#Dataflow
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
What is Dataflow?
This post is inspired by another post about the Crowd Strike IT disaster and a bunch of people being interested in what I mean by Dataflow. Dataflow is my absolute jam and I'm happy to answer as many questions as you like on it. I even put referential pictures in like I'm writing an article, what fun!
I'll probably split this into multiple parts because it'll be a huge post otherwise but here we go!
A Brief History

Our world is dependent on the flow of data. It exists in almost every aspect of our lives and has done so arguably for hundreds if not thousands of years.
At the end of the day, the flow of data is the flow of knowledge and information. Normally most of us refer to data in the context of computing technology (our phones, PCs, tablets etc) but, if we want to get historical about it, the invention of writing and the invention of the Printing Press were great leaps forward in how we increased the flow of information.
Modern Day IT exists for one reason - To support the flow of data.
Whether it's buying something at a shop, sitting staring at an excel sheet at work, or watching Netflix - All of the technology you interact with is to support the flow of data.
Understanding and managing the flow of data is as important to getting us to where we are right now as when we first learned to control and manage water to provide irrigation for early farming and settlement.
Engineering Rigor
When the majority of us turn on the tap to have a drink or take a shower, we expect water to come out. We trust that the water is clean, and we trust that our homes can receive a steady supply of water.
Most of us trust our central heating (insert boiler joke here) and the plugs/sockets in our homes to provide gas and electricity. The reason we trust all of these flows is because there's been rigorous engineering standards built up over decades and centuries.

For example, Scottish Water will understand every component part that makes up their water pipelines. Those pipes, valves, fitting etc will comply with a national, or in some cases international, standard. These companies have diagrams that clearly map all of this out, mostly because they have to legally but also because it also vital for disaster recovery and other compliance issues.
Modern IT
And this is where modern day IT has problems. I'm not saying that modern day tech is a pile of shit. We all have great phones, our PCs can play good games, but it's one thing to craft well-designed products and another thing entirely to think about they all work together.
Because that is what's happened over the past few decades of IT. Organisations have piled on the latest plug-and-play technology (Software or Hardware) and they've built up complex legacy systems that no one really knows how they all work together. They've lost track of how data flows across their organisation which makes the work of cybersecurity, disaster recovery, compliance and general business transformation teams a nightmare.

Some of these systems are entirely dependent on other systems to operate. But that dependency isn't documented. The vast majority of digital transformation projects fail because they get halfway through and realise they hadn't factored in a system that they thought was nothing but was vital to the organisation running.
And this isn't just for-profit organisations, this is the health services, this is national infrastructure, it's everyone.
There's not yet a single standard that says "This is how organisations should control, manage and govern their flows of data."
Why is that relevant to the companies that were affected by Crowd Strike? Would it have stopped it?
Maybe, maybe not. But considering the global impact, it doesn't look like many organisations were prepared for the possibility of a huge chunk of their IT infrastructure going down.
Understanding dataflows help with the preparation for events like this, so organisations can move to mitigate them, and also the recovery side when they do happen. Organisations need to understand which systems are a priority to get back operational and which can be left.
The problem I'm seeing from a lot of organisations at the moment is that they don't know which systems to recover first, and are losing money and reputation while they fight to get things back online. A lot of them are just winging it.
Conclusion of Part 1
Next time I can totally go into diagramming if any of you are interested in that.
How can any organisation actually map their dataflow and what things need to be considered to do so. It'll come across like common sense, but that's why an actual standard is so desperately needed!
789 notes
·
View notes
Text
Vue.js is a progressive JavaScript framework for building user interfaces. One of the challenges in large-scale applications is handling state management across multiple components. As applications grow, managing and sharing data between components can become complex. Vuex is a state management library specifically designed for Vue.js to manage state in a predictable and centralized way. Vuex helps you maintain consistent state and enables efficient data flow, making your Vue.js application more maintainable and scalable.
#VueJS#Vuex#StateManagement#FrontendDevelopment#JavaScript#WebDevelopment#VueComponents#VueRouter#VueJSArchitecture#SinglePageApplications#SPA#Reactivity#Store#Mutations#Actions#Getters#Modules#VueJSStateManagement#JavaScriptFramework#VueDevTools#ComponentCommunication#Vue3#Vuex4#WebAppDevelopment#FrontendArchitecture#UIStateManagement#AppState#DataFlow
0 notes
Text
Mastering Power BI Data Migration with Dataflows
Data migration is a vital step for organizations looking to modernize their data infrastructure, and Power BI dataflows provide an efficient way to handle this transition. With features like centralized data preparation, reusability, and seamless integration with Azure Data Lake Storage, dataflows streamline the ETL (Extract, Transform, Load) process for businesses.
