#Store Location Data Scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
E-commerce data scraping provides detailed information on market dynamics, prevailing patterns, pricing data, competitors’ practices, and challenges.
Scrape E-commerce data such as products, pricing, deals and offers, customer reviews, ratings, text, links, seller details, images, and more. Avail of the E-commerce data from any dynamic website and get an edge in the competitive market. Boost Your Business Growth, increase revenue, and improve your efficiency with Lensnure's custom e-commerce web scraping services.
We have a team of highly qualified and experienced professionals in web data scraping.
#web scraping services#data extraction#ecommerce data extraction#ecommerce web scraping#retail data scraping#scrape#retail store location data#Lensnure Solutions#web scraper#big data
1 note
·
View note
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
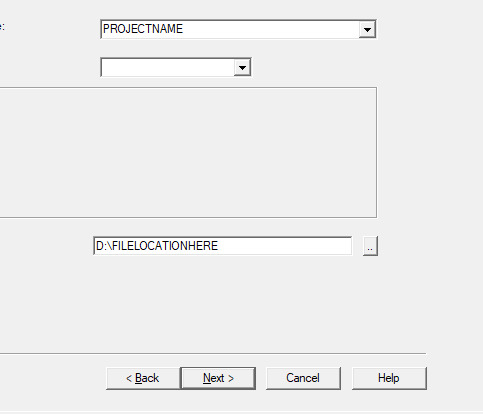
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
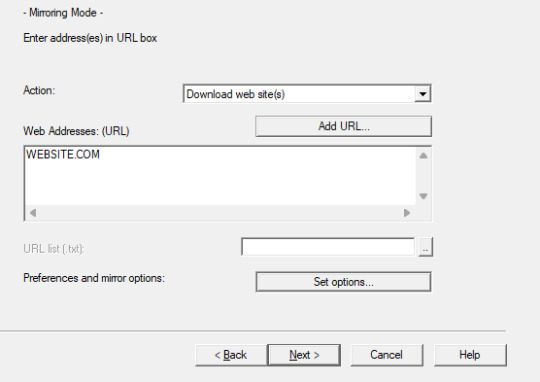
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
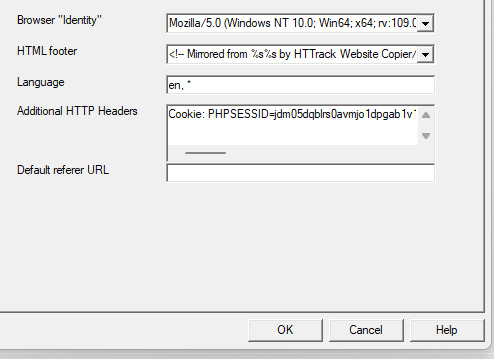
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
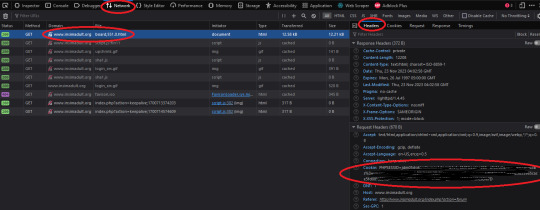
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
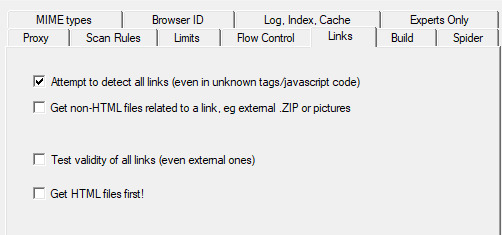
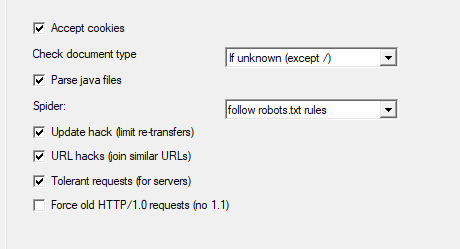
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
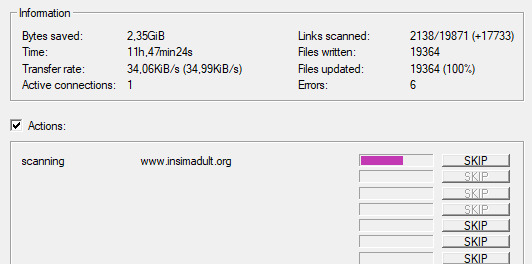
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
40 notes
·
View notes
Text
youtube
‘Blood-Soaked’ Eyes: NASA’s Webb, Hubble Examine Galaxy Pair
The telescope’s MIRI instrument, managed through launch by JPL, helps reveal new features of a galactic near-miss.
Stare deeply at these galaxies. They appear as if blood is pumping through the top of a flesh-free face. The long, ghastly “stare” of their searing eye-like cores shines out into the supreme cosmic darkness.
It’s good fortune that looks can be deceiving.
These galaxies have only grazed one another to date, with the smaller spiral on the left, cataloged as IC 2163, ever so slowly “creeping” behind NGC 2207, the spiral galaxy at right, millions of years ago.
The pair’s macabre colors represent a combination of mid-infrared light from NASA’s James Webb Space Telescope with visible and ultraviolet light from NASA’s Hubble Space Telescope.
Look for potential evidence of their “light scrape” in the shock fronts, where material from the galaxies may have slammed together. These lines represented in brighter red, including the “eyelids,” may cause the appearance of the galaxies’ bulging, vein-like arms.
The galaxies’ first pass may have also distorted their delicately curved arms, pulling out tidal extensions in several places. The diffuse, tiny spiral arms between IC 2163’s core and its far left arm may be an example of this activity. Even more tendrils look like they’re hanging between the galaxies’ cores. Another extension “drifts” off the top of the larger galaxy, forming a thin, semi-transparent arm that practically runs off-screen.
Both galaxies have high star formation rates, like innumerable individual hearts fluttering all across their arms. Each year, the galaxies produce the equivalent of two dozen new stars that are the size of the Sun. Our Milky Way galaxy only forms the equivalent of two or three new Sun-like stars per year. Both galaxies have also hosted seven known supernovae in recent decades, a high number compared to an average of one every 50 years in the Milky Way. Each supernova may have cleared space in their arms, rearranging gas and dust that later cooled, and allowed many new stars to form.
To spot the star-forming “action sequences,” look for the bright blue areas captured by Hubble in ultraviolet light, and pink and white regions detailed mainly by Webb’s mid-infrared data. Larger areas of stars are known as super star clusters. Look for examples of these in the top-most spiral arm that wraps above the larger galaxy and points left. Other bright regions in the galaxies are mini-starbursts — locations where many stars form in quick succession. Additionally, the top and bottom “eyelid” of IC 2163, the smaller galaxy on the left, is filled with newer star formation and burns brightly.
What’s next for these spirals? Over many millions of years, the galaxies may swing by one another repeatedly. It’s possible that their cores and arms will meld, leaving behind completely reshaped arms, and an even brighter, cyclops-like “eye” at the core. Star formation will also slow down once their stores of gas and dust deplete, and the scene will calm.

