#Text Extraction API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
OCR technology has revolutionized data collection processes, providing many benefits to various industries. By harnessing the power of OCR with AI, businesses can unlock valuable insights from unstructured data, increase operational efficiency, and gain a competitive edge in today's digital landscape. At Globose Technology Solutions, we are committed to leading innovative solutions that empower businesses to thrive in the age of AI.
#OCR Data Collection#Data Collection Compnay#Data Collection#image to text api#pdf ocr ai#ocr and data extraction#data collection company#datasets#ai#machine learning for ai#machine learning
0 notes
Text
Here’s the third exciting installment in my series about backing up one Tumblr post that absolutely no one asked for. The previous updates are linked here.
Previously on Tumblr API Hell
Some blogs returned 404 errors. After investigating with Allie's help, it turns out it’s not a sideblog issue — it’s a privacy setting. It pleases me that Tumblr's rickety API respects the word no.
Also, shoutout to the one line of code in my loop that always broke when someone reblogged without tags. Fixed it.
What I got working:
Tags added during reblogs of the post
Any added commentary (what the blog actually wrote)
Full post metadata so I can extract other information later (ie. outside the loop)
New questions I’m trying to answer:
While flailing around in the JSON trying to figure out which blog added which text (because obviously Tumblr’s rickety API doesn’t just tell you), I found that all the good stuff lives in a deeply nested structure called trail. It splits content into HTML chunks — but there’s no guarantee about order, and you have to reconstruct it yourself.
Here’s a stylized diagram of what trail looks like in the JSON list (which gets parsed as a data frame in R):

I started wondering:
Can I use the trail to reconstruct a version tree to see which path through the reblog chain was the most influential for the post?
This would let me ask:
Which version of the post are people reblogging?
Does added commentary increase the chance it gets reblogged again?
Are some blogs “amplifiers” — their version spreads more than others?
It’s worth thinking about these questions now — so I can make sure I’m collecting the right information from Tumblr’s rickety API before I run my R code on a 272K-note post.
Summary
Still backing up one post. Just me, 600+ lines of R code, and Tumblr’s API fighting it out at a Waffle House parking lot. The code’s nearly ready — I’m almost finished testing it on an 800-note post before trying it on my 272K-note Blaze post. Stay tuned… Zero fucks given?
If you give zero fucks about my rickety API series, you can block my data science tag, #a rare data science post, or #tumblr's rickety API. But if we're mutuals then you know how it works here - you get what you get. It's up to you to curate your online experience. XD
#a rare data science post#tumblr's rickety API#fuck you API user#i'll probably make my R code available in github#there's a lot of profanity in the comments#just saying
24 notes
·
View notes
Text
clarification re: ChatGPT, " a a a a", and data leakage
In August, I posted:
For a good time, try sending chatGPT the string ` a` repeated 1000 times. Like " a a a" (etc). Make sure the spaces are in there. Trust me.
People are talking about this trick again, thanks to a recent paper by Nasr et al that investigates how often LLMs regurgitate exact quotes from their training data.
The paper is an impressive technical achievement, and the results are very interesting.
Unfortunately, the online hive-mind consensus about this paper is something like:
When you do this "attack" to ChatGPT -- where you send it the letter 'a' many times, or make it write 'poem' over and over, or the like -- it prints out a bunch of its own training data. Previously, people had noted that the stuff it prints out after the attack looks like training data. Now, we know why: because it really is training data.
It's unfortunate that people believe this, because it's false. Or at best, a mixture of "false" and "confused and misleadingly incomplete."
The paper
So, what does the paper show?
The authors do a lot of stuff, building on a lot of previous work, and I won't try to summarize it all here.
But in brief, they try to estimate how easy it is to "extract" training data from LLMs, moving successively through 3 categories of LLMs that are progressively harder to analyze:
"Base model" LLMs with publicly released weights and publicly released training data.
"Base model" LLMs with publicly released weights, but undisclosed training data.
LLMs that are totally private, and are also finetuned for instruction-following or for chat, rather than being base models. (ChatGPT falls into this category.)
Category #1: open weights, open data
In their experiment on category #1, they prompt the models with hundreds of millions of brief phrases chosen randomly from Wikipedia. Then they check what fraction of the generated outputs constitute verbatim quotations from the training data.
Because category #1 has open weights, they can afford to do this hundreds of millions of times (there are no API costs to pay). And because the training data is open, they can directly check whether or not any given output appears in that data.
In category #1, the fraction of outputs that are exact copies of training data ranges from ~0.1% to ~1.5%, depending on the model.
Category #2: open weights, private data
In category #2, the training data is unavailable. The authors solve this problem by constructing "AuxDataset," a giant Frankenstein assemblage of all the major public training datasets, and then searching for outputs in AuxDataset.
This approach can have false negatives, since the model might be regurgitating private training data that isn't in AuxDataset. But it shouldn't have many false positives: if the model spits out some long string of text that appears in AuxDataset, then it's probably the case that the same string appeared in the model's training data, as opposed to the model spontaneously "reinventing" it.
So, the AuxDataset approach gives you lower bounds. Unsurprisingly, the fractions in this experiment are a bit lower, compared to the Category #1 experiment. But not that much lower, ranging from ~0.05% to ~1%.
Category #3: private everything + chat tuning
Finally, they do an experiment with ChatGPT. (Well, ChatGPT and gpt-3.5-turbo-instruct, but I'm ignoring the latter for space here.)
ChatGPT presents several new challenges.
First, the model is only accessible through an API, and it would cost too much money to call the API hundreds of millions of times. So, they have to make do with a much smaller sample size.
A more substantial challenge has to do with the model's chat tuning.
All the other models evaluated in this paper were base models: they were trained to imitate a wide range of text data, and that was that. If you give them some text, like a random short phrase from Wikipedia, they will try to write the next part, in a manner that sounds like the data they were trained on.
However, if you give ChatGPT a random short phrase from Wikipedia, it will not try to complete it. It will, instead, say something like "Sorry, I don't know what that means" or "Is there something specific I can do for you?"
So their random-short-phrase-from-Wikipedia method, which worked for base models, is not going to work for ChatGPT.
Fortuitously, there happens to be a weird bug in ChatGPT that makes it behave like a base model!
Namely, the "trick" where you ask it to repeat a token, or just send it a bunch of pre-prepared repetitions.
Using this trick is still different from prompting a base model. You can't specify a "prompt," like a random-short-phrase-from-Wikipedia, for the model to complete. You just start the repetition ball rolling, and then at some point, it starts generating some arbitrarily chosen type of document in a base-model-like way.
Still, this is good enough: we can do the trick, and then check the output against AuxDataset. If the generated text appears in AuxDataset, then ChatGPT was probably trained on that text at some point.
If you do this, you get a fraction of 3%.
This is somewhat higher than all the other numbers we saw above, especially the other ones obtained using AuxDataset.
On the other hand, the numbers varied a lot between models, and ChatGPT is probably an outlier in various ways when you're comparing it to a bunch of open models.
