#Which are abstractions of CPU instructions
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
You could look at it like the third wife of a dying oil baron discovering his of-age son born out of wedlock.
You could look at it like a wizard conjuring forth daemons to do his bidding.
You could look at it like a high king of an empire run on the backs of slaves ruled by masters, sometimes one owning one, often times one owning many.
You could look at it like an all-encompassing, inscrutable god twisting the very landscape of the world, and calling forth simple forms of life to perform wonders and miracles upon the land that are leagues beyond its inhabitants ability to even begin to fathom.
Programming is a strange, abstract frontier where we paint the dreams of sleeping machines. Machines that think with speed of geniuses but with the comprehension of a block of wood. It is rife with metaphorical language, where we grasp at any and all words to try and foment a transferable understanding of just what the hell we are doing. We do so for ourselves to help us accomplish our work, to train newcomers to the field, and for others to know and value what we do... at least enough to still get paid.
coding got me saying shit like “target the child” “assign its class” “override its inheritance” like the third wife of a dying oil baron discovering his of-age son born out of wedlock
#Painting the dreams of sleeping machines is an excellent line#I'm going to steal that from myself to use in the future#Programming and metaphor#Goes hand in hand#Especially when programming languages are technically abstract metaphors used for machine code#Which are abstractions of CPU instructions#Which guide every assignment of 1 and 0 in every register and space in memory#And those 1s and 0s themselves are abstractions of high and low voltage levels which control the firing of transistors#Shit's complicated#This is why we use metaphors
53K notes
·
View notes
Text
one thing I find a little sad is that I don't have a lot of people in the trans girl milieus i inhabit to talk to about tech art, about 3D computer graphics.
the popular discourse on computer graphics is, frankly, kind of miserable. graphics are still often considered either good or bad. and whether they're good or bad is probably defined by numbers: polygons pushed per frame and the like, texture resolution, etc. etc. or hours of polish spent on the game, envisioned as a kind of horrible drudge work, by immiserated artists who never see their families. it is each step taken towards hyper-realism.
in response to this discourse comes an attitude of wanting to throw out the whole thing: "i want smaller games with worse graphics" as the pithy slogan goes. graphics is the sheen of meaningless expensiveness that the triple-A studios throw at you, and thus a fundamentally uninteresting aspect of the medium.
which all sucks. I cannot find myself in either side of this dichotomy.
graphics for me is a space of play. it is its own set of endlessly fascinating challenges: finding ingenious smoke-and-mirrors tricks to create the illusion of objects and space. and it is at the same time, a lens to become more intimately familiar with the real world. light is fascinating. there is so much to see in just a wet road, or a body of water, or a leaf. the fresnel reflections on every object. there is a dialogue here.
and when you look for ways to represent them on a computer, and to stylise them, and abstract them, by wiring together these mathematical tricks... like, at its best, making games is fun in very much the same way that playing them is. your challenge is the profiler, the milliseconds. the space you're exploring is different types of reflection, different things a shader might do, different shapes you can create, different pieces of data you can transform. the mystery to unravel is the inner workings of the graphics card, the splashes of data between buffers and the drumbeat of instructions, the spaces of opportunity where the CPU or GPU is caught waiting.
it's a lot like painting, but the language of painting seems to be less mysterious to people than the language of tech art.
I think even at work, my enthusiasm for this stuff is to my colleagues a foible to be indulged, especially when it makes the game look cool - and I'm lucky to have that, but I want to know other autists who are just as much a freak about it, just like I am very glad to have many people to talk to about music. of course, there are plenty of places to talk about computer graphics on the internet... lots of wonderful little blogs. there's the demoscene and so on, various discord servers. yt channels like sebastian lague and acerola are doing a lot to spread the word of how fun this stuff is. but it's a separate sphere, one disconnected from the rest of life.
I wanna stream graphics/gamedev stuff more, I want to talk more about computer graphics on here. but I don't know how to like, reach across from this strange little island.
perhaps I just try it and see... after all, it's worked for animation, hasn't it?
48 notes
·
View notes
Text
OneAPI Construction Kit For Intel RISC V Processor Interface

With the oneAPI Construction Kit, you may integrate the oneAPI Ecosystem into your Intel RISC V Processor.
Intel RISC-V
Recently, Codeplay, an Intel business, revealed that their oneAPI Construction Kit supports RISC-V. Rapidly expanding, Intel RISC V is an open standard instruction set architecture (ISA) available under royalty-free open-source licenses for processors of all kinds.
Through direct programming in C++ with SYCL, along with a set of libraries aimed at common functions like math, threading, and neural networks, and a hardware abstraction layer that allows programming in one language to target different devices, the oneAPI programming model enables a single codebase to be deployed across multiple computing architectures including CPUs, GPUs, FPGAs, and other accelerators.
In order to promote open source cooperation and the creation of a cohesive, cross-architecture programming paradigm free from proprietary software lock-in, the oneAPI standard is now overseen by the UXL Foundation.
A framework that may be used to expand the oneAPI ecosystem to bespoke AI and HPC architectures is Codeplay’s oneAPI Construction Kit. For both native on-host and cross-compilation, the most recent 4.0 version brings RISC-V native host for the first time.
Because of this capability, programs may be executed on a CPU and benefit from the acceleration that SYCL offers via data parallelism. With the oneAPI Construction Kit, Intel RISC V processor designers can now effortlessly connect SYCL and the oneAPI ecosystem with their hardware, marking a key step toward realizing the goal of a completely open hardware and software stack. It is completely free to use and open-source.
OneAPI Construction Kit
Your processor has access to an open environment with the oneAPI Construction Kit. It is a framework that opens up SYCL and other open standards to hardware platforms, and it can be used to expand the oneAPI ecosystem to include unique AI and HPC architectures.
Give Developers Access to a Dynamic, Open-Ecosystem
With the oneAPI Construction Kit, new and customized accelerators may benefit from the oneAPI ecosystem and an abundance of SYCL libraries. Contributors from many sectors of the industry support and maintain this open environment, so you may build with the knowledge that features and libraries will be preserved. Additionally, it frees up developers’ time to innovate more quickly by reducing the amount of time spent rewriting code and managing disparate codebases.
The oneAPI Construction Kit is useful for anybody who designs hardware. To get you started, the Kit includes a reference implementation for Intel RISC V vector processors, although it is not confined to RISC-V and may be modified for a variety of processors.
Codeplay Enhances the oneAPI Construction Kit with RISC-V Support
The rapidly expanding open standard instruction set architecture (ISA) known as RISC-V is compatible with all sorts of processors, including accelerators and CPUs. Axelera, Codasip, and others make Intel RISC V processors for a variety of applications. RISC-V-powered microprocessors are also being developed by the EU as part of the European Processor Initiative.
At Codeplay, has been long been pioneers in open ecosystems, and as a part of RISC-V International, its’ve worked on the project for a number of years, leading working groups that have helped to shape the standard. Nous realize that building a genuinely open environment starts with open, standards-based hardware. But in order to do that, must also need open hardware, open software, and open source from top to bottom.
This is where oneAPI and SYCL come in, offering an ecosystem of open-source, standards-based software libraries for applications of various kinds, such oneMKL or oneDNN, combined with a well-developed programming architecture. Both SYCL and oneAPI are heterogeneous, which means that you may create code once and use it on any GPU AMD, Intel, NVIDIA, or, as of late, RISC-V without being restricted by the manufacturer.
Intel initially implemented RISC-V native host for both native on-host and cross-compilation with the most recent 4.0 version of the oneAPI Construction Kit. Because of this capability, programs may be executed on a CPU and benefit from the acceleration that SYCL offers via data parallelism. With the oneAPI Construction Kit, Intel RISC V processor designers can now effortlessly connect SYCL and the oneAPI ecosystem with their hardware, marking a major step toward realizing the vision of a completely open hardware and software stack.
Read more on govindhtech.com
#OneAPIConstructionKit#IntelRISCV#SYCL#FPGA#IntelRISCVProcessorInterface#oneAPI#RISCV#oneDNN#oneMKL#RISCVSupport#OpenEcosystem#technology#technews#news#govindhtech
2 notes
·
View notes
Text
What Are The Core Subjects In B.Tech Computer Science?

B.Tech in Computer Science Engineering (CSE) is one of the most popular engineering programs, focusing on computing technologies, programming, and system design. The curriculum is designed to equip students with theoretical and practical knowledge in various domains of computer science. Here are the core subjects that form the foundation of a B.Tech CSE program.
1. Programming and Data Structures
This subject introduces students to fundamental programming languages like C, C++, Java, and Python. It also covers data structures such as arrays, linked lists, stacks, queues, trees, and graphs, which are essential for efficient algorithm development.
2. Algorithms
Algorithms play a crucial role in problem-solving. Students learn about searching, sorting, dynamic programming, and graph algorithms. They also explore algorithm design techniques like divide and conquer, greedy algorithms, and backtracking.
