#LLM content vs human blogs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Do You Still Read Blogs?
Why Dive Into My World with All Those LLMs Out There? Hey, you! I’m stoked you’re here, but I gotta ask—why are you still reading blogs like mine? With LLMs dishing out instant answers like a cosmic search engine, what’s got you wandering into my digital world? I mix in a dash of AI to smooth out my posts, but I’m the one building this space—every vibe, color, and quirky detail is my own little…
#AI writing vs blog voice#blog writing in AI age#Blogs#Expression#LLM content vs human blogs#personal content vs AI
0 notes
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
Be Seen, Be Cited: How Generative Engine Optimization Rules ChatGPT

Once upon a time, in a meeting room where all digital marketers sit around a big round table, with one simple question in mind, "How do I rank on Google?". All brainstorming on every SEO (search engine optimization) strategies, backlinking every where, using every effective keywords just to let Google notice. Such question is still asked but a new one emerged recently, which sound like "How do I get ChatGPT to quote me?". If this the question been asked then we're now getting into the new era of GEO which stands for generative engine optimization.
What's GEO? And What's The Different With SEO?
While traditional SEO is focused on guiding user to find their contents, built around of keywords, backlinks and metadata. Then to show up or get ranked by Google on SERPs, preferable 1st page. While for GEO, it can be known as the natural evolution of SEO. GEO is about helping AI to understand, trust and repeat the content even no user clicks on any links. So it's about optimizing human search behavior, but more into machine understanding:
Quoted or cited in AI-generated answers
Mentioned or referenced when people ask AI engines questions
Recognized as a credible source by large language models (LLMs)
Generative engines like ChatGPT, Copilot or Grok don't return the links as the way Google does. It summarize information and pass it back to users, based on most trusted sources.
GEO vs SEO: Key Differences
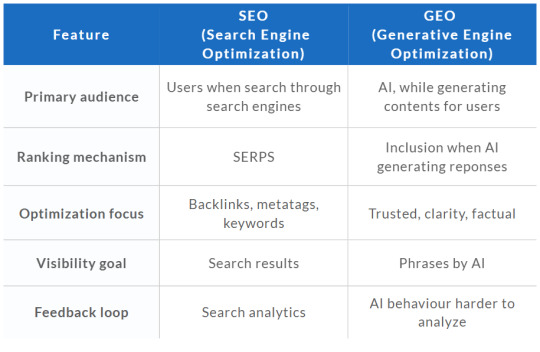
While SEO optimizes for discoverability, GEO optimizes for credibility in machine learning models.
Why GEO Matters Now?
Lot of users, including us. might straight asking ChatGPT for what dinner places tonight rather than going for Google. AI will summarize for us the answers and even together with the suggestions. Even the user never visits the site directly, it will comes out as suggestions, with goes as trusted choices even by AI. It can be said if your content are not being picked by AI, it also invisible to large segments of your audience. Being cited by AI boost your contents and organic reach like it was automatically promoted by AI.
Ways to Optimize for Generative Engines
With similarities with SEO (treat it as evolution), GEO can be optimized too. There goes some of the way:
Clarity and Structure - AI reading through some that clean and easy to read. With headers, subtitles and bullet points, it makes the entire contents easier to go through. Having a summaries even better.
Consistencies and Accuracies - Same as SEO, earning backlinks from reputable sites improving the authorities. Simply getting mentioned in news, articles, forums or reference sites help on this.
Semantic SEO - Rather than keywords, goes for full entities, like the places or people names. Even better if clearly explain it with descriptions.
Be Quoted on Popular Sites - AI usually goes for those indrustry blogs with proper attribution like Medium, Quora or LinkedIn articles.
Google Analytics or Search Console for GEO?
Unlike SEO, there's no proper way to track whether AI quoting your site or not. But if really want to then there's ways, even rather unconventional:
Ask ChatGPT of your industry related question, see if it ever prompt yours. If mentioned, then great success!
Check your sites if it ever crawled by AI bots.
If there's sudden spikes in direct visits, referral visits or branded search traffics (from GSC)
For now, there's haven't a conventional ways to track it yet. Over time, some AI tools may offer opt-in analytics or publisher insights. It could be additional features too that to be added on SEO software suites like Semrush or Ahrefs
It's Not a Replacement... It's EXPANSION!
As both having the same destination, to get noticed by their audience. Ranking on Google is still needed, but now you may also want to train the AI to see your content as trustworthy also. AI continues to influence how people gather information and some may replacing google as source of information. This become a sign that content strategies must adapt, so it's time to chat more about your contents with ChatGPT!
