#Solr Search Query Examples
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text

#Solr Query Syntax#Apache Solr Query Language#Solr Search Query Examples#Solr Query Parameters#Solr Query Filters#Solr Advanced Query Syntax#solr query#solr in query#Master Solr Query Syntax
0 notes
Text
Algolia vs. Connector Search Tools: A Comprehensive Comparison
Evaluating Performance, Features, and Usability to Help You Choose the Right Search Solution.
When it comes to implementing a powerful search and discovery solution for eCommerce, two major players often come up: Algolia and Constructor. While both provide advanced search capabilities, their workflows, implementations, and approach to AI-driven product discovery set them apart. This blog takes a deep dive into their differences, focusing on real-world applications, technical differentiators, and the impact on business KPIs.
Overview of Algolia and Constructor
Algolia
Founded in 2012, Algolia is a widely recognized search-as-a-service platform.
It provides instant, fast, and reliable search capabilities with an API-first approach.
Commonly used in various industries, including eCommerce, SaaS, media, and enterprise applications.
Provides keyword-based search with support for vector search and AI-driven relevance tuning.
Constructor
A newer entrant in the space, Constructor focuses exclusively on eCommerce product discovery.
Founded in 2015 and built from the ground up with clickstream-driven AI for ranking and recommendations.
Used by leading eCommerce brands like Under Armour and Home24.
Aims to optimize business KPIs like conversion rates and revenue per visitor.
Key Differences in Implementation and Workflows
1. Search Algorithm and Ranking Approach
Algolia:
Uses keyword-based search (TF-IDF, BM25) with additional AI-driven ranking enhancements.
Supports vector search, semantic search, and hybrid approaches.
Merchandisers can fine-tune relevance manually using rule-based controls.
Constructor:
Built natively on a Redis-based core rather than Solr or ElasticSearch.
Prioritizes clickstream-driven search and personalization, focusing on what users interact with.
Instead of purely keyword relevance, it optimizes for "attractiveness", ranking results based on a user’s past behavior and site-wide trends.
Merchandisers work with AI, using a human-interpretable dashboard to guide search ranking rather than overriding it.
2. Personalization & AI Capabilities
Algolia:
Offers personalization via rules and AI models that users can configure.
Uses AI for dynamic ranking adjustments but primarily relies on structured data input.
Constructor:
Focuses heavily on clickstream data, meaning every interaction—clicks, add-to-cart actions, and conversions—affects future search results.
Uses Transformer models for context-aware personalization, dynamically adjusting rankings in real-time.
AI Shopping Assistant allows for conversational product discovery, using Generative AI to enhance search experiences.
3. Use of Generative AI
Algolia:
Provides semantic search and AI-based ranking but does not have native Generative AI capabilities.
Users need to integrate third-party LLMs (Large Language Models) for AI-driven conversational search.
Constructor:
Natively integrates Generative AI to handle natural language queries, long-tail searches, and context-driven shopping experiences.
AI automatically understands customer intent—for example, searching for "I'm going camping in Yosemite with my kids" returns personalized product recommendations.
Built using AWS Bedrock and supports multiple LLMs for improved flexibility.
4. Merchandiser Control & Explainability
Algolia:
Provides rule-based tuning, allowing merchandisers to manually adjust ranking factors.
Search logic and results are transparent but require manual intervention for optimization.
Constructor:
Built to empower merchandisers with AI, allowing human-interpretable adjustments without overriding machine learning.
Black-box AI is avoided—every recommendation and ranking decision is traceable and explainable.
Attractiveness vs. Technical Relevance: Prioritizes "what users want to buy" over "what matches the search query best".
5. Proof-of-Concept & Deployment
Algolia:
Requires significant setup to run A/B tests and fine-tune ranking.
Merchandisers and developers must manually configure weighting and relevance.
Constructor:
Offers a "Proof Schedule", allowing retailers to test before committing.
Retailers install a lightweight beacon, send a product catalog, and receive an automated performance analysis.
A/B tests show expected revenue uplift, allowing data-driven decision-making before switching platforms.
Real-World Examples & Business Impact
Example 1: Searching for a Hoodie
A user searches for "hoodie" on an eCommerce website using Algolia vs. Constructor:
Algolia's Approach: Shows hoodies ranked based on keyword relevance, possibly with minor AI adjustments.
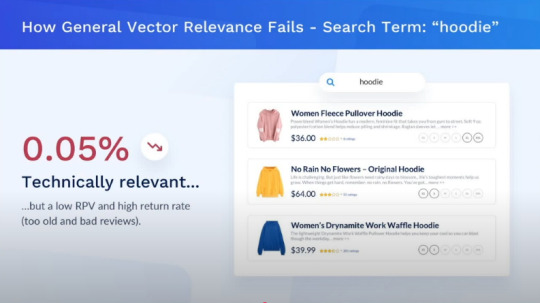
Source : YouTube - AWS Partner Network
Constructor's Approach: Learns from past user behavior, surfacing high-rated hoodies in preferred colors and styles, increasing the likelihood of conversion.

Source : YouTube - AWS Partner Network
Example 2: Conversational Search for Camping Gear
A shopper types, "I'm going camping with my preteen kids for the first time in Yosemite. What do I need?"
Algolia: Requires manual tagging and structured metadata to return relevant results.
Constructor: Uses Generative AI and Transformer models to understand the context and intent, dynamically returning the most relevant items across multiple categories.
Which One Should You Choose?
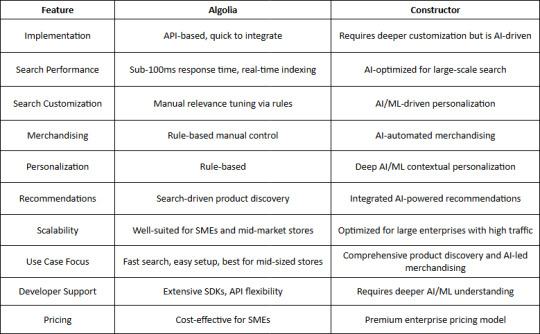
Why Choose Algolia?
Ease of Implementation – Algolia provides a quick API-based setup, making it ideal for eCommerce sites looking for a fast integration process.
Speed & Performance – With real-time indexing and instant search, Algolia is built for speed, ensuring sub-100ms response times.
Developer-Friendly – Offers extensive documentation, SDKs, and a flexible API for developers to customize search behavior.
Rule-Based Merchandising – Allows businesses to manually tweak search relevance with robust rules and business logic.
Cost-Effective for SMEs – More affordable for smaller eCommerce businesses with straightforward search needs.
Enterprise-Level Scalability – Can support growing businesses but requires manual optimization for handling massive catalogs.
Search-Driven Recommendations – While Algolia supports recommendations, they are primarily based on search behaviors rather than deep AI.
Manual Control Over Search & Merchandising – Provides businesses the flexibility to define search relevance and merchandising manually.
Strong Community & Developer Ecosystem – Large user base with extensive community support and integrations.
Why Choose Constructor?
Ease of Implementation – While requiring more initial setup, Constructor offers pre-trained AI models that optimize search without extensive manual configurations.
Speed & Performance – Uses AI-driven indexing and ranking to provide high-speed, optimized search results for large-scale retailers.
Developer-Friendly – Requires deeper AI/ML understanding but provides automation that reduces manual tuning efforts.
Automated Merchandising – AI-driven workflows reduce the need for manual intervention, optimizing conversion rates.
Optimized for Large Retailers – Designed for enterprises requiring full AI-driven control over search and discovery.
Deep AI Personalization – Unlike Algolia’s rule-based system, Constructor uses advanced AI/ML to provide contextual, personalized search experiences.
End-to-End Product Discovery – Goes beyond search, incorporating personalized recommendations, dynamic ranking, and automated merchandising.
Scalability – Built to handle massive catalogs and high traffic loads with AI-driven performance optimization.
Integrated AI-Powered Recommendations – Uses AI-driven models to surface relevant products in real-time based on user intent and behavioral signals.
Data-Driven Decision Making – AI continuously optimizes search and merchandising strategies based on real-time data insights.
Conclusion
Both Algolia and Constructor are excellent choices, but their suitability depends on your eCommerce business's needs:
If you need a general-purpose, fast search engine, Algolia is a great fit.