Why Choose Power BI Dataflows for Data Migration?
🔹 Reusability – Apply transformations across multiple Power BI reports, ensuring consistency. 🔹 Simplified ETL Process – Use Power Query Editor to transform and clean data effortlessly. 🔹 Azure Data Lake Integration – Secure and scalable storage for large datasets. 🔹 Improved Data Consistency – Centralized data management eliminates inconsistencies across reports.
Step-by-Step Guide to Dataflow Migration
📌 Migrating Queries from Power BI Desktop: ✅ Copy M code from Power Query Editor and paste it into a new dataflow in the Power BI service. ✅ Save and refresh the dataflow to activate the new data pipeline.
📌 Upgrading from Dataflow Gen1 to Gen2: ✅ Assess existing dataflows and review Microsoft’s migration guidelines. ✅ Update connections and ensure reports are linked to Dataflow Gen2 for better performance and scalability.
0 notes
Text
DataFlow Group – Primary Source Verification (PSV): Overview
0 notes
Text
Marketing Data Flow Diagram
Visualizing Airbnb’s Marketing Data Flow
To succeed in a new market, it’s crucial to understand how product/service data flows through Airbnb’s marketing channels. A Data Flow Diagram (DFD) can help visualize this process, ensuring that data is managed efficiently and reaches the right audiences.
Chapter 19.4 of Business Statistics discusses revising probabilities in light of new data, which is essential when managing complex marketing data flows (Black, 2023, pp. C19-22–29). For Airbnb, continuously updating and revising marketing data based on real-time feedback is crucial for optimizing campaigns and reaching target audiences effectively.
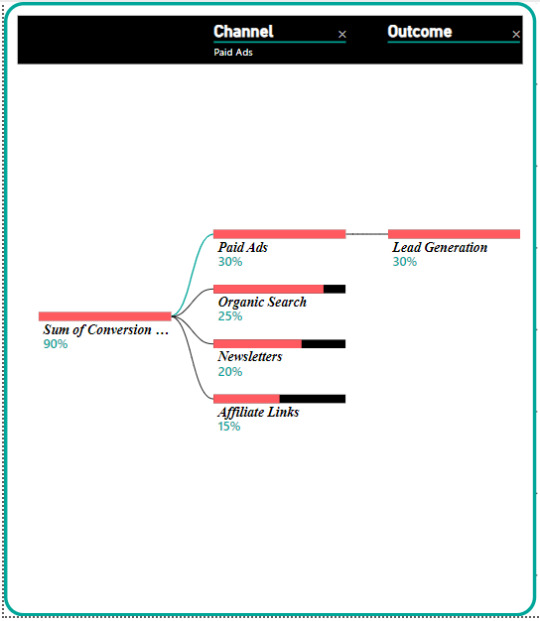

0 notes
Text
Introducing Datastream GCP’s new Stream Recovery Features

Replication pipelines can break in the complicated and dynamic world of data replication. Restarting replication with little impact on data integrity requires a number of manual procedures that must be completed after determining the cause and timing of the failure.
With the help of Datastream GCP‘s new stream recovery capability, you can immediately resume data replication in scenarios like database failover or extended network outages with little to no data loss.
Think about a financial company that replicates transaction data to BigQuery for analytics using DataStream from their operational database. A planned failover to a replica occurs when there is a hardware failure with the primary database instance. Due to the unavailability of the original source, Datastream’s replication pipeline is malfunctioning. In order to prevent transaction data loss, stream recovery enables replication to continue from the failover database instance.
Consider an online shop that replicates user input to BigQuery for sentiment analysis using BigQuery ML utilising Datastream. An extended network disruption breaks the source database connection. Some of the updates are no longer accessible on the database server by the time network connectivity is restored. Here, the user can rapidly resume replication from the first available log point thanks to stream recovery. For ongoing sentiment analysis and trend identification, the merchant prioritises obtaining the most recent data, even though some feedback may be lost.
The advantages of recovering streams
Benefits of stream recovery include the following
Reduced data loss: Get back data lost by events like unintentional log file deletion and database instance failovers.
Minimise downtime: Get back up and running as soon as possible to resume continuous CDC consumption and swiftly restore your stream.
Recovery made easier: A user-friendly interface makes it simple to retrieve your stream.
Availables of Datastream GCP
Minimise latency in data replication and synchronisation
Reduce the impact on source performance while ensuring reliable, low-latency data synchronization across diverse databases, storage systems, and applications.
