#apache spark architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Why Python Will Thrive: Future Trends and Applications
Python has already made a significant impact in the tech world, and its trajectory for the future is even more promising. From its simplicity and versatility to its widespread use in cutting-edge technologies, Python is expected to continue thriving in the coming years. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Let's explore why Python will remain at the forefront of software development and what trends and applications will contribute to its ongoing dominance.
1. Artificial Intelligence and Machine Learning
Python is already the go-to language for AI and machine learning, and its role in these fields is set to expand further. With powerful libraries such as TensorFlow, PyTorch, and Scikit-learn, Python simplifies the development of machine learning models and artificial intelligence applications. As more industries integrate AI for automation, personalization, and predictive analytics, Python will remain a core language for developing intelligent systems.
2. Data Science and Big Data
Data science is one of the most significant areas where Python has excelled. Libraries like Pandas, NumPy, and Matplotlib make data manipulation and visualization simple and efficient. As companies and organizations continue to generate and analyze vast amounts of data, Python’s ability to process, clean, and visualize big data will only become more critical. Additionally, Python’s compatibility with big data platforms like Hadoop and Apache Spark ensures that it will remain a major player in data-driven decision-making.
3. Web Development
Python’s role in web development is growing thanks to frameworks like Django and Flask, which provide robust, scalable, and secure solutions for building web applications. With the increasing demand for interactive websites and APIs, Python is well-positioned to continue serving as a top language for backend development. Its integration with cloud computing platforms will also fuel its growth in building modern web applications that scale efficiently.
4. Automation and Scripting
Automation is another area where Python excels. Developers use Python to automate tasks ranging from system administration to testing and deployment. With the rise of DevOps practices and the growing demand for workflow automation, Python’s role in streamlining repetitive processes will continue to grow. Businesses across industries will rely on Python to boost productivity, reduce errors, and optimize performance. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

5. Cybersecurity and Ethical Hacking
With cyber threats becoming increasingly sophisticated, cybersecurity is a critical concern for businesses worldwide. Python is widely used for penetration testing, vulnerability scanning, and threat detection due to its simplicity and effectiveness. Libraries like Scapy and PyCrypto make Python an excellent choice for ethical hacking and security professionals. As the need for robust cybersecurity measures increases, Python’s role in safeguarding digital assets will continue to thrive.
6. Internet of Things (IoT)
Python’s compatibility with microcontrollers and embedded systems makes it a strong contender in the growing field of IoT. Frameworks like MicroPython and CircuitPython enable developers to build IoT applications efficiently, whether for home automation, smart cities, or industrial systems. As the number of connected devices continues to rise, Python will remain a dominant language for creating scalable and reliable IoT solutions.
7. Cloud Computing and Serverless Architectures
The rise of cloud computing and serverless architectures has created new opportunities for Python. Cloud platforms like AWS, Google Cloud, and Microsoft Azure all support Python, allowing developers to build scalable and cost-efficient applications. With its flexibility and integration capabilities, Python is perfectly suited for developing cloud-based applications, serverless functions, and microservices.
8. Gaming and Virtual Reality
Python has long been used in game development, with libraries such as Pygame offering simple tools to create 2D games. However, as gaming and virtual reality (VR) technologies evolve, Python’s role in developing immersive experiences will grow. The language’s ease of use and integration with game engines will make it a popular choice for building gaming platforms, VR applications, and simulations.
9. Expanding Job Market
As Python’s applications continue to grow, so does the demand for Python developers. From startups to tech giants like Google, Facebook, and Amazon, companies across industries are seeking professionals who are proficient in Python. The increasing adoption of Python in various fields, including data science, AI, cybersecurity, and cloud computing, ensures a thriving job market for Python developers in the future.
10. Constant Evolution and Community Support
Python’s open-source nature means that it’s constantly evolving with new libraries, frameworks, and features. Its vibrant community of developers contributes to its growth and ensures that Python stays relevant to emerging trends and technologies. Whether it’s a new tool for AI or a breakthrough in web development, Python’s community is always working to improve the language and make it more efficient for developers.
Conclusion
Python’s future is bright, with its presence continuing to grow in AI, data science, automation, web development, and beyond. As industries become increasingly data-driven, automated, and connected, Python’s simplicity, versatility, and strong community support make it an ideal choice for developers. Whether you are a beginner looking to start your coding journey or a seasoned professional exploring new career opportunities, learning Python offers long-term benefits in a rapidly evolving tech landscape.
#python course#python training#python#technology#tech#python programming#python online training#python online course#python online classes#python certification
2 notes
·
View notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
What is Amazon EMR architecture? And Service Layers

Describe Amazon EMR architecture
The storage layer includes your cluster's numerous file systems. Examples of various storage options.
The Hadoop Distributed File System (HDFS) is scalable and distributed. HDFS keeps several copies of its data on cluster instances to prevent data loss if one instance dies. Shutting down a cluster recovers HDFS, or ephemeral storage. HDFS's capacity to cache interim findings benefits MapReduce and random input/output workloads.
Amazon EMR improves Hadoop with the EMR File System (EMRFS) to enable direct access to Amazon S3 data like HDFS. The file system in your cluster may be HDFS or Amazon S3. Most input and output data are stored on Amazon S3, while intermediate results are stored on HDFS.
A disc that is locally attached is called the local file system. Every Hadoop cluster Amazon EC2 instance includes an instance store, a specified block of disc storage. Amazon EC2 instances only store storage volume data during their lifespan.
Data processing jobs are scheduled and cluster resources are handled via the resource management layer. Amazon EMR defaults to centrally managing cluster resources for multiple data-processing frameworks using Apache Hadoop 2.0's YARN component. Not all Amazon EMR frameworks and apps use YARN for resource management. Amazon EMR has an agent on every node that connects, monitors cluster health, and manages YARN items.
Amazon EMR's built-in YARN job scheduling logic ensures that running tasks don't fail when Spot Instances' task nodes fail due to their frequent use. Amazon EMR limits application master process execution to core nodes. Controlling active jobs requires a continuous application master process.
YARN node labels are incorporated into Amazon EMR 5.19.0 and later. Previous editions used code patches. YARN capacity-scheduler and fair-scheduler use node labels by default, with yarn-site and capacity-scheduler configuration classes. Amazon EMR automatically labels core nodes and schedules application masters on them. This feature can be disabled or changed by manually altering yarn-site and capacity-scheduler configuration class settings or related XML files.
