#compare GPUs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
my friend built a tiny itx based PC and its so so SO cute and i've always wanted to make a htpc or something but never had a reason to and so i've just been obsessing over this idea for weeks now but still cant even decide on a cpu. or a case. or what im even going to use it for.
also goddamn smaller parts are expensive
itx goes as far back as LGA 775 which is crazy. I'd love to make a tiny Win XP machine but for gaming in that era you really need a GPU *and* soundcard and obv itx boards dont have PCI slots so... probably wont do that
a small and compact NAS for Plex would be super useful. something low powered so i dont have to turn on my main, power hungry, PC just to watch something on the TV in the other room.
but also thats kinda boring on its own...so switch emulation? PS3 too.
but man theres like no good case options for a NAS that also can hold a normal sized GPU. single slots/low profile are cute and all but holy shit the prices.
actually theres like no good case options in general
i've only managed to find two cases i genuinely like and i've looked at hundreds and hundreds already.
i'm half considering doing a console case mod honestly. wouldnt wanna do it in a console i already own but i like how the (white) Xbox One's look. but then thats a whole bunch of work getting it to all fit and not overheat like crazy (and, again, the itx tax).. but it would be a fun project
...and i *still* havent even found a proper case for my Win 98 machine
#if its a modern system i've at least narrowed it down to either AM4 or AM5#i've never made a PC with an AMD CPU before#im tempted on the APUs cuz size#but im not sure i'd be happy with the results compared to a dedicated GPU#hypatia rambles
2 notes
·
View notes
Text
Queue me realizing my CPU was released 12 years ago... Like I knew it was old, but Jesus no wonder it keeps fighting me lmao
#it is such a fucking money sink replacing the cpu tho#bc its old enough that id have to replace the motherboard too... which is also old so id have to replace the ram too....#makes for hilarious metrics when im playing minecraft tho bc my gpu is pretty new comparatively#its like chaining a young sled dog to a bunch of geriatric lap dogs
4 notes
·
View notes
Text
Computer: has 24gb RAM
Excel: Monopolizing over half of that, still froze on a real big copy/paste
#tbh this time it isn't excel's fault per se#the files are simply too big#but i'm still annoyed at how good my work laptop is compared to what use i'll be putting it to#this laptop could play majima pirate game so nicely i bet.........#cpu better than 'recommended' cpu on steam... gpu better than 'minimum' if not nearly as good as 'recommended'....#and then obviously all that memory#ugh!
0 notes
Text
#I have a GIANT computer case#and this barely fits inside#I had to get a little GPU support leg to hold her up#so she didn’t break my motherboard pci slot#I saw pictures online but they looked comparable to my old one#I WAS WRONG
1 note
·
View note
Text
I just saw someone call a pc that had an i5 and windows 10 retro. Buddy win10 hasn't even reached end of support yet???? You can still buy PCs with i5's in them from big box stores??? Is it retro because it actually has decent I/O? Is it retro to have decent I/O, expansion and compatibility options???? It had a blu-ray drive. They still make those too. IT DIDN'T EVEN HAVE A SOUNDCARD. Like sure it had a floppy drive, but the addition of a floppy drive doesn't make the entire device retro. If I plug a USB floppy drive into a high end gaming pc, the whole PC isn't considered retro.
#tetranymous.txt#It only had 5 expansion bays. For a full size actually retro pc I'd expect at least 8#Personally around the 15 year old mark is when I start considering a pc to be retro#This was not it#For example my 17 year old laptop and 19 year old XP pc are firmly in retro territory; although recently#My IBM portable is undoubtedly in retro territory at 42 years old; with my amigas at 35#But my 13 year old thinkpad? Not there yet. Hasn't breached the 15 year old threshold.#I say this as a person who still used a beige box pc w a floppy drive until 2013. It still wasn't retro then.#(was a 2000s beige box; not a 90s beige box. It had a blue swoosh and 2 gpus in crossfire. What a beast)#Gosh looking back at the numbers my surface is a baby compared to the rest of them. It's 4.