IMAGE: Hubble’s ultraviolet- and visible-light observation of spiral galaxies IC 2163 and NGC 2207, left, shows bright blue glowing arms and the galaxies’ cores in orange. In the James Webb Space Telescope’s mid-infrared observation, right, cold dust takes c… Credit: NASA, ESA, CSA, STScI
4 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Text
Okay, time for a little life update. Rambling under the cut.
TLDR: I haven't been able to write in a while and until I can get real life under control writing won't happen for a while longer.
I currently don't have the spoons to look for a new job AND write. Actually, I honestly don't even have the spoons for either right now, which tells me I need to scrape together some spoons to spend on finding a new job. Unfortunately that's not a particularly easy task.
For those of you that don't know: I decorate cakes at a grocery store for a living. My options are 1. transfer to a different location of the same chain store or 2. start my own business. As you can imagine neither of those is really feasible. For 1 a different location is going to have most of if not all of the same problems, even if I at least won't have the same awful store manager, assuming my awful manager will allow me to transfer (I've been told point blank he's not). For 2 I am the breadwinner of our household, we literally can't afford it.
I do have a secret third option: change careers. This is way harder, I'd be going from a labor intense career to a more office style career (I'm looking into things like data entry), and that's already a hard transition. But to complicate things: I'm turning 40 next year. You can cry age-ism all you want, it doesn't change the fact that being my age and trying to start completely over is near impossible.
So in short: until this situation can be sorted out I just don't have the energy or motivation to write. I've tried, it just isn't happening. I'm sorry to everyone who's been waiting on new chapters, I want to. I really do.
Be careful out there, watch out for burn out, take care of yourselves, and don't take no shit from awful managers.
9 notes
·
View notes
Text
Web scraping for effective price comparison is a powerful tool for collecting updated information from stores and locations. Advanced scraping tools can help handle data volumes and maintain ethical procedures to avoid legal consequences.
Using web scraping helps learn more complex patterns and relationships with user behavior, leading to more accurate and practical recommendations.
0 notes
Text
Extract Publix Grocery Data for Competitive Advantage
How Can You Extract Publix Grocery Data for Competitive Advantage?
April 29, 2025
Introduction
The grocery industry is dynamic and competitive, with retailers like Publix Super Markets playing a pivotal role in shaping consumer behavior and market trends. Publix, a beloved supermarket chain primarily operating in the southeastern United States, has built a reputation for quality, customer service, and a diverse product range. Extract Publix Grocery Data to offer a treasure trove of insights into consumer preferences, pricing strategies, product availability, and regional market dynamics. In this blog, we’ll explore the significance of Publix grocery data, its potential applications, and how it can illuminate broader trends in the retail grocery sector. By leveraging Publix Grocery Data Scraping Services, businesses can tap into real-time data streams that provide valuable market intelligence. Additionally, the ability to Extract Publix Product Listings & Prices enables brands to track price fluctuations, monitor product availability, and make data-driven decisions to enhance their competitive positioning.
The Value of Publix Grocery Data
Publix operates over 1,300 stores across Florida, Georgia, Alabama, South Carolina, North Carolina, Tennessee, and Virginia. As an employee-owned company, it has cultivated a loyal customer base through its commitment to quality and community engagement. The data generated by Publix’s operations—ranging from product catalogs to pricing, promotions, and inventory—provides a detailed snapshot of its business strategies and market positioning. Scrape Publix Grocery Data to gather structured information about products, categories, prices, discounts, and availability. This data can reveal patterns in consumer demand, seasonal trends, and competitive pricing. For businesses, researchers, and analysts, such data is invaluable for understanding how a major player like Publix navigates the complexities of the grocery retail market. From product assortment to promotional campaigns, Publix Grocery Products and Prices Scraping provides a comprehensive view of its operations. Utilizing Publix Grocery Data Scraping Services enables access to these insights for better decision-making and strategic planning.
Why Publix Data Matters?
Publix data provides essential insights into consumer preferences, pricing strategies, and regional market dynamics. By analyzing this data, businesses can optimize inventory management, track competitor activities, and align marketing efforts, ultimately gaining a competitive advantage in the retail grocery industry.
Consumer Behavior Insights: Publix’s product offerings and pricing reflect the preferences of its diverse customer base. Data on top-selling items, such as organic produce or bakery goods, can highlight shifts in consumer priorities, like a growing demand for plant-based foods or gluten-free options. Extract Publix Supermarket Data to help businesses gain insights into these evolving consumer preferences.
Regional Market Trends: Publix’s store network spans multiple states with unique demographic and economic characteristics. Analyzing data from different regions can uncover variations in purchasing habits, such as a preference for seafood in coastal areas or higher sales of comfort foods in colder climates. Extract Publix Grocery & Gourmet Food Data from different locations to identify regional patterns.
Competitive Analysis: Publix competes with national chains like Walmart, Kroger, and Whole Foods, as well as regional players. By examining Publix’s pricing and promotional strategies, businesses can benchmark their approaches and identify opportunities to differentiate. Web Scraping Publix Data allows companies to monitor these strategies in real time.
Supply Chain and Inventory Management: Data on product availability and stock levels can illuminate Publix’s supply chain efficiency. For instance, frequent out-of-stock items may indicate supply chain bottlenecks, while consistent availability of perishables suggests robust logistics. Extract Grocery & Gourmet Food Data to track product availability and supply chain trends.
Marketing and Promotions: Publix is known for its weekly ads, BOGO (buy one, get one) deals, and loyalty programs. Data on promotional campaigns can reveal which incentives resonate most with customers and how Publix balances profitability with customer satisfaction.
Key Data Points in Publix Grocery Data
To fully appreciate the scope of Publix grocery data, it’s essential to understand the types of information available. While the specifics may vary, the following categories are typically central to any data extraction effort:
Product Information: This includes product names, descriptions, categories (e.g., dairy, produce, bakery), brands, and SKUs. For example, data might show that Publix carries multiple brands of almond milk, each with different flavors and price points.
Pricing: Price data is critical for understanding Publix’s market positioning. This includes regular prices, sale prices, and discounts for loyalty program members. For instance, a gallon of Publix-branded milk might be priced at $3.49, while a national brand is $4.29.
Promotions: Publix’s BOGO deals, weekly specials, and digital coupons are a cornerstone of its marketing strategy. Data on these promotions can reveal which products are most frequently discounted and how promotions vary by region.
Availability: Stock levels and product availability data indicate how well Publix manages its inventory. For example, a consistently low stock of organic avocados might suggest high demand or supply chain challenges.
Store Locations: Geographic data, such as store addresses and operating hours, can be used to analyze Publix’s market penetration and expansion strategies.
Customer Reviews: While not always part of structured data, customer feedback on products (e.g., through Publix’s website or third-party platforms) can provide qualitative insights into product popularity and quality.
Applications of Publix Grocery Data
The applications of Publix grocery data are vast, spanning industries from retail and marketing to academia and technology. Below are some key use cases that demonstrate the versatility of this data:
Market Research and Competitive Intelligence: Market researchers can use Publix data to analyze trends in the grocery industry. For instance, a spike in sales of plant-based proteins might indicate a broader shift toward vegan diets. Comparing Publix’s prices with competitors can reveal whether it positions itself as a premium or value-driven retailer—crucial for refining strategies or market entry.
Product Development and Innovation: Food manufacturers and CPG companies can identify gaps using Publix data. For example, strong sales of gluten-free snacks but limited variety may inspire product innovation. Trends in flavors or ingredients can guide new formulations.
Personalized Marketing: Marketers can design targeted campaigns using regional insights—for example, promoting organic offerings where demand is high. Loyalty program performance and discount trends can further tailor outreach strategies.
Supply Chain Optimization: Inventory and availability data from Publix can highlight bottlenecks or inefficiencies. Frequent stockouts might suggest the need for new suppliers or improved ordering processes—leading to better service and cost control.
Academic Research: Publix data can support studies in economics, sociology, or consumer behavior. For instance, pricing data could help analyze inflation effects, while product preferences may reveal cultural consumption patterns.
Technology and Data Science: Publix grocery data is ideal for predictive modeling and ML applications. Algorithms might forecast stockouts or predict promotional impacts—enhancing inventory, pricing, and marketing optimization.
The Broader Implications of Grocery Data Extraction
While Publix is a single retailer, its data reflects broader trends in the grocery industry. The rise of e-commerce, for instance, has transformed how consumers shop for groceries. Publix’s online platform, which offers delivery and curbside pickup, generates additional data on digital shopping habits. Analyzing this data can reveal how consumers balance convenience, cost, and product quality when shopping online.
Moreover, grocery data extraction contributes to our understanding of sustainability and food systems. Data on the popularity of organic or locally sourced products can inform efforts to promote sustainable agriculture. Similarly, insights into food waste—such as products frequently discounted due to approaching expiration dates—can guide initiatives to reduce waste.
Real-World Impact: How Publix Data Shapes Decisions
To illustrate the power of Publix grocery data, consider a hypothetical scenario involving a regional food manufacturer. The manufacturer wants to launch a new line of frozen meals but needs to understand consumer preferences. Analyzing Publix data, the manufacturer discovers that frozen meals with organic ingredients and bold flavors (e.g., spicy Thai or Mediterranean) are top sellers in Florida stores. Armed with this insight, the manufacturer develops a line of organic, globally inspired frozen meals and pitches them to Publix buyers, securing a distribution deal.
In another example, a data analytics firm uses Publix’s pricing and promotion data to help a competing retailer optimize its discounts. The firm finds that Publix’s BOGO deals on snacks drive significant foot traffic on weekends. The competitor responds by launching similar promotions tailored to its customer base and seeing a sales boost.
Unlock valuable insights and stay ahead of the competition—contact us today to start leveraging our grocery data scraping services!
Contact Us Today!
The Future of Grocery Data Extraction
As technology evolves, so will the methods and applications of grocery data extraction. Advances in artificial intelligence and machine learning are making it easier to process large datasets and uncover hidden patterns. This could mean more sophisticated demand forecasting, personalized promotions, or even dynamic pricing based on real-time data for Publix. Additionally, the growing emphasis on transparency and sustainability will likely shape how retailers like Publix collect and share data. Consumers are increasingly interested in the origins of their food, from farm to table. Data on product sourcing, carbon footprints, and ethical practices could become as important as price and availability. Leveraging a Grocery Store Dataset will allow retailers to align with these trends and meet customer expectations. Web Scraping Grocery Data will play a key role in gathering this information efficiently, providing brands with the insights they need to stay competitive and socially responsible.
How Product Data Scrape Can Help You?
Real-Time Data Access: Our grocery data scraping services provide up-to-the-minute insights on product pricing, availability, promotions, and stock levels, allowing you to make quick, data-driven decisions.
Competitive Analysis: By scraping competitor grocery data, you can benchmark your pricing, promotions, and product assortment against industry leaders, gaining a strategic edge in the market.
Consumer Insights: Our services help you extract data on consumer behavior, popular products, and seasonal trends, enabling you to align your inventory and marketing strategies with customer demand.
Efficient Inventory Management: With real-time product availability and stock level data, you can optimize your supply chain, reducing stockouts and ensuring consistent product availability.
Data-Driven Marketing: Leverage our grocery data scraping services to analyze promotional campaigns and consumer feedback, helping you create targeted, effective marketing strategies that resonate with your audience.
Conclusion
Extracting Publix grocery data is more than a technical exercise—it’s a gateway to understanding the intricacies of the grocery retail industry. This data offers businesses, researchers, and innovators actionable insights from consumer preferences to competitive strategies. As Publix continues to grow and adapt to changing market dynamics, its data will remain a critical resource for anyone looking to navigate the complex world of grocery retail. By harnessing the power of this data, stakeholders can make informed decisions that drive growth, enhance customer satisfaction, and contribute to a more sustainable food ecosystem. Web Scraping Grocery & Gourmet Food Data from Publix provides a comprehensive view of product offerings and trends. Using Grocery & Supermarket Data Scraping Services, businesses can gain real-time access to pricing, promotions, and inventory data. Additionally, Grocery Data Scraping Services enable deep insights into the dynamics of the grocery market, empowering brands to stay competitive and informed.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
Read More>>https://www.productdatascrape.com/extract-publix-grocery-data-for-competitive-edge.php
#ExtractPublixGroceryData#PublixGroceryDataScrapingServices#ExtractPublixProductListingsAndPrices#ScrapePublixGroceryData#PublixGroceryProductsAndPricesScraping#ExtractPublixSupermarketData#WebScrapingPublixData
0 notes
Text
Monitor Competitor Pricing with Food Delivery Data Scraping

