#data lake vs. data warehouse: which is the best data architecture?
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
ETL Engineer vs. Data Engineer: Which One Do You Need?

If your business handles large data volumes you already know how vital it is to have the right talent managing it. But when it comes to scalability or improving your data systems, you must know whether to hire ETL experts or hire data engineers.
While the roles do overlap in some areas, they each have unique skills to bring forth. This is why an understanding of the differences can help you make the right hire. Several tech companies face this question when they are outlining their data strategy. So if you are one of those then let’s break it down and help you decide which experts you should hire.
Choosing the Right Role to Build and Manage Your Data Pipeline
Extract, Transform, Load is what ETL stands for. The duties of an ETL engineer include:
Data extraction from various sources.
Cleaning, formatting, and enrichment.
Putting it into a central system or data warehouse.
Hiring ETL engineers means investing in a person who will make sure data moves accurately and seamlessly across several systems and into a single, usable format.
Businesses that largely rely on dashboards, analytics tools, and structured data reporting would benefit greatly from this position. ETL engineers assist business intelligence and compliance reporting for a large number of tech organizations.
What Does a Data Engineer Do?
The architecture that facilitates data movement and storage is created and maintained by a data engineer. Their duties frequently consist of:
Data pipeline design
Database and data lake management
Constructing batch or real-time processing systems
Developing resources to assist analysts and data scientists
When hiring data engineers, you want someone with a wider range of skills who manages infrastructure, performance optimization, and long-term scalability in addition to using ETL tools.
Remote Hiring and Flexibility
Thanks to cloud platforms and remote technologies, you can now hire remote developers, such as data engineers and ETL specialists, with ease. This strategy might be more economical and gives access to worldwide talent, particularly for expanding teams.
Which One Do You Need?
If your main objective is to use clean, organized data to automate and enhance reporting or analytics, go with ETL engineers.
If you're scaling your current infrastructure or creating a data platform from the ground up, hire data engineers.
Having two responsibilities is ideal in many situations. While data engineers concentrate on the long-term health of the system, ETL engineers manage the daily flow.
Closing Thoughts
The needs of your particular project will determine whether you should hire a data engineer or an ETL. You should hire ETL engineers if you're interested in effectively transforming and transporting data. It's time to hire data engineers if you're laying the framework for your data systems.
Combining both skill sets might be the best course of action for contemporary IT organizations, particularly if you hire remote talent to scale swiftly and affordably. In any case, hiring qualified personnel guarantees that your data strategy fosters expansion and informed decision-making.
0 notes
Text
Data Warehousing vs. Data Lakes: Choosing the Right Approach for Your Organization
As a solution architect, my journey into data management has been shaped by years of experience and focused learning. My turning point was the data analytics training online, I completed at ACTE Institute. This program gave me the clarity and practical knowledge I needed to navigate modern data architectures, particularly in understanding the key differences between data warehousing and data lakes.
Both data warehousing and data lakes have become critical components of the data strategies for many organizations. However, choosing between them—or determining how to integrate both—can significantly impact how an organization manages and utilizes its data.
What is a Data Warehouse?
Data warehouses are specialized systems designed to store structured data. They act as centralized repositories where data from multiple sources is aggregated, cleaned, and stored in a consistent format. Businesses rely on data warehouses for generating reports, conducting historical analysis, and supporting decision-making processes.
Data warehouses are highly optimized for running complex queries and generating insights. This makes them a perfect fit for scenarios where the primary focus is on business intelligence (BI) and operational reporting.
Features of Data Warehouses:
Predefined Data Organization: Data warehouses rely on schemas that structure the data before it is stored, making it easier to analyze later.
High Performance: Optimized for query processing, they deliver quick results for detailed analysis.
Data Consistency: By cleansing and standardizing data from multiple sources, warehouses ensure consistent and reliable insights.
Focus on Business Needs: These systems are designed to support the analytics required for day-to-day business decisions.
What is a Data Lake?
Data lakes, on the other hand, are designed for flexibility and scalability. They store vast amounts of raw data in its native format, whether structured, semi-structured, or unstructured. This approach is particularly valuable for organizations dealing with large-scale analytics, machine learning, and real-time data processing.
Unlike data warehouses, data lakes don’t require data to be structured before storage. Instead, they use a schema-on-read model, where the data is organized only when it’s accessed for analysis.
Features of Data Lakes:
Raw Data Storage: Data lakes retain data in its original form, providing flexibility for future analysis.
Support for Diverse Data Types: They can store everything from structured database records to unstructured video files or social media content.
Scalability: Built to handle massive amounts of data, data lakes are ideal for organizations with dynamic data needs.
Cost-Effective: Data lakes use low-cost storage options, making them an economical solution for large datasets.
Understanding the Differences
To decide which approach works best for your organization, it’s essential to understand the key differences between data warehouses and data lakes:
Data Structure: Data warehouses store data in a structured format, whereas data lakes support structured, semi-structured, and unstructured data.
Processing Methodology: Warehouses follow a schema-on-write model, while lakes use a schema-on-read approach, offering greater flexibility.
Purpose: Data warehouses are designed for business intelligence and operational reporting, while data lakes excel at advanced analytics and big data processing.
Cost and Scalability: Data lakes tend to be more cost-effective, especially when dealing with large, diverse datasets.
How to Choose the Right Approach
Choosing between a data warehouse and a data lake depends on your organization's goals, data strategy, and the type of insights you need.
When to Choose a Data Warehouse:
Your organization primarily deals with structured data that supports reporting and operational analysis.
Business intelligence is at the core of your decision-making process.
You need high-performance systems to run complex queries efficiently.
Data quality, consistency, and governance are critical to your operations.

When to Choose a Data Lake:
You work with diverse data types, including unstructured and semi-structured data.
