#data science data cleaning data cleaning technique what is data cleaning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
Tenipuri Complete Character Profile - Ryoma Echizen

[PROFILE]

Birthday: December 24th (Capricorn)
Blood Type: O
Birthplace: Los Angeles
Relatives: Father (Nanjirou Echizen), mother (Rinko Echizen), cousin (Nanako Meino), cat (Karupin)
Father’s Occupation: Temple priest (local)
Elementary School: Los Angeles Saint Youth Elementary School

Middle School: Seishun Academy Junior High School
Grade & Class: First Year | Class 1-2 | Seat 3
Club: Tennis Club (regular)
Committee: Library Committee
Strong Subjects: English, chemistry
Weak Subjects: Science experiments, Japanese
Most Visited Spot at School: Under the big tree behind the school building
World Cup Team: U-17 World Cup USA Representatives ➜ U-17 World Cup Japanese Representatives
Favorite Motto: “All or Nothing.”
Daily Routines: Playing with Karupin
Hobbies: Bathing with bath salts from Japan’s famous hot springs ➜ Clearing games he’s borrowed, watching cat videos [23.5]
Favorite Color: Silver
Favorite Music: J-Pop
Favorite Movie: Any kind of Hollywood film
Favorite Book: Monthly Pro Tennis ➜ TENNIS LIFE (an American tennis magazine) [23.5]
Favorite Food: Grilled fish (with little bones), chawanmushi, local confections [23.5], shrimp senbei (plum and kimchi flavor) [removed]
Favorite Anniversary: Any day he can play tennis
Preferred Type: A girl that looks good with a ponytail
Ideal Date Spot: Santa Montica Third Street Promenade ➜ Santa Monica Pier Pacific Park [23.5]
His Gift for a Special Person: “Just tell me what you want.”
Where He Wants to Travel: A snow-viewing hot spring
What He Wants Most Right Now: Nintendo DS ➜ Nintendo 3DS [10.5 II] ➜ A smart watch [23.5]
Dislikes: Waking up early, cleaning the temple floors [removed], paparazzi [23.5]

Skills Outside of Tennis: Animals take a liking to him for some reason, can cleanly peel fruit [23.5], horseback riding(?) [TP]
Spends Allowance On: Fanta/Ponta
Routine During the World Cup: Soaking in an open-air bath
[DATA]
Height: 151cm | 4’11” ➜ 152.5cm | 5’0” [23.5]
Weight: 50kg | 110 lbs ➜ 47kg | 103 lbs [23.5]
Shoe Size: 24cm
Dominant Arm: Left
Vision: 1.5 Left & Right
Play Style: All-Rounder
Signature Moves: Twist Serve, Drive A, Drive B, Drive C, Drive D, Cool Drive, Selfless State, Pinnacle of Perfection, Samurai Drive, Hope [23.5]
Number of Times His Friends Visited Him in the US: 7.8 times a month
Equipment Brands:
Hats: FILA
Clothing: FILA
Racket: BRIDGESTONE (DYNABEAM GRANDEA)
Shoes: FILA (Mark Philippoussis Mid)
Fitness Test Results:
Side Steps: 71
Shuttle Run: 119
Back Strength: 102kg
Grip Strength: 42.3kg (left)
Backbend: 59.5cm
Seated Forward Bend: 39cm
50m Run: 6.1 seconds
Standing Long Jump: 237cm
Handball Throw: 28m
Endurance Run (1500m): 4:46
Overall Rating: Speed: 4 / Power: 3 / Stamina: 4 / Mental: 5 / Technique: 5 / Total: 21
Kurobe Memo: “Even though many areas already have a high degree of perfection, I suspect it’s highly likely he’ll continue to grow and improve. I would like to see him work on building his body without sacrificing balance.” <Official Description>
[POSSESSIONS]
What’s in His Bedroom [10.5]:
Trophies from past competitions: They’re randomly placed on top of his dresser since he doesn’t really care for them
Alarm clock on his bed: The alarm doesn’t necessarily wake him up…
TV and game consoles: He has several types of game consoles but keeps the one he uses the most (Nintendo 64) connected to the TV
Closet: Where his school uniforms are stored. His mother will put them away if they’re left out
His pajamas he had left out: Left strewn on his bed. He’s always in a rush when he gets ready for school
Karupin’s favorite cat toy: A fluffy cat tail toy
What’s in His Bag [10.5]:
A beginner’s guide to doubles: A guide he bought after playing doubles with Momoshiro. He forgot it was still in there…
Notebook: His math notebook that he forgot to take out
Photos of Karupin: He insists that he didn’t put them in there
Notepad: He’s written down emergency phone numbers since he’s always late
Pen case: His pen case he always uses for school. He left it in his bag
Game Boy Advance: Bought for him as a starting school gift, he plays it during his free time
Senbei: He likes drinking Fanta/Ponta when eating senbei
What’s in His Locker at the U-17 Training Camp [10.5 II]:
Game console: A PlayStation PSP. He’s absorbed in video games when he’s not playing tennis and was seen playing a tennis game before practice
Photo of Karupin: One of his favorite photos of Karupin that’s been framed. He takes it with him on trips and expeditions
Fanta/Ponta: Grape flavor, his favorite
Senbei: His favorite snack. Having Fanta and senbei together is a must for him
What’s in His Travel Bag [23.5]:
Shio senbei from Okinawa: Gifted to him by Tanishi to celebrate his return to team Japan
[TRIVIA]
The Prince of Tennis 10.5 Fanbook | Publication Date: 11/02/2001
Although he’s lived in the USA, he still prefers Japanese food and isn’t fond of Western food
People tend to be aggravated by him due to his abrasive personality, but he means no ill-intent by it
He gained his arrogant and abrasive personality from growing up in the USA
He will speak his mind regardless of how it sounds as he believes it’s a way of being kind
His first name is written in katakana rather than kanji. It’s alluded that it may be due to his mother being another nationality besides Japanese
Konomi had Ryoma wear a hat since he thought it was cool, and wanted people to associate his FILA hat with him
He is called “Shorty” by Kikumaru but does not mind it since he states height doesn’t matter in tennis
He likes grape-flavored Fanta/Ponta
He keeps everything he needs for school in his tennis bag, hence why he gets confused when some items are still in it
He is described as pessimistic, but shy, gentle, and always striving for improvement
Konomi originally did not intend for him to be the protagonist. The role was originally going to be given to Kintarou, with Ryoma being his rival. He initially thought Ryoma would be difficult to portray as a protagonist, be better as a side character, and that making him the protagonist would dampen the mood of the series. He eventually decided on Ryoma and built the other characters around him
Konomi describes him as a “bad guy,” and that him defeating people who are even worse is a focal point of the series
The Prince of Tennis 20.5 Fanbook | Publication Date: 12/04/2003
He is described to easily get engaged in a single subject and then excel in that area
When he concentrates, he will become so absorbed in what he’s doing that he will not pay attention to his surroundings
He is described to be suited for professions that require special skills, such as a pilot or astronaut
He is very susceptible to change and has an insatiable desire to become stronger
One of his favorite subjects is chemistry since the science behind the substances changing, combining, and gaining different properties reminds him of tennis
He does not remember when he started playing tennis, and states he thinks he’s been playing it since he was born
His secondary sport would be soccer
The Prince of Tennis 40.5 Fanbook | Publication Date: 12/04/2007
He is described to be sociable and lively, but doesn’t get too involved in his personal relationships and tends to be reserved
His friends and schoolmates often visited his house when he lived in the US
He did not know what “Old Maid” was until he played it at the joint training camp with Rokkaku
In Genius 305, when he had won his match against Atobe and everyone huddled around him, someone had quietly handed him the shaver, but it’s a mystery on who it was
He considers Kintarou to be quite strong, and wouldn’t mind having an official match with him someday
He is the character Konomi states he has the least in common with, the second being Tezuka
The Prince of Tennis II Official Character Guide: PairPuri Vol. 1 | Publication Date: 11/04/2009
He, Krauser, Atobe, and Yagyuu were heard having a conversation together in English
The Prince of Tennis II Official Character Guide: PairPuri Vol. 2 | Publication Date: 12/04/2009
He takes naps around the training camp along with Jirou
The Prince of Tennis II Official Character Guide: PairPuri Vol. 4 | Publication Date: 02/04/2010
He had gotten his hat mixed up with Sanada’s
The Prince of Tennis II Official Character Guide: PairPuri Vol. 5 | Publication Date: 03/04/2010
He likes his grilled fish with not many bones and finds removing them to be annoying
The person he currently dislikes the most is his father
If he had a long vacation, he would go play tennis on the western side of Japan since he states they have strong opponents
He wants to win all four major world tennis championships
When asked what kind of plant or animal he is like, he replies with a cat since they’re free-spirited
When asked what his current goals are, he replies that he wants to fight more stronger opponents and win against them
He is named after Ooka Echizen, also known as Ooka Tadasuke
Konomi came up with his “Selfless State” technique since he wanted to write a story where the main character’s dormant power would awaken when faced against an unbeatable enemy. And since Ryoma was a returnee, he had him speak in English to surprise the audience and give his scenes a fantasy-like feel
Konomi corrects his statement that Ryoma didn’t win national USA junior tournaments four years in a row, he had meant that when Ryoma started tennis, he had competed and won in regular USA junior tournaments four times in a row
Konomi states he has tried drawing Ryoma more mature as the series progresses and draws Ryoma’s shoes and racket bigger to make him appear smaller
One of His School Days:
6:30am - Woken up by his cousin
6:45am - Eats breakfast while half-asleep, then goes to school
7:30am - Late for morning practice, does thirty laps
8:40am - 1st Period: Math, half-asleep and dozing off
9:40am - 2nd Period: English (grammar), is half-asleep and dozing off)
11:00am - 3rd Period: PE (bar exercises)
12:00pm - 4th Period: Geography (quiz)
12:50pm - Lunch, buys bread at the school store after eating
1:10pm - Gives in, buys and drinks milk
1:20pm - 5th Period: Science I (physics), is sleepy from eating
2:20pm - 6th Period: Japanese (classic literature), thinks of ideas for volleys
3:20pm - Library committee meeting, wasn’t listening
4:00pm - Club activities, earnestly practices volleys
5:30pm - Stops by Momoshiro and a CD shop, then returns home
6:00pm - Dinner, bathes (with bath salts from Beppu Onsen)
6:30pm - Rallies with his father
10:30pm - Plays with Karupin while listening to music
11:00pm - Falls asleep while playing games on his bed
The Prince of Tennis II Official Character Guide: PairPuri Vol. 9 | Publication Date: 09/02/2011
Mifune’s eagles are shown to be fond and gentle towards him
The Prince of Tennis II 10.5 Fanbook | Publication Date: 09/04/2013
He texts his mother everyday asking her to send him pictures of Karupin
He quickly became friends with the dogs at the training camp
The Prince of Tennis II 23.5 Fanbook | Publication Date: 05/02/2018
When he and Ryoga were younger, they went out to play and had gotten lost for three days. They eventually managed to hitchhike home
Konomi had originally intended to show him being anxious about joining team USA, and then being helped by them to join team Japan again
Konomi states he may continue Ryoma and Fuji’s match in the rain
The items Horio had brought to the camp for him were Fanta/Ponta
The Prince of Tennis 20th Anniversary Book: Tenipuri Party | Publication Date: 08/02/2019
He did not mind playing for team USA and states the country doesn’t matter as long as he can play tennis
He did not care about being on the same team as Ryoga and had actually wanted to play against him
He states he felt some changes when viewing team Japan from an outside perspective
He returned to team Japan because he had thought of the people who made him stronger and wanted to fight alongside them
32 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
3 notes
·
View notes
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
9 notes
·
View notes
Text
Exploring Photonics and the Role of Photonics Simulation

