#aws rds postgres
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
#aws cloud#aws ec2#aws s3#aws serverless#aws ecs fargate tutorial#aws tutorial#aws cloud tutorial#aws course#aws cloud services#aws apprunner#aws rds postgres
0 notes
Text
U.S. Cloud DBaaS Market Set for Explosive Growth Amid Digital Transformation Through 2032
Cloud Database And DBaaS Market was valued at USD 17.51 billion in 2023 and is expected to reach USD 77.65 billion by 2032, growing at a CAGR of 18.07% from 2024-2032.
Cloud Database and DBaaS Market is witnessing accelerated growth as organizations prioritize scalability, flexibility, and real-time data access. With the surge in digital transformation, U.S.-based enterprises across industries—from fintech to healthcare—are shifting from traditional databases to cloud-native solutions that offer seamless performance and cost efficiency.
U.S. Cloud Database & DBaaS Market Sees Robust Growth Amid Surge in Enterprise Cloud Adoption
U.S. Cloud Database And DBaaS Market was valued at USD 4.80 billion in 2023 and is expected to reach USD 21.00 billion by 2032, growing at a CAGR of 17.82% from 2024-2032.
Cloud Database and DBaaS Market continues to evolve with strong momentum in the USA, driven by increasing demand for managed services, reduced infrastructure costs, and the rise of multi-cloud environments. As data volumes expand and applications require high availability, cloud database platforms are emerging as strategic assets for modern enterprises.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6586
Market Keyplayers:
Google LLC (Cloud SQL, BigQuery)
Nutanix (Era, Nutanix Database Service)
Oracle Corporation (Autonomous Database, Exadata Cloud Service)
IBM Corporation (Db2 on Cloud, Cloudant)
SAP SE (HANA Cloud, Data Intelligence)
Amazon Web Services, Inc. (RDS, Aurora)
Alibaba Cloud (ApsaraDB for RDS, ApsaraDB for MongoDB)
MongoDB, Inc. (Atlas, Enterprise Advanced)
Microsoft Corporation (Azure SQL Database, Cosmos DB)
Teradata (VantageCloud, ClearScape Analytics)
Ninox (Cloud Database, App Builder)
DataStax (Astra DB, Enterprise)
EnterpriseDB Corporation (Postgres Cloud Database, BigAnimal)
Rackspace Technology, Inc. (Managed Database Services, Cloud Databases for MySQL)
DigitalOcean, Inc. (Managed Databases, App Platform)
IDEMIA (IDway Cloud Services, Digital Identity Platform)
NEC Corporation (Cloud IaaS, the WISE Data Platform)
Thales Group (CipherTrust Cloud Key Manager, Data Protection on Demand)
Market Analysis
The Cloud Database and DBaaS (Database-as-a-Service) Market is being fueled by a growing need for on-demand data processing and real-time analytics. Organizations are seeking solutions that provide minimal maintenance, automatic scaling, and built-in security. U.S. companies, in particular, are leading adoption due to strong cloud infrastructure, high data dependency, and an agile tech landscape.
Public cloud providers like AWS, Microsoft Azure, and Google Cloud dominate the market, while niche players continue to innovate in areas such as serverless databases and AI-optimized storage. The integration of DBaaS with data lakes, containerized environments, and AI/ML pipelines is redefining the future of enterprise database management.
Market Trends
Increased adoption of multi-cloud and hybrid database architectures
Growth in AI-integrated database services for predictive analytics
Surge in serverless DBaaS models for agile development
Expansion of NoSQL and NewSQL databases to support unstructured data
Data sovereignty and compliance shaping platform features
Automated backup, disaster recovery, and failover features gaining popularity
Growing reliance on DBaaS for mobile and IoT application support
Market Scope
The market scope extends beyond traditional data storage, positioning cloud databases and DBaaS as critical enablers of digital agility. Businesses are embracing these solutions not just for infrastructure efficiency, but for innovation acceleration.
Scalable and elastic infrastructure for dynamic workloads
Fully managed services reducing operational complexity
Integration-ready with modern DevOps and CI/CD pipelines
Real-time analytics and data visualization capabilities
Seamless migration support from legacy systems
Security-first design with end-to-end encryption
Forecast Outlook
The Cloud Database and DBaaS Market is expected to grow substantially as U.S. businesses increasingly seek cloud-native ecosystems that deliver both performance and adaptability. With a sharp focus on automation, real-time access, and AI-readiness, the market is transforming into a core element of enterprise IT strategy. Providers that offer interoperability, data resilience, and compliance alignment will stand out as leaders in this rapidly advancing space.
Access Complete Report: https://www.snsinsider.com/reports/cloud-database-and-dbaas-market-6586
Conclusion
The future of data is cloud-powered, and the Cloud Database and DBaaS Market is at the forefront of this transformation. As American enterprises accelerate their digital journeys, the demand for intelligent, secure, and scalable database services continues to rise.
Related Reports:
Analyze U.S. market demand for advanced cloud security solutions
Explore trends shaping the Cloud Data Security Market in the U.S
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
0 notes
Video
youtube
AWS RDS Aurora Postgres Database Setup: Create/Drop using Python Script
0 notes
Text
Hosting Options for Full Stack Applications: AWS, Azure, and Heroku

Introduction
When deploying a full-stack application, choosing the right hosting provider is crucial. AWS, Azure, and Heroku offer different hosting solutions tailored to various needs. This guide compares these platforms to help you decide which one is best for your project.
1. Key Considerations for Hosting
Before selecting a hosting provider, consider: ✅ Scalability — Can the platform handle growth? ✅ Ease of Deployment — How simple is it to deploy and manage apps? ✅ Cost — What is the pricing structure? ✅ Integration — Does it support your technology stack? ✅ Performance & Security — Does it offer global availability and robust security?
2. AWS (Amazon Web Services)
Overview
AWS is a cloud computing giant that offers extensive services for hosting and managing applications.
Key Hosting Services
🚀 EC2 (Elastic Compute Cloud) — Virtual servers for hosting web apps 🚀 Elastic Beanstalk — PaaS for easy deployment 🚀 AWS Lambda — Serverless computing 🚀 RDS (Relational Database Service) — Managed databases (MySQL, PostgreSQL, etc.) 🚀 S3 (Simple Storage Service) — File storage for web apps
Pros & Cons
✔️ Highly scalable and flexible ✔️ Pay-as-you-go pricing ✔️ Integration with DevOps tools ❌ Can be complex for beginners ❌ Requires manual configuration
Best For: Large-scale applications, enterprises, and DevOps teams.
3. Azure (Microsoft Azure)
Overview
Azure provides cloud services with seamless integration for Microsoft-based applications.
Key Hosting Services
🚀 Azure Virtual Machines — Virtual servers for custom setups 🚀 Azure App Service — PaaS for easy app deployment 🚀 Azure Functions — Serverless computing 🚀 Azure SQL Database — Managed database solutions 🚀 Azure Blob Storage — Cloud storage for apps
Pros & Cons
✔️ Strong integration with Microsoft tools (e.g., VS Code, .NET) ✔️ High availability with global data centers ✔️ Enterprise-grade security ❌ Can be expensive for small projects ❌ Learning curve for advanced features
Best For: Enterprise applications, .NET-based applications, and Microsoft-centric teams.
4. Heroku
Overview
Heroku is a developer-friendly PaaS that simplifies app deployment and management.
Key Hosting Features
🚀 Heroku Dynos — Containers that run applications 🚀 Heroku Postgres — Managed PostgreSQL databases 🚀 Heroku Redis — In-memory caching 🚀 Add-ons Marketplace — Extensions for monitoring, security, and more
Pros & Cons
✔️ Easy to use and deploy applications ✔️ Managed infrastructure (scaling, security, monitoring) ✔️ Free tier available for small projects ❌ Limited customization compared to AWS & Azure ❌ Can get expensive for large-scale apps
Best For: Startups, small-to-medium applications, and developers looking for quick deployment.
