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2024-01-06 | Boston, MA, US | Boston Rust Meetup
Beacon Hill Rust Lunch
2024-01-08 | Chicago, IL, US | Deep Dish Rust
Rust Hack Night
2024-01-09 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-01-09 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2024-01-14 | Cambridge, MA, US | Boston Rust Meetup
Alewife Rust Lunch
2024-01-16 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-01-17 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
The Tianyi-33 satellite is a 50kg class space science experimental satellite equipped with an operating system independently developed by Beijing University of Posts and Telecommunications—the Rust-based dual-kernel real-time operating system RROS. RROS will carry out general tasks represented by tensorflow/k8s and real-time tasks represented by real-time file systems and real-time network transmission on the satellite. It will ensure the normal execution of upper-layer applications and scientific research tasks, such as time-delay measurement between satellite and ground, live video broadcasting, onboard web chat services, pseudo-SSH experiments, etc. This marks the world’s first official application of a Rust-written dual-kernel operating system in a satellite scenario.
– Qichen on the RROS web page
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
Hello!!
Hello! So sorry for the late post this week! School has been crazy and I got a little behind.
Anyways, because last week I discussed what metadata is, I figured this week I could talk about my process for processing!
Below you will find a chaotic picture of what my screen looks like when I’m processing. On the left is the sheet that I’m working on to turn in to my supervisor. On the top right is a completed sheet that I reference. Because much of the data that I put into the spreadsheet is repeated I find it really helpful to have a completed one to reference. Also, it is useful for referencing the format of the items that I do have to type in. Overall, while my supervisor is very kind, and I regularly have her help me proofread, I want to make sure I am turning in my best work. The bottom right tab is all the documents that I am referencing. The parts that I do have to type in come from the AV-log and Biodata a sheet that we have the veterans fill out before the interview. The AV log is like a pdf of the metadata spreadsheet but a little more simple. It has most of the information concerning hte interview, the contents of the interview, etc. Occasionally I have to go digging for information that is missing from both the biodata sheet and AV log, but for the most part, it is all there.
Now for the parts that you don't see. On my desk, I have a bunch of sticky notes… Here I make notes on parts that are confusing, if I see missing information or errors within the files that I’m working on, or make note of questions that I need to ask my supervisor during our meetings.
All in all, it is much more messy than my system for transcription. I would be remiss if I said I didn’t miss the simplicity of transcription just a little. On the other hand, metadata is like a puzzle. I have a love-hate relationship with puzzles. It is really satisfying to see it all come together and even more rewarding when after I finish proceeding, these interviews are one step closer to being archived and available to the public.

0 notes
Text
What Happens If My Song Isn’t Showing Up After Distribution? A Musician’s Guide
As an independent artist, getting your music distributed to platforms like Spotify, Apple Music, and YouTube is an exhilarating step forward in your career. You’ve spent countless hours perfecting your sound, curating your album art, and planning your release strategy. Naturally, the next big milestone is seeing your music live on streaming platforms where fans can discover and enjoy your art. However, what happens if your song isn’t showing up after being distributed through Deliver My Tune? The process can feel frustrating, especially when you’re eagerly awaiting streams and royalties. But before you panic, there are several common reasons for this delay, and most of them can be easily addressed with the right steps.
In this comprehensive guide, we’ll dive deep into why your music might not appear on platforms after distribution, how to resolve these issues, and what you can do to avoid future problems. Whether it's a minor metadata error or an unexpected platform review delay, understanding the distribution process and troubleshooting early can save you time, stress, and even money.
So, what should you do if your music is not showing up on a platform after being distributed through Deliver My Tune? Let’s explore the most common issues and solutions.
1. Understand the Distribution Timeline
Before we dive into troubleshooting, it’s essential to understand the timeline for music distribution. When you distribute your music via a service like Deliver My Tune, the time it takes for your song to go live on platforms can vary significantly. Major platforms like Spotify, Apple Music, and Amazon Music typically take anywhere from 2 to 7 days to publish a new release. However, smaller platforms or international services may take longer, up to 10 or even 14 days.
It’s also important to remember that delays can occur if the platform is facing a high volume of new releases or technical issues. Additionally, some platforms, particularly Apple Music, perform manual reviews on content before it goes live, which can contribute to the delay.
What you can do:
Check Deliver My Tune’s estimated timelines for each platform.
Be patient for at least a week after submission before raising concerns.
Track your music’s status through the Deliver My Tune dashboard for any progress updates.
2. Verify Your Metadata and Assets
One of the most common reasons for delays or non-appearance of your music on platforms is incorrect metadata. Metadata refers to the information attached to your music file, such as the song title, artist name, album title, release date, and genre. If even one small detail is incorrect, the platform may reject or delay your release.
For instance, if there’s a spelling mistake in your artist name or if the ISRC code (International Standard Recording Code) is incorrect, platforms may not recognize the song as yours, causing confusion in their system. Similarly, incorrect album artwork dimensions, resolution, or explicit content without proper labeling can lead to rejection.
What you can do:
Double-check all metadata fields before submitting your track to Deliver My Tune.
Ensure your ISRC codes and UPC (Universal Product Code) are correct.
Verify that your album artwork meets the platform’s specifications in terms of size, resolution, and file type.
3. Ensure Your Music Meets Platform Guidelines
Each streaming platform has its own set of content guidelines, which can sometimes vary. Platforms like Apple Music or Tidal may have stricter content guidelines, especially when it comes to explicit content, cover art, or even regional restrictions.
For example, if your cover art contains graphic or explicit images without a content advisory label, your music may be blocked until proper edits or labels are applied. Some platforms also reject audio files with low-quality formats or incorrect bitrates.
What you can do:
Review each platform’s content guidelines, especially for artwork and explicit content.
Make sure that the audio quality meets the industry standard (typically 16-bit, 44.1kHz WAV files).
If necessary, edit your track to meet these specifications before resubmitting through Deliver My Tune.
