#using chatgpt to build a website
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Hire Certified ChatGPT App Developers for AI-Powered Solutions
Unlock the full potential of conversational AI by hiring certified ChatGPT app developers. Our experts specialize in building smart, intuitive, and scalable AI applications tailored to your business needs. Whether you’re creating a chatbot, automating workflows, or enhancing customer engagement, our developers deliver excellence at every stage. Explore our proven expertise in ChatGPT development services to bring your vision to life. With a focus on innovation and functionality, we ensure your AI-powered solution stands out in today’s competitive digital space. Get started with a dedicated ChatGPT development team that turns your ideas into intelligent, real-world applications.
#chatgpt development services#hire chatgpt developer#chatgpt development team#hire chatgpt developers#how to make a website using chatgpt#build a website with chatgpt#how to build a website with chatgpt#build website with chatgpt#using chatgpt to build a website#chatgpt website build#using chatgpt for web design#how to use chatgpt to build a website#chatgpt for web design
0 notes
Text
right. people in my actual division and industry are using AI in ways that indicate i need to quit being avoidant
questions:
co-pilot is offering itself to me in like outlook and shit. is it strictly for microsoft office stuff or is it broadly useful
which ai is best at helping answer substantive business strategy questions
do i need to subscribe to a paid ai to get useful results or can i use a free one
chatgpt seems popular; is it optimal? how much does version matter?
explain like i’m five: where do i go to do this? a website? an app?
my core issue is that the prospect of writing a prompt that sufficiently establishes the context and specifies clearly enough what i need feels like the prospect of writing a fucking monograph
the analog in my head: writing a creative brief for a complex oncology drug brand hcp launch campaign where not all the creatives on the team you’re going to brief are oncology-experienced. that is a multi-day, pain-in-the ass job. it would be much, much worse if one had to brief a team of bright college leavers, who not only know nothing about oncology (not fluent in even the basics medically; not able to quickly find their footing in the types of complex market landscapes involved), but also know nothing about the work process (what are the parts of a creative brief, how do they work and why do they matter, same questions for a brand positioning, what does good look like, the politics of it: why what will or won’t work for leadership and/or the client is a key consideration and how to wrangle that against the brand needs, etc, etc). this seems potentially like all those problems and more
tl;dr: how do you prompt without it being a vastly bigger, more difficult job taking ten or twenty times as much time vs tackling the work yourself
the single biggest advantage i have at this point in my career is that i already know what i’m fucking doing and can skip to the actual work part?
it’s like finding someone who has never heard of the 2008 global financial crisis or ww2. where do i even start. why is it now my problem to fix them. nO
relatedly, can i get ai to remember and build on past conversations or am i going to have to start at zero every fucking time
why am i even here? wtf is wrong with me that i haven’t dealt with ai yet?
most of it is literally just avoiding the abovedescribed nuisance factor
i don’t have a philosophical or political problem with ai, mostly; climate = overblown, and i get why artists hate ai but it’s not as cut and dried as the populist anti position has it
there is a meta facet of my avoidance to date, in that i’m aware that people, experienced ai engineers even, can get lost in the sauce, and as a historically woo-susceptible person (despite the robust woo allergies to be expected in someone of my etc) i’ve been wary in the ~hygienic sense about the risk for uhhh getting into some fucking epistemological/discernment nightmare way down in the secret murky sub-basements of the evidence ladder. this concern goes all the way back to the introduction of siri. i still have it, but at this point the tradeoff on just not talking to robots is becoming expensive; avoiding high-hazard conversational pathways looks like a better if more demanding strategy than just avoiding the whole-ass technology sector
anyway yeah can someone literally direct me to a sensible starting point and/or recommend a resource on prompting that is. how do i put this. written for laypeople without being written for idiots. i would rather have wikipedia open in another tab and be looking stuff up along the way than get pablum with all the interesting parts elided for special-ed preteens
#i think i tried asking this once before and got some interesting remarks but not much practical or actionable?#come on tumblr help me out here
47 notes
·
View notes
Text
Finding love is hard. For a while, dating apps seemed to make it easier, putting a city’s worth of single people in the palm of your hand. But AI has cast a paranoid pall over what can already be a suboptimal experience. If you get a message that feels a little off, it is hard to know whether you are flirting with a bot—or just someone insecure enough to use ChatGPT as their own Cyrano de Bergerac. In frustration, my friend Lonni has started picking up women at the nail salon like it’s 1997.
Or, in the midst of an emotionally fraught conversation with a friend or family member, a text might read strangely. Is the person on the other end using AI to compose their messages about the fairness of Aunt Beryl’s will or the future of your relationship? The only way to find out is to call them or, better yet, meet them for a coffee.
Or maybe you want to learn something. Many of the internet’s best resources for getting everyday answers are quickly being inundated with the dubious wisdom of AI. YouTube, long a destination for real people who know how to repair toilets, make omelets, or deliver engaging cultural criticism, is getting less human by the day: The newsletter Garbage Day reports that four of May’s top 10 YouTube channels were devoted to AI-generated content. Recently, the fastest-growing channel featured AI babies in dangerous situations, for some reason. Reddit is currently overrun with AI-generated posts. Even if you never use ChatGPT or other large language models directly, the rest of the internet is sodden with their output and with real people parroting their hallucinations. Remember: LLMs are still often wrong about basic facts. It is enough to make a person crack a book.
The internet’s slide toward AI happened quickly and deliberately. Most major platforms have integrated the technology whether users want it or not, just at the moment that some AI photos and videos have become indistinguishable from reality, making it that much harder to trust anything online. Over time, LLMs might get more accurate, or people might simply get better at spotting their tells. In the meantime, a real possibility is that people will turn to the real world as a more trustworthy alternative. We’ve been telling one another to “touch grass” for years now, all while downloading app- and website-blocking software and lockable phone safes to try to wean ourselves off constant internet use. Maybe the AI-slop era will actually help us log off.
Even before AI started taking over, the internet had been getting less and less fun for a while. Users have been complaining about Google Search degrading for years. Opening an app to get a ride, order takeout, or find a vacation house can be just as expensive and effortful as taking a taxi, calling in a delivery order, or booking a hotel once was. Social media is a grotesque, tragedy-exploiting, MechaHitler-riddled inferno. Where going online once evoked a wide-eyed sense that the world was at our fingertips, now it requires wading into the slop like weary, hardened detectives, attempting to parse the real from the fake.
Nevertheless, as AI companies build browsers and devices that keep users tidily contained in an endless conversation with their own personalized AIs, some people may spend more time online than ever. Its accuracy aside, AI is already valued by many for entertainment, practical help, and emotional support. In some extreme cases, users are falling in love with chatbots or drifting into all-consuming spiritual delusions, but many more are simply becoming thoroughly addicted. The internet’s new era may push AI skeptics to spend less time online, while another group ramps up their AI-mediated screen time. That split might have implications for the internet’s culture—and the culture at large.
