#amazonbot
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text





I JUST CAN'T STOP PLEASE HELP
#amazonbot#digital art#artists on tumblr#stalker 2 heart of chornobyl#stalker skif#stalker strelok#stalker 2#stalker richter#richter x skif#skifter#s.t.a.l.k.e.r. 2 heart of chornobyl#s.t.a.l.k.e.r 2#s.t.a.l.k.e.r.#down boy meme#down boy#strilec#marked one#colonel korshunov
84 notes
·
View notes
Text
!Friendica Admins
Hi everyone, how useful is it to exclude the various AI bots via .htaccess?
# Block specific bots based on User-Agent RewriteCond %{HTTP_USER_AGENT} (AhrefsBot|Baiduspider|SemrushBot|DotBot|MJ12bot|PetalBot|SeznamBot|Mediapartners-Google|Bytespider|Claude-Web|GPTBot|PerplexityBot|Applebot|Amazonbot|Meta-ExternalAgent|Meta-ExternalFetcher|FacebookBot|DuckAssistBot|Anthropic-ai) [NC] RewriteRule ^.* - [F,L]
Or does the addon "blockbot" already do this job? If not, would it make sense to include an option there?
0 notes
Text
But I did check.
I distinctly remember the crawl-delay being active, as well as the GPTbot section. The only item commented out was for Amazonbot. I specifically looked at those things when I composed the post.
I'm kicking myself now for not including the robots.txt file as it existed when I made the post. It was different than what's there now. I know how to read a robots.txt file.
I'll own the other mistakes in my post. I should've clarified that the crawler is not the LLM parser/trainer, it merely collects stuff for the input hopper. Thought that was obvious, but still amused they were wasting time & resources sucking up millions of nonsense pages.
Only 1.2 million pages, not 3 million. My bad. Still a lot.
Thanks for helping set the record straight.
But I still think it's interesting & important to keep reporting that these AI companies are trawling through public spaces to build their for-profit projects. Not enough people realize that's what's going on, and it won't stop until we reach some sort of critical mass.
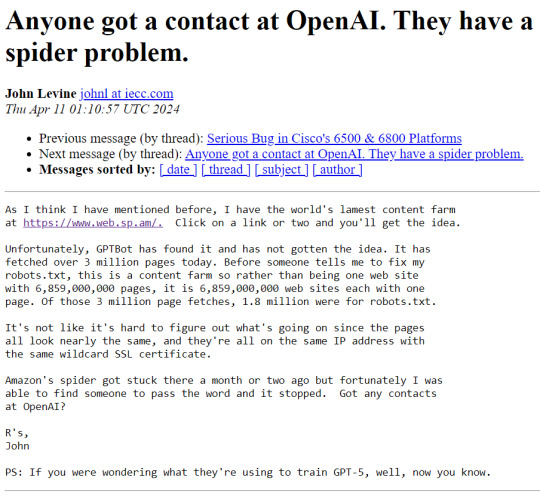
To understand what's going on here, know these things:
OpenAI is the company that makes ChatGPT
A spider is a kind of bot that autonomously crawls the web and sucks up web pages
robots.txt is a standard text file that most web sites use to inform spiders whether or not they have permission to crawl the site; basically a No Trespassing sign for robots
OpenAI's spider is ignoring robots.txt (very rude!)
the web.sp.am site is a research honeypot created to trap ill-behaved spiders, consisting of billions of nonsense garbage pages that look like real content to a dumb robot
OpenAI is training its newest ChatGPT model using this incredibly lame content, having consumed over 3 million pages and counting...
It's absurd and horrifying at the same time.
16K notes
·
View notes
Text

Les bots d'IA les plus populaires vus sur le réseau de Cloudflare en termes de volume de requêtes.
Cloudflare a dévoilé une nouvelle fonctionnalité de son réseau de diffusion de contenu (CDN) qui empêche les développeurs d'IA de récupérer du contenu sur le web. En examinant le nombre de requêtes adressées aux sites de Cloudflare, Cloudflare a constaté que Bytespider, Amazonbot, ClaudeBot et GPTBot sont les quatre principaux crawlers d'IA. Exploité par ByteDance, la société chinoise propriétaire de TikTok, Bytespider serait utilisé pour recueillir des données d'entraînement pour ses grands modèles linguistiques (LLM), y compris ceux qui soutiennent son rival ChatGPT, Doubao. Amazonbot et ClaudeBot suivent Bytespider en termes de volume de requêtes. Amazonbot, qui serait utilisé pour indexer le contenu pour les questions-réponses d'Alexa, a envoyé le deuxième plus grand nombre de requêtes et ClaudeBot, utilisé pour former le chat bot Claude, a récemment augmenté son volume de requêtes.
1 note
·
View note
Text
Relationship chart idea- might change stuff but this is basically it!
So here’s a chart of the relationships my OC has. It might change but yeah this is how it is for the most part.