4. Platform-Specific Review Delays
Streaming services like Spotify and Apple Music may sometimes review your content manually, especially if they suspect anything that violates their terms or if you’re a first-time distributor. Manual reviews typically cause the longest delays, as they depend on the platform’s internal review queues.
This kind of review may happen if your music contains explicit lyrics without proper labeling, unauthorized samples, or questionable cover art. If your music is flagged, you may need to edit and resubmit it, which can delay your release by days or even weeks.
What you can do:
Anticipate platform review times by submitting your music at least 2 weeks ahead of your desired release date.
Contact Deliver My Tune or the platform’s support to expedite the process or inquire about any flags on your submission.
For future releases, ensure you have properly labeled explicit content and own all the rights to any samples used in your track.
5. Monitor Your Royalties: What Happens After Your Song Goes Live?
Once your song goes live, another critical area of concern is royalty payments. Many artists expect immediate financial returns, but it’s essential to understand the payment cycle of various platforms. Royalties are typically calculated and reported monthly or quarterly, depending on the platform. Even after your song appears on streaming services, royalty payouts often take anywhere from 1 to 3 months to reach your account.
To ensure you’re getting the royalties you deserve, you need to regularly check your Deliver My Tune dashboard for royalty reports. These reports provide valuable insights into how your song is performing on different platforms, allowing you to track streams and revenue.
What you can do:
Set up a royalty account with Deliver My Tune to ensure timely payouts.
Regularly review your performance reports to understand how your music is generating revenue.
Adjust your marketing efforts based on streaming data to boost visibility and increase royalties.
6. Contact Deliver My Tune Support Early
If your music isn’t appearing on platforms after several days, and you’ve ruled out common issues like metadata or platform delays, it’s time to contact Deliver My Tune support. The quicker you report the problem, the sooner they can intervene. It’s possible that a technical issue during the submission process caused the delay.
Support teams can provide insight into whether your music is stuck in a processing queue or if a particular platform has flagged your content.
What you can do:
Contact support with detailed information about your release (e.g., submission date, platform names).
Include screenshots or relevant details from the platform’s dashboard showing the issue.
Stay patient and follow up as needed while waiting for a resolution.
Conclusion:
Dealing with delays in music distribution can be frustrating, but it’s important to stay proactive and address potential issues early. Whether it’s a metadata error, platform-specific review delays, or problems with your album artwork, understanding the root cause will help ensure a smooth release process in the future. If you’re ever in doubt, contacting Deliver My Tune’s support is your best option for resolving issues quickly.
So, what should you do if your music is not showing up on a platform after being distributed through Deliver My Tune? First, check all metadata and assets, make sure you meet platform guidelines, and, if needed, get in touch with their support team to resolve the problem as soon as possible.
0 notes
Text
Why Metadata is Key to Maximizing Earnings on Streaming Platforms
In today's digital music landscape, metadata plays an essential role in how artists are discovered, credited, and paid on streaming platforms. Whether you're an independent artist or working with a label, ensuring that your music metadata is accurate and optimized can make a significant difference in your earnings. Deliver My Tune, a leading music distribution platform, understands the importance of metadata and offers tools and services to help artists maximize their revenue by managing their metadata efficiently.
What is Metadata and Why Does It Matter?
Metadata refers to the information associated with a piece of music that goes beyond the actual audio. It includes details such as the song title, artist name, album name, genre, release date, credits (songwriters, producers, and other contributors), and more. In essence, it’s the data that describes the content of the song, which streaming platforms use to categorize, recommend, and pay for your music.
Properly tagging your music with metadata is critical because:
Searchability: Metadata ensures that your music can be found on streaming platforms. Without accurate metadata, your songs might not show up when listeners search for specific genres, moods, or even your name.
Royalties: Streaming platforms use metadata to track plays and pay royalties to the correct rights holders. Inaccurate or incomplete metadata can lead to missed payments or delays in receiving royalties.
Crediting: Proper metadata ensures that all contributors, from songwriters to producers, get the credit they deserve. This is particularly important for collaborations, where multiple people might have a stake in the song's earnings.
How Deliver My Tune Helps Artists Manage Metadata
Deliver My Tune has developed a seamless system for helping artists manage and optimize their metadata when distributing their music to streaming platforms. They understand that for independent artists, managing metadata can be overwhelming, and errors are common, especially for those who are new to the process.
Here’s how Deliver My Tune supports artists in managing their metadata for better monetization:
Metadata Entry Simplified: Deliver My Tune makes it easy to enter and organize your metadata during the music upload process. Their platform provides fields for every critical piece of information needed, ensuring you don’t miss anything that could impact your royalties or discoverability.
Automatic Metadata Checks: The platform has built-in checks to alert you if any crucial metadata is missing or inconsistent. This reduces the risk of mistakes that could lead to your music being miscredited or under-credited on streaming platforms.
Optimization Tips: Deliver My Tune offers guidance on optimizing metadata to increase the likelihood of playlist placements and algorithmic recommendations. By ensuring your genre, mood tags, and other descriptive fields are filled in accurately, you improve the chances of your music being pushed to the right audiences.
The Impact of Metadata on Music Discovery
One of the most significant benefits of having optimized metadata is that it increases your chances of being discovered by new listeners. Streaming platforms like Spotify, Apple Music, and YouTube Music rely heavily on algorithms to recommend music to users. These algorithms take metadata into account when deciding which songs to push to playlists or recommend based on a listener's history.
If your metadata is incomplete or inaccurate, the algorithm might not know where to place your music. For instance, if your genre is mislabeled or missing, your song might not appear in playlists tailored to your intended audience. Deliver My Tune helps ensure that your metadata aligns with the type of audience you want to reach, increasing your chances of discovery.
Ensuring Proper Royalty Payments with Accurate Metadata
Earnings from streaming platforms depend on accurate tracking of who played your song and how many times it was streamed. Platforms like Spotify calculate royalties based on the number of plays, and they use metadata to track these streams and ensure the correct rights holders get paid.