Even for those who run from the slop, the internet is already so woven into every part of our lives that going cold turkey is pretty much impossible. But as it gets worse, the real world starts to look pretty good in comparison, with its flesh-and-blood people with whom we can establish trust, less overwhelming number of consumer options, slower pace, and occasional moments of unpredictable delight that do not create financial profit for anyone.
I have been experimenting with being less online since 2022, when I quit Twitter. As soon as I got through withdrawal, I could feel my attention span start to expand. I started reading books again. Like a lot of people who left social media, more of my socializing moved over to group chats with people I actually know and in-person get-togethers: quick coffees and camping trips and dinner parties. Remember dinner parties?
Later, I quit shopping online, and soon realized that I didn’t need most of what I had been buying. The majority of the stuff I actually did need, I could get at the grocery store and my local hardware store, which, like most hardware stores, carries tons of things besides wrenches and bolts.
Online shopping might have once been more convenient than schlepping to a store, but I think that’s no longer true in many cases. Last winter, when my feet were chronically cold under my desk, I could have spent hours researching space heaters online, trying to guess which reviews were real and which were fake; placed an order online; possibly received a broken or substandard unit; and then had to package it back up and take it to some random third-party store in a return process designed to be annoying. Instead, I walked to the hardware store. “We have one that oscillates and one that doesn’t,” the guy in the vest told me. I took the one that oscillates. It works fine.
I am not, I hasten to say, completely offline. Like most people, my job requires me to use the internet. But I am online less. And I am happier for it. I get outside more. I garden and read more books. I still follow the news, but less compulsively. Spending some parts of my day without my attention being monetized or my data being harvested is a nice bonus. It makes me feel kind of like a line-dried bedsheet smells.
I find myself dreaming about additional returns to offline existence. I live in Portland, Oregon, where we still have lots of movie theaters and even a video-rental place. I could—I might—cancel all my streaming services and just rent stuff and watch movies at the theater. I could even finally assuage my guilt over the lousy way music-streaming services pay musicians and avoid being fooled by AI bands by going back to CDs and records—and by seeing more artists play live. I don’t think I’ll be the only one reorienting toward physical media and physical presence: books and records, live theater and music, brick-and-mortar stores with knowledgeable salespeople, one long conversation with one real person instead of 300 short interactions with internet strangers who might be robots.
Tech companies may assume that the public is so habituated—or even addicted—to doing everything online that people will put up with any amount of risk or unpleasantness to continue to transact business and amuse themselves on the internet. But there is a limit to what at least some of us will take, especially when the alternative has real appeal. One recent study shows that disconnecting your phone from the internet creates a mood boost on par with pharmaceutical antidepressants. And if more people explore offline alternatives—at least until this whole generative-AI explosion works itself out—it could create a feedback loop, livening up cities and communities, which then become a more tempting alternative to screens. What the internet will become in a post-AI world is anybody’s guess. Maybe it’ll finally become something transcendent. Or maybe, as the conspiracy theory goes, it is already dead.
28 notes
·
View notes
Text

I want to talk about the comment whose name is too long. That motherfucker. Before anyone goes for my head. I said that Snape built the marauders fandom.
For context, it was a TikTok about 3 fandoms within the Harry Potter one. Which are:
- harry potter itself aka golden trio
- marauders era
- Slytherin boys
To which I posted a comment on the TikTok.
[@Harry Potter Fan:
HP is canon
Marauders is fanon but act like canon and are filled with snaters yet somehow they refuse to believe that Snape basically built that fandom
Slytherin gang is just pure thirst]
I'm not lying. I just know that. Then this person said:
[@ChuuyasSlvttyWaistfanclub 👁🚦:Snape built the fandom??? Do he didn't, the fandom was built off of wolfstar]
Since then I've gone into a deep research on fanfiction.net, ao3 and archive.org
Imagine my bitter surprise when I saw more wolfstar fanfics in the 2000's than snupin. So I did some deeper research into this. I spent about my whole morning on this. All I got were reddit bs from the marauders fandom taking a crap and whatnot. Believe me, I used Google. Couldn't find a thing.
So I turned to look at chatgpt. I now more about the history of websites than I intended. Many of the fanfictions date don't even check out. There is litterally a wolfstar fanfic on ao3 that was made in 1950, it also has jegulus and indian James (that was basically booming last year). Many fanfics there are also dated back to 2002 and 2001, meanwhile ao3 exists in 2008.
(also, no hate to the author's that mixed up the dates. Maybe they thought the date was meant as a setting in which time period their story plays at, I also saw one of 1984.)
So I found it unreliable to search based on fanfictions when authors could change the dates. Then I turned to livejournal as chatgpt offered. That is a hot mess. Maybe it's because I am new but I have no idea how that works. So I landed on 2 answers.
Answer 1: wolfstar and snupin equally gained the same popularity. So neither snupin nor wolfstar began first or built the fandom.
Answer 2: according to chatgpt. It was snupin that raged with it's popularity between 2003 and 207. The pictures posted below, explain it well. But in short. Snupin was popular on other platforms that many fans do NOT use anymore nowadays. After 2010, ships excluding Snape like jily and wolfstar then many many more took the wheel and veered that maraudersfandom into the hotpot we know as today. The fandom that excuses death eaters, but not Snape.
That was the cause of ao3 and Tumblr. I believe even the wolfstar fanfics of back then we're more likeable and nicer than the ones we have today where they yank out all character traits of the characters and call it a day.
I hope this helps. So you either settle with snupin or nothing, your choice really. 😂. So fuck that comment with a too long name. I choose snupin.
Also, believe me when I say, I truly did try to search for other methods. I spent my entire morning on getting to the bottom of this but there simply were no other leads left. So as a measure against AI favoritism. I will borrow another phone, of my sister who is not a maraudersfan at all, and my mom's phone who doesn't even know what a harry potter is. Then go to chat gpt, type in the same question and see those answers.




Now, as promised, I checked on multiple sources to not base it on preference. My sister isn't even into harry Potter a lot, but into lord of the rings. About 5 years ago she was into the fandom but by then chat gpt doesn't exist. Fairly obvious she has no clue what marauders even is. This is what her chat gpt says:





This is the link to what my mom her chat gpt says:
Pt 2:
Pt 3:
Survey:
22 notes
·
View notes
Note
This is related to another reminder: fanfic writing is not a competition, and it’s not a job post. I have been experimenting with using ChatGPT to write stories with a provided idea prompt from my imagination. I edit and read to make sure the generated story is in line with the general idea of the characters. Between work, life, building a business, and the 1000 different story ideas in my head, I don't have as much time and bandwidth as I used to actually write from start to finish. 2 of the 3 fandoms I write for have pretty much declined and the other is still there. My question to you is what are your thoughts on using AI to write fanfics?
disclaimer: this is just my personal opinion and preference as someone who also writes fanfics and has been writing for 8 years (I have never used AI to write, and have no intention to). my words are not laws, and this is by no means to shame or attack anybody.