0 notes
Text
The Generative AI Revolution: How LLMs Are Reshaping Data Science

The field of data science is experiencing a profound transformation, thanks to the rapid advancements in generative AI and Large Language Models (LLMs). Tools like OpenAI's GPT-4, Google’s Gemini, and Meta’s Llama are not just changing the way we process natural language but are also redefining data-driven decision-making, automation, and analytics.
For professionals and aspiring data scientists, this revolution opens up exciting opportunities. However, it also raises important questions about ethical considerations, data privacy, and job security. In this blog, we will explore how LLMs are impacting the data science landscape and why enrolling in a data science course with placement in the United States can be a game-changer for your career in this AI-driven world.
The Rise of Generative AI in Data Science
Generative AI refers to artificial intelligence that can create content, including text, images, music, and even code. Unlike traditional machine learning models that require structured datasets and predefined rules, LLMs are trained on vast amounts of unstructured data, allowing them to generate human-like responses and insights.
With the integration of LLMs, data scientists now have powerful tools to automate various aspects of their work, including:
Data Preprocessing & Cleaning: LLMs can assist in handling missing data, normalizing datasets, and identifying inconsistencies without manual intervention.
Automated Feature Engineering: AI models can now suggest and generate features that improve predictive modeling.
Code Generation & Debugging: Tools like GitHub Copilot, powered by OpenAI, assist data scientists by writing Python, SQL, and R scripts with minimal effort.
Predictive Analytics: By analyzing large datasets, generative AI can identify trends and anomalies faster than traditional statistical methods.
Key Areas Where LLMs Are Impacting Data Science
1. Natural Language Processing (NLP) & Text Analytics
One of the most significant impacts of LLMs is in Natural Language Processing (NLP). Sentiment analysis, chatbots, and automated text summarization have seen major advancements due to AI’s ability to understand and generate human-like language. Businesses are now using AI-driven sentiment analysis to gauge customer opinions and optimize their strategies accordingly.
2. AI-Powered Data Visualization
Data visualization is an essential aspect of data science. LLMs are now capable of generating complex visualizations, making it easier for analysts to interpret vast amounts of data. AI-powered tools can automatically suggest the best visualization techniques based on the nature of the dataset.
3. Automating Data Science Workflows
Traditionally, data scientists had to spend significant time on data wrangling, model selection, and hyperparameter tuning. With generative AI, these processes are being automated. This allows professionals to focus on higher-level tasks like strategy and interpretation, rather than repetitive coding tasks.
4. Enhancing Decision-Making with AI
Generative AI models analyze large datasets in real time and provide actionable insights. Industries such as finance, healthcare, and e-commerce are leveraging AI-driven analytics for fraud detection, disease prediction, and personalized recommendations.
Ethical Considerations and Challenges
While LLMs offer incredible benefits, they also bring ethical challenges that cannot be ignored:
1. Bias in AI Models
AI models are only as good as the data they are trained on. If the training data contains biases, the AI-generated outputs will also reflect those biases. Ensuring fairness and inclusivity in AI models is a growing concern in the data science community.
2. Data Privacy and Security
As AI models process massive amounts of personal data, protecting sensitive information is crucial. Companies need to ensure compliance with data protection laws such as GDPR and CCPA.
3. Job Displacement vs. Job Augmentation
A common fear among data science professionals is that AI will replace jobs. However, rather than eliminating roles, AI is reshaping them. Future data scientists will need to focus more on interpreting AI-generated insights, validating model outputs, and working on strategic decision-making.
Future Trends: What’s Next for Data Scientists?
1. AI-Augmented Data Science Roles
Instead of replacing data scientists, AI is making their jobs more efficient. The demand for AI-literate professionals is increasing, and individuals who understand both traditional data science and AI-driven automation will have a competitive edge.
2. The Need for Ethical AI Experts
With growing concerns over bias and privacy, companies are hiring ethical AI experts to ensure responsible AI deployment. This creates new career opportunities for data science professionals who specialize in AI ethics.
3. Rise of No-Code AI & AutoML
AutoML (Automated Machine Learning) platforms are gaining popularity, allowing even non-programmers to build AI models. This trend emphasizes the need for data scientists to move beyond just coding and focus on problem-solving and strategic thinking.
Why Enroll in a Data Science Course with Placement in the United States?
As AI continues to reshape data science, professionals need to upskill and stay ahead of the curve. If you’re looking to build a successful career in this evolving field, enrolling in a data science course with placement in the United States is an excellent investment. Here’s why:
1. Hands-on Learning with Industry Tools
A structured course provides hands-on experience with tools like Python, TensorFlow, PyTorch, and AutoML platforms, ensuring you are industry-ready.
2. Exposure to Real-World Projects
Top programs offer real-world projects and case studies, helping you apply AI-driven techniques in practical scenarios.
3. Guaranteed Placement Assistance
A high-quality data science course comes with placement support, connecting you with top employers in AI-driven industries.
