#SQL Server Change Data Capture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
Tracking Changes in SQL Server 2022
In the latest update of SQL Server 2022, keeping an eye on database table alterations has gotten a bit easier for the folks who build and maintain our databases. This piece is all about giving you the lowdown on how to make the most of SQL Server’s built-in goodies for change tracking. We’re zeroing in on Change Data Capture (CDC) and Temporal Tables, which are like superheroes for making sure…
View On WordPress
#CDC SQL Server#Change Data Capture#Data Auditing SQL Server#System-Versioned Temporal Tables#Temporal Tables SQL Server
1 note
·
View note
Text
How Oracle GoldenGate works
Oracle GoldenGate operates by capturing changes directly from the transaction logs of source databases. It supports both homogeneous and heterogeneous environments, enabling real-time data replication across different types of databases, such as Oracle, MySQL, SQL Server, PostgreSQL, and more. Oracle GoldenGate Data Flow Explanation Target DatabaseThis is the destination where the replicated…
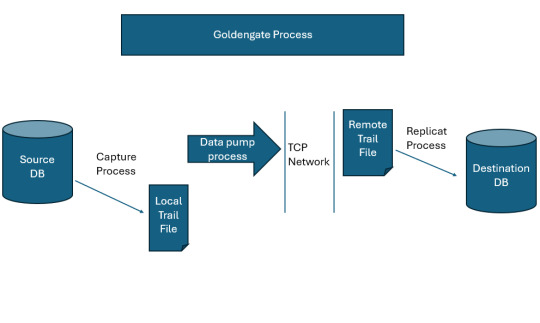
View On WordPress
0 notes
Text
Green Forms Nulled Script 1.40

Download Green Forms Nulled Script for Free – Ultimate Form Builder Solution If you're looking for a powerful, flexible, and user-friendly form builder, then the Green Forms Nulled Script is your go-to solution. With its drag-and-drop interface, real-time editing, and broad compatibility, Green Forms is the perfect tool for developers, marketers, and business owners who want to create stunning forms without writing a single line of code. And the best part? You can download it for free right here! What is Green Forms Nulled Script? The Green Forms Nulled Script is a premium standalone form builder that allows users to create responsive, customizable forms with ease. Unlike other plugins that require WordPress or third-party integrations, Green Forms operates independently, giving you full control and performance efficiency. It’s not just another form builder—it’s a high-performance tool tailored for businesses that demand speed, elegance, and reliability in their web forms. Whether you're collecting leads, feedback, surveys, or subscriptions, this tool ensures your data flow is smooth and secure. Technical Specifications Language: PHP, JavaScript Database: MySQL File Size: Lightweight and optimized for performance Framework: Standalone (no CMS required) Mobile Ready: Fully responsive and adaptive layout Key Features and Benefits Drag-and-Drop Interface: Build forms visually without touching any code. Real-Time Editing: See your changes instantly, making the design process seamless. Conditional Logic: Create intelligent forms that adapt based on user input. Multi-Step Forms: Enhance user experience with beautifully designed progress steps. Built-in Anti-Spam: No need for captchas—Green Forms keeps bots at bay. Email Notifications: Stay informed with real-time submission alerts. Third-Party Integrations: Supports popular tools like Mailchimp, PayPal, and Zapier. Why Choose Green Forms Nulled Script? There are countless form builders out there, but what sets the Green Forms Nulled Script apart is its robust functionality combined with simplicity. You don’t need a developer background to create advanced forms. From simple contact forms to complex conditional surveys, Green Forms handles it all. Furthermore, by downloading the nulled version from our website, you're gaining access to premium features without the premium cost. This empowers startups and freelancers to use top-tier software while staying within budget. Practical Use Cases Lead Generation: Capture potential customer information with clean and engaging forms. Customer Feedback: Gather insights and suggestions directly from your users. Online Bookings: Create appointment or reservation systems tailored to your business. Surveys & Polls: Run interactive surveys to gather opinions and data efficiently. Subscription Forms: Grow your email list with integrated opt-in forms. Installation Guide Download the Green Forms Nulled Script from our secure link. Unzip the downloaded file to your local machine. Upload the script files to your preferred web hosting server. Set up the MySQL database using the provided SQL file. Update your configuration file with your database credentials. Access the admin panel to start building your first form! The installation process is straightforward, and with just a few steps, you'll be ready to collect submissions and scale your project effortlessly. Frequently Asked Questions (FAQs) Is it safe to use the Green Forms Nulled Script? Yes, the version provided on our website is carefully checked and free from malware. We always ensure clean and functional scripts for our users. Can I integrate payment gateways? Absolutely! Green Forms supports PayPal and other popular gateways, making it ideal for donation and sales forms. Does this script work with other themes? Yes, since it’s a standalone application, it works independently of any WordPress theme. However, for compatibility inspiration, check out Enfold NULLED, a flexible and stylish theme you might also find useful.
Where can I find similar tools? If you’re looking for another premium form or theme builder, explore avada nulled, a highly customizable and robust solution used by thousands worldwide. Final Thoughts The Green Forms Nulled Script is a game-changer for anyone looking to create professional-grade forms with ease. From entrepreneurs and freelancers to developers and digital agencies, this tool adds real value to any web project. Download it now and take your form-building capabilities to the next level—without spending a dime!