Adapt to changing needs using a serverless design
Quickly get up and running with a simple, serverless application that scales up and down without any hassle and requires no infrastructure management.
Google Cloud services offer unparalleled flexibility
Utilise the best Google Cloud services, such as BigQuery, as Spanner, Dataflow, and Data Fusion, to connect and integrate data throughout your company.
Important characteristics
The unique strategy of Datastream GCP
Data streaming via relational databases
Your MySQL, PostgreSQL, AlloyDB, SQL Server, and Oracle databases can be read and updated by Datastream, which then transfers the changes to BigQuery, Cloud SQL, Cloud Storage, and Spanner. It consistently broadcasts every event as it happens and is Google native and agentless. More than 500 trillion events are processed monthly by Datastream.
Robust pipelines with sophisticated recovery
Unexpected disruptions may incur high expenses. You can preserve vital business activities and make defensible decisions based on continuous data pipelines thanks to Datastream GCP‘s strong stream recovery, which reduces downtime and data loss.
Resolution of schema drift
Datastream GCP enables quick and easy resolution of schema drift when source schemas change. Every time a schema is changed, Datastream rotates the files, adding a new file to the target bucket. With a current, versioned Schema Registry, original source data types are only a call away via an API.
Safe by design
To safeguard data while it’s in transit, Datastream GCP offers a variety of private, secure connectivity options. You can relax knowing your data is safe while it streams because it is also encrypted while it is in transit and at rest.
The application of stream recovery
Depending on the particular failure circumstance and the availability of current log files, stream recovery offers you a few options to select from. You have three options when it comes to MySQL and Oracle: stream from the most recent position, skip the current position and stream from the next available position, or retry from the current log position. Additionally, you can provide the stream a precise log position to resume from for example, the Log Sequence Number (LSN) or Change Sequence Number (CSN) giving you more precise control over making sure that no data is lost or duplicated in the destination.
You can tell Datastream to start streaming again from the new replication slot after creating a new one in your PostgreSQL database for PostgreSQL sources.
From a given position, begin a stream
Apart from stream recovery, there are several situations in which you might need to begin or continue a stream from a particular log location. For instance, when the source database is being upgraded or moved, or when historical data from a particular point in time (where the historical data terminates) is already present in the destination and you would like to merge it. In these situations, you can utilise the stream recovery API to set a starting position before initiating the stream.
Get going
For all available Datastream sources across all Google Cloud regions, stream recovery is now widely accessible via the Google Cloud dashboard and API.
Read more on Govindhtech.com
#DatastreamGCP#BigQuery#GoogleCloud#spanner#dataflow#BigQueryML#SQLServer#PostgreSQL#oracle#MySQL#cloudstorage#news#technews#technology#technologynews#technologytrends#govindhtech
1 note
·
View note
Text
Dataflow Verification: A Time-Saving Tool for Streamlining the Healthcare Hiring Process: A Guide by Healthcare Naukri
In today’s competitive healthcare job market, efficiency is key. Healthcare institutions constantly strive to find the best qualified candidates while filling vacancies quickly. Here at Healthcare Naukri, we understand the importance of a streamlined hiring process. That’s where dataflow verification comes in — a powerful tool that can save valuable time and resources.
What is Dataflow Verification?
Dataflow verification involves confirming the accuracy and authenticity of the information a healthcare candidate provides in their application. This typically focuses on credentials like:
Education Degrees & Diplomas: Verification ensures candidates possess the required educational qualifications.
Professional Licenses: This confirms candidates hold valid and active licenses to practice in the state or jurisdiction.
Employment History: Past employers can verify work experience and job duties.
How Does Dataflow Verification Save Time?
Traditional verification methods can be time-consuming and labor-intensive. Here’s how dataflow verification streamlines the process:
Automated Verification: Dataflow verification services utilize electronic verification methods, significantly reducing manual verification tasks.
Faster Turnaround Times: Verifications can be completed in a matter of days compared to weeks with traditional methods.
Reduced Administrative Burden: Healthcare institutions free up HR staff time for other crucial tasks by delegating verification processes.
Benefits Beyond Time Savings:
While time-saving is a significant advantage, dataflow verification offers additional benefits:
Improved Accuracy: Electronic verification minimizes the risk of errors compared to manual processes.
Enhanced Compliance: Dataflow verification helps institutions comply with credentialing and privileging regulations.
Increased Candidate Confidence: Streamlined verification provides candidates with a faster hiring experience.
