#Amazon Web Scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
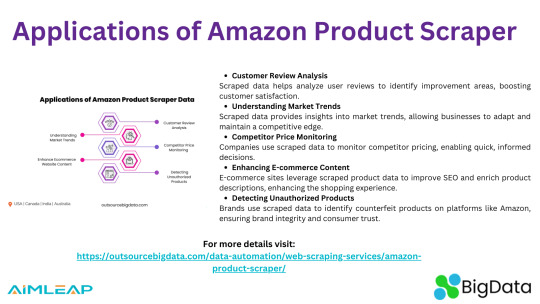
Amazon product scrapers provide businesses with valuable insights by extracting data such as customer reviews, competitor prices, and market trends. This data helps companies enhance their product listings, optimize pricing strategies, improve SEO, and detect unauthorized or counterfeit products, ultimately boosting sales and customer satisfaction.
0 notes
Text
Want to stay ahead of Amazon price changes? Learn how to automate price tracking using Scrapingdog’s Amazon Scraper API and Make.com. A step-by-step guide for smarter, hands-free eCommerce monitoring.
0 notes
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Text
IWeb Scraping scrapes the Amazon keywords data using a web scraping tool and helps sellers to list their products on the e-commerce platform.
For More Information:-
0 notes
Text
Develop your own Amazon product scraper bot in Python
How to scrape data from amazon.com? Scraping amazon products details benefits to lots of things as product details, images, pricing, stock, rating, review, etc and it analyzes how particular brand being popular on amazon and competitive analysis. Read more
1 note
·
View note
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
ShadowDragon sells a tool called SocialNet that streamlines the process of pulling public data from various sites, apps, and services. Marketing material available online says SocialNet can “follow the breadcrumbs of your target’s digital life and find hidden correlations in your research.” In one promotional video, ShadowDragon says users can enter “an email, an alias, a name, a phone number, a variety of different things, and immediately have information on your target. We can see interests, we can see who friends are, pictures, videos.”
The leaked list of targeted sites include ones from major tech companies, communication tools, sites focused around certain hobbies and interests, payment services, social networks, and more. The 30 companies the Mozilla Foundation is asking to block ShadowDragon scrapers are Amazon, Apple, BabyCentre, BlueSky, Discord, Duolingo, Etsy, Meta’s Facebook and Instagram, FlightAware, Github, Glassdoor, GoFundMe, Google, LinkedIn, Nextdoor, OnlyFans, Pinterest, Reddit, Snapchat, Strava, Substack, TikTok, Tinder, TripAdvisor, Twitch, Twitter, WhatsApp, Xbox, Yelp, and YouTube.
437 notes
·
View notes
Text
A year in illustration, 2023 edition (part two)

(This is part two; part one is here.)

The West Midlands Police were kind enough to upload a high-rez of their surveillance camera control room to Flickr under a CC license (they've since deleted it), and it was the perfect frame for dozens of repeating clown images with HAL9000 red noses. This worked out great. The clown face is from a 1940s ad for novelty masks.
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop

I spent an absurd amount of time transforming a photo I took of three pinball machines into union-busting themed tables, pulling in a bunch of images from old Soviet propaganda art. An editorial cartoon of Teddy Roosevelt with his big stick takes center stage, while a NLRB General Counsel Jennifer Abruzzo's official portrait presides over the scene. I hand-made the eight-segment TILT displays.
https://pluralistic.net/2023/09/06/goons-ginks-and-company-finks/#if-blood-be-the-price-of-your-cursed-wealth

Working with the highest-possible rez sources makes all the difference in the world. Syvwlch's extremely high-rez paint-scraper is a gift to people writing about web-scraping, and the Matrix code waterfall mapped onto it like butter.
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/

This old TWA ad depicting a young man eagerly pitching an older man has incredible body-language – so much so that when I replaced their heads with raw meat, the intent and character remained intact. I often struggle for background to put behind images like this, but high-rez currency imagery, with the blown up intaglio, crushes it.
https://pluralistic.net/2023/10/04/dont-let-your-meat-loaf/#meaty-beaty-big-and-bouncy

I transposed Photoshop instructions for turning a face into a zombie into Gimp instructions to make Zombie Uncle Sam. The guy looking at his watch kills me. He's from an old magazine illustration about radio broadcasting. What a face!
https://pluralistic.net/2023/10/18/the-people-no/#tell-ya-what-i-want-what-i-really-really-want