0 notes
Text
Intuitive Powerful Visual Web Scraper - WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. WebHarvy Web Scraper can be used to scrape data from www.yellowpages.com. Data fields such as name, address, phone number, website URL etc can be selected for extraction by just clicking on them! - Point and Click Interface WebHarvy is a visual web scraper. There is absolutely no need to write any scripts or code to scrape data. You will be using WebHarvy's in-built browser to navigate web pages. You can select the data to be scraped with mouse clicks. It is that easy ! - Scrape Data Patterns Automatic Pattern Detection WebHarvy automatically identifies patterns of data occurring in web pages. So if you need to scrape a list of items (name, address, email, price etc) from a web page, you need not do any additional configuration. If data repeats, WebHarvy will scrape it automatically. - Export scraped data Save to File or Database You can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. You can also export the scraped data to an SQL database. - Scrape data from multiple pages Scrape from Multiple Pages Often web pages display data such as product listings in multiple pages. WebHarvy can automatically crawl and extract data from multiple pages. Just point out the 'link to the next page' and WebHarvy Web Scraper will automatically scrape data from all pages. - Keyword based Scraping Keyword based Scraping Keyword based scraping allows you to capture data from search results pages for a list of input keywords. The configuration which you create will be automatically repeated for all given input keywords while mining data. Any number of input keywords can be specified. - Scrape via proxy server Proxy Servers To scrape anonymously and to prevent the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers. Either a single proxy server address or a list of proxy server addresses may be used. - Category Scraping Category Scraping WebHarvy Web Scraper allows you to scrape data from a list of links which leads to similar pages within a website. This allows you to scrape categories or subsections within websites using a single configuration. - Regular Expressions WebHarvy allows you to apply Regular Expressions (RegEx) on Text or HTML source of web pages and scrape the matching portion. This powerful technique offers you more flexibility while scraping data. - WebHarvy Support Technical Support Once you purchase WebHarvy Web Scraper you will receive free updates and free support from us for a period of 1 year from the date of purchase. Bug fixes are free for lifetime. WebHarvy 7.7.0238 Released on May 19, 2025 - Updated Browser WebHarvy’s internal browser has been upgraded to the latest available version of Chromium. This improves website compatibility and enhances the ability to bypass anti-scraping measures such as CAPTCHAs and Cloudflare protection. - Improved ‘Follow this link’ functionality Previously, the ‘Follow this link’ option could be disabled during configuration, requiring manual steps like capturing HTML, capturing more content, and applying a regular expression to enable it. This process is now handled automatically behind the scenes, making configuration much simpler for most websites. - Solved Excel File Export Issues We have resolved issues where exporting scraped data to an Excel file could result in a corrupted output on certain system environments. - Fixed Issue related to changing pagination type while editing configuration Previously, when selecting a different pagination method during configuration, both the old and new methods could get saved together in some cases. This issue has now been fixed. - General Security Updates All internal libraries have been updated to their latest versions to ensure improved security and stability. Sales Page:https://www.webharvy.com/ DOWNLOAD LINKS & INSTRUCTIONS: Sorry, You need to be logged in to see the content. Please Login or Register as VIP MEMBERS to access. Read the full article
0 notes
Text
Building Complex Data Workflows with Azure Data Factory Mapping Data Flows

Building Complex Data Workflows with Azure Data Factory Mapping Data Flows
Azure Data Factory (ADF) Mapping Data Flows allows users to build scalable and complex data transformation workflows using a no-code or low-code approach.
This is ideal for ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) scenarios where large datasets need processing efficiently.
1. Understanding Mapping Data Flows
Mapping Data Flows in ADF provide a graphical interface for defining data transformations without writing complex code. The backend execution leverages Azure Databricks, making it highly scalable.
Key Features
✅ Drag-and-drop transformations — No need for complex scripting. ✅ Scalability with Spark — Uses Azure-managed Spark clusters for execution. ✅ Optimized data movement — Push-down optimization for SQL-based sources. ✅ Schema drift handling — Auto-adjusts to changes in source schema. ✅ Incremental data processing — Supports delta loads to process only new or changed data.
2. Designing a Complex Data Workflow
A well-structured data workflow typically involves:
📌 Step 1: Ingest Data from Multiple Sources
Connect to Azure Blob Storage, Data Lake, SQL Server, Snowflake, SAP, REST APIs, etc.
Use Self-Hosted Integration Runtime if data is on-premises.
Optimize data movement with parallel copy.
📌 Step 2: Perform Data Transformations
Join, Filter, Aggregate, and Pivot operations.
Derived columns for computed values.
Surrogate keys for primary key generation.
Flatten hierarchical data (JSON, XML).
📌 Step 3: Implement Incremental Data Processing
Use watermark columns (e.g., last updated timestamp).
Leverage Change Data Capture (CDC) for tracking updates.
Implement lookup transformations to merge new records efficiently.
📌 Step 4: Optimize Performance
Use Partitioning Strategies: Hash, Round Robin, Range-based.
Enable staging before transformations to reduce processing time.
Choose the right compute scale (low, medium, high).
Monitor debug mode to analyze execution plans.
📌 Step 5: Load Transformed Data to the Destination
Write data to Azure SQL, Synapse Analytics, Data Lake, Snowflake, Cosmos DB, etc.
Optimize data sinks by batching inserts and using PolyBase for bulk loads.
3. Best Practices for Efficient Workflows
✅ Reduce the number of transformations — Push down operations to source SQL engine when possible. ✅ Use partitioning to distribute workload across multiple nodes. ✅ Avoid unnecessary data movement — Stage data in Azure Blob instead of frequent reads/writes. ✅ Monitor with Azure Monitor — Identify bottlenecks and tune performance. ✅ Automate execution with triggers, event-driven execution, and metadata-driven pipelines.
Conclusion
Azure Data Factory Mapping Data Flows simplifies the development of complex ETL workflows with a scalable, graphical, and optimized approach.
By leveraging best practices, organizations can streamline data pipelines, reduce costs, and improve performance.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Firebird to Snowflake Migration A comprehensive Guide
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download from Github and deploy on your own servers, whereas with enterprise version, you can use AskOnData as a managed service.
Advantages of using Ask On Data
Built using advanced AI and LLM, hence there is no learning curve.
Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
No dependence on technical resources
Super fast to implement (at the speed of typing)
No technical knowledge required to use
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download from Github and deploy on your own servers, whereas with enterprise version, you can use AskOnData as a managed service.
