#SparkSQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text

📂 Managed vs. External Tables in Microsoft Fabric
Q: What’s the difference between managed and external tables?
✅ A:
Managed tables: Both the table definition and data files are fully managed by the Spark runtime for the Fabric Lakehouse.
External tables: Only the table definition is managed, while the data itself resides in an external file storage location.
🧠 Use managed tables for simplicity and tight Fabric integration, and external tables when referencing data stored elsewhere (e.g., OneLake, ADLS).
💬 Which one do you use more in your projects—and why?
#MicrosoftFabric#FabricLakehouse#ApacheSpark#ManagedTables#ExternalTables#DataEngineering#BigData#OneLake#DataPlatform#DataStorage#SparkSQL#FabricCommunity#DataArchitecture
0 notes
Text
Decrease Price of Intel Spark SQL Workloads On Google Cloud

Reduce Google Cloud Expenses for Intel Spark SQL Workloads: Businesses are trying to take advantage of the abundance of data coming in from gadgets, consumers, websites, and more as artificial intelligence (AI) takes over the news. Innovation is still fueled by big data analytics, which offers vital insights into consumer demographics, AI technology, and new prospects. The decision of when to add or grow your big data analytics is more important than whether you will need to do so.
Intel will be discussing Apache Spark SQL large data analytics applications and how to get the most out of Intel CPUs in the Spark blog series. The Spark SQL‘s value and performance outcomes on Google Cloud instances in this article.
Combining Apache Spark with Google Cloud Instances Powered by the Latest Intel Processors
The robust Apache Spark framework is used by many commercial clients to handle massive amounts of data in the cloud. For instance, in some use cases like processing retail transactions not completing tasks on time may result in service-level agreement (SLA) breaches, which can then result in fines, decreased customer satisfaction, and harm to the company’s image. Businesses can manage additional projects, analyze more data, and meet deadlines by optimizing Apache Spark performance. More resilience and flexibility are the results, since administrators may diagnose and fix any faults without endangering overall performance.
Applications that need to ingest data from IoT sensors or streaming data applications where it is essential to unify data processing across many languages in real time are examples of workloads that often use Apache Spark to ingest data from numerous sources into files or batches. After processing them, it creates a target dataset, which businesses may use to create business intelligence dashboards, provide decision-makers insights, or send data to other parties.
The increased processing capability of a well-designed Spark cluster system, like Google Cloud with N4 5th Generation Intel Xeon instances, makes it possible to stream and analyze massive amounts of data efficiently. This enables businesses to promptly distribute the processed data to suppliers or dependent systems.
Businesses may increase the efficacy and economy of AI workloads, particularly in the data pretreatment phases, by combining open-source Spark with Intel Xeon 5th Gen CPUs. Large datasets may be prepared for AI models in less time because to Spark’s ability to execute complicated ETL (“extract, transform, and load”) processes more quickly and effectively thanks to the most recent Intel CPUs.
This allows businesses to optimize resource consumption, which reduces costs, and shortens the AI development cycle. The combination of Spark with the newest Intel CPUs provides crucial scalability for AI applications that use big and complicated datasets, such those in real-time analytics or deep learning. Businesses can quickly and accurately use AI models and get real-time insights that facilitate data-driven, efficient decision-making.
Google Cloud Offerings
When transferring your Spark SQL workloads to the cloud, Google Cloud provides a variety of service alternatives, ranging from managed Spark services to infrastructure-as-a-service (IaaS) instances. Look at Google Cloud-managed services for serverless, integrated Spark setups. However, the IaaS option is the best choice for workloads where you want to build, expand, administer, and have greater control over your own Spark environment.
Google Cloud provides a wide variety of instance families that are categorized based on workload resource requirements. General-purpose, storage-optimized, compute-optimized, memory-optimized, and accelerator-optimized are some of these types. As their names suggest, the examples in these categories include GPUs to satisfy diverse task requirements, improved storage performance, and varying memory to CPU core ratios.
Furthermore, inside instance families, you may choose between various vCPU-to-memory ratios using instances of the “highcpu” or “highmem” categories. Large databases, memory-intensive workloads like Spark, and large-scale data transformations are better suited for high memory instance types, which enhance performance and execution durations.