The mansplaining guy from the TWA ad is back, but this time he's telling a whopper. It took so much work to give him that Pinnocchio nose. Clearly, he's lying about capitalism, hence the Atlas Shrugged cover. Bosch's "Garden of Earthly Delights" makes for an excellent, public domain hellscape fit for a nonconensual pitch about the miracle of capitalism.
https://pluralistic.net/2023/10/27/six-sells/#youre-holding-it-wrong

There's no better image for stories about techbros scamming rubes than Bosch's 'The Conjurer.' Throw in Jeff Bezos's head and an Amazon logo and you're off to the races. I boobytrapped this image by adding as many fingers as I could fit onto each of these figures in the hopes that someone could falsely accuse me of AI-generating this. No one did.
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens

Once again, it's Bosch to the rescue. Slap a different smiley-face emoji on each of the tormented figures in 'Garden of Earthly Delights' and you've got a perfect metaphor for the 'brand safety' problem of hard news dying online because brands don't want to be associated with unpleasant things, and the news is very unpleasant indeed.
https://pluralistic.net/2023/11/11/ad-jacency/#brand-safety

I really struggle to come up with images for my linkdump posts. I'm running out of ways to illustrate assortments and varieties. I got to noodling with a Kellogg's mini-cereal variety pack and I realized it was the perfect place for a vicious gorilla image I'd just found online in a WWI propaganda poster headed 'Destroy This Mad Brute.' I put so many fake AI tells in this one – extra pupils, extra fingers, a super-AI-esque Kellogg's logo.
https://pluralistic.net/2023/11/05/variegated/#nein

Bloodletting is the perfect metaphor for using rate-hikes to fight inflation. A vintage image of the Treasury, spattered with blood, makes a great backdrop. For the foreground, a medieval woodcut of bloodletting quacks – give one the head of Larry Summers, the other, Jerome Powell. For the patient, use Uncle Sam's head.
https://pluralistic.net/2023/11/20/bloodletting/#inflated-ego

I killed a long videoconference call slicing up an old pulp cover showing a killer robot zapping a couple of shrunken people in bell-jars. It was the ideal image to illustrate Big Tech's enshittification, especially when it was decorated with some classic tech slogans.
https://pluralistic.net/2023/11/22/who-wins-the-argument/#corporations-are-people-my-friend

There's something meditative about manually cutting out Tenniel engravings from Alice – the Jabberwock was insane. But it was worth it for this Tron-inflected illustration using a distorted Cartesian grid to display the enormous difference between e/acc and AI doomers, and everyone else in the world.
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Multilayer source images for your remixing pleasure:
Scientist in chemlabhttps://craphound.com/images/scientist-in-chem-lab.psd
Humpty Dumpty and the millionaires https://craphound.com/images/humpty-dumpty-and-the-millionaires.psd
Demon summoning https://craphound.com/images/demon-summoning.psd
Killer Robot and People in Bell Jars https://craphound.com/images/killer-robot-and-bell-jars.psd
TWA mansplainer https://craphound.com/images/twa-mansplainer.psd
Impatient boss https://craphound.com/images/impatient-boss.psd
Destroy This Mad Brute https://craphound.com/images/destroy-this-mad-brute.psd
(Images: Heinz Bunse, West Midlands Police, Christopher Sessums, CC BY-SA 2.0; Mike Mozart, Jesse Wagstaff, Stephen Drake, Steve Jurvetson, syvwlch, Doc Searls, https://www.flickr.com/photos/mosaic36/14231376315, Chatham House, CC BY 2.0; Cryteria, CC BY 3.0; Mr. Kjetil Ree, Trevor Parscal, Rama, “Soldiers of Russia” Cultural Center, Russian Airborne Troops Press Service, CC BY-SA 3.0; Raimond Spekking, CC BY 4.0; Drahtlos, CC BY-SA 4.0; Eugen Rochko, Affero; modified)
201 notes
·
View notes
Quote
In recent months, the signs and portents have been accumulating with increasing speed. Google is trying to kill the 10 blue links. Twitter is being abandoned to bots and blue ticks. There’s the junkification of Amazon and the enshittification of TikTok. Layoffs are gutting online media. A job posting looking for an “AI editor” expects “output of 200 to 250 articles per week.” ChatGPT is being used to generate whole spam sites. Etsy is flooded with “AI-generated junk.” Chatbots cite one another in a misinformation ouroboros. LinkedIn is using AI to stimulate tired users. Snapchat and Instagram hope bots will talk to you when your friends don’t. Redditors are staging blackouts. Stack Overflow mods are on strike. The Internet Archive is fighting off data scrapers, and “AI is tearing Wikipedia apart.” The old web is dying, and the new web struggles to be born.
AI is killing the old web, and the new web struggles to be born
67 notes
·
View notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Extract Amazon Product Prices with Web Scraping | Actowiz Solutions
Introduction
In the ever-evolving world of e-commerce, pricing strategy can make or break a brand. Amazon, being the global e-commerce behemoth, is a key platform where pricing intelligence offers an unmatched advantage. To stay ahead in such a competitive environment, businesses need real-time insights into product prices, trends, and fluctuations. This is where Actowiz Solutions comes into play. Through advanced Amazon price scraping solutions, Actowiz empowers businesses with accurate, structured, and actionable data.
Why extract Amazon Product Prices?

