#HTTrack
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
How to Back up a Tumblr Blog
This will be a long post.
Big thank you to @afairmaiden for doing so much of the legwork on this topic. Some of these instructions are copied from her verbatim.
Now, we all know that tumblr has an export function that theoretially allows you to export the contents of your blog. However, this function has several problems including no progress bar (such that it appears to hang for 30+ hours) and when you do finally download the gargantuan file, the blog posts cannot be browsed in any way resembling the original blog structure, searched by tag, etc.
What we found is a tool built for website archiving/mirroring called httrack. Obviously this is a big project when considering a large tumblr blog, but there are some ways to help keep it manageable. Details under the cut.
How to download your blog with HTTrack:
Website here
You will need:
A reliable computer and a good internet connection.
Time and space. For around 40,000 posts, expect 48 hours and 40GB. 6000 posts ≈ 10 hours, 12GB. If possible, test this on a small blog before jumping into a major project. There is an option to stop and continue an interrupted download later, but this may or may not actually resume where it left off. Keep in mind that Tumblr is a highly dynamic website with things changing all the time (notes, icons, pages being updated with every post, etc).
A custom theme. It doesn't have to be pretty, but it does need to be functional. That said, there are a few things you may want to make sure are in your theme before starting to archive:
the drop down meatball menu on posts with the date they were posted
tags visible on your theme, visible from your blog's main page
no icon images on posts/notes (They may be small, but keep in mind there are thousands of them, so if nothing else, they'll take up time. Instructions on how to exclude them below.)
Limitations: This will not save your liked or private posts, or messages. Poll results also may not show up.
What to expect from HTTrack:
HTTrack will mirror your blog locally by creating a series of linked HTML files that you can browse with your browser even if tumblr were to entirely go down. The link structure mimics the site structure, so you should be able to browse your own blog as if you had typed in the url of your custom theme into the browser. Some elements may not appear or load, and much of the following instructions are dedicated to making sure that you download the right images without downloading too many unnecessary images.
There will be a fair bit of redundancy as it will save:
individual posts pages for all your tags, such as tagged/me etc (If you tend to write a lot in your tags, you may want to save time and space by skipping this option. Instructions below.)
the day folder (if you have the meatball menu)
regular blog pages (page/1 etc)
How it works: HTTrack will be going through your url and saving the contents of every sub directory. In your file explorer this will look like a series of nested folders.
How to Start
Download and run HTTrack.
In your file directory, create an overarching folder for the project in some drive with a lot of space.
Start a new project. Select this folder in HTTrack as the save location for your project. Name your project.
For the url, enter https://[blogname].tumblr.com. Without the https:// you'll get a robots.txt error and it won't save anything.
Settings:
Open settings. Under "scan rules":
Check the box for filetypes .gif etc. Make sure the box for .zip etc. is unchecked. Check the box for .mov etc.
Under "limits":
Change the max speed to between 100,000 - 250,000. The reason this needs to be limited is because you could accidentally DDOS the website you are downloading. Do not DDOS tumblr.
Change the link limit to maybe 200,000-300,000 for a cutoff on a large blog, according to @afairmaiden. This limit is to prevent you from accidentally having a project that goes on infinitely due to redundancy or due to getting misdirected and suddenly trying to download the entirety of wikipedia.
Go through the other tabs. Check the box that says "Get HTML first". Uncheck "find every link". Uncheck "get linked non-html files". If you don't want to download literally the entire internet. Check "save all items in cache as well as HTML". Check "disconnect when finished".
Go back to Scan Rules.
There will be a large text box. In this box we place a sort of blacklist and whitelist for filetypes.
Paste the following text into that box.
+*.mp4 +*.gifv -*x-callback-url* -*/sharer/* -*/amp -*tumblr.com/image* -*/photoset_iframe/*
Optional:
-*/tagged/* (if you don't want to save pages for all your tags.)
-*/post/* (if you don't want to save each post individually. not recommended if you have readmores that redirect to individual posts.)
