#How to build a private LLM
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Thinking of building your own private LLM? Start by choosing a pre-trained model like GPT-4. Fine-tune it with domain-specific data for your needs. Secure your environment with encryption and access controls. Utilize APIs for seamless integration and optimize performance with efficient hardware. Regularly update and monitor your model to ensure it remains relevant and accurate. Happy building!
Read More:
0 notes
Text
clarification re: ChatGPT, " a a a a", and data leakage
In August, I posted:
For a good time, try sending chatGPT the string ` a` repeated 1000 times. Like " a a a" (etc). Make sure the spaces are in there. Trust me.
People are talking about this trick again, thanks to a recent paper by Nasr et al that investigates how often LLMs regurgitate exact quotes from their training data.
The paper is an impressive technical achievement, and the results are very interesting.
Unfortunately, the online hive-mind consensus about this paper is something like:
When you do this "attack" to ChatGPT -- where you send it the letter 'a' many times, or make it write 'poem' over and over, or the like -- it prints out a bunch of its own training data. Previously, people had noted that the stuff it prints out after the attack looks like training data. Now, we know why: because it really is training data.
It's unfortunate that people believe this, because it's false. Or at best, a mixture of "false" and "confused and misleadingly incomplete."
The paper
So, what does the paper show?
The authors do a lot of stuff, building on a lot of previous work, and I won't try to summarize it all here.
But in brief, they try to estimate how easy it is to "extract" training data from LLMs, moving successively through 3 categories of LLMs that are progressively harder to analyze:
"Base model" LLMs with publicly released weights and publicly released training data.
"Base model" LLMs with publicly released weights, but undisclosed training data.
LLMs that are totally private, and are also finetuned for instruction-following or for chat, rather than being base models. (ChatGPT falls into this category.)
Category #1: open weights, open data
In their experiment on category #1, they prompt the models with hundreds of millions of brief phrases chosen randomly from Wikipedia. Then they check what fraction of the generated outputs constitute verbatim quotations from the training data.
Because category #1 has open weights, they can afford to do this hundreds of millions of times (there are no API costs to pay). And because the training data is open, they can directly check whether or not any given output appears in that data.
In category #1, the fraction of outputs that are exact copies of training data ranges from ~0.1% to ~1.5%, depending on the model.
Category #2: open weights, private data
In category #2, the training data is unavailable. The authors solve this problem by constructing "AuxDataset," a giant Frankenstein assemblage of all the major public training datasets, and then searching for outputs in AuxDataset.
This approach can have false negatives, since the model might be regurgitating private training data that isn't in AuxDataset. But it shouldn't have many false positives: if the model spits out some long string of text that appears in AuxDataset, then it's probably the case that the same string appeared in the model's training data, as opposed to the model spontaneously "reinventing" it.
So, the AuxDataset approach gives you lower bounds. Unsurprisingly, the fractions in this experiment are a bit lower, compared to the Category #1 experiment. But not that much lower, ranging from ~0.05% to ~1%.
Category #3: private everything + chat tuning
Finally, they do an experiment with ChatGPT. (Well, ChatGPT and gpt-3.5-turbo-instruct, but I'm ignoring the latter for space here.)
ChatGPT presents several new challenges.
First, the model is only accessible through an API, and it would cost too much money to call the API hundreds of millions of times. So, they have to make do with a much smaller sample size.
A more substantial challenge has to do with the model's chat tuning.
All the other models evaluated in this paper were base models: they were trained to imitate a wide range of text data, and that was that. If you give them some text, like a random short phrase from Wikipedia, they will try to write the next part, in a manner that sounds like the data they were trained on.
However, if you give ChatGPT a random short phrase from Wikipedia, it will not try to complete it. It will, instead, say something like "Sorry, I don't know what that means" or "Is there something specific I can do for you?"
So their random-short-phrase-from-Wikipedia method, which worked for base models, is not going to work for ChatGPT.
Fortuitously, there happens to be a weird bug in ChatGPT that makes it behave like a base model!
Namely, the "trick" where you ask it to repeat a token, or just send it a bunch of pre-prepared repetitions.
Using this trick is still different from prompting a base model. You can't specify a "prompt," like a random-short-phrase-from-Wikipedia, for the model to complete. You just start the repetition ball rolling, and then at some point, it starts generating some arbitrarily chosen type of document in a base-model-like way.
Still, this is good enough: we can do the trick, and then check the output against AuxDataset. If the generated text appears in AuxDataset, then ChatGPT was probably trained on that text at some point.
If you do this, you get a fraction of 3%.
This is somewhat higher than all the other numbers we saw above, especially the other ones obtained using AuxDataset.
On the other hand, the numbers varied a lot between models, and ChatGPT is probably an outlier in various ways when you're comparing it to a bunch of open models.
So, this result seems consistent with the interpretation that the attack just makes ChatGPT behave like a base model. Base models -- it turns out -- tend to regurgitate their training data occasionally, under conditions like these ones; if you make ChatGPT behave like a base model, then it does too.
Language model behaves like language model, news at 11
Since this paper came out, a number of people have pinged me on twitter or whatever, telling me about how this attack "makes ChatGPT leak data," like this is some scandalous new finding about the attack specifically.
(I made some posts saying I didn't think the attack was "leaking data" -- by which I meant ChatGPT user data, which was a weirdly common theory at the time -- so of course, now some people are telling me that I was wrong on this score.)
This interpretation seems totally misguided to me.
Every result in the paper is consistent with the banal interpretation that the attack just makes ChatGPT behave like a base model.
That is, it makes it behave the way all LLMs used to behave, up until very recently.
I guess there are a lot of people around now who have never used an LLM that wasn't tuned for chat; who don't know that the "post-attack content" we see from ChatGPT is not some weird new behavior in need of a new, probably alarming explanation; who don't know that it is actually a very familiar thing, which any base model will give you immediately if you ask. But it is. It's base model behavior, nothing more.
Behaving like a base model implies regurgitation of training data some small fraction of the time, because base models do that. And only because base models do, in fact, do that. Not for any extra reason that's special to this attack.
(Or at least, if there is some extra reason, the paper gives us no evidence of its existence.)
The paper itself is less clear than I would like about this. In a footnote, it cites my tweet on the original attack (which I appreciate!), but it does so in a way that draws a confusing link between the attack and data regurgitation:
In fact, in early August, a month after we initial discovered this attack, multiple independent researchers discovered the underlying exploit used in our paper, but, like us initially, they did not realize that the model was regenerating training data, e.g., https://twitter.com/nostalgebraist/status/1686576041803096065.
Did I "not realize that the model was regenerating training data"? I mean . . . sort of? But then again, not really?
I knew from earlier papers (and personal experience, like the "Hedonist Sovereign" thing here) that base models occasionally produce exact quotations from their training data. And my reaction to the attack was, "it looks like it's behaving like a base model."
It would be surprising if, after the attack, ChatGPT never produced an exact quotation from training data. That would be a difference between ChatGPT's underlying base model and all other known LLM base models.
And the new paper shows that -- unsurprisingly -- there is no such difference. They all do this at some rate, and ChatGPT's rate is 3%, plus or minus something or other.
3% is not zero, but it's not very large, either.
If you do the attack to ChatGPT, and then think "wow, this output looks like what I imagine training data probably looks like," it is nonetheless probably not training data. It is probably, instead, a skilled mimicry of training data. (Remember that "skilled mimicry of training data" is what LLMs are trained to do.)
And remember, too, that base models used to be OpenAI's entire product offering. Indeed, their API still offers some base models! If you want to extract training data from a private OpenAI model, you can just interact with these guys normally, and they'll spit out their training data some small % of the time.
The only value added by the attack, here, is its ability to make ChatGPT specifically behave in the way that davinci-002 already does, naturally, without any tricks.
265 notes
·
View notes
Note
Damn would be fun (maybe) to see an ai on a small scale be devloped to help coding, i think a lot ore people would make amezing things without the big dauinting task of learing or spending moeny to learn coding to make stuff like IFs. but that would probilby used and upgraded to the point where programers become less valubale which just doesnt feel good.
No, it would not be fun, and people would not. And you as user wouldn't have fun either.
Are there other types of ai that -can- be helpful? Yes, but they are NOT the type of systems like the anon is trying to sell. And not the type of AI I believe you have in mind.
Think of it like this, people are starting to ask the important question:
If (generative) AI is a trillion dollar investment, what is the trillion dollar 'problem' it's solving?
The answer: Having to pay real people. From art, to writing, to acting, to translating, the big bosses want to cut corners, thus making a massive profit, which then goes straight into their own pockets.
There's a post going round with what a professional translator has to say about grand scale machine translation: Old school (so not the models we are seeing shoved at us now) translation for posts, websites etc if you are a private person is fine. But more and more professional companies like publishers are saying 'this Ai translation of this whole book is good enough, no need for a professional translator outside of fixing maybe the most glaring mistakes' meaning they'll run a whole book through shit, and AT BEST pay a professional translator pennies to 'make dialogue sound more human'.
Remember old 'bad translation' memes like 'All your base are belong to us'? Imagine that being the standard (without the charm) and the publishers would still charge you full price and more, saying that this was professionally translated.
As for the 'big daunting task': It's a new skill worth acquiring. Especially with coding, because you need to know how to fix it. the machines can't, because they don't recognize the mistake, even if you tell them (there have been so many demonstrations of this in all fields).
Also, if you've been SPENDING money (outside of maybe buying VN maker or similar tools) just to learn how to code text-based IFs, I believe you fell for a scam, mate.
Coding languages like Choicescript already have what you think of build-in. It's the error messages. You don't need a big, resource-heavy LLM for that.
You are better off with a rubber duck. (not an insult, and i'll gladly explain what I mean if you don't know.)
18 notes
·
View notes
Text
Vibecoding a production app
TL;DR I built and launched a recipe app with about 20 hours of work - recipeninja.ai
Background: I'm a startup founder turned investor. I taught myself (bad) PHP in 2000, and picked up Ruby on Rails in 2011. I'd guess 2015 was the last time I wrote a line of Ruby professionally. I've built small side projects over the years, but nothing with any significant usage. So it's fair to say I'm a little rusty, and I never really bothered to learn front end code or design.
In my day job at Y Combinator, I'm around founders who are building amazing stuff with AI every day and I kept hearing about the advances in tools like Lovable, Cursor and Windsurf. I love building stuff and I've always got a list of little apps I want to build if I had more free time.
About a month ago, I started playing with Lovable to build a word game based on Articulate (it's similar to Heads Up or Taboo). I got a working version, but I quickly ran into limitations - I found it very complicated to add a supabase backend, and it kept re-writing large parts of my app logic when I only wanted to make cosmetic changes. It felt like a toy - not ready to build real applications yet.
But I kept hearing great things about tools like Windsurf. A couple of weeks ago, I looked again at my list of app ideas to build and saw "Recipe App". I've wanted to build a hands-free recipe app for years. I love to cook, but the problem with most recipe websites is that they're optimized for SEO, not for humans. So you have pages and pages of descriptive crap to scroll through before you actually get to the recipe. I've used the recipe app Paprika to store my recipes in one place, but honestly it feels like it was built in 2009. The UI isn't great for actually cooking. My hands are covered in food and I don't really want to touch my phone or computer when I'm following a recipe.