Photonics is a cutting-edge field of science and engineering focused on the generation, manipulation, and detection of light (photons). From powering high-speed internet connections to enabling precision medical diagnostics, photonics drives innovation across industries. With advancements in photonics simulation, engineers and researchers can now design and optimize complex photonic systems with unparalleled accuracy, paving the way for transformative technologies.
What Is Photonics?
Photonics involves the study and application of photons, the fundamental particles of light. It encompasses the behavior of light across various wavelengths, including visible, infrared, and ultraviolet spectrums. Unlike electronics, which manipulates electrons, photonics harnesses light to transmit, process, and store information.
The applications of photonics span diverse fields, such as telecommunications, healthcare, manufacturing, and even entertainment. Technologies like lasers, optical fibers, and sensors all rely on principles of photonics to function effectively.
Why Is Photonics Important?
Photonics is integral to the modern world for several reasons:
Speed and Efficiency Light travels faster than electrons, making photonics-based systems ideal for high-speed data transmission. Fiber-optic networks, for instance, enable lightning-fast internet and communication.
Miniaturization Photonics enables the development of compact and efficient systems, such as integrated photonic circuits, which are smaller and more energy-efficient than traditional electronic circuits.
Precision Applications From laser surgery in healthcare to high-resolution imaging in astronomy, photonics offers unparalleled precision in diverse applications.
The Role of Photonics Simulation
As photonic systems become more complex, designing and optimizing them manually is increasingly challenging. This is where photonics simulation comes into play.
Photonics simulation involves using advanced computational tools to model the behavior of light in photonic systems. It allows engineers to predict system performance, identify potential issues, and fine-tune designs without the need for costly and time-consuming physical prototypes.
Key Applications of Photonics Simulation
Telecommunications Photonics simulation is crucial for designing optical fibers, waveguides, and integrated photonic circuits that power high-speed data networks. Simulations help optimize signal strength, reduce loss, and enhance overall system efficiency.
Healthcare In the medical field, photonics simulation aids in the development of imaging systems, laser-based surgical tools, and diagnostic devices. For instance, simulation tools are used to design systems for optical coherence tomography (OCT), a non-invasive imaging technique for detailed internal body scans. Medical device consulting provides expert guidance on the design, development, and regulatory compliance of innovative medical technologies.
Semiconductors and Electronics Photonics simulation supports the creation of photonic integrated circuits (PICs) that combine optical and electronic components. These circuits are essential for applications in computing, sensing, and communication.
Aerospace and Defense Photonics simulation enables the design of systems like lidar (Light Detection and Ranging), which is used for navigation and mapping. Simulations ensure these systems are accurate, reliable, and robust for real-world applications. Aerospace consulting offers specialized expertise in designing, analyzing, and optimizing aerospace systems for performance, safety, and innovation.
Energy and Sustainability Photonics plays a vital role in renewable energy technologies, such as solar cells. Simulation tools help optimize light capture and energy conversion efficiency, making renewable energy more viable and cost-effective. Clean energy consulting provides expert guidance on implementing sustainable energy solutions, optimizing efficiency, and reducing environmental impact.
Benefits of Photonics Simulation
Cost-Efficiency: By identifying potential issues early in the design phase, simulation reduces the need for multiple physical prototypes, saving time and resources.
Precision and Accuracy: Advanced algorithms model light behavior with high accuracy, ensuring designs meet specific performance criteria.
Flexibility: Simulations can model a wide range of photonic phenomena, from simple lenses to complex integrated circuits.
Innovation: Engineers can experiment with new materials, configurations, and designs in a virtual environment, fostering innovation without risk.
Challenges in Photonics Simulation
Despite its advantages, photonics simulation comes with its own set of challenges:
Complexity of Light Behavior Modeling light interactions with materials and components at nanoscales requires sophisticated algorithms and powerful computational resources.
Integration with Electronics Photonics systems often need to work seamlessly with electronic components, adding layers of complexity to the simulation process.
Material Limitations Accurately simulating new or unconventional materials can be challenging due to limited data or untested behavior.
The Future of Photonics and Photonics Simulation
Photonics is at the forefront of technological innovation, with emerging trends that promise to reshape industries. Some of these trends include:
Quantum Photonics: Leveraging quantum properties of light for applications in secure communication, advanced sensing, and quantum computing.
Silicon Photonics: Integrating photonics with silicon-based technologies for cost-effective and scalable solutions in telecommunications and computing.
Artificial Intelligence (AI) in Photonics: Using AI algorithms to enhance photonics simulation, enabling faster and more accurate designs.
Biophotonics: Exploring the interaction of light with biological systems to advance healthcare and life sciences.
As photonics continues to evolve, the role of simulation will only grow in importance. Advanced simulation tools will empower engineers to push the boundaries of what is possible, enabling innovations that improve lives and drive progress.
Conclusion
Photonics and photonics simulation are shaping the future of technology, offering solutions that are faster, more efficient, and precise. By harnessing the power of light, photonics is revolutionizing industries, from healthcare to telecommunications and beyond. With the aid of simulation tools, engineers can design and optimize photonic systems to meet the challenges of today and tomorrow. As this exciting field continues to advance, its impact on society will be nothing short of transformative.
2 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
AI Frameworks Help Data Scientists For GenAI Survival

