#data lake
Photo
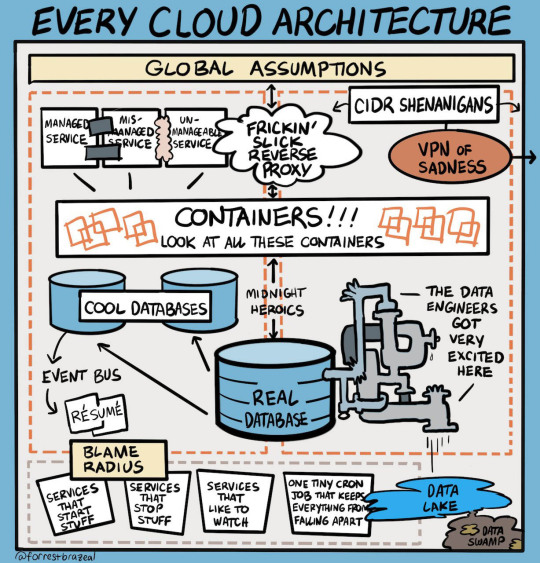
Every Cloud Architecture
#The Cloud#cloud services#CIDR Shenanigans#VPN of Sadness#cool databases#blame radius#one tiny cron#midnight heroics#data lake
1 note
·
View note
Text
Understanding On-Premise Data Lakehouse Architecture
New Post has been published on https://thedigitalinsider.com/understanding-on-premise-data-lakehouse-architecture/
Understanding On-Premise Data Lakehouse Architecture
In today’s data-driven banking landscape, the ability to efficiently manage and analyze vast amounts of data is crucial for maintaining a competitive edge. The data lakehouse presents a revolutionary concept that’s reshaping how we approach data management in the financial sector. This innovative architecture combines the best features of data warehouses and data lakes. It provides a unified platform for storing, processing, and analyzing both structured and unstructured data, making it an invaluable asset for banks looking to leverage their data for strategic decision-making.
The journey to data lakehouses has been evolutionary in nature. Traditional data warehouses have long been the backbone of banking analytics, offering structured data storage and fast query performance. However, with the recent explosion of unstructured data from sources including social media, customer interactions, and IoT devices, data lakes emerged as a contemporary solution to store vast amounts of raw data.
The data lakehouse represents the next step in this evolution, bridging the gap between data warehouses and data lakes. For banks like Akbank, this means we can now enjoy the benefits of both worlds – the structure and performance of data warehouses, and the flexibility and scalability of data lakes.
Hybrid Architecture
At its core, a data lakehouse integrates the strengths of data lakes and data warehouses. This hybrid approach allows banks to store massive amounts of raw data while still maintaining the ability to perform fast, complex queries typical of data warehouses.
Unified Data Platform
One of the most significant advantages of a data lakehouse is its ability to combine structured and unstructured data in a single platform. For banks, this means we can analyze traditional transactional data alongside unstructured data from customer interactions, providing a more comprehensive view of our business and customers.
Key Features and Benefits
Data lakehouses offer several key benefits that are particularly valuable in the banking sector.
Scalability
As our data volumes grow, the lakehouse architecture can easily scale to accommodate this growth. This is crucial in banking, where we’re constantly accumulating vast amounts of transactional and customer data. The lakehouse allows us to expand our storage and processing capabilities without disrupting our existing operations.
Flexibility
We can store and analyze various data types, from transaction records to customer emails. This flexibility is invaluable in today’s banking environment, where unstructured data from social media, customer service interactions, and other sources can provide rich insights when combined with traditional structured data.
Real-time Analytics
This is crucial for fraud detection, risk assessment, and personalized customer experiences. In banking, the ability to analyze data in real-time can mean the difference between stopping a fraudulent transaction and losing millions. It also allows us to offer personalized services and make split-second decisions on loan approvals or investment recommendations.
Cost-Effectiveness
By consolidating our data infrastructure, we can reduce overall costs. Instead of maintaining separate systems for data warehousing and big data analytics, a data lakehouse allows us to combine these functions. This not only reduces hardware and software costs but also simplifies our IT infrastructure, leading to lower maintenance and operational costs.
Data Governance
Enhanced ability to implement robust data governance practices, crucial in our highly regulated industry. The unified nature of a data lakehouse makes it easier to apply consistent data quality, security, and privacy measures across all our data. This is particularly important in banking, where we must comply with stringent regulations like GDPR, PSD2, and various national banking regulations.
On-Premise Data Lakehouse Architecture
An on-premise data lakehouse is a data lakehouse architecture implemented within an organization’s own data centers, rather than in the cloud. For many banks, including Akbank, choosing an on-premise solution is often driven by regulatory requirements, data sovereignty concerns, and the need for complete control over our data infrastructure.
Core Components
An on-premise data lakehouse typically consists of four core components:
Data storage layer
Data processing layer
Metadata management
Security and governance
Each of these components plays a crucial role in creating a robust, efficient, and secure data management system.
Data Storage Layer
The storage layer is the foundation of an on-premise data lakehouse. We use a combination of Hadoop Distributed File System (HDFS) and object storage solutions to manage our vast data repositories. For structured data, like customer account information and transaction records, we leverage Apache Iceberg. This open table format provides excellent performance for querying and updating large datasets. For our more dynamic data, such as real-time transaction logs, we use Apache Hudi, which allows for upserts and incremental processing.
Data Processing Layer
The data processing layer is where the magic happens. We employ a combination of batch and real-time processing to handle our diverse data needs.
For ETL processes, we use Informatica PowerCenter, which allows us to integrate data from various sources across the bank. We’ve also started incorporating dbt (data build tool) for transforming data in our data warehouse.
Apache Spark plays a crucial role in our big data processing, allowing us to perform complex analytics on large datasets. For real-time processing, particularly for fraud detection and real-time customer insights, we use Apache Flink.
Query and Analytics
To enable our data scientists and analysts to derive insights from our data lakehouse, we’ve implemented Trino for interactive querying. This allows for fast SQL queries across our entire data lake, regardless of where the data is stored.
