#CDC SQL Server
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Tracking Changes in SQL Server 2022
In the latest update of SQL Server 2022, keeping an eye on database table alterations has gotten a bit easier for the folks who build and maintain our databases. This piece is all about giving you the lowdown on how to make the most of SQL Server’s built-in goodies for change tracking. We’re zeroing in on Change Data Capture (CDC) and Temporal Tables, which are like superheroes for making sure…
View On WordPress
#CDC SQL Server#Change Data Capture#Data Auditing SQL Server#System-Versioned Temporal Tables#Temporal Tables SQL Server
1 note
·
View note
Text
"Understanding SQL Server Change Data Capture (CDC): Enhancing Data Management and Insights"
Key Features and Benefits of SQL Server CDC:
Real-Time Change Capture: CDC operates in near real-time, capturing changes made to tables without impacting database performance, ensuring a non-intrusive data capture mechanism.
Granular Data Tracking: It captures all changes at a row level, providing a detailed record of inserts, updates, and deletes, facilitating precise data analysis and reporting.

Efficient Data Replication: SQL Server CDC facilitates seamless data replication to other systems or databases, enabling synchronized data across various platforms for consistent insights.
Simplified Data Auditing: With CDC, organizations can perform comprehensive data audits, track historical changes, and analyze trends for compliance and auditing purposes.
Implementing SQL Server CDC:
Configuration and Setup: Enable CDC on the SQL Server database and configure it for the desired tables to start capturing changes effectively.
Monitoring and Maintenance: Regularly monitor CDC processes to ensure smooth operation, and perform necessary maintenance to optimize performance.
Utilizing Captured Data: Leverage CDC-captured data for reporting, analytics, and other business intelligence initiatives to derive meaningful insights.
Advantages of Using SQL Server CDC:
Data Integration: Employ CDC to integrate data from SQL Server to various analytics and reporting platforms, ensuring data consistency and accuracy.
Real-Time Analytics: Enable real-time analytics by leveraging CDC to stream updated data for immediate analysis and reporting.
Efficient Data Warehousing: CDC facilitates efficient data movement from transactional databases to data warehouses, ensuring timely updates for analytics.
Compliance and Governance: Utilize CDC to maintain data integrity and comply with regulatory requirements, offering accurate and traceable data changes for auditing purposes.
0 notes
Text
Building Complex Data Workflows with Azure Data Factory Mapping Data Flows

Building Complex Data Workflows with Azure Data Factory Mapping Data Flows
Azure Data Factory (ADF) Mapping Data Flows allows users to build scalable and complex data transformation workflows using a no-code or low-code approach.
This is ideal for ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) scenarios where large datasets need processing efficiently.
1. Understanding Mapping Data Flows
Mapping Data Flows in ADF provide a graphical interface for defining data transformations without writing complex code. The backend execution leverages Azure Databricks, making it highly scalable.
Key Features
✅ Drag-and-drop transformations — No need for complex scripting. ✅ Scalability with Spark — Uses Azure-managed Spark clusters for execution. ✅ Optimized data movement — Push-down optimization for SQL-based sources. ✅ Schema drift handling — Auto-adjusts to changes in source schema. ✅ Incremental data processing — Supports delta loads to process only new or changed data.
2. Designing a Complex Data Workflow
A well-structured data workflow typically involves:
📌 Step 1: Ingest Data from Multiple Sources
Connect to Azure Blob Storage, Data Lake, SQL Server, Snowflake, SAP, REST APIs, etc.
Use Self-Hosted Integration Runtime if data is on-premises.
Optimize data movement with parallel copy.
📌 Step 2: Perform Data Transformations
Join, Filter, Aggregate, and Pivot operations.
Derived columns for computed values.
Surrogate keys for primary key generation.
Flatten hierarchical data (JSON, XML).
📌 Step 3: Implement Incremental Data Processing
Use watermark columns (e.g., last updated timestamp).
Leverage Change Data Capture (CDC) for tracking updates.
Implement lookup transformations to merge new records efficiently.
📌 Step 4: Optimize Performance
Use Partitioning Strategies: Hash, Round Robin, Range-based.
Enable staging before transformations to reduce processing time.
Choose the right compute scale (low, medium, high).
Monitor debug mode to analyze execution plans.
📌 Step 5: Load Transformed Data to the Destination
Write data to Azure SQL, Synapse Analytics, Data Lake, Snowflake, Cosmos DB, etc.
Optimize data sinks by batching inserts and using PolyBase for bulk loads.
3. Best Practices for Efficient Workflows
✅ Reduce the number of transformations — Push down operations to source SQL engine when possible. ✅ Use partitioning to distribute workload across multiple nodes. ✅ Avoid unnecessary data movement — Stage data in Azure Blob instead of frequent reads/writes. ✅ Monitor with Azure Monitor — Identify bottlenecks and tune performance. ✅ Automate execution with triggers, event-driven execution, and metadata-driven pipelines.
Conclusion
Azure Data Factory Mapping Data Flows simplifies the development of complex ETL workflows with a scalable, graphical, and optimized approach.
By leveraging best practices, organizations can streamline data pipelines, reduce costs, and improve performance.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
The Evolution and Functioning of SQL Server Change Data Capture (CDC)
The SQL Server CDC feature was introduced by Microsoft in 2005 with advanced “after update”, “after insert”, and “after delete” functions. Since the first version did not meet user expectations, another version of SQL Server CDC was launched in 2008 and was well received. No additional activities were required to capture and archive historical data and this form of this feature is in use even today.
Functioning of SQL Server CDC
The main function of SQL Server CDC is to capture changes in a database and present them to users in a simple relational format. These changes include insert, update, and delete of data. All metrics required to capture changes to the target database like column information and metadata are available for the modified rows. These changes are stored in tables that mirror the structure of the tracked stored tables.
