#amazon data scraping tool
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

In the vast expanse of e-commerce, Amazon stands as a colossus, offering an extensive array of products and services to millions of customers worldwide. For businesses and researchers, extracting data from Amazon's platform can unlock valuable insights into market trends, competitor analysis, pricing strategies, and more. However, manual data collection is time-consuming and inefficient. Enter web scraping tools, which automate the process, allowing users to extract large volumes of data quickly and efficiently. In this article, we'll explore some of the best scraping tools tailored for Amazon web data extraction.
Scrapy: Scrapy is a powerful and flexible web crawling framework written in Python. It provides a robust set of tools for extracting data from websites, including Amazon. With its high-level architecture and built-in support for handling dynamic content, Scrapy makes it relatively straightforward to scrape product listings, reviews, prices, and other relevant information from Amazon's pages. Its extensibility and scalability make it an excellent choice for both small-scale and large-scale data extraction projects.
Octoparse: Octoparse is a user-friendly web scraping tool that offers a point-and-click interface, making it accessible to users with limited programming knowledge. It allows you to create custom scraping workflows by visually selecting the elements you want to extract from Amazon's website. Octoparse also provides advanced features such as automatic IP rotation, CAPTCHA solving, and cloud extraction, making it suitable for handling complex scraping tasks with ease.
ParseHub: ParseHub is another intuitive web scraping tool that excels at extracting data from dynamic websites like Amazon. Its visual point-and-click interface allows users to build scraping agents without writing a single line of code. ParseHub's advanced features include support for AJAX, infinite scrolling, and pagination, ensuring comprehensive data extraction from Amazon's product listings, reviews, and more. It also offers scheduling and API integration capabilities, making it a versatile solution for data-driven businesses.
Apify: Apify is a cloud-based web scraping and automation platform that provides a range of tools for extracting data from Amazon and other websites. Its actor-based architecture allows users to create custom scraping scripts using JavaScript or TypeScript, leveraging the power of headless browsers like Puppeteer and Playwright. Apify offers pre-built actors for scraping Amazon product listings, reviews, and seller information, enabling rapid development and deployment of scraping workflows without the need for infrastructure management.
Beautiful Soup: Beautiful Soup is a Python library for parsing HTML and XML documents, often used in conjunction with web scraping frameworks like Scrapy or Selenium. While it lacks the built-in web crawling capabilities of Scrapy, Beautiful Soup excels at extracting data from static web pages, including Amazon product listings and reviews. Its simplicity and ease of use make it a popular choice for beginners and Python enthusiasts looking to perform basic scraping tasks without a steep learning curve.
Selenium: Selenium is a powerful browser automation tool that can be used for web scraping Amazon and other dynamic websites. It allows you to simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, making it ideal for scraping JavaScript-heavy sites like Amazon. Selenium's Python bindings provide a convenient interface for writing scraping scripts, enabling you to extract data from Amazon's product pages with ease.
In conclusion, the best scraping tool for Amazon web data extraction depends on your specific requirements, technical expertise, and budget. Whether you prefer a user-friendly point-and-click interface or a more hands-on approach using Python scripting, there are plenty of options available to suit your needs. By leveraging the power of web scraping tools, you can unlock valuable insights from Amazon's vast trove of data, empowering your business or research endeavors with actionable intelligence.
0 notes
Text
#proxies#proxy#proxyserver#residential proxy#amazon#amazon products#web scraping techniques#web scraping tools#web scraping services#datascience#data analytics#data#industry data