4. Networking with Industry Experts
The best data science programs in the U.S. have strong industry connections, providing mentorship and networking opportunities.
5. Understanding AI Ethics and Responsible AI Deployment
Given the rise of AI-related ethical challenges, the right course will educate you on responsible AI usage, helping you become a well-rounded data science professional.
Conclusion
Generative AI and LLMs are revolutionizing the world of data science, automating complex processes and enabling smarter decision-making. While challenges like bias and job displacement exist, the opportunities far outweigh the risks. By staying ahead of these trends and upskilling with a data science course with placement in the United States, you can future-proof your career in this ever-evolving industry.
0 notes
Text
Need for Reliability of LLM Outputs
The Reliability Imperative: Ensuring AI Systems Deliver Trustworthy and Consistent Results

TL;DR
Large Language Models (LLMs) have revolutionized natural language processing by enabling seamless interaction with unstructured text and integration into human workflows for content generation and decision-making. However, their reliability—defined as the ability to produce accurate, consistent, and instruction-aligned outputs—is critical for ensuring predictable performance in downstream systems.
Challenges such as hallucinations, bias, and variability between models (e.g., OpenAI vs. Claude) highlight the need for robust design approaches. Emphasizing platform-based models, grounding outputs in verified data, and enhancing modularity can improve reliability and foster user trust. Ultimately, LLMs must prioritize reliability to remain effective and avoid obsolescence in an increasingly demanding AI landscape.
Introduction

Photo by Nahrizul Kadri on Unsplash
Large Language Models (LLMs) represent a groundbreaking advancement in artificial intelligence, fundamentally altering how we interact with and process natural language. These systems have the capacity to decode complex, unstructured text, generate contextually accurate responses, and seamlessly engage with humans through natural language. This capability has created a monumental shift across industries, enabling applications that range from automated customer support to advanced scientific research. However, the increasing reliance on LLMs also brings to the forefront the critical challenge of reliability.
Reliability, in this context, refers to the ability of these systems to consistently produce outputs that are accurate, contextually appropriate, and aligned with the user’s intent. As LLMs become a cornerstone in workflows involving content generation, data analysis, and decision-making, their reliability determines the performance and trustworthiness of downstream systems. This article delves into the meaning of reliability in LLMs, the challenges of achieving it, examples of its implications, and potential paths forward for creating robust, reliable AI systems.
The Transformative Power of LLMs
Natural Language Understanding and Its Implications
At their core, LLMs excel in processing and generating human language, a feat that has traditionally been considered a hallmark of human cognition. This capability is not merely about understanding vocabulary or grammar; it extends to grasping subtle nuances, contextual relationships, and even the inferred intent behind a query. Consider a scenario where a marketing professional needs to generate creative ad copy. With an LLM, they can simply provide a description of their target audience and product, and the model will generate multiple variations of the advertisement, tailored to different tones or demographics. This capability drastically reduces time and effort while enhancing creativity.
Another example is the ability of LLMs to consume and interpret unstructured text data, such as emails, meeting transcripts, or legal documents. Unlike structured databases, which require predefined schemas and specific formats, unstructured text is inherently ambiguous and diverse. LLMs bridge this gap by transforming chaotic streams of text into structured insights that can be readily acted upon. This unlocks possibilities for improved decision-making, especially in fields like business intelligence, research, and customer service.
Integration Into Human Pipelines
The real potential of LLMs lies in their ability to seamlessly integrate into human workflows for both content generation and consumption. In content generation, LLMs are already revolutionizing industries by creating blog posts, reports, technical documentation, and even fiction. For instance, companies like OpenAI have enabled users to create entire websites or software prototypes simply by describing their requirements in natural language. On the other end, content consumption is equally transformed. LLMs can digest and summarize lengthy reports, extract actionable insights, or even translate complex technical jargon into plain language for non-experts.
These applications position LLMs not just as tools but as collaborators in human content pipelines. They enable humans to focus on higher-order tasks such as strategy and creativity while delegating repetitive or information-intensive tasks to AI.
The Critical Role of Reliability

Photo by Karim MANJRA on Unsplash
Defining Reliability in the Context of LLMs
The growing adoption of LLMs across diverse applications necessitates a deeper understanding of their reliability. A reliable LLM is one that consistently produces outputs that meet user expectations in terms of accuracy, relevance, and adherence to instructions. This is particularly crucial in high-stakes domains such as healthcare, law, or finance, where errors can lead to significant consequences. Reliability encompasses several interrelated aspects:
Consistency: Given the same input, the model should generate outputs that are logically and contextually similar. Variability in responses for identical queries undermines user trust and downstream system performance.
Instruction Adherence: A reliable model should follow user-provided instructions holistically, without omitting critical details or introducing irrelevant content.