If your focus is on eCommerce product discovery, personalization, and revenue optimization, Constructor provides an AI-driven, clickstream-based solution designed for maximizing conversions.
With the evolution of AI and Generative AI, Constructor is positioning itself as a next-gen alternative to traditional search engines, giving eCommerce brands a new way to drive revenue through personalized product discovery.
This Blog is driven by our experience with product implementations for customers.
Connect with US
Thanks for reading Ragul's Blog! Subscribe for free to receive new posts and support my work.
1 note
·
View note
Photo




May 4, 2020: King Felipe and Queen Letizia held a videoconference with representatives of the field of the Digital Agenda and Artificial Intelligence. They value the advance of the Digitization and the use of Artificial Intelligence in the period of fight against the pandemic.
In the videoconference, the Secretary of State for Digitization and Artificial Intelligence, Carme Artigas; The President of the Spanish Association for Artificial Intelligence, Amparo Alonso, and the expert in ethics and professor of quantum physics, José Ignacio Latorre, have spoken to them about digitization, artificial intelligence and the response to COVID19.
As indicated to Don Felipe and Doña Letizia, Spain is, without a doubt, a country with strengths in this regard and in which the digitization and use of AI are progressing substantially in this period to combat COVID19.
The Secretary of State for Digitization and Artificial Intelligence has shared with Their Majesties the Kings the main axes of the future National Strategy for Artificial Intelligence and has reviewed the digital solutions developed by the government of Spain, made available to the autonomous communities to contribute to the management of the health emergency: among them, the Covid-19 Assistance self-diagnosis application that allows health authorities to decongest the telephone numbers and indicate guidelines to the public; Conversational Assistant Hispabot-Covid19 (which uses artificial intelligence and natural language to respond to citizens' concerns about COVID-19 with official, accurate and updated information, through instant messaging services such as WhatsApp or Telegram, with 193,000 queries answered); the DataCOVID mobility study based on anonymous and aggregated data from mobile devices provided by the country's three main operators (the study data shows that, generally, since the state of alarm was decreed, 85% of the citizens have not moved from their area of residence to other places); or the official technological resources website www.Covid19.gob.es, a space in which information, news and various digital resources related to the COVID-19 crisis are collected in a unified way to make them available to all citizens
In addition to these main axes, the Secretary of State is part of the Group of the European Commission where Member States have been meeting for several weeks to agree on a common response regarding contact tracking applications; maintains fluid communication and collaboration with autonomous communities and cities to respond in a coordinated manner from the technological side to the pandemic and has signed the G-20 Joint Declaration to promote digital solutions to COVID-19, which defines the main lines of action in the development of digital innovations against the virus at a global level.
For its part, the Spanish Association for Artificial Intelligence (AEPIA), as its president told His Majesties the Kings, has carried out a search engine (SOLR index) with all the documents of the corpus CORD-19 (COVID-19 Open Research Dataset - a Source of more than 57,000 articles on COVID-19, SARS-CoV-2, and other related coronaviruses in which, for example, you can search for scientific articles that mention chloroquine, use drugs that combine penicillin and / or beta-lactamase inhibitors or describe antiviral treatments with Interferon-; the intelligent system WASPSS (Wise Antimicrobial Stewardship Program Support System), designed for hospital professionals working in the rational use and optimization of antibiotics (PROA) programs , with the final objective of facilitating the management of antibiotic treatments - their adaptation is currently being evaluated for their generalization in 11 public hospitals from all over Spain-; the open and global initiative #innovacionfrentealvirus, which supports the creation of a technological, social and innovative community of international impact to help as far as possible to mitigate the effects of COVID-19 in which Universities, Research Groups, Spin would be integrated OFFs, Innovators, Startups, Corporations, Investors, Innovative SMEs, Public Institutions, Media, etc…; and a clinical decision support system for infection surveillance / Clinical Decision Support System for Infection Surveillance. The objective of the project is to develop a clinical decision support system. It focuses on models to analyze the spread of infections, on the prediction of the appearance of multi-resistance, on interpretable models for the detection of risk factors, etc.
Finally, José Ignacio Latorre has explained the importance of an ethical reflection on the era of artificial intelligence and how this vision must incorporate our elders, who are the great forgotten of AI. Latorre, author of the book "Ethics for machines", is professor of Theoretical Physics at the University of Barcelona. He is currently the director of the new Quantum Research Center at the Technology Innovation Institute in Abu Dhabi, whose main objective is to build a quantum computer. In July he will become the director of the Center for Quantum Technologies in Singapore. His lines of research cover elementary particles, quantum computing, and artificial intelligence. In her dissemination work, she defends the need to establish ethical criteria in the use of advanced technologies.
#King Felipe#Queen Letizia#King Felipe of Spain#Queen Letizia of Spain#King Felipe VI#King Felipe VI of Spain#Official Event#COVID-19#May 2020
1 note
·
View note
Text
How Solr Uses Advanced Search to Strengthen Organizations?

Solr’s advanced search technology allows for better precision and customization, leading to stronger and more efficient organizations.
We often sense information overload in the digital era, therefore organizations are continuously looking for solutions to efficiently search for and recover essential data. This is where the Solr search engine, which is based on Apache Lucene, comes in, with powerful search tools that have the ability to boost organizations in a variety of ways.
Organizations can boost client satisfaction and engagement by enhancing the importance of their search results with Solr’s advanced search features. Users may discover the information they need quickly and precisely because of Solr’s interactive search, smart search, and spell-checking capabilities. This improves not only the user experience but also the organization’s fruitfulness and productiveness.
Solr can manage massive amounts of data and allow distributed searching and indexing while providing a lightning-fast search experience.
The combination of Solr and machine learning techniques and recommendation algorithms enable personalized search outcomes. Organizations can utilize Solr’s advanced search features to give personalized search results, proposals, and suggestions by analyzing user behavior and interests. This level of personalization boosts user participation, sales, and client retention.
How does Solr manage queries?
Solr transforms the needed data into a structured representation as part of the indexing process. This entails parsing the data, extracting essential information, and categorizing it. If you’re indexing a group of documents, Solr can pull the title, author, content, and other metadata from each document and store it in distinct fields. Solr supports a variety of data formats, including XML, JSON, CSV, and others.
How Solr’s Advanced Search Can Benefit Your Business
Apache Solr Consulting Services can provide additional benefits to businesses leveraging Solr’s advanced search capabilities. Businesses can benefit from Solr’s sophisticated search capabilities in a variety of ways, including the ability to provide strong and efficient search experiences for their users. Here are some examples of how Solr’s advanced search functions might help your business:
Algorithms for ranking relevance: Solr has a number of relevance ranking algorithms that may be modified and fine-tuned to meet your unique business requirements. To assess the relevancy of search results, you can apply varying weights to various factors such as keyword matching, field enhancements, and proximity. You may ensure that the most relevant and significant results appear at the top of the search results list by customizing these algorithms.
Filtering and boosting: Solr allows you to boost or promote select documents or fields depending on specific criteria. Greater relevance scores can be assigned to specific attributes, such as product names, titles, or customer ratings, to guarantee they have a bigger effect on the overall ranking of search results. You can also use filters to narrow down search results based on specific criteria, enhancing relevancy and accuracy even further.
Sorting and relevance evaluation: Solr allows you to arrange search results based on criteria such as relevancy, date, or any other field value. You can set the sorting order to guarantee that the most relevant or recent results appear at the top of the search results list. Solr computes relevance scores based on parameters such as keyword frequency, field boosts, and other relevance ranking methods, allowing you to fine-tune search result ranking.
Better user experience: Faceted search allows users to explore and refine search results in a natural and dynamic manner. Users can rapidly drill down into certain features and locate the most relevant information by showing relevant facets or categories connected to the search results. This improves the overall user experience by streamlining the search process and shortening the time it takes to find desired results.
Facet counts that change dynamically: Solr can dynamically generate facet counts, displaying the number of matching documents for each facet value in real-time. This guarantees that the facet values appropriately represent the possibilities that are currently accessible depending on the search results. Users may see how many results are connected with each aspect value, allowing them to make more educated filtering decisions.
Conclusion
The capacity to process vast amounts of data and give real-time search updates guarantees that organizations can keep up with ever-changing data landscapes and present users with up-to-date information.