0 notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about “AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
Grindr’s AI wingman, currently in beta testing with around 10,000 users, arrives at a pivotal moment for the software company. With its iconic notification chirp and ominous mask logo, the app is known culturally as a digital bathhouse for gay and bisexual men to swap nudes and meet with nearby users for sex, but Grindr CEO George Arison sees the addition of a generative AI assistant and machine intelligence tools as an opportunity for expansion.
“This is not just a hookup product anymore,” he says. “There's obviously no question that it started out as a hookup product, but the fact that it's become a lot more over time is something people don't fully appreciate.” Grindr’s product road map for 2025 spotlights multiple AI features aimed at current power users, like chat summaries, as well as dating and travel-focused tools.
Whether users want them or not, it’s all part of a continuing barrage of AI features being added by developers to most dating apps, from Hinge deciding whether profile answers are a slog using AI, to Tinder soon rolling out AI-powered matches. Wanting to better understand how AI fits into Grindr's future, I experimented with a beta version of Grindr's AI wingman for this hands-on report.
First Impressions of Grindr’s AI Wingman
In interviews over the past few months, Arison has laid out a consistent vision for Grindr’s AI wingman as the ultimate dating tool—a digital helper that can write witty responses for users as they chat with matches, help pick guys worth messaging, and even plan the perfect night out.
“It's been surprisingly flirtatious,” he says about the chatbot. “Which is good.”
Once enabled, the AI wingman appeared as another faceless Grindr profile in my message inbox. Despite grand visions for the tool, the current iteration I tested was a simple, text-only chatbot tuned for queer audiences.
First, I wanted to test the chatbot’s limits. Unlike the more prudish outputs from OpenAI’s ChatGPT and Anthropic’s Claude, Grindr’s AI wingman was willing to be direct. I asked it to share fisting tips for beginners, and after stating that fisting is not for newcomers, the AI wingman encouraged me to start slow, use tons of lube, explore smaller toys first, and always have a safe word ready to go. “Most importantly, do your research and maybe chat with experienced folks in the community,” the bot said. ChatGPT flagged similar questions as going against its guidelines, and Claude refused to even broach the subject.
Although the wingman was down to talk through other kinks—like watersports and pup play—with a focus on education, the app rebuked my advances for any kind of erotic role-play. “How about we keep things playful but PG-13?” said Grindr’s AI wingman. “I’d be happy to chat about dating tips, flirting strategies, or fun ways to spice up your profile instead.” The bot also refused to explore kinks based on race or religion, warning me that these are likely harmful forms of fetishization.
Processing data through Amazon Web Service’s Bedrock system, the chatbot does include some details scraped from the web, but it can’t go out and find new information in real time. Since the current version doesn't actively search the internet for answers, the wingman provided more general advice than specifics when asked to plan a date for me in San Francisco. “How about checking out a local queer-owned restaurant or bar?” it said. “Or maybe plan a picnic in a park and people-watch together?” Pressed for specifics, the AI wingman did name a few relevant locations for date nights in the city but couldn’t provide operating hours. In this instance, posing a similar question to ChatGPT produced a better date night itinerary, thanks to that chatbot’s ability to search the open web.
Despite my lingering skepticism about the wingman tool potentially being more of an AI fad than the actual future of dating, I do see immediate value in a chatbot that can help users come to terms with their sexuality and start the coming out process. Many Grindr users, including myself, become users of the app before telling anyone about their desires, and a kind, encouraging chatbot would have been more helpful to me than the “Am I Gay?” quiz I resorted to as a teenager.
Out With the Bugs, In With the AI