How Healthcare Naukri Can Help:
At Healthcare Naukri, we understand the importance of a smooth and efficient hiring process. Here’s how we can help:
Job Board: Our platform connects healthcare institutions with top-tier candidates who are prepared for dataflow verification.
Resources: We offer informative resources on dataflow verification to educate both healthcare professionals and employers.
Partnerships: We explore partnerships with dataflow verification service providers to offer exclusive benefits to our users.
Embrace Efficiency with Dataflow Verification
Dataflow verification is more than just a time-saving tool; it’s an essential component of a modern healthcare hiring process. By leveraging dataflow verification, healthcare institutions can expedite the hiring process, ensure qualified candidates, and focus on building successful healthcare teams.
Start streamlining your hiring process today! Explore the wealth of healthcare professionals and resources available on Healthcare Naukri.
0 notes
Text
What is Large Language Models(LLM)?
Large Language Models #llm #datascience #dataengineering #machinelearning
Large Language models or LLMs are Artificial Intelligence(AI) software that uses machine learning and other models to generate and recognize text and similar content. They use neural network models called transformation models that can learn context and meaning by tracking relationships in sequential data. They are trained in large columns of data with millions or billions of parameters. Why is…
View On WordPress
0 notes
Text
Delve into the intricacies of network architecture with a breakdown of Layer 3 switches versus routers. Explore how each device navigates data packets through your network, understanding their unique functionalities and roles in optimizing traffic flow.
#Layer3Switch#RouterComparison#NetworkingDebate#TechTalk#NetworkInfrastructure#SwitchVersusRouter#ITInsights#Networking101#TechExploration#DataFlow
0 notes
Text
𝐁𝐫𝐢𝐝𝐠𝐢𝐧𝐠 𝐭𝐡𝐞 𝐆𝐚𝐩, 𝐁𝐨𝐨𝐬𝐭𝐢𝐧𝐠 𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞: 𝐂𝐡𝐨𝐨𝐬𝐞 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐲 𝐄𝐱𝐜𝐞𝐥𝐥𝐞𝐧𝐜𝐞❗

Discover how API proxies from VPS PROXIES INC can revolutionize your online operations with seamless connectivity and top-notch security. Elevate your digital endeavors with these powerful tools, ensuring a streamlined and protected online experience. Explore the transformative potential of API proxies for a more efficient online presence.
🔄 𝐖𝐡𝐚𝐭 𝐚𝐫𝐞 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 ❓
API proxies function as intermediaries, serving as essential bridges that facilitate smooth communication between diverse software applications. Acting as a conduit for data exchange, these proxies are pivotal in optimizing interactions between an application or client and external APIs. In essence, API proxies simplify and secure the flow of requests and responses, ensuring a seamless and efficient exchange of information. By adding an extra layer of functionality and security, these proxies play a critical role in managing and enhancing the overall communication process between applications and external services.
🛠️ 𝐇𝐨𝐰 𝐝𝐨 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐖𝐨𝐫𝐤 ❓
API proxies work by intercepting and managing the communication between a client application and an external API (Application Programming Interface). Here’s a simplified overview of how API proxies function:
👉 𝑻𝒉𝒆 𝑪𝒍𝒊𝒆𝒏𝒕 𝑼𝒏𝒗𝒆𝒊𝒍𝒔 𝑰𝒕𝒔 𝑹𝒆𝒒𝒖𝒆𝒔𝒕: A client application initiates a request to access data or services from an external API.
👉 𝑰𝒏𝒕𝒆𝒓𝒄𝒆𝒑𝒕𝒊𝒏𝒈 𝒕𝒉𝒆 𝑪𝒍𝒊𝒆𝒏𝒕❜𝒔 𝑷𝒍𝒆𝒂: Before the request reaches the external API, it passes through an API proxy. The proxy intercepts the request, acting as an intermediary.
👉 𝑷𝒓𝒐𝒄𝒆𝒔𝒔𝒊𝒏𝒈 𝒂𝒏𝒅 𝑻𝒓𝒂𝒏𝒔𝒇𝒐𝒓𝒎𝒂𝒕𝒊𝒐𝒏: The API proxy can perform various actions on the request, such as modifying headers, transforming data, or enforcing security measures. This step allows the proxy to optimize the request for the external API.
👉 𝑺𝒆𝒄𝒖𝒓𝒊𝒕𝒚 𝑴𝒆𝒂𝒔𝒖𝒓𝒆𝒔 𝑨𝒑𝒑𝒍𝒊𝒆𝒅: API proxies often incorporate security features like authentication and encryption. Authentication ensures that the client is authorized to access the API, and encryption secures the data during transit.