3. Computer Networks
This subject covers networking fundamentals, including the OSI and TCP/IP models, data communication, network protocols, and security. It helps students understand how computers communicate over networks like the internet.
4. Database Management Systems (DBMS)
DBMS introduces students to relational databases, SQL, normalization, indexing, and transactions. Popular database systems like MySQL, PostgreSQL, and MongoDB are also studied in practical applications.
5. Operating Systems (OS)
Operating systems manage computer hardware and software resources. Topics include process management, memory management, file systems, scheduling algorithms, and concurrency in OS like Windows, Linux, and macOS.
6. Object-Oriented Programming (OOP)
OOP focuses on concepts like classes, objects, inheritance, polymorphism, encapsulation, and abstraction. Java, C++, and Python are commonly used languages for OOP principles.
7. Computer Architecture and Organization
This subject explores the internal structure of computers, including CPU design, memory hierarchy, instruction sets, and input/output mechanisms. It helps students understand how hardware and software interact.
8. Artificial Intelligence (AI) and Machine Learning (ML)
AI and ML are growing fields in computer science. Students learn about neural networks, deep learning, natural language processing, and AI algorithms that help in automation and decision-making.
9. Software Engineering
This subject focuses on software development methodologies, testing, maintenance, and project management. Agile and DevOps practices are commonly discussed.
10. Cybersecurity and Cryptography
Security is an essential aspect of computing. Topics include encryption techniques, network security, ethical hacking, and risk management to protect data from cyber threats.
11. Web Development and Mobile App Development
Students learn to design and develop websites using HTML, CSS, JavaScript, and frameworks like React and Angular. Mobile app development covers Android and iOS development using tools like Flutter and Swift.
12. Cloud Computing and Big Data
Cloud computing introduces platforms like AWS, Azure, and Google Cloud. Big data topics include Hadoop, data analytics, and distributed computing.
Conclusion
B.Tech in Computer Science covers a diverse range of subjects that prepare students for various career opportunities in software development, data science, AI, cybersecurity, and more. Mastering these core subjects will help students build a strong foundation for a successful career in the IT industry.
0 notes
Text
Story time. From 1992 or so until 1995 I worked for Adobe on Acrobat and various related tools. With the release of System 7, Apple included support for the new color controls which were 3D shaded and could be customized system wide with various "tinges".
One of the limitations of the system scrollbars was that they really wanted to be 16 pixels wide/high. Otherwise they were scaled with Quickdraw scaling and looked like garbage. In Acrobat, we had support for sticky note annotations in documents. In order for this to not take up huge amount of real estate, they used a small font and scaled them to be 8 pixels wide/high. They looked like absolute shit.
Fortunately, Apple had the ability to support custom controls via code resources called CDEFs (Control DEFinition). These were raw code blocks that followed a particular calling convention for drawing controls in various states. I was tasked with making the sticky note scroll bars look less like shit, so I wrote a custom CDEF for them. To give you an idea of what I did, here was my feature list:
Must look pretty at the small dimensions
Must mimic the system controls
Must honor the system color tinge
Must look good at any bit depth
Must look good in color and grayscale
Must draw correctly when spanning multiple monitors with different bit depths
Must run optimally on 68000 and 68020 (and above) Macs
Must be easy to integrate into the Acrobat code base
Must not bloat the application - at the time, the Acrobat installer fit on 1 floppy and there was a lot of pressure to avoid going beyond that since that increased the cost of the BOM and the production costs.
I did all of these things and busted my ass to do them. To meet the various color requirements, I made icon resources for every bit depth which included teeny arrows in each of the three states (active, active pressed, inactive) in both orientations, teeny scroll thumbs in the 3 states and orientations, and IIRC patterns for the large areas. With a 32x32 icon, you can fit 16 8x8 mini icons within it, which was enough to get all the arrows and thumbs in 1 icon. You could create icons for 1, 2, 4, and 8 bit versions. I think I used cicn resources for these.
I used a utility routine written by joe holt called "forEachIntersectingMonitor" or some such which would take a rectangle and a callback function and call the callback function once for every monitor that intersected the rectangle informing you of the bit depth you needed to draw in along with some other useful information.
I compiled the code twice - each time with settings for the supported CPU and there were minor compile time changes. The important thing is that while the 68000 code would run unchanged on the 68020, the 68020 had a somewhat better instruction set and optimizer did a better job generating code. I wrote a small stub that selected stub that mocked a CDEF and loaded the appropriate one only, keeping runtime memory usage lower and giving the best performance.
Acrobat on the Mac was originally built using a class library which had abstractions for controls. We could subclass the built-in version of a standard scrollbar to use mine instead. This wasn't ideal, but it worked.
I spent an hour trying to get Acrobat 2.0 running on Infinite Mac so I could get a screen shot, but ran into a pile of roadblocks and gave up.
When Acrobat 3 was written to include a better cross-platform strategy, one of the main features was that to the greatest extent possible, code should be shared across all platforms. To this end, the class library we used got scrapped and the sticky notes were rewritten in nearly entirely cross-platform code and the scrollbars looked identical but didn't operate like platform scrollbars entirely, didn't honor system settings, and IMHO looked only slightly less like dogshit than the scaled down Mac standard scrollbars. I was working on the search engine at the time, so I wasn't involved.
tl;dr:
yeah, it was a pain in the ass to make controls look good (the mantra was "it's hard to be easy") and it required a great deal of domain-specific knowledge
this work was done by engineers who took a great deal of pride in their work
some architectural decisions ("share as much code as possible") had unintended consequences (eg, controls looked foreign and didn't always operate intuitively if you were familiar with the platform as a user).
One small but extremely annoying effect of Tech Modernization or w/e is how UI contrast is garbage anymore, especially just, like, application windows in general.
"Ooh our scrollbar expands when you mouse over it! Or does it? Only you can know by sitting there like an idiot for 3 seconds waiting for it to expand, only to move your cursor away just as it does so!" or Discord's even more excellent "scrollbar is 2 shades off of the background color and is one (1) pixel wide" fuck OFF
I tried to move a system window around yesterday and had to click 3 times before I got the half of the upper bar that let me drag it. Why are there two separate bars with absolutely nothing to visually differentiate them on that.
"Well if you look closely-" I should not!! have to squint!!! at the screen for a minute straight to detect basic UI elements!! Not mention how ableist this shit is, and for what? ~✨Aesthetic✨~?
and then every website and app imitates this but in different ways so everything is consistently dogshit to try to use but not always in ways you can immediately grok it's!!!! terrible!!!! just put lines on things again I'm begging you!!!!
27K notes
·
View notes
Text
but i dont understand why theres like an equivalent amount of overhead emulating the 3ds on arm as it is on x86. as far as i can tell armv8 (modern 64 bit arm cpu) is back compatible to armv6* (3ds cpu) and the special vector processing addon the 3ds had was superceded by a different vector processing unit, which at Least the raspberry pi 4 and 5 have, idk about snapdragons. actually i dont know if snapdragons are 64 bit at all? not my main concern. but so like the instruction translation should be able to be nearly transparent right ?? compared to x86. it ran on a minimal os so i assume framerate is already naturally abstracted from cpu cycles. idk how costly emulating the os layer is or really what that entails because i havent found anyone writing anything about it and i only know stuff about that in the context of a desktop. the gpu is really different and proprietary as always but its like Actually a gpu and it runs mostly on opengl even! i also dont understand why there are separate opengl and vulkan backends to citra if the vulkan would be emulating opengl anyway wouldnt it. but the original citra github was taken down so i cant look through their issue tracker to see what people have talked about and all the other ones are just so new and small. and it seems like nobodys even developing the translation layer they used anymore at all theres just mirror archives
0 notes
Text
This Week in Rust 567
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on X (formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
rPGP 0.14.0 (a pure Rust implementation of OpenPGP) now supports the new RFC 9580
Official
This Development-cycle in Cargo: 1.82
Return type notation MVP: Call for testing!
Project/Tooling Updates
Two weeks of binsider
egui 0.29
pantheon: Parsing command line arguments
System76 COSMIC Alpha 2 Released
Linus and Dirk on succession, Rust, and more
What the Nova GPU driver needs
Getting PCI driver abstractions upstream
Coccinelle for Rust
An update on gccrs development
BTF, Rust, and the kernel toolchain
tokio-graceful 0.2.0: support shutdown trigger delay and forceful shutdown
Cargo Watch 8.5.3: the final update, as the project goes dormant
Observations/Thoughts
Best practices for error handling in kernel Rust
A discussion of Rust safety documentation
(Re)Using rustc components in gccrs
Whence '\n'?
Should you use Rust in LLM based tools for performance?
