#Solr Query Parameters
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text

#Solr Query Syntax#Apache Solr Query Language#Solr Search Query Examples#Solr Query Parameters#Solr Query Filters#Solr Advanced Query Syntax#solr query#solr in query#Master Solr Query Syntax
0 notes
Text
Every Developer Should Know About These 15 Ruby on Rails Gems
If you are looking forward to creating a web application with robust features Ruby on Rails is the best framework to work with. Ruby on Rails framework can be further extended with Ruby gems. Gems allow developers to finish the web development process within days rather than months. They can be easily integrated and every Ruby on Rails development services tends to use these gems to create powerful web apps that are rich in functionalities.

There are a large number of Gems created by the RoR community, but we enlist the top 15 Gems that are regularly used by the Ruby on Rails web development company.
#1. The Active Record-Import
With ActiveRecord-Import, developers can insert the bulk of records in one go, they don’t have to deal with the N+1 insert problem. Thus, importing external data becomes possible as the conversion time is reduced.
#2. Draper
To build decorators around the model, developers use Draper gem. With Draper, the view can be made cleaner, developers can simply define a decorator without having to write helpers. Drapers offer attributes and extend methods for the object.
#3. Pry
Library integration can be an issue and even binding of the gems while writing the codes. This invites a lot of error, and in order to eliminate these issues or debug these errors, PRY gem can be really useful. Developers establish breakpoints and start code debugging. PRY offers exclusive features including runtime invocation, Syntax highlighting, exotic object support, flexible and powerful command system, and command shell integration. PRY is the active feature in ruby on rails development services.
#4. RSpec Rails
Developers choose RSpec Rails when they have to write unit test cases, it facilitates the developers with the integration of RSpec framework into any Rails project. It is used in TDD and BDD environments, it also features descriptive and neat syntax.
#5. Figaro
Figaro is used for secure configuration of the applications, it keeps the configuration data and SCM separate and passes the YAML file and loads the value in the ENV.
#6. Devise
While creating an application or an eCommerce solution, developers need to create authorization or authentication to access the same, in simpler words creating a login process for the users. Some developers prefer using their own codes to create the login system while others prefer using Devise gem for authentication which of course is an easier and faster process to do so. Devise has 11 different models which are Database_Authenticatable, Authenticatable, Lockable, Confirmable, Omniauthable, Recoverable, Rememberable, Registrable, Trackable, Timeoutable, Validatable respectively.
#7. Ahoy
It is an analytics platform, used to track the events and the visit in the native apps like JavaScript and Ruby. Ahoy is more of a Ruby engine rather than a gem, responsible for creating visit tickets that consists of the traffic source, client device information, and the location. Users can also check the UTM parameters of the website visits.
#8. Paperclips
Working with file attachments can be a hefty task, it takes a lot of time and effort of the developers to ensure secure implementation of the task. This is where Paperclip saves the day; it keeps track of the whole process in the Rails app. It can also convert images to thumbnails.
#9. Delayed Job
The Delayed Job can handle the longer running actions for the background tasks. Features of Delayed Job include sending a large number of newsletters, Image resizing, spam checks, updating smart collections, batch imports, HTTP downloads, and updating solr.
#10. Kaminari
Paginate anything through Kaminari. This is one of the most popular gems among the developers. It already has 5 million downloads under its kitty. The developers of Ruby on rails web development company are sure to use this gem.
#11. CanCanCan
It is used to build complex applications, developers can easily set up the restrictions to users’ access. The authorizations definition library module lets developers set the rules to restrict access to certain users.
#12. Active Admin
This framework builds the interfaces of administration style. Active Admin extracts the business application patterns and makes it easy for engineers to implement rich and wonderful interfaces with less exertion. Its different features incorporate User Authentication, Scopes, Action Items, Global Navigation, Sidebar Sections, Filters, Index Styles, Downloads, and APIS.
#13. Active Merchant
This gem facilitates the users with a unified API to provide access to various payment gateways. This gem can also be incorporated as a plug-in. It is majorly used for RoR web applications and also used majorly by any web application development company.
#14. Bullet
It reduces the queries and increases the performance of the application. It notifies the users when the (N+1) queries are required and when the counter cache should be used.
#15. Webpacker
It supports JavaScript, CSS, fonts, and images relevant to component-based JavaScript. It works wonders for Rails app development.
Conclusion
Using Ruby gems is standard practice for the providers of Ruby on Rails web development services. These gems can easily resolve the issues pertaining to uploads, file testing, authorization, and authentication. But it’s better to hire a professional agency who has the right knowledge to build & offer RoR custom web application development services. W3villa Technologies has experience with the technology and the gems. The developers here can build the latest applications to suit your business process.
1 note
·
View note
Text
How Solr Uses Advanced Search to Strengthen Organizations?

Solr’s advanced search technology allows for better precision and customization, leading to stronger and more efficient organizations.
We often sense information overload in the digital era, therefore organizations are continuously looking for solutions to efficiently search for and recover essential data. This is where the Solr search engine, which is based on Apache Lucene, comes in, with powerful search tools that have the ability to boost organizations in a variety of ways.
Organizations can boost client satisfaction and engagement by enhancing the importance of their search results with Solr’s advanced search features. Users may discover the information they need quickly and precisely because of Solr’s interactive search, smart search, and spell-checking capabilities. This improves not only the user experience but also the organization’s fruitfulness and productiveness.
Solr can manage massive amounts of data and allow distributed searching and indexing while providing a lightning-fast search experience.
The combination of Solr and machine learning techniques and recommendation algorithms enable personalized search outcomes. Organizations can utilize Solr’s advanced search features to give personalized search results, proposals, and suggestions by analyzing user behavior and interests. This level of personalization boosts user participation, sales, and client retention.
How does Solr manage queries?
Solr transforms the needed data into a structured representation as part of the indexing process. This entails parsing the data, extracting essential information, and categorizing it. If you’re indexing a group of documents, Solr can pull the title, author, content, and other metadata from each document and store it in distinct fields. Solr supports a variety of data formats, including XML, JSON, CSV, and others.
How Solr’s Advanced Search Can Benefit Your Business
Apache Solr Consulting Services can provide additional benefits to businesses leveraging Solr’s advanced search capabilities. Businesses can benefit from Solr’s sophisticated search capabilities in a variety of ways, including the ability to provide strong and efficient search experiences for their users. Here are some examples of how Solr’s advanced search functions might help your business:
Algorithms for ranking relevance: Solr has a number of relevance ranking algorithms that may be modified and fine-tuned to meet your unique business requirements. To assess the relevancy of search results, you can apply varying weights to various factors such as keyword matching, field enhancements, and proximity. You may ensure that the most relevant and significant results appear at the top of the search results list by customizing these algorithms.
Filtering and boosting: Solr allows you to boost or promote select documents or fields depending on specific criteria. Greater relevance scores can be assigned to specific attributes, such as product names, titles, or customer ratings, to guarantee they have a bigger effect on the overall ranking of search results. You can also use filters to narrow down search results based on specific criteria, enhancing relevancy and accuracy even further.
Sorting and relevance evaluation: Solr allows you to arrange search results based on criteria such as relevancy, date, or any other field value. You can set the sorting order to guarantee that the most relevant or recent results appear at the top of the search results list. Solr computes relevance scores based on parameters such as keyword frequency, field boosts, and other relevance ranking methods, allowing you to fine-tune search result ranking.
Better user experience: Faceted search allows users to explore and refine search results in a natural and dynamic manner. Users can rapidly drill down into certain features and locate the most relevant information by showing relevant facets or categories connected to the search results. This improves the overall user experience by streamlining the search process and shortening the time it takes to find desired results.
Facet counts that change dynamically: Solr can dynamically generate facet counts, displaying the number of matching documents for each facet value in real-time. This guarantees that the facet values appropriately represent the possibilities that are currently accessible depending on the search results. Users may see how many results are connected with each aspect value, allowing them to make more educated filtering decisions.
Conclusion
The capacity to process vast amounts of data and give real-time search updates guarantees that organizations can keep up with ever-changing data landscapes and present users with up-to-date information.
Furthermore, Solr’s connection with external systems and support for multilingual search enables organisations to search and index data from multiple sources smoothly, eliminating language barriers and offering a uniform search experience across disparate datasets.
The advanced search features of Solr serve as a foundation for organisations, allowing them to strengthen their operations, drive innovation, and gain meaningful insights from their data, eventually leading to better efficiency and success in today’s data-driven world.
Originally published by: How Solr Uses Advanced Search to Strengthen Organizations?
#Apache Solr Consulting Services#Apache Solr Development#Machine Learning Development#Advanced Strength of Solr#Solr search features
1 note
·
View note
Text
Top Technology Blogs to read
Qatar Insurance Company’s success with 10x customer engagement Qatar Insurance Company, the largest insurance company in the MENA region, is increasing sales and creating amazing customer experiences with chatbots.
Let’s Talk Quantum In Banking & Finance We’re living in a golden age of big data, according to data scientist Utpal Chakraborty. Discover how quantum computing is transforming banking & finance here.
Re-ranking of search results in SOLR Any e-commerce search engines rely on parameters such as product popularity, rating, click through rate etc to influence the result set for an input user query.
You should know this about Real Estate Chatbots by now(2023) Rule-based or AI-automated chatbots programmed to engage customers for real estate agencies. Chatbots are virtual agents that save time and grow sales.
10 reasons why your eCommerce business needs an AI chatbot The ever-increasing expectations of the customers can be met with the implementation of an artificial intelligent chatbot in e-commerce websites…….
6 ways to slash your Customer Acquisition Cost Learn how to calculate your customer acquisition cost (CAC) and explore six powerful ways to optimize it with the help of chatbots and live chat. Read now!