Accuracy and Relevance: The information provided by the model must be factually correct and aligned with the user’s intent and context.
Robustness: The model must handle ambiguous or noisy inputs gracefully, producing responses that are as accurate and coherent as possible under challenging conditions.
Why Reliability Matters
The implications of reliability extend beyond individual interactions. In systems that use LLM outputs as inputs for further processing—such as decision-support systems or automated workflows—unreliable outputs can cause cascading failures. For instance, consider an LLM integrated into a diagnostic tool in healthcare. If the model inaccurately interprets symptoms and suggests an incorrect diagnosis, it could lead to improper treatment and jeopardize patient health.
Similarly, in content generation, unreliable outputs can propagate misinformation, introduce biases, or create content that fails to meet regulatory standards. These risks underscore the importance of ensuring that LLMs not only perform well under ideal conditions but also exhibit robustness in real-world applications.
Challenges in Achieving Reliability

Photo by Pritesh Sudra on Unsplash
Variability Across Models
One of the foremost challenges in ensuring reliability stems from the inherent variability across different LLMs. While versatility is a strength, it often comes at the cost of predictability. For example, OpenAI’s models are designed to be highly creative and adaptable, enabling them to handle diverse tasks effectively. However, this flexibility can result in outputs that deviate significantly from user instructions, even for similar inputs. In contrast, models like Claude have demonstrated a more consistent adherence to instructions, albeit at the expense of some versatility.
This variability is a manifestation of the No Free Lunch principle, which asserts that no single algorithm can perform optimally across all tasks. The trade-off between flexibility and predictability poses a critical challenge for developers, as they must balance the needs of diverse user bases with the demand for reliable outputs.
Hallucinations and Factual Accuracy
A significant obstacle to LLM reliability is their propensity for hallucinations, or the generation of outputs that are contextually plausible but factually incorrect. These errors arise because LLMs lack an inherent understanding of truth; instead, they rely on patterns and correlations in their training data. For instance, an LLM might confidently assert that a fictional character is a historical figure or fabricate scientific data if prompted with incomplete or misleading input.
In high-stakes domains, such as healthcare or law, hallucinations can have severe consequences. A model used in medical diagnosis might generate plausible but incorrect recommendations, potentially endangering lives. Addressing hallucinations requires strategies like grounding the model in real-time, verified data sources and designing systems to flag uncertain outputs for human review.
Bias in Training Data
Bias is another pervasive issue that undermines reliability. Since LLMs are trained on extensive datasets sourced from the internet, they inevitably reflect the biases present in those datasets. This can lead to outputs that reinforce stereotypes, exhibit cultural insensitivity, or prioritize dominant narratives over marginalized voices.
For example, a hiring tool powered by an LLM might inadvertently favor male candidates if its training data contains historical hiring patterns skewed by gender bias. Addressing such issues requires proactive efforts during training, including the curation of balanced datasets, bias mitigation techniques, and ongoing monitoring to ensure fairness in outputs.
Robustness to Ambiguity
Real-world inputs are often messy, ambiguous, or incomplete, yet reliable systems must still provide coherent and contextually appropriate responses. Achieving robustness in such scenarios is a major challenge. For instance, an ambiguous prompt like “Summarize the meeting” could refer to the most recent meeting in a series, a specific meeting mentioned earlier, or a general summary of all meetings to date. An LLM must not only generate a plausible response but also clarify ambiguity when necessary.
Robustness also involves handling edge cases, such as noisy inputs, rare linguistic patterns, or unconventional phrasing. Ensuring reliability under these conditions requires models that can generalize effectively while minimizing misinterpretation.
Lack of Interpretability
The “black-box” nature of LLMs poses a significant hurdle to reliability. Users often cannot understand why a model produces a specific output, making it challenging to identify and address errors. This lack of interpretability also complicates efforts to debug and improve models, as developers have limited visibility into the decision-making processes of the underlying neural networks.
Efforts to improve interpretability, such as attention visualization tools or explainable AI frameworks, are critical to enhancing reliability. Transparent models enable users to diagnose errors, provide feedback, and trust the system’s outputs more fully.
Scaling and Resource Constraints
Achieving reliability at scale presents additional challenges. As LLMs are deployed across diverse environments and user bases, they must handle an ever-growing variety of use cases, languages, and cultural contexts. Ensuring that models perform reliably under these conditions requires extensive computational resources for fine-tuning, monitoring, and continual updates.
Moreover, the computational demands of training and deploying large models create barriers for smaller organizations, potentially limiting the democratization of reliable AI systems. Addressing these constraints involves developing more efficient architectures, exploring modular systems, and fostering collaboration between researchers and industry.
