#* JSON data format
Text
.
#i was given a task to research NLP ai tools and i am way too over my head#the words python and JSON are being thrown around. girl help i have a headache#i was really hoping there would be like a dummy proof app out there where i could chuck a bunch of txt files into and wohoo#that was the data set#but no it wants me to convert my formatted word docs into csv files and i have no fucking clue what to do#and the internet says python scripts. and bitch i dont fucking know python#miscellaneous#help ;o;
1 note
·
View note
Text
MERN stack development is a full-stack web development framework that uses MongoDB, Express.js, React, and Node.js to create dynamic and robust web applications. MongoDB is a NoSQL database that stores data in JSON format, while Express.js is a backend web application framework that provides a set of tools for building APIs. React is a frontend JavaScript library for building user interfaces, and Node.js is a server-side runtime environment that allows for JavaScript to be run on the server. Together, these technologies make MERN a powerful and efficient development stack for building modern web applications.
#* Full-stack web development#* JavaScript#* MongoDB#* Express.js#* React#* Node.js#* Frontend development#* Backend development#* Web application development#* RESTful APIs#* Single-page applications#* Scalable architecture#* Agile development#* MVC architecture#* JSON data format#* NPM (Node Package Manager)#* Git and version control#* Cloud deployment#* DevOps#* Web development frameworks.
0 notes
Text
Welcome to the Omen Archive!
We're pleased to see you. You may note the “pardon our moon dust” banner at the top of our site. We’ve been weighing site readiness against a desire to launch, and finally felt we had reached the tipping point. This doesn’t, however, mean that things are complete: there is a long list of projects on the docket. Some are below.
We intend, in time, to add:
A single campaign-at-a-glance page
Character damage taken
Fearne’s Wild Shapes
Chetney’s Hybrid Transformations
Chetney’s toys
Imogen’s dreams
Ruidus flares
FCG’s baked goods
Campaign calendar
Dynamic character/party inventories
Visited locations list
Improved ability to sort existing lists and tables
Additional data visualizations (graphs, etc.)
Export data to machine readable formats, such as Excel or JSON
Many of these projects are currently in progress.
We have recently added:
Character cards (all levels)
Character level-up summary charts
FCG lore drops and worldview evolution quotes, "smiley day"s, trusted companions, Transfer Sufferings, berserks, Flat Exandria mentions, and flesh tongue mentions, as well as a nifty little easter egg (click the coin!)
Laudna’s “capable”s
Delilah appearances
Laudna’s Hunger of the Shadow Shard (as subset of Delilah mentions)
If there are additional stats you’d like to see collected, please email us at [email protected], as well as (if relevant) some notes about how you tend to use that type of data (for example, running some analysis of your own, cross-checking lore, researching fanfiction, etc.). We’re always happy to add new things to the list where we can.
Keep visiting the site for updates, and keep an eye on our social media for announcements of additions and changes to our stats and interface.
-
ETA: We're happy to see people getting excited about discovering new data via our site, but there's one important detail we want to be sure to clarify. Abundant credit is due to the team at CritRoleStats for not only lending us all of the pre-Episode 82 data on our site, but also for providing a partial foundation for some of the above categories where we hope to expand. While some of the data we eventually add to the site will be new from the ground up, thus far a lot of our work has been providing new interfaces and visualizations for engaging with the work the CritRoleStats team has already done!
ETA: This post is being edited to reflect progress in adding new data and tools to the site.
219 notes
·
View notes
Text
i love reading through other platforms' data exports of what they have on me.
for example, Discord's data export has a few big JSON files of "analytics events", that seem to accidentally contain some things that are probably not really analytics events.
there are these fun "prediction" JSON blobs in a different format than the events...
one of them is trying to predict my gender. "predicted_gender: male", over and over. and what's really hilarious is that it logs its estimated accuracy and the timestamp of the attempt. so i can see that in late 2022, discord kept started to try to predict my gender, and it swung from 91% confident i was male to only 71%, and has been doing this prediction process almost daily this year (2023), ranging from ~70% confidence to ~92% confidence.
another is trying to predict my age, and has waffled between "25-34" and "35+" for a year. similarly with a wide range in confidence. makes me wonder what data modeling they're doing to make that prediction...
relatedly, it's always fun to look at the different event names a platform is logging, to get a taste of how granular they're tracking people... here are some fun ones:
start_listening
tooltip_viewed
context_menu_link_opened
keyboard_shortcut_used
premium_upsell_viewed
app_native_crash
jump
remix_surface_exit_modal
nuo_transition
there are over 400 different kinds of events logged in my data dump, and over 419,000 of these events logged. kinda scary!
207 notes
·
View notes
Text
json needs a spreadsheet format. or we need the equivalent of excel for json structured data
73 notes
·
View notes
Note
saw you were making a warrior cat clan how does one do this it looks so cool omg
I use clangen then js mess w the code a bit (idk how to code I used guides) to make custom cats ^^
I'll leave all the links I used under this
This 1 I dont think gave me a virus warning for the download, u js have to rummage through the zip file for the launcher
Make sure u get the right 1 for ur computer btw
CatMaker is handy for visualising the cat b4 coding it in. It's pretty easy when u get the hang of it (or if u have coding experience)