Data processing frameworks power data analysis and processing. Many frameworks use YARN or their own resource management systems. Streaming, in-memory, batch, interactive, and other processing frameworks exist. Use case determines framework. Application layer languages and interfaces that communicate with processed data are affected. Amazon EMR uses Spark and Hadoop MapReduce mostly.
Distributed computing employs open-source Hadoop MapReduce. You provide Map and Reduce functions, and it handles all the logic, making parallel distributed applications easier. Map converts data to intermediate results, which are key-value pairs. The Reduce function combines intermediate results and runs additional algorithms to produce the final output. Hive is one of numerous MapReduce frameworks that can automate Map and Reduce operations.
Apache Spark: Spark is a cluster infrastructure and programming language for big data. Spark stores datasets in memory and executes using directed acyclic networks instead of Hadoop MapReduce. EMRFS helps Spark on Amazon EMR users access S3 data. Interactive query and SparkSQL modules are supported.
Amazon EMR supports Hive, Pig, and Spark Streaming. The programs can build data warehouses, employ machine learning, create stream processing applications, and create processing workloads in higher-level languages. Amazon EMR allows open-source apps with their own cluster management instead of YARN.
Amazon EMR supports many libraries and languages for app connections. Streaming, Spark SQL, MLlib, and GraphX work with Spark, while MapReduce uses Java, Hive, or Pig.
#AmazonEMRarchitecture#EMRFileSystem#HadoopDistributedFileSystem#Localfilesystem#Clusterresource#HadoopMapReduce#Technology#technews#technologynews#NEWS#govindhtech
0 notes
Text

🚀 Need Help with Your ITECH7407 Real-Time Analytics Assignment? 📊⏱️
Real-time data, streaming analytics, Apache Kafka, Spark Streaming... Feeling overwhelmed? 😰 Don’t worry — expert help for ITECH7407: Real-Time Analytics is just a message away! 🧠💡
✅ What We Offer:
🔸 Guidance on real-time data processing frameworks
🔸 Assistance with coding, implementation & visualization
🔸 Help with academic writing, reports & referencing
🔸 Timely delivery & 100% original work
🎯 Whether you're stuck on architecture design or just need clarity on streaming concepts, we’ve got you covered!
📥 DM us now or drop a “YES” in the comments to get instant help!
📞 𝗣𝗵𝗼𝗻𝗲/𝗪𝗵𝗮𝘁𝘀𝗮𝗽𝗽:+91-9772078620/+61-872-000-185
#ITECH7407 #RealTimeAnalytics #AssignmentHelp #BigData #StudentSupport #AnalyticsAssignment #FederationUniversity #AcademicAssistance #FederationUniversity #Australia
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
How to Optimize ETL Pipelines for Performance and Scalability

As data continues to grow in volume, velocity, and variety, the importance of optimizing your ETL pipeline for performance and scalability cannot be overstated. An ETL (Extract, Transform, Load) pipeline is the backbone of any modern data architecture, responsible for moving and transforming raw data into valuable insights. However, without proper optimization, even a well-designed ETL pipeline can become a bottleneck, leading to slow processing, increased costs, and data inconsistencies.
Whether you're building your first pipeline or scaling existing workflows, this guide will walk you through the key strategies to improve the performance and scalability of your ETL pipeline.
1. Design with Modularity in Mind
The first step toward a scalable ETL pipeline is designing it with modular components. Break down your pipeline into independent stages — extraction, transformation, and loading — each responsible for a distinct task. Modular architecture allows for easier debugging, scaling individual components, and replacing specific stages without affecting the entire workflow.
For example:
Keep extraction scripts isolated from transformation logic
Use separate environments or containers for each stage
Implement well-defined interfaces for data flow between stages
2. Use Incremental Loads Over Full Loads
One of the biggest performance drains in ETL processes is loading the entire dataset every time. Instead, use incremental loads — only extract and process new or updated records since the last run. This reduces data volume, speeds up processing, and decreases strain on source systems.
Techniques to implement incremental loads include:
Using timestamps or change data capture (CDC)
Maintaining checkpoints or watermark tables
Leveraging database triggers or logs for change tracking
3. Leverage Parallel Processing
Modern data tools and cloud platforms support parallel processing, where multiple operations are executed simultaneously. By breaking large datasets into smaller chunks and processing them in parallel threads or workers, you can significantly reduce ETL run times.
Best practices for parallelism:
Partition data by time, geography, or IDs
Use multiprocessing in Python or distributed systems like Apache Spark
Optimize resource allocation in cloud-based ETL services
4. Push Down Processing to the Source System
Whenever possible, push computation to the database or source system rather than pulling data into your ETL tool for processing. Databases are optimized for query execution and can filter, sort, and aggregate data more efficiently.
Examples include:
Using SQL queries for filtering data before extraction
Aggregating large datasets within the database
Using stored procedures to perform heavy transformations
This minimizes data movement and improves pipeline efficiency.
5. Monitor, Log, and Profile Your ETL Pipeline
Optimization is not a one-time activity — it's an ongoing process. Use monitoring tools to track pipeline performance, identify bottlenecks, and collect error logs.
What to monitor:
Data throughput (rows/records per second)
CPU and memory usage
Job duration and frequency of failures
Time spent at each ETL stage
Popular tools include Apache Airflow for orchestration, Prometheus for metrics, and custom dashboards built on Grafana or Kibana.
6. Use Scalable Storage and Compute Resources
Cloud-native ETL tools like AWS Glue, Google Dataflow, and Azure Data Factory offer auto-scaling capabilities that adjust resources based on workload. Leveraging these platforms ensures you’re only using (and paying for) what you need.
Additionally:
Store intermediate files in cloud storage (e.g., Amazon S3)
Use distributed compute engines like Spark or Dask
Separate compute and storage to scale each independently
Conclusion
A fast, reliable, and scalable ETL pipeline is crucial to building robust data infrastructure in 2025 and beyond. By designing modular systems, embracing incremental and parallel processing, offloading tasks to the database, and continuously monitoring performance, data teams can optimize their pipelines for both current and future needs.
In the era of big data and real-time analytics, even small performance improvements in your ETL workflow can lead to major gains in efficiency and insight delivery. Start optimizing today to unlock the full potential of your data pipeline.
0 notes
Text
What Are the Hadoop Skills to Be Learned?
