#data scraping company
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
A Detailed Website Scraping Guide for Businesses

Web data scraping for various business industries is vital in a data driven world for extracting useful information to help make smart decisions, reformulate strategies, unlock market insights, and more. Here’s a comprehensive guide on website scraping for businesses.
#web scraping services#data scraping services#database scraping service#web scraping company#data scraping service#data scraping company#data scraping companies#web scraping companies#web scraping services usa#web data scraping services#web scraping services india
2 notes
·
View notes
Text
The process of gathering information from multiple sources—including websites, databases, spreadsheets, documents, text files, and more—is known as data scraping. Data integration, migration, analysis, and information retrieval are just a few of the uses for data scraping.
#data scraping#data scraping service providers#data scraping company#data scraping services company#data scraping services company in india#data scraping services#web scraper in india#Data integration
1 note
·
View note
Note
your last reblog might have some misinfo
genuinely, thanks for caring, but can you be more specific?
because if you mean the post about nightshade and glaze being ineffective and you're referencing the "debunk" in the notes from someone who clearly doesn't understand the technology involved and only cites the devs themselves (who obviously wouldnt be advertising the many ways in which the tech they're pushing fails to perform as intended), you're just mistaken I'm afraid.
also like. i know the op of that post and trust their knowledge on the subject a lot more than some rando misusing buzzwords
#look i hate the way ai companies indiscriminately scrape data and the way it has INSTANTLY oversaturated everything too#but the uninformed reactionary bullshit it's spawned is VERY unhelpful#not enabling reblogging on this either bc i dont want people to be annoying at me
37 notes
·
View notes
Text
Can someone explain to me why the idea of Automattic selling data to Midjourney is so awful?
I get that people don't want their posts and art being used to train generative models but... they already are being used to train generative models. If you make something public on the internet, then you can't stop anyone from scraping it and add it to a training set (there's no such thing as DRM that works against a well-funded opponent), and as I understand it all the big "AI" companies are already doing this.
So it seems like Tumblr is basically telling Midjourney etc. "Hey, wouldn't you like to get this data without having to process out the noise from webscraping? We'll give you cleaner data if you A) pay us and B) don't mind that we're going to let users opt out of it."
Shouldn't this be strictly better than the alternative, which is "Midjourney etc. just keep scraping all publicly available data regardless of what users want and also Tumblr doesn't have enough money to cover its operating expenses"? What am I missing here?
#like if a company is turning over private data that's one thing#but 'we take the data you were going to scrape anyway and sell it to you minus the users who opted out' seems like a step forwards#inasmuch as it becomes possible to opt out#which is not currently a thing you can do except by making your blog private#metatumblr
35 notes
·
View notes
Text
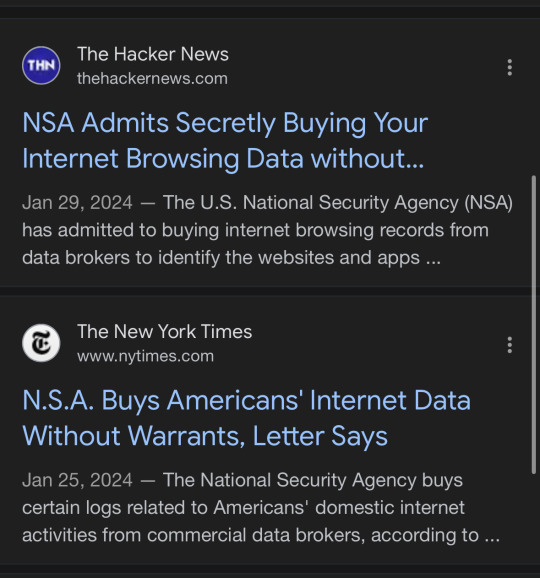
Like come on guys
26 notes
·
View notes
Text
observation-wise i do think it's interesting how enraged people were about how a giant query that returned pretty much everything ever posted (and unposted. drafts and unanswered asks and whatnot) on the site was done (which. to my knowledge. STILL doesn't have an answer regarding the question of whether or not the data included in that query was already sold) and that tumblr was going to start partnering with AI companies to train their models and then a couple of posts went around like "okie dokie guys NOW after that query was done we implemented an opt-out toggle <3 and we trust in Good Faith that the companies will respect this toggle <3" and then everyone was like Oh Okay <3 Yay <3 and suddenly everyone's fine again. 10/10 example of a collective sunk cost fallacy mentality. at this point it's kind of free entertainment to watch
#obviously if you post anything online you are implicitly acknowledging the risk of it being scraped. that isn't the point#the point is that a REALLY shitty dick move was pulled and like. nobody cares about it. at all#despite the fact that if this happened a year ago to another site like half the people posting about it would've been saying shit like#'haha that's what those idiots get for staying on a site that just wants to mine them for data. companies don't care about their users.#thank god tumblr is different <3' when it's like. guys. you realize tumblr hasn't been different for at least 6 years now. right.#you realize that the 'hellsite (affectionate)' marketing ploy was just that. a marketing ploy.#i realize some people will read this and go 'get off your high horse you're literally posting this on tumblr'#and i mean. yeah. that's the point HAHA
2 notes
·
View notes
Text
Kroger Grocery Data Scraping | Kroger Grocery Data Extraction

Shopping Kroger grocery online has become very common these days. At Foodspark, we scrape Kroger grocery apps data online with our Kroger grocery data scraping API as well as also convert data to appropriate informational patterns and statistics.