In order to satisfy different performance and capacity needs, Google Cloud offers a range of block storage choices that strike the ideal balance between price and performance. For instance, SSD solutions that are locally connected provide superior performance, whereas Standard Persistent Discs are a viable option for low-cost, standard performance requirements. Google Cloud provides design guidelines, price calculators, comparison guides, and more to assist you in selecting the best alternatives for your workload.
Because Spark SQL requires a lot of memory, it chose to test on general-purpose “highmem” Google Cloud instances. But it wasn’t the end of our decision-making process. In addition, users choose the series they want to utilize within the instance family and an instance size. Although older instance series with older CPUs are often less expensive, employing legacy hardware may result in performance issues. Additionally, you have a choice between CPU manufacturers such as AMD and Intel. Google provides instances of the N-, C-, E-, and T-series in the general-purpose family.
The N-series is recommended for applications such as batch processing, medium-traffic web apps, and virtual desktops. The C-series is ideal for workloads like network appliances, gaming servers, and high-traffic web applications since it offers greater CPU frequencies and network restrictions. E-series instances are used for development, low-traffic web servers, and background operations. Lastly, the T-series are excellent for workloads including scale-out and media transcoding.
Let’s now examine the tests to be conducted on the N4 instance, which has 5th Gen Intel Xeon Scalable processors; an earlier N2 instance, which has 3rd Gen Xeon Scalable processors from Previous Generation Xeon; and an N2D instance, which has AMD processors from the N series. Additionally, it tested a C3 instance with AMD C series processors and a C3D instance with 4th Gen Intel Xeon Scalable CPUs.
Performance Overview
The performance statistics to collected and compared the different instance kinds and families it evaluated are examined in this part.
Generation Over Generation
To demonstrate how your decisions might affect the performance and value of your workload, it will first examine just the examples that use Intel Xeon Scalable processors. Google cloud used a TPC-DS-based benchmark that simulates a general-purpose DSS with 99 distinct database queries. Intel compared the Spark SQL instance clusters to see how long it took a single user to execute all 99 queries once. When it evaluated the 80 vCPU instances, the N4-highmem-80 instances with 5th Gen Intel Xeon Scalable processors completed the task 1.13 times faster and had 1.15 times the performance per dollar compared to the N2-highmem-80 instances with older 3rd Gen Intel Xeon Scalable processors.
The N4-highmem-80 instances were 1.18 times faster to finish the queries with a commanding 1.38 times the performance per dollar when compared to the C3-highmem-88 instance with 4th Gen Intel Xeon Scalable CPUs. Intel selected the closest size with 88 vCPUs since the C3 series does not support an instance size of 80 vCPU.
These findings demonstrate that purchasing more recent instances with more recent Intel CPUs not only improves Spark SQL performance but also offers greater value. The performance of N4 instances is up to 1.38 times better than that of earlier instances for every dollar spent.
Competitive
It can now evaluate the N-series instances with AMD processors after comparing them to previous instances that use 5th Gen Intel Xeon Scalable CPUs. It’ll start by comparing older N2D series computers, which may include AMD EPYC CPUs from the second or third generation. With 1.19 times the performance per dollar, the N4 instance with Intel CPUs completed the queries 1.30 times faster than the N2D instance.
Lastly, it contrasted the C3D instance with 4th Gen AMD EPYC processors with the N4 instance with 5th Gen Intel Xeon Scalable processors. Because there isn’t an instance with 80 vCPUs in the C3D series, Intel chose the closest choice, which has 90 vCPUs, which gives the C3D instance a little edge. The research indicates that the N4 instance achieved 1.21 times the performance per dollar, but with a somewhat lower performance, even with less vCPUs.
According to our findings, for Spark SQL workloads, Google Cloud instances with the newest Intel processors may provide the highest performance and value when compared to instances with AMD processors or older Intel instances.
In conclusion
A potent technique to maximize workloads, improve performance, and save operating costs is to integrate Apache Spark with more recent Google Cloud instances that include Intel Xeon 5th Gen CPUs. The findings demonstrate that, despite their higher cost, these more recent examples might provide much superior value. For your Spark SQL applications, instances with the newest 5th Gen Intel Xeon Scalable processors are the logical option since they can provide up to 1.38 times the performance per dollar.