So a little side note, A I’m sorry for my chicken scratch hand writing, and B since Tumblr voted Aemond to be the “Lover” of Victoria (my oc) that’s what I did. They also voted him for the husband poll I did and I saw here and there were vastly different. It was also like 200+ votes which shook me cause wtf- Aemond is a fan favorite- anyway that’s when I did the lover poll and many voted him to be a lover so that’s what happened.
Now about the graph above is quite simple. *Ahem* (pulls out paper) Victoria and Viserys I respect one another, although she gets frustrated cause she’s trying to warn him about future events. He however thinks she’s a story teller and sets her job to become one.
On that note, when she does the story telling, it attracts Daemon. Although she is a strange one, she interested him somewhat. Even growing closer as he thinks that maybe her prophecies/ stories might be real. Soon she notices Daemon’s relationship with his niece, Rheanerya. As well as hears of their marriage and grows distant to him, making him angry. Soon they talk about it “surprisingly” and Daemon persuades his wife, Rheanerya, to wed Victoria as well. Eventually she agrees. The three of them wed soon after a few years.
Victoria’s relationship with Aemond is a strange one. As Victoria told the prophecies/stories to him and his older brother Aegon. Like Daemon, he saw something within Victoria that interested him. Even as a child, he looked up to her as a prize. (I know it’s weird… >_>) As he grew older he watched her in the shadows as she tells Aegon and Heleana’s children the same stories. When Daemon leaves to marry Leana, who eventually dies years later, Aemond tries to get Victoria to fall in love with him. Weird as it might be, she doesn’t automatically accept him. As she says he’s only a teenager and she’s an adult, he says it’s no different the other way around. She again doesn’t fall into his antics. Until he tells her that her prophecies were true as he believed her. They soon become lovers right until Daemon talks to her and brings her to the Blacks. Aemond is set to get her back… but his revenge comes first.
Victoria’s relationship with her sister wife is a bit of a shaky thing. As she sees Rheanerya as someone who is high and mighty. She respects her sister wives. Awhile Rheanerya herself is jealous of her. As Daemon seems to not be as interested as he was before with her. She thinks it’s because of her status as queen and that’s why. Whether or not this is true is unknown.
As for Victoria’s daughter Jasmine Targaryen/ Jasmine Oak, she is her daughter but the father is unknown. Many say it is Daemon’s child, but some theorize that it is Aemond’s as well. It isn’t confirmed who of the two is her father, all is said is that Victoria somehow managed to change the outcome of the Dance of the Dragons… but another threat gleams on the horizon and many will backstab the Targaryens. So Victoria tells Jasmine that her surname isn’t Targaryen but Oak to protect her identity from assassins.
Other than that’s about it. Now it might change in a few weeks maybe? But this is basically all of it. Twists and turns in this… crazy chart.
Also here’s the credits for the art aboveArt credits:
https://www.deviantart.com/amazonbot/art/House-of-the-Dragon-Prince-Daemon-Targaryen-960187348
https://www.instagram.com/alexineskiba/?igsh=Nm1iZGloMXE5djg3
https://www.tumblr.com/vickyshinoa12/753376623889465344/made-me-in-the-hotd-series-d
https://awoiaf.westeros.org/index.php/Alys_Rivers
https://www.tumblr.com/vickyshinoa12/753760491510366208/jasmine-targaryen-daughter-of-victoria-hula
0 notes
Text
Ai and the Fediverse, and Indieweb.Social
As we see Apple, Meta, and Google deeply integrate their AI systems deeply into their platforms, browsers, and operating systems, I think one of the competitive advantages of the Fediverse will be that it is place where USERS are in control of how they consume, share, and interact with AI generated content.
This advantage to users relating to AI, I think, will rival the advantage that the Fediverse already sees in terms of being free from and in control of algorithmic manipulation, free from centralized control, free from micro-targeted ads, and free from and free from data mining.
But I am putting some thoughts into how the Federation needs to evolve to better empower users. And I’ll write more about this and soon make two additions to indieweb.social’s “about” sections. One where I commit to never sell the 11,400+ users' content to any AI platform for their training, and the other announcement where I list new server rules requiring posts here to use AI-generated content to either label their accounts as “automated” or add a specific AI content hashtag to their posts, or both.
Lastly, we have already updated our Robots.txt file for this server to disallow all AI-generated content from being indexed by all AI systems we could identify. And we will be continually updating that list. It is an important note: this does not protect your public posts that federate out to the public Fediverse servers beyond this one…
But this should be an important speedbump to protect any direct scraping of public posts on this site. And some speedbumps are better than none.
For other admins, here are the robots.txt settings we added, and always up for notes to optimize this further:
User-agent: Amazonbot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Diffbot
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ImagesiftBot
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: Omgili
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: YouBot
Disallow: /
0 notes
Text
Ask me if you want to know smth about my TPOM headcanons :)
Okay here's an ask game
Send me a ship and I'll answer three questions based on if I ship it or not.
Ship It
What made you ship it?
What are your favorite things about the ship?
Is there an unpopular opinion you have on your ship?
Don't Ship It
Why don't you ship it?
What would have made you like it?
Despite not shipping it, do you have anything positive to say about it?
#Pom#amazonbot#pom humanized#Tpom#penguins of madagascar humanized#Penguins of madagascar#Ask me#headcanon
19K notes
·
View notes
Text

