#Integration Runtime in Azure Data Factory
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Unraveling the Power of Integration Runtime in Azure Data Factory: A Comprehensive Guide
Table of Contents
Introduction
Understanding Integration Runtime
Key Features and Benefits
Use Cases
Best Practices for Integration Runtime Implementation:
Conclusion
FAQS on Integration runtime In Azure Data Factory
Introduction
Within the time of data-driven decision-making, businesses depend on robust information integration arrangements to streamline their operations and gain important experiences. Azure Data Factory stands out as a chief choice for orchestrating and automating information workflows within the cloud. At the heart of Azure Data Factory lies Integration Runtime (IR), a flexible and effective engine that facilitates consistent data movement over diverse environments. Whether you are a seasoned data engineer or a newcomer to Azure Data Factory, this article aims to prepare you with the information to harness the total potential of Integration Runtime for your information integration needs. In this comprehensive guide, we dive profound into Integration Runtime in Azure Data Factory, investigating its key features, benefits, use cases, and best practices.
Understanding Integration Runtime
Integration Runtime serves as the backbone of Azure Data Factory, enabling productive information development and change over different sources and goals. It functions as a compute framework inside Azure, encouraging a network between the data stores, compute services, and pipelines in Azure Data Factory.

There are three types of Integration Runtime in Azure Data Factory
1. Azure Integration Runtime
This type of Integration Runtime is fully managed by Microsoft and is best suited for information movement within Azure administrations and between cloud environments.
2. Self-hosted Integration Runtime
Offering adaptability and control, self-hosted Integration Runtime allows data movement between on-premises data stores and cloud administrations without exposing your arrange to the web.
3. Azure-SSIS Integration Runtime
The platform-as-a-service (PaaS) environment offered by this runtime is tailored to run SQL Server Integration Administrations (SSIS) bundles in Azure Data Factory. This allows SSIS processes to be executed in the cloud.
Key Features and Benefits
Integration Runtime in Azure Data Factory offers a plethora of features and benefits that enable organizations to proficiently manage their information integration workflows:
● Hybrid Connectivity
With self-hosted Integration Runtime, organizations can securely interface to on-premises data sources behind firewalls, ensuring seamless integration between cloud and on-premises situations.
● Scalability and Performance
Azure Integration Runtime scales dynamically to meet the demands of data-intensive workloads, giving high throughput and low latency information movement over Azure services.
● Fault Tolerance
Integration Runtime guarantees data integrity and reliability by naturally retrying failed information exchange operations and providing fault tolerance components for dealing with transitory errors.
● Data Encryption and Security
Integration Runtime employs industry-standard encryption protocols to secure information in transit and at rest, guaranteeing compliance with regulatory requirements and information administration policies.
● Extensibility
Integration Runtime seamlessly coordinating with other Azure services and third-party devices, allowing organizations to leverage a wealthy environment of data integration solutions.
Use Cases
Integration Runtime in Azure Data Factory caters to a wide range of use cases over businesses:
● Real-time Analytics
Organizations can use Integration Runtime to ingest, change, and analyze streaming information in real-time, empowering timely decision-making and significant insights.
● Data Warehousing
Integration Runtime encourages the extraction, transformation, and loading (ETL) of data into Azure Synapse Analytics and other data warehouse solutions, empowering comprehensive analytics and announcing.
● Data Migration
Whether moving from on-premises information centers to the cloud or between cloud environments, Integration Runtime simplifies the migration process by providing seamless data development and change capabilities.
● Batch Processing
Integration Runtime automates batch processing workflows, empowering organizations to effectively prepare expansive volumes of information at planned intervals for reporting, analytics, and archival purposes.
Best Practices for Integration Runtime Implementation
To maximize the viability of Integration Runtime in Azure Data Factory, consider the following best practices:
1. Optimize Data Transfer: Utilize parallelism and dividing strategies to optimize data transfer performance and diminish latency.
2. Monitor and Troubleshoot: Regularly monitor Integration Runtime performance measurements and logs to recognize and troubleshoot issues proactively.
3. Secure Connectivity: Actualize network security best practices to safeguard data during travel between on-premises and cloud situations.
4. Adaptation Control: Keep up adaptation control for information integration pipelines and artifacts to ensure consistency and reproducibility over environments.
Conclusion
Integration Runtime in Azure Data Factory is a foundation of modern information integration design, enabling organizations to consistently interface, change, and analyze data over different situations. By understanding its key highlights, benefits, use cases, and best practices, businesses can open the total potential of Azure Data Factory to drive advancement, accelerate decision-making, and accomplish competitive advantage in today's data-driven world.
FAQS
Q1: How does Integration Runtime ensure data security during data movement?
Ans: Integration Runtime implements robust security measures such as encryption, access controls, and compliance measures to secure data amid transit and at rest. It guarantees information integrity and privacy all through the information integration preparation.
Q2: What are the key highlights of Integration Runtime?
Ans: Integration Runtime offers features like network to diverse information sources, adaptability to handle changing workloads, fault tolerance mechanisms for reliability, effective information development, and adherence to stringent security guidelines.
Q3: Can Integration Runtime handle data movement between cloud and on-premises environments?
Ans: Yes, Self-hosted Integration Runtime enables information development between Azure cloud administrations and on-premises data sources safely. It acts as a bridge between cloud and on-premises situations, facilitating seamless data integration.
1 note
·
View note
Text
Azure Data Factory (ADF) is a cloud-based data integration service provided by Microsoft Azure. It is designed to enable organizations to create, schedule, and manage data pipelines that can move data from various source systems to destination systems, transforming and processing it along the way.
2 notes
·
View notes
Text
Azure Data Factory Pricing Explained: Estimating Costs for Your Pipelines

Azure Data Factory Pricing Explained: Estimating Costs for Your Pipelines
When you’re building data pipelines in the cloud, understanding the cost structure is just as important as the architecture itself. Azure Data Factory (ADF), Microsoft’s cloud-based data integration service, offers scalable solutions to ingest, transform, and orchestrate data — but how much will it cost you?
In this post, we’ll break down Azure Data Factory pricing so you can accurately estimate costs for your workloads and avoid surprises on your Azure bill.
1. Core Pricing Components
Azure Data Factory pricing is mainly based on three key components:
a) Pipeline Orchestration and Execution
Triggering and running pipelines incurs charges based on the number of activities executed.
Pricing model: You’re billed per activity run. The cost depends on the type of activity (e.g., data movement, data flow, or external activity).
Activity TypeCost (approx.)Pipeline orchestration$1 per 1,000 activity runsExternal activities$0.00025 per activity runData Flow executionBased on compute usage (vCore-hours)
💡 Tip: Optimize by combining steps in one activity when possible to minimize orchestration charges.
b) Data Movement
When you copy data using the Copy Activity, you’re charged based on data volume moved and data integration units (DIUs) used.
RegionPricingData movement$0.25 per DIU-hourData volumeCharged per GB transferred
📝 DIUs are automatically allocated based on file size, source/destination, and complexity, but you can manually scale for performance.
c) Data Flow Execution and Debugging
For transformation logic via Mapping Data Flows, charges are based on Azure Integration Runtime compute usage.
Compute TierApproximate CostGeneral Purpose$0.193/vCore-hourMemory Optimized$0.258/vCore-hour
Debug sessions are also billed the same way.
⚙️ Tip: Always stop debug sessions when not in use to avoid surprise charges.
2. Azure Integration Runtime and Region Impact
ADF uses Integration Runtimes (IRs) to perform activities. Costs vary by:
Type (Azure, Self-hosted, or SSIS)
Region deployed
Compute tier (for Data Flow
3. Example Cost Estimation
Let’s say you run a daily pipeline with:
3 orchestrated step
1 copy activity moving 5 GB of data
1 mapping data flow with 4 vCores for 10 minutes
Estimated monthly cost:
Pipeline runs: (3 x 30) = 90 activity runs ≈ $0.09
Copy activity: 5 GB/day = 150 GB/month = ~$0.50 (depending on region)
DIU usage: Minimal for this size
Data flow: (4 vCores x 0.167 hrs x $0.193) x 30 ≈ $3.87
✅ Total Monthly Estimate: ~$4.50
4. Tools for Cost Estimation
Use these tools to get a more precise estimate:
Azure Pricing Calculator: Customize based on region, DIUs, vCores, etc.
Cost Management in Azure Portal: Analyze actual usage and forecast future costs
ADF Monitoring: Track activity and performance per pipeline.
5. Tips to Optimize ADF Costs
Use data partitioning to reduce data movement time.
Consolidate activities to limit pipeline runs.
Scale Integration Runtime compute only as needed.
Schedule pipelines during off-peak hours (if using other Azure services).
Keep an eye on debug sessions and idle IRs.
Final Thoughts
Azure Data Factory offers powerful data integration capabilities, but smart cost management starts with understanding how pricing works. By estimating activity volumes, compute usage, and leveraging the right tools, you can build efficient and budget-conscious data pipelines.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Azure Data Factory Pipeline
Azure Data Factory (ADF) is a critical cloud-based data integration tool that manages and automates data transfer and transformation. Given the growing relevance of big data, understanding how to create and manage pipelines in ADF is critical for modern data workers. This article will walk you through the major parts of Azure Data Factory pipelines, from their components to actual applications, to ensure you're fully prepared to take advantage of their capabilities. If you're seeking for Azure or Azure DevOps training in Hyderabad, this article will explain how these programs can help you improve your abilities and job possibilities.

Introduction to Azure Data Factory
Azure Data Factory is a cloud-based ETL (Extract, Transform, Load) tool that enables you to build data-driven workflows to organize data transportation and transformation at scale. It supports a wide range of data sources and offers a platform for creating data pipelines that simplify data integration across several systems.
Key Features of Azure Data Factory
ETL and ELT Capabilities: ADF supports both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, enabling flexible data integration.
Data Movement: Seamlessly move data from on-premises or cloud sources to your desired destinations.
Data Transformation: Transform data using data flow activities within pipelines, utilizing mapping data flows for code-free transformations.
Integration with Azure Services: ADF integrates with various Azure services like Azure Synapse Analytics, Azure Machine Learning, and more.
Components of Azure Data Factory Pipelines
To effectively use ADF, it’s essential to understand its core components:
Pipelines
Pipelines in ADF are logical groupings of activities that perform a unit of work. Each pipeline can contain multiple activities that define the actions to be performed on your data.
Activities
Activities represent the processing steps in a pipeline. There are several types of activities available in ADF:
Data Movement Activities: Copy data from one location to another.
Data Transformation Activities: Transform data using services like Azure Databricks, HDInsight, or SQL Server.
Control Activities: Manage the workflow of pipelines, including activities like loops, conditions, and triggers.
Datasets
Datasets are the data structures within the data stores that the activities interact with. They specify the schema and location of the data source.
Linked Services
Linked Services are linkages between data repositories and computing services. They specify the connection details required for ADF to access data sources and destinations.
Integration Runtimes
Integration Runtimes (IR) provide the compute environment for data movement and data transformation activities. There are three types of IRs:
Azure Integration Runtime: For data movement and transformation within Azure.
Self-hosted Integration Runtime: For data movement between on-premises and cloud data stores.
Azure-SSIS Integration Runtime: For running SQL Server Integration Services (SSIS) packages in Azure.
Building and Managing Pipelines
Creating a Pipeline
Define the Pipeline: Start by defining the pipeline and adding activities.
Configure Activities: Configure each activity with the necessary parameters and settings.
Link Datasets: Associate datasets with activities to define the data sources and destinations.
Set Up Triggers: Schedule pipeline execution using triggers based on time or events.
Monitoring and Managing Pipelines
ADF provides a robust monitoring and management interface to track pipeline execution, identify issues, and ensure data processing is on track. Key features include:
Pipeline Runs: Track the status and performance of each pipeline run.
Activity Runs: Monitor the execution of individual activities within the pipelines.
Alerts and Notifications: Set up alerts for pipeline failures or other critical events.
Advanced Features and Best Practices
Data Flow Activities
Data Flow activities enable complex data transformations within ADF. They offer a visual interface for designing data transformations without writing code.
Integration with Azure Synapse Analytics
ADF integrates smoothly with Azure Synapse Analytics, delivering a comprehensive solution for large data processing and analysis. Use ADF to manage data transfer and transformation, and Synapse to perform sophisticated analytics.
Security and Compliance
Managed identities, secure connections, and data encryption can all help to ensure data security and compliance. ADF can integrate with Azure Key Vault to manage secrets and credentials.
Performance Optimization
Optimize the performance of your data pipelines by:
Using Parallelism: Execute activities in parallel where possible.
Optimizing Data Movement: Use the appropriate data movement technology for your data volume and latency requirements.
Monitoring and Tuning: Continuously monitor pipeline performance and adjust configurations as needed.
Real-World Applications
Data Migration
ADF is ideal for migrating data from on-premises systems to the cloud. Use it to move large volumes of data with minimal disruption to your operations.
Data Integration
Integrate data from various sources, including databases, file systems, and APIs, to create a unified data platform for analytics and reporting.
Data Transformation
Use ADF to transform raw data into meaningful insights. Apply data cleansing, aggregation, and enrichment processes to prepare data for analysis.
Azure Training in Hyderabad
Comprehensive Curriculum
Azure training in Hyderabad provides a comprehensive curriculum that covers every area of Azure Data Factory and Azure DevOps. From comprehending the essential components to constructing and managing data pipelines, the course ensures that you have a complete understanding of the services.
Experienced Trainers
The trainers' expertise has a significant impact on training quality. Azure training in Hyderabad is delivered by industry veterans with considerable experience in cloud computing and data engineering. These trainers offer practical insights and real-world knowledge to the classroom, ensuring that you master theoretical topics while also understanding how to apply them in real-world circumstances.
Hands-On Training
One of the primary benefits of Azure training in Hyderabad is the emphasis on practical experience. Training programs include practical laboratories, live projects, and real-time case studies that allow you to apply what you've learned. This practical experience is crucial in reinforcing your understanding and preparing you for the obstacles you will face in the job.
Flexible Learning Options
Balancing work and learning can be difficult, but Azure training in Hyderabad provides adaptable solutions to fit your schedule. Whether you prefer weekend batches, evening sessions, or online seminars, there is a training program to meet your requirements.
Placement Assistance
Many Azure training institutes in Hyderabad provide comprehensive placement services, including as resume preparation, mock interviews, and job counseling. This support considerably boosts your chances of getting a position at a major multinational corporation and expanding your career in cloud computing.
Azure DevOps Training in Hyderabad
The Synergy Between ADF and Azure DevOps
Combining Azure Data Factory training with Azure DevOps training in Hyderabad might result in a well-rounded skill set that is highly valued in the market. Azure DevOps is a set of development tools that streamline the software development and deployment processes, ensuring that applications are delivered efficiently and consistently.
Key Components of Azure DevOps
Azure Boards: Tools for planning and tracking work, code defects, and issues using agile methods like Kanban and Scrum.
Azure Pipelines: CI/CD workflows for building, testing, and deploying code.
Azure Repos: Version control for code using Git or Team Foundation Version Control (TFVC).
Azure Test Plans: Tools for manual and exploratory testing to ensure application quality.
Azure Artifacts: Hosting and sharing packages with your team, managing dependencies in CI/CD pipelines.
Benefits of Azure DevOps Training
Comprehensive Curriculum: Covering all aspects of Azure DevOps tools and practices.
Experienced Trainers: Industry veterans providing practical insights and guidance.
Hands-On Training: Emphasis on practical learning through live projects and real-time case studies.
Placement Assistance: Robust support for securing jobs, including resume preparation and mock interviews.
Flexible Learning Options: Various schedules to accommodate working professionals.
Conclusion
Azure Data Factory is an extremely effective tool for modern data integration and transformation. Understanding its components and features allows you to create effective data pipelines that streamline data workflows and improve your analytics. Azure training in Hyderabad provides a thorough curriculum, skilled trainers, hands-on experience, and strong placement help, making it a good alternative for people pursuing careers in cloud computing and data engineering.
Integrating Azure DevOps training in Hyderabad with Azure Data Factory training may help you expand your skill set and become a valuable asset in the market. Whether you're transferring data to the cloud, merging disparate data sources, or transforming data for analysis, Azure Data Factory has the tools and flexibility you need to meet your data integration objectives.
Enroll in Azure Data Factory training today and take the first step toward learning this critical data integration technology. Improve your job possibilities with comprehensive Azure and Azure DevOps training in Hyderabad, and discover new opportunities in the fast developing sector of cloud computing.
0 notes
Text
Azure Data Factory ensures efficient data processing with parallel processing, data integration runtime, and built-in pipeline optimization.
0 notes
Text
What are the components of Azure Data Lake Analytics?
Azure Data Lake Analytics consists of the following key components:
Job Service: This component is responsible for managing and executing jobs submitted by users. It schedules and allocates resources for job execution.
Catalog Service: The Catalog Service stores and manages metadata about data stored in Data Lake Storage Gen1 or Gen2. It provides a structured view of the data, including file names, directories, and schema information.
Resource Management: Resource Management handles the allocation and scaling of resources for job execution. It ensures efficient resource utilization while maintaining performance.
Execution Environment: This component provides the runtime environment for executing U-SQL jobs. It manages the distributed execution of queries across multiple nodes in the Azure Data Lake Analytics cluster.
Job Submission and Monitoring: Azure Data Lake Analytics provides tools and APIs for submitting and monitoring jobs. Users can submit jobs using the Azure portal, Azure CLI, or REST APIs. They can also monitor job status and performance metrics through these interfaces.
Integration with Other Azure Services: Azure Data Lake Analytics integrates with other Azure services such as Azure Data Lake Storage, Azure Blob Storage, Azure SQL Database, and Azure Data Factory. This integration allows users to ingest, process, and analyze data from various sources seamlessly.
These components work together to provide a scalable and efficient platform for processing big data workloads in the cloud.
#Azure#DataLake#Analytics#BigData#CloudComputing#DataProcessing#DataManagement#Metadata#ResourceManagement#AzureServices#DataIntegration#DataWarehousing#DataEngineering#AzureStorage#magistersign#onlinetraining#support#cannada#usa#careerdevelopment
1 note
·
View note
Text
Question 14: What are the different integration runtime types in Azure Data Factory and when should I use each?
Interview Questions on Azure Data Factory Development: #interview, #interviewquestions, #Microsoft, #azure, #adf , #eswarstechworld, #azuredataengineer, #development, #azuredatafactory , #azuredeveloper
Integration runtimes in Azure Data Factory provide the infrastructure and execution environment for data integration processes. Integration runtimes in Azure Data Factory are compute resources that execute data integration workflows, including data movement, data transformation, and data orchestration tasks. They provide connectivity to various data sources and destinations, enabling data…

View On WordPress
#adf#azure#azuredataengineer#azuredatafactory#azuredeveloper#development#eswarstechworld#interview#interviewquestions#Microsoft
0 notes
Video
youtube
Excellent introduction to Azure Data Factory. I love the review of multiple hosted integration runtimes.
1 note
·
View note
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Over 90 recipes to help you collect and transform data from multiple sources into a single data source which makes it easier to perform analytics on the data Key Features * Build data pipelines from scratch and find solutions to common problems in data engineering lifecycle * Learn how to work with Data Factory, Azure Data Lake, Azure Databricks and Azure Synapse Analytics * Monitor and troubleshoot your data engineering pipelines using log analytics and Azure monitor Book Description Data is the new oil and gaining maximum insights out of data is extremely critical for an organization's success. Building performant data engineering pipelines to ingest, store, process and visualize data is one of the major challenges organizations face in leveraging value out of data. This book shares 90 useful recipes covering common scenarios in building data engineering pipelines in Azure. The book, a second edition of the immensely successful first edition written by Ahmad Osama, covers several recent enhancements in Azure data engineering. This edition explores recipes from Azure Synapse Analytics workspaces - gen 2, covering topics like Synapse spark pools, SQL Serverless pools, Synapse integration pipelines and synapse data flows. The book also dives deep into Synapse SQL Pool optimization techniques in the second edition. Besides Synapse enhancements, it covers building the semantic and visualization layer using Power BI and establishing connectivity of Databricks and Synapse pools with Power BI. Finally, the book covers overall data engineering pipeline management focusing on areas like tracking impact and data lineage using Azure Purview. By the end of this book, it will serve as your go-to guide in building excellent data engineering pipelines. What you will learn * Perform data ingestion and orchestration using Azure Data Factory * Move data from on-premise sources to Azure using Data Factory Integration Runtime * Process your raw data using Azure Databricks and Azure Synapse * Perform data orchestration and ETL tasks using Azure Synapse analytics * Implement high availability and monitor performance of Azure SQL Database * Build effective Synapse SQL pools which can be consumed by Power BI * Monitor the performance of Synapse SQL and Spark pools using log analytics Who This Book Is For This book is targeted at Data engineers, Data architects, database administrators and data professionals who want to get well versed with the Azure data services for building data pipelines. Basic understanding of cloud and data engineering concepts would be beneficial. Publisher : Packt Publishing Limited; 2nd edition (16 September 2022) Language : English Paperback : 529 pages ISBN-10 : 1803246782 ISBN-13 : 978-1803246789 Item Weight : 1 kg 30 g Dimensions : 19.05 x 3.48 x 23.5 cm Country of Origin
: India [ad_2]
0 notes
Text
What is azure data factory?
What is azure data factory?
Data-driven cloud workflows for orchestrating and automating data movement and transformation can be created with Azure Data Factory, a cloud-based data integration service.
ADF itself does not store any data. Data-driven workflows can be created to coordinate the movement of data between supported data stores and then processed using compute services in other regions or an on-premise environment.
It also lets you use both UI and programmatic mechanisms to monitor and manage workflows.
What is Azure Data Factory's operation?
Data pipelines that move and transform data can be created with the Data Factory service and run on a predetermined schedule (hourly, daily, weekly, etc.).
This indicates that workflows consume and produce time-sliced data, and the pipeline mode can be scheduled (once per day) or one time.
There are typically three steps in data-driven workflows called Azure Data Factory pipelines.
Step 1: Connect and CollectConnect to all of the necessary processing and data sources, including file shares, FTP, SaaS services, and web services.
Use the Copy Activity in a data pipeline to move data from both on-premise and cloud source data stores to a centralization data store in the cloud for further analysis, then move the data as needed to a centralized location for processing.
Step 2: Transform and Enrich Once data is stored in a cloud-based centralized data store, compute services like HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Machine Learning are used to transform it.
Step 3: PublishDeliver transferred data from the cloud to on-premise sources like SQL Server or stored it in cloud storage for BI and analytics tools and other applications to use.
Important components of Azure Data Factory
In order to define input and output data, processing events, and the timetable and resources required to carry out the desired data flow, Azure Data Factory consists of four key components that collaborate with one another: Within the data stores, data structures are represented by datasets.
The input for an activity in the pipeline is represented by an input dataset. The activity's output is represented by an output dataset. An Azure Blob dataset, for instance, specifies the Azure Blob Storage folder and blob container from which the pipeline should read data.
Or, the table to which the activity writes the output data is specified in an Azure SQL Table dataset. A collection of tasks is called a pipeline.
They are used to organize activities into a unit that completes a task when used together. There may be one or more pipelines in a data factory.
For instance, a pipeline could contain a gathering of exercises that ingests information from a Purplish blue mass and afterward runs a Hive question on an HDInsight bunch to segment the information.
The actions you take with your data are referred to as activities. At the moment, two kinds of activities are supported by Azure Data Factory data transformation and movement.
The information required for Azure Data Factory to connect to external resources is defined by linked services. To connect to the Azure Storage account, for instance, a connection string is specified by the Azure Storage-linked service.
Integration Runtime
The interface between ADF and the actual data or compute resources you require is provided by an integration runtime.ADF can communicate with native Azure resources like an Azure Data Lake or Databricks if you use it to marshal them.
There is no need to set up or configure anything; all you have to do is make use of the integrated integration runtime.
But suppose you want ADF to work with computers and data on your company's private network or data stored on an Oracle Database server under your desk.
In these situations, you must use a self-hosted integration runtime to set up the gateway.
The integrated integration runtime is depicted in this screenshot. When you access native Azure resources, it is always present and comes pre-installed.
Linked Service
A linked service instructs ADF on how to view the specific computers or data you want to work on. You must create a linked service for each Azure storage account and include access credentials in order to access it. You need to create a second linked service in order to read or write to another storage account. Your linked service will specify the Azure subscription, server name, database name, and credentials to enable ADF to operate on an Azure SQL database.
I hope that my article was beneficial to you. To learn more, click the link here
0 notes
Text
Building Dynamic Pipelines in Azure Data Factory Using Variables and Parameters

Azure Data Factory (ADF) is a powerful ETL and data integration tool, and one of its greatest strengths is its dynamic pipeline capabilities. By using parameters and variables, you can make your pipelines flexible, reusable, and easier to manage — especially when working with multiple environments, sources, or files.
In this blog, we’ll explore how to build dynamic pipelines in Azure Data Factory using parameters and variables, with practical examples to help you get started.
🎯 Why Go Dynamic?
Dynamic pipelines:
Reduce code duplication
Make your solution scalable and reusable
Enable parameterized data loading (e.g., different file names, table names, paths)
Support automation across multiple datasets or configurations
🔧 Parameters vs Variables: What’s the Difference?
FeatureParametersVariablesScopePipeline level (readonly)Pipeline or activity levelUsagePass values into a pipelineStore values during executionMutabilityImmutable after pipeline startsMutable (can be set/updated)
Step-by-Step: Create a Dynamic Pipeline
Let’s build a sample pipeline that copies data from a source folder to a destination folder dynamically based on input values.
✅ Step 1: Define Parameters
In your pipeline settings:
Create parameters like sourcePath, destinationPath, and fileName.
json"parameters": { "sourcePath": { "type": "string" }, "destinationPath": { "type": "string" }, "fileName": { "type": "string" } }
✅ Step 2: Create Variables (Optional)
Create variables like status, startTime, or rowCount to use within the pipeline for tracking or conditional logic.json"variables": { "status": { "type": "string" }, "rowCount": { "type": "int" } }
✅ Step 3: Use Parameters Dynamically in Activities
In a Copy Data activity, dynamically bind your source and sink:
Source Path Example:json@concat(pipeline().parameters.sourcePath, '/', pipeline().parameters.fileName)
Sink Path Example:json@concat(pipeline().parameters.destinationPath, '/', pipeline().parameters.fileName)
✅ Step 4: Set and Use Variables
Use a Set Variable activity to assign a value:json"expression": "@utcnow()"
Use an If Condition or Switch to act based on a variable value:json@equals(variables('status'), 'Success')
📂 Real-World Example: Dynamic File Loader
Scenario: You need to load multiple files from different folders every day (e.g., sales/, inventory/, returns/).
Solution:
Use a parameterized pipeline that accepts folder name and file name.
Loop through a metadata list using ForEach.
Pass each file name and folder as parameters to your main data loader pipeline.
🧠 Best Practices
🔁 Use ForEach and Execute Pipeline for modular, scalable design.
🧪 Validate parameter inputs to avoid runtime errors.
📌 Use variables to track status, error messages, or row counts.
🔐 Secure sensitive values using Azure Key Vault and parameterize secrets.
🚀 Final Thoughts
With parameters and variables, you can elevate your Azure Data Factory pipelines from static to fully dynamic and intelligent workflows. Whether you’re building ETL pipelines, automating file ingestion, or orchestrating data flows across environments — dynamic pipelines are a must-have in your toolbox.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Update Microsoft DP-203 Practice Test Questions
Candidates who pass the DP-203 Data Engineering on Microsoft Azure exam will earn the Microsoft Certified: Azure Data Engineer Associate certification. PassQuestion provides the high quality Microsoft Azure Data Engineer DP-203 Practice Test Questions to help you best prepare for your Microsoft DP-203 exam. With the help of our Microsoft Azure Data Engineer DP-203 Practice Test Questions, you will be able to practice as much as you want before taking the real exam. It will give you a clear idea to understand the real exam scenario and you will be able to improve your preparation. You just have to prepare the provided DP-203 Practice Test Questions once and you will be able to clear the exam in a single attempt.
Data Engineering on Microsoft Azure (DP-203)
The Microsoft Azure Data Engineer (DP-203) is an advanced-level certification exam from Microsoft Azure. By enrolling for this certification you get the credibility and can validate your Azure Data Engineer skills such as designing and implementing data storage and data security, Designing and Developing data processing, and Monitoring and optimizing data storage and data processing.
Being an Azure Data Engineer, you can ensure that data pipelines and data stores are high-performing, efficient, organized, and reliable, based on business requirements and constraints. You will also be able to design, implement, monitor, and optimize data platforms to meet the needs of data pipelines. Therefore, once you understand and master these concepts you can easily become a successful Azure Data Engineer.
Exam Information
Exam Code: DP-203 Number of Questions: 40-60 questions Duaration: 130 Minutes Cost: $165 USD Passing Score: 700 Language: English
Learning Objectives
Design and implement data storage on Azure Design and develop data processing on Azure Design and implement data security on Azure Monitor and optimize data storage and data processing on Azure
View Online Microsoft Certified: Azure Data Engineer Associate DP-203 Free Questions
You need to integrate the on-premises data sources and Azure Synapse Analytics. The solution must meet the data integration requirements. Which type of integration runtime should you use? A. Azure-SSIS integration runtime B. self-hosted integration runtime C. Azure integration runtime Answer: C
You need to design a data retention solution for the Twitter teed data records. The solution must meet the customer sentiment analytics requirements. Which Azure Storage functionality should you include in the solution? A. time-based retention B. change feed C. soft delete D. Iifecycle management Answer: D
You need to design a data retention solution for the Twitter feed data records. The solution must meet the customer sentiment analytics requirements. Which Azure Storage functionality should you include in the solution? A. change feed B. soft delete C. time-based retention D. lifecycle management Answer: D
What should you do to improve high availability of the real-time data processing solution? A. Deploy identical Azure Stream Analytics jobs to paired regions in Azure. B. Deploy a High Concurrency Databricks cluster. C. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops. D. Set Data Lake Storage to use geo-redundant storage (GRS). Answer: A
You have two Azure Data Factory instances named ADFdev and ADFprod. ADFdev connects to an Azure DevOps Git repository. You publish changes from the main branch of the Git repository to ADFdev. You need to deploy the artifacts from ADFdev to ADFprod. What should you do first? A. From ADFdev, modify the Git configuration. B. From ADFdev, create a linked service. C. From Azure DevOps, create a release pipeline. D. From Azure DevOps, update the main branch. Answer: C
You need to trigger an Azure Data Factory pipeline when a file arrives in an Azure Data Lake Storage Gen2 container. Which resource provider should you enable? A. Microsoft.Sql B. Microsoft-Automation C. Microsoft.EventGrid D. Microsoft.EventHub Answer: C
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination. You need to ensure that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs. What should you do? A. Clone the cluster after it is terminated. B. Terminate the cluster manually when processing completes. C. Create an Azure runbook that starts the cluster every 90 days. D. Pin the cluster. Answer: D
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact table named Table1. You need to identify the extent of the data skew in Table1. What should you do in Synapse Studio? A. Connect to the built-in pool and run dbcc pdw_showspaceused. B. Connect to the built-in pool and run dbcc checkalloc. C. Connect to Pool1 and query sys.dm_pdw_node_scacus. D. Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_scacs. Answer: D
0 notes
Text
Transform your corporate critical data with Data Bricks
Systems are working with massive amounts of data in petabytes or even more and it is still growing at an exponential rate. Big data is present everywhere around us and comes in from different sources like social media sites, sales, customer data, transactional data, etc. And I firmly believe, this data holds its value only if we can process it both interactively and faster.

Simply put, Databricks is the implementation of Apache Spark on Azure. With fully managed Spark clusters, it is used to process large workloads of data and also helps in data engineering, data exploring and also visualizing data using Machine learning.
While working on databricks, found that analytic platform to be extremely developer-friendly and flexible with ease to use APIs like Python, R, etc. To explain this a little more, say you have created a data frame in Python, with Azure Databricks, you can load this data into a temporary view and can use Scala, R or SQL with a pointer referring to this temporary view. This allows you to code in multiple languages in the same notebook. This was just one of the cool features of it.
Evidently, the adoption of Databricks is gaining importance and relevance in a big data world for a couple of reasons. Apart from multiple language support, this service allows us to integrate easily with many Azure services like Blob Storage, Data Lake Store, SQL Database and BI tools like Power BI, Tableau, etc. It is a great collaborative platform letting data professionals share clusters and workspaces, which leads to higher productivity.
Before we get started digging Databricks in Azure, I would like to take a minute here to describe how this article series is going to be structured. I intend to cover the following aspects of Databricks in Azure in this series. Please note – this outline may vary here and there when I actually start writing on them.
How to access Azure Blob Storage from Azure Databricks
Processing and exploring data in Azure Databricks
Connecting Azure SQL Databases with Azure Databricks
Load data into Azure SQL Data Warehouse using Azure Databricks
Integrating Azure Databricks with Power BI
Run an Azure Databricks Notebook in Azure Data Factory and many more…
In this article, we will talk about the components of Databricks in Azure and will create a Databricks service in the Azure portal. Moving further, we will create a Spark cluster in this service, followed by the creation of a notebook in the Spark cluster.
The below screenshot is the diagram puts out by Microsoft to explain Databricks components on Azure:

There are a few features worth to mention here:
Databricks Workspace – It offers an interactive workspace that enables data scientists, data engineers and businesses to collaborate and work closely together on notebooks and dashboards
Databricks Runtime – Including Apache Spark, they are an additional set of components and updates that ensures improvements in terms of performance and security of big data workloads and analytics. These versions are released on a regular basis
As mentioned earlier, it integrates deeply with other services like Azure services, Apache Kafka and Hadoop Storage and you can further publish the data into machine learning, stream analytics, Power BI, etc.
Since it is a fully managed service, various resources like storage, virtual network, etc. are deployed to a locked resource group. You can also deploy this service in your own virtual network. We are going to see this later in the article
Databricks File System (DBFS) – This is an abstraction layer on top of object storage. This allows you to mount storage objects like Azure Blob Storage that lets you access data as if they were on the local file system. I will be demonstrating this in detail in my next article in this series
As a Microsoft Gold certified partner and certified Azure consultants in Sydney, Canberra & Melbourne. We have extensive experience in delivering database solutions in Azure platform. For more information, please contact us from [email protected]
0 notes
Text
Overview of Azure Data Factory
Azure data factory is a fully managed and server less data integrations service that integrates all your data. It easily re-hosts SQL Server Integration Services and builds ETL (extract, transform, and load) and ETL pipelines, ELT (Extract, Load, transform), and data integration without the need for coding.
Data Factory is a system that hosts multiple interconnections and thus data engineers get a complete end-to-end platform. Following are some important technical concepts of data factory crucial for aspiring data engineers and professionals necessary for Azure data certifications.

Connect and collect
Enterprises have a huge amount of various data stored at different locations such as cloud, structured, unstructured, and semi-structured. Data factory allows moving data from both on-premises and cloud source data stores to a centralized server or data store and carries further analysis.
Transform and enrich
Azure data factory uses the ADF mapping data flows to process and transform the data stored in a centralized data store. Moreover, data transformation graphs can be built and managed using mapping data flows. ADF mapping data flows does without the need to understand Spark clusters or Spark programming.
CI/CD and publish
Data factory fully supports CI/CD of your data pipelines. It allows users to develop and deliver ETL processes before publishing the finished product.
Monitor
Once the data integration pipeline is built and deployed, the data factory monitors the scheduled activities and pipelines that provide success and failure rates.
Explore the Building Blocks of Azure Data Factory
Pipeline
A data factory has one or multiple pipelines that contain a logical group of activities performing certain tasks. The pipeline allows managing the activities in a set rather than managing each activity individually. The activities are chained together and can undergo sequencing or even operate independently in parallel.
Mapping data flows
Data factory creates and manages graphs for transforming any size of data. Data engineers can develop graphical data transformations without the need for coding. Data flows within the ADF are executed using scaled-out Azure Databricks clusters.
Activity
Activities in a pipeline are those actions that are performed on the data in the pipeline. Data Factory carries out control activities, data transformation activities, and data movement activities.
Datasets
Datasets retrieve data from various data stores like documents, tables, files, and folders. You can use data from these data stores as inputs or outputs.
Linked services
Linked services are similar to connection strings. Linked services to the data factory provide the connection information necessary to connect it with external sources. Data Factory uses linked services for two purposes such as to represent a data store and to represent a compute resource.
Integration Runtime
In a Data Factory, activity is the action performed in a pipeline whereas linked service is a target store or compute service. Integration runtime in a Data Factory connects activity and linked services. Azure Data factory provides three types of integration runtime namely Azure, Azure-SSIS, and Self-hosted integration runtime.
Triggers
Triggers schedule when a pipeline execution needs to be kicked off. Different types of triggers are used to schedule different types of events.
These concepts are extremely important to pass the DP 203 exam and successfully gain Azure Certification.
#Azure Data Factory#Azure certification#Azure Data Engineer Certification#Azure data certifications#DP 203
0 notes
Photo

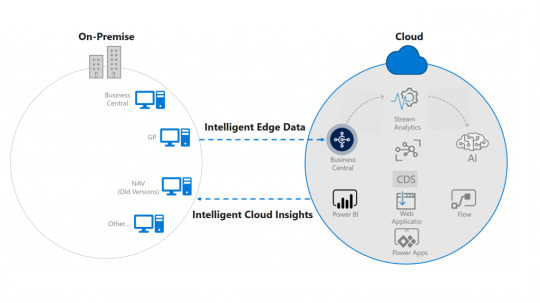
Unlock the Power of Intelligent Cloud with your On-Premises solution
The “Intelligent Cloud” refers to the cloud applications built with artificial intelligence. It’s an Infinite scale with a global presence and massive compute capability. Cloud is not just bound to store and access information, but it helps us to make a decision, predict things and to automate many things that we are used to doing manually. Advanced Algorithms used by technologies like Artificial Intelligence and Machine Learning have indeed made the Cloud ‘Very Intelligent’.
On-Premises Microsoft Dynamics solutions can take advantage of Cloud-based applications through Intelligent Cloud. Customers running their businesses with On-Premises solutions can get access to the same intelligent cloud features and applications that Customers using online can have. Each On-Premises solution that connects to the Intelligent Cloud will be able to replicate data from On-Premises to the cloud tenant. So, users can leverage the Cloud for Data & AI, Machine Learning, Cortana Intelligence, Power BI, Flow, Power Apps, etc.
Intelligent Cloud is recurrently used with the term Intelligent Edge. Intelligent Edge means devices and services that are connected to the cloud and data gets transmitted back and forth between the device and the cloud.
Benefits of Intelligent Cloud for businesses
Major benefits available have been listed in the below pointers:
Seamless Transition
Intelligent Cloud extensions make the transition seamless from On-Premises solution to cloud tenant.
Analytics and Reporting
Availability of data on the cloud enables leveraging the analytics and reporting capabilities /tools. Power BI coupled with the Azure offering to store and manage huge data is worth investing in. The starting point is the embedded Power BI within Business Central.
Machine Learning & AI
Cortana intelligence available with Business Central enables taking the first step towards Machine learning and AI. The complete gamut of AI is then available to be used and benefits derived by the business
Collaboration solutions
Close-knit integration of Business Central with Power Platform, Customer engagement and Office 365 allows the business significantly increasing the efficiency.
Read-Only Access
Provides read-only access to the users, it prevents users from accidentally entering any data else it will generate issues in data replication.
Mobility
Business ‘on the move’ with multiple devices adds another dimension to the way the operations are currently executed
Intelligent Cloud Insights
Insights Page shows Cash Availability, Sales Profitability, Net Income and Inventory Value which are key areas of interest for most of the businesses and this page can be hosted within On-Premises solution also but users need Business Central license to view the data.
Microsoft offers inbuilt extensions to facilitate business using On-Premises solutions like Dynamics NAV 2018, Business Central On-Premises, Dynamics GP and Dynamics SL to take advantage of the cloud offering. Configuring the intelligent cloud environment will have no impact on current data or users of existing On-Premises solution.
A connection is to be built between Intelligent Cloud and On-Premises solution through Business Central Online and then they will be able to replicate data from On-Premises to the cloud tenant.
Intelligent Cloud Management
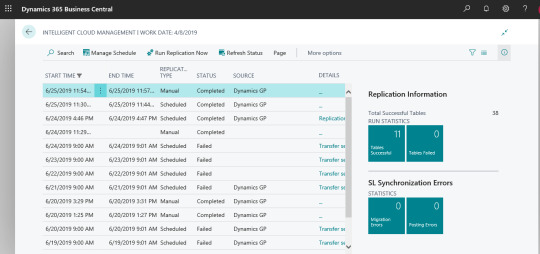
Out of the box, 150 GB data can be replicated for any tenant in the current version of Business Central. If your database is greater than 150GB, a selected number of Companies can be replicated using the Company selection in the assisted setup guide in Business Central. There is no restriction on the type of data that can be replicated through Intelligent Cloud. Only the data from the tables available in both On-Premises solution and Business Central online tenant can be replicated. For customized functionalities, tables/extensions need to be made and installed in On-Premises and Business Central Online Tenant both to replicate the data.
For configuring intelligent cloud, a data pipeline is to be created within the ADF (Azure Data Factory) service. If the data source is a local SQL Server instance, then self-hosted integration runtime (SHIR) is to be configured and there is no limit on the number of tenants that can be added to the SHIR. In case of multi-
If you no longer require connection to Business Central Online Tenant, then you can switch it off any time and can continue to use On-Premises Solution.
0 notes
Link
SQL Server Management Studio (SSMS) is an integrated environment for managing SQL Server instances. By using SSMS, one could access, configure, manage, administer, and develop all components of SQL Server.
As official and the most recognizable “all in one” client user interface, its design is quite user friendly and comprehensive. Furthermore, the software combines and brings together a range of both graphical and visual design tools and rich script editors to ensure simplified interaction with SQL Server.
On top of all, it’s worth mentioning that with every major release, the application is better in terms of security and performance.
And to any database administrator (DBA) productivity and versatility may prove to be very important. Productivity will allow the job to be done easily and swiftly, and versatility ensures different ways of accomplishing one single task.
However, with all the mentioned perks, there are some downsides to its functionality, that are time-consuming and sometimes very tedious.
One of which, that SSMS clearly lacks the possibility of adding multiple SQL Server instances at once.
Understanding the problem
Don’t think that this is an overblown statement. Just imagine large corporations with a huge amount of SQL Servers, we’re talking hundreds here, both local and scattered around the network waiting to be discovered and used.
And now, here is a person that needs to do a simple task like pulling the build numbers for all SQL instances that are currently managed. First and foremost, the connection between every single one of those instances needs to be established in order to use and manage them. To connect them via the SSMS, every SQL Server instance needs to be manually added. Just imagine hundreds of instances that need to be added one-by-one. It is clearly an exhausting task, without any exaggeration.
In this case, the performance and productiveness of a database administrator could take a massive hit, and to some, this may end up being a dealbreaker, to others the necessary hassle.
Another thing that needs to be mentioned here is that once the SSMS is closed or restarted, on the new application launch, the connection to previously managed instances is lost, and those needs to be added again, manually.
In this article, we will take a look into the process of adding SQL Server instance via SSMS and then provide an insight into the different ways of accomplishing the same by using the 3rd party alternative, ApexSQL Manage.
With all being said, let’s dive into the process of connecting a SQL instance in the SQL Server Management Studio.
Connect SQL instance in SSMS
To connect a SQL instance in SSMS, one should do the following:
Launch the SQL Server Management Studio
Once the software is initialized, by default, the Connect to Server window will pop-up:
Here, configure the following:
From the Server type drop-down list bellow can be selected:
Database Engine – the core component of SQL Server instance used for storing, processing and securing
Analysis Services – SSAS is a multidimensional analysis tool that features Online Analytical Processing (OLAP), powerful data mining abilities and reporting used in Business Intelligence to ease your managing data tasks
Reporting Services – SSRS is a reporting and visualization tool for SQL Server, and by using it, one can create, manage and publish reports and dashboards
Integration Services – SSIS is a fast and flexible data warehousing tool that can be used for data extraction and for executing a wide range of data migration tasks
Azure-SSIS Integration Runtime – the Integration Runtime (IR) is the compute infrastructure used by Azure Data Factory to provide the data integration capabilities across different network environments
This is where the Database Engine option should be chosen.
In the Server name drop-down list, choose the preferred SQL Server instance to make a connection with. Here, the previously used SQL instances are listed:
If the desired SQL instance is not listed, choose the Browse for more… option at the bottom of the drop-down list:
Under the Local Servers tab of the Browse for Servers window, displayed are all SQL instances installed on the local machine. In addition to this, under the same tab, all configured SQL Server Services are listed as well:
In the Network Servers tab, SQL instances discovered across the network are shown:
Once the SQL Server instance is selected, proceed to choose the Authentication mode. In its drop-down list the following options are displayed, and the majority of those with their own set of configurable settings:
Windows Authentication – this mode allows a user to connect through a Windows user account
SQL Server Authentication – anytime this mode is used, proper login and password credentials are required
Azure Active Directory – Universal with MFA – this mode delivers strong authentication with a range of different verification options the user can choose from: phone call, text message, smart cards with a pin or mobile app notifications
Azure Active Directory – Password – use this mode for connecting to SQL Server instance database and when logged in to Windows using Azure AD credentials from a domain not combined with Azure
Azure Active Directory – Integrated – this mode is used when connecting to SQL Database and logged in to Windows using Azure Active Directory credentials from a federated domain
After the proper authentication is chosen, click the Connect button to establish the connection between the SQL Server Management Studio and the selected SQL Server instance:
Now, the SQL instance is shown in the Object Explorer on the left with all its properties and objects:
To view the build number for this newly connected instance, right-click on its name and choose Properties:
Build number details are now listed in the General tab of the Server Properties window:
To add another SQL instance and view its build number, click the Connect drop-down menu and choose the Database Engine option:
In the Connect to Server window, configure the same settings based on the previously described steps:
Once a new instance is added, repeat the same steps to see its build number.
And this set of actions will have to be repeated numerous times in order to complete one simple task.
Using 3rd party software
ApexSQL Manage is a powerful application used for managing SQL instances. Some of its core features and capabilities ensure the user can easily discover instances across the network, execute high-level analysis in the search for SQL Server health issues, capture real-time state and condition of SQL Server instance by creating its snapshot, to make a comparison between instances and snapshots as well as to document them in various file formats.
In this section, the focus will be on the versatility mentioned in the introduction part of this article.
In that regard, the SQL manage instance tool offers a few more options when it comes to adding SQL Servers and making connections to the preferred SQL instance and the application itself. Also, it offers the “welcomed” capability of easily adding multiple SQL instances at the same time.
Following are the mentioned options:
Add SQL Instances manually – like in SSMS, SQL Server instances could be added manually and only one at a time
Add SQL instances discovered on a network – configure a search setting that will ensure scan will be executed on the specific area of network
Add SQL instances from the last scan – no new scan is required since the SQL manage instance tool remembers the results from the last scan being performed
Add SQL instances automatically – a scan can be automated and set to be executed in the desired time and frequency
Add SQL instances with quick action option – execute quick scan based on the previously configured settings
Note: For more information on this topic, please visit the Different ways of adding SQL Server instances in a SQL manage instance software article.
Completion of the example task will now look quite different, i.e., it can be done in just a couple of steps. The first step is to choose the preferred method for adding SQL instances, and with the connection between them and SQL manage instance software is established, they will be listed in the main grid of the Inventory tab. Their build versions will be displayed in the Build number column.
The second and final action would be to just read out build versions from the column. It is quite convenient that all build versions of connected instances can be seen at once:
Conclusion
When in need to manage multiple SQL instances at the same time, one doesn’t have to add them one-by-one to perform certain management tasks since there is a solution to achieve this feat instantly and quickly. This will save some valuable hours from daily work chores, helping up in reducing some pressure and, to an extent, increasing one’s productivity.
0 notes