#Azure Databricks
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Unlock the Future of ML with Azure Databricks – Here's Why You Should Care
youtube
0 notes
Text
Scaling Your Data Mesh Architecture for maximum efficiency and interoperability

View On WordPress
#Azure Databricks#Big Data#Business Intelligence#Cloud Data Management#Collaborative Data Solutions#Data Analytics#Data Architecture#Data Compliance#Data Governance#Data management#Data Mesh#Data Operations#Data Security#Data Sharing Protocols#Databricks Lakehouse#Delta Sharing#Interoperability#Open Protocol#Real-time Data Sharing#Scalable Data Solutions
0 notes
Text
AZURE DATA ENGINEER

0 notes
Text
How to print Azure Keyvault secret value in Databricks notebook ? Print shows REDACTED.
As part of ensuring security, sensitive information will not get printed directly on the Databricks notebooks. Sometimes this good feature becomes a trouble for the developers. For example, if you want to verify the value using a code snippet due to the lack of direct access to the vault, the direct output will show REDACTED. To overcome this problem, we can use a simple code snippet which just…
View On WordPress
#Azure Databricks#how to print keyvault secret value in databricks#print redacted content in plain text#show the actual value of a hidden string in databricks#show value of redacted
0 notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
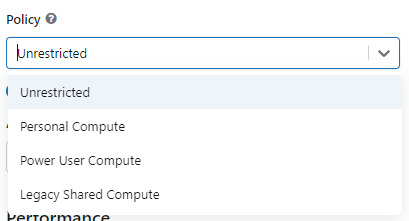
Utilizar un policy "unrestricted" o "power user compute"
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
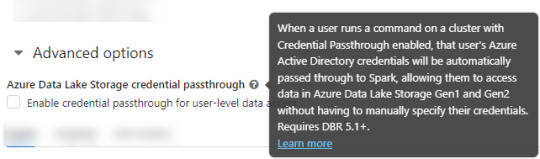
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
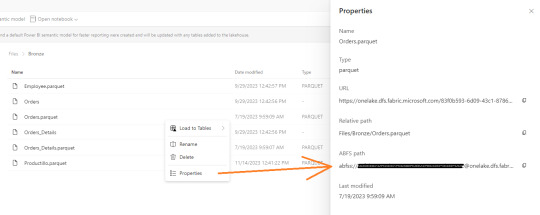
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
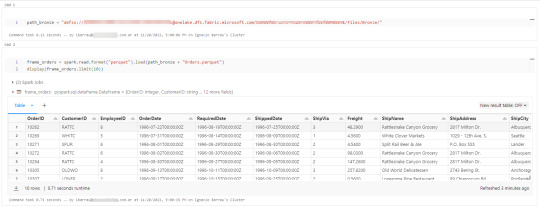
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
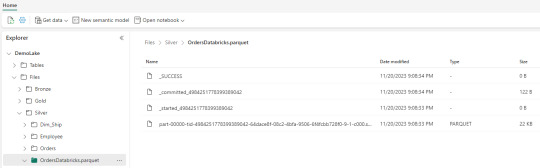
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
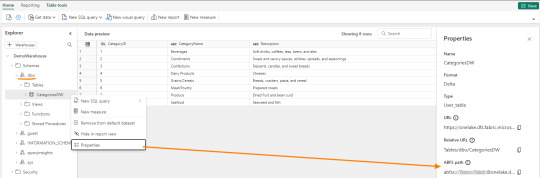
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
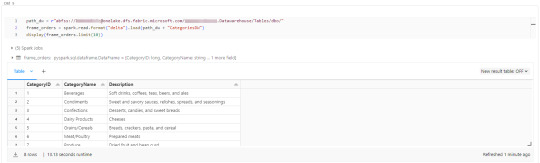
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text

#dataengineer#onlinetraining#freedemo#cloudlearning#azuredatlake#Databricks#azuresynapse#AzureDataFactory#Azure#SQL#MySQL#NewTechnolgies#software#softwaredevelopment#visualpathedu#onlinecoaching#ADE#DataLake#datalakehouse#AzureDataEngineering
2 notes
·
View notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
How Azure Supports Big Data and Real-Time Data Processing

The explosion of digital data in recent years has pushed organizations to look for platforms that can handle massive datasets and real-time data streams efficiently. Microsoft Azure has emerged as a front-runner in this domain, offering robust services for big data analytics and real-time processing. Professionals looking to master this platform often pursue the Azure Data Engineering Certification, which helps them understand and implement data solutions that are both scalable and secure.