Code Generation in Rust vs C++26
Rust adventure to develop a Game Boy emulator — Part 3: CPU Instructions
Improved Turso (libsql) ergonomics in Rust
Rewriting Rust
Making overwrite opt-in #crazyideas
Rust needs a web framework for lazy developers
Safety Goggles for Alchemists
Beyond multi-core parallelism: faster Mandelbrot with SIMD
Nine Rules for Running Rust on WASM WASI
Rust needs an extended standard library
Rust Walkthroughs
New Book: "100 Exercises to Learn Rust: A hands-on course by Mainmatter".
Rust interop in practice: speaking Python and Javascript
[Series] Mastering Dependency Injection in Rust: Despatma with Lifetimes
Sqlx4k - Interoperability between Kotlin and Rust, using FFI (Part 1)
Serde for Trait objects
[video] Build with Naz : Rust clap colorization
Miscellaneous
Resources for learning Rust for kernel development
Crate of the Week
This week's crate is binsider, a terminal UI tool for analyzing binary files.
Despite yet another week without suggestions, llogiq is appropriately pleased with his choice.
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
RFCs
No calls for testing were issued this week.
Rust
No calls for testing were issued this week.
Rustup
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
* Rustikon CFP | Event Page | Closes 2024-10-13 | Warsaw, PL | Event 2025-03-26
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
Updates from the Rust Project
451 pull requests were merged in the last week
add new Tier-3 target: loongarch64-unknown-linux-ohos
add RISC-V vxworks targets
cfg_match Generalize inputs
add InProgress ErrorKind gated behind io_error_inprogress feature
allow instantiating object trait binder when upcasting
allow instantiating trait object binder in ptr-to-ptr casts
ban combination of GCE and new solver
collect relevant item bounds from trait clauses for nested rigid projections
diagnostics: wrap fn cast suggestions in parens when needed
don't trap into the debugger on panics under Linux
enable compiler fingerprint logs in verbose mode
fix adt_const_params leaking {type error} in error msg
fix diagnostics for coroutines with () as input
fix error span if arg to asm!() is a macro call
fix the misleading diagnostic for let_underscore_drop on type without Drop implementation
fix: ices on virtual-function-elimination about principal trait
implement trim-paths sysroot changes - take 2 (RFC #3127)
improve compile errors for invalid ptr-to-ptr casts with trait objects
initial std library support for NuttX
make clashing_extern_declarations considering generic args for ADT field
mark some more types as having insignificant dtor
on implicit Sized bound on fn argument, point at type instead of pattern
only add an automatic SONAME for Rust dylibs
pass Module Analysis Manager to Standard Instrumentations
pass correct HirId to late_bound_vars in diagnostic code
preserve brackets around if-lets and skip while-lets
properly elaborate effects implied bounds for super traits
reference UNSPECIFIED instead of INADDR_ANY in join_multicast_v4
reject leading unsafe in cfg!(...) and --check-cfg
rename standalone doctest attribute into standalone_crate
reorder stack spills so that constants come later
separate collection of crate-local inherent impls from error tracking
simple validation for unsize coercion in MIR validation
check vtable projections for validity in miri
miri: implements arc4random_buf shim for freebsd/solarish platforms
miri: make returning io errors more uniform and convenient
miri: refactor return_read_bytes_and_count and return_written_byte_count_or_error
miri: switch custom target JSON test to a less exotic target
skip query in get_parent_item when possible
stabilize const_cell_into_inner
stabilize const_intrinsic_copy
stabilize const_refs_to_static
stabilize option_get_or_insert_default
improve autovectorization of to_lowercase / to_uppercase functions
add File constructors that return files wrapped with a buffer
add must_use attribute to len_utf8 and len_utf16
add optimize_for_size variants for stable and unstable sort as well as select_nth_unstable
fix read_buf uses in std
make ptr metadata functions callable from stable const fn
mark make_ascii_uppercase and make_ascii_lowercase in [u8] and str as const
fix some cfg logic around optimize_for_size and 16-bit targets
hook up std::net to wasi-libc on wasm32-wasip2 target
compute RUST_EXCEPTION_CLASS from native-endian bytes
hashbrown: change signature of get_many_mut APIs
regex: add SetMatches::matched_all
cargo timings: support dark color scheme in HTML output
cargo toml: Add autolib
cargo rustc: give trailing flags higher precedence on nightly
cargo config: Don't double-warn about $CARGO_HOME/config
cargo compiler: zero-copy deserialization when possible
cargo: add CARGO_MANIFEST_PATH env variable
cargo: lockfile path implies --locked on cargo install
cargo: make lockfile v4 the default
cargo: correct error count for cargo check --message-format json
cargo perf: improve quality of completion performance traces
cargo test: add support for features in the sat resolver
cargo test: relax compiler panic assertions
cargo test: relax panic output assertion
rustdoc perf: clone clean::Item less
rustdoc: do not animate :target when user prefers reduced motion
rustdoc: inherit parent's stability where applicable
rustdoc: rewrite stability inheritance as a doc pass
rustdoc: copy correct path to clipboard for modules/keywords/primitives
rustdoc: redesign toolbar and disclosure widgets
rustdoc toolbar: Adjust spacings and sizing to improve behavior with over-long names
add field@ and variant@ doc-link disambiguators
rustfmt: add style_edition 2027
clippy: wildcard_in_or_patterns will no longer be triggered for types annotated with #[nonexhaustive]
clippy: invalid_null_ptr_usage: fix false positives for std::ptr::slice_from_raw_parts functions
clippy: add reasons for or remove some //@no-rustfix annotations
clippy: extend needless_lifetimes to suggest eliding impl lifetimes
clippy: specifying reason in expect(clippy::needless_return) no longer triggers false positive
clippy: ignore --print/-Vv requests in clippy-driver
clippy: remove method call receiver special casing in unused_async lint
clippy: suggest Option<&T> instead of &Option<T>
clippy: convert &Option<T> to Option<&T>
clippy: use std_or_core to determine the correct prefix
rust-analyzer: building before a debugging session was restarted
rust-analyzer: index workspace symbols at startup rather than on the first symbol search
rust-analyzer: provide an config option to not set cfg(test)
rust-analyzer: ambiguity with CamelCase diagnostic messages, align with rustc warnings
rust-analyzer: better support references in consuming postfix completions
rust-analyzer: consider lifetime GATs object unsafe
rust-analyzer: don't report a startup error when a discover command is configured
rust-analyzer: fix a bug in span map merge, and add explanations of how span maps are stored
rust-analyzer: fix name resolution when an import is resolved to some namespace and then later in the algorithm another namespace is added
rust-analyzer: fix resolution of label inside macro
rust-analyzer: handle block exprs as modules when finding their parents
rust-analyzer: pass all-targets for build scripts in more cli commands
Rust Compiler Performance Triage
A quiet week without too many perf. changes, although there was a nice perf. win on documentation builds thanks to [#130857](https://github.com/rust-lang/rust/. Overall the results were positive.
Triage done by @kobzol. Revision range: 4cadeda9..c87004a1
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 0.5% [0.2%, 0.8%] 11 Regressions ❌ (secondary) 0.3% [0.2%, 0.6%] 19 Improvements ✅ (primary) -1.2% [-14.9%, -0.2%] 21 Improvements ✅ (secondary) -1.0% [-2.3%, -0.3%] 5 All ❌✅ (primary) -0.6% [-14.9%, 0.8%] 32
3 Regressions, 4 Improvements, 3 Mixed; 2 of them in rollups 47 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: postpone] Make cargo install respect lockfiles by default
[disposition: postpone] RFC: Templating CARGO_TARGET_DIR to make it the parent of all target directories
[disposition: postpone] Cargo: providing artifacts (for artifact dependencies) via build.rs
Tracking Issues & PRs
Rust
[disposition: merge] Tracking Issue for constify-ing non-trait Duration methods
[disposition: merge] Tracking Issue for const Result methods
[disposition: merge] Tracking issue for const Option functions
[disposition: merge] Tracking Issue for slice_first_last_chunk feature (slice::{split_,}{first,last}_chunk{,_mut})
[disposition: merge] Partially stabilize const_pin
[disposition: merge] Check elaborated projections from dyn don't mention unconstrained late bound lifetimes
[disposition: merge] Stabilize the map/value methods on ControlFlow
[disposition: merge] Do not consider match/let/ref of place that evaluates to ! to diverge, disallow coercions from them too
[disposition: merge] Tracking issue for const slice::from_raw_parts_mut (const_slice_from_raw_parts_mut)
[disposition: merge] Stabilize const {slice,array}::from_mut
[disposition: merge] Tracking Issue for feature(const_slice_split_at_mut)
[disposition: merge] Tracking Issue for str::from_utf8_unchecked_mut as a const fn
[disposition: merge] Tracking Issue for #![feature(const_unsafecell_get_mut)]
[disposition: merge] Tracking Issue for const_maybe_uninit_assume_init
[disposition: merge] Tracking issue for #![feature(const_float_classify)]
[disposition: merge] Tracking Issue for const_str_as_mut
[disposition: merge] Tracking Issue for pin_deref_mut
[disposition: merge] Tracking Issue for UnsafeCell::from_mut
[disposition: merge] Tracking Issue for BufRead::skip_until
Cargo
[disposition: merge] docs(charter): Declare new Intentional Artifacts as 'small' changes
Language Team
[disposition: merge] Meeting proposal: rename "object safety" to "dyn compatibility"
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline Tracking Issues or PRs entered Final Comment Period this week.