Read more on Govindhtech.com
#GoogleCloud#IntelSparkSQL#SparkSQL#AI#ApacheSparkSQL#GoogleCloudinstances#AImodels#vCPU#C3Dinstance#IntelXeonScalableprocessors#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Link
0 notes
Text
Azure Bigdata Specialist
Job title: Azure Bigdata Specialist Company: PradeepIT Job description: About the job Azure Bigdata Specialist Job Description Overall, 4 to 8 years of experience in IT Industry. Min 4…, Python, SparkSQL, Scala, Azure Blob Storage. Experience in Real-Time Data Processing using Apache Kafka/EventHub/IoT… Expected salary: Location: Bangalore, Karnataka Job date: Wed, 26 Feb 2025 08:02:25 GMT Apply…
0 notes
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
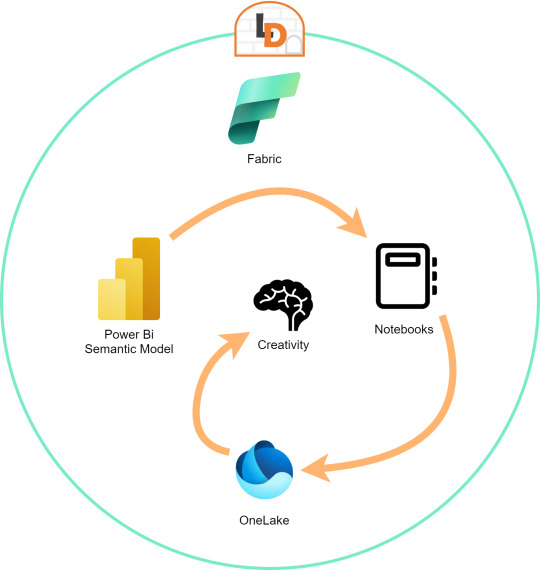
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
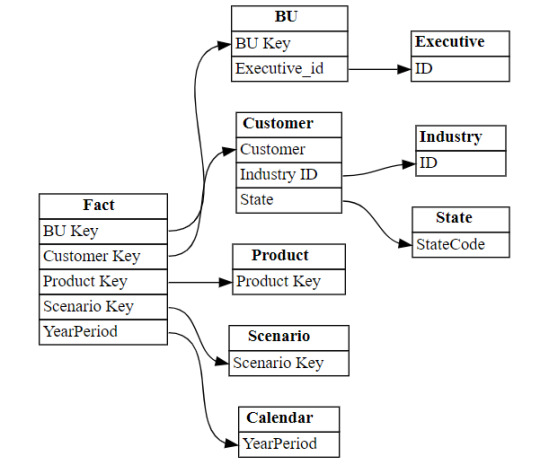
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
From reddit:
How to get more analysts to think of PowerBI (and other BI tools) as a valuable skill worth investing in?
Curious what other data team managers experience has been on this topic.
I have some theories on why "BI" has gotten a bad reputation: 1) other "keyword" skills often pay more. If you just search for BI analyst on any job portal maybe you'll see a 70k average while say a "data engineer" who focuses on python may be $120k+ 2) some parts of the core BI skills, like DAX or QlikScript are not as portable to new jobs as say getting really good at something like Python. 3) 90% of BI usage is frontend dashboard creation, relatively few analysts get deep in the weeds of the more advanced functionality like maintaining semantic layers at scale, role based permissioning etc.. Thus maybe mostly only leads or managers handle these and most others don't touch it. Maybe most BI users are doing like local tableu dashboards from Excel imports and don't even host it in the cloud anywhere?
Bullet 1 is definitely true, similar to the title of "data scientist" within the realm of "BI" there is an insanely wide range of skillsets and it's hard for the market to tease out and properly reward
Bullet 2 is true in that specific BI syntax is not portable beyond 1 vendor. However the same could be said of SparkSQL vs BigQuerySQL or dplyr vs. data.tables or keras vs pytorch, yet the underlying skills are quite transferrable. In particular proper data modeling and being able to transform business metrics into reliable code are timeless skills and worth their weight in gold.
Bullet 3 could potentially be true but I imagine large orgs using say PowerBI at scale HAVE TO employ principal PowerBI engineers with many years of tech experience, or else their mission critical reporting tools would just break... All the time. So maybe these job titles doing the more advanced work are just hidden as software engineers or something else?