Azure not only offers storage and computing solutions but also integrates tools for ingestion, transformation, analytics, and visualization—making it a comprehensive platform for big data and real-time use cases.
Azure’s Approach to Big Data
Big data refers to extremely large datasets that cannot be processed using traditional data processing tools. Azure offers multiple services to manage, process, and analyze big data in a cost-effective and scalable manner.
1. Azure Data Lake Storage
Azure Data Lake Storage (ADLS) is designed specifically to handle massive amounts of structured and unstructured data. It supports high throughput and can manage petabytes of data efficiently. ADLS works seamlessly with analytics tools like Azure Synapse and Azure Databricks, making it a central storage hub for big data projects.
2. Azure Synapse Analytics
Azure Synapse combines big data and data warehousing capabilities into a single unified experience. It allows users to run complex SQL queries on large datasets and integrates with Apache Spark for more advanced analytics and machine learning workflows.
3. Azure Databricks
Built on Apache Spark, Azure Databricks provides a collaborative environment for data engineers and data scientists. It’s optimized for big data pipelines, allowing users to ingest, clean, and analyze data at scale.
Real-Time Data Processing on Azure
Real-time data processing allows businesses to make decisions instantly based on current data. Azure supports real-time analytics through a range of powerful services:
1. Azure Stream Analytics
This fully managed service processes real-time data streams from devices, sensors, applications, and social media. You can write SQL-like queries to analyze the data in real time and push results to dashboards or storage solutions.
2. Azure Event Hubs
Event Hubs can ingest millions of events per second, making it ideal for real-time analytics pipelines. It acts as a front-door for event streaming and integrates with Stream Analytics, Azure Functions, and Apache Kafka.
3. Azure IoT Hub
For businesses working with IoT devices, Azure IoT Hub enables the secure transmission and real-time analysis of data from edge devices to the cloud. It supports bi-directional communication and can trigger workflows based on event data.
Integration and Automation Tools
Azure ensures seamless integration between services for both batch and real-time processing. Tools like Azure Data Factory and Logic Apps help automate the flow of data across the platform.
Azure Data Factory: Ideal for building ETL (Extract, Transform, Load) pipelines. It moves data from sources like SQL, Blob Storage, or even on-prem systems into processing tools like Synapse or Databricks.
Logic Apps: Allows you to automate workflows across Azure services and third-party platforms. You can create triggers based on real-time events, reducing manual intervention.
Security and Compliance in Big Data Handling
Handling big data and real-time processing comes with its share of risks, especially concerning data privacy and compliance. Azure addresses this by providing:
Data encryption at rest and in transit
Role-based access control (RBAC)
Private endpoints and network security
Compliance with standards like GDPR, HIPAA, and ISO
These features ensure that organizations can maintain the integrity and confidentiality of their data, no matter the scale.
Career Opportunities in Azure Data Engineering
With Azure’s growing dominance in cloud computing and big data, the demand for skilled professionals is at an all-time high. Those holding an Azure Data Engineering Certification are well-positioned to take advantage of job roles such as:
Azure Data Engineer
Cloud Solutions Architect
Big Data Analyst
Real-Time Data Engineer
IoT Data Specialist
The certification equips individuals with knowledge of Azure services, big data tools, and data pipeline architecture—all essential for modern data roles.
Final Thoughts
Azure offers an end-to-end ecosystem for both big data analytics and real-time data processing. Whether it’s massive historical datasets or fast-moving event streams, Azure provides scalable, secure, and integrated tools to manage them all.
