#Scrape Images Data from Amazon
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Amazon Product Data Scraping Services - Scrape Amazon Product Data
Leverage the benefit of our Amazon product data scraping services to efficiently scrape Amazon product data, encompassing essential details such as ASIN, product titles, pricing information, and more.
know more:
#Amazon Product Data Scraping Services#Scrape Amazon Product Data#Scrape Images Data from Amazon#Scrape Product Review Data from Amazon
0 notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about “AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
Astrophysicists may have solved the mystery of Uranus’s unusual radiation belts

- By Nuadox Crew -
The weak radiation belts around Uranus, observed by Voyager 2 nearly 50 years ago, may actually be due to changes in particle speed caused by the planet’s asymmetric magnetic field.
Uranus's magnetic field is tilted 60° from its spin axis, creating an unusual magnetic environment.
Researchers, including Acevski et al., used new modeling incorporating a quadrupole field to simulate this asymmetry and found that particle speeds vary in different parts of their orbits.
This variation spreads particles out, decreasing their density by up to 20%, which could explain Voyager 2's observations.
Although this does not completely account for the weaker radiation belts, it offers insights into Uranus's magnetic anomalies. NASA’s proposed mission to the ice giants may provide further data to understand these mechanisms.
Header image: The planet Uranus, depicted in this James Webb Space Telescope image, features a tilted magnetic field and unusual radiation belts. Future missions to this icy giant may uncover more details. Credit: NASA, ESA, CSA, STScI.
Read more at Eos
Scientific paper: M. Acevski et al, Asymmetry in Uranus' High Energy Proton Radiation Belt, Geophysical Research Letters (2024). DOI: 10.1029/2024GL108961
--
Other recent news
Google is investigating claims of AI-generated content scraping, which affects search result rankings.
Amazon is reviewing whether Perplexity AI improperly scraped online content.
A bone analysis provides new insights into the Denisovans, an ancient human species, and their survival in extreme environments.
#astronomy#ai#space#uranus#planets#physics#google#big tech#search#generative ai#amazon#Perplexity AI#copyright#bone#paleontology#Denisovans#dna#genomics
5 notes
·
View notes
Text
How I'm Tracking My Manga Reading Backlog
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
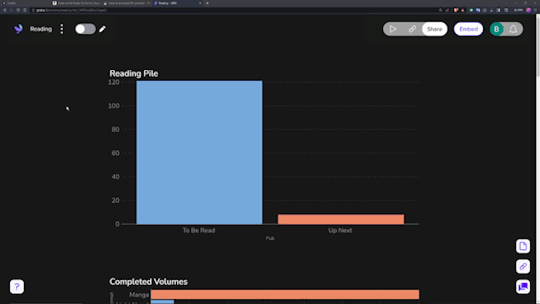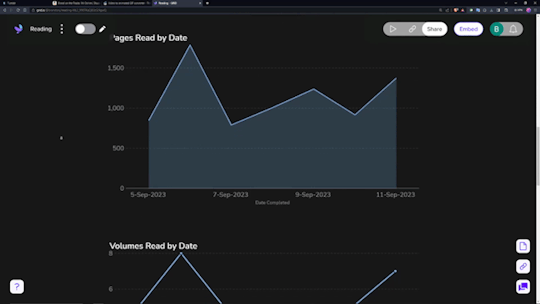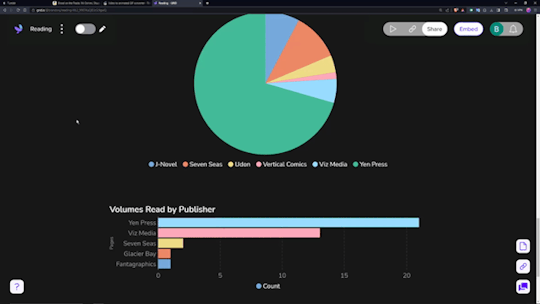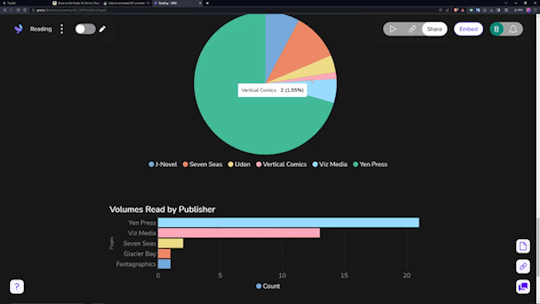
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
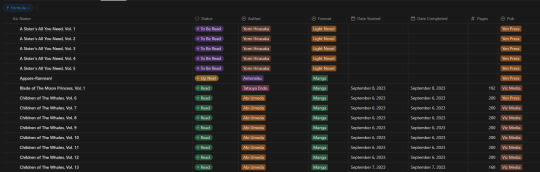
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

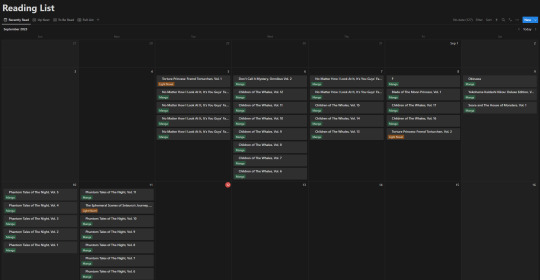
Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
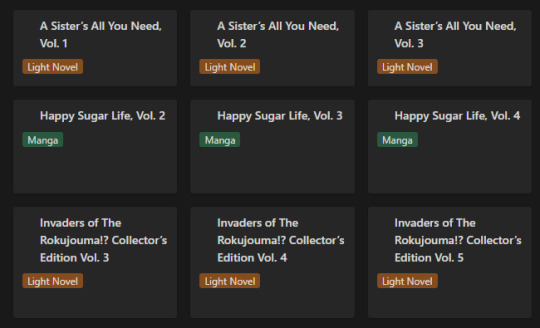
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes
Text
Amazon Product Review Data Scraping | Scrape Amazon Product Review Data