In the highly competitive food delivery industry, pricing can be the deciding factor between winning and losing a customer. With the rise of aggregators like DoorDash, Uber Eats, Zomato, Swiggy, and Grubhub, users can compare restaurant options, menus, and—most importantly—prices in just a few taps. To stay ahead, food delivery businesses must continually monitor how competitors are pricing similar items. And that’s where food delivery data scraping comes in.
Data scraping enables restaurants, cloud kitchens, and food delivery platforms to gather real-time competitor data, analyze market trends, and adjust strategies proactively. In this blog, we’ll explore how to use web scraping to monitor competitor pricing effectively, the benefits it offers, and how to do it legally and efficiently.
What Is Food Delivery Data Scraping?
Data scraping is the automated process of extracting information from websites. In the food delivery sector, this means using tools or scripts to collect data from food delivery platforms, restaurant listings, and menu pages.
What Can Be Scraped?
Menu items and categories
Product pricing
Delivery fees and taxes
Discounts and special offers
Restaurant ratings and reviews
Delivery times and availability
This data is invaluable for competitive benchmarking and dynamic pricing strategies.
Why Monitoring Competitor Pricing Matters
1. Stay Competitive in Real Time
Consumers often choose based on pricing. If your competitor offers a similar dish for less, you may lose the order. Monitoring competitor prices lets you react quickly to price changes and stay attractive to customers.
2. Optimize Your Menu Strategy
Scraped data helps identify:
Popular food items in your category
Price points that perform best
How competitors bundle or upsell meals
This allows for smarter decisions around menu engineering and profit margin optimization.
3. Understand Regional Pricing Trends
If you operate across multiple locations or cities, scraping competitor data gives insights into:
Area-specific pricing
Demand-based variation
Local promotions and discounts
This enables geo-targeted pricing strategies.
4. Identify Gaps in the Market
Maybe no competitor offers free delivery during weekdays or a combo meal under $10. Real-time data helps spot such gaps and create offers that attract value-driven users.
How Food Delivery Data Scraping Works
Step 1: Choose Your Target Platforms
Most scraping projects start with identifying where your competitors are listed. Common targets include:
Aggregators: Uber Eats, Zomato, DoorDash, Grubhub
Direct restaurant websites
POS platforms (where available)
Step 2: Define What You Want to Track
Set scraping goals. For pricing, track:
Base prices of dishes
Add-ons and customization costs
Time-sensitive deals
Delivery fees by location or vendor
Step 3: Use Web Scraping Tools or Custom Scripts
You can either:
Use scraping tools like Octoparse, ParseHub, Apify, or
Build custom scripts in Python using libraries like BeautifulSoup, Selenium, or Scrapy
These tools automate the extraction of relevant data and organize it in a structured format (CSV, Excel, or database).
Step 4: Automate Scheduling and Alerts
Set scraping intervals (daily, hourly, weekly) and create alerts for major pricing changes. This ensures your team is always equipped with the latest data.
Step 5: Analyze the Data
Feed the scraped data into BI tools like Power BI, Google Data Studio, or Tableau to identify patterns and inform strategic decisions.
Tools and Technologies for Effective Scraping
Popular Tools:
Scrapy: Python-based framework perfect for complex projects
BeautifulSoup: Great for parsing HTML and small-scale tasks
Selenium: Ideal for scraping dynamic pages with JavaScript
Octoparse: No-code solution with scheduling and cloud support
Apify: Advanced, scalable platform with ready-to-use APIs
Hosting and Automation:
Use cron jobs or task schedulers for automation
Store data on cloud databases like AWS RDS, MongoDB Atlas, or Google BigQuery
Legal Considerations: Is It Ethical to Scrape Food Delivery Platforms?
This is a critical aspect of scraping.
Understand Platform Terms
Many websites explicitly state in their Terms of Service that scraping is not allowed. Scraping such platforms can violate those terms, even if it’s not technically illegal.
Avoid Harming Website Performance
Always scrape responsibly:
Use rate limiting to avoid overloading servers
Respect robots.txt files
Avoid scraping login-protected or personal user data
Use Publicly Available Data
Stick to scraping data that’s:
Publicly accessible
Not behind paywalls or logins
Not personally identifiable or sensitive
If possible, work with third-party data providers who have pre-approved partnerships or APIs.
Real-World Use Cases of Price Monitoring via Scraping
A. Cloud Kitchens
A cloud kitchen operating in three cities uses scraping to monitor average pricing for biryani and wraps. Based on competitor pricing, they adjust their bundle offers and introduce combo meals—boosting order value by 22%.
B. Local Restaurants
A family-owned restaurant tracks rival pricing and delivery fees during weekends. By offering a free dessert on orders above $25 (when competitors don’t), they see a 15% increase in weekend orders.
C. Food Delivery Startups
A new delivery aggregator monitors established players’ pricing to craft a price-beating strategy, helping them enter the market with aggressive discounts and gain traction.
Key Metrics to Track Through Price Scraping
When setting up your monitoring dashboard, focus on:
Average price per cuisine category
Price differences across cities or neighborhoods
Top 10 lowest/highest priced items in your segment
Frequency of discounts and offers
Delivery fee trends by time and distance
Most used upsell combinations (e.g., sides, drinks)
Challenges in Food Delivery Data Scraping (And Solutions)
Challenge 1: Dynamic Content and JavaScript-Heavy Pages
Solution: Use headless browsers like Selenium or platforms like Puppeteer to scrape rendered content.
Challenge 2: IP Blocking or Captchas
Solution: Rotate IPs with proxies, use CAPTCHA-solving tools, or throttle request rates.
Challenge 3: Frequent Site Layout Changes
Solution: Use XPaths and CSS selectors dynamically, and monitor script performance regularly.
Challenge 4: Keeping Data Fresh
Solution: Schedule automated scraping and build change detection algorithms to prioritize meaningful updates.
Final Thoughts
In today’s digital-first food delivery market, being reactive is no longer enough. Real-time competitor pricing insights are essential to survive and thrive. Data scraping gives you the tools to make informed, timely decisions about your pricing, promotions, and product offerings.
Whether you're a single-location restaurant, an expanding cloud kitchen, or a new delivery platform, food delivery data scraping can help you gain a critical competitive edge. But it must be done ethically, securely, and with the right technologies.
0 notes
Text
Understanding Telegram Data: Uses, Privacy, and the Future of Messaging
In the age of digital communication, messaging platforms have become central to our personal and professional lives. Among these, Telegram has emerged as a prominent player known for its speed, security, and versatile features. However, as with any digital service, the term "Telegram data" raises important questions about what information is collected, how it is stored and shared, and how it can be used by users, developers, marketers, or even state actors. This article provides a comprehensive look into Telegram data, dissecting its components, usage, and implications.
1. What is Telegram Data?
Telegram data refers to the entire range of information generated, transmitted, and stored through the Telegram platform. This can be broadly categorized into several components:
a. User Data
Phone numbers: Telegram accounts are tied to mobile numbers.
Usernames and profile information: Including names, bios, and profile pictures.
Contacts: Synced from the user’s address book if permission is granted.
User settings and preferences.
b. Chat and Media Data
Messages: Both individual and group chats. Telegram offers two types of chats:
Cloud Chats: Stored on Telegram’s servers and accessible from multiple devices.
Secret Chats: End-to-end encrypted and stored only on the users’ devices.
Media Files: Photos, videos, voice messages, and documents shared via chats.
Stickers and GIFs.
c. Usage Data
Log data: Includes metadata such as IP addresses, timestamps, and device information.
Activity patterns: Group participation, usage frequency, and interaction rates.
d. Bot and API Data
Telegram allows developers to build bots and integrate third-party services using its Bot API. Data includes:
Commands and messages sent to bots.
Bot logs and interactions.
Callback queries and inline queries.
2. Where is Telegram Data Stored?
Telegram is a cloud-based messaging platform. This means that most data (excluding secret chats) is stored on Telegram’s distributed network of data centers. According to Telegram, these centers are spread across various jurisdictions to ensure privacy and availability. Notably, Telegram’s encryption keys are split and stored in separate locations, telegram data a measure intended to protect user privacy.
For regular cloud chats, data is encrypted both in transit and at rest using Telegram’s proprietary MTProto protocol. However, Telegram—not the users—retains the encryption keys for these chats, meaning it can technically access them if compelled by law enforcement.
On the other hand, secret chats use end-to-end encryption, ensuring that only the sender and receiver can read the messages. These messages are never uploaded to Telegram’s servers and cannot be retrieved if one device is lost.
3. How is Telegram Data Used?
a. For User Functionality
The main use of Telegram data is to enable seamless messaging experiences across devices. Users can:
Access their chats from multiple devices.
Restore messages and media files after reinstalling the app.
Sync their contacts and communication preferences.
b. For Bots and Automation
Developers use Telegram data via the Telegram Bot API to create bots that:
Provide customer support.
Automate tasks like reminders or notifications.
Conduct polls and surveys.
Offer content feeds (e.g., news, RSS).
Telegram bots do not have access to chat history unless explicitly messaged or added to groups. This limits their data access and enhances security.
c. For Business and Marketing
Telegram’s growing popularity has made it a platform for digital marketing. Data from public channels and groups is often analyzed for:
Tracking trends and discussions.
Collecting feedback and user sentiment.
Delivering targeted content or product updates.
Some third-party services scrape public Telegram data for analytics. These activities operate in a legal grey area, especially if they violate Telegram’s terms of service.
4. Telegram’s Approach to Privacy
Telegram has built a reputation for being a privacy-focused platform. Here’s how it addresses user data privacy:
a. Minimal Data Collection