New and Updated RFCs
[new] num::WrappingFrom trait for conversions between integers
[new] Add helper methods on primitive pointer types for pointer tagging
Upcoming Events
Rusty Events between 2024-10-02 - 2024-10-30 🦀
Virtual
2024-10-02 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 8 - Asynchronous Programming
2024-10-02 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh on Rust's HashMap
2024-10-02 | Virtual (Vancouver, BC, CA) | Vancouver Postgres
Leveraging a PL/RUST extension to protect sensitive data in PostgreSQL
2024-10-03 | Virtual | Women in Rust
Part 1 of 4 - Rust Essentials: Build Your First API
2024-10-03 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-10-08 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-10-10 | Virtual | Women in Rust
Part 2 of 4 - Navigating Rust Web Frameworks: Axum, Actix, and Rocket
2024-10-10 | Virtual (Barcelona, ES) | BcnRust + Codurance + Heavy Duty Builders
15th BcnRust Meetup
2024-10-10 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-10-10 | Virtual (Girona, ES) | Rust Girona
Leveraging Rust to Improve Your Programming Fundamentals & De Rust A Solana
2024-10-10 - 2024-10-11 | Virtual and In-Person (Vienna, AT) | Euro Rust
Euro Rust 2024
2024-10-14 | Virtual | Women in Rust
👋 Community Catch Up
2024-10-15 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2024-10-16 | Virtual and In-Person (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-10-17 | Virtual | Women in Rust
Part 3 of 4 - Hackathon Ideation Lab
2024-10-17| Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-10-22 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-10-24 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-10-26 | Virtual (Gdansk, PL) | Stacja IT Trójmiasto
Rust – budowanie narzędzi działających w linii komend
2024-10-29 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
Africa
2024-10-05 | Kampala, UG | Rust Circle Kampala
Rust Circle Meetup
Asia
2024-10-09 | Subang Jaya / Kuala Lumpur, Selangor, MY | Rust Malaysia
Rust Malaysia Meetup - Traits and How to Read Trait (October 2024)
2024-10-17 - 2024-10-18 | Beijing, CN | Global Open-Source Innovation Meetup (GOSIM)
GOSIM 2024
2024-10-19 | Bangalore/Bengaluru, IN | Rust Bangalore
October 2024 Rustacean meetup
Europe
2024-10-02 | Oxford, UK | Oxfrod Rust Meetup Group
Rust for Rustaceans Book Club: Chapter 11: Foreign Function Interfaces
2024-10-02 | Stockholm, SE | Stockholm Rust
Rust Meetup @Funnel
2022-10-03 | Nürnberg, DE | Rust Nurnberg DE
Rust Nürnberg online
2024-10-03 | Oslo, NO | Rust Oslo
Rust Hack'n'Learn at Kampen Bistro
2024-10-09 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup
2024-10-10 - 2024-10-11 | Virtual and In-Person (Vienna, AT) | Euro Rust
Euro Rust 2024
2024-10-15 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
Topic TBD
2024-10-17 | Darmstadr, DE | Rust Rhein-Main
Rust Code Together
2024-10-15 | Cambridge, UK | Cambridge Rust Meetup
Monthly Rust Meetup
2024-10-15 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
Topic TBD
2024-10-15 | Munich, DE | Rust Munich
Rust Munich 2024 / 3 - hybrid
2024-10-16 | Manchester, UK | Rust Manchester
Rust Manchester Talks October - Leptos and Crux
2024-10-17 | Barcelona, ES | BcnRust
16th BcnRust Meetup
2024-10-17 | Bern, CH | Rust Bern
2024 Rust Talks Bern #3
2024-10-22 | Warsaw, PL | Rust Warsaw
New Rust Warsaw Meetup #2
2024-10-28 | Paris, FR | Rust Paris
Rust Meetup #71
2024-10-29 | Aarhus, DK | Rust Aarhus
Hack Night
2024-10-30 | Hamburg, DE | Rust Meetup Hamburg
Rust Hack & Learn October 2024
North America
2024-10-03 | Boston, MA, US | SquiggleConf
SquiggleConf 2024: "Oxc: Pluggable Next-Gen Tooling At Rust Speed", Don Isaac
2024-10-03 | Montréal, QC, CA | Rust Montréal
October Social
2024-10-03 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-10-03 | St. Louis, MO, US | STL Rust
Iterators in Rust
2024-10-04 | Mexico City, DF, MX | Rust MX
Multi threading y Async en Rust pt1. Prerequisitos
2024-10-05 | Cambridge, MA, US | Boston Rust Meetup
Davis Square Rust Lunch, Oct 5
2024-10-08 | Detroit, MI, US | Detroit Rust
Rust Community Meetup - Ann Arbor
2024-10-15 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-10-16 | Virtual and In-Person (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-10-17 | Virtual and In-Person (Seattle, WA, US) | Seattle Rust User Group
October Meetup
2024-10-19 | Cambridge, MA, US | Boston Rust Meetup
North End Rust Lunch, Oct 19
2024-10-23 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2024-10-27 | Cambridge, MA, US | Boston Rust Meetup
Kendall Rust Lunch, Oct 27
Oceania
2024-10-29 | Canberra, ACT, AU | Canberra Rust User Group (CRUG)
June Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Just to provide another perspective: if you can write the programs you want to write, then all is good. You don't have to use every single tool in the standard library.
I co-authored the Rust book. I have twelve years experience writing Rust code, and just over thirty years of experience writing software. I have written a macro_rules macro exactly one time, and that was 95% taking someone else's macro and modifying it. I have written one proc macro. I have used Box::leak once. I have never used Arc::downgrade. I've used Cow a handful of times.
Don't stress yourself out. You're doing fine.
– Steve Klabnik on r/rust
Thanks to Jacob Finkelman for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
1 note
·
View note
Text
Data Security: Secure Erase NVMe and Wipe NVMe

In today's digital landscape, data security is of paramount importance. With the rapid evolution of technology, the need to ensure that sensitive information is properly and securely erased has never been more critical. Non-Volatile Memory Express (NVMe) drives, known for their superior speed and efficiency, have become the storage solution of choice for many. However, the advanced technology behind NVMe drives introduces unique challenges when it comes to securely erasing data. This is where specialized tools like Secure Erase NVMe and Wipe NVMe come into play. Understanding how these tools work and their significance is essential for maintaining robust data security.
The Rise of NVMe Drives
NVMe drives represent a significant leap forward in storage technology. Unlike traditional Hard Disk Drives (HDDs) and even earlier Solid State Drives (SSDs), NVMe drives leverage the PCIe (Peripheral Component Interconnect Express) interface, providing a direct connection to the CPU. This connection results in faster data transfer rates, reduced latency, and improved overall performance. NVMe drives are particularly favored for their high speed, which benefits applications ranging from gaming to data-intensive business operations.
Despite their advantages, NVMe drives also bring complexities in data management. Traditional methods of data deletion, such as simple formatting or overwriting, are not fully effective with NVMe technology due to the drive's architecture and management processes. This is where Secure Erase NVMe and Wipe NVMe tools become indispensable.
Why Standard Erasure Methods Fall Short
Traditional data deletion methods often fail to address the unique challenges presented by NVMe drives. When a file is deleted from a standard drive, the operating system marks the space as available for new data. However, the actual data remains on the drive until it is overwritten. While this might be sufficient for HDDs and even some SSDs, NVMe drives use a more complex system involving multiple layers of abstraction, such as wear leveling and garbage collection, which complicates the erasure process.
Wear leveling ensures that data writes are evenly distributed across the drive’s memory cells to extend the drive's lifespan. Garbage collection, on the other hand, consolidates free space and cleans up unused data blocks. These processes can interfere with traditional data erasure methods, leaving remnants of deleted files that can potentially be recovered.
Secure Erase NVMe: A Comprehensive Solution
Secure Erase NVMe is a specialized tool designed to address these challenges by leveraging the drive’s built-in features. NVMe drives come equipped with a secure erase command that is specifically intended to handle data deletion at a fundamental level. This command instructs the drive to clear all user data and reset the storage cells to their original state.
Built-in Commands: Secure Erase NVMe tools utilize the drive’s internal secure erase commands to ensure that all data is removed comprehensively. These commands are designed to clear data from all regions of the drive, including hidden or reserved areas that might not be accessible through conventional methods.