In the vast ocean of e-commerce, Amazon stands as an undisputed titan, housing millions of products and catering to the needs of countless consumers worldwide. Amidst this plethora of offerings, product reviews serve as guiding stars, illuminating the path for prospective buyers. Harnessing the insights embedded within these reviews can provide businesses with a competitive edge, offering invaluable market intelligence and consumer sentiment analysis.
In the realm of data acquisition, web scraping emerges as a potent tool, empowering businesses to extract structured data from the labyrinthine expanse of the internet. When it comes to Amazon product review data scraping, this technique becomes particularly indispensable, enabling businesses to glean actionable insights from the vast repository of customer feedback.
Understanding Amazon Product Review Data Scraping
Amazon product review data scraping involves the automated extraction of reviews, ratings, and associated metadata from Amazon product pages. This process typically entails utilizing web scraping tools or custom scripts to navigate through product listings, access review sections, and extract relevant information systematically.
The Components of Amazon Product Review Data:
Review Text: The core content of the review, containing valuable insights, opinions, and feedback from customers regarding their experience with the product.
Rating: The numerical or star-based rating provided by the reviewer, offering a quick glimpse into the overall satisfaction level associated with the product.
Reviewer Information: Details such as the reviewer's username, profile information, and sometimes demographic data, which can be leveraged for segmentation and profiling purposes.
Review Date: The timestamp indicating when the review was posted, aiding in trend analysis and temporal assessment of product performance.
The Benefits of Amazon Product Review Data Scraping
1. Market Research and Competitive Analysis:
By systematically scraping Amazon product reviews, businesses can gain profound insights into market trends, consumer preferences, and competitor performance. Analyzing the sentiment expressed in reviews can unveil strengths, weaknesses, opportunities, and threats within the market landscape, guiding strategic decision-making processes.
2. Product Enhancement and Innovation:
Customer feedback serves as a treasure trove of suggestions and improvement opportunities. By aggregating and analyzing product reviews at scale, businesses can identify recurring themes, pain points, and feature requests, thus informing product enhancement strategies and fostering innovation.
3. Reputation Management:
Proactively monitoring and addressing customer feedback on Amazon can be instrumental in maintaining a positive brand image. Through sentiment analysis and sentiment-based alerts derived from scraped reviews, businesses can swiftly identify and mitigate potential reputation risks, thereby safeguarding brand equity.
4. Pricing and Promotion Strategies:
Analyzing Amazon product reviews can provide valuable insights into perceived product value, price sensitivity, and the effectiveness of promotional campaigns. By correlating review sentiments with pricing fluctuations and promotional activities, businesses can refine their pricing strategies and promotional tactics for optimal market positioning.
Ethical Considerations and Best Practices
While Amazon product review data scraping offers immense potential, it's crucial to approach it ethically and responsibly. Adhering to Amazon's terms of service and respecting user privacy are paramount. Businesses should also exercise caution to ensure compliance with relevant data protection regulations, such as the GDPR.
Moreover, the use of scraped data should be guided by principles of transparency and accountability. Clearly communicating data collection practices and obtaining consent whenever necessary fosters trust and credibility.
Conclusion
Amazon product review data scraping unlocks a wealth of opportunities for businesses seeking to gain a competitive edge in the dynamic e-commerce landscape. By harnessing the power of automated data extraction and analysis, businesses can unearth actionable insights, drive informed decision-making, and cultivate stronger relationships with their customers. However, it's imperative to approach data scraping with integrity, prioritizing ethical considerations and compliance with regulatory frameworks. Embraced judiciously, Amazon product review data scraping can be a catalyst for innovation, growth, and sustainable business success in the digital age.
3 notes
·
View notes
Text
Unlocking Data Science's Potential: Transforming Data into Perceptive Meaning
Data is created on a regular basis in our digitally connected environment, from social media likes to financial transactions and detection labour. However, without the ability to extract valuable insights from this enormous amount of data, it is not very useful. Data insight can help you win in that situation. Online Course in Data Science It is a multidisciplinary field that combines computer knowledge, statistics, and subject-specific expertise to evaluate data and provide useful perception. This essay will explore the definition of data knowledge, its essential components, its significance, and its global transubstantiation diligence.

Understanding Data Science: To find patterns and shape opinions, data wisdom essentially entails collecting, purifying, testing, and analysing large, complicated datasets. It combines a number of fields.
Statistics: To establish predictive models and derive conclusions.
Computer intelligence: For algorithm enforcement, robotization, and coding.
Sphere moxie: To place perceptivity in a particular field of study, such as healthcare or finance.
It is the responsibility of a data scientist to pose pertinent queries, handle massive amounts of data effectively, and produce findings that have an impact on operations and strategy.
The Significance of Data Science
1. Informed Decision Making: To improve the stoner experience, streamline procedures, and identify emerging trends, associations rely on data-driven perception.
2. Increased Effectiveness: Businesses can decrease manual labour by automating operations like spotting fraudulent transactions or managing AI-powered customer support.
3. Acclimatised Gests: Websites like Netflix and Amazon analyse user data to provide suggestions for products and verified content.
4. Improvements in Medicine: Data knowledge helps with early problem diagnosis, treatment development, and bodying medical actions.
Essential Data Science Foundations:

1. Data Acquisition & Preparation: Databases, web scraping, APIs, and detectors are some sources of data. Before analysis starts, it is crucial to draw the data, correct offences, eliminate duplicates, and handle missing values.
2. Exploratory Data Analysis (EDA): EDA identifies patterns in data, describes anomalies, and comprehends the relationships between variables by using visualisation tools such as Seaborn or Matplotlib.
3. Modelling & Machine Learning: By using techniques like
Retrogression: For predicting numerical patterns.
Bracket: Used for data sorting (e.g., spam discovery).
For group segmentation (such as client profiling), clustering is used.
Data scientists create models that automate procedures and predict problems. Enrol in a reputable software training institution's Data Science course.
4. Visualisation & Liar: For stakeholders who are not technical, visual tools such as Tableau and Power BI assist in distilling complex data into understandable, captivating dashboards and reports.
Data Science Activities Across Diligence:
1. Online shopping
personalised recommendations for products.
Demand-driven real-time pricing schemes.
2. Finance & Banking
identifying deceptive conditioning.
trading that is automated and powered by predictive analytics.
3. Medical Care
tracking the spread of complaints and formulating therapeutic suggestions.
using AI to improve medical imaging.
4. Social Media
assessing public opinion and stoner sentiment.
curation of feeds and optimisation of content.
Typical Data Science Challenges:
Despite its potential, data wisdom has drawbacks.
Ethics & Sequestration: Preserving stoner data and preventing algorithmic prejudice.
Data Integrity: Inaccurate perception results from low-quality data.
Scalability: Pall computing and other high-performance structures are necessary for managing large datasets.
The Road Ahead:
As artificial intelligence advances, data wisdom will remain a crucial motorist of invention. unborn trends include :
AutoML – Making machine literacy accessible to non-specialists.
Responsible AI – icing fairness and translucency in automated systems.
Edge Computing – Bringing data recycling near to the source for real- time perceptivity.
Conclusion:
Data wisdom is reconsidering how businesses, governments, and healthcare providers make opinions by converting raw data into strategic sapience. Its impact spans innumerous sectors and continues to grow. With rising demand for professed professionals, now is an ideal time to explore this dynamic field.
0 notes
Text
Unlock Business Insights with Web Scraping eBay.co.uk Product Listings by DataScrapingServices.com

