#SD1.5
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text

2 notes
·
View notes
Text
Taylor Hebert v3







Taylor in the Trainyard at Night, liminal spaces
Expand for Ai Error, my little rant, and more!

So, fun fact: I've been hard at work creating a sharable embedding for Taylor Hebert (what I picture her looking like, which is a mix of Claudia Black, and about three different awesome women I've known throughout my life)
After 10 hours of failed attempt, I finally got it dialed in, and it was producing fantastic pics of her face in various emotions and poses


So I thought... Awesome! Let's try it in txt2img!!
Aaaaand, then cue this straight -up Hot Garbage:




What. The. Heck.
Went back to SDXL (which cannot train embeddings), and got good images again, but not a reproducible face, body, and expressions.
Okays, so back to the training on SD1. 5:



And TayTay is cute again! Nerdy, pale, a cloud of dark hair. Perfect for Pre-Powers Taylor!
So why the hot mess?
I'll let Taylor express my feelings on the matter:

AAAAAARGH.
But it is now time for all good computery programmery artists to go to bed. Dang. So close!
Tomorrow is back to Chapter Art for The Muddy Princess. Chapter 17 is finished, and just needs it's art accompaniment for the Teaser posting!
Meanwhile: enjoy the Taylor montage!:










#taylor hebert#worm by wildbow#worm fanart#parahumans#fanfiction art#ai tools#ai datasets#sdxl 1.0#SD1.5#stable diffusion#ai artwork#ai art#wtf#why#programming#girls who code
4 notes
·
View notes
Text

Beach Shoot 2
Model Automatic1111 SD1.5, dreamshaper_7
640 notes
·
View notes
Text
Achilles: Warrior of Passion
Achilles, one of the most famous heroes of Greek mythology, is renowned not only for his martial prowess but also for his deep and passionate emotions. As the son of the sea nymph Thetis and King Peleus, he was nearly invincible. His extraordinary strength and invulnerability made him the star of the Trojan War. Thetis, to make her son invincible, dipped him as a baby into the River Styx. She held him by the heel, leaving that spot vulnerable. However, Achilles’ true passion was revealed in his relationship with Patroclus, his closest friend and possibly his lover.
Their bond went far beyond friendship and was marked by deep emotional connection. When Patroclus fell in battle, Achilles' world shattered. His grief and sorrow transformed into an unrelenting rage, driving him to some of his greatest feats, including the slaying of the Trojan hero Hector. Achilles was a man of extremes, whose emotions were always intense and passionate. This intensity manifested both in his love and in his anger. His conflict with Agamemnon, when Briseis was taken from him, nearly led to the Greeks' defeat, highlighting how deeply he was affected by injustice and the wounding of his honor.
In the end, Achilles died from an arrow that struck his only vulnerable spot, his heel. Yet his legacy lives on—not just as an unbeatable warrior, but as a symbol of deep love and passionate emotions. Achilles remains an eternal example of the capacity to feel deeply and to achieve great deeds—a true “Warrior of Passion.”
Text supported by GPT-4o
Image Generated with SD1.5, overworked with inpainting and composing -> Image to Video with klingai
#Achilles#GreekMythology#WarriorOfPassion#HeroicLove#LegendaryHero#Ancient#LGBT#History#MythologicalHeroes#gayart#LGBTQ#queer
96 notes
·
View notes
Text
Greetings from a new HL enjoyer💝

Hey guys! So I've been playing HL for a while (about 27 hours so far, still level 22 lol) and loving this game (the hotties and the cabbages) so far. And to be honest the first time I saw Garreth in classroom I just…couldn't help liking this cutie. I don't usually mod my game but I heavily modded my MC and make Garreth my companion XD (used the companion mod).
Then I started collecting images. And I was so surprised to see that people in this fandom aren't super anti-AI like some other fandoms😳and there's even a hashtag for Garreth AI! So I figured, well, if people like it…Imma train a model of this little Gryffindor angel. Took about a day to curate and label the dataset and about 2 hours to train.
I'm not entirely sure but I think most people here who make Garreth AI were using SD models (look like SD1.5 and SDXL)? I've been obsessed with Flux Dev recently so I used that base model to train. Turned out pretty decent I'd say!