Advantages of using Ask On Data
Built using advanced AI and LLM, hence there is no learning curve.
Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
No dependence on technical resources
Super fast to implement (at the speed of typing)
No technical knowledge required to use
Below are the steps to do the data migration activity
Step 1: Connect to Firebird (which acts as source)
Step 2 : Connect to Snowflake (which acts as target)
Step 3: Create a new job. Select your source (Firebird) and select which all tables you would like to migrate.
Step 4 (OPTIONAL): If you would like to do any other tasks like data type conversion, data cleaning, transformations, calculations those also you can instruct to do in natural English. NO knowledge of SQL or python or spark etc required.
Step 5: Orchenstrate/schedule this. While scheduling you can run it as one time load, or change data capture or truncate and load etc.
For more advanced users, Ask On Data is also providing options to write SQL, edit YAML, write PySpark code etc.
There are other functionalities like error logging, notifications, monitoring, logs etc which can provide more information like the amount of data transferred, logs, any error information if the job did not run and other kind of monitoring information etc.
Trying Ask On Data
You can reach out to us on [email protected] for a demo, POC, discussion and further pricing information. You can make use of our managed services or you can also download and install on your own servers our community edition from Github.
0 notes
Text
API Automation Testing: Challenges and How to Overcome Them
API automation testing is crucial for validating backend systems, ensuring robust integration, and maintaining seamless communication between applications. However, it comes with its own set of challenges.
Test Data Management:
APIs often require dynamic data that changes with each test. Generating appropriate test data, handling data dependencies, and ensuring data consistency can be difficult. To overcome this, implement data-driven testing and use mock servers to simulate data responses.
API Versioning:
As APIs evolve, maintaining test scripts across versions can be tricky. API Automated Testing may break due to changes in API endpoints or parameters. A solution is to design adaptable test scripts that can easily handle version control by using proper tagging and modular code.
Error Handling:
Automating edge cases and error scenarios, such as server downtime or rate limits, is challenging. Employ robust error-handling mechanisms in your scripts to capture and log all possible failure points for future analysis.
Security Testing:
Ensuring APIs are secure from vulnerabilities such as SQL injection or unauthorized access requires specialized tools. Use security testing tools and integrate them into your CI/CD pipeline to test API security continuously.
By addressing these challenges, API automation testing can lead to more reliable and secure software.
#api automation#api automation framework#api automation testing#api automation testing tools#api automation tools#api testing framework#api testing techniques#api testing tools#api tools
0 notes
Text
The Evolution and Functioning of SQL Server Change Data Capture (CDC)
The SQL Server CDC feature was introduced by Microsoft in 2005 with advanced “after update”, “after insert”, and “after delete” functions. Since the first version did not meet user expectations, another version of SQL Server CDC was launched in 2008 and was well received. No additional activities were required to capture and archive historical data and this form of this feature is in use even today.
Functioning of SQL Server CDC
The main function of SQL Server CDC is to capture changes in a database and present them to users in a simple relational format. These changes include insert, update, and delete of data. All metrics required to capture changes to the target database like column information and metadata are available for the modified rows. These changes are stored in tables that mirror the structure of the tracked stored tables.
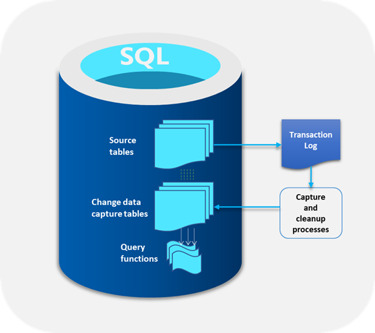
One of the main benefits of SQL Server CDC is that there is no need to continuously refresh the source tables where the data changes are made. Instead, SQL Server CDC makes sure that there is a steady stream of change data with users moving them to the appropriate target databases.
Types of SQL Server CDC
There are two types of SQL Server CDC
Log-based SQL Server CDC where changes in the source database are shown in the system through the transaction log and file which are then moved to the target database.
Trigger-based SQL Server CDC where triggers placed in the database are automatically set off whenever a change occurs, thereby lowering the costs of extracting the changes.
Summing up, SQL Server Change Data Capture has optimized the use of the CDC feature for businesses.
0 notes
Text
Why Oracle GoldenGate Online Training is Essential for Data Management Experts

In today's data-driven world, managing and integrating managing and integrating data seamlessly is crucial for business success. Organizations rely on accurate, timely data to make informed decisions, and the demand for skilled professionals who can ensure data integrity is higher than ever. Oracle GoldenGate stands out as a leading real-time data integration and replication solution. For data management experts, enrolling in Oracle GoldenGate Online Training is beneficial—it's essential for keeping pace with industry demands and advancing their careers.
Understanding the Importance of Real-Time Data
Real-time data integration is moving and synchronizing data across different systems instantly. In finance, healthcare, and e-commerce industries, organizations cannot afford delays in data availability. Customers expect immediate access to information, and businesses must ensure that their data is consistent across platforms. Oracle GoldenGate enables real-time data replication, making it a critical tool for maintaining operational efficiency and data accuracy.
As businesses increasingly operate in hybrid environments that combine on-premises and cloud solutions, data management becomes more complex. Data management experts must understand how to implement solutions that facilitate real-time data movement across these varied landscapes. This is where Oracle GoldenGate Online Training becomes invaluable, providing the skills to navigate and optimize data flows.
Key Features of Oracle GoldenGate
Oracle GoldenGate offers several features that make it indispensable for data management:
Real-Time Replication: GoldenGate allows for the continuous capture and replication of data changes in real time, ensuring that all systems have the most current data.
High Availability: The tool supports high availability configurations, meaning businesses can continue operations despite failure. This is crucial for industries where downtime can result in significant financial losses.
Cross-Platform Support: GoldenGate can replicate data across various databases and platforms, including Oracle, SQL Server, and cloud solutions. This flexibility makes it suitable for organizations with diverse IT environments.