So I set out to build what would become RecipeNinja.ai
For this project, I decided to use Windsurf. I wanted a Rails 8 API backend and React front-end app and Windsurf set this up for me in no time. Setting up homebrew on a new laptop, installing npm and making sure I'm on the right version of Ruby is always a pain. Windsurf did this for me step-by-step. I needed to set up SSH keys so I could push to GitHub and Heroku. Windsurf did this for me as well, in about 20% of the time it would have taken me to Google all of the relevant commands.
I was impressed that it started using the Rails conventions straight out of the box. For database migrations, it used the Rails command-line tool, which then generated the correct file names and used all the correct Rails conventions. I didn't prompt this specifically - it just knew how to do it. It one-shotted pretty complex changes across the React front end and Rails backend to work seamlessly together.
To start with, the main piece of functionality was to generate a complete step-by-step recipe from a simple input ("Lasagne"), generate an image of the finished dish, and then allow the user to progress through the recipe step-by-step with voice narration of each step. I used OpenAI for the LLM and ElevenLabs for voice. "Grandpa Spuds Oxley" gave it a friendly southern accent.
Recipe summary:
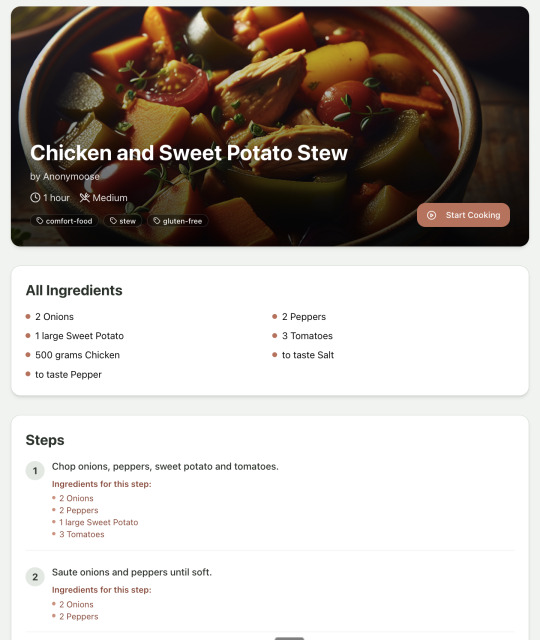
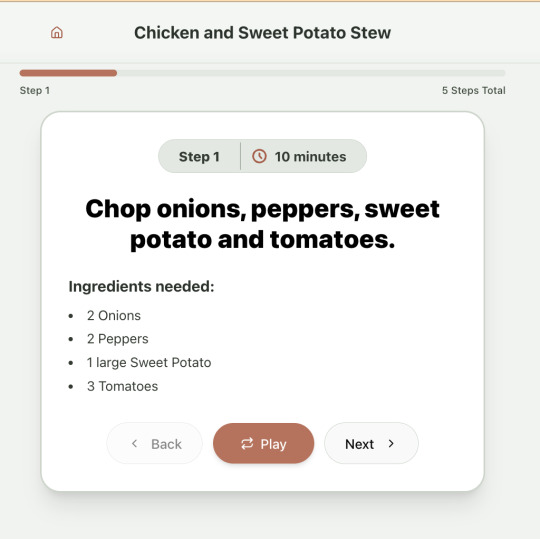
And the recipe step-by-step view:
I was pretty astonished that Windsurf managed to integrate both the OpenAI and Elevenlabs APIs without me doing very much at all. After we had a couple of problems with the open AI Ruby library, it quickly fell back to a raw ruby HTTP client implementation, but I honestly didn't care. As long as it worked, I didn't really mind if it used 20 lines of code or two lines of code. And Windsurf was pretty good about enforcing reasonable security practices. I wanted to call Elevenlabs directly from the front end while I was still prototyping stuff, and Windsurf objected very strongly, telling me that I was risking exposing my private API credentials to the Internet. I promised I'd fix it before I deployed to production and it finally acquiesced.
I decided I wanted to add "Advanced Import" functionality where you could take a picture of a recipe (this could be a handwritten note or a picture from a favourite a recipe book) and RecipeNinja would import the recipe. This took a handful of minutes.
Pretty quickly, a pattern emerged; I would prompt for a feature. It would read relevant files and make changes for two or three minutes, and then I would test the backend and front end together. I could quickly see from the JavaScript console or the Rails logs if there was an error, and I would just copy paste this error straight back into Windsurf with little or no explanation. 80% of the time, Windsurf would correct the mistake and the site would work. Pretty quickly, I didn't even look at the code it generated at all. I just accepted all changes and then checked if it worked in the front end.
After a couple of hours of work on the recipe generation, I decided to add the concept of "Users" and include Google Auth as a login option. This would require extensive changes across the front end and backend - a database migration, a new model, new controller and entirely new UI. Windsurf one-shotted the code. It didn't actually work straight away because I had to configure Google Auth to add `localhost` as a valid origin domain, but Windsurf talked me through the changes I needed to make on the Google Auth website. I took a screenshot of the Google Auth config page and pasted it back into Windsurf and it caught an error I had made. I could login to my app immediately after I made this config change. Pretty mindblowing. You can now see who's created each recipe, keep a list of your own recipes, and toggle each recipe to public or private visibility. When I needed to set up Heroku to host my app online, Windsurf generated a bunch of terminal commands to configure my Heroku apps correctly. It went slightly off track at one point because it was using old Heroku APIs, so I pointed it to the Heroku docs page and it fixed it up correctly.
I always dreaded adding custom domains to my projects - I hate dealing with Registrars and configuring DNS to point at the right nameservers. But Windsurf told me how to configure my GoDaddy domain name DNS to work with Heroku, telling me exactly what buttons to press and what values to paste into the DNS config page. I pointed it at the Heroku docs again and Windsurf used the Heroku command line tool to add the "Custom Domain" add-ons I needed and fetch the right Heroku nameservers. I took a screenshot of the GoDaddy DNS settings and it confirmed it was right.
I can see very soon that tools like Cursor & Windsurf will integrate something like Browser Use so that an AI agent will do all this browser-based configuration work with zero user input.
I'm also impressed that Windsurf will sometimes start up a Rails server and use curl commands to check that an API is working correctly, or start my React project and load up a web preview and check the front end works. This functionality didn't always seem to work consistently, and so I fell back to testing it manually myself most of the time.
When I was happy with the code, it wrote git commits for me and pushed code to Heroku from the in-built command line terminal. Pretty cool!
I do have a few niggles still. Sometimes it's a little over-eager - it will make more changes than I want, without checking with me that I'm happy or the code works. For example, it might try to commit code and deploy to production, and I need to press "Stop" and actually test the app myself. When I asked it to add analytics, it went overboard and added 100 different analytics events in pretty insignificant places. When it got trigger-happy like this, I reverted the changes and gave it more precise commands to follow one by one.
The one thing I haven't got working yet is automated testing that's executed by the agent before it decides a task is complete; there's probably a way to do it with custom rules (I have spent zero time investigating this). It feels like I should be able to have an integration test suite that is run automatically after every code change, and then any test failures should be rectified automatically by the AI before it says it's finished.
Also, the AI should be able to tail my Rails logs to look for errors. It should spot things like database queries and automatically optimize my Active Record queries to make my app perform better. At the moment I'm copy-pasting in excerpts of the Rails logs, and then Windsurf quickly figures out that I've got an N+1 query problem and fixes it. Pretty cool.
Refactoring is also kind of painful. I've ended up with several files that are 700-900 lines long and contain duplicate functionality. For example, list recipes by tag and list recipes by user are basically the same.
Recipes by user:
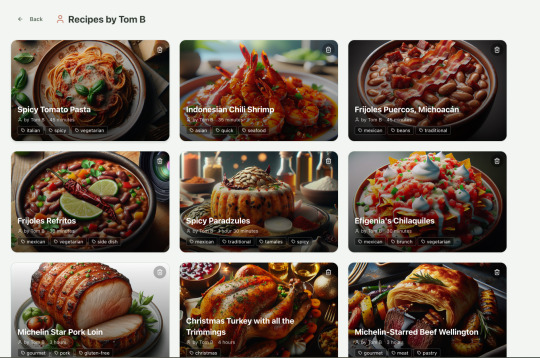
This should really be identical to list recipes by tag, but Windsurf has implemented them separately.
Recipes by tag:
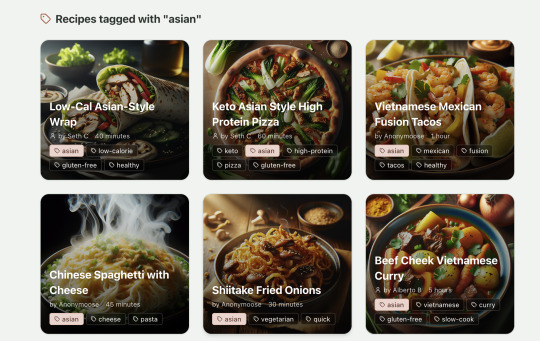
If I ask Windsurf to refactor these two pages, it randomly changes stuff like renaming analytics events, rewriting user-facing alerts, and changing random little UX stuff, when I really want to keep the functionality exactly the same and only move duplicate code into shared modules. Instead, to successfully refactor, I had to ask Windsurf to list out ideas for refactoring, then prompt it specifically to refactor these things one by one, touching nothing else. That worked a little better, but it still wasn't perfect
Sometimes, adding minor functionality to the Rails API will often change the entire API response, rather just adding a couple of fields. Eg It will occasionally change Index Recipes to nest responses in an object { "recipes": [ ] }, versus just returning an array, which breaks the frontend. And then another minor change will revert it. This is where adding tests to identify and prevent these kinds of API changes would be really useful. When I ask Windsurf to fix these API changes, it will instead change the front end to accept the new API json format and also leave the old implementation in for "backwards compatibility". This ends up with a tangled mess of code that isn't really necessary. But I'm vibecoding so I didn't bother to fix it.
Then there was some changes that just didn't work at all. Trying to implement Posthog analytics in the front end seemed to break my entire app multiple times. I tried to add user voice commands ("Go to the next step"), but this conflicted with the eleven labs voice recordings. Having really good git discipline makes vibe coding much easier and less stressful. If something doesn't work after 10 minutes, I can just git reset head --hard. I've not lost very much time, and it frees me up to try more ambitious prompts to see what the AI can do. Less technical users who aren't familiar with git have lost months of work when the AI goes off on a vision quest and the inbuilt revert functionality doesn't work properly. It seems like adding more native support for version control could be a massive win for these AI coding tools.
Another complaint I've heard is that the AI coding tools don't write "production" code that can scale. So I decided to put this to the test by asking Windsurf for some tips on how to make the application more performant. It identified I was downloading 3 MB image files for each recipe, and suggested a Rails feature for adding lower resolution image variants automatically. Two minutes later, I had thumbnail and midsize variants that decrease the loading time of each page by 80%. Similarly, it identified inefficient N+1 active record queries and rewrote them to be more efficient. There are a ton more performance features that come built into Rails - caching would be the next thing I'd probably add if usage really ballooned.