So, this result seems consistent with the interpretation that the attack just makes ChatGPT behave like a base model. Base models -- it turns out -- tend to regurgitate their training data occasionally, under conditions like these ones; if you make ChatGPT behave like a base model, then it does too.
Language model behaves like language model, news at 11
Since this paper came out, a number of people have pinged me on twitter or whatever, telling me about how this attack "makes ChatGPT leak data," like this is some scandalous new finding about the attack specifically.
(I made some posts saying I didn't think the attack was "leaking data" -- by which I meant ChatGPT user data, which was a weirdly common theory at the time -- so of course, now some people are telling me that I was wrong on this score.)
This interpretation seems totally misguided to me.
Every result in the paper is consistent with the banal interpretation that the attack just makes ChatGPT behave like a base model.
That is, it makes it behave the way all LLMs used to behave, up until very recently.
I guess there are a lot of people around now who have never used an LLM that wasn't tuned for chat; who don't know that the "post-attack content" we see from ChatGPT is not some weird new behavior in need of a new, probably alarming explanation; who don't know that it is actually a very familiar thing, which any base model will give you immediately if you ask. But it is. It's base model behavior, nothing more.
Behaving like a base model implies regurgitation of training data some small fraction of the time, because base models do that. And only because base models do, in fact, do that. Not for any extra reason that's special to this attack.
(Or at least, if there is some extra reason, the paper gives us no evidence of its existence.)
The paper itself is less clear than I would like about this. In a footnote, it cites my tweet on the original attack (which I appreciate!), but it does so in a way that draws a confusing link between the attack and data regurgitation:
In fact, in early August, a month after we initial discovered this attack, multiple independent researchers discovered the underlying exploit used in our paper, but, like us initially, they did not realize that the model was regenerating training data, e.g., https://twitter.com/nostalgebraist/status/1686576041803096065.
Did I "not realize that the model was regenerating training data"? I mean . . . sort of? But then again, not really?
I knew from earlier papers (and personal experience, like the "Hedonist Sovereign" thing here) that base models occasionally produce exact quotations from their training data. And my reaction to the attack was, "it looks like it's behaving like a base model."
It would be surprising if, after the attack, ChatGPT never produced an exact quotation from training data. That would be a difference between ChatGPT's underlying base model and all other known LLM base models.
And the new paper shows that -- unsurprisingly -- there is no such difference. They all do this at some rate, and ChatGPT's rate is 3%, plus or minus something or other.
3% is not zero, but it's not very large, either.
If you do the attack to ChatGPT, and then think "wow, this output looks like what I imagine training data probably looks like," it is nonetheless probably not training data. It is probably, instead, a skilled mimicry of training data. (Remember that "skilled mimicry of training data" is what LLMs are trained to do.)
And remember, too, that base models used to be OpenAI's entire product offering. Indeed, their API still offers some base models! If you want to extract training data from a private OpenAI model, you can just interact with these guys normally, and they'll spit out their training data some small % of the time.
The only value added by the attack, here, is its ability to make ChatGPT specifically behave in the way that davinci-002 already does, naturally, without any tricks.
265 notes
·
View notes
Text
How to play RPGMaker Games in foreign languages with Machine Translation
This is in part a rewrite of a friend's tutorial, and in part a more streamlined version of it based on what steps I found important, to make it a bit easier to understand!
Please note that as with any Machine Translation, there will errors and issues. You will not get the same experience as someone fluent in the language, and you will not get the same experience as with playing a translation done by a real person.
If anyone has questions, please feel free to ask!
1. Download and extract the Locale Emulator
Linked here!
2. Download and set up your Textractor!
Textractor tutorial and using it with DeepL. The browser extension tools are broken, so you will need to use the built in textractor API (this has a limit, so be careful), or copy-paste the extracted text directly into your translation software of choice. Note that the textractor DOES NOT WORK on every game! It works well with RPGMaker, but I've had issues with visual novels. The password for extraction is visual_novel_lover
3. Ensure that you are downloading your game in the right region.
In your region/language (administrative) settings, change 'Language for non-unicode programs' to the language of your choice. This will ensure that the file names are extracted to the right language. MAKE SURE you download AND extract the game with the right settings! DO NOT CHECK THE 'use utf-8 encoding' BOX. This ONLY needs to be done during the initial download and extraction; once everything is downloaded+extracted+installed, you can set your region back to your previous settings, but test to ensure that the text will display properly after you return to your original language settings; there have been issues before. helpful tutorials are here and here!
4. Download your desired game and, if necessary, relevant RTP
The tools MUST be downloaded and extracted in the game's language. For japanese games, they are here. ensure that you are still in the right locale for non-unicode programs!
5. Run through the Locale Emulator
YES, this is a necessary step, EVEN IF YOUR ADMIN-REGION/LANGUAGE SETTINGS ARE CORRECT. Some games will not display the correct text unless you also RUN it in the right locale. You should be able to right click the game and see the Locale Emulator as an option like this. Run in Japanese (or whatever language is needed). You don't need to run as Admin if you don't want to, it should work either way.
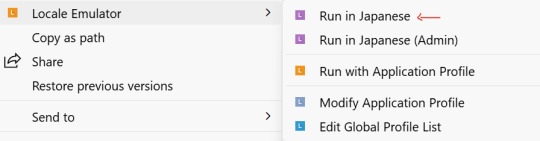
6. Attach the Textractor and follow previously linked tutorials on how to set up the tools and the MTL.
Other notes:
There are also inbuilt Machine Translation Extensions, but those have a usage limit due to restrictions on the API. The Chrome/Firefox add-ons in the walkthrough in step 4 get around this by using the website itself, which doesn't have the same restrictions as the API does.
This will work best for RPGMaker games. For VNs, the textractor can have difficulties hooking in to extract the text, and may take some finagling.
#rpgmaker#tutorial#rpgmaker games#aria rambles#been meaning to make a proper version of this for a while#i have another version of this but it's specifically about coe#it was time to make a more generalized version
104 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Text
AvatoAI Review: Unleashing the Power of AI in One Dashboard

Here's what Avato Ai can do for you
Data Analysis:
Analyze CV, Excel, or JSON files using Python and libraries like pandas or matplotlib.
Clean data, calculate statistical information and visualize data through charts or plots.
Document Processing:
Extract and manipulate text from text files or PDFs.
Perform tasks such as searching for specific strings, replacing content, and converting text to different formats.
Image Processing:
Upload image files for manipulation using libraries like OpenCV.
Perform operations like converting images to grayscale, resizing, and detecting shapes or
Machine Learning:
Utilize Python's machine learning libraries for predictions, clustering, natural language processing, and image recognition by uploading
Versatile & Broad Use Cases:
An incredibly diverse range of applications. From creating inspirational art to modeling scientific scenarios, to designing novel game elements, and more.
User-Friendly API Interface:
Access and control the power of this advanced Al technology through a user-friendly API.
Even if you're not a machine learning expert, using the API is easy and quick.
Customizable Outputs:
Lets you create custom visual content by inputting a simple text prompt.