-*/day/* (if you don't feel it's necessary to search by date)
Optional but recommended:
-*/s64x64u*.jpg -*tumblr_*_64.jpg -*avatar_*_64.jpg -*/s16x16u*.jpg -*tumblr_*_16*.jpg -*avatar_*_16.jpg -*/s64x64u*.gif -*tumblr_*_64.gif -*avatar_*_64.gif -*/s16x16u*.gif -*tumblr_*_16.gif -*avatar_*_16.gif
This will prevent the downloading of icons/avatars, which tend to be extremely redundant as each image downloads a separate time for each appearance.
Many icons are in .pnj format and therefore won't download unless you add the extension (+*.pnj), so you may be able to whitelist the URLs for your and your friends' icons. (Honestly, editing your theme to remove icons from your notes may be the simpler solution here.)
You should now be ready to start.
Make sure your computer doesn't overheat during the extremely long download process.
Pages tend to be among the last things to save. If you have infinite scroll on, your first page (index.html) may not have a link to page 2, but your pages will be in the folder.
Shortly after your pages are done, you may see the link progress start over. This may be to check that everything is complete. At this point, it should be safe to click cancel if you want to stop, but you run the risk of more stuff being missing. You will need to wait a few minutes for pending transfers to be competed.
Once you're done, you'll want to check for: Files without an extension.
Start with your pages folder, sort items by file type, and look for ones that are simply listed as "file" rather than HTML. Add the appropriate extension (in this case, .html) and check to see if it works. (This may cause links to this page to appear broken.)
Next, sort by file size and check for 0B files. HTMLs will appear as a blank page. Delete these. Empty folders. View files as large icons to find these quickly.
If possible, make a backup copy of your project file and folder, especially if you have a fairly complete download and you want to update it.
Finally, turn off your computer and let it rest.
138 notes
·
View notes
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
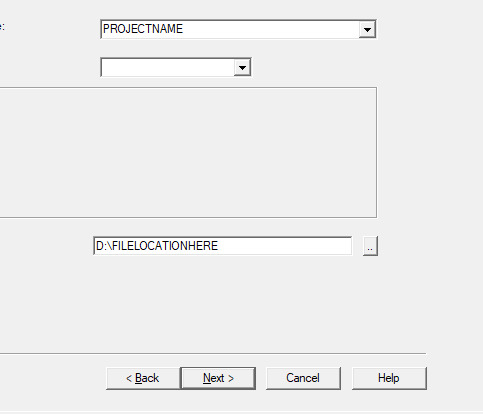
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
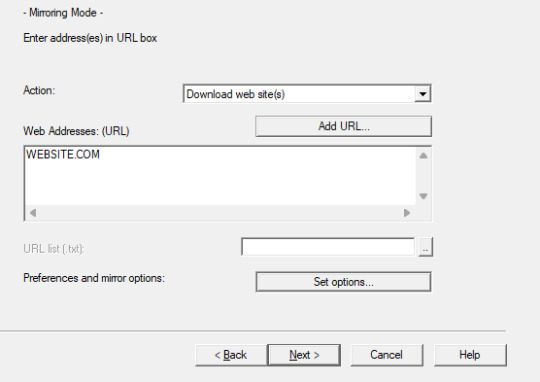
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
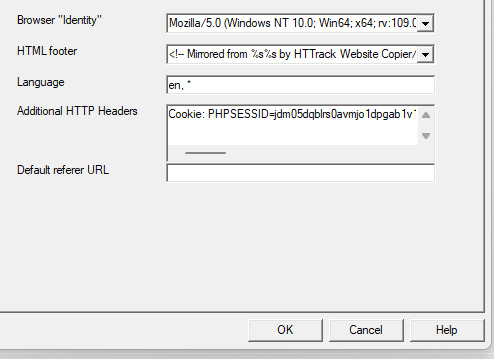
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
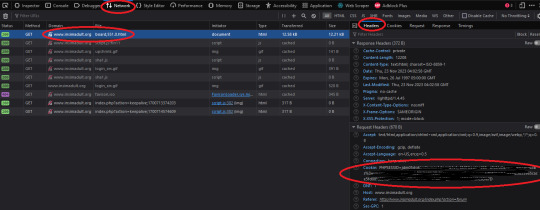
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
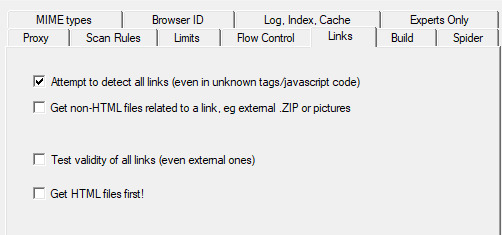
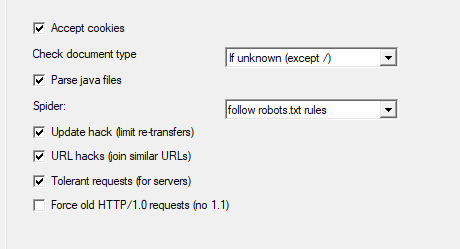
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
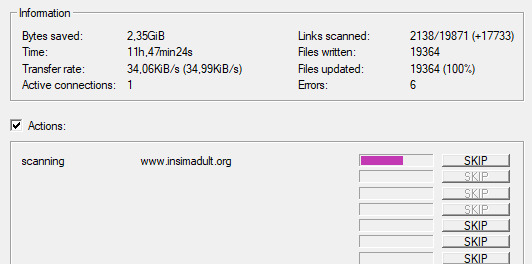
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
40 notes
·
View notes
Text
Ah sick.
I found some software to mirror a website locally with all associated files (HTTrack).
Time to preserve Digimon Seekers before they take it down lol
4 notes
·
View notes
Text