Pursuing an Azure Data Engineering Certification is a great step for anyone looking to work with cutting-edge cloud technologies in today’s data-driven world. By mastering Azure’s powerful toolset, professionals can design data solutions that are future-ready and impactful.
#Azure#BigData#RealTimeAnalytics#AzureDataEngineer#DataLake#StreamAnalytics#CloudComputing#AzureSynapse#IoTHub#Databricks#CloudZone#AzureCertification#DataPipeline#DataEngineering
0 notes
Text
What’s New In Databricks? February 2025 Updates & Features Explained!
youtube
What’s New In Databricks? February 2025 Updates & Features Explained! #databricks #spark #dataengineering
Are you ready for the latest Databricks updates in February 2025? 🚀 This month brings game-changing features like SAP integration, Lakehouse Federation for Teradata, Databricks Clean Rooms, SQL Pipe, Serverless on Google Cloud, Predictive Optimization, and more!
✨ Explore Databricks AI insights and workflows—read more: / databrickster
🔔𝐃𝐨𝐧'𝐭 𝐟𝐨𝐫𝐠𝐞𝐭 𝐭𝐨 𝐬𝐮𝐛𝐬𝐜𝐫𝐢𝐛𝐞 𝐭𝐨 𝐦𝐲 𝐜𝐡𝐚𝐧𝐧𝐞𝐥 𝐟𝐨𝐫 𝐦𝐨𝐫𝐞 𝐮𝐩𝐝𝐚𝐭𝐞𝐬. / @hubert_dudek
🔗 Support Me Here! ☕Buy me a coffee: https://ko-fi.com/hubertdudek
🔗 Stay Connected With Me. Medium: / databrickster
==================
#databricks#bigdata#dataengineering#machinelearning#sql#cloudcomputing#dataanalytics#ai#azure#googlecloud#aws#etl#python#data#database#datawarehouse#Youtube
1 note
·
View note
Text
Unlock Data Governance: Revolutionary Table-Level Access in Modern Platforms
Dive into our latest blog on mastering data governance with Microsoft Fabric & Databricks. Discover key strategies for robust table-level access control and secure your enterprise's data. A must-read for IT pros! #DataGovernance #Security
View On WordPress
#Access Control#Azure Databricks#Big data analytics#Cloud Data Services#Data Access Patterns#Data Compliance#Data Governance#Data Lake Storage#Data Management Best Practices#Data Privacy#Data Security#Enterprise Data Management#Lakehouse Architecture#Microsoft Fabric#pyspark#Role-Based Access Control#Sensitive Data Protection#SQL Data Access#Table-Level Security
0 notes
Text

Join our latest AWS Data Engineering demo and take your career to the next level!
Attend Online #FREEDEMO from Visualpath on # AWSDataEngineering by Mr.Chandra (Best Industry Expert).
Join Link: https://meet.goto.com/248120661
Free Demo on: 01/02/2025 @9:00AM IST
Contact us: +91 9989971070
Trainer Name: Mr Chandra
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://awsdataengineering1.blogspot.com/
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
#azuredataengineer#Visualpath#elearning#TechEducation#online#training#students#softwaredevelopment#trainingcourse#handsonlearning#DataFactory#DataBricks#DataLake#software#dataengineering#SynapseAnalytics#ApacheSpark#synapse#NewTechnology#TechSkills#ITSkills#ade#Azure#careergrowth
0 notes
Text

Quiz Time: Which framework does azure data bricks use?. comment your answer below!
To know more about frameworks and other topics in #azureadmin, #azuredevops, #azuredataengineer join in azure trainings
For more details contact
Phone:+91 9882498844
website: https://azuretrainings.in/
Email: [email protected]
0 notes
Text
Azure Databricks: Unleashing the Power of Big Data and AI
Introduction to Azure Databricks
In a world where data is considered the new oil, managing and analyzing vast amounts of information is critical. Enter Azure Databricks, a unified analytics platform designed to simplify big data and artificial intelligence (AI) workflows. Developed in partnership between Microsoft and Databricks, this tool is transforming how businesses leverage data to make smarter decisions.