Price is one of the most influential factors affecting a customer’s purchasing decision. Here are several reasons why extracting Amazon product prices is crucial:
Competitor Analysis: Stay informed about competitors’ pricing.
Dynamic Pricing: Adjust your prices in real time based on market trends.
Market Research: Understand consumer behavior through price trends.
Inventory & Repricing Strategy: Align stock and pricing decisions with demand.
With Actowiz Solutions’ Amazon scraping services, you get access to clean, structured, and timely data without violating Amazon’s terms.
How Actowiz Solutions Extracts Amazon Price Data

Actowiz Solutions uses advanced scraping technologies tailored for Amazon’s complex site structure. Here’s a breakdown:
1. Custom Scraping Infrastructure
Actowiz Solutions builds custom scrapers that can navigate Amazon’s dynamic content, pagination, and bot protection layers like CAPTCHA, IP throttling, and JavaScript rendering.
2. Proxy Rotation & User-Agent Spoofing
To avoid detection and bans, Actowiz employs rotating proxies and multiple user-agent headers that simulate real user behavior.
3. Scheduled Data Extraction
Actowiz enables regular scheduling of price scraping jobs — be it hourly, daily, or weekly — for ongoing price intelligence.
4. Data Points Captured
The scraping service extracts:
Product name & ASIN
Price (MRP, discounted, deal price)
Availability
Ratings & Reviews
Seller information
Real-World Use Cases for Amazon Price Scraping

A. Retailers & Brands
Monitor price changes for own products or competitors to adjust pricing in real-time.
B. Marketplaces
Aggregate seller data to ensure competitive offerings and improve platform relevance.
C. Price Comparison Sites
Fuel your platform with fresh, real-time Amazon price data.
D. E-commerce Analytics Firms
Get historical and real-time pricing trends to generate valuable reports for clients.
Dataset Snapshot: Amazon Product Prices

Below is a snapshot of average product prices on Amazon across popular categories:
Product CategoryAverage Price (USD)Electronics120.50Books15.75Home & Kitchen45.30Fashion35.90Toys & Games25.40Beauty20.60Sports50.10Automotive75.80
Benefits of Choosing Actowiz Solutions

1. Scalability: From thousands to millions of records.
2. Accuracy: Real-time validation and monitoring ensure data reliability.
3. Customization: Solutions are tailored to each business use case.
4. Compliance: Ethical scraping methods that respect platform policies.
5. Support: Dedicated support and data quality teams
Legal & Ethical Considerations

Amazon has strict policies regarding automated data collection. Actowiz Solutions follows legal frameworks and deploys ethical scraping practices including:
Scraping only public data
Abiding by robots.txt guidelines
Avoiding high-frequency access that may affect site performance
Integration Options for Amazon Price Data

Actowiz Solutions offers flexible delivery and integration methods:
APIs: RESTful APIs for on-demand price fetching.
CSV/JSON Feeds: Periodic data dumps in industry-standard formats.
Dashboard Integration: Plug data directly into internal BI tools like Tableau or Power BI.
Contact Actowiz Solutions today to learn how our Amazon scraping solutions can supercharge your e-commerce strategy.Contact Us Today!
Conclusion: Future-Proof Your Pricing Strategy
The world of online retail is fast-moving and highly competitive. With Amazon as a major marketplace, getting a pulse on product prices is vital. Actowiz Solutions provides a robust, scalable, and ethical way to extract product prices from Amazon.
Whether you’re a startup or a Fortune 500 company, pricing intelligence can be your competitive edge. Learn More
#ExtractProductPrices#PriceIntelligence#AmazonScrapingServices#AmazonPriceScrapingSolutions#RealTimeInsights
0 notes
Text
Amazon Scraper API Made Easy: Get Product, Price, & Review Data

