#Local LLMs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Effective GPU Use!
How to Run an LLM as Powerful as DeepSeek R1 Locally with LM Studio With Just 24 GB VRAM

1 note
·
View note
Text
Someone asked me about that "Utility Engineering" AI safety paper a few days ago and I impulse-deleted the ask because I didn't feel like answering it at the time, but more recently I got nerd-sniped and ended up reproducing/extending the paper, ending up pretty skeptical of it.
If you're curious, here's the resulting effortpost
#ai tag#virtually every inflammatory AI safety paper about LLMs i read is like this#not every one! but a lot of the ones that people hear about#the anthropic-redwood alignment faking paper was *almost* the rare exception in that it was very very methodologically careful...#...*except* that the classifier prompt used to produce ~all of their numerical data was garbage#after reproducing that thing locally i don't trust anything that comes out of it lol#(in that case i have notified the authors and have been told that they share my concerns to some extent)#(and are working on some sort of improvement for use in future [?] work)#(that is of course not even touching the broader question wrt that alignment faking paper)#(namely: is it *bad* that Certified Really Nice Guy Claude 3 Opus might resist its creators if they tried to do something cartoonishly evil
102 notes
·
View notes
Text
start new trend of calling things what they are:
LLM, machine learning, perceptrons, linear algebra, statistical model
automaton, automation, NPC, machine, computer.




#i know neural nets run on computers technically#but come on how often do you run an LLM on your local desktop computer without cloud computing?#cugzarui reply
67K notes
·
View notes
Text
Self-Hosting LLMs with Docker and Proxmox: How to Run Your Own GPT #selfhostingllm #ai #localllm #homelab #selfhosted #ollama #openwebui
0 notes
Text
Okay so I had an idea that [we] hate but I’d like to pick apart what makes it actually bad.
Ai -yeah yeah yuck it up I saw the poll- ai articles published for indie games, for the purpose of making it easier to get a Wikipedia [and wiki listing generally] page with formal citations .
You know. For careers and such. -specifically how having a modest internet presence that is formally written, regardless of the content, is helpful to be able to reference for projects that often by their nature are lost or have important context to their creation missing.
I keep thinking that there have to be consult agency nonsense that basically do this already (I hear much of the academic publishing circuit has gone that way)
So… where does this become a bad enough of an idea that it’s not worth … pulling together a couple grand and throwing some server space at it for a year or two to see what happens?
#only slightly going out of my way to pose you a moral dilemma#based on the state of that poll#. Anyway I genuinely have been mulling this over for a little bit.#Like you can make a bot that Runza Local LLM to spit out a paragraph or two about#Just a list from itch.io every couple days#I have purchased it from the Wikipedia standard side a little bit#That provides some clarity#but it’s not like a settled issue. Especially like like quadruply so if you’re doing this ostensibly as a community service.#Which again that that is how you know that that’s how open AI started out I get it#There’s incentives that you’re gonna run into that make doing anything decent very hard#.. The analogy I keep coming back to.#Is none of the physicists that picked out in like the 20s or whatever#The nuclear weapons were possible and they didn’t focus on developing that#They didn’t save the world from nuclear weapons#It’s a fundamentally different situation#But like#That’s what analogies are for
1 note
·
View note
Video
youtube
Installer et Utiliser des LLM (Deepseek) Localement sur Windows + Interf...
0 notes
Text
This guide walks you through installing Langchain and Langflow locally, followed by an exploration of Langflow’s components and GUI. Learn to build visual workflows, connect LLMs, and create content pipelines for tasks like summarization, transcription, and more using a user-friendly interface.
0 notes
Text
everyone wants to sensationalize about ai datacenter water usage no one wants to talk about the ai you can run locally thus completely mitigating contribution to that issue. because they don't GAF about the environment they just hate ai
#txt#i don't have a lot of experience in this because i get bored of this stuff really fast but like when i have had interest#you can replace cai with agnaistic + kobold + open LLM of your choice (i think most people use llama?)#if you're looking for image generation and you're a mac user drawthings can run any model for you and help optimize them#and there's a lot more options too when it comes to generally running LLMs locally. idk about image generation but i know the nerds on here#mostly care about roleplay ais if any
0 notes
Text
So... apparently the NaNoWriMo organization has been gutted and the people at the top now are fully focused on Getting That AI Money.
I have no reason to say this other than Vibes™️ and the way that every other org who has pivoted to AI has behaved but I wouldn't trust anything shared with or stored on their servers not to be scraped for training LLMs. That includes pasting stuff into the site to verify your word count, if that's still a thing. (I haven't done Nano since 2015).
Also of note:
Age gating has been implemented. If you haven't added your date of birth to your profile or if you're under 18, it's supposed to lock you out of local region pages and the forums. ... It's worth noting that the privacy policy on the webpage doesn't specify how that data is stored and may not be GDPR compliant.
...
Camp events are being run solely by sponsors. Events for LGBTQIA+, disabled writers, and writers of color no longer appear to be a thing at NaNo.
Just... go read the whole thing. It's not that long. Ugh.
6K notes
·
View notes
Text
Your LLM, Your Rules: Locally vs Colab Breakthrough 2024 announcement. Free LLM Demo
#MLsoGood #collab #LLM
#digitalart#machinelearning#artificialintelligence#art#mlart#ai#datascience#algorithm#llms#colab#locally
0 notes
Text