Apple’s and Amazon’s secret to success: Customer effort score Ever wonder what makes Apple and Amazon so insanely successful? Reducing the customer effort score is always the focus & that’s what drives these big giants
5 not-so-basic ways to reduce customer friction Reducing customer friction boosts loyalty & customer lifetime value. Here’s a comprehensive guide on improving your CX by eliminating customer friction
5 pillars of responsible and ethical AI How do you ensure that your AI systems are ethical? Maria Luciana Axente, the Responsible AI & AI for Good lead at PwC UK, helps identify key considerations.
Re(view) our Engati chatbot platform! Reviews are important for both the company and its customers, so we’re opening the floor for you to tell us why you think Engati is the best chatbot platform.
Ritualizing the customer experience Customer experience guru, Shep Hyken talks about the importance of ritualizing customer experiences and making sure they happen consistently, every time.
5 roles your entertainment and media chatbots can play! Entertainment and media chatbots are making customer experience interactive and helping people consume content in an easier manner. Check it out now!
Here’s why sentence similarity is a tough NLP problem Find out why sentence similarity is a challenging NLP problem and why training computers to read, understand and write language has become a big business.
How to use BERT for sentiment analysis? Sentiment analysis helps your chatbot reply to customers in an appropriate tone and enhance customer experience. Learn how to use BERT for sentiment analysis.
How to set up Solr as a system service Instagram, eBay, Netflix, and even Disney makes use of Solr. This quick guide will show you how to set up Solr as a service. Don’t miss out, read it now.
Black Friday tips | 17 tips to prepare your Shopify store for BFCM Want to get your Shopify store ready for Black Friday and Cyber Monday 2021? Here are 17 tips to help you do just that and sell more during these holidays!
How to improve your Shopify conversion rate by 30% If your conversion rate isn’t high, trying to send more traffic to your store might be a waste. Here’s what you can do to improve your Shopify conversion rate.
Top 20 Shopify Experts to follow for 2023 Setting up a Shopify store is easy; but challenging because you have to keep pace with your ever-growing competitors. Here is a list of 20 Shopify experts
14 tips to get your Shopify store ready for the holiday season Have your best-performing holiday sales yet by getting your Shopify store ready for the holiday season in advance. Here are 14 tips to get you started!
9 Shopify marketing strategies you need to adopt ASAP! Looking for the best marketing strategies to get the world to know about your Shopify store and send your sales through the roof? Here are 9 effective tips!
12 ways to retain customers on your Shopify store Loyal customers tend to make more purchases and buy higher value products from your store. Here’s how you can increase customer retention on your Shopify store.
How can small businesses survive COVID crisis? Small Businesses are taking massive hits due to the lockdowns triggered by the novel coronavirus. Here are some tips for small business survival. Check it out.
Building intelligent chatbots | What makes a chatbot smart? With features like Contextual Conversations, Voice Support, Natural Language Processing integrations, etc., it is now easier to build smarter chatbots.
Social engineering: 5 Types of attacks and how to prevent them Social Engineering refers to non-technical cyber attacks that rely on human interactions & involve tricking people for information & breaking security practices
How can small businesses survive COVID crisis? Small Businesses are taking massive hits due to the lockdowns triggered by the novel coronavirus. Here are some tips for small business survival. Check it out.
Building intelligent chatbots | What makes a chatbot smart? With features like Contextual Conversations, Voice Support, Natural Language Processing integrations, etc., it is now easier to build smarter chatbots.
How to speed up customer service with a small team Faster resolution and quicker service has always been associated with having a larger customer support team. But what if you didn’t need a big team for that?
Stay ahead of the Machine Learning curve In this blog, we’ll see what machine learning is all about. How is it growing big globally. How are businesses stepping up their game with machine learning.
Taking 3 extra steps to deliver amazing customer service Always aim to give your customers an experience better than any they expected because a little creativity & some extra efforts can make a big difference.
30 tech terms you HAVEN’T heard before Want to dive into the world of technology? Here’s a list of 30 tech terms that you’ve never heard of before. Begin your tech journey right here, check it out!
1 note
·
View note
Text
Top AI blogs to read before 2022
How to drive business success and create marketing magic on WhatsApp We’re showing you the best ways to run marketing campaigns and reach your customers in a more effective manner on their favourite touchpoint — WhatsApp.
5 ways how AI can improve your business’s software testing AI is improving & simplifying the life of developers & testers everywhere, by automating processes & allowing testers to provide accurate results & bug finds.
How much does it cost to give great customer service? Shep Hyken shows you how to take care of your customers and provide first-class customer service and experience without breaking the bank. Check it out!
How to generate leads with chatbots and live chat? Learn how to build a lead generation funnel with chatbots and live chat. You’ll also get insights on how to use them to nurture your leads and drive sales.
5 powerful ways to increase your customer lifetime value Increase your customer lifetime value with psychology and consumer neuroscience-backed techniques. Get your customers to spend more and stick around longer.
7 powerful ways to increase eCommerce customer retention To increase eCommerce customer retention, you need to simplify purchases. You also need to tempt and delight your customers. Here are 7 ways to do just that.
25 customer experience books you need to read in 2022 Want to improve your business’s CX substantially in 2022? Here are 15 customer experience books (and two bonus recommendations) that you need to read this year.
Stay ahead of the Machine Learning curve In this blog, we’ll see what machine learning is all about. How is it growing big globally. How are businesses stepping up their game with machine learning.
Let the sales cycle begin with chatbots! Sales cycle is a process that companies create selling a product to a customer. Using chatbots, companies collect customer data to facilitate the sales cycle
2 low-investment ways to ride the conversational automation wave The way we interact with tech influences how we market products. It’s time to hop on the conversational automation wave in 2 powerful, low-investment ways.
11 sectors where chatbots act as a digital personal assistant Chatbots have transformed into becoming a virtual personal assistant, built with providing efficiency and available at affordable prices. Check it out!
Re-ranking of search results in SOLR Any e-commerce search engines rely on parameters such as product popularity, rating, click through rate etc to influence the result set for an input user query.
5 Foolproof Ways to Choose the Right Platform for Your Online Store From the business idea to putting the idea into motion, you will need a solid understanding of how online shops operate. This article will show you how.
Are Instagram bots about to transform how you do business? Instagram now allows businesses to automate customer conversations via bots. Ready to take the leap? Read this article to discover why you need an Instagram bot
Asia: Becoming a Powerhouse through AI Adoption AI is taking the world, especially markets in Asia by storm. We’re exploring AI and its many use cases in markets such as China, Japan, and India in this blog
Taking 3 extra steps to deliver amazing customer service Always aim to give your customers an experience better than any they expected because a little creativity & some extra efforts can make a big difference.
The Basics of Threads and Thread Dumps Threads are the core of most processing units in the entire world of computers. They make up the basic part of every operation in java-based applications.
Black Friday tips | 17 tips to prepare your Shopify store for BFCM Want to get your Shopify store ready for Black Friday and Cyber Monday 2021? Here are 17 tips to help you do just that and sell more during these holidays!
Engati supports RTL (Right-to-Left) chatbots on its platform Overcome the language barrier in MENA regions with Engati’s RTL (Right-to-left) feature. Connect with customers who speak in Arabic, Urdu, Persian, and more!
You should know this about Real Estate Chatbots by now.(2023) Rule-based or AI-automated chatbots programmed to engage customers for real estate agencies. Chatbots are virtual agents that save time and grow sales.
4 ways AI chatbots are transforming customer experiences Enhancing customer experiences should always be a priority for businesses. Here’s how to improve your CX and make your customers keep coming back for more!
Engage your customers at scale with these security measures At Engati, we have strict security controls in place for our chatbot and live chat solution. Here is how we empower you to engage your customers safely.
Top 20 influencers revolutionizing the eCommerce industry Engati has compiled a handbook of insights by influencers that can be applied to eCommerce, leading to a meaningful impact in the eCommerce industry in 2021.
0 notes
Text
Mac os x apache tika automatic

#Mac os x apache tika automatic how to
See the section Types of Replicas for more information about replica types. This type of replica maintains a transaction log but only updates its index via replication from a leader. tlogReplicas The number of TLOG replicas to create for this collection. If you want all of your replicas to be of this type, you can simply use replicationFactor instead. This type of replica maintains a transaction log and updates its index locally. nrtReplicas The number of NRT (Near-Real-Time) replicas to create for this collection. If you want another type of replica, see the tlogReplicas and pullReplica parameters below. The number of replicas to be created for each shard. This is a required parameter when the router.name is implicit. shards A comma separated list of shard names, e.g., shard-x,shard-y,shard-z. This is a required parameter when the router.name is compositeId. numShards The number of shards to be created as part of the collection. When using the compositeId router, the numShards parameter is required.įor more information, see also the section Document Routing. When using the implicit router, the shards parameter is required. The compositeId router hashes the value in the uniqueKey field and looks up that hash in the collection’s clusterstate to determine which shard will receive the document, with the additional ability to manually direct the routing. Whichever shard you indicate on the indexing request (or within each document) will be used as the destination for those documents. The implicit router does not automatically route documents to different shards. Possible values are implicit or compositeId, which is the default. The router defines how documents will be distributed among the shards. Name The name of the collection to be created. The CREATE action allows the following parameters: admin/collections?action=CREATE&name= name CREATE Parameters
#Mac os x apache tika automatic how to
How to Contribute to Solr DocumentationĪ collection is a single logical index that uses a single Solr configuration file ( solrconfig.xml) and a single index schema.Configuring Authentication, Authorization and Audit Logging.Monitoring Solr with Prometheus and Grafana.RequestHandlers and SearchComponents in SolrConfig.Schema Factory Definition in SolrConfig.DataDir and DirectoryFactory in SolrConfig.Adding Custom Plugins in SolrCloud Mode.Introduction to Scaling and Distribution.Migrating Rule-Based Replica Rules to Autoscaling Policies.SolrCloud Autoscaling Automatically Adding Replicas.Cross Data Center Replication Operations.SolrCloud with Legacy Configuration Files.Using ZooKeeper to Manage Configuration Files.Setting Up an External ZooKeeper Ensemble.SolrCloud Query Routing And Read Tolerance.SolrCloud Recoveries and Write Tolerance.Interpolation, Derivatives and Integrals.The Extended DisMax (eDismax) Query Parser.Uploading Structured Data Store Data with the Data Import Handler.Uploading Data with Solr Cell using Apache Tika.Understanding Analyzers, Tokenizers, and Filters.Working with External Files and Processes.Working with Currencies and Exchange Rates.Overview of Documents, Fields, and Schema Design.Using the Solr Administration User Interface.