AI Frameworks: Crucial to the Success of GenAI
Develop Your AI Capabilities Now
You play a crucial part in the quickly growing field of generative artificial intelligence (GenAI) as a data scientist. Your proficiency in data analysis, modeling, and interpretation is still essential, even though platforms like Hugging Face and LangChain are at the forefront of AI research.
Although GenAI systems are capable of producing remarkable outcomes, they still mostly depend on clear, organized data and perceptive interpretation areas in which data scientists are highly skilled. You can direct GenAI models to produce more precise, useful predictions by applying your in-depth knowledge of data and statistical techniques. In order to ensure that GenAI systems are based on strong, data-driven foundations and can realize their full potential, your job as a data scientist is crucial. Here’s how to take the lead:
Data Quality Is Crucial
The effectiveness of even the most sophisticated GenAI models depends on the quality of the data they use. By guaranteeing that the data is relevant, AI tools like Pandas and Modin enable you to clean, preprocess, and manipulate large datasets.
Analysis and Interpretation of Exploratory Data
It is essential to comprehend the features and trends of the data before creating the models. Data and model outputs are visualized via a variety of data science frameworks, like Matplotlib and Seaborn, which aid developers in comprehending the data, selecting features, and interpreting the models.
Model Optimization and Evaluation
A variety of algorithms for model construction are offered by AI frameworks like scikit-learn, PyTorch, and TensorFlow. To improve models and their performance, they provide a range of techniques for cross-validation, hyperparameter optimization, and performance evaluation.
Model Deployment and Integration
Tools such as ONNX Runtime and MLflow help with cross-platform deployment and experimentation tracking. By guaranteeing that the models continue to function successfully in production, this helps the developers oversee their projects from start to finish.
Intel’s Optimized AI Frameworks and Tools
The technologies that developers are already familiar with in data analytics, machine learning, and deep learning (such as Modin, NumPy, scikit-learn, and PyTorch) can be used. For the many phases of the AI process, such as data preparation, model training, inference, and deployment, Intel has optimized the current AI tools and AI frameworks, which are based on a single, open, multiarchitecture, multivendor software platform called oneAPI programming model.
Data Engineering and Model Development:
To speed up end-to-end data science pipelines on Intel architecture, use Intel’s AI Tools, which include Python tools and frameworks like Modin, Intel Optimization for TensorFlow Optimizations, PyTorch Optimizations, IntelExtension for Scikit-learn, and XGBoost.
Optimization and Deployment
For CPU or GPU deployment, Intel Neural Compressor speeds up deep learning inference and minimizes model size. Models are optimized and deployed across several hardware platforms including Intel CPUs using the OpenVINO toolbox.
You may improve the performance of your Intel hardware platforms with the aid of these AI tools.
Library of Resources
Discover collection of excellent, professionally created, and thoughtfully selected resources that are centered on the core data science competencies that developers need. Exploring machine and deep learning AI frameworks.
What you will discover:
Use Modin to expedite the extract, transform, and load (ETL) process for enormous DataFrames and analyze massive datasets.
To improve speed on Intel hardware, use Intel’s optimized AI frameworks (such as Intel Optimization for XGBoost, Intel Extension for Scikit-learn, Intel Optimization for PyTorch, and Intel Optimization for TensorFlow).
Use Intel-optimized software on the most recent Intel platforms to implement and deploy AI workloads on Intel Tiber AI Cloud.
How to Begin
Frameworks for Data Engineering and Machine Learning
Step 1: View the Modin, Intel Extension for Scikit-learn, and Intel Optimization for XGBoost videos and read the introductory papers.
Modin: To achieve a quicker turnaround time overall, the video explains when to utilize Modin and how to apply Modin and Pandas judiciously. A quick start guide for Modin is also available for more in-depth information.
Scikit-learn Intel Extension: This tutorial gives you an overview of the extension, walks you through the code step-by-step, and explains how utilizing it might improve performance. A movie on accelerating silhouette machine learning techniques, PCA, and K-means clustering is also available.
Intel Optimization for XGBoost: This straightforward tutorial explains Intel Optimization for XGBoost and how to use Intel optimizations to enhance training and inference performance.
Step 2: Use Intel Tiber AI Cloud to create and develop machine learning workloads.
On Intel Tiber AI Cloud, this tutorial runs machine learning workloads with Modin, scikit-learn, and XGBoost.
Step 3: Use Modin and scikit-learn to create an end-to-end machine learning process using census data.
Run an end-to-end machine learning task using 1970–2010 US census data with this code sample. The code sample uses the Intel Extension for Scikit-learn module to analyze exploratory data using ridge regression and the Intel Distribution of Modin.
Deep Learning Frameworks
Step 4: Begin by watching the videos and reading the introduction papers for Intel’s PyTorch and TensorFlow optimizations.
Intel PyTorch Optimizations: Read the article to learn how to use the Intel Extension for PyTorch to accelerate your workloads for inference and training. Additionally, a brief video demonstrates how to use the addon to run PyTorch inference on an Intel Data Center GPU Flex Series.
Intel’s TensorFlow Optimizations: The article and video provide an overview of the Intel Extension for TensorFlow and demonstrate how to utilize it to accelerate your AI tasks.
Step 5: Use TensorFlow and PyTorch for AI on the Intel Tiber AI Cloud.
In this article, it show how to use PyTorch and TensorFlow on Intel Tiber AI Cloud to create and execute complicated AI workloads.
Step 6: Speed up LSTM text creation with Intel Extension for TensorFlow.
The Intel Extension for TensorFlow can speed up LSTM model training for text production.
Step 7: Use PyTorch and DialoGPT to create an interactive chat-generation model.
Discover how to use Hugging Face’s pretrained DialoGPT model to create an interactive chat model and how to use the Intel Extension for PyTorch to dynamically quantize the model.
Read more on Govindhtech.com
#AI#AIFrameworks#DataScientists#GenAI#PyTorch#GenAISurvival#TensorFlow#CPU#GPU#IntelTiberAICloud#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
How Can You Ensure Data Quality in Healthcare Analytics and Management?

Healthcare facilities are responsible for the patient’s recovery. Pharmaceutical companies and medical equipment manufacturers also work toward alleviating physical pain, stress levels, and uncomfortable body movement issues. Still, healthcare analytics must be accurate for precise diagnosis and effective clinical prescriptions. This post will discuss data quality management in the healthcare industry.
What is Data Quality in Healthcare?
Healthcare data quality management includes technologies and statistical solutions to verify the reliability of acquired clinical intelligence. A data quality manager protects databases from digital corruption, cyberattacks, and inappropriate handling. So, medical professionals can get more realistic insights using data analytics solutions.
Laboratories have started emailing the test results to help doctors, patients, and their family members make important decisions without wasting time. Also, assistive technologies merge the benefits of the Internet of Things (IoT) and artificial intelligence (AI) to enhance living standards.
However, poor data quality threatens the usefulness of healthcare data management solutions.
For example, pharmaceutical companies and authorities must apply solutions that remove mathematical outliers to perform high-precision data analytics for clinical drug trials. Otherwise, harmful medicines will reach the pharmacist’s shelf, endangering many people.
How to Ensure Data Quality in the Healthcare Industry?
Data quality frameworks utilize different strategies to prevent processing issues or losing sensitive intelligence. If you want to develop such frameworks to improve medical intelligence and reporting, the following 7 methods can aid you in this endeavor.
Method #1| Use Data Profiling
A data profiling method involves estimating the relationship between the different records in a database to find gaps and devise a cleansing strategy. Data cleansing in healthcare data management solutions has the following objectives.
Determine whether the lab reports and prescriptions match the correct patient identifiers.
If inconsistent profile matching has occurred, fix it by contacting doctors and patients.
Analyze the data structures and authorization levels to evaluate how each employee is accountable for specific patient recovery outcomes.