Advanced analytics, machine learning, or big data solutions are part of your strategy.
Scalability and cost-efficiency are essential for managing large datasets.
You need a flexible solution that can adapt to emerging data use cases.
Combining Data Warehouses and Data Lakes
In many cases, organizations find value in adopting a hybrid approach that combines the strengths of data warehouses and data lakes. For example, raw data can be ingested into a data lake, where it’s stored until it’s needed for specific analytical use cases. The processed and structured data can then be moved to a data warehouse for BI and reporting purposes.
This integrated strategy allows organizations to benefit from the scalability of data lakes while retaining the performance and reliability of data warehouses.
My Learning Journey with ACTE Institute
During my career, I realized the importance of mastering these technologies to design efficient data architectures. The data analytics training in Hyderabad program at ACTE Institute provided me with a hands-on understanding of both data lakes and data warehouses. Their comprehensive curriculum, coupled with practical exercises, helped me bridge the gap between theoretical knowledge and real-world applications.
The instructors at ACTE emphasized industry best practices and use cases, enabling me to apply these concepts effectively in my projects. From understanding how to design scalable data lakes to optimizing data warehouses for performance, every concept I learned has played a vital role in my professional growth.
Final Thoughts
Data lakes and data warehouses each have unique strengths, and the choice between them depends on your organization's specific needs. With proper planning and strategy, it’s possible to harness the potential of both systems to create a robust and efficient data ecosystem.
My journey in mastering these technologies, thanks to the guidance of ACTE Institute, has not only elevated my career but also given me the tools to help organizations make informed decisions in their data strategies. Whether you're working with structured datasets or diving into advanced analytics, understanding these architectures is crucial for success in today’s data-driven world.
#machinelearning#artificialintelligence#digitalmarketing#marketingstrategy#adtech#database#cybersecurity#ai
0 notes
Text
Data Lake vs Data Warehouse: 10 Key difference

Today, we are living in a time where we need to manage a vast amount of data. In today's data management world, the growing concepts of data warehouse and data lake have often been a major part of the discussions. We are mainly looking forward to finding the merits and demerits to find out the details. Undeniably, both serve as the repository for storing data, but there are fundamental differences in capabilities, purposes and architecture.
Hence, in this blog, we will completely pay attention to data lake vs data warehouse to help you understand and choose effectively.
We will mainly discuss the 10 major differences between data lakes and data warehouses to make the best choice.
Data variety: In terms of data variety, data lake can easily accommodate the diverse data types, which include semi-structured, structured, and unstructured data in the native format without any predefined schema. It can include data like videos, documents, media streams, data and a lot more. On the contrary, a data warehouse can store structured data which has been properly modelled and organized for specific use cases. Structured data can be referred to as the data that confirms the predefined schema and makes it suitable for traditional relational databases. The ability to accommodate diversified data types makes data lakes much more accessible and easier.
Processing approach: When it is about the data processing, data lakes follow a schema-on-read approach. Hence, it can ingest raw data on its lake without the need for structuring or modelling. It allows users to apply specific structures to the data while analyzing and, therefore, offers better agility and flexibility. However, for data warehouse, in terms of processing approach, data modelling is performed prior to ingestion, followed by a schema-on-write approach. Hence, it requires data to be formatted and structured as per the predefined schemes before being loaded into the warehouse.
Storage cost: When it comes to data cost, Data Lakes offers a cost-effective storage solution as it generally leverages open-source technology. The distributed nature and the use of unexpected storage infrastructure can reduce the overall storage cost even when organizations are required to deal with large data volumes. Compared to it, data warehouses include higher storage costs because of their proprietary technologies and structured nature. The rigid indexing and schema mechanism employed in the warehouse results in increased storage requirements along with other expenses.
Agility: Data lakes provide improved agility and flexibility because they do not have a rigid data warehouse structure. Data scientists and developers can seamlessly configure and configure queries, applications and models, which enables rapid experimentation. On the contrary, Data warehouses are known for their rigid structure, which is why adaptation and modification are time-consuming. Any changes in the data model or schema would require significant coordination, time and effort in different business processes.
Security: When it is about data lakes, security is continuously evolving as big data technologies are developing. However, you can remain assured that the enhanced data lake security can mitigate the risk of unauthorized access. Some enhanced security technology includes access control, compliance frameworks and encryption. On the other hand, the technologies used in data warehouses have been used for decades, which means that they have mature security features along with robust access control. However, the continuously evolving security protocols in data lakes make it even more robust in terms of security.
User accessibility: Data Lakes can cater to advanced analytical professionals and data scientists because of the unstructured and raw nature of data. While data lakes provide greater exploration capabilities and flexibility, it has specialized tools and skills for effective utilization. However, when it is about Data warehouses, these have been primarily targeted for analytic users and Business Intelligence with different levels of adoption throughout the organization.
Maturity: Data Lakes can be said to be a relatively new data warehouse that is continuously undergoing refinement and evolution. As organizations have started embracing big data technologies and exploring use cases, it can be expected that the maturity level has increased over time. In the coming years, it will be a prominent technology among organizations. However, even when data warehouses can be represented as a mature technology, the technology faces major issues with raw data processing.
Use cases: The data lake can be a good choice for processing different sorts of data from different sources, as well as for machine learning and analysis. It can help organizations analyze, store and ingest a huge volume of raw data from different sources. It also facilitates predictive models, real-time analytics and data discovery. Data warehouses, on the other hand, can be considered ideal for organizations with structured data analytics, predefined queries and reporting. It's a great choice for companies as it provides a centralized representative for historical data.
Integration: When it comes to data lake, it requires robust interoperability capability for processing, analyzing and ingesting data from different sources. Data pipelines and integration frameworks are commonly used for streamlining data, transformation, consumption and ingestion in the data lake environment. Data warehouse can be seamlessly integrated with the traditional reporting platforms, business intelligence, tools and data integration framework. These are being designed to support external applications and systems which enable data collaborations and sharing across the organization.