b. No Ads or Tracking
As of 2025, Telegram does not show personalized ads and has stated that it does not monetize user data. This is a significant departure from other platforms owned by large tech corporations.
c. Two-Layer Encryption
Telegram uses two layers of encryption:
Server-client encryption for cloud chats.
End-to-end encryption for secret chats.
While this model allows for cloud-based features, critics argue that Telegram’s control of the encryption keys for cloud chats is a potential vulnerability.
d. Self-Destruct and Privacy Settings
Users can:
Set messages to auto-delete after a specific period.
Disable forwarding of messages.
Hide last seen status, phone number, and profile picture.
Enable two-factor authentication.
5. Risks and Controversies Around Telegram Data
While Telegram markets itself as a secure platform, it has not been free from criticism:
a. MTProto Protocol Concerns
Security researchers have criticized Telegram’s proprietary MTProto protocol for not being independently verified to the same extent as open protocols like Signal’s. This has raised questions about its true robustness.
b. Use by Malicious Actors
Telegram’s relative anonymity and support for large groups have made it attractive for:
Illegal marketplaces.
Extremist propaganda.
Data leaks and doxxing.
Governments in countries like Iran, Russia, and India have, at various times, tried to ban or restrict Telegram citing national security concerns.
c. Data Requests and Compliance
Telegram claims it has never shared user data with third parties or governments. However, it does reserve the right to disclose IP addresses and phone numbers in terrorism-related cases. To date, Telegram reports zero such disclosures, according to its transparency reports.
6. Telegram Data for Researchers and Analysts
Telegram data scraping from public channels and groups has become a valuable resource for researchers studying:
Social movements.
Disinformation campaigns.
Public opinion on political events.
Online behavior in encrypted spaces.
Tools like Telethon and TDLib (Telegram Database Library) are used for accessing Telegram’s API. They allow developers to build advanced tools to collect and analyze public messages.
However, scraping Telegram data comes with legal and ethical responsibilities. Researchers must ensure:
Data anonymity.
Respect for Telegram’s API rate limits.
Avoidance of private or personally identifiable information.
7. Future Trends in Telegram Data
As Telegram continues to grow—reportedly reaching over 900 million monthly active users in 2025—the data generated on the platform will increase in scale and value. Here are some expected trends:
a. Monetization Through Premium Features
Telegram launched Telegram Premium offering additional features like faster downloads, larger uploads, and exclusive stickers. These premium tiers may lead to more data on user preferences and consumption patterns.
b. AI Integration
With the AI revolution in full swing, Telegram may integrate or allow AI-powered bots for content generation, moderation, and summarization, all of which will involve new types of data processing.
c. Regulatory Scrutiny
As governments worldwide tighten data protection laws (e.g., GDPR in Europe, DPDP Act in India), Telegram will face increased scrutiny over how it handles user data.
Thanks for Reading…..
SEO Expate Bangladesh Ltd.
0 notes
Text
Phone Number Data: The Digital Identifier Transforming Communication and Business
Introduction In today’s hyper connected digital world, phone numbers have evolved from mere contact points to powerful identifiers that fuel communication, commerce, security, and digital identity. “Phone number data” refers to the information associated with and derived from phone numbers, including their usage, location, metadata, and relationships to user identities. This data has become a valuable asset in sectors ranging from marketing to cybersecurity, but it also poses significant privacy and regulatory challenges. This article explores the meaning of phone number data, its applications, implications, and the future of how this data is used and protected.
What is Phone Number Data?
Phone number data encompasses a wide range of information linked to mobile or landline phone numbers. This can include:
Basic identifiers: Phone number, country code, carrier name, line type (mobile, landline, VoIP).
User metadata: Name, email, location, and other personal identifiers tied to the number.
Usage data: Call logs, text message records, and app interaction history.
Location data: Real-time or historical data based on tower triangulation or GPS (for mobile numbers).
Behavioral insights: Frequency of communication, network patterns, or geospatial movement trends.
Together, these components form a rich data profile that organizations can leverage for various purposes phone number data from identity verification to targeted marketing.
Sources of Phone Number Data
Phone number data can originate from multiple sources:
Telecom Providers: Phone companies collect call logs, SMS activity, and data usage.
Apps and Websites: Many apps request users’ phone numbers for registration and may collect contact data and device information.
Public Records and Directories: Some databases aggregate public contact information from business listings, customer databases, or government records.
Data Brokers: Specialized firms compile phone number databases by scraping, purchasing, or licensing user data from various sources.
The way phone number data is collected and used depends significantly on regional privacy laws and user consent mechanisms.
Common Uses of Phone Number Data
1. Marketing and Customer Engagement
Businesses often use phone number data to run SMS marketing campaigns, personalized promotions, or customer support outreach. With platforms like WhatsApp Business, Viber, or SMS gateways, phone numbers become a direct channel to consumers.
Example: E-commerce companies may send cart reminders or shipping updates to users via SMS.
2. Authentication and Security
Phone numbers are a key part of multi-factor authentication (MFA). Services send verification codes via SMS or call to confirm a user's identity.
Use Cases:
Two-factor authentication (2FA)
Account recovery
Fraud detection via SIM swap detection
3. Lead Generation and Data Enrichment
Sales and marketing teams enrich existing leads by adding phone number data to contact records. Data providers offer reverse lookup tools to identify company roles, job titles, or social media profiles from a number.
4. Communication Analytics
Call centers and telecoms analyze phone number data to study patterns, optimize service delivery, and reduce call fraud or spam.
5. Government and Emergency Services
Authorities use phone data for contact tracing (e.g., during COVID-19), disaster alerts, and emergency location tracking. This data can also help law enforcement track criminal activity.
Phone Number Data in Business Intelligence
Phone numbers help businesses:
Map consumer journeys across channels
Create segmentation models based on call behavior
Track user response to campaigns
Monitor customer satisfaction in service departments
Modern CRMs (Customer Relationship Management systems) store not just the number but all associated interactions—calls, texts, and support tickets—to create a 360-degree view of each contact.
Risks and Concerns with Phone Number Data
Despite its usefulness, phone number data presents several risks, especially related to privacy and cybersecurity.
1. Privacy Invasion
Phone numbers are often linked to other personally identifiable information (PII). When shared without proper consent, it can result in privacy violations, spam, or harassment.
2. Phishing and Scam Calls
Fraudsters often spoof caller IDs or use leaked numbers to impersonate legitimate entities. This has led to a surge in robocalls, vishing (voice phishing), and SMS scams.
3. Data Breaches
Phone numbers are commonly leaked in data breaches, sometimes alongside passwords and personal data. Leaked phone data can be weaponized for identity theft or account hijacking.

Notable Incident: The 2019 Facebook data leak exposed phone numbers of over 500 million users, emphasizing the risks associated with poor phone data handling.
4. SIM Swapping
Hackers use phone number data to execute SIM swap attacks—porting a number to a new SIM to gain control of bank accounts, emails, and crypto wallets.
Legal and Regulatory Considerations
As data protection laws tighten globally, the handling of phone number data is under increased scrutiny.
GDPR (EU)
Considers phone numbers as personal data.
Requires explicit consent for collecting and processing.
Grants users the right to access, correct, or delete their data.
CCPA (California)
Gives consumers the right to opt out of phone data sales.
Requires companies to disclose what data is collected and why.
TRAI (India)
Imposes strict regulations on unsolicited commercial communication (UCC) to prevent spam.
Requires telemarketers to register and follow opt-in principles.
Organizations must implement proper data protection policies, encryption standards, and consent management practices to comply with these regulations.
Phone Number Data in the Age of AI and Automation
Artificial Intelligence (AI) and machine learning are transforming how phone number data is processed:
1. Predictive Analytics
AI models analyze call and message patterns to predict user behavior, identify churn risks, or target high-value customers.
2. Voice and Sentiment Analysis
AI can evaluate tone and emotion in voice calls to assess customer satisfaction or detect potential fraud.
3. Spam Detection
Machine learning algorithms detect spam calls and automatically block them based on number patterns and crowd-sourced data.
4. Virtual Assistants
Chatbots and voice bots use phone number data to authenticate users and personalize responses during interactions.
The Future of Phone Number Data
1. Decentralized Identity Systems
Blockchain and self-sovereign identity (SSI) systems may reduce reliance on centralized phone number databases, giving users more control over their identity and privacy.
2. eSIM and Number Portability
With the rise of eSIMs and number portability, users can change networks without changing their number. This increases the longevity of phone number data and its use as a long-term identifier.
3. Phone Numbers as Digital IDs
In many developing countries, phone numbers serve as digital IDs for banking, government services, and mobile payments. This trend is likely to expand as mobile-first economies grow.
4. Enhanced Consent and Transparency
Future data systems will likely include dashboards where users can see how their phone number data is used and revoke access in real-time.
Best Practices for Managing Phone Number Data
Organizations that collect and use phone number data should adhere to these best practices:
Obtain Explicit Consent: Always inform users why their number is needed and how it will be used.
Encrypt Data: Store numbers securely and ensure they are encrypted both at rest and in transit.
Implement Access Controls: Limit access to phone data to only those who need it.
Monitor for Breaches: Use tools to detect unauthorized access or data leaks.
Honor Opt-Out Requests: Make it easy for users to opt out of communications or data sharing
Thanks for reading..
SEO Expate Bangladesh Ltd.
0 notes
Text
WineOnline.ca Wine Price Extraction