#food data scraping services#restaurantdataextraction#restaurant data scraping#web scraping services#grocerydatascraping#zomato api#fooddatascrapingservices#Scrape Kroger Grocery Data#Kroger Grocery Websites Apps#Kroger Grocery#Kroger Grocery data scraping company#Kroger Grocery Data#Extract Kroger Grocery Menu Data#Kroger grocery order data scraping services#Kroger Grocery Data Platforms#Kroger Grocery Apps#Mobile App Extraction of Kroger Grocery Delivery Platforms#Kroger Grocery delivery#Kroger grocery data delivery
2 notes
·
View notes
Text
You should get an AO3 account
With the rise of AI and the well known epidemic of AI companies scraping Ao3 for training data most authors on Ao3 have locked down their fics to logged in users only. This is unfortunate for authors and readers. As an author I've noticed a steep drop in readership on fics restricted to logged in users and when recommending fics to my friends I've noticed that the folks without an account can't find the fics. The logged in users only toggle, not only keeps people without an account from reading a fic, but also from seeing its listing at all. More than 50% of fics I come across have this setting turned on. So, you should get an AO3 account. I know this seems daunting and unfair because it's an invite only system but, you can invite yourself through the homepage if you don't already have one, and in the past few years I've never heard of someone who requested an invitation through this method, not getting one. And for those of you who are hesitant because you don't write, that's okay. It's not weird at all to click on a commenter username and find that they have 0 works and 10,000 bookmarks. It might take a week for the invitation to actually show up, but I can almost guarantee you will get one, just keep an eye on your email. It's free to join and donations are optional. You'll have more to read if you have an account and maybe give your favorite author the chance to protect their work from AI without a loss of readership and feedback.
19K notes
·
View notes
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text
Unlock powerful insights with eCommerce data scraping. Monitor competitor prices, track product availability, analyze trends, and optimize your business strategy.
0 notes
Text
Unlock the Power of Data with Uniquesdata's Data Scraping Services!











In today’s data-driven world, timely and accurate information is key to gaining a competitive edge. 🌐
At Uniquesdata, our Data Scraping Services provide businesses with structured, real-time data extracted from various online sources. Whether you're looking to enhance your e-commerce insights, analyze competitors, or improve decision-making processes, we've got you covered!
💼 With expertise across industries such as e-commerce, finance, real estate, and more, our tailored solutions make data accessible and actionable.
📈 Let’s connect and explore how our data scraping services can drive value for your business.
#web scraping services#data scraping services#database scraping service#web scraping company#data scraping service#data scraping company#data scraping companies#web scraping companies#web scraping services usa#web data scraping services#web scraping services india
3 notes
·
View notes
Text
Denas Grybauskas, Chief Governance and Strategy Officer at Oxylabs – Interview Series
New Post has been published on https://thedigitalinsider.com/denas-grybauskas-chief-governance-and-strategy-officer-at-oxylabs-interview-series/
Denas Grybauskas, Chief Governance and Strategy Officer at Oxylabs – Interview Series

Denas Grybauskas is the Chief Governance and Strategy Officer at Oxylabs, a global leader in web intelligence collection and premium proxy solutions.
Founded in 2015, Oxylabs provides one of the largest ethically sourced proxy networks in the world—spanning over 177 million IPs across 195 countries—along with advanced tools like Web Unblocker, Web Scraper API, and OxyCopilot, an AI-powered scraping assistant that converts natural language into structured data queries.
You’ve had an impressive legal and governance journey across Lithuania’s legal tech space. What personally motivated you to tackle one of AI’s most polarising challenges—ethics and copyright—in your role at Oxylabs?
Oxylabs have always been the flagbearer for responsible innovation in the industry. We were the first to advocate for ethical proxy sourcing and web scraping industry standards. Now, with AI moving so fast, we must make sure that innovation is balanced with responsibility.