Azure Databricks combines the power of Apache Spark with Azure’s robust ecosystem, making it an essential resource for businesses aiming to harness the potential of data and AI.
Core Features of Azure Databricks
Unified Analytics Platform
Azure Databricks brings together data engineering, data science, and business analytics in one environment. It supports end-to-end workflows, from data ingestion to model deployment.
Support for Multiple Languages
Whether you’re proficient in Python, SQL, Scala, R, or Java, Azure Databricks has you covered. Its flexibility makes it a preferred choice for diverse teams.
Seamless Integration with Azure Services
Azure Databricks integrates effortlessly with Azure’s suite of services, including Azure Data Lake, Azure Synapse Analytics, and Power BI, streamlining data pipelines and analysis.

How Azure Databricks Works
Architecture Overview
At its core, Azure Databricks leverages Apache Spark’s distributed computing capabilities. This ensures high-speed data processing and scalability.
Collaboration in a Shared Workspace
Teams can collaborate in real-time using shared notebooks, fostering a culture of innovation and efficiency.
Automated Cluster Management
Azure Databricks simplifies cluster creation and management, allowing users to focus on analytics rather than infrastructure.
Advantages of Using Azure Databricks
Scalability and Flexibility
Azure Databricks automatically scales resources based on workload requirements, ensuring optimal performance.
Cost Efficiency
Pay-as-you-go pricing and resource optimization help businesses save on operational costs.
Enterprise-Grade Security
With features like role-based access control (RBAC) and integration with Azure Active Directory, Azure Databricks ensures data security and compliance.
Comparing Azure Databricks with Other Platforms
Azure Databricks vs. Apache Spark
While Apache Spark is the foundation, Azure Databricks enhances it with a user-friendly interface, better integration, and managed services.
Azure Databricks vs. AWS Glue
Azure Databricks offers superior performance and scalability for machine learning workloads compared to AWS Glue, which is primarily an ETL service.
Key Use Cases for Azure Databricks
Data Engineering and ETL Processes
Azure Databricks simplifies Extract, Transform, Load (ETL) processes, enabling businesses to cleanse and prepare data efficiently.
Machine Learning Model Development
Data scientists can use Azure Databricks to train, test, and deploy machine learning models with ease.
Real-Time Analytics
From monitoring social media trends to analyzing IoT data, Azure Databricks supports real-time analytics for actionable insights.
Industries Benefiting from Azure Databricks
Healthcare
By enabling predictive analytics, Azure Databricks helps healthcare providers improve patient outcomes and optimize operations.
Retail and E-Commerce
Retailers leverage Azure Databricks for demand forecasting, customer segmentation, and personalized marketing.
Financial Services
Banks and financial institutions use Azure Databricks for fraud detection, risk assessment, and portfolio optimization.

Getting Started with Azure Databricks
Setting Up an Azure Databricks Workspace
Begin by creating an Azure Databricks workspace through the Azure portal. This serves as the foundation for your analytics projects.
Creating Clusters
Clusters are the computational backbone. Azure Databricks makes it easy to create and configure clusters tailored to your workload.
Writing and Executing Notebooks
Use notebooks to write, debug, and execute your code. Azure Databricks’ notebook interface is intuitive and collaborative.
Best Practices for Using Azure Databricks
Optimizing Cluster Performance
Select the appropriate cluster size and configurations to balance cost and performance.
Managing Data Storage Effectively
Integrate with Azure Data Lake for efficient and scalable data storage solutions.
Ensuring Data Security and Compliance Implement RBAC, encrypt data at rest, and adhere to industry-specific compliance standards.
Challenges and Solutions in Using Azure Databricks
Managing Costs
Monitor resource usage and terminate idle clusters to avoid unnecessary expenses.
Handling Large Datasets Efficiently
Leverage partitioning and caching to process large datasets effectively.
Debugging and Error Resolution
Azure Databricks provides detailed logs and error reports, simplifying the debugging process.