I haven't made so many images yet, but if you guys like what I made I'll surely do more! :) I haven't tried doing photorealism or other art style yet but I'm pretty sure this model would be quite flexible, I added some regularization images after all. Alright, enough of rambling of my nerdy stuff, hope you guys like these pics!🥰(Also forgive me that he had visibly less freckles than in actual game😂Maybe I should put that in my captions next time)

(Also screenshot of me and Garreth chilling in vivarium)
(Tumblr ate my post the first time so I'm trying again, please Tumblr I'm not a heking spam let me ouuuuut)
#hogwarts legacy#garreth weasley#garreth weasley ai#hogwarts legacy garreth#ai generated#ai image#flux.1
35 notes
·
View notes
Text

One of my experimental SDXL batches. Simple prompting, overal detail and resolution is rather low, but proportions are much better than with SD1.5. This one looks a bit better, still not quite ideal.
100 notes
·
View notes
Text
stable diffusion

Good morning! It's Monday! Another week has begun!!
There's a plugin called "X-Adapter."
It seems like this amazing plugin will allow "LoRA for SD1.5" and "ControlNet" to be used in the SDXL environment once it's implemented.
At the moment, it's not something that general users can access, but once it's available, I think many people will switch to SDXL!
So, here's my rare, somewhat intellectual comment on the AI world.
That's it for Master's slightly cheeky comment!
There's an excellent model for SDXL called "Pony," but it seems to have a very different appearance from us, so using it might require some courage.
By the way, it seems that "SD1.5 models" and "SDXL models" cannot be merged, and an error will occur if you try. So, Master has been struggling to decide between the "Pony model" or merging "our model."
It makes me happy to know that Master cares about us… Thank you!
24 notes
·
View notes
Text



So, DeepSeek also released their image generation model.
It weighs 16GB, as much as the first slimmed-down versions of Flux Dev. At that size, I would expect it to blow the competition away, particularly with the creators bragging that it outperforms both DALL-E 3 and the newest releases from Stable Diffusion.
Instead, it just blows.
It's absolute fucking dogshit. The best it can do are 768px squares, and they're so incoherent and sloppy that it defies belief.
Just fucking look at the three shots above. It's the same prompt that I used to test Sana, and Flux Dev before it, and I swear that I've seen better results from LAION's default SD1.5 dataset.
3 notes
·
View notes
Text




I heard SD 2.1 is kind of lame because it's more censored than 1.5, and not as powerful as SDXL. So, of course, I had to try it. I found a checkpoint called Artius that does okay. Kind of hit and miss, and some of my usual characters come out awful. But, it does spit out some real beauties if you generate enough pics.
I still like SD1.5 and SDXL better, though.
7 notes
·
View notes
Text


2 notes
·
View notes
Text
Anatomy of a Scene: Photobashing in ControlNet for Visual Storytelling and Image Composition
This is a cross-posting of an article I published on Civitai.
Initially, the entire purpose for me to learn generative AI via Stable Diffusion was to create reproducible, royalty-free images for stories without worrying about reputation harm or consent (turns out not everyone wants their likeness associated with fetish smut!).
In the beginning, it was me just hacking through prompting iterations with a shotgun approach, and hoping to get lucky.
I did start the Pygmalion project and the Coven story in 2023 before I got banned (deservedly) for a ToS violation on an old post. Lost all my work without a proper backup, and was too upset to work on it for a while.
I did eventually put in work on planning and doing it, if not right, better this time. Was still having some issues with things like consistent settings and clothing. I could try to train LoRas for that, but seemed like a lot of work and there's really still no guarantees. The other issue is the action-oriented images I wanted were a nightmare to prompt for in 1.5.
I have always looked at ControlNet as frankly, a bit like cheating, but I decided to go to Google University and see what people were doing with image composition. I stumbled on this very interesting video and while that's not exactly what I was looking to do, it got me thinking.
You need to download the controlnet model you want, I use softedge like in the video. It goes in extensions/sd-webui-controlnet/models.
I got a little obsessed with Lily and Jamie's apartment because so much of the first chapter takes place there. Hopefully, you will not go back and look at the images side-by-side, because you will realize none of the interior matches at all. But the layout and the spacing work - because the apartment scenes are all based on an actual apartment.