We saw this as a huge problem facing the AI industry, and we could also see the solution. By providing these datasets, we’re enabling AI companies and creators to be on the same page regarding fair AI development, which is beneficial for everyone involved. We knew how important it was to keep creators’ rights at the forefront but also provide content for the development of future AI systems, so we created these datasets as something that can meet the demands of today’s market.
The UK is in the midst of a heated copyright battle, with strong voices on both sides. How do you interpret the current state of the debate between AI innovation and creator rights?
While it’s important that the UK government favours productive technological innovation as a priority, it’s vital that creators should feel enhanced and protected by AI, not stolen from. The legal framework currently under debate must find a sweet spot between fostering innovation and, at the same time, protecting the creators, and I hope in the coming weeks we see them find a way to strike a balance.
Oxylabs has just launched the world’s first ethical YouTube datasets, which requires creator consent for AI training. How exactly does this consent process work—and how scalable is it for other industries like music or publishing?
All of the millions of original videos in the datasets have the explicit consent of the creators to be used for AI training, connecting creators and innovators ethically. All datasets offered by Oxylabs include videos, transcripts, and rich metadata. While such data has many potential use cases, Oxylabs refined and prepared it specifically for AI training, which is the use that the content creators have knowingly agreed to.
Many tech leaders argue that requiring explicit opt-in from all creators could “kill” the AI industry. What’s your response to that claim, and how does Oxylabs’ approach prove otherwise?
Requiring that, for every usage of material for AI training, there be a previous explicit opt-in presents significant operational challenges and would come at a significant cost to AI innovation. Instead of protecting creators’ rights, it could unintentionally incentivize companies to shift development activities to jurisdictions with less rigorous enforcement or differing copyright regimes. However, this does not mean that there can be no middle ground where AI development is encouraged while copyright is respected. On the contrary, what we need are workable mechanisms that simplify the relationship between AI companies and creators.
These datasets offer one approach to moving forward. The opt-out model, according to which content can be used unless the copyright owner explicitly opts out, is another. The third way would be facilitating deal-making between publishers, creators, and AI companies through technological solutions, such as online platforms.
Ultimately, any solution must operate within the bounds of applicable copyright and data protection laws. At Oxylabs, we believe AI innovation must be pursued responsibly, and our goal is to contribute to lawful, practical frameworks that respect creators while enabling progress.
What were the biggest hurdles your team had to overcome to make consent-based datasets viable?
The path for us was opened by YouTube, enabling content creators to easily and conveniently license their work for AI training. After that, our work was mostly technical, involving gathering data, cleaning and structuring it to prepare the datasets, and building the entire technical setup for companies to access the data they needed. But this is something that we’ve been doing for years, in one way or another. Of course, each case presents its own set of challenges, especially when you’re dealing with something as huge and complex as multimodal data. But we had both the knowledge and the technical capacity to do this. Given this, once YouTube authors got the chance to give consent, the rest was only a matter of putting our time and resources into it.
Beyond YouTube content, do you envision a future where other major content types—such as music, writing, or digital art—can also be systematically licensed for use as training data?
For a while now, we have been pointing out the need for a systematic approach to consent-giving and content-licensing in order to enable AI innovation while balancing it with creator rights. Only when there is a convenient and cooperative way for both sides to achieve their goals will there be mutual benefit.
This is just the beginning. We believe that providing datasets like ours across a range of industries can provide a solution that finally brings the copyright debate to an amicable close.
Does the importance of offerings like Oxylabs’ ethical datasets vary depending on different AI governance approaches in the EU, the UK, and other jurisdictions?
On the one hand, the availability of explicit-consent-based datasets levels the field for AI companies based in jurisdictions where governments lean toward stricter regulation. The primary concern of these companies is that, rather than supporting creators, strict rules for obtaining consent will only give an unfair advantage to AI developers in other jurisdictions. The problem is not that these companies don’t care about consent but rather that without a convenient way to obtain it, they are doomed to lag behind.
On the other hand, we believe that if granting consent and accessing data licensed for AI training is simplified, there is no reason why this approach should not become the preferred way globally. Our datasets built on licensed YouTube content are a step toward this simplification.
With growing public distrust toward how AI is trained, how do you think transparency and consent can become competitive advantages for tech companies?
Although transparency is often seen as a hindrance to competitive edge, it’s also our greatest weapon to fight mistrust. The more transparency AI companies can provide, the more evidence there is for ethical and beneficial AI training, thereby rebuilding trust in the AI industry. And in turn, creators seeing that they and the society can get value from AI innovation will have more reason to give consent in the future.
Oxylabs is often associated with data scraping and web intelligence. How does this new ethical initiative fit into the broader vision of the company?