With the constantly changing nature of big data, Hadoop is among the most essential technologies for processing and storing big datasets. With companies in all sectors gathering more structured and unstructured data, those who have skills in Hadoop are highly sought after. So what exactly does it take to master Hadoop? Though Hadoop is an impressive open-source tool, to master it one needs a combination of technical and analytical capabilities. Whether you are a student looking to pursue a career in big data, a data professional looking to upskill, or someone career transitioning, here's a complete guide to the key skills that you need to learn Hadoop. 1. Familiarity with Big Data Concepts Before we jump into Hadoop, it's helpful to understand the basics of big data. Hadoop was designed specifically to address big data issues, so knowing these issues makes you realize why Hadoop operates the way it does. • Volume, Variety, and Velocity (The 3Vs): Know how data nowadays is huge (volume), is from various sources (variety), and is coming at high speed (velocity). • Structured vs Unstructured Data: Understand the distinction and why Hadoop is particularly suited to handle both. • Limitations of Traditional Systems: Know why traditional relational databases are not equipped to handle big data and how Hadoop addresses that need. This ground level knowledge guarantees that you're not simply picking up tools, but realizing their context and significance.
2. Fundamental Programming Skills Hadoop is not plug-and-play. Though there are tools higher up the stack that layer over some of the complexity, a solid understanding of programming is necessary in order to take advantage of Hadoop. • Java: Hadoop was implemented in Java, and much of its fundamental ecosystem (such as MapReduce) is built on Java APIs. Familiarity with Java is a major plus. • Python: Growing among data scientists, Python can be applied to Hadoop with tools such as Pydoop and MRJob. It's particularly useful when paired with Spark, another big data application commonly used in conjunction with Hadoop. • Shell Scripting: Because Hadoop tends to be used on Linux systems, Bash and shell scripting knowledge is useful for automating jobs, transferring data, and watching processes. Being comfortable with at least one of these languages will go a long way in making Hadoop easier to learn. 3. Familiarity with Linux and Command Line Interface (CLI) Most Hadoop deployments run on Linux servers. If you’re not familiar with Linux, you’ll hit roadblocks early on. • Basic Linux Commands: Navigating the file system, editing files with vi or nano, and managing file permissions are crucial. • Hadoop CLI: Hadoop has a collection of command-line utilities of its own. Commands will need to be used in order to copy files from the local filesystem and HDFS (Hadoop Distributed File System), to start and stop processes, and to observe job execution. A solid comfort level with Linux is not negotiable—it's a foundational skill for any Hadoop student.
4. HDFS Knowledge HDFS is short for Hadoop Distributed File System, and it's the heart of Hadoop. It's designed to hold a great deal of information in a reliable manner across a large number of machines. You need: • Familiarity with the HDFS architecture: NameNode, DataNode, and block allocation. • Understanding of how writing and reading data occur in HDFS. • Understanding of data replication, fault tolerance, and scalability. Understanding how HDFS works makes you confident while performing data work in distributed systems.
5. MapReduce Programming Knowledge MapReduce is Hadoop's original data processing engine. Although newer options such as Apache Spark are currently popular for processing, MapReduce remains a topic worth understanding. • How Map and Reduce Work: Learn about the divide-and-conquer technique where data is processed in two phases—map and reduce. • MapReduce Job Writing: Get experience writing MapReduce programs, preferably in Java or Python. • Performance Tuning: Study job chaining, partitioners, combiners, and optimization techniques. Even if you eventually favor Spark or Hive, studying MapReduce provides you with a strong foundation in distributed data processing.
6. Working with Hadoop Ecosystem Tools Hadoop is not one tool—its an ecosystem. Knowing how all the components interact makes your skills that much better. Some of the big tools to become acquainted with: • Apache Pig: A data flow language that simplifies the development of MapReduce jobs. • Apache Sqoop: Imports relational database data to Hadoop and vice versa. • Apache Flume: Collects and transfers big logs of data into HDFS. • Apache Oozie: A workflow scheduler to orchestrate Hadoop jobs. • Apache Zookeeper: Distributes systems. Each of these provides useful functionality and makes Hadoop more useful. 7. Basic Data Analysis and Problem-Solving Skills Learning Hadoop isn't merely technical expertise—it's also problem-solving. • Analytical Thinking: Identify the issue, determine how data can be harnessed to address it, and then determine which Hadoop tools to apply. • Data Cleaning: Understand how to preprocess and clean large datasets before analysis. • Result Interpretation: Understand the output that Hadoop jobs produce. These soft skills are typically what separate a decent Hadoop user from a great one.
8. Learning Cluster Management and Cloud Platforms Although most learn Hadoop locally using pseudo-distributed mode or sandbox VMs, production Hadoop runs on clusters—either on-premises or in the cloud. • Cluster Management Tools: Familiarize yourself with tools such as Apache Ambari and Cloudera Manager. • Cloud Platforms: Learn how Hadoop runs on AWS (through EMR), Google Cloud, or Azure HDInsight. It is crucial to know how to set up, monitor, and debug clusters for production-level deployments. 9. Willingness to Learn and Curiosity Last but not least, you will require curiosity. The Hadoop ecosystem is large and dynamic. New tools, enhancements, and applications are developed regularly. • Monitor big data communities and forums. • Participate in open-source projects or contributions. • Keep abreast of tutorials and documentation. Your attitude and willingness to play around will largely be the distinguishing factor in terms of how well and quickly you learn Hadoop. Conclusion Hadoop opens the door to the world of big data. Learning it, although intimidating initially, can be made easy when you break it down into sets of skills—such as programming, Linux, HDFS, SQL, and problem-solving. While acquiring these skills, not only will you learn Hadoop, but also the confidence in creating scalable and intelligent data solutions. Whether you're creating data pipelines, log analysis, or designing large-scale systems, learning Hadoop gives you access to a whole universe of possibilities in the current data-driven age. Arm yourself with these key skills and begin your Hadoop journey today.
Website: https://www.icertglobal.com/course/bigdata-and-hadoop-certification-training/Classroom/60/3044
0 notes
Text
Snowflake vs Redshift vs BigQuery vs Databricks: A Detailed Comparison
In the world of cloud-based data warehousing and analytics, organizations are increasingly relying on advanced platforms to manage their massive datasets. Four of the most popular options available today are Snowflake, Amazon Redshift, Google BigQuery, and Databricks. Each offers unique features, benefits, and challenges for different types of organizations, depending on their size, industry, and data needs. In this article, we will explore these platforms in detail, comparing their performance, scalability, ease of use, and specific use cases to help you make an informed decision.
What Are Snowflake, Redshift, BigQuery, and Databricks?