I'm moving on with my 6-ships-challenge. Luis Serra/Leon Kennedy from Resident evil 4 remake. My poor boys 😭😭😭

And here is the story:
#amazonbot#digital art#artists on tumblr#resident evil 4#re4#luis serra#leon resident evil#leon kennedy#Leon x Luis#luis sera resident evil#re 4 remake#serrenedy#6ships
159 notes
·
View notes
Text
Yet again, I find myself sending emails to Amazon to get them to stop crawling my site. You’d think this was clear enough in robots.txt
# Go fuck off in your dick rocket Bezos User-agent: Amazonbot Disallow: /
0 notes
Text
Get new instacart batch! Get yours today only $400. Text: (972) 882-6532 Works for android and iOS. Payment via zelle, Apple pay or bitcoin. Pay only when instructed. We have instacart bot for android and iPhone we also reactivate instacart account.

1 note
·
View note
Text
Hello guys 👋🏾 Are you having hard time getting orders with high prices on your Instacart, DoorDash, Vaho, Spark, Ubereat, Shipt, Amazonflex accounts etc or you got deactivated!?… Contact us today and get your problems solved…
COST: $300
CONTACT US HERE:
Facebook Page: https://m.facebook.com/GigApps.Agent/
WHATSAPP: https://wa.me/14108704313
TEXT NUMBER: (209) 315-5188 . . . .
.
.
.
. #poshmarkseller #poshmark
#poshmarkcommunity #ebayseller #ebay #poshmarkcloset #ebaycommunity #instacartshopper #indiana #amazonbot
#alaska #instacartfail #instacartadventures #usashoppingke #quarantineandchill #resellercommunity #quarantine #samedaydelivery #staysfe #allstate #anystate #fastdelivery
#stayhome #homedeliverv #uber #uberbot #onlieshop #onlineshopping #uber #uberx #uberxl #lyft #doordash #gighustle #gigeconomy #sidehustle #extraincome #giglife #driving
#hustling #denver #colorado #bringbackthesurge #instacart #instacartshopper #instacartoon #instacartbot #instacartshoppers #instacartoons
#instacartorio #instacartagena #instacartoonist #instacarte #instacartfail #instacartpartner #instacartlife #instacartdriver #shopping #shoppingonline #onlineshopping #onlinestore
#onlinebusiness #onlineshop #onlinemarketing #onlinemoney #onlinemoneymaking #onlinefood #onlinefooddelivery #onlinefoodordering #onlinefoodstore #uber #doordash #busymom #walmart #extremecouponing #groceryshopping
#carbuying #carfax #krogerdeals #extremecouponingcommunities #gottaeat #ralphs #targetrun #stimulus #instacartagena
#instacartorio #instacartoonist #instacarte #instacartfail #instacartoonfx #instacarter #instacartera #instacarton #instacartier
#instacartel #instacart #uber #amazon #amazonbot
#usashoppingke #anystore #allstores
#thisishowishop #grocerydelivery #fooddelivered
#stavoutofstores #anystore #allstores instacartbot #instacartfail #uberbot #uber #amazon #amazonbot #california #washington #washingtondc #houston #instacart #instacartshoppers #usashoppingKE
#anystore #allstores #instacratsavings
#instacartcode #instacartpromotion
#ketosismom #happyday #instacartpartner #instacartaffiliate #thisishowishop
#grocerydelivery #fooddelivered
#stayoutofstores #pandemic ##groceries
#anystore #allstores #instacratsavings #instacartcode #instacartpromotion #gigworker #giglife #doordash #doordasher #doordashdelivery #7eleven #doordashbike #doordashbiker #bikedelivery #bikecourier #doordashdriver
2 notes
·
View notes
Text