Zero-Downtime Migration: The ability to perform migrations without downtime is a significant advantage. Organizations frequently upgrade their systems or move to the cloud, and GoldenGate enables these transitions to be smooth.
Disaster Recovery: GoldenGate plays a vital role in disaster recovery strategies by ensuring that data is backed up and accessible, minimizing the risk of data loss.
The Curriculum of Oracle GoldenGate Online Training
ProExcellency's Oracle GoldenGate Online Training covers a comprehensive curriculum that provides participants with foundational knowledge and advanced skills. The course includes:
Introduction to Oracle GoldenGate: Understanding the architecture and components of GoldenGate, including its installation and configuration.
Data Replication Techniques: Learning to set up unidirectional and bidirectional replication processes to ensure data consistency across systems.
Real-Time Data Integration: Hands-on experience with real-time data replication, transformations, and synchronization tasks.
Zero-Downtime Migrations: Practical exercises on executing migrations without impacting business operations, a critical skill for IT professionals.
High Availability and Disaster Recovery: Strategies for implementing robust disaster recovery solutions using Oracle GoldenGate.
Hands-On Learning Experience
One of the standout features of the Oracle GoldenGate Online Training is its emphasis on hands-on learning. Participants engage in practical labs that simulate real-world scenarios, allowing them to apply their skills effectively. This hands-on approach is crucial for building confidence and competence in complex data integration tasks.
By working through real-life case studies and scenarios, participants gain valuable experience that prepares them to handle similar challenges in their professional roles. This practical training enhances learning and ensures that graduates can hit the ground running when they enter or advance in the job market.
Career Advancement Opportunities
The demand for professionals skilled in Oracle GoldenGate is rising as more organizations recognize the importance of real-time data management. Completing Oracle GoldenGate Online Training opens up numerous career paths, including roles such as:
Data Architect: Designing data systems and integration solutions for organizations.
Database Administrator: Manage databases and ensure data availability and integrity.
Data Integration Specialist: Focusing on integrating data across platforms and ensuring consistency.
IT Consultant: Advising businesses on data management strategies and best practices.
Conclusion
In conclusion, Oracle GoldenGate Online Training is essential for data management experts looking to enhance their skills and advance their careers. The training equips professionals with the knowledge and hands-on experience to manage real-time data integration, high availability, and effective disaster recovery solutions. As the demand for skilled data professionals grows, investing in Oracle GoldenGate training positions you as a valuable asset to any organization. Don't miss the opportunity to elevate your expertise and unlock new career paths in data management. With ProExcellency's training, you are set to thrive in a data-driven world.
0 notes
Text
GCP Database Migration Service Boosts PostgreSQL migrations

GCP database migration service
GCP Database Migration Service (DMS) simplifies data migration to Google Cloud databases for new workloads. DMS offers continuous migrations from MySQL, PostgreSQL, and SQL Server to Cloud SQL and AlloyDB for PostgreSQL. DMS migrates Oracle workloads to Cloud SQL for PostgreSQL and AlloyDB to modernise them. DMS simplifies data migration to Google Cloud databases.
This blog post will discuss ways to speed up Cloud SQL migrations for PostgreSQL / AlloyDB workloads.
Large-scale database migration challenges
The main purpose of Database Migration Service is to move databases smoothly with little downtime. With huge production workloads, migration speed is crucial to the experience. Slower migration times can affect PostgreSQL databases like:
Long time for destination to catch up with source after replication.
Long-running copy operations pause vacuum, causing source transaction wraparound.
Increased WAL Logs size leads to increased source disc use.
Boost migrations
To speed migrations, Google can fine-tune some settings to avoid aforementioned concerns. The following options apply to Cloud SQL and AlloyDB destinations. Improve migration speeds. Adjust the following settings in various categories:
DMS parallels initial load and change data capture (CDC).
Configure source and target PostgreSQL parameters.
Improve machine and network settings
Examine these in detail.
Parallel initial load and CDC with DMS
Google’s new DMS functionality uses PostgreSQL multiple subscriptions to migrate data in parallel by setting up pglogical subscriptions between the source and destination databases. This feature migrates data in parallel streams during data load and CDC.
Database Migration Service’s UI and Cloud SQL APIs default to OPTIMAL, which balances performance and source database load. You can increase migration speed by selecting MAXIMUM, which delivers the maximum dump speeds.
Based on your setting,
DMS calculates the optimal number of subscriptions (the receiving side of pglogical replication) per database based on database and instance-size information.
To balance replication set sizes among subscriptions, tables are assigned to distinct replication sets based on size.
Individual subscription connections copy data in simultaneously, resulting in CDC.
In Google’s experience, MAXIMUM mode speeds migration multifold compared to MINIMAL / OPTIMAL mode.
The MAXIMUM setting delivers the fastest speeds, but if the source is already under load, it may slow application performance. So check source resource use before choosing this option.
Configure source and target PostgreSQL parameters.
CDC and initial load can be optimised with these database options. The suggestions have a range of values, which you must test and set based on your workload.
Target instance fine-tuning
These destination database configurations can be fine-tuned.
max_wal_size: Set this in range of 20GB-50GB
The system setting max_wal_size limits WAL growth during automatic checkpoints. Higher wal size reduces checkpoint frequency, improving migration resource allocation. The default max_wal_size can create DMS load checkpoints every few seconds. Google can set max_wal_size between 20GB and 50GB depending on machine tier to avoid this. Higher values improve migration speeds, especially beginning load. AlloyDB manages checkpoints automatically, therefore this argument is not needed. After migration, modify the value to fit production workload requirements.
pglogical.synchronous_commit : Set this to off
As the name implies, pglogical.synchronous_commit can acknowledge commits before flushing WAL records to disc. WAL flush depends on wal_writer_delay parameters. This is an asynchronous commit, which speeds up CDC DML modifications but reduces durability. Last few asynchronous commits may be lost if PostgreSQL crashes.