Snowflake: A cloud-based data warehousing platform known for its unique architecture that separates storage from compute. It’s designed for high performance and ease of use, offering scalability without complex infrastructure management.
Amazon Redshift: Amazon’s managed data warehouse service that allows users to run complex queries on massive datasets. Redshift integrates tightly with AWS services and is optimized for speed and efficiency in the AWS ecosystem.
Google BigQuery: A fully managed and serverless data warehouse provided by Google Cloud. BigQuery is known for its scalable performance and cost-effectiveness, especially for large, analytic workloads that require SQL-based queries.
Databricks: More than just a data warehouse, Databricks is a unified data analytics platform built on Apache Spark. It focuses on big data processing and machine learning workflows, providing an environment for collaborative data science and engineering teams.
Snowflake Overview
Snowflake is built for cloud environments and uses a hybrid architecture that separates compute, storage, and services. This unique architecture allows for efficient scaling and the ability to run independent workloads simultaneously, making it an excellent choice for enterprises that need flexibility and high performance without managing infrastructure.
Key Features:
Data Sharing: Snowflake’s data sharing capabilities allow users to share data across different organizations without the need for data movement or transformation.
Zero Management: Snowflake handles most administrative tasks, such as scaling, optimization, and tuning, so teams can focus on analyzing data.
Multi-Cloud Support: Snowflake runs on AWS, Google Cloud, and Azure, giving users flexibility in choosing their cloud provider.
Real-World Use Case:
A global retail company uses Snowflake to aggregate sales data from various regions, optimizing its supply chain and inventory management processes. By leveraging Snowflake’s data sharing capabilities, the company shares real-time sales data with external partners, improving forecasting accuracy.
Amazon Redshift Overview
Amazon Redshift is a fully managed, petabyte-scale data warehouse solution in the cloud. It is optimized for high-performance querying and is closely integrated with other AWS services, such as S3, making it a top choice for organizations that already use the AWS ecosystem.
Key Features:
Columnar Storage: Redshift stores data in a columnar format, which makes querying large datasets more efficient by minimizing disk I/O.
Integration with AWS: Redshift works seamlessly with other AWS services, such as Amazon S3, Amazon EMR, and AWS Glue, to provide a comprehensive solution for data management.
Concurrency Scaling: Redshift automatically adds additional resources when needed to handle large numbers of concurrent queries.
Real-World Use Case:
A financial services company leverages Redshift for data analysis and reporting, analyzing millions of transactions daily. By integrating Redshift with AWS Glue, the company has built an automated ETL pipeline that loads new transaction data from Amazon S3 for analysis in near-real-time.
Google BigQuery Overview
BigQuery is a fully managed, serverless data warehouse that excels in handling large-scale, complex data analysis workloads. It allows users to run SQL queries on massive datasets without worrying about the underlying infrastructure. BigQuery is particularly known for its cost efficiency, as it charges based on the amount of data processed rather than the resources used.
Key Features:
Serverless Architecture: BigQuery automatically handles all infrastructure management, allowing users to focus purely on querying and analyzing data.
Real-Time Analytics: It supports real-time analytics, enabling businesses to make data-driven decisions quickly.
Cost Efficiency: With its pay-per-query model, BigQuery is highly cost-effective, especially for organizations with varying data processing needs.
Real-World Use Case:
A digital marketing agency uses BigQuery to analyze massive amounts of user behavior data from its advertising campaigns. By integrating BigQuery with Google Analytics and Google Ads, the agency is able to optimize its ad spend and refine targeting strategies.
Databricks Overview
Databricks is a unified analytics platform built on Apache Spark, making it ideal for data engineering, data science, and machine learning workflows. Unlike traditional data warehouses, Databricks combines data lakes, warehouses, and machine learning into a single platform, making it suitable for advanced analytics.
Key Features:
Unified Analytics Platform: Databricks combines data engineering, data science, and machine learning workflows into a single platform.
Built on Apache Spark: Databricks provides a fast, scalable environment for big data processing using Spark’s distributed computing capabilities.
Collaboration: Databricks provides collaborative notebooks that allow data scientists, analysts, and engineers to work together on the same project.
Real-World Use Case:
A healthcare provider uses Databricks to process patient data in real-time and apply machine learning models to predict patient outcomes. The platform enables collaboration between data scientists and engineers, allowing the team to deploy predictive models that improve patient care.

People Also Ask
1. Which is better for data warehousing: Snowflake or Redshift?
Both Snowflake and Redshift are excellent for data warehousing, but the best option depends on your existing ecosystem. Snowflake’s multi-cloud support and unique architecture make it a better choice for enterprises that need flexibility and easy scaling. Redshift, however, is ideal for organizations already using AWS, as it integrates seamlessly with AWS services.
2. Can BigQuery handle real-time data?
Yes, BigQuery is capable of handling real-time data through its streaming API. This makes it an excellent choice for organizations that need to analyze data as it’s generated, such as in IoT or e-commerce environments where real-time decision-making is critical.
3. What is the primary difference between Databricks and Snowflake?
Databricks is a unified platform for data engineering, data science, and machine learning, focusing on big data processing using Apache Spark. Snowflake, on the other hand, is a cloud data warehouse optimized for SQL-based analytics. If your organization requires machine learning workflows and big data processing, Databricks may be the better option.
Conclusion
When choosing between Snowflake, Redshift, BigQuery, and Databricks, it's essential to consider the specific needs of your organization. Snowflake is a flexible, high-performance cloud data warehouse, making it ideal for enterprises that need a multi-cloud solution. Redshift, best suited for those already invested in the AWS ecosystem, offers strong performance for large datasets. BigQuery excels in cost-effective, serverless analytics, particularly in the Google Cloud environment. Databricks shines for companies focused on big data processing, machine learning, and collaborative data science workflows.
The future of data analytics and warehousing will likely see further integration of AI and machine learning capabilities, with platforms like Databricks leading the way in this area. However, the best choice for your organization depends on your existing infrastructure, budget, and long-term data strategy.
0 notes
Text
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
New Post has been published on https://thedigitalinsider.com/anais-dotis-georgiou-developer-advocate-at-influxdata-interview-series/
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
Anais Dotis-Georgiou is a Developer Advocate for InfluxData with a passion for making data beautiful with the use of Data Analytics, AI, and Machine Learning. She takes the data that she collects, does a mix of research, exploration, and engineering to translate the data into something of function, value, and beauty. When she is not behind a screen, you can find her outside drawing, stretching, boarding, or chasing after a soccer ball.