Metadata Management
Effective metadata management is crucial for maintaining order in our data lakehouse. We use Apache Hive metastore in conjunction with Apache Iceberg to catalog and index our data. We’ve also implemented Amundsen, LinkedIn’s open-source metadata engine, to help our data team discover and understand the data available in our lakehouse.
Security and Governance
In the banking sector, security and governance are paramount. We use Apache Ranger for access control and data privacy, ensuring that sensitive customer data is only accessible to authorized personnel. For data lineage and auditing, we’ve implemented Apache Atlas, which helps us track the flow of data through our systems and comply with regulatory requirements.
Infrastructure Requirements
Implementing an on-premise data lakehouse requires significant infrastructure investment. At Akbank, we’ve had to upgrade our hardware to handle the increased storage and processing demands. This included high-performance servers, robust networking equipment, and scalable storage solutions.
Integration with Existing Systems
One of our key challenges was integrating the data lakehouse with our existing systems. We developed a phased migration strategy, gradually moving data and processes from our legacy systems to the new architecture. This approach allowed us to maintain business continuity while transitioning to the new system.
Performance and Scalability
Ensuring high performance as our data grows has been a key focus. We’ve implemented data partitioning strategies and optimized our query engines to maintain fast query response times even as our data volumes increase.
In our journey to implement an on-premise data lakehouse, we’ve faced several challenges:
Data integration issues, particularly with legacy systems
Maintaining performance as data volumes grow
Ensuring data quality across diverse data sources
Training our team on new technologies and processes
Best Practices
Here are some best practices we’ve adopted:
Implement strong data governance from the start
Invest in data quality tools and processes
Provide comprehensive training for your team
Start with a pilot project before full-scale implementation
Regularly review and optimize your architecture
Looking ahead, we see several exciting trends in the data lakehouse space:
Increased adoption of AI and machine learning for data management and analytics
Greater integration of edge computing with data lakehouses
Enhanced automation in data governance and quality management
Continued evolution of open-source technologies supporting data lakehouse architectures
The on-premise data lakehouse represents a significant leap forward in data management for the banking sector. At Akbank, it has allowed us to unify our data infrastructure, enhance our analytical capabilities, and maintain the highest standards of data security and governance.
As we continue to navigate the ever-changing landscape of banking technology, the data lakehouse will undoubtedly play a crucial role in our ability to leverage data for strategic advantage. For banks looking to stay competitive in the digital age, seriously considering a data lakehouse architecture – whether on-premise or in the cloud – is no longer optional, it’s imperative.
#access control#ai#Analytics#Apache#Apache Spark#approach#architecture#assessment#automation#bank#banking#banks#Big Data#big data analytics#Business#business continuity#Cloud#comprehensive#computing#customer data#customer service#data#data analytics#Data Centers#Data Governance#Data Integration#data lake#data lakehouse#data lakes#Data Management
0 notes
Text

Data fabric and data lake are two different but compatible ways of processing and storing data. This blog explains the benefits and use cases of each approach, how they relate to each other, and how to choose the best data management approach for your business.
0 notes
Text
Data Lake vs Data Warehouse: 10 Key difference

Today, we are living in a time where we need to manage a vast amount of data. In today's data management world, the growing concepts of data warehouse and data lake have often been a major part of the discussions. We are mainly looking forward to finding the merits and demerits to find out the details. Undeniably, both serve as the repository for storing data, but there are fundamental differences in capabilities, purposes and architecture.
Hence, in this blog, we will completely pay attention to data lake vs data warehouse to help you understand and choose effectively.
We will mainly discuss the 10 major differences between data lakes and data warehouses to make the best choice.
Data variety: In terms of data variety, data lake can easily accommodate the diverse data types, which include semi-structured, structured, and unstructured data in the native format without any predefined schema. It can include data like videos, documents, media streams, data and a lot more. On the contrary, a data warehouse can store structured data which has been properly modelled and organized for specific use cases. Structured data can be referred to as the data that confirms the predefined schema and makes it suitable for traditional relational databases. The ability to accommodate diversified data types makes data lakes much more accessible and easier.
Processing approach: When it is about the data processing, data lakes follow a schema-on-read approach. Hence, it can ingest raw data on its lake without the need for structuring or modelling. It allows users to apply specific structures to the data while analyzing and, therefore, offers better agility and flexibility. However, for data warehouse, in terms of processing approach, data modelling is performed prior to ingestion, followed by a schema-on-write approach. Hence, it requires data to be formatted and structured as per the predefined schemes before being loaded into the warehouse.
Storage cost: When it comes to data cost, Data Lakes offers a cost-effective storage solution as it generally leverages open-source technology. The distributed nature and the use of unexpected storage infrastructure can reduce the overall storage cost even when organizations are required to deal with large data volumes. Compared to it, data warehouses include higher storage costs because of their proprietary technologies and structured nature. The rigid indexing and schema mechanism employed in the warehouse results in increased storage requirements along with other expenses.
Agility: Data lakes provide improved agility and flexibility because they do not have a rigid data warehouse structure. Data scientists and developers can seamlessly configure and configure queries, applications and models, which enables rapid experimentation. On the contrary, Data warehouses are known for their rigid structure, which is why adaptation and modification are time-consuming. Any changes in the data model or schema would require significant coordination, time and effort in different business processes.
Security: When it is about data lakes, security is continuously evolving as big data technologies are developing. However, you can remain assured that the enhanced data lake security can mitigate the risk of unauthorized access. Some enhanced security technology includes access control, compliance frameworks and encryption. On the other hand, the technologies used in data warehouses have been used for decades, which means that they have mature security features along with robust access control. However, the continuously evolving security protocols in data lakes make it even more robust in terms of security.
User accessibility: Data Lakes can cater to advanced analytical professionals and data scientists because of the unstructured and raw nature of data. While data lakes provide greater exploration capabilities and flexibility, it has specialized tools and skills for effective utilization. However, when it is about Data warehouses, these have been primarily targeted for analytic users and Business Intelligence with different levels of adoption throughout the organization.