👉 𝑹𝒐𝒖𝒕𝒊𝒏𝒈 𝒕𝒐 𝑬𝒙𝒕𝒆𝒓𝒏𝒂𝒍 𝑨𝑷𝑰: After processing the request, the API proxy forwards it to the external API. The external API processes the request and generates a response.
👉 𝑹𝒆𝒔𝒑𝒐𝒏𝒔𝒆 𝑰𝒏𝒕𝒆𝒓𝒄𝒆𝒑𝒕𝒆𝒅 𝒃𝒚 𝑨𝑷𝑰 𝑷𝒓𝒐𝒙𝒚: As the response travels back from the external API to the client, it passes through the API proxy again. The proxy can intercept the response for further processing.
👉 𝑨𝒅𝒅𝒊𝒕𝒊𝒐���𝒂𝒍 𝑷𝒓𝒐𝒄𝒆𝒔𝒔𝒊𝒏𝒈 𝒂𝒏𝒅 𝑻𝒓𝒂𝒏𝒔𝒇𝒐𝒓𝒎𝒂𝒕𝒊𝒐𝒏: The API proxy can perform additional actions on the response, such as modifying data or headers. This step allows the proxy to tailor the response to the client’s needs.
𝐊𝐞𝐲 𝐄��𝐞𝐦𝐞𝐧𝐭𝐬 𝐢𝐧 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐲 𝐌𝐚𝐬𝐭𝐞𝐫𝐲
🚥 𝑻𝒓𝒂𝒇𝒇𝒊𝒄 𝑶𝒓𝒄𝒉𝒆𝒔𝒕𝒓𝒂𝒕𝒊𝒐𝒏 API proxies can implement features like rate limiting and caching to optimize the flow of data between the client and the external API.
📊 𝑰𝒏𝒔𝒊𝒈𝒉𝒕𝒇𝒖𝒍 𝑨𝒏𝒂𝒍𝒚𝒕𝒊𝒄𝒔 𝒂𝒏𝒅 𝑴𝒐𝒏𝒊𝒕𝒐𝒓𝒊𝒏𝒈 API proxies often log information about requests and responses, providing valuable insights for monitoring, analytics, and issue resolution.
🔄𝑺𝒆𝒂𝒎𝒍𝒆𝒔𝒔 𝑽𝒆𝒓𝒔𝒊𝒐𝒏 𝑪𝒐𝒏𝒕𝒓𝒐𝒍 API proxies can handle different versions of APIs, ensuring compatibility between clients and external services, even when updates or changes occur.
𝐏𝐫𝐚𝐜𝐭𝐢𝐜𝐚𝐥 𝐒𝐜𝐞𝐧𝐚𝐫𝐢𝐨𝐬: 𝐖𝐡𝐞𝐫𝐞 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐢𝐞𝐬 𝐒𝐡𝐢𝐧𝐞 🌟
🔒 𝑭𝒐𝒓𝒕𝒊𝒇𝒚𝒊𝒏𝒈 𝑫𝒂𝒕𝒂 𝑺𝒆𝒄𝒖𝒓𝒊𝒕𝒚 API proxies are frequently employed to bolster the security of data transmission. By encrypting information, they ensure that sensitive details remain confidential during the exchange.
⚙️ 𝑶𝒑𝒕𝒊𝒎𝒊𝒛𝒊𝒏𝒈 𝑷𝒆𝒓𝒇𝒐𝒓𝒎𝒂𝒏𝒄𝒆 Additionally, API proxies play a vital role in optimizing performance. Through techniques like caching, they reduce response times, making interactions between applications and external services quicker and more efficient.
🚦 𝑻𝒓𝒂𝒇𝒇𝒊𝒄 𝑪𝒐𝒏𝒕𝒓𝒐𝒍 Another notable use case involves traffic management. API proxies regulate the flow of data, employing measures such as rate limiting to prevent overwhelming external services with a barrage of requests.
🔄 𝑪𝑶𝑹𝑺 𝑴𝒂𝒔𝒕𝒆𝒓𝒚 𝒇𝒐𝒓 𝑼𝒏𝒓𝒆𝒔𝒕𝒓𝒊𝒄𝒕𝒆𝒅 𝑫𝒂𝒕𝒂 𝑹𝒆𝒕𝒓𝒊𝒆𝒗𝒂𝒍 In scenarios where applications need to fetch data from different domains, API proxies shine in handling Cross-Origin Resource Sharing. They enable secure data retrieval from multiple sources without running into browser restrictions.