Create a data governance framework to enforce access and data modification rights strictly.
Identify recurring data cleaning and preparation challenges.
Brainstorm ideas to minimize data collection issues that increase your data cleaning efforts.
Ensure consistency in report formatting and recovery measurement techniques to improve data quality in healthcare.
Data cleaning and profiling allow you to eliminate unnecessary and inaccurate entries from patient databases. Therefore, healthcare research institutes and commercial life science businesses can reduce processing errors when using data analytics solutions.
Method #2| Replace Empty Values
What is a null value? Null values mean the database has no data corresponding to a field in a record. Moreover, these missing values can skew the results obtained by data management solutions used in the healthcare industry.
Consider that a patient left a form field empty. If all the care and life science businesses use online data collection surveys, they can warn the patients about the empty values. This approach relies on the “prevention is better than cure” principle.
Still, many institutions, ranging from multispecialty hospitals to clinical device producers, record data offline. Later, the data entry officers transform the filled papers using scanners and OCR (optical character recognition).
Empty fields also appear in the database management system (DBMS), so the healthcare facilities must contact the patients or reporting doctors to retrieve the missing information. They use newly acquired data to replace the null values, making the analytics solutions operate seamlessly.
Method #3| Refresh Old Records
Your physical and psychological attributes change with age, environment, lifestyle, and family circumstances. So, what was true for an individual a few years ago is less likely to be relevant today. While preserving historical patient databases is vital, hospitals and pharma businesses must periodically update obsolete medical reports.
Each healthcare business maintains a professional network of consulting physicians, laboratories, chemists, dietitians, and counselors. These connections enable the treatment providers to strategically conduct regular tests to check how patients’ bodily functions change throughout the recovery.
Therefore, updating old records in a patient’s medical history becomes possible. Other variables like switching jobs or traveling habits also impact an individual’s metabolism and susceptibility to illnesses. So, you must also ask the patients to share the latest data on their changed lifestyles. Freshly obtained records increase the relevance of healthcare data management solutions.
Method #4| Standardize Documentation
Standardization compels all professionals to collect, store, visualize, and communicate data or analytics activities using unified reporting solutions. Furthermore, standardized reports are integral to improving data governance compliance in the healthcare industry.
Consider the following principles when promoting a documentation protocol to make all reports more consistent and easily traceable.
A brand’s visual identities, like logos and colors, must not interfere with clinical data presentation.
Observed readings must go in the designated fields.
Both the offline and online document formats must be identical.
Stakeholders must permanently preserve an archived copy of patient databases with version control as they edit and delete values from the records.
All medical reports must arrange the data and insights to prevent ambiguity and misinterpretation.
Pharma companies, clinics, and FDA (food and drug administration) benefit from reporting standards. After all, corresponding protocols encourage responsible attitudes that help data analytics solutions avoid processing problems.
Method #5| Merge Duplicate Report Instances
A report instance is like a screenshot that helps you save the output of visualization tools related to a business query at a specified time interval. However, duplicate reporting instances are a significant quality assurance challenge in healthcare data management solutions.
For example, more than two nurses and one doctor will interact with the same patients. Besides, patients might consult different doctors and get two or more treatments for distinct illnesses. Such situations result in multiple versions of a patient’s clinical history.
Data analytics solutions can process the data collected by different healthcare facilities to solve the issue of duplicate report instances in the patients’ databases. They facilitate merging overlapping records and matching each patient with a universally valid clinical history profile.
Such a strategy also assists clinicians in monitoring how other healthcare professionals prescribe medicine to a patient. Therefore, they can prevent double dosage complications arising from a patient consuming similar medicines while undergoing more than one treatment regime.
Method #6| Audit the DBMS and Reporting Modules
Chemical laboratories revise their reporting practices when newly purchased testing equipment offers additional features. Likewise, DBMS solutions optimized for healthcare data management must receive regular updates.
Auditing the present status of reporting practices will give you insights into efficient and inefficient activities. Remember, there is always a better way to collect and record data. Monitor the trends in database technologies to ensure continuous enhancements in healthcare data quality.
Simultaneously, you want to assess the stability of the IT systems because unreliable infrastructure can adversely affect the decision-making associated with patient diagnosis. You can start by asking the following questions.
Questions to Ask When Assessing Data Quality in Healthcare Analytics Solutions
Can all doctors, nurses, agents, insurance representatives, patients, and each patient’s family members access the required data without problems?
How often do the servers and internet connectivity stop functioning correctly?
Are there sufficient backup tools to restore the system if something goes wrong?
Do hospitals, research facilities, and pharmaceutical companies employ end-to-end encryption (E2EE) across all electronic communications?
Are there new technologies facilitating accelerated report creation?
Will the patient databases be vulnerable to cyberattacks and manipulation?
Are the clinical history records sufficient for a robust diagnosis?
Can the patients collect the documents required to claim healthcare insurance benefits without encountering uncomfortable experiences?
Is the presently implemented authorization framework sufficient to ensure data governance in healthcare?
Has the FDA approved any of your prescribed medications?
Method #7| Conduct Skill Development Sessions for the Employees
Healthcare data management solutions rely on advanced technologies, and some employees need more guidance to use them effectively. Pharma companies are aware of this as well, because maintaining and modifying the chemical reactions involved in drug manufacturing will necessitate specialized knowledge.
Different training programs can assist the nursing staff and healthcare practitioners in developing the skills necessary to handle advanced data analytics solutions. Moreover, some consulting firms might offer simplified educational initiatives to help hospitals and nursing homes increase the skill levels of employees.
Cooperation between employees, leadership, and public authorities is indispensable to ensure data quality in the healthcare and life science industries. Otherwise, a lack of coordination hinders the modernization trends in the respective sectors.
Conclusion
Healthcare analytics depends on many techniques to improve data quality. For example, cleaning datasets to eliminate obsolete records, null values, or duplicate report instances remains essential, and multispecialty hospitals agree with this concept.
Therefore, medical professionals invest heavily in standardized documents and employee education to enhance data governance. Also, you want to prevent cyberattacks and data corruption. Consider consulting reputable firms to audit your data operations and make clinical trials more reliable.
SG Analytics is a leader in healthcare data management solutions, delivering scalable insight discovery capabilities for adverse event monitoring and medical intelligence. Contact us today if you want healthcare market research and patent tracking assistance.
3 notes
·
View notes
Text
Exploring the Depths of Data Science: My Journey into Advanced Topics
In my journey through the ever-evolving landscape of data science, I've come to realize that the possibilities are as vast as the data itself. As I venture deeper into this realm, I find myself irresistibly drawn to the uncharted territories of advanced data science topics. The data universe is a treasure trove of intricate patterns, concealed insights, and complex challenges just waiting to be unraveled. This exploration isn't merely about expanding my knowledge; it's about discovering the profound impact that data can have on our world.