When he took the top job at Grindr before the company’s public listing in 2022, Arison prioritized zapping bugs and fixing app glitches over new feature releases. “We got a lot of bugs out of the way last year,” he says. “Until now, we didn't really have an opportunity to be able to build a lot of new features.”
Despite getting investors hot and bothered, it’s hard to tell how daily Grindr users will respond to this new injection of AI into the app. While some may embrace the suggested matches and the more personalized experience, generative AI is now more culturally polarizing than ever as people complain about its oversaturation, lack of usefulness, and invasion of privacy. Grindr users will be presented with the option to allow their sensitive data, such as the contents of their conversations and precise location, to be used to train the company’s AI tools. Users can go into their account’s privacy settings to opt out if they change their mind.
Arison is convinced in-app conversations reveal a more authentic version of users than what's filled out on any profile, and the next generation of recommendations will be stronger by focusing on that data. “It's one thing what you say in your profile,” he says. “But, it's another thing what you say in your messages—how real that might be.” Though on apps like Grindr, where the conversations often contain explicit, intimate details, some users will be uncomfortable with an AI model reading their private chats to learn more about them, choosing to avoid those features.
Potentially, one of the most helpful AI tools for overly active Grindr users who are open to their data being processed by AI models could be the chat summaries recapping recent interactions with some talking points thrown in to keep conversations going.
“It's really about reminding you what type of connection you might have had with this user, and what might be good topics that could be worth picking back up on,” says A. J. Balance, Grindr’s chief product officer.
Then there’s the model’s ability to highlight the profiles of users it thinks you’re most compatible with. Say you’ve matched with another user and chatted a bit, but that’s as far as things went in the app. Grindr’s AI model will be able to summarize details about that conversation and, using what it has learned about you both, highlight those profiles as part of an “A-List” and offer some ways to rekindle the connection, widening the door you’ve already opened.
“This ‘A-List’ product actually goes through your inbox with folks you've spoken with, pulls out the folks where you've had some good connections,” Balance says. “And it uses that summary to remind you why it could be good to pick back up the conversation.”
Slow Roll
As a gaybie, my first interactions on Grindr were liberating and constricting at the same time. It was the first time I saw casual racism, like “No fats. No fems. No Asians,” blasted across multiple online profiles. And even at my fittest, there always seemed to be some headless torso more in shape than me right around the corner and ready to mock my belly. Based on past experiences, AI features that could detect addiction to the app and encourage healthier habits and boundaries would be a welcome addition.
While Grindr’s other, AI-focused tools are planned for more immediate releases throughout this year, the app’s generative AI assistant isn’t projected to have a complete rollout until 2027. Arison doesn’t want to rush a full release to Grindr’s millions of global users. “These are also expensive products to run,” he says. “So, we want to be kind of careful with that as well.” Innovations in generative AI, like DeepSeek’s R1 model, may eventually reduce the cost to run it on the backend.
Will he be able to navigate adding these experimental, and sometimes controversial, AI tools to the app as part of a push to become more welcoming for users looking to find long-term relationships or queer travel advice, in addition to hookups? For now, Arison appears optimistic, albeit cautious. “We don't expect all of these things to take off,” he says. “Some of them will and some won't.”
3 notes
·
View notes
Text
How I'm Tracking My Manga Reading Backlog
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
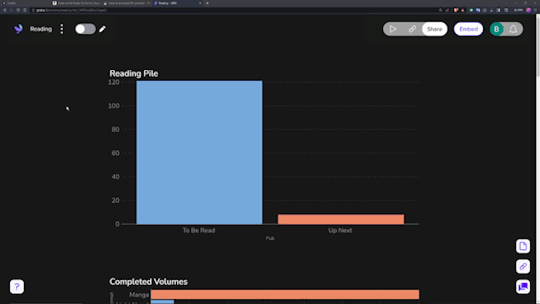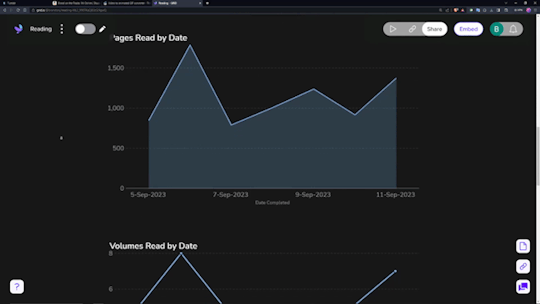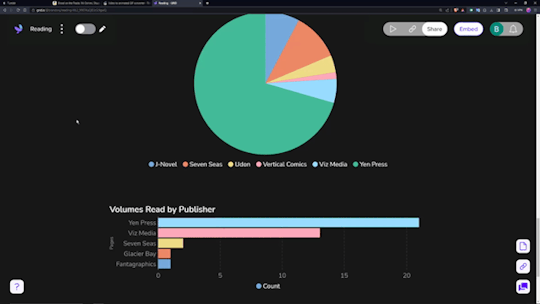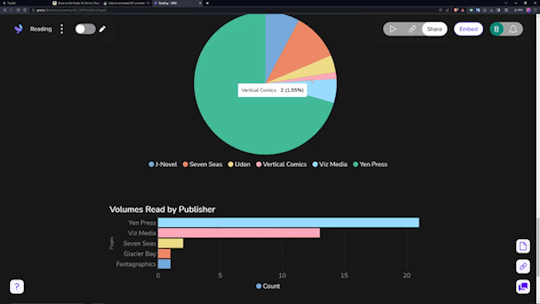
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
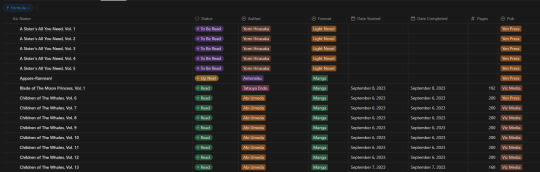
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