If you’re in the world of e-commerce, market research, or product analytics, then you know how vital it is to have the right data at the right time. Enter the Amazon Scraper API—your key to unlocking real-time, accurate, and comprehensive product, price, and review information from the world's largest online marketplace. With this amazon scraper, you can streamline data collection and focus on making data-driven decisions that drive results.
Accessing Amazon’s extensive product listings and user-generated content manually is not only tedious but also inefficient. Fortunately, the Amazon Scraper API automates this process, allowing businesses of all sizes to extract relevant information with speed and precision. Whether you're comparing competitor pricing, tracking market trends, or analyzing customer feedback, this tool is your secret weapon.
Using an amazon scraper is more than just about automation—it’s about gaining insights that can redefine your strategy. From optimizing listings to enhancing customer experience, real-time data gives you the leverage you need. In this blog, we’ll explore what makes the Amazon Scraper API a game-changer, how it works, and how you can use it to elevate your business.
What is an Amazon Scraper API?
An Amazon Scraper API is a specialized software interface that allows users to programmatically extract structured data from Amazon without manual intervention. It acts as a bridge between your application and Amazon's web pages, parsing and delivering product data, prices, reviews, and more in machine-readable formats like JSON or XML. This automated process enables businesses to bypass the tedious and error-prone task of manual scraping, making data collection faster and more accurate.
One of the key benefits of an Amazon Scraper API is its adaptability. Whether you're looking to fetch thousands of listings or specific review details, this amazon data scraper can be tailored to your exact needs. Developers appreciate its ease of integration into various platforms, and analysts value the real-time insights it offers.
Why You Need an Amazon Scraper API
The Amazon marketplace is a data-rich environment, and leveraging this data gives you a competitive advantage. Here are some scenarios where an Amazon Scraper API becomes indispensable:
1. Market Research: Identify top-performing products, monitor trends, and analyze competition. With accurate data in hand, businesses can launch new products or services with confidence, knowing there's a demand or market gap to fill.
2. Price Monitoring: Stay updated with real-time price fluctuations to remain competitive. Automated price tracking via an amazon price scraper allows businesses to react instantly to competitors' changes.
3. Inventory Management: Understand product availability and stock levels. This can help avoid stock outs or overstocking. Retailers can optimize supply chains and restocking processes with the help of an amazon product scraper.
4. Consumer Sentiment Analysis: Use review data to improve offerings. With Amazon Review Scraping, businesses can analyze customer sentiment to refine product development and service strategies.
5. Competitor Benchmarking: Compare products across sellers to evaluate strengths and weaknesses. An amazon web scraper helps gather structured data that fuels sharper insights and marketing decisions.
6. SEO and Content Strategy: Extract keyword-rich product titles and descriptions. With amazon review scraper tools, you can identify high-impact phrases to enrich your content strategies.
7. Trend Identification: Spot emerging trends by analyzing changes in product popularity, pricing, or review sentiment over time. The ability to scrape amazon product data empowers brands to respond proactively to market shifts.
Key Features of a Powerful Amazon Scraper API
Choosing the right Amazon Scraper API can significantly enhance your e-commerce data strategy. Here are the essential features to look for:
Scalability: Seamlessly handle thousands—even millions—of requests. A truly scalable Amazon data scraper supports massive workloads without compromising speed or stability.
High Accuracy: Get real-time, up-to-date data with high precision. Top-tier Amazon data extraction tools constantly adapt to Amazon’s evolving structure to ensure consistency.
Geo-Targeted Scraping: Extract localized data across regions. Whether it's pricing, availability, or listings, geo-targeted Amazon scraping is essential for global reach.
Advanced Pagination & Sorting: Retrieve data by page number, relevance, rating, or price. This allows structured, efficient scraping for vast product categories.
Custom Query Filters: Use ASINs, keywords, or category filters for targeted extraction. A flexible Amazon scraper API ensures you collect only the data you need.
CAPTCHA & Anti-Bot Bypass: Navigate CAPTCHAs and Amazon’s anti-scraping mechanisms using advanced, bot-resilient APIs.
Flexible Output Formats: Export data in JSON, CSV, XML, or your preferred format. This enhances integration with your applications and dashboards.
Rate Limiting Controls: Stay compliant while maximizing your scraping potential. Good Amazon APIs balance speed with stealth.
Real-Time Updates: Track price drops, stock changes, and reviews in real time—critical for reactive, data-driven decisions.
Developer-Friendly Documentation: Enjoy a smoother experience with comprehensive guides, SDKs, and sample codes—especially crucial for rapid deployment and error-free scaling.
How the Amazon Scraper API Works
The architecture behind an Amazon Scraper API is engineered for robust, scalable scraping, high accuracy, and user-friendliness. At a high level, this powerful Amazon data scraping tool functions through the following core steps:
1. Send Request: Users initiate queries using ASINs, keywords, category names, or filters like price range and review thresholds. This flexibility supports tailored Amazon data retrieval.
2. Secure & Compliant Interactions: Advanced APIs utilize proxy rotation, CAPTCHA solving, and header spoofing to ensure anti-blocking Amazon scraping that mimics legitimate user behavior, maintaining access while complying with Amazon’s standards.
3. Fetch and Parse Data: Once the target data is located, the API extracts and returns it in structured formats such as JSON or CSV. Data includes pricing, availability, shipping details, reviews, ratings, and more—ready for dashboards, databases, or e-commerce tools.