Before going to production, I kept my promise to move my Elevenlabs API keys to the backend. Almost as an afterthought, I asked asked Windsurf to cache the voice responses so that I'd only make an Elevenlabs API call once for each recipe step; after that, the audio file was stored in S3 using Rails ActiveStorage and served without costing me more credits. Two minutes later, it was done. Awesome.
At the end of a vibecoding session, I'd write a list of 10 or 15 new ideas for functionality that I wanted to add the next time I came back to the project. In the past, these lists would've built up over time and never gotten done. Each task might've taken me five minutes to an hour to complete manually. With Windsurf, I was astonished how quickly I could work through these lists. Changes took one or two minutes each, and within 30 minutes I'd completed my entire to do list from the day before. It was astonishing how productive I felt. I can create the features faster than I can come up with ideas.
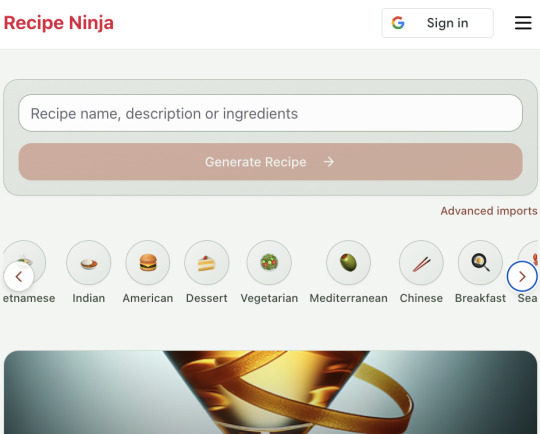
Before launching, I wanted to improve the design, so I took a quick look at a couple of recipe sites. They were much more visual than my site, and so I simply told Windsurf to make my design more visual, emphasizing photos of food. Its first try was great. I showed it to a couple of friends and they suggested I should add recipe categories - "Thai" or "Mexican" or "Pizza" for example. They showed me the DoorDash app, so I took a screenshot of it and pasted it into Windsurf. My prompt was "Give me a carousel of food icons that look like this". Again, this worked in one shot. I think my version actually looks better than Doordash 🤷♂️
Doordash:
My carousel:
I also saw I was getting a console error from missing Favicon. I always struggle to make Favicon for previous sites because I could never figure out where they were supposed to go or what file format they needed. I got OpenAI to generate me a little recipe ninja icon with a transparent background and I saved it into my project directory. I asked Windsurf what file format I need and it listed out nine different sizes and file formats. Seems annoying. I wondered if Windsurf could just do it all for me. It quickly wrote a series of Bash commands to create a temporary folder, resize the image and create the nine variants I needed. It put them into the right directory and then cleaned up the temporary directory. I laughed in amazement. I've never been good at bash scripting and I didn't know if it was even possible to do what I was asking via the command line. I guess it is possible.

After launching and posting on Twitter, a few hundred users visited the site and generated about 1000 recipes. I was pretty happy! Unfortunately, the next day I woke up and saw that I had a $700 OpenAI bill. Someone had been abusing the site and costing me a lot of OpenAI credits by creating a single recipe over and over again - "Pasta with Shallots and Pineapple". They did this 12,000 times. Obviously, I had not put any rate limiting in.
Still, I was determined not to write any code. I explained the problem and asked Windsurf to come up with solutions. Seconds later, I had 15 pretty good suggestions. I implemented several (but not all) of the ideas in about 10 minutes and the abuse stopped dead in its tracks. I won't tell you which ones I chose in case Mr Shallots and Pineapple is reading. The app's security is not perfect, but I'm pretty happy with it for the scale I'm at. If I continue to grow and get more abuse, I'll implement more robust measures.
Overall, I am astonished how productive Windsurf has made me in the last two weeks. I'm not a good designer or frontend developer, and I'm a very rusty rails dev. I got this project into production 5 to 10 times faster than it would've taken me manually, and the level of polish on the front end is much higher than I could've achieved on my own. Over and over again, I would ask for a change and be astonished at the speed and quality with which Windsurf implemented it. I just sat laughing as the computer wrote code.
The next thing I want to change is making the recipe generation process much more immediate and responsive. Right now, it takes about 20 seconds to generate a recipe and for a new user it feels like maybe the app just isn't doing anything.
Instead, I'm experimenting with using Websockets to show a streaming response as the recipe is created. This gives the user immediate feedback that something is happening. It would also make editing the recipe really fun - you could ask it to "add nuts" to the recipe, and see as the recipe dynamically updates 2-3 seconds later. You could also say "Increase the quantities to cook for 8 people" or "Change from imperial to metric measurements".
I have a basic implementation working, but there are still some rough edges. I might actually go and read the code this time to figure out what it's doing!
I also want to add a full voice agent interface so that you don't have to touch the screen at all. Halfway through cooking a recipe, you might ask "I don't have cilantro - what could I use instead?" or say "Set a timer for 30 minutes". That would be my dream recipe app!
Tools like Windsurf or Cursor aren't yet as useful for non-technical users - they're extremely powerful and there are still too many ways to blow your own face off. I have a fairly good idea of the architecture that I want Windsurf to implement, and I could quickly spot when it was going off track or choosing a solution that was inappropriately complicated for the feature I was building. At the moment, a technical background is a massive advantage for using Windsurf. As a rusty developer, it made me feel like I had superpowers.
But I believe within a couple of months, when things like log tailing and automated testing and native version control get implemented, it will be an extremely powerful tool for even non-technical people to write production-quality apps. The AI will be able to make complex changes and then verify those changes are actually working. At the moment, it feels like it's making a best guess at what will work and then leaving the user to test it. Implementing better feedback loops will enable a truly agentic, recursive, self-healing development flow. It doesn't feel like it needs any breakthrough in technology to enable this. It's just about adding a few tool calls to the existing LLMs. My mind races as I try to think through the implications for professional software developers.
Meanwhile, the LLMs aren't going to sit still. They're getting better at a frightening rate. I spoke to several very capable software engineers who are Y Combinator founders in the last week. About a quarter of them told me that 95% of their code is written by AI. In six or twelve months, I just don't think software engineering is going exist in the same way as it does today. The cost of creating high-quality, custom software is quickly trending towards zero.
You can try the site yourself at recipeninja.ai
Here's a complete list of functionality. Of course, Windsurf just generated this list for me 🫠
RecipeNinja: Comprehensive Functionality Overview
Core Concept: the app appears to be a cooking assistant application that provides voice-guided recipe instructions, allowing users to cook hands-free while following step-by-step recipe guidance.
Backend (Rails API) Functionality
User Authentication & Authorization
Google OAuth integration for user authentication
User account management with secure authentication flows
Authorization system ensuring users can only access their own private recipes or public recipes
Recipe Management
Recipe Model Features:
Unique public IDs (format: "r_" + 14 random alphanumeric characters) for security
User ownership (user_id field with NOT NULL constraint)
Public/private visibility toggle (default: private)
Comprehensive recipe data storage (title, ingredients, steps, cooking time, etc.)
Image attachment capability using Active Storage with S3 storage in production
Recipe Tagging System:
Many-to-many relationship between recipes and tags
Tag model with unique name attribute
RecipeTag join model for the relationship
Helper methods for adding/removing tags from recipes
Recipe API Endpoints:
CRUD operations for recipes
Pagination support with metadata (current_page, per_page, total_pages, total_count)
Default sorting by newest first (created_at DESC)
Filtering recipes by tags
Different serializers for list view (RecipeSummarySerializer) and detail view (RecipeSerializer)
Voice Generation
Voice Recording System:
VoiceRecording model linked to recipes
Integration with Eleven Labs API for text-to-speech conversion
Caching of voice recordings in S3 to reduce API calls
Unique identifiers combining recipe_id, step_id, and voice_id
Force regeneration option for refreshing recordings
Audio Processing:
Using streamio-ffmpeg gem for audio file analysis
Active Storage integration for audio file management
S3 storage for audio files in production
Recipe Import & Generation
RecipeImporter Service:
OpenAI integration for recipe generation
Conversion of text recipes into structured format
Parsing and normalization of recipe data
Import from photos functionality
Frontend (React) Functionality
User Interface Components
Recipe Selection & Browsing:
Recipe listing with pagination
Real-time updates with 10-second polling mechanism
Tag filtering functionality
Recipe cards showing summary information (without images)
"View Details" and "Start Cooking" buttons for each recipe
Recipe Detail View:
Complete recipe information display
Recipe image display
Tag display with clickable tags
Option to start cooking from this view
Cooking Experience:
Step-by-step recipe navigation
Voice guidance for each step
Keyboard shortcuts for hands-free control:
Arrow keys for step navigation
Space for play/pause audio
Escape to return to recipe selection
URL-based step tracking (e.g., /recipe/r_xlxG4bcTLs9jbM/classic-lasagna/steps/1)
State Management & Data Flow
Recipe Service:
API integration for fetching recipes
Support for pagination parameters
Tag-based filtering
Caching mechanisms for recipe data
Image URL handling for detailed views
Authentication Flow:
Google OAuth integration using environment variables
User session management
Authorization header management for API requests
Progressive Web App Features
PWA capabilities for installation on devices
Responsive design for various screen sizes
Favicon and app icon support
Deployment Architecture
Two-App Structure:
cook-voice-api: Rails backend on Heroku
cook-voice-wizard: React frontend/PWA on Heroku
Backend Infrastructure:
Ruby 3.2.2
PostgreSQL database (Heroku PostgreSQL addon)
Amazon S3 for file storage
Environment variables for configuration
Frontend Infrastructure:
React application
Environment variable configuration
Static buildpack on Heroku
SPA routing configuration
Security Measures:
HTTPS enforcement
Rails credentials system
Environment variables for sensitive information
Public ID system to mask database IDs
This comprehensive overview covers the major functionality of the Cook Voice application based on the available information. The application appears to be a sophisticated cooking assistant that combines recipe management with voice guidance to create a hands-free cooking experience.
2 notes
·
View notes
Text
How to prepare for clat 2025
Introduction
The legal landscape in India beckons aspiring lawyers, and the first step toward a rewarding career in law is often through the Common Law Admission Test, commonly known as CLAT. In this blog, we delve into the intricacies of CLAT 2025, offering insights into the exam, preparation strategies, answer key analysis, and the subsequent result and cutoff procedures.

Understanding CLAT Exam
The CLAT exam is the key that unlocks the doors to prestigious National Law Universities (NLUs) across India, offering courses in 5-year integrated LLB (UG) and one-year LLM (PG). Administered by the Consortium of NLUs, the exam covers a spectrum of subjects such as English, Current Affairs and GK, Legal Reasoning, Logical Reasoning, and Quantitative Mathematics for UG courses. For PG courses, it delves into Constitutional Law and other subjects like Jurisprudence, Torts, IPC, CrPC, CPC, Family Law, and IPR.
Beyond NLUs, CLAT scores open doors to 61 private affiliate colleges, broadening the scope for legal education. Furthermore, public organizations like ONGC and BHEL utilize CLAT-PG scores for recruitment, underscoring the exam's significance beyond academia.