Inaccurate metadata can lead to confusion about who owns the rights to a song, resulting in delayed or missed payments. For example, if a co-writer is not listed in the metadata, they might not receive their share of the royalties. Deliver My Tune’s system is designed to prevent such errors by prompting you to provide all necessary information during the upload process.
Additionally, metadata is essential for tracking international plays. Streaming platforms operate in multiple countries, and having accurate metadata ensures that your music is correctly credited and paid for, no matter where it's streamed.
Common Metadata Mistakes That Hurt Monetization
Many independent artists make simple metadata mistakes that can hurt their chances of monetizing their music. Some common mistakes include:
Misspelling Artist Names: Even a minor typo can prevent your song from being linked to your artist profile.
Incorrect Genre Tags: Failing to properly tag your genre can lead to your music being recommended to the wrong audience, resulting in fewer streams.
Missing Songwriter Credits: Not listing all contributors can lead to disputes and delays in royalty payments.
Outdated Contact Information: If your contact or publisher information changes, make sure to update your metadata to avoid issues with payments.
Deliver My Tune’s platform helps artists avoid these common mistakes by providing clear guidelines and built-in checks to ensure metadata is correct and up to date.
Conclusion
Metadata might seem like a small detail, but it plays a critical role in the success of your music on streaming platforms. From ensuring proper credit and royalty payments to increasing discoverability, accurate metadata is key to maximizing your earnings. Deliver My Tune makes it easy for artists to manage and optimize their metadata, ensuring they can focus on their music while the platform handles the technical aspects of distribution. By prioritizing metadata, artists can unlock more opportunities and ensure they get paid what they deserve for their creative work.
0 notes
Text
SEO Best Practices for SaaS Companies in 2024
SaaS businesses know how vital SEO is, especially nowadays. SEO is essential as it improves website visibility, hence increasing ROI. Nevertheless, SEO is not limited to only a few effective keywords, backlinks, and website usability. While these are critical in search engine results, SaaS's SEO includes an entire approach with several essential elements.
In this article, we will discuss effective SEO strategies for SaaS businesses.
Let’s dive in.
Definition of SEO for SaaS
SaaS SEO involves optimizing a SaaS website to increase its ranking and attract potential customers. It includes a range of technologies and tactics used to optimize SaaS companies' visibility in search engines. We can also refer to it as SEO for B2B and B2C companies, as most software companies nowadays have shifted to the SaaS Business model.
SEO Strategy for SaaS Businesses
Here are the SEO strategies to implement for SAAS Businesses:
Understanding User Intent and Semantic Search
User intent is the principal component of an SEO strategy for SaaS businesses. SaaS businesses must prioritize user-friendly content that aligns with users' search queries to improve relevance and attention. Semantic search focuses on context and meaning and can also improve visibility. Create content that comprehensively resolves user queries and covers related topics.
Focus on Technical SEO
Technical Holds the same position as other SEO factors. It is important even in 2024, and you shouldn’t overlook it. Here are some crucial elements of technical SEO that you should prioritize:
Optimize Robots.txt to prevent indexing of duplicate or irrelevant content.
Effectively manage redirects & redirect chains to avoid slow page load times.
Address Crawlability issues to navigate and index your site effectively.
Regularly update XML for search engines and HTML sitemaps for user navigation.
Optimize MetaData (title tags, meta descriptions) for improved visibility and CTR.
Implement structured data to provide search engines with additional context about your content.
Regularly check 4xx errors to prevent user feedback and negative impact on SEO.
Prioritize a clean and distinctive URL for improved search engine and user understanding.
Use Hreflang tags (for international websites) to showcase regional and language variations.
Implement Google Analytics & Search Console for performance tracking and get valuable insights about the site’s health and user behavior.
Invest in Voice Search Engine Optimization
The voice search engine continues to gain traction, particularly with the growing number of smartphones and digital devices. SaaS businesses should optimize content for voice search engines. This will improve user experience and potentially improve search engine rankings. Additionally, FAQ sections and structured markup should be incorporated to improve visibility in search engine results.

High-Quality Content
If you know how why content holds the most special place in the SEO diary, you will never ignore it. SaaS businesses should also make user-centric content with thorough research and understand their audience needs. Experiment with different formats, including whitepapers, case studies, and videos tailored to the preferences of diverse audiences. Utilize content data and insight to create personalized content that delivers targeted solutions.
On-Page Optimization
On-page optimization is a crucial SEO strategy for SaaS businesses. It establishes a stronger foundation for your website and improves its visibility, helping it reach out to customers actively looking for the services you offer. Prioritize all the aspects of on-page SEO, from page titles to image optimization and content structure.
Optimize meta description using the below-mentioned method :
Keep it within 60-70 characters
Use user-oriented language
Include call-to-action
If you’re unsure how to implement these technical aspects effectively, consider hiring a SaaS SEO service provider to guide you through the process and optimize your SEO strategy for optimum results.
Image Optimization
Image optimization for your SaaS business is as crucial as other SEO factors. Optimize your image by combining different factors such as file names, alt text, and image sitemaps. Add image description to boost accessibility and SEO. Describe what your image is about, such as a screenshot of your SaaS analytics where user data is shown. Compress the images to keep your site loaded faster. Ensure all your images are mobile responsive. Using the HTML’s srcset is the best way to choose the appropriate image size that keeps your website loading faster. Also, create sitemaps to help search engines find the images hosted on your device.
Use the Power of Video SEO
Video content continues to grow in SEO, making it a crucial SEO strategy for SaaS businesses. Incorporate video content into your business strategy, optimizing it for relevant content, keywords, descriptions, and tags. Also, host videos on your website through different platforms like YouTube and Vimeo to Increase visibility and gain more organic traffic.
Conclusion
SEO is the foundation that you build for long-term success. SaaS Companies must adapt their strategies according to the latest trends and algorithmic changes. To optimize your business potential, follow the tips in this blog. If you are unsure how to implement these trends, you can hire a specialized SEO agency for SaaS businesses. Digitech India offers the best SaaS SEO services to help you stay ahead of trends. Include SEO as a critical strategy when creating your SaaS website. SEO may be challenging initially, but you may expect profitable returns once you learn its fundamentals. Consistent efforts and following evolving trends will drive sustained growth and online visibility for your SaaS business.