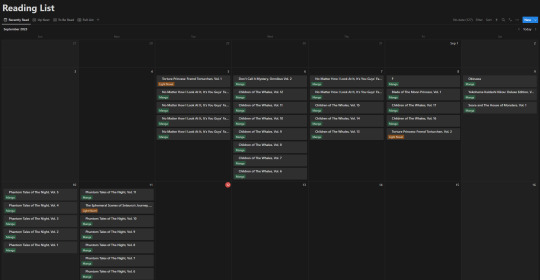
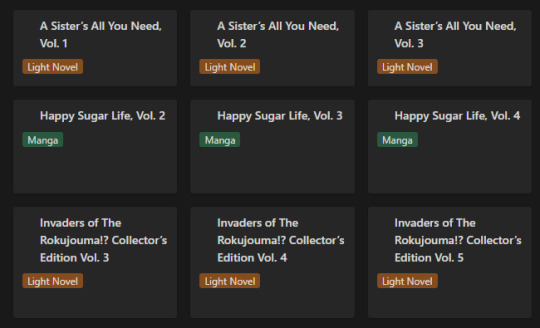
Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Various web scraping tools will help you to extract Amazon data to the spreadsheet. It is a reliable solution for scraping Amazon data and fetching valuable and important information.
For More Information:-
0 notes
Text
Unlocking Data Science's Potential: Transforming Data into Perceptive Meaning
Data is created on a regular basis in our digitally connected environment, from social media likes to financial transactions and detection labour. However, without the ability to extract valuable insights from this enormous amount of data, it is not very useful. Data insight can help you win in that situation. Online Course in Data Science It is a multidisciplinary field that combines computer knowledge, statistics, and subject-specific expertise to evaluate data and provide useful perception. This essay will explore the definition of data knowledge, its essential components, its significance, and its global transubstantiation diligence.