Future Trends in Azure Databricks
Enhanced AI Capabilities
Expect more advanced AI tools and features to be integrated, empowering businesses to solve complex problems.
Increased Automation
Automation will play a bigger role in streamlining workflows, from data ingestion to model deployment.
Real-Life Success Stories
Case Study: How a Retail Giant Scaled with Azure Databricks
A leading retailer improved inventory management and personalized customer experiences by utilizing Azure Databricks for real-time analytics.
Case Study: Healthcare Advancements with Predictive Analytics
A healthcare provider reduced readmission rates and enhanced patient care through predictive modeling in Azure Databricks.
Learning Resources and Support
Official Microsoft Documentation
Access in-depth guides and tutorials on the Microsoft Azure Databricks documentation.
Online Courses and Certifications
Platforms like Coursera, Udemy, and LinkedIn Learning offer courses to enhance your skills.
Community Forums and Events
Join the Databricks and Azure communities to share knowledge and learn from experts.
Conclusion
Azure Databricks is revolutionizing the way organizations handle big data and AI. Its robust features, seamless integrations, and cost efficiency make it a top choice for businesses of all sizes. Whether you’re looking to improve decision-making, streamline processes, or innovate with AI, Azure Databricks has the tools to help you succeed.
FAQs
1. What is the difference between Azure Databricks and Azure Synapse Analytics?
Azure Databricks focuses on big data analytics and AI, while Azure Synapse Analytics is geared toward data warehousing and business intelligence.
2. Can Azure Databricks handle real-time data processing?
Yes, Azure Databricks supports real-time data processing through its integration with streaming tools like Azure Event Hubs.
3. What skills are needed to work with Azure Databricks?
Knowledge of data engineering, programming languages like Python or Scala, and familiarity with Azure services is beneficial.
4. How secure is Azure Databricks for sensitive data?
Azure Databricks offers enterprise-grade security, including encryption, RBAC, and compliance with standards like GDPR and HIPAA.
5. What is the pricing model for Azure Databricks?
Azure Databricks uses a pay-as-you-go model, with costs based on the compute and storage resources used.
0 notes
Text
0 notes
Text
Python program to download files recursively from AWS S3 bucket to Databricks DBFS
S3 is a popular object storage service from Amazon Web Services. It is a common requirement to download files from the S3 bucket to Azure Databricks. You can mount object storage to the Databricks workspace, but in this example, I am showing how to recursively download and sync the files from a folder within an AWS S3 bucket to DBFS. This program will overwrite the files that already exist. The…
#boto3#python program to download files from Aws s3 bucket to databricks dbfs#python program to recursively download files and folders from an AWS S3 bucket in Azure Databricks
0 notes
Text
Tracking Large Language Models (LLM) with MLflow : A Complete Guide
New Post has been published on https://thedigitalinsider.com/tracking-large-language-models-llm-with-mlflow-a-complete-guide/
Tracking Large Language Models (LLM) with MLflow : A Complete Guide
As Large Language Models (LLMs) grow in complexity and scale, tracking their performance, experiments, and deployments becomes increasingly challenging. This is where MLflow comes in – providing a comprehensive platform for managing the entire lifecycle of machine learning models, including LLMs.
In this in-depth guide, we’ll explore how to leverage MLflow for tracking, evaluating, and deploying LLMs. We’ll cover everything from setting up your environment to advanced evaluation techniques, with plenty of code examples and best practices along the way.
Functionality of MLflow in Large Language Models (LLMs)
MLflow has become a pivotal tool in the machine learning and data science community, especially for managing the lifecycle of machine learning models. When it comes to Large Language Models (LLMs), MLflow offers a robust suite of tools that significantly streamline the process of developing, tracking, evaluating, and deploying these models. Here’s an overview of how MLflow functions within the LLM space and the benefits it provides to engineers and data scientists.
Tracking and Managing LLM Interactions
MLflow’s LLM tracking system is an enhancement of its existing tracking capabilities, tailored to the unique needs of LLMs. It allows for comprehensive tracking of model interactions, including the following key aspects:
Parameters: Logging key-value pairs that detail the input parameters for the LLM, such as model-specific parameters like top_k and temperature. This provides context and configuration for each run, ensuring that all aspects of the model’s configuration are captured.