Complementarity: Data lakes complement data warehouse by properly and seamlessly accommodating different Data sources in their raw formats. It includes unstructured, semi-structured and structured data. It provides a cost-effective and scalable solution to analyze and store a huge volume of data with advanced capabilities like real-time analytics, predictive modelling and machine learning. The Data warehouse, on the other hand, is generally a complement transactional system as it provides a centralized representative for reporting and structured data analytics.
So, these are the basic differences between data warehouses and data lakes. Even when data warehouses and data lakes share a common goal, there are certain differences in terms of processing approach, security, agility, cost, architecture, integration, and so on. Organizations need to recognize the strengths and limitations before choosing the right repository to store their data assets. Organizations who are looking for a versatile centralized data repository which can be managed effectively without being heavy on your pocket, they can choose Data Lakes. The versatile nature of this technology makes it a great decision for organizations. If you need expertise and guidance on data management, experts in Hexaview Technologies will help you understand which one will suit your needs.
0 notes
Text
AMAZON SNOWFLAKE

Unlocking the Power of Amazon Snowflake: Your Guide to a Scalable Data Warehouse
In today’s data-driven world, finding the right tools to manage massive amounts of information is critical to business success. Enter Amazon Snowflake, a powerhouse cloud data warehouse built to revolutionize how you store, process, and unlock insights from your data. Let’s explore why Snowflake on AWS is a game-changer.
What is Amazon Snowflake?
At its core, Snowflake is a fully managed, cloud-based data warehouse solution offered as a Software-as-a-Service (SaaS). That means no installation headaches and no hardware to maintain – just scalable, lightning-fast data power on demand! Here’s what sets it apart:
Cloud-Native Architecture: Snowflake leverages Amazon Web Services (AWS) ‘s power and flexibility to enable virtually unlimited scalability and seamless integration with other AWS services.
Separation of Storage and Compute: You pay separately for the data you store and the compute resources (virtual warehouses) you use to process it. This offers incredible cost control and the ability to scale up or down based on workload.
Multi-Cluster Shared Data: Snowflake allows access to the same data from multiple compute clusters. This is perfect for separating workloads (e.g., development vs. production) without duplicating data.
Near-Zero Maintenance: Forget manual tuning and optimization; let Snowflake handle the heavy lifting.
Key Benefits of Snowflake
Effortless Scalability: Handle fluctuating data volumes with ease. Need more power during peak seasons? Spin additional virtual warehouses and scale them back down quickly when the rush ends.
Concurrency without Compromise: Snowflake can support numerous simultaneous users and queries without performance suffering, which is essential for data-intensive businesses.
Pay-As-You-Go Pricing: Only pay for the resources you use. This model appeals to businesses with unpredictable workloads or those looking to control costs tightly.
Seamless Data Sharing: Securely share governed data sets within your organization or with external partners and customers without any complex data movement.
Broad Support: Snowflake works with various business intelligence (BI) and data analysis tools as well as SQL and semi-structured data formats (like JSON and XML).
Typical Use Cases
Modern Data Warehousing: Snowflake is tailor-made to centralize data from multiple sources, creating a single source of truth for your organization.
Data Lakes: Combine structured and semi-structured data in a Snowflake environment, streamlining big data analytics.
Data-Driven Applications: Thanks to Snowflake’s speed and scalability, build applications powered by real-time data insights.
Business Intelligence and Reporting: Snowflake powers your BI dashboards and reports, enabling faster and more informed business decisions.
Getting Started with Snowflake on AWS
Ready to try it out? Snowflake offers a generous free trial so that you can test the waters. If you’re already using AWS, integration is a breeze.
Let’s Summarize
Amazon Snowflake is a cloud data warehousing force to be reckoned with. If you need a solution that combines limitless scale, ease of use, flexibility, cost-effectiveness, and lightning-fast performance, Snowflake warrants a serious look. Embrace the power of the cloud and let Snowflake become the backbone of your data strategy.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
Data Lake and Data Warehouse: 5 key differences
Data Lake is not considered to be the direct replacement for any data warehouse. Instead, they are recognized as supplemental technologies capable of serving a plethora of use cases and few overlaps. The majority of the business enterprises, which include Data Lake, possess a data warehouse. Both the data warehouse and Data lakes are used on an immense scale to store massive data amount. However, they are not known to be interchangeable terms.

Data Lake happens to be a vast pool, which includes raw data. However, the objective of the data is not yet defined. On the other hand, the data warehouse happens to be the repository to hold filtered and structured data, which are processed already for a particular objective. Though both the terms associated with data storage appear to be the same, they are quite different.
You will be surprised to know that the only difference between these data varieties is that they serve the high-level to store the data. The distinction is crucial as they serve different objectives and need various eye sets for the right optimization. Here are some of the crucial differences between Data Lakes and Data Warehouses:
Structure of data: Processed vs. Raw
Raw Data contributes to being the data that is yet to be processed for the objective. The difference between the data warehouse and Data Lake Solutions is known to be the varying structure of processed vs. Raw Data. Data Lakes are responsible for storing unprocessed and raw data primarily, whereas the data warehouses offer a helping hand in storing the refined and processed data. Owing to this, Data lakes need larger storage capacity compared to the Data Warehouse.
In addition to this, unprocessed and raw data is known to be malleable. You can analyze it faster to accomplish all data needs. It is also believed to be an excellent option for machine learning. However, certain risks are associated with raw data as data lakes get converted into data swamps without the data governance measures and appropriate data quality. Data warehouses are beneficial in storing processed data. So, they prevent a massive cut off from the pocket as the company does not need to carry the hassles of maintaining the unnecessary data.