A. Setting the Stage for Advanced Data Science Exploration
Data science has transcended its initial boundaries of basic analyses and simple visualizations. It has evolved into a field that delves into the intricacies of machine learning, deep learning, big data, and more. Advanced data science is where we unlock the true potential of data, making predictions, uncovering hidden trends, and driving innovation.
B. The Evolving Landscape of Data Science
The field of data science is in a perpetual state of flux, with new techniques, tools, and methodologies emerging constantly. The boundaries of what we can achieve with data are continually expanding, offering exciting opportunities to explore data-driven solutions for increasingly complex problems.
C.My Motivation for Diving into Advanced Topics
Fueled by an insatiable curiosity and a desire to make a meaningful impact, I've embarked on a journey to explore advanced data science topics. The prospect of unearthing insights that could reshape industries, enhance decision-making, and contribute to societal progress propels me forward on this thrilling path.
II. Going Beyond the Basics: A Recap of Foundational Knowledge
Before diving headfirst into advanced topics, it's paramount to revisit the fundamentals that serve as the bedrock of data science. This refresher not only reinforces our understanding but also equips us to confront the more intricate challenges that lie ahead.

A. Revisiting the Core Concepts of Data Science
From the nitty-gritty of data collection and cleaning to the art of exploratory analysis and visualization, the core concepts of data science remain indomitable. These foundational skills provide us with a sturdy platform upon which we construct our advanced data science journey.
B. The Importance of a Strong Foundation for Advanced Exploration
Just as a towering skyscraper relies on a solid foundation to reach great heights, advanced data science hinges on a strong understanding of the basics. Without this firm grounding, the complexities of advanced techniques can quickly become overwhelming.
C. Reflecting on My Own Data Science Journey
When I look back on my personal data science journey, it's evident that each step I took paved the way for the next. As I progressed from being a novice to an intermediate practitioner, my hunger for knowledge and my drive to tackle more intricate challenges naturally led me toward the realm of advanced topics.
III. The Path to Mastery: Advanced Statistical Analysis
Advanced statistical analysis takes us far beyond the realm of simple descriptive statistics. It empowers us to draw nuanced insights from data and make informed decisions with a heightened level of confidence.
A. An Overview of Advanced Statistical Techniques
Advanced statistical techniques encompass the realm of multivariate analysis, time series forecasting, and more. These methods enable us to capture intricate relationships within data, providing us with a richer and more profound perspective.
B. Bayesian Statistics and Its Applications
Bayesian statistics offers a unique perspective on probability, allowing us to update our beliefs as new data becomes available. This powerful framework finds applications in diverse fields such as medical research, finance, and even machine learning.
C. The Role of Hypothesis Testing in Advanced Data Analysis
Hypothesis testing takes on a more intricate form in advanced data analysis. It involves designing robust experiments, grasping the nuances of p-values, and addressing the challenges posed by multiple comparisons.
IV. Predictive Modeling: Beyond Regression
While regression remains an enduring cornerstone of predictive modeling, the world of advanced data science introduces us to a spectrum of modeling techniques that can elegantly capture the complex relationships concealed within data.
A. A Deeper Dive into Predictive Modeling
Predictive modeling transcends the simplicity of linear regression, offering us tools like decision trees, random forests, and gradient boosting. These techniques furnish us with the means to make more precise predictions for intricate data scenarios.
B. Advanced Regression Techniques and When to Use Them
In the realm of advanced regression, we encounter techniques such as Ridge, Lasso, and Elastic Net regression. These methods effectively address issues of multicollinearity and overfitting, ensuring that our models remain robust and reliable.
C. Embracing Ensemble Methods for Enhanced Predictive Accuracy
Ensemble methods, a category of techniques, ingeniously combine multiple models to achieve higher predictive accuracy. Approaches like bagging, boosting, and stacking harness the strengths of individual models, resulting in a formidable ensemble.
V. The Power of Unstructured Data: Natural Language Processing (NLP)
Unstructured text data, abundant on the internet, conceals a trove of valuable information. NLP equips us with the tools to extract meaning, sentiment, and insights from text.
A. Understanding the Complexities of Unstructured Text Data
Text data is inherently messy and nuanced, making its analysis a formidable challenge. NLP techniques, including tokenization, stemming, and lemmatization, empower us to process and decipher text data effectively.
B. Advanced NLP Techniques, Including Sentiment Analysis and Named Entity Recognition
Sentiment analysis gauges the emotions expressed in text, while named entity recognition identifies entities like names, dates, and locations. These advanced NLP techniques find applications in diverse fields such as marketing, social media analysis, and more.
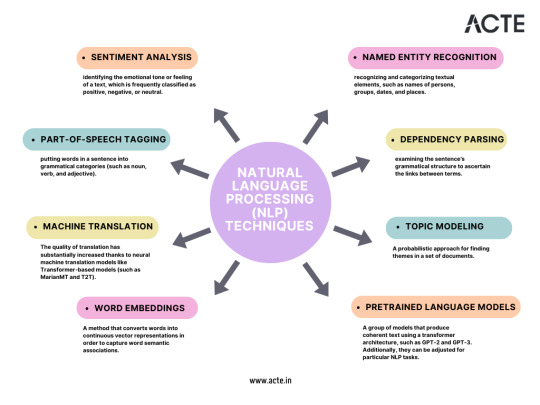
C. Real-World Applications of NLP in Data Science
NLP's applications span from dissecting sentiment in customer reviews to generating human-like text with deep learning models. These applications not only drive decision-making but also enhance user experiences.
VI. Deep Learning and Neural Networks
At the heart of deep learning lies the neural network architecture, enabling us to tackle intricate tasks like image recognition, language translation, and even autonomous driving.
A. Exploring the Neural Network Architecture
Grasping the components of a neural network—layers, nodes, and weights—forms the foundation for comprehending the intricacies of deep learning models.
B. Advanced Deep Learning Concepts like CNNs and RNNs
Convolutional Neural Networks (CNNs) excel at image-related tasks, while Recurrent Neural Networks (RNNs) proficiently handle sequences like text and time series data. These advanced architectures amplify model performance, expanding the horizons of what data-driven technology can accomplish.
C. Leveraging Deep Learning for Complex Tasks like Image Recognition and Language Generation
Deep learning powers image recognition in self-driving cars, generates human-like text, and translates languages in real time. These applications redefine what's possible with data-driven technology, propelling us into an era of boundless potential.
VII. Big Data and Distributed Computing
As data scales to unprecedented sizes, the challenges of storage, processing, and analysis necessitate advanced solutions like distributed computing frameworks.
A. Navigating the Challenges of Big Data in Data Science
The era of big data demands a paradigm shift in how we handle, process, and analyze information. Traditional methods quickly become inadequate, making way for innovative solutions to emerge.
B. Introduction to Distributed Computing Frameworks like Apache Hadoop and Spark
Distributed computing frameworks such as Apache Hadoop and Spark empower us to process massive datasets across clusters of computers. These tools enable efficient handling of big data challenges that were previously insurmountable.
C. Practical Applications of Big Data Technologies
Big data technologies find applications in diverse fields such as healthcare, finance, and e-commerce. They enable us to extract valuable insights from data that was once deemed too vast and unwieldy for analysis.
VIII. Ethical Considerations in Advanced Data Science
As data science advances, ethical considerations become even more pivotal. We must navigate issues of bias, privacy, and transparency with heightened sensitivity and responsibility.
A. Addressing Ethical Challenges in Advanced Data Analysis
Advanced data analysis may inadvertently perpetuate biases or raise new ethical dilemmas. Acknowledging and confronting these challenges is the initial step toward conducting ethical data science.
B. Ensuring Fairness and Transparency in Complex Models
Complex models can be opaque, making it challenging to comprehend their decision-making processes. Ensuring fairness and transparency in these models is a pressing concern that underscores the ethical responsibilities of data scientists.
C. The Responsibility of Data Scientists in Handling Sensitive Data
Data scientists shoulder a profound responsibility when handling sensitive data. Employing advanced encryption techniques and data anonymization methods is imperative to safeguard individual privacy and uphold ethical standards.
IX. The Journey Continues: Lifelong Learning and Staying Updated
In the realm of advanced data science, learning is an unending odyssey. Staying abreast of the latest advancements is not just valuable; it's imperative to remain at the vanguard of the field.
A. Embracing the Mindset of Continuous Learning in Advanced Data Science
Continuous learning isn't a choice; it's a necessity. As data science continually evolves, so must our skills and knowledge. To stand still is to regress.
B. Resources and Communities for Staying Updated with the Latest Advancements
The ACTE Institute provides an array of resources, from books and Data science courses to research papers and data science communities, offers a wealth of opportunities to remain informed about the latest trends and technologies.
C. Personal Anecdotes of Growth and Adaptation in the Field
My expedition into advanced data science has been replete with moments of growth, adaptation, and occasionally, setbacks. These experiences have profoundly influenced my approach to confronting complex data challenges and serve as a testament to the continuous nature of learning.
In conclusion, the journey into advanced data science is an exhilarating odyssey. It's a voyage that plunges us into the deepest recesses of data, where we unearth insights that possess the potential to transform industries and society at large. As we reflect on the indispensable role of essential data science tools, we comprehend that the equilibrium between tools and creativity propels us forward. The data universe is boundless, and with the right tools and an insatiable curiosity, we are poised to explore its ever-expanding horizons.
So, my fellow data enthusiasts, let us persist in our exploration of the data universe. There are discoveries yet to be unearthed, solutions yet to be uncovered, and a world yet to be reshaped through the power of data.
8 notes
·
View notes
Text
The Ever-Evolving Canvas of Data Science: A Comprehensive Guide
In the ever-evolving landscape of data science, the journey begins with unraveling the intricate threads that weave through vast datasets. This multidisciplinary field encompasses a diverse array of topics designed to empower professionals to extract meaningful insights from the wealth of available data. Choosing the Top Data Science Institute can further accelerate your journey into this thriving industry. This educational journey is a fascinating exploration of the multifaceted facets that constitute the heart of data science education.

Let's embark on a comprehensive exploration of what one typically studies in the realm of data science.
1. Mathematics and Statistics Fundamentals: Building the Foundation
At the core of data science lies a robust understanding of mathematical and statistical principles. Professionals delve into Linear Algebra, equipping themselves with the knowledge of mathematical structures and operations crucial for manipulating and transforming data. Simultaneously, they explore Probability and Statistics, mastering concepts that are instrumental in analyzing and interpreting data patterns.
2. Programming Proficiency: The Power of Code
Programming proficiency is a cornerstone skill in data science. Learners are encouraged to acquire mastery in programming languages such as Python or R. These languages serve as powerful tools for implementing complex data science algorithms and are renowned for their versatility and extensive libraries designed specifically for data science applications.
3. Data Cleaning and Preprocessing Techniques: Refining the Raw Material
Data rarely comes in a pristine state. Hence, understanding techniques for Handling Missing Data becomes imperative. Professionals delve into strategies for managing and imputing missing data, ensuring accuracy in subsequent analyses. Additionally, they explore Normalization and Transformation techniques, preparing datasets through standardization and transformation of variables.
4. Exploratory Data Analysis (EDA): Unveiling Data Patterns
Exploratory Data Analysis (EDA) is a pivotal aspect of the data science journey. Professionals leverage Visualization Tools like Matplotlib and Seaborn to create insightful graphical representations of data. Simultaneously, they employ Descriptive Statistics to summarize and interpret data distributions, gaining crucial insights into the underlying patterns.
5. Machine Learning Algorithms: Decoding the Secrets
Machine Learning is a cornerstone of data science, encompassing both supervised and unsupervised learning. Professionals delve into Supervised Learning, which includes algorithms for tasks such as regression and classification. Additionally, they explore Unsupervised Learning, delving into clustering and dimensionality reduction for uncovering hidden patterns within datasets.
6. Real-world Application and Ethical Considerations: Bridging Theory and Practice
The application of data science extends beyond theoretical knowledge to real-world problem-solving. Professionals learn to apply data science techniques to practical scenarios, making informed decisions based on empirical evidence. Furthermore, they navigate the ethical landscape, considering the implications of data usage on privacy and societal values.
7. Big Data Technologies: Navigating the Sea of Data
With the exponential growth of data, professionals delve into big data technologies. They acquaint themselves with tools like Hadoop and Spark, designed for processing and analyzing massive datasets efficiently.
8. Database Management: Organizing the Data Universe
Professionals gain proficiency in database management, encompassing both SQL and NoSQL databases. This skill set enables them to manage and query databases effectively, ensuring seamless data retrieval.
9. Advanced Topics: Pushing the Boundaries
As professionals progress, they explore advanced topics that push the boundaries of data science. Deep Learning introduces neural networks for intricate pattern recognition, while Natural Language Processing (NLP) focuses on analyzing and interpreting human language data.
10. Continuous Learning and Adaptation: Embracing the Data Revolution
Data science is a field in constant flux. Professionals embrace a mindset of continuous learning, staying updated on evolving technologies and methodologies. This proactive approach ensures they remain at the forefront of the data revolution.

In conclusion, the study of data science is a dynamic and multifaceted journey. By mastering mathematical foundations, programming languages, and ethical considerations, professionals unlock the potential of data, making data-driven decisions that impact industries across the spectrum. The comprehensive exploration of these diverse topics equips individuals with the skills needed to thrive in the dynamic world of data science. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science.
4 notes
·
View notes
Text
What is a PGP in Data Science? A Complete Guide for Beginners