0 notes
Text
Essential Content Writing Tools and Resources Every Writer Should Know About

Content writing is a dynamic field that requires a blend of creativity, research, and technical skills. To produce high-quality, engaging content consistently, writers need to leverage a variety of tools and resources. This comprehensive guide covers essential tools and resources that can help content writers at every stage of their writing journey.
1. Grammar and Style Checkers
Grammarly: Grammarly is a versatile writing assistant that checks for grammar, punctuation, and style errors. It offers suggestions for improving sentence structure and word choice, helping you write clear and error-free content. Grammarly also provides a tone detector to ensure your writing matches the intended voice.
Hemingway Editor: The Hemingway Editor focuses on readability. It highlights complex sentences, passive voice, and adverbs, encouraging you to write in a clear, concise, and direct manner. This tool is excellent for making your content more accessible and engaging for readers.
2. Keyword Research Tools
Google Keyword Planner: A free tool from Google, the Keyword Planner helps you find relevant keywords and understand their search volume. It’s an excellent starting point for optimizing your content for search engines.
SEMrush: SEMrush is a comprehensive SEO tool that offers keyword research, competitive analysis, and insights into trending topics. It provides data on keyword difficulty, search volume, and related keywords, helping you create content that ranks well on search engines.
Ahrefs: Known for its robust backlink analysis, Ahrefs also offers powerful keyword research features. It helps you find keywords with high traffic potential and low competition, and provides insights into your competitors’ keyword strategies.
3. Content Planning and Management
Trello: Trello is an easy-to-use project management tool that helps you organize your content calendar, assign tasks, and track progress. You can create boards for different projects, use cards to represent tasks, and set deadlines to ensure timely content delivery.
Asana: Asana is another popular project management tool that helps teams collaborate on content creation. It allows you to create tasks, set priorities, and monitor progress, making it easier to manage complex content projects.
4. AI Content Creation Tools
ChatGPT: Developed by OpenAI that uses a deep learning model to generate human-like text based on the input it receives. It belongs to the GPT (Generative Pre-trained Transformer) family of models and is trained on a diverse range of internet text to understand and generate coherent responses in natural language.
Gemini: Refers to an advanced AI service provided by Google AI Studio, aimed at integrating robust content generation capabilities into applications. This API likely leverages Google's extensive AI technologies to enable developers to create and manage content more effectively using AI-driven solutions.
5. Research and Reference
Google Scholar: Google Scholar is a freely accessible search engine that indexes the full text or metadata of scholarly literature across various publishing formats and disciplines. It’s an excellent resource for finding credible sources and supporting your content with authoritative references.
JSTOR: JSTOR is a digital library for scholars, researchers, and students, offering access to thousands of academic journals, books, and primary sources. It’s a valuable resource for conducting in-depth research and finding high-quality references.
5. Plagiarism Checkers
Plagiarism Checker: A plagiarism checker app is a digital tool designed to detect instances of plagiarism in written content. It helps ensure the originality of their work and avoid the serious consequences of plagiarism.
Copyscape: Copyscape helps you check for duplicate content and ensure your work is original. It’s an essential tool for maintaining the integrity of your writing and avoiding plagiarism issues.
Turnitin: Widely used in academic settings, Turnitin checks for plagiarism and helps maintain the originality of your work. It provides detailed reports highlighting any similarities with existing content.
6. Writing and Editing Tools
Google Docs: Google Docs is a cloud-based word processor that allows for real-time collaboration and easy sharing. It offers extensive formatting options, making it a versatile tool for content creation.
Microsoft Word: Microsoft Word is a powerful word processing tool with a wide range of features. It includes advanced formatting options, templates, and editing tools, making it ideal for professional writing.
7. Visual Content Creation
Canva: Canva is a user-friendly graphic design tool that helps you create stunning visuals for your content. It offers a wide range of templates, images, and design elements, making it easy to produce professional-quality graphics.
Piktochart: Piktochart is a tool for creating infographics, presentations, and other visual content. It’s ideal for visualizing data and making your content more engaging and shareable.
8. SEO Optimization
Rank Math SEO: A popular SEO plugin for WordPress that helps website owners optimize their content for search engines. It provides a wide range of features to enhance the SEO performance of your website, making it easier to achieve higher rankings in search engine results pages (SERPs).
Yoast SEO: A WordPress plugin that helps you optimize your content for search engines. It provides real-time analysis and suggestions for improving your content’s SEO, readability, and overall quality.
Moz: An SEO tool that offers keyword research, link building, and site audits. It provides insights into your content’s performance and helps you identify opportunities for improvement.
9. Analytics and Insights
Google Analytics: Google Analytics is essential for tracking your website’s performance, understanding user behavior, and measuring the effectiveness of your content. It provides detailed reports on traffic sources, user engagement, and conversion rates.
Hotjar: Hotjar provides heatmaps and session recordings to help you understand how users interact with your content. It offers insights into user behavior, helping you optimize your content and improve user experience.
10. Writing Communities and Learning Resources
Blogger: A free, user-friendly blogging platform provided by Google. It allows individuals and businesses to create, publish, and manage blogs with ease. A popular choice for both novice and experienced bloggers due to its simplicity and integration with other Google services.
Medium: Medium is a platform where writers can publish their work, engage with a community of readers and writers, and find inspiration. It’s an excellent place to share your content and build an audience.
Coursera and Udemy: These platforms offer a wide range of writing courses, from content writing and SEO to creative writing and storytelling. They provide valuable learning resources to help you improve your skills and stay updated with industry trends.
Conclusion
Equipping yourself with the right tools and resources can significantly enhance your content writing process and help you produce high-quality, engaging content. From grammar checkers and keyword research tools to visual content creation and SEO optimization, these essential tools will support you at every stage of your writing journey. Stay updated with the latest trends, continuously improve your skills, and leverage these resources to become a successful content writer. With the right tools at your disposal, you’ll be well-prepared to create compelling content that resonates with your audience and achieves your content marketing goals.