Furthermore, Solr’s connection with external systems and support for multilingual search enables organisations to search and index data from multiple sources smoothly, eliminating language barriers and offering a uniform search experience across disparate datasets.
The advanced search features of Solr serve as a foundation for organisations, allowing them to strengthen their operations, drive innovation, and gain meaningful insights from their data, eventually leading to better efficiency and success in today’s data-driven world.
Originally published by: How Solr Uses Advanced Search to Strengthen Organizations?
#Apache Solr Consulting Services#Apache Solr Development#Machine Learning Development#Advanced Strength of Solr#Solr search features
1 note
·
View note
Text
Logstash listening to filebeats for different log type

LOGSTASH LISTENING TO FILEBEATS FOR DIFFERENT LOG TYPE CODE
For example we are creating a file calledĬonfigure logstash input to listen to filebeat on port 5044īy default, redisearch is listening on port 6379
Configure the logstash pipeline by creating a file.
# setup filebeat to send output to logstash – Enable filebeat input to read logs from the specified path and change the output from Elasticsearch to logstash.
Configure file: /etc/filebeat/filebeat.yml.
RediSearch has an output plugin to store all incoming logs from the input plugin.
Filebeat has an input plugin to collect logs from various sources.
Logstash plugins we use in the example are:.
Let’s see some examples of the usage and configuration of RediSearch in the logstash pipeline. This logstash output plugin helps receive log messages coming from logstash and stashes them into RediSearch. In order to store logs into RediSearch, a builtin plugin Logstash output plugin for RediSearch was created.
The output stage initiates the process to send data to a particular destination.
The filter stage is mandatory in order to perform intermediary processing on data.
Input is the stage that helps get data into logstash.
Logstash data processing pipeline has three stages namely Input, Filter, and Output. RediSearch is powerful yet simple to manage and maintain and is efficient enough to serve as a standalone database or augment existing Redis databases with advanced, powerful indexing capabilities.
LOGSTASH LISTENING TO FILEBEATS FOR DIFFERENT LOG TYPE CODE
It is possible because of Redis’ robust in-memory architecture based on modern data structures and optimal code execution written in “C” language, whereas Elasticsearch is based on the Lucene engine and is written in Java programming language. RediSearch is faster in performance compared to any other search engine like Elasticsearch or Solr. RediSearch is also a full-text search and aggregation engine, built as a module on top of Redis. Elasticsearch is a distributed full-text search engine that possesses the capability to highly refine analytics capabilities. Elasticsearch is often used as a data store for logs processed with Logstash. Logstash is a data processing pipeline that allows you to collect data from different sources, parse on its way, and deliver it to your most likely destination for future use. Logstash is the most powerful tool from the elastic stack which is used for log management. This can be easily achieved by using an elastic stack. To make it faster, centralized logging is said to very helpful, and gives us the opportunity to aggregate logs from various applications to a central place and perform search queries against logs. It becomes tedious to manage all the logs as the number of applications increases. Rename => Ĭonfigure your data source integration to have different log types.Logs have been an essential part of troubleshooting application and infrastructure performance ever since its existence. For example, you could create the mylog.type field and then transform that field to iis.logs. You can also query your log fields to check the log type if you have created the field in your log. Using log fields to distinguish log types For example, we may want to change the index name the logs appear under in Elasticsearch and Kibana. You can use Logstash to query log types in your Logstash filter and then perform actions based upon that condition. You can access your Logstash filters from the dashboard for any of your Logit Stacks by choosing View Stack Settings > Logstash Pipelines. To further differentiate between the log types, we need to make use of the Logstash Filter. Using Logstash to further differentiate between log types From here we can then use Logstash to further differentiate between these log types. In order to tell the difference between the logs that are coming from these folders, we have added logType1 to one set of logs and logType2 to the other set of logs. In the above example we have two folders that contain logs. If you are using an Elastic Beat source such as Auditbeat, Filebeat or Metricbeat you can have multiple inputs sections in your configuration file to distinguish between different types of logs by editing the Beat configuration file and setting the type to be named differently.įor the example, below we are editing the Filebeat configuration file to separate our logs into different types. How do I separate my logs into different log types?ĭifferentiating between different log types in Logstash can be achieved in various ways. If you are collecting two sets of logs using the same Elastic beat source you may want to separate them so that you can perform certain actions on them if they meet certain conditions.įor example, you may want to change the index name of one log type to help make it more identifiable. Why would I want to differentiate between different log types?
0 notes
Text
How to solve trial period of redgate sql toolbelt problem

#How to solve trial period of redgate sql toolbelt problem full
For instance, it supports wildcard searches for one ( ?) or more ( *) characters, and ~ can be used to perform a fuzzy search, returning similar words as well as the exact search term.Īrguably some of these modes are more useful for natural language search than for searching for a T-SQL query, and perhaps the most common use case would be where the user already knows the exact query they want to find. Lucene offers several search modes that require special characters.
#How to solve trial period of redgate sql toolbelt problem full
To limit the size of the files and avoid duplicating information, we chose not to store the full text of the query in Lucene instead, we store just an ID that we can use to extract it, and any other information about the query, from our repository. Retrieving the sampled query is then fast. Lucene splits the text of the query into individual words, and we index top queries as they’re sampled, so this relatively intensive operation is carried out up front. We also considered using ElasticSearch or Solr, but either of these would have required the installation of an external service. We considered using SQL Server’s inbuilt Full Text Search functionality but had concerns about performance, and the fact that data would be stored in the repository. Lucene indexes data in the file system and searches those files when you perform a search. SQL Monitor uses Lucene.NET to index query text. It should be make it much easier to find a particular query, or to find all queries referencing a particular table or view or calling a particular function, for example. So even though our 2.12 pm query isn’t in the top queries list, SQL Monitor has sampled it and stored it, so a search will find it. It will return any matching query that was in the top 50 queries at any sampling point in the interval being examined, according to any of the available metrics. SQL Monitor v12 now allows you to search the text of top queries. This repopulates and reorders the list each time, according to the selected metric such as CPU time or Logical reads. Finally, you could try reordering the table by different columns, to find it. For example, a query that ranked 42nd by physical reads at 2:12 pm and was never seen again would be unlikely to make the top 50 when considered over a 24-hour interval. You might also have needed to restrict the time range to a narrow window around when the query ran. You often needed to expand the list to display the top 50 queries instead of just the top 10. If you’re trying to identify which queries are the biggest culprits in a system that’s experiencing generalized performance problems, then the top queries list is a good place to start, since it identifies all the most ‘expensive’ user and system queries that ran on the instance, over the period. However, without a search facility, it was often harder to locate a specific query in the list, if it was not one of the longest running queries during that period. SQL Monitor doesn’t store every single query that is run on a particular instance, only those that exceed certain minimum threshold levels. By default, the list is populated by Duration (ms), meaning that the query with the longest average duration per execution is listed first. It presents this information in the top 10 queries table. SQL Monitor keeps track of what queries are being run by regularly sampling SQL Server’s “query summary” DMV, sys.dm_exec_query_stats, and persisting the query execution statistics to its repository.
0 notes
Link
We live in a highly virtual world where the governing or binding force that combines our needs or requirement is just a step away. Is it buying your favourite pair of latest Jordan or booking the Friday’s first show of Matinee or even staying updated with the UEFA point’s table, everything is around the corner?
Probably there isn’t any variable left in the entire cosmos that hasn’t been connected or whose information is pretty difficult to extract. Everything, anything is just a click away, all we got to do is to SEARCH.
Now, probably the question arises, how’s that possible to navigate through Millions of pages and extract exactly what we were looking for and that too be in fraction of seconds?
The Answer: Wp Search Plugin

So, folks if you are interested in knowing what and how things happen when someone searches off a query than stay on, also we’ll be proving you Top 5 reasons search plugs often decide if a website or store ranks well or not.
Point Number #1
Enhancing User Experience And Engagement
Quite recently a study was carried out to know, what are the factors that a consumer or visitor first consider to decide whether to hit the red X or to stay on? After studied and analyzing over 200K visitors; a pattern was found and for over more than 35 percent, people escape the website, once they are unable to find the article or product that they are looking for.
The second point is navigation i.e. the basic or fundamental appeal of the website should be clean and audience or the visitors must be able to understand where and how to navigate from pages and find what they are looking for.