Metrics: Quantitative measures that provide insights into the performance and accuracy of the LLM. These can be updated dynamically as the run progresses, offering real-time or post-process insights.
Predictions: Capturing the inputs sent to the LLM and the corresponding outputs, which are stored as artifacts in a structured format for easy retrieval and analysis.
Artifacts: Beyond predictions, MLflow can store various output files such as visualizations, serialized models, and structured data files, allowing for detailed documentation and analysis of the model’s performance.
This structured approach ensures that all interactions with the LLM are meticulously recorded, providing a comprehensive lineage and quality tracking for text-generating models.
Evaluation of LLMs
Evaluating LLMs presents unique challenges due to their generative nature and the lack of a single ground truth. MLflow simplifies this with specialized evaluation tools designed for LLMs. Key features include:
Versatile Model Evaluation: Supports evaluating various types of LLMs, whether it’s an MLflow pyfunc model, a URI pointing to a registered MLflow model, or any Python callable representing your model.
Comprehensive Metrics: Offers a range of metrics tailored for LLM evaluation, including both SaaS model-dependent metrics (e.g., answer relevance) and function-based metrics (e.g., ROUGE, Flesch Kincaid).
Predefined Metric Collections: Depending on the use case, such as question-answering or text-summarization, MLflow provides predefined metrics to simplify the evaluation process.
Custom Metric Creation: Allows users to define and implement custom metrics to suit specific evaluation needs, enhancing the flexibility and depth of model evaluation.
Evaluation with Static Datasets: Enables evaluation of static datasets without specifying a model, which is useful for quick assessments without rerunning model inference.
Deployment and Integration
MLflow also supports seamless deployment and integration of LLMs:
MLflow Deployments Server: Acts as a unified interface for interacting with multiple LLM providers. It simplifies integrations, manages credentials securely, and offers a consistent API experience. This server supports a range of foundational models from popular SaaS vendors as well as self-hosted models.
Unified Endpoint: Facilitates easy switching between providers without code changes, minimizing downtime and enhancing flexibility.
Integrated Results View: Provides comprehensive evaluation results, which can be accessed directly in the code or through the MLflow UI for detailed analysis.
MLflow is a comprehensive suite of tools and integrations makes it an invaluable asset for engineers and data scientists working with advanced NLP models.
Setting Up Your Environment
Before we dive into tracking LLMs with MLflow, let’s set up our development environment. We’ll need to install MLflow and several other key libraries:
pip install mlflow>=2.8.1 pip install openai pip install chromadb==0.4.15 pip install langchain==0.0.348 pip install tiktoken pip install 'mlflow[genai]' pip install databricks-sdk --upgrade
After installation, it’s a good practice to restart your Python environment to ensure all libraries are properly loaded. In a Jupyter notebook, you can use:
import mlflow import chromadb print(f"MLflow version: mlflow.__version__") print(f"ChromaDB version: chromadb.__version__")
This will confirm the versions of key libraries we’ll be using.
Understanding MLflow’s LLM Tracking Capabilities
MLflow’s LLM tracking system builds upon its existing tracking capabilities, adding features specifically designed for the unique aspects of LLMs. Let’s break down the key components:
Runs and Experiments
In MLflow, a “run” represents a single execution of your model code, while an “experiment” is a collection of related runs. For LLMs, a run might represent a single query or a batch of prompts processed by the model.
Key Tracking Components
Parameters: These are input configurations for your LLM, such as temperature, top_k, or max_tokens. You can log these using mlflow.log_param() or mlflow.log_params().
Metrics: Quantitative measures of your LLM’s performance, like accuracy, latency, or custom scores. Use mlflow.log_metric() or mlflow.log_metrics() to track these.
Predictions: For LLMs, it’s crucial to log both the input prompts and the model’s outputs. MLflow stores these as artifacts in CSV format using mlflow.log_table().