Unlock Business Insights with Web Scraping eBay.co.uk Product Listings by DataScrapingServices.com
In today's competitive eCommerce environment, businesses need reliable data to stay ahead. One powerful way to achieve this is through web scraping eBay.co.uk product listings. By extracting essential information from eBay's vast marketplace, businesses can gain valuable insights into market trends, competitor pricing, and customer preferences. At DataScrapingServices.com, we offer comprehensive web scraping solutions that allow businesses to tap into this rich data source efficiently.
Web Scraping eBay.co.uk Product Listings enables businesses to access critical product data, including pricing, availability, customer reviews, and seller details. At DataScrapingServices.com, we offer tailored solutions to extract this information efficiently, helping companies stay competitive in the fast-paced eCommerce landscape. By leveraging real-time data from eBay.co.uk, businesses can optimize pricing strategies, monitor competitor products, and gain valuable market insights. Whether you're looking to analyze customer preferences or track market trends, our web scraping services provide the actionable data needed to make informed business decisions.
Key Data Fields
With our eBay.co.uk product scraping, you can access:
1. Product titles and descriptions
2. Pricing information (including discounts and offers)
3. Product availability and stock levels
4. Seller details and reputation scores
5. Shipping options and costs
6. Customer reviews and ratings
7. Product images
8. Item specifications (e.g., size, color, features)
9. Sales history and volume
10. Relevant categories and tags
What We Offer?
Our eBay.co.uk product listing extraction service provides detailed information on product titles, descriptions, pricing, availability, seller details, shipping costs, and even customer reviews. We tailor our scraping services to meet specific business needs, ensuring you get the exact data that matters most for your strategy. Whether you're looking to track competitor prices, monitor product availability, or analyze customer reviews, our team has you covered.
Benefits for Your Business
By leveraging web scraping of eBay.co.uk product listings, businesses can enhance their decision-making process. Competitor analysis becomes more efficient, enabling companies to adjust their pricing strategies or identify product gaps in the market. Sales teams can use the data to focus on best-selling products, while marketing teams can gain insights into customer preferences by analyzing product reviews.
Moreover, web scraping eBay product listings allows for real-time data collection, ensuring you’re always up to date with the latest market trends and fluctuations. This data can be instrumental for businesses in pricing optimization, inventory management, and identifying potential market opportunities.
Best Web Scraping eBay.co.uk Product Listings in UK:
Liverpool, Dudley, Cardiff, Belfast, Northampton, Coventry, Portsmouth, Birmingham, Newcastle upon Tyne, Glasgow, Wolverhampton, Preston, Derby, Hull, Stoke-on-Trent, Luton, Swansea, Plymouth, Sheffield, Bristol, Leeds, Leicester, Brighton, London, Southampton, Edinburgh, Nottingham, Manchester, Aberdeen and Southampton.
Best eCommerce Data Scraping Services Provider
Amazon.ca Product Information Scraping
Marks & Spencer Product Details Scraping
Amazon Product Price Scraping
Retail Website Data Scraping Services
Tesco Product Details Scraping
Homedepot Product Listing Scraping
Online Fashion Store Data Extraction
Extracting Product Information from Kogan
PriceGrabber Product Pricing Scraping
Asda UK Product Details Scraping
Conclusion
At DataScrapingServices.com, our goal is to provide you with the most accurate and relevant data possible, empowering your business to make informed decisions. By utilizing our eBay.co.uk product listing scraping services, you’ll be equipped with the data needed to excel in the competitive world of eCommerce. Stay ahead of the game and unlock new growth opportunities with the power of data.
Contact us today to get started: Datascrapingservices.com
#ebayproductlistingscraping#webscrapingebayproductprices#ecommerceproductlistingextraction#productdataextraction#marketanalysis#competitorinsights#businessgrowth#datascrapingservices#productpricingscraping#datadriven
0 notes
Text
Scrape Product Info, Images & Brand Data from E-commerce | Actowiz
Introduction
In today’s data-driven world, e-commerce product data scraping is a game-changer for businesses looking to stay competitive. Whether you're tracking prices, analyzing trends, or launching a comparison engine, access to clean and structured product data is essential. This article explores how Actowiz Solutions helps businesses scrape product information, images, and brand details from e-commerce websites with precision, scalability, and compliance.
Why Scraping E-commerce Product Data Matters

E-commerce platforms like Amazon, Walmart, Flipkart, and eBay host millions of products. For retailers, manufacturers, market analysts, and entrepreneurs, having access to this massive product data offers several advantages:
- Price Monitoring: Track competitors’ prices and adjust your pricing strategy in real-time.
- Product Intelligence: Gain insights into product listings, specs, availability, and user reviews.
- Brand Visibility: Analyze how different brands are performing across marketplaces.
- Trend Forecasting: Identify emerging products and customer preferences early.
- Catalog Management: Automate and update your own product listings with accurate data.
With Actowiz Solutions’ eCommerce data scraping services, companies can harness these insights at scale, enabling smarter decision-making across departments.
What Product Data Can Be Scraped?

When scraping an e-commerce website, here are the common data fields that can be extracted:
✅ Product Information
Product name/title
Description
Category hierarchy
Product specifications
SKU/Item ID
Price (Original/Discounted)
Availability/Stock status
Ratings & reviews
✅ Product Images
Thumbnail URLs
High-resolution images
Zoom-in versions
Alternate views or angle shots
✅ Brand Details
Brand name
Brand logo (if available)
Brand-specific product pages
Brand popularity metrics (ratings, number of listings)
By extracting this data from platforms like Amazon, Walmart, Target, Flipkart, Shopee, AliExpress, and more, Actowiz Solutions helps clients optimize product strategy and boost performance.
Challenges of Scraping E-commerce Sites

While the idea of gathering product data sounds simple, it presents several technical challenges:
Dynamic Content: Many e-commerce platforms load content using JavaScript or AJAX.
Anti-bot Mechanisms: Rate-limiting, captchas, IP blocking, and login requirements are common.
Frequent Layout Changes: E-commerce sites frequently update their front-end structure.
Pagination & Infinite Scroll: Handling product listings across pages requires precise navigation.
Image Extraction: Downloading, renaming, and storing image files efficiently can be resource-intensive.
To overcome these challenges, Actowiz Solutions utilizes advanced scraping infrastructure and intelligent algorithms to ensure high accuracy and efficiency.
Step-by-Step: How Actowiz Solutions Scrapes E-commerce Product Data

Let’s walk through the process that Actowiz Solutions follows to scrape and deliver clean, structured, and actionable e-commerce data:
1. Define Requirements
The first step involves understanding the client’s specific data needs:
Target websites
Product categories
Required data fields
Update frequency (daily, weekly, real-time)
Preferred data delivery formats (CSV, JSON, API)
2. Website Analysis & Strategy Design
Our technical team audits the website’s structure, dynamic loading patterns, pagination system, and anti-bot defenses to design a customized scraping strategy.
3. Crawler Development
We create dedicated web crawlers or bots using tools like Python, Scrapy, Playwright, or Puppeteer to extract product listings, details, and associated metadata.
4. Image Scraping & Storage
Our bots download product images, assign them appropriate filenames (using SKU or product title), and store them in cloud storage like AWS S3 or GDrive. Image URLs can also be returned in the dataset.
5. Brand Attribution
Products are mapped to brand names by parsing brand tags, logos, and using NLP-based classification. This helps clients build brand-level dashboards.
6. Data Cleansing & Validation
We apply validation rules, deduplication, and anomaly detection to ensure only accurate and up-to-date data is delivered.
7. Data Delivery
Data can be delivered via:
REST APIs
S3 buckets or FTP
Google Sheets/Excel
Dashboard integration
All data is made ready for ingestion into CRMs, ERPs, or BI tools.
Supported E-Commerce Platforms

Actowiz Solutions supports product data scraping from a wide range of international and regional e-commerce websites, including:
Amazon
Walmart
Target
eBay
AliExpress
Flipkart
BigCommerce
Magento
Rakuten
Etsy
Lazada
Wayfair
JD.com
Shopify-powered sites
Whether you're focused on electronics, fashion, grocery, automotive, or home décor, Actowiz can help you extract relevant product and brand data with precision.
Use Cases: How Businesses Use Scraped Product Data

Retailers
Compare prices across platforms to remain competitive and win the buy-box.
🧾 Price Aggregators
Fuel price comparison engines with fresh, accurate product listings.
📈 Market Analysts
Study trends across product categories and brands.
🎯 Brands
Monitor third-party sellers, counterfeit listings, or unauthorized resellers.
🛒 E-commerce Startups
Build initial catalogs quickly by extracting competitor data.
📦 Inventory Managers
Sync product stock and images with supplier portals.
Actowiz Solutions tailors the scraping strategy according to the use case and delivers the highest ROI on data investment.
Benefits of Choosing Actowiz Solutions