Secure vs. flexible
Ease of use and accessibility contribute to being the data repository use as a whole and just not the data present. It would be best if you keep in mind that data lake architecture does not include any architecture. So, it is easy to change and access. In addition to this, it is possible to introduce changes to the data in no time as data lakes come with certain limitations. Data warehouses feature a more structured design. Another massive benefit of data warehouse architecture is that the structure and processing of data make the deciphering of data faster. Due to certain limitations in the structure, creating a data warehouse might be challenging.
Business professionals vs. Data scientists
It is challenging to navigate the data lakes. Unstructured and raw data needs to be handled by data scientists. In addition to this, the data scientist needs to use specialized tools for understanding and translating it for different business requirements. In addition to this, there is a rising momentum behind different data preparation tools that provide access to the information present in the Data Lakes. Processed data is beneficial in spreadsheets, charts, tables, to name a few.
Cost of Data storage
The cost to store the data is high in the data warehouse. It is due to the fact that the software which is used by such data warehouses involves a reduced cut off from the pocket. In addition to this, the cost of data maintenance seems to be high as they comprise of cooling, power, telecommunications, and space.
Another point you need to keep in mind that as the data warehouse includes massive data amount in the denormalized format, it might take an ample amount of disk space. However, speaking of the data lake, the cost of storing data seems to be low. They make use of open-source software, which includes a lesser price. As the data seems to be unstructured, the data lakes will scale to higher data volume at reduced costs.
Kinds of operation
The data warehouse is used on an immense scale for OLAP or Online Analytical processing. It is inclusive of aggregating queries, running reports, performing the analysis, and creating the models, like the OLAP models. Such operations are conducted after the completion of the transactions.
For instance, you might want to monitor different transactions, which are completed by a specific customer. As the data gets stored within the denormalized format, you will be successful in fetching the data from a particular table at ease, after which you should make sure to reveal the required report.
The data lake is used on a wide scale for performing raw data analysis. The raw data includes pdf, images, XML files, which are collected for additional research. As you try to capture the data, you do not require carrying the hassles of defining the schema. You might not be aware that such data will be beneficial in the near future. So, you will be able to perform various kinds of analytics for unrevealing valuable insights.
Data Warehouses are useful in a business organization to store the data in folders and files, which are effective in using and organizing the data. It provides a helping hand in making different strategic decisions. Such type of storage system provides a multi-dimensional view of the summary and atomic data. Other functions that are considered to be an indispensable part of Data Warehouses include Data Cleaning, Data Extraction, Data Transformation, Data Refreshing, and Data Loading.
A Data Lake contributes to being the storage repository of considerable size, which is useful in storing raw data in enormous amounts to its original format until the required time. A unique identifier is offered to each data element present in the Data Lake, after which it is tagged with a unique set of various extended metadata tags. It provides different varieties of analytical abilities.
1 note
·
View note
Video
youtube
Amazon (AWS) QuickSight, Glue, Athena & S3 Fundamentals
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data…
View On WordPress
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data…
View On WordPress
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data…
View On WordPress
0 notes
Text
Best Azure Data Engineer | Azure Data Engineer Course Online
Azure Data Factory vs SSIS: Understanding the Key Differences
Azure Data Factory (ADF) is a modern, cloud-based data integration service that enables organizations to efficiently manage, transform, and move data across various systems. In contrast, SQL Server Integration Services (SSIS) is a traditional on-premises ETL tool designed for batch processing and data migration. Both are powerful data integration tools offered by Microsoft, but they serve different purposes, environments, and capabilities. In this article, we’ll delve into the key differences between Azure Data Factory and SSIS, helping you understand when and why to choose one over the other. Microsoft Azure Data Engineer

1. Overview
SQL Server Integration Services (SSIS)
SSIS is a traditional on-premises ETL (Extract, Transform, Load) tool that is part of Microsoft SQL Server. It allows users to create workflows for data integration, transformation, and migration between various systems. SSIS is ideal for batch processing and is widely used for enterprise-scale data warehouse operations.
Azure Data Factory (ADF)
ADF is a cloud-based data integration service that enables orchestration and automation of data workflows. It supports modern cloud-first architectures and integrates seamlessly with other Azure services. ADF is designed for handling big data, real-time data processing, and hybrid environments.
2. Deployment Environment
SSIS: Runs on-premises or in virtual machines. While you can host SSIS in the Azure cloud using Azure-SSIS Integration Runtime, it remains fundamentally tied to its on-premises roots.
ADF: Fully cloud-native and designed for Azure. It leverages the scalability, reliability, and flexibility of cloud infrastructure, making it ideal for modern, cloud-first architectures. Azure Data Engineering Certification
3. Data Integration Capabilities
SSIS: Focuses on traditional ETL processes with strong support for structured data sources like SQL Server, Oracle, and flat files. It offers various built-in transformations and control flow activities. However, its integration with modern cloud and big data platforms is limited.
ADF: Provides a broader range of connectors, supporting over 90 on-premises and cloud-based data sources, including Azure Blob Storage, Data Lake, Amazon S3, and Google Big Query. ADF also supports ELT (Extract, Load, Transform), enabling transformations within data warehouses like Azure Synapse Analytics.
4. Scalability and Performance
SSIS: While scalable in an on-premises environment, SSIS’s scalability is limited by your on-site hardware and infrastructure. Scaling up often involves significant costs and complexity.
ADF: Being cloud-native, ADF offers elastic scalability. It can handle vast amounts of data and scale resources dynamically based on workload, providing cost-effective processing for both small and large datasets.
5. Monitoring and Management
SSIS: Includes monitoring tools like SSISDB and SQL Server Agent, which allow you to schedule and monitor package execution. However, managing SSIS in distributed environments can be complex.