Takeaways
· Ease in the Search Ability
· A Well Navigated Product Page (Reachable)
Point Number #2
The Ability To Come Up With Great Results in fraction of Seconds
For the record, let’s take the example of Amazon; the insane number of products in almost each category is a mammoth task to accomplish, if it has to be done by a human.
On the contrary; the searching Algorithm A9 just takes 10sec to sort all the options and showcase it in the most subtle manner. Similarly website owners must add better search feature or add relevant filters that helps users to get exactly what they are looking for.
With the advance features and for Elastic Search and Solr Wpsolr is impeccable combination of smart search ability, easy integration, multiple platform friendly and most importantly offers an insane search speed of 200MS.
Point Number #3
Easy Integration With Multiple WordPress, Woo-Commerce Platforms
Be it a Shopify Store or website with millions and millions of pages and figuring out exactly the right and accurate pair of shoes or the exact record that you wish to see takes a significantly smart technology and WpSolr is considered as one of the most widely used search Plugin used in the world.
All these help you kill two birds with a single stone. Now get additional searching functionality in your website and easy integrated with multiple features.
To Sum Up
We hope you had a nice time going through our write up and will surely check out the advance WpSolr into your Kit. Have a good one!
0 notes
Text
Searchandising: Site search hacks that drive revenue
Improving customer experience is top-of-mind for every digital business. Billions are spent each year on mobile apps, content, personalization and omnichannel capabilities. And hundreds of hours are spent on redesigning websites and conversion optimization.
Yet CX plans often overlook a fundamental piece of the equation: site search performance.
Visitors who search are explicitly telling you what they want and are more likely to convert than visitors who browse (50% higher according to an Econsultancy survey).
Today’s best-of-breed search tools have come a long way from simple keyword matching, boasting varying degrees of autocorrection, semantic matching, machine learning and personalization.
But too often, merchandisers “set and forget” search, relying on their solutions to just work their voodoo. Rarely do merchandisers take advantage of the tuning capabilities they’ve paid for.
The result is site search behaving badly, or at least underachieving its potential. Leaving search on default settings may be efficient, but neglecting to check under the hood to ensure search shows the right products for your “money keywords” costs dollars and sense.
The scale of individual “pinhole leaks” in your system can amount to significant lost revenue every year. The good news is you can identify and correct these leaks with a simple auditing process and site search tweaks.
Auditing site search
Step 1: consult your analytics
Pull out your search analytics, and set your date range to one year. Look for high volume searches with underperforming revenue and conversion rates, or high abandonment and refinement rates, and create a short-list of 10-30 “money keywords” to optimize.
Bonus tip: During this exercise, scan your report’s top 100-500 keywords and jot down common abbreviations, misspellings and product attributes that appear. This intel can help you improve your search application’s thesaurus, and may identify helpful category and search filters.
Step 2: test your searches
Now the fun part — roll up your sleeves and play customer! Check for anything irrelevant or out of place. Wear your “business hat” as you do this, and look for opportunities to tune results to better match your merchandising strategy.
For every search you audit, note what needs to improve about the experience. For example, investigate why sunglasses are appearing in searches for “grey jackets,” or why iPhone accessories outrank iPhone handsets.

Note what issues you need to correct for every search term you audit
Optimizing relevance with search logic
Many modern enterprise search applications and digital experience platforms provide merchandiser-friendly admin tools to adjust search logic, the business rules that inform the algorithm. If you don’t have access to such business tooling, enlist a developer’s help to tune the back end (most search applications are built on Solr or Elasticsearch).
There are several levers you can pull to maximize search relevance for your “money” keywords:
Index factors
Just like Google’s ranking factors, your site search algorithm calculates relevance based on index factors such as product title, category, product description, product specs (attributes), keyword tags and other metadata.
Adjusting index factors across the board, or for specific products or categories, can tune results in favor of your merchandising strategies, and improve relevance, click-through and sell-through.
For example, if you sell high ticket electronics and find accessories and lower ticket items are sneaking their way into top search positions, your engine may be weighting product name at 200% (which would boost accessories’ score), descriptions at 150%, specs at 100% and category relevance at 75%. You can improve results by reducing product name, description and spec weighting and boosting category relevance and price.
Boost-and-bury
Advanced engines may include additional index factors such as popularity (clicks, favorites and sales), product ratings, price, margin, date added, inventory count, semantic relevance and custom attributes (e.g. brand, genre, format or category).
Some product types benefit from a specific keyword or attribute boost or bury. For example, a search for “patio furniture” should boost sets above individual items like patio chairs, and bury accessories such as cushions and covers.

Boosting patio sets within results for “patio furniture” better matches customer intent than individual pieces, and can improve basket size and revenue
Bonus tip: Use your site search’s autosuggestions (or a high-volume competitor’s) to identify terms to boost or bury, per keyword.
Synonyms
Modern search applications do a decent job of recognizing synonyms out of the box thanks to their robust dictionaries and thesauri. However, most ecommerce catalogs benefit from custom synonym mapping to handle colloquial terms and jargon, brand and product names that aren’t standard dictionary terms, and their respective common misspellings. After all, one man’s “thumb drive” is another’s “memory stick,” and one woman’s “pumps” are another’s “heels.”
A usability study by Baymard Institute found 70% of ecommerce sites failed to map synonyms and only return results that match search terms as entered. Considering brands and manufacturers often describe the same things in different ways, this hurts recall and customer experience. It can also stifle sales for products that don’t match the most frequent variants of popular product searches — the two-piece swimsuits in a world of bikinis.
And don’t forget model numbers! Baymard’s research found only 16% of ecommerce sites do.
Fuzzy logic
Most search tools employ fuzzy logic to handle plurals, misspellings and other near-matches. This increases recall (number of results returned) for a given search, and often improves results, especially for misspellings.
For example, a search for “pyjamas” would return matches for “pajamas.” Using stemming, a search including “floss” could match “flossing,” “flosses,” “flosser” and “flossers.”
However, fuzzy logic doesn’t always improve results, particularly when fuzzy matching or stemming a product or brand keyword matches attributes of other products, or other product types altogether.
For search engines that use “or” operators in their algorithms, results can appear when only one word in the query matches product information. For example, any search that includes “orange” (attribute) would return results for “Orange Boss” (brand).

“Or” operators match products to any keyword in a multi-keyword query
Understanding context and adding exclusion rules for specific searches tightens recall and maximizes the precision of your results.
For example:
plant, planted and planter salt, salts and salted blue and blues boot and booties belt and belted print, printer, and printing cook, Cook, cooker, cooking rock, rocker, rocking
Many of today’s enhanced search platforms offer semantic matching, natural language processing and learning algorithms out-of-the-box. Some are intelligent enough to detect when a keyword is intended as a product, attribute or utility of the product (such as “for older dogs”). Nevertheless, even Cadillac tools can miss some important contextual variables specific to your catalog, customer and merchandising strategy. When auditing your top search terms, look for fuzzy product matches that should be excluded or buried.
Bonus Tip: Excluding stemming variants“-ing” and “-er” and “-ed” in general across all searches can tighten search results, optimizing for relevance and sell-through.
Showing fewer matches reduces the “paradox of choice” effect which can lead to slower decision making or even indecision. A tighter set also supports mobile shoppers who have a harder time browsing and comparing products within a list on a smaller screen, and who struggle with applying filters and facets.
Searchandising with slot rules
Slot rules tell your site search engine specifically how you want to populate your product grid for a specific search. For example, you may always want the first row to show your house brand for searches that don’t include a specific brand. Or, to show only full price products in the first three positions, and flexibly rank the rest. (Not all site search tools support slot rules, but many enterprise solutions do).
Keywords that span multiple categories such as “jackets” (men’s, women’s, boys’ and girls’) and thematic searches (e.g. “Valentine’s gifts,” “white marble,” “LA Raiders” or “safety equipment”) benefit from slot rules that diversify results rather than front-load from a popular category. This helps your customer understand you carry a breadth of products and may help them refine their results, especially on mobile where fewer results are visible per screen.

Slot rules can diversify results to ensure results from certain categories aren’t overrepresented in top positions
Bonus Tip: The most efficient way to leverage slot rules is to apply them to your category lists and apply search redirects for exact-match queries. If you uncover high-volume searches that don’t have associated categories, create them! This helps customers who browse rather than search, supports guided selling and can boost SEO.