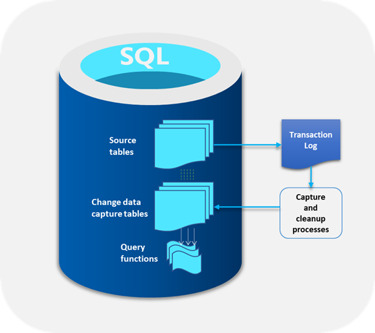
One of the main benefits of SQL Server CDC is that there is no need to continuously refresh the source tables where the data changes are made. Instead, SQL Server CDC makes sure that there is a steady stream of change data with users moving them to the appropriate target databases.
Types of SQL Server CDC
There are two types of SQL Server CDC
Log-based SQL Server CDC where changes in the source database are shown in the system through the transaction log and file which are then moved to the target database.
Trigger-based SQL Server CDC where triggers placed in the database are automatically set off whenever a change occurs, thereby lowering the costs of extracting the changes.
Summing up, SQL Server Change Data Capture has optimized the use of the CDC feature for businesses.
0 notes
Text
GCP Database Migration Service Boosts PostgreSQL migrations

GCP database migration service
GCP Database Migration Service (DMS) simplifies data migration to Google Cloud databases for new workloads. DMS offers continuous migrations from MySQL, PostgreSQL, and SQL Server to Cloud SQL and AlloyDB for PostgreSQL. DMS migrates Oracle workloads to Cloud SQL for PostgreSQL and AlloyDB to modernise them. DMS simplifies data migration to Google Cloud databases.
This blog post will discuss ways to speed up Cloud SQL migrations for PostgreSQL / AlloyDB workloads.
Large-scale database migration challenges
The main purpose of Database Migration Service is to move databases smoothly with little downtime. With huge production workloads, migration speed is crucial to the experience. Slower migration times can affect PostgreSQL databases like:
Long time for destination to catch up with source after replication.
Long-running copy operations pause vacuum, causing source transaction wraparound.
Increased WAL Logs size leads to increased source disc use.
Boost migrations
To speed migrations, Google can fine-tune some settings to avoid aforementioned concerns. The following options apply to Cloud SQL and AlloyDB destinations. Improve migration speeds. Adjust the following settings in various categories:
DMS parallels initial load and change data capture (CDC).
Configure source and target PostgreSQL parameters.
Improve machine and network settings
Examine these in detail.
Parallel initial load and CDC with DMS
Google’s new DMS functionality uses PostgreSQL multiple subscriptions to migrate data in parallel by setting up pglogical subscriptions between the source and destination databases. This feature migrates data in parallel streams during data load and CDC.
Database Migration Service’s UI and Cloud SQL APIs default to OPTIMAL, which balances performance and source database load. You can increase migration speed by selecting MAXIMUM, which delivers the maximum dump speeds.
Based on your setting,
DMS calculates the optimal number of subscriptions (the receiving side of pglogical replication) per database based on database and instance-size information.
To balance replication set sizes among subscriptions, tables are assigned to distinct replication sets based on size.
Individual subscription connections copy data in simultaneously, resulting in CDC.
In Google’s experience, MAXIMUM mode speeds migration multifold compared to MINIMAL / OPTIMAL mode.
The MAXIMUM setting delivers the fastest speeds, but if the source is already under load, it may slow application performance. So check source resource use before choosing this option.
Configure source and target PostgreSQL parameters.
CDC and initial load can be optimised with these database options. The suggestions have a range of values, which you must test and set based on your workload.
Target instance fine-tuning
These destination database configurations can be fine-tuned.
max_wal_size: Set this in range of 20GB-50GB
The system setting max_wal_size limits WAL growth during automatic checkpoints. Higher wal size reduces checkpoint frequency, improving migration resource allocation. The default max_wal_size can create DMS load checkpoints every few seconds. Google can set max_wal_size between 20GB and 50GB depending on machine tier to avoid this. Higher values improve migration speeds, especially beginning load. AlloyDB manages checkpoints automatically, therefore this argument is not needed. After migration, modify the value to fit production workload requirements.
pglogical.synchronous_commit : Set this to off
As the name implies, pglogical.synchronous_commit can acknowledge commits before flushing WAL records to disc. WAL flush depends on wal_writer_delay parameters. This is an asynchronous commit, which speeds up CDC DML modifications but reduces durability. Last few asynchronous commits may be lost if PostgreSQL crashes.
wal_buffers : Set 32–64 MB in 4 vCPU machines, 64–128 MB in 8–16 vCPU machines
Wal buffers show the amount of shared memory utilised for unwritten WAL data. Initial load commit frequency should be reduced. Set it to 256MB for greater vCPU objectives. Smaller wal_buffers increase commit frequency, hence increasing them helps initial load.
maintenance_work_mem: Suggested value of 1GB / size of biggest index if possible
PostgreSQL maintenance operations like VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY employ maintenance_work_mem. Databases execute these actions sequentially. Before CDC, DMS migrates initial load data and rebuilds destination indexes and constraints. Maintenance_work_mem optimises memory for constraint construction. Increase this value beyond 64 MB. Past studies with 1 GB yielded good results. If possible, this setting should be close to the destination’s greatest index to replicate. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_maintenance_workers: Proportional to CPU count
Following data migration, DMS uses pg_restore to recreate secondary indexes on the destination. DMS chooses the best parallel configuration for –jobs depending on target machine configuration. Set max_parallel_maintenance_workers on the destination for parallel index creation to speed up CREATE INDEX calls. The default option is 2, although the destination instance’s CPU count and memory can increase it. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_workers: Set proportional max_worker_processes
The max_parallel_workers flag increases the system’s parallel worker limit. The default value is 8. Setting this above max_worker_processes has no effect because parallel workers are taken from that pool. Maximum parallel workers should be equal to or more than maximum parallel maintenance workers.
autovacuum: Off
Turn off autovacuum in the destination until replication lag is low if there is a lot of data to catch up on during the CDC phase. To speed up a one-time manual hoover before promoting an instance, specify max_parallel_maintenance_workers=4 (set it to the Cloud SQL instance’s vCPUs) and maintenance_work_mem=10GB or greater. Note that manual hoover uses maintenance_work_mem. Turn on autovacuum after migration.