wal_buffers : Set 32–64 MB in 4 vCPU machines, 64–128 MB in 8–16 vCPU machines
Wal buffers show the amount of shared memory utilised for unwritten WAL data. Initial load commit frequency should be reduced. Set it to 256MB for greater vCPU objectives. Smaller wal_buffers increase commit frequency, hence increasing them helps initial load.
maintenance_work_mem: Suggested value of 1GB / size of biggest index if possible
PostgreSQL maintenance operations like VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY employ maintenance_work_mem. Databases execute these actions sequentially. Before CDC, DMS migrates initial load data and rebuilds destination indexes and constraints. Maintenance_work_mem optimises memory for constraint construction. Increase this value beyond 64 MB. Past studies with 1 GB yielded good results. If possible, this setting should be close to the destination’s greatest index to replicate. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_maintenance_workers: Proportional to CPU count
Following data migration, DMS uses pg_restore to recreate secondary indexes on the destination. DMS chooses the best parallel configuration for –jobs depending on target machine configuration. Set max_parallel_maintenance_workers on the destination for parallel index creation to speed up CREATE INDEX calls. The default option is 2, although the destination instance’s CPU count and memory can increase it. After migration, reset this parameter to the default value to avoid affecting application query processing.
max_parallel_workers: Set proportional max_worker_processes
The max_parallel_workers flag increases the system’s parallel worker limit. The default value is 8. Setting this above max_worker_processes has no effect because parallel workers are taken from that pool. Maximum parallel workers should be equal to or more than maximum parallel maintenance workers.
autovacuum: Off
Turn off autovacuum in the destination until replication lag is low if there is a lot of data to catch up on during the CDC phase. To speed up a one-time manual hoover before promoting an instance, specify max_parallel_maintenance_workers=4 (set it to the Cloud SQL instance’s vCPUs) and maintenance_work_mem=10GB or greater. Note that manual hoover uses maintenance_work_mem. Turn on autovacuum after migration.
Source instance configurations for fine tuning
Finally, for source instance fine tuning, consider these configurations:
Shared_buffers: Set to 60% of RAM
The database server allocates shared memory buffers using the shared_buffers argument. Increase shared_buffers to 60% of the source PostgreSQL database‘s RAM to improve initial load performance and buffer SELECTs.
Adjust machine and network settings
Another factor in faster migrations is machine or network configuration. Larger destination and source configurations (RAM, CPU, Disc IO) speed migrations.
Here are some methods:
Consider a large machine tier for the destination instance when migrating with DMS. Before promoting the instance, degrade the machine to a lower tier after migration. This requires a machine restart. Since this is done before promoting the instance, source downtime is usually unaffected.
Network bandwidth is limited by vCPUs. The network egress cap on write throughput for each VM depends on its type. VM network egress throughput limits disc throughput to 0.48MBps per GB. Disc IOPS is 30/GB. Choose Cloud SQL instances with more vCPUs. Increase disc space for throughput and IOPS.
Google’s experiments show that private IP migrations are 20% faster than public IP migrations.
Size initial storage based on the migration workload’s throughput and IOPS, not just the source database size.
The number of vCPUs in the target Cloud SQL instance determines Index Rebuild parallel threads. (DMS creates secondary indexes and constraints after initial load but before CDC.)
Last ideas and limitations
DMS may not improve speed if the source has a huge table that holds most of the data in the database being migrated. The current parallelism is table-level due to pglogical constraints. Future updates will solve the inability to parallelise table data.
Do not activate automated backups during migration. DDLs on the source are not supported for replication, therefore avoid them.
Fine-tuning source and destination instance configurations, using optimal machine and network configurations, and monitoring workflow steps optimise DMS migrations. Faster DMS migrations are possible by following best practices and addressing potential issues.
Read more on govindhtech.com
#GCP#GCPDatabase#MigrationService#PostgreSQL#CloudSQL#AlloyDB#vCPU#CPU#VMnetwork#APIs#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Creating an Effective Power BI Dashboard: A Comprehensive Guide

Introduction to Power BI Power BI is a suite of business analytics tools that allows you to connect to multiple data sources, transform data into actionable insights, and share those insights across your organization. With Power BI, you can create interactive dashboards and reports that provide a 360-degree view of your business.
Step-by-Step Guide to Creating a Power BI Dashboard
1. Data Import and Transformation The first step in creating a Power BI dashboard is importing your data. Power BI supports various data sources, including Excel, SQL Server, Azure, and more.
Steps to Import Data:
Open Power BI Desktop.
Click on Get Data in the Home ribbon.
Select your data source (e.g., Excel, SQL Server, etc.).
Load the data into Power BI.
Once the data is loaded, you may need to transform it to suit your reporting needs. Power BI provides Power Query Editor for data transformation.
Data Transformation:
Open Power Query Editor.
Apply necessary transformations such as filtering rows, adding columns, merging tables, etc.
Close and apply the changes.
2. Designing the Dashboard After preparing your data, the next step is to design your dashboard. Start by adding a new report and selecting the type of visualization you want to use.
Types of Visualizations:
Charts: Bar, Line, Pie, Area, etc.
Tables and Matrices: For detailed data representation.
Maps: Geographic data visualization.
Cards and Gauges: For key metrics and KPIs.
Slicers: For interactive data filtering.
Adding Visualizations:
Drag and drop fields from the Fields pane to the canvas.
Choose the appropriate visualization type from the Visualizations pane.
Customize the visual by adjusting properties such as colors, labels, and titles.
3. Enhancing the Dashboard with Interactivity Interactivity is one of the key features of Power BI dashboards. You can add slicers, drill-throughs, and bookmarks to make your dashboard more interactive and user-friendly.
Using Slicers:
Add a slicer visual to the canvas.
Drag a field to the slicer to allow users to filter data dynamically.
Drill-throughs:
Enable drill-through on visuals to allow users to navigate to detailed reports.