InfluxData is the company building InfluxDB, the open source time series database used by more than a million developers around the world. Their mission is to help developers build intelligent, real-time systems with their time series data.
Can you share a bit about your journey from being a Research Assistant to becoming a Lead Developer Advocate at InfluxData? How has your background in data analytics and machine learning shaped your current role?
I earned my undergraduate degree in chemical engineering with a focus on biomedical engineering and eventually worked in labs performing vaccine development and prenatal autism detection. From there, I began programming liquid-handling robots and helping data scientists understand the parameters for anomaly detection, which made me more interested in programming.
I then became a sales development representative at Oracle and realized that I really needed to focus on coding. I took a coding boot camp at the University of Texas in data analytics and was able to break into tech, specifically developer relations.
I came from a technical background, so that helped shape my current role. Even though I didn’t have development experience, I could relate to and empathize with people who had an engineering background and mind but were also trying to learn software. So, when I created content or technical tutorials, I was able to help new users overcome technical challenges while placing the conversation in a context that was relevant and interesting to them.
Your work seems to blend creativity with technical expertise. How do you incorporate your passion for making data ‘beautiful’ into your daily work at InfluxData?
Lately, I’ve been more focused on data engineering than data analytics. While I don’t focus on data analytics as much as I used to, I still really enjoy math—I think math is beautiful, and will jump at an opportunity to explain the math behind an algorithm.
InfluxDB has been a cornerstone in the time series data space. How do you see the open source community influencing the development and evolution of InfluxDB?
InfluxData is very committed to the open data architecture and Apache ecosystem. Last year we announced InfluxDB 3.0, the new core for InfluxDB written in Rust and built with Apache Flight, DataFusion, Arrow, and Parquet–what we call the FDAP stack. As the engineers at InfluxData continue to contribute to those upstream projects, the community continues to grow and the Apache Arrow set of projects gets easier to use with more features and functionality, and wider interoperability.
What are some of the most exciting open-source projects or contributions you’ve seen recently in the context of time series data and AI?
It’s been cool to see the addition of LLMs being repurposed or applied to time series for zero-shot forecasting. Autolab has a collection of open time series language models, and TimeGPT is another great example.
Additionally, various open source stream processing libraries, including Bytewax and Mage.ai, that allow users to leverage and incorporate models from Hugging Face are pretty exciting.
How does InfluxData ensure its open source initiatives stay relevant and beneficial to the developer community, particularly with the rapid advancements in AI and machine learning?
InfluxData initiatives remain relevant and beneficial by focusing on contributing to open source projects that AI-specific companies also leverage. For example, every time InfluxDB contributes to Apache Arrow, Parquet, or DataFusion, it benefits every other AI tech and company that leverages it, including Apache Spark, DataBricks, Rapids.ai, Snowflake, BigQuery, HuggingFace, and more.
Time series language models are becoming increasingly vital in predictive analytics. Can you elaborate on how these models are transforming time series forecasting and anomaly detection?
Time series LMs outperform linear and statistical models while also providing zero-shot forecasting. This means you don’t need to train the model on your data before using it. There’s also no need to tune a statistical model, which requires deep expertise in time series statistics.
However, unlike natural language processing, the time series field lacks publicly accessible large-scale datasets. Most existing pre-trained models for time series are trained on small sample sizes, which contain only a few thousand—or maybe even hundreds—of samples. Although these benchmark datasets have been instrumental in the time series community’s progress, their limited sample sizes and lack of generality pose challenges for pre-training deep learning models.
That said, this is what I believe makes open source time series LMs hard to come by. Google’s TimesFM and IBM’s Tiny Time Mixers have been trained on massive datasets with hundreds of billions of data points. With TimesFM, for example, the pre-training process is done using Google Cloud TPU v3–256, which consists of 256 TPU cores with a total of 2 terabytes of memory. The pre-training process takes roughly ten days and results in a model with 1.2 billion parameters. The pre-trained model is then fine-tuned on specific downstream tasks and datasets using a lower learning rate and fewer epochs.
Hopefully, this transformation implies that more people can make accurate predictions without deep domain knowledge. However, it takes a lot of work to weigh the pros and cons of leveraging computationally expensive models like time series LMs from both a financial and environmental cost perspective.
This Hugging Face Blog post details another great example of time series forecasting.
What are the key advantages of using time series LMs over traditional methods, especially in terms of handling complex patterns and zero-shot performance?
The critical advantage is not having to train and retrain a model on your time series data. This hopefully eliminates the online machine learning problem of monitoring your model’s drift and triggering retraining, ideally eliminating the complexity of your forecasting pipeline.
You also don’t need to struggle to estimate the cross-series correlations or relationships for multivariate statistical models. Additional variance added by estimates often harms the resulting forecasts and can cause the model to learn spurious correlations.
Could you provide some practical examples of how models like Google’s TimesFM, IBM’s TinyTimeMixer, and AutoLab’s MOMENT have been implemented in real-world scenarios?
This is difficult to answer; since these models are in their relative infancy, little is known about how companies use them in real-world scenarios.
In your experience, what challenges do organizations typically face when integrating time series LMs into their existing data infrastructure, and how can they overcome them?
Time series LMs are so new that I don’t know the specific challenges organizations face. However, I imagine they’ll confront the same challenges faced when incorporating any GenAI model into your data pipeline. These challenges include:
Data compatibility and integration issues: Time series LMs often require specific data formats, consistent timestamping, and regular intervals, but existing data infrastructure might include unstructured or inconsistent time series data spread across different systems, such as legacy databases, cloud storage, or real-time streams. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
Model scalability and performance: Time series LMs, especially deep learning models like transformers, can be resource-intensive, requiring significant compute and memory resources to process large volumes of time series data in real-time or near-real-time. This would require teams to deploy models on scalable platforms like Kubernetes or cloud-managed ML services, leverage GPU acceleration when needed, and utilize distributed processing frameworks like Dask or Ray to parallelize model inference.
Interpretability and trustworthiness: Time series models, particularly complex LMs, can be seen as “black boxes,” making it hard to interpret predictions. This can be particularly problematic in regulated industries like finance or healthcare.
Data privacy and security: Handling time series data often involves sensitive information, such as IoT sensor data or financial transaction data, so ensuring data security and compliance is critical when integrating LMs. Organizations must ensure data pipelines and models comply with best security practices, including encryption and access control, and deploy models within secure, isolated environments.
Looking forward, how do you envision the role of time series LMs evolving in the field of predictive analytics and AI? Are there any emerging trends or technologies that particularly excite you?