1 note
·
View note
Text
Why I started using DXT1 texture format for TS2 CC again (sometimes)
In the past I discouraged ppl from using it. But it has one benefit, which TS2 CC creators shouldn't ignore: DXT1 textures are about half the size of DXT3. DXT1 is best for stuff that is not meant to be looked at from close distance - where you don't need high quality, but you need original texture - 1024x or even 2048x - to keep it crisp. Large and very large CC hood decor, for example.
There are two facts about textures that some ts2 cc creators and cc hoarders are probably unaware of:
Lossless compression (compressorizer etc) significantly reduces file sizes, but it does NOT help texture memory, because texture files get uncompressed before being stored in GPU texture memory cache
Byte size does NOT equal resolution. For example: Raw32Bit texture takes up around four times more space in texture memory cache than DXT5
DXT3 2048*2048 px takes up ~4MB, but DXT1 2048*2048, thanks to its harsh 8:1 compression, takes up only ~2MB of texture memory cache, which is an equivalent of two makeup textures 512*512 px Raw32Bit format (TS2 makeup creators' favourite :S ).
@episims posted a comparison of DXT formats here - but please note Epi compared texture sizes after those were compressorized.
To change texture format in SimPe you need to install Nvidia DDS utilities, which can be downloaded here (SFS).
*This is about GPU texture memory. As far as I know, it's unclear how internal TS2 texture memory works - does it benefit from lossless file compression or not? No idea. But IMO we don't have a reason to be optimistic about it :/ What we know for sure is - the easiest way to summon pink soup in TS2 on modern systems, is to make the game load large amounts of texture data (large for TS2 standards anyway) in a short amount of time.
DXT formats use lossy compression which affects texture quality - this compression matters for texture memory.
DXT1 512*512*4 (4 bytes per pixel) / 8 (divided by 8, because of 8:1 compression ratio) = ~131 KB
DXT3 512x512 px (4:1 compression) = ~262 KB
Raw32Bit 512x512 px = ~1MB
2048x1024 px DXT1 texture takes up around as much texture memory as 1024x1024 px DXT3 or DXT5 (non transparent*) = ~1 MB
*DXT5 has 4:1 compression just like DXT3 but it can store more data in alpha channel, and that allows for much better looking transparency (if smooth alpha is present, size is increased). DXT1 does not support transparency.
I don't want my game to look like crap, but if texture looks OK as DXT1, then why not use it. Aside from hood decor, I've been reconverting some wall and floor textures for myself to DXT1 recently, instead of resizing.
Some ppl might cringe on seeing 2048x2048 skybox textures but to me large texture is justified for such a giant object. I cringe at Raw32Bit makeup.
I'm slowly turning all Raw32 makeup content in my game to DXT5 (no mipmaps). I've edited enough of those to know, that quite often the actual texture quality is not great. If a texture has been converted to DXT3 at some point, alpha channel is a bit choppy. "Upgrading" such texture to Raw32 doesn't do anything, other than multiplying texture size by four. I don't know how 'bout you, but I only use one or two skyboxes at a time, while my sims walk around with tons of face masks on them, so it's a real concern to me. And don't make me start on mip maps in CAS CC. Textures more blurry on zoom-out, and at a price of 33% larger size? What a deal :S
Note: Raw8Bit (bump maps) / ExtRaw8Bit (shadows etc) are also uncompressed formats, but don't contain color data and weight around as much as DXT3.
/I've taken out this part from a long post I'm writing RN /
94 notes
·
View notes
Text
I've been putting together a parts list for a hypothetical computer for speedrunning, and I've come to the conclusion that it should have 128gb of ram, an i9 13900kf, and a gtx1660 super.