ADF: Provides a centralized, user-friendly interface within the Azure portal for monitoring and managing data pipelines. It also offers advanced logging and integration with Azure Monitor, making it easier to track performance and troubleshoot issues. Azure Data Engineer Course
6. Cost and Licensing
SSIS: Requires SQL Server licensing, which can be cost-prohibitive for organizations with limited budgets. Running SSIS in Azure adds additional infrastructure costs for virtual machines and storage.
ADF: Operates on a pay-as-you-go model, allowing you to pay only for the resources you consume. This makes ADF a more cost-effective option for organizations looking to minimize upfront investment.
7. Flexibility and Modern Features
SSIS: Best suited for organizations with existing SQL Server infrastructure and a need for traditional ETL workflows. However, it lacks features like real-time streaming and big data processing.
ADF: Supports real-time and batch processing, big data workloads, and integration with machine learning models and IoT data streams. ADF is built to handle modern, hybrid, and cloud-native data scenarios.
8. Use Cases
SSIS: Azure Data Engineer Training
On-premises data integration and transformation.
Migrating and consolidating data between SQL Server and other relational databases.
Batch processing and traditional ETL workflows.
ADF:
Building modern data pipelines in cloud or hybrid environments.
Handling large-scale big data workloads.
Real-time data integration and IoT data processing.
Cloud-to-cloud or cloud-to-on-premises data workflows.
Conclusion
While both Azure Data Factory and SSIS are powerful tools for data integration, they cater to different needs. SSIS is ideal for traditional, on-premises data environments with SQL Server infrastructure, whereas Azure Data Factory is the go-to solution for modern, scalable, and cloud-based data pipelines. The choice ultimately depends on your organization’s infrastructure, workload requirements, and long-term data strategy.
By leveraging the right tool for the right use case, businesses can ensure efficient data management, enabling them to make informed decisions and gain a competitive edge.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Azure Data Engineering worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://azuredataengineering2.blogspot.com/
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data warehouses” and “data lakes.” Think of a data warehouse like a shopping mall. It has discrete “shops” within it that store structured data — bits that are presorted into formats that database software can interact with.
In contrast, a data lake is like a disorganized flea market. It has “stalls,” but where one stops and the next one begins is not so clear. Unlike data warehouses, data lakes can contain both structured and unstructured data. Unstructured data, as the name implies, refers to “messy” digital information, such as audio, images, and video.
Complicating things further is the “data marketplace.” Unlike the first two concepts, this isn’t an architecture but rather an interface to a data lake that enables those outside of the IT team, such as business analysts, to its contents. Through a search function, it allows users to fish what they need out of the lake. Think of data marketplaces like personal tour guides for flea markets, showing shoppers where to find the best deals.
Inside the Data Warehouse and Data Lake
For a firm that’s looking to analyze large but structured data sets, a data warehouse is a good option. In fact, if the company is only interested in descriptive analytics — the process of merely summarizing the data one has — a data warehouse may be all it needs.
Let’s say, for example, company leaders want to look at sales figures across a particular time period, the number of inquiries about a product, or the view counts on various marketing videos. A data warehouse would be perfect for those applications because all of the associated figures are stored in the form of structured data.
But for most companies embarking on big data initiatives, structured data is only part of the story. Each year, businesses generate a staggering quantity of unstructured data. In fact, 451 Research in conjunction with Western Digital found that 63 percent of enterprises and service providers are keeping at least 25 petabytes of unstructured data. For those firms, data lakes are attractive options because of their ability to store vast quantities of such data.
What’s more, data lakes allow analysts to go beyond descriptive analytics and into the exciting — and highly rewarding — domain of predictive or prescriptive analytics. Predictive analysis is the practice of using existing data to predict future trends relevant to one’s business, such as next year’s revenue.
Prescriptive analytics goes a big step further, using artificial intelligence technologies to make recommendations in response to predictions. For both predictive and prescriptive analytics, a data lake is a must. Often, leaders manage data lakes using software like Apache Hadoop, a popular ecosystem of analytics tools.
Before springing for either a data lake or a data warehouse, think about who’ll be conducting data analyses and what sort of data they’ll need. Data warehouses are often accessible only by IT teams, while data lakes can be configured for access by analysts and business personnel across the company.
A healthcare organization my company worked with recently, for example, requested a data warehouse solution. Soon, though, it became apparent that the firm would instead require a data lake. Not only was it interested in predictive modeling, but it also sought to input all sort of unstructured data, such as handwritten doctor’s notes.
Analysts at a healthcare company might pull treatment data from a data lake to predict patient outcomes. They might add a prescriptive layer to then recommend the best course of treatment for each patient’s needs — one that minimizes cost and risk while providing the highest quality of care.
Making the Most of the Data Lake
Given their ability to store both types of data and their suitability for future analytics needs, it’s tempting to think that data lakes are the obvious answer. But due to their loose structure, they’re sometimes derided as more of a data “swamp” than a lake.
In fact, Adam Wray, CEO and president of NoSQL database Basho, described them as “evil because they’re unruly” and “incredibly costly.” In Basho’s experience, “the extraction of value [from data lakes] is infinitesimal compared to the value promised.”
But one shouldn’t count data lakes out just yet. Data marketplaces can rescue the promise of data lakes by organizing them for the end user. Just as the internet was much more difficult to navigate before Google, data marketplaces unlock the powerful data lake architecture.In the analytics world, there’s no one-size-fits-all system. Data warehouses can give even smaller companies a taste of data analytics, while data lakes (when combined with data marketplaces) can enable enterprises to dive headfirst into big data. These systems aren’t mutually exclusive, either. If its analytics needs change, a company that chooses a warehouse can later add a lake and a marketplace.