Maturity: Data Lakes can be said to be a relatively new data warehouse that is continuously undergoing refinement and evolution. As organizations have started embracing big data technologies and exploring use cases, it can be expected that the maturity level has increased over time. In the coming years, it will be a prominent technology among organizations. However, even when data warehouses can be represented as a mature technology, the technology faces major issues with raw data processing.
Use cases: The data lake can be a good choice for processing different sorts of data from different sources, as well as for machine learning and analysis. It can help organizations analyze, store and ingest a huge volume of raw data from different sources. It also facilitates predictive models, real-time analytics and data discovery. Data warehouses, on the other hand, can be considered ideal for organizations with structured data analytics, predefined queries and reporting. It's a great choice for companies as it provides a centralized representative for historical data.
Integration: When it comes to data lake, it requires robust interoperability capability for processing, analyzing and ingesting data from different sources. Data pipelines and integration frameworks are commonly used for streamlining data, transformation, consumption and ingestion in the data lake environment. Data warehouse can be seamlessly integrated with the traditional reporting platforms, business intelligence, tools and data integration framework. These are being designed to support external applications and systems which enable data collaborations and sharing across the organization.
Complementarity: Data lakes complement data warehouse by properly and seamlessly accommodating different Data sources in their raw formats. It includes unstructured, semi-structured and structured data. It provides a cost-effective and scalable solution to analyze and store a huge volume of data with advanced capabilities like real-time analytics, predictive modelling and machine learning. The Data warehouse, on the other hand, is generally a complement transactional system as it provides a centralized representative for reporting and structured data analytics.
So, these are the basic differences between data warehouses and data lakes. Even when data warehouses and data lakes share a common goal, there are certain differences in terms of processing approach, security, agility, cost, architecture, integration, and so on. Organizations need to recognize the strengths and limitations before choosing the right repository to store their data assets. Organizations who are looking for a versatile centralized data repository which can be managed effectively without being heavy on your pocket, they can choose Data Lakes. The versatile nature of this technology makes it a great decision for organizations. If you need expertise and guidance on data management, experts in Hexaview Technologies will help you understand which one will suit your needs.
0 notes
Text
What is Microsoft Fabric?
Introduction
Microsoft Fabric is a complete analytics and data platform for businesses needing a single, integrated solution. It includes report creation, real-time event routing, data transportation, processing, ingestion, and transformation. It provides a full range of services, including databases, data warehouses, data science, data engineering, data factories, and real-time…

View On WordPress
0 notes
Text
7 Benefits Of Using Azure Data Lake ?
Azure Data Lake offers a range of benefits that empower businesses to manage, analyze, and derive insights from large volumes of data. Here are seven key benefits of using Azure Data Lake:
Scalability: Azure Data Lake provides virtually unlimited storage capacity, allowing businesses to store and process massive volumes of structured and unstructured data. With its scalable architecture, Azure Data Lake can accommodate growing data volumes and handle processing demands with ease.
Cost-Effectiveness: Azure Data Lake offers a cost-effective storage solution, enabling businesses to pay only for the storage and processing resources they use. By leveraging features such as pay-as-you-go pricing and storage tiering, businesses can optimize costs and achieve better cost efficiency.
Flexibility: Azure Data Lake supports a wide range of data types, including structured data, semi-structured data, and unstructured data. This flexibility enables businesses to ingest, store, and analyze diverse data sources, including text, images, videos, and IoT data, without the need for data transformation or preprocessing.
Unified Data Platform: Azure Data Lake integrates seamlessly with other Azure services and tools, such as Azure Synapse Analytics, Azure Databricks, and Power BI, creating a unified data platform for end-to-end data analytics and insights. This integration enables businesses to streamline data workflows, improve collaboration, and derive more value from their data assets.
Advanced Analytics: Azure Data Lake provides built-in support for advanced analytics and machine learning, enabling businesses to derive insights and make data-driven decisions. With features such as Azure Data Lake Analytics and Azure Machine Learning, businesses can perform complex data processing, predictive analytics, and AI modeling at scale.
Security and Compliance: Azure Data Lake offers robust security and compliance features to protect sensitive data and ensure regulatory compliance. With features such as encryption, access controls, auditing, and compliance certifications (e.g., GDPR, HIPAA, SOC), businesses can maintain data privacy, integrity, and security across the data lifecycle.
Real-Time Insights: Azure Data Lake supports real-time data processing and analysis, enabling businesses to derive insights and take action on data in near-real-time. By leveraging streaming data processing capabilities with services like Azure Stream Analytics and Azure Event Hubs, businesses can monitor, analyze, and respond to events and trends as they occur.
#marketing#microsoft#machine learning#business#commercial#technology#success#artificial intelligence#crm software#data lake#database#backup#databackup
0 notes
Text
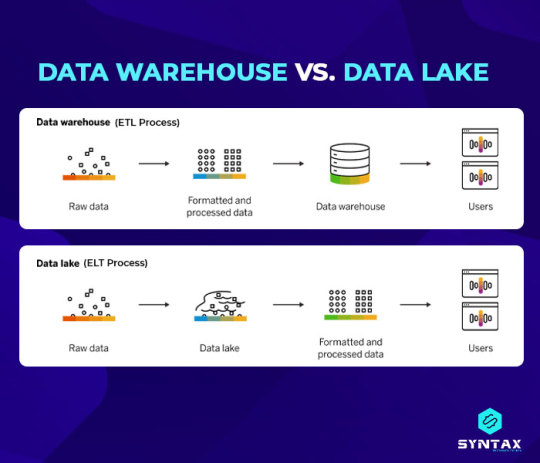
A data warehouse organizes structured data for analysis, prioritizing schema and processing. A data lake stores structured, semi-structured, and unstructured data in its raw format, allowing for flexible exploration and analysis.