Feel free to contact ThinkSpot Content if you are looking for comprehensive copywriting services in Palakkad.
1 note
·
View note
Text
Rhythmic variation in proteomics: challenges and opportunities for statistical power and biomarker identification
Time-of-day variation in the molecular profile of biofluids and tissues is a well-described phenomenon, but - especially for proteomics - is rarely considered in terms of the challenges this presents to reproducible biomarker identification. In this work we demonstrate these confounding issues using a small scale proteomics analysis of male participants in a constant routine protocol following an 8-day laboratory study, in which sleep-wake, light-dark and meal timings were controlled. We provide a case study analysis of circadian and ultradian rhythmicity in proteins in the complement and coagulation cascades, as well as apolipoproteins, and demonstrate that rhythmicity increases the risk of Type II errors due to the reduction in statistical power from increased variance. For the proteins analysed herein we show that to maintain statistical power if chronobiological variation is not controlled for, n should be increased (by between 9% and 20%); failure to do so would increase {beta}, the chance of Type II error, from a baseline value of 20% to between 22% and 28%. Conversely, controlling for rhythmic time-of-day variation in study design offers the opportunity to improve statistical power and reduce the chances of Type II errors. Indeed, control of time-of-day sampling is a more cost-effective strategy than increasing sample sizes. We recommend that best practice in proteomics study design should account for temporal variation as part of sampling strategy where possible. Where this is impractical, we recommend that additional variance from chronobiological effects be considered in power calculations, that time of sampling be reported as part of study metadata, and that researchers reference any previously identified rhythmicity in biomarkers and pathways of interest. These measures would mitigate against both false and missed discoveries, and improve reproducibility, especially in studies looking at biomarkers, pathways or conditions with a known chronobiological component. http://dlvr.it/T8x2Gw
0 notes
Text
The Ultimate Guide to On-Page SEO Optimization Tools

On-Page SEO is the foundation of any successful SEO strategy. Without solid on-page optimization, even the best off-page SEO efforts will struggle to deliver results.
In this comprehensive guide, we'll dive deep into the world of on-page SEO optimization tools. We'll explore essential tools that can streamline your workflow, boost your rankings, and drive more organic traffic to your website. Whether you're a seasoned SEO professional or just starting out, this guide will equip you with the knowledge to leverage the best on-page SEO software solutions.
Understanding On-Page SEO
Before we dive into the tools, let's briefly cover what on-page SEO entails. On-page SEO refers to the practice of optimizing various elements on your website to improve its visibility and ranking in search engine results pages (SERPs). This includes optimizing aspects like:
Title tags
Meta descriptions
Header tags (H1, H2, H3)
Content quality and relevance
Image optimization
Internal linking structure
User experience factors like page speed and mobile-friendliness
By nailing these on-page factors, you create a solid foundation for your overall SEO efforts and ensure that search engines can easily understand, crawl, and index your website.
On-Page SEO Optimization Tools
1. Keyword Research Tools
The backbone of any SEO strategy starts with keyword research. Tools like Ahrefs, SEMrush, and KWFinder provide robust keyword data to help you identify high-value, low-competition keywords to target. These SEO software solutions offer valuable insights into search volume, keyword difficulty, related terms, and more, enabling you to make informed decisions about your content strategy.
2. On-Page SEO Checkers and Site Crawlers
Tools like Screaming Frog and Sitebulb crawl your website and provide detailed insights into your on-page optimization. These on-page SEO solutions analyze factors like title tags, meta descriptions, header tags, and more, highlighting areas that need improvement. Additionally, they can identify technical issues, such as broken links, redirect loops, or duplicate content, that may be hindering your SEO performance.
3. Content Optimization Tools
Once you've identified your target keywords, you'll need to optimize your content accordingly. Tools like Clearscope, MarketMuse, and Surfer SEO analyze your content and provide data-driven recommendations for improvement. These content optimization solutions help ensure your content comprehensively covers the topic, includes relevant keywords and semantic variations, and aligns with search intent.
4. Image Optimization Tools
Optimizing images is often overlooked but can significantly impact your website's performance and SEO. Tools like Kraken.io, Optimizilla, TinyPNG, and Shortpixel compress your images without sacrificing quality, reducing load times and improving user experience. Some of these tools also offer features like image resizing, converting formats, and stripping metadata for added optimization.
5. Internal Linking Tools
A well-structured internal linking strategy is crucial for SEO. Tools like Link Whisper and Internal Link Juicer analyze your content and suggest relevant internal links, helping you create a seamless user journey and distributing link equity throughout your website. These tools can save you countless hours of manual work and ensure your internal linking is optimized for both users and search engines.
6. Technical SEO Auditing Tools
While on-page optimization is essential, technical SEO factors play a critical role in your overall performance. Tools like DeepCrawl, WebSite Auditor, and Screaming Frog SEO Spider identify and help you fix technical issues like broken links, redirect loops, crawl errors, and server issues, ensuring that search engines can effectively crawl and index your website. Many of these tools also offer insights into site architecture, URL structure, and other technical factors that can impact SEO.
7. On-Page SEO Plugins for CMS Platforms
If your website is built on a content management system (CMS) like WordPress, Drupal, or Joomla, you can take advantage of on-page SEO plugins to streamline your optimization efforts. Plugins like Yoast SEO (for WordPress), Metatags (for Drupal), and sh404SEF (for Joomla) provide easy-to-use interfaces to optimize meta tags, titles, descriptions, and more, right from your CMS dashboard.
8. Rank Tracking Tools
Once you've optimized your on-page elements, you'll want to monitor your rankings to track progress and identify areas for improvement. Rank tracking tools like Accuranker, Advanced Web Ranking, and Pro Rank Tracker allow you to monitor your website's rankings for specific keywords across various search engines and locations. These tools provide valuable insights into your SEO performance and can help you make data-driven decisions about your optimization efforts.