Businesses in the data-driven world of today mostly depend on insights from vast amounts of data. From predicting customer behavior to optimizing supply chains, data science plays a vital role in decision-making processes across industries. As the demand for skilled data scientists continues to grow, many aspiring professionals are turning to specialized programs like the PGP in Data Science to build a strong foundation and excel in this field.
If you’re curious about what a Post Graduate Program in Data Science entails and how it can benefit your career, this comprehensive guide is for you.
What is Data Science?
Data science is a multidisciplinary field that uses statistical methods, machine learning, data analysis, and computer science to extract insights from structured and unstructured data. It is used to solve real-world problems by uncovering patterns and making predictions.
The role of a data scientist is to collect, clean, analyze, and interpret large datasets to support strategic decision-making. With the growth of big data, cloud computing, and AI technologies, data science has become a highly lucrative and in-demand career path.
What is a PGP in Data Science?
A PGP in Data Science (Post Graduate Program in Data Science) is a comprehensive program designed to equip learners with both theoretical knowledge and practical skills in data science, analytics, machine learning, and related technologies. Unlike traditional degree programs, PGPs are typically more industry-focused, tailored for working professionals or graduates who want to quickly upskill or transition into the field of data science.
These programs are often offered by reputed universities, tech institutions, and online education platforms, with durations ranging from 6 months to 2 years.
Why Choose a Post Graduate Program in Data Science?
Here are some key reasons why a Post Graduate Program in Data Science is worth considering:
High Demand for Data Scientists
Data is the new oil, and businesses need professionals who can make sense of it. According to various industry reports, there is a massive talent gap in the data science field, and a PGP can help bridge this gap.
Industry-Relevant Curriculum
Unlike traditional degree programs, a PGP focuses on the tools, techniques, and real-world applications currently used in the industry.
Fast-Track Career Transition
PGP programs are structured to deliver maximum value in a shorter time frame, making them ideal for professionals looking to switch to data science.
Global Career Opportunities
Data scientists are in demand not just in India but globally. Completing a PGP in Data Science makes you a competitive candidate worldwide.
Key Components of a Post Graduate Program in Data Science
Most PGP in Data Science programs cover the following key areas:
Statistics and Probability
Python and R Programming
Data Wrangling and Visualization
Machine Learning Algorithms
Deep Learning & Neural Networks
Natural Language Processing (NLP)
Big Data Technologies (Hadoop, Spark)
SQL and NoSQL Databases
Business Analytics
Capstone Projects
Some programs include soft skills training, resume building, and interview preparation sessions to boost job readiness.
Who Should Enroll in a PGP in Data Science?
A Post Graduate Program in Data Science is suitable for:
Fresh graduates looking to enter the field of data science
IT professionals aiming to upgrade their skills
Engineers, mathematicians, and statisticians transitioning to data roles
Business analysts who want to learn data-driven decision-making
Professionals from non-technical backgrounds looking to switch careers
Whether you are a beginner or have prior knowledge, a PGP can provide the right blend of theory and hands-on learning.
Skills You Will Learn
By the end of a PGP in Data Science, you will gain expertise in:
Programming languages: Python, R
Data preprocessing and cleaning
Exploratory data analysis
Model building and evaluation
Machine learning algorithms like Linear Regression, Decision Trees, Random Forests, SVM, etc.
Deep learning frameworks like TensorFlow and Keras
SQL for data querying
Data visualization tools like Tableau or Power BI
Real-world business problem-solving
These skills make you job-ready and help you handle real-time projects with confidence.
Curriculum Overview
Here’s a general breakdown of a Post Graduate Program in Data Science curriculum:
Module 1: Introduction to Data Science
Fundamentals of data science
Tools and technologies overview
Module 2: Programming Essentials
Python programming
R programming basics
Jupyter Notebooks and IDEs
Module 3: Statistics & Probability
Descriptive and inferential statistics
Hypothesis testing
Probability distributions
Module 4: Data Manipulation and Visualization
Pandas, NumPy
Matplotlib, Seaborn
Data storytelling
Module 5: Machine Learning
Supervised and unsupervised learning
Model training and tuning
Scikit-learn
Module 6: Deep Learning and AI
Neural networks
Convolutional Neural Networks (CNN)
Recurrent Neural Networks (RNN)
Module 7: Big Data Technologies
Introduction to Hadoop ecosystem
Apache Spark
Real-time data processing
Module 8: Projects & Capstone
Industry case studies
Group projects
Capstone project on end-to-end ML pipeline
Duration and Mode of Delivery
Most PGP in Data Science programs are designed to be completed in 6 to 12 months, depending on the institution and the pace of learning (part-time or full-time). Delivery modes include:
Online (Self-paced or Instructor-led)
Hybrid (Online + Offline workshops)
Classroom-based (Less common today)
Online formats are highly popular due to flexibility, recorded sessions, and access to mentors and peer groups.
Admission Requirements
Admission criteria for a Post Graduate Program in Data Science generally include:
A bachelor’s degree (any discipline)
Basic understanding of mathematics and statistics
Programming knowledge (optional, but beneficial)
An exam or interview may be required by some institutions.
Why a Post Graduate Program in Data Science from Career Amend?
Career Amend offers a comprehensive Post Graduate Program (PGP) in Data Science designed to be completed in just one year, making it an ideal choice for professionals and graduates who wish to enter the field of data science without spending multiple years in formal education. This program has been thoughtfully curated to combine foundational theory with hands-on practical learning, ensuring that students not only understand the core principles. Still, it can also apply them to real-world data challenges.
The one-year structure of Career Amend’s PGP in Data Science is intensive yet flexible, catering to both full-time learners and working professionals. The curriculum spans various topics, including statistics, Python programming, data visualization, machine learning, deep learning, and big data tools. Learners are also introduced to key technologies and platforms like SQL, Tableau, TensorFlow, and cloud services like AWS or Azure. This practical approach helps students gain industry-relevant skills that are immediately applicable.
What sets Career Amend apart is its strong focus on industry integration. The course includes live projects, case studies, and mentorship from experienced data scientists. Learners gain exposure to real-time business problems and data sets through these components, making them job-ready upon completion. The capstone project at the end of the program allows students to showcase their comprehensive knowledge by solving a complex, practical problem, an asset they can add to their portfolios.
Additionally, Career Amend offers dedicated career support services, including resume building, mock interviews, and job placement assistance. Whether a student is looking to switch careers or upskill within their current role, this one-year PGP in Data Science opens doors to numerous high-growth roles such as data scientist, machine learning engineer, data analyst, and more.
Final Thoughts
A PGP in Data Science is an excellent option for anyone looking to enter the field of data science without committing to a full-time degree. It combines the depth of a traditional postgraduate degree with the flexibility and industry alignment of modern learning methods. Whether a recent graduate or a mid-level professional, enrolling in a Post Graduate Program in Data Science can provide the competitive edge you need in today's tech-driven job market.
So, suppose you're asking yourself, "Is a PGP in Data Science worth it?". In that case, the answer is a YES, especially if you are serious about building a career in one of the most dynamic and high-paying domains of the future.
#PGP in Data Science#Post Graduate Program in Data Science#data science#machine learning#data analysis#data analytics#datascience
1 note
·
View note
Text
Tenipuri Complete Character Profile - Kaoru Kaidoh

[PROFILE]

Birthday: May 11th (Taurus)
Blood Type: B
Relatives: Father (Shibuki Kaidoh), mother (Hozumi Kaidoh), younger brother (Hazue Kaidoh)
Father’s Occupation: Company employee (banker)
Elementary School: Tamakawa Central Elementary School
Middle School: Seishun Academy Junior High School
Grade & Class: Second Year | Class 2-7 | Seat 4
Club: Tennis Club (regular, future captain)
Committee: None
Strong Subjects: English
Weak Subjects: Math, science
Most Visited Spot at School: Training room
Favorite Motto: “In for a penny, in for a pound.” ➜ “Slow and steady wins the race.” [23.5]
Daily Routines: Long distance runs, cleaning his room

Hobbies: Marathoning, collecting bandanas, rock climbing [TP]
Favorite Color: Blue
Favorite Music: Japanese traditional instrumental music
Favorite Movie: Japanese films
Favorite Book: Japanese literature from the Meiji Era
Favorite Food: Tororo soba (zaru style), yogurt, 100% fruit juice (white peach flavor [TP])
Favorite Anniversary: Father’s Day, Mother’s Day
Preferred Type: A girl who eats food with gusto