0 notes
Photo


Are you searching for reasons to integrate Azure Synapse Analytics into your traditional #financial services framework? Well, here are three! Swipe left to learn more about how #AzureSynapseAnalytics can help you transform your services into intelligent financial services. To get started with Azure Synapse Analytics, book a free consultation session with the experts at [email protected] https://www.linkedin.com/feed/update/urn:li:activity:6913025072936972288 #azure #analytics #financialservices #bfsi #comment #share #like #businessintelligence #technology #sparksql #data #ai #ml #power #productivity #powerbi #engineer #digtaltransformation #innovation #cloud #visualization #security #business #integrations #network #bigdata #sql #bi #automation #dataanalytics #celebaltech
#azure#analytics#financialservices#bfsi#comment#share#businessintelligence#technology#sparksql#data#powerbi#digtaltransformation#cloud
0 notes
Photo

Big Data and Hadoop for Beginners.Everything you need to know about Big Data, and Learn Hadoop, HDFS, MapReduce, Hive & Pig by designing Data Pipeline. Interested people can inbox me. Check our Info : www.incegna.com Reg Link for Programs : http://www.incegna.com/contact-us Follow us on Facebook : www.facebook.com/INCEGNA/? Follow us on Instagram : https://www.instagram.com/_incegna/ For Queries : [email protected] #apache,#scala,#mapreducce,#hadoop,#bigdata,#apachespark,#dataframes,#awscertified,#sparksMLlib,#DynamoDB,#SparkSQL,#IMDb,#datapipeline https://www.instagram.com/p/B8gdeeNg7rC/?igshid=u6ey7p7axgke
#apache#scala#mapreducce#hadoop#bigdata#apachespark#dataframes#awscertified#sparksmllib#dynamodb#sparksql#imdb#datapipeline
0 notes
Link
11 notes
·
View notes
Text
Apache Spark For Java Developers
Apache Spark For Java Developers
Get processing Big Data using RDDs, DataFrames, SparkSQL and Machine Learning – and real time streaming with Kafka!
What you’ll learn
Use functional style Java to define complex data processing jobs
Learn the differences between the RDD and DataFrame APIs
Use an SQL style syntax to produce reports against Big Data sets
Use Machine Learning Algorithms with Big Data and SparkML
Connect…
View On WordPress
0 notes
Text
What to Expect for Big Data and Apache Spark in 2017
New Post has been published on http://dasuma.es/es/expect-big-data-apache-spark-2017/
What to Expect for Big Data and Apache Spark in 2017
Big data remains a rapidly evolving field with new applications and infrastructure appearing every year. In this talk, Matei Zaharia will cover new trends in 2016 / 2017 and how Apache Spark is moving to meet them. In particular, he will talk about work Databricks is doing to make Apache Spark interact better with native code (e.g. deep learning libraries), support heterogeneous hardware, and simplify production data pipelines in both streaming and batch settings through Structured Streaming.
youtube
This talk was originally presented at Spark Summit East 2017.
You can view the slides on Slideshare: http://www.slideshare.net/databricks/…
0 notes
Text
Gluten And Intel CPUs Boost Apache Spark SQL Performance

The performance of Spark may be improved by using Intel CPUs and Gluten.
The tools and platforms that businesses use to evaluate the ever-increasing amounts of data that are coming in from devices, consumers, websites, and more are more crucial than ever. Efficiency and performance are crucial as big data analytics provides insights that are both business- and time-critical.
Workloads involving large data analytics on Apache Spark SQL often run constantly, necessitating excellent performance to accelerate time to insight. This implies that businesses may defend paying a bit more overall in order to get greater results for every dollar invested. It looked at Spark SQL performance on Google Cloud instances in the last blog.
Spark Enables Scalable Data Science
Apache Spark is widely used by businesses for large-scale SQL, machine learning and other AI applications, and batch and stream processing. To enable data science at scale, Spark employs a distributed paradigm; data is spread across many computers in clusters. Finding the data for every given query requires some overhead due to this dispersion. A key component of every Spark workload is query speed, which leads to quicker business decisions. This is particularly true for workloads including machine learning training.
Utilizing Gluten to Quicken the Spark
Although Spark is a useful tool for expediting and streamlining massive data processing, businesses have been creating solutions to improve it. Intel’s Optimized Analytics Package (OAP) Spark-SQL execution engine, Gluten, is one such endeavor that reduces computation-intensive vital data processing and transfers it to native accelerator libraries.