📈 𝑳𝒐𝒈𝒈𝒊𝒏𝒈 𝒂𝒏𝒅 𝑴𝒐𝒏𝒊𝒕𝒐𝒓𝒊𝒏𝒈 Furthermore, API proxies are instrumental in logging and monitoring interactions. This continuous oversight helps identify issues, track performance metrics, and troubleshoot potential challenges seamlessly.
🔄 𝑽𝒆𝒓𝒔𝒊𝒐𝒏 𝑪𝒐𝒏𝒕𝒓𝒐𝒍 Version control is another critical aspect where API proxies prove their worth. They assist in managing different versions of APIs, ensuring smooth transitions and compatibility between evolving applications and services.
⚖️ 𝑳𝒐𝒂𝒅 𝑩𝒂𝒍𝒂𝒏𝒄𝒊𝒏𝒈 For applications dealing with varying levels of traffic, API proxies offer the advantage of load balancing. This means distributing incoming requests evenly among multiple servers, preventing any single server from becoming overloaded.
🚀 𝑨𝒅𝒂𝒑𝒕𝒊𝒏𝒈 𝒕𝒐 𝑬𝒎𝒆𝒓𝒈𝒊𝒏𝒈 𝑻𝒆𝒄𝒉𝒏𝒐𝒍𝒐𝒈𝒊𝒆𝒔 As technology evolves, API proxies remain adaptable. They smoothly transition into supporting emerging technologies, ensuring that applications can seamlessly integrate new functionalities without disruptions.
🤔 𝐂𝐨𝐧𝐬𝐢𝐝𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐬 𝐰𝐡𝐞𝐧 𝐜𝐡𝐨𝐨𝐬𝐢𝐧𝐠 𝐚𝐧 𝐀𝐏𝐈 𝐏𝐫𝐨𝐱𝐲
When selecting an API proxy, several crucial considerations come into play to ensure optimal performance, security, and compatibility. Let’s explore these key factors:
🔐 𝑺𝒆𝒄𝒖𝒓𝒊𝒕𝒚 𝑴𝒆𝒂𝒔𝒖𝒓𝒆𝒔 : First and foremost, assess the security features offered by the API proxy. Look for encryption, authentication mechanisms, and other security measures to safeguard your data during transit.
⚙️ 𝑷𝒆𝒓𝒇𝒐𝒓𝒎𝒂𝒏𝒄𝒆 𝑶𝒑𝒕𝒊𝒎𝒊𝒛𝒂𝒕𝒊𝒐𝒏 : Consider how the API proxy contributes to performance optimization. Evaluate features such as caching, which can significantly enhance response times and reduce latency.
🚦 𝑻𝒓𝒂𝒇𝒇𝒊𝒄 𝑴𝒂𝒏𝒂𝒈𝒆𝒎𝒆𝒏𝒕 𝑪𝒂𝒑𝒂𝒃𝒊𝒍𝒊𝒕𝒊𝒆𝒔 : Examine the API proxy’s ability to manage traffic effectively. Features like rate limiting and traffic shaping can prevent overload, ensuring consistent and reliable service.
🔄 𝑪𝒓𝒐𝒔𝒔-𝑶𝒓𝒊𝒈𝒊𝒏 𝑹𝒆𝒔𝒐𝒖𝒓𝒄𝒆 𝑺𝒉𝒂𝒓𝒊𝒏𝒈 (𝑪𝑶𝑹𝑺) 𝑺𝒖𝒑𝒑𝒐𝒓𝒕 : If your applications need to interact with resources from different domains, check if the API proxy provides robust support for Cross-Origin Resource Sharing. This ensures seamless data retrieval without encountering browser restrictions.
📊 𝑳𝒐𝒈𝒈𝒊𝒏𝒈 𝒂𝒏𝒅 𝑴𝒐𝒏𝒊𝒕𝒐𝒓𝒊𝒏𝒈 𝑻𝒐𝒐𝒍𝒔 : Assess the logging and monitoring capabilities of the API proxy. Having detailed insights into interactions can aid in issue identification, performance tracking, and overall system health.
🔄 𝑽𝒆𝒓𝒔𝒊𝒐𝒏 𝑪𝒐𝒏𝒕𝒓𝒐𝒍 𝑴𝒆𝒄𝒉𝒂𝒏𝒊𝒔𝒎𝒔 : Evaluate how the API proxy handles version control. Ensure it supports different versions of APIs to facilitate smooth transitions and maintain compatibility as your applications evolve.