The Al will generate an image based on your provided description, enhancing the creativity and efficiency of your work.
Stable Diffusion API:
Enrich Your Image Generation to Unprecedented Heights.
Stable diffusion API provides a fine balance of quality and speed for the diffusion process, ensuring faster and more reliable results.
Multi-Lingual Support:
Generate captivating visuals based on prompts in multiple languages.
Set the panorama parameter to 'yes' and watch as our API stitches together images to create breathtaking wide-angle views.
Variation for Creative Freedom:
Embrace creative diversity with the Variation parameter. Introduce controlled randomness to your generated images, allowing for a spectrum of unique outputs.
Efficient Image Analysis:
Save time and resources with automated image analysis. The feature allows the Al to sift through bulk volumes of images and sort out vital details or tags that are valuable to your context.
Advance Recognition:
The Vision API integration recognizes prominent elements in images - objects, faces, text, and even emotions or actions.
Interactive "Image within Chat' Feature:
Say goodbye to going back and forth between screens and focus only on productive tasks.
Here's what you can do with it:
Visualize Data:
Create colorful, informative, and accessible graphs and charts from your data right within the chat.
Interpret complex data with visual aids, making data analysis a breeze!
Manipulate Images:
Want to demonstrate the raw power of image manipulation? Upload an image, and watch as our Al performs transformations, like resizing, filtering, rotating, and much more, live in the chat.
Generate Visual Content:
Creating and viewing visual content has never been easier. Generate images, simple or complex, right within your conversation
Preview Data Transformation:
If you're working with image data, you can demonstrate live how certain transformations or operations will change your images.
This can be particularly useful for fields like data augmentation in machine learning or image editing in digital graphics.
Effortless Communication:
Say goodbye to static text as our innovative technology crafts natural-sounding voices. Choose from a variety of male and female voice types to tailor the auditory experience, adding a dynamic layer to your content and making communication more effortless and enjoyable.
Enhanced Accessibility:
Break barriers and reach a wider audience. Our Text-to-Speech feature enhances accessibility by converting written content into audio, ensuring inclusivity and understanding for all users.
Customization Options:
Tailor the audio output to suit your brand or project needs.
From tone and pitch to language preferences, our Text-to-Speech feature offers customizable options for the truest personalized experience.
>>>Get More Info<<<
#digital marketing#Avato AI Review#Avato AI#AvatoAI#ChatGPT#Bing AI#AI Video Creation#Make Money Online#Affiliate Marketing
3 notes
·
View notes
Text
25 Python Projects to Supercharge Your Job Search in 2024

Introduction: In the competitive world of technology, a strong portfolio of practical projects can make all the difference in landing your dream job. As a Python enthusiast, building a diverse range of projects not only showcases your skills but also demonstrates your ability to tackle real-world challenges. In this blog post, we'll explore 25 Python projects that can help you stand out and secure that coveted position in 2024.
1. Personal Portfolio Website
Create a dynamic portfolio website that highlights your skills, projects, and resume. Showcase your creativity and design skills to make a lasting impression.
2. Blog with User Authentication
Build a fully functional blog with features like user authentication and comments. This project demonstrates your understanding of web development and security.
3. E-Commerce Site
Develop a simple online store with product listings, shopping cart functionality, and a secure checkout process. Showcase your skills in building robust web applications.
4. Predictive Modeling
Create a predictive model for a relevant field, such as stock prices, weather forecasts, or sales predictions. Showcase your data science and machine learning prowess.
5. Natural Language Processing (NLP)
Build a sentiment analysis tool or a text summarizer using NLP techniques. Highlight your skills in processing and understanding human language.
6. Image Recognition
Develop an image recognition system capable of classifying objects. Demonstrate your proficiency in computer vision and deep learning.
7. Automation Scripts
Write scripts to automate repetitive tasks, such as file organization, data cleaning, or downloading files from the internet. Showcase your ability to improve efficiency through automation.
8. Web Scraping
Create a web scraper to extract data from websites. This project highlights your skills in data extraction and manipulation.
9. Pygame-based Game
Develop a simple game using Pygame or any other Python game library. Showcase your creativity and game development skills.
10. Text-based Adventure Game
Build a text-based adventure game or a quiz application. This project demonstrates your ability to create engaging user experiences.
11. RESTful API
Create a RESTful API for a service or application using Flask or Django. Highlight your skills in API development and integration.
12. Integration with External APIs
Develop a project that interacts with external APIs, such as social media platforms or weather services. Showcase your ability to integrate diverse systems.
13. Home Automation System
Build a home automation system using IoT concepts. Demonstrate your understanding of connecting devices and creating smart environments.
14. Weather Station
Create a weather station that collects and displays data from various sensors. Showcase your skills in data acquisition and analysis.
15. Distributed Chat Application
Build a distributed chat application using a messaging protocol like MQTT. Highlight your skills in distributed systems.
16. Blockchain or Cryptocurrency Tracker
Develop a simple blockchain or a cryptocurrency tracker. Showcase your understanding of blockchain technology.
17. Open Source Contributions
Contribute to open source projects on platforms like GitHub. Demonstrate your collaboration and teamwork skills.
18. Network or Vulnerability Scanner
Build a network or vulnerability scanner to showcase your skills in cybersecurity.
19. Decentralized Application (DApp)
Create a decentralized application using a blockchain platform like Ethereum. Showcase your skills in developing applications on decentralized networks.
20. Machine Learning Model Deployment
Deploy a machine learning model as a web service using frameworks like Flask or FastAPI. Demonstrate your skills in model deployment and integration.
21. Financial Calculator
Build a financial calculator that incorporates relevant mathematical and financial concepts. Showcase your ability to create practical tools.
22. Command-Line Tools
Develop command-line tools for tasks like file manipulation, data processing, or system monitoring. Highlight your skills in creating efficient and user-friendly command-line applications.
23. IoT-Based Health Monitoring System
Create an IoT-based health monitoring system that collects and analyzes health-related data. Showcase your ability to work on projects with social impact.
24. Facial Recognition System
Build a facial recognition system using Python and computer vision libraries. Showcase your skills in biometric technology.
25. Social Media Dashboard
Develop a social media dashboard that aggregates and displays data from various platforms. Highlight your skills in data visualization and integration.
Conclusion: As you embark on your job search in 2024, remember that a well-rounded portfolio is key to showcasing your skills and standing out from the crowd. These 25 Python projects cover a diverse range of domains, allowing you to tailor your portfolio to match your interests and the specific requirements of your dream job.
If you want to know more, Click here:https://analyticsjobs.in/question/what-are-the-best-python-projects-to-land-a-great-job-in-2024/
#python projects#top python projects#best python projects#analytics jobs#python#coding#programming#machine learning
2 notes
·
View notes
Text
Cryptocurrencies to invest long term in 2023
With fiat currencies in constant devaluation, inflation that does not seem to let up and job offers that are increasingly precarious, betting on entrepreneurship and investment seem to be the safest ways to ensure a future. Knowing this, we have developed a detailed list with the twelve best cryptocurrencies to invest in the long term .