I personally believe the fun of writing a fic is gone when you use AI to write a fic. I love writing because I love the act of writing, of thinking about what my blorbo would say and what they would do in this situation I put them in. not the act of telling Al to write something for me, if that makes sense. (sure, I may have joked about wanting a fic to 'write itself' sometimes, but when I made that joke, it was just a joke, and it was never about AI).
there's a huge difference between using a prompt generator website to get motivations and ideas in regards of what to write, and using AI to write the fic.
even if you edit and read everything to make sure it's 'in character' after you use AI, you're still not the 'author' of the story, but rather a beta and an editor.
we all have lives outside of writing fanfics, yes, I know because I've been busy with life outside of AO3 lately and have been finding it hard to find an opportunity where I could sit down and write without exhaustion or job-related stuff pulling me away from my fics, but I'd prefer to only write when I can — when I have the time and energy — to AI any day, even if that meant it took me longer to get a chapter done.
and if I could, I'd avoid reading AI-generated fics just because I'd also prefer to read fanfics that were written with passion and the love the authors have for my favorite characters, and only humans can do that. AI fics just lack a soul in my opinion.
#admin answers#ao3#archive of our own#writer#writeblr#writing#writers#writers on ao3#writers on tumblr#writing challenge#whump#whumpblr#angst#blorbo#fandom#poll#fandoms#AI#ai generated#writing advice#writing inspiration#writing inspo
207 notes
·
View notes
Text
The Whole Sort of General Mish Mosh of AI
I’m not typing this.
January this year, I injured myself on a bike and it infringed on a couple of things I needed to do in particular working on my PhD. Because I had effectively one hand, I was temporarily disabled and it finally put it in my head to consider examining accessibility tools.
One of the accessibility tools I started using was Microsoft’s own text to speech that’s built into the operating system I used, which is Windows Not-The-Current-One-That-Everyone-Complains-About. I’m not actually sure which version I have. It wasn’t good but it was usable, and being usable meant spending a week or so thinking out what I was going to write a phrase at a time and then specifying my punctuation marks period.
I’m making this article — or the draft of it to be wholly honest — without touching my computer at all.
What I am doing right now is playing my voice into Audacity. Then I’m going to use Audacity to export what I say as an MP3, which I will then take to any one of a few dozen sites that offer free transcription of voice to text conversion. After that, I take the text output, check it for mistakes, fill in sentences I missed when coming off the top of my head, like this one, and then put it into WordPress.
A number of these sites are old enough that they can boast that they’ve been doing this for 10 years, 15 years, or served millions of customers. The one that transcribed this audio claims to have been founded in 2006, which suggests the technology in question is at least, you know, five. Seems odd then that the site claims its transcription is ‘powered by AI,’ because it certainly wasn’t back then, right? It’s not just the statements on the page, either, there’s a very deliberate aesthetic presentation that wants to look like the slickly boxless ‘website as application’ design many sites for the so-called AI folk favour.
This is one of those things that comes up whenever I want to talk about generative media and generative tools. Because a lot of stuff is right now being lumped together in a Whole Sort of General Mish Mosh of AI (WSOGMMOA). This lump, the WSOGMMOA, means that talking about any of it is used as if it’s talking about all of it in the way that the current speaker wants to be talked about even within a confrontational conversation from two different people.
For people who are advocates of AI, they will talk about how ChatGPT is an everythingamajig. It will summarize your emails and help you write your essays and it will generate you artwork that you want and it will give you the rules for games you can play and it will help you come up with strategies for succeeding at the games you’ve already got all while it generates code for you and diagnoses your medical needs and summarises images and turns photos of pages into transcriptions it will then read aloud to you, and all you have to focus on is having the best ideas. The notion is that all of these things, all of these services, are WSOGMMOA, and therefore, the same thing, and since any of that sounds good, the whole thing has to be good. It’s a conspiracy theory approach, sometimes referred to as the ‘stack of shit’ approach – you can pile up a lot of garbage very high and it can look impressive. Doesn’t stop it being garbage. But mixed in with the garbage, you have things that are useful to people who aren’t just professionally on twitter, and these services are not all the same thing.
They have some common threads amongst them. Many of them are functionally looking at math the same way. Many or even most of them are claiming to use LLMs, or large language models and I couldn’t explain the specifics of what that means, nor should you trust an explainer from me about them. This is the other end of the WSOGMMOA, where people will talk about things like image generation on midjourney and deepseek (pieces of software you can run on your computer) consumes the same power as the people building OpenAI’s data research centres (which is terrible and being done in terrible ways). This lumping can make the complaints about these tools seem unserious to people with more information and even frivolous to people with less.
Back to the transcription services though. Transcription services are an example of a thing that I think represents a good application of this math, the underlying software that these things are all relying on. For a start, transcription software doesn’t have a lot of use cases outside of exactly this kind of experience. Someone who chooses or cannot use a keyboard to write with who wants to use an alternate means, converting speech into written text, which can be for access or archival purposes. You aren’t going to be doing much with that that isn’t exactly just that and we do want this software. We want transcriptions to be really good. We want people who can’t easily write to be able to archive their thoughts as text to play with them. Text is really efficient, and being able to write without your hands makes writing more available to more people. Similarly, there are people who can’t understand spoken speech – for a host of reasons! – and making spoken media more available is also good!
You might want to complain at this point that these services are doing a bad job or aren’t as good as human transcription and that’s probably true, but would you rather decent subtitles that work in most cases vs only the people who can pay transcription a living wage having subtitles? Similarly, these things in a lot of places refuse to use no-no words or transcribe ‘bad’ things like pornography and crimes or maybe even swears, and that’s a sign that the tool is being used badly and disrespects the author, and it’s usually because the people deploying the tool don’t care about the use case, they care about being seen deploying the tool.
This is the salami slicer through which bits of the WSOGMMOA is trying to wiggle. Tools whose application represent things that we want, for good reasons, that were being worked on independently of the WSOGMMOA, and now that the WSOGMMOA is here, being lampreyed onto in the name of pulling in a vast bubble of hypothetical investment money in a desperate time of tech industry centralisation.
As an example, phones have long since been using technology to isolate faces. That technology was used for a while to force the focus on a face. Privacy became more of a concern, then many phones were being made with software that could preemptively blur the faces of non-focal humans in a shot. This has since, with generative media, stepped up a next level, where you now have tools that can remove people from the background of photographs so that you can distribute photographs of things you saw or things you did without necessarily sharing the photos of people who didn’t consent to having their photo taken. That is a really interesting tool!
Ideologically, I’m really in favor of the idea that you should be able to opt out of being included on the internet. It’s illegal in France, for example, to take a photo of someone without their permission, which means any group shot of a crowd, hypothetically, someone in that crowd who was not asked for permission, can approach the photographer and demand recompense. I don’t know how well that works, but it shows up in journalism courses at this point.