Understanding Data Science: To find patterns and shape opinions, data wisdom essentially entails collecting, purifying, testing, and analysing large, complicated datasets. It combines a number of fields.
Statistics: To establish predictive models and derive conclusions.
Computer intelligence: For algorithm enforcement, robotization, and coding.
Sphere moxie: To place perceptivity in a particular field of study, such as healthcare or finance.
It is the responsibility of a data scientist to pose pertinent queries, handle massive amounts of data effectively, and produce findings that have an impact on operations and strategy.
The Significance of Data Science
1. Informed Decision Making: To improve the stoner experience, streamline procedures, and identify emerging trends, associations rely on data-driven perception.
2. Increased Effectiveness: Businesses can decrease manual labour by automating operations like spotting fraudulent transactions or managing AI-powered customer support.
3. Acclimatised Gests: Websites like Netflix and Amazon analyse user data to provide suggestions for products and verified content.
4. Improvements in Medicine: Data knowledge helps with early problem diagnosis, treatment development, and bodying medical actions.
Essential Data Science Foundations:

1. Data Acquisition & Preparation: Databases, web scraping, APIs, and detectors are some sources of data. Before analysis starts, it is crucial to draw the data, correct offences, eliminate duplicates, and handle missing values.
2. Exploratory Data Analysis (EDA): EDA identifies patterns in data, describes anomalies, and comprehends the relationships between variables by using visualisation tools such as Seaborn or Matplotlib.
3. Modelling & Machine Learning: By using techniques like
Retrogression: For predicting numerical patterns.
Bracket: Used for data sorting (e.g., spam discovery).
For group segmentation (such as client profiling), clustering is used.
Data scientists create models that automate procedures and predict problems. Enrol in a reputable software training institution's Data Science course.
4. Visualisation & Liar: For stakeholders who are not technical, visual tools such as Tableau and Power BI assist in distilling complex data into understandable, captivating dashboards and reports.
Data Science Activities Across Diligence:
1. Online shopping
personalised recommendations for products.
Demand-driven real-time pricing schemes.
2. Finance & Banking
identifying deceptive conditioning.
trading that is automated and powered by predictive analytics.
3. Medical Care
tracking the spread of complaints and formulating therapeutic suggestions.
using AI to improve medical imaging.
4. Social Media
assessing public opinion and stoner sentiment.
curation of feeds and optimisation of content.
Typical Data Science Challenges:
Despite its potential, data wisdom has drawbacks.
Ethics & Sequestration: Preserving stoner data and preventing algorithmic prejudice.
Data Integrity: Inaccurate perception results from low-quality data.
Scalability: Pall computing and other high-performance structures are necessary for managing large datasets.
The Road Ahead:
As artificial intelligence advances, data wisdom will remain a crucial motorist of invention. unborn trends include :
AutoML – Making machine literacy accessible to non-specialists.
Responsible AI – icing fairness and translucency in automated systems.
Edge Computing – Bringing data recycling near to the source for real- time perceptivity.
Conclusion:
Data wisdom is reconsidering how businesses, governments, and healthcare providers make opinions by converting raw data into strategic sapience. Its impact spans innumerous sectors and continues to grow. With rising demand for professed professionals, now is an ideal time to explore this dynamic field.
0 notes
Text
Insights via Amazon Prime Movies and TV Shows Dataset

Introduction
In a rapidly evolving digital landscape, understanding viewer behavior is critical for streaming platforms and analytics companies. A leading streaming analytics firm needed a reliable and scalable method to gather rich content data from Amazon Prime. They turned to ArcTechnolabs for a tailored data solution powered by the Amazon Prime Movies and TV Shows Dataset. The goal was to decode audience preferences, forecast engagement, and personalize content strategies. By leveraging structured, comprehensive data, the client aimed to redefine content analysis and elevate user experience through data-backed decisions.
The Client
The client is a global streaming analytics firm focused on helping OTT platforms improve viewer engagement through data insights. With users across North America and Europe, the client analyzes millions of data points across streaming apps. They were particularly interested in Web scraping Amazon Prime Video content to refine content curation strategies and trend forecasting. ArcTechnolabs provided the capability to extract Amazon Prime Video data efficiently and compliantly, enabling deeper analysis of the Amazon Prime shows and movie dataset for smarter business outcomes.
Key Challenges
The firm faced difficulties in consistently collecting detailed, structured content metadata from Amazon Prime. Their internal scraping setup lacked scale and often broke with site updates. They couldn’t track changing metadata, genres, cast info, episode drops, or user engagement indicators in real time. Additionally, there was no existing pipeline to gather reliable streaming media data from Amazon Prime or track regional content updates. Their internal tech stack also lacked the ability to filter, clean, and normalize data across categories and territories. Off-the-shelf Amazon Prime Video Data Scraping Services were either limited in scope or failed to deliver structured datasets. The client also struggled to gain competitive advantage due to limited exposure to OTT Streaming Media Review Datasets, which limited content sentiment analysis. They required a solution that could extract Amazon Prime streaming media data at scale and integrate it seamlessly with their proprietary analytics platform.

Key Solution
ArcTechnolabs provided a customized data pipeline built around the Amazon Prime Movies and TV Shows Dataset, designed to deliver accurate, timely, and well-structured metadata. The solution was powered by our robust Web Scraping OTT Data engine and supported by our advanced Web Scraping Services framework. We deployed high-performance crawlers with adaptive logic to capture real-time data, including show descriptions, genres, ratings, and episode-level details. With Mobile App Scraping Services , the dataset was enriched with data from Amazon Prime’s mobile platforms, ensuring broader coverage. Our Web Scraping API Services allowed seamless integration with the client's existing analytics tools, enabling them to track user engagement metrics and content trends dynamically. The solution ensured regional tagging, global categorization, and sentiment analysis inputs using linked OTT Streaming Media Review Datasets , giving the client a full-spectrum view of viewer behavior across platforms.