9. Page Speed Optimization Tools
Page speed is a critical factor for both user experience and SEO. Tools like Google PageSpeed Insights, WebPageTest, and GTmetrix analyze your website's speed performance and provide recommendations for improving load times. These tools can help you identify bottlenecks, such as unoptimized images, render-blocking resources, or inefficient code, and guide you towards optimizing your website for faster load times.
10. SEO Software Suites
While standalone tools excel in specific areas, many SEO professionals prefer comprehensive SEO software solutions that combine multiple functionalities into a single platform. Tools like Semrush, Ahrefs, and Moz offer a suite of features ranging from keyword research and rank tracking to on-page optimization, backlink analysis, and more. These all-in-one solutions can streamline your SEO workflow and provide a centralized view of your optimization efforts.
Integrating On-Page SEO Optimization Tools
To truly maximize the benefits of on-page SEO optimization tools, it's essential to integrate them into your workflow seamlessly. Many of these tools offer APIs, integrations, or plugins that allow you to connect them with other platforms, such as your content management system, project management tools, or analytics platforms.
By integrating your on-page SEO tools, you can automate processes, streamline data flow, and create a unified view of your SEO efforts. For example, you could set up integrations to automatically check for on-page optimization issues during the content creation process or trigger rank tracking updates whenever you publish new content.
Conclusion
On-page SEO optimization is a continuous process that requires diligence, strategy, and the right tools. By leveraging the best on-page SEO software solutions, you can streamline your workflow, stay ahead of the competition, and drive more organic traffic to your website. Remember, SEO is an ever-evolving landscape, and staying up-to-date with the latest tools, techniques, and best practices is crucial for long-term success.
What on-page SEO optimization tools or strategies have you found most effective? Let us know in the comments below!
0 notes
Text
Automated Data Archiving & Offline Storage for Secure Backup

As we live in an era where data is one of the most valuable assets a business has, the need for effective and secure data management has never been greater. Automated data archiving and offline storage solutions are essential for businesses that want to ensure the integrity, security, and accessibility of their data for the long term. This blog post highlights the intricacies of automated data archiving and offline storage, highlighting their importance, benefits, and best practices for implementation.
Introduction to Data Archiving and Offline Storage
Data archiving involves the process of moving data that is no longer actively used so that it can be retained for a longer period. This data remains important for reference, regulatory compliance, or historical analysis. Offline storage, on the other hand, refers to the storage of data on physical devices that are not connected to the network or the Internet, providing an additional layer of protection against cyber threats.
The combination of automated data archiving and offline storage provides a robust solution for secure data backup. Automated systems ensure that the collection process is consistent and error-free, while offline storage protects data from online vulnerabilities such as hacking, ransomware, and accidental deletion.
Key Features of Automated Data Collection Systems
1. Automated Scheduling: Automated data collection systems allow businesses to set predefined schedules for data backup and archiving. This ensures that data is archived regularly without manual intervention, reducing the risk of human error.
2. Data Compression and Deduplication: Advanced archiving systems incorporate data compression and deduplication techniques to reduce storage space requirements. This makes it possible to store large amounts of data efficiently.
3. Metadata Management: Effective data collection systems manage metadata to facilitate easy retrieval and management of stored data. Metadata includes information such as date of collection, file type, and content summary.
4. Compliance and Retention Policies: Automated archiving solutions help businesses comply with legal and regulatory requirements by enforcing data retention policies. These policies ensure that data is retained for the required period and disposed of securely when it is no longer needed.
5. Scalability: Modern archive systems are designed to scale with the growing data needs of businesses. Whether you are a small enterprise or a large corporation, scalable solutions ensure that your archive infrastructure can expand as your data grows.
6. Security Features: Automated data archive systems provide strong security features such as encryption, access controls, and audit trails to protect sensitive data from unauthorized access and breaches.
Benefits of Automated Data Archive and Offline Storage
1. Enhanced Data Security: By storing data offline, businesses can protect their information from online threats such as cyber-attacks and ransomware. Offline storage provides an air gap that isolates data from network vulnerabilities.
2. Regulatory Compliance: Many industries are subject to strict data retention regulations. Automated archive systems ensure compliance by systematically managing data according to regulatory requirements.
3. Cost Savings: Efficient data compression and deduplication reduce the amount of storage space, leading to cost savings on storage infrastructure. Additionally, automated systems reduce the need for manual inspection, saving labour costs.
4. Improved Data Management: Automated systems ensure that data is stored consistently and accurately, making it easier to manage and retrieve information when needed. This improves operational efficiency and decision-making.
5. Disaster Recovery: Offline storage provides a reliable backup in case of disaster, ensuring that critical data can be restored even if online systems are compromised or fail.
6. Long-term Data Preservation: Archiving ensures that important historical data is preserved for future reference. This is valuable for businesses that need to maintain records for many years or even decades.
Best Practices for Implementing Data Archiving and Offline Storage
1. Assess Data Value: Not all data needs to be archived. Assess the value of your data to determine what should be archived and for how long. Focus on critical data that needs long-term preservation and compliance data that must be retained by law.
2. Define Retention Policies: Establish clear data retention policies that specify how long different types of data should be stored. Make sure these policies comply with industry regulations and business requirements.
3. Automate Processes: Implement automated archiving solutions to ensure that data is archived regularly and systematically. Automation reduces the risk of human error and ensures consistency.
4. Secure Offline Storage: Use secure offline storage solutions such as tape drives, external hard drives, or optical disks. Make sure these storage devices are stored in a secure, climate-controlled environment to prevent data degradation.
5. Test Data Recovery: Regularly test your ability to recover stored data. This ensures that your archiving system is working correctly and that data can be restored quickly when needed.
6. Monitoring and Auditing: Implement monitoring and auditing processes to track the performance and security of your archiving system. This helps to identify and resolve any issues before they become serious problems.
7. Encrypt Sensitive Data: Make sure that sensitive data is encrypted before archiving. This adds a layer of security and protects data from unauthorized access during storage and transportation.