0 notes
Text
Data Persistence
Introduction to Data Persistence
Information systems process data and convert them into information.
The data should persist for later use;
To maintain the status
For logging purposes
To further process and derive knowledge
Data can be stored, read, updated/modified, and deleted.
At run time of software systems, data is stored in main memory, which is volatile.
Data should be stored in non-volatile storage for persistence.
Two main ways of storing data
- Files
- Databases
Data, Files, Databases and DBMSs
Data : Data are raw facts and can be processed and convert into meaningful information.
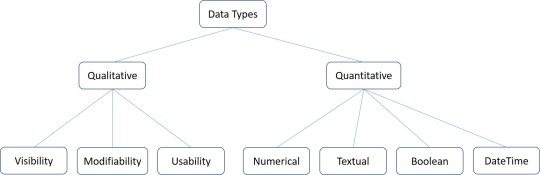
Data Arrangements
Un Structured : Often include text and multimedia content.
Ex: email messages, word processing documents, videos, photos, audio files, presentations, web pages and many other kinds of business documents.
Semi Structured : Information that does not reside in a relational database but that does have some organizational properties that make it easier to analyze.
Ex: CSV but XML and JSON, NoSQL databases
Structured : This concerns all data which can be stored in database SQL in table with rows and columns
Databases : Databases are created and managed in database servers
SQL is used to process databases
- DDL - CRUD Databases
- DML - CRUD data in databases
Database Types
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database model, data is organized into a tree like structure.
The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children
Ex: The IBM Information Management System (IMS) and Windows Registry
Advantages : Hierarchical database can be accessed and updated rapidly
Disadvantages : This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers.
A network database looks more like a cobweb or interconnected network of records.
Ex: Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Ex: Oracle, SQL Server, MySQL, SQLite, and IBM DB2
Object Oriented model
Object DBMS's increase the semantics of the C++ and Java. It provides full-featured database programming capability, while containing native language compatibility.
It adds the database functionality to object programming languages.
Ex: Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Ex: The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic
ER Model Databases
An ER model is typically implemented as a database.
In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents.
Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Ex: Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB
DBMSs : DBMSs are used to connect to the DB servers and manage the DBs and data in them
Data Arrangements
Data warehouse
Big data
- Volume
- Variety
- Velocity
Applications to Files/DB
Files and DBs are external components
Software can connect to the files/DBs to perform CRUD operations on data
- File – File path, URL
- Databases – Connection string
To process data in DB
- SQL statements
- Prepared statements
- Callable statements
Useful Objects
o Connection
o Statement
o Reader
o Result set
SQL Statements - Execute standard SQL statements from the application
Prepared Statements - The query only needs to be parsed once, but can be executed multiple times with the same or different parameters.
Callable Statements - Execute stored procedures
ORM
Stands for Object Relational Mapping
Different structures for holding data at runtime;
- Application holds data in objects
- Database uses tables
Mismatches between relational and object models
o Granularity – Object model has more granularity than relational model.
o Subtypes – Subtypes are not supported by all types of relational databases.
o Identity – Relational model does not expose identity while writing equality.
o Associations – Relational models cannot determine multiple relationships while looking into an object domain model.
o Data navigations – Data navigation between objects in an object network is different in both models.
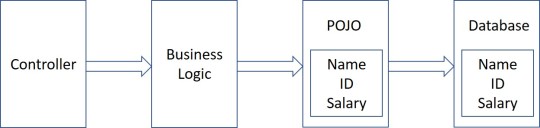
ORM implementations in JAVA
JavaBeans
JPA (JAVA Persistence API)
Beans use POJO
POJO stands for Plain Old Java Object.
It is an ordinary Java object, not bound by any special restriction
POJOs are used for increasing the readability and re-usability of a program
POJOs have gained most acceptance because they are easy to write and understand
A POJO should not;·
Extend pre-specified classes
Implement pre-specified interfaces
Contain pre-specified annotations
Beans
Beans are special type of POJOs
All JavaBeans are POJOs but not all POJOs are JavaBeans
Serializable
Fields should be private
Fields should have getters or setters or both
A no-arg constructor should be there in a bean
Fields are accessed only by constructor or getters setters
POJO/Bean to DB
Java Persistence API
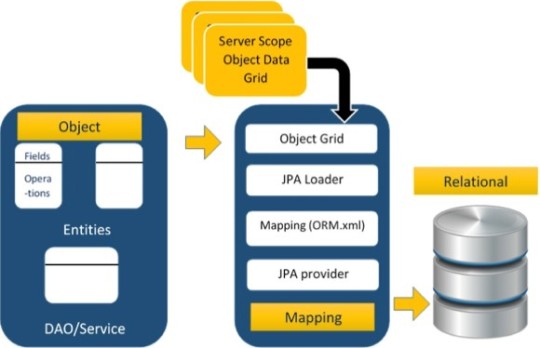
The above architecture explains how object data is stored into relational database in three phases.
Phase 1
The first phase, named as the Object data phase contains POJO classes, service interfaces and classes. It is the main business component layer, which has business logic operations and attributes.
Phase 2
The second phase named as mapping or persistence phase which contains JPA provider, mapping file (ORM.xml), JPA Loader, and Object Grid
Phase 3
The third phase is the Relational data phase. It contains the relational data which is logically connected to the business component.
JPA Implementations
Hybernate
EclipseLink
JDO
ObjectDB
Caster
Spring DAO
NoSQL and HADOOP
Relational DBs are good for structured data and for semi-structured and un-structured data, some other types of DBs can be used.
- Key value stores
- Document databases
- Wide column stores
- Graph stores
Benefits of NoSQL
Compared to relational databases, NoSQL databases are more scalable and provide superior performance
Their data model addresses several issues that the relational model is not designed to address
NoSQL DB Servers
o MongoDB
o Cassandra
o Redis
o Hbase
o Amazon DynamoDB
HADOOP
It is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
HADOOP Core Concepts
HADOOP Distributed File System
- A distributed file system that provides high-throughput access to application data
HADOOP YARN
- A framework for job scheduling and cluster resource management
HADOOP Map Reduce
- A YARN-based system for parallel processing of large data sets
Information Retrieval
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
1. Keyword Search
2. Full-text search
The output can be
1. Text
2. Multimedia
The information retrieval process should be;
Fast/performance
Scalable
Efficient
Reliable/Correct
Major implementations
Elasticsearch
Solr
Mainly used in search engines and recommendation systems
Additionally may use
Natural Language Processing
AI/Machine Learning
Ranking
References
https://www.tutorialspoint.com/jpa/jpa_orm_components.htm
https://www.c-sharpcorner.com/UploadFile/65fc13/types-of-database-management-systems/
0 notes
Text
How Minted scaled their online marketplace on Cyber Monday 2019 by migrating to AWS cloud and Amazon Aurora
This is a guest post by Minted. In their own words, “Minted is an online marketplace for independent artists. Connecting a global creative community directly to consumers, Minted uses technology that enables products to be shared by independent artists who typically lack access to traditional retail outlets. Products available on Minted include works of art, holiday cards, home decor, and stationery created by independent artists and designers spread across all 50 states and across 96 countries. Minted’s community members share a deep love of creative expression, personal development, risk taking, and most importantly, paying it forward by helping each other.” Minted runs several apps, including main ecommerce platforms, community-related sites to interact with independent artists and designers, wedding websites, and digital invitation platforms. Holiday card sales are one of our key businesses. Because of that, our ecommerce platform gets 10 times more traffic during November and December, especially during traffic peaks on Black Friday and Cyber Monday. Originally, most of our apps shared a single, centralized MySQL database (DB) cluster backend. We struggled to keep the on-premises database stable and avoid site-wide outages during peak traffic. After we chose Aurora for our databases, it solved most of our database-related scaling problems. We could also move away from our centralized DB cluster to multiple, app-specific DB cluster architectures for better scaling. This post discusses Minted’s scalability challenges and how we addressed them by migrating our infrastructure to AWS cloud, and in particular how we migrated our database clusters to the Amazon Aurora platform and scaled our online marketplace for Cyber Monday, 2019. Infrastructure before AWS The following diagram illustrates our infrastructure architecture before migrating to AWS. Our original infrastructure was hosted in a hybrid platform that spanned multiple data centers. For example, in the Rackspace public cloud, we had application servers, Kubernetes clusters, Kafka, Elasticsearch, and solr. We also had MySQL DB clusters in a Rackspace DFW data center, image assets in Amazon Simple Storage Service (Amazon S3), and fulfillment and community peripheral services in AWS. The hybrid infrastructure presented major challenges for us, primarily: The Rackspace public cloud didn’t have an instance type powerful enough to handle our peak database load. Our database load peaked at around 20,000 select QPS, 3000 DML QPS, and 18000 database connections. We had to host our MySQL DB clusters in their on-premises data center, which was harder to maintain and scale. Our production database infrastructure was in a single data center. Any outage in the Rackspace DFW data center would cause a significant site-wide outage. We used a physical F5 Big-IP load balancer to route all L4/L7 traffic in Rackspace. Because of this, we had to plan in advance every year to scale the device vertically for the required throughput. We had to preplan our application server capacity needs for holiday traffic and make the request to Rackspace months in advance. This approach wasn’t sustainable and there was no room to accommodate any last-minute capacity increases. The Rackspace server provisioning system was comparatively slow to support our frequent deployments. Migrating to AWS Migrating all our apps to the AWS Cloud solved most of our capacity- and scalability-related problems. Aurora, in particular, helped address our database scalability problems. We also migrated to cloud services like Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Managed Streaming for Kafka (Amazon MSK) for our Kubernetes and Kafka infrastructure. We built our entire infrastructure using Terraform, which greatly simplified our deployment automation framework. Our hosting cost decreased as well. Now we can quickly scale up application servers and Aurora DB clusters for peak days and scale them down as soon as they’re no longer needed. This wasn’t possible at Rackspace, where we usually provisioned 30% more for both application servers and