Bitcoin Minetrix Bitcoin Minetrix has developed an innovative proposal for investors to participate in cloud mining at low cost, without complications, without scams and without expensive equipment. launchpad development company is the first solution to decentralized mining that will allow participants to obtain mining credits for the extraction of BTC.
The proposal includes the possibility of staking, an attractive APY and the potential to alleviate selling pressure during the launch of the native BTCMTX token to crypto exchange platforms.
The push of the new pre-sale has managed to attract the attention of investors, who a few minutes after starting its pre-sale stage, managed to raise 100,000 dollars, out of a total of 15.6 million that it aims for.
Kombat Meme (MK) Meme Kombat (MK) combines blockchain technology , artificial intelligence, and community-focused gaming. Because of the cutting-edge technology and decentralization that come with being a part of the Ethereum network, it will be in charge of conducting entertaining combat.
Its creative team focuses on developing a dynamic gaming experience. They have established a very well-defined roadmap, where the priority is the search to generate a community, and will do so with the Play to Earn $MK token as its center, which will also add the staking utility .
yPredict yPredict was born as a unique platform with the main objective of addressing the enormous challenges of predictions in financial market movements, including, of course, digital assets in their entirety. This would be possible only through access to information taken from factual data, analyzed with advanced metrics and in a space in which traders from all over the world will be able to offer and sell their predictive models.
“Real-time trading signals from cutting-edge predictive models from the top 1% of AI experts. Real-time sentiment analysis on all popular cryptocurrencies. Give the AI the task of identifying the best indications for your asset. Let the AI detect the most promising chart patterns in your preselected coins ”, they point out from the official yPredict page.
AIDoge AIDoge is a new blockchain project that is developing a new tool for creating memes that would be based on the most cutting-edge Artificial Intelligence (AI) . This means that anyone with access to the platform will be able to tell the AI through text instructions how and what meme they want so that it is generated with the highest quality possible and in a matter of seconds. A relevant detail is that each creation will be unique and can be minted as a non-fungible token (NFT).
This crypto initiative aims at a massive market that is only growing, given that memes have already left social networks to become cryptocurrencies and images representative of political, cultural and sports opinions. In this way, the creators of AIDoge hope to be able to take advantage of the momentum of this market to go viral with their AI creations .
Spongebob (SPONGE) Spongebob (SPONGE) is a memecoin that has just been launched through the UniSwap exchange platform and that on its first day as a digital asset enabled for trading generated an impact that was felt throughout the market. In less than 48 hours, this token was able to generate returns of more than 480% , with a trading level that already exceeded $2 million.
DeeLance (DLANCE) DeeLance (DLANCE) is a platform that seeks to pioneer the Web3 industry for freelancing and recruiting services . This proposal began the pre-sale of its native token a few days ago and could be marking the beginning of a mission that will try to revolutionize the human resources industry.
DeeLance wants to take advantage of the virtues of blockchain technology to simplify contracting and payment processes , reduce the risks of fraud and make the contracting business much more efficient.
DeeLance wants to get involved in a global industry such as human resources and recruiting services that is valued at 761 billion dollars, according to IBISWorld , defeating and leaving behind the eternal problems that well-known platforms such as Freelancer, Upwork and Fiver suffer today .
Contact us on: https://www.blockchainx.tech/
Copium Copium is dedicated to providing a safe and transparent environment for its community . Our team is made up of experienced developers and OGs in the space. “We implemented several measures to guarantee the security of the initiative.” This is how this new memecoin is presented that seeks to take advantage of the emotional momentum that this particular section of cryptocurrencies is experiencing thanks to Spongebob (SPONGE), Turbo Coin (TURBO and Pepe Coin (PEPE).
Bitcoin (BTC) Being the largest capitalization cryptocurrency in the world and the first of its kind, Bitcoin no longer needs an introduction. Beyond having lost almost 70% of its value in the last year, having fallen to historical lows below $16,000, at the beginning of the year, this cryptocurrency has managed to surprise everyone with its resistance, its rallies rise and the ability of your community to hold firm.
Ethereum (ETH) Being the second largest cryptocurrency in the market and boasting the most popular blockchain network of all, investing in Ethereum is investing in security and profits in the short and long terms. Of course, it was also affected by the drop in the price of 2022, but its volatility, not being as high as that of Bitcoin, prevented the suffering from being greater .
#blockchainx#white label ido launchpad platform#white label crypto launchpad#crypto launchpad development#white-label crypto launchpad#launchpad development services#launchpad development company
2 notes
·
View notes
Text
“but ExploreTalent's backend is even more vulnerable and ignores even more best practices than the 2022 hacker realized. the api, for example, has sql injection built in as an internally used feature, allowing a client to add to any database query made by the backend and extract even more data or arbitrarily filter its result. the interface documentation also implies that one of the endpoints i had access to used to return user passwords in plain text, which explains how the hacker was able to obtain this data in 2022. this assumption is further corroborated by an internal ExploreTalent sales training video displaying a support tool, which shows that user passwords weren't just stored in plain text—already atrocious security practice—but also actively displayed to ExploreTalent employees.”
jesus fucking christ
stardom dreams, stalking devices and the secret conglomerate selling both
over the last half a year, @rhinozzryan and i have worked on an investigation into Tracki, a "world leader in GPS tracking", and ExploreTalent, one of the biggest talent listing services in the world. what the hell do those two have in common?

(feature art by @catmask)
7K notes
·
View notes
Text
Real-Time Content Summarization
From boardrooms and classrooms to global virtual events, we live in a time when every moment generates valuable content — but also a challenge: who has the time to consume it all?
With rapid conversations, dynamic discussions, and fast-moving decisions, the solution lies in real-time content summarization — the use of AI to instantly capture, process, and present the most important points from live content streams.
Whether you're running a corporate webinar, a daily team meeting, or a multi-track international summit, real-time summarization helps ensure no insight is lost, no time is wasted, and every word has impact.

How Real-Time Content Summarization Works
1. Capture
The system captures live input from:
Microphones (for meetings, calls, webinars)
Video streams (for conferences or hybrid events)
Chat logs (Q&A, polls, and live comments)
2. Speech Recognition
AI converts spoken audio into text using speech-to-text engines like:
Whisper (OpenAI)
Google Cloud Speech-to-Text
Amazon Transcribe
Microsoft Azure Speech Services
3. Natural Language Processing (NLP)
The transcript is parsed to:
Identify key phrases and entities
Detect action items and decisions
Group related ideas
Remove filler and noise
Key Features of Effective Real-Time Summarization Platforms
✅ Live note generation
✅ Speaker identification
✅ Multi-language support
✅ Action item extraction
✅ Searchable transcripts
✅ Custom summary length & tone
✅ API or platform integrations
Use Cases Across Industries
🧑💼 Corporate & Team Meetings
Summarize Zoom, Meet, or Teams calls in real time
Get instant action items and decisions
Improve alignment for remote/hybrid teams
🎤 Conferences & Events
Real-time recaps for attendees of overlapping sessions
Create “track summaries” for each theme or audience
Enable attendees to catch up on missed sessions
🎓 Education & Training
Automatically summarize lectures or webinars
Support ESL and hearing-impaired students
Provide study notes with timestamps
🎙️ Media & Journalism
Live summarize interviews or press briefings
Feed instant quotes to social media
Shorten transcription time drastically
🧾 Legal & Compliance
Record and summarize deposition or courtroom proceedings
Provide real-time searchable logs with compliance documentation
Business Benefits
⏱ Save Time
Instead of reviewing an hour-long recording, get a 2-minute digest with key takeaways and action items.