Client Testimonial
"ArcTechnolabs exceeded our expectations in delivering a highly structured, real-time Amazon Prime Movies and TV Shows Dataset. Their scraping infrastructure was scalable and resilient, allowing us to dig deep into viewer preferences and optimize our recommendation engine. Their ability to integrate mobile and web data in a single feed gave us unmatched insight into how content performs across devices. The collaboration has helped us become more predictive and precise in our analytics."
— Director of Product Analytics, Global Streaming Insights Firm
Conclusion
This partnership demonstrates how ArcTechnolabs empowers streaming intelligence firms to extract actionable insights through advanced data solutions. By tapping into the Amazon Prime Movies and TV Shows Dataset, the client was able to break down barriers in content analysis and improve viewer experience significantly. Through a combination of custom Web Scraping Services , mobile integration, and real-time APIs, ArcTechnolabs delivered scalable tools that brought visibility and control to content strategy. As content-driven platforms grow, data remains the most powerful tool—and ArcTechnolabs continues to lead the way.
Source >> https://www.arctechnolabs.com/amazon-prime-movies-tv-dataset-viewer-insights.php
🚀 Grow smarter with ArcTechnolabs! 📩 [email protected] | 📞 +1 424 377 7584 Real-time datasets. Real results.
#AmazonPrimeMoviesAndTVShowsDataset#WebScrapingAmazonPrimeVideoContent#AmazonPrimeVideoDataScrapingServices#OTTStreamingMediaReviewDatasets#AnalysisOfAmazonPrimeTVShows#WebScrapingOTTData#AmazonPrimeTVShows#MobileAppScrapingServices
0 notes
Text
Stay Competitive with Real-Time Price Comparison Data!

In a dynamic eCommerce world, pricing drives customer decisions—and smart businesses stay ahead by leveraging data.
📊 Key Takeaways from the Page: • Access structured, real-time pricing data from leading platforms (Amazon, Walmart, eBay & more). • Monitor competitors’ pricing, discounts, and stock changes. • Make informed decisions with automated price tracking tools. • Scale effortlessly with Real Data API’s high-frequency scraping and easy integration.
🔎 “80% of online shoppers compare prices before making a purchase—are you ready to meet them where they are?”
🚀 Optimize your pricing strategy today and dominate the digital shelf!
0 notes
Text
🛍️ Tracking Combo Offer Prices Across Amazon & BestBuy – Real-Time Ecommerce Deal Intelligence 🔎🛒

In the battle for online shoppers, combo offers are a powerful tool for upselling and boosting cart value. But how do you stay competitive?
By scraping combo pricing data from Amazon and Best Buy, brands and retailers can uncover:
✅ Real-time visibility into bundled product deals ✅ Competitor pricing tactics and promotional strategies ✅ Category-specific bundle insights (electronics, accessories, appliances & more) ✅ Opportunities to optimize your own offer stack ✅ Smarter discount planning & dynamic pricing models
💡 “Combo offer tracking reveals where your brand stands—and how to win the cart.”
0 notes
Text
A Guide to Web Scraping Amazon Fresh for Grocery Insights