3 minecraft is not enough... need more.........
#for the people who don't know things about computers this would be a very cursed setup for like most games#the gpu would be pretty underpowerd compared to the CPU#minecraft speedrunning is mostly bound by CPU and ram and having a comparably bad GPU probably wont mater that much i think#this would have the added advantage of saving me many dollar since I wouldn't need to buy a new gpu
4 notes
·
View notes
Text
If it is true that the Nintendo Switch 2 WILL be revealed this week then I wanna discuss something about the console that's got me all hot and bothered.

So as we all know, Nintendo consoles get hacked pretty easily and it's for sure gonna happen with the Nintendo Switch 2.
However, what's got me incredibly excited is the power on this thing. From the leaks and rumours we've gotten, we know that this thing is gonna potentially have 12gb of ram and have a much beefier CPU and GPU compared to the Switch.
Once this thing gets hacked, it is most likely gonna be able to play nearly every single Nintendo game from almost every single console... and that... gets me REALLYYYY HYPED FOR THE HOMEBREW SCENE!!!!
The new joy cons could work with Wii emulation so well... oh... oh my god I cannot wait for the future of this thing. PS1 emulation is gonna be a breeze, PS2 emulation is gonna be absolutely bonkers.
Hell if we can get PS3 emulation running on a raspberry pi then... oh god... do you think... no.... no it couldn't.... can it?
#nintendo switch#switch 2#homebrew#emulation#game emulator#im so hyped#nintendo#nintendo gamecube#nintendo wii#sony playstation#playstation
71 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
245 notes
·
View notes
Text
History and Basics of Language Models: How Transformers Changed AI Forever - and Led to Neuro-sama
I have seen a lot of misunderstandings and myths about Neuro-sama's language model. I have decided to write a short post, going into the history of and current state of large language models and providing some explanation about how they work, and how Neuro-sama works! To begin, let's start with some history.
Before the beginning
Before the language models we are used to today, models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) were used for natural language processing, but they had a lot of limitations. Both of these architectures process words sequentially, meaning they read text one word at a time in order. This made them struggle with long sentences, they could almost forget the beginning by the time they reach the end.
Another major limitation was computational efficiency. Since RNNs and LSTMs process text one step at a time, they can't take full advantage of modern parallel computing harware like GPUs. All these fundamental limitations mean that these models could never be nearly as smart as today's models.
The beginning of modern language models
In 2017, a paper titled "Attention is All You Need" introduced the transformer architecture. It was received positively for its innovation, but no one truly knew just how important it is going to be. This paper is what made modern language models possible.
The transformer's key innovation was the attention mechanism, which allows the model to focus on the most relevant parts of a text. Instead of processing words sequentially, transformers process all words at once, capturing relationships between words no matter how far apart they are in the text. This change made models faster, and better at understanding context.
The full potential of transformers became clearer over the next few years as researchers scaled them up.
The Scale of Modern Language Models
A major factor in an LLM's performance is the number of parameters - which are like the model's "neurons" that store learned information. The more parameters, the more powerful the model can be. The first GPT (generative pre-trained transformer) model, GPT-1, was released in 2018 and had 117 million parameters. It was small and not very capable - but a good proof of concept. GPT-2 (2019) had 1.5 billion parameters - which was a huge leap in quality, but it was still really dumb compared to the models we are used to today. GPT-3 (2020) had 175 billion parameters, and it was really the first model that felt actually kinda smart. This model required 4.6 million dollars for training, in compute expenses alone.