Gluten uses a vectorized SQL processing engine called Velox (Meta’s open-source) C++ generic database acceleration toolkit to improve data processing systems and query engines. A Spark plugin called Gluten serves as “a middle layer responsible for offloading the execution of JVM-based SQL engines to native engines.” The Apache Gluten plugin with Intel processor accelerators allow users to significantly increase the performance of their Spark applications.
It functions by converting the execution plans of Spark queries into Substrait, a cross-language data processing standard, and then sending the now-readable plans to native libraries via a JNI call. The execution plan is constructed, loaded, and handled effectively by the native engine (which also manages native memory allocation) before being sent back to Gluten as a Columnar Batch. The data is then sent back to Spark JVM as ArrowColumnarBatch by Gluten.
Gluten employs a shim layer to support different Spark versions and a fallback technique to execute vanilla Spark to handle unsupported operators. It captures native engine metrics and shows them in the Spark user interface.
While outsourcing as many compute-intensive data processing components to native code as feasible, the Gluten plugin makes use of Spark’s own architecture, control flow, and JVM code. Existing data frame APIs and applications will function as previously, although more quickly, since it doesn’t need any modifications on the query end.
Enhancements in Performance Was Observed
This section examines test findings that show how performance may be enhanced by using Gluten in your Spark applications. One uses 99 distinct database queries to construct a general-purpose decision support system based on TPC-DS. The other, which is based on TPC-H, uses ten distinct database queries to simulate a general-purpose decision support system. Everyone compared the time it took for a single user to finish each query once within the Spark SQL cluster for both.
Fourth Generation Intel Xeon Scalable Processors
Help start by examining how adding Gluten to Spark SQL on servers with 4th Generation Intel Xeon Scalable Processors affects performance. The performance increased by 3.12 times when it was added, as the chart below illustrates. The accelerator enabled the system to execute the 10 database queries over three times faster on the TPC-H-like workload. Gluten more than quadrupled the pace at which all 99 database queries were completed on the workload that resembled TCP-DS. Because of these enhancements, decision-makers would get answers more quickly, proving the benefit of incorporating Gluten into your Spark SQL operations.
Fifth Generation Intel Xeon Scalable Processors
Let’s now investigate how Gluten speeds up Spark SQL applications on servers equipped with Intel Xeon Scalable Processors of the Fifth Generation. With speed up to 3.34 times as high while utilizing Gluten, you saw even bigger increases than they experienced on the servers with older CPUs, as the accompanying chart illustrates. Incorporating Gluten into your environment will help you get more out of your technology and reduce time to insight if your data center has servers of this generation.
Cloud Implications
Even though they ran these tests in a data center using bare metal hardware, they amply illustrate how Gluten may boost performance even in the cloud. Using Spark in the cloud may allow you to take advantage of further performance enhancements by using Gluten.
In conclusion
Rapid analysis completion is essential to the success of your business, regardless of whether your Spark SQL workloads are running on servers with 5th version Intel Xeon Scalable Processors or the older version. By shifting JVM data processing to native libraries, Gluten may benefit from the speed improvement that Intel processors can provide with native libraries that are optimized to instruction sets.
According to these tests, you may easily double or even treble the speed at which your servers execute database queries by integrating the Gluten plugin into Spark SQL workloads. Using Gluten may help your company optimize data analytics workloads by offering up to 3.34x the performance.
Read more on Govindhtech.com
#Gluten#IntelCPUs#SparkSQL#SQL#ApacheSpark#Spark#IntelXeonScalableProcessors#Glutenplugin#machinelearning#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Link
0 notes
Text
Dataiku : tout savoir sur la plateforme d'IA "made in France"
Dataiku :
tout savoir sur la plateforme d'IA "made in France"
Antoine Crochet-Damais
JDN
Dataiku est une plateforme d'intelligence artificielle créée en France en 2013. Elle s'est imposée depuis parmi les références mondiales des studios de data science et de machine learning.
SOMMAIRE
Dataiku, c’est quoi ?
Dataiku DSS, qu'est-ce que c'est ?
Quelles sont les fonctionnalités de Dataiku ?
Quel est le prix de Dataiku ?
Qu’est-ce que Dataiku Online ?
Dataiku Academy : formation / certification
Dataiku vs DataRobot
Dataiku vs Alteryx
Dataiku vs Databricks
Dataiku Community
Dataiku, c’est quoi ?