The release of ethically sourced YouTube datasets continues our mission at Oxylabs to establish and promote ethical industry practices. As part of this, we co-founded the Ethical Web Data Collection Initiative (EWDCI) and introduced an industry-first transparent tier framework for proxy sourcing. We also launched Project 4β as part of our mission to enable researchers and academics to maximise their research impact and enhance the understanding of critical public web data.
Looking ahead, do you think governments should mandate consent-by-default for training data, or should it remain a voluntary industry-led initiative?
In a free market economy, it is generally best to let the market correct itself. By allowing innovation to develop in response to market needs, we continually reinvent and renew our prosperity. Heavy-handed legislation is never a good first choice and should only be resorted to when all other avenues to ensure justice while allowing innovation have been exhausted.
It doesn’t look like we have already reached that point in AI training. YouTube’s licensing options for creators and our datasets demonstrate that this ecosystem is actively seeking ways to adapt to new realities. Thus, while clear regulation is, of course, needed to ensure that everyone acts within their rights, governments might want to tread lightly. Rather than requiring expressed consent in every case, they might want to examine the ways industries can develop mechanisms for resolving the current tensions and take their cues from that when legislating to encourage innovation rather than hinder it.
What advice would you offer to startups and AI developers who want to prioritise ethical data use without stalling innovation?
One way startups can help facilitate ethical data use is by developing technological solutions that simplify the process of obtaining consent and deriving value for creators. As options to acquire transparently sourced data emerge, AI companies need not compromise on speed; therefore, I advise them to keep their eyes open for such offerings.
Thank you for the great interview, readers who wish to learn more should visit Oxylabs.
#Advice#ai#AI development#ai governance#AI industry#AI innovation#AI systems#ai training#AI-powered#API#approach#Art#Building#Companies#compromise#content#content creators#copyright#course#creators#data#data collection#data protection#data scraping#data use#datasets#deal#developers#development#Digital Art
0 notes
Text
Business Processing Services Company
Fusion Digitech is a leading business processing services company in the USA, offering comprehensive solutions tailored to streamline operations and boost efficiency. With a strong commitment to quality, innovation, and client satisfaction, we specialize in data entry, document management, digital transformation, and customer support services. Our team of skilled professionals leverages the latest technology to deliver cost-effective and scalable solutions that help businesses optimize resources and focus on core objectives. Whether you’re a startup or an enterprise, Fusion Digitech is your trusted partner in driving productivity and growth through reliable business processing services. Experience excellence with Fusion Digitech.

0 notes
Text
youtube
The UK government's fifth attempt to push through a bill allowing AI companies to scrape any data by HIMediaTV Join The Community: https://discord.gg/dTb9HDmPhW Get Cool Rewards For Supporting The Show: https://himedia.gg/perks Podcasts: https://himedia.gg/podcasts Subscribe On Youtube: https://bit.ly/himvideo Social Media: https://himedia.gg/ https://facebook.com/HIMediaTV https://instagram.com/himediatv https://bsky.app/profile/himediatv.bsky.social https://twitter.com/HIMediaTV Merch Store: https://himedia.gg/merch Support HI Media! 💵💵💵💵💵💵💵💵💵💵 You Doing Content Creation? Get 9 Bucks Off A Streamlabs Sub With Most Of The Tools You Need To Stream/Create Content. Its A Decent Quick And Dirty Way To Get Started: https://streamlabs.com/refer/evanhaggard-1599-10?t=2 Want The Games We Play? Buy Them On Our Nexus And Support the Show!: http://bit.ly/himnexus ======================= Big Thank You To VLNS BEATS for making the Outro music you heard In This video https://msha.ke/vlnsbeats/ Big Thank You To Mikel From Gamechops for making the background music you heard In This video https://www.youtube.com/watch?v=wQ2OhGwZaK4 #HIMedia - via YouTube https://www.youtube.com/watch?v=BaV3jRy3yz4
#YouTube#The UK government's fifth attempt to push through a bill allowing AI companies to scrape any data#HIMediaTV
0 notes
Text
Reddit sues Anthropic, accusing the AI company of illegally scraping data from its site
Social media platform Reddit has sued the artificial intelligence company Anthropic, alleging that it is illegally “scraping” the comments of Reddit users to train its chatbot Claude. Reddit claims that Anthropic has used automated bots to access Reddit’s content despite being asked not to do so, and “intentionally trained on the personal data of Reddit users without ever requesting their…
0 notes
Text
On July 1, Cloudflare, one of the internet’s core infrastructure companies, declared “Content Independence Day.” In a landmark policy shift, the company announced it will now block AI crawlers from scraping sites hosted on its platform unless those bots pay content creators for the data they consume.
Damn. Interesting move by Cloudflare.
5K notes
·
View notes