✅ Scalable Infrastructure
Scrape millions of products across multiple websites simultaneously.
✅ IP Rotation & Anti-Bot Handling
Bypass captchas, rate-limiting, and geolocation barriers with smart proxies and user-agent rotation.
✅ Near Real-Time Updates
Get fresh data updated daily or in real-time via APIs.
✅ Customization & Flexibility
Select your data points, target pages, and preferred delivery formats.
✅ Compliance-First Approach
We follow strict guidelines and ensure scraping methods respect site policies and data usage norms.
Security and Legal Considerations
Actowiz Solutions emphasizes ethical scraping practices and ensures compliance with data protection laws such as GDPR, CCPA, and local regulations. Additionally:
Only publicly available data is extracted.
No login-restricted or paywalled content is accessed without consent.
Clients are guided on proper usage and legal responsibility for the scraped data.
Frequently Asked Questions
❓ Can I scrape product images in high resolution?
Yes. Actowiz Solutions can extract multiple image formats, including zoomable HD product images and thumbnails.
❓ How frequently can data be updated?
Depending on the platform, we support real-time, hourly, daily, or weekly updates.
❓ Can I scrape multiple marketplaces at once?
Absolutely. We can design multi-site crawlers that collect and consolidate product data across platforms.
❓ Is scraped data compatible with Shopify or WooCommerce?
Yes, we can deliver plug-and-play formats for Shopify, Magento, WooCommerce, and more.
❓ What if a website structure changes?
We monitor site changes proactively and update crawlers to ensure uninterrupted data flow.
Final Thoughts
Scraping product data from e-commerce websites unlocks a new layer of market intelligence that fuels decision-making, automation, and competitive strategy. Whether it’s tracking competitor pricing, enriching your product catalog, or analyzing brand visibility — the possibilities are endless.
Actowiz Solutions brings deep expertise, powerful infrastructure, and a client-centric approach to help businesses extract product info, images, and brand data from e-commerce platforms effortlessly. Learn More
0 notes
Text
Smart Retail Decisions Start with AI-Powered Data Scraping

In a world where consumer preferences change overnight and pricing wars escalate in real time, making smart retail decisions is no longer about instincts—it's about data. And not just any data. Retailers need fresh, accurate, and actionable insights drawn from a vast and competitive digital landscape.
That’s where AI-powered data scraping steps in.
Historically, traditional data scraping has been used to gather ecommerce data. But by leveraging artificial intelligence (AI) in scraping processes, companies can gain real-time, scalable, and predictive intelligence to make informed decisions in retailing.
Here, we detail how data scraping using AI is revolutionizing retailing, its advantages, what kind of data you can scrape, and why it enables high-impact decisions in terms of pricing, inventory, customer behavior, and market trends.
What Is AI-Powered Data Scraping?
Data scraping is an operation of pulling structured data from online and digital channels, particularly websites that do not support public APIs. In retail, these can range from product offerings and price data to customer reviews and availability of items in stock.
AI-driven data scraping goes one step further by employing artificial intelligence such as machine learning, natural language processing (NLP), and predictive algorithms to:
Clean and structure unstructured data
Interpret customer sentiment from reviews
Detect anomalies in prices
Predict market trends
Based on data collected, provide strategic proposals
It's not just about data-gathering—it’s about knowing and taking wise action based on it.
Why Retail Requires Smarter Data Solutions
The contemporary retail sector is sophisticated and dynamic. This is why AI-powered scraping is more important than ever:
Market Changes Never Cease to Occur Prices, demand, and product availability can alter multiple times each day—particularly on marketplaces such as Amazon or Walmart. AI scrapers can monitor and study these changes round-the-clock.
Manual Decision-Making is Too Slow Human analysts can process only so much data. AI accelerates decision-making by processing millions of pieces of data within seconds and highlighting what's significant.
The Competition is Tough Retailers are in a race to offer the best prices, maintain optimal inventory, and deliver exceptional customer experiences. Data scraping allows companies to monitor competitors in real time.
Types of Retail Data You Can Scrape with AI
AI-powered scraping tools can extract and analyze the following retail data from ecommerce sites, review platforms, competitor websites, and search engines:
Product Information
Titles, descriptions, images
Product variants (size, color, model)
Brand and manufacturer details
Availability (in stock/out of stock)
Pricing & Promotions
Real-time price tracking
Historical pricing trends
Discount and offer patterns
Dynamic pricing triggers
Inventory & Supply
Stock levels
Delivery timelines
Warehouse locations
SKU movement tracking
Reviews & Ratings
NLP-based sentiment analysis
Star ratings and text content
Trending complaints or praise
Verified purchase filtering
Market Demand & Sales Rank
Bestsellers by category
Category saturation metrics
Sales velocity signals
New or emerging product trends
Logistics & Shipping
Delivery options and timeframes
Free shipping thresholds
Return policies and costs
Benefits of AI-Powered Data Scraping in Retail
So what happens when you combine powerful scraping capabilities with AI intelligence? Retailers unlock a new dimension of performance and strategy.
1. Real-Time Competitive Intelligence
With AI-enhanced scraping, retailers can monitor:
Price changes across hundreds of competitor SKUs
Promotional campaigns
Inventory status of competitor bestsellers
AI models can predict when a competitor may launch a flash sale or run low on inventory—giving you an opportunity to win customers.
2. Smarter Dynamic Pricing
Machine learning algorithms can:
Analyze competitor pricing history
Forecast demand elasticity
Recommend optimal pricing
Retailers can automatically adjust prices to stay competitive while maximizing margins.
3. Enhanced Product Positioning
By analyzing product reviews and ratings using NLP, you can:
Identify common customer concerns
Improve product descriptions
Make data-driven merchandising decisions
For example, if customers frequently mention packaging issues, that feedback can be looped directly to product development.
4. Improved Inventory Planning
AI-scraped data helps detect:
Which items are trending up or down
Seasonality patterns
Regional demand variations
This enables smarter stocking, reduced overstock, and faster response to emerging trends.
5. Superior Customer Experience
Insights from reviews and competitor platforms help you:
Optimize support responses
Highlight popular product features
Personalize marketing campaigns
Use Cases: How Retailers Are Winning with AI Scraping
DTC Ecommerce Brands
Use AI to monitor pricing and product availability across marketplaces. React to changes in real time and adjust pricing or run campaigns accordingly.
Multichannel Retailers
Track performance and pricing across online and offline channels to maintain brand consistency and pricing competitiveness.
Consumer Insights Teams
Analyze thousands of reviews to spot unmet needs or new use cases—fueling product innovation and positioning.
Marketing and SEO Analysts
Scrape metadata, titles, and keyword rankings to optimize product listings and outperform competitors in search results.
Choosing the Right AI-Powered Scraping Partner
Whether building your own tool or hiring a scraping agency, here’s what to look for:
Scalable Infrastructure
The tool should handle scraping thousands of pages per hour, with robust error handling and proxy support.
Intelligent Data Processing
Look for integrated machine learning and NLP models that analyze and enrich the data in real time.
Customization and Flexibility
Ensure the solution can adapt to your specific data fields, scheduling, and delivery format (JSON, CSV, API).
Legal and Ethical Compliance
A reliable partner will adhere to anti-bot regulations, avoid scraping personal data, and respect site terms of service.
Challenges and How to Overcome Them
While AI-powered scraping is powerful, it’s not without hurdles:
Website Structure Changes
Ecommerce platforms often update their layouts. This can break traditional scraping scripts.
Solution: AI-based scrapers with adaptive learning can adjust without manual reprogramming.
Anti-Bot Measures
Websites deploy CAPTCHAs, IP blocks, and rate limiters.
Solution: Use rotating proxies, headless browsers, and CAPTCHA solvers.
Data Noise
Unclean or irrelevant data can lead to false conclusions.
Solution: Leverage AI for data cleaning, anomaly detection, and duplicate removal.
Final Thoughts
In today's ecommerce disruption, retailers that utilize real-time, smart data will be victorious. AI-driven data scraping solutions no longer represent an indulgence but rather an imperative to remain competitive.
By facilitating data capture and smarter insights, these services support improved customer experience, pricing, marketing, and inventory decisions.
No matter whether you’re introducing a new product, measuring your market, or streamlining your supply chain—smart retailing begins with smart data.
0 notes
Text
The Benefits of Using Amazon Scraping Tools for Market Research
Amazon is one of the largest e-commerce platforms in the world, with millions of products listed every day. With so much data available, Amazon can be a treasure trove for market research. Amazon scraping tools can help businesses extract valuable insights from Amazon product pages, reviews, and sales data. In this article, we will explore the benefits of using Amazon scraping tools for market research.
What are Amazon Scraping Tools?
Amazon scraping tools are software programs that extract data from Amazon product pages, reviews, and sales data. These tools can be used to extract various types of data, including:
Product information (e.g., description, specifications, images)
Reviews and ratings
Sales rankings
Pricing data
Benefits of Using Amazon Scraping Tools for Market Research
Identify Market Trends: Amazon scraping tools can help businesses identify market trends by analyzing sales data, reviews, and product listings.
Analyze Competitor Data: By scraping competitor data, businesses can gain insights into their pricing strategies, product offerings, and customer reviews.
Understand Customer Behavior: Amazon scraping tools can provide valuable insights into customer behavior, including purchasing habits and preferences.
Identify Product Opportunities: By analyzing Amazon product data, businesses can identify opportunities to develop new products or improve existing ones.
Improve Product Listings: Amazon scraping tools can help businesses optimize their product listings by analyzing top-performing listings and identifying key factors that contribute to their success.
How Amazon Scraping Tools Can Help with Market Research
Product Research: Amazon scraping tools can help businesses research products and identify opportunities to develop new products or improve existing ones.
Competitor Analysis: By scraping competitor data, businesses can gain insights into their pricing strategies, product offerings, and customer reviews.
Customer Insights: Amazon scraping tools can provide valuable insights into customer behavior, including purchasing habits and preferences.
Market Trend Analysis: Amazon scraping tools can help businesses identify market trends by analyzing sales data, reviews, and product listings.
Best Practices for Using Amazon Scraping Tools for Market Research
Choose a Reliable Tool: Choose an Amazon scraping tool that is reliable and provides accurate data.
Define Research Objectives: Define research objectives and identify the data that needs to be extracted.
Analyze Data: Analyze extracted data to identify trends, opportunities, and insights.
Monitor Competitor Activity: Monitor competitor activity to stay competitive and adjust market strategies accordingly.
Common Challenges in Using Amazon Scraping Tools for Market Research
Data Accuracy: Ensuring that extracted data is accurate and up-to-date can be a challenge.
IP Blocking: Amazon may block IP addresses that are scraping data excessively, which can disrupt market research.
Scalability: Handling large amounts of data can be a challenge, especially for businesses with limited resources.
Overcoming Challenges in Using Amazon Scraping Tools for Market Research
Use a Reliable Tool: Use a reliable Amazon scraping tool that provides accurate data and handles anti-scraping measures.
Rotate Proxies: Rotate proxies to avoid IP blocking and ensure that market research is not disrupted.
Optimize Data Storage: Optimize data storage to handle large amounts of data and ensure that data is easily accessible.
Conclusion
Amazon scraping tools can be a powerful tool for businesses looking to conduct market research. By providing valuable insights into customer behavior, market trends, and competitor activity, Amazon scraping tools can help businesses make informed decisions and stay competitive. By following best practices and overcoming challenges, businesses can unlock the potential of Amazon scraping tools and gain a competitive edge in the market.
1 note
·
View note
Text
Data Collection Through Images: Techniques and Tools