There is a small setting in HTTrack website downloader that is set by default to download files from the server at 25kb per second (that's kilobytes not megabytes)
because this software was built in 2007.
it's been 7 hours to get 600mb and I just now thought "oh I wonder why the speeds are throttled?" Not that I have great internet to begin (900k down 75k up if the other members of the household aren't also online).
but for real: mirror > modify options > limits > max transfer rate set to something less tiny.
------------------
As for downloading pictures from fandom wikis go to https:// NAMEHERE .fandom.com/wiki/Special:MIMESearch/image/jpeg?limit=500 and open a new page for each 500 files (replace the URL above to png if there are lots of pngs)
you'll want the firefox extensions:
open multiple urls (copy and paste the source code of the pages)
tab image saver (saves each image then closes the tab)
and if your internet is naf like mine, tab reloader
3 notes
·
View notes
Text
hey. pirate things. don’t know how? you can learn. people can teach you. it’s ok to ask. but seriously, pirate things. download things you love. go buy a big ass hard drive and download everything you have ever loved. download instructional manuals. download recipes. download websites (use httrack for this). download comment threads. save it all.
these things will not be here one day. in your lifetime. in my lifetime. these are all temporary constructs. and one day, someone will need to know what temperature to cook something to. one day, someone will need to identify that plant. one day, someone will need to know how this light switch works.
and the only way that this knowledge gets passed on is through you. youtube will be gone one day. the internet will be gone one day. but the knowledge we have now can live forever if you start saving it and start treating it like the finite resource it is.
knowledge is a beautiful privilege and we will not have it in such abundance forever. those days are closer than they are far. download it all. save it all. share it and spread it. it’ll be the only way that it makes it through the storm with us.
742 notes
·
View notes
Text



a blog for editing resources, including overlays, cutouts, line stickers, psds, tutorials, etc. run by @/grimescum. how to request
please at least skim over everything under the cut. if you dont, i reserve the right to be a little bit of a bitch about it
( ! ) message board –
jan 14 📌 updated tag list!
jan 4 📌 inbox & requests back open!
📌 donate to my ko-fi if you'd like! ♡
( ! ) content – with the exclusion of graphics taken from picsart and occasionally pinterest, i only upload raw, unedited graphics to be used in edits.
– the same generally applies to images of characters; i don't upload cutouts of fanart unless the artist has given permission for their artwork to be reuploaded
– my crediting can be a little wonky at times, but i generally don't credit pictures sourced from large companies such as walmart.