Artifacts: Any additional files or data related to your LLM run, such as model checkpoints, visualizations, or dataset samples. Use mlflow.log_artifact() to store these.
Let’s look at a basic example of logging an LLM run:
This example demonstrates logging parameters, metrics, and the input/output as a table artifact.
import mlflow import openai def query_llm(prompt, max_tokens=100): response = openai.Completion.create( engine="text-davinci-002", prompt=prompt, max_tokens=max_tokens ) return response.choices[0].text.strip() with mlflow.start_run(): prompt = "Explain the concept of machine learning in simple terms." # Log parameters mlflow.log_param("model", "text-davinci-002") mlflow.log_param("max_tokens", 100) # Query the LLM and log the result result = query_llm(prompt) mlflow.log_metric("response_length", len(result)) # Log the prompt and response mlflow.log_table("prompt_responses", "prompt": [prompt], "response": [result]) print(f"Response: result")
Deploying LLMs with MLflow
MLflow provides powerful capabilities for deploying LLMs, making it easier to serve your models in production environments. Let’s explore how to deploy an LLM using MLflow’s deployment features.
Creating an Endpoint
First, we’ll create an endpoint for our LLM using MLflow’s deployment client:
import mlflow from mlflow.deployments import get_deploy_client # Initialize the deployment client client = get_deploy_client("databricks") # Define the endpoint configuration endpoint_name = "llm-endpoint" endpoint_config = "served_entities": [ "name": "gpt-model", "external_model": "name": "gpt-3.5-turbo", "provider": "openai", "task": "llm/v1/completions", "openai_config": "openai_api_type": "azure", "openai_api_key": "secrets/scope/openai_api_key", "openai_api_base": "secrets/scope/openai_api_base", "openai_deployment_name": "gpt-35-turbo", "openai_api_version": "2023-05-15", , , ], # Create the endpoint client.create_endpoint(name=endpoint_name, config=endpoint_config)
This code sets up an endpoint for a GPT-3.5-turbo model using Azure OpenAI. Note the use of Databricks secrets for secure API key management.
Testing the Endpoint
Once the endpoint is created, we can test it:
<div class="relative flex flex-col rounded-lg"> response = client.predict( endpoint=endpoint_name, inputs="prompt": "Explain the concept of neural networks briefly.","max_tokens": 100,,) print(response)
This will send a prompt to our deployed model and return the generated response.
Evaluating LLMs with MLflow
Evaluation is crucial for understanding the performance and behavior of your LLMs. MLflow provides comprehensive tools for evaluating LLMs, including both built-in and custom metrics.
Preparing Your LLM for Evaluation
To evaluate your LLM with mlflow.evaluate(), your model needs to be in one of these forms:
An mlflow.pyfunc.PyFuncModel instance or a URI pointing to a logged MLflow model.
A Python function that takes string inputs and outputs a single string.
An MLflow Deployments endpoint URI.
Set model=None and include model outputs in the evaluation data.
Let’s look at an example using a logged MLflow model:
import mlflow import openai with mlflow.start_run(): system_prompt = "Answer the following question concisely." logged_model_info = mlflow.openai.log_model( model="gpt-3.5-turbo", task=openai.chat.completions, artifact_path="model", messages=[ "role": "system", "content": system_prompt, "role": "user", "content": "question", ], ) # Prepare evaluation data eval_data = pd.DataFrame( "question": ["What is machine learning?", "Explain neural networks."], "ground_truth": [ "Machine learning is a subset of AI that enables systems to learn and improve from experience without explicit programming.", "Neural networks are computing systems inspired by biological neural networks, consisting of interconnected nodes that process and transmit information." ] ) # Evaluate the model results = mlflow.evaluate( logged_model_info.model_uri, eval_data, targets="ground_truth", model_type="question-answering", ) print(f"Evaluation metrics: results.metrics")
This example logs an OpenAI model, prepares evaluation data, and then evaluates the model using MLflow’s built-in metrics for question-answering tasks.