WineOnline.ca Wine Price Extraction: Unlock Competitive Pricing Insights
The wine industry is highly competitive, and staying ahead requires real-time pricing insights. WineOnline.ca is one of Canada’s premier platforms for purchasing wines, spirits, and related products. Extracting wine price data from WineOnline.ca allows businesses to monitor price fluctuations, analyze competitor pricing, and optimize their own pricing strategies for better profitability.
With WineOnline.ca Wine Price Extraction, businesses can automate the collection of wine pricing data, helping them make informed decisions and gain a competitive advantage.
What is Wine Price Extraction?
Wine price extraction is the process of automatically collecting and structuring pricing and product-related data from WineOnline.ca. This extracted data is valuable for retailers, wine distributors, e-commerce platforms, and market researchers looking to analyze trends, compare prices, and improve sales strategies.
Key Data Fields Extracted from WineOnline.ca
Using WineOnline.ca price scraping by DataScrapingServices.com, businesses can obtain critical wine-related data, including:
Wine Name & Brand – The official name and brand of the wine.
Wine Price – The current selling price of the wine, including any discounts.
Wine Type & Category – Classification such as red, white, rosé, sparkling, or fortified.
Alcohol Percentage – The ABV (alcohol by volume) content of the wine.
Bottle Size & Packaging Details – Information on volume (e.g., 750ml, 1.5L) and packaging.
Vintage Year – The year in which the wine was produced.
Region & Country of Origin – Details about the winery location and country of production.
Customer Ratings & Reviews – Insights into consumer preferences and satisfaction levels.
Discounts & Promotions – Special offers, deals, and limited-time discounts.
Availability Status – Whether the wine is in stock, out of stock, or available for pre-order.
Benefits of Wine Price Extraction from WineOnline.ca
1. Competitive Pricing Analysis
Retailers and distributors can compare wine prices across competitors, allowing them to adjust pricing strategies and maximize profit margins.
2. Market Trend Analysis
Tracking price fluctuations and promotional offers over time helps businesses identify seasonal trends and demand patterns.
3. E-commerce Optimization
Online wine stores can use extracted price data to update their pricing dynamically, ensuring that their listings remain competitive in the market.
4. Wine Portfolio Management
Wine importers and distributors can use extracted data to evaluate pricing trends and decide which products to stock based on market demand.
5. Personalized Marketing Strategies
With access to customer reviews and ratings, businesses can tailor their marketing strategies by promoting highly-rated wines or adjusting pricing based on customer preferences.
6. Automated Data Collection
Instead of manually tracking wine prices, businesses can automate data collection, saving time and ensuring they always have real-time pricing insights.
Best Wine Website Data Scraping
Wine Sites Data Scraping
Vivino Wine Data Scraping
Whiskey and Wine Website Scraping
Wine-Searcher Price Data Extraction
Wine Stores Data Scraping
Scraping Wineries Email List
Wine-Searcher Data Scraping
Wine.com Price Data Crawling
Extracting Liquor Prices from Totalwine.com
Waitrosecellar.com Product Information Scraping
Best WineOnline.ca Wine Price Extraction Services in Canada:
St. John’s, Quebec, Ontario, Toronto, Charlottetown, Yukon, Calgary, Manitoba, Vancouver, Montreal, Victoria, Saskatchewan, Nova Scotia, Alberta and Ottawa.
Why Choose Our WineOnline.ca Price Extraction Services?
At Datascrapingservices.com, we provide customized and reliable data scraping solutions for businesses looking to gain valuable insights from WineOnline.ca. Our services ensure accurate, structured, and real-time data extraction, helping businesses stay ahead in the competitive wine market.
📧 Email: [email protected]🌐 Website: Datascrapingservices.com
Stay competitive in the wine industry with WineOnline.ca wine price extraction services and make data-driven business decisions today! 🍷🚀
#wineonlinewinepriceextraction#extractingwinepricedatafromwineonline#winesearcherpricedataextraction#winesearcherproductdatascraping#winewebsitescraping#whiskeydatascraping#datascrapingservices#webscrapingservices
0 notes
Text

Webb and Hubble examine spooky galaxy pair
Stare deeply at these galaxies. They appear as if blood is pumping through the top of a flesh-free face. The long, ghastly "stare" of their searing eye-like cores shines out into the supreme cosmic darkness.
These galaxies have only grazed one another so far. The smaller spiral on the left, cataloged as IC 2163, is ever so slowly "creeping" behind NGC 2207, the spiral galaxy on the right, millions of years ago.
The pair's macabre colors represent a combination of mid-infrared light from the NASA/ESA/CSA James Webb Space Telescope and visible and ultraviolet light from the NASA/ESA Hubble Space Telescope.
Look for potential evidence of their "light scrape" in the shock fronts, where material from the galaxies may have slammed together. These lines represented in brighter red, including the "eyelids," may cause the appearance of the galaxies' bulging, vein-like arms.
The galaxies' first pass may have also distorted their delicately curved arms, pulling out tidal extensions in several places. The diffuse, tiny spiral arms between IC 2163's core and its far left arm may be an example of this activity. Even more tendrils look like they're hanging between the galaxies' cores. Another extension 'drifts' off the top of the larger galaxy, forming a thin, semi-transparent arm that practically runs off screen.
Both galaxies have high star formation rates, like innumerable individual hearts fluttering all across their arms. Each year, the galaxies produce the equivalent of two dozen new stars that are the size of the sun. Our Milky Way galaxy only forms the equivalent of two or three new sun-like stars per year.
Both galaxies have also hosted seven known supernovae in recent decades, a high number compared to an average of one every 50 years in the Milky Way. Each supernova may have cleared space in the galaxies' arms, rearranging gas and dust that later cooled, and allowed many new stars to form.
To spot the star-forming "action sequences," look for the bright blue areas captured by Hubble in ultraviolet light, and the pink and white regions detailed mainly by Webb's mid-infrared data. Larger areas of stars are known as super star clusters. Look for examples of these in the top-most spiral arm that wraps above the larger galaxy and points left.
Other bright regions in the galaxies are mini starbursts—locations where many stars form in quick succession. Additionally, the top and bottom "eyelid" of IC 2163, the smaller galaxy on the left, is filled with newer star formation and burns brightly.
What's next for these spirals? Over many millions of years, the galaxies may swing by one another repeatedly. It's possible that their cores and arms will meld, leaving behind completely reshaped arms, and an even brighter, cyclops-like "eye" at the core. Star formation will also slow down once their stores of gas and dust deplete, and the scene will calm.
3 notes
·
View notes
Text
☕ Is Starbucks really on every corner? Let the data show you.

At Actowiz Solutions, we’ve #Mapped Starbucks' store distribution across the U.S. using #LocationBased data scraping — revealing surprising patterns in saturation, #GrowthPotential, and #competitiveGaps. 📍 Which states are oversaturated? 📊 Where are the untapped markets? 📈 What can this teach retail & real estate brands about site planning? From big cities to quiet towns, Starbucks has built more than just brand loyalty — they’ve built a playbook in location strategy. 🔎 Learn how data-backed maps can fuel smarter expansion, site selection, and competitive benchmarking for your brand too. 👉 Explore the full analysis now:
0 notes
Text
How To Scrape Airbnb Listing Data Using Python And Beautiful Soup: A Step-By-Step Guide

The travel industry is a huge business, set to grow exponentially in coming years. It revolves around movement of people from one place to another, encompassing the various amenities and accommodations they need during their travels. This concept shares a strong connection with sectors such as hospitality and the hotel industry.
Here, it becomes prudent to mention Airbnb. Airbnb stands out as a well-known online platform that empowers people to list, explore, and reserve lodging and accommodation choices, typically in private homes, offering an alternative to the conventional hotel and inn experience.
Scraping Airbnb listings data entails the process of retrieving or collecting data from Airbnb property listings. To Scrape Data from Airbnb's website successfully, you need to understand how Airbnb's listing data works. This blog will guide us how to scrape Airbnb listing data.
What Is Airbnb Scraping?

Airbnb serves as a well-known online platform enabling individuals to rent out their homes or apartments to travelers. Utilizing Airbnb offers advantages such as access to extensive property details like prices, availability, and reviews.
Data from Airbnb is like a treasure trove of valuable knowledge, not just numbers and words. It can help you do better than your rivals. If you use the Airbnb scraper tool, you can easily get this useful information.
Effectively scraping Airbnb’s website data requires comprehension of its architecture. Property information, listings, and reviews are stored in a database, with the website using APIs to fetch and display this data. To scrape the details, one must interact with these APIs and retrieve the data in the preferred format.
In essence, Airbnb listing scraping involves extracting or scraping Airbnb listings data. This data encompasses various aspects such as listing prices, locations, amenities, reviews, and ratings, providing a vast pool of data.
What Are the Types of Data Available on Airbnb?