Introduction
In the contemporary landscape driven by data, the Data Collection Images -based data has emerged as a fundamental element across numerous sectors, including artificial intelligence (AI), healthcare, retail, and security. The evolution of computer vision and deep learning technologies has made the gathering and processing of image data increasingly essential. This article delves into the primary methodologies and tools employed in image data collection, as well as their significance in current applications.
The Importance of Image Data Collection
Image data is crucial for:
Training AI Models: Applications in computer vision, such as facial recognition, object detection, and medical imaging, are heavily reliant on extensive datasets.
Automation & Robotics: Technologies like self-driving vehicles, drones, and industrial automation systems require high-quality image datasets to inform their decision-making processes.
Retail & Marketing: Analyzing customer behavior and enabling visual product recognition utilize image data for enhanced personalization and analytics.
Healthcare & Biometric Security: Image-based datasets are essential for accurate medical diagnoses and identity verification.
Methods for Image Data Collection
1. Web Scraping & APIs
Web scraping is a prevalent technique for collecting image data, involving the use of scripts to extract images from various websites. Additionally, APIs from services such as Google Vision, Flickr, and OpenCV offer access to extensive image datasets.
2. Manual Image Annotation
The process of manually annotating images is a critical method for training machine learning models. This includes techniques such as bounding boxes, segmentation, and keypoint annotations.
3. Crowdsourcing
Services such as Amazon Mechanical Turk and Figure Eight facilitate the gathering and annotation of extensive image datasets through human input.
4. Synthetic Data Generation
In situations where real-world data is limited, images generated by artificial intelligence can be utilized to produce synthetic datasets for training models.
5. Sensor & Camera-Based Collection
Sectors such as autonomous driving and surveillance utilize high-resolution cameras and LiDAR sensors to gather image data in real-time.
Tools for Image Data Collection
1. Labeling
A widely utilized open-source tool for bounding box annotation, particularly effective for object detection models.
2. Roboflow
A robust platform designed for the management, annotation, and preprocessing of image datasets.
3. OpenCV
A well-known computer vision library that facilitates the processing and collection of image data in real-time applications.
4. Super Annotate
A collaborative annotation platform tailored for AI teams engaged in image and video dataset projects.
5. ImageNet & COCO Dataset
Established large-scale datasets that offer a variety of image collections for training artificial intelligence models.
Where to Obtain High-Quality Image Datasets
For those in search of a dataset for face detection, consider utilizing the Face Detection Dataset. This resource is specifically crafted to improve AI models focused on facial recognition and object detection.
How GTS.ai Facilitates Image Data Collection for Your Initiative
GTS.ai offers premium datasets and tools that streamline the process of image data collection, enabling businesses and researchers to train AI models with accuracy. The following are ways in which it can enhance your initiative:
Pre-Annotated Datasets – Gain access to a variety of pre-labeled image datasets, including the Face Detection Dataset for facial recognition purposes.
Tailored Data Collection – Gather images customized for particular AI applications, such as those in healthcare, security, and retail sectors.
Automated Annotation – Employ AI-driven tools to efficiently and accurately label and categorize images.
Data Quality Assurance – Maintain high levels of accuracy through integrated validation processes and human oversight.
Scalability and Integration – Effortlessly incorporate datasets into machine learning workflows via APIs and cloud-based solutions.
By utilizing GTS.ai, your initiative can expedite AI training, enhance model precision, and optimize image data collection methods.
Conclusion
The collection of image-based data is an essential aspect of advancements in Globose Technology Solutions AI and computer vision. By employing appropriate techniques and tools, businesses and researchers can develop robust models for a wide range of applications. As technology progresses, the future of image data collection is poised to become increasingly automated, ethical, and efficient.
0 notes
Text
Data Collection Strategies for Supervised and Unsupervised Learning