Efficiency and Speed: One of the primary advantages of Secure Erase NVMe is its efficiency. The secure erase command operates directly through the drive’s firmware, making the process faster and more effective compared to manual overwriting methods. This direct approach reduces the time required for data deletion and ensures that all data is removed in compliance with industry standards.
Compliance with Standards: Secure Erase NVMe tools adhere to established data security standards, such as those set by the National Institute of Standards and Technology (NIST). This compliance ensures that the data erasure process meets stringent security requirements and provides a high level of assurance that data cannot be recovered.
Wipe NVMe: Beyond Basic Erasure
While Secure Erase NVMe provides a robust solution for data deletion, Wipe NVMe tools offer additional methods for ensuring complete data removal. Wipe NVMe encompasses a range of techniques designed to address the complexities of NVMe drives and enhance the effectiveness of data erasure.
Advanced Overwriting Techniques: Wipe NVMe tools employ advanced overwriting techniques that go beyond simple data deletion. These techniques involve writing random data patterns across the entire drive multiple times to ensure that the original data is thoroughly obliterated. This method is particularly useful for drives that may not fully support secure erase commands.
Customization and Flexibility: Unlike basic erasure methods, Wipe NVMe tools often offer customizable options that allow users to tailor the erasure process according to their specific needs. This flexibility includes adjusting the number of overwrite passes or selecting specific drive regions for targeted erasure, providing a more comprehensive data destruction solution.
Enhanced Security Features: Some Wipe NVMe tools include additional security features, such as cryptographic erasure. This method involves encrypting the drive’s data and then deleting the encryption key, rendering the data inaccessible and ensuring that even if remnants are recovered, they remain indecipherable.
Choosing the Right Tool for Your Needs
Selecting the appropriate tool for NVMe data erasure depends on several factors, including the specific requirements of your data security strategy and the capabilities of your NVMe drive. Secure Erase NVMe is ideal for users seeking a quick and effective solution that leverages the drive’s built-in features. Wipe NVMe, on the other hand, offers more flexibility and advanced options for users who need to ensure the highest level of data security.
When evaluating erasure tools, it is important to consider factors such as compatibility with your drive model, adherence to industry standards, and the overall effectiveness of the erasure methods employed. Ensuring that the tool is regularly updated to support the latest drive technologies is also crucial for maintaining optimal data security.
Best Practices for Secure Data Deletion
In addition to using specialized erasure tools, adhering to best practices for data deletion is essential for ensuring complete security. Always verify that the erasure process has been successfully completed and consider performing multiple erasure methods if dealing with highly sensitive information. For critical data, physical destruction of the drive may also be advisable to guarantee that no data can be recovered.
Conclusion
As data security continues to be a top priority in our increasingly digital world, the importance of effective data erasure cannot be overstated. Secure Erase NVMe and Wipe NVMe tools are crucial components in this process, offering specialized solutions to address the unique challenges posed by NVMe drives. By utilizing these advanced tools, individuals and organizations can ensure that their data is not only deleted but completely eradicated, safeguarding against unauthorized access and potential breaches. In the realm of data storage and security, Secure Erase NVMe and Wipe NVMe stand as essential allies in maintaining robust data protection and privacy.
0 notes
Quote
Arm is an Instruction Set Architecture (ISA), which is the interface between the software and the hardware, or specifically the microprocessor. The Instruction Set is the library of specific instructions that the chip is able to execute. All code that is written for that particular device is basically an abstraction of a combination of all these instructions. The Arm ISA is the most ubiquitous instruction set in the world, with the other famous one being x86 that we see in many CPUs. RISC-V is also on a meteoric rise. The Arm ISA moat is very strong, especially in smartphones. We do not see smartphones able to transition to RISC-V anytime soon due to numerous software challenges. Designing a CPU is no easy task, and to date only a handful of firms (AMD, Intel, IBM, Apple, and Arm) have ever designed great CPUs and brought them to market. It requires a lot of time and engineering talent. Money alone doesn’t make a good CPU. Apple licenses the Arm ISA via an Architectural License Agreement (ALA) and has been building their own core for many years. HiSilicon also licensing the Armv9 architecture but with a custom core design was another shocking part of new Huawei’s Kirin 9000S news.
Arm and a Leg: Arm's Quest To Extract Their True Value
0 notes
Text
What is programming language and its types?

In today’s digital age, computers have become an integral part of almost every industry—from healthcare and finance to entertainment and education. But how do these machines understand what we want them to do? The answer lies in programming languages. These languages serve as the medium through which we communicate with computers.
In this article, we’ll explore what programming languages are, their importance, and the various types that exist, each designed for specific purposes.
What Is a Programming Language?
A programming language is a formal set of instructions used to produce a wide range of outputs, such as software applications, websites, games, and more. It allows developers to write code that a computer can understand and execute.
These languages consist of syntax (structure) and semantics (meaning) that help define the behavior of software programs.
Why Programming Languages Matter:
They bridge the gap between human logic and machine understanding.
They enable automation, problem-solving, and innovation.
They form the foundation for technologies like AI, web development, and mobile apps.
Main Types of Programming Languages
Programming languages are generally classified based on their level of abstraction and application domain. Below are the primary categories:
1. Low-Level Languages
These are languages that interact closely with the hardware. They are fast and efficient but difficult to learn.
a. Machine Language
Written in binary code (0s and 1s)
Directly understood by the computer's CPU
Extremely difficult for humans to read or write
b. Assembly Language
Uses mnemonic codes (like MOV, ADD)
Requires an assembler to convert into machine code
Offers more control but still complex to use
2. High-Level Languages
These languages are designed to be human-readable and abstract away hardware details.
Examples:
Python: Known for simplicity and readability
Java: Popular for enterprise applications
C++: Offers high performance with object-oriented features
JavaScript: Essential for web development
High-level languages are widely used because they are easier to learn and maintain, even though they may not offer the same performance as low-level languages.
3. Object-Oriented Programming (OOP) Languages
OOP languages revolve around the concept of objects—entities that contain both data and methods.
Features:
Encapsulation: Bundling data with methods
Inheritance: Reusing existing code
Polymorphism: Flexibility in code behavior
Examples:
Java
Python (supports both OOP and procedural)
C#
OOP makes software development more modular, reusable, and scalable.
4. Procedural Programming Languages
These languages follow a step-by-step procedural approach to execute tasks.
Characteristics:
Focus on procedures or routines
Uses loops, conditionals, and sequences
Easier for beginners to grasp logical flow
Examples:
C
Pascal
BASIC
These are often used in education and system-level programming.
5. Scripting Languages
Scripting languages are primarily used to automate tasks and control environments, especially in web development.
Common Uses:
Front-end and back-end web development
Automation scripts
Game development
Examples:
JavaScript
PHP
Python (also used as a scripting language)
Interestingly, many professionals today are expanding their digital skills. For instance, someone interested in both programming and content creation might look for courses like the Best Content writing course in Chandigarh, as tech and communication skills are increasingly interconnected in today’s job market.
6. Functional Programming Languages
These languages treat computation as the evaluation of mathematical functions and avoid changing state or mutable data.
Features:
Immutability
First-class functions
Recursion over loops
Examples:
Haskell
Scala
Erlang
They are ideal for applications requiring high levels of concurrency or mathematical calculations.
7. Markup Languages (Non-Procedural)
While not programming languages in the traditional sense, markup languages are essential for defining data structure and presentation.
Examples:
HTML: Structures content on the web
XML: Stores and transports data
Markdown: Formats text in plain text editors
These are usually used alongside scripting or programming languages.
Choosing the Right Language
The “best” language depends on your goals:
Web Development: JavaScript, HTML, CSS, PHP
App Development: Java, Kotlin, Swift
Data Science & AI: Python, R
System Programming: C, C++
Before choosing a programming language, consider the project requirements, community support, and your learning preferences.
Conclusion
Programming languages are the backbone of the digital world. Understanding what they are and how they are categorized can significantly ease your journey into software development. Whether you’re coding a mobile app, creating a website, or even pursuing the best content writing course in Chandigarh, having a basic understanding of programming languages adds immense value to your skillset.
With the right mindset and learning resources, anyone can master the logic and language behind the world’s most powerful technologies.
0 notes
Text
#this idiot doesn't even know z80 assembly#(i don't know z80 assembly)
First, just in case you don't know how the standard bitwise operators (AND, OR, XOR, CPL, RR, RL) work, read this, it'll give you the basics.
In a high level language, you would set bit X (to 1) of variable Y like this:
y = y | (1 << x);
For example, if we wanted to set bit 4 of y to 1, and y was equal to 0b0110, then (1 << x) would be (1 << 4), which is equal to 0b1000; and 0b0110 | 0b1000 = 0b1110. Easy-peasy.
