#NL2SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
NL2SQL With Gemini And BigQuery: A Step-by-Step Guide
Conversion of natural language to SQL
Beginning to use Gemini and BigQuery for NL2SQL (natural language to SQL)
The intriguing new technology known as Natural Language to SQL, or NL2SQL, was created by combining the classic Structured Query Language (SQL) with Natural Language Processing (NLP). It converts inquiries written in common human language into structured SQL queries.
The technology has enormous potential to change how we engage with data, which is not surprising.
With the help of NL2SQL, non-technical users like marketers, business analysts, and other subject matter experts can engage with databases, examine data, and obtain insights independently without requiring specific SQL expertise. Even SQL experts can save time by using NL2SQL to create sophisticated queries, which allows them to devote more time to strategic analysis and decision-making.
On the ground, how does that appear? Imagine having instant access to a chat interface where you can ask inquiries and receive real-time replies, or
“How many units were sold overall this month?”
“What are the main factors influencing the shift in APAC sales when comparing Q1 and Q2 sales?”
In the past, this would have required an expert to extract information from databases and turn it into business insights. By lowering obstacles to data access, it can democratize analytics by utilizing NL2SQL.
However, a number of obstacles prevent NL2SQL from being extensively used. We’ll look at NL2SQL solutions on Google Cloud and implementation best practices in this blog.
Data quality issues in practical applications
Let us first examine some of the factors that contribute to the difficulty of implementing NL2SQL.
Real-world production data poses a number of difficulties, even if NL2SQL performs best in controlled settings and straightforward queries. These difficulties include:
Data formatting variations: The same information can be expressed in a variety of ways, such as “Male,” “male,” or “M” for gender, or “1000,” “1k,” or “1000.0” for monetary amounts. Additionally, many organizations use poorly defined acronyms of their own.
Semantic ambiguity: Large Language Models (LLMs) frequently lack domain-specific schema comprehension, which results in semantic ambiguity. This can cause user queries to be misinterpreted, for example, when the same column name has many meanings.
Syntactic rigidity: If semantically correct queries don’t follow SQL’s stringent syntax, they may fail.
Unique business metrics: NL2SQL must manage intricate business computations and comprehend table relationships via foreign keys. To translate the question effectively, one must have a sophisticated understanding of the tables that need to be connected and modeled together. Additionally, there is no one standard approach to determine the business KPIs that each corporation should use in the final narrative report.
Client difficulties
Users’ questions are frequently unclear or complicated, so it’s not only the data that can be unclear or poorly formatted. These three frequent issues with user inquiries may make NL2SQL implementation challenging.
Ambiguous questions: Even questions that appear to be clear-cut can be unclear. For example, a query looking for the “total number of sold units month to date” may need to specify which date field to use and whether to use average_total_unit or running_total_unit, etc. The perfect NL2SQL solution will actively ask the user to select the correct column and use their input when creating the SQL query.
Underspecified questions: Another issue is queries that are not detailed enough. For example, a user’s question concerning “the return rate of all products under my team in Q4” does not provide enough details, such as which team should fully grasp the question. An optimal NL2SQL solution should identify areas of ambiguity in the initial input and ask follow-up questions to obtain a comprehensive representation of the query.
Complex queries that require a multi-step analysis: Numerous questions require several stages of analysis. Consider figuring out the main causes of variations in sales from quarter to quarter, for instance: A good NL2SQL solution should be able to deconstruct the study into digestible parts, produce interim summaries, and then create a thorough final report that answers the user’s question.
Dealing with the difficulties
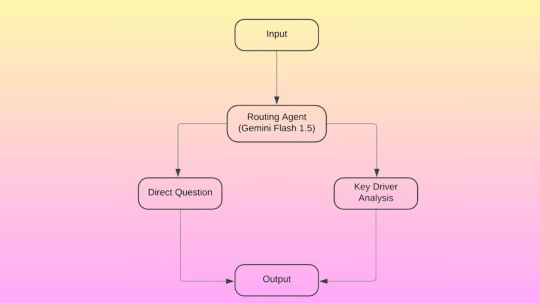
In order to address these issues, Google designed Gemini Flash 1.5 as a routing agent that can categorize queries according to their level of complexity. It can enhance its results by applying methods like contribution analysis models, ambiguity checks, vector embeddings, and semantic searches after the question has been classified.