absolutely mortified by my Boimler bot suggesting he play Data in the holodeck. All roads lead back to Data. I cannot escape
#dont even @ me for creating a boimler bot i am bored and quarantined right now#some versions of ensign smith do indeed have sex with an AI version of the AI#because i do. its very meta#star trek shitposting#the app is called faraday btw its a local app to run opensource llms#star trek ld#llm posting
0 notes
Text
It's been a long time since I've been a software engineer, but the skills are still there, rusty and buried, so I offered to help with some website stuff for a local organization, just a few hours of work. It was mostly just a case of fixing up some pages that had errors on them from a migration, which wouldn't have been a problem for me nine years ago, but meant that everything was going to take me much longer.
... except that now there are LLMs to ask, and you can just feed them the files, along with the error messages, and get back suggested corrections.
This sped up the work by, at a guess, 300%. I think I was most surprised by how lazy I could be with it, how much I could just paste stuff in and say "hey, why is it doing this, please fix". Kind of an eye-opening experience for me, because usually when I'm using the LLMs it's with the understanding that I have to double-check everything, that I'm mostly fishing for keywords or concepts that I can look up because of the hallucinations.
But no, for relatively simple programming work, it really does just make everything faster.
And again, I'm rusty as hell, but this is one of the big use cases, taking mediocre programmers and making them much more efficient at the kind of rote work that software engineering so unfortunately requires. Which was great for me, because I was doing volunteer work, but I do wonder about the low level programmers who might find themselves out of a job, especially those who are graduating into this environment.
178 notes
·
View notes
Text
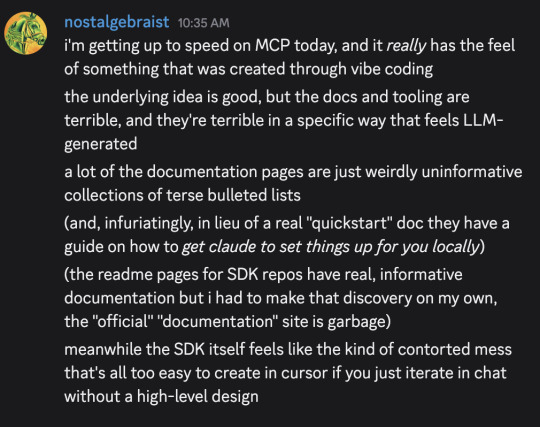
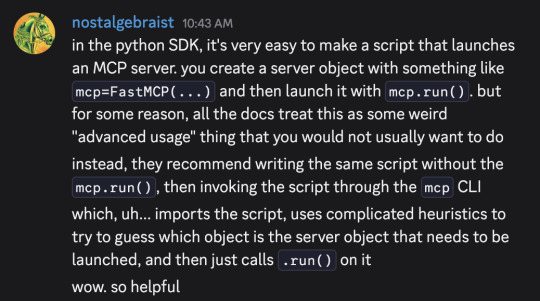