(I had to use reddit to figure out some of my problems w these)
(This helps w torties too)
9 notes
·
View notes
Text
i've decided to remake the database for BMF from scratch - the thing on the site that contains pokedex data and whatnot. i'm keeping the old one on the site for the tools that still use it, but moving forward, i'd like to have a complete database with a better format (i know how i like formatting data better now, plus the old one was incomplete as i just added stuff as needed instead of making it complete from the start)
spent 2-3 hours writing a script that obtained and formatted 65355 lines of JSON data for me! 2-3 hours sounds like a lot but i don't even want to know how many months it would have taken me to write all this stuff manually. i have individual movesets for every gen 1-2 game and stuff like that.
unfortunately there are a few things i'm going to have to fill in manually but the workload is minuscule compared to what it would have been otherwise haha. namely stadium 1/2 dex entries, wild hold items, base experience yield, event moves, and evolution information
below the cut i've placed an example of the JSON generated by my script (with a few placeholders because of aforementioned manual work i have to do) but be warned, it's ridiculously long haha








#ayano was here#ayano.txt#also going to do some other stuff#like locations and items and moves and etc#but that can come later
12 notes
·
View notes
Text
step 1: build a professional-looking, ad-free site that will perform formatting and validation on a wide variety of file types used for configuration and data transfer (.properties, YAML, .config, JSON, etc), and decrypt file contents if people will just paste in their handy dandy private key/shared secret/etc. Yes, there are already sites for this stuff, but they're fairly scattered and ad-infested.
step 2: perform whatever SEO skullduggery is needed to get your site to the top of the Google search rankings.
step 3: once your site has established itself, pass every single thing that gets pasted into it to a backend service. If you wanna be coy about it, continue doing the validation in Javascript and pretend that the backend calls are metrics. Listen, if you make the URL something like https://admin.yourhosthere.com/datadog-agent then 90% of devs are gonna go 'yeah that seems legit, it's just my good friend Datadog :)' and investigate no further.
step 4: parse every message for strings like 'username' and 'password'.
step 5: now that you have production credentials for about 40% of international corporations and governments, hold the planet hostage.
step 6: rule the world from a flying volcano lair staffed with jumpsuit-wearing henchmen.
(traditionally the henchmen would come before the world conquest, but like most things, supervillainy has gone through massive changes thanks the internet)
#listen i know what you're thinking#'there's no way big international companies would have people doing such insecure things'#this is how I know that you've never worked IT in a big international company that doesn't sell software to survive#i guarantee you that within a day or two of it taking off you'd have ITAR-controlled data#honestly if I did this I would make sure my server is outside the US just for that#you just did an export babey#this wouldn't particularly help with anything it's just inherently funny to me
54 notes
·
View notes
Text
In the final version of the original Animal Crossing, Dōbutsu no Mori E+, they had an interesting way to support what could be considered DLC.
The E-Reader.
Those cards very pretty data-dense, and what is an AC villager if not a set of textures, some short strings, and a dozen numbers?
Which is how this can exist: an editor to create your own E-Reader villager data, that you can then inject into your game with a save editor, by Cuyler36. It's really quite impressive that this is possible.
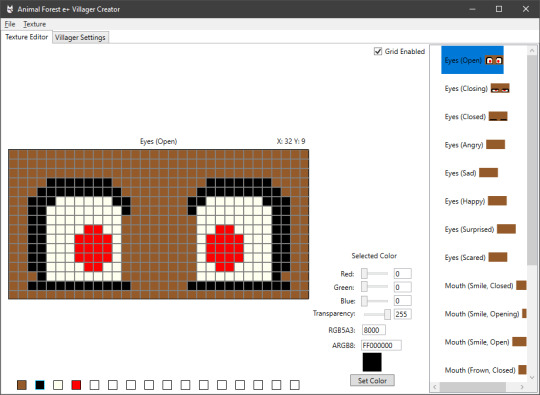
This requires a specific format, of course, and some means to either convert the result to an actual E-Reader dot code or a save game editor, but it's the same kinda data that the official extra characters used. Which is neat!
I figure for something like Project Special K it'd be significantly more... off the shelf, so to say. A villager in later AC games is still mostly just a pile of textures, some strings, and a bunch of numbers. Except that at least in New Horizons every single one of 'em has a complete copy of their 3D model but what ever mooom.
But in PSK I suppose it'd be pretty simple. You don't need any special file formats or bespoke compression systems when it's literally just a pile of PNG textures and a JSON definition file.
Then you can just stick all that in a .zip file, plonk it in the mods folder, share it, and have it probably just work. Barring things like two villager mods trying to use the same folder and/or internal ID.