What’s most important is starting the journey to a more data-driven business. Many executives will remember that a decade ago, data wasn’t even discussed outside of IT teams. Now, with the range of analytics needs and tools available, it’s executives’ turn to lead the conversation.
https://ift.tt/2KYVZvq
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data warehouses” and “data lakes.” Think of a data warehouse like a shopping mall. It has discrete “shops” within it that store structured data — bits that are presorted into formats that database software can interact with.
In contrast, a data lake is like a disorganized flea market. It has “stalls,” but where one stops and the next one begins is not so clear. Unlike data warehouses, data lakes can contain both structured and unstructured data. Unstructured data, as the name implies, refers to “messy” digital information, such as audio, images, and video.
Complicating things further is the “data marketplace.” Unlike the first two concepts, this isn’t an architecture but rather an interface to a data lake that enables those outside of the IT team, such as business analysts, to its contents. Through a search function, it allows users to fish what they need out of the lake. Think of data marketplaces like personal tour guides for flea markets, showing shoppers where to find the best deals.
Inside the Data Warehouse and Data Lake
For a firm that’s looking to analyze large but structured data sets, a data warehouse is a good option. In fact, if the company is only interested in descriptive analytics — the process of merely summarizing the data one has — a data warehouse may be all it needs.
Let’s say, for example, company leaders want to look at sales figures across a particular time period, the number of inquiries about a product, or the view counts on various marketing videos. A data warehouse would be perfect for those applications because all of the associated figures are stored in the form of structured data.
But for most companies embarking on big data initiatives, structured data is only part of the story. Each year, businesses generate a staggering quantity of unstructured data. In fact, 451 Research in conjunction with Western Digital found that 63 percent of enterprises and service providers are keeping at least 25 petabytes of unstructured data. For those firms, data lakes are attractive options because of their ability to store vast quantities of such data.
What’s more, data lakes allow analysts to go beyond descriptive analytics and into the exciting — and highly rewarding — domain of predictive or prescriptive analytics. Predictive analysis is the practice of using existing data to predict future trends relevant to one’s business, such as next year’s revenue.
Prescriptive analytics goes a big step further, using artificial intelligence technologies to make recommendations in response to predictions. For both predictive and prescriptive analytics, a data lake is a must. Often, leaders manage data lakes using software like Apache Hadoop, a popular ecosystem of analytics tools.
Before springing for either a data lake or a data warehouse, think about who’ll be conducting data analyses and what sort of data they’ll need. Data warehouses are often accessible only by IT teams, while data lakes can be configured for access by analysts and business personnel across the company.
A healthcare organization my company worked with recently, for example, requested a data warehouse solution. Soon, though, it became apparent that the firm would instead require a data lake. Not only was it interested in predictive modeling, but it also sought to input all sort of unstructured data, such as handwritten doctor’s notes.
Analysts at a healthcare company might pull treatment data from a data lake to predict patient outcomes. They might add a prescriptive layer to then recommend the best course of treatment for each patient’s needs — one that minimizes cost and risk while providing the highest quality of care.
Making the Most of the Data Lake
Given their ability to store both types of data and their suitability for future analytics needs, it’s tempting to think that data lakes are the obvious answer. But due to their loose structure, they’re sometimes derided as more of a data “swamp” than a lake.
In fact, Adam Wray, CEO and president of NoSQL database Basho, described them as “evil because they’re unruly” and “incredibly costly.” In Basho’s experience, “the extraction of value [from data lakes] is infinitesimal compared to the value promised.”
But one shouldn’t count data lakes out just yet. Data marketplaces can rescue the promise of data lakes by organizing them for the end user. Just as the internet was much more difficult to navigate before Google, data marketplaces unlock the powerful data lake architecture.In the analytics world, there’s no one-size-fits-all system. Data warehouses can give even smaller companies a taste of data analytics, while data lakes (when combined with data marketplaces) can enable enterprises to dive headfirst into big data. These systems aren’t mutually exclusive, either. If its analytics needs change, a company that chooses a warehouse can later add a lake and a marketplace.
What’s most important is starting the journey to a more data-driven business. Many executives will remember that a decade ago, data wasn’t even discussed outside of IT teams. Now, with the range of analytics needs and tools available, it’s executives’ turn to lead the conversation.
https://ift.tt/2KYVZvq
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data warehouses” and “data lakes.” Think of a data warehouse like a shopping mall. It has discrete “shops” within it that store structured data — bits that are presorted into formats that database software can interact with.
In contrast, a data lake is like a disorganized flea market. It has “stalls,” but where one stops and the next one begins is not so clear. Unlike data warehouses, data lakes can contain both structured and unstructured data. Unstructured data, as the name implies, refers to “messy” digital information, such as audio, images, and video.
Complicating things further is the “data marketplace.” Unlike the first two concepts, this isn’t an architecture but rather an interface to a data lake that enables those outside of the IT team, such as business analysts, to its contents. Through a search function, it allows users to fish what they need out of the lake. Think of data marketplaces like personal tour guides for flea markets, showing shoppers where to find the best deals.
Inside the Data Warehouse and Data Lake
For a firm that’s looking to analyze large but structured data sets, a data warehouse is a good option. In fact, if the company is only interested in descriptive analytics — the process of merely summarizing the data one has — a data warehouse may be all it needs.
Let’s say, for example, company leaders want to look at sales figures across a particular time period, the number of inquiries about a product, or the view counts on various marketing videos. A data warehouse would be perfect for those applications because all of the associated figures are stored in the form of structured data.
But for most companies embarking on big data initiatives, structured data is only part of the story. Each year, businesses generate a staggering quantity of unstructured data. In fact, 451 Research in conjunction with Western Digital found that 63 percent of enterprises and service providers are keeping at least 25 petabytes of unstructured data. For those firms, data lakes are attractive options because of their ability to store vast quantities of such data.