It reacts to instructions in a JSON format using Gemini. Gemini can act as a routing agent, for instance, by responding to the few-shot prompt.
Direct inquiries
The right column names in scope can be clarified for direct inquiries by utilizing in-context learning, draft SQL ambiguity checks, and user feedback loops. Additionally, simple questions can be guaranteed to generate SQL that is clear.
For straightforward inquiries, its method does the following:
Gathers quality question/SQL pairings.
Keeps samples in BigQuery rows.
Enables the question to have vector embeddings
Leverages BigQuery vector search to extract related examples based on the user’s query.
Adds the table structure, question, and example as the LLM context.
Produces a draft SQL
Executes a loop that includes a SQL ambiguity check, user feedback, refinement, and syntax validation.
Performs the SQL
Uses natural language to summarize the data.
Gemini appears to perform well on tasks that check for SQL ambiguity, according to its heuristic testing. Google started by creating a draft SQL model that had all of the table structure and context-related questions. This allowed Gemini to ask the user follow-up questions to get clarification.
Key driver analysis
Key driver analysis is another name for multi-step reasoning-based data analysis in which analysts must separate and organize data according to every possible combination of attributes (e.g., product categories, distribution channels, and geographies). Google suggests combining Gemini and BigQuery contribution analysis for this use case.
Key driver analysis adds the following steps to the ones done with direct questions:
The routing agent refers users to a key driver analysis special handling page when they ask a query about it.
From ground truth stored in a BigQuery vector database, the agent retrieves similar question/SQL embedding pairings using BigQuery ML vector search.
After that, it creates and verifies the CREATE MODEL statement in order to construct a report on contribution analysis.
Lastly, the SQL that follows is executed in order to obtain the contribution analysis report:
The final report appears as follows:
With Gemini, you can further condense the report in natural language:
Implementing NL2SQL on Google Cloud
Even though this can sound difficult, Google Cloud provides a comprehensive set of tools to assist you in putting an effective NL2SQL solution into place. Let’s examine it.
BigQuery vector search is used for embedding and retrieval
By using BigQuery for embedding storage and retrieval, it is possible to quickly find instances and context that are semantically meaningful for better SQL production. Vertex AI’s text embedding API or BigQuery’s ML.GENERATE_EMBEDDING function can be used to create embeddings. It is simple to match user queries and SQL pairs when BigQuery is used as a vector database because of its inherent vector search.
Contribution analysis using BigQuery
Contribution analysis modeling can find statistically significant differences throughout a dataset, including test and control data, to identify areas of the data that are producing unanticipated changes. A section of the data based on a combination of dimension values is called a region.
To help answer “why?” questions, the recently unveiled contribution analysis preview from BigQuery ML enables automated explanations and insight development of multi-dimensional data at scale. Regarding your data, “What happened?” and “What’s changed?”
The contribution analysis models in BigQuery, in summary, facilitate the generation of many queries using NL2SQL, hence increasing overall efficiency.
Ambiguity checks with Gemini
The process of translating natural language inquiries into structured SQL queries is known as NL2SQL, and it is often unidirectional. Gemini can assist in lowering ambiguity and enhancing the output statements in order to boost performance.
When a question, table, or column schema is unclear, you may utilize Gemini 1.5 Flash to get user input by asking clarifying questions. This will help you improve and refine the SQL query that is produced. Additionally, Gemini and in-context learning can be used to expedite the creation of SQL queries and results summaries in natural language.
Top NL2SQL techniques
For an advantage in your own NL2SQL endeavor, take a look at the following advice.
Start by determining which questions require attention: Depending on the final report’s goal, answering a question may seem straightforward, but getting the intended response and storyline frequently requires several steps of reasoning. Before your experiment, gather the expected natural language ground truth, SQL, and your query.
Data purification and preparation are essential, and using LLMs does not replace them. As needed, establish new table views and make sure that useful descriptions or metadata are used in place of business domain acronyms. Before going on to more complicated join-required questions, start with straightforward ones that just need one table.
Practice iteration and SQL refinement with user feedback: Google’s heuristic experiment demonstrates that iteration with feedback is more effective following the creation of an initial draft of your SQL.
For queries with multiple steps, use a custom flow: Multi-dimensional data explanations and automated insight development can be made possible by BigQuery contribution analysis models.
Next up?
A big step toward making data more accessible and useful for everyone is the combination of NL2SQL, LLMs, and data analytic methods. Enabling users to communicate with databases through natural language can democratize data access and analysis, opening up improved decision-making to a larger group of people in every company.