0 notes
Text
10 Reasons to Make Apache Iceberg and Dremio Part of Your Data Lakehouse Strategy

Get a Free Copy of "Apache Iceberg: The Definitive Guide"
Build an Iceberg Lakehouse on Your Laptop
Apache Iceberg is disrupting the data landscape, offering a new paradigm where data is not confined to the storage system of a chosen data warehouse vendor. Instead, it resides in your own storage, accessible by multiple tools. A data lakehouse, which is essentially a modular data warehouse built on your data lake as the storage layer, offers limitless configuration possibilities. Among the various options for constructing an Apache Iceberg lakehouse, the Dremio Data Lakehouse Platform stands out as one of the most straightforward, rapid, and cost-effective choices. This platform has gained popularity for on-premises migrations, implementing data mesh strategies, enhancing BI dashboards, and more. In this article, we will explore 10 reasons why the combination of Apache Iceberg and the Dremio platform is exceptionally powerful. We will delve into five reasons to choose Apache Iceberg over other table formats and five reasons to opt for the Dremio platform when considering Semantic Layers, Query Engines, and Lakehouse Management.
5 Reasons to Choose Apache Iceberg Over Other Table Formats
Apache Iceberg is not the only table format available; Delta Lake and Apache Hudi are also key players in this domain. All three formats provide a core set of features, enabling database-like tables on your data lake with capabilities such as ACID transactions, time-travel, and schema evolution. However, there are several unique aspects that make Apache Iceberg a noteworthy option to consider.
1. Partition Evolution
Apache Iceberg distinguishes itself with a feature known as partition evolution, which allows users to modify their partitioning scheme at any time without the need to rewrite the entire table. This capability is unique to Iceberg and carries significant implications, particularly for tables at the petabyte scale where altering partitioning can be a complex and costly process. Partition evolution facilitates the optimization of data management, as it enables users to easily revert any changes to the partitioning scheme by simply rolling back to a previous snapshot of the table. This flexibility is a considerable advantage in managing large-scale data efficiently.
2. Hidden Partitioning
Apache Iceberg introduces a unique feature called hidden partitioning, which significantly simplifies the workflows for both data engineers and data analysts. In traditional partitioning approaches, data engineers often need to create additional partitioning columns derived from existing ones, which not only increases storage requirements but also complicates the data ingestion process. Additionally, data analysts must be cognizant of these extra columns; failing to filter by the partition column could lead to a full table scan, undermining efficiency.
However, with Apache Iceberg's hidden partitioning, the system can partition tables based on the transformed value of a column, with this transformation tracked in the metadata, eliminating the need for physical partitioning columns in the data files. This means that analysts can apply filters directly on the original columns and still benefit from the optimized performance of partitioning. This feature streamlines operations for both data engineers and analysts, making the process more efficient and less prone to error.
3. Versioning
Versioning is an invaluable feature that facilitates isolating changes, executing rollbacks, simultaneously publishing numerous changes across different objects, and creating zero-copy environments for experimentation and development. While each table format records a single chain of changes, allowing for rollbacks, Apache Iceberg uniquely incorporates branching, tagging, and merging as integral aspects of its core table format. Furthermore, Apache Iceberg stands out as the sole format presently compatible with Nessie, an open-source project that extends versioning capabilities to include commits, branches, tags, and merges at the multi-table catalog level, thereby unlocking a plethora of new possibilities.
These advanced versioning features in Apache Iceberg are accessible through ergonomic SQL interfaces, making them user-friendly and easily integrated into data workflows. In contrast, other formats typically rely on file-level versioning, which necessitates the use of command-line interfaces (CLIs) and imperative programming for management, making them less approachable and more cumbersome to use. This distinction underscores Apache Iceberg's advanced capabilities and its potential to significantly enhance data management practices.
4. Lakehouse Management
Apache Iceberg is attracting a growing roster of vendors eager to assist in managing tables, offering services such as compaction, sorting, snapshot cleanup, and more. This support makes using Iceberg tables as straightforward as utilizing tables in a traditional database or data warehouse. In contrast, other table formats typically rely on a single tool or vendor for data management, which can lead to vendor lock-in. With Iceberg, however, there is a diverse array of vendors, including Dremio, Tabular, Upsolver, AWS, and Snowflake, each providing varying levels of table management features. This variety gives users the flexibility to choose a vendor that best fits their needs, enhancing Iceberg's appeal as a versatile and user-friendly data management solutio
5. Open Culture
One of the most persuasive arguments for adopting Apache Iceberg is its dynamic open-source culture, which permeates its development and ecosystem. Development discussions take place on publicly accessible mailing lists and emails, enabling anyone to participate in and influence the format's evolution. The ecosystem is expanding daily, with an increasing number of tools offering both read and write support, reflecting the growing enthusiasm among vendors. This open environment provides vendors with the confidence to invest their resources in supporting Iceberg, knowing they are not at the mercy of a single vendor who could unpredictably alter or restrict access to the format. This level of transparency and inclusivity not only fosters innovation and collaboration but also ensures a level of stability and predictability that is highly valued in the tech industry.
Dremio
Dremio is a comprehensive data lakehouse platform that consolidates numerous functionalities, typically offered by different vendors, into a single solution. It unifies data analytics through data virtualization and a semantic layer, streamlining the integration and interpretation of data from diverse sources. Dremio's robust SQL query engine is capable of federating queries across various data sources, offering transparent acceleration to enhance performance. Additionally, Dremio's suite of lakehouse management features includes a Nessie-powered data catalog, which ensures data is versioned and easily transportable, alongside automated table maintenance capabilities. This integration of multiple key features into one platform simplifies the data management process, making Dremio a powerful and efficient tool for organizations looking to harness the full potential of their data lakehouse.
5. Apache Arrow
One of the key reasons Dremio's SQL query engine outperforms other distributed query engines and data warehouses is its core reliance on Apache Arrow, an in-memory data format increasingly recognized as the de facto standard for analytical processing. Apache Arrow facilitates the swift and efficient loading of data from various sources into a unified format optimized for speedy processing. Moreover, it introduces a transport protocol known as Apache Arrow Flight, which significantly reduces serialization/deserialization bottlenecks often encountered when transferring data over the network within a distributed system or between different systems. This integration of Apache Arrow at the heart of Dremio's architecture enhances its query performance, making it a powerful tool for data analytics.