databases, and kept them running for weeks. The following diagram illustrates our AWS Organization. We went with multiple AWS accounts to keep production, non-production and shared internal tools environment isolated for better security as shown in the above diagram. The following diagram illustrates the ecommerce platform high-level architecture in AWS. Our ecommerce platform includes shopping funnel, community sites, pricing endpoints, back-office sites. We hosted the entire infrastructure inside an Amazon Virtual Private Cloud (Amazon VPC) in us-east-1 and DR site at another VPC in us-west-2 as shown in the above diagram. We used multi-AZ deployments for infrastructure components like ALB, ASG, Aurora DB, MSK, Elastic cache and Elastic Kubernetes Service cluster for high availability. For security and isolation, we went with separate security groups for every role and also routed all traffic going out of e-com prod VPC to peripheral service VPCs via AWS peering connections. Migrating our on-premises MySQL cluster to an Aurora DB cluster The database was the critical part of the migration. We decided to go with Aurora MySQL for the following reasons: Powerful instance types – Our ecommerce platform MySQL DB cluster primary instance needs a powerful instance type to handle our holiday peak traffic. We selected db.r5.16xlarge with 64 vCPU and 512 GB memory. Zero downtime failover – We need to perform planned DB failovers within minutes or with almost zero downtime. We have experienced a primary instance going into read-only state briefly during failovers on some occasions. However, we’ve still reduced our typical planned site downtime maintenance window from 20 minutes to less than a few minutes overall. This is a huge win for us. Low replication lag – We need to keep replication lag to a minimum for maintaining read after write consistency. Aurora replicas share the same underlying volume with the primary instance. This means that we can perform replication in milliseconds because updates made by the primary instance are instantly available to all Aurora replicas. For example, the low replication lag helped us when we modified the schema of a 60 GB table. Up to 15 read replicas – This is useful when scaling our read-heavy workload with 200 ms+ slow community and fulfillment queries. We scaled up to only five replicas during Cyber Monday. The number of read replicas mostly depends on the traffic pattern; for example, if we see more traffic on slower pages, we may have to scale up more. This also provides peace of mind knowing that we can scale up replicas in a matter of minutes. Performing an Aurora load test Because the DB primary instance is our usual choke point during Cyber Monday peak traffic, we did a load test with a newly built site focusing specifically on Aurora primary DB. We used JMeter to generate load, simulating Minted’s shopping funnel. The load test had the following parameters: Instance class was db.r5.12xlarge (48 vCPU, 384 GB memory) Aurora MySQL 5.6 version 1.12 No instances: 2 (Primary & Replica) Load test observations Aurora sustained our Cyber Monday forecasted load of more than 20,000 select queries per second (QPS) and 3000 DML QPS at around 36% CPU utilization as shown in below charts. This load test doesn’t cover all our traffic, so the lower the CPU utilization, the better. Aurora Load Test Primary DB Select Throughput Aurora Load Test Primary DB DML Throughput and Latency Aurora Load Test Primary DB CPU Utilization Replication latency stayed at around 20 ms as shown below. This gave us the motivation to unload more queries from the primary to the read replicas. Aurora Load Test Replica DB Replication Lag The only problem is the 16 K hard max_connection limit per Aurora MySQL instance. With a fleet of over 300 application servers, the number of database connections is likely to reach 16 K during real Cyber Monday traffic. We explored adding connection pooling in front of our DB cluster, but due to time constraints, we went with the following workarounds: Split the main cluster into multiple app specific Aurora DB clusters. Reduce SQLAlchemy pool_recycle to 120 seconds to close and reopen persistence connections every 2 minutes to avoid long sleeping database connections. Fortunately, we didn’t observe any additional load in Aurora when creating and closing connections frequently. Rackspace to Aurora migration process walkthrough We built a duplicate site on AWS with an exact copy of the apps that we run behind our www.minted.com DNS name as shown in above diagram. The duplicate site was only accessible with the HTTP cookie awsmig:awsmig. This way, we could use the cookie to verify the new site end to end before actual cutover. The database was the most complex part of the entire migration – we had to keep the downtime as low as possible. We also had to establish reverse replication to keep the option to roll the site traffic back to Rackspace in emergencies. The following steps review our database migration to Aurora. Phase 1: Establishing database replication from the Rackspace primary to an Aurora replica Establishing database replication from our primary to a replica included the following steps: Set up a secure VPN tunnel between the Rackspace on-premises database network to the new production Amazon VPC. Take a backup from the current production MySQL primary instance with Percona xtrabackup. Ensure the following entries in my.cnf: innodb_flush_log_at_trx_commit=1 sync_binlog=1 Use Percona xtrabackup version 2.4.0 or above. Upload the backup to an S3 bucket in AWS. Create an AWS Identity and Access Management (IAM) role for RDS (rds-s3 read-only access) with AmazonS3ReadOnlyAccess. Create a DB parameter group and DB cluster parameter group via Amazon Relational Database Service (Amazon RDS). Create an Aurora DB cluster called Temp_replica using uploaded Percona hot backup from the S3 bucket. Set up binary log replication between the Rackspace on-premises database primary to the newly created Aurora database replica Temp_replica. Start the binary log replication. Enable binary logging at the Aurora DB cluster Temp_replica. Phase 2: Database cutover The database cutover was a 20-minute site-wide planned downtime. It included the following steps: Put the apps under planned maintenance. Put the primary database in the Rackspace DFW data center into read-only mode (SET GLOBAL read_only = 1;). Wait for the replication to catch up in the Aurora replica Temp_replica at us-east-1. Stop replication and note down the binlog file name and position (show master statusG). We needed this to establish reverse replication to the Rackspace database. Promote Temp_replica to prod cluster primary. Add readers to the newly promoted prod cluster primary instance. Establish reverse binary log replication to a Rackspace database. Update the database connection string DNS to point to newly promoted aurora cluster and restart the apps. Remove the site from maintenance. Despite several failed attempts and unexpected outages during this migration process, the database portion went according to plan. Learnings We encountered a data corruption issue for timestamp and datetime columns during our initial replication sync between the on-premises MySQL primary and the new Aurora replica. This occurred because of a time zone configuration mismatch coupled with a known MySQL bug. See the following code: on-perm master mysql> select @@system_time_zone; | @@system_time_zone | @@time_zone | | PDT | SYSTEM | Aurora slave mysql> select @@system_time_zone; | @@system_time_zone | @@time_zone | | UTC | US/Pacific | In the preceding code, in the on-premises database primary, time_zone is set to SYSTEM. Because system_time_zone is set to PDT on the on-premises servers, there were no issues with replication between on-premises databases. But when the data moved from the on-premises database to Aurora with time_zone set to SYSTEM, Aurora converted the values of the timestamp and datetime columns to system_time_zone = UTC. We resolved this issue by setting time_zone = PDT instead of SYSTEM in the primary and re-syncing the data. We wrote the following data validation script using mysqldump to validate the latest subset of rows (at least 1 million) between MySQL primary and Aurora replica Temp_slave to be safe, Most of our tables have auto increment unsigned integer primary key column except a few tables, the below script compares the tables with primary key and we manually compared the ones without primary keys. _primaryKey = mysql1.run_mysql_cmd( "SELECT COLUMN_NAME FROM information_schema.KEY_COLUMN_USAGE " + "WHERE TABLE_NAME = '{table}' ".format(table=table) + "AND CONSTRAINT_NAME = 'PRIMARY' LIMIT 1" ) if not _primaryKey: print(in_red("Primary Key not found. Skipping Data compare")) continue primaryKey = _primaryKey[0][0] dumpWhere = "true ORDER BY {primaryKey} DESC LIMIT {limit}".format(limit=DUMP_LIMIT_ROWS, primaryKey=primaryKey) # Dump 1 dump_cmd = "./mysqldump --skip-comments -u {user} -h {host} --where "{where}" {database} {table}".format(user=MYSQL_1_USER, host=MYSQL_1_HOST, database=db, table=table, where=dumpWhere) mysql1_dump = subprocess.run(dump_cmd, shell=True, stdout=subprocess.PIPE, encoding="utf-8", universal_newlines=True, errors='replace') dump_cmd = "./mysqldump --skip-comments -u {user} -h {host} --where "{where}" {database} {table}" .format(user=MYSQL_2_USER, host=MYSQL_2_HOST, database=db, table=table, where=dumpWhere) mysql2_dump = subprocess.run(dump_cmd, shell=True, stdout=subprocess.PIPE, encoding="utf-8", universal_newlines=True, errors='replace') dump_diff_list = difflib.unified_diff(mysql1_dump.stdout.split('n'), mysql2_dump.stdout.split('n')) dump_diff = list(dump_diff_list) if dump_diff: print('Data - %s' % (in_red('DIFFER'))) print('Check Diff:') print('n'.join(dump_diff)) else: print('Data - %s' % (in_green('IDENTICAL'))) Migrating our self-hosted Kubernetes cluster to Amazon EKS Originally we hosted most of our critical production microservices, such as the pricing endpoint, customizer API, and flink cluster, in a self-hosted Kubernetes cluster. We built those using the Kubespray open-source tool. It was complicated to maintain and scale the self-hosted cluster with a small team, so we chose to migrate to Amazon EKS. We ran more than 3,000 pods with varying levels of memory and CPU resource quotas assigned during Cyber Monday 2019, when we usually get short and frequent surges in traffic. Amazon EKS doesn’t have monitoring data on its control plane to show the resource usage metrics of primary, etcd nodes. To be safe, we pre-provisioned our worker nodes for our anticipated traffic growth with a buffer instead of automatic scaling. We also told AWS Support in advance to adjust our control plane node resources accordingly. We plan to test automatic scaling on Amazon EKS for our Cyber Monday 2020 traffic. Moving from self-hosted clusters helped automate our deployment pipeline end to end. The following apps worked seamlessly in AWS and Amazon EKS: Cluster-autoscaler to auto scale Amazon EKS worker nodes. External-DNS to automatically create or update the