A possible next step in the evolution of time series LMs could be introducing tools that enable users to deploy, access, and use them more easily. Many of the time series LMs I’ve used require very specific environments and lack a breadth of tutorials and documentation. Ultimately, these projects are in their early stages, but it will be exciting to see how they evolve in the coming months and years.
Thank you for the great interview, readers who wish to learn more should visit InfluxData.
#access control#ai#algorithm#Analytics#anomaly detection#Apache#Apache Spark#architecture#autism#background#Beauty#benchmark#best security#bigquery#billion#Biomedical engineering#Blog#Building#chemical#Chemical engineering#Cloud#cloud storage#coding#Community#Companies#complexity#compliance#content#creativity#data
0 notes
Text
How Helical IT Solutions Helps You Achieve Seamless Data Integration with Data Lakes
Organizations must manage and analyze enormous volumes of structured and unstructured data from various sources in today's data-driven environment. Data lakes have emerged as an essential solution, enabling businesses to store, process, and analyze data efficiently. Helical IT Solutions, a leader in Data Lake Services, provides end-to-end solutions that empower organizations to achieve seamless data integration and unlock the full potential of their data ecosystems.
Expertise in Data Lake Architecture
Helical IT Solutions specializes in designing and implementing robust data lake architectures tailored to meet unique business needs. With expertise spanning various domains and geographies, their team ensures that the architecture is scalable, cost-effective, and future-proof. By leveraging advanced tools and technologies such as Apache Spark, Databricks, Snowflake, AWS Lake Formation, and Google BigQuery, Helical IT Solutions provides solutions that incorporate a variety of data sources, such as social media, RDBMS, NoSQL databases, APIs, and Internet of Things devices.
Comprehensive Data Lake Services
Helical IT Solutions offers a comprehensive suite of Data Lake Services, covering every stage of implementation:
Data Needs Assessment: Identifying the specific data requirements based on organizational goals.
Source Integration: Establishing connections with heterogeneous data sources for seamless ingestion.
Data Transformation: Processing structured and unstructured data to ensure compatibility with analytical tools.
Deployment: Implementing the solution on-premises or in the cloud based on client preferences.
Visualization & Analytics: Enabling reporting, dashboarding, prediction, and forecasting using advanced BI tools like Helical Insight.
These services are designed to help organizations transition from traditional data warehouses to modern data lakes while maintaining data integrity and optimizing costs.
Advanced Analytics with Helical Insight
To maximize the value of data lakes, Helical IT Solutions integrates its open-source BI tool, Helical Insight. This feature-rich platform supports seamless connectivity with major data lake solutions such as Databricks, Snowflake, Dremio, Presto Foundation, and more. It empowers businesses to create custom dashboards, visualize complex datasets, and perform deep analytics without incurring heavy licensing fees.
Helical Insight’s capabilities include dynamic chart customizations, embedded analytics for scalability, support for diverse file formats (e.g., Google Sheets, Excel), and advanced security features. These functionalities enable organizations to transform raw data into actionable insights that drive strategic decision-making.
Cost Optimization and Agile Project Management
One of Helical IT Solutions’ key differentiators is its focus on cost optimization. By leveraging open-source tools and minimizing cloud licensing expenses without compromising functionality, they offer high-quality services at competitive rates. Additionally, their agile project management approach ensures timely delivery and alignment with business objectives.
Driving Business Growth Through Data Lakes
Helical IT Solutions has successfully implemented over 85 DWBI projects across industries such as FMCG, education, healthcare, manufacturing, fintech, and government organizations. Their expertise in handling large-scale data integration challenges has helped clients achieve improved reporting performance and enhanced decision-making capabilities.
Conclusion
Helical IT Solutions stands out as a trusted partner for organizations looking to harness the power of data lakes. Their comprehensive Data Lake Services, combined with cutting-edge tools like Helical Insight, ensure seamless integration of diverse data sources while enabling advanced analytics at scale. By choosing Helical IT Solutions, businesses can transform their raw data into valuable insights that fuel innovation and growth.
For organizations striving to become truly data-driven in today’s competitive landscape, Helical IT Solutions provides the expertise and solutions needed to make it happen.
0 notes
Text
Data Lake Consulting Services for Scalable Data Management
Visit Site Now - https://goognu.com/services/data-warehouse-consulting-services
Harness the power of big data with our expert Data Lake Consulting Services. We help businesses design, implement, and optimize scalable data lake solutions to store, process, and analyze vast amounts of structured and unstructured data efficiently.
Our services include data lake architecture design, data ingestion, governance, security, and cloud integration. Whether you're building a data lake from scratch or optimizing an existing one, our consultants ensure seamless implementation tailored to your business needs.
We specialize in cloud-based data lakes on platforms like AWS (S3 & Lake Formation), Azure Data Lake, and Google Cloud Storage. Our team assists in real-time data streaming, batch processing, and integration with data warehouses to create a unified analytics ecosystem.
Security and compliance are at the heart of our approach. We implement role-based access control, encryption, and compliance frameworks to protect your data assets. Our data governance strategies ensure data integrity, accessibility, and regulatory compliance, including GDPR and HIPAA.
With a focus on cost optimization and performance, we help businesses reduce storage costs, improve query performance, and enable intelligent data lifecycle management. Our experts leverage serverless computing, ETL pipelines, and big data frameworks like Apache Spark and Hadoop to enhance efficiency.
For organizations looking to gain real-time insights, we integrate AI/ML capabilities, data analytics tools, and BI platforms to turn raw data into actionable intelligence. Our managed data lake services offer continuous monitoring, performance tuning, and support, ensuring long-term success.
Whether you're a startup or an enterprise, our Data Lake Consulting Services provide the expertise needed to transform raw data into a scalable, secure, and high-performing data ecosystem. Contact us today to accelerate your data-driven innovation!
0 notes
Text
Develop ChatQnA Applications with OPEA and IBM DPK

How OPEA and IBM DPK Enable Custom ChatQnA Retrieval Augmented Generation
GenAI is changing application development and implementation with intelligent chatbots and code generation. However, organisations often struggle to match commercial AI capabilities with corporate needs. Standardisation and customization to accept domain-specific data and use cases are important GenAI system development challenges. This blog post addresses these difficulties and how the IBM Data Prep Kit (DPK) and Open Platform for Enterprise AI (OPEA) designs may help. Deploying and customizing a ChatQnA application using a retrieval augmented generation (RAG) architecture will show how OPEA and DPK work together.