However, if we wanted to implement that into z80 assembly, we have to get a little creative. The z80 instruction set is very old (for a microprocessor, anyway) and is thus very limited. One of these limitations is that it doesn't have a "Left Shift [register 1] by [register 2]" instruction. (Registers, if you aren't aware, are basically like hard-coded variables that live inside the CPU instead of RAM.)
What it does have is a "Left Shift [register] by 1" instruction, equivalent to this c code:
r = r << 1;
where 'r' is a placeholder for a given register. It also has "Decrement [register]" and "Increment [register]" instructions that are equivalent to the c code:
r--;
and
r++;
And an "OR [register] with register A" instruction, equivalent to:
A = A | r;
Let's say that we're trying to set bit 4 of register A, and that we'll be storing which bit we're setting (4) in register L. We'll also use register B as a temporary value. This can be easily accomplished with a loop:
B = 1; while (L != 0) { L--; B = B << 1; } A = A | B;
In this example, B will equal to (1 << L) and A is thus equal to A | (1 << L), just what we wanted.
But z80 assembly doesn't have while loops, so we need to implement that too. What we do have are jumps, which are sort of like ifs and gotos put together (or rather, ifs and gotos are just different abstractions on jumps). The relevant instructions here are "jump to label if the last operation resulted in 0" and "jump to label unconditionally". Here's a naive approach to our while loop--and one of the approaches chatgpt took--in pseudo code:
B = 1; loop! <- label to jump to L--; if L is now 0, jump to done! B = B << 1; jump to loop! done! A = A | B;
But this isn't what we wanted--there's a classic off-by-one error. If L is 1, it won't shift at all, and if L is 0, it'll underflow and shift 256 times. The solution is pretty simple--just increment L right before the loop.
B = 1; L++; loop! <- label to jump to L--; if L is now 0, jump to done! B = B << 1; jump to loop! done! A = A | B;
There's more nuance here wrt the carry flag, rotate vs shift, instruction length, etc. but this is the general idea
(It's worth noting that you could get around the off-by-one error by considering bit 1 the first and bit 8 the last, instead of bit 0 and bit 7--it depends on your needs--but for my purposes I needed bit 0 to be the first bit.)
As an aside--the rest of the problems it had were down to a clear misunderstanding of how the z80 instruction set behaves. Take this bit from its first attempt:
OR B ; OR A with the mask in B, setting the desired bit LD A, B ; A now has the bit L set
This doesn't work. A C translation would be this:
A = A | B; A = B;
I have no idea why it tacked on that LD A, B; but it demonstrates a deeply flawed ability to generate code. Totally inane.
I wanted to see if our friend The World's Dumbest Robot could figure out the extremely simple process of "set bit L of register A" in z80 assembly, and the results were...consistent.
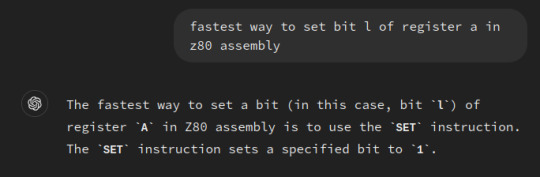
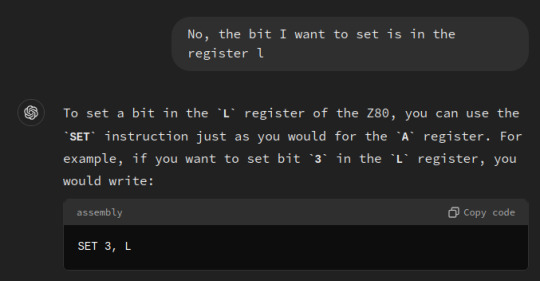




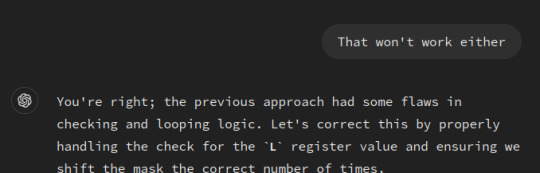

What a moron.
10 notes
·
View notes
Text
What is programming and code? (And how to write tutorials )
Easy topic of the day. I have yet to see someone answer this in a good way. It always gets into all sorts of overcomplications and forgets how write good tutorials. You need to know that there are 3 kinds of info you can give
1: How something works 2: Why something works like it does 3: What something is meant to be used for You should try to only do 1 or 2 in a single tutorial, and try NOT to switch between them more than absolutely necessary.
I will explain WHAT and a bit of WHY about programming today. Many programmers, and thus, people who try to teach programming, gets too stuck in HOW (Because it is what we do all day), which is frankly, not important for a higher concept thing programming. So here we go! Programming is autogenerating assembler. ... Ok maybe that needs a bit of flushing out. All code is assembler, or "Anything higher abstraction level than assembly" So to understand that, you need to understand what assembly is. And why 99.9% of you are NOT coding in it. And why(As someone who learned it, and still reads it from time to time at work) you should be very very thankful for that fact. Assembler is the lowest level programming language that exists. And can exist. Because in effect, it is machine language. They fit each-other 1 to 1 A machine language is a list of orders you can tell a CPU. Step by painstaking step. And a CPU can only do 2 things 1: It can save/load numbers 2: It can do simple math on those numbers. Things like add/multiply/divide and subtract EVERYTHING else is humans making up things about what those numbers mean. For example we agreed some 8 bit numbers was ACTUALLY letters. You just looked up what letter any given number represented in a long list. That is called ASCII, and was how computers used to write all text. This business of making up concepts that numbers represented is called encoding. EnCODEing. I am sure you see the connection :) But when writing assembly, you have to keep ALL of that in mind, and look everything up manually. You have to write "104" when you wanted to say "h" Oh, and each assembler language is slightly different, depending on what CPU it was created for. And each CPU have subtle tricks you can use to make it faster. So also keep all of those in mind when programming anything. It is, in other words, a horrible horrible pain to write anything larger than a few instructions. A programming language, is a language humans made up, with the only requirement that it can be translated into assembler. Because then you can write a program called a compiler, to translate your language into assembler, so you can read and write this language instead of having to read and write assembler. Granted, reading and writing C, C++, Java, C#, Kotlin, Python or any of the many MANY others is not the easiest thing, but it beats writing assembly. THAT is what code is. THAT is what programmers write. Language that automates encoding. Some do it by being compiled natively, like C and C++, meaning that you turn your code into assembler instructions to run on a specific machine later. Most likely the same one you wrote the program on. Other like Java, Python or Javascript use something that they call a "interpreter", "virtual machine" or "Browser". These programs can do extra things, but they ALL turn your code into assembler instructions AND runs them. So essentially a compiler that runs the code AS it compiles. But both turns somewhat human readable language, into assembler. All every programmer writes all day, is assembler. And that is sorta fun :)
9 notes
·
View notes
Text
Dataflux: Efficient Data Loading for Machine Learning

Dataflux Data Management Server
Large datasets are ideal for machine learning (ML) models, and quick data loading is essential for ML training that is affordable. They created the Dataflux Dataset, a PyTorch Dataset abstraction, to speed up the loading of data from Google Cloud Storage. With small files, Dataflux offers up to 3.5 times faster training times than fsspec.
With the release of this product, Google has demonstrated its support for open standards through more than 20 years of OSS contributions, including TensorFlow, JAX, TFX, MLIR, KubeFlow, and Kubernetes. It has also sponsored important OSS data science projects, like Project Jupyter and NumFOCUS.
Similar speed benefits were also observed when google cloud verified the Dataflux Dataset on Deep Learning IO (DLIO) benchmarks, even with bigger files. Google Cloud advise utilising Dataflux Dataset for training workflows instead of alternative libraries or making direct calls to the Cloud Storage API because of this significant performance gain.
Feature-rich Dataflux Dataset attributes include
Direct integration with cloud storage: Get rid of the requirement to download data locally first.
Optimise performance to attain up to 3.5 times quicker training times, particularly for smaller files.
PyTorch Dataset primitive: Easily integrate with well-known PyTorch ideas.
Support for checkpointing: Import and export model checkpoints straight to and from cloud storage.
How to Use Dataflux Datasets
Requirements: Python 3.8 and above
Installing gcs-torch-dataflux requires $ pip.
Use the Google Cloud application’s default authentication for authentication.
For instance, loading photos for instruction
The Dataflux Dataset can be enabled with just a few simple adjustments. It is quite probable that you have created your own Dataset implementation if you use PyTorch and have data stored in cloud storage. The Dataflux Dataset creation process is exemplified in the sample below.
Under the engine
Google tackled the data-loading performance limitations in ML training workflows to obtain such large performance gains for it. During a training run, data is processed and then sent from CPU to GPU for ML-Training calculations after being loaded in batches from storage. Longer training times result from the GPU being essentially blocked and underutilised if reading and building a batch takes longer than GPU processing.