🛠️ 𝑬𝒂𝒔𝒆 𝒐𝒇 𝑰𝒏𝒕𝒆𝒈𝒓𝒂𝒕𝒊𝒐𝒏 : Assess how easily the API proxy can be integrated into your existing infrastructure. A user-friendly integration process minimizes disruptions and accelerates the implementation of proxy services.
💵 𝑩𝒖𝒅𝒈𝒆𝒕𝒂𝒓𝒚 𝑨𝒏𝒂𝒍𝒚𝒔𝒊𝒔: Finally, examine the cost and licensing structure of the API proxy. Ensure that it aligns with your budgetary constraints and provides a clear understanding of any additional costs associated with scaling or feature usage.
𝑼𝒏𝒍𝒐𝒄𝒌 𝒕𝒉𝒆 𝑻𝒓𝒖𝒆 𝑷𝒐𝒕𝒆𝒏𝒕𝒊𝒂𝒍 𝒐𝒇 𝒀𝒐𝒖𝒓 𝑶𝒏𝒍𝒊𝒏𝒆 𝑷𝒓𝒆𝒔𝒆𝒏𝒄𝒆 🌐
𝐂𝐨𝐧𝐜𝐥𝐮𝐬𝐢𝐨𝐧:
The integration of an API proxy across all services offered by VPS Proxies Inc. represents a pivotal step towards optimizing performance and security. By consolidating API access through a centralized proxy layer, we enhance data integrity, mitigate potential vulnerabilities, and streamline communication channels. This proactive measure not only ensures a seamless user experience but also reinforces our commitment to delivering reliable and innovative solutions to our valued clients. With the API proxy in place, VPS Proxies Inc. is poised to meet the evolving needs of businesses with efficiency and confidence..
ℂ𝕠𝕟𝕥𝕒𝕔𝕥 𝕦𝕤:-: 👉🏻 Web: www.vpsproxies.com 👉🏻 Telegram: https://t.me/vpsproxiesinc 👉 Gmail: [email protected] 👉🏻 Skype: live:.cid.79b1850cbc237b2a
#InnovationNation#TechTrends#FutureForward#DigitalTransformation#DataDriven#CodeCrafting#APIRevolution#ConnectTheDots#TechInnovation#BytesAndBeyond#SmartTech#CodeCreators#DigitalFrontiers#TechSavvy#BeyondBoundaries#InfinitePossibilities#DataFlow#APIMagic#TechUnleashed#NextGenTech
0 notes
Text
Tumblr’s totally not the place for it but damn I could talk about how to properly map data flow for hours.
Like it’s genuinely exciting non-dystopian digital future stuff when you think how it could help organisations.
It fucking runs circles around businesses crowing about how they’re ’implementing AI’ (they are not).
Would genuinely create a sideblog or something to teach folk but again, tumblr probably not the platform for it.
508 notes
·
View notes
Text
Why Choose Celigo Integrator.Io Over Building Custom API Integration?
In the world of data integration, the debate between using a platform like Celigo integrator.io vs building a custom API integration is a hot topic. This article aims to shed light on why Celigo might be a better choice for your business.

What Is Celigo Integrator.Io?
Celigo integrator.io is a leading iPaaS (Integration Platform as a Service) platform that allows businesses to connect their applications and automate business processes. With its robust iPaaS platform, businesses can seamlessly connect their systems such as Oracle NetSuite, Salesforce, Amazon, Shopify, BigCommerce, 3PL Systems and similar other applications.
Celigo Integrator.Io Vs Custom API Integration
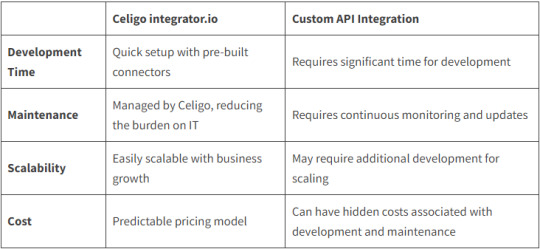
Key Advantages Of Celigo Integrator.Io
Pre-built Connectors: Celigo offers pre-built connectors for integration use cases like Oracle NetSuite ERP integration with Shopify, Amazon, BigCommerce, Salesforce, Magento 2, etc., which significantly reduces the time and effort required to set up integrations.
Scalability: As your business grows, so does your data. Celigo, integrator.io ensuring your integrations can handle increased data volume.
Reduced IT Burden: With Celigo integrator.io, the burden on IT teams is significantly reduced as the platform manages the integrations, freeing up resources for other tasks.
Cost-Effective: Unlike Custom API Integrations, which can have hidden costs associated with development and maintenance, Celigo offers a predictable pricing model.