Source instance configurations for fine tuning
Finally, for source instance fine tuning, consider these configurations:
Shared_buffers: Set to 60% of RAM
The database server allocates shared memory buffers using the shared_buffers argument. Increase shared_buffers to 60% of the source PostgreSQL database‘s RAM to improve initial load performance and buffer SELECTs.
Adjust machine and network settings
Another factor in faster migrations is machine or network configuration. Larger destination and source configurations (RAM, CPU, Disc IO) speed migrations.
Here are some methods:
Consider a large machine tier for the destination instance when migrating with DMS. Before promoting the instance, degrade the machine to a lower tier after migration. This requires a machine restart. Since this is done before promoting the instance, source downtime is usually unaffected.
Network bandwidth is limited by vCPUs. The network egress cap on write throughput for each VM depends on its type. VM network egress throughput limits disc throughput to 0.48MBps per GB. Disc IOPS is 30/GB. Choose Cloud SQL instances with more vCPUs. Increase disc space for throughput and IOPS.
Google’s experiments show that private IP migrations are 20% faster than public IP migrations.
Size initial storage based on the migration workload’s throughput and IOPS, not just the source database size.
The number of vCPUs in the target Cloud SQL instance determines Index Rebuild parallel threads. (DMS creates secondary indexes and constraints after initial load but before CDC.)
Last ideas and limitations
DMS may not improve speed if the source has a huge table that holds most of the data in the database being migrated. The current parallelism is table-level due to pglogical constraints. Future updates will solve the inability to parallelise table data.
Do not activate automated backups during migration. DDLs on the source are not supported for replication, therefore avoid them.
Fine-tuning source and destination instance configurations, using optimal machine and network configurations, and monitoring workflow steps optimise DMS migrations. Faster DMS migrations are possible by following best practices and addressing potential issues.
Read more on govindhtech.com
#GCP#GCPDatabase#MigrationService#PostgreSQL#CloudSQL#AlloyDB#vCPU#CPU#VMnetwork#APIs#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Exploring the Power of SQL Server Change Data Capture (CDC)
In the realm of database management, the concept of Change Data Capture (CDC) has emerged as a transformative tool, and SQL Server CDC stands as a prime example. As a neutral observer, we dive into the world of SQL Server CDC to provide insights into its functionalities, benefits, and the remarkable impact it can have on modern data-driven businesses.

Understanding SQL Server CDC:
Change Data Capture, or CDC, is an integral part of Microsoft SQL Server's arsenal. It’s a feature that tracks and captures changes made to data within SQL Server databases. Designed for organizations seeking real-time insights and analysis, SQL Server CDC empowers businesses to keep pace with data modifications seamlessly.
How SQL Server CDC Works:
SQL Server CDC operates through a two-step process: capture and read. During the capture phase, CDC monitors and records data changes directly from the database transaction logs. In the read phase, the captured changes are extracted and made available for consumption by external applications.
Benefits of SQL Server CDC:
Real-time Data Integration: One of the most significant advantages of SQL Server CDC is its ability to provide real-time data integration. The captured data changes can be efficiently propagated to data warehouses, data lakes, or other systems, ensuring that all downstream applications stay updated with the latest information.
Efficient ETL Processes: CDC significantly streamlines Extract, Transform, Load (ETL) processes. By capturing only the changed data, organizations can reduce the load on ETL operations, leading to faster data movement and analytics.
Historical Data Analysis: With CDC, businesses gain the ability to analyze historical data changes. This is invaluable for auditing purposes, compliance reporting, and identifying trends over time.
Minimized Latency: SQL Server CDC operates in near-real-time, ensuring that changes are captured and made available for consumption with minimal delay. This low latency is crucial for applications that require up-to-the-minute data.
Improved Data Accuracy: CDC eliminates the need for manual tracking and data entry, reducing the chances of human errors. This results in improved data accuracy across the organization.
Implementation of SQL Server CDC:
Implementing SQL Server CDC requires careful planning and execution. The process involves several key steps:
Enabling CDC: CDC must be enabled for individual tables or an entire database. Once enabled, SQL Server automatically tracks changes made to the specified tables.
CDC Control Functions: SQL Server provides a set of control functions that allow users to manage and interact with CDC. These functions provide access to captured change data.
Data Capture Jobs: SQL Server Agent jobs are used to capture changes from the transaction logs and populate CDC tables. Regular execution of these jobs ensures that the captured data remains up to date.
Consuming CDC Data: Businesses can consume the captured change data using various methods, including SQL queries, SSIS (SQL Server Integration Services) packages, and custom applications.
Challenges and Considerations:
While SQL Server CDC offers compelling advantages, its implementation is not without challenges:
Storage Requirements: CDC captures every data change, which can lead to increased storage requirements. Adequate storage planning is essential to accommodate the growing change data.
Impact on Performance: While CDC minimally impacts the performance of the source database, it may still affect transaction log size. Regular log management is necessary to prevent performance degradation.
Data Cleanup: As CDC captures data indefinitely, implementing a data cleanup strategy is crucial to prevent an overwhelming amount of historical change data.
SQL Server Change Data Capture is a potent tool for organizations aiming to make the most of their data assets. As a neutral observer, we've delved into the world of SQL Server CDC, highlighting its benefits, implementation steps, and considerations. The ability to capture and propagate real-time data changes brings unmatched efficiency, accuracy, and insights to modern businesses.
While the journey towards implementing SQL Server CDC may present challenges, the rewards in terms of enhanced data integration, historical analysis, and data accuracy are worth the effort. For businesses seeking to stay ahead in the data-driven landscape, embracing SQL Server CDC can be a game-changing decision that fuels growth, innovation, and competitive advantage.