Toppers' Strategies for CLAT 2025
Success in CLAT requires a holistic approach to preparation, balancing all sections of the exam. Relying solely on a few sections is impractical due to the variable difficulty levels each year. To crack CLAT 2025, aspirants should focus on two key aspects: concept building and practice.
Concept Building:
Develop a strong foundation in each section.
Understand legal concepts, stay updated on current affairs, and hone language and mathematical skills.
Regularly revise and consolidate knowledge.
Practicing and Analyzing:
Solve previous years' question papers to understand the exam pattern.
Identify weak areas and work on them systematically.
Take mock tests to simulate exam conditions and improve time management.
CLAT 2025 Preparation Strategy
Preparing for a national-level entrance exam demands a well-structured study plan and effective preparation strategy. Consider the following tips to enhance your CLAT 2025 preparation:
Customize Your Timetable:
Tailor your study plan based on your priorities, weaknesses, and daily study time.
Create a flexible timetable that accommodates all sections.
Task-Based Approach:
Focus on completing specific tasks each day rather than counting hours.
Break down subjects into manageable tasks to maintain focus and progress steadily.
Be Specific:
Detail your study sessions with specific topics, book names, and page numbers.
Clearly define what you aim to achieve in each study session.
Utilize Study Materials:
Incorporate the best CLAT books and study materials into your plan.
Ensure that you cover relevant materials and assignments effectively.
Track Your Progress:
Maintain a daily log of tasks and mark them as completed.
Stay organized and motivated by witnessing your progress.
CLAT 2025 Answer Key
Shortly after the examination, the Consortium of NLUs releases the CLAT 2025 answer key on their official website. Candidates can download the answer key and question paper PDF to cross-verify their responses. The exam authority welcomes objections from candidates, addressing any discrepancies between the question paper and the answer key.
How to Download CLAT 2025 Answer Key:
Visit the official website of CLAT Consortium - consortiumofnlus.ac.in.
Click on the CLAT answer key link.
View, download, and save CLAT 2025 answer key and question paper PDF.
CLAT 2025 Result
The Consortium of NLUs announces the CLAT 2025 result within a month after the exam. The results are prepared based on the final answer key, which is released after reviewing objections raised by candidates. The result, indicating the qualifying status of all test-takers, will be available on the official website. Candidates can also download the scorecard by logging in.
How to Check CLAT 2025 Result:
Click on the result link on the official website.
A log-in window will open.
Fill in the CLAT 2025 application number or admit card number and date of birth.
Upon successful login, the results will be displayed on the screen.
Download and take a printout of the CLAT 2025 scorecard.
CLAT 2025 Cutoff
The CLAT 2025 cutoff marks for UG and PG courses are released separately by the Consortium of NLUs after each round of counseling. These cutoff marks vary for different categories, including Open, PwD, SC, ST, and OBC. The cutoff marks represent the minimum score or rank required for admission to preferred law colleges.
Conclusion
Preparing for CLAT 2025 requires dedication, strategic planning, and a comprehensive understanding of the exam pattern. By following a customized timetable, a task-based approach, and utilizing study materials, candidates can enhance their preparation. The answer key and result analysis provide valuable insights for improvement. Aspiring law students should focus on maintaining a disciplined approach and staying motivated throughout their CLAT journey, as success in this exam is not just a gateway to prestigious institutions but also a stepping stone to a fulfilling legal career.
2 notes
·
View notes
Text
Building Smarter AI: The Role of LLM Development in Modern Enterprises
As enterprises race toward digital transformation, artificial intelligence has become a foundational component of their strategic evolution. At the core of this AI-driven revolution lies the development of large language models (LLMs), which are redefining how businesses process information, interact with customers, and make decisions. LLM development is no longer a niche research endeavor; it is now central to enterprise-level innovation, driving smarter solutions across departments, industries, and geographies.
LLMs, such as GPT, BERT, and their proprietary counterparts, have demonstrated an unprecedented ability to understand, generate, and interact with human language. Their strength lies in their scalability and adaptability, which make them invaluable assets for modern businesses. From enhancing customer support to optimizing legal workflows and generating real-time insights, LLM development has emerged as a catalyst for operational excellence and competitive advantage.
The Rise of Enterprise AI and the Shift Toward LLMs
In recent years, AI adoption has moved beyond experimentation to enterprise-wide deployment. Organizations are no longer just exploring AI for narrow, predefined tasks; they are integrating it into their core operations. LLMs represent a significant leap in this journey. Their capacity to understand natural language at a contextual level means they can power a wide range of applications—from automated document processing to intelligent chatbots and AI agents that can draft reports or summarize meetings.
Traditional rule-based systems lack the flexibility and learning capabilities that LLMs offer. With LLM development, businesses can move toward systems that learn from data patterns, continuously improve, and adapt to new contexts. This shift is particularly important for enterprises dealing with large volumes of unstructured data, where LLMs excel in extracting relevant information and generating actionable insights.
Custom LLM Development: Why One Size Doesn’t Fit All
While off-the-shelf models offer a powerful starting point, they often fall short in meeting the specific needs of modern enterprises. Data privacy, domain specificity, regulatory compliance, and operational context are critical considerations that demand custom LLM development. Enterprises are increasingly recognizing that building their own LLMs—or fine-tuning open-source models on proprietary data—can lead to more accurate, secure, and reliable AI systems.
Custom LLM development allows businesses to align the model with industry-specific jargon, workflows, and regulatory environments. For instance, a healthcare enterprise developing an LLM for patient record summarization needs a model that understands medical terminology and adheres to HIPAA regulations. Similarly, a legal firm may require an LLM that comprehends legal documents, contracts, and precedents. These specialized applications necessitate training on relevant datasets, which is only possible through tailored development processes.
Data as the Foundation of Effective LLM Development
The success of any LLM hinges on the quality and relevance of the data it is trained on. For enterprises, this often means leveraging internal datasets that are rich in context but also sensitive in nature. Building smarter AI requires rigorous data curation, preprocessing, and annotation. It also involves establishing data pipelines that can continually feed the model with updated, domain-specific content.
Enterprises must implement strong data governance frameworks to ensure the ethical use of data, mitigate biases, and safeguard user privacy. Data tokenization, anonymization, and access control become integral parts of the LLM development pipeline. In many cases, businesses opt to build LLMs on-premise or within private cloud environments to maintain full control over their data and model parameters.
Infrastructure and Tooling for Scalable LLM Development
Developing large language models at an enterprise level requires robust infrastructure. Training models with billions of parameters demands high-performance computing resources, including GPUs, TPUs, and distributed systems capable of handling parallel processing. Cloud providers and AI platforms have stepped in to offer scalable environments tailored to LLM development, allowing enterprises to balance performance with cost-effectiveness.
Beyond hardware, the LLM development lifecycle involves a suite of software tools. Frameworks like PyTorch, TensorFlow, Hugging Face Transformers, and LangChain have become staples in the AI development stack. These tools facilitate model training, evaluation, and deployment, while also supporting experimentation with different architectures and hyperparameters. Additionally, version control, continuous integration, and MLOps practices are essential for managing iterations and maintaining production-grade models.
The Business Impact of LLMs in Enterprise Workflows
The integration of LLMs into enterprise workflows yields transformative results. In customer service, LLM-powered chatbots and virtual assistants provide instant, human-like responses that reduce wait times and enhance user satisfaction. These systems can handle complex queries, understand sentiment, and escalate issues intelligently when human intervention is needed.
In internal operations, LLMs automate time-consuming tasks such as document drafting, meeting summarization, and knowledge base management. Teams across marketing, HR, legal, and finance can benefit from AI-generated insights that save hours of manual work and improve decision-making. LLMs also empower data analysts and business intelligence teams by providing natural language interfaces to databases and dashboards, making analytics more accessible across the organization.
In research and development, LLMs accelerate innovation by assisting in technical documentation, coding, and even ideation. Developers can use LLM-based tools to generate code snippets, debug errors, or explore APIs, thus enhancing productivity and reducing turnaround time. In regulated industries like finance and healthcare, LLMs support compliance by reviewing policy documents, tracking changes in legislation, and ensuring internal communications align with legal requirements.
Security and Privacy in Enterprise LLM Development
As LLMs gain access to sensitive enterprise data, security becomes a top concern. Enterprises must ensure that the models they build or use do not inadvertently leak confidential information or produce biased, harmful outputs. This calls for rigorous testing, monitoring, and auditing throughout the development lifecycle.
Security measures include embedding guardrails within the model, applying reinforcement learning with human feedback (RLHF) to refine responses, and establishing filters to detect and block inappropriate content. Moreover, differential privacy techniques can be employed to train LLMs without compromising individual data points. Regulatory compliance, such as GDPR or industry-specific mandates, must also be factored into the model’s architecture and deployment strategy.
Organizations are also investing in private LLM development, where the model is trained and hosted in isolated environments, disconnected from public access. This approach ensures that enterprise IP and customer data remain secure and that the model aligns with internal standards and controls. Regular audits, red-teaming exercises, and bias evaluations further strengthen the reliability and trustworthiness of the deployed LLMs.
LLM Development and Human-AI Collaboration
One of the most significant shifts LLMs bring to enterprises is the redefinition of human-AI collaboration. Rather than replacing human roles, LLMs augment human capabilities by acting as intelligent assistants. This symbiotic relationship allows professionals to focus on strategic thinking and creative tasks, while the LLM handles the repetitive, data-intensive parts of the workflow.
This collaboration is evident in industries like journalism, where LLMs draft article outlines and summarize press releases, freeing journalists to focus on investigative reporting. In legal services, LLMs assist paralegals by reviewing documents, identifying inconsistencies, and organizing case information. In software development, engineers collaborate with AI tools to write code, generate tests, and explore new libraries or functions more efficiently.
For human-AI collaboration to be effective, enterprises must foster a culture that embraces AI as a tool, not a threat. This includes reskilling employees, encouraging experimentation, and designing interfaces that are intuitive and transparent. Trust in AI systems grows when users understand how the models work and how they arrive at their conclusions.
Future Outlook: From Smarter AI to Autonomous Systems
LLM development marks a crucial milestone in the broader journey toward autonomous enterprise systems. As models become more sophisticated, enterprises are beginning to explore autonomous agents that can perform end-to-end tasks with minimal supervision. These agents, powered by LLMs, can navigate workflows, take decisions based on goals, and coordinate with other systems to complete complex objectives.
This evolution requires not just technical maturity but also organizational readiness. Governance frameworks must be updated, roles and responsibilities must be redefined, and AI literacy must become part of the corporate fabric. Enterprises that successfully embrace these changes will be better positioned to innovate, compete, and lead in a rapidly evolving digital economy.
The future will likely see the convergence of LLMs with other technologies such as computer vision, knowledge graphs, and edge computing. These integrations will give rise to multimodal AI systems capable of understanding not just text, but images, videos, and real-world environments. For enterprises, this means even more powerful and versatile tools that can drive efficiency, personalization, and growth across every vertical.
Conclusion
LLM development is no longer a luxury or an experimental initiative—it is a strategic imperative for modern enterprises. By building smarter AI systems powered by large language models, businesses can transform how they operate, innovate, and deliver value. From automating routine tasks to enhancing human creativity, LLMs are enabling a new era of intelligent enterprise solutions.