Set up drill-through pages by defining the fields that will trigger the drill-through.
Bookmarks:
Create bookmarks to capture the state of a report page.
Use bookmarks to toggle between different views of the data.
Different Styles of Power BI Dashboards Power BI dashboards can be styled to meet various business needs. Here are a few examples:
1. Executive Dashboard An executive dashboard provides a high-level overview of key business metrics. It typically includes:
KPI visuals for critical metrics.
Line charts for trend analysis.
Bar charts for categorical comparison.
Maps for geographic insights.
Example:
KPI cards for revenue, profit margin, and customer satisfaction.
A line chart showing monthly sales trends.
A bar chart comparing sales by region.
A map highlighting sales distribution across different states.
2. Sales Performance Dashboard A sales performance dashboard focuses on sales data, providing insights into sales trends, product performance, and sales team effectiveness.
Example:
A funnel chart showing the sales pipeline stages.
A bar chart displaying sales by product category.
A scatter plot highlighting the performance of sales representatives.
A table showing detailed sales transactions.
3. Financial Dashboard A financial dashboard offers a comprehensive view of the financial health of an organization. It includes:
Financial KPIs such as revenue, expenses, and profit.
Financial statements like income statement and balance sheet.
Trend charts for revenue and expenses.
Pie charts for expense distribution.
Example:
KPI cards for net income, operating expenses, and gross margin.
A line chart showing monthly revenue and expense trends.
A pie chart illustrating the breakdown of expenses.
A matrix displaying the income statement.
Best Practices for Designing Power BI Dashboards To ensure your Power BI dashboard is effective and user-friendly, follow these best practices:
Keep it Simple:
Avoid cluttering the dashboard with too many visuals.
Focus on the most important metrics and insights.
2. Use Consistent Design:
Maintain a consistent color scheme and font style.
Align visuals properly for a clean layout.
3. Ensure Data Accuracy:
Validate your data to ensure accuracy.
Regularly update the data to reflect the latest information.
4. Enhance Interactivity:
Use slicers and drill-throughs to provide a dynamic user experience.
Add tooltips to provide additional context.
5. Optimize Performance:
Use aggregations and data reduction techniques to improve performance.
Avoid using too many complex calculations.
Conclusion Creating a Power BI dashboard involves importing and transforming data, designing interactive visuals, and applying best practices to ensure clarity and effectiveness. By following the steps outlined in this guide, you can build dashboards that provide valuable insights and support data-driven decision-making in your organization. Power BI’s flexibility and range of visualizations make it an essential tool for any business looking to leverage its data effectively.
#Dynamic Data Visualization#Business Analytics#Interactive Dashboards#Data Insights#Data Transformation#KPI Metrics#Real-time Reporting#Data Connectivity#Trend Analysis#Visual Analytics#Performance Metrics#Data Modeling#Executive Dashboards#Sales Performance#Financial Reporting#Data Interactivity#Data-driven Decisions#Power Query#Custom Visuals#Data Integration
0 notes
Text
What’s So Trendy About Full Stack Development That Everyone Went Crazy Over It?
In the ever-evolving tech landscape, certain trends capture the imagination and enthusiasm of developers and companies alike. Full stack development is one such trend that has taken the tech world by storm. But what is it about full stack development that has everyone so excited? Let's dive into why full stack development is the hottest trend in the tech industry, and why you should consider joining the Full Stack Developer Course in pune at SyntaxLevelUp to ride this wave of opportunity.

Versatility and Comprehensive Skill Set
Full stack developers are the Swiss Army knives of the tech world. They possess a broad range of skills that allow them to work on both the front-end (client-side) and back-end (server-side) of applications. This versatility makes them incredibly valuable to employers. Here’s why:
- Front-End Expertise: Full stack developers course in pune can create seamless user experiences with technologies like HTML, CSS, JavaScript, and frameworks such as React.js and Angular.
- Back-End Proficiency: They can also handle server-side operations, databases, and application logic using Node.js, Python, Ruby, and other back-end technologies.
- Database Management: Full stack developers are adept at working with SQL and NoSQL databases, ensuring efficient data storage and retrieval.
High Demand and Lucrative Salaries
The demand for full stack developers is skyrocketing. Companies prefer hiring professionals who can handle multiple aspects of a project, which leads to:
- More Job Opportunities: Full stack developers course in pune have access to a broader range of job opportunities across various industries.
- Competitive Salaries: Due to their comprehensive skill set, full stack developers training in pune often command higher salaries compared to their counterparts who specialize in only front-end or back-end development.
Efficiency and Reduced Costs
Hiring full stack developers can be more cost-effective for companies. Instead of employing separate front-end and back-end developers, a full stack developer can manage both ends of the application. This leads to:
- Streamlined Development Process: With fewer team members involved, communication is more straightforward, and project timelines can be shortened.
- Cost Savings: Companies save on payroll and benefit from the increased productivity of having a versatile developer who can handle multiple tasks.
Continuous Learning and Adaptability
The tech industry is always changing, with new tools and frameworks emerging regularly. Full stack developers classes in pune are well-positioned to adapt to these changes because:
- Diverse Skill Set: Their broad knowledge base allows them to quickly learn and integrate new technologies.
- Continuous Learning: Full stack developers are lifelong learners, constantly updating their skills to stay relevant in the industry.
Why Choose SyntaxLevelUp for Full Stack Development?
Given the immense benefits of being a full stack developer class in pune, the next step is finding the right training program. SyntaxLevelUp offers an exceptional Full Stack Developer Course designed to equip you with the skills needed to thrive in this dynamic field. Here’s what sets SyntaxLevelUp apart:
1. Industry-Relevant Curriculum
SyntaxLevelUp's curriculum is crafted in collaboration with industry experts to ensure it covers the most relevant and up-to-date technologies, including:
- Front-End Development: HTML, CSS, JavaScript, React.js, and more.