Navigating via Airbnb's online world uncovers a wealth of data. To begin with, property details, like data such as the property type, location, nightly price, and the count of bedrooms and bathrooms. Also, amenities (like Wi-Fi, a pool, or a fully-equipped kitchen) and the times for check-in and check-out. Then, there is data about the hosts and guest reviews and details about property availability.
Here's a simplified table to provide a better overview:
Property Details Data regarding the property, including its category, location, cost, number of rooms, available features, and check-in/check-out schedules.
Host Information Information about the property's owner, encompassing their name, response time, and the number of properties they oversee.
Guest Reviews Ratings and written feedback from previous property guests.
Booking Availability Data on property availability, whether it's available for booking or already booked, and the minimum required stay.
Why Is the Airbnb Data Important?

Extracting data from Airbnb has many advantages for different reasons:
Market Research
Scraping Airbnb listing data helps you gather information about the rental market. You can learn about prices, property features, and how often places get rented. It is useful for understanding the market, finding good investment opportunities, and knowing what customers like.
Getting to Know Your Competitor
By scraping Airbnb listings data, you can discover what other companies in your industry are doing. You'll learn about their offerings, pricing, and customer opinions.
Evaluating Properties
Scraping Airbnb listing data lets you look at properties similar to yours. You can see how often they get booked, what they charge per night, and what guests think of them. It helps you set the prices right, make your property better, and make guests happier.
Smart Decision-Making
With scraped Airbnb listing data, you can make smart choices about buying properties, managing your portfolio, and deciding where to invest. The data can tell you which places are popular, what guests want, and what is trendy in the vacation rental market.
Personalizing and Targeting
By analyzing scraped Airbnb listing data, you can learn what your customers like. You can find out about popular features, the best neighborhoods, or unique things guests want. Next, you can change what you offer to fit what your customers like.
Automating and Saving Time
Instead of typing everything yourself, web scraping lets a computer do it for you automatically and for a lot of data. It saves you time and money and ensures you have scraped Airbnb listing data.
Is It Legal to Scrape Airbnb Data?
Collecting Airbnb listing data that is publicly visible on the internet is okay, as long as you follow the rules and regulations. However, things can get stricter if you are trying to gather data that includes personal info, and Airbnb has copyrights on that.
Most of the time, websites like Airbnb do not let automatic tools gather information unless they give permission. It is one of the rules you follow when you use their service. However, the specific rules can change depending on the country and its policies about automated tools and unauthorized access to systems.
How To Scrape Airbnb Listing Data Using Python and Beautiful Soup?

Websites related to travel, like Airbnb, have a lot of useful information. This guide will show you how to scrape Airbnb listing data using Python and Beautiful Soup. The information you collect can be used for various things, like studying market trends, setting competitive prices, understanding what guests think from their reviews, or even making your recommendation system.
We will use Python as a programming language as it is perfect for prototyping, has an extensive online community, and is a go-to language for many. Also, there are a lot of libraries for basically everything one could need. Two of them will be our main tools today:
Beautiful Soup — Allows easy scraping of data from HTML documents
Selenium — A multi-purpose tool for automating web-browser actions
Getting Ready to Scrape Data
Now, let us think about how users scrape Airbnb listing data. They start by entering the destination, specify dates then click "search." Airbnb shows them lots of places.
This first page is like a search page with many options. But there is only a brief data about each.
After browsing for a while, the person clicks on one of the places. It takes them to a detailed page with lots of information about that specific place.
We want to get all the useful information, so we will deal with both the search page and the detailed page. But we also need to find a way to get info from the listings that are not on the first search page.
Usually, there are 20 results on one search page, and for each place, you can go up to 15 pages deep (after that, Airbnb says no more).
It seems quite straightforward. For our program, we have two main tasks:
looking at a search page, and getting data from a detailed page.
So, let us begin writing some code now!
Getting the listings
Using Python to scrape Airbnb listing data web pages is very easy. Here is the function that extracts the webpage and turns it into something we can work with called Beautiful Soup.
def scrape_page(page_url): """Extracts HTML from a webpage""" answer = requests.get(page_url) content = answer.content soup = BeautifulSoup(content, features='html.parser') return soup
Beautiful Soup helps us move around an HTML page and get its parts. For example, if we want to take the words from a “div” object with a class called "foobar" we can do it like this:
text = soup.find("div", {"class": "foobar"}).get_text()
On Airbnb's listing data search page, what we are looking for are separate listings. To get to them, we need to tell our program which kinds of tags and names to look for. A simple way to do this is to use a tool in Chrome called the developer tool (press F12).
The listing is inside a "div" object with the class name "8s3ctt." Also, we know that each search page has 20 different listings. We can take all of them together using a Beautiful Soup tool called "findAll.
def extract_listing(page_url): """Extracts listings from an Airbnb search page""" page_soup = scrape_page(page_url) listings = page_soup.findAll("div", {"class": "_8s3ctt"}) return listings
Getting Basic Info from Listings
When we check the detailed pages, we can get the main info about the Airbnb listings data, like the name, total price, average rating, and more.
All this info is in different HTML objects as parts of the webpage, with different names. So, we could write multiple single extractions -to get each piece:
name = soup.find('div', {'class':'_hxt6u1e'}).get('aria-label') price = soup.find('span', {'class':'_1p7iugi'}).get_text() ...
However, I chose to overcomplicate right from the beginning of the project by creating a single function that can be used again and again to get various things on the page.
def extract_element_data(soup, params): """Extracts data from a specified HTML element"""
# 1. Find the right tag
if 'class' in params: elements_found = soup.find_all(params['tag'], params['class']) else: elements_found = soup.find_all(params['tag'])
# 2. Extract text from these tags
if 'get' in params: element_texts = [el.get(params['get']) for el in elements_found] else: element_texts = [el.get_text() for el in elements_found]
# 3. Select a particular text or concatenate all of them tag_order = params.get('order', 0) if tag_order == -1: output = '**__**'.join(element_texts) else: output = element_texts[tag_order] return output
Now, we've got everything we need to go through the entire page with all the listings and collect basic details from each one. I'm showing you an example of how to get only two details here, but you can find the complete code in a git repository.
RULES_SEARCH_PAGE = { 'name': {'tag': 'div', 'class': '_hxt6u1e', 'get': 'aria-label'}, 'rooms': {'tag': 'div', 'class': '_kqh46o', 'order': 0}, } listing_soups = extract_listing(page_url) features_list = [] for listing in listing_soups: features_dict = {} for feature in RULES_SEARCH_PAGE: features_dict[feature] = extract_element_data(listing, RULES_SEARCH_PAGE[feature]) features_list.append(features_dict)
Getting All the Pages for One Place
Having more is usually better, especially when it comes to data. Scraping Airbnb listing data lets us see up to 300 listings for one place, and we are going to scrape them all.
There are different ways to go through the pages of search results. It is easiest to see how the web address (URL) changes when we click on the "next page" button and then make our program do the same thing.
All we have to do is add a thing called "items_offset" to our initial URL. It will help us create a list with all the links in one place.
def build_urls(url, listings_per_page=20, pages_per_location=15): """Builds links for all search pages for a given location""" url_list = [] for i in range(pages_per_location): offset = listings_per_page * i url_pagination = url + f'&items_offset={offset}' url_list.append(url_pagination) return url_list
We have completed half of the job now. We can run our program to gather basic details for all the listings in one place. We just need to provide the starting link, and things are about to get even more exciting.
Dynamic Pages
It takes some time for a detailed page to fully load. It takes around 3-4 seconds. Before that, we could only see the base HTML of the webpage without all the listing details we wanted to collect.
Sadly, the "requests" tool doesn't allow us to wait until everything on the page is loaded. But Selenium does. Selenium can work just like a person, waiting for all the cool website things to show up, scrolling, clicking buttons, filling out forms, and more.
Now, we plan to wait for things to appear and then click on them. To get information about the amenities and price, we need to click on certain parts.
To sum it up, here is what we are going to do:
Start up Selenium.
Open a detailed page.
Wait for the buttons to show up.
Click on the buttons.
Wait a little longer for everything to load.
Get the HTML code.
Let us put them into a Python function.
def extract_soup_js(listing_url, waiting_time=[5, 1]): """Extracts HTML from JS pages: open, wait, click, wait, extract""" options = Options() options.add_argument('--headless') options.add_argument('--no-sandbox') driver = webdriver.Chrome(options=options) driver.get(listing_url) time.sleep(waiting_time[0]) try: driver.find_element_by_class_name('_13e0raay').click() except: pass # amenities button not found try: driver.find_element_by_class_name('_gby1jkw').click() except: pass # prices button not found time.sleep(waiting_time[1]) detail_page = driver.page_source driver.quit() return BeautifulSoup(detail_page, features='html.parser')
Now, extracting detailed info from the listings is quite straightforward because we have everything we need. All we have to do is carefully look at the webpage using a tool in Chrome called the developer tool. We write down the names and names of the HTML parts, put all of that into a tool called "extract_element_data.py" and we will have the data we want.
Running Multiple Things at Once
Getting info from all 15 search pages in one location is pretty quick. When we deal with one detailed page, it takes about just 5 to 6 seconds because we have to wait for the page to fully appear. But, the fact is the CPU is only using about 3% to 8% of its power.
So. instead of going to 300 webpages one by one in a big loop, we can split the webpage addresses into groups and go through these groups one by one. To find the best group size, we have to try different options.
from multiprocessing import Pool with Pool(8) as pool: result = pool.map(scrape_detail_page, url_list)
The Outcome
After turning our tools into a neat little program and running it for a location, we obtained our initial dataset.
The challenging aspect of dealing with real-world data is that it's often imperfect. There are columns with no information, many fields need cleaning and adjustments. Some details turned out to be not very useful, as they are either always empty or filled with the same values.
There's room for improving the script in some ways. We could experiment with different parallelization approaches to make it faster. Investigating how long it takes for the web pages to load can help reduce the number of empty columns.
To Sum It Up
We've mastered:
Scraping Airbnb listing data using Python and Beautiful Soup.
Handling dynamic pages using Selenium.
Running the script in parallel using multiprocessing.
Conclusion
Web scraping today offers user-friendly tools, which makes it easy to use. Whether you are a coding pro or a curious beginner, you can start scraping Airbnb listing data with confidence. And remember, it's not just about collecting data – it's also about understanding and using it.
The fundamental rules remain the same, whether you're scraping Airbnb listing data or any other website, start by determining the data you need. Then, select a tool to collect that data from the web. Finally, verify the data it retrieves. Using this info, you can make better decisions for your business and come up with better plans to sell things.
So, be ready to tap into the power of web scraping and elevate your sales game. Remember that there's a wealth of Airbnb data waiting for you to explore. Get started with an Airbnb scraper today, and you'll be amazed at the valuable data you can uncover. In the world of sales, knowledge truly is power.
0 notes
Text
How to Use Restaurant And Liquor Store Data Scraping for Smarter Decisions?