Recently, models have become more efficient: smaller models can achieve similar performance to bigger models from the past. This efficiency means that smarter and smarter models can run on consumer hardware. However, training costs still remain high.
How Are Language Models Trained?
Pre-training: The model is trained on a massive dataset to predict the next token. A token is a piece of text a language model can process, it can be a word, word fragment, or character. Even training relatively small models with a few billion parameters requires terabytes of training data, and a lot of computational resources which cost millions of dollars.
Post-training, including fine-tuning: After pre-training, the model can be customized for specific tasks, like answering questions, writing code, casual conversation, etc. Certain post-training methods can help improve the model's alignment with certain values or update its knowledge of specific domains. This requires far less data and computational power compared to pre-training.
The Cost of Training Large Language Models
Pre-training models over a certain size requires vast amounts of computational power and high-quality data. While advancements in efficiency have made it possible to get better performance with smaller models, models can still require millions of dollars to train, even if they have far fewer parameters than GPT-3.
The Rise of Open-Source Language Models
Many language models are closed-source, you can't download or run them locally. For example ChatGPT models from OpenAI and Claude models from Anthropic are all closed-source.
However, some companies release a number of their models as open-source, allowing anyone to download, run, and modify them.
While the larger models can not be run on consumer hardware, smaller open-source models can be used on high-end consumer PCs.
An advantage of smaller models is that they have lower latency, meaning they can generate responses much faster. They are not as powerful as the largest closed-source models, but their accessibility and speed make them highly useful for some applications.
So What is Neuro-sama?
Basically no details are shared about the model by Vedal, and I will only share what can be confidently concluded and only information that wouldn't reveal any sort of "trade secret". What can be known is that Neuro-sama would not exist without open-source large language models. Vedal can't train a model from scratch, but what Vedal can do - and can be confidently assumed he did do - is post-training an open-source model. Post-training a model on additional data can change the way the model acts and can add some new knowledge - however, the core intelligence of Neuro-sama comes from the base model she was built on. Since huge models can't be run on consumer hardware and would be prohibitively expensive to run through API, we can also say that Neuro-sama is a smaller model - which has the disadvantage of being less powerful, having more limitations, but has the advantage of low latency. Latency and cost are always going to pose some pretty strict limitations, but because LLMs just keep geting more efficient and better hardware is becoming more available, Neuro can be expected to become smarter and smarter in the future. To end, I have to at least mention that Neuro-sama is more than just her language model, though we only talked about the language model in this post. She can be looked at as a system of different parts. Her TTS, her VTuber avatar, her vision model, her long-term memory, even her Minecraft AI, and so on, all come together to make Neuro-sama.
Wrapping up - Thanks for Reading!
This post was meant to provide a brief introduction to language models, covering some history and explaining how Neuro-sama can work. Of course, this post is just scratching the surface, but hopefully it gave you a clearer understanding about how language models function and their history!
30 notes
·
View notes
Note
Gpu frotting...
robot girls comparing gpu sizes…
28 notes
·
View notes
Note
Oooh, what about Journey? I think the sand probably took a lot to pull off
it did!! i watched a video about it, god, like 6 years ago or something and it was a very very important thing for them to get just right. this is goimg to be a longer one because i know this one pretty extensively
here's the steps they took to reach it!!