– this blog has no queue, i post whenever i feel like it
( ! ) interaction – spam likes and reblogs are perfectly fine in moderation!! if you're going through an entire tag and liking/reblogging everything you see, i'll block you temporarily
– credit for my work is not necessary, but it is advised to credit the original creators for their work if provided.
– i block freely, mostly according to my main blog's dni. don't be stupid. this also includes r4dqueers and pr0ship.
( ! ) other asks – i read them all! kind comments are part of what keeps me going, so regardless of how quickly i respond to them, know i appreciate every single one deeply.
– you can also ask for a promo!
( ! ) requests – i take requests for finding pngs of or based on whatever you give me, be it a character, prompt, aesthetic, image, etc.
– i'm selective about what i choose to do, so please don't be upset if i decide not to. it's nothing against you personally.
blacklist, media i won't do or will be very picky about: d/smp or related, genshin impact or anything by hoyoverse, kp0p, harry p0tter, p0rn (because of guidelines)
whitelist, media i will do no matter what: any of the fandoms im into!
– i'll also try to find the source of any image you send to me if you can't or don't feel like doing it yourself.
– i have autism, so being as specific as you can helps a ton! there is a difference between edits "based on" and "of" a character to me. also, if you want a certain kind of graphic (ie. a drawn divider rather than an image cutout), please do clarify that
( ! ) tag directory – under construction! a new tagging system is coming soon. for now, please refer to my rentry.
edited by me, fandom, inspo, made by me, op talks, promos, psds, reblogs, resources, tutorials
backgrounds & images, banners/headers, basics, borders (cutouts), borders (drawn), colorable, cutouts, digital scrapbooking, digital stickers, dividers, drawings, fonts, frames (cutouts), frames (drawn), gifs, icons, masks, overlays, patterns, templates/bases, textures
from canva, from flaticon, from google drive, from line, from picmix, from picsart, from pinterest, from pngwing, from roblox
aesthetics
( ! ) miscellaneous links – other links worth putting here.
archive this blog! internet archive (no dl) grab-site (dl) archive bot (dl) httrack (dl) imgdownloader (no dl)
posts 99 resource sites my psds
more resources eros' resources pluto's resources
my resource drive (decode from base64 to get link) aHR0cHM6Ly9kcml2ZS5nb29nbGUuY29tL2RyaXZlL2ZvbGRlcnMvMUxDUGEyV3JnZFpVdHFvNVVPeVZYLTJCWHpJTnVZQVJD
#!! .rblgs#!! .edited by me#!! .inspo#!! .tutorials#!! .psds#!! .op talks#!! .made by me#ℹ️ : masks#ℹ️ : borders (drawn)#ℹ️ : overlays#ℹ️ : cutouts#ℹ️ : digital stickers#ℹ️ : frames (cutouts)#ℹ️ : dividers#🔎 : from pinterest#🔎 : from picsart#🔎 : from canva#🔎 : from line#🔎 : from flaticon#ℹ️ : digital scrapbooking#ℹ️ : textures#❓︎ : text
34 notes
·
View notes
Note
might be a dumb question sorry, but is there a way to easily download the entirety of the limbus storylogs for offline use?
its open source, you can download it or fork it from github
if you arent tech-savvy enough to do all that, either saving the entire page one by one as a pdf should work (especially in terms of cross-device compatibility), theres also a lot of website copier/downloaders floating around online.. ive used httrack but it seems theres better alternatives
i dont use javascript at all iirc so they should all work fine no matter which one you decide to use
3 notes
·
View notes
Text
HTTrack Website Copier
https://github.com/xroche/httrack
2 notes
·
View notes
Note
Hey what do you use to archive Tumblr blogs ? I would Absolutely love to know,i have tons of blogs that needs back up
I have only used it once so far but I used HTTrack! It's very simple and straightforward, it saves the site as an html file you can just view in browser :] there are plenty of other ones if you look for them too if this doesn't work https://www.httrack.com/
3 notes
·
View notes
Text
Also want to sound an alarm that Arizona has passed a simular bill. HB2112. Thus putting the site and database itself in jeopardy. I suggest starting to try and archive as much as possible by using something like this: HTTrack is a free and open source web crawler you can use to download entire websites. By default, HTTrack arranges the downloaded site by the original site's relative link-structure. Once you download a website with HTTrack, you can browse it in your preferred web browser.
hi. why is nobody talking about the porn ban in north carolina? the PAVE act is a bill that was passed back in september 2023 (came into law january 1st 2024) that effectively bans users from viewing websites hosting adult content without age verification. (link to the bill)
"-the act legally requires commercial ventures to verify users’ ages if a company “knowingly and intentionally publishes or distributes material harmful to minors on the internet from a website that contains a substantial portion of such material.”
In order to do so, North Carolina requires these sites to either use “a commercially available database that is regularly used by businesses or governmental entities for the purpose of age and identity verification,” or utilize “another commercially reasonable method of age and identity verification.” Companies are not allowed to hold records on any personally identifying information used to confirm users’ ages.
Additionally, North Carolina offers residents the right to a lawsuit if a site is found to record user identifying information, or if a minor’s parent or guardian finds that a website allowed their child to access a site purposefully hosting material “harmful to minors.”" obviously we don't want these websites having our IDs, but sites like e621 and pornhub just straight up aren't asking for them either- blocking their service to the state in it's entirety instead. even beyond the restriction of adult websites, obviously as the 'queerest place on the net' we can see how "material that is harmful to minors" is not just intentional vague wording, but a massive red flag. even if you dont care about the porn- which you should, this is a massive rights violation. how long until 'harmful material' is expanded to include transgender people? same-sex relationships? anything lgbtq? this is a serious fucking problem and it opens the door to hundreds of potentially worse bills that extrapolate on the same concept.
i have no idea what to do to fight it, but if someone smarter than me could add links to representatives or something, that would be awesome.
i'm also going to tag a few people to get this post out: @polyamorouspunk @safety-pin-punk @doggirlbreasts (i have no idea who else to tag, if any of you can think of someone who can help this post get out there, please tag them!)
#poltiics#e621#authoritarianism#censorship#america is a hellscape#art news#digital aritst#queer artist#adult artist#HB2112
4K notes
·
View notes
Text
Comment consulter vos sites web préférés sans connexion Internet sur Android ?
On est tous déjà passés par là : vous êtes dans un train, en avion, ou même dans un petit village perdu sans réseau, et vous aimeriez bien lire cet article intéressant ou consulter un site web. Pas de panique, c’est totalement possible grâce à ce qu’on appelle un aspirateur de site web ! Qu’est-ce qu’un aspirateur de site web ? C’est une application qui va télécharger sur votre smartphone Android une copie locale d’un site internet, avec ses pages et images, pour que vous puissiez le consulter même sans connexion Internet. Très pratique pour vos voyages, pour économiser vos données mobiles, ou juste pour avoir vos infos préférées à portée de main, partout. L’application Android idéale : HTTrack HTTrack est une appli simple et efficace, qui fait exactement ça. Elle est un peu comme la version mobile d’un logiciel très connu sur PC, et elle vous permet de : Télécharger plusieurs sites web en même temps Choisir le niveau de profondeur (combien de pages liées vous voulez récupérer) Accéder à vos sites favoris hors ligne, images incluses (attention, les vidéos ne sont pas sauvegardées) Le fonctionnement est simple : dès que vous êtes connecté à Internet, HTTrack télécharge les pages que vous avez paramétrées. Puis, dès que vous êtes hors ligne, vous pouvez les consulter tranquillement, sans aucune interruption. Pourquoi utiliser HTTrack ? Pratique en voyage : Lire vos articles préférés dans le train ou l’avion sans connexion. Économiser vos données mobiles : Téléchargez une fois, lisez plusieurs fois sans consommer de data. Sauvegarder des contenus importants : Pour les étudiants, chercheurs ou curieux qui veulent garder des infos accessibles partout. Comment commencer avec HTTrack ? Téléchargez l’application HTTrack sur le Google Play Store . Ouvrez l’application et créez un nouveau projet. Saisissez l’URL du site web que vous souhaitez aspirer. Choisissez le niveau de profondeur (plus c’est élevé, plus de pages seront téléchargées, mais attention à la taille !). Lancez le téléchargement et laissez l’appli faire le boulot. Une fois terminé, vous pourrez accéder au contenu dans l’appli, même sans réseau. Quelques astuces supplémentaires Soyez raisonnable dans la taille : Aspirer un site entier peut prendre beaucoup de place et de temps, privilégiez les sections ou pages importantes. Respectez les sites web : Certains sites interdisent l’aspiration pour protéger leurs contenus, pensez à vérifier leurs conditions d’utilisation. Mettez à jour régulièrement : Pensez à rafraîchir vos sites téléchargés quand vous avez du Wi-Fi pour garder le contenu à jour. Alternative à HTTrack Si vous recherchez un outil un peu différent, vous pouvez également essayer ces applications qui permettent de sauvegarder des articles pour une lecture hors ligne, mais uniquement sous forme d’articles, sans le reste du site. HTTrack reste néanmoins la solution la plus complète pour aspirer des sites entiers.
0 notes
Text
I'm currently using a tool called HTTrack to copy the MDN reference website at developer.mozilla.org, and also reading about how to set up a webserver on localhost Why am I like this… Because I expected my internet might get cut today, I wanted to have a way to read the MDN reference offline to make my website development easier I expected that to be an easy fix but the firefox addon Redirector, that would allow me to redirect traffic from developer.mozilla.org, can apparently not redirect from https://… to file:///… so instead of working on my website I've spent all day just trying to find a way to read the documentation what is my life
0 notes
Text
SingleFile browser extension (Firefox, Firefox Mobile, Chrome, Safari, and Edge) https://github.com/gildas-lormeau/SingleFile?tab=readme-ov-file#install HTTrack desktop/mobile application (Windows, Linux, Android) http://www.httrack.com/page/2/en/index.html If you're on Linux you can also use the wget command in place of HTTrack. https://social.lol/@klymilark/113968991391681502
0 notes
Text
As far as gathering evidence, consider downloading a backup of your blog before anything happens. That way if they cite specific posts you'll have a copy to counter the claims.
If I can find the one I've used previously, I'll edit it into this post. Your blog WILL have to be unlocked for it to work, but you can lock it again when the process is finished.
EDIT: found it, HTtrack. I haven't used it in almost two years (backed up my twitter before deleting) but I remember it being fairly simple.
so matt's absolutely giving scorched earth orders behind the scenes right. Not only are publically visible transfems dropping like flies, but every third person who musters up the audacity to comment negatively on Staff or Matt about this vanishes fucking instantly
56K notes
·
View notes
Text
How to Download W3Schools Offline for 2024
W3Schools is one of the most popular online resources for learning web development, offering tutorials on various topics like HTML, CSS, JavaScript, Python, and more. For learners who want to access these tutorials without an internet connection, downloading W3Schools for offline use is a great option.
To download W3Schools offline, there are several methods you can use. One option is using a website downloader tool like HTTrack or WebCopy, which can download the entire website onto your local machine. These tools allow you to store a copy of the tutorials, examples, and reference materials from W3Schools and access them at any time without needing an active internet connection.
However, it's essential to be cautious when using third-party tools. Always make sure that you're following the website's terms of service and not violating any copyrights. Since W3Schools is a free educational resource, it’s important to use its content responsibly and avoid misuse.
Another alternative is looking for mobile apps or PDF compilations of W3Schools tutorials, which are sometimes offered by external developers. These can provide an easy way to access lessons on-the-go, without requiring full website downloads.
Overall, downloading W3Schools offline for 2024 will help you continue your learning journey even when you're not connected to the internet.
#web3#programming#science#coding#software engineering#html#html5 css3#learn to code#frontend#frontenddevelopment
1 note
·
View note
Text
reminder: you can use HTTrack to download backup copies of entire websites that are then, in turn, accessible offline directly on your computer. it includes all of the links, images, files, etc. it doesn't work for every website, but still very useful.
24 notes
·
View notes