8. Train Employees: Train your employees on data archiving policies and procedures. Make sure they understand the importance of data archiving and how to use the archiving system correctly.
Common Use Cases for Data Archiving and Offline Storage
1. Financial Services: Financial institutions need to retain transaction records and customer data for several years. Automated archiving ensures compliance and protects sensitive financial information.
2. Healthcare: Medical records and patient data need to be preserved for the long term. Archiving solutions help healthcare providers manage and preserve this data while ensuring compliance with health regulations.
3. Law Firms: Law firms produce a lot of documents that must be retained for legal purposes. Automated archiving helps manage these records efficiently and ensure they are available when needed.
4. Education: Educational institutions need to archive student records, research data, and administrative documents. Archiving systems provide a secure way to manage and access this data for the long term.
5. Government Agencies: Government agencies often need to preserve records and documents for historical and regulatory purposes. Automated archiving ensures these records are retained securely and can be retrieved easily.
6. Corporate Enterprises: Businesses of all sizes need to store emails, contracts, financial records, and other important documents. Archiving systems help manage this data efficiently, ensure compliance, and protect business interests.
Conclusion
Automated data archiving and offline storage are indispensable tools for businesses that need to ensure the security, integrity, and accessibility of their data over the long term. By leveraging these technologies, businesses can protect themselves from cyber threats, comply with regulatory requirements, and manage their data more efficiently.
Investing in a robust data archiving and offline storage solution is a strategic decision that can provide significant benefits, including cost savings, improved data management, and enhanced security. As the volume and importance of data continue to grow, businesses that implement effective archiving solutions will be better positioned to navigate the complexities of the digital landscape and protect their valuable information assets.
For more information on automated data archiving and offline storage solutions, consult industry experts and explore the latest technologies to find the best fit for your business needs.
0 notes
Text
Top Process of Point Cloud to 3D Model: BIM Laser Scanning
The process of converting point cloud data to a 3D Building Information Model (BIM) involves several steps and employs various technologies, making it a sophisticated yet highly beneficial practice for the architecture, engineering, and construction (AEC) industries. Here’s a breakdown of this process and its significance:

Understanding Point Clouds to BIM
Point clouds are dense collections of data points captured by 3D laser scanners, representing the geometry of a physical space. These data points alone lack the intelligence and parametric capabilities of a BIM model, which includes detailed information about building components, materials, and their relationships
Step-by-Step Process
Data Capture: The process begins with 3D laser scanning using Lidar or other technologies to capture the existing conditions of a site. These scanners can be mounted on drones, tripods, or handheld devices, capturing millions of points per second to create a detailed point cloud
Point Cloud Registration: Multiple scans from different angles are registered and merged into a single unified point cloud. This step involves aligning the scans accurately using reference points or targets captured during the scanning process
Data Cleaning and Segmentation: The raw point cloud data often contains noise and irrelevant points, which need to be filtered out. The cleaned point cloud is then segmented into different elements such as walls, floors, and structural components
Modeling in BIM Software: The segmented point cloud is imported into BIM software like Autodesk Revit or AutoCAD. Here, the point cloud is used as a reference to create parametric BIM objects. These objects include walls, doors, pipes, and other building elements, enriched with metadata and functional attributes
Quality Assurance and Validation: The generated BIM model is compared with the point cloud to ensure accuracy. Any discrepancies are corrected, and the model is refined to meet the required specifications. This step may also involve clash detection and ensuring all elements fit together without conflicts
Integration and Use: The final BIM model can be used for various applications, including architectural documentation, construction planning, facility management, and renovation projects. It provides a comprehensive and accurate digital representation of the physical space, facilitating better decision-making and project management
Benefits of Scan-to-BIM
Accuracy: High precision in capturing existing conditions ensures the BIM model is an accurate representation of the site, reducing errors and rework during construction
Efficiency: The process is faster than traditional methods, with the ability to cover large areas quickly and process the data in hours rather than days
Enhanced Collaboration: BIM models integrate data from various stakeholders, providing a centralized platform for architects, engineers, and contractors to collaborate effectively
Lifecycle Management: The detailed BIM model supports the entire lifecycle of a building, from design and construction to maintenance and renovations
Challenges
Complexity: The process requires specialized skills and software to accurately convert point cloud data to BIM models.
Data Handling: Point clouds are large datasets, and managing them efficiently can be challenging, requiring robust computing resources and software capabilities.
In summary, the scan-to-BIM process is a powerful method for transforming detailed point cloud data into intelligent, usable BIM models. This technology enhances accuracy, efficiency, and collaboration in the AEC industry, making it an invaluable tool for modern construction and renovation projects.
#scan to bim#point cloud to bim#bim services#3d laser scanning#as-built drawing#bim laser scanning#scan to revit#scan to cad#as-built drawings#point cloud to cad
1 note
·
View note
Text
Enhancing Law Firm Efficiency and Client Service with Artificial Intelligence

Enhancing Law Firm Efficiency and Client Service with Artificial Intelligence
Artificial Intelligence (AI) is not just a tech buzzword—it's a transformative tool for law firms seeking to enhance their service delivery and operational efficiency. In this blog post, we will explore practical ways AI can be integrated into your law practice to provide superior client service and streamline operations.
AI in Client Data Management
One of the most immediate benefits of AI for law firms is in the realm of client data management. AI systems can automate data entry, organize data more efficiently, and ensure that client information is always up-to-date.
- Using AI to automate routine data entry tasks, reducing errors and freeing up time for more complex legal work.
- Implementing machine learning algorithms to categorize and analyze case information for better insight gathering.
Case Study: Jackson LLP's AI Integration
Jackson LLP, a real estate law firm, implemented an AI-driven system to handle their document and data management. This system was programmed to recognize and categorize legal documents by type and relevance, tagging them with metadata for easy retrieval.
The impact was significant—search and retrieval times were cut by 75%, and lawyers could access case files and related documents almost instantaneously, regardless of their location. This not only boosted the firm's productivity but also enhanced their responsiveness to client inquiries, improving client satisfaction measurably.