4. Real-Time Updates: Delivering real-time Amazon data is a core advantage. Businesses can act instantly on dynamic pricing shifts, consumer trends, or inventory changes.
5. Error Handling & Reliability: Intelligent retry logic and error management keep the API running smoothly, even when Amazon updates its site structure, ensuring maximum scraping reliability.
6. Scalable Data Retrieval: Designed for both startups and enterprises, modern APIs handle everything from small-scale queries to high-volume Amazon scraping using asynchronous processing and optimized rate limits.
Top 6 Amazon Scraper APIs to Scrape Data from Amazon
1. TagX Amazon Scraper API
TagX offers a robust and developer-friendly Amazon Scraper API designed to deliver accurate, scalable, and real-time access to product, pricing, and review data. Built with enterprise-grade infrastructure, the API is tailored for businesses that need high-volume data retrieval with consistent uptime and seamless integration.
It stands out with anti-blocking mechanisms, smart proxy rotation, and responsive documentation, making it easy for both startups and large enterprises to deploy and scale their scraping efforts quickly. Whether you're monitoring price fluctuations, gathering review insights, or tracking inventory availability, TagX ensures precision and compliance every step of the way.
Key Features:
High-volume request support with 99.9% uptime.
Smart proxy rotation and CAPTCHA bypassing.
Real-time data scraping with low latency.
Easy-to-integrate with structured JSON/CSV outputs.
Comprehensive support for reviews, ratings, pricing, and more.
2. Zyte Amazon Scraper API
Zyte offers a comprehensive Amazon scraping solution tailored for businesses that need precision and performance. Known for its ultra-fast response times and nearly perfect success rate across millions of Amazon URLs, Zyte is an excellent choice for enterprise-grade projects. Its machine learning-powered proxy rotation and smart fingerprinting ensure you're always getting clean data, while dynamic parsing helps you retrieve exactly what you need—from prices and availability to reviews and ratings.
Key Features:
Ultra-reliable with 100% success rate on over a million Amazon URLs.
Rapid response speeds averaging under 200ms.
Smart proxy rotation powered by machine learning.
Dynamic data parsing for pricing, availability, reviews, and more.
3. Oxylabs Amazon Scraper API
Oxylabs delivers a high-performing API for Amazon data extraction, engineered for both real-time and bulk scraping needs. It supports dynamic JavaScript rendering, making it ideal for dealing with Amazon’s complex front-end structures. Robust proxy management and high reliability ensure smooth data collection for large-scale operations. Perfect for businesses seeking consistency and depth in their scraping workflows.
Key Features:
99.9% success rate on product pages.
Fast average response time (~250ms).
Offers both real-time and batch processing.
Built-in dynamic JavaScript rendering for tough-to-reach data.
4. Bright Data Amazon Scraper API
Bright Data provides a flexible and feature-rich API designed for heavy-duty Amazon scraping. It comes equipped with advanced scraping tools, including automatic CAPTCHA solving and JavaScript rendering, while also offering full compliance with ethical web scraping standards. It’s particularly favored by data-centric businesses that require validated, structured, and scalable data collection.
Key Features:
Automatic IP rotation and CAPTCHA solving.
Support for JavaScript rendering for dynamic pages.
Structured data parsing and output validation.
Compliant, secure, and enterprise-ready.
5. ScraperAPI
ScraperAPI focuses on simplicity and developer control, making it perfect for teams who want easy integration with their own tools. It takes care of all the heavy lifting—proxies, browsers, CAPTCHAs—so developers can focus on building applications. Its customization flexibility and JSON parsing capabilities make it a top choice for startups and mid-sized projects.
Key Features:
Smart proxy rotation and automatic CAPTCHA handling.
Custom headers and query support.
JSON output for seamless integration.
Supports JavaScript rendering for complex pages.
6. SerpApi Amazon Scraper
SerpApi offers an intuitive and lightweight API that is ideal for fetching Amazon product search results quickly and reliably. Built for speed, SerpApi is especially well-suited for real-time tasks and applications that need low-latency scraping. With flexible filters and multi-language support, it’s a great tool for localized e-commerce tracking and analysis.
Key Features:
Fast and accurate search result scraping.
Clean JSON output formatting.
Built-in CAPTCHA bypass.
Localized filtering and multi-region support.
Conclusion
In the ever-evolving digital commerce landscape, real-time Amazon data scraping can mean the difference between thriving and merely surviving. TagX’s Amazon Scraper API stands out as one of the most reliable and developer-friendly tools for seamless Amazon data extraction.
With a robust infrastructure, unmatched accuracy, and smooth integration, TagX empowers businesses to make smart, data-driven decisions. Its anti-blocking mechanisms, customizable endpoints, and developer-focused documentation ensure efficient, scalable scraping without interruptions.
Whether you're tracking Amazon pricing trends, monitoring product availability, or decoding consumer sentiment, TagX delivers fast, secure, and compliant access to real-time Amazon data. From agile startups to enterprise powerhouses, the platform grows with your business—fueling smarter inventory planning, better marketing strategies, and competitive insights.
Don’t settle for less in a competitive marketplace. Experience the strategic advantage of TagX—your ultimate Amazon scraping API.
Try TagX’s Amazon Scraper API today and unlock the full potential of Amazon data!
Original Source, https://www.tagxdata.com/amazon-scraper-api-made-easy-get-product-price-and-review-data
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
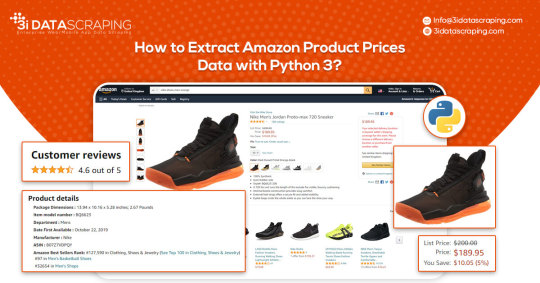
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Leverage Web Scraping Service for Grocery Store Location Data