4. Columnar Cloud Cache
One common bottleneck in querying a data lake based on object storage is the latency experienced when retrieving a large number of objects from storage. Additionally, each individual request can incur a cost, contributing to the overall storage access expenses. Dremio addresses these challenges with its C3 (Columnar Cloud Cache) feature, which caches frequently accessed data on the NVMe memory of nodes within the Dremio cluster. This caching mechanism enables rapid access to data during subsequent query executions that require the same information. As a result, the more queries that are run, the more efficient Dremio becomes. This not only enhances query performance over time but also reduces costs, making Dremio an increasingly cost-effective and faster solution as usage grows. This anti-fragile nature of Dremio, where it strengthens and improves with stress or demand, is a significant advantage for organizations looking to optimize their data querying capabilities.
3. Reflections
Other engines often rely on materialized views and BI extracts to accelerate queries, which can require significant manual effort to maintain. This process creates a broader array of objects that data analysts must track and understand when to use. Moreover, many platforms cannot offer this acceleration across all their compatible data sources.
In contrast, Dremio introduces a unique feature called Reflections, which simplifies query acceleration without adding to the management workload of engineers or expanding the number of namespaces analysts need to be aware of. Reflections can be applied to any table or view within Dremio, allowing for the materialization of rows or the aggregation of calculations on the dataset.
For data engineers, Dremio automates the management of these materializations, treating them as Iceberg tables that can be intelligently substituted when a query that would benefit from them is detected. Data analysts, on the other hand, continue to query tables and build dashboards as usual, without needing to navigate additional namespaces. They will, however, experience noticeable performance improvements immediately, without any extra effort. This streamlined approach not only enhances efficiency but also significantly reduces the complexity typically associated with optimizing query performance.
2. Semantic Layer
Many query engines and data warehouses lack the capability to offer an organized, user-friendly interface for end users, a feature known as a semantic layer. This layer is crucial for providing logical, intuitive views for understanding and discovering data. Without this feature, organizations often find themselves needing to integrate services from additional vendors, which can introduce a complex web of dependencies and potential conflicts to manage.
Dremio stands out by incorporating an easy-to-use semantic layer within its lakehouse platform. This feature allows users to organize and document data from all sources into a single, coherent layer, facilitating data discovery. Beyond organization, Dremio enables robust data governance through role-based, column-based, and row-based access controls, ensuring users can only access the data they are permitted to view.
This semantic layer enhances collaboration across data teams, offering a unified access point that supports the implementation of data-centric architectures like data mesh. By streamlining data access and collaboration, Dremio not only makes data more discoverable and understandable but also ensures a secure and controlled data environment, aligning with best practices in data management and governance.
5. Hybrid Architecture
Many contemporary data tools focus predominantly on cloud-based data, sidelining the vast reserves of on-premise data that cannot leverage these modern solutions. Dremio, however, stands out by offering the capability to access on-premise data sources in addition to cloud data. This flexibility allows Dremio to unify on-premise and cloud data sources, facilitating seamless migrations between different systems. With Dremio, organizations can enhance their on-premise data by integrating it with the wealth of data available in cloud data marketplaces, all without the need for data movement. This approach not only broadens the scope of data resources available to businesses but also enables a more integrated and comprehensive data strategy, accommodating the needs of organizations with diverse data environments.
Conclusion
Apache Iceberg and Dremio are spearheading a transformative shift in data management and analysis. Apache Iceberg's innovative features, such as partition evolution, hidden partitioning, advanced versioning, and an open-source culture, set it apart in the realm of data table formats, offering flexibility, efficiency, and a collaborative development environment. On the other hand, Dremio's data lakehouse platform leverages these strengths and further enhances the data management experience with its integrated SQL query engine, semantic layer, and unique features like Reflections and the C3 Columnar Cloud Cache.
By providing a unified platform that addresses the challenges of both on-premise and cloud data, Dremio eliminates the complexity and fragmentation often associated with data analytics. Its ability to streamline data processing, ensure robust data governance, and facilitate seamless integration across diverse data sources makes it an invaluable asset for organizations aiming to leverage their data for insightful analytics and informed decision-making.
Together, Apache Iceberg and Dremio not only offer a robust foundation for data management but also embody the future of data analytics, where accessibility, efficiency, and collaboration are key. Whether you're a data engineer looking to optimize data storage and retrieval or a data analyst seeking intuitive and powerful data exploration tools, this combination presents a compelling solution in the ever-evolving landscape of data technology.
Get a Free Copy of "Apache Iceberg: The Definitive Guide"
Build an Iceberg Lakehouse on Your Laptop
0 notes
Text
Data Warehouse Vs Data Lake: Understanding The Essential Differences

In a world full of technologies, storing numerous data become so light nowadays. And it is true, that many business organizations indeed prefer to use data warehouses and data lakes to reserve their huge company's data effortlessly.
Saving a company's data history for many years was tough in the old times. But today's technologies made this heavy thing very easy. Now, any company can store its significant data via a data warehouse and data lake.
But the thing is, a data warehouse and a data lake are different. There are many differences among them. In simple language, a data lake is raw and unorganized data. And on the other hand, a data warehouse is organized and specific data.
Let's Take An Example To Understand It More Clearly.
A water lake can be used to describe the data lake. So, a water lake contains water from anywhere in the world. That water doesn't come from one source. But it comes from a variety of sources. And all of the water got stored in one lake. This process is similar to the data lake.
Because in a data lake, multiple data come from different-different sources and are stored in one data lake. Alternatively, multiples of data from the data lake get organized and filtered, then stored in one specific place called a data warehouse.
If the data lake is compared to a water lake, then a data warehouse can be compared to a house's water tank. The reason for that is the water in a lake comes from various sources and is stored without being filtered.
However, many individuals took the lake's water and stored it in their house's water tank, filtering it so they could use it whenever needed.