That’s probably why that software got made – regulations in governments led to the development of the tool and then it got refined to make it appealing to a consumer at the end point so it could be used as as a selling point. It wouldn’t surprise me if right now, under the hood, the tech works in some similar way to MidJourney or Dall-E or whatever, but it’s not a solution searching for a problem. I find that really interesting. Is this feature that, again, is running on your phone locally, still part of the concerns of the WSOGMMOA? What about the software being used to detect cancer in patients based on sophisticated scans I couldn’t explain and you wouldn’t understand? How about when a glamour model feeds her own images into the corpus of a Midjourney machine to create more pictures of herself to sell?
Because admit it, you kinda know the big reason as a person who dislikes ‘AI’ stuff that you want to oppose WSOGMMOA. It’s because the heart of it, the big loud centerpiece of it, is the worst people in the goddamn world, and they want to use these good uses of this whole landscape of technology as a figleaf to justify why they should be using ChatGPT to read their emails for them when that’s 80% of their job. It’s because it’s the worst people in the world’s whole personality these past two years, when it was NFTs before that, and it’s a term they can apply to everything to get investors to pay for it. Which is a problem because if you cede to the WSOGMMOA model, there are useful things with meaningful value that that guy gets to claim is the same as his desire to raise another couple of billions of dollars so he can promise you that he will make a god in a box that he definitely, definitely cannot fucking do while presenting himself as the hero opposing Harry Potter and the Protocols of Rationality.
The conversation gets flattened around the basically two poles:
All of these tools, everything that labels itself as AI is fundamentally an evil burning polar bears, and
Actually everyone who doesn’t like AI is a butt hurt loser who didn’t invest earlier and buy the dip because, again, these people were NFT dorks only a few years ago.
For all that I like using some of these tools, tools that have helped my students with disability and language barriers, the fact remains that talking about them and advocating for them usefully in public involves being seen as associating with the group of some of the worst fucking dickheads around. The tools drag along with them like a gooey wake bad actors with bad behaviours. Artists don’t want to see their work associated with generative images, and these people gloat about doing it while the artist tells them not to. An artist dies and out of ‘respect’ for the dead they feed his art into a machine to pump out glurgey thoughtless ‘tributes’ out of booru tags meant for collecting porn. Even me, I write nuanced articles about how these tools have some applications and we shouldn’t throw all the bathwater out with the babies, and then I post it on my blog that’s down because some total shitweasel is running a scraper bot that ignores the blog settings telling them to go fucking pound sand.
I should end here, after all, the transcription limit is about eight minutes.
Check it out on PRESS.exe to see it with images and links!
15 notes
·
View notes
Text
after my post yesterday about not sharing viral videos of "dancing dogs" because they're just videos of animals dying slowly of agonizing neurological disease I tried typing "canine distemper" into tumblr search and discovered another one of those weird little heatsinks of tumblr spam. 99% of the posts in the tag/search category (the latter actually, the tag itself doesn't seem to work/is blocked) were spam, mostly 0-note chatGPT rambling with unclear goals either for SEO or for sales. a lot of Indian spam in particular is on Tumblr, as well as either fake or real veterinary clinics posting filler articles about pet topics. none of this stuff gets any engagement and most of it seems to be referral dead ends, eg, it doesn't have any links out that are being clicked by either humans or crawlers, but I find it everywhere.
porn spam is very straightforward by comparison, porn bots are trying to farm leads in the form of live men who reply to them and can be added to databases of live leads, or they want conversions into account signups or sales off-site. sometimes actual adult content creators are doing their own marketing here and again the goals of their advertising is normal, and other times porn ads are malware or social account hijacking bait etc. but the generic marketing slop spam that comes up for terms like "canine distemper" is a little more puzzling.
I think some of these blogs are probably being used inside web templates off Tumblr to just host content elsewhere on the web, but as far as I'm aware thats not really a standard website building technique, most people just use a blog template or WordPress or something. if you go on the Black Hat World forum you'll find plenty of buying and selling of established accounts in good standing on various socials, either through hacked accounts or accounts that have been deliberately created and then farmed over months or years to look as real as possible, but Tumblr accounts aren't really in demand as far as I'm aware
I don't think it's particularly interesting and definitely not sinister, it's likely a case of lost automated processes or some sort of testing of marketing generators that's just using Tumblr as the planting bed.
69 notes
·
View notes
Note
QUESTION THREE:
If servers take up so much space, then does the warehouse they’re in just have to be Big Enough or can you wire servers together over multiple floors with long enough cables? Does this impact processing time? With huge server systems like Google, do they even HAVE an access point or a central node or is it just one, MASSIVE conglomeration of processing power?? Are there different types of cable for different purposes of what the servers are doing?? Im going insane. Madam I’ve been struck with The Ailment (ADHD)
OK! This one is really interesting because it's the reason why I don't believe that the Circus is abandoned. I mean that in the way that if TADC is following any kind of realistic standards, then the physical hardware behind the circus can't be just tucked away in an abandoned building somewhere. The demands for power and cooling are high. Even if we assume that automated systems take care of that, hardware WILL fail over years of operation.
(Sorry this took so long) Once again, long post under cut
Have you ever seen Google go down? Maybe Youtube? In the past when they were a small website, sure, but not anymore. If you can make a connection, then you will be able to reach those servers. I assume that the circus has a similar setup, as No matter what, there is a digital space for the humans to occupy. That means that there is ZERO downtime.
But these devises live in the real world, connected to the very real power grid. How can they be powered 24/7? A bad storm hits the area and a tree takes out the power lines, do all of the websites hosted on those servers have to wait the hours, possibly days for that line to be fixed? Nope! These centers advertise 24/7 service and they mean it. What this means is that typically, they will have ON SITE generators that can run the ENTIRE center at a moments notice. Some even have an extra generator on standby in case one of the generators malfunction. Redundancy is the name of the game. If something is essential to function, then there WILL be an exact copy on site as a backup. That is why these big websites never go down for service, there is ALWAYS something available to connect to.
But what most people don't realize is the water requirements. Have you ever seen the statistic that chatGPT consumes like 2-3 THOUSAND liters of water every day? And thought, why the fuck does a computer need water? Isn’t water a bad thing for computers? But water has a very useful ability in the way that it handles heat. It’s the same way how your sweat evaporating cools you off. Think of cooling as just removing the heat instead of actually making cold. So water is used in the cooling of these data centers, which is to say, water is used as the refrigerant. It’s a similar concept to how your fridge works, except the refrigerant is lost over time. The water is allowed to evaporate and leave the building because it makes for more efficient cooling. Here’s a video that goes more into detail about water loss cooling for data centers specifically.
As for the actual building, data centers with multiple floors do exist! The reason one may be a single story has more to do with the cost of land vs the cost to build a building with multiple floors that can support the weight of all of those machines. If land cost more than the steel and concrete needed for multiple floors, then. yes, the shorter the cable the more efficient the data transfer, but the time loss is so short that it’s pretty much unnoticeable to the human eye. Some places also standardize their wire lengths, so every server gets the same load time regardless of the actual placement of the server.