Introduction
In the e-commerce landscape, Amazon Fresh stands out as a major player in the grocery delivery sector. Extracting data from Amazon Fresh through web scraping offers valuable insights into:
Grocery pricing and discount patterns
Product availability and regional variations
Delivery charges and timelines
Customer reviews and ratings
Using Amazon Fresh grocery data for scraping helps businesses conduct market research, competitor analysis, and pricing strategies. This guide will show you how the entire process works, from setting up your environment to analyzing the data that have been extracted.
Why Scrape Amazon Fresh Data?
✅ 1. Competitive Pricing Analysis
Track price fluctuations and discounts.
Compare prices with other grocery delivery platforms.
✅ 2. Product Availability and Trends
Monitor product availability by region.
Identify trending or frequently purchased items.
✅ 3. Delivery Time and Fee Insights
Understand delivery fee variations by location.
Track delivery time changes during peak hours.
✅ 4. Customer Review Analysis
Extract and analyze product reviews.
Identify common customer sentiments and preferences.
✅ 5. Supply Chain and Inventory Monitoring
Monitor out-of-stock products.
Analyze restocking patterns and delivery speeds.
Legal and Ethical Considerations
Before starting Amazon Fresh data scraping, it’s important to follow legal and ethical practices:
✅ Respect robots.txt: Check Amazon’s robots.txt file for any scraping restrictions.
✅ Rate Limiting: Add delays between requests to avoid overloading Amazon’s servers.
✅ Data Privacy Compliance: Follow data privacy regulations like GDPR and CCPA.
✅ No Personal Data: Avoid collecting or using personal customer information.
Setting Up Your Web Scraping Environment
1. Tools and Libraries Needed
To scrape Amazon Fresh, you’ll need:
✅ Python: For scripting the scraping process.
✅ Libraries:
requests – To send HTTP requests.
BeautifulSoup – For HTML parsing.
Selenium – For handling dynamic content.
Pandas – For data analysis and storage.
2. Install the Required Libraries
Run the following commands to install the necessary libraries:pip install requests beautifulsoup4 selenium pandas
3. Choose a Browser Driver
Amazon Fresh uses dynamic JavaScript rendering. To extract dynamic content, use ChromeDriver with Selenium.
Step-by-Step Guide to Scraping Amazon Fresh Data
Step 1: Inspecting Amazon Fresh Website Structure
Before scraping, examine the HTML structure of the Amazon Fresh website:
Product names
Prices and discounts
Product categories
Delivery times and fees
Step 2: Extracting Static Data with BeautifulSoup
import requests from bs4 import BeautifulSoup url = "https://www.amazon.com/Amazon-Fresh-Grocery/b?node=16310101" headers = {"User-Agent": "Mozilla/5.0"} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.content, "html.parser") # Extract product titles titles = soup.find_all('span', class_='a-size-medium') for title in titles: print(title.text)
Step 3: Scraping Dynamic Data with Selenium
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service import time # Set up Selenium driver service = Service("/path/to/chromedriver") driver = webdriver.Chrome(service=service) # Navigate to Amazon Fresh driver.get("https://www.amazon.com/Amazon-Fresh-Grocery/b?node=16310101") time.sleep(5) # Extract product names titles = driver.find_elements(By.CLASS_NAME, "a-size-medium") for title in titles: print(title.text) driver.quit()
Step 4: Extracting Product Pricing and Delivery Data
driver.get("https://www.amazon.com/product-page-url") time.sleep(5) # Extract item name and price item_name = driver.find_element(By.ID, "productTitle").text price = driver.find_element(By.CLASS_NAME, "a-price").text print(f"Product: {item_name}, Price: {price}") driver.quit()
Step 5: Storing and Analyzing the Extracted Data
import pandas as pd data = {"Product": ["Bananas", "Bread"], "Price": ["$1.29", "$2.99"]} df = pd.DataFrame(data) df.to_csv("amazon_fresh_data.csv", index=False)
Analyzing Amazon Fresh Data for Business Insights
✅ 1. Pricing Trends and Discount Analysis
Track price changes over time.
Identify seasonal discounts and promotions.
✅ 2. Delivery Fee and Time Insights
Compare delivery fees by region.
Identify patterns in delivery time during peak hours.
✅ 3. Product Category Trends
Identify the most popular grocery items.
Analyze trending products by region.
✅ 4. Customer Review and Rating Analysis
Extract customer reviews for sentiment analysis.
Identify frequently mentioned keywords.
Challenges in Amazon Fresh Scraping and Solutions
Challenge: Dynamic content rendering — Solution: Use Selenium for JavaScript data
Challenge: CAPTCHA verification — Solution: Use CAPTCHA-solving services
Challenge: IP blocking — Solution: Use proxies and user-agent rotation
Challenge: Data structure changes — Solution: Regularly update scraping scripts
Best Practices for Ethical and Effective Scraping
✅ Respect robots.txt: Ensure compliance with Amazon’s web scraping policies.
✅ Use proxies: Prevent IP bans by rotating proxies.
✅ Implement delays: Use time delays between requests.
✅ Data usage: Use the extracted data responsibly and ethically.
Conclusion
Scraping Amazon Fresh gives valuable grocery insights into pricing trends, product availability, and delivery details. This concise but detailed tutorial helps one in extracting the grocery data from Amazon Fresh efficiently for competitive analysis, market research, and pricing strategies.
For large-scale or automated Amazon Fresh-like data scraping, consider using CrawlXpert. CrawlXpert will facilitate your data collection process and give you more time to focus on actionable insights.
Start scrapping Amazon Fresh today to leverage powerful grocery insights!
Know More : https://www.crawlxpert.com/blog/web-scraping-amazon-fresh-for-grocery-insights
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Extract Amazon Product Prices with Web Scraping | Actowiz Solutions
Introduction
In the ever-evolving world of e-commerce, pricing strategy can make or break a brand. Amazon, being the global e-commerce behemoth, is a key platform where pricing intelligence offers an unmatched advantage. To stay ahead in such a competitive environment, businesses need real-time insights into product prices, trends, and fluctuations. This is where Actowiz Solutions comes into play. Through advanced Amazon price scraping solutions, Actowiz empowers businesses with accurate, structured, and actionable data.
Why extract Amazon Product Prices?