Amazon Route 53 DNS record based on an ingress value. Aws-alb-ingress-controller to automatically create application load balancers. Learnings We took away the following learnings from our Kubernetes migration: Amazon EKS supports networking via an Amazon Virtual Private Cloud (Amazon VPC) CNI plugin, which assigns every pod in the cluster with an IP from the VPC IP space. Because of this, we ran out of IP addresses and had to adjust the VPC subnet CIDR to keep a larger IP space in reserve. The AWS Application Load Balancer ingress controller adds application load balancers automatically and attaches a pod IP address as a target. An AWS target group has a 1,000 target limit, and we had to duplicate services to avoid hitting this limit. The External-dns app polls Route 53 at regular intervals. With multiple Amazon EKS clusters, each with its own external-dns, we ended up hitting a Route 53 five API calls/second rate limit, which caused deploys to fail intermittently. We had to increase the external-dns interval in non-prod environments as a workaround. Cyber Week 2019 In terms of site stability, Cyber Week 2019 was by far the smoothest event we’ve ever had. We had our highest ever sales day on Cyber Monday, and the ecommerce site performed with no outages or latency issues. We also got great feedback from our artist and designer community about their site experience. Aurora performed exceptionally well on Cyber Monday. We achieved almost 17,000 select QPS, 1000 DML QPS, and 16,000 database connections on the primary DB instance. Scaling infrastructure, particularly databases during peak traffic, has never been this simple. As of this writing, we have already moved most of our MySQL database fleet to Aurora. It’s currently our default platform for hosting MySQL databases for all our new apps. About the Author Balachandran Ramadass is a Staff Engineer at Minted in the Site Reliability Engineering team. Bala has more than 7 years of experience in DevOps and building infrastructure at the AWS cloud. He has a keen interest in Databases, building microservices in Kubernetes, API performance optimization, and planning & scaling large-scale e-commerce infrastructure for the yearly holiday peak traffic. He holds a Masters degree in Electrical and Computer engineering from Louisiana State University, in his spare time, he loves playing cricket, hiking with his son and cooking. https://aws.amazon.com/blogs/database/how-minted-scaled-their-online-marketplace-on-cyber-monday-2019-by-migrating-to-aws-cloud-and-amazon-aurora/
0 notes
Text
300+ TOP Apache SOLR Interview Questions and Answers
Apache Solr Interview Questions for freshers experienced :-
1. What is Apache Solr? Apache Solr is a standalone full-text search platform to perform searches on multiple websites and index documents using XML and HTTP. Built on a Java Library called Lucence, Solr supports a rich schema specification for a wide range and offers flexibility in dealing with different document fields. It also consists of an extensive search plugin API for developing custom search behavior. 2. What are the most common elements in solrconfig.xml? Search components Cache parameters Data directory location Request handlers 3. What file contains configuration for data directory? Solrconfig.xml file contains configuration for data directory. 4. What file contains definition of the field types and fields of documents? schema.xml file contains definition of the field types and fields of documents. 5. What are the features of Apache Solr? Allows Scalable, high performance indexing Near real-time indexing. Standards-based open interfaces like XML, JSON and HTTP. Flexible and adaptable faceting. Advanced and Accurate full-text search. Linearly scalable, auto index replication, auto failover and recovery. Allows concurrent searching and updating. Comprehensive HTML administration interfaces. Provides cross-platform solutions that are index-compatible. 6. What is Apache Lucene? Supported by Apache Software Foundation, Apache Lucene is a free, open-source, high-performance text search engine library written in Java by Doug Cutting. Lucence facilitates full-featured searching, highlighting, indexing and spellchecking of documents in various formats like MS Office docs, HTML, PDF, text docs and others. 7. What is request handler? When a user runs a search in Solr, the search query is processed by a request handler. SolrRequestHandler is a Solr Plugin, which illustrates the logic to be executed for any request.Solrconfig.xml file comprises several handlers (containing a number of instances of the same SolrRequestHandler class having different configurations). 8. What are the advantages and disadvantages of Standard Query Parser? Also known as Lucence Parser, the Solr standard query parser enables users to specify precise queries through a robust syntax. However, the parser’s syntax is vulnerable to many syntax errors unlike other error-free query parsers like DisMax parser. 9. What all information is specified in field type? A field type includes four types of information: Name of field type. Field attributes. An implementation class name. If the field type is Text Field , a description of the field analysis for the field type. 10. Explain Faceting in Solr? As the name suggests, Faceting is the arrangement and categorization of all search results based on their index terms. The process of faceting makes the searching task smoother as users can look for the exact results. 11. Define Dynamic Fields? Dynamic Fields are a useful feature if users by any chance forget to define one or more fields. They allow excellent flexibility to index fields that have not been explicitly defined in the schema. 12. What is Field Analyzer? Working with textual data in Solr, Field Analyzer reviews and checks the filed text and generates a token stream. The pre-process of analyzing of input text is performed at the time of searching or indexing and at query time. Most Solr applications use Custom Analyzers defined by users. Remember, each Analyzer has only one Tokenizer. 13. What is the use of tokenizer? It is used to split a stream of text into a series of tokens, where each token is a subsequence of characters in the text. The token produced are then passed through Token Filters that can add, remove or update the tokens. Later,that field is indexed by the resulting token stream. 14. What is phonetic filter? Phonetic filter creates tokens using one of the phonetic encoding algorithms in the org.apache.commons.codec.language package. 15. What is SolrCloud? Apache Solr facilitates fault-tolerant, high-scalable searching capabilities that enable users to set up a highly-available cluster of Solr servers. These capabilities are well revered as SolrCloud. 16. What is copying field? It is used to describe how to populate fields with data copied from another field. 17. What is Highlighting? Highlighting refers to the fragmentation of documents matching the user’s query included in the query response. These fragments are then highlighted and placed in a special section, which is used by clients and users to present the snippets. Solr consists of a number of highlighting utilities having control over different fields. The highlighting utilities can be called by Request Handlers and reused with standard query parsers. 18. Name different types of highlighters? There are 3 highlighters in Solr: Standard Highlighter : provides precise matches even for advanced queryparsers. FastVector Highlighter : Though less advanced than Standard Highlighter, it works better for more languages and supports Unicode breakiterators. Postings Highlighter : Much more precise, efficient and compact than the above vector one but inappropriate for a more number of query terms. 19. What is the use of stats.field? It is used to generate statistics over the results of arbitrary numeric functions. 20. What command is used to see how to use the bin/Solr script? Execute $ bin/Solr –helpto see how to use the bin/Solr script. 21. Which syntax is used to stop Solr? $ bin/solr stop -p 8983 is used to stop Solr. 22. Which command is used to start Solr in foreground? $ bin/solr start –f is used to start Solr in foreground. 23. What syntax is used to check whether Solr is currently running or not? $ bin/solr status is used to check Solr running status. 24. Give the syntax to start the server. $ bin/solr start is used to start the server. 25. How to shut down Apache Solr? Solr is shut down from the same terminal where it was launched. Click Ctrl+C to shut it down. 26. What data is specified by Schema? Schema declares – how to index and search each field. what kinds of fields are available. what fields are required. what field should be used as the unique/primary key 27. Name the basic Field types in Solr? date long double text float Become Master of Apache Solr by going through this online Solr Training. 28. How to install Solr? The three steps of Installation are: Server-related files, e.g. Tomcat or start.jar (Jetty). Solr webapp as a .war. Solr Home which comprises the data directory and configuration files 29. What are the important configuration files of Solr? Solr supports two important configuration files solrconfig.xml. schema.xml Apache Solr Questions and Answers Pdf Download Read the full article
0 notes
Text
Securing Solr Cluster – Enabling SSL on Multi Node
Securing solr cluster is important as much as any e-commerce websites or banking website because user query or request should not decrypt by hacker to protect confidential information.In this article we will discuss how to enable SSL on single node server with the example jetty server using self signed certificate.
In our previous Securing Single Node Solr we have discussed how to secure standalone solr.
To enable SSL on your single node solr please follow below steps.
Table of Contents [hide]
Step 1: Download apache zookeeper
Step 2: Configure zookeeper
Step 3 :Start zookeeper
Step 4: generate keys
Step 5: Set System Properties
Step 6: Configure Solr propertyies in zookeeper
Step 7: Create two SolrHome directory
Step 8: Start First node
Step 9: Start Second node
Step 10: verify SSL on both Solr nodes
Was this post helpful?
Step 4.1: Generate a Self-Signed Certificate and a Key
Step 4.2: Convert the Certificate and Key to PEM Format
Step 4.1.1: Goto Solr installation bin directory
Step 4.1.2: Generate key
Example:
Step 1: Download apache zookeeper
Apache zookeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.Download zookeeper from Here .
Step 2: Configure zookeeper
Create zoo.cfg file and add below configuration parameters.
tickTime=2000 dataDir=/tmp/data/zookeeper clientPort=2181
Step 3 :Start zookeeper
To run the instance, you can simply use the ZOOKEEPER_HOME/bin/zkServer.cmd script provided, as with this command:
zkServer.cmd start
Step 4: generate keysStep 4.1: Generate a Self-Signed Certificate and a Key
To generate a self-signed certificate and a single key that will be used to authenticate both the server and the client, we’ll use the JDK keytool command and create a separate keystore. This keystore will also be used as a truststore below.