Data, size, and value can now be rationalized more easily than ever thanks to exciting new innovations like BigQuery contribution analysis and Gemini.
Read more on govindhtech.com
#NL2SQL#Gemini#BigQuery#NaturalLanguage#SQL#SQLqueries#LLM#API#BigQueryML#Gemini1.5#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Link
[ad_1] Natural language interface to databases is a growing focus within artificial intelligence, particularly because it allows users to interact with structured databases using plain human language. This area, often known as NL2SQL (Natural Language to SQL), is centered on transforming user-friendly queries into SQL commands that can be directly executed on databases. The objective is to simplify data access for non-technical users and broaden the utility of data systems in various sectors like finance, healthcare, and retail. With the rise of LLMs, significant progress has made these conversions more accurate and context-aware, especially when dealing with simple queries or structured database layouts. Despite progress, converting natural language into accurate SQL remains difficult in complex situations involving multiple table joins, nested queries, or ambiguous semantics. The challenge is not just about generating syntactically correct SQL but producing queries that correctly reflect the user’s intent and can be generalized across domains. Standard approaches struggle to scale in high-stakes fields where interpretability and precision are critical. Moreover, many current models depend heavily on fixed schemas and training data structures, which hampers their performance in new or evolving environments. Most NL2SQL systems today rely on supervised fine-tuning, where large language models are trained on annotated datasets that pair questions with correct SQL answers. While this method has led to noticeable improvements, it introduces limitations in adaptability and interpretability. Because these models are tuned to specific datasets and schemas, they often fail in unfamiliar scenarios. Also, they follow a rigid generation strategy, which can lead to failures when the input diverges from training data. These systems also typically lack transparency in their reasoning processes, limiting their utility in domains where clear decision-making trails are necessary. Researchers from IDEA Research, the Hong Kong University of Science and Technology (Guangzhou), the University of Chinese Academy of Sciences, and DataArc Tech Ltd. introduced SQL-R1. This new NL2SQL model leverages reinforcement learning rather than traditional supervised learning. SQL-R1 uses feedback mechanisms during training to improve its performance. Instead of just learning from annotated examples, the model learns by generating SQL candidates, executing them, and receiving structured feedback on the outcome. This feedback includes whether the SQL was syntactically correct, whether it produced the proper result, and how efficient and interpretable it was. This dynamic learning process allows the model to optimize its SQL generation strategies over time and improves generalization in complex or unfamiliar scenarios. To build SQL-R1, researchers first performed supervised fine-tuning on 200,000 samples drawn from a large synthetic dataset called SynSQL-2.5M. This process, known as a cold start, ensured the model could follow basic instructions and generate simple SQL outputs. Following this, reinforcement learning was introduced using the Group Relative Policy Optimization (GRPO) algorithm. The model generated multiple SQL candidates for each query and was rewarded based on a composite scoring function. This function included four metrics: format reward (+1 or -1 depending on syntax correctness), execution reward (+2 for executable queries, -2 for failures), result reward (+3 for correct query outputs, -3 for incorrect ones), and length reward based on the depth and clarity of the reasoning trace. Each of these scores contributed to updating the model’s internal decision-making process. SQL-R1 was evaluated on two industry-standard NL2SQL benchmarks: Spider and BIRD. On the Spider development set, the model achieved 87.6% execution accuracy, and on the Spider test set, it gained 88.7%. For the BIRD dataset, which covers 95 databases from 37 domains, the model scored 66.6%. These results are competitive with or superior to larger models, including closed-source solutions like GPT-4. Notably, SQL-R1 used the Qwen2.5-Coder-7B model, which is considerably smaller than many alternatives, demonstrating that high accuracy can be achieved with efficient architectures when combined with reinforcement learning. An ablation study confirmed the contribution of each reward component. Removing the format reward, for instance, caused accuracy to drop from 63.1% to 60.4%. Removing the result reward caused a 0.7% drop, indicating that each element in the reward mechanism plays a role in guiding the model. Several Key Takeaways from the Research on SQL-R1: SQL-R1 achieved 88.7% accuracy on the Spider test set and 66.6% on the BIRD development set, using only a 7B base model (Qwen2.5-Coder-7B). The model used 200,000 samples from the SynSQL-2.5M dataset for supervised fine-tuning and 5,000 complex samples for reinforcement learning. The GRPO algorithm powered reinforcement learning, which required no value model and worked efficiently with relative performance scores. The reward function included four components: Format (+1/-1), Execution (+2/-2), Result (+3/-3), and Length (proportional). SQL-R1 outperformed larger models like GPT-4, highlighting that model architecture and feedback training are as critical as size. Ablation studies revealed the importance of each reward: removing the format reward caused a 2.7% drop in performance, while eliminating the execution reward dropped accuracy by 2.4%. The approach promotes transparency, as the model provides reasoning traces using ‘’ and ‘’ tags, improving end-user interpretability. Here is the Paper. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit. 🔥 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Develop With OCI Real-Time Speech Transcription and Oracle Database NL2SQL/Select AI To Speak With Your Data
http://securitytc.com/TBZ1qf
0 notes
Text
Mastering Natural Language to SQL with LangChain | NL2SQL
Unlock the full potential of database interactions with our guide on Natural Language to SQL using LangChain and LLM. — 到這裡瞭解: blog.futuresmart.ai/mastering-natural-language-to-sql-with-langchain-nl2sql
View On WordPress
0 notes
Text
Gemini Looker: AI-Driven Insights & Streamlined Development

Conversational, visual, AI-powered data discovery and integration are in Gemini Looker.