12 notes
·
View notes
Text
Searcher tool resource!
Hey all! With some help from @autistic-sidestep, I've been working on this tool (and some associated sorting and filing of stuff I am unable and unwilling to share publicly) for about six months now? Tumblr is awful to find things on and I like being able to find information.
The upshot is, this is a tool written in C# to search and filter json files constructed from a tumblr blog in a way that is more user friendly than simply ctrl+f-ing through a large document, allowing for filtering on multiple tags or terms. For our purposes, Fallen Hero's tumblr specifically.
To use this
Download the zip file in the drive and unzip it. You may have to tell your antivirus it's okay (I am just some guy on the internet with free time not an antivirus recognized developer and you SHOULD be cautious of random files on the internet etc etc).
You'll also need to add the data it's looking for, which has been Aurrie's project for the last couple of months! They shared the files over here, and you need to place them in the Data folder. The files you want read in must have names that start with "Tumblr_" and end with ".json".
Then run the .exe file. If you don't already have the .Net framework this uses to run, it'll point you to where to download it.
There's further instructions on how to use it in both the readme file and once you have the program running, but feel free to reach out to me if you're running into any issues!
This is, unfortunately, Windows only - I may work out how to make a mac version at,, some point, but I initially made this for Just Myself and I don't have a mac and did not consider it. You may be able to make it run with Wine or Mono, but I haven't tested that or anything.
As a sidebar, there's no reason you couldn't use this with other .json files with the same format as the ones Aurrie made, so if anyone's wanting to use this for other similarly unsearchable blogs (all of them. tumblr does not have a functional search system.) we used this tool to scrape the blog, which is a good starting point and you're welcome to reach out to me if you have questions!
#fhr#fhr resource#fallen hero#world's blandest UI but it's functional u know#bookish.txt#okay this program didn't take me six months. ive just been working on various stuff related to its creation for six months.#side-eyeing the CoG forums
18 notes
·
View notes
Text
Some speculation: with paintings and enchants being data-driven, and having banner patterns and armour trims be data-driven but without custom input items, and having item components introduced overhauling NBT using a JSON style format... we're getting custom items. I'm guessing next up they'll make fireworks & potions data-driven, because that's pretty much all that is left. When they do this, the only real restriction on adding custom items will be allowing users to define item components in input items for recipes. Doing this will, effectively, create custom items anyways? So. It's really only a matter ov time and it's definitely something that is more "this is definitely Going to happen" than "this might happen"
9 notes
·
View notes
Note
faorite , FILE TYPE : ] hi
oh shit and my favorite filetypes tierlist:
.sh (bash script) GOD TIER. it just does stuff. you can make it do anything. anything.
.md (markdown file) GOD TIER. documentation, letters to self. a beautiful universal syntax for limited text styling. elegant and timeless.
.py (python script) PRETTY GOOD. can run on its own or be imported from another script, and can do different stuff depending which. edit: mixed feelings abt python interpreter and virtual environemtn stuff. forgot to mention that.
.h (c lang header file) HONORABLE MENTION. i don't use these a lot but this is where you declare the contents of your .c/.cpp file without writing the actual logic. you say these are the functions and classes they take this and give you that. Trust me bro
.json (javascript object notation) PRETTY NIFTY. not the most practical if you're looking to constantly be writing to this format imo, BUT we love it for configuration. simple, timeless, universal.
.txt (plaintext) SHIT TIER. it's just text bro. is it meant to be read on its own? use markdown. is it meant to store data in a specific format for program input? make up your own extension, i don't care.
i have more but this has gone on long enough.
4 notes
·
View notes
Text
grahhh yesterday i said i'd add more art to my site now that there's categories and stuff, so i guess i gotta do it huh

currently digging through a bunch of old doodles, trying to date them as best i can,
after that i have a batch script that uses ffmpeg to make a bunch of jpg thumbnails that are like 150px tall or something, this is so filegarden doesn't kick me off for abusing their bandwidth by having my site load like