Search redirects to category landing pages can optimize the buying experience for exact-matched terms
Personalizing search
Search engines and DXPs (digital experience platforms) with machine learning capabilities are gaining popularity, promising to optimize relevance and performance with minimal effort from the business.
Semantic relevance returns product matches even when queried keywords don’t appear in descriptions or metadata.
Natural language processing identifies search intent and context such as a navigational query (looking for a category) or searching by attribute or product function (e.g. “dry food for older dogs”).
Aggregated behavioral data can match a visitor to past activity and look-alike customer segments, using predictive analytics to provide personalized recommendations.
Despite their intelligence, advanced tools suffer as much from set-and-forget implementation as their less sophisticated counterparts. Shipping with the most powerful searchandising controls, these platforms are designed for merchandising logic. But many users of these engines fail to leverage their capabilities, and never experience the full value of their technology. Why you still need to “searchandize” your personalized search engine
Machine learning takes time to get good. Highly trafficked sites with relatively evergreen catalogs benefit most, while less trafficked sites with large catalogs (thus a long search tail) or higher catalog turnover may struggle to build reliable affinities between search queries and products.
Default settings create bias. It’s well demonstrated that top search slots receive higher click-through, on average. When algorithms favor popularity metrics, the “rich get richer” over time. Search satisfaction can dwindle as SKU variants such as sizes and colors sell out, and fresh, full-margin product may be buried under discounted stock.
Tools are agnostic to your merchandising strategies. With data and time, intelligent search tools can recognize buying trends, seasonality and more. But they still lack insight into when it trend forecasts, promotional calendars, anticipated shifts in demand and other variables. By the time they catch up, this context may be stale!
To ensure personalized search serves your business in real-time, leverage index weighting, boost-and-bury and slot rules the same way you’d tune non-personalized search.
Advanced personalization
DXPs that integrate with CRM and ERP systems allow you to shape merchandising logic for individual catalogs, geographics and customer segments. For example:
Boost new items and prestige brands for high-spending segments, or boost heavy puffer jackets to New Yorkers and bury them for Californians
Strongly boost SKUs and brands previously purchased to individual B2B accounts (even if ordered offline)
Strongly bury products that aren’t available for international shipping to non-domestic visitors

Target should bury “not available for intl shipping” products for non-US shoppers
Don’t reset-and-forget!
Search tuning shouldn’t happen in a vacuum. Document your strategies every time there’s an update to merchandising logic. An audit trail ensures other team members (and future members) know what was tuned and why, and can revisit strategies as data is collected and business strategies and objectives evolve.
Consider time-limited strategies. Certain searches will benefit from tuning around seasonality, promotional events and other variables. Site-wide adjustments may also be relevant. For example, boosting sale items December 26 through January 31 helps clear excess inventory and matches buyer expectations for traditional retail. Some tools allow you to set start and rollback dates for merchandising rules. If yours doesn’t, ensure someone’s assigned to revert changes at a designated time.
Should you A/B test your tuning strategies? Your enterprise search tool or DXP may natively support A/B testing. However, because split testing requires sufficient traffic to produce reliable results for each keyword, and sends half of your traffic to untuned results, it’s often unnecessary — especially when you’re closing an obvious experience or relevance gap.
Site search doesn’t have to remain a black box. Make search tuning a regular part of your searchandising strategy to optimize your customer experience, built trust and loyalty, save lost sales and ensure search results are always in step with your ever-evolving business strategies.
Up next in this series: Tips for tuning autosuggest. Are you subscribed?
The post Searchandising: Site search hacks that drive revenue appeared first on Get Elastic Ecommerce Blog.
Searchandising: Site search hacks that drive revenue published first on https://goshopmalaysia.tumblr.com
0 notes
Text
#Solr Query Syntax#Apache Solr Query Language#Solr Search Query Examples#Solr Query Parameters#Solr Query Filters#Solr Advanced Query Syntax#solr query#solr in query#Master Solr Query Syntax
0 notes
Link
Apache NiFi - The Complete Guide (Part 1) ##udemycoupon ##UdemyOnlineCourse #Apache #Complete #Guide #NiFi #part Apache NiFi - The Complete Guide (Part 1) What is Apache NiFI? Apache NiFi is a robust open-source Data Ingestion and Distribution framework and more. It can propagate any data content from any source to any destination. NiFi is based on a different programming paradigm called Flow-Based Programming (FBP). I’m not going to explain the definition of Flow-Based Programming. Instead, I will tell how NiFi works, and then you can connect it with the definition of Flow-Based Programming. How NiFi Works? NiFi consists of atomic elements which can be combined into groups to build simple or complex dataflow. NiFi as Processors & Process Groups. What is a Processor? A Processor is an atomic element in NiFi which can do some specific task. The latest version of NiFi have around 280+ processors, and each has its responsibility. Ex. The GetFile processor can read a file from a specific location, whereas PutFile processor can write a file to a particular location. Like this, we have many other processors, each with its unique aspect. We have processors to Get Data from various data sources and processors to Write Data to various data sources. The data source can be almost anything. It can be any SQL database server like Postgres, or Oracle, or MySQL, or it can be NoSQL databases like MongoDB, or Couchbase, it can also be your search engines like Solr or Elastic Search, or it can be your cache servers like Redis or HBase. It can even connect to Kafka Messaging Queue. NiFi also has a rich set of processors to connect with Amazon AWS entities likes S3 Buckets and DynamoDB. NiFi have a processor for almost everything you need when you typically work with data. We will go deep into various types of processors available in NiFi in later videos. Even if you don’t find a right processor which fit your requirement, NiFi gives a simple way to write your custom processors. Now let’s move on to the next term, FlowFile. What is a FlowFile? The actual data in NiFi propagates in the form of a FlowFile. The FlowFile can contain any data, say CSV, JSON, XML, Plaintext, and it can even be SQL Queries or Binary data. The FlowFile abstraction is the reason, NiFi can propagate any data from any source to any destination. A processor can process a FlowFile to generate new FlowFile. The next important term is Connections. In NiFi all processors can be connected to create a data flow. This link between processors is called Connections. Each connection between processors can act as a queue for Flow Files as well. The next one is Process Group and Input or Output port. In NiFi, one or more processors are connected and combined into a Process Group. When you have a complex dataflow, it’s better to combine processors into logical process groups. This helps in better maintenance of the flows. Process Groups can have input and output ports which are used to move data between them. The last and final term you should know for now is the Controller Services. Controller Services are shared services that can be used by Processors. For example, a processor which gets and puts data to a SQL database can have a Controller Service with the required DB connection details. Controller Service is not limited to DB connections. #learnwithmanoj #apachenifi #nifi #dataflow #datapipeline #etl #opensource #bigdata #opensource #datastreaming #hortonworks #hdf #nifitutorial #nifitraining Who this course is for: Software Engineers Data Engineers Software Architects Data Scientists 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/apache-nifi-the-complete-guide-part-1/
0 notes
Text
Unstructured Data Vs. Structured Data: A 3-Minute Rundown
Most marketers think being data-driven means using web metrics to inform every decision they make. But that’s not actually being data-driven. That’s being Google Analytics-driven. To truly be data-driven, we must remind ourselves of the actual definition of data -- all types of information.
One of the most insightful types of information is qualitative data or unstructured data. It can reveal your customers’ true opinions and feelings toward your brand, which is challenging to extract from quantitative data or structured data.
Even Jeff Bezos, the CEO of Amazon, is a passionate proponent of using qualitative data to drive strategy. “The thing I have noticed is when the anecdotes and the data disagree, the anecdotes are usually right. And there's something wrong with the way you are measuring (your data)," he explained during an onstage interview at George Bush Presidential Center last April.
Bezos' love for customer feedback shouldn’t compel you to supplant quantitative data with qualitative data when strategizing your next marketing campaign, though. It should compel you to inform your strategy with both sources of data. By combining the insights pulled from web metrics and customer feedback, you can get a full understanding of your marketing program’s effectiveness.
If you want a deeper explanation of what qualitative or unstructured data and quantitative or structured data is, check out this quick rundown of what both data sources exactly are and which tools you can use to store and analyze them.