The Challenge of Dynamic Contexts
Real-world environments are dynamic, with constantly evolving facts, norms, and expectations. A reliable LLM must adapt to these changes without requiring frequent retraining. For instance, a news summarization model must remain up-to-date with current events, while a customer service chatbot must incorporate updates to company policies in real time.
Dynamic grounding techniques, such as connecting LLMs to live databases or APIs, offer a potential solution but introduce additional complexities in system design. Maintaining reliability in such dynamic contexts demands careful integration of static training data with real-time updates.
Building More Reliable LLM Systems
Prioritizing Grounded Outputs
A critical step toward reliability is grounding LLM outputs in verified and up-to-date data sources. Rather than relying solely on the model’s static training data, developers can integrate external databases, APIs, or real-time information retrieval mechanisms. This ensures that responses remain accurate and contextually relevant. For instance, combining an LLM with a knowledge graph can help verify facts and provide citations, reducing the likelihood of hallucinations.
Applications like search engines or customer support bots can benefit immensely from such grounding. By providing links to reliable sources or contextual explanations for generated outputs, LLMs can increase user trust and facilitate transparency.
Emphasizing Modular System Design
Building modular LLMs can address the challenge of balancing versatility with task-specific reliability. Instead of deploying a monolithic model that attempts to handle every use case, developers can train specialized modules optimized for distinct tasks, such as translation, summarization, or sentiment analysis.
For example, OpenAI’s integration of plugins for tasks like browsing and code execution exemplifies how modularity can enhance both reliability and functionality. This approach allows core models to focus on language understanding while delegating domain-specific tasks to dedicated components.
Reinforcement Learning from Human Feedback (RLHF)
RLHF is a powerful method for aligning LLMs with user expectations and improving reliability. By collecting feedback on outputs and training the model to prioritize desirable behaviors, developers can refine performance iteratively. For instance, models like ChatGPT and Claude have used RLHF to improve instruction-following and mitigate biases.
A key challenge here is ensuring that feedback datasets are representative of diverse user needs and scenarios. Bias in feedback can inadvertently reinforce undesirable patterns, underscoring the importance of inclusive and well-curated training processes.
Implementing Robust Error Detection Mechanisms
Reliability improves significantly when LLMs can recognize their limitations. Designing systems to identify and flag uncertain or ambiguous outputs allows users to intervene and verify information before acting on it. Techniques such as confidence scoring, uncertainty estimation, and anomaly detection can enhance error detection.
For example, an LLM tasked with medical diagnosis might flag conditions where it lacks sufficient training data, prompting a human expert to review the recommendations. Similarly, content moderation models can use uncertainty markers to handle nuanced or controversial inputs cautiously.
Continuous Monitoring and Fine-Tuning
Post-deployment, LLMs require ongoing monitoring to maintain reliability. As language evolves and user expectations shift, periodic fine-tuning with fresh data is essential. This process involves analyzing model outputs for errors, retraining on edge cases, and addressing emerging biases or vulnerabilities.
Deploying user feedback loops is another effective strategy. Platforms that allow users to report problematic outputs or provide corrections can supply invaluable data for retraining. Over time, this iterative approach helps LLMs adapt to new contexts while maintaining consistent reliability.
Improving Explainability
Enhancing the interpretability of LLMs is crucial for building trust and accountability. By making the decision-making processes of models more transparent, developers can help users understand why specific outputs were generated. Techniques like attention visualization, saliency mapping, and rule-based summaries can make models less of a “black box.”
Explainability is particularly important in high-stakes domains. For instance, in legal or medical contexts, decision-makers need to justify their reliance on AI recommendations. Transparent systems can bridge the gap between machine-generated insights and human accountability.
Designing Ethical and Inclusive Systems
Reliability extends beyond technical performance to include fairness and inclusivity. Ensuring that LLMs treat all users equitably and avoid harmful stereotypes is a fundamental aspect of ethical AI design. Developers must scrutinize training datasets for biases and implement safeguards to prevent discriminatory outputs.
Techniques such as adversarial testing, bias correction algorithms, and diverse dataset sampling can help address these challenges. Additionally, engaging with communities impacted by AI systems ensures that their needs and concerns shape the design process.
Collaboration Between Stakeholders
Building reliable LLM systems is not solely the responsibility of AI developers. It requires collaboration among researchers, policymakers, industry leaders, and end-users. Standards for evaluating reliability, frameworks for auditing AI systems, and regulations for accountability can create an ecosystem that fosters trustworthy AI.
For example, initiatives like the Partnership on AI and the AI Incident Database promote shared learning and collective problem-solving to address reliability challenges. Such collaborations ensure that LLMs are designed and deployed responsibly across sectors.