Dataiku est une plateforme de data science d'origine française. Elle se démarque historiquement par son caractère très packagé et intégré. Ce qui la met à la portée aussi bien des data scientists confirmés que débutants. Grâce à son ergonomie, elle permet de créer un modèle en quelques clics, tout en industrialisant en toile de fonds l'ensemble de la chaine de traitement : collecte, préparation des données…
Co-fondée en 2013 à Paris par Florian Douetteau, son CEO actuel, et Clément Stenac (tous deux anciens d'Exalead) aux côtés de Thomas Cabrol et Marc Batty, Dataiku affiche une croissance fulgurante. Dès 2015, la société s'implante aux Etats-Unis. Après une levée de 101 millions de dollars en 2018, Dataiku boucle un tour de table de 400 millions de dollars en 2021 pour une valorisation de 4,6 milliards de dollars. L'entreprise compte plus de 1000 salariés et plus de 300 clients parmi les plus grands groupes mondiaux. Parmi eux figurent les sociétés françaises Accor, BNP Paribas, Engie ou encore SNCF.
Dataiku DSS, qu'est-ce que c'est ?
Dataiku DSS (pour Dataiku Data Science Studio) est le nom de la plateforme d'IA de Dataiku.
Quelles sont les fonctionnalités de Dataiku ?
La plateforme de Dataiku compte environ 90 fonctionnalités que l'on peut regrouper en plusieurs grands domaines :
L'intégration. La plateforme s'intègre à Hadoop, Spark, mais aussi aux services des clouds AWS, Azure, Google Cloud. Au total, la plateforme est équipée de plus de 25 connecteurs.
Les plugins. Une galerie de plus de 100 plugins permet de bénéficier d'applications tierces dans de nombreux domaines : traduction, NLG, météo, moteur de recommandation, import/export de données...
La data préparation / data ops. Une console graphique gère la préparation des données. Les time series et données géospatiales sont supportées. Plus de 90 data transformers prépackagés sont disponibles.
Le développement. Dataiku prend en charge les notebooks Jupyter, les langages Python, R, Scala, SQL, Hive, Pig, Impala. Il supporte PySpark, SparkR et SparkSQL.
Le machine Learning. La plateforme inclut un moteur d'automatisation du machine learning (auto ML), une console de visualisation pour l'entrainement des réseaux de neurones profonds, le support de Scikit-learn et XGBoost, etc.
La collaboration. Dataiku intègre des fonctionnalités de gestion de projet, de chat, de wiki, de versioning (via Git)...
La gouvernance. La plateforme propose une console de monitoring des modèles, d'audit, ainsi qu'un feature store.
Le MLOps. Dataiku gère le déploiement de modèles. Il prend en charge les architecture Kubernetes mais aussi les offres de Kubernetes as a Service d'AWS, Azure et Google Cloud.
La data visualisation. Une interface de visualisation statistique est complétée par 25 graphiques de data visualisation pour identifier les relations et aperçus au sein des jeux de données.
Dataiku est conçu pour gérer graphiquement des pipelines de machine learning. © JDN / Capture
Quel est le prix de Dataiku ?
Dataiku propose une édition gratuite de sa plateforme à installer soi-même. Baptisée Dataiku Free, elle se limite à trois utilisateurs, mais donne accès à la majorité des fonctionnalités. Elle est disponible pour Windows, Linux, MacOS, Amazon EC2, Google Cloud et Microsoft Azure.
Pour aller plus loin, Dataiku commercialise trois éditions dont les prix sont disponibles sur demande : Dataiku Discover pour les petites équipes, Dataiku Business pour les équipes de taille moyenne, et Dataiku Enterprise pour déployer la plateforme à l'échelle d'une grande entreprise.
Qu’est-ce que Dataiku Online ?
Principalement conçu pour de petites structures, Dataiku Online permet de gérer les projets de data science à une échelle modérée. Il s’agit d’un dispositif de type SaaS (Software as a Service). Les fonctionnalités sont similaires à Dataiku, mais le paramétrage et le lancement de l’application sont plus rapides.