In conclusion, Custom API integration development offers flexibility, however on the other side, the quick setup, scalability, reduced IT burden, and cost-effectiveness of Celigo make it a compelling choice for businesses looking to streamline their processes with efficient integrations. The Celigo integrator.io is a testament to the platform’s capabilities and effectiveness.
Integs Cloud: Your Trusted Celigo Integration Partner
Integs Cloud is a certified Celigo partner that provides end-to-end integration services, from consulting and implementation to support and maintenance. With a team of experienced and certified Celigo experts, Integs Cloud can handle any integration challenge and deliver solutions that meet your business needs and goals.Whether you need to integrate Oracle NetSuite with Shopify, Amazon, BigCommerce, Salesforce, Magento 2 or any other applications, Integs Cloud can help you achieve it with the Celigo iPaaS platform. Contact Integs Cloud today and get a free consultation and quote for your integration project.
#IntegsCloud#DataIntegration#DataAutomation#Celigo#CeligoVsCustomAPI#IntegrationSolutions#APIIntegration#DataFlow#iPaaS#Integration#Automation#API#SaaS#Enterprise#Tech#Technology#ERP#Software
0 notes
Text
Mastering Dataflow Gen2 In Microsoft Fabric (part 2)
Data transformations are an important part of any #Lakehouse project, and with #Dataflow Gen2 In Microsoft Fabric, you can start building your transformation pipelines without much training, using an easy graphical interface. In this tutorial, I explain how to apply aggregations,de-duplications and pivoting/unpivoting transformations in Dataflow Gen2. Check out here:https://youtu.be/0upqIqKlpDk

0 notes
Text

Microsoft Fabric Online Training New Batch
Join Now: https://meet.goto.com/252420005
Attend Online New Batch On Microsoft Fabric by Mr.Viraj Pawar.
Batch on: 29th February @ 8:00 AM (IST).
Contact us: +91 9989971070.
Join us on WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit: https://visualpath.in/microsoft-fabric-online-training-hyderabad.html
#visualpathedu#onlinelearning#FreeDemo#education#Microsoft#Azure#fabric#MicrosoftFabric#dataanalytics#DataWarehouse#datawarehousing#Databricks#AzureDataFactory#datascience#dataflow#powerbi#ApacheSpark#newtechnology#SoftwareDevelopment#softwaredeveloper#softwarecourses#ITCourses
1 note
·
View note
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
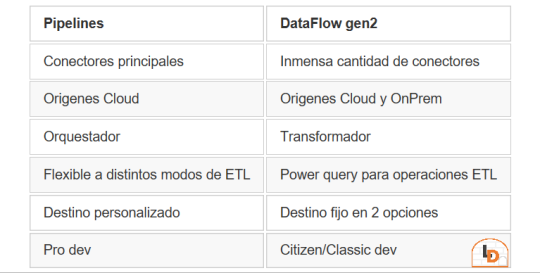
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
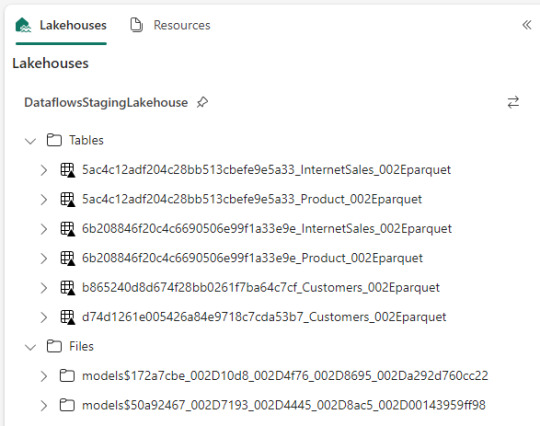
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
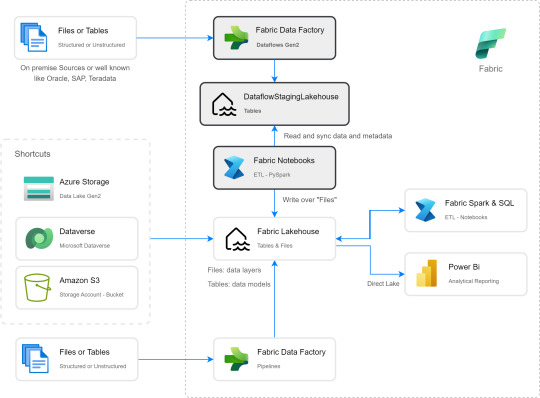
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes