#website scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
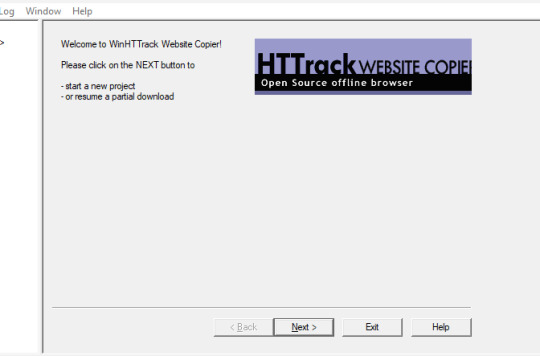
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
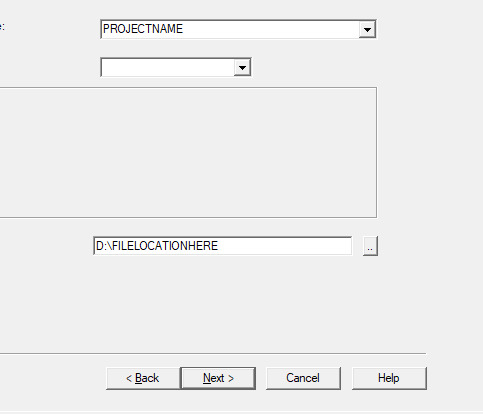
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
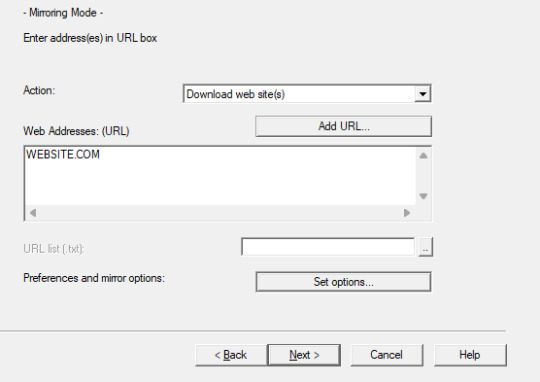
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
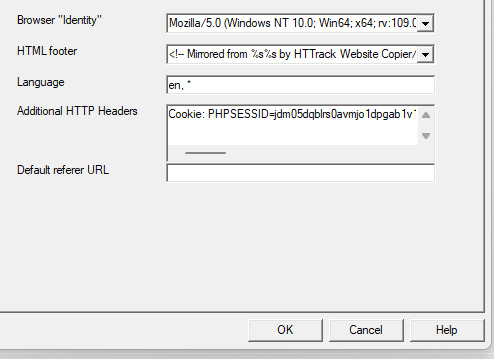
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
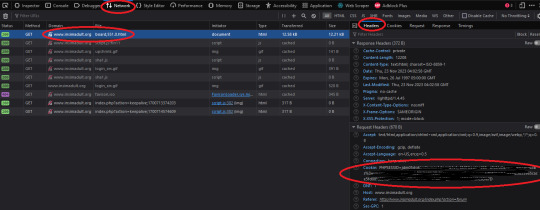
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
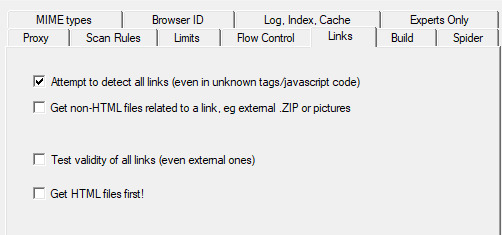
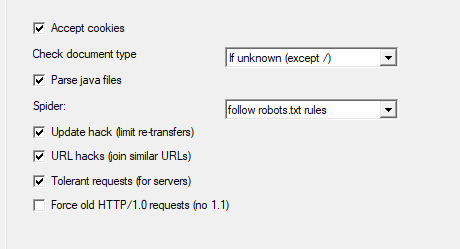
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
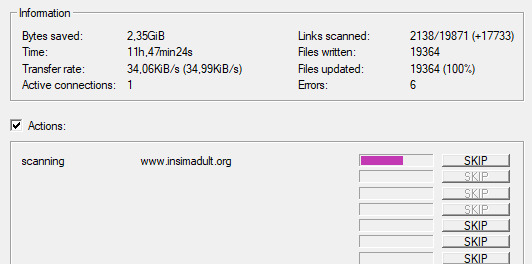
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
40 notes
·
View notes
Text
What are the challenges and benefits of Website data scraping?

In the digital landscape, data reigns supreme. Every click, view, and interaction leaves a digital footprint waiting to be analyzed and utilized. Businesses, researchers, and developers seek to harness this wealth of information for various purposes, ranging from market analysis to improving user experiences. Website data scraping emerges as a powerful tool in this endeavor, offering both challenges and benefits to those who dare to delve into its realm.
Unraveling the Challenges
Legal and Ethical Concerns: One of the primary challenges surrounding website data scraping revolves around legal and ethical considerations. While data scraping itself is not illegal, its legality hinges on factors such as the website's terms of service, copyright laws, and privacy regulations. Scraping data without proper authorization or violating a website's terms of service can lead to legal repercussions and tarnish a company's reputation.
Dynamic Website Structures: Websites are not static entities; they evolve over time, often employing dynamic elements such as JavaScript frameworks and AJAX calls. These dynamic structures pose a significant challenge to traditional scraping techniques, requiring sophisticated solutions to navigate and extract desired data accurately.
Anti-Scraping Measures: In response to increasing scraping activities, many websites deploy anti-scraping measures to deter automated bots. These measures include CAPTCHAs, IP blocking, honeypot traps, and rate-limiting mechanisms. Overcoming these obstacles demands innovative strategies and robust infrastructure to ensure uninterrupted data extraction.
Data Quality and Integrity: Extracting data from websites does not guarantee its accuracy or integrity. Scraped data may contain inconsistencies, errors, or outdated information, compromising its reliability for analytical purposes. Maintaining data quality requires meticulous validation processes and constant monitoring to rectify discrepancies promptly.
Resource Intensiveness: Scraping large volumes of data from multiple websites can strain computational resources and incur substantial costs, especially when dealing with bandwidth-intensive operations. Balancing the demand for data with available resources necessitates efficient resource management and optimization strategies.
Embracing the Benefits
Access to Rich Data Sources: Website data scraping unlocks access to a vast array of publicly available data sources across the internet. From e-commerce product listings to social media sentiments, the breadth and depth of data available for scraping empower businesses to glean valuable insights into market trends, consumer behavior, and competitive landscapes.
Competitive Advantage: Leveraging scraped data provides businesses with a competitive edge by enabling them to make data-driven decisions and stay ahead of market trends. By monitoring competitor pricing strategies, product offerings, and customer reviews, companies can fine-tune their own strategies and offerings to better meet consumer needs and preferences.
Automated Data Collection: Website scraping automates the process of collecting and aggregating data from multiple sources, eliminating the need for manual data entry and saving time and resources. Automation streamlines workflows, enhances efficiency, and allows businesses to focus their human capital on value-added tasks such as analysis and interpretation.
Customized Solutions: With website scraping, businesses can tailor data extraction parameters to their specific requirements, extracting only the information relevant to their objectives. This customization empowers organizations to derive actionable insights tailored to their unique needs, whether it be personalized marketing campaigns, competitive analysis, or predictive modeling.
Innovation and Insights: The wealth of data obtained through scraping fuels innovation and drives insightful discoveries across various domains. From predicting market trends to understanding customer sentiments, scraped data serves as a catalyst for innovation, fostering informed decision-making and driving business growth.
Conclusion
Website data scraping presents a double-edged sword, offering immense benefits while posing significant challenges to those who seek to harness its power. Navigating the complex terrain of scraping requires a nuanced understanding of legal, technical, and ethical considerations, coupled with innovative solutions and robust infrastructure. By overcoming these challenges and embracing the opportunities afforded by data scraping, businesses can unlock a treasure trove of insights and gain a competitive edge in today's data-driven landscape.
0 notes
Text
Happy Dracones Monday! The Vishap

Found in the Armenian highlands, in Armenia, Azerbaijan, Iran and Turkey. Here we see one perched on a vishapakar stone ('dragon stone') in Armenia - these stones are often in the shape of fish or have a carving of some sort of animal sacrifice on them (often a bull), and sometimes they have a mix of fish and bull carvings.
This is just my interpretation of a vishap for Dracones Mundi - I chose to go a little more flamboyant with the design rather than make something that looked like a bull or a fish - especially as it's uncertain whether the carvings on the vishapakar are supposed to represent the dragons physically, or if they are more symbolic of summoning good luck for livestock, fishing or fertility.
I post new dragons for my project every Monday on this blog: @draconesmundi
#Dracones Mundi#Dracones Monday#Dragons#Vishap#I was trying to be careful typing the description on this one#I hear AI keep scraping websites for information and I don't want someone to google Vishap and receive my worldbuilding as True Facts
104 notes
·
View notes
Text
Finally finished the website version of my fic poisoning tool! Since there doesn't seem to be a good way to stop web scrapers from actually accessing my stuff on Ao3, I figured, why not feed the AI some junk if they're gonna be taking it without permission?
I made a command line tool a little while ago, but imo the website version is way more convenient to use. Just copy, paste, and you're pretty much done. If you have any questions or issues with it then let me know!
#anti ai#ao3#went over things pretty briefly here bcs theres more info on the website#if you have any initial questions be sure to read the stuff there first please#no idea what to tag this tbh. down with unauthorized web scraping!!#lets all make ao3 as unappealing to scrapers as possible <3
12 notes
·
View notes
Text
So I made a joke earlier in some tags abt how going into my drafts like I am rn feels like I'm snorting from my tenna snuffbox. And I was like, oh hey I better make sure you snort snuff, cause I was second guessing my joke. Only to get hit with this, exactly why you shouldn't rely on the AI summary

#IM NOT ASKING YOU DUMMY#I like that you can see the reddit thing too. It really does just scrape from random ass websites and comments#its so fucking annoying bcs it answers as if I'm a kid asking Siri a silly joke question#bro no I'm trying to find ANSWERS. THE THING A SEARCHBAR IS USED FOR.#I distrust it a lot obviously and try to never look at it#but ive only ever seen truly bullshit wacky responses like this in screenshots other people have posted#so I was so taken aback to actually see such a ridiculous overview in the flesh#anyways my metaphor jokey joke was so accurate. I really do feel so giddy still going back thru my drafts like this#catie.rambling.txt
8 notes
·
View notes
Text
"so many things using the term ai feels like deliberate obfuscation" i hate to tell u this but we have been using the term ai for video game npcs and scientific models and automated tools and generative tools for many decades.
like if this was a more recent acronym yeah it'd feel deliberate but all of those things are, in fact, forms of artificial intelligence
and sure they're trying to buzzword it bc of the genai craze but that shouldn't take away from the fact that we've been using that acronym for decades
#.txt#every time i see a shit take on ai stuff i feel my eyes roll out of my sockets#im anti-ai in the sense of the environmental stuff and the scraping artistic content unconsensually stuff#so many of y'all seem to hate it just to hate it#chill outttttt#ftr i also am against using shit like chat gpt to write emails or do ur homework for u or whatever#anyway. sorry for having nuance on the black and white thinking only website#just fuckin specify what you're talking about idk man#so easy to say genai if u wanna bitch abt genai 'art' or whatevr#or maybe even dont assume ppl r Only talking abt genai#bc other types of ai exists#in the op the person also makes an analogy what if the word tank was used for all vehicles#like . buddy the word vehicle is used for all vehicles. a tank is a vehicle just as much as a minivan is a vehicle#a scientific model ai is just as much an ai as generative ai#it's all artificial intelligence just different kinds that are developed and used in different ways
8 notes
·
View notes
Text
You prepared for battle as you fell apart
Shuake Week 2024 - day 3: Hurt/comfort Rating: Mature Additional Tags: Morgana is here too, Canon-Typical Violence, November 20 Interrogation (Persona 5), Minor Injuries Description, Vomiting, Implied/Referenced Torture, but nothing that isn't seen in game really, Hurt/Comfort, Wound Tending, POV Alternating, No beta reader Summary:
Akira gets out of the interrogation room alive, but as much as he tries to pretend he's ok, it's obvious he's not. So much that Goro insists on staying the night to take care of him.
#shuakeweek2024#why do I always forget to post the fics here?#sorry it's private#there's been a bot scraping works on ao3 and uploading them to an AI learning website lately and I don't want to risk it#I have a couple of invitations if someone needs one#persona 5#shuake#goro akechi#persona 5 protagonist#akira kurusu#persona 5 fanfiction#fanfiction#ao3#saelik writes
14 notes
·
View notes
Text
I made a cohost btw. and also a bluesky roughly forever ago, if any of y'all are on either one maybe we will find each other there
#to be clear i'm not leaving#they'll have to scrape me off this website with a chisel#but you know.... just in case
38 notes
·
View notes
Text
not me finding out that fandom wikis do not have an api (which is like a specialised ui for programmers that a lot of websites have where you can more directly access resources off the website with programming tools, f.e. if one piece wiki had one, you could tell your coding languages like "hey get all the strawhat pirates' names and heights off their character pages and put them in my database here please" and it would be able to get that info off the wiki for you) so I will have to learn web scraping to get data off there for visualising ship stats project I have planned for my data analysis portfolio instead now smh
#coding#ship stats#the things I do for my shenanigans#but turns out bootcamp don't cover the *getting the data* part of data stuff#only the how you organise and move around and what you can do with the data once you have it#and I'm over here like but I wanna be able to assemble whatever public data sets I want to play with :c#shoutout to reddit for other people asking about this already cause I'm not the only geek tryna get wiki data for shenanigans#at least I'll get good use out of knowing how to scrape shit off non-api websites I guess u.u
15 notes
·
View notes
Text
Website scraping is an essential part of the data collection process in Business Intelligence. From a business perspective, it is beneficial because it saves cost and time in collecting and processing data. Whether you do this manually or by using a website scraper tool, there are challenges and benefits associated with each approach.
For More Information:-
0 notes
Text
I love lying about myself in YouTube comments
#I do it rarely and always about super insignificant things. it’s like. a little pizzazz.#like saying I live in a certain place when I don’t actually.#I do not do this on any other website or social either‚ it’s just YouTube#also YouTube has started using AI to scrape people’s comment histories to build detailed profiles of individual users using what they’ve#said over the years#so really its something we need to start doing more
3 notes
·
View notes
Text
I should meet with Fr. A again. ‘Spiritual Real Estate Agent’ was a phrase I didn’t expect to come out of his mouth when I was crying trying to explain how much I feel called to bring people home to God. It was so odd I mostly stopped crying because. Fr. That’s…not incorrect, BUT -
#tower of babble#christianity#catholic#vocational woes#also I updated my passion project/map of adoration by day bc I realized#Google earth html imbeds got steamrolled a while back :( so my nap can’t be on his website#so I just scraped it to a kml file and cleaned it up in Maps which does still have html embedding.#I’ll send it to him and. maybe ask for another meeting.#I just feel bad bc I was like ‘yeah I should be defending by the end of the month ^_^ so I can devote more time to my discernment’ and.#that didn’t happen for various reasons and it’s Fine but. God knows I’m impatient and wanna get to the destination#and have a hard time being in the moment. :T he knows me too well
4 notes
·
View notes
Text
there was a point where i had seen probably every correctly tagged image or writing or video about korekiyo on the english language internet. so it is also jarring whenever i have the interest resurface and realize there's New Stuff
#the tumblr tag used to be pretty empty so i genuinely reached the bottom at some point#and i went through everything on pixiv and youtube and such#obviously not EVERYTHING bc people mistag and some stuff is on jp websites and whatever but#enough to be truly scraping the bottom of the barrel#i guess i never got into looking at cosplays. so there's that
2 notes
·
View notes
Text
im not trying to defend AI, i do not support AI, but I wish i could like. correct people's assumptions about it because I know how it works. Maybe it's wishful thinking but if you better understand what it is and what it isn't, what it's actually doing, etc we will have a better chance at fighting it
#>sluggy personal#like my biggest thing is that it does not search websites#it scraps the data and then hosts it in its memory/training#that's why it hallucinates information. it doesn't know what any of that data is. it doesn't search up anything it's all pre scraped info
2 notes
·
View notes
Text
More stellar canning advice from the UK: "Your rowan jam will keep for up to a year in a cool cupboard and like all jams once opened should be stored in the fridge and used up within a month. Please Note – We do not usually do water bath or other canning methods here in the UK. Our preserves keep perfectly well without this."
Just as their cats are uniquely able to dodge cars & mean children and so must run free, their insects uniquely disinterested in entering open windows and thus no need for window screens, so too are their jams uniquely impervious to spoilage and thus require no proper canning. I wish I could think that this person was an outlier, but unfortunately this is the state of food preservation in this country. There's a lot of similar advice in Germany as well, though I don't know about the rest of Europe.
#I can't imagine sticking an unsealed jar of jam on a shelf for a year & hoping for the best#unsurprisingly UK canning advice also includes a lot of very cavalier suggestions about scraping away mold when you open a jar of jam#I am not a stickler for food safety nor am I overly concerned about a spot of mold#the thing about this that bugs me is the implication that UK 'method' -- ie doing basically nothing -- is somehow superior or even adequate#and that steam/water bath canning are neurotic & unnecessary activities performed by foreigners#just because your jam never killed anyone doesn't mean it's not causing other mysterious and unpleasant GI issues#which might be better avoided#plus no way am I giving someone else jam that might later show mold#have some personal dignity & pride in your preserves folks#earlier I observed Delia Smith's official website telling people to just scrape the mold off non-heat-processed jam#like lady are you _trying_ to get sued or what
7 notes
·
View notes
Text
you would think, of all possible usages of AI, coding would be like... the least offensive/most ethical. but github copilot does not recommend me useful code. it's not giving me code at all. it just auto filled my dialog with lines from undertale and tried to name the protag rose lalonde
#it's practically unusable because it doesn't answer any coding questions. it won't even do my boilerplate code.#which is like. what copilot should be used for??#ai is so useless and unusable#i'm not exactly super anti AI i do believe it can be used in a proper manner. but any ethical use of AI would have to be private#unsurprisingly#since the big AIs owned by big corpos are just lazily scraping websites.#personal text
8 notes
·
View notes