Here we have used JDK Keytool to generate keys.Perform below steps to generate keys and import.
Step 4.1.1: Goto Solr installation bin directory
Goto solr-{VERSION}/bin directory
Step 4.1.2: Generate key
Execute command to generate key.
keytool -genkeypair -alias solr-ssl -keyalg RSA -keysize 2048 -keypass secret -storepass secret -validity 9999 -keystore solr-ssl.keystore.jks -ext SAN=DNS:localhost,IP:127.0.0.1 -dname "CN=localhost, OU=Organizational Unit, O=Organization, L=Location, ST=State, C=Country"
genkeypair option is used to generate key. keytool has various option to give alias, algorithm name,keysize.etc..
here we have used RSA algorithm.Need to specify password for key, it’s validity,keystore file name.
The -ext SAN=… keytool option allows you to specify all the DNS names and/or IP addresses that will be allowed during hostname verification
Example:
keytool -genkeypair -alias solr-ssl -keyalg RSA -keysize 2048 -keypass secret -storepass secret -validity 9999 -keystore solr-ssl.keystore.jks -ext SAN=DNS:localhost,IP:192.168.1.206,IP:127.0.0.1 -dname "CN=localhost, OU=Organizational Unit, O=JavaDeveloperZone, L=Location, ST=State, C=Country"
The above command will create a keystore file named solr-ssl.keystore.jks in the current directory.
Step 4.2: Convert the Certificate and Key to PEM Format
CURL doesn’t able to understand JKS formatted key store so we need to convert it to PEM format using keystore.
keytool -importkeystore -srckeystore solr-ssl.keystore.jks -destkeystore solr-ssl.keystore.p12 -srcstoretype jks -deststoretype pkcs12
Above command will prompt you for destination keystore password and source keystore password.Use secret password in our case.
Step 5: Set System Properties
Set SSL related properties as java system property in solr-in.cmd for windows and solr-in.sh for linux.
set SOLR_SSL_KEY_STORE=D:\\solr-6.4.2\\solr-6.4.2\\bin\\solr-ssl.keystore.jks set SOLR_SSL_KEY_STORE_PASSWORD=secret set SOLR_SSL_KEY_STORE_TYPE=JKS set SOLR_SSL_TRUST_STORE=D:\\solr-6.4.2\\solr-6.4.2\\bin\\solr-ssl.keystore.jks set SOLR_SSL_TRUST_STORE_PASSWORD=secret set SOLR_SSL_TRUST_STORE_TYPE=JKS set SOLR_SSL_NEED_CLIENT_AUTH=false set SOLR_SSL_WANT_CLIENT_AUTH=false
Step 6: Configure Solr propertyies in zookeeper
Before you start any SolrCloud nodes, you must configure your solr cluster properties in ZooKeeper, so that Solr nodes know to communicate via SSL.The urlScheme cluster-wide property needs to be set to https before any Solr node starts up.Use below command:
server\scripts\cloud-scripts\zkcli.bat -zkhost localhost:2181 -cmd clusterprop -name urlScheme -val https
Step 7: Create two SolrHome directory
Create two copies of the server/solr/ directory which will serve as the Solr home directories for each of your two SolrCloud nodes:
mkdir cloud xcopy /E server\solr cloud\server1\ xcopy /E server\solr cloud\server2\
Step 8: Start First node
Start the first Solr node on port 8984.If you haven’t specified DNS/all IP address you can tell solr to skip hostname verification for inter solr node communication by setting solr.ssl.checkPeerName false.
bin\solr.cmd -cloud -s cloud\server_1 -z localhost:2181 -p 8984 -Dsolr.ssl.checkPeerName=false
Step 9: Start Second node
Start the second Solr node on port 8985.
bin\solr.cmd -cloud -s cloud\server_2 -z localhost:2181 -p 8985 -Dsolr.ssl.checkPeerName=false
Step 10: verify SSL on both Solr nodes
That’s it. Once solr started,verify it in your browser.Here we have added one sample collection to check solr node communction over SSL.
bin\solr.cmd create -c mycollection -shards 2
0 notes
Text
Original Post from Trend Micro Author: Trend Micro
By: Santosh Subramanya (Vulnerability Researcher)
Security researcher Michael Stepankin reported a vulnerability found in the popular, open-source enterprise search platform Apache Solr: CVE-2019-0192. It’s a critical vulnerability related to deserialization of untrusted data. To have a better understanding of how the vulnerability works, we replicated how it could be exploited in a potential attack by using a publicly available proof of concept (PoC).
Successfully exploiting this security flaw can let hackers execute arbitrary code in the context of the server application. For example, an unauthenticated hacker can exploit CVE-2019-0192 by sending a specially crafted Hypertext Transfer Protocol (HTTP) request to the Config API, which allows Apache Solr’s users to set up various elements of Apache Solr (via solrconfig.xml). Affected versions include Apache Solr 5.0.0 to 5.5.5 and 6.0.0 to 6.6.5.
What is Apache Solr? Apache Solr is an open-source enterprise search platform built on Apache Lucene, a Java-based library. It reportedly has a 35-percent market share among enterprise search platforms and is used by various multinational organizations.
Designed to be scalable, Apache Solr can index, query, and map sites, documents, and data from a variety of sources, and then return recommendations for related content. It supports text search, hit highlighting, database integration, and document handling (e.g., Word and PDF files) among others. It also supports JavaScript object notation (JSON) representational state transfer (REST) application programming interfaces (APIs). This means Apache Solr can be integrated with compatible systems or programming languages that support them. Apache Solr runs on port 8983.
What is CVE-2019-0192? The vulnerability is caused by an insufficient validation of request to the Config API, which lets Apache Solr’s users configure solrconfig.xml. This solrconfig.xml, in turn, controls how Apache Solr behaves in the installed system by mapping requests to different handlers. Parameters in solrconfig.xml, for instance, define how search requests and data are processed, managed, or retrieved.
Apache Solr is built on Java, which allows objects to be serialized, that is, converting and representing objects into a compact byte stream. This makes it a convenient way for the objects to be transferred over network. It can then be deserialized for use by a Java virtual machine (JVM) receiving the byte stream.
Config API allows Solr’s Java management extensions (JMX) server to be configured via HTTP POST request. An attacker could point the JMX server to a malicious remote method invocation (RMI) server and take advantage of the vulnerability to trigger remote code execution (RCE) on the Solr server.
How does CVE-2019-0192 work? An attacker can start a malicious RMI server by running a command, as seen in our example in Figure 1 (top). The ysoserial payload with class JRMPListener can be used to embed the command touch /tmp/pwn.txt, which can then get executed on a vulnerable Apache Solr. A POST request (Figure 1, bottom) can then be sent to Solr to remotely set the JMX server.
Figure 1. Snapshots of code showing how a malicious RMI server is started (top), and how a POST request is sent (bottom)
JMX enables remote clients to connect to a JVM and monitor the applications running in that JVM. The applications can be managed via managed beans (MBeans), which represents a resource. Through MBeans, developers, programmers, and Apache Solr users can access and control the inner workings of the running application. MBeans can be accessed over a different protocol via Java RMI. Apache Solr users who want to use JMX/RMI interface on a server can accordingly create a JMXService URL (service:jmx:rmi:///jndi/rmi://:/jmxrmi).
In the example showed in Figure 2, the attacker, exploiting CVE-2019-0192, could use a POST request and set the JMXService URL (jmx.serviceUrl) remotely via Config API using the ‘set-property’ JSON object.
As shown in Figure 3, it would return a 500 error, including the string “undeclared checked exception; nested exception is” in the response body.
Figure 2. Code snapshot showing how the JMXService could be set remotely
Figure 3. Snapshot of code showing the error 500
Due to improper validation, this jmx.serviceUrl can be pointed to an attacker-controlled JMRP listener (which is typically used to notify about events or conditions that occur). This causes the vulnerable Apache Solr to initiate an RMI connection to a malicious JMRP Listener. A three-way handshake will then be initiated with the malicious RMI server to set up a connection with the malicious RMI server.
An attacker can then take advantage of this to carry out RCE on the vulnerable Apache Solr. As shown in Figure 4, an attacker, for instance, can send a maliciously crafted serialized object.
Figure 4. Snapshot showing data transmission after exploiting CVE-2019-0192
How to address this vulnerability Apache Solr recommends patching or upgrading to 7.0 (or later) versions. It’s also advised to disable or restrict Config API when not in use. The network should also be proactively configured and monitored for any anomalous traffic that may be running on hosts that has Apache Solr installed.
Developers, programmers, and system administrators using and managing Apache Solr should also practice security by design as well as enforce the principle of least privilege and defense in depth to protect against threats that may exploit this vulnerability.
The Trend Micro Deep Security and Vulnerability Protection solutions protect user systems from threats that may exploit CVE-2019-0192 via this Deep Packet Inspection (DPI) rule:
1009601 – Apache Solr Remote Code Execution Vulnerability (CVE-2019-0192)
Trend Micro TippingPoint customers are protected from attacks that exploit CVE-2019-0192 this MainlineDV filter:
313798 – HTTP: Apache Solr Java Unserialized Remote Code Execution Vulnerability
The post CVE-2019-0192: Mitigating Unsecure Deserialization in Apache Solr appeared first on .
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source Author: Trend Micro CVE-2019-0192: Mitigating Unsecure Deserialization in Apache Solr Original Post from Trend Micro Author: Trend Micro By: Santosh Subramanya (Vulnerability Researcher) Security researcher Michael Stepankin…
0 notes
Text
#Solr Query Syntax#Apache Solr Query Language#Solr Search Query Examples#Solr Query Parameters#Solr Query Filters#Solr Advanced Query Syntax#solr query#solr in query#Master Solr Query Syntax
0 notes
Text
Sitecore Search Index Best Practices
I’ve seen a few Sitecore sites recently where the implementation of the search index left a lot to be desired. So i figured i’d put together a list of best practices for working with search indexes. I’ll keep this agnostic to Lucene/Solr/Azure Search.