Google's trusted semantic model underpins accurate, reliable insights in the AI era, and today at Google Cloud Next '25, it's announcing a major step towards making Looker the most powerful data analysis and exploration platform by adding powerful AI capabilities and a new reporting experience.
Conversational analytics using Google's latest Gemini models and natural language is now available to all platform users. Looker has a redesigned reporting experience to better data storytelling and exploration. All Gemini Looker clients can use both technologies.
Modern organisations require AI to find patterns, predict trends, and inspire intelligent action. Looker reports and Gemini make business intelligence easier and more accessible. This frees analysts to focus on more impactful work, empowers enterprise users, and reduces data team labour.
Looker's semantic layer ensures everyone uses a single truth source. Gemini Looker and Google's AI now automate analysis and give intelligent insights, speeding up data-driven organisational decisions.
All Looker users can now utilise Gemini
To make sophisticated AI-powered business intelligence (BI) accessible, you introduced Gemini in Looker at Google Cloud Next ’24. This collection of assistants lets customers ask their data queries in plain language and accelerates data modelling, chart and presentation building, and more.
Since then, those capabilities have been in preview, and now that the product is more accurate and mature, they should be available to all platform users. Conversational Analytics leverages natural language queries to deliver data insights, while Visualisation Assistant makes it easy to configure charts and visualisations for dashboards using natural language.
Formula Assistant provides powerful on-the-fly calculated fields and instant ad hoc analysis; Automated Slide Generation creates insightful and instantaneous text summaries of your data to create impactful presentations; and LookML Code Assistant simplifies code creation by suggesting dimensions, groups, measures, and more.
Business users may perform complex procedures and get projections using the Code Interpreter for Conversational insights in preview.
Chat Analytics API
We also released the Conversational Analytics API to expand conversational analytics beyond Gemini Looker. Developers may now immediately add natural language query capabilities into bespoke apps, internal tools, or workflows due to scalable, reliable data modelling that can adapt to changing requirements and secure data access.
This API enables you develop unique BI agent experiences using Google's advanced AI models (NL2SQL, RAG, and VizGen) and Looker's semantic model for accuracy. Developers may easily leverage this functionality in Gemini Looker to build user-friendly data experiences, ease complex natural language analysis, and share insights from these talks.
Introduce Looker reports
Self-service analysis empowers line-of-business users and fosters teamwork. Looker reports integrate Looker Studio's powerful visualisation and reporting tools into the main Looker platform, boosting its appeal and use.
Looker reports, which feature native Looker content, direct linkages to Google Sheets and Microsoft Excel data, first-party connectors, and ad hoc access to various data sources, increase data storytelling, discovery, and connectivity.
Interactive reports are easier than ever to make. Looker reports includes a huge collection of templates and visualisations, extensive design options, real-time collaboration features, and the popular drag-and-drop interface.
New reporting environment coexists with Looker Dashboards and Explores in Gemini Looker's regulated framework. Importantly, Gemini in Looker readily integrates with Looker Reports, allowing conversational analytics in this new reporting environment.