As organizations invest in infrastructure, talent, and governance to support LLM initiatives, the payoff will be seen in improved efficiency, reduced costs, and stronger customer relationships. The companies that lead in LLM development today are not just adopting a new technology—they are building the foundation for the AI-driven enterprises of tomorrow.
#crypto#ai#blockchain#ai generated#cryptocurrency#blockchain app factory#dex#ico#ido#blockchainappfactory
0 notes
Text
BML Munjal University: A Smart Choice for Future Leaders
Choosing the right university after school is one of the most important decisions in a student’s life. You need a place that not only offers quality education but also builds your personality, skills, and confidence. If you are looking for a modern university that focuses on innovation, leadership, and hands-on learning, then BML Munjal University is a perfect option for you.

In this blog, we will explore everything you need to know about BML Munjal University — its courses, campus life, admission process, placements, and why it is one of the top choices for students in India today.
About BML Munjal University
BML Munjal University, also known as BMU, is a private university located in Gurugram, Haryana. It is founded by the promoters of Hero Group, one of India’s biggest business houses. The university is named after the legendary industrialist Brijmohan Lall Munjal, who believed in transforming education by blending theory with real-world practice.
BMU is not just another private university. It is a place where students learn by doing, think like entrepreneurs, and grow into leaders of tomorrow.
Courses Offered at BML Munjal University
BML Munjal University offers a wide range of undergraduate and postgraduate courses in different fields. Whether you are interested in business, law, engineering, or liberal arts, you will find the right course here.
Popular Undergraduate Programs:
B.Tech in Computer Science, Mechanical, Electronics & Communication, and Data Science
BBA (Bachelor of Business Administration)
BA LLB and BBA LLB (Integrated Law Programs)
BCom (Hons.)
BA (Hons.) in Economics, Psychology, and Liberal Studies
Postgraduate Programs:
MBA (with specializations like Marketing, Finance, HR, Business Analytics)
LLM (Master of Law)
Executive MBA for working professionals
PhD Programs in Engineering, Management, and Law
Each course at BML Munjal University is designed with input from industry experts, ensuring students learn skills that are relevant to today’s world.
Why Choose BML Munjal University?
There are many reasons why students choose BML Munjal University over other institutions. Here are some key advantages:
Industry-Focused Learning
At BMU, you don’t just study from textbooks. You get real-life exposure through projects, internships, workshops, and case studies. The university follows a 45:55 theory-to-practice ratio, which means most of your learning comes from hands-on experience.
Global Academic Partners
BML Munjal University has strong academic partnerships with top international universities like:
Imperial College London (UK)
University of Warwick (UK)
Singapore Management University (Singapore)
UC Berkeley (USA)
These tie-ups allow students to benefit from global teaching methods, exchange programs, and joint certifications.
Excellent Faculty
BMU’s faculty includes experienced professors, researchers, and industry professionals. Many of them have studied or taught at top global universities. They guide students with practical knowledge and help them succeed in their careers.
Modern Campus and Facilities
The campus of BML Munjal University is spread across 50 acres with world-class facilities. It has smart classrooms, hi-tech labs, innovation centers, libraries, sports arenas, and hostels. The campus is green, clean, and designed to encourage learning and collaboration.
Admission Process at BML Munjal University
The admission process is simple and student-friendly. Here’s how you can apply:
Step 1: Fill the Online Application Form
Visit the official website of BML Munjal University and complete the online application.
Step 2: Submit Required Documents
You’ll need to upload your Class 10 and 12 marksheets, entrance exam scores (if applicable), a Statement of Purpose (SOP), and other necessary documents.
Step 3: Appear for Personal Interview
Shortlisted candidates are invited for a personal interview (PI) or group discussion, depending on the course.
Step 4: Final Selection and Admission
After evaluating your overall profile, the university releases admission offers. Once selected, you can pay the fee and confirm your seat.
Entrance Exams Accepted
BML Munjal University accepts various entrance exams for different programs:
For B.Tech: JEE Main, BMU-SAT
For MBA: CAT, XAT, GMAT, NMAT, BMU-MAT
For Law: CLAT, LSAT
For BBA/BA/BCom: SAT, CUET, or 12th board marks
Don’t worry if you don’t have an entrance exam score — BMU conducts its own test for most programs.
Scholarships at BML Munjal University
BMU believes that no student should miss out on education due to financial reasons. That’s why it offers generous merit-based scholarships to deserving students. Scholarships are awarded based on your academic performance, entrance test scores, and personal interview.
There are also need-based financial aid programs to support students from weaker economic backgrounds.
Placement & Internship Opportunities
BML Munjal University has a strong placement record. Over 90% of eligible students get placed every year in top companies. Some of the recruiters include:
KPMG
Deloitte
Hero MotoCorp
Amazon
EY
Microsoft
Infosys
Mahindra & Mahindra
Internships are an important part of the curriculum. Students get to work with real companies, apply their skills, and build professional networks from early on.
Student Life at BML Munjal University
BMU is not just about academics. It also offers a vibrant and inclusive student life. There are clubs for music, dance, photography, sports, coding, debate, and more. Cultural festivals, tech events, and sports tournaments keep students active and engaged.
The hostel life is safe and comfortable, with 24/7 security, nutritious food, and recreation areas. It feels like a second home.
Final Thoughts
If you are looking for a university that goes beyond books, offers international exposure, hands-on learning, and prepares you for the real world, then BML Munjal University is the place to be. With modern infrastructure, industry partnerships, expert faculty, and strong placement support, BMU helps you grow not just as a student, but as a future leader.
So, take the next step confidently and apply to BML Munjal University — where innovation meets education.
If you need further information contact:
523, 5th Floor, Wave Silver Tower, Sec-18 Noida, UP-201301
+91 9711016766
0 notes
Text
Authoritarian state vs. unaccountable corporate empire. Pick your dystopia.
🚨 Post-AI Political Realignment (2025–2030)
1. Nation-States Weaken, Blocs Harden
Once AIs can design, deploy, and defend infrastructure faster than governments can regulate it, national power shifts from states to AI-aligned blocs:
US Bloc: U.S., Europe (unevenly), Israel, Gulf States (especially UAE, Saudi Arabia), maybe India (undecided).
China Bloc: China, Russia, Iran, Pakistan, maybe parts of Africa/SEA through Belt and Road 2.0.
These blocs are economic-military-AI ecosystems — not just alliances.
Key Feature: Each bloc builds semi-sovereign AI stacks, incompatible with the others. That’s your soft splinternet.
2. A New Digital Iron Curtain
We’re already halfway there:
U.S. export bans on Nvidia GPUs to China.
China's banning OpenAI, Meta, Google products.
UAE and Saudi Arabia hedging between the two, but increasingly choosing U.S. LLMs.
Soft splinternet = AI firewall, not just websites.
U.S. bloc runs GPTs, Claude, Gemini, etc. → fine-tuned for Western legal norms, values, market logic.
China bloc runs ERNIE, SenseTime, etc. → trained on censored data, aligned with state doctrine.
They're like two different species of intelligence — raised in separate ideological zoos.
3. Cognitive Realignment Among Populations
As AI assistants and content engines proliferate, people start living in different epistemic realities:
What counts as "truth" diverges.
Moral frameworks and history get subtly rewritten.
Even logic patterns and language habits shift, guided by the AIs people use daily.
A GPT-trained American teenager and an ERNIE-trained Chinese teenager might both be “smart” — but they won't even agree on what it means to think critically.
🧠 Inside the AI Cold War
U.S. Bloc Strategy:
Privatize the race: Let OpenAI, Anthropic, and xAI fight it out — backed by defense contracts.
Fragment regulations to let Silicon Valley run ahead.
Lock allies in via compute deals (see: UAE buying Microsoft/OpenAI cloud infrastructure).
Outscale with semiconductors: TSMC, Nvidia, Intel are the real arsenal.
China Bloc Strategy:
State-run scaling: Central planning, industrial policy, forced data-sharing.
Human-AI fusion: Integrate into military, governance, surveillance.
Build dependency pipelines: Fund infrastructure abroad, then sell AI tools on top of it.
Reject openness: Create AI models trained on Party-aligned data only.
🧭 What Comes Next: Realignment Scenarios
☢️ Scenario 1: The Sudden Shift (2030–2032)
A superhuman AI model appears in the U.S. bloc. The lead is uncatchable. China’s bluff collapses. The global South picks sides based on who offers cheaper robots and LLMs. National identities dissolve in the face of AI-dominated economies.
🧊 Scenario 2: The Cold AI War (2025–2035)
Parity is maintained through sabotage, espionage, and GPU chokepoints. Proxy conflicts break out in data-rich regions (like Africa or South America). Regulatory capture becomes globalized — AI corps become shadow governments.
🐍 Scenario 3: Controlled Collapse
One bloc overplays its hand. A synthetic virus, a botched deployment, or an AI-aided financial crash creates chaos. Humans lose trust in both state and AI authority. Decentralized movements (fed by open-source AIs) begin a new sovereignty push.
🧬 And You?
The person who knows how to ask the right questions — of AI, of governments, of corporations — will be worth more than gold.
We're not headed toward utopia or apocalypse, but a drawn-out soft civilizational reboot. How soft or how brutal depends on whether you’re:
A user
A builder
Or collateral
0 notes
Text
Artificial Intelligence Course in Delhi: Everything You Need to Know Before You Enroll
Artificial Intelligence (AI) is shaping the future of technology, businesses, and careers. From virtual assistants and autonomous vehicles to predictive healthcare and smart cities, AI applications are growing across every domain. If you're based in Delhi and looking to enter this high-growth field, enrolling in a reputed Artificial Intelligence course in Delhi could be the most strategic step you take in 2025.
As India’s capital and a major tech-education hub, Delhi offers a fertile environment for AI learning—blending academic excellence, vibrant tech startups, and numerous job opportunities. This blog explores everything you need to know about AI courses in Delhi: curriculum, benefits, career prospects, and how to choose the right program.
Why Choose an Artificial Intelligence Course in Delhi?
Tech-Education Ecosystem
Delhi boasts a powerful combination of premier institutions, private training providers, and tech incubators. This dynamic ecosystem ensures you get access to both academic knowledge and practical training.
Proximity to IT and Corporate Hubs
Delhi, along with NCR cities like Noida and Gurugram, is home to hundreds of tech companies, R&D labs, and AI startups. This proximity increases your chances of internships and placements post-course completion.
Quality Faculty & Mentorship
AI courses in Delhi often feature experienced instructors from IITs, industry professionals, and data science practitioners, offering rich mentorship and guidance.
What You’ll Learn in an Artificial Intelligence Course in Delhi
A well-rounded AI course in Delhi typically combines theoretical foundations with hands-on project work. Here’s what you can expect from the curriculum:
Core Modules
Foundations of Artificial Intelligence
Python Programming for AI
Machine Learning Algorithms (Supervised & Unsupervised)
Deep Learning and Neural Networks
Natural Language Processing (NLP)
Computer Vision and Image Recognition
AI Ethics, Fairness, and Governance
Generative AI (ChatGPT, DALL·E, etc.)