Why Should Retailers Invest in a Web Scraping Service for Grocery Store Location Data?
In today's digital-first world, web scraping has become a powerful tool for businesses seeking to make data-driven decisions. The grocery industry is no exception. Retailers, competitors, and market analysts leverage web scraping to access critical data points like product listings, pricing trends, and store-specific insights. This data is crucial for optimizing operations, enhancing marketing strategies, and staying competitive. This article will explore the significance of web scraping grocery data, focusing on three critical areas: product information, pricing insights, and store-level data from major retailers.
By using Web Scraping Service for Grocery Store Location Data, businesses can also gain geographical insights, particularly valuable for expanding operations or analyzing competitor performance. Additionally, companies specializing in Grocery Store Location Data Scraping Services help retailers collect and analyze store-level data, enabling them to optimize inventory distribution, track regional pricing variations, and tailor their marketing efforts based on specific locations.
The Importance of Web Scraping in Grocery Retail
The grocery retail landscape is increasingly dynamic, influenced by evolving consumer demands, market competition, and technological innovations. Traditional methods of gathering data, such as surveys and manual research, are insufficient in providing real-time, large-scale insights. Scrape Grocery Store Locations Data to automate the data collection, enabling access to accurate, up-to-date information from multiple sources. This enables decision-makers to react swiftly to changes in the market.
Moreover, grocery e-commerce platforms such as Walmart, Instacart, and Amazon Fresh host vast datasets that, when scraped and analyzed, reveal significant trends and opportunities. This benefits retailers and suppliers seeking to align their strategies with consumer preferences and competitive pricing dynamics. Extract Supermarket Store Location Data to gain insights into geographical performance, allowing businesses to refine store-level strategies better and meet local consumer demands.
Grocery Product Data Scraping: Understanding What's Available
At the heart of the grocery shopping experience is the product assortment. Grocery Delivery App Data Collection focuses on gathering detailed information about the items that retailers offer online. This data can include:
Product Names and Descriptions: Extracting Supermarket Price Data can capture product names, detailed descriptions, and specifications such as ingredients, nutritional information, and packaging sizes. This data is essential for companies involved in product comparison or competitive analysis.
Category and Subcategory Information: By scraping product categories and subcategories, businesses can better understand how a retailer structures its product offerings. This can reveal insights into the breadth of a retailer's assortment and emerging product categories that may be gaining traction with consumers, made possible through a Web Scraping Grocery Prices Dataset.
Brand Information: Scraping product listings also allows businesses to track brand presence and popularity across retailers. For example, analyzing the share of shelf space allocated to private label brands versus national brands provides insights into a retailer's pricing and promotional strategies using a Grocery delivery App Data Scraper.
Product Availability: Monitoring which products are in or out of stock is a critical use case for grocery data scraping. Real-time product availability data can be used to optimize inventory management and anticipate potential shortages or surpluses. Furthermore, it allows retailers to gauge competitor stock levels and adjust their offerings accordingly through a Grocery delivery App data scraping api.
New Product Launches: Scraping data on new product listings across multiple retailers provides insights into market trends and innovation. This is particularly useful for suppliers looking to stay ahead of the competition by identifying popular products early on or tracking how their new products are performing across various platforms.
Scraping Grocery Data for Pricing Insights: The Competitive Advantage
Pricing is arguably the most dynamic and critical component of the grocery industry. Prices fluctuate frequently due to promotions, competitor actions, supply chain constraints, and consumer demand shifts. Web scraping enables businesses to monitor real-time pricing data from major grocery retailers, providing several key advantages:
Price Monitoring Across Retailers: Scraping pricing data from different retailers allows businesses to compare how similar products are priced in the market. This information can be used to adjust pricing strategies, ensure competitiveness, and maximize profit margins. Retailers can quickly react to competitor price changes and optimize their promotional activities to attract price-sensitive customers.