1) Don’t use the sitecore_web_index
I’ve seen a lot of solutions that override the default sitecore indexes to add their own custom fields etc. This index is used by Sitecore’s UI, and it indexes all items in Sitecore’s web database. So it will get huge as your site content grows. It also adds another config to look out for when upgrading Sitecore.
2) Don’t change the DefaultIndexConfiguration.config
Some people will do things like add computed fields to the default index configuration. This is bad as it will add these fields to all of your indexes that use this configuration. There is no point in adding these to the Core database index for example. If you need to do something outside of the default configuration update the setting in the index config file.
3) Do use custom indexes, with one per functional area
For each area of functionality that requires a search, create a custom search index. For example, it you have a sub section of your content tree for Product Info give that its own index. You can then define only the fields you need for this function and the root item for the index (reducing the size of it). Do this by creating a new config file for your index.
4) Don’t use generic Search functions
I’ve seen a few implementation where the developers have created a very generic search function used for completely different areas of functionality. This makes life easier for the developer at first; but when something needs to be done differently (e.g. you need to add a function like Search suggestions) or you need more performance you will have a bad time.
You also end up in a scenario where your index needs to have many fields to cover everything. In reality a Product Info index might only need to look at 2 or 3 sitecore template types and a couple of fields on them.
5) Do use a Search Result Mapping Class
When pulling results from the index using a generic search function, you might use Sitecore’s SearchResultItem class for the result items. It is always better to have a custom class that has the fields of your custom index explicitly defined. A strongly typed class is always the way to go. Here’s an example:
https://gist.github.com/blacktambourine/958b3c96a82b43b0e73c7a6d49251aa8
The thinking is that you only want fields in your index that are needed, so enforce this in the config file definition and the mapping class used by your application.
6) Use Luke Index Toolbox
Learn to use Luke; it allows you to view the fields in the index and run searches. Which version you need will depend on which version of Lucene/Solr you have installed.
https://github.com/DmitryKey/luke/releases
7) Use the .Net Predicate Builder for building query parameters
The easiest way to build up query parameters for your index is to use the Predicate Builder. It allows you to do nested AND’s and OR’s, as well as boost the priority of particular fields. There is also the ability to add a Fuzzy tolerance. This allows you to find similar terms in the index (e.g. “potatoe” as well as “potatoes” when searching for “potatoe”). For example:
https://gist.github.com/blacktambourine/fed8b361f4c362d75b448405f5461f97
8) Computed Fields are great but don’t overdo it
Computed fields allow you to programmatically generate the content of an index field when building the index. This can useful, but it is open to abuse (i.e. long running functions, overly complex, functions that could be better implemented elsewhere, or having too many unused computed fields).
Some gotchas for computed fields:
- Note that Sitecore is in the “Shell” context when indexing. So if you need to get a Sitecore item from the database you will need to explicitly state the context (i.e. “web” database) and can’t easily use tools like Glassmapper. You might need to use this syntax to access the Web database:
static readonly Database WebDb = global::Sitecore.Configuration.Factory.GetDatabase("web");
- Always return null from a computed field if there is nothing to store; this will save space in the index.
9) Indexing PDF’s
It is possible to search the content of PDF’s. You need to define the node to spider in the Locations node of your index config file.
You will either need to install Adobe ifilter on the server or use the .Net library PDFBox.
I’ve seen implementations that try to share the same index content field for PDF’s as webpages in the index. I’d recommend using a separate computed field for the PDF’s and then adding this to your predicates as an OR condition.
Also note that some PDF’s are generating as a stack of images instead of text, so won’t return anything to the index. These pdf’s can be quite large, causing your index to take much longer to build.
10) Use Facets for your search category filters
A generic facet class can be used to give you a count per category in your search index. If you plan on implementing filters for the search index, consider using a facet.
https://gist.github.com/blacktambourine/17feefd36cf2ad86d8cfc947c86f0087
0 notes
Text
Sitecore, Solr, and Many languages
Sitecore 7 added a content search API to interact with Lucene and Solr. I'm sure anyone who has ever worked with search will tell you that search is hard, as it requires a lot of customisation that is entirely per-site, and what works for someone else might not work for you.
I'm here to tell you what worked for me, a really specific use case involving Sitecore 8.1 update 4, Apache Solr 6.2, and searching 7 regions with 4 different languages.
We're using some internal libraries on top of the content search API, but they eventually make the same calls as everyone else.
We started out with a fairly standard content search, which... mostly worked, even across languages. Condensed form:
var context = SearchIndex.CreateSearchContext(); var query = context.GetQueryable<oursearchresults>(); query.Content.Like(queryArgs);
There are actually a few issues with this approach:
The way our site is set up, 90% of the content we care about is actually in an item's components, not on the item itself.
This treats all languages the same way. Sitecore will send the same query to solr no matter the language being searched: _content:(*queryArgs*)
This will only give exact matches (even though .Like() is used)
Issue 1 is solved with a computed index field.
public class VisualizationField : MediaItemContentExtractor { public override object ComputeFieldValue(IIndexable indexable) { string baseValue = base.ComputeFieldValue(indexable) as string; Item indexItem = indexable as SitecoreIndexableItem; if (!ShouldIndexItem(indexItem)) { return baseValue; } var dataSources = Globals.LinkDatabase .GetReferences(indexItem) .Where(link => ShouldProcessLink(link, indexItem)) .Select(link => link.GetTargetItem()) .Where(targetItem => targetItem != null && targetItem.Versions.Count > 0) .Distinct(); var result = new StringBuilder(); if (!string.IsNullOrEmpty(baseValue)) { result.AppendLine(baseValue); } foreach (var dataSource in dataSources.Where(ShouldIndexDataSource)) { dataSource.Fields.ReadAll(); foreach (var field in dataSource.Fields.Where(ShouldIndexField)) { result.AppendLine(field.Value); } } return result.ToString(); } }
The ShouldProcess and ShouldIndex methods check to see whether or not something is actually related, and whether or not something should be put into the solr index based on some pretty basic parameters (correct content type, whether or not the component is actually being rendered).
Issue 2 caused me a great deal of stress until I stumbled across a blog post from the Sitecore 7 era. Sitecore added the concept of CultureExecutionContexts, which is a really fancy way of saying you can tell Sitecore to send over a search for content_t_{lang} instead of just _content by using this:
var context = SearchIndex.CreateSearchContext(); var culture = new CultureInfo(Sitecore.Context.Language.Name); var cultureCtx = new CultureExecutionContext(culture); var query = context.GetQueryable<oursearchresults>(cultureCtx); query.Content.Like(queryArgs);
And now your solr queries will look like this:
`content_t_{lang}:(*queryArgs*)`
Huzzah! You're searching specific languages! The problem quickly becomes, now you're doing language-specific exact match queries, which isn't very helpful.
Enter stemming algorithms.
The basic idea is that you give solr a word like engineer, and it boils the word down to the word's stem, so that you can run queries like engineer, engineers, engineered, or engineering and it will give you the same results. There are stemmers for basically every language you can think of, and the solr documentation explains how to use them far better than I ever could. The example schema.xml file generated by Sitecore actually contains basic analyzers that work fairly well. You will likely want to tweak them to fit your needs, but for an out-of-the-box solution, they work.
Once you've put the correct analyzers in place, restarted solr (this is important, solr does not pick up schema changes on the fly), and reindexed, you should now be getting decent search results in multiple languages.
Now is when language-specifics come into play. One of the languages this client supports is Polish, which does not come with out-of-the-box support from solr. Thankfully, there are already instructions for how to set that up.
The problem language for us, so far, has been German. German is what's known as a fusional language, which means that they tend to make new words by shoving old ones together. For instance, the German word for engineer is "ingenieur" and the word for civil engineer is "bauingenieur." This creates an issue for our search purposes, as "bauingenieur" and "ingenieur" should both return results for "ingenieur." The problem is solved with the Dictionary Compound Word Token Filter, a solr filter that will break words like bauingenieur down into their components "bau" and "ingenieur," so your results become what you'd expect. This requires a German word list, which can be a bit tricky to find, but once you have it, it works beautifully.
At this point, our search results have become downright useful and accurate (though we haven't implemented nice-to-haves like spellchecking and synonym searches), but there's a subtle bug. Sitecore isn't sending over the _content field to solr for each individual language properly. If your setup is like ours, with a very thin item and all of the pertinent content in subcomponents, the _content field in the index is going to be very sparse, basically containing nothing but the content in the top level item itself.
This is a subtle bug, and one that took several hours of debugging and someone far more versed in Sitecore than me to finally solve, but the issue is in the computed index field for the _content field.
var dataSources = Globals.LinkDatabase .GetReferences(indexItem) .Where(link => ShouldProcessLink(link, indexItem)) .Select(link => link.GetTargetItem()) .Where(targetItem => targetItem != null && targetItem.Versions.Count > 0) .Distinct();
This code will only get the components in Sitecore's default language. The rest of the code will properly put the correct language content from the top-level item into the index, but one of the checks it makes is whether or not a component is in the layout of that item in that version and language. If you have an item that only exists in the default Sitecore language, this works fine, but for any other language it's not going to get any of the subcomponents.
I haven't found any documentation about this, but the solution that is working for us is bringing in a LanguageSwitcher:
using (var switcher = new LanguageSwitcher(indexItem.Language)) { public class VisualizationField : MediaItemContentExtractor { public override object ComputeFieldValue(IIndexable indexable) { string baseValue = base.ComputeFieldValue(indexable) as string; Item indexItem = indexable as SitecoreIndexableItem; if (!ShouldIndexItem(indexItem)) { return baseValue; } var dataSources = Globals.LinkDatabase .GetReferences(indexItem) .Where(link => ShouldProcessLink(link, indexItem)) .Select(link => link.GetTargetItem()) .Where(targetItem => targetItem != null && targetItem.Versions.Count > 0) .Distinct(); var result = new StringBuilder(); if (!string.IsNullOrEmpty(baseValue)) { result.AppendLine(baseValue); } foreach (var dataSource in dataSources.Where(ShouldIndexDataSource)) { dataSource.Fields.ReadAll(); foreach (var field in dataSource.Fields.Where(ShouldIndexField)) { result.AppendLine(field.Value); } } return result.ToString(); } } }
Once you rebuild and reindex with the proper computed index field, your components will be properly indexed, your search results correct, and, hopefully, your clients happy.