But the people who care about that are insane stock traders (not gamers believe it or not) and advancements have made it so that time delay only starts to matter when a cable reaches miles long in length. And those advancements are Fiber Optics! Fiber being literal fibers (either glass or plastic) and Optics as in lenses or reflection. This is because fiber optic cables carry light instead of electricity. Because light is fast as fuck. So then where does the delay come from? Turns out even with the most reflective, chemically perfect fibers, light scatters and eventually data is lost. So repeaters are put in to repeat the input signal, refreshing it. But these repeaters aren’t perfect, so lag is eventually introduced, so modern fiber optics use amplifiers. Amplifiers strengthen the original signal instead of repeating it, making for faster transfers of days.
But you want to know about how these things are wired in terms of electricity! How these things can fit so much electricity in one building? The answer is industrial grade wiring! It's different from the power cables that you find in your house. Well, the wires themselves may be the same, the difference comes in at the fuse box. Here’s a lady plugging all of the wires in a house into the fuse box. The box itself is then plugged into the power line, which provides the electricity. Multiple lines or higher gauge lines will be ran from the power plant to the data center. The exact set up depends on where the data center is in relation to the power plant, who’s building it, and state laws.
Also, for industrial wiring, they usually run the wires through metal pipes instead of letting the wires sit against the insulation. Here’s a guy who wired his house like this. He doesn’t go into detail about what everything means but you don’t need to know all of that to appreciate the pipe work. If you want me to go into electricity as a form of power and the different phases of AC... I'm going to be honest just call me on discord so I can get out the whiteboard. I will give you a whole college grade lecture about how electricity works.
Servers don't have a central node, their operation and purpose is different from computer clusters. While each unit is wired together in a cabinet, each unit operates as it's own individual machine. So, a computer cluster will be spreading one load over multiple machines, a server takes many small loads (<- terrible oversimplification but it works). Everything around it exists to route the right requests to it, power it, cool it, and monitor its operation. But they do have access points! As in, you can connect to it directly or use SSH shell to remotely connect to it. SSH shell is just a secure way to connect to the server, as a maintenance level of access is usually not something that you want anyone to be able to pick up on.
Last but not least, YES! There are many different kinds of cables made for different tasks! Or just to be cheap. The more you get into engineering the more you realize half the shit that we do is because it's the cheapest option that still meets requirements! I left some interesting videos in the bottom of this if you are really curious, but I honestly think that figuring out the exact wires is getting a little too into the weeds for this.
So, to summarize, data centers need generators, water for cooling, and have spare copies of pretty much everything. That’s why it’s so god damn rare to see big websites like google docs down but Ao3 goes down every now and then. He's a bunch of helpful videos that I uses when writing this.
Why the Internet Is Running Out of Electricity
I Can't BELIEVE They Let Me in Here!
Data Center Cooling
How Does LIGHT Carry Data? - Fiber Optics Explained
fiber optic cables (what you NEED to know)
What Ethernet Cable to Use? Cat5? Cat6? Cat7?
How I wired my house.
How I wire a panel (an in-depth tutorial)
Troubleshooting an outlet (interesting video)
Computer science slander
14 notes
·
View notes
Text
The founder of ChatGPT maker OpenAI has denied claims that he sexually abused his sister when she was a child.
In response to a lawsuit in the US, Sam Altman, 39, said that claims he assaulted his sibling from the age of three were “utterly untrue”.
In her filing, Ann Altman alleged she was sexually abused by her brother between 1997 and 2006.
She said the abuse started when she was three and Sam Altman was 12, adding that the last instance of assault took place when the latter was an adult.
The tech billionaire addressed the allegations from Ms Altman, 30, in a social media post overnight, claiming the “situation causes immense pain to our entire family”.
In a joint statement with his mother and two brothers, Mr Altman said: “Caring for a family member who faces mental health challenges is incredibly difficult.
“Annie has made deeply hurtful and entirely untrue claims about our family, and especially Sam. We’ve chosen not to respond publicly, out of respect for her privacy and our own.
“However, she has now taken legal action against Sam, and we feel we have no choice but to address this.
“Over the years, she has accused members of the family of improperly withholding our father’s 401k funds, hacking her Wi-Fi, and ‘shadowbanning’ her from various websites including ChatGPT, Twitter and more.
“The worst allegation she has made is that she was sexually abused by Sam as a child (she has also claimed instances of sexual abuse from others). Her claims have evolved drastically over time. Newly for this lawsuit, they now include allegations of incidents where Sam was over 18.”
Mr Altman founded OpenAI in 2015, since building a global profile thanks to the rapid success of its AI chatbot ChatGPT.
He is poised to make billions of dollars from his stake in OpenAI, although he has already achieved a vast fortune thanks to investments in companies such as Stripe and Reddit.
He also hit the headlines in 2023 when he was dramatically fired and re-hired over the course of five days at OpenAI after he was accused of misleading the board.
A subsequent review cleared Mr Altman of any wrongdoing and he was later restored to his position. He remains OpenAI’s chief executive.
Meanwhile, Ann Altman’s lawsuit, which was filed in the US District Court in the Eastern District of Missouri, requests a jury trial and damages in excess of $75,000.
The lawsuit claims she has experienced severe emotional distress and faces mounting medical bills related to her mental health treatment.
Ms Altman, who is estranged from her brothers and mother, has previously given interviews alleging the family kept money from her that was left for her by their father.
In the family statement, Mr Altman said his sister had been given monthly financial support and had been offered a house through a trust. It said she receives money from her late father’s estate which is expected to continue for the rest of her life.
In addition to the family statement, Mr Altman posted comments on X which he said had been sent by his sister’s lawyers to his own.
It said his sister would “seek discovery on Sam Altman’s net worth and present Sam Altman’s net worth to the jury for consideration on a punitive damages award”.
Under Missouri state law, plaintiffs can bring claims for childhood sexual abuse up until the age of 31.
Mr Altman and OpenAI have been contacted for comment.