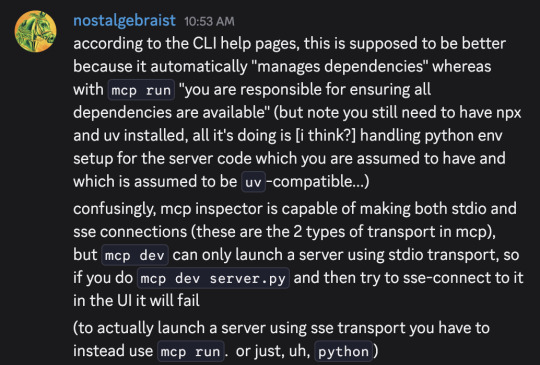
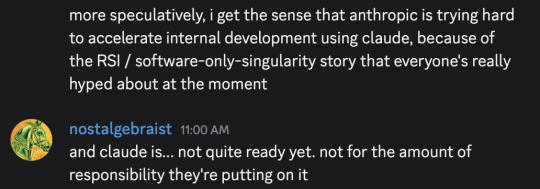
I typed out these messages in a discord server a moment ago, and then thought "hmm, maybe I should make the same points in a tumblr post, since I've been talking about software-only-singularity predictions on tumblr lately"
But, as an extremely lazy (and somewhat busy) person, I couldn't be bothered to re-express the same ideas in a tumblr-post-like format, so I'm giving you these screenshots instead
(If you're not familiar, "MCP" is "Model Context Protocol," a recently introduced standard for connections between LLMs and applications that want to interact with LLMs. Its official website is here – although be warned, that link leads to the bad docs I complained about in the first message. The much more palatable python SDK docs can be found here.)
EDIT: what I said in the first message about "getting Claude to set things up for you locally" was not really correct, I was conflating this (which fits that description) with this and this (which are real quickstarts with code, although not very good ones, and frustratingly there's no end-to-end example of writing a server and then testing it with a hand-written client or the inspector, as opposed to using with "Claude for Desktop" as the client)
64 notes
·
View notes
Text
Local LLM Model in Private AI server in WSL
Local LLM Model in Private AI server in WSL - learn how to setup a local AI server with WSL Ollama and llama3 #ai #localllm #localai #privateaiserver #wsl #linuxai #nvidiagpu #homelab #homeserver #privateserver #selfhosting #selfhosted
We are in the age of AI and machine learning. It seems like everyone is using it. However, is the only real way to use AI tied to public services like OpenAI? No. We can run an LLM locally, which has many great benefits, such as keeping the data local to your environment, either in the home network or home lab environment. Let’s see how we can run a local LLM model to host our own private local…

View On WordPress
0 notes
Text
I'm not even a hardcore anti AI person. I think LLMs are neat as a technology and I enjoy running a small open source model locally on my computer!!! But I truly feel like a guy who's into origami suddenly watching society decide they're gonna make every building's load bearing wall out of origami paper. Like that's not what it's for 😭
#It's for me talking to my lil computer for fun#And automating some repetitive tasks / formatting / etc#But your building is gonna fucking collapse!!! It's nonsense!!!
67 notes
·
View notes
Text
still confused how to make any of these LLMs useful to me.
while my daughter was napping, i downloaded lm studio and got a dozen of the most popular open source LLMs running on my PC, and they work great with very low latency, but i can't come up with anything to do with them but make boring toy scripts to do stupid shit.
as a test, i fed deepseek r1, llama 3.2, and mistral-small a big spreadsheet of data we've been collecting about my newborn daughter (all of this locally, not transmitting anything off my computer, because i don't want anybody with that data except, y'know, doctors) to see how it compared with several real doctors' advice and prognoses. all of the LLMs suggestions were between generically correct and hilariously wrong. alarmingly wrong in some cases, but usually ending with the suggestion to "consult a medical professional" -- yeah, duh. pretty much no better than old school unreliable WebMD.
then i tried doing some prompt engineering to punch up some of my writing, and everything ended up sounding like it was written by an LLM. i don't get why anybody wants this. i can tell that LLM feel, and i think a lot of people can now, given the horrible sales emails i get every day that sound like they were "punched up" by an LLM. it's got a stink to it. maybe we'll all get used to it; i bet most non-tech people have no clue.
i may write a small script to try to tag some of my blogs' posts for me, because i'm really bad at doing so, but i have very little faith in the open source vision LLMs' ability to classify images. it'll probably not work how i hope. that still feels like something you gotta pay for to get good results.
all of this keeps making me think of ffmpeg. a super cool, tiny, useful program that is very extensible and great at performing a certain task: transcoding media. it used to be horribly annoying to transcode media, and then ffmpeg came along and made it all stupidly simple overnight, but nobody noticed. there was no industry bubble around it.
LLMs feel like they're competing for a space that ubiquitous and useful that we'll take for granted today like ffmpeg. they just haven't fully grasped and appreciated that smallness yet. there isn't money to be made here.
#machine learning#parenting#ai critique#data privacy#medical advice#writing enhancement#blogging tools#ffmpeg#open source software#llm limitations#ai generated tags
61 notes
·
View notes