Introduction:
In the realm of Data Collection Machine Learning, data serves as the essential resource that drives model performance. The absence of high-quality data can hinder even the most advanced algorithms from yielding significant outcomes. The process of data collection is a vital component of the machine learning workflow, as it has a direct influence on the efficacy and dependability of the models. The approaches to data collection may differ based on the learning paradigm—whether it is supervised or unsupervised learning. This article will examine effective strategies customized for each category and emphasize best practices to ensure the creation of robust datasets.
Supervised Learning: Accuracy in Data Collection
Supervised learning depends on labeled data, where each input instance is associated with a specific output or target label. This necessity renders data collection for supervised learning more organized yet also more complex, as the labels must be both precise and consistent.
Establish Clear Objectives
Prior to data collection, it is essential to explicitly define the problem that your supervised learning model intends to address. A thorough understanding of the problem domain will assist in determining the necessary data types and labels. For instance, if the goal is to develop an image classification model for distinguishing between cats and dogs, a dataset containing images labeled as “cat” or “dog” will be required.
2. Leverage Publicly Accessible Datasets
Utilizing publicly available datasets can significantly reduce both time and resource expenditure. Resources such as Kaggle, the UCI Machine Learning Repository, and Open Images offer pre-labeled datasets across a variety of fields. It is crucial, however, to ensure that the dataset is suitable for your specific application.
3. Annotation Tools and Crowdsourcing Methods
For the collection of custom data, employing annotation tools such as Labelbox, CVAT, or RectLabel can enhance the efficiency of the labeling process. Additionally, crowdsourcing platforms like Amazon Mechanical Turk can engage a broader audience for data annotation, which is particularly beneficial when managing large datasets.
4. Ensure Data Quality
The accuracy of the labels plays a critical role in the performance of the model. To reduce errors and inconsistencies, it is advisable to implement quality control measures, including checks for inter-annotator agreement and the use of automated validation scripts.
5. Achieve Dataset Balance
An imbalanced dataset can distort model predictions in supervised learning scenarios. For example, in a binary classification task where 90% of the data is from one class, the model may become biased towards that class. To mitigate this issue, consider gathering additional data for the underrepresented classes or employing strategies such as data augmentation and oversampling.
Unsupervised Learning: Investigating the Uncharted
Unsupervised learning models operate on unlabeled datasets to uncover patterns or structures, such as clusters or associations. The absence of a need for labeled data allows for a more adaptable data collection process, which remains equally vital.
Utilize Extensive Data Repositories
Unsupervised learning excels with large volumes of data. Techniques such as web scraping, application programming interfaces (APIs), and Internet of Things (IoT) sensors serve as valuable means for gathering substantial amounts of unprocessed data. For instance, extracting data from online retail platforms can facilitate customer segmentation initiatives.
2. Emphasize Data Heterogeneity
A diverse dataset is essential for effective unsupervised learning. It is important to gather data from various sources and ensure a broad spectrum of features to reveal significant patterns. For example, when clustering customer behaviors, it is beneficial to incorporate demographics, purchasing history, and online activity.
3. Data Preparation and Feature Development
Raw data frequently contains extraneous noise or irrelevant elements. Implementing preprocessing techniques such as normalization, outlier elimination, and feature extraction can greatly enhance dataset quality. Methods like Principal Component Analysis (PCA) can help in reducing dimensionality while retaining critical information.
4. Ongoing Data Acquisition
Unsupervised learning often gains from the continuous acquisition of data. For example, in the context of anomaly detection, real-time data streams allow models to adjust to evolving conditions and identify anomalies swiftly.
Ethical Considerations in Data Collection

Ethical considerations are paramount in the process of data collection, regardless of the learning paradigm employed. The following are recommended best practices:
Obtain Consent: It is essential to secure permission for the collection and utilization of data, especially when handling sensitive information.
Protect Privacy: Personal data should be anonymized to safeguard the identities of individuals.
Avoid Bias: Aim for a diverse dataset to reduce biases that may result in unjust or inaccurate predictions from models.
Comply with Regulations: Follow legal standards such as GDPR or CCPA to uphold ethical data practices.
Best Practices for Data Collection
Automate Data Collection: Implement tools and scripts to streamline the data collection process, thereby minimizing manual labor and potential errors.
Validate Data: Conduct regular validations of the collected data to ensure adherence to quality standards.
Document the Process: Keep comprehensive records of data sources, collection techniques, and preprocessing methods to promote transparency and reproducibility.
Iterative Improvement: Regularly update and enhance the dataset in response to model performance and user feedback.
Conclusion
The significance of data collection in machine learning is paramount and should not be underestimated. In the context of supervised learning, it is essential to gather precise, labeled data that aligns with the specific challenges you are addressing. Conversely, for unsupervised learning, it is crucial to emphasize the diversity of data and engage in thorough preprocessing to effectively reveal underlying patterns.
In supervised learning, the focus is on collecting labeled data, where Globose Technology Solutions experts play a critical role in ensuring labels are accurate and contextually relevant. Strategies such as active learning, transfer learning, and synthetic data generation can help optimize data collection when resources are constrained.
For unsupervised learning, the emphasis shifts to gathering diverse, comprehensive datasets that allow the model to detect patterns and clusters. Here, GTS experts can assist in designing sampling methods and curating datasets to represent the complexity of the problem domain.
0 notes
Text
Data Collection for Machine Learning: Laying the Foundation for AI Excellence

