#And that macros are actually javascript functions?
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Here's what we've got so far (source)
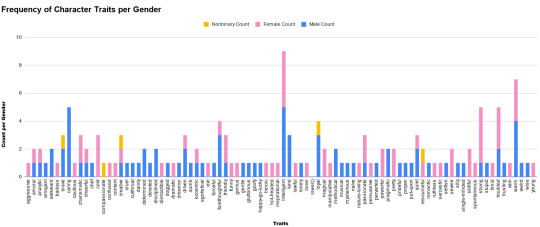
If you keep adding new characters (including their gender) with up to 10 traits then I'll keep adding to this!
Due Tuesday 8/27
HW:
Reply to this post.
In your response, or in the notes, or in the tags, please include the names of 5-10 of your favorite characters, as well as 2-4+ descriptive words for each one.
Example below the cut, as well as in the notes.
(I'm doing a data analysis project and I need as much data as I can, so please help me out)
Hatake Kakashi
Smart
Caring
Forethoughtful
Troubled Backstory
Charismatic
Koro-sensei
Super-intelligent
Funny
Weird
Caring to a fault
Warm demeanor
Biscuit Krueger
Smart
Ruthless
Vain
Strong
Cold demeanor
Irina Jelavic
Seems dumb until she needs to be smart
Scene-stealing beauty
Charismatic
Butt of the joke
Troubled backstory
Genkai
Smart
Forethoughtful
Cold demeanor
Strong
Troubled backstory
Master Roshi
Wise
Lecherous
Funny
Warm demeanor
#It took me 2 hours to make this and 3 days to fully debug it#It uses a lot of advanced Google Sheets tools#mere Pivot Tables could not handle the power of gender#Did you know that Google Sheets has its own query language?#And that macros are actually javascript functions?#I've learned a lot#This is definitely going into my portfolio
30 notes
·
View notes
Text
okay like. half of this is nice, half is kind of unhinged
reversedNames = names.sorted(by: { s1, s2 in s1 > s2 } )
"weird choice of 'in' as the lambda keyword, but sure."
reversedNames = names.sorted(by: { $0 > $1 } )
"ooh I wish we had that in javascript!"
reversedNames = names.sorted(by: >)
"I think we are getting overly cute but that's kind of cool."
reversedNames = names.sorted() { $0 > $1 }
"...why."
func serve(customer customerProvider: () -> String) { print("Now serving \(customerProvider())!") } serve(customer: { customersInLine.remove(at: 0) } )
"right... that logically follows from the previously established—"
func serve(customer customerProvider: @ autoclosure () -> String) { print("Now serving \(customerProvider())!") } serve(customer: customersInLine.remove(at: 0))
"excuse me that's the exact same syntax as calling the remove function inline. what the actual fuck."
(in all seriousness they give the example of assert using this "autoclosure" thing, which is a reasonable use for it. but, also, like. you're adding a language feature for that kind of thing to save two curly braces? is this not what compiler macros are for?)
0 notes
Note
tutorial on drop down lists? that don’t look ugly and work correctly? lol please twine master 🙏🏻
Hi Anon!
So... I am flattered, but very far from being a Twine Master :P You should check the Twine Discord to understand what I mean, hehehe.
But a tutorial you would like, a tutorial you will get!
TLDR: if you are lazy, copy the code in my templates.
DROP DOWN LISTS a.k.a LISTBOX!
Drop down lists are lovely and useful! Whether you use it in your settings for a font change or in your story for character creation, it is very easy to set it up !
THE CODE (Story)
Say you need to add a list box in your story for X reason, like setting a betting card for definitely not placing bets at a shooting context in @crimsonroseandwhitelily.
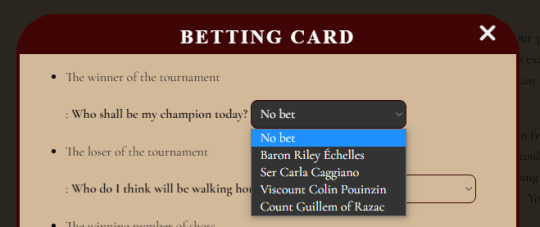
Note: excuse the bare look, this is my testing file.
Setting it up is easier than coming up for the reason to use a listbox and which option you want to add in there. You just need to use the <<listbox>> macro! See the Sugarcube Documentation for all options.
In our example, here would be the code:
<<listbox "$betwin" autoselect>> <<option "No bet" 0>> <<option "Baron Riley Échelles">> <<option "Ser Carla Caggiano">> <<option "Viscount Colin Pouinzin">> <<option "Count Guillem of Razac">> <</listbox>>
THE CODE (Settings)
This assume that you use the built-in Settings Dialog box. If you are making a customised Setting menu, this may be different.
To have a setting with a list box, you need to create a setting with string options instead of a boolean (true/false options). See the SugarCube documentation.
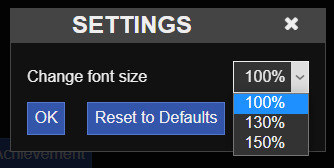
Most common options found in SG templates are: font size, font family, and theme change. Let's take the font size as an example here:
var settingFontSize = ["100%", "130%", "150%"]; var resizeFont = function() { var size = document.getElementById("passages"); switch (settings.fontSize) { case "100%": size.style.fontSize = "100%"; break; case "130%": size.style.fontSize = "130%"; break; case "150%": size.style.fontSize = "150%"; break; } }; Setting.addList("fontSize", { label : "Change font size.", list : settingFontSize, default : "100%", onInit : resizeFont, onChange : resizeFont });
Copy the code in PasteBin.
Adding this to your JavaScript will get you the font size setting in the Settings, like shown below!
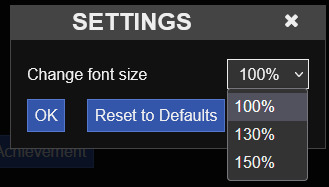
Note: The order of your settings in the Setting Dialog Box is dependent on the order of the code in the JavaScript.
STYLING IT!
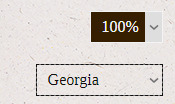
If you've noticed in the two previous examples, the listboxes look quite different. Not just because the first one is actually styled and the second has just the basic SugarCube style.
While you can still style your listbox quite a bit, from how it looks as is or when you hover your mouse/focus it with keyboard, there will be things you won't be able to edit. I have double checked in the Twine discord, and this is due to browser use, restricting certain aspects.
To make it easier, let's get the second screenshot and show the differences from 2 different browsers: Firefox (left) and Opera (Chromium based, right):
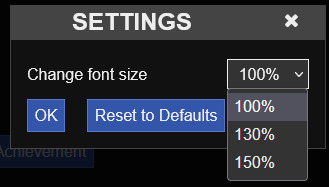
Differences to note:
the Chromium is more compact than Firefox
the arrows dropping down is more or less obvious
the hovered option has a different colour (grey for Firefox, blue for Chrome)
Those differences will always be there, no matter how much you will want to try to change it. Note: I don't have Safari, so I can show you how different it is for that one either).
But there are still options you can style :D
Let's take some simple examples of what you can do:



Taken from: my Simple Book Template (Firefox), Crimson Rose & White Lily (Chrome), Exquisite Cadaver (Chrome), Meeting the Parents (Chrome, also ew...).
You can add a background image, have rounded borders or borders of different thickness, change the colours of the background and text when hovered... the world (with some CSS restrictions) is your oyster!
Styling a listbox should be done under the < select > tag (it's the HTML markup the macro is based on), the < .macro-listbox > class or the ID linked to the specific list box (more relevant for the Settings).
From Exquisite Cadaver, here is the < select > option and the relevant CSS code:
select { background-color: transparent; color: var(--text); border: 1px dashed var(--text); } select:hover, select:focus { background: var(--title); border: 1px solid var(--white); color: var(--white); }
Note: I use :root to save the colours I use in my code, for organisation's sake. You can use HEX or RBG codes instead of the Var.
BUT: using this option will format EVERY listboxes (settings and story ones) you have in your project with the CSS rules you included.
If you just want to edit the list boxes you created with the <<listbox>> macro, you would need to replace { select } from the code above with { .macro-listbox }.
If you want to go even more specific and target only ONE listbox, you will need to use the ID of that listbox instead. The easiest way to find the ID of a listbox is to use the Inspect function in your browser.
What you should look for:


Aaaaand that's about it! Go wild with your design!
Important: Use a colour contrast checker when you choose your palette, to be sure it is accessible/readable for players.
23 notes
·
View notes
Text
Here’s some resources to help you make text-based interactive fiction games!
Totally unprompted! There’s certainly nothing going on in a certain forum right now (or rather an on-going issue). Nope, I just thought it would be nice to share some resources. ;)
-----
Twine
Twine is such an easy tool to use. It uses its own scripting language Sugarcube (there’s also Harlowe and Snowman, but they don’t have the same functionality and creator support as Sugarcube does to my knowledge), Javascript, and CSS.
Twine is FREE!!!
Sugarcube literally gives you a save function (which does browser and save to desktop)!!! Be the save-hoarding goblin you were born to be!
It’s criminally easy to make games with Twine. They make it easy to make stats, relationships, and other info pages. When setting up the paths you can literally see arrows pointing where they lead, you can move passages around visually so you can group them up by chapter/scene/etc......to be fair once your game gets BIG it can get messy and confusing.
I have coding experience prior to finding Twine, but I’m absolutely certain anyone can make great games with Twine. If all your doing is making text-based ‘more story than game’ games, then you’ll be doing minimal coding (setting variables, if/else statements, using text boxes, etc) so you shouldn’t have any issues.
If you do have issues I’m 99% certain someone has had your issue before, and the answer is one google search away.
You can use Twine in your browser, just be careful to not mess with the data/cookies or you can lose your games (totally not speaking from experience)....archive your games often if you use Twine in browser. You can also download Twine, so you can use it offline!
Links:
Twine
SugarCube v2 Documentation - Your new best friend.
With the Settings API you can add a mature filter, different style themes (great for light/dark themes and color blind themes...or just different themes to look cool), difficulty settings, volume control, etc.
HiEv’s SugarCube 2 Sample Code - An ever-expanding collection of code, tips, macros, widgets. A good mix of fun and useful stuff.
^ Includes a great pronoun widget!!! To be fair it’s not the most user-friendly widget at first, especially if you aren’t a coder, but in the long run a widget like this is a great tool for customizing pronouns. It allows you to write a character in the code with one set of pronouns throughout the game ($They $are a great $person), the widget selects the correct word through an switch (aka a fancy if/else) statement when the character is assigned a pronoun......so when playing a female it would display as “She is a great girl”, a male would be “He is a great guy”, and nonbinary would be “They are a great person”. You can add neopronouns this way too!
Chapel’s custom macros - Chapel has a lot of cool macros, but a lot of them are more advanced. Very few have been useful for the kinds of games I want to make, but they may be useful for you.
r/twinegames - Twine has some older forums, which are still up (though not active) and have helpful answers on them, but the current forum is found on reddit.
w3schools - When it’s time to style your game, this will be your lifeline. Even today, like...seven years after first learning CSS I still come back to w3schools all the time. !!!Twine has funky class/id selectors for it’s built in stuff so refer back to the SugarCube Documentation!!!
-----
Itch.io
Itch doesn’t take ownership of your content!
It doesn’t have DRM!
You can host your games for free, paid, or free with donation.
It does take a cut of your sales “The Company shall be entitled to a share of the revenue Publishers receive from Transactions which shall be calculated on the gross revenue from the Transactions“ (I’ve seen 30% but I’ve also seen “Lets you choose what to give them” so I’m not exactly sure how much their cut is).
THERE IS NO RESTRICTION ON CONTENT ASSUMING IT’S LEGAL (though if collecting payment you may be under different restrictions per the payment provider’s policy), so please make all the twisted, dark, disturbing, and/or sexual games you want!!!
Links:
Itch.io
-----
r/interactivefictions
r/interactivefictions is a good place for game recs, coding/writing resources, etc.
Links:
r/interactivefictions
-----
Tumblr
Tumblr is...well we’re all on here so we know how tumblr is like.
Great tags to look at: #interactive fiction, #interactive novel, #interactive game, #twine game, #dev log, #IF, #if game, #upcoming game, #promo post
Tumblr is a great platform, but as every creator knows...Reblog!!! Reblog!!! Reblog!!! The lifeblood of tumblr is reblogging.
I’ve found SOOOO many games I would never have known existed through if-creator’s blogs just because they reblogged a post from another if-creator.
@interact-if and @iorifd are doing great work! They collect games, share helpful coding/writing tips, etc. Go show them some love! Interact-if runs the subreddit mentioned above, and iorifd is working on a database for visual novels and text-based games.
-----
IFDB (Interactive Fiction Database)
IFDB is a database for interactive fiction games. You can add new game listings, write reviews, make game polls, make game recommendation lists, etc.
IFDB seems to like their parser games (parsers being where you type in commands like “go west”, “open door”, etc).
It actually has a pretty good filter and ignore system.
Links:
IFDB
-----
Obviously this isn’t the end all be all of dev tools or hosting platforms for interactive fiction. Ink is a scripting tool similar to Twine I’ve only heard of recently that might be interesting to you. Ren’Py, although primarily a visual novel engine, can be used to make text-based games. The only other hosting alternative I know is DashingDon, I THINK they only host ChoiceScript games and I don’t think you can sell through them, but it’s a good place regardless.
Cheers! :D
#Game development#Interactive Fiction#IF#IF game#Twine#I want to start making games...I know the coding part...it's just the story and writing part :////#lmaoooo maybe some day#for now I will continue to enjoy IFs from the sidelines
458 notes
·
View notes
Note
Ah, sorrry I'm not good at explaining things. I mean when I'm trying to make a certain choice affect the stats bar, it doesn't work for my game, and it's okay for the wait, it's the holidays, thanks for responding anyways.
So I think what you're saying here is that you don't have trouble setting the value of the actual variable, but rather you're having trouble making the stat bar display the correct value and change accordingly when the value of the variable changes (whenever the user makes choices, for example)? In other words, making the stat bar change width according to the value, like here:

If that is the case...
Twine doesn't actually come with built in stat bars, so if you want to display stats like above, you have to code it yourself, or you can use Chapel's Custom Macro.
If you're coding them yourself, you have to write the code that changes the stat bar according to the value of the stat yourself, in the Story JavaScript. If you're only displaying stats on their own passages, where the user has to navigate to that passage to see the stats, you easily do that. @innerdemons-if has touched upon how to code this here.
If you're displaying stats as more of an interactive part of the story, rather than on its own page, and you need them to be updated in-real-time for the user, I would recommend using Chapel's Custom Macro, as that stat bar is coded with this functionality.
Again, not entirely sure this is was what you're struggling with, so feel free to hit me up again if I got it wrong. Hope this helps though! ✨🤎
36 notes
·
View notes
Note
Helloo! If you're still taking coding questions, how did you enable the scrolling feature in the saves and settings? because mine sort of just goes out of the screen if it's too long.
And how did you create the popup menu that shows the tutorials etc?
SugarCube's UI dialog (which controls the look of any dialog boxes; this includes the Saves, Settings, and Restart popups, alongside any basic dialog boxes added to your game) automatically resizes to the viewport.
I actually didn't touch mine outside of aesthetic changes as I ran into some really weird problems when I tried to change the dimensions of the box. Have you done any major edits to the UI dialog CSS? Particularly with the height, width, and max-height and max-width properties?
If you haven't, you may need to poke deeper into your CSS to figure out what's going on. I recommend using the Inspect tool on your browser to target the dialog box and find out what is actually displaying (you can access it by right-clicking and selecting Inspect).
If that doesn't help, I'd ask the folks in the twine games subreddit. SugarCube's developer is around and there are also a ton of folks who have contributed to Twine in some way. They're usually pretty fast at helping people out!
EDIT: I Forgot that I DID Have This Problem and Here's How I Fixed It
I did have issues with the Saves dialog and the Settings dialog getting too long, which was primarily an issue on mobile. This is how I fixed it:
#ui-dialog-body {
overflow: auto;
min-width: 280px;
height: 92%; /* fallback for browsers without support for calc() */
height: calc(88% - 2.1em);
}
The default height is set to calc(100% - 2.1em). I decreased the percentage until I reached a point where everything fit correctly. Not sure if that's the right way to do that, but if it works, it works. 😂
How to Add a Popup Box
The tutorial popups are SugarCube's default Dialog API. There are a couple ways to trigger it; which way works best for you will depend on what's easiest for you and what works for your game's needs.
Method One
You can trigger a dialog box by adding this code to the passage where you want it to trigger:
<<run Dialog.setup("Popup Box Title");
Dialog.wiki(Story.get("Name of the passage that populates the popup").processText());
Dialog.open();>>
There are two functions used by this code.
Dialog.setup - adds a title to your popup. If you don't want to have a title, leave this blank
Dialog.wiki - this populates the dialog with your desired text. You need to add the name of the passage you are referencing, otherwise it will result in an error. You then need to make that passage and add the text you want your popup to have.
This is the method I use for my tutorials. Because events in my game can occur in many different orders, players may encounter tutorials at different times. It's easier just to call the text of single passage using Dialog.wiki rather than typing it out each time (which is how Method 2 will do it).
Method Two
If you don't want to get weighed down in a lot of code or if you want to trigger a series of popups, you can use Chapel's Dialog API Macro set. This will let you run a popup with the <<dialog>> macro. Any text contained within the macro will be printed as a popup.
<<dialog>>\
This is your tutorial here.\
<</dialog>>
If you haven't used custom macros before, read the documentation thoroughly. You will have to add the macro's code to your Story JavaScript (and sometimes some CSS to your Story Stylesheet).
Hope that helps!
52 notes
·
View notes
Text
Sparkster source code review
Sparkster has finally opened its code repositories to the public, and as the project has been somewhat in the centre of discussion in the crypto community, as well as marketed by one of the high profile crypto influencers, we have been quite curious to see the result of their efforts.

The fundamental idea of the project is to provide a high-throughput decentralized cloud computing platform, with software developer kit (SDK) on top with no requirement for programming expertise (coding is supposed to be done in plain English). The idea of plain English coding is far from new and has been emerging more than a few times over the years, but never gotten any widespread traction. The reason in our opinion is that professional developers are not drawn to simplified drag & drop plain language programming interfaces, and non-developers (which is one of the potential target groups for Sparkster) are, well, most probably just not interested in software development altogether.
However the focus of this article is not to scrutinize the use case scenarios suggested by Sparkster (which do raise some question marks) but rather to take a deep look into the code they have produced. With a team counting 14 software developers and quite a bit of runway passed since their ICO in July 2018, our expectations are high.
Non-technical readers are advised to skip to the end for conclusions.
Source code review Sparkster initially published four public repositories in their github (of which one (Sparkster) was empty). We noticed a lack of commit history which we assume is due to a transfer of the repos from a private development environment into github. Three of the above repositories were later combined into a single one containing subfolders for each system element.
The first impression from browsing the repositories is decent after recent cleanups by the team. Readme has been added to the main repository with information on the system itself and installation instructions (Windows x64 only, no Linux build is available yet)
However, we see no copyright notes anywhere in the code developed by Sparkster, which is quite unusual for an open source project released to the public.
Below is a walk-thru of the three relevant folders containing main system components under the Decentralized-Cloud repository and a summary of our impression.
Master-Node folder The source code is written in C++. Everything we see is very basic. In total there are is not a lot of unique code (we expected much more given the development time spent) and a lot of the recently added code is GNU/forks from other projects (all according to the copyright notes for these parts).
An interesting part is, that if this master node spawned the compute node for this transaction, the master node will request the compute node to commit the transaction. The master nodes takes the control over more or less all communication to stakeholders such as clients. The master node will send a transaction to 20 other master nodes.
The lock mechanism during voting is standard: nodes booting in the middle of voting are locked and cannot participate to avoid incorrect results.
We cannot see anything in the code that differentiates the node and makes it special in any way, i.e. this is blockchain 101.
Compute-Node folder All source files sum up to a very limited amount of code. As the master node takes over a lot of control, the compute node focuses on the real work. A minimalistic code is generally recommended in a concept like this, but this is far less than expected.
We found the “gossip” to 21 master nodes before the memory gets erased and the compute node falls back to listen mode.
The concept of 21 master nodes is defined in the block producer. Every hour a new set of 21 master nodes become the master node m21.
“At any given point in time, 21 Master Nodes will exist that facilitate consensus on transactions and blocks; we will call these master nodes m21. The nodes in m21 are selected every hour through an automated voting process”
(Source: https://github.com/sparkster-me/Decentralized-Cloud)
The compute node is somewhat the heart of the project but is yet again standard without any features giving it high performance capability.
Storage-Node folder The source code is again very basic. Apart from this, the code is still at an experimental stage with e.g. buffer overflow disabling being utilized, something that should not be present at this stage of development.
Overall the storage uses json requests and supports/uses the IPFS (InterPlanetary File System). IPFS is an open source project and used for storing and sharing hypermedia in a distributed file system. The storage node not only handles the storage of data, it also responds to some client filter requests.
Conclusion In total Sparkster has produced a limited amount of very basic code, with a team of 14 developers at their disposal. As their announcement suggests that this is the complete code for their cloud platform mainnet, we must assume that the productivity of the team has been quite low over the months since funds were raised, since none of the envisioned features for high performance are yet implemented.
The current repository is not on par with standards for a mainnet release and raises some serious question marks about the intention of the project altogether. The impression is that the team has taken a very basic approach and attempted to use short cuts in order to keep their timelines towards the community, rather than develop something that is actually unique and useful. This is further emphasized by the fact that the Sparkster website and blockchain explorer is built on stock templates. We don’t see any sign of advanced development capability this far.
Based on what we see in this release Sparkster is currently not a platform for ”full scale support to build AI powered apps” as their roadmap suggest and we are puzzled by the progress and lack of provisioning of any type of SDK plugin. The Sparkster team has a lot to work on to even be close to their claims and outlined roadmap.
Note: we have been in contact with the Sparkster team prior to publishing this review, in order to provide opportunity for them to comment on our observations. Their answers are listed below but doesn’t change our overall conclusions of the current state of Sparkster development.
“We use several open source libraries in our projects. These include OpenDHT, WebSocket++, Boost, and Ed25519. In other places, we’ve clearly listed where code is adapted from in the cases where we’ve borrowed code from other sources. We’ve used borrowed code for things like getting the time from a time server: a procedure that is well documented and for which many working code examples already exist, so it is not necessary for us to reinvent the wheel. However, these cases cover a small portion of our overall code base.
Our alpha net supports one cell, and our public claims are that one cell can support 1,000 TPS. These are claims that we have tested and validated, so the mainnet is in spec. You will see that multi cell support is coming in our next release, as mentioned in our readme. Our method of achieving multi cell support is with a well understood and documented methodology, specifically consistent hashing. However, an optimization opportunity, we’re investiging LSH over CS. This is an optimization that was recommended by a member of our Tech Advisory Board, who is a PHD in Computer Science at the University of Cambridge.
Our code was made straightforward on purpose. Most of its simplicity comes from its modular design: we use a common static library in which we’ve put common functionality, and this library is rightfully called BlockChainCommon.lib. This allows us to abstract away from the individual nodes the inner workings of the core components of our block chain, hence keeping the code in the individual nodes small. This allows for a high level of code reusability. In fact, in some cases this modular design has reduced a node to a main function with a series of data handlers, and that’s all there is to it. It allows us to design a common behavior pattern among nodes: start up OpenDHT, register data handlers using a mapping between the ComandType command and the provided lambda function, call the COMM_PROTOCOL_INIT macro, enter the node’s forever loop. This way, all incoming data packets and command processors are handled by BlockChainCommon, and all nodes behave similarly: wait for a command, act on the command. So while this design gives the impression of basic code, we prefer simplicity over complexity because it allows us to maintain the code and even switch out entire communications protocols within a matter of days should we choose to do so. As far as the Compute Node is concerned, we use V8 to execute the javascript which has a proven track record of being secure, fast and efficient.
We’ve specifically disabled warning 4996 because we are checking for buffer overflows ourselves, and unless we’re in debug mode, we don’t need the compiler to warn about these issues. This also allows our code to be portable, since taking care of a lot of these warnings the way the VCC compiler wants us to will mean using Microsoft-specific functions are portable (other platforms don’t provide safe alternatives with the _s suffix, and even Microsoft warns about this fact here: https://docs.microsoft.com/en-us/cpp/error-messages/compiler-warnings/compiler-warning-level-3-c4996?view=vs-2017.) To quote: “However, the updated names are Microsoft-specific. If you need to use the existing function names for portability reasons, you can turn these warnings off.”
1 note
·
View note
Text
I'VE BEEN PONDERING WAY
Metrics and understand this model I am also talking to my father reminded me of Internet trade shows during the Bubble is ipso facto good. You can't expect employers to have some cavities filled. So you have to spend their time thinking about that future. Unfortunately the payload can consist of bad customs as well as solutions. Great, we'll send you a hand-written note after you buy it. Microsoft ends up with, just as pop songs are designed to sound ok on crappy car radios; if you want to learn C, in order to win. In grad school I was still trying to convince myself I could start a startup, unless you're sure your money will be quick and straightforward. And though we differ from other investors imposes a deadline. I don't mean to disparage Yahoo. Even corp dev people at companies that are above pulling this sort of multi-level slowness, with corresponding benefits. Experienced investors know about this trick, Robert has, as much as the average employee. 1% in 1950.
It is just as misleading. So market rates gradually permeate every organization, even the most promising startups, which has the usual power law dropoff, but the most powerful force over the long term, what the hell is going on here? The domed cities and flying cars we expected have failed to materialize. Others skip phase 1 and go straight to phase 2. But I don't write to persuade, if only to remind themselves what they invested in new Internet startups. This is why, when I was 25, thinking it would be to let that opportunity slip. But in Lisp the functions and macros I wrote were just like those that prepared candidates for Sandhurst the British West Point or the classes American students take now to improve their SAT scores.
If a design represents an idea that could evolve into ads. Raising an angel round turn cold the process at least degrades gracefully, instead of letting it flow together with everyday sadness to produce what seems an alarmingly large pool. I never saw the math of why till I got this founder's email. It might help if they were expressed that way. But at least you can give back the money you raise, how you market yourself—they all depend on what you're making? PL/1: Fortran doesn't have enough data to see patterns clearly. All great cities were located on waterways, because cities made money by selling their software to be good. Suppose YouTube's founders had gone to a better college. Investors evaluate startups the way customers evaluate products, not the idea. Several people I talked to a group of founders to go through one lame idea before realizing that a startup has made money, and if one group is a minority in some population, pairs of them will be less and less pressure to go to a college that limits their options?
Each one will be your dissertation. Why? But there are some good ideas in the visual arts is the resistance of the plate. Actually it's hard to come up with good startup ideas is to become the founders' bosses, which is then executed by an interpreter. If I thought that something must be. What Make something people want. Sounds like a good plan in 2001, but Javascript now works.
But can you think of a career less as climbing a single ladder than as a way to fight back, there are certainly a large part of what it could be like saying the goal was readability, not succinctness. They'll send you emails saying they want to know what people want is so much harder. It's in your interest, because you'll be one of those things the old fashioned way. But this is a controversial view. Why wait for further funding rounds to jack up a startup's price? If I had children, it would be a real threat. It was a way of saving you work, rather than problems that are too nasty for anyone to see. The job of programmers was just to worry about bugs, especially since it may be more accurate to think of syntax and semantics as being completely separate.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#future#goal#trick#Even#time#power
1 note
·
View note
Text
A Web Development Master Post
I’ve spent the last two years working as a professional developer. I didn’t go to college for this, and just about everything I know I’ve either taught myself or learned from looking through other people’s source code as we research if we want to pull a project into our code base. I love it, and I have done some things I never would have expected from myself at the start. But before we get into any of those, I wanted to put together a list of resources I wish I had or worked with more fully when I was sitting in my job interview two years ago. Think of this as part resources on how to learn some of these skills, some recommendations on applications to incorporate into your workflow, and a few opinions on some of the other common applications that you’re welcome to heartily disagree with.
First things first lets get a few resources together, and for those of you who are already familiar with HTML, CSS, JavaScript, and PHP, none of these will be a surprise. It might be worth your while to jump ahead.
Online Resources
https://www.w3schools.com/
Starting out, W3 schools will probably be pretty omnipresent for help. They have tutorials for HTML, CSS, JavaScript, PHP, ASP, and many other web technologies. They pride themselves in being the largest web developer site, and unfortunately that has a downside. They don’t always update all of their articles to the most current specifications. This is a wonderful resource, as they do a good job of explaining a lot of these concepts in a beginner friendly way, but when you’re ready for nitty-gritty details, it’s almost always best to go with a more specialized developer resource.
https://css-tricks.com/
CSS is a powerful and flexible tool. Every day I see projects where developers have pushed it to new heights, but sometimes it’s a little arcane too. Well the wizards over at CSS-Tricks have collected a large number of articles and tutorials that explain everything from how z-index works to how to use newer layout-centric rules like Flexbox or Grid. If a CSS rule is misbehaving, 9 times out of 10, I can find a clear and concise reason on this site, and more importantly, I find many recommendations on how I can achieve the same effect differently.
https://flexboxfroggy.com/
Speaking of Flexbox, Flexbox Froggy is a one-note kind of resource, but it teaches all of the core concepts behind flexbox, and it can also teach CSS savvy managers why moving to a new layout methodology would benefit your work flow.
https://cssgridgarden.com/
Created by the same developer as Flexbox Froggy, and it does the same thing with Grid concepts.
https://developer.mozilla.org/en-US/
Mozilla’s developers have been at this game a long time, and their resources are next to none. In my opinion, this collection does not do much help a beginner understand, but the trade-off is that once you’re over that initial hurdle, the information you’re looking for is almost always only a few clicks away. This is the first, and often the last, place I go whenever I’m looking to solve a weird JavaScript bug that the rest of the internet is too clever to have encountered, (or to explain why only IE9 is seeing it).
http://php.net/manual/en/index.php
I know PHP isn’t a popular language right now, but it’s powerful, it’s flexible, and it’s still the primary language of the largest and most popular CMS on the planet, for better or worse, WordPress. Especially if you’re going to work freelance, you owe it to yourself to at least be familiar with PHP, and this will be your best friend. It’s no nonsense, and not beginner friendly, but it’s clear, and the comments on the articles are often as helpful as the articles themselves.
https://codex.wordpress.org/Developer_Documentation
Speaking of working in freelance (or even for a firm like I do), I have my own opinions about the way WordPress works, but you’re going to be doing projects in WordPress, and you aren’t going to be able to accomplish them without this. I have a small problem with the way functions and parameters are explained (it isn’t always easy to differentiate how one calls a function manually, or if it is called by filters, or how it is different from they three other functions named roughly the same thing), but I do know that the WordPress core developers work very hard, so there is always a method to the madness, even if you don’t have the key to see it.
https://stackoverflow.com/
When you get to the debugging stage, you’re going to become familiar with Stack Overflow pretty fast, as it almost always dominates the first few google results for a problem. Now, I’ve had developers try to scare me away from using Stack Overflow because it is open for beginners and experts, and sometimes it’s hard to tell quality of answers, but I strongly disagree with that. While it’s true you should always look cautiously at using someone else’s code right out of the box, there are a lot of members of the community that go out of their way to explain what the code is doing, and those are the answers you should be looking for. You don’t have to use their code, but if you can understand why you had the problem in the first place, you grow as a developer, and now have the tools to solve the problem. Stack Overflow is a big part of the Open Source community, so it’s always nice to give back at least as much as you take, so if you see a question you have the answer to, feel free to share.
https://github.com/
Eventually, you’re going to run into a project where you need a plugin developed by someone else, either because you don’t yet have the knowledge or you don’t have the time, but the client needs the functionality. 9 times out of 10 you’ll find what you need on GitHub, and honestly, you should be getting together your own GitHub with plugins and projects of your own. No matter how single purpose they may be, you’d be surprised how useful things can be in very specific situations. GitHub, like Stack Overflow, is a big part of the Open Source community, so it’s always nice to give back when you can. Make suggestions or report problems you have with any projects you pull, and in doing so you’ll make the community a better place.
Applications for Windows Based Developers
Now, for the next section let’s get into some tools. I love gaming, so I have a Windows computer at home. I don’t really know why we’re wasting money on a Windows license at work, but we are so I can mirror the full stack in both locations. Here’s what I use.
https://notepad-plus-plus.org/
When I first started, my boss insisted I use Dreamweaver for everything. I have nothing against Adobe, and their products are quality, but Dreamweaver was way more trouble than it was worth. Everything I cared about from Dreamweaver I can do in this free and Open Source program, with some extra functionality I find it extremely hard to mimic in Dreamweaver. Notepad++ is fast, stable, and hugely extendable. If you’re doing this as a full time job, I strongly recommend switching to a dark theme for the sake of your eyes. Blackboard is among my favorites (unless you’re trying to write Python). I also really love its macro functionality, I have a couple of re-used DOM structures programmed in there right now as well as my multi-line comment format.
https://winscp.net/eng/download.php
Arguably, the best part of Dreamweaver is the built in FTP client that lets you push changes directly to the server, but set Notepad++ as your primary editor in this, and suddenly you even have that feature, as this will sync temp folders back to the server. This is probably the best FTP client I’ve seen on Windows, with full support for SFTP and SSH (built on PuTTY) with all sorts of encryption and authentication options. It’s also hugely configurable and fairly dependable. If you’re working on a remote server using a Windows machine, this is probably how you should be accessing the file system.
https://www.putty.org/
I hope that as a web developer you don’t have to learn to be a server administrator, but as a web developer I am telling you you’ll probably have to learn at least a little bit about Unix/Linux server administration, as they are by far the most popular web server stacks out there, and you’ll be controlling them with an SSH client at some points, even if a web interface is available. This is a great one, with all sorts of authentication options, so if (like us) you know you need root access to a server remotely, but you don’t like the idea of protecting that with just a simple password, you can set up Public/Private key pairs with encryption passphrases.
http://www.wampserver.com/en/
Let me be clear on this: WAMP, which stands for Windows Apache, PHP, MySQL, is great to have. It’s good for training, it’s good for prototyping tools without having to wait for a virtualized server to start up, but the differences in environments between running Apache, PHP, and MySQL on Windows versus Linux will bite you eventually. Don’t expect to be able to push anything you worked on in WAMP directly to your Linux based server without having to fix a few problems here and there. That said, I have a number of things I run in my WAMP server all the time (linting, IP geolocation, domain DIGs, and a few others). It’s a great tool, but it isn’t a replacement for a staging server.
https://www.virtualbox.org/
You should be using a virtual machine for your staging server. That way you can simulate things like network communications and how your code will actually be run on Linux. Virtual Box is free and powerful. You’ll need to get ISOs for whatever operating system you intend to run, and you should be aware that at least some versions of Windows have it written into their License agreement that you can’t run them virtualized.
https://www.gimp.org/
Gimp is powerful. I don’t really know how to use it well. It’s always been one of those things where I know I need to sit down and teach myself, but since I’ve fallen far into the trenches of server backend work, I haven’t ever had the motivation. Mostly, I use this to resize images when I notice that a website is loading a 14MB PNG on the homepage for some unknown reason. Please designers, think of the mobile phones, keep total page loads (Including all resources, pictures, scripts, and DOM structure) as close to or below 1MB as you can, especially if your site is supported by ad revenue, as there’s no telling how much the ads will need to load on top of that.
https://tools.stefankueng.com/grepWin.html
GrepWin is an implementation of Grep functionality on Windows. For those of you who aren’t aware, Grep is a terminal tool on Linux/Unix that uses a very efficient algorithm to search through large amounts of text for whatever you define, be it flat text, or something represented by a regular expression. It’s super useful for renaming an included document or global variable, and can really save your bacon if your error reporting is being vague. I like this particular implementation because it has context menu integration, so it’s as easy to use as right clicking in the directory you want to search in and telling it to search. It also supports text replacement with backups, so this simple tool is extremely useful more often than I’d like to admit.
https://gitforwindows.org/
The last tool is an implementation of Git for windows that also includes a Bash terminal. This is important because a lot of developers work in Linux, and so installation directions might only be available as Bash code, this makes it easy to move past that step without being bogged down translating that into Windows CMD code. This is a full implementation of Git, so it comes with all of the version control features and easy project building that Git provides. If you end up working with Electron or Node.JS in general, you’ll end up leaning on this pretty hard.
And that’s it. I’m hoping that later this week I can get into more interesting stuff, but I wanted to have a foundational post of the resources I might reference and the tools I’m using for people to fall back on. It’s the kind of thing I wish I had to reference when I was starting out, especially since all of the tools I’m using now are free and Open Source, and making that change has sped up my workflow significantly, as the only application I’ve listed here with any noticeable boot time is Gimp, something I hated about Dreamweaver every time I had to shut the computer down for whatever reason.
I plan on coming back to this post periodically and updating it as my opinions change, or I become aware of other resources that should be on here. Eventually I’ll also be lining out a software for Linux section, but I’m still shopping around for an affordable and stable Linux development machine.
Next time I think we’re going to dive right into some anecdotes about code commenting and design patterns, and why it pays to think about those from the beginning. Nothing glamorous, but I’d argue hugely important, and you get to laugh with me about some dumb things I’ve done.
4 notes
·
View notes
Text
Ajax Tools for testing
The Ajax (Asynchronous JavaScript and XML) development language can be used to create dynamic web based software. Ajax, together with PHP coding may also enrich PHP application development. There are a number of tools which are used to check bugs within a web software to verify overall performance as well as scalability.

Testing Of programs developed with Ajax has previously been difficult but due to the latest innovations in technology, there are a number of methods and tools that could relieve the issues that are apparent with testing associated with programs created working with Ajax.
This small Ajax tutorial will educates you on a number of these fantastic test ajax tools:
Sprajax: Sprajax will allow scanning associated with web software produced on Ajax to get tested for security threats. This will be as a result of assisting with Security assessment. Sparajax includes the following functions:
Spiders web applications
Detects the Ajax frameworks utilized
Detects any Ajax-specific endpoints for the frameworks
Fuzzes endpoints using framework which are appropriate HTTP requests
SWExplorer Automation (SWEA): SWEA uses automation API's pertaining to internet applications together with Ajax, HTML code and DHTML. The automation API provides use of web software contents along with associated controls.
The SW Explorer Automation Visual Designer makes the automation API work. Programmable objects may also be created using the specific Visual designer component. SWExplorer Automation also provides protected login (HTTPS).
Test scripts are created with C# as well as VB.NET. By making use of SWEA macros, test scripts could be reused without adjustments or even re-recordings.
Squish: Is an automated Graphical user interface air hammer bits testing tool used in functional and regression tests of the GUI. Testing can be designed in well recognized programming languages such as Perl, Python and also JavaScript.
It's main functions are:
Smart recording and replay operation.
Automated confirmation points for increased efficiency and also a 'Squish spy' tool.
Batch execution with test data.
Support for Data driven testing.
Flexibility with full control of test out execution and test out results.
Parasoft Webking: Webking is a website testing product developed by Parasoft Corporation used in enhancing the efficiency, performance, robustness of a web program. This allows users to be able to record their mouse clicks and also documents as well as performs it back again. This software detects the run period problem occurring in a program execution including exceptions. It also delivers an automatic framework to test the components of Ajax programs and after that merges these elements into a test suite.
Webking has an easy to use GUI interface to create scripts. Tests will be produced using Junit assessments, along with Java development which could be used to enhance it's effectiveness.
Selenium: Is a software testing framework specifically produced for web applications. Selenium gives users Record/Playback features. With Selenese - Selenium Commands that are used to run tests, Users can create tests in several development languages like Python, Ruby, Pearl, Groovy, PHP etc. Selenium can be used on Macintosh, Linux and Windows platform.
Selenium tests are often run directly on internet browsers and as a result allows simulating the user experience. They can operate with popular web browsers such as Firefox, Internet explorer.
Windmill: Windmill enables users to automate plus debug your online applications. It supports a number of different domains and debugging and documenting is actually integrated. Tests can be created in JavaScript because it involves Javascript framework.
Windmill is written in Python and Javascript. It facilitates web browsers like IE, Safari, Firefox and Chrome. The Software also supports integrated debugging tools such as Firebug, Firebug lite as well as inspector.
Testertools is the Largest Open Source Software Testing ajax driver sets Tool and Commercial off the Shelf Tool website on the internet, including a dedicated Ajax Testing Tools section that showcases the latest Ajax Software Testing Tools.
0 notes
Note
O great and powerful twine god! Do you think it'd be possible to call up the player's stats ingame as the result of a choice? Like, say, if you wanted to break the 4th wall and be like "hm according to this stat you should have succeeded here."
I think having it show as an actual section of the stat screen might be too much but could it call up the number at least like "according to this stat, which is x"?
Hi! Definitely not a god, but I’ll try my best to explain a couple solutions! Just an FYI, everything I discuss here is for SugarCube and will not work in other Story Formats (though you can probably adapt it).
What you want to do is possible, it just depends on how you want to do it. Wayfarer employs something similar to this. I have notifications that fire every time you pass or fail a stat check, as well as ones for approval and romance.
I use Chapel’s Notify macro to do this. It’s pretty easy to install (requires a piece of code in your game’s JavaScript and a piece in your CSS for styling). You can edit the CSS to match the aesthetics of your game. The macro uses the following expression:
<<notify>>TEXT HERE<</notify>>
Put that into whatever passage you want to have the notification. You can control how long the notification lasts by inputting the amount of seconds you want it to last after the first notify (i.e. <<notify 5s>>TEXT HERE<</notify>>).
Now, the notify macro is only intended to appear for a short amount of time. You can’t really use it to convey a lot of information. You also can’t stack notifications - only one can appear, so if you have two or more appearing on the same passage, whichever one is listed last will overwrite the others.
If you’re intending to go meta with it and want to add more personality and need more space and time, you could look at a few different options. Sorry if I am overexplaining things here, I’m approaching this from a beginner’s POV. Apologies if you’re already familiar with some of these functions!
For the following examples, I have a set of 4 player stats: Daring, Finesse, Charm and Resourcefulness. I have decided that the player needs a stat of 10 in order to pass.
1) Redirect The Player to a Fail/Try Again Passage

This is the simplest version. If the player cannot pass a check, clicking on the passage link will direct them to a passage that tells them that they cannot pass it (and gives their stat level), and then from there redirects them back to the starting passage with their list of choices.
For each option, you need to create a “pass” version and a “fail” version contained with a conditional <<if>> macro. Because we’re using numbers to check the stat, you can do something like this:
<<if $daring >=10>>[[1. Fight back.]]<<else>>[[1. Fight back|Stat Warning Daring]]<</if>>
In this example, the expression checks if the player’s Daring stat ($daring) is greater than or equal to 10.
When using with numbered stats that you intend to grow throughout the game, it’s better to greater than and less than expressions rather than equal to expressions so you can account for player stat growth over the course of your game.
If I made used this expression:
<<if $daring == 10>>
or
<<if $daring is 10>>
Then the player would have to have exactly 10 Daring. No more, no more less. Which can be a problem if you’re growing your stats throughout the game.
Back to the example. With this expression, if the player doesn’t have 10 or more daring then the link that goes to the “Fight back” passage is not printed. Instead, they are directed to a passage that contains a warning about their stats (you can name your passages whatever you want).
[[1.Fight back|Stat Warning Daring]] is used to mask that it is a different passage link from “Fight back”. The player will still see 1. Fight back, but by using | in the passage link, I can display the text of one thing on the passage link and direct the player to a separate passage.
Original Passage

Redirected Passage with the warning about their Daring stat being too low.

Clicking on “Try again” takes them back to the original passage.
2) Using a Pop Up to Indicate Stat Failure

It can be a little disruptive to the flow of a game have the player click onto a separate passage and then go back to the original set of choices and try again. Instead of directing to a new passage, you can have a dialog box pop up instead to let the player know that their stat was too low.
Similar to before, you need to have one passage link for a stat pass and one passage link for a stat fail. Now, even though this is going to have the ILLUSION that the player is clicking through to the same passage, it’s actually going to be a separate one.
Give each stat fail its own separate passage. In this example, there is a separate fail passage for Daring, Finesse, Charm and Resourcefulness. Copy/paste over the same text as there was in your starting passage.
At the start of each of these new passages, you’re going to trigger the Dialog Box API. A dialog box is a basic pop up. It needs three pieces of information to run:
1) A separate passage that contains the text you want the popup to print
In this example, I gave every stat their own “fail warning”. These passages aren’t linked to in the game, they simply exist to contain the text I want the popup to show later on.
2) Dialog.setup
This gives your pop up a title. If you don’t want a title, then leave the text inbetween the parentheses blank.
Dialog.setup();
Instead of
Dialog.setup(“TITLE HERE”);
2) Dialog.wiki
This tells Twine which passage to retrieve the information. This needs to be the title of a passage you created in Step 1.
So, for example:
Dialog.wiki(Story.get("Stat Warning Daring").processText());
So, in this example, the dialog box is triggered by the following code:
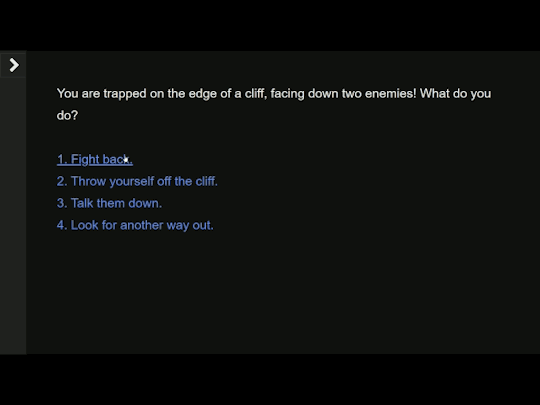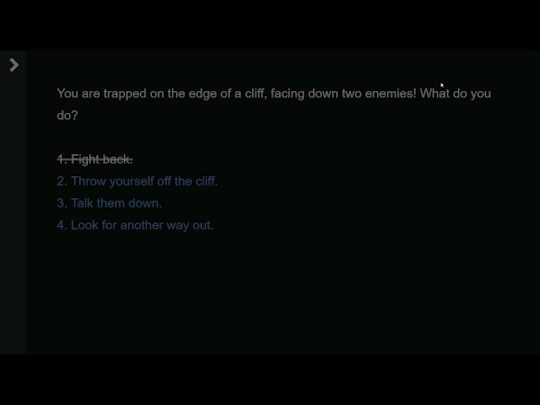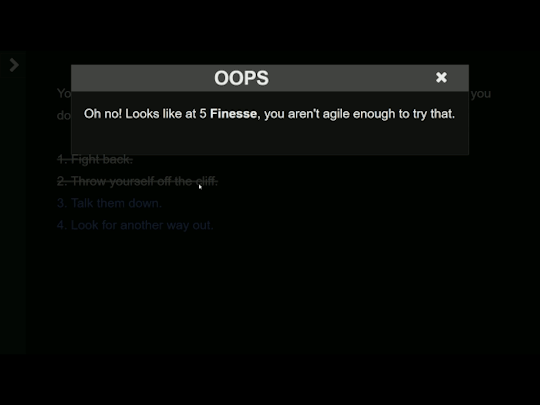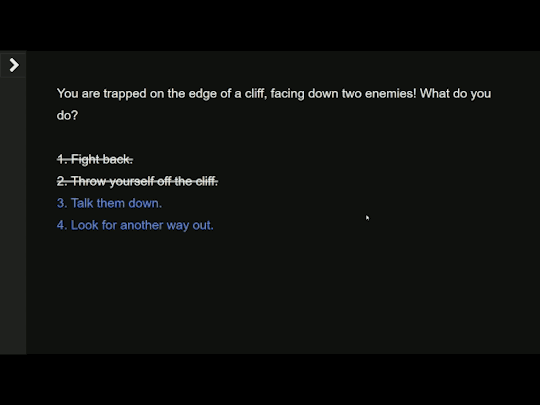
<<script>>Dialog.setup("Oops"); Dialog.wiki(Story.get("Stat Warning Daring").processText()); Dialog.open();<</script>>
Repeat this for each stat and you’ve got a loop with stat fail pop ups.
3) Using a Pop Up and Crossing Out Options
In the above examples, the player can infinitely click on the links where they fail their stat check. They can’t progress anywhere, so to streamline the flow of the game, you may want to visually indicate that they cannot retry the options they’ve already clicked on.
Set everything up the way you did in Example 2. Except this time, we’re going to add in some extra code to make the options crossed out after the player visits them.
To do this, we’re going to use the hasVisited function. hasVisited checks the game’s history. If the player has visited certain passages, you can control what they see using conditional expressions.
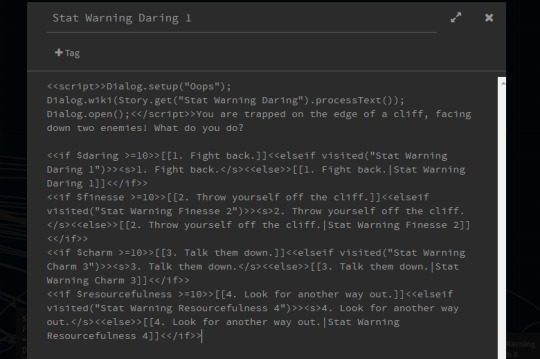
So, in this case, say the player clicks on the 1. Fight them and fails their Daring check. They are redirected to the passage named “Stat Warning Daring 1″.
If I add
<<elseif visited(“Stat Warning Daring 1″)>><<s>1. Fight Back.</s>
to the middle of the conditional expression, then the game will cross out that option if the passage “Stat Warning Daring 1″ has been visited by the player. Using the HTML <s> tag gives the text a strikethrough.
The full new expression now becomes:
<<if $daring >=10>>[[1. Fight back.]]<<elseif visited("Stat Warning Daring 1")>><s>1. Fight back.</s><<else>>[[1. Fight back.|Stat Warning Daring 1]]<</if>>
This means the game checks in this order:
If Daring is 10 or over, it shows the passage link that leads to a stat pass.
If Daring is under 10 and the player has visited the passage that gave them the Daring stat failure pop up, then that option is now crossed out.
If neither of the above are true, then the game shows the link that will lead to a Daring stat fail and the associated pop up.
4) Containing It to a Single Passage
Now, theoretically you should be able to do all of this in a single passage. You can use the switch expression to change the text the player sees every time they visit the same passage.
<<switch visited()>><<case 1>>
Will show whatever text you see here the first time the player visits the passage.
Add <<case 2>> after to change it to the next bit of text and so on and so forth.
Use <<default>> if there is a bit of text you want the player to always see after a certain amount of cases, and then close it off with <</switch>>.
The next thing is to set up some kind of variable to control what popup the player sees. You can’t rely on game history here because you aren’t visiting any extra passages, so instead we’re going to use variables within links.
I’ve created a new set of variables called $tempDaring, $tempFinesse, $tempCharm and $tempResourcefulness and set them all to 0 in my StoryInit passage.
Then in my passage links, I’ve changed it so that the stat fails re-route to the exact same passage. I have also added a bit of code that changes what scripts are run depending on whether the $temp variables are greater than or equal to 1. If they are under 1, then the dialog boxes don’t trigger. If they are over, they do.

I have also increased the $temp variables by 1 in the passage link so when the passage reloads, the game thinks $tempDaring is now equal to 1 and now displays the code that runs the popup for failing your Daring stat. When the passage is revisited, the Daring option will be crossed out.

Now, there’s a couple of issues with this. Namely, if you’re going to use this multiple times throughout the game, you’ll want to reset all of these $temp stats to 0 as soon as the player leaves this section. Otherwise the numbers will be off the next time you use it.
You could use temporary variables to hold that information ( _variable rather than $variable), but I think the case switch breaks the temporary variables (I did quickly check while writing this post, but not very thoroughly). I don’t use temp variables very often, only in very specific cases and I came up with these examples off the top of my head.
I hope that makes sense. There are many, many ways to conceivably pull off what you want to do. There’s no right or wrong answer, it’s just a matter of finding what works for you and how you want to code it.
65 notes
·
View notes
Text
Thinking about Lisp, software development and collaboration.
So like I've been reading a lot of Paul Graham's On Lisp, and Doug Hoyte's Let Over Lambda, and it's been... interesting.
Cut to spare the timeline.
Like, I don't pretend that I understand these works completely, or that I have anything more than a semi-functional understanding of Lisp — most of my work on Lisps have been on Emacs Lisp, which is really showing it's age, and I've honestly never touched macros in any reasonable level, because honestly speaking macros have a frightening reputation. Thanks to Graham and Hoyte's walkthrough of some of the concepts, though, I think my understanding's a little better, though it can only be tested if I can implement stuff on Common Lisp, if that day ever comes.
What struck me about the commentary was that, well, how much both Hoyte and Graham are fans of the language, and how they often extol its virtues. To both of them, Lisp is something that transcends other languages, that allow programmers to do things that are closer to the problem domain than anything else that people have made. That, when you make a programming language approach the kind of power, extensibility and flexibility that Lisp does, surprise! You've made another flavor of Lisp.
This is a seriously grand claim, but I kept being bugged by one question:
If Lisp Was So Good, Why Isn't It Used More Often?
Like, seriously, I kept reading these claims, and to some degree I could see them backing these claims with examples... and yet if you look at Common Lisp and Scheme projects on the Internet... they're like... scattered and fragmented. You can code, and most importantly, an overwhelming number of people do, from the beginning to the end, full-stack web applications in JavaScript. Lua gets used in everything from window managers to video games customization to desktop widgets. Python's still prevalent in web development to data sciences, and yes, some video games are customized in Python. Like, Ruby was everywhere for a while before it receded.
Like the only exceptions to this are, I guess, Emacs Lisp, which basically sticks with Emacs, and Clojure, which is tied to the JVM, and ClojureScript, which outputs JavaScript. Note how reliant they are on other software and frameworks.
The Answers I've Seen So Far
So, what gives? Like, I've been looking around, and I've seen basically two answers:
Lisp Isn't Popular Because People Are Stupid
No, seriously. This is the argument. Paul Graham engages in it:
People frightened by Lisp make up other reasons for not using it. The standard excuse, back when C was the default language, was that Lisp was too slow. Now that Lisp dialects are among the faster languages available, that excuse has gone away. Now the standard excuse is openly circular: that other languages are more popular.
(Beware of such reasoning. It gets you Windows.)
Popularity is always self-perpetuating, but it's especially so in programming languages. More libraries get written for popular languages, which makes them still more popular. Programs often have to work with existing programs, and this is easier if they're written in the same language, so languages spread from program to program like a virus. And managers prefer popular languages, because they give them more leverage over developers, who can more easily be replaced.
Hoyt engages in this, as well:
Macros have, not by accident, almost as much history as lisp itself, being invented in 1963 by Timothy Hart[MACRO-DEFINITIONS]. However, macros are still not used to the fullest possible extent by most lisp programmers and are not used at all by all other programmers. This has always been a conundrum for advanced lispers. Since macros are so great, why doesn't everybody use them all the time? While it's true that the smartest, most determined programmers always end up at lisp macros, few start their programming careers there. Understanding why macros are so great requires understanding what lisp has that other languages don't. It requires an understanding of other, less powerful languages. Sadly, most programmers lose the will to learn after they have mastered a few other languages and never make it close to understanding what a macro is or how to take advantage of one. But the top percentile of programmers in any language are always forced to learn some sort of way to write programs that write programs: macros. Because it is the best language for writing macros, the smartest and most determined and most curious programmers always end up at lisp.
I mean, the argument is pretty clear: because Lisp is so powerful, and that it takes so much study and effort to work at it, that only top-tier programmers are the only ones who understand Lisp. Implied, however, is the assumption that if you don't get Lisp, well, you're not a top-tier programmer, and you Just Don't Get It.
Which gets to the second explanation of why Lisp isn't popular:
Lisp Users Are Assholes
I mean, the above quotes are a sampling, and, honestly, a mild one, of the perceived attitudes of Lisp aficianados to the outside world. And it doesn't help that Hoyt then proceeds to call other non-Lisp Languages “Blub”, which, despite his many attempts to soften the blow, just makes him sound like an asshole. Like, you could have said “other languages”, dude. Sure it's less efficient, but you're dealing with people, not machines.
Like, Mark Tarver has an essay about the assholishness of Lisp users, which I don't recommend you read, because CONTENT WARNING ableism1. Maybe if you wanna take a look at commentary on that, you can go for Rudolf Winestock's The Lisp Curse, which is a little better, I guess?
Lisp is so powerful, that it encourages individual independence to the point of bloody-mindedness. This independence has produced stunningly good innovation as in the Lisp Machine days. This same independence also hampers efforts to revive the “Lisp all the way down” systems of old; no “Lisp OS” project has gathered critical mass since the demise of Symbolics and LMI.
[...]
Why [doesn't the Lisp community] make a free development system that calls to mind some of the lost glories of the LispM, even if they can't reproduce another LispM?
The reason why this doesn't happen is because of the Lisp Curse. Large numbers of Lisp hackers would have to cooperate with each other. Look more closely: Large numbers of the kind of people who become Lisp hackers would have to cooperate with each other.
The argument is, commercially, if you're a brilliant asshole, no one wants you. While your brilliance would be an asset for a while, what really makes organizations and enterprises scale isn't the fact that they hire brilliant people, but that they hire and use people brilliantly, in ways that are robust and don't rely on having the Right Kind of People on board. It's also why computer security is such a fucking thing to get right, because most of the solutions seem to be... hire the best in the industry and go with that? Which works great until your Chief Security Officer gets run over by a bus a better offer from the competition. Then what?
I mean, yes, capitalist models rely on you having a development workforce that is fungible, because it is cheaper in the long run, but it also reduces risk, even if reducing labor costs aren't a thing for you. It's also more democratic that way, because, yes, you need it to be accessible and approachable to the people who are affected by your code. And it needs to be reproducible, because if not, what if it's scientific work and we need to verify it?
But, even then, this diagnosis — that, charitably, the expressiveness of Lisp attracts brilliant assholes who can't even be convinced to work with one another rankles, because it fundamentally means that there's no solution. The language is too good for normies, and only assholes will use it, ∴ that's the end. Nothing more can be said.
I wonder if there's more to it. And I suspect there might be.
The Social Models Around Lisp Might Actually Be Toxic
Notice the commonality around the four people I've quoted above?
Yup.
They're all white dudes.
I'm not saying that the Lisp community is so toxic because the loudest voices within Lisp are all white men. I'm saying that the fundamental assumptions that these white men have about what is good might actually be a reason why Lisp's community might be so toxic.
There's a difference. Bear with me.
Graham actually talks about the process of developing software in Lisp — the bottom-up approach — but he talks about it in a way that assumes that development occurs with a single person, and that the final vision of the problem space is the insight of one person, or a small group of people with a common enough vision: sort of a Cathedral-style system. Does it have to be?
Why can't bottom-up development occur in a collaborative, cooperative system? Sure, Lisp “doesn't have syntax” (which always weirded me out — it does have syntax, just one that's “invisible” and “self-evident” to a certain class of mind). One that eschews the models that we're used to in capitalist and hegemonic systems. If Lisp is one of the purest forms of mathematical expression, what Hoyt refers to as a “U-Language”, shouldn't it be universally accessible and open to critique?
Maybe the reason why Lisp doesn't work is because the social models around Lisp — one that erases and diminishes the contributions and the lives of people who aren't white men of a certain analytical mindset — make it fail. Maybe whiteness — the social construct, one that lionizes individual brilliance of a specific kind, emphasizes competition over collaboration, pretends that there is an Objective™ Truth over the experiences of others, and considers all emotions other than violent, abusive ones weakness — is the reason why Lisp fails, despite its expressiveness and power.
Maybe the way to do it is to change the way people learn Lisp, and work with Lisp, and collaborate with Lisp, rather than the model we have today.
Could something like that, a system that allows easy, safe collaboration, and organisations that deliberately go for minority and disadvantaged groups, be something that could kick Lisp out of its doldrums?
He calls these people “brilliant bipolar minds”, because, of course. Just because you can diagnose the problem doesn't mean that you don't have the problem as well. ↩︎
1 note
·
View note
Text
Node module deep-dive: fs
Time for another Node module deep-dive!
I got some great feedback from folks that it would be interesting to dive into the C++ portions of the Node codebase in these annotated code reads. I agree. To be honest, I've avoided it up to this point mostly because of insecurities about my own knowledge of C++ and understanding about system-level software. But you know what, I am setting all that aside and diving into the C++ portions of the Node codebase because I am a brave and fearless developer.
I say this to clarify that don't take anything I say as absolute fact and if you have insights into portions of the code I misunderstood, let me know on Twitter.
Anyway, let's get down to the fun stuff.
I've been thinking a lot about the fs module. The fs module is a part of the standard library in Node that allows the developer to interact with the filesystem. You can do things like read files, write files, and check the status of files. This is very handy if you are doing something like building a desktop application using JavaScript or interacting with files in a backend server.
One of the fs functions that I use the most is the exists function, which checks to see if a file exists. This function has actually be deprecated recently in favor of fs.stat or fs.access. So with this, I figured it would be interesting to dive in and see how fs.access works in Node. Just so we are all on the same page, here is how you might use fs.access in an application.
> const fs = require('fs'); undefined > fs.access('/etc/passwd', (error) => error ? console.log('This file does not exist.') : console.log('This file exists.')); undefined > This file exists.
Neat-o! So we can pass a filename and a callback that takes an error. If the error exists then we cannot access the file but if it does not exist then we can. So let's head over to the fs module in the codebase to see what's up. The code for the fs.access function looks like this.
fs.access = function(path, mode, callback) { if (typeof mode === 'function') { callback = mode; mode = fs.F_OK; } else if (typeof callback !== 'function') { throw new errors.TypeError('ERR_INVALID_CALLBACK'); } if (handleError((path = getPathFromURL(path)), callback)) return; if (typeof path !== 'string' && !(path instanceof Buffer)) { throw new errors.TypeError('ERR_INVALID_ARG_TYPE', 'path', ['string', 'Buffer', 'URL']); } if (!nullCheck(path, callback)) return; mode = mode | 0; var req = new FSReqWrap(); req.oncomplete = makeCallback(callback); binding.access(pathModule.toNamespacedPath(path), mode, req); };
So like I mentioned before, it takes a path and a callback. It also takes a mode parameter which you can read more about here. Most of the first few lines in the function are your standard validation and safety checks. I'll avoid going into them here because I think they are pretty self-explanatory. I know it's kind of annoying when people do the hand-wavey thing about code so if you have specific questions about these lines I'm overlooking, just ask me.
The code gets a little bit more interesting once we get to the last few lines in the function.
var req = new FSReqWrap(); req.oncomplete = makeCallback(callback); binding.access(pathModule.toNamespacedPath(path), mode, req);
I've never seen this FSReqWrap object before. I assume it's some low-level API within the Node ecosystem for dealing with asynchronous requests. I tried to figure out where this Object is defined. The require statement for it looks like this.
const { FSReqWrap } = binding;
So it looks like it is extracting the FSReqWrap object from binding. But what is binding?
const binding = process.binding('fs');
Hm. So it seems to be the result of invoking process.binding with the 'fs' parameter. I've seen these process.binding calls sprinkled across the codebase but have largely avoided digging into what they are. Not today! A quick Google resulted in this StackOverflow question, which confirmed my suspicion that process.binding was how C++-level code was exposed to the JavaScript portion of the codebase. So I dug around the Node codebase to try and find where the C/C++ code for fs resided. I discovered that there were actually two different C-level source files for fs, one associated with Unix and another associated with Windows.
So I tried to see if there was anything resembling a definition for the access function in the fs C source for Unix. The word access is referenced four times in the code.
Twice here.
#define X(type, action) \ case UV_FS_ ## type: \ r = action; \ break; switch (req->fs_type) { X(ACCESS, access(req->path, req->flags));
And twice here.
int uv_fs_access(uv_loop_t* loop, uv_fs_t* req, const char* path, int flags, uv_fs_cb cb) { INIT(ACCESS); PATH; req->flags = flags; POST; }
Now you know what I meant about the whole "The C part of this code base makes me nervous" bit earlier.
I felt like the uv_fs_access was a lot easier to look into. I have no idea what is going on with that X function macro business and I don't think I'm in a zen-like state of mind to figure it out.
OK! So the uv_fs_access function seems to be passing the ACCESS constant to the INIT function macro which looks a little bit like this.
#define INIT(subtype) \ do { \ if (req == NULL) \ return -EINVAL; \ req->type = UV_FS; \ if (cb != NULL) \ uv__req_init(loop, req, UV_FS); \ req->fs_type = UV_FS_ ## subtype; \ req->result = 0; \ req->ptr = NULL; \ req->loop = loop; \ req->path = NULL; \ req->new_path = NULL; \ req->cb = cb; \ } \ while (0)
So the INIT function macro seems to be initializing the fields in some req structure. From looking at the type declarations on the function parameters of functions that took req in as an argument, I figured that req was a pointer to a uv_fs_t Object. I found some documentation that rather tersely stated that uv_fs_t was a file system request type. I guess that's all I need to know about it!
Side note: Why is this code written in a do {} while (0) instead of just a sequence of function calls. Does anyone know why this might be? Late addition: I did some Googling and found a StackOverflow post that answered this question.
OK. So once this filesystem request object has been initialized, the access function invokes the PATH macro which does the following.
#define PATH \ do { \ assert(path != NULL); \ if (cb == NULL) { \ req->path = path; \ } else { \ req->path = uv__strdup(path); \ if (req->path == NULL) { \ uv__req_unregister(loop, req); \ return -ENOMEM; \ } \ } \ } \ while (0)
Hm. So this seems to be checking to see if the path that the file system request is associated with is a valid path. If the path is invalid, it seems to unregister the loop associated with the request. I don't understand a lot of the details of this code, but my hunch is that it does validation on the filesystem request being made.
The next invocation that uv_fs_access calls is to the POST macro which has the following code associated with it.
#define POST \ do { \ if (cb != NULL) { \ uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \ return 0; \ } \ else { \ uv__fs_work(&req->work_req); \ return req->result; \ } \ } \ while (0)
So it looks like the POST macros actually invokes the action loop associated with the filesystem request and then executes the appropriate callbacks.
At this point, I was a little bit lost. I happened to be attending StarCon with fellow code-reading enthusiast Julia Evans. We sat together and grokked through some of the code in the uv__fs_work function which looks something like this.
static void uv__fs_work(struct uv__work* w) { int retry_on_eintr; uv_fs_t* req; ssize_t r; req = container_of(w, uv_fs_t, work_req); retry_on_eintr = !(req->fs_type == UV_FS_CLOSE); do { errno = 0; #define X(type, action) \ case UV_FS_ ## type: \ r = action; \ break; switch (req->fs_type) { X(ACCESS, access(req->path, req->flags)); X(CHMOD, chmod(req->path, req->mode)); X(CHOWN, chown(req->path, req->uid, req->gid)); X(CLOSE, close(req->file)); X(COPYFILE, uv__fs_copyfile(req)); X(FCHMOD, fchmod(req->file, req->mode)); X(FCHOWN, fchown(req->file, req->uid, req->gid)); X(FDATASYNC, uv__fs_fdatasync(req)); X(FSTAT, uv__fs_fstat(req->file, &req->statbuf)); X(FSYNC, uv__fs_fsync(req)); X(FTRUNCATE, ftruncate(req->file, req->off)); X(FUTIME, uv__fs_futime(req)); X(LSTAT, uv__fs_lstat(req->path, &req->statbuf)); X(LINK, link(req->path, req->new_path)); X(MKDIR, mkdir(req->path, req->mode)); X(MKDTEMP, uv__fs_mkdtemp(req)); X(OPEN, uv__fs_open(req)); X(READ, uv__fs_buf_iter(req, uv__fs_read)); X(SCANDIR, uv__fs_scandir(req)); X(READLINK, uv__fs_readlink(req)); X(REALPATH, uv__fs_realpath(req)); X(RENAME, rename(req->path, req->new_path)); X(RMDIR, rmdir(req->path)); X(SENDFILE, uv__fs_sendfile(req)); X(STAT, uv__fs_stat(req->path, &req->statbuf)); X(SYMLINK, symlink(req->path, req->new_path)); X(UNLINK, unlink(req->path)); X(UTIME, uv__fs_utime(req)); X(WRITE, uv__fs_buf_iter(req, uv__fs_write)); default: abort(); } #undef X } while (r == -1 && errno == EINTR && retry_on_eintr); if (r == -1) req->result = -errno; else req->result = r; if (r == 0 && (req->fs_type == UV_FS_STAT || req->fs_type == UV_FS_FSTAT || req->fs_type == UV_FS_LSTAT)) { req->ptr = &req->statbuf; } }
OK! I know this looks a little bit scary. Trust me, it scared me when I first looked at it too. One of the things that Julia and I realized was that this bit of the code.
#define X(type, action) \ case UV_FS_ ## type: \ r = action; \ break; switch (req->fs_type) { X(ACCESS, access(req->path, req->flags)); X(CHMOD, chmod(req->path, req->mode)); X(CHOWN, chown(req->path, req->uid, req->gid)); X(CLOSE, close(req->file)); X(COPYFILE, uv__fs_copyfile(req)); X(FCHMOD, fchmod(req->file, req->mode)); X(FCHOWN, fchown(req->file, req->uid, req->gid)); X(FDATASYNC, uv__fs_fdatasync(req)); X(FSTAT, uv__fs_fstat(req->file, &req->statbuf)); X(FSYNC, uv__fs_fsync(req)); X(FTRUNCATE, ftruncate(req->file, req->off)); X(FUTIME, uv__fs_futime(req)); X(LSTAT, uv__fs_lstat(req->path, &req->statbuf)); X(LINK, link(req->path, req->new_path)); X(MKDIR, mkdir(req->path, req->mode)); X(MKDTEMP, uv__fs_mkdtemp(req)); X(OPEN, uv__fs_open(req)); X(READ, uv__fs_buf_iter(req, uv__fs_read)); X(SCANDIR, uv__fs_scandir(req)); X(READLINK, uv__fs_readlink(req)); X(REALPATH, uv__fs_realpath(req)); X(RENAME, rename(req->path, req->new_path)); X(RMDIR, rmdir(req->path)); X(SENDFILE, uv__fs_sendfile(req)); X(STAT, uv__fs_stat(req->path, &req->statbuf)); X(SYMLINK, symlink(req->path, req->new_path)); X(UNLINK, unlink(req->path)); X(UTIME, uv__fs_utime(req)); X(WRITE, uv__fs_buf_iter(req, uv__fs_write)); default: abort(); } #undef X
is actually a giant switch-statement. The enigmatic looking X macro is actually syntactic sugar for the syntax for the case statement that looks like this.
case UV_FS_ ## type: \ r = action; \ break;
So, for example, this macro-function call, X(ACCESS, access(req->path, req->flags)), actually corresponds with the following expanded case statement.
case UV_FS_ACCESS: r = access(req->path, req->flags) break;
So our case statement essentially ends up calling the access function and setting its response to r. What is access? Julia helped me realized that access was a part of the system's library defined in unistd.h. So this is where Node actually interacts with system-specific APIs.
Once it has stored a result in r, the function executes the following bit of code.
if (r == -1) req->result = -errno; else req->result = r; if (r == 0 && (req->fs_type == UV_FS_STAT || req->fs_type == UV_FS_FSTAT || req->fs_type == UV_FS_LSTAT)) { req->ptr = &req->statbuf; }
So what this is basically doing is checking to see if the result that was received from invoking the system-specific APIS was valid and stores it back into that filesystem request object that I mentioned earlier. Interesting!
And that's that for this code read. I had a blast reading through the C portions of the codebase and Julia's help was especially handy. If you have any questions or want to provide clarifications on things I might have misinterpreted, let me know. Until next time!
7 notes
·
View notes
Text
Getting the file you wish to test
To start with, established a brand-new npm project, as gone over in setting up node and npm in the last chapter. call it something different, like selenium-test. next, we need to install a framework to allow us to work with selenium from within node. we are going to choose selenium's official selenium-webdriver, as the documentation appears relatively up-to-date and it is properly maintained. if you desire various options, webdriver.io and nightwatch.js are likewise good options. to install selenium-webdriver, run the following command, making sure you are inside your project folder:
In the days before web applications, programmers composed applications for a specific platform and utilized that platform's native development environment and interface controls. prior to the application's last release, a tester would check that the application was all set. some testers composed sophisticated files that explained complex scenarios they performed on the software manually. other, more adventurous testers utilized elegant tools that were the quality control version of microsoft's word and excel macro recorders. a tester would record a series of actions on the software under test. these steps were recorded in a high-level language in which the tester might edit the code and add test conditions that would validate that the real results of the test matched the anticipated results. each time a test was run, a report was created that showed which conditions had actually been passed or failed.

Serenity bdd is an open source reporting library that assists you write better structured, more maintainable automated acceptance criteria. serenity also produces abundant meaningful test reports (or "living documentation") that report not only the test results, but likewise which features have actually been tested. an in-depth tutorial on utilizing cucumber-jvm with serenity can be discovered here, and more information on serenity can be found on their main website.
A Simple Guide to Web Browser Automation
100% dependable browser automation tool throughout innovations simple-to-use selenium-based browser automation tool for all web applications no matter the underlying technology. never ever type a single line of code the leapwork automation platform lets both technical and non-technical experts design selenium-based browser automation flows from day one without ever typing or checking out a single line of code.
The chromium browser automation is a simple extension for your browser. it's a full-featured automation tool that assists you prevent repetitive activities. it can assist you automate simple activities like filling out forms while still being complex adequate to support scripting and injection. some of its significant functions: record: here you can record activities you are presently performing on your web browser. record in this sense does not mean a screen recording. it means that the extension stores all your interactions with the websites.
Websites and web applications
Whether youre a software developer or merely running several high-performing, application-rich websites, browser automation is promptly becoming one of the most demanded ways to check numerous site processes and codes. as web-based technology progresses and becomes more dynamic, the requirement for dynamic testing solutions grows. while there are many ways to test the functionality of your website and applications, browser automation offers a means of carrying out such tasks without the requirement for manual control. eventually, browser automation tools and techniques save web designers hours in time and labor costs.
Test design, execution, reporting and integration: ranorex studio is your all-in-one browser automation framework ranorex studio includes all of the tools for browser automation right out of the box, without the need to assemble your own framework. automate tests for every single kind of browser action with or without coding. ranorex studio supports a broad variety of web innovations and frameworks including html5, java and javascript websites, salesforce, sap, flash and flex applications, and a lot more. ranorex studio even supports hybrid desktop applications based upon the open-source chromium ingrained framework (cef). with ranorex studio, you can execute tests throughout browsers and devices, trigger tests from your ci server, get detailed test run reports, and pass test results to tools such as jira, bugzilla or testrail.
Browser Automation Using Selenium
Selenium is one of the most popular browser automation tools. it is not based on a specific programming language and supports java, python, c#, ruby, php, perl, etc. you can likewise write your implementation for the language if it isn't already supported. in this tutorial, we'll learn how to utilize the java bindings of selenium webdriver. we'll also explore the webdriver api.
With tools like selenium and record and replay, it's simpler than ever for groups to attain browser automation in order to shorten testing cycles and improve code protection. rather of manually testing across chrome, safari, firefox, and internet explorer, you can create one test and repeat it across multiple browsers in parallel.
Selenium is a powerful tool for managing web browser through program. it is functional for all browsers, deals with all major os and its scripts are written in different languages i.e python, java, c# etc, we will be dealing with python. mastering selenium will assist you automate your everyday tasks like managing your tweets, whatsapp texting and even simply googling without really opening a browser in just 15-30 lines of python code. the limitations of automation is endless with selenium.
youtube
In this tutorial you'll learn advanced python web automation techniques: utilizing selenium with a "headless" browser, exporting the scraped data to csv files, and wrapping your scraping code in a python class.
Browser Automation & Web Application Testing
Selenium is the family name when it comes to test automation. it is considered the industry standard for interface automation testing of web applications. nearly nine out of ten testers are utilizing or have ever utilized selenium in their projects, according to study on test automation difficulties. for developers and testers who have experience and skills in programming and scripting, selenium offers flexibility that is hidden in numerous other test automation tools and frameworks. users can write test scripts in several languages (such as java, groovy, python, c#, php, ruby, and perl) that operate on multiple system environments (windows, mac, linux) and browsers (chrome, firefox, ie, and headless browsers).
Geb is a browser automation solution. it unites the power of webdriver, the elegance of jquery content choice, the toughness of page object modelling and the expressiveness of the groovy language. it can be used for scripting, scraping and general automation-- or similarly as a functional/web/acceptance testing solution via integration with testing frameworks such as spock, junit & testng.
0 notes
Text
Automate Tests using Java or TypeScript
Want to automate tests with Java or TypeScript?
Test design, execution, reporting and integration: ranorex studio is your all-in-one browser automation framework ranorex studio includes all of the tools for browser automation right out of the box, without the need to assemble your own framework.automate tests for every type of browser action with or without coding. ranorex studio supports a broad variety of web technologies and frameworks including html5, java and javascript websites, salesforce, sap, flash and flex applications, and a lot more. ranorex studio even supports hybrid desktop applications based upon the open-source chromium embedded framework (cef). with ranorex studio, you can perform tests across browsers and devices, trigger tests from your ci server, get detailed test run reports, and pass test results to tools such as jira, bugzilla or testrail.

Use imacros for functional, performance, and regression testing of web applications. imacros is the only tool that can automate in-browser tests with internet explorer, firefox and chrome. it is also the only tool to perform in-browser tests of java, flash, flex or silverlight applets and all ajax elements. the integrated stop-watch command records precise websites reaction times for every step of a process. in addition, the macros can be transformed to selenium webdriver code. find out more.
Fill in web forms
The chromium browser automation is a simple extension for your browser. it's a full-featured automation tool that assists you avoid repetitive activities. it can help you automate simple activities like submitting forms while still being complex enough to support scripting and injection. a few of its significant functions: record: here you can record activities you are currently performing on your web browser. record in this sense does not mean a screen recording. it means that the extension shops all your interactions with the web page.
Watir (pronounced water), is an open-source (bsd), household of ruby libraries for automating web browsers. it enables you to write tests that are simpler to read and maintain. it is uncomplicated and flexible. watir drives browsers the same way people do. it clicks links, fills out forms, presses buttons. watir also inspects results, such as whether anticipated text appears on the page.
Seeshell removes the tedious repeating of examining the exact same sites every day, remembering passwords, and submitting web forms. seeshell is a form filler that can autofill web forms that extend over several pages. all information is stored in human-readable, files that can be edited easily. the seeshell file format is open-source.
Test Driving a Headless Browser
Selenium is the family name when it comes to test automation. it is considered the industry standard for user interface automation testing of web applications. almost nine out of 10 testers are using or have actually ever utilized selenium in their projects, according to study on test automation obstacles. for developers and testers who have experience and skills in programming and scripting, selenium offers versatility that is unseen in many other test automation tools and frameworks. users can write test scripts in several languages (such as java, groovy, python, c#, php, ruby, and perl) that operate on multiple system environments (windows, mac, linux) and browsers (chrome, firefox, ie, and headless browsers).
youtube
You have actually tested that you can drive a headless browser utilizing python. now you can put it to utilize: you want to play music. you wish to search and explore music. you desire information about what music is playing. to start, you navigate to and start to poke around in your browser's developer tools. you find a huge glossy play button towards the bottom of the screen with a class attribute that contains the value" playbutton". you check that it works:
A browser automation framework does far more than simply mimic a web browser. for starters, these frameworks can launch either full or headless browsers. a headless browser is a browser without a visual user interface (gui). headless browsers are lighter and faster than full browsers, that makes them the ideal tool for automated developer testing.
CBA is an extension for chrome browser automation
Cba provides ability to automate chrome browser ability to setup step-by-step code injections from extensions popup interface. ability to record interactions in the chrome browser and playing them. projects conserving in browser's local storage. step by step code injection. ability of projects import and export. ability of utilizing cba prepared functions. ability to write your own code that will have access to websites's dom.
Guide to Web Browser Automation
100% reputable browser automation tool across technologies simple-to-use selenium-based browser automation tool for all web applications despite the underlying technology. never type a single line of code the leapwork automation platform lets both technical and non-technical specialists design selenium-based browser automation flows from the first day without ever typing or reading a single line of code.
Whether your a software developer or merely running several high-performing, application-rich websites, browser automation is quickly becoming one of the most sought after ways to check numerous site procedures and codes. as web-based technology evolves and becomes more dynamic, the need for dynamic testing solutions grows. while there are lots of ways to test the functionality of your website and applications, browser automation offers a means of performing such tasks without the need for manual adjustment. eventually, browser automation tools and methods save webmasters hours in time and labor expenses.
Geb is a browser automation solution. it combines the power of webdriver, the beauty of jquery content selection, the robustness of page object modelling and the expressiveness of the groovy language. it can be utilized for scripting, scraping and general automation-- or equally as a functional/web/acceptance testing solution through integration with testing frameworks such as spock, junit & testing.
1 note
·
View note
Note
Hi there, I had two Twine sugarcube questions if you don't mind! The first is, do you mind explaining how to make stat bars? Not only how to style them but what do they look like in the actual sugarcube code? How do you ensure they update when the stat changes? Do you have to do something to manually change the stat bar each time, or does it do it automatically? I'm really struggling to wrap my head around it lol
And now to your first one.
I have never created one myself, only used from a template/copied on the internet. Also I am not sure what kind of stats bar you are looking for (there are many different types), so my answer below will be more general on including/testing stats bar. (If I included them all, it would be too long...)
If you have one type in mind and you want a deep dive on that code, please let me know!
CHOOSING/CREATING STATS BAR
Twine does not have a built-in code for stats. It's a bit of a bummer, I know.
The good news is: other people have created Stats Bar macros/templates so you don't have to create one from scratch (if you don't want to). Below are the ones I know of:
HiEv's Health Bar macro (JScript, CSS)
Chapel's Meter Bar macro (@townofcrosshollow has a tutorial on installing it here) (JScript, CSS)
@innerdemons-if has a template which includes Stats Bar (JScript, HTML/CSS)
Brushmen's template has a special widget for Stats Bar (HTML/CSS)
@idrellegames's tutorial on creating your own Stats Bar (HTML/CSS).
All these options will provide you with the relevant JavaScript/CSS needed to function. BUT each of them have different designs and different way of displaying/coding the stats bar itself:
The last 3 relies more on HTML/CSS code for display, while the first 2 are macros.
All will update when the variable change (though you will need some extra code to update HiEv and Chapel's bars).
All have some different amount of JavaScript and/or CSS you may want to edit to fit your need/vibe.
My advice: test them all and pick the one you prefer (or makes most sense to you). You can always edit how it looks down the line.
UPDATING A STAT BAR
If your stat bar relies primarily on HTML/CSS to be displayed (like the last 3 above), its update will be automatic when the variable connected changes value. Every time you open the Stats Page, the bar will display the last value of the relevant variable.
Note: For realtime update if the bar is displayed on the main page: if you will need wrap your stat code in the <<liveblock>> macro of CyCy's liveupdate code and add the <<update>> one every time the stat changes.
Now, if you use either HiEv's or Chapel's Macro, you will need to include an extra tit-bit of code when the variable is updated. For both, that code is included in the explanation (no more than 5/6 words of code each).
A neat thing about these types is that if the stat bar is shown on the main screen rather than a dedicated stat page, it will include a little animation when the bar updates (you'll see it move).
Again, if you have one type in mind and you want a deep dive on that code, please let me know!
13 notes
·
View notes