Dynamic Pricing Strategies: Businesses can implement dynamic pricing strategies with access to real-time pricing data. For instance, if a competitor lowers the price of a particular product, a retailer can respond by adjusting its prices in near real-time. This level of responsiveness helps maintain market competitiveness while protecting margins.
Tracking Promotions and Discounts: Businesses can identify ongoing or upcoming sales events by scraping promotional and discount data. This is particularly useful for analyzing the frequency and depth of discounts, which can help retailers and suppliers evaluate the effectiveness of their promotional campaigns. Moreover, tracking promotional patterns can provide insights into seasonal or event-based price adjustments.
Historical Pricing Trends: Web scraping tools can be configured to collect and store historical pricing data, allowing businesses to analyze long-term trends. This historical data is valuable for forecasting future pricing strategies, assessing the impact of inflation, and predicting market trends.
Price Elasticity Analysis: By combining pricing data with sales data, businesses can conduct price elasticity analysis to understand how sensitive consumer demand is to price changes. This information can help retailers set optimal prices that balance consumer expectations with profitability.
Understanding Store-Level Insights Using Scraped Grocery Data
Grocery retailers often have multiple locations, and the dynamics at each store can vary significantly based on factors like local demand, competition, and supply chain logistics. Web scraping can provide valuable store-level insights by collecting data on:
Store Locations and Hours: Scraping data on store locations, hours of operation, and services offered (such as delivery or curbside pickup) helps businesses assess a retailer's geographical reach and operational strategies. This is particularly useful for competitors analyzing potential areas for expansion or companies offering location- based services.
Geographical Pricing Variations: Pricing can vary significantly across regions due to local supply and demand differences, transportation costs, and regional promotional strategies. Web scraping allows businesses to track how prices differ across geographical locations, providing valuable insights for retailers or suppliers operating in multiple markets.
Inventory Levels and Replenishment Patterns: By scraping data on product availability at different store locations, businesses can gain insights into local inventory levels and replenishment patterns. For instance, certain stores may frequently run out of stock for popular items, signaling supply chain inefficiencies or increased local demand. This information can be used to optimize logistics and improve customer satisfaction.
Localized Promotions and Discounts: Retailers often run location-specific promotions, especially during events or holidays. Scraping data on localized promotional activities allows businesses to identify regional marketing strategies and understand how retailers target specific customer segments.
Competitor Store Performance: Analyzing store-level data from competitors can provide critical insights into their operational performance. For example, frequent stockouts or changes in store hours might indicate logistical challenges, while new store openings could signal an expansion strategy.
Scraping Data from Major Grocery Retailers for Data-Driven Decisions
Scraping grocery data from several major grocery retailers, including Walmart, Kroger, and Amazon Fresh, helps gather critical data for making informed decisions.
Walmart: As one of the largest grocery retailers in the world, Walmart is known for its wide range of products. Businesses can employ sophisticated data collection techniques to monitor competitor pricing, analyze product assortment trends, and optimize inventory management. Walmart's expansive product catalog and broad geographical reach make it a valuable data source for competitors and market analysts.
Kroger: Kroger is a leader in data analytics and enhancing the customer experience. By scraping data from its online platform and competitors, businesses can identify trends in consumer preferences, optimize pricing strategies, and improve product availability across their stores.
Amazon Fresh: Amazon Fresh is a digital-first grocery platform popular for delivery. Businesses can extensively use web scraping to monitor pricing and product trends in real-time. Knowing Amazon's dynamic pricing strategies, businesses can adjust theirs based on competitor prices and demand fluctuations.
Instacart: Instacart partners with various grocery retailers, and its platform serves as a hub for scraping data on product availability, pricing, and promotions from multiple stores. This data is valuable for market analysts and competitors, providing insights into regional pricing trends and consumer preferences.