Data Warehouse VS Date Lake - Differences
Structure Of The Data
All data is refined and organized in the data warehouse. And all these data come from a data lake. Additionally, data in a data warehouse is usually normalized, which indicates that duplicate information is decreased to ensure uniformity and reduce storage requirements.
As an alternative, all the data is raw and unclear in the data lake because it comes from various sources.
Storage Capacity

The data lakes always contain big data. That's the reason it has a large storage capacity for data. The data stored in data lakes are unorganized and unstructured. That's why it provides flexible and scalable solutions to reserving large volumes of data.
But for data warehouses, the storage capacity is not that large. That's why it contains flexible and perfectly analyzed data. Also, the storage capacity of a data warehouse depends on its hardware. And many data warehouses are designed to manage terabytes to petabytes of data.
Approaches/Processing
The approach used by data warehouses is a schema-on-write approach for processing the data. It is a form of organizing and reserving data where the structure and schema of data are determined and implemented before writing the data into the storage system.
On the other hand, the data lakes used a schema-on-read approach to processing their data. In this approach, the data stored are semi-structured, raw, and without format form. While reading or querying data, this approach implements the schema or data structure.
Cost
The cost of a data warehouse is high. Because it provides its users with powerful hardware and infrastructure. Currently, many business organizations prefer to use the cloud-based data warehouse for storing and preserving their company's data effortlessly. The expense of cloud-based data warehouses varies according to the usage and cloud provider.
Apart from that, the data lake cost is lower and reasonable. The reason behind it data lakes always store data in a raw and unorganized form. And they are compatible with a wide range of data processing tools and frameworks. That is why the data lake cost is lower than the data warehouse.
Objective
The objective or purpose of using the data of a data warehouse is specific. And the best advantage of a data warehouse is its storage capacity. Because a data warehouse's storage space is not wasted on data that will never be used in the coming future.
A data lake is a storage for raw data that may or may not have a defined future use. As a result, data in the data lake is less ordered and filtered.
Users

The users of data warehouses are IT sectors or many business professionals. Because as an IT company, they have to use specific and organized data for their services. That is the main reason they always prefer to use the data warehouse for saving and storing the salient data of their company.
Aside from that, the users of data lakes are data scientists and engineers. These people prefer to use data lakes for storing and reserving their data because they contain data from multiple sources. These data include raw, semi-structured, and unorganized data.
Accessibility
The data warehouse structure is perfectly designed by the developer. As a result, it is tough to exaggerate and manipulate. However, the users of a data warehouse can excess their data by using SQL (Structured Query Language). Moreover, Once data has been entered into a data warehouse, it is usually not directly altered or changed.
In contrast, the data lake has few constraints and is simple to access and modify. It is one of the most significant data lake advantages. As compared to a standard data warehouse, where data is often deemed read-only once imported, data in a data lake can be modified or changed.
So, What To Choose?
Choosing whether a business organization should utilize a data warehouse or a data lake to store data is the simplest option for anyone who understands the difference between a data warehouse and a data lake.
Furthermore, the data warehouse and data lake are great for storing valuable data for a business organization. And many companies prefer to use both data solutions in their business for smooth storage.
So, this article will help business owners to know the difference between them and selecting the perfect storing place for all their significant data.
Thanks for reading!!!
0 notes
Text
Top Data Management Trends for 2024: Navigating the Data Deluge
From customer transactions to sensor readings, the volume and variety of data is growing exponentially. Through 2024, we see organisations adopting data management strategies and technologies that help them to make sense of this data deluge.
Here are some key data management trends that will shape 2024:
Cloud-Based Data Management: Transition to a Cloud-Centric Approach
Automation & AI:…

View On WordPress
#ai#cloud#data democratisation#data governance#data lake#data lineage#data privacy#data strategy#real-time#self-service BI
0 notes
Text
Omri Kohl, CEO & Co-Founder of Pyramid Analytics – Interview Series
New Post has been published on https://thedigitalinsider.com/omri-kohl-ceo-co-founder-of-pyramid-analytics-interview-series/
Omri Kohl, CEO & Co-Founder of Pyramid Analytics – Interview Series
Omri Kohl is the CEO and co-founder of Pyramid Analytics. The Pyramid Decision Intelligence Platform delivers data-driven insights for anyone to make faster, more intelligent decisions. He leads the company’s strategy and operations through a fast-growing data and analytics market. Kohl brings a deep understanding of analytics and AI technologies, valuable management experience, and a natural ability to challenge conventional thinking. Kohl is a highly experienced entrepreneur with a proven track record in developing and managing fast-growth companies. He studied economics, finance, and business management at Bar-Ilan University and has an MBA in International Business Management from New York University, Leonard N. Stern School of Business.
Could you start by explaining what GenBI is, and how it integrates Generative AI with business intelligence to enhance decision-making processes?
GenBI is the framework and mechanics to bring the power of GenAI, LLMs and general AI into analytics, business intelligence and decision making.
Right now, it’s not practical to use GenAI alone to access insights to datasets. It could take over a week to upload enough data to your GenAI tool to get meaningful results. That’s simply not workable, as business data is too dynamic and too sensitive to use in this way. With GenBI, anyone can extract valuable insights from their data, just by asking a question in natural language and seeing the results in the form of a BI dashboard. It takes as little as 30 seconds to receive a relevant, useful answer.
What are the key technological innovations behind GenBI that allow it to understand and execute complex business intelligence tasks through natural language?
Well, without giving away all our secrets, there are essentially three components. First, GenBI prompts LLMs with all the elements they need to produce the correct analytical steps that will produce the requested insight. This is what allows the user to form queries using natural language and even in vague terms, without knowing exactly what type of chart, investigation, or format to request.
Next, the Pyramid Analytics GenBI solution applies these steps to your company’s data, regardless of the specifics of your situation. We’re talking the most basic datasets and simple queries, all the way up to the most sophisticated use cases and complex databases.
Third, Pyramid can carry out these queries on the underlying data and manipulate the results on the fly. An LLM alone can’t produce deep analysis on a database. You need a robot element to find all the necessary information, interpret the user request to produce insights, and pass it on to the BI platform to articulate the results either in plain language or as a dynamic visualization that can later be refined through follow-up queries.