Price is one of the most influential factors affecting a customer’s purchasing decision. Here are several reasons why extracting Amazon product prices is crucial:
Competitor Analysis: Stay informed about competitors’ pricing.
Dynamic Pricing: Adjust your prices in real time based on market trends.
Market Research: Understand consumer behavior through price trends.
Inventory & Repricing Strategy: Align stock and pricing decisions with demand.
With Actowiz Solutions’ Amazon scraping services, you get access to clean, structured, and timely data without violating Amazon’s terms.
How Actowiz Solutions Extracts Amazon Price Data

Actowiz Solutions uses advanced scraping technologies tailored for Amazon’s complex site structure. Here’s a breakdown:
1. Custom Scraping Infrastructure
Actowiz Solutions builds custom scrapers that can navigate Amazon’s dynamic content, pagination, and bot protection layers like CAPTCHA, IP throttling, and JavaScript rendering.
2. Proxy Rotation & User-Agent Spoofing
To avoid detection and bans, Actowiz employs rotating proxies and multiple user-agent headers that simulate real user behavior.
3. Scheduled Data Extraction
Actowiz enables regular scheduling of price scraping jobs — be it hourly, daily, or weekly — for ongoing price intelligence.
4. Data Points Captured
The scraping service extracts:
Product name & ASIN
Price (MRP, discounted, deal price)
Availability
Ratings & Reviews
Seller information
Real-World Use Cases for Amazon Price Scraping

A. Retailers & Brands
Monitor price changes for own products or competitors to adjust pricing in real-time.
B. Marketplaces
Aggregate seller data to ensure competitive offerings and improve platform relevance.
C. Price Comparison Sites
Fuel your platform with fresh, real-time Amazon price data.
D. E-commerce Analytics Firms
Get historical and real-time pricing trends to generate valuable reports for clients.
Dataset Snapshot: Amazon Product Prices

Below is a snapshot of average product prices on Amazon across popular categories:
Product CategoryAverage Price (USD)Electronics120.50Books15.75Home & Kitchen45.30Fashion35.90Toys & Games25.40Beauty20.60Sports50.10Automotive75.80
Benefits of Choosing Actowiz Solutions

1. Scalability: From thousands to millions of records.
2. Accuracy: Real-time validation and monitoring ensure data reliability.
3. Customization: Solutions are tailored to each business use case.
4. Compliance: Ethical scraping methods that respect platform policies.
5. Support: Dedicated support and data quality teams
Legal & Ethical Considerations

Amazon has strict policies regarding automated data collection. Actowiz Solutions follows legal frameworks and deploys ethical scraping practices including:
Scraping only public data
Abiding by robots.txt guidelines
Avoiding high-frequency access that may affect site performance
Integration Options for Amazon Price Data

Actowiz Solutions offers flexible delivery and integration methods:
APIs: RESTful APIs for on-demand price fetching.
CSV/JSON Feeds: Periodic data dumps in industry-standard formats.
Dashboard Integration: Plug data directly into internal BI tools like Tableau or Power BI.
Contact Actowiz Solutions today to learn how our Amazon scraping solutions can supercharge your e-commerce strategy.Contact Us Today!
Conclusion: Future-Proof Your Pricing Strategy
The world of online retail is fast-moving and highly competitive. With Amazon as a major marketplace, getting a pulse on product prices is vital. Actowiz Solutions provides a robust, scalable, and ethical way to extract product prices from Amazon.
Whether you’re a startup or a Fortune 500 company, pricing intelligence can be your competitive edge. Learn More
#ExtractProductPrices#PriceIntelligence#AmazonScrapingServices#AmazonPriceScrapingSolutions#RealTimeInsights
0 notes