Introduction
The food and beverage industry is evolving rapidly, making real-time insights essential for businesses to stay ahead of the competition. To make informed decisions, restaurants and liquor stores must keep track of market trends, pricing fluctuations, customer preferences, and competitor strategies. This is where Restaurant And Liquor Store Data Scraping becomes indispensable.
Through Restaurant Data Scraping, businesses can analyze menu trends, pricing structures, and customer reviews, allowing them to refine their offerings and stay relevant. Likewise, Liquor Store Data Scraping empowers retailers to assess product availability, pricing trends, and promotional strategies, helping them optimize inventory management and boost profitability. By leveraging web scraping, businesses can access accurate, real-time data to make strategic, data-driven decisions in an increasingly competitive market.
This blog delves into how businesses can utilize Restaurant And Liquor Store Data Scraping to gain actionable insights, fine-tune pricing strategies, and elevate the customer experience.
What is Restaurant And Liquor Store Data Scraping
Restaurant And Liquor Store Data Scraping is the automated process of extracting crucial information from various online platforms, including restaurant websites, liquor store portals, food delivery applications, and customer review sites.
This technique enables businesses to gather valuable insights such as:
Pricing trends for food, beverages, and alcoholic products.
Menu items and inventory availability across different locations.
Customer reviews and ratings to assess brand perception.
Competitor strategies and promotions for market benchmarking.
By utilizing advanced web scraping techniques, businesses can enhance their market intelligence, streamline operational efficiency, and make data-driven decisions to stay ahead of the competition.
The Business Value of Data Collection

Leveraging Restaurant Data Scraping strategically can provide valuable benefits that drive business growth and operational efficiency. Some of the key advantages include:
1. For Restaurant Owners and Managers
As a restaurant owner or manager, leveraging data-driven insights can significantly enhance your business strategy.
Market Gap Analysis : Understand unmet customer demands and introduce new menu items or services that cater to specific preferences.
Competitive Menu Pricing : Compare pricing structures across similar restaurants to ensure your menu remains competitive while maximizing profitability.
Trending Dishes Insights : Track emerging food trends and seasonal customer preferences to update your menu accordingly and attract more diners.
Reputation Monitoring : Analyze online reviews and feedback to gauge customer satisfaction and address potential concerns proactively.
Industry Staffing Trends : Gain insights into industry-wide staffing trends for better hiring, scheduling, and workforce management decisions.
By utilizing these insights, restaurant owners and managers can refine their strategies, enhance customer experiences, and drive long-term business growth.
2. For Liquor Store Operators
As a liquor store operator, staying ahead of the competition and adapting to shifting consumer demands is crucial. Here’s how data-driven insights can help you manage your business more effectively.
Pricing Trend Analysis : Gain insights into pricing fluctuations across various brands and categories to maintain competitive pricing and maximize margins.
Product Availability Tracking : Keep track of distribution patterns to ensure a well-stocked inventory and meet customer demand effectively.
Emerging Trend Identification : Stay ahead of market shifts by recognizing popular products before they peak in demand.
Regional & Seasonal Insights : Understand consumer behavior across locations and periods to optimize product offerings.
Inventory Optimization : Compare competitive offerings to ensure a well-balanced selection that attracts and retains customers.
These insights allow liquor store operators to make data-driven decisions that enhance sales, improve customer satisfaction, and drive business growth.
3. For Suppliers and Distributors
Suppliers and distributors play a critical role in the success of various businesses within the food service and retail sectors. They can make informed decisions to optimize their operations and strategies by leveraging data and insights.
Client Identification : Analyze menu profiles to determine which businesses align with your product offerings and market preferences.
Product Penetration Tracking : Assess how well your products are integrated across different establishments to refine distribution strategies.
Regional Pricing Analysis : Compare pricing trends across geographic regions to maintain competitiveness and adjust pricing strategies accordingly.
Seasonal Demand Forecasting : Track menu updates to anticipate shifts in demand, enabling proactive inventory planning and marketing efforts.
Utilizing these strategies can enhance suppliers' and distributors' operations, ensuring more precise decision-making and improved market performance.
4. For Market Analysts and Consultants
Market analysts and consultants are pivotal in helping businesses make informed decisions by providing valuable insights and data-driven strategies.
Comprehensive Market Reports : Conduct in-depth analyses of industry performance, competitive benchmarks, and consumer behavior to support strategic decision-making.
Expansion Opportunity Insights : Leverage data insights to pinpoint high-potential markets based on demographics, economic indicators, and demand trends.
Trend & Innovation Tracking : Monitor emerging technologies, consumer preferences, and competitive movements to stay ahead of market shifts.
Franchise Growth Monitoring : Analyze growth patterns, market penetration strategies, and competitive positioning to identify key opportunities and risks.
By utilizing these capabilities, market analysts and consultants can provide more accurate insights, helping businesses stay competitive and make strategic decisions based on data.
Key Data Points for Extraction
Extracting relevant data is crucial for Restaurant Menu Scraping to analyze offerings, pricing, and availability. Likewise, Liquor Price Data Extraction captures pricing trends and product details. Essential data points include:
1. Restaurant Data Points

Restaurant Data Points refer to crucial information that helps analyze and optimize restaurant operations, customer experience, and competitive positioning. These data points encompass various aspects, from menu details to pricing strategies and customer feedback.
Menu Items and Descriptions : This section includes dish names, descriptions, ingredients, and categorization (appetizers, entrées, etc.), along with nutritional details and seasonal offerings.
Pricing Informati onCovers regular prices, special deals like happy hour discounts, bundle offers, and a comparison of delivery vs. dine-in pricing.
Operational Details : Provides business hours, reservation systems, wait times, delivery radius, partnerships, and special services like catering and private events.
Customer Feedback : Analyzes star ratings, review sentiment, frequent mentions of service, food quality, ambiance, and management response patterns.
2. Liquor Store Data Points

Liquor store data points are essential for analyzing product availability, pricing trends, and customer engagement. These metrics help retailers and suppliers optimize inventory, implement competitive pricing strategies, and enhance consumer experiences.
Product Information : Brand names and categories, vintage/age details, origin information, special releases, and limited editions.
Pricing Structure : Regular pricing, promotional discounts, bulk purchase options, and loyalty program pricing.
Inventory Management : Stock availability, new product introductions, discontinued items, seasonal inventory patterns.
Customer Engagement : Review ratings, popular product mentions, service satisfaction metrics, and community engagement indicators.
Legal and Ethical Considerations

Before starting any data collection project, it is essential to understand the legal and ethical framework. When Scraping Liquor Store Pricing And Product Availability, businesses must ensure compliance with regulations. Similarly, Extracting Restaurant Reviews For Competitor Analysis should be done responsibly, following ethical data practices.
1. Legal Boundaries
Legal boundaries define the restrictions and regulations that govern data scraping practices to ensure compliance with laws and website policies.
Respect website Terms of Service agreements.
Avoid bypassing technical restrictions such as CAPTCHAs.
Do not access password-protected information.
Comply with data privacy laws like GDPR, CCPA, and similar regulations.
Be mindful of copyright implications when using extracted content.
2. Ethical Guidelines
Ethical guidelines establish responsible web scraping practices that minimize negative impacts on websites and ensure fair usage of collected data.
Apply reasonable rate limiting to prevent excessive server load.
Ensure proper identification of scraping activities in user agents.
Use collected data strictly for legitimate business purposes.
Anonymize sensitive information before storage or analysis.
Assess the competitive impact of your data extraction practices.
Practical Applications for Restaurants
Understanding How To Scrape Restaurant Data For Business Insights is the first step. The real advantage lies in applying these insights effectively:
Menu Engineering and Optimization : Analyzing competitor menus helps refine pricing, track trends, optimize categories, enhance descriptions, and boost upsells.
Competitive Positioning : Review analysis uncovers service gaps, customer needs, winning promotions, adequate staffing, and operational pitfalls.
Expansion Planning : Data-driven insights aid in competitive analysis, price mapping, cuisine gaps, service models, and demographic alignment.
Operational Benchmarking : Industry data sets standards for turnover rates, hours, staffing, pricing strategies, and seasonal adjustments.
How Web Data Crawler Can Help You?