How does GenBI democratize data analytics, particularly for non-technical users?
Quite simply, GenBI allows anyone to tap into the insights they need, regardless of their level of expertise. Traditional BI tools require the user to know which is the best data manipulation technique to receive the necessary results. But most people don’t think in pie charts, scatter charts or tables. They don’t want to have to work out which visualization is the most effective for their situation – they just want answers to their questions.
GenBI delivers these answers to anyone, regardless of their expertise. The user doesn’t need to know all the professional terms or work out if a scattergraph or a pie chart is the best option, and they don’t need to know how to code database queries. They can explore data by using their own words in a natural conversation.
We think of it as the difference between using a paper map to plan your route, and using Google Maps or other navigational app. With a traditional map, you have to work out the best roads to take, think about potential traffic jams, and compare different route possibilities. Today, people just put their destination into the app and hit the road – there’s so much trust in the algorithms that no one questions the suggested route. We’d like to think that GenBI is bringing the same kind of automated magic to corporate datasets.
What has been the feedback from early adopters about the ease of use and learning curve?
We’ve been receiving overwhelmingly positive feedback. The best way we can sum it up is, “Wow!” Users and testers highly appreciate Pyramid’s ease of use, powerful features, and meaningful insights.
Pyramid Analytics has virtually zero learning curve, so there’s nothing holding people back from adopting it on the spot. Approximately three-quarters of all the business teams who’ve tested our solution have adopted it and use it today, because it’s so easy and effective.
Can you share how GenBI has transformed decision-making processes within organizations that have implemented it? Any specific case studies or examples?
Although we’ve been developing it for a long time, we only rolled out GenBI a few weeks ago, so I’m sure you’ll understand that we don’t yet have fully-fledged case studies that we can share, or customer examples that we can name. However, I can tell you that organizations that have thousands of users are suddenly becoming truly data-driven, because everyone can access insights. Users can now unlock the true value of all their data.
GenBI is having a transformative effect on industries like insurance, banking, and finance, as well as retail, manufacturing, and many other verticals. Suddenly, it’s possible for financial advisors, for example, to tap into instant suggestions about the best way to optimize a customer’s portfolio.
What are some of the biggest challenges you faced in developing GenBI, and how did you overcome them?
Pyramid Analytics was already leveraging AI for analytics for many years before we launched the new solution, so most challenges have been ironed out long ago.
The main new element is the addition of a sophisticated query generation technology that works with any LLM to produce accurate results, while keeping data private. We’ve accomplished this by decoupling the data from the query (more on this in a moment).
Another big challenge we had to deal with was that of speed. We’re talking about the Google era, where people expect answers now, not in an hour or even half an hour. We made sure to speed up processing and optimize all workflows to reduce friction.
Then there’s the need to prevent hallucination. Chatbots are prone to hallucinations which skew results and undermine reliability. We’ve worked hard to avoid those while still maintaining dynamic results.
How do you handle issues related to data security and privacy?
That’s a great question, because data privacy and security is the biggest obstacle to successful GenAI analytics. Everyone is – quite rightly – concerned about the idea of exposing highly sensitive corporate data to third-party AI engines, but they also want the language interpretation capabilities and data insights that these engines can deliver.
That’s why we never share actual data with the LLMs we work with. Pyramid flips the entire premise on its head by serving as an intermediary between your company’s information and the LLM. We allow you to submit the request, and then we hand it to the LLM along with descriptions of what we call the “ingredients,” basically just the metadata.
The LLM then returns a “recipe,” which explains how to turn the user’s question into a data analytics prompt. Then Pyramid runs that recipe on the data that you’ve already connected securely on your self-hosted install, so that no data ever reaches the LLM. We mash up the results to serve them back to you in an easily understandable, visual format. Essentially, nothing that could compromise your security and privacy gets exposed or leaves the safety of your organization’s firewall.
For organizations looking to integrate GenBI into their existing data infrastructures, what does the implementation process look like? Are there any prerequisites or preparations needed?
The implementation process for Pyramid Analytics couldn’t be easier or faster. Users need very few prerequisites and preparations, and you can get the whole thing up and running in under an hour. You don’t need to move data into a new framework or change anything about your data strategy, because Pyramid queries your data directly where it resides.
There’s also no need to explain your data to the solution, or to define columns. It’s as simple as uploading a CSV dataset or connecting your SQL database. The same goes for any relational database of any sort. It takes only a few minutes to connect your data, and then you can ask your first question seconds later.
That said, you can tweak the structure if you want, like changing the joining model or redefining columns. It does take some time and effort, but we’re talking minutes, not a months-long dev project. Our customers are often shocked that Pyramid is up and running on their classic data warehouse or data lake within five minutes or so.
You also don’t need to come up with very specific, accurate, or even intelligent questions to get powerful results. You can make spelling mistakes and use incorrect phrasing, and Pyramid will unravel them and produce a meaningful and valuable answer. What you do need is some knowledge about the data you’re asking about.
Looking ahead, what’s your strategic vision for Pyramid Analytics over the next five years? How do you see your solutions evolving to meet changing market demands?
The next big frontier is supporting scalable, highly specific queries. Users are eager to be able to ask very precise questions, such as questions about personalized entities, and LLMs can’t yet produce intelligent answers in these cases, because they don’t have that kind of detailed insight into the specifics of your database.
We’re facing the challenge of how to use language models to ask about the specifics of your data without instantly connecting your entire, gigantic data lake to the LLM. How do you finetune your LLM about data that gets rehydrated every two seconds? We can manage this for fixed points like countries, locations, and even dates, but not for something idiosyncratic like names, even though we are very close to it today.
Another challenge is for users to be able to ask their own mathematical interpretations of the data, applying their own formulae. It’s difficult not because the formula is hard to enact, but because understanding what the user wants and getting the correct syntax is challenging. We’re working on solving both these challenges, and when we do, we’ll have passed the next eureka point.
Thank you for the great interview, readers who wish to learn more should visit Pyramid Analytics.