Ideal Date Spot: Zoo (he wants to see the polar bears) ➜ “A cat café—I mean, going cycling.” [TP]
His Gift for a Special Person: Imabari towels
Where He Wants to Travel: “Nowhere.” (a magazine featuring Malta is visible in his bag)
What He Wants Most Right Now: New training equipment ➜ For Seigaku to win the national tournament again [23.5]
Dislikes: Monsters, ghosts ➜ Supernatural things, konjac [TP]
Skills Outside of Tennis: General housework (particularly cleaning and sewing [TP]), can quickly grab beans with chopsticks [TP]
Spends Allowance On: Training equipment
Routine During the World Cup: Sending postcards to his family
[DATA]
Height: 173cm | 5’8” ➜ 174cm | 5’8.5” [23.5]
Weight: 57kg | 125 lbs
Shoe Size: 26.5cm
Dominant Arm: Right
Vision: 1.5 Left & Right
Play Style: Counter Puncher
Signature Moves: Snake, Boomerang Snake, Short Snake, Tornado Snake, Gyro Laser
Daily Running Distance: 25km
Equipment Brands:
Racket: HEAD (Ti.S7)
Shoes: PUMA (Cell Factor PTO634)
Fitness Test Results:
Sidesteps: 58
Shuttle Run: 140
Back Strength: 122kg
Grip Strength: 54.5kg
Backbend: 62.8cm
Seated Forward Bend: 49.6cm
50m Run: 6.74 seconds
Standing Long Jump: 224cm
Handball Throw: 33m
Endurance Run (1500m): 4:47
Overall Rating: Speed: 3 / Power: 3 / Stamina: 4.5 / Mental: 3 / Technique: 3 / Total: 16.5
Kurobe Memo: “His unyielding personality and endurance are all part of his charm. I’m sure he’ll grow into bring the type of player that can strip off an opponent’s control as the match goes on. His match with Tezuka was a great learning opportunity for him to stop being so reserved with others.” <Official Description>
[POSSESSIONS]
What’s in His Bedroom [10.5]:
TV and audio equipment: Various equipment along with a DVD player and collection of DVDs
Glass table: Used for studying, it’s always clean and not a single fingerprint can be found on it
Japanese-style bed area: A spacious area in his bedroom with Japanese motifs. He uses it strictly for his bed and has a double-size futon laying out
Training area: An area where he keeps various training equipment including a bench press. He trains hard everyday even in his bedroom
Full-length mirror: He had bought it to check on his form, but he doesn’t use it much
What’s in His Bag [10.5]:
Bandanas: He always has two or three of them with him so he can replace one if it gets dirty
Writing supplies: He doesn’t use mechanical pencils and only takes notes with a ballpoint pen
Notebook: He uses a spiral notebook so important sections can easily be taken out and filed
Bento: Made in luxurious, lacquered jubako (tiered lunch boxes) and furoshiki wrapped. He also brings chopsticks and a chopstick rest with him
Sewing kit: Along with nail clippers. He always maintains his nails before practice
Handkerchief and tissues: He is particular about staying clean and tidy
Pass case: He keeps his student ID in it. His photos are said to be frightening…
[TRIVIA]
The Prince of Tennis 10.5 Fanbook | Publication Date: 11/02/2001
He is described to have large, upturned eyes and slightly big lips
He is secretly compassionate and easily moved
He prefers girls with big eyes and who can trust him with her heart and soul
He loves yogurt and eats it to stay healthy, he particularly likes the Morinaga brand
He does a great amount of daily training, including intense strength training unbeknownst to the other members
He glares at people who approach him and exudes an aura that keeps them at bay. In reality, it is because he is nervous over his appearance and is not good at interacting with others
His hissing is a habit of how he breathes, Konomi wanted him to give off an eerie feeling by doing it
He is Konomi’s favorite member of Seigaku
He is one of few characters who wear no show socks
He wears bandanas to help motivate himself
He trained and mastered his Snake Shot after losing a rookie match in the fall when he was a first year
He will stay silent and glare when asked personal questions, he usually is not angry, however
He does not mind being called by his first name, but gets angry when people call him “viper”
His sharp, arching eyebrows are natural
His unnerving aura tends to scare off animals as well
He believes he is stronger than Momoshiro and could easily beat him
He does tennis training and long distance runs (morning and evening) even on off days
He secretly loves animals, especially cats
He is described as someone who is misunderstood and frightens others because of it, but is actually kind and afraid of hurting others more than anything else
Konomi describes him as “hardworking” and that he’s not just unpleasant, he’s a hard worker who happens to be unpleasant. An “I am who I am” type of character
The Prince of Tennis 20.5 Fanbook | Publication Date: 12/04/2003
He is described as stoic and tenacious, and would be suited for event planning
He has a temperament of never giving up, which gives him leadership qualities
He will go on runs even after matches
His secondary sport would be boxing
The Prince of Tennis 40.5 Fanbook | Publication Date: 12/04/2007
He tends to let his emotions overtake him and is considered a “troublemaker” because of it
He is very just, moral, and will get angry when someone disrespects his teammates or rivals
He has a hard time accepting people and tends to clash with them, which puts a strain on his relations. He does however, have a strong sense of camaraderie and exhibits a cooperative nature with his friends
He is described to have a jealous side to him and has a tendency to want to control his friends and/or lovers
His daily running distance is 25km, and he will continue to run even further until he reaches his physical limits
He has been popular with the older women in the area of the national tournament. He was spotted at the shopping district surrounded by women trying to feed him
Konomi had been inspired to give him a Devil Mode from commercials of the film Spider-Man 3, depicting the titular hero wearing a dark version of his suit
The Prince of Tennis II Official Character Guide: PairPuri Vol. 3 | Publication Date: 01/04/2010
Yagyuu had given him a handkerchief and told him to keep it since he had been injured during a training session
The Prince of Tennis II Official Character Guide: PairPuri Vol. 6 | Publication Date: 06/03/2011
He wants next year’s tennis club to be unbeatable and win the national tournament again, stating it would be pointless otherwise
He hates being called “viper” and even hates saying it
He does not ask his parents for gifts
When asked random questions, he becomes outwardly annoyed and frank
He is described as being a “strict” upperclassman
Konomi states that he does not remember how he came up with his name, but wanted there to be a contrast between his “cute” name and “cool” face
Konomi came up with his Snake Shot since a senior member of his tennis club had used it. When Konomi had drawn his match with Ryoma, he wanted convey the power of tennis without any dialogue since he was Ryoma’s first serious opponent
Konomi is particular about drawing the shape of his mouth and under eyelashes. He wanted to make his eyes look angry and give off a sense of hunger
Konomi gradually began showing off his good side, but wants to show off the same “hunger” he had when he faced off against Tezuka
One of His School Days:
5:00am - Wakes up, goes on a run
6:00am - Breakfast (handmade soba with homemade fruits)
6:50am - Arrives at school, attends morning practice
8:20am - Cleans the teacher’s desk, etc. for morning duties
8:40am - 1st Period: Science II (astronomy)
9:40am - 2nd Period: PE (sprints)
10:30am - Runs around the schoolyard during break
11:00am - 3rd Period: Japanese (modern Japanese)
12:00pm - 4th Period: Home Economics (sewing aprons)
12:50pm - Lunch, jubako bento (lobster with hollandaise sauce)
1:00pm - Strength training in the training room
1:20pm - 5th Period: Math II
2:20pm - 6th Period: Social Studies (civics)
4:00pm - Club activities (basic training)
6:00pm - Returns home, has dinner, bathes
7:00pm - Cleans his room, irons his shirts
8:30pm - Watches the DVD “The Arctic: The Life of Polar Bears”
9:00pm - Goes on a run after training in his room
1:00am - Takes a quick shower, then goes to bed
The Prince of Tennis II Official Character Guide: PairPuri Vol. 7 | Publication Date: 07/04/2011
He and Gakuto had been frightened and mistook Inui for a mummy since the latter was asleep in the cave covered in bandages
He and Momoshiro had found a natural hot spring near the training camp and invited Ryoma to join them
The Prince of Tennis II 10.5 Fanbook | Publication Date: 09/04/2013
He and Hiyoshi get into constant fights with Kirihara and Zaizen since the former two like going to bed early while the latter two like staying up to play video games
The Prince of Tennis II 23.5 Fanbook | Publication Date: 05/02/2018
He recently visited a family-owned candy store for the first time and was impressed by the old-fashioned sweets
The Prince of Tennis 20th Anniversary Book: Tenipuri Party | Publication Date: 08/02/2019
Since he is afraid of spirits and ghosts, when he runs at night, he’ll think that he’s being chased by a ghost and won’t slow down
24 notes
·
View notes
Text
What Is Feature Engineering and Why Does It Matter?