- Back-End Development: Node.js, Express.js, Python, Django, and others.
- Database Management: SQL, NoSQL, MongoDB, and PostgreSQL.
- DevOps Practices: Basic DevOps, version control with Git, and CI/CD pipelines.
2. Hands-On Projects
SyntaxLevelUp emphasizes practical learning through real-world projects that mirror industry standards. This hands-on experience ensures you are job-ready upon course completion.
3. Experienced Instructors
Learn from industry professionals who bring their real-world experience into the classroom. Their mentorship and insights are invaluable for your learning journey.
4. Comprehensive Career Support
SyntaxLevelUp provides robust career support, including:
- Resume Building: Craft a standout resume that highlights your skills and projects.
- Interview Preparation: Ace technical interviews with mock sessions and expert guidance.
- Job Placement Assistance: Leverage SyntaxLevelUp’s network of hiring partners to secure your dream job.
5. Flexible Learning Options
Understanding the diverse needs of learners, SyntaxLevelUp offers flexible learning options, including weekend batches and online classes, allowing you to learn at your own pace and convenience.
Join the Full Stack Revolution Today!
If you're ready to embrace the trend and become a versatile, in-demand full stack developer, the Full Stack Developer Course in pune at SyntaxLevelUp in Pune is your gateway to success. With comprehensive training, experienced instructors, and unparalleled career support, you’ll be well-equipped to thrive in the tech industry.
Visit [SyntaxLevelUp](https://www.syntaxlevelup.com) to learn more about the course details, fees, and batch start dates. Don't miss out on the opportunity to level up your career and become a sought-after full stack developer!
Unlock your potential with full stack training in Pune at SyntaxLevelUp. Our full stack developer classes in Pune offer comprehensive education, making it the best full stack developer course in Pune. With a curriculum designed to meet industry standards, the full stack developer course in Pune ensures you gain practical experience. Join our full stack courses in Pune to master both front-end and back-end technologies. Enroll in our full stack classes in Pune and kickstart your career with SyntaxLevelUp!
#full stack training in pune#full stack developer classes in pune#best full stack developer course in pune#full stack developer course in pune#full stack courses in pune#full stack classes in pune#full stack developers in pune#full stack developer
0 notes
Text
API Security Testing in the Retail Sector
API security testing is crucial in the retail sector to ensure the protection of sensitive customer data, financial information, and overall system integrity. Here are some key considerations and best practices for API security testing in the retail sector:
Authentication and Authorization Testing:
Verify that proper authentication mechanisms are in place.
Test the effectiveness of access controls to ensure that users or systems can only access the data and functionalities they are authorized to use.
Data Encryption:
Ensure that data transmitted between the client and the server is encrypted using secure protocols such as HTTPS.
Test for vulnerabilities related to data encryption, including SSL/TLS vulnerabilities.
Input Validation:
Validate and sanitize input parameters to prevent injection attacks (e.g., SQL injection, XSS).
Test for proper handling of special characters and unexpected input.
Session Management:
Assess the effectiveness of session management mechanisms to prevent session hijacking or fixation.
Test for session timeout, logout functionality, and session token security.
Error Handling:
Verify that error messages do not reveal sensitive information and are generic to avoid information leakage.
Test the application's response to invalid input to ensure that it fails securely.
Rate Limiting and Throttling:
Implement rate limiting and throttling mechanisms to prevent abuse and protect against denial-of-service (DoS) attacks.
Test the system's response to a high volume of API requests.
API Versioning:
Ensure that the API supports versioning to allow for updates and changes without disrupting existing clients.
Test backward compatibility and the handling of deprecated features.
Logging and Monitoring:
Implement robust logging mechanisms to capture and analyze API activity.
Set up monitoring tools to detect unusual or malicious patterns of API usage.
Third-Party Integration Security:
Assess the security of third-party APIs and integrations for vulnerabilities.
Verify that permissions granted to third-party services are minimal and necessary.
Compliance with Standards:
Ensure compliance with industry standards and regulations, such as PCI DSS for payment processing.
Regularly update security measures based on evolving industry standards.
Penetration Testing:
Conduct regular penetration testing to simulate real-world attacks and identify vulnerabilities.
Use automated tools and manual testing to cover a wide range of security issues.
API Documentation Security:
Securely manage and restrict access to API documentation.
Ensure that sensitive information is not exposed in publicly accessible documentation.
Security Training and Awareness:
Train developers, testers, and other stakeholders about secure coding practices and common API security threats.
Foster a security-aware culture within the organization.
Incident Response Planning:
Develop and regularly test an incident response plan to respond quickly and effectively to any security incidents.
Continuous Security Testing:
Integrate security testing into the continuous integration/continuous deployment (CI/CD) pipeline for ongoing security assessments.
By incorporating these practices into the development and maintenance processes, retailers can enhance the security of their APIs and protect sensitive customer information and business operations. Regularly updating and adapting security measures is essential to stay ahead of emerging threats and vulnerabilities.
0 notes
Text
24. What are the techniques for handling incremental data extraction in SSIS?
Interview questions on SSIS Development #etl #ssis #ssisdeveloper #integrationservices #eswarstechworld #sqlserverintegrationservices #interview #interviewquestions #interviewpreparation
Incremental data extraction in SQL Server Integration Services (SSIS) involves extracting only the changed or newly added data since the last extraction, reducing the processing load and improving efficiency during the ETL process. Categories/Classifications/Types: Date-Based Incremental Extraction: Extracts data based on a date column, capturing records modified or added after a specified…

View On WordPress
#eswarstechworld#etl#integrationservices#interview#interviewpreparation#interviewquestions#sqlserverintegrationservices#ssis#ssisdeveloper
0 notes
Text
Explore how ADF integrates with Azure Synapse for big data processing.