#ai#AI engines#Algorithms#Analysis#Analytics#app#banking#bi#bi tools#Business#Business Intelligence#business management#CEO#challenge#change#chart#charts#chatbots#code#columns#Companies#compromise#dashboard#data#data analytics#data lake#data privacy#data privacy and security#data security#data strategy
1 note
·
View note
Text
Exploring Data Lakes: A Comprehensive Approach to Storing and Analyzing Data
Data lakes have revolutionized the world of data storage and analysis, offering a centralized repository capable of storing vast amounts of raw and unprocessed data, including structured, semi-structured, and unstructured formats. This innovative approach eliminates the need for immediate data cleansing and transformation, making data lakes a flexible and dynamic solution for modern data needs. They empower organizations to handle massive data volumes seamlessly and democratize data access across teams, fostering collaboration and innovation.
To fully harness the potential of data lakes, individuals can benefit from enrolling in well-structured Data Analytics Courses. These courses not only teach the intricacies of data lake design and management but also focus on extracting meaningful insights from raw data, ensuring data quality, and maintaining privacy. Hands-on experience with relevant tools and technologies equips students with the skills needed to navigate the evolving landscape of data-driven decision-making. As data lakes continue to play a pivotal role in data analytics, individuals with expertise in this field are well-positioned to shape the future of data analysis and decision-making. Click on the Link for more detailed information: https://sooperposting.com/exploring-data-lakes-a-comprehensive-approach-to-storing-and-analyzing-data/
0 notes
Text
Impact of Data Lakehouses on AI Goal Outcomes

In order to help businesses reimagine processes, enhance customer experiences, and preserve a competitive advantage, artificial intelligence (AI) is increasingly at the forefront of how they use data. It is now a crucial component of a successful data strategy rather than just a nice-to-have. Access to reliable, regulated data is necessary to power and scale AI, and it is the first step toward success. Your teams can get the most out of your data with an open data lakehouse design strategy, enabling better, quicker insights and a successful adoption of AI.
Why does AI require a lakehouse architecture for open data?
Take this into consideration: According to an IDC prediction, global spending on AI will reach $300 billion in 2026, with a 26.5% compound annual growth rate (CAGR) from 2022 to 2026. Even though two thirds of respondents indicated they used AI-driven data analytics, the majority of them claimed that less than half of the managed data was accessible for these analyses. In fact, according to an IDC DataSphere study, only 5,063 exabytes (EB) of data (47.6%) will be examined in 2022 out of the 10,628 exabytes (EB) of data that IDC predicted would be beneficial if analyzed.
In order to grow AI and meet the issues presented by the complex data landscape of today, a data lakehouse architecture combines the performance of data warehouses with the flexibility of data lakes. Data lakes can produce low-performing data science workloads, whereas data warehouses are typically constrained by high storage costs that hinder AI and ML model collaboration and deployments.
However, enterprises can benefit from more dependable analytics and AI project execution by combining the power of lakes and warehouses in one strategy the data lakehouse.
It should be simple to merge mission-critical data about customers and transactions that are stored in existing repositories with fresh data from a range of sources using a lakehouse. This combo reveals new relationships and insights. Additionally, a lakehouse can provide definitional metadata to guarantee clarity and consistency, allowing for more reliable, controlled data.
All of this is in favor of using AI. And to access these fresh big data insights at scale, AI both supervised and unsupervised machine learning is frequently the best or even the only option.
How does AI assist an open data lakehouse architecture?
To expand AI workloads for all of your data, everywhere, enter IBM Watsonx.data, a fit-for-purpose data store based on an open data lakehouse. Watsonx.data is a component of IBM’s Watsonx AI and data platform, which enables businesses to grow and accelerate the effect of AI throughout the organization.
With a shared metadata layer distributed across clouds and on-premises systems, Watsonx.data enables users to access all data through a single point of entry. It supports open data and open table formats, allowing businesses to store enormous amounts of data in vendor-neutral formats like Parquet, Avro, and Apache ORC and communicate massive amounts of data using Apache Iceberg’s open table format designed for high-performance analytics.
Organizations can reduce costs associated with warehouse workloads by utilizing several query engines that are appropriate for the job at hand. They will also no longer need to maintain multiple copies of the same data across repositories for analytics and AI use cases.
As a self-service, collaborative platform, your teams’ access to non-technical users means that they are no longer restricted to just data scientists and engineers working with data. Later this year, watsonx.data will integrate watsonx.ai generative AI capabilities to simplify and expedite the way people engage with data, with the ability to utilize natural language to discover, augment, improve and visualize data and metadata powered by a conversational, natural language interface.
Your data and AI strategy’s next points
Spend some time ensuring that your company data and AI strategy is prepared for the effect of AI and the scale of data. You may benefit from a data lakehouse with watsonx.data to scale AI workloads for all of your data, everywhere.
0 notes
Text
Evaluating Data Fabric and Data Lake Architectures

Choosing a data management approach can be challenging, especially when you have to compare data lake and data fabric. Go through the blog to learn to understand the key differences between them and make an informed decision.
0 notes
Text
Data Lake & Data Warehouse
Although both Data Lakes and Data Warehouses are frequently used to store massive data, the words are not equivalent. A data lake is a sizable collection of unprocessed data and data warehouse is pool of processed & stored for a particular purpose. matted, filtered, and stored in a data warehouse. The differentiation is crucial since they have diverse functions and must be effectively optimised by various viewpoints. Data Lakehouse, an emerging trend in data management architecture, combines the adaptability of a data lake with the data management skills of a data warehouse.
Data Lake: A data lake is a central location that holds massive data in its original, unprocessed form. Data is stored using a flat architecture and object storage with metadata tags and a unique identifier, making it simpler to find and retrieve desired information. Data lakes make it possible for numerous applications to use the data through open formats and cheap object storage.
0 notes
Last Seen Blogs

3l3ctrical
Untitled


worldyachtgroup-me-blog
World Yacht Group

norckde
NORCK De

onajourneytohappiness
live, dont just exist.