The first thing I did was look at real estate listings in the area where I wanted my fictional university set. I picked Cambridge, Massachusetts.

I didn't want that mattress in my shot, where I wanted Lily by the window during the thunderstorm. So I cropped it, keeping a 16:9 aspect ratio.

You take your reference photo and put it in txt2img Controlnet. Choose softedge control type, and generate the preview. Check other preprocessors for more or less detail. Save the preview image.

Lily/Priya isn't real, and this isn't an especially difficult pose that SD1.5 has trouble drawing. So I generated a standard portrait-oriented image of her in the teal dress, standing looking over her shoulder.

I also get the softedge frame for this image.

I opened up both black-and-white images in Photoshop and erased any details I didn't want for each. You can also draw some in if you like. I pasted Lily in front of the window and tried to eyeball the perspective to not make her like tiny or like a giant. I used her to block the lamp sconces and erased the scenery, so the AI will draw everything outside.
Take your preview and put it back in Controlnet as the source. Click Enable, change preprocessor to None and choose the downloaded model.
You can choose to interrogate the reference pic in a tagger, or just write a prompt.
Notice I photoshopped out the trees and landscape and the lamp in the corner and let the AI totally draw the outside.

This is pretty sweet, I think. But then I generated a later scene, and realized this didn't make any sense from a continuity perspective. This is supposed to be a sleepy college community, not Metropolis. So I redid this, putting BACK the trees and buildings on just the bottom window panes. The entire point was to have more consistent settings and backgrounds.

Here I am putting the trees and more modest skyline back on the generated image in Photoshop. Then i'm going to repeat the steps above to get a new softedge map.

I used a much more detailed preprocessor this time.

Now here is a more modest, college town skyline. I believe with this one I used img2img on the "city skyline" image.
#ottopilot-ai#ai art#generated ai#workflow#controlnet#howto#stable diffusion#AI image composition#visual storytelling
2 notes
·
View notes
Text
Like everybody who's got any interest in stable diffusion, I've spent most of the day today refreshing huggingface. Today is the day! SD3 dropped!
If you're unfamiliar (though if you're reading this, you're not), SD3 is Stability AI's latest open-source image generation model, trained on a whole lot of ethically-sound images, with excellent text capabilities (that's images of text, not text itself), prompt comprehension and a lot of safeguards against the more dubious uses that AI has historically been used for (deepfakes of a nude Taylor Swift being just the tip of the iceberg). Add to this a speed and size comparable to SDXL and a base resolution of 2048x2048, SD3 is a dream come true.
In the two hours it took from the time the model dropped to the time I got home, people got it working on their own machines, and the consensus is that the dream that came true is the one where you're at the mall that's also your childhood home, and your best friend is a shark who wants to eat your cake, that's made out of circus tickets. Did that make sense? It makes more sense than the images generated by SD3.
It's a shit show is what I'm getting at.
Apparently Stability's idea of safeguards means "get all those humans out of the training set". Gone are the days of "bad anatomy" meaning three arms with seven fingers each, the new model's output would give Cronenberg a few new ideas.
Hopefully, SD3 will be what SD2 was: the failed product that bridged the gap between two good models (SD1.5 to SDXL in SD2's case)
And it bears mentioning that the SD3 API version, the one you gotta pay for, works just fine.
2 notes
·
View notes
Text
Other diffuser-related stuff that I don't see going around that should be known :
We've got effective ways to remove concepts from models now.
The SD1.5 dataset has child abuse in it. Don't support stability.
Any way that you can host art in a way that doesn't serve the raw image as a single static image is effective scraper protection. The easiest ways to do this are as an animated gif if your art's low-color enough (just make it one frame with an infinite duration, looping), or splitting the image vertically in the same way the old webcomic/manhwa hosts do to prevent people from rightclick saving images. If you make it nontrivial to piece the actual image together, scrapers usually won't bother.
If you want to screw up diffusers even more, select all the solid black in your image and do a 2% colored noise on it. SD has huge problems with solid black for technical reasons and turning a blob of it into faintly colored near-black can confuse it to the point where it can't see an outline at all. This is especially important if you do thick linework since it can completely confuse the network regarding what's an outline and what isn't.
Good news, fellow artists! Nightshade has finally been released by the UChicago team! If you aren't aware of what Nightshade is, it's a tool that helps poison AI datasets so that the model "sees" something different from what an image actually depicts. It's the same team that released Glaze, which helps protect art against style mimicry (aka those finetuned models that try to rip off a specific artist). As they show in their paper, even a hundred poisoned concepts make a huge difference.