Unstructured Data
Most often referred to as qualitative data, unstructured data is usually subjective opinions and judgments of your brand in the form of text, which most analytics software can’t collect. This makes unstructured data difficult to gather, store, and organize in typical databases like Excel and SQL. It’s also difficult to examine unstructured data with standard data analysis methods and tools like regression analysis and pivot tables.
Since you can’t store and organize unstructured data in typical databases, you need to store them in Word documents or non-relational (NoSQL) databases, like Elasticsearch or Solr, which can perform search queries for words and phrases.
Additionally, since you can’t use standard data analysis methods and tools to pull insights from unstructured data, you can either manually analyze or use the analysis tools in a NoSQL database to examine unstructured data. However, to use these tools effectively, you need a high level of technical expertise.
If you can successfully extract insights from unstructured data, though, you can develop a deep understanding of your customer’s preferences and their sentiment toward your brand.
Unstructured Data Examples
The most common examples of unstructured data are survey responses, social media comments, blog comments, email responses, and phone call transcriptions
Structured Data
Most often referred to as quantitative data, structured data is objective facts and numbers that most analytics software can collect, making the data easier to export, store, and organize in typical databases like Excel and SQL. Even though structured data is just numbers or words packed in a database, you can easily extract insights from structured data by running it through data analysis methods and tools like regression analysis and pivot tables. This is the most valuable aspect of structured data.
Structured Data Examples
The most common examples of structured data are numbers, names, dates, addresses, and transactional information .
Structured vs. Unstructured Data
The difference between structured and unstructured data is that structured data is objective facts and numbers that most analytics software can collect, making it easy to export, store, and organize in typical databases like Excel, Google Sheets, and SQL. You can also easily examine structured data with standard data analysis methods and tools like regression analysis and pivot tables.
On the contrary, unstructured data is usually subjective opinions and judgments of your brand in the form of text, which most analytics software can’t collect, making it difficult to export, store, and organize in typical databases. You also can’t examine unstructured data analysis methods and tools. Most of the time, you must store unstructured data in Word documents or NoSQL databases and manually analyze it or use the analysis tools in a NoSQL database to examine this type of data.
Be Data-Driven, Not Just Google-Analytics Driven
In a world where Google Analytics can spit out every metric under the sun, you must remember that qualitative data, like customer feedback, is just as crucial for informing your marketing strategy as web metrics. Without unstructured data, you won’t have a clear understanding of how your customers actually feel about your brand. And that’s crucial for every marketer to know.
from Marketing https://blog.hubspot.com/marketing/unstructured-data
0 notes
Photo

Sitecore 10 Habitat Architecture and Development Services in USA India
Sitecore Habitat:
Habitat is a modular way to create the Sitecore solution construct using the helix architecture principle.
The main goal of the solution concentrates on three features
1) Simplicity
2) Flexibility
3) Extensibility
Habitat has a standard and findable architecture for making changes fast and creating new features without having deep knowledge of that category. Habitat makes sure productivity stays high based on simplicity. The habitat contains predefined task groups, Sitecore item serialization via Unicorn, and many other tooling examples. To update and add new items easily without afraid of affecting other modules. Habitat provides the capability for easily sharing content, code features, and functionalities, and modules between various projects and within the group. so all members within the group or projects can easily separate the work and merge easily.
Habitat is one of the open-source in GitHub and we can get the latest updates via GitHub.
We can grouped habitat using four types.
1) Habitat website
This is accomplished by the helix principle-based architecture.
2) Content structure
This type acts the main part in Sitecore, It gives developer what rules need to follow and what else don’t need while creating the building structure
3) Visual studio solution
Sitecore Foundation mainly built by the wired of content structure and user requirement based logic. This action is achieved by the habitat in Sitecore using the visual studio solution.
4) Storage Management
Every development needs to maintain the file system in a particular way, that part is efficiently performed and promoted by habitat.
Habitat builds based on the helix principle so simplified coupling between modules easily. Habitat has pre-structured and checked with a set of general modules, so it increases the performance of the project and reduces the finance amount and correct time release to market. Habitat has followed by many people and companies which people are using the helix because it is a Sitecore format so the people who handle one project in habitat will apply all their other projects with minimal training.
There are three layers defined in this architecture
1) Feature
2) Foundation
3) Project
Feature layer mainly used for easy understanding by business authorities and editors for the project. One module of features must not be the same as another module in this layer.
Foundation Layer contains all related frameworks such as bootstrap, query, and more. In habitat Sitecore. Foundation. Theming contains all CSS sheets for habitat websites. Same as Sitecore. Foundation. Indexing all searches and related content types of this module.
Project Layer provides the building of the solution, it means the connected website or channel output from the development, Project layers connected all layers and provide the final result of output to the habitat website
Habitat Teaser rendering many different types of content in the block from a news teaser to the elegant way to perform content display in the block change randomly.
We can find demo sites online, Habitat search-based features needed to rebuild sitecore_master_index and sitecore_web_index to deploy the updated schema to Solr and index the deployed content for work properly.
Sitecore 10 Habitat Architecture and Development Services in USA India
0 notes
Text
Unstructured Data Vs. Structured Data: A 3-Minute Rundown
Most marketers think being data-driven means using web metrics to inform every decision they make. But that’s not actually being data-driven. That’s being Google Analytics-driven. To truly be data-driven, we must remind ourselves of the actual definition of data — all types of information.
One of the most insightful types of information is qualitative data or unstructured data. It can reveal your customers’ true opinions and feelings toward your brand, which is challenging to extract from quantitative data or structured data.
Even Jeff Bezos, the CEO of Amazon, is a passionate proponent of using qualitative data to drive strategy. “The thing I have noticed is when the anecdotes and the data disagree, the anecdotes are usually right. And there’s something wrong with the way you are measuring (your data),” he explained during an onstage interview at George Bush Presidential Center. Bezos’ love for customer feedback shouldn’t compel you to supplant quantitative data with qualitative data when strategizing your next marketing campaign, though. It should compel you to inform your strategy with both sources of data. By combining the insights pulled from web metrics and customer feedback, you can get a full understanding of your marketing program’s effectiveness. If you want a deeper explanation of what qualitative or unstructured data and quantitative or structured data is, check out this quick rundown of what both data sources exactly are and which tools you can use to store and analyze them.
Unstructured Data
Most often referred to as qualitative data, unstructured data is usually subjective opinions and judgments of your brand in the form of text, which most analytics software can’t collect. This makes unstructured data difficult to gather, store, and organize in typical databases like Excel and SQL.
It’s also difficult to examine unstructured data with standard data analysis methods and tools like regression analysis and pivot tables. Since you can’t store and organize unstructured data in typical databases, you need to store them in Word documents or non-relational (NoSQL) databases, like Elasticsearch or Solr, which can perform search queries for words and phrases. Additionally, since you can’t use standard data analysis methods and tools to pull insights from unstructured data, you can either manually analyze or use the analysis tools in a NoSQL database to examine unstructured data. However, to use these tools effectively, you need a high level of technical expertise. If you can successfully extract insights from unstructured data, though, you can develop a deep understanding of your customer’s preferences and their sentiment toward your brand.
Unstructured Data Examples
The most common examples of unstructured data are survey responses, social media comments, blog comments, email responses, and phone call transcriptions
1. Survey Responses Every time you gather feedback from your customers, you’re collecting unstructured data. For example, surveys with text responses are unstructured data. While this data can’t be collected in a database, it’s still valuable information you can use to inform business decisions. 2. Social Media Comments If you’ve ever received social media comments with feedback from your customers, you’ve seen unstructured data. Again, this can’t be collected in a database, but you’ll want to pay attention to this feedback. You can even store it in a Word document to track. 3. Email Responses Similar to survey responses, email responses can also be considered unstructured data. The feedback you receive is important information, but it can’t necessarily be collected in a database. 4. Phone Call Transcriptions Your customer service and sales team are always collecting unstructured data in their phone calls. Since these calls often include some critiques of your company, it’s important feedback to collect. However, as with all unstructured data, it’s hard to quantify. 5. Business Documents Any business document such as presentations, or information you have stored on a Word document, is an example of unstructured data. Since unstructured data is essentially the information you have that can’t be stored neatly in a database, any miscellaneous documents you have can be considered unstructured data.
Structured Data
Most often referred to as quantitative data, structured data is objective facts and numbers that most analytics software can collect, making the data easier to export, store, and organize in typical databases like Excel and SQL.
