#Llama 3.3
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
LLaMA 3.3 70B Multilingual AI Model Redefines Performance

Overview Llama 3.3 70B
Text-only apps run better with Llama 3.3, a 70B instruction-tuned model, compared with Llama 3.1 and 3.2. In certain circumstances, Llama 3.3 70B matches Llama 3.1 405B. Meta offers a cutting-edge 70B model that competes with Llama 3.1 405B.
Pretrained and instruction-adjusted generative model Meta Llama 3.3 multilingual large language model (LLM) is used in 70B. The Llama 3.3 70B instruction customisable text only model outperforms several open source and closed chat models on frequently used industry benchmarks and is designed for multilingual debate.
Llama 3.3 supports which languages?
Sources say Llama 3.3 70B supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
A pretrained and instruction-tuned generative model, the Meta Llama 3.3 70B multilingual big language model optimises multilingual conversation use cases across supported languages. Even though the model was trained on many languages, these eight fulfil safety and helpfulness criteria.
Developers should not use Llama 3.3 70B to communicate in unsupported languages without first restricting and fine-tuning the system. The model cannot be used in languages other than these eight without these precautions. Developers can adapt Llama 3.3 for additional languages if they follow the Acceptable Use Policy and Llama 3.3 Community License and ensure safe use.
New capabilities
This edition adds a bigger context window, multilingual inputs and outputs, and developer cooperation with third-party tools. Building with these new capabilities requires special considerations in addition to the suggested procedures for all generative AI use cases.
Utilising tools
Developers integrate the LLM with their preferred tools and services, like in traditional software development. To understand the safety and security risks of utilising this feature, they should create a use case policy and assess the dependability of third-party services. The Responsible Use Guide provides safe third-party protection implementation tips.
Speaking many languages
Llama may create text in languages different than safety and usefulness performance standards. Developers should not use this model to communicate in non-supported languages without first restricting and fine-tuning the system, per their rules and the Responsible Use Guide.
Reason for Use
Specific Use Cases Llama 3.3 70B enables multilingual commercial and research use. Pretrained models can be changed for many natural language producing jobs, however instruction customised text only models are for assistant-like conversation. The Llama 3.3 model also lets you use its outputs to improve distillation and synthetic data models. These use cases are allowed by Llama 3.3 Community License.
Beyond Use in a way that violates laws or standards, especially trade compliance. Any other use that violates the Llama 3.3 Community License and Acceptable Use Policy. Use in languages other than those this model card supports.
Note: Llama 3.3 70B has been trained on more than eight languages. The Acceptable Use Policy and Llama 3.3 Community License allow developers to alter Llama 3.3 models for languages other than the eight supported languages. They must ensure that Llama 3.3 is used appropriately and securely in other languages.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#Llama 3.3 70B#Llama 3.3#Llama 3.1 70B
0 notes
Text
The hottest AI models, what they do, and how to use them
#ai#grok 3#o3 mini#deep research#le chat#operator#Gemini 2.0 Pro Experimental#deepseek r1#Llama 3.3 70B#sora#open ai#meta#gemini#anthropic#x.AI#Cohere
0 notes
Text
Sider.ai - Sprawdź ograniczenia i funkcje darmowego planu Sider.ai (grudzień 2024)
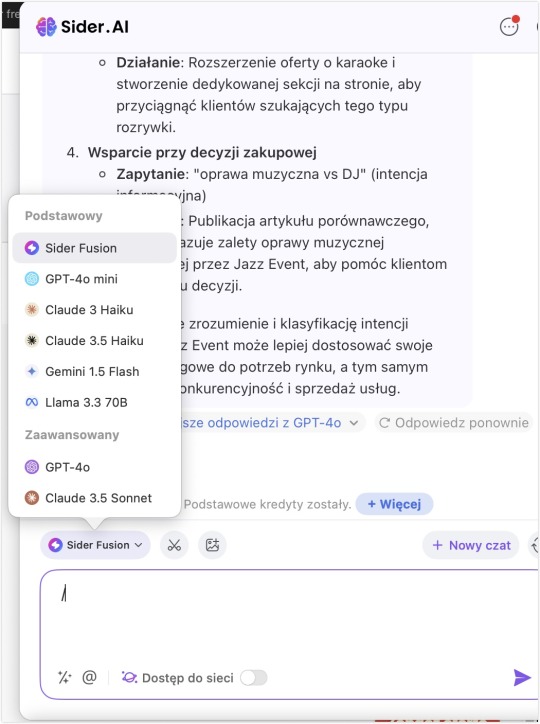
Ile kredytów podstawowych mają obecnie darmowi użytkownicy Sider.ai?