AI for Enhanced Legal Research
Artificial Intelligence can drastically reduce the time spent on legal research by using natural language processing to find relevant case law and statutes from vast databases of legal texts.
- Integrating AI tools to conduct comprehensive legal research in a fraction of the time normally required.
- Employing AI to stay updated on the latest legal developments and precedents that could affect ongoing cases.
Improving Client Interactions with AI
AI can also play a crucial role in enhancing the client experience. From personalized communication to predictive analytics predicting client needs, AI tools are reshaping client-lawyer interactions.
- Using AI chatbots to provide clients with 24/7 access to basic legal guidance and case status updates.
- Leveraging predictive analytics to anticipate client needs and proactively address potential legal issues.
Frequently Asked Questions (FAQ)
How can AI improve the efficiency of law firms?
AI enhances efficiency by automating routine tasks, improving data management, and speeding up legal research, allowing lawyers to focus on more strategic activities.
What are the ethical considerations of using AI in law firms?
While AI can significantly improve efficiency and client service, it must be used responsibly, ensuring privacy, security, and compliance with all legal standards.
Ready to transform your law firm with AI? Dive deeper into the possibilities by accessing our Ultimate Lawyer Digital Marketing Checklist and start integrating AI into your practice today.
References:1. Harvard Law Review: 2. TechCrunch:
Read the full article
0 notes
Text
Engineering Data Management: Optimizing Processes and Performance in Engineering Projects
In the realm of engineering, efficient management of data and information is paramount for ensuring project success, compliance with regulations, and maintaining competitiveness in the market. Engineering data management (EDM) encompasses the processes, tools, and strategies employed to effectively organize, store, retrieve, and utilize engineering data throughout the project lifecycle. In this comprehensive guide, we’ll delve into the significance of managing engineering data, explore key components and best practices, and discuss its impact on productivity, collaboration, and innovation in engineering endeavors.
Understanding Engineering Data Management (EDM)
Engineering data management (EDM) refers to the systematic management of engineering data, including design documents, technical specifications, CAD drawings, simulation models, and project documentation, to support engineering projects and processes. EDM aims to ensure data integrity, accessibility, and traceability while facilitating collaboration and decision-making among stakeholders.
Importance of Engineering Data Management
1. Data Integrity and Accuracy:
EDM ensures the integrity and accuracy of engineering data, reducing the risk of errors, inconsistencies, or misinterpretations that could lead to costly rework or project delays.
2. Regulatory Compliance:
Compliance with industry standards, regulatory requirements, and quality management systems is facilitated through EDM practices, ensuring adherence to specifications, codes, and safety regulations.
3. Collaboration and Communication:
EDM enables seamless collaboration and communication among multidisciplinary teams, allowing engineers, designers, and stakeholders to access, share, and review project information in real time.
4. Knowledge Management:
Engineering data management serves as a repository for institutional knowledge, lessons learned, and best practices, enabling organizations to leverage past experiences and expertise to inform future projects.
Key Components of Engineering Data Management
1. Data Capture and Acquisition:
Capturing and acquiring engineering data from various sources, including design software, sensors, test equipment, and external partners, is the initial step in the EDM process.
2. Data Organization and Classification:
Organizing and classifying engineering data according to predefined taxonomies, naming conventions, and metadata standards ensures consistency, accessibility, and usability.
3. Data Storage and Retrieval:
Utilizing robust data storage systems, such as document management systems (DMS), product data management (PDM) software, or cloud-based repositories, enables efficient storage, retrieval, and version control of engineering data.
4. Data Security and Confidentiality:
Implementing measures to safeguard engineering data against unauthorized access, data breaches, or cyber threats is essential for protecting sensitive information and intellectual property.
5. Change Management and Version Control:
Establishing change management processes and version control mechanisms ensures that changes to engineering data are documented, tracked, and audited to maintain data integrity and traceability.
Best Practices for Engineering Data Management
1. Standardization and Documentation:
Standardizing data formats, naming conventions, and documentation practices fosters consistency and clarity, simplifying data management and facilitating interoperability.
2. Automation and Integration:
Leveraging automation tools and integrating EDM systems with other engineering software platforms streamlines workflows, reduces manual errors, and improves productivity.
3. Training and Education:
Providing training and education to engineering teams on EDM principles, tools, and workflows enhances adoption and proficiency, empowering users to maximize the benefits of EDM practices.
4. Continuous Improvement:
Embracing a culture of continuous improvement and feedback enables organizations to identify inefficiencies, address pain points, and evolve their EDM processes to meet changing needs and requirements.
What is its Impact?
1. Improved Productivity:
EDM streamlines engineering workflows reduces duplication of effort and accelerates decision-making, leading to improved productivity and project efficiency.
2. Enhanced Collaboration:
EDM fosters collaboration and knowledge sharing among team members, enabling interdisciplinary teams to work together seamlessly and leverage collective expertise.
3. Risk Mitigation:
By ensuring data accuracy, traceability, and compliance with regulations, EDM helps mitigate risks associated with errors, rework, and non-compliance, safeguarding project success and reputation.
4. Innovation Enablement:
Access to accurate and up-to-date engineering data fuels innovation and creativity, empowering engineers to explore new ideas, optimize designs, and drive technological advancements.
Conclusion
Engineering data management (EDM) is a cornerstone of success in engineering projects, providing the foundation for efficient collaboration, informed decision-making, and continuous improvement. By implementing robust EDM practices, organizations can optimize processes, enhance productivity, mitigate risks, and foster innovation in engineering endeavors. As the complexity of engineering projects continues to grow and the volume of data expands, the importance of effectively managing engineering data will only increase, underscoring its role as a strategic enabler of success in the engineering industry.
0 notes
Last Seen Blogs

sirweltynew
SirWeltyNew

profitinsulationcom
Pro-fit Insulation Contractors

yourhealthplus
Untitled

beritatahun2024
beritaupdate

lauren-north
We Won't Stop