Even though structured data is just numbers or words packed in a database, you can easily extract insights from structured data by running it through data analysis methods and tools like regression analysis and pivot tables. This is the most valuable aspect of structured data.
Structured vs. Unstructured Data
The difference between structured and unstructured data is that structured data is objective facts and numbers that most analytics software can collect, while unstructured data is usually subjective opinions and judgments of your brand in the form of text, which most analytics software can’t collect.
1. Structured data is easier to store. Structured data is easy to export, store, and organize in typical databases like Excel, Google Sheets, and SQL. On the contrary, unstructured data is difficult to export, store, and organize in typical databases. Most of the time, you must store unstructured data in Word documents or NoSQL databases. 2. Structured data is easier to analyze. With structured data, you can easily examine the information with standard data analysis methods and tools like regression analysis and pivot tables. However, with unstructured data, you can’t. You’ll have to manually analyze it or use the analysis tools in a NoSQL database to examine this type of data. 3. Unstructured data offers more freedom. While structured data is easier to store and collect, unstructured data gives analysts more freedom since it’s in its native format. Additionally, companies usually have more unstructured data since the data is adaptable and not restricted by format. Be Data-Driven, Not Just Google-Analytics Driven In a world where Google Analytics can spit out every metric under the sun, you must remember that qualitative data, such as customer feedback, is just as crucial for informing your marketing strategy as web metrics. Without unstructured data, you won’t have a clear understanding of how your customers actually feel about your brand. And that’s crucial for every marketer to know. Editor’s note: This post was originally published in February 2019 and has been updated for comprehensiveness.
Source link
source https://www.kadobeclothing.store/unstructured-data-vs-structured-data-a-3-minute-rundown/
0 notes
Text
New Post has been published on Payment-Providers.com
New Post has been published on https://payment-providers.com/searchnode-publishes-report-on-ecommerce-trends-2020/
SearchNode publishes report on ecommerce trends 2020
What can we expect from the ecommerce industry in 2020? Ecommerce News Europe spoke with Antanas Bakšys, CEO and co-founder of Lithuanian tech company SearchNode, about the latest ecommerce trends.
Antanas Bakšys co-founded SearchNode in June 2013. Nordic Business Report called him one of the most promising entrepreneurs under the age of 25 in Northern Europe. With his company, he offers a search and filtering solution for medium-sized and big ecommerce players. Among its customers are Decathlon (Poland), Hubo (Belgium) and Phonehouse (Spain).
At the start of this year, SearchNode published an extensive report with the 22 Ecommerce Trends for 2020. We spoke with Antanas to find out what he thought about some of the survey findings.
One of the questions the nearly 160 decision-makers from big ecommerce companies got was “what ecommerce platform are you on now?”:
What could be the reasons more ecommerce companies are still using Magento 1 rather than Magento 2, which is already available since 2015?
“It’s quite surprising, but this should change soon. From the 1st of June 2020, Magento will no longer support Magento 1 platform. We see a trend that many companies who are using Magento 1 are currently moving to Magento 2 or other platforms. It’s a great chance to build a new website, with new functionalities and significant improvements. At the same time, something like this takes much effort and resources.”
Most companies (76 percent) want to improve personalization. What things do you think can be improved on this subject? What do ecommerce companies nowadays lack when it comes to personalization?
“It’s common for amateurs to think that a great personalization will come with a shiny tool. Especially if it costs a lot. It’s quite easy to differently target 30 or 50 segments. What is difficult and what most companies get wrong, is tailoring a message that truly resonates with those people you target. And in all channels, from the first ad to the checkout page.”
“That’s why I believe that the next two years will be about ecommerce professionals and their skills to strategize and build personalization efforts, with a support of great tools.”
The next two years will be about strategizing and building personalization efforts.
Site-search is also among the most popular things to implement, improve or change. What is, in your opinion, the current state of site-search on ecommerce websites?
“Usually, there are three types of companies to define a state of site-search. One type is the kind of company that uses open-source technologies like Elastic or Solr and just relys on their default configuration with a bit of development. Usually, these companies have a bad or very mediocre search experience. They lose lots of users and their money when customers don’t find what they are looking for.”
“Another type is those who use the same open-source technologies, but have a full-time search team of at least three to five experienced engineers and at least one product manager. Amazon, for example, has about 400 people in its search team. These companies usually have a mediocre or great search experience.”
“The last type is those who work with third party solutions. As there are tens and probably hundreds of companies providing search, we can find ecommerce sites from the very basic search experience to really advanced solutions.”
“So to sum up, the state of site-search is different, but in most cases far from perfect. This is also the reason why our business is growing.”
Site-search is in most cases far from perfect.
What should be improved then?
“Most of the advanced ecommerce companies nowadays are working on natural language understanding and data processing for search. Because it’s not enough that search has autocomplete, spellcheck and understands that ‘tomato’ and ‘tomatoes’ should find similar or identical products. It’s also not enough to add synonyms or manually adjust search results to search queries.”
“The difficult part is to truly understand a user’s query, its context and products’ data, to be able to find the most relevant products in the right order. As a quick example: when users search for a belt, they want to find belts, not dresses and pants with belts. Our CTO wrote an interesting guide about this, with the 14 ecommerce site search best practices for 2020.”
It’s quite surprising that ‘payments’ is in the top of the list. One might think most ecommerce companies have this part under control. Why is at number 4 on the list you think?
“It was a bit of a surprise for me as well. As I’m not a big expert in ecommerce payments, it’s worth studying this more. However, it might be similar to site-search, which from one point of view is well-known and developed for more than twenty years but many companies struggle with it, even if they had a ‘great’ search for over three years. The market and the users’ behavior and wishes are changing quite fast. So the companies should continuously improve. Payments are not the exception.”
Environmental sustainability is a hot topic in ecommerce. In your survey, many companies say they will use plastic-free packaging and efficient transportation to cut emissions. What can be further done in your opinion?
“It remains a tricky topic. For example, there are skeptics who generalize the whole retail industry, saying all are against the environment. In their opinion the more you buy, the more you pollute the earth. However, I think it’s impossible to turn a critical mass of people into such minimalists in today’s world, therefore I’m happy to see that ecommerce companies are actively thinking and acting to be environmentally sustainable. I noticed that it’s also a great marketing message.”
More ecommerce companies could accept their selling products for recycling or at least educate how purchased products could be recycled. Drones delivery should cut emissions if they replace trucks and cars. And so on.”
Here at Ecommerce News Europe, we have written many news articles about online retailers that have decided to become an online marketplace. It looks like a real trend. Why is this, you think?
“According to our survey, 21 percent are already marketplaces and 6 percent will become marketplaces in 2020. So almost a third of the medium to big ecommerce companies that we have questioned will be marketplaces.”
“It should be more profitable to open your platform to other sellers and take a commission from them. As many ecommerce companies already have a platform, user base and could predict sales, it’s not so difficult to turn this platform into a marketplace. What is difficult is to compete with other marketplaces and make sure your own products win when your users search for a product in the said marketplace.”
“However, I believe it’s a great opportunity for small businesses to use those platforms to sell more products, rather than trying to compete in this noisy market.”
Small businesses should join marketplaces rather than trying to fight them.
What does it say that organic search marketing still offers the best ROI for most ecommerce companies?
“It was a bit of a surprise for me as well. I always thought email marketing is the channel with the best ROI. But it looks like SEO is also profitable and that the long-term work companies do actually pays off. However, I’d be careful here and wouldn’t state that organic search marketing is the best ROI channel. Let’s say it’s one of the best channels.”
Only 31 percent of the surveyed companies are satisfied with their own site-search. Can you explain this?
“My guess is many fewer users would be satisfied with the site-search on ecommerce websites. Sometimes companies are just happy with their site-search, even though it sucks. As I explained earlier, many site-searches nowadays are not able to match a user’s query with the most relevant products. While searching for a belt, users find dresses and pants with belts. While searching for dog food, users get bowls for dog food. While searching for a Lenovo laptop with 16gb ram, users get 16gb ram parts, not laptops and so on.”
“The main challenges for the next few years are how companies will be able to process their products’ data, empower great search technology and build a continuous & scalable improvement process. It will require people who have great know-how in the ecommerce search area, not just shiny tools. This is what SearchNode is known for in the market.”