0 notes
Text
Top AI and Machine learning centric blog to read in 2023
Qatar Insurance Company’s success with 10x customer engagement Qatar Insurance Company, the largest insurance company in the MENA region, is increasing sales and creating amazing customer experiences with chatbots.
Let’s Talk Quantum In Banking & Finance We’re living in a golden age of big data, according to data scientist Utpal Chakraborty. Discover how quantum computing is transforming banking & finance here.
Re-ranking of search results in SOLR Any e-commerce search engines rely on parameters such as product popularity, rating, click through rate etc to influence the result set for an input user query.
You should know this about Real Estate Chatbots by now(2023) Rule-based or AI-automated chatbots programmed to engage customers for real estate agencies. Chatbots are virtual agents that save time and grow sales.
10 reasons why your eCommerce business needs an AI chatbot The ever-increasing expectations of the customers can be met with the implementation of an artificial intelligent chatbot in e-commerce websites…….
6 ways to slash your Customer Acquisition Cost Learn how to calculate your customer acquisition cost (CAC) and explore six powerful ways to optimize it with the help of chatbots and live chat. Read now!
Apple’s and Amazon’s secret to success: Customer effort score Ever wonder what makes Apple and Amazon so insanely successful? Reducing the customer effort score is always the focus & that’s what drives these big giants
5 not-so-basic ways to reduce customer friction Reducing customer friction boosts loyalty & customer lifetime value. Here’s a comprehensive guide on improving your CX by eliminating customer friction
5 pillars of responsible and ethical AI How do you ensure that your AI systems are ethical? Maria Luciana Axente, the Responsible AI & AI for Good lead at PwC UK, helps identify key considerations.
Re(view) our Engati chatbot platform! Reviews are important for both the company and its customers, so we’re opening the floor for you to tell us why you think Engati is the best chatbot platform.
Ritualizing the customer experience Customer experience guru, Shep Hyken talks about the importance of ritualizing customer experiences and making sure they happen consistently, every time.
5 roles your entertainment and media chatbots can play! Entertainment and media chatbots are making customer experience interactive and helping people consume content in an easier manner. Check it out now!
5 sales engagement best practices that you need to adopt now! Looking to step your sales engagement & get more prospects to flow down the sales funnel? Here are 5 sales engagement best practices that you need to follow!
Here’s why sentence similarity is a tough NLP problem Find out why sentence similarity is a challenging NLP problem and why training computers to read, understand and write language has become a big business.
How to use BERT for sentiment analysis? Sentiment analysis helps your chatbot reply to customers in an appropriate tone and enhance customer experience. Learn how to use BERT for sentiment analysis.
How to set up Solr as a system service Instagram, eBay, Netflix, and even Disney makes use of Solr. This quick guide will show you how to set up Solr as a service. Don’t miss out, read it now.
Black Friday tips | 17 tips to prepare your Shopify store for BFCM Want to get your Shopify store ready for Black Friday and Cyber Monday 2021? Here are 17 tips to help you do just that and sell more during these holidays!
1 note
·
View note
Text
Java APIs to Build Solr Suggester and Get Suggestion
Via http://ift.tt/2iJvxV0
User Case Usually we provide Rest APIs to manage Solr, same for suggestor. This article focuses on how to programmatically build Solr suggester and get suggestions using java code. The implementation Please check the end of the article for Solr configuration files. Build Suggester In Solr, after we add docs to Solr, we call suggest?suggest.build=true to build the suggestor to make them available for autocompletion. The only trick here is the suggest.build request doesn't build suggester for all cores in the collection, BUT only builds suggester to the core that receives the request. We need get all replicas urls of the collection, add them into shards parameter, and also add shards.qt=/suggest: shards=127.0.0.1:4567/solr/myCollection_shard1_replica3,127.0.0.1:4565/solr/myCollection_shard1_replica2,127.0.0.1:4566/solr/myCollection_shard1_replica1,127.0.0.1:4567/solr/myCollection_shard2_replica3,127.0.0.1:4566/solr/myCollection_shard2_replica1/,127.0.0.1:4565/solr/myCollection_shard2_replica2&shards.qt=/suggest
public void buildSuggester() { final SolrQuery solrQuery = new SolrQuery(); final List<String> urls = getAllSolrCoreUrls(getSolrClient()); solrQuery.setRequestHandler("/suggest").setParam("suggest.build", "true") .setParam(ShardParams.SHARDS, COMMA_JOINER.join(urls)) .setParam(ShardParams.SHARDS_QT, "/suggest"); try { final QueryResponse queryResponse = getSolrClient().query(solrQuery); final int status = queryResponse.getStatus(); if (status >= 300) { throw new BusinessException(ErrorCode.data_access_error, MessageFormat.format("Failed to build suggestions: status: {0}", status)); } } catch (SolrServerException | IOException e) { throw new BusinessException(ErrorCode.data_access_error, e, "Failed to build suggestions"); } } public static List<String> getAllSolrCoreUrls(final CloudSolrClient solrClient) { final ZkStateReader zkReader = getZKReader(solrClient); final ClusterState clusterState = zkReader.getClusterState(); final Collection<Slice> slices = clusterState.getSlices(solrClient.getDefaultCollection()); if (slices.isEmpty()) { throw new BusinessException(ErrorCode.data_access_error, "No slices"); } return slices.stream().map(slice -> slice.getReplicas()).flatMap(replicas -> replicas.stream()) .map(replica -> replica.getCoreUrl()).collect(Collectors.toList()); } private static ZkStateReader getZKReader(final CloudSolrClient solrClient) { final ZkStateReader zkReader = solrClient.getZkStateReader(); if (zkReader == null) { // This only happens when we first time call solrClient to do anything // Usually we will call solrClient to do something during abolition starts: such as // healthCheck, so in most cases, its already connected. solrClient.connect(); } return solrClient.getZkStateReader(); }
Get Suggestions
public Set<SearchSuggestion> getSuggestions(final String prefix, final int limit) { final Set<SearchSuggestion> result = new LinkedHashSet<>(limit); try { final SolrQuery solrQuery = new SolrQuery().setRequestHandler("/suggest").setParam("suggest.q", prefix) .setParam("suggest.count", String.valueOf(limit)).setParam(CommonParams.TIME_ALLOWED, mergedConfig.getConfigByNameAsString("search.suggestions.time_allowed.millSeconds")); // context filters solrQuery.setParam("suggest.cfq", getContextFilters()); final QueryResponse queryResponse = getSolrClient().query(solrQuery); if (queryResponse != null) { final SuggesterResponse suggesterResponse = queryResponse.getSuggesterResponse(); final Map<String, List<Suggestion>> map = suggesterResponse.getSuggestions(); final List<Suggestion> infixSuggesters = map.get("infixSuggester"); if (infixSuggesters != null) { for (final Suggestion suggester : infixSuggesters) { if (result.size() < limit) { result.add(new SearchSuggestion().setText(suggester.getTerm()) .setHighlightedText(replaceTagB(suggester.getTerm()))); } else { break; } } } } logger.info( MessageFormat.format("User: {0}, query: {1}, limit: {2}, result: {3}", user, query, limit, result)); return result; } catch (final Exception e) { throw new BusinessException(ErrorCode.data_access_error, e, "Failed to get suggestions for " + query); } } private static final Pattern TAGB_PATTERN = Pattern.compile("<b>|</b>"); public static String replaceTagB(String input) { return TAGB_PATTERN.matcher(input).replaceAll(""); }
Schema.xml We define textSuggest and suggesterContextField, copy fields which are shown in the autocompletion to textSuggest field, and copy filter fields such as zipCodes, genres to suggesterContextField. Solr suggester supports filters on multiple fields, all we just need copy all these filter fields to suggesterContextField.
<field name="suggester" type="textSuggest" indexed="true" stored="true" multiValued="true" /> <field name="suggesterContextField" type="string" indexed="true" stored="true" multiValued="true" /> <copyField source="seriesTitle" dest="suggester" /> <copyField source="programTitle" dest="suggester" /> <copyField source="zipCodes" dest="suggesterContextField" /> <copyField source="genres" dest="suggesterContextField" />
SolrConfig.xml We can add multiple suggester implementations to searchComponent. Another very useful is FileDictionaryFactory which allows us to using an external file that contains suggest entries. We may use it in future.
<searchComponent name="suggest" class="solr.SuggestComponent"> <lst name="suggester"> <str name="name">infixSuggester</str> <str name="lookupImpl">BlendedInfixLookupFactory</str> <str name="dictionaryImpl">DocumentDictionaryFactory</str> <str name="blenderType">position_linear</str> <str name="field">suggester</str> <str name="contextField">suggesterContextField</str> <str name="minPrefixChars">4</str> <str name="suggestAnalyzerFieldType">textSuggest</str> <str name="indexPath">infix_suggestions</str> <str name="highlight">true</str> <str name="buildOnStartup">false</str> <str name="buildOnCommit">false</str> </lst> </searchComponent> <requestHandler name="/suggest" class="solr.SearchHandler" > <lst name="defaults"> <str name="suggest">true</str> <str name="suggest.dictionary">infixSuggester</str> <str name="suggest.onlyMorePopular">true</str> <str name="suggest.count">10</str> <str name="suggest.collate">true</str> </lst> <arr name="components"> <str>suggest</str> </arr> </requestHandler>
Resources Solr Suggester
From lifelongprogrammer.blogspot.com
0 notes