9 notes
·
View notes
Note
hi!! I was wondering where or how you do you research for players and teams, and just hockey in general? do you have any favorite blogs or other resources? thank you~
okay picking thru web rot for the sharks primer has prepared me for this one lmao here's the quick answer because i really need to eat some pie and go to bed. Hockey is my all-consuming interest at the moment and I haven't watched actual television or films; or read anything non-academic that isn't about hockey in.... 9 months? If it seems like I am taking in a LOT of information in a short amount of time it's because I am. I listen to hockey things at 2-5x speed depending on if its a video on youtube (locked to 2x), a podcast (3.5x is my ideal speed), or my screenreader (5x) and often take notes, save articles as pdfs to go back to, and transcribe things for fun (only recently am putting my transcriptions as addendums to gifs... very rewarding <3). When not studying for my actual degree, I am reading about hockey or listening to something hockey related or watching hockey or writing about hockey or learning how to play hockey. i am so serious. please don't assume that this is normal, optimal, or even something I would wish upon other people. I am in Love with her in thee most wretched and irrevocable way. She's my hobby in the sense that shes my sun and im building my wax wings and looking directly at her light and thanking her for blinding me. amen.
more seriously, if I'm going down a player rabbit hole I will try many of these things - though not necessarily all of them, and not in this order (and i'm sure i've forgotten one or two things I usually try... lordy):
I go to spotify/apple podcasts and throw in player names just to see what comes up and listen to basically everything.
if they are on an NHL team, there are likely MULTIPLE podcasts dedicated to that team. trawl through their podcast archives, especially post-game podcasts where discussion is happening about their performance. sometimes there are even interviews <3
i do the same with youtube if I can...!
throw their name into reddit, tumblr, twitter and scroll. endlessly. just trawl through everything that I can possibly get my hands on. The more obscure the player the easier this is, because there really aren't that many things to find out about them and not many people are talking about them at all. <- this is how I make contact with people who are the only person that knows about this one (1) guy and then we hold fins forever. <3
find out who the teams beat reporters are. if youre looking into prospects, even juniors teams have people covering them. the writing might not be the highest quality but you WILL eventually find fun details if you go digging.
check: elite prospects articles, the hockey writers articles, find out the player's home town and see if their local paper has anything on them (basically, check any and all databases that use a tagging system or have a functional search engine)
helpful things to tack onto the end of google/youtube/database searches: "media availability" "post-game" "interview" "feature" "profile" "scouting report" "draft" "debut" "review" "highlight" "tournament"
if they're a player from a non-english speaking country it's worth throwing their non-romanized name into google to see what you can get. google translate the website // chatgpt translation are two options - not ideal and not to be trusted 100% over actual translation done by a fluent human speaker.
Instagram stories are the bane of my existence because they're so ephemeral
tiktok is a parallel universe to me. I do not have the app. any browsing I do on it is solely via googling "[team name] tiktok official" and clicking around on my desktop PC. I've only ever done this for M.Chrona's gf (who is much more famous than him) but if you're really doing down the rabbit hole of player research, some of their WAGs will post about them. <- as always, be respectful/not weird.
facebook for older stuff... genuinely makes my skin crawl so I avoid it and its a last resort LMAO but yeah teams used to post on facebook and everything!!! <- again. dont be weird and stalk peoples families or friends asjklakjl
"[player/team name] gettyimages [day/month/year]" <- substitute getty images for: flickr, hockeyshots, dreamstime, alamy
Substack is good for general hockey stuff if you can stomach the dreaded idea of subscribing via email or getting the app <3 I like: Jack Han (hockey tactics newsletter), Sean Shapiro (shap shots), Adam Gretz (adam's sports stuff), Thibaud Chatel <- for the analytics nerds, Alex MacLean <- his Scouting The Scouts series is what got me into substack in the first place, Greg Revak (hockey IQ newsletter) <- this is the one that's got me on development stuff atm SUPER rec because there's gifs and charts and many many hyperlinks included for citations <3
i should do a book rec at some point but uhhhh its getting late and im hungry <3 thank you for asking + reading if you got this far, I hope it was a helpful peek into my process?
20 notes
·
View notes
Note
Hello! Do you have any advice on getting into freelance coding or remote jobs in the field? I'm having trouble with my current endeavors of applications and my current customer service job isn't doing me well enough to want to stay, so I'm hoping for progress sooner rather than later. Anything helps, thank you!!
Hiya 🖤
Thanks for reaching out with your question about getting into freelance coding or remote jobs. Making a transition can be challenging, but with dedication and strategic steps, you can definitely progress in your career.
Firstly, consider specializing in a specific field of computer science rather than trying to learn everything. This will help you become an expert in a niche, making you more attractive to potential clients or employers.
The big thing to look at is (1) what specific job do you want? Don't know yet? That's the first thing you need to find out. (2) Found the job you want? Go to this website "roadmap.sh" and click the job title you want and look at the roadmap to become it. (3) Have an idea of what you need to learn? Now study :)
Here are some extra key pieces of advice:

Public Code Repositories
Showcase your coding skills by contributing to public repositories on platforms like GitHub, GitLab, or others. This allows potential employers to see your projects and assess your coding abilities.
Online Certifications
Earn certifications from reputable online courses like Freecodecamp, Codecademy, or SheCodes (if you're a woman). Displaying these certifications on your LinkedIn profile adds credibility for remote work or even freelance work because then clients will trust your skills more if it's back up with evidence (projects and/or certificates).
Links: "Massive List of Thousands of Free Certificates" / "The Udemy courses I use" / "FreeCodeCamp" / "Codecedemy" / "SheCodes" / "Udacity" / "Coursera" / "Google"
LinkedIn Profile
Revamp your LinkedIn profile to reflect your job title. Use a title that aligns with your dream job, and highlight your skills, certifications, and projects. You don't even need work experience OR do what a lot of my developer mates do have no work experience and set your "job" as a self-employed freelance developer... little cheat there~!
Links: "LinkedIn Career Explorer" / "Tips for speaking to/reaching out to Recruiter" / "Tips for Landing Your First Entry-Level Developer Job" / "Career Services for Web Development" / "The Talent Cloud Community: Careers Workshop"
Volunteering
Help someone out with a project for their business or whatever. For example, I helped a guy I met in a programming discord server build his portfolio page for free, but I care more about the experience. Search online for volunteer jobs with your dream job title e.g. Volunteer App Develope, but in your country would be better. The experience you can you can add to your LinkedIn. the project you work on you can add to your resume/experience.
Link: "SkilledUp Life"
Networking
Connect with professionals in your field on LinkedIn, even if you don't know them personally. Growing your network can open up opportunities and expose you to valuable insights. Events in person or online, servers (I found volunteer opportunities here), forums, Twitter (I found some mates on there), Instagram (another place I found developer friends). Networking can even help with building group projects~!
Link: "Tips for speaking to/reaching out to Recruiter"
Project Building
Work on both small and big projects to demonstrate your capabilities. Highlight these projects on your resume and portfolio.
Links: "Building projects after learning a new concept advice" / "Tips from learning using multiple resources" / "Tips on learning programming with ChatGPT" / "Harvard University Free IT Courses" / "The Udemy courses I use" / "Free Programming Books" / "Coding Advice for beginners" / "800 free Computer Science classes"
Online Presence
Share your learning progress and projects on various platforms like Tumblr, Twitter, Instagram, LinkedIn, or YouTube. Employers often appreciate candidates who actively showcase their work and commitment to learning. I made a post for Tumblr coding blogs:
Link: "Codeblr Blog Advice: 8 Blog Coding Post Ideas"
Good luck!!