and heres it all broken down:
so first off comes the base lighting!! when it comes to lighting things in videogames, a pretty common model is the lambert model. essentially you get how bright things are just by comparing the normal (the direction your pixel is facing in 3d space) with the light direction (so if your pixel is facing the light, it returns 1, full brightness. if the light is 90 degrees perpendicular to the pixel, it returns 0, completely dark. and pointing even further away you start to go negative. facing a full 180 gives you -1. thats dot product baybe!!!)

but they didnt like it. so. they just tried adding and multiplying random things!!! literally. until they got the thing on the right which they were like yeah this is better :)

you will also notice the little waves in the sand. all the sand dunes were built out of a heightmap (where things lower to the ground are closer to black and things higher off the ground are closer to white). so they used a really upscaled version of it to map a tiling normal map on top. they picked the map automatically based on how steep the sand was, and which direction it was facing (east/west got one texture, north/south got the other texture)

then its time for sparkles!!!! they do something very similar to what i do for sparkles, which is essentially, they take a very noisy normal map like this and if you are looking directly at a pixels direction, it sparkles!!

this did create an issue, where the tops of sand dunes look uh, not what they were going for! (also before i transition to the next topic i should also mention the "ocean specular" where they basically just took the lighting equation you usually use for reflecting the sun/moon off of water, and uh, set it up on the sand instead with the above normal map. and it worked!!! ok back to the tops of the sand dunes issue)

so certain parts just didnt look as they intended and this was a result of the anisotropic filtering failing. what is anisotropic filtering you ask ?? well i will do my best to explain it because i didnt actually understand it until 5 minutes ago!!!! this is going to be the longest part of this whole explanation!!!
so any time you are looking at a videogame with textures, those textures are generally coming from squares (or other Normal Shapes like a healthy rectangle). but ! lets say you are viewing something from a steep angle
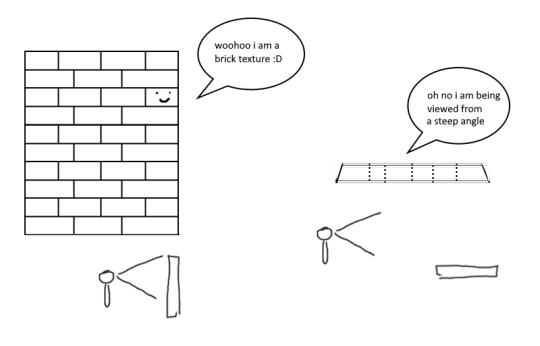
it gets all messed up!!! so howww do we fix this. well first we have to look at something called mip mapping. this is Another thing that is needded because video game textures are generally squares. because if you look at them from far away, the way each pixel gets sampled, you end up with some artifacting!!
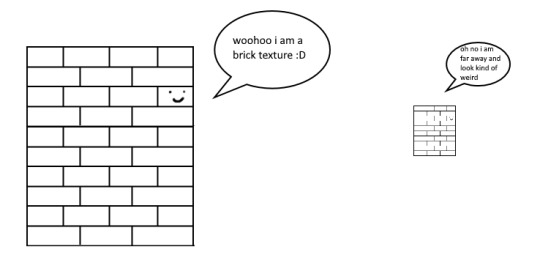
so mip maps essentially just are the original texture, but a bunch of times scaled down Properly. and now when you sample that texture from far away (so see something off in the distance that has that texture), instead of sampling from the original which might not look good from that distance, you sample from the scaled down one, which does look good from that distance
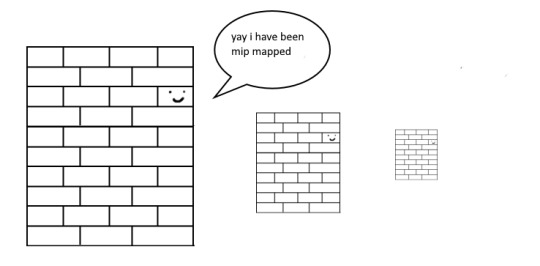

ok. do you understand mip mapping now. ok. great. now imagine you are a GPU and you know exactly. which parts of each different mip map to sample from. to make the texture look the Absolute Best from the angle you are looking at it from. how do you decide which mip map to sample, and how to sample it? i dont know. i dont know. i dont know how it works. but thats anisotropic filtering. without it looking at things from a steep angle will look blurry, but with it, your GPU knows how to make it look Crisp by using all the different mip maps and sampling them multiple times. yay! the more you let it sample, the crisper it can get. without is on the left, with is on the right!!

ok. now. generally this is just a nice little thing to have because its kind of expensive. BUT. when you are using a normal map that is very very grainy like the journey people are, for all the sparkles. having texture fidelity hold up at all angles is very very important. because without it, your textures can get a bit muddied when viewing it from any angle that isnt Straight On, and this will happen

cool? sure. but not what they were going for!! (16 means that the aniso is allowed to sample the mip maps sixteen times!! thats a lot)
but luckily aniso 16 allows for that pixel perfect normal map look they are going for. EXCEPT. when viewed from the steepest of angles. bringing us back here

so how did they fix this ? its really really clever. yo uguys rmemeber mip maps right. so if you have a texture. and have its mip maps look like this

that means that anything closer to you will look darker, because its sampling from the biggest mip map, and the further away you get, the lighter the texture is going to end up. EXCEPT !!!! because of aisononotropic filtering. it will do the whole sample other mip maps too. and the places where the anisotropic filtering fail just so happen to be the places where it starts sampling the furthest texture. making the parts that fail that are close to the camera end up as white!!!