This is, in fact, a fresh age of possibilities initiated by accelerating data collection for Machine Learning; ML models redefining how we tackle complex problems are self-driving cars on the surface to precisely detecting diseases. However, behind every brilliant AI system is a crucial task-data collection.
In any ML project, data collection is the first step of the whole process. Without such data, there is just no basis for even high-tech algorithms to work on. It is basically about gathering, sorting, and processing raw data to make it ready for training machine learning models. This blog will dig into the importance of data collection, ways for data collection, challenges ahead, and how this channelizes excellence for AI.
Why Is Data Collection Critical for Machine Learning?
In machine learning, data acts as the fuel that powers algorithms. It provides the examples that models use to learn patterns, make predictions, and refine their accuracy over time.
This is the significance of data collection:
A Foundation for Learning: ML models gain knowledge of relationships and trends from examples. It is practically impossible to map something without the dataset required for the learning process. Thus, data collection is vital to ensure these relevant and diverse sets of information are available at this stage.
Model Performance Improvement: Data quality and variation are critical to the accuracy and reliability of an ML model. The more wrapped up in creating a good dataset, the better the model generalizes and performs in the real world.
Addressing Domain-Specific Challenges: Every industry/application has certain peculiar data requirements. A healthcare AI system needs medical imaging data, while an autonomous vehicle system needs road and traffic data. Data collection allows the features in the input space to be tailored relative to the specific problem under question.
Supporting Continuous Improvement: AI models are not static—they evolve with time and usage. Continuous data collection enables these systems to adapt to new environments, trends, and user behaviors.
Methods of Data Collection for Machine Learning
Data can be collected in several ways, depending on the type of project and the domain it serves.
Here are some common methods:
Manual Data Collection: In this method, human operators gather data by observing, recording, or annotating it. Though time-intensive, manual collection ensures high-quality, precise data, especially in tasks like labeling images or annotating medical scans.
Automated Data Collection: Automated methods use scripts, sensors, or APIs to gather large volumes of data efficiently. For example, web scraping tools can extract data from websites, while IoT sensors collect environmental data.
Crowdsourced Data: Platforms like Amazon Mechanical Turk enable crowdsourcing for data collection and annotation. This approach is cost-effective and scalable but may require additional quality checks.
Synthetic Data Generation: Synthetic data is artificially created to mimic real-world data. This is particularly useful when collecting actual data is expensive, risky, or impossible, such as in autonomous driving simulations.
Open-Source Datasets: Many organizations and academic institutions release publicly available datasets. Platforms like Kaggle, UCI Machine Learning Repository, and ImageNet are popular sources for diverse datasets.
Key Considerations for Effective Data Collection
Not all data is created equal. To ensure that the collected data serves its purpose effectively, it’s essential to focus on the following aspects:
Relevance: The data should align with the specific problem the ML model aims to solve. Irrelevant data adds noise and hinders model performance.
Diversity: Diverse datasets improve the model’s ability to generalize. For example, a facial recognition model should be trained on images representing different ethnicities, ages, and lighting conditions.
Quality: High-quality data is clean, accurate, and well-annotated. Data preprocessing, such as removing duplicates, handling missing values, and resolving inconsistencies, is critical to maintaining quality.
Scalability: As ML projects grow, so does the need for more data. Scalable data collection methods ensure that datasets can be expanded without compromising quality.
Ethical Compliance: Data collection must adhere to ethical guidelines and legal regulations, such as GDPR or HIPAA. Respecting privacy and obtaining consent are paramount.
Challenges in Data Collection
While data collection is vital, it is not without challenges. Some of the most common obstacles include:
Data Scarcity: In some domains, such as rare diseases or emerging technologies, relevant data may be hard to find or collect. Synthetic data and simulation environments can help mitigate this issue.
High Costs: Manual annotation, especially for large datasets, can be expensive. Automated tools and crowdsourcing platforms can help reduce costs while maintaining quality.
Data Imbalance: Many datasets suffer from imbalances, where one class or category is overrepresented. For instance, in fraud detection, fraudulent transactions may be rare, making it harder for the model to detect them.
Privacy Concerns: Collecting data that involves personal or sensitive information requires stringent measures to protect user privacy and comply with regulations.
Data Drift: As real-world conditions evolve, previously collected data may no longer represent current trends. Continuous data collection and periodic updates are necessary to address this issue.
Applications of Data Collection in AI and ML
Data collection fuels innovation across industries, enabling transformative AI solutions. Here are a few examples:
Healthcare: AI models trained on medical imaging datasets are improving diagnostics and treatment planning. Data collection from wearable devices and patient records supports personalized medicine.
Retail and E-commerce: Retailers use data on customer preferences, browsing behavior, and transaction history to train recommendation systems and optimize supply chains.
Autonomous Vehicles Self-driving cars rely on video and sensor data collected from real-world driving scenarios. This data helps train models to navigate roads, detect obstacles, and ensure passenger safety.
Finance: In the financial sector, datasets of transaction records, market trends, and user behavior are used for fraud detection, credit scoring, and risk management.
Agriculture: Satellite and drone imagery provide data for AI models that monitor crop health, predict yields, and optimize irrigation.
Conclusion
Data collection is the foundation upon which every successful ML model is built. It’s not just about data gathering; it’s about curating a rich, diverse, and high-quality data set from relevant sources, so that AI systems can perform efficiently and responsibly.
As the demand for smarter AI solutions keeps on rising, investment in strong data collection methods becomes a key factor in realizing machine learning excellence. While some certainly need to address challenges and accept new trends, industries and researchers globally can unlock the full potential of AI and bring the world one step closer to an intelligent future driven by data.
Visit Globose Technology Solutions to see how the team can speed up your facial recognition projects.
0 notes
Text
Unlock Fashion Intelligence: Scraping Fashion Products from Namshi.com

Unlock Fashion Intelligence: Scraping Fashion Products from Namshi.com
In the highly competitive world of online fashion retail, data is power. Whether you're a trend tracker, competitive analyst, eCommerce business owner, or digital marketer, having access to accurate and real-time fashion product data gives you a serious edge. At DataScrapingServices.com, we offer tailored Namshi.com Fashion Product Scraping Services to help you extract structured and up-to-date product data from one of the Middle East’s leading online fashion retailers.
Namshi.com has emerged as a prominent eCommerce platform, particularly in the UAE and other GCC countries. With a wide range of categories such as men’s, women’s, and kids’ clothing, shoes, bags, beauty, accessories, and premium brands, it offers a treasure trove of data for fashion retailers and analysts. Scraping data from Namshi.com enables businesses to keep pace with shifting fashion trends, monitor competitor pricing, and optimize product listings.
✅ Key Data Fields Extracted from Namshi.com
When scraping Namshi.com, we extract highly relevant product information, including:
Product Name
Brand Name
Price (Original & Discounted)
Product Description
Category & Subcategory
Available Sizes & Colors
Customer Ratings and Reviews
Product Images
SKU/Item Code
Stock Availability
These data points can be customized to meet your specific needs and can be delivered in formats such as CSV, Excel, JSON, or through APIs for easy integration into your database or application.
💡 Benefits of Namshi.com Fashion Product Scraping
1. Competitor Price Monitoring
Gain real-time insights into how Namshi.com prices its fashion products across various categories and brands. This helps eCommerce businesses stay competitive and optimize their pricing strategies.
2. Trend Analysis
Scraping Namshi.com lets you track trending items, colors, sizes, and brands. You can identify which fashion products are popular by analyzing ratings, reviews, and availability.
3. Catalog Enrichment
If you operate an online fashion store, integrating scraped data from Namshi can help you expand your product database, improve product descriptions, and enhance visuals with high-quality images.
4. Market Research
Understanding the assortment, discounts, and promotional tactics used by Namshi helps businesses shape their marketing strategies and forecast seasonal trends.
5. Improved Ad Targeting
Knowing which products are popular in specific regions or categories allows fashion marketers to create targeted ad campaigns for better conversion.
6. Inventory Insights
Tracking stock availability lets you gauge demand patterns, optimize stock levels, and avoid overstock or stockouts.
🌍 Who Can Benefit?
Online Fashion Retailers
Fashion Aggregators
eCommerce Marketplaces
Brand Managers
Retail Analysts
Fashion Startups
Digital Marketing Agencies
At DataScrapingServices.com, we ensure all our scraping solutions are accurate, timely, and fully customizable, with options for daily, weekly, or on-demand extraction.
Best eCommerce Data Scraping Services Provider
Scraping Kohls.com Product Information
Scraping Fashion Products from Namshi.com
Ozon.ru Product Listing Extraction Services
Extracting Product Details from eBay.de
Fashion Products Scraping from Gap.com
Scraping Currys.co.uk Product Listings
Extracting Product Details from BigW.com.au
Macys.com Product Listings Scraping
Scraping Argos.co.uk Home and Furniture Product Listings
Target.com Product Prices Extraction
Amazon Price Data Extraction
Best Scraping Fashion Products from Namshi.com in UAE:
Fujairah, Umm Al Quwain, Dubai, Khor Fakkan, Abu Dhabi, Sharjah, Al Ain, Ajman, Ras Al Khaimah, Dibba Al-Fujairah, Hatta, Madinat Zayed, Ruwais, Al Quoz, Al Nahda, Al Barsha, Jebel Ali, Al Gharbia, Al Hamriya, Jumeirah and more.
📩 Need fashion data from Namshi.com? Contact us at: [email protected]
Visit: DataScrapingServices.com
Stay ahead of the fashion curve—scrape smarter, sell better.
#scrapingfashionproductsfromnamshi#extractingfashionproductsfromnamshi#ecommercedatascraping#productdetailsextraction#leadgeneration#datadrivenmarketing#webscrapingservices#businessinsights#digitalgrowth#datascrapingexperts
0 notes
Text
Extract product data from Shopbop using ScrapeStom
Shopbop is a fashion shopping website for women in the United States. It was founded in 1999 and is headquartered in Madison, Wisconsin; it was acquired by Amazon on February 27, 2006; Free shipping service; In 2011, launched twelve different currency settlement services, officially becoming a shopping website with a high-quality global shopping experience.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Web Scraping 103 : Scrape Amazon Product Reviews With Python –