5. Comparison Table
FeatureAWSAzureHerokuScalabilityHighHighMediumEase of UseComplexModerateEasyPricingPay-as-you-goPay-as-you-goFixed plansBest ForLarge-scale apps, enterprisesEnterprise apps, Microsoft usersStartups, small appsDeploymentManual setup, automated pipelinesIntegrated DevOpsOne-click deploy
6. Choosing the Right Hosting Provider
✅ Choose AWS for large-scale, high-performance applications.
✅ Choose Azure for Microsoft-centric projects.
✅ Choose Heroku for quick, hassle-free deployments.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
Veeam backup for aws Processing postgres rds failed: No valid combination of the network settings was found for the worker configuration
In this article, we shall discuss various errors you can encounter when implementing “Veeam Backup for AWS to protect RDS, EC2 and VPC“. Specifically, the following error “veeam backup for aws Processing postgres rds failed: No valid combination of the network settings was found for the worker configuration” will be discussed. A configuration is a group of network settings that Veeam Backup for…

View On WordPress
#AWS#AWS SSM Service#AWS System State Manager#Backup#Backup and Recovery#Create Production Worker Node#EC2#Enable Auto Assign Public IP Address on AWS#rds#The Worker Node for region is not set#VBAWS#VBAWS Session Status#Veeam Backup for AWS#Veeam backup for AWS Errors
0 notes
Text
Become an Expert with Amazon Aurora Developer Certification
Get Your Hands On with Edchart Certification - Edchart.com
In today's highly competitive job market, having the appropriate Amazon Aurora certification can significantly enhance your career opportunities. With Edchart.com as the world's pioneer in online certification providers that you can now improve your skills to the next level by completing our comprehensive certification programs. You may want to confirm qualifications, improve your resume, or progress in your career, Edchart Amazon Aurora Certification can provide the perfect solution.

Description of Edchart Certification
The exam is offered by Edchart Certified Amazon Aurora Developer Subject Matter Expert, we offer the widest range of examinations for certification online that demonstrate your knowledge in a variety of areas. Our Amazon Aurora Certification are recognized worldwide and accepted by experts from industry they are a valuable tool for professionals from various areas. After obtaining certification with an Edchart Amazon Aurora certification, you are demonstrating your commitment to continual learning and professional development, which sets yourself apart from others in the competitive job market.
Advantages and Benefits of Edchart Certification
Recognition Edchart AWS RDS Mysql certifications are widely recognized in the workplace, giving you a competitive edge in your job look.
Trustworthiness: Our AWS RDS Mysql certifications are supported by industry experts. This guarantees the validity and reliability of our certifications for the constantly evolving job market.
Career advancement: With an Edchart Aurora Postgres certification, you'll be able get new career options and advance in your chosen field.
Flexible: AWS Aurora DB Our online exams let you study at your own pace. Schedule exams according to your timetable.
global credentials: This is the reason we've joined forces with Credly who manages our global credentials making sure it is that Aurora Mysql credentials are easily verified as well as accessible to employers in all countries.
Scopes & Features for Edchart Certification
Edchart Aurora Mysql certification covers a wide array of topics, including but not only:
Information Technology
Project Management
Digital Marketing
Data Science
Finance
Healthcare
and many more.
All of our Postgresql AWS Aurora certification programs were designed to offer a complete as well as up-to-date. This ensures that you acquire the latest skills and knowledge to perform well in your area of expertise. With interactive study guides with practice tests, as well as professional support to make it easier in your preparation to take and take those RDS Aurora Certification exams with confidence.
Why Should One Take Edchart Certification
The process of obtaining one of the Edchart Aurora Database AWS certification comes with many benefits, which include:
Achieving your competence and qualifications in your field of expertise Aurora DB Aurora DB
Enhancing your resume and increasing your ability to be found by employers
Believing in continuous learning and professional development. Aurora Postgres
Accessing different career options and making progress your career
Joining a worldwide community of certified professionals and building your professional network with AWS's RDS Mysql.
Whether you're a recent graduate hoping to begin your career or an experienced professional who is aiming for advancement in your career, Edchart Aurora Mysql certification will aid you in reaching your goals and gain access to new opportunities.
Who Will Benefit from The Taking Edchart Certification
Edchart-certified Amazon Aurora Developer Subject Matter Expert is designed for professionals from different industries, such as:
IT professionals looking to verify their technical skills and progress their professional careers Amazon Aurora
Project managers looking to develop their skills in managing projects and qualifications
Aurora Postgres Marketing professionals aiming to stay abreast of the modern trends and strategies that are used in digital marketing
Data scientists who wish to acquire new skills and remain at the top of their game in the job marketplace. AWS Aurora DB.
Finance professionals looking to expand their expertise and understanding of related disciplines to finance
Healthcare professionals aiming to enhance their clinical capabilities and improve the quality of care for patients. Aurora Mysql.
Get an edge with Amazon Aurora Developer Certification
Master Amazon Aurora with Edchart Certification
In the field of cloud computing and database management The ability to be proficient in the AWS Aurora Certificate has become increasingly vital for IT professionals. At Edchart.com we offer a comprehensive Amazon Aurora Development Certification program that will help you master this cutting-edge technology and raise your professional career to new heights.
Amazon Aurora Certification is the Best in Certification
Amazon Aurora Certification is a top certification for professionals searching for expertise in cloud-based solutions for databases. If you're certified with Edchart.com's Amazon Aurora Developer Certification certification, you'll gain the knowledge and practical skills to create, develop and improve the performance of Aurora Database AWS effectively.
Description of Amazon Aurora
Amazon Aurora is an ultra-fast, fully-managed relational database service that is offered via Amazon Web Services RDS Mysql. It is suitable for MySQL and PostgreSQL with the same performance and availability of commercial databases as well as the convenience and affordability provided by free-of-cost databases. With features such as the ability to automate backups as well as failover along with seamless scaling AWS Aurora DB is the ideal option for businesses that want to build large, durable, and cost-effective databases in the cloud.
Advantages and Benefits of AWS RDS MySQL Certification
Validation of Expertise: AWS RDS Mysql certificate validates your experience in operating, managing, or improving MySQL databases using the RDS Aurora platform. It also increases your authority and appeal for employers.
Career Development: With AWS Aurora Postgresql certification, you'll be able to discover new career opportunities and move up the ladder to roles such as database administrator, cloud architect, in addition to solutions architects.
Advanced Expertise: By undergoing Aurora Database AWS certification training, you'll acquire advanced capabilities in database administration, the optimization of performance and troubleshooting, making you a invaluable asset to any business.
industry recognition: AWS's RDSMysql certification is recognized by business leaders and employers worldwide, giving you a advantages in your job search.
Zugang to Resource Resources as a registered Aurora Mysql Professional, you'll gain access to exclusive community resources, communities, and potential job openings in AWS. AWS ecosystem.
Scopes & Features for Aurora PostgreSQL Certification
Complete Curriculum Edchart.com's AWS Aurora Postgresql certification covers a wide array of subjects such as database design, administration, performance tuning, and also high-availability.
Hands-on Labs Our certification program includes hands-on labs and real-world projects that will help you gain experience and confidence working through the AWS Aurora DB.
Expert guidance: You'll receive expert guidance and assistance from certified instructors who are industry professionals with extensive experience dealing with Aurora Postgresql SQL.
Flexible Learning Options: If you're interested in self-paced on-line classes or instructor-led training We offer a variety of flexible learning choices to accommodate your schedule and learning style.
Industrial Recognition Aurora Postgres SQL certification from Edchart.com is widely recognized by employers and other organizations around the world providing many new career options and career growth opportunities.
Why Should One Take AWS Aurora DB Certification
AWS Aurora DB Certification is crucial for IT professionals looking to demonstrate their skills in designing or deploying high-performance databases on the cloud. If you are awarded Accreditation for AWS AuroraDB it will prove your abilities and expertise regarding one of the most in-demand technologies in the industry, placing your self as a valuable asset to any organization.
Who Will Benefit from the Aurora MySQL Certification? Aurora MySQL Certification
Aurora MySQL certification is ideal for:
Database Administrators AWS Aurora Certification Seeking to develop their expertise in managing improving MySQL databases on the cloud.
Cloud architects: Are you looking for ways to conceptualize and deploy scalable resilient and cost-effective data solutions through Amazon Aurora.
Software Designers Want to create applications utilize the performance and power of Aurora Mysql to meet their backend data storage needs.