you can see that little ridge that was causing problems is a solid white at the tip, when it should still be grey. so they used this and essentially just told it not to render sparkles on the white parts. problem solved

we arent done yet though because you guys remember the mip maps? well. they are causing their own problems. because when you shrink down the sparkly normal map, it got Less Sparkly, and a bit smooth. soooo . they just made the normal map mip maps sharper (they just multipled them by 2. this just Worked)

the Sharp mip maps are on the left here!!
and uh... thats it!!!! phew. hope at least some of this made sense
433 notes
·
View notes
Text
alright, let's keep moving with that DCEU watch bc i have the time today. time for David F. Sandberg's Shazam! Fury of the Gods (2023). here's to hoping this has retained the spirit and heart of the original and improved the superhero aspects because they were the worst part of Shazam! (2019).
i've been trying to get a more accurate video player setup working for like 2 hours, i was using basically stock MPC-BE for the most part but some of the images looked a little soft to me even compared to something basic like a VLC (which i only really keep for its subtitle downloading feature bc it's the easiest to use, and tbh it could've been using sharpening filters, i didn't really check) and Potplayer (which is the only way i can get two subtitles to display simultaneously for media with multiple subs like fansubs or different translations or something, and also it's got like pretty good video output). i tried to look into MPV and the amount of work and scripts everyone was recommending kind of broke me, so i'm just using like the base form of mpv.net bc it's got a GUI, with like GPU decoding turned on which was the one common thing everyone recommended from my research.
hopefully this is better image quality then like standard VLC stuff and my previous MPC-BE setup though i obviously haven't sat through entire movies to compare frame by frame, so beware that if i say anything about the visuals it might not be the most accurate. MPV is supposed to be the most accurate and flexible option around but i don't know how much futzing around people do with it and there's a lot of like upscaling and downscaling scripts for no fucking reason, which is kind of antithetical to the entire point of accuracy to me, but it's fine. i'm just sticking to the base options and hoping it's good and better than what i had. the image does look just a tad sharper to me than in VLC and MPC so i don't know if they have sharpening filters on or something, but this is like the most base form with nothing changed (except the subtitle font) so i cannot imagine they are messing with the video signal with too much filtering. i tried to look into madVR and MPC-HC and got them installed and almost lost my mind trying to get it set up bc there's no real guides anywhere so don't fucking tell me to go look up madVR bc i will kill you. maybe some other day when i have 15 hours to dedicate to going through forums to try to find something that works for me and get enough knowledge to understand what the fuck everybody's talking about, maybe i'll check it out. i cannot believe there's not like some fucking guide for some anime noob because you know those anime people are on the cutting edge of video tech and playback for accuracy, that there's not some fucking guide for people that don't know what they're doing. i mean it's not that i don't know what i'm doing, it's that there's so much fucking shit to sort through that it would be nice if somebody narrowed it down for me. there's nothing even on YouTube or like some shitty github page or an old reddit comment or something, trust me i've like checked fucking everywhere i could think of but if i missed something, please feel free to link it somewhere in the comments or something, i don't know.
anyway, that is entirely an aside, that's just a forewarning that if i do say something about the visuals and you think it's not accurate to what the movie looks like or is not properly representative of the movie, feel free to take it with a grain of salt. i'm trying out something new.
#james talks#james watches stuff#shazam fury of the gods#shazam! fury of the gods#Shazam! Fury of the Gods (2023)#Shazam Fury of the Gods (2023)#david f. sandberg#dceu
50 notes
·
View notes
Text
Sky using all your CPU? It's more likely than you think.
I wrote this in a comment on a Reddit post of someone complaining that Sky isn't using their GPU properly and that it's stuttering for them. However, it's detailed enough that I feel like it deserves its own post in this blog. As always, this is a very technical post. But if you like seeing how games work behind the scenes, then this might be for you.