0 notes
Text
Replicating data from Postgres to MS SQL Server using Kafka
You might have heard the expression that “Data is the new oil”, that’s because data is key for any business decision system of an organization. But then, the required data is not stored in one place like a regular & vanilla RDBMS. Normally, the data remains scattered across various RDBMS & other data silos. So, it’s quite common to come across situations where data is siting across different kind of sources, and the DBA needs to find a solution to pull all relevant data into a centralized location for further analysis.

The Challenge
Consider a particular scenario – we have some sales data in AWS Postgres RDS Instance and that data has to be replicated into some tables in their Azure VM with MS SQL Server. But the challenge is heterogeneous replication is marked as deprecated, and it doesn’t work anywhere but only between SQL Server and Oracle. No Postgres allowed in the batch. Also, native heterogeneous replication is not found on the Postgres side. We need third-party tools to achieve this or work manually in HIGH effort mode, creating a CDC (change data capture) mechanism through the use of triggers, and then getting data from control tables. It sounds fun to implement, but time is of the essence. Getting such a solution on ground would take quite some time. Therefore, another solution had to be used to complete this data movement.
A Possible Solution
The Big Data scenario has many tools that can achieve this objective, but they don’t have the advantages that Kafka offered.
Initially, Apache Kafka was designed as a message queue like app (like IBM MQ Series or even SQL Server Service Broker). The best definition of it is perhaps – “Apache Kafka is more like a community distributed event streaming technology which can handle trillions of events per day”. But a streaming system must have the ability to get data from different data sources and deliver the messages on different data endpoints.
There are many tools to achieve this – Azure Event Hubs, AWS Kinesis, or Kafka managed in Confluent Cloud. However, to show how things work under the hood, and since they have similar backgrounds (Apache Kafka open-source code) we have decided to show how to set up the environment from scratch without any managed services for the stream processing. So, the picture would look something like this: Read more ...
0 notes
Text
The Function of the Change Data Capture Feature in SQL Server
This post examines the various intricacies of how the CDC (Change Data Capture) feature applies to SQL Server tables.
The basic functioning is as follows. All changes like Insert, Update, and Delete that are applied to SQL Server tables are tracked by SQL Server CDC. These changes are then recorded and transformed into relational change tables that are easy to understand. Moreover, these change tables show the structure of the columns of the source table that is being tracked. Users can understand the changes that have been made by SQL Server CDC through metadata that is available to them.

Evolution of SQL Server CDC
It is a critical requirement of businesses that the value of data in a database should be recorded before the specifications of an application are changed. That means that the history of the changes made to the data must be saved, specifically for safety and security purposes. In the past, timestamps, triggers, and complex queries to audit data were widely used for this purpose.
In 2005, Microsoft launched SQL Server CDC with ‘after update’, ‘after insert’, and ‘after delete’ triggers that solved the problem of tracking changes to the data. However, a more optimized version was released in 2008 that rectified a few glitches of the 2005 release. This Change Data Capture (CDC) model helped developers to provide SQL Server data archiving and capturing without going through additional programming to do so.
The main point of difference between the 2005 and the 2008 versions is that in the latter case, SQL Server CDC tracks changes only in user-created tables. These can be later assessed and retrieved quickly through the standard T-SQL as the data captured is stored in relational tables.
The Functioning of the SQL Server CDC
When the SQL Server CDC feature is applied to a database table, a mirror is created of the tracked table with the same column structure as the original table. However, the additional columns that have the metadata in the original tables are retained as they are used to track the changes in the database table row. Users monitoring the SQL Server CDC can track the activity of the logged tables by using the new audit tables.
All changes are recorded in mirrored tables by SQL Server CDC but the other columns are recorded in different formats. They are as follows.
For every Insert statement, one record is written by the SQL Server showing the inserted values.
For every Delete statement, one record is written by the SQL Server showing the deleted values.
For every Update statement, two records are written by the SQL Server showing the updated values.
SQL Server CDC first fills the database change tables with the changed data and then cleans the change tables by deleting those records that are older than the configurable retention.
0 notes
Text
How to Migrate Databases from Microsoft SQL Server to Amazon S3
In the modern data-driven business environment, organizations that have critical workloads running on an on-premises Microsoft SQL Server database are increasingly exploring avenues to migrate to the cloud due to its many inherent benefits. All the while, the same database engine (homogeneous migration) can be maintained with minimal to near-zero stoppage in work or downtime.
One way to get around this issue is to migrate databases from the Microsoft SQL Server to S3. To avoid downtime, this process is done using the SQL Server backup and restore method in collaboration with the Amazon Web Service Database Migration Service (AWS DMS). This method is very effective for migrating database code objects including views, storing procedures, and functions as a part of database migration.
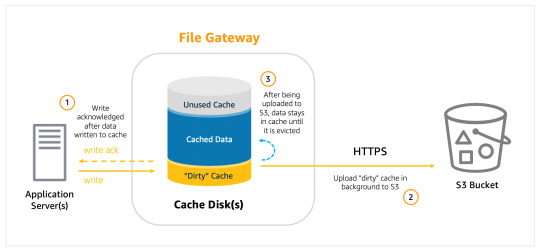
The solution of database migration from SQL Server to S3applies to all SQL Server databases regardless of size. Further, it can also be applied when there is a need to validate the target database during data replication from source to target, thereby saving time on data validation. The only limitation is that this solution may be used only when there are no restrictions on using SQL Server as a source for AWS DMS.
The critical issue here is why do organizations want to migrate databases from SQL Server to S3 (Amazon Simple Storage Service).It is primarily because S3 operates in the cloud and thereby provides unmatched data durability and scalabilityand unlimited storage capabilities. This is a big help for businesses as they do not have to invest in additional hardware and software to increase capacities whenever there is a sudden surge in demand for additional storage facilities.
Other cutting-edge features offered by Amazon S3 are data protection, access management, data replication, and cost affordability.S3 can go through billions of objects of Batch Operationsand the database replication process of SQL Server to S3 can be carried out both within and outside the region.