The Value of Standardisation and Customization
Businesses implementing generative AI (GenAI) applications struggle to reconcile extensive customization with standardisation. Balance is needed to create scalable, effective, and business-relevant AI solutions. Companies creating GenAI apps often face these issues due to lack of standardisation:
Disparate models and technology make it hard to maintain quality and reliability across corporate divisions.
Without common pipelines and practices, expanding AI solutions across teams or regions is challenging and expensive.
Support and maintenance of a patchwork of specialist tools and models strain IT resources and increase operational overhead.
Regarding Customization
Although standardisation increases consistency, it cannot suit all corporate needs. Businesses operate in complex contexts that often span industries, regions, and regulations. Off-the-shelf, generic AI models disappoint in several ways:
AI models trained on generic datasets may perform badly when confronted with industry-specific language, procedures, or regulatory norms, such as healthcare, finance, or automotive.
AI model customization helps organisations manage supply chains, improve product quality, and tailor consumer experiences.
Data privacy and compliance: Building and training bespoke AI systems with private data keeps sensitive data in-house and meets regulatory standards.
Customization helps firms innovate, gain a competitive edge, and discover new insights by solving challenges generic solutions cannot.
How can we reconcile uniformity and customization?
OPEA Blueprints: Module AI
OPEA, an open source initiative under LF AI & Data, provides enterprise-grade GenAI system designs, including customizable RAG topologies.
Notable traits include:
Modular microservices: Equivalent, scalable components.
End-to-end workflows: GenAI paradigms for document summarisation and chatbots.
Open and vendor-neutral: Uses open source technology to avoid vendor lockage.
Flexibility in hardware and cloud: supports AI accelerators, GPUs, and CPUs in various scenarios.
The OPEA ChatQnA design provides a standard RAG-based chatbot system with API-coordinated embedding, retrieval, reranking, and inference services for easy implementation.
Simplified Data Preparation with IBM Data Prep Kit
High-quality data for AI and LLM applications requires a lot of labour and resources. IBM's Data Prep Kit (DPK), an open source, scalable toolkit, facilitates data pretreatment across data formats and corporate workloads, from ingestion and cleaning to annotation and embedding.
DPK allows:
Complete preprocessing includes ingestion, cleaning, chunking, annotation, and embedding.
Scalability: Apache Spark and Ray-compatible.
Community-driven extensibility: Open source modules are easy to customize.
Companies may quickly analyse PDFs and HTML using DPK to create structured embeddings and add them to a vector database. AI systems can respond precisely and domain-specifically.
ChatQnA OPEA/DPK deployment
The ChatQnA RAG process shows how standardised frameworks and customized data pipelines operate in AI systems. This end-to-end example illustrates how OPEA's modular design and DPK's data processing capabilities work together to absorb raw texts and produce context-aware solutions.
This example shows how enterprises may employ prebuilt components for rapid deployment while customizing embedding generation and LLM integration while maintaining consistency and flexibility. This OPEA blueprint may be used as-is or modified to meet your architecture utilising reusable pieces like data preparation, vector storage, and retrievers. DPK loads Milvus vector database records. If your use case requires it, you can design your own components.
Below, we step-by-step explain how domain-specific data processing and standardised microservices interact.
ChatQnA chatbots show OPEA and DPK working together:
DPK: Data Preparation
Accepts unprocessed documents for OCR and extraction.
Cleaning and digestion occur.
Fills vector database, embeds
OPEA—AI Application Deployment:
Uses modular microservices (inference, reranking, retrieval, embedding).
Easy to grow or replace components (e.g., databases, LLM models)
End-user communication:
Context is embedded and retrieved upon user request.
Additional background from LLM responses
This standardised yet flexible pipeline ensures AI-driven interactions, scales well, and accelerates development.
#IBMDPK#RetrievalAugmentedGeneration#OPEABlueprints#OPEA#IBMDataPrepKit#OPEAandDPK#technology#TechNews#technologynews#news#govindhtech
0 notes
Text
How Data Engineering Consultancy Builds Scalable Pipelines
To drive your business growth and make informed decision making, data integration, transformation, and its analysis is very crucial. How well you collect, transfer, analyze and utilize your data impacts your business or organization’s success. So, it becomes essential to partner with a professional data engineering consultancy to ensure your important data is managed effectively using scalable data pipelines.
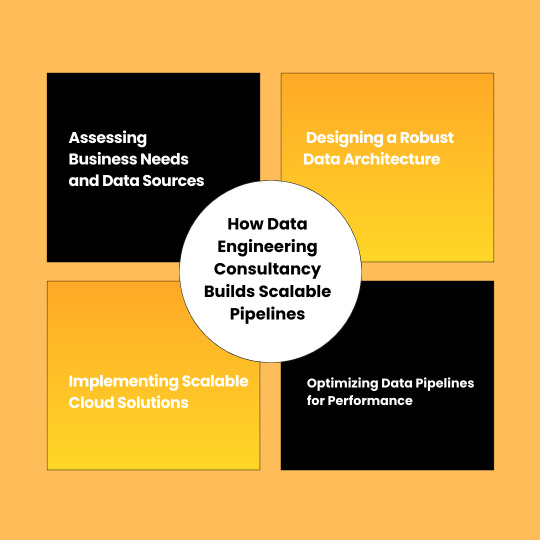
What are these scalable data pipelines? How does a Data Engineering Consultancy build them? The role of Google Analytics consulting? Let’s discuss all these concerns in this blog.
What are Scalable Data Pipelines?
Scalable data pipelines are the best approach used for moving and processing data from various sources to analytical platforms. This approach increases data volume and complexity while the performance remains consistent. Data Engineering Consultancy designs these data pipelines that handle massive data sets which is also known as the backbone of modern data infrastructure.
Key Components of a Scalable Data Pipeline
The various key components of a scalable data pipelines are:
Data Ingestion – Collect data from multiple sources. These sources are APIs, cloud services, databases and third-party applications.
Data Processing – Clean, transform, and structure raw data for analysis. These tools are Apache Spark, Airflow, and cloud-based services.
Storage & Management – Store and manage data in scalable cloud-based solutions. These solutions are Google BigQuery, Snowflake, and Amazon S3.
Automation & Monitoring – Implement automated workflows and monitor systems to ensure smooth operations and detect potential issues.
These are the various key components of scalable data pipelines that are used by Data Engineering Consultancy. These data pipelines ensure businesses manage their data efficiently, allow faster insights, and improved decision-making.