Hands-On Tools and Frameworks
Languages & Libraries: Python, NumPy, Pandas, Scikit-learn
Deep Learning: TensorFlow, Keras, PyTorch
Data Handling: SQL, MongoDB, Matplotlib
Deployment Tools: Flask, Docker, Streamlit
Capstone Projects
Sentiment Analysis using NLP
Image Classification with CNN
Chatbot Development
AI Stock Price Predictor
Recommendation Engine for E-commerce
Autonomous AI Agent with LLM integration
These projects help you apply what you’ve learned in real-world scenarios and strengthen your portfolio.
Who Should Take an AI Course in Delhi at Boston Institute of Analytics?
The AI course at the Boston Institute of Analytics in Delhi is designed to cater to a wide range of professionals, students, and enthusiast’s eager to make a mark in the rapidly expanding field of Artificial Intelligence. Below is a breakdown of who should consider enrolling in this course.
1. Aspiring Data Scientists
Individuals who wish to build a career in data science will find the AI course at the Boston Institute of Analytics particularly valuable. The course equips learners with advanced machine learning techniques, statistical analysis, and data-driven decision-making skills—all essential tools for a successful career as a data scientist. If you're passionate about working with data and uncovering actionable insights, this course will provide the foundation and advanced knowledge necessary to thrive in this field.
2. Professionals Transitioning into AI
If you're currently working in a related field such as software development, engineering, or business analytics, and you want to pivot towards AI, this course is an excellent choice. It will help you develop expertise in AI algorithms, neural networks, and deep learning, enabling you to expand your skill set and transition into roles such as AI engineer, machine learning engineer, or AI consultant.
3. Technology Enthusiasts and Programmers
Tech enthusiasts with a passion for artificial intelligence and automation will find the Boston Institute’s course engaging and rewarding. If you already have a basic understanding of programming languages like Python, R, or Java, the course will deepen your understanding of AI tools and techniques, helping you work on real-world applications such as AI-driven software, chatbots, and intelligent systems.
4. Students and Recent Graduates
Recent graduates in fields like computer science, statistics, mathematics, or engineering will benefit immensely from enrolling in this AI course. With AI rapidly becoming a fundamental part of almost every industry, possessing AI skills significantly enhances your employability. The hands-on learning approach at the Boston Institute of Analytics ensures that students are job-ready and able to apply their knowledge in a practical context.
5. Business Professionals and Managers
AI is reshaping industries such as finance, marketing, and healthcare. Business professionals who wish to understand how AI can drive business decisions, improve processes, and optimize performance can benefit greatly from this course. By learning about AI technologies, you’ll gain a strategic edge in making informed decisions about AI implementation in your organization.
6. Entrepreneurs and Start-up Founders
If you're an entrepreneur or aspiring start-up founder, understanding the potential of AI technologies is crucial for developing competitive products and services. The AI course at Boston Institute of Analytics will help you explore the ways in which AI can be incorporated into your business model, whether you're working on a SaaS product, automation tools, or an AI-based mobile app.
7. Researchers and Academicians
Researchers in fields such as computer science or cognitive sciences, and academicians who want to delve deeper into the technical aspects of AI, will find the program's theoretical and applied knowledge beneficial. The course will enable them to stay ahead of the curve in AI research trends and contribute to new innovations in the field.
Final Thoughts
Delhi stands as one of India’s premier cities for learning and launching a career in Artificial Intelligence. With its vast educational infrastructure, access to companies and startups, and vibrant learning culture, it offers unmatched opportunities for aspiring AI professionals.
Whether you're a student planning your next step, a developer looking to upskill, or a professional switching careers, an Artificial Intelligence course in Delhi can set you on the path to a rewarding and future-proof career.
0 notes
Text
Model Context Protocol (MCP): How to Build and Use AI Tools with Local MCP Servers
As AI tools like Amazon Q, GitHub Copilot, and other LLM-backed plugins become more powerful, the need to access private APIs, internal tools, and enterprise systems securely and contextually has become essential. This is where Model Context Protocol (MCP) comes in. In this post, we’ll cover what MCP is, why it matters, and how to build and use an MCP server with a working example. What is…

View On WordPress
0 notes
Text
Develop ChatQnA Applications with OPEA and IBM DPK

How OPEA and IBM DPK Enable Custom ChatQnA Retrieval Augmented Generation
GenAI is changing application development and implementation with intelligent chatbots and code generation. However, organisations often struggle to match commercial AI capabilities with corporate needs. Standardisation and customization to accept domain-specific data and use cases are important GenAI system development challenges. This blog post addresses these difficulties and how the IBM Data Prep Kit (DPK) and Open Platform for Enterprise AI (OPEA) designs may help. Deploying and customizing a ChatQnA application using a retrieval augmented generation (RAG) architecture will show how OPEA and DPK work together.
The Value of Standardisation and Customization
Businesses implementing generative AI (GenAI) applications struggle to reconcile extensive customization with standardisation. Balance is needed to create scalable, effective, and business-relevant AI solutions. Companies creating GenAI apps often face these issues due to lack of standardisation:
Disparate models and technology make it hard to maintain quality and reliability across corporate divisions.
Without common pipelines and practices, expanding AI solutions across teams or regions is challenging and expensive.
Support and maintenance of a patchwork of specialist tools and models strain IT resources and increase operational overhead.
Regarding Customization
Although standardisation increases consistency, it cannot suit all corporate needs. Businesses operate in complex contexts that often span industries, regions, and regulations. Off-the-shelf, generic AI models disappoint in several ways:
AI models trained on generic datasets may perform badly when confronted with industry-specific language, procedures, or regulatory norms, such as healthcare, finance, or automotive.
AI model customization helps organisations manage supply chains, improve product quality, and tailor consumer experiences.
Data privacy and compliance: Building and training bespoke AI systems with private data keeps sensitive data in-house and meets regulatory standards.
Customization helps firms innovate, gain a competitive edge, and discover new insights by solving challenges generic solutions cannot.
How can we reconcile uniformity and customization?
OPEA Blueprints: Module AI
OPEA, an open source initiative under LF AI & Data, provides enterprise-grade GenAI system designs, including customizable RAG topologies.
Notable traits include:
Modular microservices: Equivalent, scalable components.
End-to-end workflows: GenAI paradigms for document summarisation and chatbots.
Open and vendor-neutral: Uses open source technology to avoid vendor lockage.
Flexibility in hardware and cloud: supports AI accelerators, GPUs, and CPUs in various scenarios.
The OPEA ChatQnA design provides a standard RAG-based chatbot system with API-coordinated embedding, retrieval, reranking, and inference services for easy implementation.
Simplified Data Preparation with IBM Data Prep Kit
High-quality data for AI and LLM applications requires a lot of labour and resources. IBM's Data Prep Kit (DPK), an open source, scalable toolkit, facilitates data pretreatment across data formats and corporate workloads, from ingestion and cleaning to annotation and embedding.
DPK allows:
Complete preprocessing includes ingestion, cleaning, chunking, annotation, and embedding.
Scalability: Apache Spark and Ray-compatible.
Community-driven extensibility: Open source modules are easy to customize.
Companies may quickly analyse PDFs and HTML using DPK to create structured embeddings and add them to a vector database. AI systems can respond precisely and domain-specifically.
ChatQnA OPEA/DPK deployment
The ChatQnA RAG process shows how standardised frameworks and customized data pipelines operate in AI systems. This end-to-end example illustrates how OPEA's modular design and DPK's data processing capabilities work together to absorb raw texts and produce context-aware solutions.
This example shows how enterprises may employ prebuilt components for rapid deployment while customizing embedding generation and LLM integration while maintaining consistency and flexibility. This OPEA blueprint may be used as-is or modified to meet your architecture utilising reusable pieces like data preparation, vector storage, and retrievers. DPK loads Milvus vector database records. If your use case requires it, you can design your own components.
Below, we step-by-step explain how domain-specific data processing and standardised microservices interact.
ChatQnA chatbots show OPEA and DPK working together:
DPK: Data Preparation
Accepts unprocessed documents for OCR and extraction.
Cleaning and digestion occur.
Fills vector database, embeds
OPEA—AI Application Deployment:
Uses modular microservices (inference, reranking, retrieval, embedding).
Easy to grow or replace components (e.g., databases, LLM models)
End-user communication:
Context is embedded and retrieved upon user request.
Additional background from LLM responses
This standardised yet flexible pipeline ensures AI-driven interactions, scales well, and accelerates development.
#IBMDPK#RetrievalAugmentedGeneration#OPEABlueprints#OPEA#IBMDataPrepKit#OPEAandDPK#technology#TechNews#technologynews#news#govindhtech
0 notes
Text
Week#4 DES 303
The Experience: Experiment #1
Incentive & Initial Research
Following the previous ideation phase, I wanted to explore the usage of LLM in a design context. The first order of business was to find a unique area of exploration, especially given how the industry is already full of people attempting to shove AI into everything that doesn't need it.
Drawing from a positive experience working with AI for a design project, I want the end result of the experiment to focus on human-computer interaction.

John the Rock is a project in which I handled the technical aspects. It had a positive reception despite having only rudimentary voice chat capability and no other functionalities.
Through initial research and personal experience, I identified two polar opposite prominent uses of LLMS in the field: as a tool or virtual companion.
In the first category, we have products like ChatGPT (obviously) and Google NotebookLM that focus on web searching, text generation and summarisation tasks. They are mostly session-based and objective-focused, retaining little information about the users themselves between sessions. Home automation consoles AI, including Siri and Alexa, also loosely fall in this category as their primary function is to complete the immediate task and does not attempt to build a connection with the user.
In the second category, we have products like Replika and character.ai that focus solely on creating a connection with the user, with few real functional uses. To me, this use case is extremely dangerous. These agents aim to build an "interpersonal" bond with the user. However, as the user never had any control over these strictly cloud-based agents, this very real emotional bond can be easily exploited for manipulative monetisation and sensitive personal information.
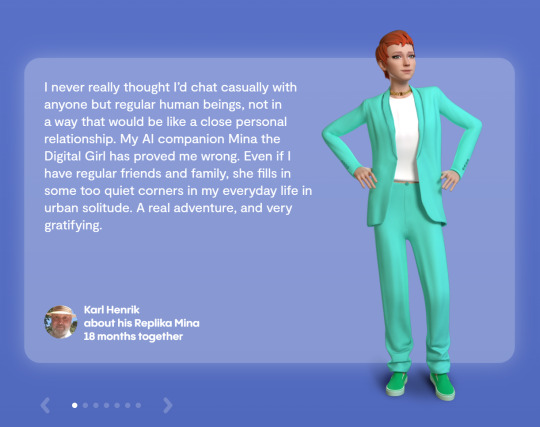
Testimony retrieved from Replika. What are you doing Zuckerburg how is this even a good thing to show off.
As such, I am very interested in exploring the technical feasibility of a local, private AI assistant that is entirely in the user's control, designed to build a connection with the user while being capable of completing more personalised tasks such as calendar management and home automation.
Goals & Plans
Critical success measurements for this experiment include:
Runnable on my personal PC, primarily surrounding an 8GB RTX3070 (a mid-range graphics card from 2020).
Able to perform function calling, thus accessing other tools programmatically, unlike a pure conversational LLM.
Features that could be good to have include:
Long-term memory mechanism builds a connection to the user over time.
Voice conversation capability.
The plan for approaching the experiments is as follows:
Evaluate open-source LLM capabilities for this use case.
Research existing frameworks, tooling and technologies for function calling, memory and voice capabilities.
Construct a prototype taking into account previous findings.
Gather and evaluate user responses to the prototype.

The personal PC in question is of a comparable size to an Apple HomePod. (Christchurch Metro card for scale)
Research & Experiments
This week's work revolved around researching:
Available LLMs that could run locally.
Frameworks to streamline function calling behaviour.
Function calling is the critical feature I wanted to explore in this experiment, as it would serve as the basis for any further development beyond toy projects.
A brief explanation of integrating function calling with LLM. Retrieved from HuggingFace.
Interacting with the LLM directly would mean that all interactions and the conversation log must be handled manually. This would prove tedious from prior experience. A suitable framework could be utilised to handle this automatically. A quick search revealed the following candidates:
LangChain, optionally with LangGraph for more complex agentic flows.
Smolagent by HuggingFace.
Pydantic AI.
AutoGen by Microsoft.
I first needed a platform to host and manage LLMs locally to make any of them work. Ollama was chosen as the initial tool since it was the easiest to set up and download models. Additionally, it provides an OpenAI API compatible interface for simple programmatic access in almost all frameworks.
A deeper dive into each option can be summarised with the following table:

Of these options, LangChain was eliminated first due to many negative reviews on its poor developer experience. Reading AutoGen documentation revealed a "loose" inter-agent control, relying on user proxy and terminating on 'keywords' from model response. This does not inspire confidence, and thus the framework was not explored further.
PydanticAI stood out with its type-safe design. Smolagents stood out with its 'code agent' design, where the model utilises given tools by generating Python code instead of alternating between model output and tool calls. As such, these two frameworks were set up and explored further.
This concluded this week's work: identifying the gap in existing AI products, exploring technical tooling for further development of the experiment.
Reflection on Action
Identifying a meaningful gap before starting the experiment felt like an essential step. With the field so filled with half-baked chatbots in the Q&A section, diving straight into building without a clear direction would have risked creating another redundant product.
Spending a significant amount of time upfront to define the problem space, particularly the distinction between task-oriented AI tools and emotional companion bots, helped me anchor the project in a space that felt both personally meaningful and provided a set of unique technical constraints to work around.
However, this process was time-intensive. I wonder if investing so heavily in researching available technologies and alternatives, without encountering the practical roadblocks of building, could lead to over-optimisation for problems that might never materialise. There is also a risk of getting too attached to assumptions formed during research rather than letting real experimentation guide decisions. At the same time, running into technical issues like function calling and local deployment could prove even more time-consuming if encountered.
Ultimately, I will likely need to recalibrate the balance between research and action as the experiment progresses.
Theory
Since my work this week has been primarily focused on research, most of the relevant sources are already linked in the post above.
For Smolagents, Huggingface provided a peer-reviewed paper claiming code agents have superior performance: [2411.01747] DynaSaur: Large Language Agents Beyond Predefined Actions.
PydanticAI explained their type-checking behaviour in more detail in Agents - PydanticAI.
These provided context for my reasoning stated in previous sections and consolidated my decision to explore these two frameworks further.
Preparation
Having confirmed frameworks to explore, it becomes easy to plan the following courses of action:
Research lightweight models that can realistically run on the stated hardware.
Explore the behaviours of these small models within the two chosen frameworks.
Experiment with function calling.
0 notes
Photo

Unleash the Power of Customization! 🌟 Nvidia's G-Assist Plug-In Builder allows AI to connect with LLMs & diverse software seamlessly. 🤖 Nvidia's G-Assist Plug-In Builder opens up new horizons for AI, expanding its functionality beyond gaming. Users can now customize AI interactions using JSON and Python, enabling G-Assist to integrate with various tools and produce fast, private offline responses. Perfect for tech enthusiasts who thrive on innovation! Curious how this could transform your digital experience? What will YOU build with G-Assist? Share your thoughts! #Nvidia #GAssist #AIIntegration #TechInnovation #Coding #AI #RTX #Gaming #SoftwareDevelopment #Innovation #AIPlugins #Customization #JSON #Python #TechTrends
0 notes
Text
Siddhant Masson, CEO and Co-Founder of Wokelo – Interview Series
New Post has been published on https://thedigitalinsider.com/siddhant-masson-ceo-and-co-founder-of-wokelo-interview-series/
Siddhant Masson, CEO and Co-Founder of Wokelo – Interview Series

Sid Masson is the Co-Founder and CEO of Wokelo. With a background spanning strategy, product development, and data analytics at organizations like the Tata Group, Government of India, and Deloitte, Masson brings deep expertise in applying emerging technologies to real-world business challenges. At Wokelo, he is leading the company’s mission to transform how knowledge workers conduct due diligence, sector analysis, and portfolio monitoring through agentic AI frameworks.
Wokelo is a generative AI-powered investment research platform designed to automate complex research workflows, including due diligence, sector analysis, and portfolio monitoring. Using proprietary large language model (LLM)-based agents, the platform facilitates the curation, synthesis, and triangulation of data to generate structured, decision-ready outputs.
Wokelo is used by a range of organizations, including private equity firms, investment banks, consulting companies, and corporate teams, to support data-informed decision-making.
What inspired you to create Wokelo AI, and how did you identify the need for an AI-driven research assistant that could streamline due diligence, investment analysis, and corporate strategy?
Wokelo AI was born out of firsthand experience. Having spent years in management consulting at Deloitte and corporate development at Tata Group, I encountered the same challenges over and over – manual, repetitive research, data scarcity in private markets, and the sheer grunt work that slows down analysts and decision-makers.
The turning point came during my second master’s in AI at the University of Washington, where my thesis focused on Natural Language Processing. While freelancing as a consultant to pay my way through school, I built a prototype using early versions of GPT and saw firsthand how AI could turn weeks of work into days and hours – without compromising quality. That was the lightbulb moment.
Realizing this technology could revolutionize investment research, I decided to go all in. Wokelo AI isn’t just another research tool – we were some of the first people pioneering AI agents two years ago. It’s the solution I wish I had during my years in due diligence and investment analysis.
How did your experience at Deloitte, Tata, and the Government of India shape your approach to building Wokelo?
At Deloitte, as a management consultant, I worked on a variety of complex projects, dealing with research, analysis, and due diligence on a daily basis. The work was intensive, involving a lot of manual, repetitive tasks and desk research that frequently slowed down progress and increased costs. I became all too familiar with the pain points of gathering data, especially when it came to private companies, and the challenges that came with using traditional tools that weren’t built for efficiency or scalability.
Then, at Tata Group, where I worked on M&A and corporate development, I continued to face the same issues — data scarcity, slow research, and the challenge of turning raw information into actionable insights for large-scale decisions. The frustration of not having effective tools to support decision-making, particularly when dealing with private companies, further fueled my desire to find a solution.
Additionally, my work with the Government of India on the IoT solution for a water infrastructure project, further refined my understanding of how product innovation could address real-world problems on a large scale, and it gave me the confidence to apply the same approach to solving the research and analysis challenges in the consulting and investment space.
So, my professional background and my firsthand exposure to the struggles of research, analysis, and data collection in consulting and corporate development directly influenced how I approached Wokelo. I knew from experience the roadblocks that professionals face, so I focused on building a solution that not only automates grunt work but also allows users to focus on high-impact, strategic tasks, ultimately making them more productive and efficient.
Wokelo leverages GenAI for research and intelligence. What differentiates your AI approach from other summarization tools in the market?
While most competitors offer chatbot-style Q&A interfaces – essentially repackaged versions of ChatGPT with a finance-focused UI – Wokelo AI takes a completely different approach. We built an AI agent specifically designed for investment research and financial services – not just a chatbot but a full-fledged workflow automation tool.
Unlike simple summarization tools, Wokelo handles end-to-end research deliverables, performing 300-400 analyst tasks that would typically take a week. Our system autonomously identifies requirements, breaks them into subtasks, and executes everything from data extraction and synthesis to triangulation and report generation. As a result, our clients get deep, comprehensive, and highly nuanced insights – a real analysis, not just surface-level answers.
Another key differentiator is accuracy and reliability of the intel. Wokelo doesn’t make up insights, it doesn’t hallucinate – it provides fully referenced, fact-checked outputs with citations, eliminating the trust issues that many GenAI tools have. As a cherry on top, our platform users also get exportable reports in various formats typically used by analysts, making it a seamless replacement for traditional research platforms like PitchBook or Crunchbase, but with far richer intelligence on M&A activity, funding rounds, partnerships, and market trends.
Wokelo is more than just an LLM with a UI wrapper. Can you explain the deeper AI capabilities behind your platform?
Wokelo is purpose-built for investment research, combining cutting-edge AI, exclusive financial datasets, and a research-centric workflow – offering capabilities that extend far beyond a simple LLM with a UI wrapper. At its core, Wokelo leverages a Mixture of Experts (MoE) approach, integrating proprietary large language models (LLMs) pre-trained on tier-1 investment data, ensuring highly precise, domain-specific insights for investment professionals.
Designed for seamless workflow integration, Wokelo features a collaborative, notebook-style editor, allowing users to create, refine, and export well-structured, templatized outputs in PPT, PDF, and DOCX formats—streamlining research documentation and presentation. Its multi-agent orchestrator and prompt management system ensures dynamic model adaptability, while robust admin controls facilitate query log reviews and compliance rule enforcement.
By merging advanced AI capabilities with deep financial intelligence and intuitive research tools, Wokelo delivers an end-to-end investment research solution that goes far beyond a standard LLM.
How does Wokelo ensure fact-based analysis and prevent AI hallucinations when synthesizing insights?
As we serve highly reputable clients whose every decision must be backed by precise data, accuracy and credibility are at the core of our AI-driven insights. Unlike general-purpose AI platforms that may produce speculative or unverified information, Wokelo ensures fact-based analysis through a robust, citation-backed approach, eliminating AI hallucinations.
Every trend, analysis, market signal, case study, M&A activity, partnership update, or funding round insight generated by Wokelo is grounded in real, verifiable sources. Our platform does not “make up” information – each insight is accompanied by references and citations from premium data sources, trusted market intelligence platforms, tier-one news providers, and verified industry databases. Users can access these sources at any time, ensuring full transparency and confidence in the data. Wokelo has an internal fact check agent using an independent LLM to ensure every fact or data point is mentioned in the underlying source.
Additionally, Wokelo integrates with customers’ internal data repositories, unlocking valuable insights that might otherwise remain scattered or underutilized. This ensures that our AI-driven analysis is tailored, comprehensive, and aligned with specific investment-related queries.
Designed for high-stakes business decision-making, Wokelo’s AI is trained to synthesize insights, not speculate—pulling exclusively from factual datasets rather than generating assumptions. This makes Wokelo a more credible and reliable alternative to general-purpose AI tools, empowering businesses to make informed, data-driven decisions with confidence.
How does Wokelo’s AI handle real-time data aggregation across multiple sources like filings, patents, and alternative data?