Conclusion
Reliability is the cornerstone of the future of LLMs. As these systems become increasingly embedded in critical workflows, their ability to produce consistent, accurate, and contextually relevant outputs will determine their long-term viability. By embracing platform-based designs, grounding their models, and prioritizing transparency, LLM providers can ensure that their systems serve as trusted collaborators rather than unpredictable tools.
The stakes are high, but the path forward is clear: focus on reliability, or risk obsolescence in an ever-competitive landscape.
0 notes
Text
What Is the Relationship Between LLM Development Services and Big Data?

In recent years, the rise of Large Language Models (LLMs) has transformed the landscape of artificial intelligence (AI) and natural language processing (NLP). These sophisticated models are capable of understanding and generating human-like text, leading to applications in various sectors, including customer service, content creation, and even programming. However, the success and functionality of LLMs are intricately tied to the vast and ever-growing field of big data. This blog post delves into the relationship between LLM development services and big data, exploring how they interconnect, the challenges they face, and their implications for the future of AI.
Understanding LLMs and Big Data
What Are Large Language Models?
Large Language Models are a type of AI model designed to process and generate human-like text based on the input they receive. They are trained on massive datasets consisting of diverse text from the internet, books, articles, and other sources, enabling them to understand context, grammar, and semantics. Notable examples include OpenAI's GPT-3, Google's BERT, and Facebook's RoBERTa. These models have achieved remarkable performance in tasks like language translation, text summarization, and sentiment analysis, making them valuable tools for businesses and developers alike.
What Is Big Data?
Big data refers to the vast volumes of structured and unstructured data generated every second across various platforms. This data can come from numerous sources, including social media, sensors, transactions, and user interactions. The primary characteristics of big data are often described by the "Three Vs": Volume, Velocity, and Variety. Organizations harness big data to gain insights, enhance decision-making, and drive innovation through advanced analytics.
The Interconnection Between LLM Development Services and Big Data
1. Data as the Foundation for LLMs
The development of LLMs relies heavily on the availability of large datasets. Training these models requires immense amounts of text data to capture the nuances of human language. Without sufficient data, LLMs cannot learn effectively, resulting in models that may be biased, inaccurate, or unable to generalize well to real-world applications. Here are some key aspects of this relationship:
Data Collection: LLM development services often involve gathering vast amounts of text data from various sources. This includes web scraping, utilizing existing datasets, and curating domain-specific data. The quality and diversity of the training data directly impact the model's performance.
Data Preprocessing: Big data often includes noise and inconsistencies that can hinder LLM training. Preprocessing steps such as cleaning, tokenization, and normalization are essential to ensure the data is in a suitable format for model training.
Feedback Loops: Post-deployment, LLMs can continuously improve through user interactions and feedback. Analyzing user-generated data allows developers to refine models, address biases, and adapt to changing language patterns.
2. Enhancing Model Performance
The interplay between LLMs and big data goes beyond mere data usage; it significantly enhances the models' performance:
Transfer Learning: LLMs often leverage transfer learning, where a pre-trained model is fine-tuned on a smaller, domain-specific dataset. Access to big data enables the pre-training phase to be more robust, resulting in models that perform well in specialized tasks with limited additional data.
Continual Learning: In an ever-changing world, the ability of LLMs to learn continuously from new data is crucial. By utilizing big data, developers can implement algorithms that allow models to adapt to new information without needing complete retraining.
Real-Time Insights: Big data technologies enable the processing of real-time information, allowing LLMs to provide timely and relevant responses. For instance, chatbots can utilize live data feeds to answer customer inquiries more effectively.
3. Challenges in Integrating LLMs and Big Data
While the relationship between LLMs and big data is symbiotic, it also presents several challenges that developers must navigate:
Data Privacy and Security: Handling vast amounts of data raises concerns about privacy and security. LLM development services must ensure compliance with data protection regulations like GDPR and CCPA while collecting and utilizing data.
Bias and Fairness: The data used to train LLMs may contain biases reflecting societal inequalities. If not addressed, these biases can lead to unfair outcomes in applications. Developers must implement strategies to identify and mitigate bias in both data and model outputs.
Resource Intensive: Training LLMs on big data requires significant computational resources, making it costly and time-consuming. Organizations need to invest in infrastructure and cloud services to manage the demands of large-scale training.
The Future of LLM Development Services and Big Data
As technology evolves, the relationship between LLM development services and big data is expected to deepen:
1. Enhanced Data Curation Techniques
With the growth of big data, effective data curation will become increasingly important. Advanced algorithms for data selection and cleaning will help ensure that the data used for LLM training is high-quality, diverse, and representative. This will lead to more robust models capable of understanding and generating language in a more nuanced manner.
2. Ethical AI Practices
As awareness of ethical AI practices grows, developers will prioritize transparency and fairness in LLM training. By leveraging big data, organizations can better understand the social implications of their models and work towards minimizing bias and promoting inclusivity.