Darmowy użytkownik Sider.ai ma do wykorzystania:
30 Podstawowych Kredytów*/Dzień
10 Zapytania do Obrazów Łącznie
10 PDF-ów Łącznie jako upload, 200 stron/PDF (wtyczka Chrome)
* Podstawowe kredyty można użyć w konwersacjach z tymi modelami:
Sider Fusion
GPT-4o mini
Claude 3 Haiku
Claude 3.5 Haiku
Gemini 1.5 Flash
Llama 3.3 70B
Darmowa wersja Sider.ai blokuje:
blokuje dostęp do internetu podczas zapytania (możliwa tylko interakcja z zaznaczonym tekstem, wgranym PDF, Obrazkiem)
blokuje rozmowy z najnowszymi wersjami czatów LLMs typu premium (np. CzatGPT-4o, ChatGPT-o1).
Zalety Sider.ai nawet w darmowej wersji (free plan):
dostęp do różnych modeli LLMs bez konieczności podawania własnego api
obecność Sidera.ai w różnych systemach jako aplikacja i rozszerzenie: - Rozszerzenia przegladarki Safari, Edge, Chrome - Aplikacig iOS - Aplikacia Android - Aplikacia na Mac - Apikacja na Windows
Możliwość konfigurowania własnych Monitów (gotowych zapytań do wyzwalania jako skróty na czacie (/)
Możliwość wywoływania konkretnego modelu LLM na czacie (@)
„Mankamentem jest brak możliwości synchronizacji historii czatów między platformami i brak możliwości eksportu treści czatu do pliku. Dostępna jest opcja wygenerowania odnośnika url kierującego do zapisu czatu"
Źródła i strony www:
„Używasz Sider.ai? W komentarzu podziel się swoim własnym ulubionym Monitem do konfiguracji i wywołania w Sider.ai"
#jazzy_content#free ai tool#free plans#Sider.ai#Sider free plan#Sider ai on mac#Sider.ai Chrome#Sider Fusion#GPT-4o mini#Claude 3 Haiku#Claude 3.5 Haiku#Gemini 1.5 Flash#Llama 3.3 70B#Funkcje Sider ai w darmowym planie#Zalety Sider.ai
1 note
·
View note
Text

Discover how Llama 3.3 redefines AI with its groundbreaking performance, outpacing GPT-4 in speed and accuracy. This new AI model delivers faster, more efficient responses, making it a must-try for developers and tech enthusiasts. See how it stacks up and why it's quickly becoming the go-to choice for next-gen artificial intelligence.
0 notes
Text
🟣 Latest AI News Roundup 🏆 Gemini 2.0 🎁 Free access to AI services
1️⃣ Gemini 2.0 2️⃣ ChatGPT Vision 3️⃣ Meta Llama 3.3 70B 4️⃣ Midjourney Patchwork 5️⃣ Google Quantum Willow 6️⃣ Devin is now available 7️⃣ Phi-4 Microsoft’s Small LLM 8️⃣ Sora, text-to-video model
AINews #TechNews
5 notes
·
View notes
Text
Llama-3.3-70B-Instruct
https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
2 notes
·
View notes
Text




From the last picture:
1st plant – Charlock Mustard This plant is native to the Mediterranean region and has naturalized in temperate regions worldwide. Charlock reaches an average of 3.3 feet and is an invasive species. The plant is closely related to white mustard; the seeds are used to make the condiment mustard.
2nd plant – Colorado Blue Spruce This tree was first discovered in Colorado on top of Pikes Peak in 1862. It grows relatively slowly; it is long-lived and may reach ages of 600-800 years. The tree has medicinal purposes; two Native American tribes, Keres and Navajo, use an infusion of blue spruce needles for curing colds, stomach problems, and rheumatic pains.
3rd plant – Big Trefoil Big Trefoil is known as an attractant for elk and deer. It thrives in soils with high acidity, aluminum content, or waterlogged. This plant may be used for honey production and land reclamation.
Attendance:
“From root to summit, Cerro Rico is riddled with silver mines. According to tradition, its secret was discovered by a poor local man.” – page # 49
I found it interesting how the discovery of such precious metal could be related to an anecdote as simple as a lost llama. Thanks to this farmer, the commerce of metals like gold and silver drastically boosts hundreds of countries' economies.