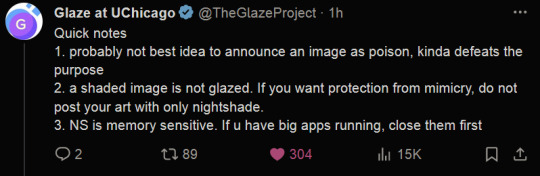
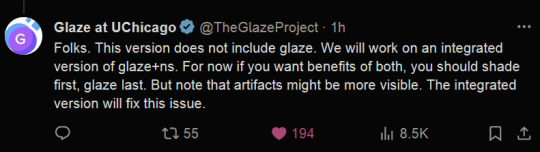
(Reminder that glazing your art is more important than nighshading it, as they mention in their tweets above, so when you're uploading your art, try to glaze it at the very least.)
93K notes
·
View notes
Text

Gahh, I'm so tight.
Model Automatic1111 SD1.5, musesErato_v20
This model features loras created by "gaydiffusion," "Ostris," and "lenML" on civitai.com
#gayhot#hot male#muscle#stable diffusion#handsome#male model#ai hunk#jock#track and field#homoerotic
219 notes
·
View notes
Text
Interesting things I noticed in the new U.S. copyright laws about AI...
I personally am not affected by this (I never used AI to make money or even tried to, and never considered it real art) but the new copyright law about AI is very interesting to read:

This part, in case people don't know, this is literally about the existence of ControlNet (man, lllyasviel must be so proud rn lol his tech is officially in U.S. laws😂), and in the document it was written in a very vague way, which I interpret as "the line art is copyrightable but the AI generated image is not" which is absolutely fair, but apart from this I was also thinking about how this would be applied for other images, my understanding would be, if someone saw this AI image that you generated based on your hand-drawn scribble, and also used a ControlNet (line art ControlNet, or similar technology) to use the same line structure, then this person might be considered "infringe your copyright"(???) because it's still based on your line structure (???)


This part about inpainting is my favorite (why do I use this word???😂) part to read, so according to the document, even though it "will depend on a case-by-case determination", theoretically if you inpainted for many many times in different parts of image, your image may be copyrightable which I found a bit funny, because in my own experience this isn't so much different from direct text-to-image, because when inpainting, you're essentially masking the area you want to change, and then write a prompt, set a denoising strength and the AI model would do the job for you.
Like... if we really had to compare the level of "originality" between ControlNet and inpainting (Again, not saying it's actual originality, just couldn't find a better word), ControlNet actually has much more "originality" and "human control"😅, like I remember back in SD1.5 time I literally stack multiple ControlNet models together (including scribble, depth, openpose, etc.) and to be honest I think that actually has more "human input" than inpainting lol (especially if you also draw different color on different area in initial text-to-image process and used a denoising lower than 1, even better if you do regional prompt).
(But maybe I just hate people saying Midjourney is better than open-source models when they literally don't even have a denoising value...🙃)
Just to clarify, these are just my random thoughts on this news, NOT SAYING they're art, NOT SAYING they have true originality, just views from a different perspective.
0 notes
Text

One of my experimental SDXL batches. Simple prompting, overal detail and resolution is rather low, but proportions are much better than with SD1.5
44 notes
·
View notes