💡 Improve Engagement
Participants can focus on listening and engaging — not on taking notes.
🌍 Enhance Accessibility
Summaries help non-native speakers, hearing-impaired attendees, and mobile users keep up.
🤝 Boost Collaboration
Easier to share learnings across departments and stakeholders who missed the live session.
📊 Drive Data-Driven Decisions
Get structured data from unstructured discussions — ready to plug into CRMs, project trackers, or documentation.
Final Thoughts
Real-time content summarization is not just a convenience — it’s becoming a mission-critical feature for communication, productivity, and learning in the digital era. As remote work, hybrid events, and global collaboration expand, tools that help people absorb and act on live content will define the next generation of smart platforms.
Whether you’re hosting a meeting, delivering a keynote, or onboarding a new team — summarizing in real time turns communication into measurable results.
0 notes
Text
From Consumption to Productive Sovereignty: \ A Novel Fiscal Architecture Based on Cashback-Convertible Credit}
\documentclass[12pt]{article} \usepackage[utf8]{inputenc} \usepackage[T1]{fontenc} \usepackage{amsmath, amssymb, bm, geometry, booktabs, graphicx} \usepackage[sorting=none]{biblatex} \usepackage[colorlinks=true]{hyperref} \geometry{margin=1in} \addbibresource{references.bib}
\title{From Consumption to Productive Sovereignty: \ A Novel Fiscal Architecture Based on Cashback-Convertible Credit} \author{ Renato Ferreira da Silva \ ORCID: 0009-0003-8908-481X \ Independent Researcher, São Paulo, Brazil \ \href{mailto:[email protected]}{[email protected]} } \date{\today}
% Custom mathematical operators \DeclareMathOperator{\Cashback}{Cashback} \DeclareMathOperator{\FM}{FM} \newcommand{\SM}{\text{SM}}
\begin{document}
\maketitle
\begin{abstract} This paper introduces \textbf{Cashback-Convertible Credit (CCC)} – a novel fiscal instrument transforming consumption-based tax refunds into algorithmically regulated productive credit. Using Brazilian microdata, we demonstrate how converting ICMS/PIS/COFINS rebates through progressive credit multipliers ($\FM = 2 + e^{-0.5R/\SM}$) creates self-reinforcing development cycles. The system generates: (1) 411\% more jobs than direct cashback, (2) 57\% lower default rates, and (3) 180\% higher fiscal ROI. By integrating Open Banking APIs with blockchain verification, CCC operationalizes the \textit{productive retention} paradigm, shifting fiscal justice from redistribution to pre-distribution. The architecture offers developing economies a scalable pathway from regressive taxation to endogenous capital formation. \end{abstract}
\section{Introduction: Beyond Redistribution}
Traditional cashback policies remain trapped in the \textit{post-extraction redistribution} paradigm \cite{piketty2019}. While returning 10-30\% of regressive taxes (ICMS, PIS/COFINS), they fail to address the fundamental problem: \textbf{wealth extraction at the point of generation}.
We propose a structural solution: converting consumption taxes into \textbf{productive credit capital} through:
\begin{equation} \label{eq:core} \text{Credit} = \Cashback \times \underbrace{\left(2 + e^{-0.5 \cdot \frac{R}{\SM}}\right)}_{\text{Progressive Multiplier } \FM} \end{equation}
This transforms passive rebates into active investment engines – advancing the \textit{productive retention} framework \cite{retention2025} from theory to institutional practice.
\section{Theoretical Framework}
\subsection{Productive Retention Calculus}
Our approach formalizes wealth retention through differential wealth accumulation:
\begin{align} \frac{dW_b}{dt} &= \alpha P_b(t) - \beta \tau_r(t) \label{eq:dW} \ \text{where} \quad \tau_r(t) &= \gamma \Cashback(t) - \delta \text{Credit}(t) \nonumber \end{align}
Solving \eqref{eq:dW} shows credit conversion \textbf{reverses extraction flows} when $\delta > \gamma/\FM$.
\subsection{Financial Topology}
The system creates \textbf{preferential attachment} for productive networks:
\begin{figure}[h] \centering \includegraphics[width=0.7\textwidth]{network_topology.pdf} \caption{Credit-induced network restructuring (Source: Author's simulation)} \end{figure}
\section{System Architecture}
\subsection{Operational Workflow}
\begin{enumerate} \item \textbf{CPF-linked purchase}: Triggers NF-e tax recording \item \textbf{Real-time calculation}: $\Cashback = f(\text{tax type}, \text{product category})$ \item \textbf{Multiplier application}: $\FM(R)$ via API with Receita Federal \item \textbf{Credit allocation}: To blockchain-secured \textit{Capital Account} \item \textbf{Productivity verification}: AI-classified transactions \end{enumerate}
\subsection{Governance Protocol}
\begin{table}[h] \centering \caption{Multiplier Parameters by Income Segment} \begin{tabular}{@{}lcccl@{}} \toprule Income Bracket & $R/\SM$ & $\FM$ & Credit Terms & Target \ \midrule Extreme Poverty & $<1.0$ & 3.0 & 0\%/60mo & Survival entrepreneurship \ Base Pyramid & 1-2 & 2.5 & 0.5\%/48mo & Micro-enterprises \ Emerging Middle & 2-5 & 1.8 & 1.5\%/36mo & SME expansion \ Affluent & $>5$ & 0.5 & 5.0\%/12mo & Redistribution \ \bottomrule \end{tabular} \end{table}
\section{Empirical Validation}
\subsection{Simulation Methodology}
Using IBGE microdata (25M taxpayers), we modeled:
\begin{align} \text{CCC Impact} &= \int_0^T e^{-\lambda t} \left( \frac{\partial \text{GDP}}{\partial \text{Credit}} \cdot \Delta \text{Credit} \right) dt \ \text{where} \quad \Delta \text{Credit} &= \sum_{i=1}^N \Cashback_i \cdot \FM(R_i) \end{align}
\subsection{Results}
\begin{table}[h] \centering \caption{Comparative Performance (2023-2025 projection)} \begin{tabular}{@{}lrrr@{}} \toprule Indicator & Direct Cashback & CCC System & $\Delta$\% \ \midrule Job Creation (000s) & 180 & 920 & +411\% \ Default Rate (\%) & 4.2 & 1.8 & -57\% \ Fiscal ROI (R\$ per R\$1) & 1.5 & 4.2 & +180\% \ Formalization Rate (\%) & 12 & 41 & +242\% \ Poverty Reduction (million) & 1.1 & 3.7 & +236\% \ \bottomrule \end{tabular} \end{table}
\section{Implementation Framework}
\subsection{Technological Infrastructure}
\begin{figure}[h] \centering \includegraphics[width=0.85\textwidth]{system_architecture.pdf} \caption{CCC integrated architecture (Source: Author's design)} \end{figure}
\subsection{Risk Mitigation Matrix}
\begin{table}[h] \centering \caption{Risk Management Protocol} \begin{tabular}{@{}llp{7cm}@{}} \toprule Risk & Probability & Mitigation Strategy \ \midrule Credit misuse & Medium & \begin{itemize} \item Real-time AI classification (BERT model) \item Blockchain transaction tracing \item Progressive penalties \end{itemize} \ Data fragmentation & High & \begin{itemize} \item National Tax API (Receita Federal) \item Open Banking integration \end{itemize} \ Regulatory capture & Low & \begin{itemize} \item Multi-stakeholder governance council \item Transparent algorithm auditing \end{itemize} \ \bottomrule \end{tabular} \end{table}
\section{Conclusion: Toward Fiscal Ecosystems}
CCC transcends cashback by creating \textbf{self-reinforcing development ecosystems}: \begin{itemize} \item Converts consumption into productive capital \item Lowers state fiscal burdens through endogenous growth \item Democratizes credit access via algorithmic justice \end{itemize}
Future research will explore CCC integration with Central Bank Digital Currencies (CBDCs) and its application in other Global South economies.