There are many reasons why Sky doesn't use your GPU as much compared to other games. It's actually a common issue in many games, and while the general reasoning is the same, the details of it can vary. The short version is that it uses the CPU a whole lot more than your GPU. Hence, it's not using a lot of power because increasing it won't have much of an effect. The bottleneck isn't on GPU speed, and that's what higher power draw tries to address. It also does most of its work on one thread, which means that it won't display a high CPU usage, as that counts work done on all logical processors. The long version is a technical explanation of how Sky was designed and the resulting implementation decisions that were done because of it.
Disclaimer: I cannot confirm these because I do not have access to Sky's source code. All of these are hypotheses based on the game's visible behavior and general development decision making.
Long version below the cut. (This isn't in the actual comment, but this is a blog post. Come on now.)
A lot of things that Sky does is CPU-bound. As an example, unless it's been updated along with the AURORA concert which used GPU-bound procedural animations, the animations of the butterflies are done on the CPU. They created the butterfly animation system long before the AURORA concert, and with only around 80 butterflies at any given time instead of 100 thousand, it doesn't make sense to go through the trouble of making their animations run on the GPU. Stuff that requires network requests to do (e.g.: forging candles, buying spirit items, etc.) are also done on the CPU because there's no way for it to be done on the GPU. This means that unless you have a weak GPU, your CPU usually dictates the frame rate of Sky.
As an additional point, Sky does not have a lot of advanced rendering features which will use the GPU more. Remember that Sky was first designed for iOS as a casual, social game. While the option for adding advanced rendering techniques like raytracing and HDR rendering are available, doing so used more power, which isn't good for a mobile game that you play with friends. Sure, you can play it with the phone plugged and have no issues with it running out of power, but that's not as fun as playing it with your friends around you. As such, there's not a lot of tasks for the GPU to run, reducing its power usage.
Sky also does not run some things asynchronously, even if it could. What this means is that, instead of performing some tasks in a separate thread, it does them in a single thread. This means that what really matters most for Sky is single-core performance rather than multi-core performance. It's not completely single-threaded; you can see that it uses more than one logical processor when you open Task Manager. However, it's not using multithreading to its maximum capability. In particular, it does not load resources asynchronously.
Asynchronous resource loading just means that resources (e.g.: models, terrain data, textures, etc.) are loaded in a background thread, allowing the main thread to continue updating the game and continuing rendering. You can tell this behavior is happening because, when you switch areas, the game becomes unresponsive for a moment while it's loading the next area. The main thread is occupied with loading the resources, which means that it's not responding to window events and it's not rendering anything. This could actually be the reason for some stuttering that happens. When the game tries to load something, it will freeze because the game stops doing any updates and renders. I don't think this happens a lot — Sky seems to always load all resources it will need for an area when you enter it — but it's a possibility.
Because the GPU isn't being used as much, it's also not drawing as much power as other games. Doing so would just be wasteful since it'll still do just as much work for higher power usage, lowering its utilization. Better to have lower power draw but higher utilization since that gives you more power efficiency, which is beneficial for a laptop.
There's not much you can do to improve Sky's performance in this case. A lot of the bottlenecks here are on Sky's implementation rather than its settings. Most you can do is lower the game's target frame rate down to 30 FPS, but that's not going to help much. Frame rate limiting is generally done to reduce GPU load, not CPU. Plus, gaming in 30 FPS nowadays generally isn't desirable. It's still in the realm of "playable", but I wouldn't recommend playing in 30 FPS unless there's a specific reason to.