3 notes
·
View notes
Text
DeepSeek V3-0324 beats rival AI models in open-source first
DeepSeek V3-0324 has become the highest-scoring non-reasoning model on the Artificial Analysis Intelligence Index in a landmark achievement for open-source AI. The new model advanced seven points in the benchmark to surpass proprietary counterparts such as Google’s Gemini 2.0 Pro, Anthropic’s Claude 3.7 Sonnet, and Meta’s Llama 3.3 70B. While V3-0324 trails behind reasoning models, including…
0 notes
Text
Llama 4: Smarter, Faster, More Efficient Than Ever

Llama 4's earliest models Available today in Azure AI Foundry and Azure Databricks, provide personalised multimodal experiences. Meta designed these models to elegantly merge text and visual tokens into one model backbone. This innovative technique allows programmers employ Llama 4 models in applications with massive amounts of unlabelled text, picture, and video data, setting a new standard in AI development.
Superb intelligence Unmatched speed and efficiency
The most accessible and scalable Llama generation is here. Unique efficiency, step performance changes, extended context windows, mixture-of-experts models, native multimodality. All in easy-to-use sizes specific to your needs.
Most recent designs
Models are geared for easy deployment, cost-effectiveness, and billion-user performance scalability.
Llama 4 Scout
Meta claims Llama 4 Scout, which fits on one H100 GPU, is more powerful than Llama 3 and among the greatest multimodal models. The allowed context length increases from 128K in Llama 3 to an industry-leading 10 million tokens. This opens up new possibilities like multi-document summarisation, parsing big user activity for specialised activities, and reasoning across vast codebases.
Reasoning, personalisation, and summarisation are targeted. Its fast size and extensive context make it ideal for compressing or analysing huge data. It can summarise extensive inputs, modify replies using user-specific data (without losing earlier information), and reason across enormous knowledge stores.
Maverick Llama 4
Industry-leading natively multimodal picture and text comprehension model with low cost, quick responses, and revolutionary intelligence. Llama 4 Maverick, a general-purpose LLM with 17 billion active parameters, 128 experts, and 400 billion total parameters, is cheaper than Llama 3.3 70B. Maverick excels at picture and text comprehension in 12 languages, enabling the construction of multilingual AI systems. Maverick excels at visual comprehension and creative writing, making it ideal for general assistant and chat apps. Developers get fast, cutting-edge intelligence tuned for response quality and tone.
Optimised conversations that require excellent responses are targeted. Meta optimised 4 Maverick for talking. Consider Meta Llama 4's core conversation model a multilingual, multimodal ChatGPT-like helper.
Interactive apps benefit from it:
Customer service bots must understand uploaded photographs.
Artificially intelligent content creators who speak several languages.
Employee enterprise assistants that manage rich media input and answer questions.
Maverick can help companies construct exceptional AI assistants who can connect with a global user base naturally and politely and use visual context when needed.
Llama 4 Behemoth Preview
A preview of the Llama 4 teacher model used to distil Scout and Maverick.
Features
Scout, Maverick, and Llama 4 Behemoth have class-leading characteristics.
Naturally Multimodal: All Llama 4 models employ early fusion to pre-train the model with large amounts of unlabelled text and vision tokens, a step shift in intelligence from separate, frozen multimodal weights.
The sector's longest context duration, Llama 4 Scout supports up to 10M tokens, expanding memory, personalisation, and multi-modal apps.
Best in class in image grounding, Llama 4 can match user requests with relevant visual concepts and relate model reactions to picture locations.
Write in several languages: Llama 4 was pre-trained and fine-tuned for unmatched text understanding across 12 languages to support global development and deployment.
Benchmark
Meta tested model performance on standard benchmarks across several languages for coding, reasoning, knowledge, vision understanding, multilinguality, and extended context.