Whatever your background or goals in your career, Edchart.com's Aurora Mysql certification will lead you to the top and further professional advancement in the rapidly evolving field of cloud-based database management. Begin your journey towards becoming an expert in the Amazon Aurora certification today!
0 notes
Text
Replicating data from Postgres to MS SQL Server using Kafka
You might have heard the expression that “Data is the new oil”, that’s because data is key for any business decision system of an organization. But then, the required data is not stored in one place like a regular & vanilla RDBMS. Normally, the data remains scattered across various RDBMS & other data silos. So, it’s quite common to come across situations where data is siting across different kind of sources, and the DBA needs to find a solution to pull all relevant data into a centralized location for further analysis.

The Challenge
Consider a particular scenario – we have some sales data in AWS Postgres RDS Instance and that data has to be replicated into some tables in their Azure VM with MS SQL Server. But the challenge is heterogeneous replication is marked as deprecated, and it doesn’t work anywhere but only between SQL Server and Oracle. No Postgres allowed in the batch. Also, native heterogeneous replication is not found on the Postgres side. We need third-party tools to achieve this or work manually in HIGH effort mode, creating a CDC (change data capture) mechanism through the use of triggers, and then getting data from control tables. It sounds fun to implement, but time is of the essence. Getting such a solution on ground would take quite some time. Therefore, another solution had to be used to complete this data movement.
A Possible Solution
The Big Data scenario has many tools that can achieve this objective, but they don’t have the advantages that Kafka offered.
Initially, Apache Kafka was designed as a message queue like app (like IBM MQ Series or even SQL Server Service Broker). The best definition of it is perhaps – “Apache Kafka is more like a community distributed event streaming technology which can handle trillions of events per day”. But a streaming system must have the ability to get data from different data sources and deliver the messages on different data endpoints.
There are many tools to achieve this – Azure Event Hubs, AWS Kinesis, or Kafka managed in Confluent Cloud. However, to show how things work under the hood, and since they have similar backgrounds (Apache Kafka open-source code) we have decided to show how to set up the environment from scratch without any managed services for the stream processing. So, the picture would look something like this: Read more ...
0 notes
Text
Aws postgresql licensing

#Aws postgresql licensing full
#Aws postgresql licensing code
#Aws postgresql licensing license
#Aws postgresql licensing professional
#Aws postgresql licensing series
#Aws postgresql licensing code
It is the expectation that PostgresConf community members will adhere to the PostgresConf Code of Conduct (CoC).
#Aws postgresql licensing professional
We expect everyone who participates to conduct themselves in a professional manner, acting with common courtesy and in the common interest, with respect for all of our community. Postgres Conference (PostgresConf) prides itself on the quality of our community and our work, and the technical and professional accomplishments of our community.
#Aws postgresql licensing full
Half and Full Day trainings (NOTE: Paid registrants receive priority seating, and trainings are restricted according to badge level).PostgresConf offers several presentation opportunities: Sponsors are welcome to present on any topic as long as it follows the guideline of: Does it promote the success of Postgres? Types of Presentations However, we offer presentation opportunities to our sponsors that may or may not advocate Open Source Postgres. Yes, the end goal is that the deployed Postgres is the Open Source Postgres and preference will always be given to Open Source Postgres presentations. Shouldn’t the community be promoting Open Source solutions over proprietary closed source solutions? That means the community embraces all forms of use for Postgres as long as it abides by the license.Ī presentation on RDS Postgres, Google Cloud Postgres or Greenplum increases overall success via visibility, lowers the barrier of entry for new Postgres users, and supports our commercial community with hard earned efforts to create Postgres products.
#Aws postgresql licensing license
The only license that maintains a higher level of freedom for Open Source development is the anti-license: Public Domain. The BSD license is a true freedom license. How do presentations on forks or closed source versions help the success of Postgres? These types projects and products ultimately contribute to the success of Postgres. It also includes forks of Postgres both closed and Open Source. This includes limitations of our great database. When considering whether to submit a topic or not, ask yourself, “Is this presentation in some way related to the success of Postgres?” If it is, then it will be considered. If you do not have a HDMI port, it is the speaker’s responsibility to provide an adapter. The Postgres Conference will provide a HDMI connection. Presentations that are not related to the success of Postgres will not be considered. As a conference that makes it a goal to incorporate the entire community we also consider business cases, product talks, and service presentations. This includes, but is not limited to, presentations on Open Source Projects, Postgres forks, extensions, new APIs, and languages. It had great content with knowledgeable professionals, educators and advocates!” Types of Presentations We AcceptĪny presentation that has a tie-in to Postgres will be considered for acceptance into one of our event programs. We work hard to create a professional, valuable, and highly educational environment that produces a net result of, “Wow, that conference was very well done. The community is comprised of users, developers, core-contributors, sponsors, advocates, and external communities. In an effort to create a productive and profitable environment for our community we must set a bar of expectation for content and we set the bar high.
#Aws postgresql licensing series
The Postgres Conference is a non-profit, community driven conference series delivering the largest education and advocacy platform for Postgres.
1 note
·
View note
Text
Postgres app

Postgres app free#
The pgAdmin Development Team is pleased to announce pgAdmin 4 version 6.11. Please note that the survey is entirely anonymous (although Google will see your IP address, and may know who you are if you are logged in to your Google account), unless you choose to include any identifying information in any of your responses.
Postgres app free#
Feel free to share the link with any friends or colleagues who you think may also want to provide their input. We'd like to gather feedback from as many users as possible, so please take a few minutes and complete the survey below. In order to help us better plan the future of pgAdmin, it's essential that we hear from users so we can focus our efforts in the areas that matter most. Fixed an issue where new folders cannot be created in the save dialog.ĭownload your copy now! - pgAdmin User Survey.Preserve the settings set by the user in the import/export data dialog.Ensure that geometry should be shown for all the selected cells.Ensure that notices should not disappear from the messages tab.Ensure that the splash screen can be moved.Port change password, master password, and named restore point dialog to React.Port the file/storage manager to React.Allow users to delete files/folders from the storage manager.Allow users to search within the file/storage manager.Pin Flask-SocketIO Query Tool -> Auto completion -> ‘Autocomplete on key press’ to disable it.Fixed improper parsing of HTTP requests in Pallets Werkzeug v2.1.0 and below (CVE-2022-29361).Port Role Reassign, User Management, Change Ownership, and URL Dialogs to React.Added support to create triggers from existing trigger functions in EPAS.You can view details regarding Backup, Restore, Maintenance, Import/Export, and creating a Cloud instance. Added support to show all background processes in separate panel.īy using this feature, the background process can be seen in the new processes panel.For more details please see the release notes. This release of pgAdmin 4 includes 37 bug fixes and new features. The pgAdmin Development Team is pleased to announce pgAdmin 4 versions 6.13. For example, type "SELECT * FROM " (without quotes, but with a trailing space), and then press the Control + Space key combination to select from a popup menu of autocomplete options. To use autocomplete, begin typing your query when you would like the query editor to suggest object names or commands that might be next in your query, press the Control + Space key combination. Read more Autocomplete feature in Query ToolĪuthor: Akshay Joshi, date: June 10, 2022 If you would like to take a look at the results yourself. In this blog post I'll go through the high level topics of the survey and attempt to summarise what has been reported, and draw some initial conclusions. Responses were generally positive as well, with a number of people expressing their appreciation for the work of the development team, which is always nice to hear. We had a fantastic response with 278 people taking the time to complete the survey - far exceeding our expectations. The aim of the survey was to help us understand how users are using pgAdmin to help us shape and focus our future development efforts. On Monday 11th July the pgAdmin Development Team opened the first pgAdmin user survey which we then ran for three weeks, closing it on Monday 1st August. This blog explains and provides a walkthrough of the pgAdmin AWS RDS deployment wizard which can be used to deploy a new PostgreSQL database in the Amazon AWS cloud and register it with pgAdmin so you can begin working with it immediately. Latest Blog Posts AWS RDS PostgreSQL Deployment with pgAdmin 4Īuthor: Yogesh Mahajan, date: Aug.