How Data Engineering Consultancy Builds Scalable Pipelines
Data Engineering Consultancy builds scalable pipelines in step by step process, let’s explore these steps.
1. Assessing Business Needs and Data Sources
Step 1 is accessing your business needs and data sources. We start by understanding your data requirements and specific business objectives. Our expert team determines the best approach for data integration by analyzing data sources such as website analytics tools, third-party applications, and CRM platforms.
2. Designing a Robust Data Architecture
Step 2 is designing a robust data plan. Our expert consultants create a customized data plan based on your business needs. We choose the most suitable technologies and frameworks by considering various factors such as velocity, variety, and data volume.
3. Implementing Scalable Cloud Solutions
Step 3 is implementing scalable cloud based solutions. We implement solutions like Azure, AWS, and Google Cloud to ensure efficiency and cost-effectiveness. Also, these platforms provide flexibility of scale storage and computing resources based on real-time demand.
4. Optimizing Data Pipelines for Performance
Step 4 is optimizing data pipelines for performance. Our Data Engineering Consultancy optimizes data pipelines by automating workflows and reducing latency. Your business can achieve near-instant data streaming and processing capabilities by integrating tools like Apache Kafka and Google Dataflow.
5. Google Analytics Consulting for Data Optimization
Google Analytics consulting plays an important role for data optimization as it understands the user behaviors and website performance.. With our Google Analytics consulting your businesses can get actionable insights by -
Setting up advanced tracking mechanisms.
Integrating Google Analytics data with other business intelligence tools.
Enhancing reporting and visualization for better decision-making.
Data Engineering Consultancy - What Are Their Benefits?
Data engineering consultancy offers various benefits,let's explore them.
Improve Data Quality and Reliability
Enhance Decision-Making
Cost and Time Efficiency
Future-Proof Infrastructure
With Data engineering consultancy, you can get access to improved data quality and reliability. This helps you to get accurate data with no errors.
You can enhance your informed decision-making using real-time and historical insights.This helps businesses to make informed decisions.
Data Engineering consultancy reduces manual data handling and operational costs as it provides cost and time efficiency.
Data Engineering consultancy provides future proof infrastructure. Businesses can scale their data operations seamlessly by using latest and exceptional technologies.
Conclusion: Boost Business With Expert & Top-Notch Data Engineering Solutions
Let’s boost business growth with exceptional and top-notch data engineering solutions. We at Kaliper help businesses to get the full potential of their valuable data to make sustainable growth of their business. Our expert and skilled team can assist you to thrive your business performance by extracting maximum value from your data assets. We can help you to gain valuable insights about your user behavior. To make informed decisions, and get tangible results with our top-notch and innovative Google Analytics solutions.
Kaliper ensures your data works smarter for you by integrating with data engineering consultancy. We help you to thrive your business with our exceptional data engineering solutions. Schedule a consultation with Kaliper today and let our professional and expert team guide you toward your business growth and success.
0 notes
Text

The modern enterprise runs on data, but without a strong data engineering foundation, insights remain scattered, unreliable, and slow. At #RoundTheClockTechnologies, a scalable, high-performance data ecosystem is built to ensure businesses get faster, more accurate, and real-time insights at every stage.
By leveraging cloud-native architectures, real-time ETL processing, and automated data pipelines, structured and unstructured data seamlessly flow into centralized lakes and warehouses—ready for AI-driven analytics, reporting, and operational intelligence. Technologies like Apache Spark, AWS Glue, Snowflake, and Databricks ensure zero data loss, high availability, and unmatched speed. With security-first engineering, data is safeguarded at every stage, ensuring compliance with global standards. Performance optimization techniques eliminate bottlenecks, enabling instant access to mission-critical data.
Learn more about our services at https://rtctek.com/data-engineering-services/
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
What to Look for When Hiring Remote Scala Developers

Scala is a popular choice if you as a SaaS business are looking to build scalable, high-performance applications. Regarded for its functional programming potential and seamless integration with Java, Scala is widely implemented in data-intensive applications, distributed systems, and backend development.
However, to identify and hire skilled remote software developers with Scala proficiency can be challenging. An understanding of the needed key skills and qualifications can help you find the right fit. Operating as a SaaS company makes efficiency and scalability vital, which is why the best Scala developers can ensure smooth operations and future-proof applications.
Key Skills and Qualities to Look for When Hiring Remote Scala Developers
Strong knowledge of Scala and functional programming
A Scala developer's proficiency with the language is the most crucial consideration when hiring them. Seek applicants with:
Expertise in Scala's functional programming capabilities, such as higher-order functions and immutability.
Strong knowledge of object-oriented programming (OOP) principles and familiarity with Scala frameworks such as Play, Akka, and Cats.
You might also need to hire backend developers who are adept at integrating Scala with databases and microservices if your project calls for a robust backend architecture.
Experience in distributed systems and big data
Scala is widely used by businesses for large data and distributed computing applications. The ideal developer should be familiar with:
Kafka for real-time data streaming.
Apache Spark, a top framework for large data analysis.
Proficiency in NoSQL databases, such as MongoDB and Cassandra.
Hiring a Scala developer with big data knowledge guarantees effective processing and analytics for SaaS organizations managing massive data volumes.
Ability to operate in a remote work environment
Hiring remotely is challenging since it poses several obstacles. Therefore, remote developers must be able to:
Work independently while still communicating with the team.
Use collaboration technologies like Jira, Slack, and Git for version control.
Maintain productivity while adjusting to distinct time zones.
Employing engineers with excellent communication skills guarantees smooth project management for companies transitioning to a remote workspace.
Knowledge of JVM and Java interoperability
Scala's interoperability with Java is one of its main benefits. Make sure the developer has experience with Java libraries and frameworks and is knowledgeable about JVM internals and performance tuning before employing them. They must be able to work on projects that call for integration between Java and Scala. Businesses switching from Java-based apps to Scala will find this very helpful.
Problem-solving and code optimization skills
Writing clear, effective, and maintainable code is a must for any competent Scala developer. Seek applicants who can:
Optimize and debug code according to best practices.
Refactor current codebases to increase performance.
Possess expertise in continuous integration and test-driven development (TDD).
Conclusion
It takes more than just technical know-how to choose and hire the best Scala developer. Seek out experts who can work remotely, have experience with distributed systems, and have good functional programming abilities. Long-term success will result from hiring developers with the appropriate combination of skills and expertise. Investing in top Scala talent enables SaaS organizations to create high-performing, scalable applications that propel business expansion.
0 notes