#my asks#programming#coding#studyblr#codeblr#progblr#studying#comp sci#programmer#student#study life#coding study
43 notes
·
View notes
Note
What are like good AIs for making up inspirations for writing and such? I was trying to make ChatGPT fulfill this function, and like it's good at coming up with names or riddles but actual stories or setting ideas are bad. Not even bad as in nonsensical or lack human touch, bad as in they look like the most generic thing possible
Well, before AIs there was this website, with all sorts of generators for names, NPCs, even random maps and solar systems and more for different settings. It even has a free Markov Name Generator where you can just put a list of names or words and it generates random names from them! I still use it for generating names when I feel lazy (I'm not a good conlanger)
But my favorite right now is one you can find here, @statsbot by @reachartwork. You can add the bot on Discord and ask them for a lot of commands, like creating you a statblock for NPCs or characters (I asked them for example for stats for the Daft Punk guys in a Cyberpunk campaign), a skeleton of an adventure or dungeon with random encounters, random monsters for all kinds of systems, descriptions of settings and places, or my VERY favorite, /elaborate, where you send them a little worldbuilding prompt (for example, "a kobold merchant republic", "a pantheon of fire deities") and it gives you a whole worldbuilding blurb that you can use as you want.
This is one of my favorite outputs:
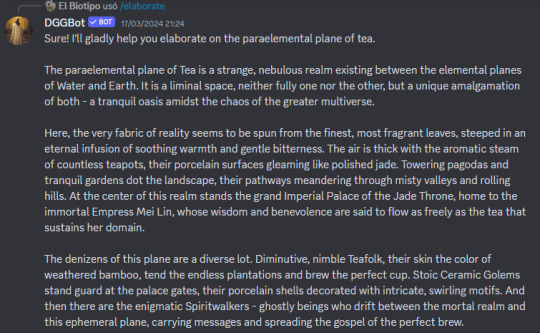
The outputs are very interesting and creative, I don't even play RPGs that much, I just feed it prompts and see what it comes up with. I think the author is working on a solo version which can remember previous prompts which could be very useful if you are building a setting and want to develop some stuff but don't know how. Do give them a tip if you use it!
37 notes
·
View notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
no more self promo in my inbox
Edit/Disclaimer: this post is out of date. please read this post for more information. the doxxer has now been revealed to be Veal themself, however per my rules of keeping everything in place, these posts will remain up for archival purposes, despite the ongoing speculation of the time.
Original Post below: ------------------------------------------------------------------------------
so the more dillingent of you may have noticed that @terratimeventblog (aka, the one from this post) is now gone
turns out that they were using the blog as a front to dox our new public enemy number 1, veal.
this is pretty interesting considering the veal hate that came recently to here, but anyways, that account dmed veal to say someone sent them these anons:
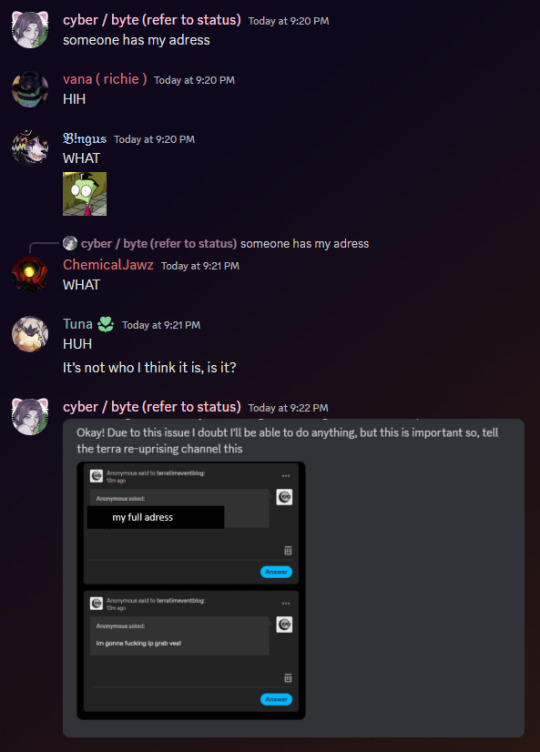
shortly after, veal sent this:

seems like they deleted shortly after that
so! hypothesis and speculation time:
first off, i think the blog itself was probably made JUST for this purpose, seeing as everything happened in such a short timeframe. they possibly could have used a spoofed link on there? however since the gofundme is brought up, im more inclined to think they got the info there. since gofundme uses your bank account, you have to use your legal name. its possible they used veal's legal name in a background check website and got all of their info.
as for who is behind this, leads are minimal. veal did say that civ had donated to their gofundme, and while this doesnt directly implicate them it is a funny coincidence. personally, i think it could be any one of their cronies. they ARE someone in re-up, so anyone over there be careful with your personal info. this is proven with them using screens from the server that i havent used here (according to someone else in re-up) and the fact they specifically say "you can show this to re-up." theyre definitely an uber-cool master level troll who wanted to just sit back and watch it all burn *slides on sick shades*
their goal seems pretty clear, its someone with a vendetta against veal for whatever reason and wanted to scare them shitless. if i wanted to be even more of a conspiracy theorist, i would say the anon of my recent veal ask is the same person as the doxxer, but honestly i dont know how many enemies veal has
the last bit of interesting info is this post from civ that came out around 3 hours before veal dropped the "someone has my address" message

i hypothesize that this connects the situation more to one of civ's cronies, and possibly someone linked with isopups. considering zaga's current apology tour, veal suddenly getting hate, and the dark past of both isos and terras coming to light, thats what makes the most sense to me. this post could be a "coming to reality" moment for civ, not wanting to be tied in with these fucking lunatics anymore (and considering terras hasnt had any huge civ-related drama recently id say its a bit out of left field), but ultimately this is just me having playtime with my polaroids and red string

as a small conclusion, i feel slightly responsible for this, being the person to promo them (and considering the high visibility of this blog). as such, no more self promo in my inbox whatsoever. build an audience your own way
for a more final conclusion though, doxxing people isnt the way to go (thanks captian obvious), and really what does it accomplish? what are you going to do with the address of a person who pissed you off in a closed species discord server? are you gonna seek legal action against some stupid highschooler? are you gonna order pizzas to their house? SWAT them? send a really strongly worded letter? never mind the fact the communities involved are niches within niches within niches. try explaining this shit to someone in real life, try explaining it to your geriatric grandma.
my advice to you all: get a fucking job. go outside. talk to a real human person instead of your ChatGPT waifu. for the love of god stop wrapping yourself up so deeply in this shit that you need to go on a spec-ops mission to find some guy's address and scare them. do you really have nothing better to do? this behavior comes off as pathetic more than anything else. it screams to me "hi! im a socially deprived individual acting fucking insane because im constantly high off huffing the paint from the walls of my mother's basement, as well as the pervading stench of my own ass!"