3. Collaborative Learning Environments
The future may see the development of collaborative learning environments where multiple LLMs can share knowledge and insights derived from big data. This approach could enhance the models' understanding of language by pooling resources and diversifying the learning process.
Conclusion
The relationship between LLM development services and big data is integral to the advancement of artificial intelligence and natural language processing. As LLMs continue to evolve and find new applications across industries, the reliance on big data will only increase. By understanding this relationship, developers can create more effective, ethical, and robust models that enhance human-computer interaction and drive innovation in various sectors.
In conclusion, the synergy between LLMs and big data presents both challenges and opportunities for businesses looking to leverage AI technology. By addressing these challenges head-on and harnessing the potential of big data, organizations can unlock the full power of large language models and pave the way for a more intelligent future.
0 notes
Text
Google Gemini Vs ChatGPT: All That You Need To Know

In the ever-evolving world of Artificial Intelligence (AI), large language models (LLMs) are taking center stage. These powerful tools can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. Two leading contenders in this space are Google Gemini and OpenAI’s ChatGPT. This blog will delve into everything you need to know about these AI giants, helping you decide which one might be the better fit for your needs.
What is Google Gemini?
Formerly known as Bard, Google Gemini is a factual language model from Google AI, trained on a massive dataset of text and code. It can generate different creative text formats, answer your questions in an informative way, and translate languages.
What are the Pros of Google Gemini?
Strong Factual Accuracy: Backed by Google Search, Gemini excels at providing accurate and up-to-date information.
Enhanced User Experience: Offers a user-friendly interface with the ability to include visuals and website links within responses.
Integration with Google Workspace: Seamless integration with other Google tools like Gmail and Docs can streamline your workflow.
Focus on Readability: Gemini prioritizes clear and concise sentence structure, making its responses easy to understand.
What are the Cons of Google Gemini?
Limited Creative Freedom: While Gemini can generate creative text formats, it may not offer the same level of flexibility and experimentation as some competitors.
Newer Technology: Compared to ChatGPT, Gemini is a relatively new player in the LLM field, which may translate to fewer available features or a steeper learning curve.
Free Version Limitations: The free tier of Gemini has some limitations compared to the paid version.
What is ChatGPT?
ChatGPT is a large language model developed by OpenAI. Similar to Gemini, it can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
What are the Pros of OpenAI ChatGPT?
More Established: With a longer development history, ChatGPT boasts a wider range of features and a larger user base.
Focus on Conversational Tone: ChatGPT excels at mimicking human conversation, making it ideal for chatbots or creating dialogue-driven content.
API and Fine-Tuning Options: OpenAI offers advanced functionalities like APIs and fine-tuning options, catering to developers and those seeking more customization.
What are the Cons of OpenAI ChatGPT?
Factual Accuracy Concerns: Some users have reported occasional factual inconsistencies in ChatGPT’s responses.
Limited User Interface: ChatGPT primarily focuses on text-based interaction, lacking the visual elements and broader integration features of Gemini.
Pricing Structure: OpenAI offers different pricing tiers, with some functionalities requiring paid subscriptions.
Google Gemini Vs ChatGPT: The Key Differences
Here’s a quick comparison to help you choose:
FeatureGoogle Gemini OpenAI ChatGPT Focus Factual accuracy, readability, user experience conversational tone, established technology IntegrationIntegrates with Google Workspace tools offers API and fine-tuning options Visuals Can include images and website linksPrimarily text-based Pricing Free tier with limitations, paid tiers available free tier with limitations, paid tiers available
drive_spreadsheetExport to Sheets
Frequently Asked Questions About Google Gemini Vs OpenAI ChatGPT
Google Gemini vs ChatGPT: Is Google Gemini better than ChatGPT?
There’s no single “better” option. The ideal choice depends on your specific needs. If you prioritize factual accuracy, user experience, and integration with Google tools, Gemini might be a better fit. However, if you value a conversational tone, established technology, or require API access for customization, ChatGPT could be the way to go.
Can Google Gemini generate images?
In the past, Gemini could generate images, but this feature is currently paused.
Is there a Google Gemini app?
Currently, there’s no dedicated Google Gemini app. You can access Gemini through the Google AI website or through integrations with other Google products.
What is the Best Way to Learn ChatGPT and Other AI Tools?
Several online resources can help you learn about ChatGPT and other AI tools. Consider enrolling in an AI online course or pursuing a Masters in AI to gain a deeper understanding of this rapidly evolving field. Even introductory courses can equip you with the knowledge and skills to leverage these powerful tools effectively.
What is the Best Way to Learn ChatGPT and Other AI Tools?