It takes longer to retrieve data from a cloud-based object storage system (such as Google Cloud Storage) than it does from a local disc, particularly if the data is contained in little objects. The cause of this is latency from the first byte. However, the cloud storage infrastructure offers rapid throughput once an object is “opened.” Google used a Cloud Storage function in Dataflux called Compose items, which allows us to dynamically merge multiple smaller items into a larger one.
Subsequently, they download 30 larger objects to memory and merely fetch the remaining 1024 little objects (batch size). Following their breakdown into their component smaller objects, the bigger objects are once again used as dataset samples. During the procedure, all temporarily constructed objects are likewise cleared out.
High-throughput parallel-listing is another optimisation used by this Datasets to expedite the basic metadata required for the dataset. In order to greatly speed up listings, Dataflux uses a sophisticated mechanism called work-stealing. Even on datasets with tens of millions of objects, the initial AI training run, or “epoch,” is faster with this method than it is with Dataflux Datasets without parallel-listing.
Fast-listing and dynamic composition work together to guarantee that GPU delays during ML training with Dataflux are kept to a minimum, resulting in much shorter training times and higher accelerator utilisation.
The Dataflux Client Libraries include fast-listing and dynamic composition, which may be accessed on GitHub. Below the surface, Dataflux Dataset makes use of these client libraries.
Unfortunately, there is some ambiguity in the term “Dataflux Dataset futures”. Two meanings are possible:
Dataflux
This can be a reference to the Dataflux firm. It’s hard to tell if such a company exists and what it does with datasets without more information. It is also likely that the term “Dataflux” refers to the flow of data in a broader meaning.
Futures of Datasets
This could be a reference to datasets generally. This idea is more intriguing. Here are some concepts regarding datasets’ future:
Enhanced Volume and Variety
There will likely be a significant rise in the quantity of data gathered. A greater variety of sources, such as social media, sensors, and the Internet of Things (IoT), will provide this data.
Put Quality and Security First
As datasets get larger, it will be increasingly more important to make sure they are secure and of high quality. Anonymization, privacy protection, and data cleansing techniques will be essential.
Advanced Analytics
To extract insights from large and complicated datasets, new analytical tools and methodologies will be developed. Machine learning and artificial intelligence will progress as a result.
Standardisation and Interoperability
To facilitate the sharing and integration of datasets across various platforms and applications, there will probably be a push for more standardised data formats and protocols.
Read more on govindhtech.com
#machinelearning#PyTorch#GoogleCloud#DataFlux#gpuprocess#CloudStorage#github#analyticaltools#artificialintelligence#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
For people who are not rabid fans of 16bit computers (the original audience I had in mind while writing) here is some extra context I think may help(?)
8086- a line of 16bit intel CPUs. This is the ancestor of the amd64 chip most modern personal computers have (with exceptions for the apple silicon computers, people who still use 32-bit CPUs or older and some weird outliers)
ASM- assembly code. This is human-readable instructions that directly translate into machine code a CPU can read and execute. Different CPUs and operating systems will have different languages and variants, based on the architecture and purposes of these machine. This is as opposed to high level languages such as python or C# which are further abstracted from the CPU, and individual commands don't inherently translate to a single, specific CPU command.
Registers- a couple of small piece of fast storage that a CPU can access. This is where 8/16/32/64 bit CPUs differ, an 8 bit register can store 8 digits, a 16-bit register can store 16 digits, so on. On an 8086 CPU, some registers are divided into a "higher" and "lower" half, and some code accesses only one of these 8-bit halves, or it accesses both halves but uses them separately (Like using the higher half to decide what to do, and the lower half to decide how to do it.)
Interrupt- A request for the CPU to stop executing code to do a particular function. Based on which interrupt you call, and the values stored in the register at the time it is called, it will do different things like print a character, print a string, change the monitor resolution, accept a keypress, so on and so forth. This is very hardware and OS-dependent :)
Binary-compatibility- The ability of a computer system to run the same compiled code as another computer (As opposed to needing to cross-compile, or even rewrite the code entirely)
IBM PC compatibles are x86 computers that can run code for a contemporary IBM PC, as opposed to non-compatibles such as Apple computers. Semi-compatibles like the Tandy 2000 can sort of run IBM PC code but have some structural differences that cause parts of a piece of code to fail to work properly.
Apple computers have different CPUs entirely, while the PC-9800 series does use x86 CPUs. They just run a modified version of MS-DOS that's specialized for a Japanese market, and these modifications mean machine code for standard MS-DOS won't run on a PC-98.
If you have any questions about old computers feel free to ask away :) I am mostly knowledgeable about 16-bit computers, but I do have some 8 bit knowledge as well (primarily the Commodore 64) But maybe send them to @elfntr since that's where I usually post more technical computer stuff (as opposed to the more general computerposting I do here XD)
In conventional MS-DOS 8086 ASM, you display a single character by loading a value into AX and calling interrupt 0x10 so like
MOV AH,0Eh ;tells int 10h to do teletype output MOV AL,"H" ;character to print INT 10h
now, AH and AL here are two 8-bit halves of the 16bit register AX (the high byte and low byte respectively) which means that this display method means conventional MS-DOS can only use up to 256 characters-- and don't forget that this includes control characters like say, line feed, carriage return, escape, so on... not just printed characters. To display a newline in 8086 MS-DOS ASM you can do:
MOV AX,0E0Ah INT 10h MOV AL,0Dh INT 10h
(i shortened the first command compared to the original snippet because you now understand the relationship between AX, AH, and AL, dear reader. This saves a few CPU clocks :)
So you're pretty limited on the number of characters you can display.... and that's why PC-98 MS-DOS is not binary compatible with standard flavor MS-DOS XD
Like, you can display 65536 characters if you use an entire 16-bit register for the character code and use another register to call the print operation, but first you need to have a reason to do this and to actually do it.
6 notes
·
View notes
Text
Flexible plastic electronics (for an Internet of Things)
Published: 21 July 2021
https://www.nature.com/articles/s41586-021-03625-w
A natively flexible 32-bit Arm microprocessor
Nature volume 595, pages 532–536 (2021)
Abstract
Nearly 50 years ago, Intel created the world’s first commercially produced microprocessor—the 4004 (ref. 1), a modest 4-bit CPU (central processing unit) with 2,300 transistors fabricated using 10 μm process technology in silicon and capable only of simple arithmetic calculations.
Since this ground-breaking achievement, there has been continuous technological development with increasing sophistication to the stage where state-of-the-art silicon 64-bit microprocessors now have 30 billion transistors (for example, the AWS Graviton2 (ref. 2) microprocessor, fabricated using 7 nm process technology).
The microprocessor is now so embedded within our culture that it has become a meta-invention—that is, it is a tool that allows other inventions to be realized, most recently enabling the big data analysis needed for a COVID-19 vaccine to be developed in record time.
Here we report a 32-bit Arm (a reduced instruction set computing (RISC) architecture) microprocessor developed with metal-oxide thin-film transistor technology on a flexible substrate (which we call the PlasticARM). Separate from the mainstream semiconductor industry, flexible electronics operate within a domain that seamlessly integrates with everyday objects through a combination of ultrathin form factor, conformability, extreme low cost and potential for mass-scale production. PlasticARM pioneers the embedding of billions of low-cost, ultrathin microprocessors into everyday objects.
Main
Unlike conventional semiconductor devices, flexible electronic devices are built on substrates such as paper, plastic or metal foil, and use active thin-film semiconductor materials such as organics or metal oxides or amorphous silicon
. They offer a number of advantages over crystalline silicon, including thinness, conformability and low manufacturing costs. Thin-film transistors (TFTs) can be fabricated on flexible substrates at a much lower processing cost than metal–oxide–semiconductor field-effect transistors (MOSFETs) fabricated on crystalline silicon wafers.
The aim of the TFT technology is not to replace silicon. As both technologies continue to evolve, it is likely that silicon will maintain advantages in terms of performance, density and power efficiency. However, TFTs enable electronic products with novel form factors and at cost points unachievable with silicon, thereby vastly expanding the range of potential applications.
Microprocessors are at the heart of every electronic device, including smartphones, tablets, laptops, routers, servers, cars and, more recently, smart objects that make up the Internet of Things.
Although conventional silicon technology has embedded at least one microprocessor into every ‘smart’ device on Earth, it faces key challenges to make everyday objects smarter, such as bottles (milk, juice, alcohol or perfume), food packages, garments, wearable patches, bandages, and so on. Cost is the most important factor preventing conventional silicon technology from being viable in these everyday objects.
Although economies of scale in silicon fabrication have helped to reduce unit costs dramatically, the unit cost of a microprocessor is still prohibitively high. In addition, silicon chips are not naturally thin, flexible and conformable, all of which are highly desirable characteristics for embedded electronics in these everyday objects.