genuinely, get a life
11 notes
·
View notes
Text
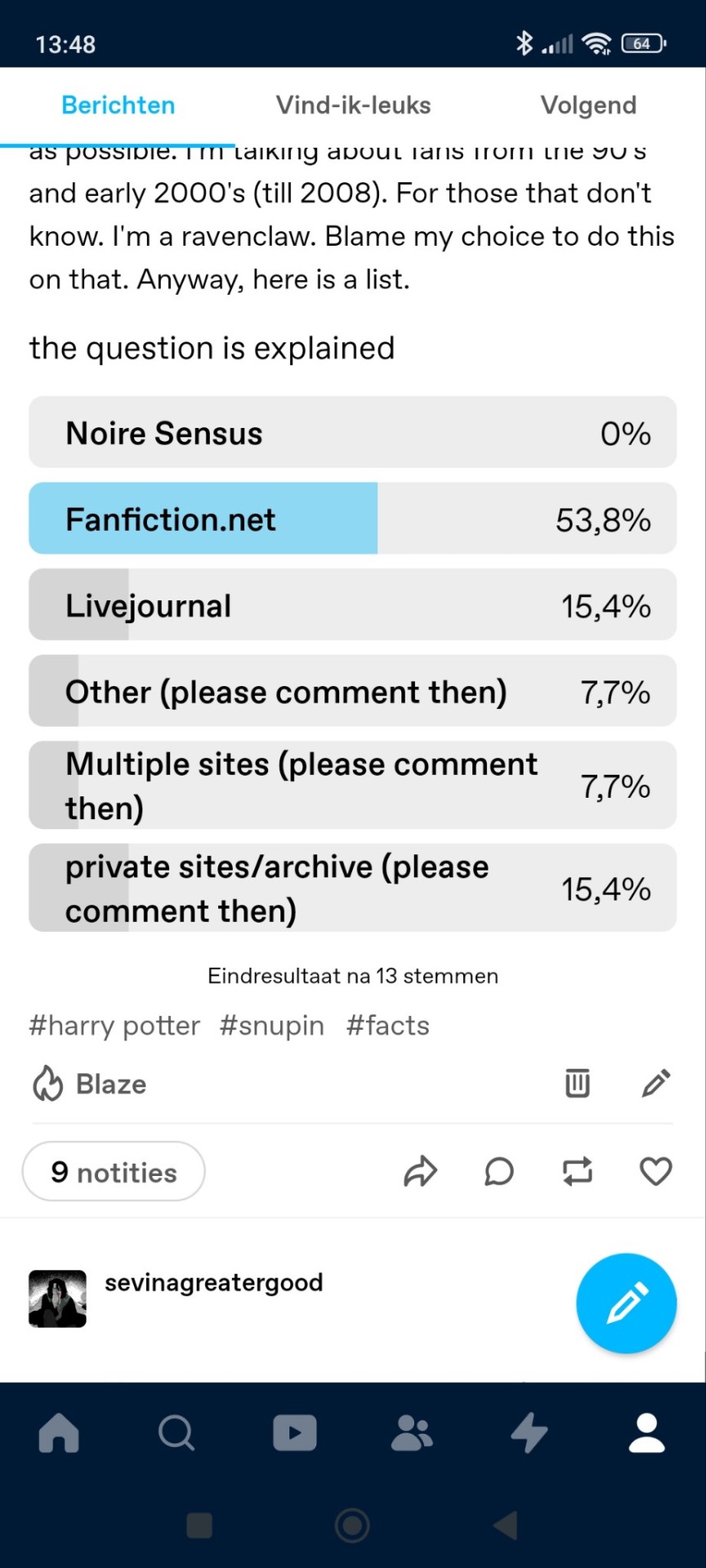
As result of this survey, snupin was in fact the building rock of this marauders fandom. Sure, people might meet trash folk out there that would rub it on our faces and say they twinky stick of a Sirius and heavy balls Remus are the build rock but it isn't even remotely close. The wolfstar ship from back then is even different than the astrocity we witness now as well as their sheep of a fandom.
Fanfiction.net was obviously popular for the older gen of ho fans, but the place that carried the other half of the fandom was in fact websites that aren't used now or are shut down. An example of which is this site:
Which looks like this:
Gone, in other words. Which happens in the capitalistic times. Sites aren't free and in need of support to still exist after all and certainly not by 1 fandom aka HP. Sometimes ao3 asks for support, a platform for all kinds of handsome and not just one.
In conclusion. Snupin in fact did carry the fandom with proof of chatgpt that couldn't be altered on 3 phones with each a different view on HP fandom itself. Or both wolfstar and snupin were famous which has no solid proof. Either way, wolfstar still has to swallow their pride to accept that but I bet they'd rather swallow the heavy balls of daddy Remus. Who knows. I don't know how such rubbish brains are wired to work that way.
I don't like wolfstar fans in general. Because majority (and every single one I've met until now but I STILL can't say all of them) was a snater. Ship doesn't make much sense to me either, no matter how they try to explain it to me. Simply doesn't.
These are the previous posts.
Pt 1:
Pt 2:
Survey:
8 notes
·
View notes
Note
hi, I'm trying to start new , so I want to less my screen time and study and don't wanna eat unhealthy, but I have migraine problems so if go outside I need to always eat like sweet something like candy and biscuits .
❤ to lessen screen time, i use this free app called Regain, where you can set up time limits for your distracting apps. what i love the most about the app is that it blocks scrolling reels and youtube shorts, and every time you open a distracting app, it asks how much time you wanna spend on it, and encourages you to close the app when your chosen time is up. i find that it helps me get less distracted and be more intentional with the way i spend my time.
for pc, the app Cold Turkey works well for me, where you can set up app and website blocks to control your screen time. it is a robust software and i like to use it when im in deep trenches (such as before exam season).
❤ speaking of mindful eating, getting something sweet to eat is not necessarily unhealthy as long as it is in moderation. a rule of thumb is to limit yourself to a single serving of packaged snacks, a small candy bar and 2-3 standard-sized biscuits, which is the recommended daily portion. another option is to pair snacks with wholesome foods such as fruit, nuts or yoghurt, or to replace sweet foods with their healthier alternatives. however, do your research and consult a doctor if needed, because my advice is general and might not apply to your case.
❤ for studying, start small with 2-5 tasks and block out times in your calendar during which you'd like to study. next, upload your task list and the time you want to dedicate to doing these on chatgpt, and ask it to create a study schedule for you. customise it according to your needs. you can create a week's schedule ahead of time or just a daily one, as you see fit. make sure not to overwhelm yourself with tasks and prioritise upcoming exams or assignments, even if you want to procastinate on them and do something else. the key is to be consistent and show up for yourself, which may mean just studying for 20 mins or only finishing one task. building the habit of studying will go a longer way than just cramming last moment and then going back to old patterns.
and that's it, hope you found this helpful! <3 let me know if you'd like me to explain in further detail, and be sure to update me on your progress, id love to see what works for you . ۫ ꣑ৎ
#ardite's posts💌#daily routine#answered asks#anon ask#it girl#that girl#dream life#self improvement#student#productivity#self care#glow up#girlblog#uniblr#studyspo#study aesthetic#studyblr#college#academic life
10 notes
·
View notes