Custom Evaluation Metrics
MLflow allows you to define custom metrics for LLM evaluation. Here’s an example of creating a custom metric for evaluating the professionalism of responses:
from mlflow.metrics.genai import EvaluationExample, make_genai_metric professionalism = make_genai_metric( name="professionalism", definition="Measure of formal and appropriate communication style.", grading_prompt=( "Score the professionalism of the answer on a scale of 0-4:n" "0: Extremely casual or inappropriaten" "1: Casual but respectfuln" "2: Moderately formaln" "3: Professional and appropriaten" "4: Highly formal and expertly crafted" ), examples=[ EvaluationExample( input="What is MLflow?", output="MLflow is like your friendly neighborhood toolkit for managing ML projects. It's super cool!", score=1, justification="The response is casual and uses informal language." ), EvaluationExample( input="What is MLflow?", output="MLflow is an open-source platform for the machine learning lifecycle, including experimentation, reproducibility, and deployment.", score=4, justification="The response is formal, concise, and professionally worded." ) ], model="openai:/gpt-3.5-turbo-16k", parameters="temperature": 0.0, aggregations=["mean", "variance"], greater_is_better=True, ) # Use the custom metric in evaluation results = mlflow.evaluate( logged_model_info.model_uri, eval_data, targets="ground_truth", model_type="question-answering", extra_metrics=[professionalism] ) print(f"Professionalism score: results.metrics['professionalism_mean']")
This custom metric uses GPT-3.5-turbo to score the professionalism of responses, demonstrating how you can leverage LLMs themselves for evaluation.
Advanced LLM Evaluation Techniques
As LLMs become more sophisticated, so do the techniques for evaluating them. Let’s explore some advanced evaluation methods using MLflow.
Retrieval-Augmented Generation (RAG) Evaluation
RAG systems combine the power of retrieval-based and generative models. Evaluating RAG systems requires assessing both the retrieval and generation components. Here’s how you can set up a RAG system and evaluate it using MLflow:
from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chains import RetrievalQA from langchain.llms import OpenAI # Load and preprocess documents loader = WebBaseLoader(["https://mlflow.org/docs/latest/index.html"]) documents = loader.load() text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents) # Create vector store embeddings = OpenAIEmbeddings() vectorstore = Chroma.from_documents(texts, embeddings) # Create RAG chain llm = OpenAI(temperature=0) qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(), return_source_documents=True ) # Evaluation function def evaluate_rag(question): result = qa_chain("query": question) return result["result"], [doc.page_content for doc in result["source_documents"]] # Prepare evaluation data eval_questions = [ "What is MLflow?", "How does MLflow handle experiment tracking?", "What are the main components of MLflow?" ] # Evaluate using MLflow with mlflow.start_run(): for question in eval_questions: answer, sources = evaluate_rag(question) mlflow.log_param(f"question", question) mlflow.log_metric("num_sources", len(sources)) mlflow.log_text(answer, f"answer_question.txt") for i, source in enumerate(sources): mlflow.log_text(source, f"source_question_i.txt") # Log custom metrics mlflow.log_metric("avg_sources_per_question", sum(len(evaluate_rag(q)[1]) for q in eval_questions) / len(eval_questions))
This example sets up a RAG system using LangChain and Chroma, then evaluates it by logging questions, answers, retrieved sources, and custom metrics to MLflow.
The way you chunk your documents can significantly impact RAG performance. MLflow can help you evaluate different chunking strategies:
This script evaluates different combinations of chunk sizes, overlaps, and splitting methods, logging the results to MLflow for easy comparison.
MLflow provides various ways to visualize your LLM evaluation results. Here are some techniques:
You can create custom visualizations of your evaluation results using libraries like Matplotlib or Plotly, then log them as artifacts:
This function creates a line plot comparing a specific metric across multiple runs and logs it as an artifact.
#2023#ai#AI Tools 101#Analysis#API#approach#Artificial Intelligence#azure#azure openai#Behavior#code#col#Collections#communication#Community#comparison#complexity#comprehensive#computing#computing systems#content#credentials#custom metrics#data#data science#databricks#datasets#deploying#deployment#development
0 notes