Dataiku Academy : formation et certification Dataiku
La Dataiku Academy regroupe une série de formations en ligne à la plateforme de Dataiku. Elle propose un programme Quicks Start qui permet de commencer à utiliser la solution en quelques heures, mais aussi des sessions Learning Paths pour acquérir des compétences plus avancées. Chaque programme permet de décrocher une certification Dataiku : Core Designer Certificate, ML Practitioner Certificate, Advanced Designer Certificate, Developer Certificate et MLOps Practitioner Certificate.
Dataiku prend en charge les time series et données géospatiales. © JDN / Capture
Dataiku vs DataRobot
Créé en 2012, l'américain DataRobot peut être considéré comme le pure player historique du machine learning automatisé (auto ML). Un terrain sur lequel Dataiku s'est positionne plus tard. Au fur et à mesure de leur développement, les deux plateformes tendent désormais à être de plus en plus comparables.
Face à DataRobot, Dataiku se distingue cependant sur le front de la collaboration. L'éditeur multiplie les fonctionnalités dans ce domaine : wiki, partage de tableaux de bord de résultats, système de gestion des rôles et de traçabilité des actions, etc.
Dataiku vs Alteryx
Alors que Dataiku est avant tout une plateforme de data science orientée machine learning, Alteryx, lui, se positionne comme un solution d'intelligence décisionnelle ciblant potentiellement tout décideur d'entreprise, bien au-delà des équipes de data science.
La principale valeur ajoutée d'Alteryx est d'automatiser la création de tableaux de bord analytics. Des tableaux de bord qui pourront inclure des indicateurs prédictifs basés sur des modèles de machine learning. Dans cet optique, Alteryx intègre des fonctionnalités de machine learning automatisé (auto ML) pour permettre aux utilisateurs de générer ce type d'indicateur. C'est son principal point commun avec Dataiku.
Dataiku vs Databricks
Dataiku et Databricks sont des plateformes très différentes. La première s'oriente vers la data science, la conception et le déploiement de modèles de machine learning. La seconde se présente sous la forme d'une data platform universelle répondant à la fois aux cas d'usage orientés entrepôt de données et BI, data lake, mais aussi streaming de données et calcul distribué.
Reste que Databricks s'enrichit de plus en plus de fonctionnalités orientées machine learning. La société de San Francisco a acquis l'environnement de data science low-code / no code 8080 Labs en octobre 2021, puis la plateforme de MLOps Cortex Labs en avril 2022. Deux technologies qu'elle est en train d'intégrer.
Dataiku Community : tutoriels et documentation
Dataiku Community est un espace d'échange et de documentation pour parfaire ses connaissances sur Dataiku et ses champs d'application. Après inscription, il est possible d'intégrer le forum de discussions.
CONTENUS SPONSORISÉS
L'État vous offrira des
panneaux solaires si vous...
Subventions Écologiques
Nouvelle loi 2023 pour la pompe à chaleur
OUTILS D'INTELLIGENCE ARTIFICIELLE
Cinq outils d'IA no code à la loupe
Tensorflow c'est quoi
Scikit-learn : bibliothèque star de machine learning Python
Rapid miner
Comparatif MLOps : Dataiku et DataRobot face aux alternatives open source
Aws sagemaker
Sas viya
Ibm watson
Keras
Quels KPI pour mesurer la réussite d'un projet d'IA ?
Comment créer un bot
Ai platform
Domino data lab
H2O.ai : une plateforme de machine learning open source
DataRobot : tout savoir sur la plateforme d'IA no code
Matplotlib : maîtriser la bibliothèque Python de data visualisation
Plateformes cloud d'IA : Amazon et Microsoft distancés par Google
Azure Machine Learning : la plateforme d'IA de Microsoft
Comparatif des outils français de création de bots : Dydu se démarque
MXNet : maitriser ce framework de deep learning performant
EN CE MOMENT
Taux d'usure
Impôt sur le revenu 2023
Date impôt
Déclaration d'impôt 2023
Guides
Dictionnaire comptable
Dictionnaire cryptomonnaie
Dictionnaire économique
Dictionnaire de l'IoT
Dictionnaire marketing
Dictionnaire webmastering
Droit des affaires
Guide des fournitures de bureau
Guides d'achat
Guide d'achat des imprimantes
Guide d'achat informatique
Guide de l'entreprise digitale
Guide de l'immobilier
Guide de l'intelligence artificielle
Guide de l'iPhone
Guide des finances personnelles
Guide des produits Apple
Guide des troubles de voisinage
Guide du management
Guide du jeu vidéo
Guide du recrutement
Guide du streaming
Repères
Chômage
Classement PIB
Dette publique
Contrat de location
PIB France
Salaire moyen
Assurance-vie
Impôt sur le revenu
LDD
LEP
Livret A
Plus-value immobilière
Prix immobilier
Classement Forbes
Dates soldes
Netflix
Prix du cuivre
Prime d'activité
RSA
Smic
Black Friday
No code
ChatGPT
1 note
·
View note
Text
[Python] PySpark to M, SQL or Pandas
Hace tiempo escribí un artículo sobre como escribir en pandas algunos códigos de referencia de SQL o M (power query). Si bien en su momento fue de gran utilidad, lo cierto es que hoy existe otro lenguaje que representa un fuerte pie en el análisis de datos.