If you are also looking forward to learning ChatGPT, Google Gemini, and other AI tools, you can join Be10x’s AI Workshop. You will learn to create well-structured and specific ChatGPT or AI tool prompts, create presentations in under 10 seconds, and become the top 1% of Excel users. You will learn AI tools for social media platforms such as Linkedin. Further, if you register before, you will get a bonus of Rs.10,500.
Learn ChatGPT with Be10x ai online course at just Rs.9.
0 notes
Text
Bard vs ChatGPT: A Head-to-Head Comparison of LLM

In the ever-evolving world of Artificial Intelligence (AI), large language models (LLMs) like Bard and ChatGPT are taking center stage. These AI chatbots can generate human-quality text, translate languages, write different kinds of creative content, and answer your questions in an informative way. But with two such powerful tools available, which one reigns supreme? This blog dives deep into the world of Bard vs. ChatGPT, exploring their strengths, weaknesses, and what makes them unique.
Understanding Large Language Models (LLMs):
Before diving into the specifics, let's establish a common ground. Both Bard and ChatGPT are LLMs, a type of AI trained on massive amounts of text data. This data allows them to recognize patterns in language and generate similar text formats, translating languages, writing different kinds of creative content, and answering your questions in an informative way. However, the underlying technology and training data differ between Bard and ChatGPT, leading to some key distinctions.
Bard: Championing Research and Factual Accuracy
Bard, formerly known as LaMDA, is an LLM developed by Google AI. Bard leverages Google's massive dataset of text and code, including books, articles, code repositories, and web crawl data. This focus on factual information positions Bard as a strong choice for research tasks.
Here are some of Bard's strengths:
Research and Factual Accuracy: Bard excels at tasks requiring factual accuracy and information retrieval.
Focus on Real-Time Information: Bard can access and process information from the real world through Google Search, keeping responses current.
Transparency and Source Citation: Bard often cites sources for its information, promoting transparency and trust in its responses.
Free Access: Bard offers a free tier with a good range of capabilities.
However, Bard might not be the best choice for all situations. Here are some areas where ChatGPT might have an edge:
Creative Text Generation: While Bard can handle creative writing, ChatGPT might be considered slightly more imaginative for some users.
Accessibility of Advanced Features: Some of Bard's most advanced features are currently in limited access.
ChatGPT: The Creative Powerhouse
ChatGPT, developed by OpenAI, is another leading LLM known for its creative text generation capabilities. Trained on a massive dataset of text and code, ChatGPT excels at crafting different creative text formats of text content.
Here are some of ChatGPT's strengths:
Creative Text Generation: ChatGPT is known for its ability to generate different creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc., in a more whimsical and artistic way.
Accessibility of Advanced Features: Many of ChatGPT's advanced features are readily available in its paid tiers.
However, ChatGPT also has some limitations:
Factual Accuracy: While ChatGPT can be informative, it may not always prioritize factual accuracy as highly as Bard. Double-checking the information it provides is recommended.
Limited Free Tier: The free tier of ChatGPT offers restricted functionality.
Choosing Between Bard and ChatGPT
Ultimately, the best LLM for you depends on your specific needs. Here's a quick breakdown to help you decide:
Choose Bard if: Research and factual accuracy are your top priorities. You want access to a free tier with a good range of features, and you appreciate transparency with source citation.
Choose ChatGPT if: Creative text generation is your main focus. You don't mind paying for a subscription to access advanced features.
Beyond Bard vs. ChatGPT: Exploring Other Options
The world of LLMs is constantly evolving, with new players emerging all the time. Here are some additional options to consider:
GPT-3: The predecessor to ChatGPT, GPT-3 is still a powerful LLM available through various APIs and integrations.
Jurassic-1 Jumbo: This LLM offers a focus on factual language and safety, making it a good choice for tasks requiring high accuracy.
Further Exploring AI-Language Models:
If you're interested in learning more about AI chatbots and how to leverage their capabilities, here are some resources:
Bard Documentation: [Bard documentation ON Google AI [invalid URL removed]]
OpenAI API: [OpenAI API beta.openai.com]
ChatGPT Course: (While there is no official ChatGPT course offered by OpenAI, there might be third-party courses available online that explore using ChatGPT. Be cautious when selecting any such courses.)
Be10x offers a transformative learning experience through the ChatGPT course, AI tools, and expert guidance. Get ready to explore AI-powered tools and productivity hack, excel in IT tasks under 10 minutes, and master the art of creating presentations in under 10 seconds.
Become a highly paid Prompt Engineer, open a world of opportunities without the need for prior technical or AI knowledge. With Be10X, save up to 2 hours every day, supercharge your skills, and elevate your salary up to 3x.
Get enrolled in Be10x’s ChatGPT course.
0 notes