Several backup processes need to be completed before the database migration from SQL Server to S3can be taken up.
First, ensure that the AWS account used for migration has an IAM role and specific permissions have to be given for activities like write and delete access to the target S3 bucket. Next, be sure that the S3 bucket being used as the target and the DMS replication instance for migrating the data are in the same AWS region. Further, add a tagging access in the role so that objects that are written to the target bucket can be tagged via AWS CDC S3. Finally, DMS (dms.amazonaws.com) should be present in the IAM role as an additional entity.
It is also necessary to check whether the role assigned to the user for completing the migration task has the required permissions to do so.
0 notes
Text
Exploring the Power of SQL Server Change Data Capture
Understanding SQL Server Change Data Capture (CDC)
SQL Server CDC is a feature integrated into Microsoft SQL Server that captures insert, update, and delete activities performed on specified tables. It creates a historical record of changes, providing insight into how data evolves over time.
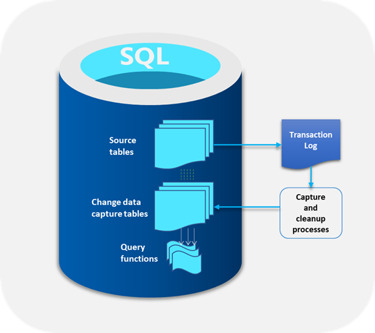
Key Aspects of SQL Server CDC
Granular Data Tracking: Sql server change data capture changes at a granular level, recording modifications made to individual rows, enabling organizations to trace the history of data changes effectively.
Efficiency and Performance: By capturing changes asynchronously, SQL Server CDC minimizes the impact on database performance, ensuring that routine operations continue smoothly.
Real-time Data Synchronization: The captured changes are made available in real time, allowing downstream applications to consume updated data promptly without latency.
Support for ETL Processes: CDC facilitates Extract, Transform, Load (ETL) processes by providing a streamlined way to identify and extract changed data for integration into data warehousing or reporting systems.
Optimized Change Identification: It offers an optimized way to identify changes through specialized system tables, making it easier for users to retrieve change data efficiently.
Implementing SQL Server CDC
Implementing CDC involves enabling it on the SQL Server instance and specifying the tables to be tracked for changes. Users can leverage the captured data to replicate changes to other systems or perform analytical tasks without affecting the source database.
SEO-Optimized Content for SQL Server CDC
SQL Server CDC introduces a paradigm shift in how businesses manage and leverage their database changes. Its ability to capture, track, and replicate data alterations offers a comprehensive solution for organizations seeking real-time insights and efficient data synchronization.
For businesses considering the implementation of SQL Server CDC, understanding its capabilities, implications, and potential use cases is crucial. With its ability to streamline data synchronization, enhance data analytics, and minimize performance impact, SQL Server CDC emerges as a vital tool in the realm of database management, empowering organizations to make data-driven decisions with confidence.
0 notes
Text
Explore how ADF integrates with Azure Synapse for big data processing.
How Azure Data Factory (ADF) Integrates with Azure Synapse for Big Data Processing
Azure Data Factory (ADF) and Azure Synapse Analytics form a powerful combination for handling big data workloads in the cloud.
ADF enables data ingestion, transformation, and orchestration, while Azure Synapse provides high-performance analytics and data warehousing. Their integration supports massive-scale data processing, making them ideal for big data applications like ETL pipelines, machine learning, and real-time analytics. Key Aspects of ADF and Azure Synapse Integration for Big Data Processing
Data Ingestion at Scale ADF acts as the ingestion layer, allowing seamless data movement into Azure Synapse from multiple structured and unstructured sources, including: Cloud Storage: Azure Blob Storage, Amazon S3, Google
Cloud Storage On-Premises Databases: SQL Server, Oracle, MySQL, PostgreSQL Streaming Data Sources: Azure Event Hubs, IoT Hub, Kafka
SaaS Applications: Salesforce, SAP, Google Analytics 🚀 ADF’s parallel processing capabilities and built-in connectors make ingestion highly scalable and efficient.
2. Transforming Big Data with ETL/ELT ADF enables large-scale transformations using two primary approaches: ETL (Extract, Transform, Load): Data is transformed in ADF’s Mapping Data Flows before loading into Synapse.
ELT (Extract, Load, Transform): Raw data is loaded into Synapse, where transformation occurs using SQL scripts or Apache Spark pools within Synapse.
🔹 Use Case: Cleaning and aggregating billions of rows from multiple sources before running machine learning models.
3. Scalable Data Processing with Azure Synapse Azure Synapse provides powerful data processing features: Dedicated SQL Pools: Optimized for high-performance queries on structured big data.
Serverless SQL Pools: Enables ad-hoc queries without provisioning resources.
Apache Spark Pools: Runs distributed big data workloads using Spark.
💡 ADF pipelines can orchestrate Spark-based processing in Synapse for large-scale transformations.
4. Automating and Orchestrating Data Pipelines ADF provides pipeline orchestration for complex workflows by: Automating data movement between storage and Synapse.
Scheduling incremental or full data loads for efficiency. Integrating with Azure Functions, Databricks, and Logic Apps for extended capabilities.
⚙️ Example: ADF can trigger data processing in Synapse when new files arrive in Azure Data Lake.
5. Real-Time Big Data Processing ADF enables near real-time processing by: Capturing streaming data from sources like IoT devices and event hubs. Running incremental loads to process only new data.
Using Change Data Capture (CDC) to track updates in large datasets.
📊 Use Case: Ingesting IoT sensor data into Synapse for real-time analytics dashboards.
6. Security & Compliance in Big Data Pipelines Data Encryption: Protects data at rest and in transit.
Private Link & VNet Integration: Restricts data movement to private networks.
Role-Based Access Control (RBAC): Manages permissions for users and applications.
🔐 Example: ADF can use managed identity to securely connect to Synapse without storing credentials.