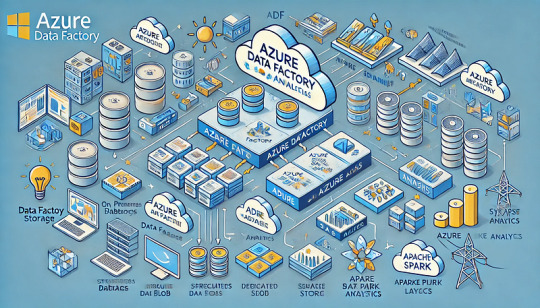
How Azure Data Factory (ADF) Integrates with Azure Synapse for Big Data Processing
Azure Data Factory (ADF) and Azure Synapse Analytics form a powerful combination for handling big data workloads in the cloud.
ADF enables data ingestion, transformation, and orchestration, while Azure Synapse provides high-performance analytics and data warehousing. Their integration supports massive-scale data processing, making them ideal for big data applications like ETL pipelines, machine learning, and real-time analytics. Key Aspects of ADF and Azure Synapse Integration for Big Data Processing
Data Ingestion at Scale ADF acts as the ingestion layer, allowing seamless data movement into Azure Synapse from multiple structured and unstructured sources, including: Cloud Storage: Azure Blob Storage, Amazon S3, Google
Cloud Storage On-Premises Databases: SQL Server, Oracle, MySQL, PostgreSQL Streaming Data Sources: Azure Event Hubs, IoT Hub, Kafka
SaaS Applications: Salesforce, SAP, Google Analytics 🚀 ADF’s parallel processing capabilities and built-in connectors make ingestion highly scalable and efficient.
2. Transforming Big Data with ETL/ELT ADF enables large-scale transformations using two primary approaches: ETL (Extract, Transform, Load): Data is transformed in ADF’s Mapping Data Flows before loading into Synapse.
ELT (Extract, Load, Transform): Raw data is loaded into Synapse, where transformation occurs using SQL scripts or Apache Spark pools within Synapse.
🔹 Use Case: Cleaning and aggregating billions of rows from multiple sources before running machine learning models.
3. Scalable Data Processing with Azure Synapse Azure Synapse provides powerful data processing features: Dedicated SQL Pools: Optimized for high-performance queries on structured big data.
Serverless SQL Pools: Enables ad-hoc queries without provisioning resources.
Apache Spark Pools: Runs distributed big data workloads using Spark.
💡 ADF pipelines can orchestrate Spark-based processing in Synapse for large-scale transformations.
4. Automating and Orchestrating Data Pipelines ADF provides pipeline orchestration for complex workflows by: Automating data movement between storage and Synapse.
Scheduling incremental or full data loads for efficiency. Integrating with Azure Functions, Databricks, and Logic Apps for extended capabilities.
⚙️ Example: ADF can trigger data processing in Synapse when new files arrive in Azure Data Lake.
5. Real-Time Big Data Processing ADF enables near real-time processing by: Capturing streaming data from sources like IoT devices and event hubs. Running incremental loads to process only new data.
Using Change Data Capture (CDC) to track updates in large datasets.
📊 Use Case: Ingesting IoT sensor data into Synapse for real-time analytics dashboards.
6. Security & Compliance in Big Data Pipelines Data Encryption: Protects data at rest and in transit.
Private Link & VNet Integration: Restricts data movement to private networks.
Role-Based Access Control (RBAC): Manages permissions for users and applications.
🔐 Example: ADF can use managed identity to securely connect to Synapse without storing credentials.
Conclusion
��The integration of Azure Data Factory with Azure Synapse Analytics provides a scalable, secure, and automated approach to big data processing.
By leveraging ADF for data ingestion and orchestration and Synapse for high-performance analytics, businesses can unlock real-time insights, streamline ETL workflows, and handle massive data volumes with ease.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Exploring the Power of SQL Server Change Data Capture
Understanding SQL Server Change Data Capture (CDC)
SQL Server CDC is a feature integrated into Microsoft SQL Server that captures insert, update, and delete activities performed on specified tables. It creates a historical record of changes, providing insight into how data evolves over time.
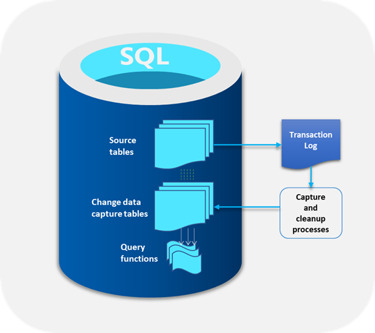
Key Aspects of SQL Server CDC
Granular Data Tracking: Sql server change data capture changes at a granular level, recording modifications made to individual rows, enabling organizations to trace the history of data changes effectively.
Efficiency and Performance: By capturing changes asynchronously, SQL Server CDC minimizes the impact on database performance, ensuring that routine operations continue smoothly.
Real-time Data Synchronization: The captured changes are made available in real time, allowing downstream applications to consume updated data promptly without latency.
Support for ETL Processes: CDC facilitates Extract, Transform, Load (ETL) processes by providing a streamlined way to identify and extract changed data for integration into data warehousing or reporting systems.
Optimized Change Identification: It offers an optimized way to identify changes through specialized system tables, making it easier for users to retrieve change data efficiently.
Implementing SQL Server CDC
Implementing CDC involves enabling it on the SQL Server instance and specifying the tables to be tracked for changes. Users can leverage the captured data to replicate changes to other systems or perform analytical tasks without affecting the source database.
SEO-Optimized Content for SQL Server CDC
SQL Server CDC introduces a paradigm shift in how businesses manage and leverage their database changes. Its ability to capture, track, and replicate data alterations offers a comprehensive solution for organizations seeking real-time insights and efficient data synchronization.
For businesses considering the implementation of SQL Server CDC, understanding its capabilities, implications, and potential use cases is crucial. With its ability to streamline data synchronization, enhance data analytics, and minimize performance impact, SQL Server CDC emerges as a vital tool in the realm of database management, empowering organizations to make data-driven decisions with confidence.
0 notes