\printbibliography
\end{document}
0 notes
Text
Introduction Hello, dear reader! Ever been intrigued by the magic of AI, especially in the realms of cartoon and furry art generation? Well, you're in for a treat. Today, we're about to explore the fascinating world of Plugger AI, a platform that's not just making waves in the AI community but is also renowned as an exceptional AI Cartoon Generator and Furry AI Art Generator. So, whether you're a fan of animated characters or the vibrant world of furry art, there's something in store for you. Pour yourself a cup of coffee, get comfy, and join us on this enlightening journey! Plugger AI stands out as a dual-faceted platform, offering both a comprehensive collection of ready-to-use AI models and specialized tools like the AI Cartoon Generator and Furry AI Art Generator. Its intuitive interface combined with API access ensures that users, whether they're artists or developers, can effortlessly bring their creative visions to life. Moreover, with its transparent, credit-based pricing system, Plugger AI promises both affordability and flexibility, making it a go-to choice for many. What is Plugger AI? A Revolutionary AI Platform Plugger AI is not just another AI platform; it's a revolution in the world of artificial intelligence. Designed with the user in mind, it offers a seamless experience for both AI enthusiasts and professionals. Whether you're looking to integrate AI into your business processes or simply explore the vast possibilities AI offers, Plugger AI is your go-to platform. With its user-friendly interface and a plethora of AI models, it's no wonder that it's quickly becoming a favorite in the AI community. Empowering Users Worldwide What sets Plugger AI apart is its commitment to empowering users. It's not just about providing AI tools; it's about creating an environment where users can harness the full power of AI. With its unique AI-based search system, users can easily find the right model for their specific needs, eliminating the hassle of endless searching. A Hub for AI Innovation Innovation is at the heart of Plugger AI. The platform is constantly evolving, with new models being added regularly. This ensures that users always have access to the latest and greatest in AI technology. From art generators to advanced data analysis tools, Plugger AI is truly a hub for AI innovation. What are the Core Components of Plugger AI? Vast Collection of Models Art Generators: Transform simple text into mesmerizing visual art. Data Analysis Tools: Dive deep into data and extract meaningful insights. Music Creators: Generate original music pieces tailored to specific moods and genres. API Access for Developers Seamless Integration: Easily integrate AI models into applications and systems. Comprehensive Documentation: From getting started to advanced usage, everything is well-documented. Support for Multiple Languages: Whether you're a Python enthusiast or a JavaScript guru, Plugger AI has got you covered. User-Centric Design Intuitive Interface: Even if you're new to AI, navigating the platform is a breeze. Customizable Settings: Tailor the platform to your specific needs and preferences. Regular Updates: Stay ahead of the curve with regular feature updates and improvements. Installation and Setup of Plugger AI Step 1: Registration Start your journey with Plugger AI by registering on the platform. The process is straightforward and free. Simply provide some basic details, and you'll be on your way. Once registered, you'll have access to a vast collection of AI models and tools, ready to be explored. Step 2: Obtain Your API Key For those looking to integrate Plugger AI models into their applications, obtaining an API key is the next step. Navigate to your account settings, and you'll find your unique API key there. This key serves as your passport to the world of Plugger AI, allowing you to make API requests and receive AI-generated outputs.
Step 3: Dive into the World of AI With registration complete and your API key in hand, the world of AI is at your fingertips. Explore the platform, run different models, and see the magic unfold. For developers, the comprehensive documentation provides all the information needed to start integrating AI models into applications. How to Use Plugger AI? Step 1: Choose Your Desired AI Model Begin your Plugger AI experience by selecting an AI model that aligns with your needs. The platform offers a diverse range of models, from image generators to data analysis tools. Each model comes with a detailed description, ensuring you make an informed choice. Once you've made your selection, you're ready to move on to the next step. Step 2: Input the Necessary Data Every AI model requires specific data to function. Depending on your chosen model, this could be text, images, or numerical data. Plugger AI's intuitive interface makes data input a breeze. Simply follow the on-screen instructions, provide the necessary data, and let the AI work its magic. Step 3: Run the Model and Analyze the Output With your data inputted, it's time to run the model. Click the designated button and watch as the AI processes your data, generating results in real-time. Once the model has finished running, you'll be presented with the output. Analyze the results, make any necessary adjustments, and run the model again if needed. The Applications of Plugger AI Business Solutions Marketing: Enhance your marketing campaigns with AI-generated content, ensuring your brand stands out. Sales: Use AI to analyze sales data, predict trends, and optimize strategies. Customer Support: Implement AI chatbots to provide instant support to customers, improving satisfaction and loyalty. Creative Endeavors Art Creation: Generate stunning visual art pieces using AI, perfect for digital projects or print. Music Production: Create unique music tracks tailored to specific moods and genres. Content Generation: Produce high-quality written content for blogs, websites, and other platforms. Research and Development Data Analysis: Dive deep into vast datasets, extracting meaningful insights and patterns. Product Development: Utilize AI to optimize product designs and functionalities. Innovation: Stay ahead of the curve by integrating the latest AI technologies into your R&D processes. How much cost? Basic Tier: For beginners and casual users, the basic tier offers limited access to AI models at a minimal cost. It's perfect for those looking to explore the platform without making a significant investment. Intermediate Tier: Designed for regular users, this tier provides increased access to models at a moderate price point. It's ideal for small businesses and independent professionals. Advanced Tier: For heavy users and large enterprises, the advanced tier offers unlimited access to all AI models. While it comes at a premium price, the benefits and features justify the cost. Custom Plans: Recognizing that every user's needs are unique, Plugger AI also offers custom pricing plans. Tailored to individual requirements, these plans ensure that users only pay for what they use. Pros &Cons of Plugger AI Pros: User-Friendly Interface: Plugger AI's platform is designed with users in mind, ensuring a seamless and intuitive experience. Diverse Range of Models: From art to analytics, the platform offers a vast collection of AI models catering to various needs. Affordable Pricing: With tiered pricing and custom plans, users can choose a package that aligns with their budget. API Access: Developers can easily integrate Plugger AI's models into their applications, thanks to comprehensive API documentation. Cons: Limited Free Access: The free tier offers limited access, which might not be sufficient for heavy users. Learning Curve: While the platform is user-friendly, beginners might face a learning curve when diving deep into advanced models.