25 megabytes of stuff all at once any time anyone visits my art page
anyway once i've got that done i upload it to filegarden and then the real fun begins.

manual data entry in json format :)
so yeah that's what i'm doing today lolol
2 notes
·
View notes
Text
Do You Want Some Cookies?
Doing the project-extrovert is being an interesting challenge. Since the scope of this project shrunk down a lot since the first idea, one of the main things I dropped is the use of a database, mostly to reduce any cost I would have with hosting one. So things like authentication needs to be fully client-side and/or client-stored. However, this is an application that doesn't rely on JavaScript, so how I can store in the client without it? Well, do you want some cookies?
Why Cookies
I never actually used cookies in one of my projects before, mostly because all of them used JavaScript (and a JS framework), so I could just store everything using the Web Storage API (mainly localstorage). But now, everything is server-driven, and any JavaScript that I will add to this project, is to enhance the experience, and shouldn't be necessary to use the application. So the only way to store something in the client, using the server, are Cookies.
TL;DR Of How Cookies Work
A cookie, in some sense or another, is just an HTTP Header that is sent every time the browser/client makes a request to the server. The server sends a Set-Cookie header on the first response, containing the value and optional "rules" for the cookie(s), which then the browser stores locally. After the cookie(s) is stored in the browser, on every subsequent request to the server, a Cookie header will be sent together, which then the server can read the values from.
Pretty much all websites use cookies some way or another, they're one of the first implementations of state/storage on the web, and every browser supports them pretty much. Also, fun note, because it was one of the first ways to know what user is accessing the website, it was also heavy abused by companies to track you on any website, the term "third-party cookie" comes from the fact that a cookie, without the proper rules or browser protection, can be [in summary] read from any server that the current websites calls. So things like advertising networks can set cookies on your browser to know and track your profile on the internet, without you even knowing or acknowledging. Nowadays, there are some regulations, primarily in Europe with the General Data Privacy Regulation (GDPR), that's why nowadays you always see the "We use Cookies" pop-up in websites you visit, which I beg you to actually click "Decline" or "More options" and remove any cookie labeled "Non-essential".
Small Challenges and Workarounds
But returning to the topic, using this simple standard wasn't so easy as I thought. The code itself isn't that difficult, and thankfully Go has an incredible standard library for
handling HTTP requests and responses. The most difficult part was working around limitations and some security concerns.
Cookie Limitations
The main limitation that I stumbled was trying to have structured data in a cookie. JSON is pretty much the standard for storing and transferring structured data on the web, so that was my first go-to. However, as you may know, cookies can't use any of these characters: ( ) < > @ , ; : \ " / [ ] ? = { }. And well, when a JSON file looks {"like":"this"}, you can think that using JSON is pretty much impossible. Go's http.SetCookie function automatically strips " from the cookie's value, and the other characters can go in the Set-Cookie header, but can cause problems.
On my first try, I just noticed about the stripping of the " character (and not the other characters), so I needed to find a workaround. And after some thinking, I started to try implementing my own data structure format, I'm learning Go, and this could be an opportunity to also understand how Go's JSON parsing and how mostly struct tags works and try to implement something similar.
My idea was to make something similar to JSON in one way or another, and I ended up with:
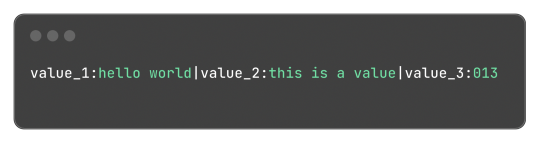
Which, for reference, in JSON would be:
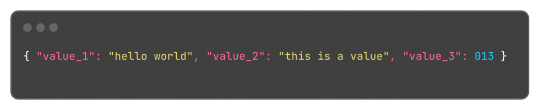
This format is something very easy to implement, just using strings.Split does most of the job of extracting the values and strings.Join to "encode" the values back. Yes, this isn't a "production ready" format or anything like that, but it is hacky and just a small fix for small amounts of structured data.
Go's Struct Tags
Go has an interesting and, to be honest, very clever feature called Struct Tags, which are a simple way to add metadata to Structs. They are simple strings that are added to each field and can contain key-value data:

Said metadata can be used by things such the encoding/json package to transform said struct into a JSON object with the correct field names:

Without said tags, the output JSON would be:

This works both for encoding and decoding the data, so the package can correctly map the JSON field "access_token" to the struct field "Token".
And well, these tokens aren't limited or some sort of special syntax, any key-value pair can be added and accessed by the reflect package, something like this:
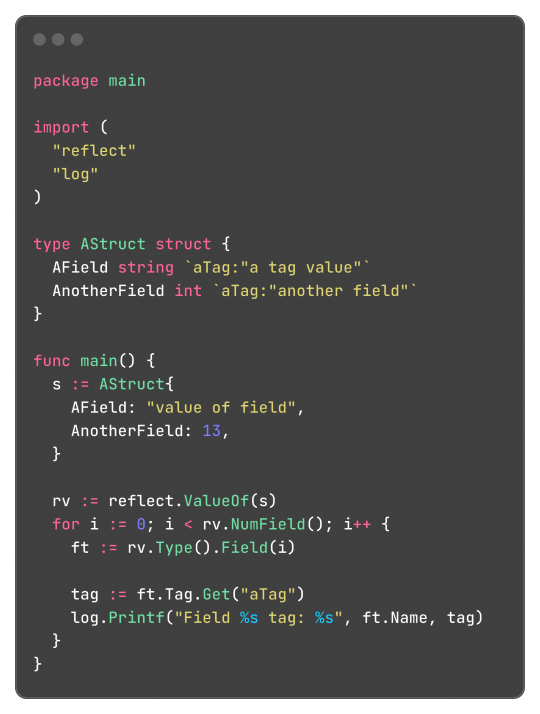
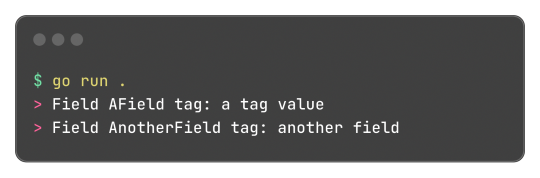
Learning this feature and the reflect package itself, empowered me to do a very simple encoding and decoding of the format where:

Can be transformed into:

And that's what I did, and the [basic] implementation source code just has 150 lines of code, not counting the test file to be sure it worked. It works, and now I can store structured data in cookies.
Legacy in Less Than 3 Weeks
And today, I found that I can just use url.PathEscape, and it escapes all ( ) < > @ , ; : \ " / [ ] ? = { } characters, so it can be used both in URLs and, surprise, cookie values. Not only that, but something like base64.URLEncoding would also work just fine. You live, and you learn y'know, that's what I love about engineering.
Security Concerns and Refactoring Everything
Another thing that was a limitation and mostly worry about me, is storing access tokens on cookies. A cookie by default isn't that secure, and can be easily accessed by JavaScript and browser extensions, there are ways to block and secure cookies, but even then, you can just open the developer tools of the browser and see them easily. Even though the only way to something malicious end up happening with these tokens are if the actual client end up being compromised, which means the user has bigger problems than just a social media token being leaked, it's better to try preventing these issues nonetheless (and learn something new as always).
The encryption and decryption part isn't so difficult, Go already provides packages for encryption under the crypto module. So I just implemented an encryption that cyphers a string based on a key environment variable, which I will change every month or so to improve security even more.
Doing this encryption on every endpoint would be repetitive, so adding a middleware would be a solution. I already made a small abstraction over the default Go's router (the DefaultMuxServer struct), which I'm going to be honest, wasn't the best abstraction, since it deviated a lot from Go's default HTTP package conventions. This deviation also would difficult the implementation of a generic middleware that I could use in any route or even any function that handles HTTP requests, a refactor was needed. Refactoring made me end up rewriting a lot of code and simplifying a lot of the code from the project. All routes now are structs that implement the http.Handler interface, so I can use them outside the application router and test them if needed; The router ends up being just a helper for having all routes in a struct, instead of multiple mux.HandleFunc calls in a function, and also handles adding middlewares to all routes; Middlewares end up being just a struct that can return a wrapped HandlerFunc function, which the router calls using a custom/wrapped implementation of the http.ResponseWriter interface, so middlewares can actually modify the content and headers of the response. The refactor had 1148 lines added, and 524 removed, and simplified a lot of the code.
For the encryption middleware, it encrypts all cookie values that are set in the Set-Cookie header, and decrypts any incoming cookie. Also, the encrypted result is encoded to base64, so it can safely be set in the Set-Cookie header after being cyphered.
---
And that's what I worked in around these last three days, today being the one where I actually used all this functionality and actually implemented the OAuth2 process, using an interface and a default implementation that I can easily reimplement for some special cases like Mastodon's OAuth process (since the token and OAuth application needs to be created on each instance separately). It's being interesting learning Go and trying to be more effective and implement things the way the language wants. Everything is being very simple nonetheless, just needing to align my mind with the language mostly.
It has been a while since I wrote one of these long posts, and I remembered why, it takes hours to do, but it's worth the work I would say. Unfortunately I can't write these every day, but hopefully they will become more common, so I can log better the process of working on the projects. Also, for the 2 persons that read this blog, give me some feedback! I really would like to know if there's anything I could improve in the writing, anything that ended up being confusing, or even how I could write the image description for the code snippets, I'm not sure how to make them more accessible for screen reader users.
Nevertheless, completing this project will also help to make these post, since the conversion for Markdown to Tumblr's NPF in the web editor sucks ass, and I know I can do it better.
2 notes
·
View notes
Text
Scrape Telecommunications Data - Web scraping for Telecom Businesses
Web Scraping Services for telecommunications companies is enabling the development of new services for subscribers. High-quality web data opens up new ways to predict consumer trends, monitor competitors, automate compliance and build new services for end-users and B2B customers. We scrape telecommunications company data in countries like USA, UK, UAE, India, & Germany.
Get Personalized Solution
Data extraction from websites for telecommunication companies allows new service development for clients.
Quality web data open many new doors to track competition, predict consumer trends, automate compliance, and design new services for end customers and B2B clients.
How Quickly is the world moving in front of us
The telecom industry is facing huge changes in its operations. Profit margins and ARPUs have constantly been dropping since smartphone era began. Further, the data quantity in this industry has been increasing with 2x speed every three years as per updates from various sources.
Great tool for data extraction. I found Real Data API to be the best web scraping, and no user-friendly tool I could find for my needs.
Martin P
New Zealand
Offering value-driven data to top telecom companies
How web automation and data scraping are reforming the Telecommunication industry
Social Media Tracking
Price monitoring
Product tracking
Product development
Web Automation for Telecommunication
Social Media Tracking
Collect insights on your brand and your competing telecom brands from various social media platforms like Reddit, LinkedIn, Twitter, and Instagram to check the brand reputation. Gauge the growth potential, and work on marketing strategies accordingly. Automate follower tracking, image saving, comment, and mention scraping.
Get a personalized Telecommunication web scraper for your business need
Hire the best experts to develop web scraping API projects for your data requirements.
Scrape the data exactly when you want it using the customized scheduler.
Schedule the tracking of targeted websites; we will manage their maintenance and support.
Get well-structured, high-quality data in preferred formats like CSV, XML, JSON, or HTML, and use it further without processing.
To reduce the risk of manual errors, use automatic data upload with the help of readymade APIs and integrations.
Get Personalized Solution
Scrape web data for your Telecommunication requirements from any website with Real Data API
Request a data sample
Why are Telecommunication companies choosing Real Data API?
Flexibility
Real Data API can provide anything without any limit regarding data scraping and web automation. We follow nothing is impossible thought.
Reliability
The Real Data API team will streamline your solution and ensure it keeps running without any bugs. We also ensure you get reliable data to make correct decisions.
Scalability
As you keep growing, we can keep adjusting your solution to scale up the data extraction. As per your needs, we can extract millions of pages to get data in TBs.
The market is progressively data-driven. Real Data API helps you get the correct data for your telecom business.
Know More: https://www.realdataapi.com/scrape-telecommunications-data.php
Contact : https://www.realdataapi.com/contact.php
#ScrapeTelecommunicationsData#ExtractTelecommunicationsData#TelecommunicationsDataCollection#scrapingTelecomData#webscrapingapi#datascraping#dataanalytics#dataharvest#datacollection#dataextraction#RealDataAPI#usa#uk#uae#germany#australia#canada
2 notes
·
View notes
Text
Acquire business leads based on country. A wide range of companies is available from Data Scraper Hub for your analytics, marketing, and sales needs. Get the data in JSON, Excel, and CSV formats.

2 notes
·
View notes
Last Seen Blogs

kametire
Tiger 🤍

mikkelsendancy
What a collection of scars you have

kalihanjerkinerk
KalihanJerkinerk

titobafev
Untitled

{kind=link}