0 notes
Text
Why we moved from AWS RDS to Postgres in Kubernetes
https://nhost.io/blog/individual-postgres-instances Comments
0 notes
Video
youtube
Create an AWS RDS POSTGRES Database : AWS Free Tier
0 notes
Text
Bạn đã biết AWS Free Tier hay chưa?
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aws-free-tier/ - Cloudemind.com
Bạn đã biết AWS Free Tier hay chưa?
Sử dụng Cloud nói chung và AWS Cloud nói riêng các bạn sẽ nghe cứ nghe hoài là nó rẻ, nó ổn định. Câu trả lời của Kevin là nó còn tùy thuộc vào tình huống sử dụng và trình độ của người sử dụng n��a. Cloud giống như cung cấp cho các bạn một chiếc xe xịn, các bạn ko biết lái (sử dụng) nó đúng nhu cầu đúng mục đích bạn có thể sẽ gây họa cho bản thân và tổ chức. Vậy làm sao để giảm thiểu tai họa, rủi ro khi sử dụng cloud?
Chỉ có một cách duy nhất là các bạn cần phải biết cách sử dụng Cloud. Ah thì có thể học các khóa học, các hướng dẫn trên internet, may mắn hơn thì tổ chức các bạn có các hoạt động liên quan đào tạo. Nhưng đào tạo thì nó cũng chỉ đáp ứng phần nhỏ thôi, cái chính các bạn cần phải làm thực (hands-on) trên các hệ thống thật mới đem lại sự tin cậy nhất định.
Đôi lúc đọc tài liệu mà ko có thời gian thao tác hệ thống dịch vụ thật có thể đem lại cho các bạn tư duy ko chính xác về thực tế, dễ dẫn đến cách nghĩ, cách tư vấn sai cho tổ chức hay thậm chí khách hàng của các bạn. Bản thân Kevin thấy sử dụng Cloud đã rất dễ so với cách làm truyền thống, tập trung tối đa thời gian vào innovation ứng dụng và business của các bạn, nhưng cũng có cái khó là Cloud là một mảng rất rộng, các bạn cần chọn một hướng nào đó mà mình thích thú và đào sâu thì mới có “đẳng” để làm chứ ko chỉ để nói. Lúc này thì gọi là Experienced!
Chúc các bạn ngày càng Experienced với AWS Cloud.
Well Done is better than Well Said!
Unknown
AWS Free Tier
AWS cung cấp hơn 175 dịch vụ trong đó có hơn 85 cho phép bạn dùng miễn phí. Có 03 loại miễn phí bạn có thể có là:
12 months free – Sử dụng miễn phí trong 12 tháng. Đây có lẽ là loại phổ biến nhất.
Always free – Miễn phí suốt đời. Quá tuyệt vời.
Trials – thông thường có một giới hạn nhất định dùng thử. Ví dụ: 2 tháng.
Chúng ta hãy cùng điểm qua một số dịch vụ chính mà ban đầu các bạn có thể gặp phải phổ biến. Đây là cách sắp xếp các nhân của Kevin để dễ nhớ hơn, bạn có thể group các services theo cách bạn nhớ nhé:
Bộ ba Amazon EC2, S3 và RDS
Đây có lẽ là bộ phổ biến nhất mà dường như ai khi bắt đầu cũng có làm qua.
EC2: compute cung cấp các virtual machine trên nền tảng AWS Cloud.
S3: storage service. Cung cấp dịch vụ lưu trữ đối tượng. S3 cũng là dịch vụ serverless hỗ trợ lưu trữ không giới hạn trong mỗi bucket.
RDS – Relational Database Service – dịch vụ CSDL.
Với AWS free tier bạn có thể dùng như sau: Amazon EC2 Free tier:
Resizable compute capacity in the Cloud.
12 months free
750 hours t2.micro or t3.micro (depends on region available)
OS: Linux, RHEL, SLES, Windows
Amazon S3 Free Tier:
Secure, durable, and scalable object storage infrastructure.
12 months free
5GB storage
20K Read requests
2K Put requests
Amazon RDS Free Tier:
12 months free
750 hours
Instance type: db.t2.micro
Storage: 20GB gp
Backup Storage: 20GB
Engine: mysql, postgres, mariadb, mssql, oracle BYOL
Bộ AWS Serverless
Nằm trong bộ này Kevin sắp xếp đó là Amazon DynamoDB, AWS Lambda, API Gateway, Step Functions.
Amazon DynamoDB Free Tier:
Fast and flexible NoSQL database with seamless scalability.
Always free
Storage: 25GB
WCU: 25
RCU: 25
AWS Lambda Free Tier
Compute service that runs your code in response to events and automatically manages the compute resources.
Always free
1M requests per month
3.2M seconds of compute time
Amazon API Gateway Free Tier
Publish, maintain, monitor, and secure APIs at any scale.
12 months free
1M received api per month
AWS Step Functions Free Tier
Coordinate components of distributed applications.
Always free
4K state transition per month
Amazon SQS Free Tier
Scalable queue for storing messages as they travel between computers.
Always free
1M requests
Amazon SNS Free Tier
Fast, flexible, fully managed push messaging service.
Always free
1M publics
100K HTTP/S deliveries
1K email deliveries
AWS AppSync Free Tier
Develop, secure and run GraphQL APIs at any scale.
12 months free
250K query or data modification
250K real time updates
600K connection minutes
Bộ Data Science
Bộ này bao gồm các dịch vụ liên quan Data Analys, Data Visualization, Machine Learning, AI.
Amazon SageMaker Free Tier
Machine learning for every data scientist and developer.
2 months free trial
Studio notebooks: 250 hours per month ml.t3.medium or
SageMaker Data Wrangler: 25 hours per month ml.m5.4xlarge
Storage: 25GB per month, 10M write units
Training: 50 hours per month m4.xlarge or m5.xlarge
Inference: 125 hours per month of m4.xlarge or m5.xlarge
Amazon SageMaker GroundTruth Free Tier
Build highly-accurate training datasets quickly, while reducing data labeling costs by up to 70% .
2 months free trials
500 objects labeled per month
Amazon Forecast Free Tier
Amazon Forecast is a fully managed service that uses machine learning (ML) to deliver highly accurate forecasts.
2 months free trials
10K time series forecasts per month
Storage: 10GB per month
Training hours: 10h per month
Amazon Personalize Free Tier
Amazon Personalize enables developers to build applications with the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations.
2 months free trials
Data processing & storage: 20GB per month
Training: 100 hours per month
Recommendation: 50 TPS hours of real time recommendations / month
Amazon Rekognition Free Tier
Deep learning-based image recognition service.
12 months free
5,000 images per month
Store: 1,000 face metadata per month
Amazon Augmented AI
Amazon Augmented AI (Amazon A2I) makes it easy to build the workflows required for human review of ML predictions.
12 months free
42 objects per month (500 human reviews per year)
AWS Deepracer Free Tier
DeepRacer is an autonomous 1/18th scale race car designed to test RL models by racing on a physical track.
30 days free trials
10 hours for 30 days
Free storage: 5GB
Amazon Fraud Detector
Amazon Fraud Detector uses machine learning (ML)to identify potentially fraudulent activity so customers can catch more online fraud faster.
2 months free
model training per month: 50 compute hours
model hosting per month: 500 compute hours
fraud detection: 30K real time online fraud insight predictions & 30K real time rules based fraud predictions per month
Nhóm dịch vụ lưu trữ AWS
AWS cung cấp nhiều loại hình lưu trữ từ file, object đến cả block storage. Tùy loại dữ liệu và cách sử dụng dữ liệu mà chọn loại hình lưu trữ phù hợp. Một số dịch vụ lưu trữ phổ biến như: S3 (đã nói ở trên), EFS, EBS, Storage Gateway, CloudFront… Hãy cùng xem qua các dịch vụ chính nhé.
Amazon Elastic Block Store (EBS) Free Tier
Persistent, durable, low-latency block-level storage volumes for EC2 instances.
12 months free
Storage: 30GB (gp or magnetic)
2M IOPS với EBS Magnetic
Snapshot storage: 1GB
Amazon Elastic File Service (EFS) Free Tier
Simple, scalable, shared file storage service for Amazon EC2 instances.
Storage: 5GB
Amazon CloudFront Free Tier
Web service to distribute content to end users with low latency and high data transfer speeds.
12 months free
Data Transfer out: 50GB per month
HTTP / HTTPS requests: 2M per month
AWS Storage Gateway Free Tier
Hybrid cloud storage with seamless local integration and optimized data transfer.
Always free
First 100GB
Conclusion
AWS cung cấp rất nhiều dịch vụ miễn phí để các bạn có thể vọc trước khi triển khai ra môi trường production. Thậm chí nếu các bạn biết cách tận dụng thì hàng tháng sẽ ko tốn phí cho các website nho nhỏ phục vụ em yêu khoa học AWS.
Lưu ý khi các bạn sử dụng vượt quá free tier thì bạn sẽ trả giá theo từng loại dịch vụ quy định.
Bài này Kevin chỉ điểm qua các dịch chính hay ho mà có thể phổ biến cho các bạn sử dụng. Còn dịch vụ nào hay ho thì bạn chia sẻ chúng ta cùng học nhé.
Have fun!
Tham khảo: https://aws.amazon.com/free/
Xem thêm: https://cloudemind.com/aws-free-tier/
0 notes
Text
Amazon Aurora PostgreSQL parameters, Part 2: Replication, security, and logging
Organizations today have a strategy to migrate from traditional databases and as they plan their migration, they don’t want to compromise on performance, availability, and security features. Amazon Aurora is a cloud native relational database service that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases. The PostgreSQL-compatible edition of Aurora delivers up to 3X the throughput of standard PostgreSQL running on the same hardware, enabling existing PostgreSQL applications and tools to run without requiring modification. The combination of PostgreSQL compatibility with Aurora enterprise database capabilities provides an ideal target for commercial database migrations. Aurora PostgreSQL has enhancements at the engine level, which improves the performance for high concurrent OLTP workload, and also helps bridge the feature gap between commercial engines and open-source engines. While the default parameter settings for Aurora PostgreSQL are good for most of the workloads, customers who migrate their workloads from commercial engines may need to tune some of the parameters according to performance and other non-functional requirements. Even workloads which are migrated from PostgreSQL to Aurora PostgreSQL may need to relook at some of the parameter settings because of architectural differences and engine level optimizations. In this four part series, we explain parameters specific to Aurora PostgreSQL. We also delve into certain PostgreSQL database parameters that apply to Aurora PostgreSQL, how they behave differently, and how to set these parameters to leverage or control additional features in Aurora PostgreSQL. In part one of this series, we discussed the instance memory-related parameters and Query Plan Management parameters that can help you tune Amazon Aurora PostgreSQL. In this post, we discuss parameters related to replication, security, and logging. We will cover Aurora PostgreSQL optimizer parameters in part three which can improve performance of queries. In part four, we will cover parameters which can align Aurora PostgreSQL closer to American National Standards Institute (ANSI) standards and reduce the migration effort when migrating from commercial engines. Durability and high availability Aurora PostgreSQL uses a unique mechanism for replication in comparison to the community PostgreSQL to optimize over and above the decoupled storage layer. The Aurora storage engine writes data to six copies in parallel spread across three Availability Zones. The storage layer in Aurora is not just a block device but a cluster of machines functioning as storage nodes capable of decrypting database transaction logs. Aurora has a quorum algorithm for writes—as soon as four of the six writes are durable, the system successfully returns a committed transaction to the database. From a durability point of view, the Aurora storage engine can handle an Availability Zone plus one failure, sustaining continued write despite loss of an Availability Zone. The Aurora storage engine can continue to serve reads despite an Availability Zone plus a failure of an additional copy. Failure of a storage copy is mitigated by repairing it from the surviving three copies. Although all the nodes of an Aurora PostgreSQL cluster share the same storage, only one node can send write requests to the log-based storage engine and process acknowledgements for the same. For replication, the changes on writer nodes are shipped to the replica in a stream and applied to pages in the buffer cache. There is no need for the replica to write changes out to storage or to read pages to apply changes if they’re not in buffer cache. For more information about the architecture and fault tolerance capabilities of the Aurora storage engine, see Introducing the Aurora Storage Engine. In this section, we cover the behavior of key replication-related parameters that you might be familiar with in PostgreSQL. rds.logical_replication Aurora PostgreSQL 2.2 (compatible with PostgreSQL v10.6) and later allows you to enable logical decoding that can be used by AWS Database Migration Service (AWS DMS) or to set up native logical replication (with Aurora PostgreSQL as publisher). To enable logical replication, you need to set rds.logical_replication to 1. You can set this parameter in the DB cluster parameter group and it needs a restart to take effect. After you enable rds.logical_replication, whether you create a logical replication slot or not, Aurora PostgreSQL produces additional Write ahead logs (WAL) for the purpose of logical decoding. This can cause an increase in the billed metric for the Aurora cluster, VolumeWriteIOPs. After you set up a replication slot, Aurora PostgreSQL starts retaining WAL files that haven’t been consumed by the slot. This can cause an increase in the billed metric VolumeBytesUsed. You can use TransactionLogsDiskUsage to keep track of storage utilized by WAL files. Logical replication also incurs additional read input/output operations (IOPs) to Aurora PostgreSQL’s distributed storage engine, which causes an increase in the billed metric VolumeReadIOPs. synchronous_commit PostgreSQL ensures durability of a change before acknowledging a commit request from the client. In case of implicit transactions, every DML statement’s durability is ensured before acknowledging back to the client. In Amazon RDS for PostgreSQL, as with PostgreSQL running on Amazon Elastic Compute Cloud (Amazon EC2), durability is ensured by making sure that the change is written to the WAL file upon every commit (whether explicitly requested or implicit). You can control this behavior by setting synchronous_commit. If you disable synchronous_commit, PostgreSQL doesn’t try to ensure durability of every transaction. Instead, PostgreSQL writes committed transactions to the WAL file in groups. This can offer performance benefits at the risk of losing transactions. You should be very careful when changing this parameter from its default value. Disabling synchronous_commit compromises durability of your DB instance and can lead to data loss. Aurora PostgreSQL uses a log-based storage engine to persist all modifications. Every commit is sent to six copies of data; after it’s confirmed by a quorum of four, Aurora PostgreSQL can acknowledge the commit back to client. If you disable synchronous_commit, every commit requested by client doesn’t wait for the four out of six quorum. Ideally, you shouldn’t disable this parameter because that compromises the durability benefits offered by Aurora PostgreSQL. You can disable the parameter in the DB cluster parameter group. It can also be set for individual transactions in a session before starting a new transaction. You can get similar performance by grouping transactions and batching commits at the application layer. This approach allows for implementing proper exception handling for any transaction failure during a restart of a writer instance. max_standby_streaming_delay Aurora PostgreSQL allows you to add up to 15 Aurora replica instances in a cluster, which can be used for read queries. The Aurora replica nodes use the same storage as the writer instance. Any modifications on the writer is replicated to the replica. The replica invalidates the modified pages from its own buffer cache. The storage architecture and in-memory replication of Aurora helps reduce replication lag. It’s possible that while a change is being replicated from writer to a replica, another active query on the replica is trying to read the same page in buffer, which needs to be invalidated. This results in an access conflict, and the replication waits for the select query to finish. This can result in increased replication lag on the replica. If you’re experiencing frequent spikes in replication lag because of a long-running query, you can set max_standby_streaming_delay to a lower value. This cancels conflicting queries on the replica. If a query is canceled on the replica instance, you receive an error similar to the following, along with additional detail indicating the reason for the conflict: ERROR: canceling statement due to conflict with recovery DETAIL: User was holding a relation lock for too long. You can set this parameter in the DB cluster parameter group or for individual replicas in their respective DB parameter groups, and the change is applied without a restart. The valid value is between 1,000–30,000 milliseconds (1–30 seconds). A lower value can result in frequent cancellation of queries. A higher value may result in higher replication lag on the replica, which means other application sessions may fetch stale data until the conflicting query is completed or cancelled. Security In this section, we cover some parameters that control key security features in Aurora PostgreSQL. We also see how these features behave differently than PostgreSQL. rds.restrict_password_command PostgreSQL allows you to change your own password, and any user with the CREATEROLE privilege can change a password and password validity for any user. For example, as a normal user, I can’t alter my password’s validity, but I can change the password, as in the following code: postgres=> du List of roles Role name | Attributes | Member of -----------------+------------------------------------------------------------+------------------------------------------------------------- pgadmin | Create role, Create DB +| {rds_superuser,pgtraining} | Password valid until infinity | monitoring_user | | {rds_superuser} pgadmin | | {rds_superuser} pgtraining | | {} rds_ad | Cannot login | {} rds_iam | Cannot login | {} rds_password | Cannot login | {} rds_replication | Cannot login | {} rds_superuser | Cannot login | {pg_monitor,pg_signal_backend,rds_replication,rds_password} rdsadmin | Superuser, Create role, Create DB, Replication, Bypass RLS+| {} | Password valid until infinity | rdsproxyadmin | Password valid until infinity | {} sameer | Password valid until 2020-12-31 00:00:00+00 | {} postgres=> select current_user; current_user -------------- sameer (1 row) postgres=> alter role sameer valid until '2022-12-31'; ERROR: permission denied postgres=> alter role sameer password 'simple_password'; ALTER ROLE postgres=> On Aurora and Amazon RDS for PostgreSQL, you can set rds.restrict_password_command to restrict password management commands for members of the group rds_postgres. Setting up restrictions on which user can do password management can be useful when you want users to comply with specific password requirements, such as complexity. You can implement a separate client application as an interface that allows users to change their password. The following are some examples of SQL commands that are restricted when restricted password management is enabled: postgres=> CREATE ROLE myrole WITH PASSWORD 'mypassword'; postgres=> CREATE ROLE myrole WITH PASSWORD 'mypassword' VALID UNTIL '2020-01-01'; postgres=> ALTER ROLE myrole WITH PASSWORD 'mypassword' VALID UNTIL '2020-01-01'; postgres=> ALTER ROLE myrole WITH PASSWORD 'mypassword'; postgres=> ALTER ROLE myrole VALID UNTIL '2020-01-01'; postgres=> ALTER ROLE myrole RENAME TO myrole2; You can give other roles membership for the rds_password role by using the GRANT SQL command. Ideally, membership to rds_password should be restricted to only a few roles that you use solely for password management. These roles also require the CREATEROLE authority to modify other roles. The rds_superuser role has membership for the rds_password role by default. This parameter doesn’t impose a check on password validity, nor does it impose a password complexity requirement. You have to implement these checks at the client application that is used for changing the password. This parameter can only be set in parameter groups and can’t be modified at session level. Changing this parameter requires a restart. rds.force_ssl By default, Aurora PostgreSQL has the SSL parameter enabled. Also, by default, PostgreSQL clients and drivers try to make an SSL connection using sslmodel prefer. That means if you use default settings for Aurora PostgreSQL and your PostgreSQL client, you always have a secure TCP connection. However, it’s possible for clients to explicitly request a connection without SSL. You can check whether a connection is using SSL by using pg_stat_ssl: $ psql "sslmode=disable user=pgadmin" psql (11.8, server 11.7) Type "help" for help. postgres=> select * from pg_stat_ssl where pid=pg_backend_pid(); pid | ssl | version | cipher | bits | compression | clientdn -------+-----+---------+--------+------+-------------+---------- 11765 | f | | | | | (1 row) You can make sure that the Aurora PostgreSQL instance only allows connections that request SSL connection by setting rds.force_ssl in the DB cluster parameter group: $ psql "sslmode=disable user=pgadmin" psql: FATAL: no pg_hba.conf entry for host "10.1.0.135", user "pgadmin", database "postgres", SSL off $ psql "sslmode=prefer user=pgadmin" psql (11.8, server 11.7) SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) Type "help" for help. postgres=> select * from pg_stat_ssl where pid=pg_backend_pid(); pid | ssl | version | cipher | bits | compression | clientdn ------+-----+---------+-----------------------------+------+-------------+---------- 1192 | t | TLSv1.2 | ECDHE-RSA-AES256-GCM-SHA384 | 256 | f | (1 row) This parameter can be dynamically changed in the DB cluster parameter group and doesn’t require a restart to make the change. This parameter is also applicable to Amazon RDS for PostgreSQL. ssl_min_protocol_version and ssl_max_protocol_version Aurora PostgreSQL v3.3.0 (compatible with PostgreSQL v11.8) introduces the ability to set a version requirement on clients making TLS connections to the database server. You can set ssl_min_protocol_version to set the minimum SSL/TLS protocol version to use and set ssl_max_protocol_version to set the maximum SSL/TLS protocol version to use. For example, to limit client connections to the Aurora PostgreSQL server to at least TLS 1.2 protocol version, you can set the ssl_min_protocol_version to TLSv1.2. Logging In this section, we cover parameters that you can use to increase the amount of information written to log files in Aurora PostgreSQL. Aurora PostgreSQL stores the logs in the temporary EBS volume attached to the Aurora DB instance. Setting these parameters may result in more logs to be generated, resulting in space constraints on the temporary volume. You can configure your Aurora instance to have a relatively shorter log retention period and publish logs to Amazon CloudWatch Logs for long-term retention. For more information, see Publishing Aurora PostgreSQL logs to Amazon CloudWatch Logs. rds.force_autovacuum_logging When you enable autovacuum logging by setting log_autovacuum_min_duration to 0 or higher, PostgreSQL logs operations performed by autovacuum workers. If you set it to 200, all autovacuum operations—autovacuum and autoanalyze—taking more than 200 milliseconds are logged. On Aurora PostgreSQL (and also Amazon RDS for PostgreSQL), setting log_autovacuum_min_duration alone doesn’t enable autovacuum logging. To enable autovacuum logging, you also have to set rds.force_autovacuum_logging_level. The allowed values for this parameter are disabled, debug5, debug4, debug3, debug2, debug1, info, notice, warning, error, log, fatal, and panic. When you set this parameter to a value other than disabled, such as info, the PostgreSQL engine starts logging the autovacuum and autoanalyze activity as per the threshold that the parameter log_autovacuum_min_duration set. Setting it to debug1 – debug5 produces very detailed log entries and is required only when you’re debugging a specific issue and logs generated by less verbose values (like info) aren’t enough. You can set this parameter in the DB cluster parameter group attached to the Aurora PostgreSQL cluster. It’s dynamic in nature and doesn’t need a restart after it has been set. After you enable autovacuum logging by setting log_autovacuum_min_duration and rds.force_autovacuum_logging, autovacuum events are Aurora PostgreSQL logs. For example, see the following event from log: 2020-09-14 07:39:32 UTC::@:[13513]:LOG: automatic analyze of table "rdsadmin.public.rds_heartbeat2" system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s 2020-09-14 07:40:04 UTC::@:[8261]:LOG: automatic vacuum of table "pgtraining.public.item_inventory": index scans: 1 pages: 0 removed, 37024269 remain, 0 skipped due to pins, 0 skipped frozen tuples: 1427 removed, 2147396171 remain, 0 are dead but not yet removable, oldest xmin: 10877634 buffer usage: 5909857 hits, 0 misses, 0 dirtied avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s system usage: CPU: user: 116.42 s, system: 1.33 s, elapsed: 149.76 s rds.force_admin_logging_level Amazon RDS for PostgreSQL and Aurora PostgreSQL have an internal superuser named rdsadmin. This user is only used for database management activities. For example, you might forget the password for the primary user and want to reset it. The rdsadmin user performs the password reset when you change your password on the AWS Management Console. This user’s activities aren’t captured even after setting the logging parameters for PostgreSQL. If there is a requirement to capture the activities from this user, enable this by setting rds.force_admin_logging_level to log. When you set this parameter, the Amazon RDS for PostgreSQL engine starts capturing all queries run by this admin user in any of the user databases. Conclusion This series of blogs discusses Aurora PostgreSQL specific parameters and how they can be tuned to control database behavior. In this post, we covered how the difference in replication architecture affects the parameter behavior in Aurora PostgreSQL. We also covered security and logging parameters that can be useful for DBAs to implement additional scrutiny for Aurora PostgreSQL clusters. In part three we discuss query optimizer parameters which improves query performance by using Aurora specific query optimization steps. In part four we will dive deep into Aurora PostgreSQL parameters that adds ANSI compatibility options. About the authors Sameer Kumar is a Database Specialist Technical Account Manager at Amazon Web Services. He focuses on Amazon RDS, Amazon Aurora and Amazon DocumentDB. He works with enterprise customers providing technical assistance on database operational performance and sharing database best practices. Gopalakrishnan Subramanian is a Database Specialist solutions architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS https://aws.amazon.com/blogs/database/amazon-aurora-postgresql-parameters-part-2-replication-security-and-logging/
0 notes
Text
11 Dịch vụ AWS Serverless xịn nên sử dụng trong kiến trúc cloud
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aws-serverless-services/ - Cloudemind.com
11 Dịch vụ AWS Serverless xịn nên sử dụng trong kiến trúc cloud
Serverless services là những dịch vụ thuộc dạng fully managed services có nghĩa là mọi thứ liên quan đến hạ tầng underlying hardware, provision, maintenance, patching, hay thậm chí cao hơn về bảo mật sử dụng cũng được AWS làm sẵn cho mình. Serverless có thể gọi là lý tưởng cho các developer thay vì nỗi lo về máy chủ cấp phát, cấp phát có thừa hay quá thiếu hay không, sau khi đưa vào sử dụng có cần phải update, upgrade patching gì không (Đây thực sự là ác mộng với các bạn developer mà ko rành về hạ tầng, về CLI, shell này nọ).
AWS hiểu được điều này và offer một số dạng dịch vụ gọi là serverless như thế.
Serverless là gì?
Serverless dịch Tiếng Việt là “Phi máy chủ” nhưng dịch ra có vẻ hơi ngớ ngẩn, mình cũng không biết dịch sao cho thoát nghĩa. Serverless không phải là không có máy chủ theo nghĩa đen, bản chất của serverless nằm lớp bên dưới vẫn là các máy chủ, nhưng AWS làm cho việc này một cách mờ đi (transparency hay invisibility) và tự động quản lý vận hành lớp hạ tầng này miễn sao cung cấp đủ capacity như thiết kế cho bạn.
AWS Serverless
Definition of serverless computing: Serverless computing is a cloud computing execution model in which the cloud provider allocates machine resources on demand, taking care of the servers on behalf of the their customers – Wikipedia
Serverless refers to applications where the management and allocation of servers and resources are completely managed by the cloud provider. – Serverless-Stack
Serverless is a cloud-native development model that allows developers to build and run applications without having to manage servers. There are still servers in serverless, but they are abstracted away from app development. – Redhat
Kevin tập trung vào việc phát triển các product sử dụng Cloud Native cho nên luôn ưu tiên các dịch vụ Serverless trong kiến trúc của mình để tăng tốc độ phát triển, dễ dàng scaling, và chi phí cũng rẻ hơn rất nhiều so với cách làm Cloud truyền thống.
Nào, mình cùng điểm qua các dịch vụ AWS Serverless hiện có nào:
1. AWS Lamda
Type: Compute Services
Description: Chạy code không cần quan tâm đến máy chủ, hỗ trợ coding bằng các ngôn ngữ phổ biến như: Python, Node.js, Go, Java. Đặc biệt hơn từ 2020 Lambda mở rộng năng lực tới 6vCPU và 10GB RAM và hỗ trợ chạy docker.
Pricing Model:
Number of requests
Duration of execution
Reference: https://aws.amazon.com/lambda/
2. Amazon API Gateway
Type: API, proxy
Description: Giúp bạn triển khai các API ở quy mô lớn, hỗ trợ Restfull và Websocket APIs,
Pricing Model:
Number of requests
Caching
Reference: https://aws.amazon.com/api-gateway/
3. Amazon DynamoDB
Type: NoSQL DB
Description: Dịch vụ CSDL NoSQL của AWS, hỗ trợ keyvalue-pair và document DB. Đây là loại cơ sở dữ liệu có tốc độ truy xuất rất nhanh tính bằng single-digit-milisecond, nếu kết hợp thêm Cache của DAX nữa sẽ giảm xuống còn micro-milisecond, có thể scale tới 20 triệu request per second.
Pricing Model (on-demand and provisioned):
Write Capacity Unit
Read Capacity Unit
Storage
Data Transfer
etc
Reference: https://aws.amazon.com/dynamodb/
4. Amazon EventBridge
Type: Controller
Description: Amazon EventBridge được xem như event bus là nơi tập trung sự kiện của nhiều loại ứng dụng SaaS và AWS Services. EventBridge thu thập các sự kiện từ nhiều loại ứng dụng như Zendesk, Datadog, Pagerduty và route các dữ liệu này đến AWS Lambda. Mình cũng có thể setup các rule để route dữ liệu này đến các ứng dụng khác nhau. EventBridge giúp bạn build các ứng dụng hướng sự kiện (event-driven-application). EventBridge schema hỗ trợ Python, Typescript, Java giúp developer thuận tiện trong quá trình phát triển ứng dụng.
Pricing Model:
Pay for events to your event bus
Events ingested to Schema Discovery
Event Replay
Reference: https://aws.amazon.com/eventbridge/
5. Amazon SNS (Simple Notification Service)
Type: Messaging
Description: dịch vụ messaging pub/sub hỗ trợ SMS, Email, mobile push notification.
Pricing Model:
Number of requests
Notification deliveries
Data Transfer
Reference: https://aws.amazon.com/sns/
6. Amazon SQS (Simple Queue Service)
Type: Messaging, Queuing
Description: Message queue, xây dựng các hàng chờ cho các thông tin giúp decoupling nhiều nhóm dịch vụ, cũng là cách giúp các ứng dụng triển khai trên cloud tăng tính Reliable. SQS hỗ trợ standard queue để tăng tối đa throughput và FIFO queue để đảm bảo message được delivery chính xác một lần theo thứ tự gởi đi.
Pricing Model:
Number of requests
Data Transfer
Reference: https://aws.amazon.com/sqs/
7. Amazon S3 (Simple Storage Service)
Type: Storage
Description: Dịch vụ lưu trữ file dạng đối tượng (Object). S3 cung cấp khả năng lưu trữ vô hạn trong mỗi bucket, mỗi file lưu trữ có thể tới 5TB, quản lý dễ dàng thông qua AWS Management Console, API và CLI. S3 cũng dễ dàng tích hợp các dịch vụ AWS khác rất sâu như dịch vụ về governance, phân tích dữ liệu, machine learning, web integration…
Pricing Model:
Storage actual usage
Request type (PUT, GET, LIST…)
Data transfer
Retrieving
Reference: https://aws.amazon.com/s3
8. AWS AppSync
Type: API, Mobile service
Description: AppSync là dịch vụ AWS cho phép xây dựng các ứng dụng dạng real-time communication như data-driven mobile app hay web app với sự hỗ trợ của của GraphQL APIs.
Pricing Model:
Query operation
Data modification operation
real-time update data
Reference: https://aws.amazon.com/appsync/
9. AWS Fargate
Type: Compute, container
Description: Serverless compute khi dùng với container. Fargate có thể dùng với cả EKS và ECS (orchestration)
Pricing Model:
Resource vCPU per hour
Resource RAM per hour
10. AWS Step Function
Type: Controller, Cron job
Description: Đã qua cái thời mà viết các cron job ở hệ điều hành rồi rẽ nhánh theo các business logic tương ứng. AWS Step Function là dịch vụ giúp bạn build các ứng dụng xử lý logic theo các bước nhảy thời gian thông qua các state machine. Đây là dịch vụ rất rất đỉnh.
Pricing Model:
State Transition.
Reference: https://aws.amazon.com/step-functions/
11. Amazon RDS Aurora Serverless
Type: Database, SQL
Description: Aurora là một loại engine trong Amazon RDS được đưa ra bởi AWS (AWS Property). Aurora MySQL nhanh 5x so với MySQL thông thường và 3x so với Postgres. Khác với DynamoDB, Aurora là SQL service. Một ứng dụng lớn bạn có thể phải kết hợp nhiều loại DB services để đem lại hiệu năng tốt nhất.
Pricing model:
ACU (Aurora Capacity Unit)
Storage
Reference: https://aws.amazon.com/rds/aurora/serverless/
Conclusion
Kevin tin rằng sẽ ngày càng có nhiều dịch vụ hướng Serverless và chi phí sử dụng cloud ngày càng được tối ưu có lợi cho người dùng. Cảm ơn vì AWS, Azure, GCP đang ngày càng đưa ra nhiều dịch vụ cloud tốt.
Have fun!
Xem thêm: https://cloudemind.com/aws-serverless-services/
0 notes
Text
The art of a seamless migration of Coinbase’s internal ledger
Lessons learned from a large cross-database data migration on a critical production system

By Alex Ghise, Staff Software Engineer
If you’re interested in distributed systems and building reliable shared services to power all of Coinbase, the Platform team is hiring!
In 2019, Coinbase set out to strengthen the infrastructure upon which its products are built and to create a solid foundation to support current and future product lines. As part of that effort, we decided to adopt AWS RDS PostgreSQL as our database of choice for relational workloads and AWS DynamoDB as our key-value store.
One of the first areas we decided to focus on was how to keep track of balances and move funds. Our products had each devised their own solutions and some legacy systems were also plagued by tech debt and performance issues. The ability to quickly and accurately process transactions is central to Coinbase’s mission to build an open financial system for the world.
We designed and built a new ledger service to be fast, accurate and serve all current and future needs across products and have undertaken our biggest migration as of yet, moving over 1 billion rows of corporate and customer transaction and balance information from the previous data storage to our new PostgreSQL-based solution, without scheduled maintenance and no perceptible impact to users.
Our key learnings:
Make it repeatable — You may not get it right the first time.
Make it fast — So you can quickly iterate.
Make it uneventful — By designing the process so that it runs without disrupting normal business operations.
Here’s how we did it…
Migration Requirements
Accuracy and Correctness: Since we’re dealing with funds, we knew this would be a very sensitive migration and wanted to take every precaution, make sure that every last satoshi is accounted for.
Repeatable: Additionally, the shape of our data was completely different in the new system vs the legacy system. Further, we had to deal with technical debt and cruft accumulated over time in our monolithic application. We knew we needed to account for the possibility of not getting everything right in a single go, so we wanted to devise a repeatable process that we could iterate on until getting it right.
No Maintenance Downtime: We wanted every transaction on Coinbase to execute while working on this. We didn’t want to do any scheduled maintenance or take any downtime for the transition.
The Setup
We can deconstruct the migration into 2 separate problems: Switching live writes and reads over the new service, and migrating all of the historical data into the new service.
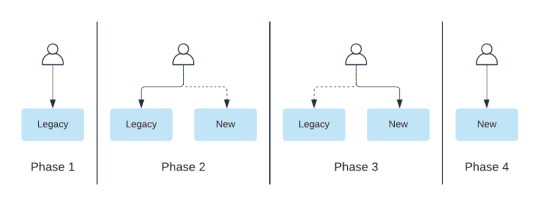
For the migration we decided to take a dual-write / dual-read phased approach. Phase 1 is before the migration, where we only have the legacy system in place. In Phase 2, we introduce the new system. We dual write to both the legacy and new system the read path we read from both, then log discrepancies and return the result from the legacy system. With Phase 3, we’ve built up the confidence in our new setup, so we favor it when returning results. We still have the old system around and can switch back to it if needed. Finally, we phase out unused code to finish the migration (Phase 4).
We won’t go into details about our dual-write implementation, since the general idea has been previously covered by industry blog posts.
What’s interesting is something that happens in between Phase 2 and Phase 3, namely the backfill of all customer data into our new system so that we can achieve parity.
The Repeatable Backfill Process
We considered multiple approaches to backfilling the billion-plus rows that represent all the transactions carried out on Coinbase from its inception, all with pros and cons.
The most straightforward solution would have been to do it all at the application level, leveraging the ledger client implementation we had in place for the dual writes. It has the advantage of exercising the same code paths we have in place for live writes — there would be a single mapping from old to new to maintain. However, we would have had to modify the service interface to allow for the backfill and we would have had to set up long running processes together with a checkpointing mechanism in case of failure. We also benchmarked this solution, and found that it would be too slow to meet our requirements for fast iteration.
We eventually decided to pursue an ETL-based solution. At a high level, this entailed generating the backfill data from the ETL-ed source database, dumping it into S3 and loading it directly into the target Postgres database. One key advantage to this approach is that doing data transformation using SQL is fast and easy. We could run the entire data generation step in ~20 minutes, examine the output, verify internal consistency and do data quality checks directly on the output without having to run the entire backfill pipeline.
Our data platform provider offers a variety of connectors and drivers for programmatic access. This means that we could use our standard software development tools and lifecycle — the code that we wrote for the data transformation was tested, reviewed and checked into a repository.
It also has first-class support for unloading data into S3, which made it easy for us to export the data after provisioning the appropriate resources.
One the other end, AWS provides the aws_s3 postgres extension, which allows bulk importing data into a database from an S3 bucket. Directly importing into live, production tables however proved problematic, since inserting hundreds of millions of rows into indexed tables is slow, and it also affected the latency of live writes.
We solved this problem by creating unindexed copies of the live tables, as follows:
DROP TABLE IF EXISTS table1_backfill cascade;
CREATE TABLE table1_backfill (LIKE table1 INCLUDING DEFAULTS INCLUDING STORAGE);
The import now becomes limited by the I/O, which becomes a bottleneck. We ended up slowing it down a bit by splitting the data into multiple files and adding short sleep intervals in between the sequential imports.
Next up, recreating the indexes on the tables. Luckily, Postgres allows for index creation without write-locking the table, by using the CONCURRENT keyword. This allows the table to continue taking writes while the index is being created.
So far, so good. The real complexity however comes from our requirement to have a migration that doesn’t involve scheduled maintenance or halting transaction processing. We want the target database to be able to sustain live writes without missing a single one, and we want the backfilled data to seamlessly connect to the live data. This is further complicated by the fact that every transaction stores information about the cumulative balances of all accounts involved — this makes it easy for us to evaluate and maintain data integrity and to look up point in time balances for any account at any timestamp.
We solved for this by using triggers that replicate inserts, updates, deletes to the live tables into the backfill tables. Our concurrent index generation allows us to write to these tables while the indexes are being created.
After indexing is complete, in a single transaction, we flipped the backfill and live tables, drop the triggers, and drop the now unneeded tables. Live writes continue as if nothing happened.
At the end of this process, we run another script that goes through all of the data and restores data integrity by recreating the cumulative balances and the links between sequential transactions.
Last but not least, we run another round of integrity checks and comparisons against the legacy datastore to make sure that the data is correct and complete.
Putting it all together, the sequence looks as follows:
Clean slate: reset ledger database, start dual writing
Wait for dual written data to be loaded into ETL, so that we have overlap between live written data and backfill data.
Generate backfill data, unload it into S3
Create backfill tables, set up triggers to replicate data into backfill tables.
Import data from S3
Create indexes
Flip tables, drop triggers, drop old tables.
Run repair script
Verify data integrity, correctness, completeness
The process would take 4 to 6 hours to run and was mostly automated. We did this over and over while working through data quality issues and fixing bugs.
The Aftermath
Our final migration and backfill was not a memorable one. We didn’t have a “war room”, no standby on-call engineers, just another run of our process after which we decided that it was time to flip the switch. Most people within the company were blissfully unaware. An uneventful day.
We’ve been live with the ledger service for almost a year now. We have the capacity to sustain orders of magnitude more transactions per second than with our previous system, and with tight bounds on latency. Existing and new features, such as the Coinbase Card, all rely on the ledger service for fast and accurate balances and transactions.
If you’re interested in distributed systems and building reliable shared services to power all of Coinbase, the Platform team is hiring!
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
All images provided herein are by Coinbase.
The art of a seamless migration of Coinbase’s internal ledger was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Money 101 https://blog.coinbase.com/the-art-of-a-seamless-migration-of-coinbases-internal-ledger-76c4c0d5f028?source=rss----c114225aeaf7---4 via http://www.rssmix.com/
0 notes