robots.txt: How to resolve a problem caused by robots.txt
robots.txt file that informs Google what pages, URLs, or URLs they crawl. robots.txt format allows Google to crawl pages or not.
What exactly is robots.txt?
The majority of Search engines, such as Google, Bing, and Yahoo, employ a particular program that connects to the web to gather the data on the site and transfer it from one site to another; this program is referred to as spiders, crawlers bots, crawlers, etc.
In the beginning, internet computing power and memory were both costly; at that time, some website owner was disturbed by the search engine's crawler. The reason is that at that time, websites were not that successful for robots to, again and again, visit every website and page. Due to that, the server was mainly down, the results were not shown to the user, and the website resource was finished.
This is why they came up with the idea of giving search engines that idea called robot.txt. This means we tell which pages are allowed to crawl or not; the robot.txt file is located in the main file.
When robots visit your site, they adhere to your robots.txt instructions; however, if your robots cannot find your robots.txt file, they will crawl the entire website. If it crawls your entire site, users may encounter numerous issues with your website.
User-agent :*
Disallow :/
User-agent: Googlebot - Google
User-agent: Amazonbot - Micro office
The question is, how will it impact SEO?
Today, 98% of traffic is controlled by Google; therefore, let's focus on Google exclusively. Google gives each site to set a crawl budget. This budget determines the amount of time to spend crawling your website.
The crawl budget is contingent on two factors.
1- The server is slow during crawl time, and when a robot visits your site, it makes your site load slower during the visit.
2- How popular is your website is, and how much content on your site? Google crawls first, as the robots want to stay current, which is why it crawls the most popular websites with more content.
To use you use the robots.txt document, your site should be maintained. If you want to disable any file, you could block it by robots.txt.
What format should be used for this robots.txt file?
If you'd like to block the page with information about your employees and prevent the same information from being crawled, you can block the crawling, then seek help from your robots.txt file.
For instance,
your website name - htps://www.your
Your folder's name is a sample
of the name of your page sample.html
Then you block robots.txt
user-agent: / *
Disallow; / sample.html
How do I fix a problem caused by robots.txt?
If you find that the Google search console appears as blocked robots.txt within the category called Excluded and you're worried about it, there is a remedy. If you are a friend, when you see that the Google search console appears as blocked robots.txt, it indicates problems with your websites or URLs.
Let's find out how to fix this issue.
Visit your blog
Click the settings
Click on the custom robots.txt
Turn on
and copy and paste the robots.txt and paste the robots.txt
and then save.
How do you get your website's robots.txt file?
Visit this Sitemap Generator
paste your website URL
Click on generate sitemap
copy the code from below into the sitemap.
And copy and paste it into your robots.txt section.
User-agent : *
Searching is blocked
Disallow:/ category/
Tags Disallow: tags
Allow:/
After these settings, go to the custom robots header tags
Allow custom robot header tags for your robots.
Click on the home page tags. switch on all tags, noodp
Click on the archive, then search the tag page. Turn on noindex or noodp
Just click the link to open it and tag the page. Turn on all Noodp
After completing this step, Google crawlers index your website, which takes a few days or weeks.
What is the process behind the Google bot function?
Google bots will browse your website and locate it in the robot.txt file. It will not visit pages that are not allowed, but those that are permitted will be crawled before being indexed. Once it has completed the indexing and crawling, it will rank your site on a search engine's get position.
How do you check your website's robots.txt file?
It's accessible to Search for keywords in the Google search engine.
Type :
site: https://yourwebsite.com/robots.txt
In the
In the above article, I tried in my very best attempt to describe what exactly robots.txt is and how it could affect SEO, what's its format for the robots.txt file, how to resolve issues caused by robots.txt, How to obtain your website's robots.txt document, as well as finally, what exactly is Google bot function. robots.txt is required to provide the directions for the Google bot.
I hope I removed all doubts and doubt through my post. If you want to make any suggestions in the article, you're free to provide suggestions.
Website Link- aglodiyas.blogspot.com
Questions: What is a robots.txt file used for?
answer : Robots.txt is a text file that instructs the search engine's crawler which pages to crawl and which not.
This file is required for SEO. It is used to provide security to a webpage.
For example, Banking Websites, Company Login Webpage.
This text file is also used to hide information from crawlers. These pages are not displayed on search engines when someone searches for a query about your webpage.
questions: Is robots.txt good for SEO?
Answer: Robot.txt files help the web crawler Algorithm determine which folders/files should be crawled on your website. It is a good idea to have a robot.txt in your root directory. This file is essential, in my opinion.
question: Is robots.txt legally binding?
Answer: When I was researching this issue a few decades ago, cases indicated that the existence or absence of a robots.txt wasn't relevant in determining whether a scraper/user had violated any laws: CFAA. Trespass, unjust enrichment, CFAA. Other state laws are similar to CFAA. Terms of service are important in such determinations. Usually, there is terms and conditions of service/terms.txt.
1 note
·
View note
Photo

Transporters 2018: la rivincita sugli Amazonbot
1 note
·
View note