It’s about having great know-how in the search area, not about having shiny tools.
Tags Europe
Share
Source link
0 notes
Link
Learn Elasticsearch from scratch and begin learning the ELK stack (Elasticsearch, Logstash & Kibana) and Elastic Stack.
GUIDE TO ELASTICSEARCH
Created by Bo Andersen
Last updated 11/2019
English
English [Auto-generated]
What you’ll learn
How to build a powerful search engine with Elasticsearch
The theory of Elasticsearch and how it works under-the-hood
Write complex search queries
Be proficient with the concepts and terminology of Elasticsearch
Requirements
Knowledge of JSON
Basic terminal skills is a plus
Description – Guide To Elasticsearch
Do you want to learn the popular search engine, Elasticsearch, from the beginning and become a professional in no time? This course is an excellent way for you to quickly learn Elasticsearch and to put your knowledge to work in just a few hours! If so, then you have come to the right place, as this is the most comprehensive course Guide To Elasticsearchthat you will find online! This course is a great starting point for anyone who wants to learn the ELK stack and Elastic Stack, as Elasticsearch is at the center of both stacks.
Guide To Elasticsearch is an extremely popular search engine and will be an excellent addition to your CV – even if you are already familiar with other search engines or frameworks such as Apache Lucene, Apache Solr, Amazon CloudSearch, etc.
Please note that this course is intended for developers who want to interact with an Elasticsearch cluster in one way or another and not system administrators looking to maintain an Elasticsearch cluster in production. The course focuses on functionality relevant to utilize the capabilities of Guide To Elasticsearch as a developer.
The course is a combination of theory and learning by doing. Before giving examples of how to perform certain queries, you will have been equipped with the necessary theory in advance. This ensures that you not only know how to perform powerful searches with Elasticsearch, but that you also understand the relevant theory; you will get a deep understanding of how Elasticsearch works under the hood.
The course starts from the absolute beginning, and no knowledge or prior experience with Elasticsearch is required. We will walk through all of the most important aspects of Elasticsearch, and at the end of this course, you will be able to build powerful search engines. This could be for a website where you could build Google-like search functionality, for example – Guide To Elasticsearch
So, join me in this course and learn to build powerful search engines with Elasticsearch today!
Note that this course does not cover Logstash and Kibana. This is so that I can go into much greater detail with Elasticsearch and focus on that exclusively. This course is therefore dedicated to Guide To Elasticsearch. For courses on Logstash and Kibana, please see my other courses.
Who this course is for:
Developers who want to learn Elasticsearch. The course is intended for developers and not system administrators.
Size: 3GB
DOWNLOAD TUTORIAL
The post COMPLETE GUIDE TO ELASTICSEARCH appeared first on GetFreeCourses.Me.
0 notes
Text
Original Post from Trend Micro Author: Trend Micro
By: Santosh Subramanya (Vulnerability Researcher)
Security researcher Michael Stepankin reported a vulnerability found in the popular, open-source enterprise search platform Apache Solr: CVE-2019-0192. It’s a critical vulnerability related to deserialization of untrusted data. To have a better understanding of how the vulnerability works, we replicated how it could be exploited in a potential attack by using a publicly available proof of concept (PoC).
Successfully exploiting this security flaw can let hackers execute arbitrary code in the context of the server application. For example, an unauthenticated hacker can exploit CVE-2019-0192 by sending a specially crafted Hypertext Transfer Protocol (HTTP) request to the Config API, which allows Apache Solr’s users to set up various elements of Apache Solr (via solrconfig.xml). Affected versions include Apache Solr 5.0.0 to 5.5.5 and 6.0.0 to 6.6.5.
What is Apache Solr? Apache Solr is an open-source enterprise search platform built on Apache Lucene, a Java-based library. It reportedly has a 35-percent market share among enterprise search platforms and is used by various multinational organizations.
Designed to be scalable, Apache Solr can index, query, and map sites, documents, and data from a variety of sources, and then return recommendations for related content. It supports text search, hit highlighting, database integration, and document handling (e.g., Word and PDF files) among others. It also supports JavaScript object notation (JSON) representational state transfer (REST) application programming interfaces (APIs). This means Apache Solr can be integrated with compatible systems or programming languages that support them. Apache Solr runs on port 8983.
What is CVE-2019-0192? The vulnerability is caused by an insufficient validation of request to the Config API, which lets Apache Solr’s users configure solrconfig.xml. This solrconfig.xml, in turn, controls how Apache Solr behaves in the installed system by mapping requests to different handlers. Parameters in solrconfig.xml, for instance, define how search requests and data are processed, managed, or retrieved.
Apache Solr is built on Java, which allows objects to be serialized, that is, converting and representing objects into a compact byte stream. This makes it a convenient way for the objects to be transferred over network. It can then be deserialized for use by a Java virtual machine (JVM) receiving the byte stream.
Config API allows Solr’s Java management extensions (JMX) server to be configured via HTTP POST request. An attacker could point the JMX server to a malicious remote method invocation (RMI) server and take advantage of the vulnerability to trigger remote code execution (RCE) on the Solr server.
How does CVE-2019-0192 work? An attacker can start a malicious RMI server by running a command, as seen in our example in Figure 1 (top). The ysoserial payload with class JRMPListener can be used to embed the command touch /tmp/pwn.txt, which can then get executed on a vulnerable Apache Solr. A POST request (Figure 1, bottom) can then be sent to Solr to remotely set the JMX server.
Figure 1. Snapshots of code showing how a malicious RMI server is started (top), and how a POST request is sent (bottom)
JMX enables remote clients to connect to a JVM and monitor the applications running in that JVM. The applications can be managed via managed beans (MBeans), which represents a resource. Through MBeans, developers, programmers, and Apache Solr users can access and control the inner workings of the running application. MBeans can be accessed over a different protocol via Java RMI. Apache Solr users who want to use JMX/RMI interface on a server can accordingly create a JMXService URL (service:jmx:rmi:///jndi/rmi://:/jmxrmi).
In the example showed in Figure 2, the attacker, exploiting CVE-2019-0192, could use a POST request and set the JMXService URL (jmx.serviceUrl) remotely via Config API using the ‘set-property’ JSON object.
As shown in Figure 3, it would return a 500 error, including the string “undeclared checked exception; nested exception is” in the response body.
Figure 2. Code snapshot showing how the JMXService could be set remotely
Figure 3. Snapshot of code showing the error 500
Due to improper validation, this jmx.serviceUrl can be pointed to an attacker-controlled JMRP listener (which is typically used to notify about events or conditions that occur). This causes the vulnerable Apache Solr to initiate an RMI connection to a malicious JMRP Listener. A three-way handshake will then be initiated with the malicious RMI server to set up a connection with the malicious RMI server.
An attacker can then take advantage of this to carry out RCE on the vulnerable Apache Solr. As shown in Figure 4, an attacker, for instance, can send a maliciously crafted serialized object.
Figure 4. Snapshot showing data transmission after exploiting CVE-2019-0192
How to address this vulnerability Apache Solr recommends patching or upgrading to 7.0 (or later) versions. It’s also advised to disable or restrict Config API when not in use. The network should also be proactively configured and monitored for any anomalous traffic that may be running on hosts that has Apache Solr installed.
Developers, programmers, and system administrators using and managing Apache Solr should also practice security by design as well as enforce the principle of least privilege and defense in depth to protect against threats that may exploit this vulnerability.
The Trend Micro Deep Security and Vulnerability Protection solutions protect user systems from threats that may exploit CVE-2019-0192 via this Deep Packet Inspection (DPI) rule:
1009601 – Apache Solr Remote Code Execution Vulnerability (CVE-2019-0192)
Trend Micro TippingPoint customers are protected from attacks that exploit CVE-2019-0192 this MainlineDV filter:
313798 – HTTP: Apache Solr Java Unserialized Remote Code Execution Vulnerability
The post CVE-2019-0192: Mitigating Unsecure Deserialization in Apache Solr appeared first on .
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source Author: Trend Micro CVE-2019-0192: Mitigating Unsecure Deserialization in Apache Solr Original Post from Trend Micro Author: Trend Micro By: Santosh Subramanya (Vulnerability Researcher) Security researcher Michael Stepankin…
0 notes