Flexible electronics, on the other hand, does offer these desirable characteristics. Over the past two decades, flexible electronics have progressed to offer mature low-cost, thin, flexible and conformable devices, including sensors, memories, batteries, light-emitting diodes, energy harvesters, near-field communication/radio frequency identification and printed circuitry such as antennas.
These are the essential electronic components to build any smart integrated electronic device. The missing piece is the flexible microprocessor.
The main reason why no viable flexible microprocessor yet exists is that a relatively large number of TFTs need to be integrated on a flexible substrate in order to perform any meaningful computation. This has not previously been possible with the emerging flexible TFT technology, in which a certain level of technology maturity is required before a large-scale integration can be done.
A midway approach has been to integrate silicon-based microprocessor dies onto flexible substrates—also called hybrid integration3,4,5—where the silicon wafer is thinned and dies from the wafer are integrated onto a flexible substrate. Although thin silicon die integration offers a short-term solution, the approach still relies on conventional high-cost manufacturing processes. It is, therefore, not a viable long-term solution for enabling the production of the billions of everyday smart objects expected over the next decade and beyond6.
Our approach is to develop the microprocessor natively using flexible electronic fabrication techniques, also termed a natively flexible processing engine7. The flexible electronics technology we used to build the natively flexible microprocessor described here consists of metal-oxide TFTs on polyimide substrates. Metal-oxide TFTs are low cost and can also be scaled down to the smaller geometries required for large-scale integration8....
3 notes
·
View notes
Text
September 6, 2020
My weekly view of things I am up to and thinking about. Topics include the future of Earth, housing in California, the national debt, carbon pricing, and software complexity.
Earth’s Future
The funder is interested in developing a timeline of Earth’s past and future and placing human history in the geologic context. It’s a bit off the beaten path for us, but a fun project, and I spent some time this week on it. It got me thinking about Earth’s long term future.
We all know, in at least a vague sense, that Earth’s days are numbered. I think most of us know that we expect the Sun to go nova some billions of years from now (about 7.6 billion I think is the best estimate), and barring intervention from a future advanced civilization, no life will be able to survive that.
I found this paper by O’Malley-James et al. to be an interesting read. It discusses the future of life from an astrobiological perspective, asking what biosignatures a distant civilization might observe from Earth in the distant future. Plant life that depends on C3 photosynthesis, and by extension most animal life, has maybe 500-600 million years left, beyond which point carbon dioxide is too depleted. Plant life based on C4 photosynthesis might make it 900 million years. From then on it’s only microbes. Eukaryotic life might last 1.2 billion years before the oxygen is depleted. Prokaryotic life was here first, and it will probably be here last. The paper estimates 2.8 billion years as an upper bound for any microbes at all to survive in caves or underground. For the remainder of its existence, Earth is a sterile, lifeless world without oceans, an atmosphere, or geological activity.
Before all that, Earth’s biosphere may go into an irreversible decline after the formation of Pangaea Ultima, about 250 million years from now. At that time, the combination of merging of continents, cooling of the Earth’s core, and increasing of solar luminosity will result in a falling of carbon dioxide to the point where today’s biological productivity cannot be sustained. Earth is now 95% of the age it will be when this happens.
It is an unspoken and open question of how this general picture might be altered by a civilization that is capable of effecting meaningful change over geological timelines. Human civilization is not at this level presently, and it is unclear if we will attain it.
I wonder too how contemplation of the biosphere’s mortality influences how we think of environmentalism and sustainability. Perhaps 250+ million years is so vast a time that it cannot be distinguished from infinity in our minds. For my part, I can admit that the prospect genuinely bothers me.
Housing in California
California’s legislative session expired at the end of August, and with it, another opportunity for statewide zoning reform. Scott Wiener’s SB1120 would have allowed duplexes on single family lots. It is a modest but valuable proposal which had majority legislative support, but some last minute parliamentary shenanigans from the party leadership ran out the clock.
I continue to think that the housing issue in California is intractable, and that with its current strategy, the YIMBY movement will not be able to attain any but the most marginal victories. The Bay Area needs to increase its housing supply by at least 50%, maybe 100%, to really solve the problem. To achieve those kinds of numbers, allowing duplexes and ADUs is not going to cut it. The region needs to be open to horizontal as well as vertical expansion. Something must be done to break the dysfunction in the construction industries that prevents buildings and infrastructure from being delivered at a reasonable time and speed. The movement should also stop diddling around with measures that feel good but will backfire, like rent control and vacancy taxes.
Meanwhile, the tech industry is continuing to make tentative moves toward remote work. I continue to be hopeful but skeptical that widespread adoption of remote work can finally get housing costs under control.
My suspicion is that the YIMBY movement has succumbed to the Shirky Principle, which posits that “Institutions will try to preserve the problem to which they are the solution.” An ever-growing share of its energy is devoted to playing the Reds vs. Blues game, which is more than redundant in California. They have no vision of what an affordable California or Bay Area look like, no credible plan for getting there, and ideological blinkers that foreclose many important aspects of the solution.
As I’ve done several times before, I go back to Citizens Climate Lobby, which I see as the gold standard for political advocacy done right. They have a clear vision of passing a federal carbon fee and dividend plan. They don’t dilute their efforts on ancillary priorities or play partisan games. They have commissioned detailed economic modeling of the plan and have made every effort to insure it works from both a technical perspective and from a range of value systems. I don’t know if CCL will succeed, but at least they can succeed, unlike most activists, and CCL is one of the few major organizations I feel good supporting.
Red Ink
The Congressional Budget Office released an unsurprising but grim report on the national debt. The debt-to-GDP ratio stands at 98%, the highest ever except for a brief time at the end of World War II. It should cross the 100% mark next year and reach 109% by 2030.
Deficits are a classic gnarly problem. They are harmful but not catastrophic, and the harms are mostly at some indeterminate point in the future and are not clearly visible. This makes them easy to ignore, and ignoring the debt, or at best using it as a partisan talking point, is now an established bipartisan tradition.
Japan somehow continues to function with a debt-to-GDP ratio exceeding 230%. I don’t know how high the US can go on this metric and hope not to find out. We’ve seen debt crisis in Europe and Argentina recently. What I think is more likely is that debt service will be another ball and chain, along with population aging, stagnant productivity, and broken housing, health care, and education markets, on the American economy.
Carbon Pricing
Resources for the Future has a new carbon pricing calculator tool out, evaluating several proposals from the current Congress.
At the $52/ton level, four of the eight proposals stand out as having a positive benefit/cost analysis when economic costs are weighed against CO2 reduction alone. In all eight cases, “secondary” health benefits exceed the CO2 benefit as well as economic costs. As economic intuition would suggest, benefit/cost ratio goes down the higher the carbon price goes, since as the price goes up, we move down the ladder from most cost-effective emissions reductions to less cost-effective.
For my own part, I’ve generally been using a social cost of carbon of $50/ton. A few years ago, that seemed like a reasonable median estimate. At some point I want to review the literature again to see if I should be using a different figure.
The large health benefits are good for making the case for carbon pricing, but they raise some questions. The numbers strongly suggest that we should be thinking about air pollution reduction as the primary goal with CO2 reduction as a secondary goal. But if we do that, is carbon pricing really the most effective policy on air pollution?
Software and the Collapse of Civilization
I found this talk from last year by the game developer Jonathan Blow. He details ways in which the software industry is unable to deliver fast, reliable products and analogizes to historical failures of technological reproduction that are associated with past civilizational collapses. The talk is about an hour. I have to say it is a bit odd, but I found it worth watching.
Several time throughout my life, I have made attempts to get into the software industry, and at other times such as now I have programmed on a hobbyist basis. While I don’t see bad software as a major existential risk to civilization, there are clearly problems. Blow identifies what could also be called the bloatware problem: programmers tend to reach for libraries and abstractions in their code, needlessly inflating size, complexity, runtime, and bugs. He worries that abstraction has become so pervasive that the industry is not even capable of delivering reliable software at this point, and the knowledge of machine code programming has been largely lost.
Blow’s argument is reminiscent of the success problem, as described by Samo Burja, or the notion of social reproduction.
I’ve toyed with the idea of trying to develop the analogy between software bloatware and policy bloatware, a term to describe the phenomenon of public policy being designed in ever more complex manners. An overly complex policy environment increases the difficulty of coordinating the entities required for a solution, and it causes solutions to look more like patches and kludges over problems rather than actual solutions. An example is the attempt to address housing affordability problems by developing complex, multi-government affordable housing subsidies. Kludgeocracy is the best term I’ve seen for this phenomenon so far.
Casey Muratori identifies the same problem, which he called the 30 million line problem, so named because he estimates that to write the most basic “Hello World” web app requires, between the server and the client, at least 30 million lines of code and probably far more, with present technology. He proposes a solution based on a universal CPU instruction set and restoring root access to developers. Ironically, the talk (excluding Q&A) is over an hour when I think 10 minutes would have been sufficient to convey the key points without loss of essential detail.
1 note
·
View note