What’s more, data lakes allow analysts to go beyond descriptive analytics and into the exciting — and highly rewarding — domain of predictive or prescriptive analytics. Predictive analysis is the practice of using existing data to predict future trends relevant to one’s business, such as next year’s revenue.
Prescriptive analytics goes a big step further, using artificial intelligence technologies to make recommendations in response to predictions. For both predictive and prescriptive analytics, a data lake is a must. Often, leaders manage data lakes using software like Apache Hadoop, a popular ecosystem of analytics tools.
Before springing for either a data lake or a data warehouse, think about who’ll be conducting data analyses and what sort of data they’ll need. Data warehouses are often accessible only by IT teams, while data lakes can be configured for access by analysts and business personnel across the company.
A healthcare organization my company worked with recently, for example, requested a data warehouse solution. Soon, though, it became apparent that the firm would instead require a data lake. Not only was it interested in predictive modeling, but it also sought to input all sort of unstructured data, such as handwritten doctor’s notes.
Analysts at a healthcare company might pull treatment data from a data lake to predict patient outcomes. They might add a prescriptive layer to then recommend the best course of treatment for each patient’s needs — one that minimizes cost and risk while providing the highest quality of care.
Making the Most of the Data Lake
Given their ability to store both types of data and their suitability for future analytics needs, it’s tempting to think that data lakes are the obvious answer. But due to their loose structure, they’re sometimes derided as more of a data “swamp” than a lake.
In fact, Adam Wray, CEO and president of NoSQL database Basho, described them as “evil because they’re unruly” and “incredibly costly.” In Basho’s experience, “the extraction of value [from data lakes] is infinitesimal compared to the value promised.”
But one shouldn’t count data lakes out just yet. Data marketplaces can rescue the promise of data lakes by organizing them for the end user. Just as the internet was much more difficult to navigate before Google, data marketplaces unlock the powerful data lake architecture.In the analytics world, there’s no one-size-fits-all system. Data warehouses can give even smaller companies a taste of data analytics, while data lakes (when combined with data marketplaces) can enable enterprises to dive headfirst into big data. These systems aren’t mutually exclusive, either. If its analytics needs change, a company that chooses a warehouse can later add a lake and a marketplace.
What’s most important is starting the journey to a more data-driven business. Many executives will remember that a decade ago, data wasn’t even discussed outside of IT teams. Now, with the range of analytics needs and tools available, it’s executives’ turn to lead the conversation.
https://ift.tt/2KYVZvq
0 notes
Text
DATABRICKS AND SNOWFLAKE

Databricks and Snowflake: Powerhouses in the Cloud Data Landscape
The rise of cloud computing has completely transformed data management and analysis. Today’s organizations face the challenge of choosing the right platforms for their ever-increasing data demands. Two leaders in this space are Databricks and Snowflake, and understanding their core strengths is essential for making the right decision.
The Essence of Databricks
Databricks, centered on the Apache Spark framework, champions the concept of the “data lakehouse.” The lakehouse is a paradigm that unifies the best aspects of data warehouses (structure, reliability, performance) with those of data lakes (scale, openness to various data types). Here’s what Databricks brings to the table:
Data Engineering Efficiency: Databricks is a dream tool for data engineers. It handles structured, semi-structured, and unstructured data seamlessly and streamlines ETL (Extract, Transform, Load) processes.
Collaborative Data Science: Databricks provides a workspace where data scientists can efficiently build, experiment with, and deploy machine learning models. Its support for languages like Python, SQL, Scala, and R makes it widely accessible.
AI and ML Acceleration: Databricks is designed with machine learning in mind. It integrates with popular libraries like MLflow, TensorFlow, and PyTorch, empowering businesses to harness the power of AI.
Snowflake’s Distinguishing Features
Snowflake is a star player in the realm of cloud data warehousing. It utilizes a distinctive architecture that decouples storage and computing, leading to remarkable ease of use and scalability. Its key advantages include:
Performance for Analytics: Snowflake is meticulously optimized for SQL analytics workloads. Businesses can effortlessly query vast datasets and get rapid insights.
Proper Elasticity: Snowflake’s decoupled structure allows you to scale storage and compute resources independently. Pay for what you use and when you use it.
Minimal Maintenance: As a fully managed SaaS (Software-as-a-Service), Snowflake eliminates the overhead of infrastructure and software management.
Databricks vs. Snowflake: When to Choose What
The best choice fundamentally depends on your specific use cases:
Choose Databricks if:
You prioritize advanced data engineering pipelines with diverse data types.
Your focus is on building and leveraging powerful machine learning and AI solutions.
You embrace open-source technologies and want flexibility in customization.
Choose Snowflake if:
Your primary need is a high-performance SQL-based data warehouse.
You want a low-maintenance solution that scales easily.
Faster time-to-market is a top concern.
Complementary Power: The Rise of Integration
It’s important to realize that Databricks and Snowflake don’t have to be mutually exclusive. In many modern data architectures, they work in tandem:
Databricks can excel in the preparation, transformation, and machine learning phases.
Snowflake can be a robust warehouse serving dashboards and business intelligence tools.
The Future of Data in the Cloud
The cloud data world is continuously evolving. Databricks and Snowflake are constantly innovating, and the lines between them might blur over time. The most effective strategy is to stay updated on their advancements and carefully evaluate which platform, or combination of platforms, aligns best with your evolving data requirements.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
Data Lake vs. Data Warehouse: Which Is the Best Data Architecture?
For a business in digital transition, data architecture is a big decision. Selecting the right model is one of the first and most important choices of any such initiative. But given the breadth of options and confusing terminology, choosing a solution that meets the company’s needs without blowing its budget is no easy task.
Two of the most popular options are often referred to as “data warehouses” and “data lakes.” Think of a data warehouse like a shopping mall. It has discrete “shops” within it that store structured data — bits that are presorted into formats that database software can interact with.