Amazon is a well-known e-commerce platform with a large amount of data available in various formats on the web. This data can be invaluable for gaining business insights, particularly by analyzing product reviews to understand the quality of products provided by different vendors.
In this guide we will look into web scraping steps to extract amazon reviews of a particular product and save it in excel or csv format. Since manually copying information online can be tedious, in this guide we’ll focus on scraping reviews from Amazon. This hands-on experience will enhance our practical understanding of web scraping techniques.
Before we start, make sure you have Python installed in your system, you can do that from this link: python.org. The process is very simple, just install it like you would install any other application.
Now that everything is set let’s proceed:
How to Scrape Amazon Reviews Using Python
Install Anaconda using this link: https://www.anaconda.com/download . Be sure to follow the default settings during installation. For more guidance, please click here.
We can use various IDEs, but to keep it beginner-friendly, let’s start with Jupyter Notebook in Anaconda. You can watch the video linked above to understand and get familiar with the software.
Steps for Web Scraping Amazon Reviews:
Create New Notebook and Save it. Step 1: Let’s start importing all the necessary modules using the following code:
import requests from bs4 import BeautifulSoup import pandas as pd
Step 2: Define Headers to avoid getting your IP blocked. Note that you can search my user agent on google to get your user agent details and replace it below “User-agent”: “here goes your useragent below”.
custom_headers = { "Accept-language": "en-GB,en;q=0.9", "User-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15", }
Step 3: Create a python function, to fetch the webpage, check for errors and return a BeautifulSoup object for further processing.
# Function to fetch the webpage and return a BeautifulSoup object def fetch_webpage(url): response = requests.get(url, headers=headers) if response.status_code != 200: print("Error in fetching webpage") exit(-1) page_soup = BeautifulSoup(response.text, "lxml") return page_soup
Step 4: Inspect Element to find the element and attribute from which we want to extract data, Lets Create another function to select the div and attribute and set it to variable , extract_reviews identifies review-related elements on a webpage, but it doesn’t yet extract the actual review content. You would need to add code to extract the relevant information from these elements (e.g., review text, ratings, etc.).
Function to extract reviews from the webpage def extract_reviews(page_soup): review_blocks = page_soup.select('div[data-hook="review"]') reviews_list = []
Step 5: Below code processes each review element and extracts the customer’s name (if available), and stores it in the customer variable. If no customer information is found, customer remains none.
#for review in review_blocks: author_element = review.select_one('span.a-profile-name') customer = author_element.text if author_element else None rating_element = review.select_one('i.review-rating') customer_rating = rating_element.text.replace("out of 5 stars", "") if rating_element else None title_element = review.select_one('a[data-hook="review-title"]') review_title = title_element.text.split('stars\n', 1)[-1].strip() if title_element else None content_element = review.select_one('span[data-hook="review-body"]') review_content = content_element.text.strip() if content_element else None date_element = review.select_one('span[data-hook="review-date"]') review_date = date_element.text.replace("Reviewed in the United States on ", "").strip() if date_element else None image_element = review.select_one('img.review-image-tile') image_url = image_element.attrs["src"] if image_element else None
Step 6: The purpose of this function is to process scraped reviews. It takes various parameters related to a review (such as customer, customer_rating, review_title, review_content, review_date, and image URL), and the function returns the list of processed reviews.
review_data = { "customer": customer, "customer_rating": customer_rating, "review_title": review_title, "review_content": review_content, "review_date": review_date, "image_url": image_url } reviews_list.append(review_data) return reviews_list
Step 7: Now, Let’s initialize a search_url variable with an Amazon product review page URL
def main(): review_page_url = "https://www.amazon.com/BERIBES-Cancelling-Transparent-Soft-Earpads-Charging-Black/product- reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews" page_soup = fetch_webpage(review_page_url) scraped_reviews = extract_reviews(page_soup)
Step 8: Now let’s print(“Scraped Data:”, data) scraped review data (stored in the data variable) to the console for verification purposes.
# Print the scraped data to verify print("Scraped Data:", scraped_reviews)
Step 9: Next, Create a dataframe from the data which will help organize data into tabular form.
# create a DataFrame and export it to a CSV file reviews_df = pd.DataFrame(data=scraped_reviews)
Step 10: Now exports the DataFrame to a CSV file in current working directory
reviews_df.to_csv("reviews.csv", index=False) print("CSV file has been created.")
Step 11: below code construct acts as a protective measure. It ensures that certain code runs only when the script is directly executed as a standalone program, rather than being imported as a module by another script.
# Ensuring the script runs only when executed directly if __name__ == '__main__': main()
Result:

Why Scrape Amazon Product Reviews?
Scraping Amazon product reviews can provide valuable insights for businesses. Here’s why you should consider it:
● Feedback Collection: Every business needs feedback to understand customer requirements and implement changes to improve product quality. Scraping reviews allows businesses to gather large volumes of customer feedback quickly and efficiently.
● Sentiment Analysis: Analyzing the sentiments expressed in reviews can help identify positive and negative aspects of products, leading to informed business decisions.
● Competitor Analysis: Scraping allows businesses to monitor competitors’ pricing and product features, helping to stay competitive in the market.
● Business Expansion Opportunities: By understanding customer needs and preferences, businesses can identify opportunities for expanding their product lines or entering new markets.
Manually copying and pasting content is time-consuming and error-prone. This is where web scraping comes in. Using Python to scrape Amazon reviews can automate the process, reduce manual errors, and provide accurate data.
Benefits of Scraping Amazon Reviews
● Efficiency: Automate data extraction to save time and resources.
● Accuracy: Reduce human errors with automated scripts.
● Large Data Volume: Collect extensive data for comprehensive analysis.
● Informed Decision Making: Use customer feedback to make data-driven business decisions.
I found an amazing, cost-effective service provider that makes scraping easy. Follow this link to learn more.
Conclusion
Now that we’ve covered how to scrape Amazon reviews using Python, you can apply the same techniques to other websites by inspecting their elements. Here are some key points to remember:
● Understanding HTML: Familiarize yourself with HTML structure. Knowing how elements are nested and how to navigate the Document Object Model (DOM) is crucial for finding the data you want to scrape.
● CSS Selectors: Learn how to use CSS selectors to accurately target and extract specific elements from a webpage.
● Python Basics: Understand Python programming, especially how to use libraries like requests for making HTTP requests and BeautifulSoup for parsing HTML content.
● Inspecting Elements: Practice using browser developer tools (right-click on a webpage and select “Inspect” or press Ctrl+Shift+I) to examine the HTML structure. This helps you find the tags and attributes that hold the data you want to scrape.
● Error Handling: Add error handling to your code to deal with possible issues, like network errors or changes in the webpage structure.
● Legal and Ethical Considerations: Always check a website’s robots.txt file and terms of service to ensure compliance with legal and ethical rules of web scraping.
By mastering these areas, you’ll be able to confidently scrape data from various websites, allowing you to gather valuable insights and perform detailed analyses.
1 note
·
View note