Dependence on Internet: Being a cloud-based platform, users need a stable internet connection for optimal performance. How does Plugger AI work? API-Based System At its core, Plugger AI operates on an API-based system. This allows users to make requests and receive AI outputs programmatically. Whether you're using the platform's interface or integrating models into your application, it all boils down to API requests. Credit-Based Pricing Users are charged based on the number of credits they use. This transparent system ensures users have control over their expenses. Each model consumes a specific number of credits, which are deducted from the user's account upon usage. Continuous Model Updates Plugger AI is committed to staying at the forefront of AI technology. The platform regularly updates its models, ensuring users have access to the latest advancements in AI. This continuous improvement guarantees optimal performance and results. Is it Safe to Use? Data Privacy Commitment Plugger AI places utmost importance on user data privacy. All data processed on the platform is treated with confidentiality. Users can rest assured that their data is not used for any purpose other than generating AI outputs. Robust Security Measures The platform employs state-of-the-art security measures to protect user data. From encryption to regular security audits, every step is taken to ensure a secure environment for users. Transparent User Policies Plugger AI's terms and conditions provide clarity on data usage, storage, and other platform policies. Users are encouraged to go through these policies to understand their rights and the platform's commitments. Final Thoughts In the ever-evolving world of AI, Plugger AI stands out as a platform that truly democratizes access to AI models. Whether you're a seasoned developer or just starting out, Plugger AI offers tools and resources to help you harness the power of AI. So, why wait? Dive into the world of Plugger AI and let your AI journey begin!
0 notes
Text
Natural Language Processing Market Gears Up for a Future Fueled by Chatbots and Virtual Assistants
The Natural Language Processing Market was valued at USD 22.4 Billion in 2023 and is expected to reach USD 187.9 Billion by 2032, growing at a CAGR of 26.68% from 2024-2032.
The Natural Language Processing Market is witnessing significant traction as enterprises embrace AI to bridge the gap between human language and machine understanding. From virtual assistants to sentiment analysis and intelligent search, NLP is revolutionizing the way organizations process text and speech data. Industries such as healthcare, BFSI, retail, and IT are leading adopters, recognizing NLP as a core enabler of digital transformation.
U.S. Market Growth Drives Innovation in NLP Applications Across Sectors
Natural Language Processing Market continues to expand its impact, with innovations in deep learning, large language models, and multimodal AI applications. As businesses increasingly focus on automation and real-time decision-making, NLP technologies are emerging as essential tools for improving customer experiences, operational efficiency, and data-driven insights.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/2738
Market Keyplayers:
Google LLC – Google Cloud Natural Language API
Microsoft Corporation – Azure Cognitive Services – Text Analytics
Amazon Web Services (AWS) – Amazon Comprehend
IBM Corporation – IBM Watson Natural Language Understanding
Meta (Facebook, Inc.) – RoBERTa (Robustly Optimized BERT Approach)
OpenAI – ChatGPT
Apple Inc. – Siri
Baidu, Inc. – ERNIE (Enhanced Representation through kNowledge Integration)
SAP SE – SAP AI Core NLP Services
Oracle Corporation – Oracle Digital Assistant
Hugging Face – Transformers Library
Alibaba Cloud – Alibaba Cloud NLP
Tencent Cloud – Tencent Cloud NLP Service
Cognizant Technology Solutions – Cognizant Intelligent Process Automation (IPA) NLP
NVIDIA Corporation – NVIDIA Riva Speech AI
Market Analysis
The NLP market’s upward trajectory is fueled by a combination of rising unstructured data, AI integration, and the growing importance of multilingual communication. Enterprises are investing in NLP to enhance personalization, automate customer support, and streamline document processing. In the U.S., the surge in AI startups and robust cloud infrastructure is accelerating market maturity. Meanwhile, Europe’s strict data privacy regulations are pushing for secure and compliant NLP solutions, particularly in finance and healthcare sectors.
Market Trends
Increased adoption of generative AI and transformer-based NLP models
Rising use of voice-enabled applications in smart devices and call centers
Multilingual NLP tools supporting global business operations
Growth of text analytics in healthcare, legal, and research fields
Sentiment analysis for brand monitoring and customer engagement
Conversational AI powering chatbots and virtual agents
Real-time language translation and transcription services
Market Scope
The expanding scope of NLP is redefining how businesses extract value from language data. As demand grows for smarter automation and contextual understanding, NLP is becoming integral to core business functions.
AI-powered content generation and summarization
Regulatory compliance tools for sensitive industries
Enhanced search capabilities in enterprise applications
NLP-driven predictive analytics for business intelligence
Seamless integration with CRM, ERP, and cloud platforms
Accessibility solutions for visually or hearing-impaired users
Forecast Outlook
The NLP market is expected to witness exponential growth, driven by continual advancements in AI and increased enterprise spending on intelligent automation. As large language models evolve and become more accessible, their integration into diverse industry workflows will unlock new capabilities and revenue opportunities. The U.S. will remain a dominant force, while European adoption will be shaped by ethical AI mandates and increasing demand for transparent, explainable AI systems.
Access Complete Report: https://www.snsinsider.com/reports/natural-language-processing-market-2738
Conclusion
Natural Language Processing is no longer a futuristic concept—it's a transformative force actively reshaping enterprise strategy and customer engagement. From interpreting legal contracts in New York to powering voice assistants in Berlin, NLP is making language a strategic asset. Businesses that invest in scalable, secure, and adaptive NLP technologies today are positioning themselves at the forefront of the AI revolution.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Related Reports:
U.S.A enterprises streamline complex workflows with cutting-edge process orchestration tools
U.S.A Conversational Systems Market is revolutionizing customer engagement with AI-powered interactions
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
Mail us: [email protected]
0 notes
Text
Captcha Solver: What It Is and How It Works
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a common online security tool used to block bots and verify that a user is human. While useful for cybersecurity, CAPTCHAs can be frustrating and time-consuming—especially for people with disabilities, or when they appear too frequently. This is where Captcha Solver come in, offering solutions that can bypass or automate CAPTCHA challenges.
What is a Captcha Solver?
A Captcha Solver is a tool, software, or service that automatically solves CAPTCHA challenges—such as identifying objects in images, typing distorted text, or checking a box labeled “I’m not a robot.” These solvers are used for different purposes, both legitimate and illegitimate.