Continuous integration ensures faster, more dependable development
Google Cloud is automating SQL and LookML testing and validation by purchasing Spectacles.dev, enabling faster and more reliable development cycles. Strong CI/CD methods build data confidence by ensuring semantic model precision and consistency, which is critical for AI-powered BI.
Looker reports, the Conversational Analytics API, Gemini, and native Continuous Integration features promote an AI-for-BI platform. Nous make powerful AI, accurate insights, and a data-driven culture easier than ever.
Attend Google Cloud Next to see Gemini Looker and hear how complete AI for BI can convert your data into a competitive advantage. After the event, Gemini Looker offers AI for BI lecture.
#technology#technews#govindhtech#news#technologynews#AI#artifical intelligence#Gemini Looker#Gemini#Looker reports#Google cloud Looker#Gemini in Looker#Analytics API
0 notes
Text
Vodafone And Google Cloud Unlock Gen AI For Telecom

Vodafone And Google Cloud Explore Telecom Gen AI Potential
Globally, generative AI is changing sectors, and the telecom sector is no exception. Generative AI has the potential to completely change the telecom sector, from individualized customer service and efficient content production to network optimization and increased efficiency.
Leading telecoms company Vodafone is aware of the enormous potential of advanced AI to transform its network engineering, development, and operations. Vodafone is starting an exciting journey to include generative AI into its network operations as part of its expanding, multi-decade cooperation with Google Cloud. The goal is to boost productivity, stimulate innovation, and optimize costs.
This blog post will explore the innovative ways that Google Cloud and Vodafone have used generative AI to increase productivity, creativity, and customer pleasure. They look at practical applications and give an overview of how this game-changing technology will develop inside Vodafone in the future.
The genesis of generative AI in Vodafone’s network
When Vodafone and Google Cloud began talking about the possible uses of gen AI in network use cases in late 2023, the roots of this partnership were planted. In March 2024, Vodafone and Google Cloud launched a hackathon in recognition of the technology’s revolutionary potential, bringing together more than 120 network experts with extensive knowledge of networks and telecoms but little expertise with AI/ML.
Innovation was sparked by this event, which led to the creation of 13 demonstration use cases using a combination of classical machine learning methods, Vertex AI Search & Conversation, Gemini 1.5 Pro, and a code generation model. These comprised:
AI-powered site evaluations: Using pictures, determine whether installing solar panels at RAN locations is feasible right away.
Using natural language searches, Doc Search for Root-Cause-Analysis (RCA) enables staff members to find pertinent material fast.
Natural language to SQL (NL2SQL): Developing intuitive user interfaces to enable colleagues who are not technical to use generative AI for activities such as SQL query generation.
Network optimization is the process of creating AI-driven tools to identify problems with networks, forecast possible outages, and help with setup.
With the help of Vodafone’s industry knowledge and the expanding possibilities of cloud computing, these creative solutions show how easily generative AI can be applied to real-world problems in the telecom sector. When the creative use cases from the Vodafone and Google Cloud hackathon specifically, RCA and NL2SQL were presented together at DTW 2024 in Copenhagen, other telecom companies keen to leverage the potential of generative AI expressed a great deal of interest.
Unveiling the potential: Understanding the network design, deployment and operations workflows
In order to have a thorough grasp of the normal workday in network departments, Vodafone and Google Cloud conducted in-depth interviews with a variety of network stakeholders. Network professionals’ problems and difficulties were clarified by these interviews, which also showed a wide range of areas where gen AI may be very beneficial.
The business case study that followed showed how using modern AI technologies might result in significant time and cost savings.
Vodafone and Google Cloud demonstrated the concrete advantages of gen AI in optimizing workflows, improving decision-making, and boosting efficiency, with over 100 use cases emerging from this network space discovery phase. Vodafone is working with Google Cloud to produce the following prioritized sample of gen AI for network use cases:
Empowering network operations with knowledge at their fingertips
During complicated occurrences, network operations teams frequently struggle to obtain vital information. It can take a lot of effort and impede quick resolution to move away from extensive documentation, incident reports, network topologies, and strategic plans. Vodafone is giving network operators immediate access to the information they require by leveraging Vertex AI Agent Builder‘s capability to extract and synthesize relevant information from these documents. They are able to make well-informed decisions more quickly as a result, which lowers downtime and improves network dependability overall.