#sky cotl#sky children of the light#that sky game#programming#game development#i didn't plan on turning this blog into a deep dive into sky's implementation#but i guess that's just what happens when you go into game dev#what better way to learn how games work than by looking into how other games work#if you guys have more questions about how sky works#the ask box is open
17 notes
·
View notes
Text
After much deliberation and reading and fucking around I ended up getting a 4k oled. I really liked the 4k miniled that I ended up having to return because it was defective but like by the time you look at new-ish miniLEDs the price difference is so narrow that it made sense.
It's funny right, like, inherently if you have two colour-accurate displays they look the same, if they don't one of them has fucked up. My previous display was a pretty accurate IPS. Watching some of my Good Demo Videos and like these look great but they look great on anything, they're Arri tech demos they've been scrutinzed and reshot and tweaked to within an inch of their lives.
What I did not count on was contrast. I'm looking at some of the photos I've taken in darker environments and realizing I have a really bad habit of crushing my dark tones in a way that really stands out when black is actually black. I was on a IPS panel before which has okay black levels all told but this is something else. Some of my undergrowth photos from Muir Woods look like I went ham with the contrast slider because the blacks are so deep, I'd be interested to pull some of my demo prints and compare them to this display side by side.
More accurate blacks is probably good for printing, black ink is really dark and that's part of why printed photos look a lot darker than computer screen photos even accounting for the fact that displays are self-illuminating, inks have higher contrast.
165Hz which isn't a huge upgrade over what I had before, but I don't think my GPU can drive any non-esports games past 90Hz anyway so who give a shit. Most oleds can't do huge bright spots like miniLED but I don't think that will be an issue, and the high contrast covers for the low brightness remarkably well. Genuinely kind of weird, mark another one down for human perception!
9 notes
·
View notes
Text
Does Raw32bit texture format make TS2 CC makeup look better?
Raw 32bit format is basically what it says it is. It doesn't use compression unlike standard DXT format.
Textures are stored in GPU texture memory in its original size. File compression doesn't matter - only DXT compression counts: DXT3 / DXT5 formats both use 4:1 compression ratio. DTX1 uses 8:1 compression (and is not suitable for CAS content).
Raw32bit texture takes up four times more texture memory than DXT5. It's like loading FOUR textures instead of ONE.. Is it worth it?
Apparently there's a myth that Raw format is 'best for makeup' (but you can find Raw32 or Raw24 textures in all sorts of custom content). It increases the file size and clogs texture memory. Is it a good idea to use it in CC for the game that is not even able to display 8bit color depth correctly? After all, banding artifacts on dark colour gradients still show up, no matter what format you use.
Below is a little comparison. In extreme close-up, both 512x512 eyelashes are more crunchy - but also, quite crisp.
1024x1024 DXT5 lash mask looks a bit different to 1024x1024 Raw32, which is more smooth, but also a little blurry - none of those two looks as crisp as actual texture viewed in SimPe.
That's because the game shrinks 1024x1024 to 512 x 512 px, which is the default size of TS2 face texture (and also the scalp) and so the quality suffers from it.
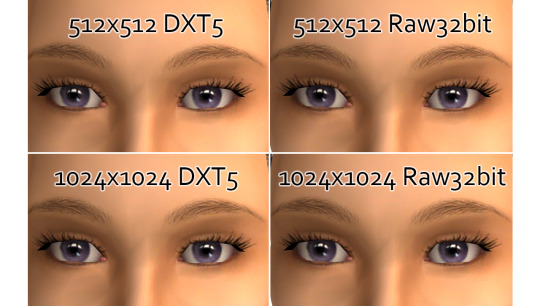
I've shown my comparative pics to a few people, some said 1024x1024 DXT5 lashes look better. Let's zoom out just a little bit:

There's still a difference. But personally I prefer crisper-looking details.
If you go through TS2 game files, you'll find very few Raw colour textures that are actually being used. I only know about this one - lamp debris contains Raw24bit texture and I bet it was done by mistake.
If you often use layered face masks and you get pink flashing a lot, then it's something to think about.
Here's part2 and a few more comparative pics if you're interested.
*Lashes come from this really nice set by @goingmintal - textures are 1024x1024 raw32 so I had to suppress the urge to download all of it 😉
#sims 2#the sims 2#hey creators#I dont accept 1024x face masks in my game - raw32 or not - I either resize it to 512x512 DXT5 or delete it#ts2 tutorial#well it's not really a tutorial
156 notes
·
View notes