Spark se convirtió en el jugar principal para lectura de datos en Lakes. Aunque sea cierto que existe SparkSQL, no quise dejar de traer estas analogías de código entre PySpark, M, SQL y Pandas para quienes estén familiarizados con un lenguaje, puedan ver como realizar una acción con el otro.
Lo primero es ponernos de acuerdo en la lectura del post.
Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #“Paso anterior” hablamos de una tabla.
En Python, asumiremos a "df" como un pandas dataframe (pandas.DataFrame) ya cargado y a "spark_frame" a un frame de pyspark cargado (spark.read)
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, PySpark, Pandas, Power Query.
En SQL:
SELECT TOP 5 * FROM table
En PySpark
spark_frame.limit(5)
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
spark_frame.count()
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
spark_frame.select("column1", "column2")
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]] O podría ser: Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
spark_frame.filter("column1 = 2") # OR spark_frame.filter(spark_frame['column1'] == 2)
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
spark_frame.filter((spark_frame['column1'] > 1) & (spark_frame['column2'] < 25)) O con operadores OR y NOT spark_frame.filter((spark_frame['column1'] > 1) | ~(spark_frame['column2'] < 25))
df.loc[(df['column1'] > 1) & (df['column2'] < 25)] O con operadores OR y NOT df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 ) O con operadores OR y NOT Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
from pyspark.sql.functions import col spark_frame.filter( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').like('%arcelona%')) ) # O spark_frame.where( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').contains('arcelona')) )
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Sería correcto cambiar el alias de columnas de mismo nombre así:
spark_frame1.join(spark_frame2, spark_frame1["column_id"] == spark_frame2["column_id"], "left").select(spark_frame1["column1"].alias("column1_df1"), spark_frame2["column1"].alias("column1_df2"))
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left') df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]] #"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter) #"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
from pyspark.sql.functions import count spark_frame.groupBy("column1").agg(count("*").alias("count"))
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
from pyspark.sql.functions import sum as spark_sum spark_frame.groupBy("store").agg(spark_sum("sales").alias("total_sales")).filter("total_sales > 1000")
df_grouped = df.groupby('store')['sales'].sum() df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}}) #"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
spark_frame.orderBy("column1", ascending=False)
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
spark_frame1.union(spark_frame2)
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2) pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre PySpark, Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL. Puede que su resultado no sea idéntico pero si similar para el caso a resolver.
Analizar el contenido de una tabla
spark_frame.summary()
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
spark_frame.groupBy("column1").count().show()
df.value_counts("columna1")
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
spark_frame = spark.createDataFrame([(1, "Boris Yeltsin"), (2, "Mikhail Gorbachev")], inferSchema=True)
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
spark_frame.drop("column1")
df.drop(columns=['column1']) df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
spark_frame.withColumn("column1", col("column1") + 1)
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con PySpark, SQL, Pandas y Power Query para que conociendo uno sepamos usar el otro.
#spark#pyspark#python#pandas#sql#power query#powerquery#notebooks#ladataweb#data engineering#data wrangling#data cleansing
0 notes
Text
WEEK 4: Introduction to Data-Frames & SparkSQL
1) Select the statements that are true about a Directed Acyclic Graph, known as a DAG. -> If a node goes down, Spark replicates the DAG and restores the node. -> Every new edge of a DAG is obtained from an older vertex. -> In Apache Spark, RDDs are represented by the vertices of a DAG while the transformations and actions are represented by directed edges. -> A DAG is a data structure with…
View On WordPress
0 notes