Streamlining network engineering with automated documentation
It takes a lot of effort and time to create technical documentation, including network diagrams, high-level designs (HLDs), and low-level designs (LLDs). Multiple engineers and vendors are frequently involved, which might cause delays and irregularities. Vodafone plans to automate the creation of these papers by utilizing Gemini’s multimodal capabilities and artificial intelligence. Although human inspection is still essential, gen AI may offer a strong basis, saving engineers time, speeding up time to market, and enhancing the precision and coherence of technical documentation.
Transforming network development with data-driven insights
Large volumes of contractual data are thrown at network development teams, making analysis and decision-making difficult. Vodafone will using gen AI to examine thousands of contracts, extracting important terms and provide insightful information for the creation of contract templates. Together with ground categorization skills, gen AI can also make it possible to create digital twins of the Vodafone network. This minimizes mistakes and maximizes resource allocation by enabling more precise and efficient design and implementation of new network actions.
Enhancing customer fulfillment with AI-powered field technicians
Field technicians are essential to guaranteeing client pleasure. On-site visits, or truck rolls, are expensive and time-consuming. Vodafone will reduce the need for truck rolls, enable more efficient on-field responses, and prevent repeat dispatch by utilizing gen AI to provide field professionals with real-time information and multimodal troubleshooting help. Vodafone will save a lot of money as a result, and customers will have better experiences.
These applications demonstrate how gen AI has the ability to completely change a number of facets of Vodafone’s network operations. Vodafone’s usage of Gen AI is driving innovation and enabling a more customer-focused, agile, and efficient future.
Vodafone’s big bet: generative AI for the future
Vodafone’s network divisions stand to gain a great deal from the incorporation of Gen AI:
Zero-touch operations and accelerated automation: Gen AI can speed up network job automation, helping Vodafone meet its automation objectives more quickly and effectively.
Cost reduction: Gen AI can drastically cut Vodafone’s operating expenses by automating repetitive processes and streamlining network operations.
Time savings: Network workers may save a significant amount of time by using Gen AI-powered solutions to optimize operations and facilitate quicker decision-making.
Increased effectiveness: Gen AI has the potential to increase Vodafone’s network operations’ overall effectiveness through clever automation and optimization.
Innovation catalyst: Gen AI gives Vodafone the ability to stay ahead of the curve by creating new opportunities for innovation in network management, optimization, and design.
Building on past success: AI Booster and Neuron
Vodafone’s ambitious aim to integrate generative AI into all facets of its company is based on AI Booster and Neuron. Vodafone relies on these programs to research and apply cutting-edge AI.
Vodafone uses AI Booster, a Google Cloud Vertex AI-based machine learning platform, to build AI. Fast and efficient design allows this platform to create and apply AI models quickly. AI Booster’s strong automation and security features enable Vodafone’s data scientists to move from proof-of-concept to production with ease, greatly speeding up the rate of innovation.
Neuron, Vodafone’s specially designed “data ocean” hosted on Google Cloud, is a perfect match for AI Booster. As a central hub, Neuron compiles enormous volumes of data from all throughout the company into a single, easily accessible storehouse. The creation of potent generative AI applications is fueled by this data, which is essential for AI models training and analysis.
Imagine having an AI that can forecast possible problems, evaluate the performance of network components, and even recommend the best settings to avoid downtime. Vodafone is enabling this kind of revolutionary impact by fusing the extensive data resources of Neuron with the model creation capabilities of AI Booster.
Vodafone is able to create and implement innovative AI solutions with speed and efficiency thanks to the collaboration between AI Booster and Neuron. Faster insights, more precise forecasts, and eventually an improved customer experience are the results of this. Vodafone is putting itself at the forefront of the generative AI revolution in the telecom sector by making an investment in this strong foundation.
In conclusion
Vodafone’s work on generative AI marked a turning point in CSPs’ AI-powered future. Vodafone can use current AI to generate remarkable productivity, innovation, and cost savings. Vodafone’s dedication to pushing the limits of technical progress and providing its customers with outstanding network experiences is shown by this strategic cooperation with Google Cloud.
Read more on Govindhtech.com
#GenerativeAI#Google#googlecloud#Vodafone#telecom#govindhtech#NEWS#TechNews#technology#technologies#technologytrends#technologynews#ai
0 notes
Link
Author(s): Pere Martra Originally published on Towards AI. This article is part of a free course about Large Language Models available on GitHub. Created by Author with Dall-E2 In the previous article, we learned how to set up a prompt able to gener #AI #ML #Automation
0 notes