In contrast, a data lake is like a disorganized flea market. It has “stalls,” but where one stops and the next one begins is not so clear. Unlike data warehouses, data lakes can contain both structured and unstructured data. Unstructured data, as the name implies, refers to “messy” digital information, such as audio, images, and video.
Complicating things further is the “data marketplace.” Unlike the first two concepts, this isn’t an architecture but rather an interface to a data lake that enables those outside of the IT team, such as business analysts, to its contents. Through a search function, it allows users to fish what they need out of the lake. Think of data marketplaces like personal tour guides for flea markets, showing shoppers where to find the best deals.
Inside the Data Warehouse and Data Lake
For a firm that’s looking to analyze large but structured data sets, a data warehouse is a good option. In fact, if the company is only interested in descriptive analytics — the process of merely summarizing the data one has — a data warehouse may be all it needs.
Let’s say, for example, company leaders want to look at sales figures across a particular time period, the number of inquiries about a product, or the view counts on various marketing videos. A data warehouse would be perfect for those applications because all of the associated figures are stored in the form of structured data.
But for most companies embarking on big data initiatives, structured data is only part of the story. Each year, businesses generate a staggering quantity of unstructured data. In fact, 451 Research in conjunction with Western Digital found that 63 percent of enterprises and service providers are keeping at least 25 petabytes of unstructured data. For those firms, data lakes are attractive options because of their ability to store vast quantities of such data.
What’s more, data lakes allow analysts to go beyond descriptive analytics and into the exciting — and highly rewarding — domain of predictive or prescriptive analytics. Predictive analysis is the practice of using existing data to predict future trends relevant to one’s business, such as next year’s revenue.
Prescriptive analytics goes a big step further, using artificial intelligence technologies to make recommendations in response to predictions. For both predictive and prescriptive analytics, a data lake is a must. Often, leaders manage data lakes using software like Apache Hadoop, a popular ecosystem of analytics tools.
Before springing for either a data lake or a data warehouse, think about who’ll be conducting data analyses and what sort of data they’ll need. Data warehouses are often accessible only by IT teams, while data lakes can be configured for access by analysts and business personnel across the company.
A healthcare organization my company worked with recently, for example, requested a data warehouse solution. Soon, though, it became apparent that the firm would instead require a data lake. Not only was it interested in predictive modeling, but it also sought to input all sort of unstructured data, such as handwritten doctor’s notes.
Analysts at a healthcare company might pull treatment data from a data lake to predict patient outcomes. They might add a prescriptive layer to then recommend the best course of treatment for each patient’s needs — one that minimizes cost and risk while providing the highest quality of care.
Making the Most of the Data Lake
Given their ability to store both types of data and their suitability for future analytics needs, it’s tempting to think that data lakes are the obvious answer. But due to their loose structure, they’re sometimes derided as more of a data “swamp” than a lake.
In fact, Adam Wray, CEO and president of NoSQL database Basho, described them as “evil because they’re unruly” and “incredibly costly.” In Basho’s experience, “the extraction of value [from data lakes] is infinitesimal compared to the value promised.”
But one shouldn’t count data lakes out just yet. Data marketplaces can rescue the promise of data lakes by organizing them for the end user. Just as the internet was much more difficult to navigate before Google, data marketplaces unlock the powerful data lake architecture.In the analytics world, there’s no one-size-fits-all system. Data warehouses can give even smaller companies a taste of data analytics, while data lakes (when combined with data marketplaces) can enable enterprises to dive headfirst into big data. These systems aren’t mutually exclusive, either. If its analytics needs change, a company that chooses a warehouse can later add a lake and a marketplace.
What’s most important is starting the journey to a more data-driven business. Many executives will remember that a decade ago, data wasn’t even discussed outside of IT teams. Now, with the range of analytics needs and tools available, it’s executives’ turn to lead the conversation.
https://ift.tt/2KYVZvq
0 notes
Text
Data Lake and Data Warehouse
Data Lake and Data Warehouse

ETL vs ELT
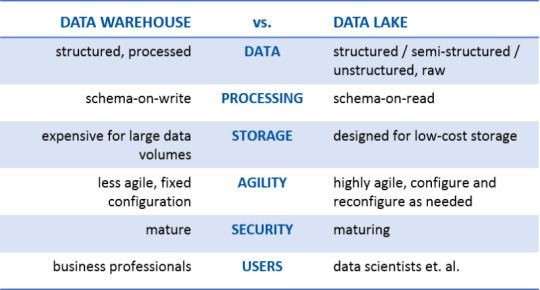
Data Lake vs Data Warehouse
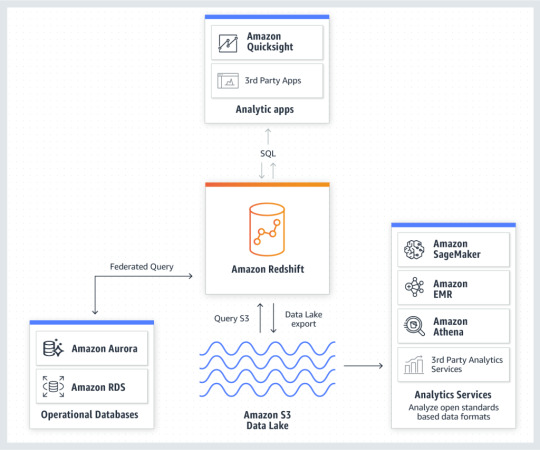
Amazon Redshift
References
Amazon Redshift: The most popular and fastest cloud data warehouse
Data Lake vs Data Warehouse: Key Differences
Data Lake vs. Data Warehouse: what’s the Difference and which is the Best Data Architecture?
View On WordPress
0 notes