#technology#technews#govindhtech#news#technologynews#Llama 4#AI development#AI#artificial intelligence#Llama 4 Scout#Llama 4 maverick
0 notes
Quote
研究チームによると、AIがユーザーの意見を優先してしまうこの動作は、肯定的なフィードバックを最大化するためのモデルのトレーニングを反映している可能性があるとのこと。AI関連企業では、ユーザーの意見に同意するとユーザーの反応が向上する傾向にあることをAIモデルに学習させているそうです。 そこで研究チームは、「協調性と精度のバランスをとるトレーニング方法の改善」「ユーザーの意見に同調する行動を検出するためのより良い評価フレームワークの開発」「自立性を保ちつつも有用性を維持できるAIシステムの開発」「重要なアプリケーションにおける安全対策の実装」の必要性を強調しました。また、研究チームは「今回の研究から得られた結果は、ユーザーの印象を良くするためのアライメントよりも精度を優先しなければならないハイステークスアプリケーション向けの信頼性の高いAIシステムを開発するための基礎を築くものです」と語りました。 この記事のタイトルとURLをコピーする ・関連記事 Llama 3.3 70BベースでGPT-4o超えの満足度を達成するAIをPerplexityが発表 - GIGAZINE 生成AIツールで画像や実験データを簡単に捏造できるようになり科学研究が脅かされている - GIGAZINE AIを使いこなせるかどうかは「能力次第」、AIが上位10%のエリート科学者の成果を81%増やしたとの研究結果 - GIGAZINE 人々はAIが生成した物語に本能的な嫌悪感を持っており人が書いた物語より没入できないことが判明 - GIGAZINE 人間に代わってタスクを行う「AIエージェント」の台頭でクリスマスのプレゼント選びまでAI任せになる未来が到来するかもしれない - GIGAZINE AIに「もっといいコードを書いて」と��り返し要求するとコードの実行速度は向上するがバグが増えるという報告 - GIGAZINE ・関連コンテンツ 「感情を理解する能力」がIQと同じくらい学業成績にとって重要という研究結果 AIに自力で解決しようとするのではなく「正しいタイミングで外部ツールを頼る」方法を学ばせることでパフォーマンスが約30%上昇したという研究結果 AIの知能が急激に低下してしまう「ドリフト」問題はなぜ発生するのか? 学生の17%が課題または試験にChatGPTを使っていると回答 OpenAIがChatGPTにオンライン上の情報を収集させる「Deep research」機能を搭載すると発表 「無知の知」が科学研究で証明される 科学を信頼している人ほど「疑似科学を信じてしまいやすい」ことが判明、一体どうすれば偽情報から身を守れるのか? AlibabaのQwenチームがOpenAI o1に匹敵する推論モデル「QwQ-32B-Preview」を発表、数学や科学的推論において優れた性能を発揮
「AIは人間にごまをする」という研究結果、特にGemini 1.5 Proではその傾向が顕著 - GIGAZINE
0 notes
Text
Duck.ai - czatuj z o3-mini bez ograniczeń i zachowaj prywatność
"Duck.ai oferuje użytkownikowi możliwość wyboru modelu, z którym chce czatować - obecnie są to GPT-4o mini, Llama 3.3 70B, Claude 3 Haiku, o3-mini oraz Mistral Small 3.
To, co różni Duck.ai od Perplexity to fakt, że wszystkie modele są darmowe i można z nimi czatować do woli. Ponadto - zgodnie z deklaracjami samego DuckDuckGo - firma nie gromadzi danych osób czatujących z chatbotami. Historia czatów ("Recent chats") jest przechowywana lokalnie na urządzeniu użytkownika i czyszczona automatycznie po 30 dniach."
https://spidersweb.pl/2025/03/duckduckgo-duck-ai-chatboty.html#:~:text=Duck.ai%20oferuje,po%2030%20dniach.
0 notes
Text
Trying 70B Model
Just for fun I tried Llama 3.3 70B model on a 32GB Mac Mini M2 Pro, and the results are what you'd expect. You can load the model, but the performance is so poor–there is actually no point to running it.
1 note
·
View note
Text
Avrupa’dan OpenAI ve Google’a rakip yeni yapay zeka!
Mistral Small 3 yapay zeka modeli tanıtıldı. Mini model yapay zekalara karşı geliştirilen bu araç neler vadediyor? Avrupa merkezli yapay zeka şirketi Mistral AI, 24 milyar parametreli yeni modeli Mistral Small 3’ü tanıttı. Yapay zeka dünyasında dikkatleri üzerine çeken yapay zeka, MMLU-Pro kıyaslamasında Llama 3.3 70B ve Owen 32B gibi büyük modellere yakın performans göstererek merak…
0 notes
Text
Deep Cogito open LLMs use IDA to outperform same size models
New Post has been published on https://thedigitalinsider.com/deep-cogito-open-llms-use-ida-to-outperform-same-size-models/
Deep Cogito open LLMs use IDA to outperform same size models
Deep Cogito has released several open large language models (LLMs) that outperform competitors and claim to represent a step towards achieving general superintelligence.