We specialize in delivering tailored data collection solutions for the food and beverage industry. Our expertise in Restaurant And Liquor Store Data Scraping has empowered countless businesses to enhance their decision-making processes with data-driven insights.
Our Specialized Services:
Custom data collection strategies designed to align seamlessly with your unique business objectives.
Legally compliant are solutions for secure and ethical data extraction.
Real-time competitor monitoring systems to keep you ahead in dynamic markets.
Automated pricing intelligence dashboards for data-driven pricing strategies.
Review sentiment analysis and reputation monitoring to enhance brand perception.
Market expansion opportunity identification to uncover new growth avenues.
Custom reporting and visualization solutions for actionable business insights.
Our Service Advantage:
Industry-Specific Expertise : Our team possesses deep knowledge of the critical data points that fuel success in the food and beverage industry.
ble Infrastructure : Whether you operate a single outlet or manage a nationwide chain, our solutions adapt and expand to meet your evolving needs.
Legal Compliance : Our Web Scraping Services are built with a strong focus on legal and ethical best practices, ensuring responsible data collection.
Actionable Intelligence : We go beyond just providing raw data—we deliver meaningful insights that empower strategic decision-making.
Integration Capabilities : Our systems are designed for seamless connectivity with your existing business tools and workflows, ensuring smooth data integration.
Conclusion
The strategic use of Restaurant And Liquor Store Data Scraping unlocks new growth opportunities for businesses in the food and beverage industry. From optimizing menus to refining pricing strategies, data-driven insights are now essential for staying ahead in a competitive market.
As discussed, the applications of Liquor Store Data Scraping are vast, but success depends on a well-planned approach, technical expertise, and adherence to legal and ethical standards.
Are you looking to leverage Restaurant Data Scraping for your business? Contact Web Data Crawler for expert guidance. Our team will craft a tailored data strategy to help you gain a competitive edge. Don’t miss out—start making more intelligent, data-driven decisions today!
Originally published at https://www.webdatacrawler.com.
#RestaurantAndLiquorStoreDataScraping#RestaurantDataScraping#LiquorStoreDataScraping#ExtractRestaurantData#ExtractLiquorStoreData#RestaurantMenuScraping#LiquorPriceDataExtraction#ExtractingRestaurantReviews#CompetitorAnalysisScraping#ScrapingLiquorStorePricing#ProductAvailabilityScraping#WebScrapingServices#WebDataCrawler
0 notes
Text
Why Scrape Google Maps Now For Business Contacts Data?

Google Maps has around 1 billion active monthly users, making it a valuable resource for various businesses. When you search for a company, users get access to key essential details, such as the name, phone number, operating hours, address, website URLs, and reviews as required.
Businesses can highlight their products and services through their GMB (Google My Business) profile. With excellent market competition, improving your marketing strategies and generating better leads is crucial.
What Is Google Maps Scraping?
Google Maps scraping is simply gathering relevant information for analysis and strategies. Ethically extracting data is essential to avoid legal consequences and to protect brand reputation.
Any business's purpose for scraping Google Maps is different. It can include market research, lead generation, customer sentiment analysis, and potential locations for scaling. Automated data scraping for business contact details will give you a better chance to reach targets and improve market techniques.
Why Scrape Google Maps For Contact Details?
Google Maps is a repository of quality POI (Point-of-Interest) data, such as retail outlets, hotels, stores, and markets looking to make better decisions. Here are some benefits of getting real-time datasets of contact by scraping Google Maps:
Gain Business Information
Use efficient data scraping tools to analyze Google Maps' contact data, making connecting and generating leads easier. With accurate results, your business or services can make necessary changes to provide a smooth customer experience.
Location-Based Results
It becomes simple to organize the data and keep relevant information based on a particular location. Making it effortless to reach nearby hotels, bookshops, restaurants, and other interesting points as needed.
Geographic Analysis
Some businesses might require the contact information of their competitors to understand the accuracy and filters they have applied. Also, study urban development over time and in patterns to focus on traffic flow.
Lead Generation
Gather potential partners or customers' contact information, such as phone numbers, websites, and email addresses. Build targeted B2B and B2C contact lists to reach local businesses and improve your services.
Businesses Databases
Some people might maintain local business directories or market research, which require structured information regularly. With Google Maps scraping, you can filter data based on categories, operational hours, customer engagement, and popularity.
Customer Sentiments
By extracting contact information from Google Maps, businesses can look at positive trends in the market. With customer contact details, you can connect to understand their everyday issues and improvements to deliver better solutions.
What Are The Challenges And Ethical Measures Of Scraping Google Maps?
Gathering contact details from Google Maps provides multiple benefits, but that is impossible without handling the challenges and ethical concerns. Businesses need professional service providers to ensure they scrape data responsibly. Here are some ethical considerations you must consider:
Technical Challenges
Scraping business contacts data from Google Maps becomes complex due to some reasons:
Anti-Scraping Strategies
Google has integrated advanced anti-scraping strategies to prevent automated data extraction. These include IP blocking, rate limiting, and CAPTCHAs. It is essential to have scraping measures like headless browsers and rotating proxies.
Data Volume
Extracting bulk data consumes a lot of time, so you must ensure consistency and accuracy while scraping data, which requires additional support.
Data Structure
Google continuously updates its Maps interface, which can affect your scraping scripts and the accuracy of datasets. Maintain these scripts with technical expertise to meet the demands of the page structure.
Ethical Considerations
With ethical compliances, businesses also consider the moral implications of scraping contact details from Google Maps. Let us look at the segments you need to focus on:
Privacy
Even if the data is publicly available, some contact information may require consent to be scraped. Businesses should be responsible for avoiding exploiting sensitive information from the target platform.
Data Transparency
Companies should be transparent about gathering and utilizing data. This helps to avoid overwhelming small businesses by scraping data that is ethically allowed.
Legal Challenges
Scraping Google Maps data requires reviewing the target platform's legal concerns or business details.
Terms of Service
Google will explicitly ban unauthorized data scraping on its platforms. Violating the terms of services can result in legal consequences and spoil your brand reputation.
Data Security
Depending on your requirements, you should adhere to the laws before extracting data. Also, sometimes, even scraping customer reviews can lead to compliance issues.
What Are The Benefits Of Scraping Google Maps For Contact Details?
Scraping Google Maps for contact details of specific businesses is not just a strategy, it's a pathway to growth and improvement. The platform offers unparalleled opportunities to enhance operations, drive growth, and improve customer targeting, giving businesses a reason to be optimistic.
Below are the key benefits of scraping Google Maps to gather business contact information:
Sales Cycle Optimization
One of the best advantages of scraping data is maintaining a database for lead generation and outreach for the sales team. With these, businesses can:
Build targeted B2B and B2C contact lists depending on the location, industry, and business type.
Find potential clients, resellers, or partners in specific locations.
Optimize sales efforts by focusing on relevant business details.
Improve email marketing and cold-calling campaigns by reaching out to verified businesses.
Automating data scraping solutions will help businesses quickly expand their customer base.
Competitive Analysis
Understanding the competitors is essential for businesses to succeed in the market. Scraping Google Maps helps in analyzing:
Business categories and service areas that competitors target.
Pricing strategies are based on the solutions offered at various locations.
Analyze customer feedback and ratings to identify the pros and cons of businesses.
Figure out competitor locations and their geographical distribution.
Local Businesses
Companies that are dealing with business directories, industry databases, and local listing websites can use Google Maps scraping to gather filtered datasets, which will include:
Name, contact, and address of local businesses.
Website URLs and social media links for quality user engagement.
User ratings and reviews to make informed decisions.
Understand operating hours and service details to find a convenient time.
This information helps enhance online directors, power local search engines, and create updated business databases.
Plan Business Expansion
Extraction contact data from Google Maps gives you a clear picture of geographic expansion. Companies can use the location data to:
Find potential business partners and franchise opportunities.
Identify high-demand regions to build a strong customer base.
Optimize logistics strategies based on the business density at various locations.
Use the data to make informed decisions before opening new stores, enter new markets, and launch services.
Local Marketing Strategies
Digital marketers and local businesses help in running marketing campaigns with precise details and also:
Improve local SEO by optimizing your listings in real time.
Use geo-targeted advertising to engage with customers.
Send personalized marketing messages to potential clients.
This approach will boost conversion rates and enhance brand visibility with specific location datasets.
Summing It Up!
Scraping Google Maps for contact details offers excellent benefits, helping businesses with competitive analysis, local marketing, business expansion, and lead generation. Gathering data ethically, such as phone numbers, websites, reviews, and websites, helps build targeted sales.
This approach helps deal with business directories, customer experience, and location-based decisions for service providers. With professionals, you can ensure compliance with privacy laws and Terms of service to maintain credibility.
Resource: https://www.websitescraper.com/how-to-scrape-business-contact-details-from-google-maps.php
0 notes