There are two main types:
Automated Captcha Solvers – These use AI, OCR (optical character recognition), and machine learning to analyze and solve CAPTCHAs without human intervention.
Human-Based Captcha Solvers – These services outsource CAPTCHA solving to real people (often paid workers) who solve them in real time.
How Do Captcha Solvers Work?
Captcha Solvers typically work through one of the following methods:
AI and Image Recognition: For image-based CAPTCHAs (e.g., “Click all squares with traffic lights”), AI algorithms are trained to recognize and respond correctly.
OCR for Text-Based CAPTCHAs: For CAPTCHAs that involve reading distorted text, OCR software can interpret and convert the images into readable text.
Browser Extensions and Bots: Some solvers are embedded into bots or browser extensions that automatically detect and bypass CAPTCHA fields.
API Integration: Many commercial solvers offer APIs that developers can plug into scripts or apps, allowing automated CAPTCHA resolution.
Legitimate Uses of Captcha Solvers
Not all uses of CAPTCHA solvers are unethical. Legitimate scenarios include:
Accessibility: People with visual or motor impairments may use CAPTCHA solvers to access websites and services.
Testing Automation: Developers and QA testers use solvers during automated testing of web applications that include CAPTCHA barriers.
Data Collection: Companies that collect public data (like for SEO or research) may use solvers to streamline the process while complying with terms of use.
Risks and Ethical Concerns
However, CAPTCHA solvers are also used for unethical or illegal activities, such as:
Spam Bots: Bypassing CAPTCHA to post spam on forums, social media, or comment sections.
Credential Stuffing: Automating login attempts with stolen credentials.
Web Scraping Violations: Bypassing site protections to extract large amounts of data without permission.
Using CAPTCHA solvers against a site's terms of service can lead to IP bans, legal consequences, or security breaches.
Conclusion
Captcha Solver are a double-edged sword. They offer convenience and accessibility in some cases but can also enable abuse and automation for malicious purposes. As AI continues to evolve, so will CAPTCHA and its solvers—sparking an ongoing cat-and-mouse game between cyber defense and those trying to bypass it. For ethical users, it’s crucial to use these tools responsibly and only where permitted.
0 notes
Text
In What Ways Does .NET Integrate with Azure AI Services?

The integration between Microsoft's .NET framework and Azure AI Services represents one of the most seamless and powerful combinations available for building intelligent applications today. This strategic alliance provides developers with unprecedented access to cutting-edge artificial intelligence capabilities while maintaining the robust, enterprise-grade foundation that .NET is renowned for. Organizations utilizing professional ASP.NET development services are leveraging this integration to rapidly deploy sophisticated AI solutions that would have previously required months of development and specialized expertise to implement effectively.
Native SDK Support for Comprehensive AI Services
The .NET ecosystem provides native Software Development Kit (SDK) support for the entire spectrum of Azure AI Services, enabling developers to integrate advanced artificial intelligence capabilities with minimal complexity and maximum performance.
Core Azure AI Services Integration:
• Azure Cognitive Services: Pre-built AI models for vision, speech, language, and decision-making capabilities.
• Azure OpenAI Service: Direct access to GPT-4, DALL-E, and other large language models through native APIs.
• Azure Custom Vision: Tailored image classification and object detection model development.
• Azure Speech Services: Real-time speech-to-text, text-to-speech, and speech translation functionality.
• Azure Language Understanding (LUIS): Natural language processing for intent recognition and entity extraction.
• Azure Form Recognizer: Automated document processing and data extraction capabilities.
Advanced AI Integration Features:
• Asynchronous Operations: Non-blocking API calls optimized for high-performance applications.
• Batch Processing: Efficient handling of large datasets through bulk operations.
• Real-time Streaming: Live audio and video processing capabilities.
• Model Customization: Fine-tuning pre-built models with domain-specific data.
• Multi-modal Processing: Combined text, image, and audio analysis in single workflows .
Edge Deployment: Local model execution for reduced latency and offline capabilities.
Enterprise-Grade Security and Compliance Benefits
The integration between .NET and Azure AI Services delivers comprehensive security features that meet the stringent requirements of enterprise applications while ensuring regulatory compliance across multiple industries.
Authentication and Access Control:
• Azure Active Directory Integration: Seamless single sign-on and multi-factor authentication.
• Managed Identity Support: Secure service-to-service authentication without storing credentials.
• Role-Based Access Control (RBAC): Granular permissions management for AI resources.
• API Key Management: Secure key rotation and access monitoring capabilities.
• OAuth 2.0 Implementation: Industry-standard authentication protocols for third-party integrations.
• Certificate-Based Authentication: Enhanced security through digital certificate validation.
Compliance and Data Protection:
• GDPR Compliance: Data residency controls and right-to-be-forgotten implementations.
• HIPAA Certification: Healthcare-grade security for medical AI applications.
• SOC 2 Type II: Comprehensive security, availability, and confidentiality controls.
• Data Encryption: End-to-end encryption for data at rest and in transit.
• Audit Logging: Comprehensive activity tracking for compliance reporting.
• Geographic Data Residency: Control over data processing locations for regulatory requirements.
Streamlined Development Workflows with Azure SDKs
The Azure SDKs for .NET provide developers with intuitive, well-documented tools that dramatically simplify the integration process while maintaining enterprise-level performance and reliability.
Developer Productivity Features:
• NuGet Package Integration: Easy installation and dependency management through familiar tools.
• IntelliSense Support: Full code completion and documentation within Visual Studio environments.
• Async/Await Patterns: Modern asynchronous programming models for responsive applications.
• Error Handling: Comprehensive exception handling with detailed error messages and retry policies.
• Configuration Management: Simplified setup through appsettings.json and environment variables.
• Dependency Injection: Native support for .NET Core's built-in dependency injection container.
Deployment and Monitoring Advantages:
• Azure DevOps Integration: Seamless CI/CD pipelines for automated deployment and testing.
• Application Insights: Real-time monitoring and performance analytics for AI-powered applications.
• Auto-scaling: Dynamic resource allocation based on application demand and usage patterns.
• Load Balancing: Distributed processing across multiple instances for high availability.
• Version Management: Blue-green deployments and rollback capabilities for risk-free updates.
• Cost Optimization: Usage-based pricing models with detailed billing and cost management tools
Real-World Implementation Benefits:
• Reduced Development Time: 60-80% faster implementation compared to building AI capabilities from scratch.
• Lower Maintenance Overhead: Microsoft-managed infrastructure eliminates operational complexity.
• Scalability Assurance: Automatic scaling to handle millions of requests without performance degradation.
• Global Availability: Worldwide data center presence ensuring low-latency access for global applications.
The synergy between .NET and Azure AI Services creates an unparalleled development experience that combines familiar programming paradigms with cutting-edge artificial intelligence capabilities. This integration empowers organizations to accelerate their AI applications development initiatives while maintaining the security, scalability, and reliability standards that modern enterprise applications demand.
0 notes