Tesco: In the UK, Tesco has extensive data on products, pricing, delivery, etc. Businesses can leverage data extraction processes to collect data on grocery items. This helps them refine their product offerings and pricing strategies to remain competitive in a highly saturated market.
The Future of Web Scraping in Grocery Retail
Web scraping is poised to become even more critical as the grocery industry evolves. The rise of e-commerce grocery platforms and the increasing consumer demand for real-time, personalized shopping experiences will only amplify the need for accurate and comprehensive data. Several emerging trends are expected to shape the future of web scraping in grocery retail:
Artificial Intelligence (AI) and Machine Learning (ML) Integration: AI and ML technologies will be increasingly used to enhance web scraping capabilities. These technologies can help businesses identify patterns in large datasets, predict future trends, and make more informed pricing and product assortment decisions.
Voice-Enabled Shopping Insights: As voice search becomes more prevalent, grocery retailers may use web scraping to analyze voice-enabled shopping queries. This data can provide insights into how consumers interact with digital assistants and inform strategies for optimizing voice-based search functionality.
Increased Focus on Data Privacy: As governments worldwide introduce stricter data privacy regulations, businesses engaged in web scraping will need to ensure compliance. This will likely result in more sophisticated data anonymization techniques and a greater emphasis on responsible data collection practices.
Real-Time Personalization: As consumer expectations for personalized shopping experiences grow, web scraping will deliver real-time, individualized recommendations. By analyzing a customer's purchases, preferences, and browsing history, retailers can offer tailored product suggestions and promotions.
Conclusion
Web Scraping Service for Grocery Store Location Data is a game-changing tool for retailers, suppliers, and market analysts seeking a competitive edge. By automating the collection of product, pricing, and store-level data, businesses can unlock a wealth of insights that drive more intelligent decision-making. Whether it's monitoring product availability, adjusting pricing strategies, or understanding geographical differences in in-store performance, web scraping offers an unparalleled opportunity to stay ahead in the fast-paced world of grocery retail. As the industry continues to evolve, web scraping will remain a critical tool for harnessing the power of data to shape the future of grocery shopping.
Experience top-notch web scraping service and mobile app scraping solutions with iWeb Data Scraping. Our skilled team excels in extracting various data sets, including retail store locations and beyond. Connect with us today to learn how our customized services can address your unique project needs, delivering the highest efficiency and dependability for all your data requirements.
Source: https://www.iwebdatascraping.com/leverage-web-scraping-service-for-grocery-store-location-data.php
#WebScrapingGroceryStoreLocationData#ExtractSupermarketStoreLocationData#GroceryDeliveryAppDataCollection#WebScrapingGroceryPricesDataset#WebScrapingGroceryData#SupermarketDataScraper
0 notes
Text
Extract product data from Shopbop using ScrapeStom
Shopbop is a fashion shopping website for women in the United States. It was founded in 1999 and is headquartered in Madison, Wisconsin; it was acquired by Amazon on February 27, 2006; Free shipping service; In 2011, launched twelve different currency settlement services, officially becoming a shopping website with a high-quality global shopping experience.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Top Amazon Product Scrapers for 2024: Extract Data Like a Pro
Outsource BigData's AI-augmented Amazon Product Scraper is user-friendly and portable, and it allows for searches through either an application or a website. We use a unique algorithm to identify best-sellers, allowing us to scrape detailed data on ASINs or URLs. We've got all your scraping needs covered, whether it's competitor analysis, comparison shopping, or API development!
For more details visit: https://outsourcebigdata.com/data-automation/web-scraping-services/amazon-product-scraper/
About AIMLEAP Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered IT & digital transformation projects, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, copyright; and more.
-An ISO 9001:2015 and ISO/IEC 27001:2013 certified -Served 750+ customers -11+ Years of industry experience -98% client retention -Great Place to Work® certified -Global delivery centers in the USA, copyright, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform APISCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations: USA: 1-30235 14656 copyright: +1 4378 370 063 India: +91 810 527 1615 Australia: +61 402 576 615 Email: [email protected]
0 notes