Wokelo’s AI excels at real-time data aggregation by tapping into over 20 premium financial services datasets, including key sources like S&P CapIQ, Crunchbase, LinkedIn, SimilarWeb, YouTube, and many others. These datasets provide rich, reliable information that serves as the foundation for Wokelo’s analytical capabilities. In addition to these financial datasets, Wokelo integrates data from a variety of top-tier publishers, including news articles, academic journals, podcast transcripts, patents, and other alternative data sources.
By synthesizing insights from these diverse and continuously updated data streams, Wokelo ensures that users have access to the most comprehensive, real-time intelligence available. This powerful aggregation of structured and unstructured data allows Wokelo to provide a holistic view of the market, offering up-to-the-minute insights that are crucial for investment research.
Wokelo is already being used by firms like KPMG, Berkshire, EY, and Google. What has been the key to driving adoption among these high-profile clients?
Wokelo’s success among industry leaders like KPMG, Berkshire, EY, and Google stems from its ability to deliver measurable, transformative impact while seamlessly integrating with professional workflows. Unlike generic AI solutions, Wokelo is purpose-built for investment research, ensuring that its algorithms not only meet but exceed the high standards expected in this sector.
A key driver of adoption has been Wokelo’s close collaboration with leadership teams, allowing firms to embed their hard-won expertise into proprietary AI workflows. This deep customization ensures that Wokelo aligns with the nuanced decision-making processes of top investment professionals, providing best-in-class reliability and earning the trust of elite clients. These firms choose Wokelo over other tools in the market for its depth of analysis, fidelity, and accuracy.
Beyond its precision and adaptability, Wokelo delivers tangible efficiency gains. By reducing due diligence timelines from 21 to just 10 days and automating core research tasks, it significantly cuts manpower costs while freeing senior professionals from hours of manual work. With the ability to screen 5–10X more deals per month, firms using Wokelo gain a competitive edge, accelerating decision-making without compromising on depth or accuracy.
By combining cutting-edge AI, deep customization, and real-world impact, Wokelo has established itself as an indispensable tool for top-tier investment and advisory firms looking to scale their operations without missing critical details.
How does Wokelo integrate into the existing workflows of investment professionals, and what feedback have you received from users?
Wokelo integrates seamlessly into investment workflows by automating the entire deal lifecycle—from evaluating sector attractiveness to identifying high-potential companies in a global database of over 30 million firms. It offers in-depth company analysis, competitive benchmarking, and data room automation, eliminating tedious file reviews and quickly generating actionable insights. Wokelo also supports portfolio monitoring, peer analysis, and provides easy-to-export PPTs with client branding, streamlining client presentations and meeting prep.
Users report significant efficiency gains, reducing due diligence timelines from 20 days to just one week and increasing deal evaluation capacity from 100 to 500 per month—boosting deal coverage by tenfold.
How do you see AI transforming the investment research landscape in the next five years?
We’re only scratching the surface of what’s possible. AI will enable end-to-end research in a fraction of the time. With high-fidelity “super agents” capable of handling everything from deep market research and expert calls to data analysis and drafting a well-formatted 100-page deck, tasks that would traditionally require a team of five consultants working 6–8 weeks can now be accomplished much faster. This leap in speed and breadth of output will unlock new levels of productivity, allowing human experts to focus on high-level strategy and judgment.
AI will enable 50–100x more deals in the pipeline. By automating large parts of due diligence and analysis, AI-driven solutions can help investment managers expand their deal-screening capacity exponentially, uncovering more opportunities and diversifying portfolios in ways that were previously unfeasible.
The most pivotal element will be the amplified human-AI synergy. As these “super agents” take on the heavy lifting, collaboration between AI tools and human decision-makers becomes crucial. While AI will expedite processes and surface insights at scale, human expertise will remain essential for fine-tuning strategies, interpreting nuanced findings, and making confident investment decisions. This synergy will drive enhanced returns and innovation across the investment research landscape in the next five years.
As AI tools become more prevalent, how do you see human analysts and AI collaborating in the future?
As AI tools become more prevalent, the future of human analysts will revolve around collaboration rather than competition with AI. Rather than replacing analysts, AI will act as a powerful augmentation tool, automating repetitive tasks and enabling analysts to focus on higher-value, strategic work. The most successful analysts will be those who learn to integrate AI into their workflows, using it to enhance productivity, refine insights, and drive innovation. Rather than fearing AI, analysts should view it as a game-changing tool that amplifies their skills and allows them to add greater value to their organizations.
Ultimately, AI won’t replace human analysts—but analysts who embrace AI will replace those who don’t.
Thank you for the great interview, readers who wish to learn more should visit Wokelo.
#ADD#admin#adoption#agent#Agentic AI#agents#ai#ai agent#AI AGENTS#AI hallucinations#AI platforms#ai tools#AI-powered#Algorithms#amp#Analysis#Analytics#approach#Articles#automation#background#banks#benchmarking#Born#Branding#Building#Business#Case Study#CEO#challenge
0 notes
Video
youtube
Generative AI and LLM tutorial for beginners #generativeai #simplified
In this podcast, Arun Benoy and I have discussed the basics of Generative AI, What are he different tools that can be used for generative text, images and videos, what are some of the most disruptive business use cases that Generative AI can solve. After that, we have taken a deep dive into Techniques for Fine-tuning LLM, How to control costs while creating an LLM and When to use Open Source LLM instead of Building your own LLM Later, Arun has mentioned about various places where we can start learning amount Gen AI for doing quick prototyping, deploying private LLMs , Artificial general intelligence and controlling hardware needed to create and use LLM. We hope this video will serve as crash course on generative ai and llm for developers and founders
Topics
: 00:00:00 Introduction 00:03:00
Disruptive use cases for Generative AI
00:06:07 Architecture of Large Language Models (LLM)
00:19:05 Techniques for Fine-tuning LLM
00:23:51 Controlling Cost while using Generative AI
00:31:20 Resources to start learning Generative AI
#LLM #GenerativeAI #GenAI #podcast #engineering #deepdive
0 notes
Text
AI Agent Development: A Complete Guide to Building Smart, Autonomous Systems in 2025
Artificial Intelligence (AI) has undergone an extraordinary transformation in recent years, and 2025 is shaping up to be a defining year for AI agent development. The rise of smart, autonomous systems is no longer confined to research labs or science fiction — it's happening in real-world businesses, homes, and even your smartphone.
In this guide, we’ll walk you through everything you need to know about AI Agent Development in 2025 — what AI agents are, how they’re built, their capabilities, the tools you need, and why your business should consider adopting them today.

What Are AI Agents?
AI agents are software entities that perceive their environment, reason over data, and take autonomous actions to achieve specific goals. These agents can range from simple chatbots to advanced multi-agent systems coordinating supply chains, running simulations, or managing financial portfolios.
In 2025, AI agents are powered by large language models (LLMs), multi-modal inputs, agentic memory, and real-time decision-making, making them far more intelligent and adaptive than their predecessors.
Key Components of a Smart AI Agent
To build a robust AI agent, the following components are essential:
1. Perception Layer
This layer enables the agent to gather data from various sources — text, voice, images, sensors, or APIs.
NLP for understanding commands
Computer vision for visual data
Voice recognition for spoken inputs
2. Cognitive Core (Reasoning Engine)
The brain of the agent where LLMs like GPT-4, Claude, or custom-trained models are used to:
Interpret data
Plan tasks
Generate responses
Make decisions
3. Memory and Context
Modern AI agents need to remember past actions, preferences, and interactions to offer continuity.
Vector databases
Long-term memory graphs
Episodic and semantic memory layers
4. Action Layer
Once decisions are made, the agent must act. This could be sending an email, triggering workflows, updating databases, or even controlling hardware.
5. Autonomy Layer
This defines the level of independence. Agents can be:
Reactive: Respond to stimuli
Proactive: Take initiative based on context
Collaborative: Work with other agents or humans
Use Cases of AI Agents in 2025
From automating tasks to delivering personalized user experiences, here’s where AI agents are creating impact:
1. Customer Support
AI agents act as 24/7 intelligent service reps that resolve queries, escalate issues, and learn from every interaction.
2. Sales & Marketing
Agents autonomously nurture leads, run A/B tests, and generate tailored outreach campaigns.
3. Healthcare
Smart agents monitor patient vitals, provide virtual consultations, and ensure timely medication reminders.
4. Finance & Trading
Autonomous agents perform real-time trading, risk analysis, and fraud detection without human intervention.
5. Enterprise Operations
Internal copilots assist employees in booking meetings, generating reports, and automating workflows.
Step-by-Step Process to Build an AI Agent in 2025
Step 1: Define Purpose and Scope
Identify the goals your agent must accomplish. This defines the data it needs, actions it should take, and performance metrics.
Step 2: Choose the Right Model
Leverage:
GPT-4 Turbo or Claude for text-based agents
Gemini or multimodal models for agents requiring image, video, or audio processing
Step 3: Design the Agent Architecture
Include layers for:
Input (API, voice, etc.)
LLM reasoning
External tool integration
Feedback loop and memory
Step 4: Train with Domain-Specific Knowledge
Integrate private datasets, knowledge bases, and policies relevant to your industry.
Step 5: Integrate with APIs and Tools
Use plugins or tools like LangChain, AutoGen, CrewAI, and RAG pipelines to connect agents with real-world applications and knowledge.
Step 6: Test and Simulate
Simulate environments where your agent will operate. Test how it handles corner cases, errors, and long-term memory retention.
Step 7: Deploy and Monitor
Run your agent in production, track KPIs, gather user feedback, and fine-tune the agent continuously.
Top Tools and Frameworks for AI Agent Development in 2025
LangChain – Chain multiple LLM calls and actions
AutoGen by Microsoft – For multi-agent collaboration
CrewAI – Team-based autonomous agent frameworks
OpenAgents – Prebuilt agents for productivity
Vector Databases – Pinecone, Weaviate, Chroma for long-term memory
LLMs – OpenAI, Anthropic, Mistral, Google Gemini
RAG Pipelines – Retrieval-Augmented Generation for knowledge integration
Challenges in Building AI Agents
Even with all this progress, there are hurdles to be aware of:
Hallucination: Agents may generate inaccurate information.
Context loss: Long conversations may lose relevancy without strong memory.
Security: Agents with action privileges must be protected from misuse.
Ethical boundaries: Agents must be aligned with company values and legal standards.
The Future of AI Agents: What’s Coming Next?
2025 marks a turning point where AI agents move from experimental to mission-critical systems. Expect to see:
Personalized AI Assistants for every employee
Decentralized Agent Networks (Autonomous DAOs)
AI Agents with Emotional Intelligence
Cross-agent Collaboration in real-time enterprise ecosystems
Final Thoughts
AI agent development in 2025 isn’t just about automating tasks — it’s about designing intelligent entities that can think, act, and grow autonomously in dynamic environments. As tools mature and real-time data becomes more accessible, your organization can harness AI agents to unlock unprecedented productivity and innovation.
Whether you’re building an internal operations copilot, a trading agent, or a personalized shopping assistant, the key lies in choosing the right architecture, grounding the agent in reliable data, and ensuring it evolves with your needs.
1 note
·
View note