Conclusion
The integration of Azure Data Factory with Azure Synapse Analytics provides a scalable, secure, and automated approach to big data processing.
By leveraging ADF for data ingestion and orchestration and Synapse for high-performance analytics, businesses can unlock real-time insights, streamline ETL workflows, and handle massive data volumes with ease.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Sql server 2016 express json

#SQL SERVER 2016 EXPRESS JSON HOW TO#
#SQL SERVER 2016 EXPRESS JSON INSTALL#
#SQL SERVER 2016 EXPRESS JSON UPDATE#
Improvement: Size and retention policy are increased in default XEvent trace system_health in SQL Server 2019, 2017, and 2016 Improvement: Improve CDC supportability and usability with In-Memory Databases INSERT EXEC failed because the stored procedure altered the schema of the target table error in SQL Server 2016 Improvement: Enable DNN feature in SQL Server 2019 and 2016 FCI
#SQL SERVER 2016 EXPRESS JSON INSTALL#
Improvement: Availability Group listener without the load balancer in SQL Server 2019, 2017, and 2016įIX: Transaction log isn't truncated on a single node Availability Group in SQL ServerįIX: Non-yielding Scheduler error may occur with Always On availability group in Microsoft SQL ServerįIX: Log line is verbose when Always On Availability Group has many databases in SQL Server 20įixes an access violation exception that may occur when sp_server_diagnostics is executedįixes an issue that causes the database log_reuse_wait_desc to change to AVAILABILITY_REPLICA when a database is removed from Availability Groupįixes security vulnerabilities CVE-2015-6420 and CVE-2017-15708įIX: Setup fails when you install SQL Server on FCI with mount points This list will be updated when more articles are released.įor more information about the bugs that are fixed in SQL Server 2016 SP3, go to the following Microsoft Knowledge Base articles.
#SQL SERVER 2016 EXPRESS JSON UPDATE#
In addition to the fixes that are listed in this article, SQL Server 2016 SP3 includes hotfixes that were included in SQL Server 2016 Cumulative Update 1 (CU1) to SQL Server 2016 SP2 CU17.įor more information about the cumulative updates that are available in SQL Server 2016, see SQL Server 2016 build versions.Īdditional fixes that aren't documented here may also be included in the service pack. SQL Server 2016 SP3 upgrades all editions and service levels of SQL Server 2016 to SQL Server 2016 SP3. Microsoft SQL Server 2016 service packs are cumulative updates. List of fixes included in SQL Server 2016 SP3 Note After you install this service pack, the SQL Server service version should be. Microsoft SQL Server 2016 SP3 Feature Pack SQL Server 2016 SP3, Microsoft SQL Server 2016 SP3 Express, and Microsoft SQL Server 2016 SP3 Feature Pack are available for manual download and installation at the following Microsoft Download Center websites.
#SQL SERVER 2016 EXPRESS JSON HOW TO#
More information How to get SQL Server 2016 SP3 It includes all the information that you previously found in the release notes and Readme.txt files. Note This article serves as a single source of information to locate all documentation that's related to this service pack. It describes how to get the service pack, the list of fixes that are included in the service pack, known issues, and a list of copyright attributions for the product. This article contains important information to read before you install Microsoft SQL Server 2016 Service Pack 3 (SP3). SQL Server 2016 SQL Server 2016 Service Pack 3 More.
1 note
·
View note
Text
Introducing Datastream GCP’s new Stream Recovery Features

Replication pipelines can break in the complicated and dynamic world of data replication. Restarting replication with little impact on data integrity requires a number of manual procedures that must be completed after determining the cause and timing of the failure.
With the help of Datastream GCP‘s new stream recovery capability, you can immediately resume data replication in scenarios like database failover or extended network outages with little to no data loss.
Think about a financial company that replicates transaction data to BigQuery for analytics using DataStream from their operational database. A planned failover to a replica occurs when there is a hardware failure with the primary database instance. Due to the unavailability of the original source, Datastream’s replication pipeline is malfunctioning. In order to prevent transaction data loss, stream recovery enables replication to continue from the failover database instance.
Consider an online shop that replicates user input to BigQuery for sentiment analysis using BigQuery ML utilising Datastream. An extended network disruption breaks the source database connection. Some of the updates are no longer accessible on the database server by the time network connectivity is restored. Here, the user can rapidly resume replication from the first available log point thanks to stream recovery. For ongoing sentiment analysis and trend identification, the merchant prioritises obtaining the most recent data, even though some feedback may be lost.
The advantages of recovering streams
Benefits of stream recovery include the following
Reduced data loss: Get back data lost by events like unintentional log file deletion and database instance failovers.
Minimise downtime: Get back up and running as soon as possible to resume continuous CDC consumption and swiftly restore your stream.
Recovery made easier: A user-friendly interface makes it simple to retrieve your stream.
Availables of Datastream GCP
Minimise latency in data replication and synchronisation
Reduce the impact on source performance while ensuring reliable, low-latency data synchronization across diverse databases, storage systems, and applications.
Adapt to changing needs using a serverless design
Quickly get up and running with a simple, serverless application that scales up and down without any hassle and requires no infrastructure management.
Google Cloud services offer unparalleled flexibility
Utilise the best Google Cloud services, such as BigQuery, as Spanner, Dataflow, and Data Fusion, to connect and integrate data throughout your company.
Important characteristics
The unique strategy of Datastream GCP
Data streaming via relational databases
Your MySQL, PostgreSQL, AlloyDB, SQL Server, and Oracle databases can be read and updated by Datastream, which then transfers the changes to BigQuery, Cloud SQL, Cloud Storage, and Spanner. It consistently broadcasts every event as it happens and is Google native and agentless. More than 500 trillion events are processed monthly by Datastream.
Robust pipelines with sophisticated recovery
Unexpected disruptions may incur high expenses. You can preserve vital business activities and make defensible decisions based on continuous data pipelines thanks to Datastream GCP‘s strong stream recovery, which reduces downtime and data loss.
Resolution of schema drift
Datastream GCP enables quick and easy resolution of schema drift when source schemas change. Every time a schema is changed, Datastream rotates the files, adding a new file to the target bucket. With a current, versioned Schema Registry, original source data types are only a call away via an API.
Safe by design
To safeguard data while it’s in transit, Datastream GCP offers a variety of private, secure connectivity options. You can relax knowing your data is safe while it streams because it is also encrypted while it is in transit and at rest.
The application of stream recovery
Depending on the particular failure circumstance and the availability of current log files, stream recovery offers you a few options to select from. You have three options when it comes to MySQL and Oracle: stream from the most recent position, skip the current position and stream from the next available position, or retry from the current log position. Additionally, you can provide the stream a precise log position to resume from for example, the Log Sequence Number (LSN) or Change Sequence Number (CSN) giving you more precise control over making sure that no data is lost or duplicated in the destination.
You can tell Datastream to start streaming again from the new replication slot after creating a new one in your PostgreSQL database for PostgreSQL sources.
From a given position, begin a stream
Apart from stream recovery, there are several situations in which you might need to begin or continue a stream from a particular log location. For instance, when the source database is being upgraded or moved, or when historical data from a particular point in time (where the historical data terminates) is already present in the destination and you would like to merge it. In these situations, you can utilise the stream recovery API to set a starting position before initiating the stream.
Get going
For all available Datastream sources across all Google Cloud regions, stream recovery is now widely accessible via the Google Cloud dashboard and API.
Read more on Govindhtech.com
#DatastreamGCP#BigQuery#GoogleCloud#spanner#dataflow#BigQueryML#SQLServer#PostgreSQL#oracle#MySQL#cloudstorage#news#technews#technology#technologynews#technologytrends#govindhtech
1 note
·
View note
Text
Unlock Real-Time Insights with SQL Server Change Data Capture
Introduction:
In today's fast-paced digital landscape, businesses need real-time insights to stay competitive. SQL Server Change Data Capture (CDC) is a powerful feature that enables organizations to capture and track changes made to their SQL Server databases. In this article, we will explore the benefits of SQL Server Change Data Capture and how it empowers businesses to make informed decisions based on real-time data.

Efficient Tracking of Data Changes:
SQL Server Change Data Capture provides a reliable and efficient way to track changes made to the database. With CDC, you can capture changes at the row level, including inserts, updates, and deletes. This granular level of tracking allows you to understand the evolution of your data over time and enables you to analyze trends, identify anomalies, and make data-driven decisions. By capturing changes efficiently, CDC reduces the overhead on your SQL Server and ensures minimal impact on the database performance.
Real-Time Data Integration:
One of the significant advantages of SQL Server Change Data Capture is its ability to facilitate real-time data integration. CDC captures and stores changed data in a separate change table, allowing you to easily access and integrate it with other systems or applications. This enables real-time data synchronization between different databases, data warehouses, or analytical platforms. By having access to up-to-date data, you can gain valuable insights, streamline business processes, and improve decision-making efficiency.
Auditing and Compliance:
Maintaining data integrity and meeting regulatory compliance requirements are essential for businesses across various industries. SQL Server Change Data Capture helps organizations fulfill auditing and compliance needs by providing a reliable and transparent trail of all changes made to the database. The captured change data includes the old and new values, timestamps, and user information, allowing you to track and monitor data modifications. This level of auditing capability ensures data accountability and helps organizations comply with industry regulations and internal policies.
Simplified Data Warehousing and Reporting:
SQL Server Change Data Capture simplifies the process of data warehousing and reporting. By capturing changes at the source database, CDC eliminates the need for complex and time-consuming extraction, transformation, and loading (ETL) processes. You can directly access the captured change data and populate your data warehouse in near real-time, enabling faster and more accurate reporting. This streamlined approach to data warehousing enhances the overall efficiency of your analytics and reporting workflows.
Efficient Data Recovery and Rollbacks:
In the event of data corruption or unintended changes, SQL Server Change Data Capture proves invaluable for efficient data recovery and rollbacks. By utilizing the captured change data, you can identify and isolate specific changes made to the database. This allows you to restore the affected data to its previous state, minimizing the impact of errors and reducing downtime. The ability to quickly recover and roll back changes enhances data reliability and safeguards the integrity of your SQL Server databases.
Integration with Third-Party Tools:
SQL Server Change Data Capture seamlessly integrates with various third-party tools and technologies. Whether you need to feed change data into a data integration platform, perform advanced analytics using business intelligence tools, or trigger event-driven workflows, CDC provides the necessary flexibility and compatibility. This integration capability expands the possibilities of utilizing change data across your entire data ecosystem, enabling you to derive maximum value from your SQL Server databases.
Conclusion:
SQL Server Change Data Capture empowers organizations to unlock real-time insights and make informed decisions based on up-to-date data. With efficient tracking of data changes, real-time data integration, auditing and compliance features, simplified data warehousing, efficient data recovery, and seamless integration with third-party tools, CDC offers a comprehensive solution for capturing and utilizing change data. By implementing SQL Server Change Data Capture, businesses can stay ahead of the competition, improve decision-making processes, and drive success in today's data-driven world.
0 notes
Text
Google Professional Cloud Database Engineer Exam Questions
Preparing for the Professional Cloud Database Engineer certification can improve your proficiency in database migration and management in the cloud. PassQuestion provides Google Professional Cloud Database Engineer Certification Questions to help you prepare for the Google Cloud Certified Professional Cloud Database Engineer exam by testing your abilities and knowledge. Our Google Professional Cloud Database Engineer Certification Questions allow you to assess your knowledge before taking the final exam. You may rest assured that you will find everything you need to pass the Google Cloud Certified - Professional Cloud Database Engineer exam on your first try.