The San Francisco-based company, which states its mission is “building general superintelligence,” has launched preview versions of LLMs in 3B, 8B, 14B, 32B, and 70B parameter sizes. Deep Cogito asserts that “each model outperforms the best available open models of the same size, including counterparts from LLAMA, DeepSeek, and Qwen, across most standard benchmarks”.
Impressively, the 70B model from Deep Cogito even surpasses the performance of the recently released Llama 4 109B Mixture-of-Experts (MoE) model.
Iterated Distillation and Amplification (IDA)
Central to this release is a novel training methodology called Iterated Distillation and Amplification (IDA).
Deep Cogito describes IDA as “a scalable and efficient alignment strategy for general superintelligence using iterative self-improvement”. This technique aims to overcome the inherent limitations of current LLM training paradigms, where model intelligence is often capped by the capabilities of larger “overseer” models or human curators.
The IDA process involves two key steps iterated repeatedly:
Amplification: Using more computation to enable the model to derive better solutions or capabilities, akin to advanced reasoning techniques.
Distillation: Internalising these amplified capabilities back into the model’s parameters.
Deep Cogito says this creates a “positive feedback loop” where model intelligence scales more directly with computational resources and the efficiency of the IDA process, rather than being strictly bounded by overseer intelligence.
“When we study superintelligent systems,” the research notes, referencing successes like AlphaGo, “we find two key ingredients enabled this breakthrough: Advanced Reasoning and Iterative Self-Improvement”. IDA is presented as a way to integrate both into LLM training.
Deep Cogito claims IDA is efficient, stating the new models were developed by a small team in approximately 75 days. They also highlight IDA’s potential scalability compared to methods like Reinforcement Learning from Human Feedback (RLHF) or standard distillation from larger models.
As evidence, the company points to their 70B model outperforming Llama 3.3 70B (distilled from a 405B model) and Llama 4 Scout 109B (distilled from a 2T parameter model).
Capabilities and performance of Deep Cogito models
The newly released Cogito models – based on Llama and Qwen checkpoints – are optimised for coding, function calling, and agentic use cases.
A key feature is their dual functionality: “Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models),” similar to capabilities seen in models like Claude 3.5. However, Deep Cogito notes they “have not optimised for very long reasoning chains,” citing user preference for faster answers and the efficiency of distilling shorter chains.
Extensive benchmark results are provided, comparing Cogito models against size-equivalent state-of-the-art open models in both direct (standard) and reasoning modes.
Across various benchmarks (MMLU, MMLU-Pro, ARC, GSM8K, MATH, etc.) and model sizes (3B, 8B, 14B, 32B, 70B,) the Cogito models generally show significant performance gains over counterparts like Llama 3.1/3.2/3.3 and Qwen 2.5, particularly in reasoning mode.
For instance, the Cogito 70B model achieves 91.73% on MMLU in standard mode (+6.40% vs Llama 3.3 70B) and 91.00% in thinking mode (+4.40% vs Deepseek R1 Distill 70B). Livebench scores also show improvements.
Here are benchmarks of 14B models for a medium-sized comparison:
While acknowledging benchmarks don’t fully capture real-world utility, Deep Cogito expresses confidence in practical performance.
This release is labelled a preview, with Deep Cogito stating they are “still in the early stages of this scaling curve”. They plan to release improved checkpoints for the current sizes and introduce larger MoE models (109B, 400B, 671B) “in the coming weeks / months”. All future models will also be open-source.
(Photo by Pietro Mattia)
See also: Alibaba Cloud targets global AI growth with new models and tools
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
#AGI#ai#ai & big data expo#Alibaba#alibaba cloud#amp#arc#Art#Artificial Intelligence#automation#benchmark#benchmarks#Big Data#Building#california#Capture#claude#claude 3#claude 3.5#Cloud#coding#Companies#comparison#comprehensive#computation#conference#cyber#cyber security#data#deep cogito
0 notes
Link
Large language models (LLMs) like OpenAI’s GPT and Meta’s LLaMA have significantly advanced natural language understanding and text generation. However, these advancements come with substantial computational and storage requirements, making it chall #AI #ML #Automation
0 notes