Professional Cloud Database Engineer Certification
A Professional Cloud Database Engineer is a database professional with two years of Google Cloud experience and five years of overall database and IT experience. The Professional Cloud Database Engineer designs, creates, manages, and troubleshoots Google Cloud databases used by applications to store and retrieve data. The Professional Cloud Database Engineer should be comfortable translating business and technical requirements into scalable and cost-effective database solutions.
About this certification exam
Length: 2 hours Registration fee: $200 (plus tax where applicable) Language: English Exam format: Multiple choice and multiple select Exam Delivery Method: a. Take the online-proctored exam from a remote location. b. Take the onsite-proctored exam at a testing center. Prerequisites: None Recommended experience: 5+ years of overall database and IT experience, including 2 years of hands-on experience working with Google Cloud database solutions
Exam Content
The Professional Cloud Database Engineer exam assesses your ability to: Design scalable and highly available cloud database solutions Manage a solution that can span multiple database solutions Migrate data solutions Deploy scalable and highly available databases in Google Cloud
View Online Google Professional Cloud Database Engineer Free Questions
Your company wants to migrate its MySQL, PostgreSQL, and Microsoft SQL Server on-premises databases to Google Cloud. You need a solution that provides near-zero downtime, requires no application changes, and supports change data capture (CDC). What should you do? A.Use the native export and import functionality of the source database. B.Create a database on Google Cloud, and use database links to perform the migration. C.Create a database on Google Cloud, and use Dataflow for database migration. D.Use Database Migration Service. Answer: B
You are running a large, highly transactional application on Oracle Real Application Cluster (RAC) that is multi-tenant and uses shared storage. You need a solution that ensures high-performance throughput and a low-latency connection between applications and databases. The solution must also support existing Oracle features and provide ease of migration to Google Cloud. What should you do? A.Migrate to Compute Engine. B.Migrate to Bare Metal Solution for Oracle. C.Migrate to Google Kubernetes Engine (GKE) D.Migrate to Google Cloud VMware Engine Answer: A
You are choosing a new database backend for an existing application. The current database is running PostgreSQL on an on-premises VM and is managed by a database administrator and operations team. The application data is relational and has light traffic. You want to minimize costs and the migration effort for this application. What should you do? A.Migrate the existing database to Firestore. B.Migrate the existing database to Cloud SQL for PostgreSQL. C.Migrate the existing database to Cloud Spanner. D.Migrate the existing database to PostgreSQL running on Compute Engine. Answer: B
Your organization is currently updating an existing corporate application that is running in another public cloud to access managed database services in Google Cloud. The application will remain in the other public cloud while the database is migrated to Google Cloud. You want to follow Google-recommended practices for authentication. You need to minimize user disruption during the migration. What should you do? A.Use workload identity federation to impersonate a service account. B.Ask existing users to set their Google password to match their corporate password. C.Migrate the application to Google Cloud, and use Identity and Access Management (IAM). D.Use Google Workspace Password Sync to replicate passwords into Google Cloud. Answer: C
You are configuring the networking of a Cloud SQL instance. The only application that connects to this database resides on a Compute Engine VM in the same project as the Cloud SQL instance. The VM and the Cloud SQL instance both use the same VPC network, and both have an external (public) IP address and an internal (private) IP address. You want to improve network security. What should you do? A.Disable and remove the internal IP address assignment. B.Disable both the external IP address and the internal IP address, and instead rely on Private Google Access. C.Specify an authorized network with the CIDR range of the VM. D.Disable and remove the external IP address assignment. Answer: B
You are designing a payments processing application on Google Cloud. The application must continue to serve requests and avoid any user disruption if a regional failure occurs. You need to use AES-256 to encrypt data in the database, and you want to control where you store the encryption key. What should you do? A.Use Cloud Spanner with a customer-managed encryption key (CMEK). B.Use Cloud Spanner with default encryption. C.Use Cloud SQL with a customer-managed encryption key (CMEK). D.Use Bigtable with default encryption. Answer: C
0 notes
Text
Change Data Capture Feature of the Microsoft SQL Server
In the current data-driven business environment, the focus is primarily on ensuring data security, an aspect that is strengthened by the Change Data Capture feature. Apart from insulating against data breaches and hacking, organizations have to be sure that the values of changed and modified data are stored in a manner that their history is not compromised. Various solutions for saving changed data have been tried in the past such as complex queries, triggers, timestamps, and even data auditing but none of them have been fool-proof enough.
In this respect, the pioneers in Change Data Capture (CDC) have been Microsoft SQL Server. In 2015, the SQL Server Change Data Capture was launched with “after update”, “after insert”, and “after delete” features. But it was not until 2008 that a version of the CDC was launched that made it easy for DBAs and developers to capture and archive data without the trouble of going through additional programming.

SQL Server Change Data Capture applies change activities like insert, update, and delete to a table, the details of which are easily available in a user-friendly relational format. Required inputs for marking changes to a target environment like column information and metadata are captured for the modified rows. Later, the changes made are stored in tables that reflect the column structure of the tracked stored tables. Permissions for access to the changed data are controlled by specific table-valued functions.
Functioning of SQL Server Change Data Capture
All changes made by a user in tables are tracked and monitored by the Change Data Capture which is then stored in relational tables that can be easily accessed for retrieval of the data with T-SQL. Whenever the features of the CDDC technology are applied to a database table, a mirrored image is created of that table.
The types of changes made in the database row are checked by the additional columns of metadata that are inherent in the column structure of the replicated table. Barring this, all other aspects of the replicated tables and the source tables are similar. After going through a SQL Server Change Data Capture task,the audit tables can be used by the SQL DBAto track the logged tables and other activities that have occurred.
The source of change in CDC is the transaction log and when modification is identified in the tracked source tables (inserts, updates, deletes), details of these entries are added to the log and taken as a reference point in CDC. This transaction log is then read and all descriptions of the changes are linked to the change table segment of the original table. They are monitored by the SQL Server Change Data Capture DC and loaded from the OLTP source to the OLAP warehouse source through the ETL or the T-SQL processes.
0 notes