In data science and machine learning, having access to data isn’t enough—how that data is prepared makes all the difference. That’s where feature engineering becomes essential. It involves refining and transforming raw information into useful inputs that help algorithms detect patterns and produce better results. Whether you're developing a model for prediction or analyzing data trends, having the right features can greatly improve your outcome.
For anyone serious about enhancing their data science learning, grasping the concept of feature engineering is a key milestone that unlocks better accuracy and deeper insights.
What Is Feature Engineering?
Feature engineering is the practice of converting raw datasets into structured and useful variables—commonly known as features—that enhance how machine learning models interpret information. These features act as the inputs that guide the learning process, helping algorithms detect patterns, relationships, and trends more effectively.
The process may include creating new attributes, refining or combining existing ones, managing missing or inconsistent values, encoding text or categories into numbers, and normalizing data for uniformity. The main objective is to ensure the model is fed with high-quality, relevant information that can lead to more accurate and reliable predictions.
Why Is Feature Engineering Important?
1. Improves Model Accuracy
The quality of the features you use can often have a greater impact on model performance than the choice of algorithm itself. Well-engineered features make it easier for models to recognize patterns and make accurate predictions. Even simple models like linear regression can perform surprisingly well when powered by strong, relevant features.
2. Handles Real-World Complexity
Raw data is often messy, incomplete, and inconsistent. Feature engineering helps clean and refine this data, allowing models to work effectively in real-world scenarios. For example, transforming timestamps into “day of the week” or “hour of the day” can reveal patterns that the model wouldn’t recognize otherwise.
3. Helps Prevent Overfitting One of the key benefits of feature engineering is its ability to reduce overfitting. By crafting features that represent the core behavior of the data, models are less likely to memorize noise or irrelevant details. Instead, they focus on meaningful patterns, which improves their ability to make accurate predictions on new, unseen datasets.
4. Translates Data for Machine Learning Models Machine learning systems process data differently from humans. Feature engineering helps translate complex, human-readable information into formats that algorithms can understand. For instance, converting text descriptions into numeric values like keyword counts or sentiment ratings allows models to extract useful insights from unstructured data.
Common Feature Engineering Techniques
Imputation – Filling in missing data with statistical values like mean, median, or more advanced methods such as KNN imputation.
Encoding – Converting categorical data into numerical format using techniques like one-hot encoding or label encoding.
Scaling and Normalization – Adjusting values to a standard range (e.g., 0 to 1) to improve model performance, especially for algorithms sensitive to scale like SVM or KNN.
Binning – Grouping continuous variables into discrete bins to reduce noise and capture non-linear relationships.
Interaction Features – Combining two or more features to create new variables that capture the interaction between them.
Time-Based Features – Extracting elements such as day, month, year, or season from timestamp data to identify temporal trends.
Real-World Example
Consider a dataset of house sales. The raw data may include the date of sale, square footage, number of bedrooms, and location. Feature engineering can enhance this dataset by:
Extracting the month from the sale date to see if sales peak during certain seasons.
Creating a feature for price per square foot.
Encoding location into zones or price brackets.
Binning square footage into size categories like "small", "medium", or "large".
These new features can make the data more informative for the model and lead to more accurate predictions.
Feature engineering blends technical expertise with creative problem-solving. It goes beyond simply applying algorithms—it demands a deep understanding of both the data and the problem at hand. While advanced models are valuable, their effectiveness relies heavily on the strength of the features they're built on. For learners aiming to grow in the field of data science, developing feature engineering skills is essential. It sharpens critical thinking and boosts the ability to extract real value from data. Well-designed features can elevate a basic model to deliver impactful, real-world results by turning raw information into powerful insights.
0 notes
Text
In 2025 – watch out for these future trends in data science
In today’s tech-driven world, data science is evolving at a rapid pace, transforming industries and shaping the way we make decisions. As we move into 2025 and beyond, the demand for skilled professionals is expected to skyrocket. For aspiring data professionals looking to stay ahead, the best data science training in Hyderabad can provide the foundation needed to master the latest tools and techniques. With continuous advancements in technology, understanding upcoming trends is essential to remain competitive in this ever-changing field.
Integration of AI and Data Science
One of the most significant trends is the deep integration of Artificial Intelligence (AI) with data science. AI-driven tools are now being used not just to analyze data, but also to automate data cleaning, model building, and interpretation. In 2025, we can expect AI to enhance the speed and accuracy of insights, allowing businesses to make smarter decisions faster.
Growth of Edge Computing and Real-Time Analytics
There will be a revolution in the way data is processed thanks to edge computing. Instead of sending data to centralized servers, edge devices process data locally. This shift allows real-time analytics, especially in sectors like healthcare, autonomous vehicles, and smart cities. Data scientists must learn to work with decentralized data and optimize models for performance at the edge.
The Rise of No-Code and AutoML Tools
As accessibility becomes a priority, no-code platforms and AutoML tools are enabling non-technical users to perform complex data analysis. While this democratizes data science, it also pushes professionals to upskill and focus on more advanced, customized solutions that go beyond what automated tools can deliver.
Ethical AI and Data Governance
With great power comes great responsibility. Data science in 2025 will place a stronger emphasis on ethics, transparency, and compliance. Professionals will need to be equipped not only with technical knowledge but also with a solid understanding of data governance and responsible AI practices.
Upskilling is Key
The data science field is becoming more competitive. Continuous learning through professional training programs is crucial for staying ahead. Enrolling in the best data science training in Hyderabad can help professionals and students alike gain the skills required to meet future demands.
Conclusion
Developing technologies and exciting opportunities are leading the way in data science in the future.To navigate this dynamic landscape and build a successful career, quality education is a must. SSSIT Computer Education offers expert-led training programs that prepare you for the future of data science. Don't miss out on the data revolution. Start your journey today.
#best data science training in hyderabad#best data science training in kukatpally#best data science training in KPHB#Best data science training institute in Hyderabad
0 notes
Text
Financial Modeling in the Age of AI: Skills Every Investment Banker Needs in 2025
In 2025, the landscape of financial modeling is undergoing a profound transformation. What was once a painstaking, spreadsheet-heavy process is now being reshaped by Artificial Intelligence (AI) and machine learning tools that automate calculations, generate predictive insights, and even draft investment memos.
But here's the truth: AI isn't replacing investment bankers—it's reshaping what they do.
To stay ahead in this rapidly evolving environment, professionals must go beyond traditional Excel skills and learn how to collaborate with AI. Whether you're a finance student, an aspiring analyst, or a working professional looking to upskill, mastering AI-augmented financial modeling is essential. And one of the best ways to do that is by enrolling in a hands-on, industry-relevant investment banking course in Chennai.
What is Financial Modeling, and Why Does It Matter?
Financial modeling is the art and science of creating representations of a company's financial performance. These models are crucial for:
Valuing companies (e.g., through DCF or comparable company analysis)
Making investment decisions
Forecasting growth and profitability
Evaluating mergers, acquisitions, or IPOs
Traditionally built in Excel, models used to take hours—or days—to build and test. Today, AI-powered assistants can build basic frameworks in minutes.
How AI Is Revolutionizing Financial Modeling
The impact of AI on financial modeling is nothing short of revolutionary:
1. Automated Data Gathering and Cleaning
AI tools can automatically extract financial data from balance sheets, income statements, or even PDFs—eliminating hours of manual entry.
2. AI-Powered Forecasting
Machine learning algorithms can analyze historical trends and provide data-driven forecasts far more quickly and accurately than static models.
3. Instant Model Generation
AI assistants like ChatGPT with code interpreters, or Excel’s new Copilot feature, can now generate model templates (e.g., LBO, DCF) instantly, letting analysts focus on insights rather than formulas.
4. Scenario Analysis and Sensitivity Testing
With AI, you can generate multiple scenarios—best case, worst case, expected case—in seconds. These tools can even flag risks and assumptions automatically.
However, the human role isn't disappearing. Investment bankers are still needed to define model logic, interpret results, evaluate market sentiment, and craft the narrative behind the numbers.
What AI Can’t Do (Yet): The Human Advantage
Despite all the hype, AI still lacks:
Business intuition
Ethical judgment
Client understanding
Strategic communication skills
This means future investment bankers need a hybrid skill set—equally comfortable with financial principles and modern tools.
Essential Financial Modeling Skills for 2025 and Beyond
Here are the most in-demand skills every investment banker needs today:
1. Excel + AI Tool Proficiency
Excel isn’t going anywhere, but it’s getting smarter. Learn to use AI-enhanced functions, dynamic arrays, macros, and Copilot features for rapid modeling.
2. Python and SQL
Python libraries like Pandas, NumPy, and Scikit-learn are used for custom forecasting and data analysis. SQL is crucial for pulling financial data from large databases.
3. Data Visualization
Tools like Power BI, Tableau, and Excel dashboards help communicate results effectively.
4. Valuation Techniques
DCF, LBO, M&A models, and comparable company analysis remain core to investment banking.
5. AI Integration and Prompt Engineering
Knowing how to interact with AI (e.g., writing effective prompts for ChatGPT to generate model logic) is a power skill in 2025.
Why Enroll in an Investment Banking Course in Chennai?
As AI transforms finance, the demand for skilled professionals who can use technology without losing touch with core finance principles is soaring.
If you're based in South India, enrolling in an investment banking course in Chennai can set you on the path to success. Here's why:
✅ Hands-on Training
Courses now include live financial modeling projects, AI-assisted model-building, and exposure to industry-standard tools.
✅ Expert Mentors
Learn from professionals who’ve worked in top global banks, PE firms, and consultancies.
✅ Placement Support
With Chennai growing as a finance and tech hub, top employers are hiring from local programs offering real-world skills.
✅ Industry Relevance
The best courses in Chennai combine finance, analytics, and AI—helping you become job-ready in the modern investment banking world.
Whether you're a student, working professional, or career switcher, investing in the right course today can prepare you for the next decade of finance.
Case Study: Using AI in a DCF Model
Imagine you're evaluating a tech startup for acquisition. Traditionally, you’d:
Download financials
Project revenue growth
Build a 5-year forecast
Calculate terminal value
Discount cash flows
With AI tools:
Financials are extracted via OCR and organized automatically.
Forecast assumptions are suggested based on industry data.
Scenario-based DCF models are generated in minutes.
You spend your time refining assumptions and crafting the investment story.
This is what the future of financial modeling looks like—and why upskilling is critical.
Final Thoughts: Evolve or Be Left Behind
AI isn’t the end of financial modeling—it’s the beginning of a new era. In this future, the best investment bankers are not just Excel wizards—they’re strategic thinkers, storytellers, and tech-powered analysts.
By embracing this change and mastering modern modeling skills, you can future-proof your finance career.
And if you're serious about making that leap, enrolling in an investment banking course in Chennai can provide the training, exposure, and credibility to help you rise in the AI age.
0 notes
Text
Data Analyist Course In Kharadi Pune
Master Data Analysis with the Best Data Analyst Course in Kharadi Pune – GoDigi Infotech

In the digital era where data drives decisions, the demand for skilled data analysts is skyrocketing across industries. Whether it's retail, finance, healthcare, or tech—organizations are seeking professionals who can interpret data and convert it into actionable insights. If you're looking to build a rewarding career in this thriving domain, enrolling in a Data Analyst Course in Kharadi Pune at GoDigi Infotech is the smart move.
Located in the tech-forward area of Kharadi, Pune, GoDigi Infotech stands out as one of the most reliable and industry-oriented training institutes for data analytics. This article takes a deep dive into what makes this course unique, what you will learn, and how it can launch your career in data analytics.
Why Choose a Career in Data Analysis?
Data analysts are the brain behind strategic business moves. With their expertise, businesses optimize operations, enhance customer experiences, and increase profitability. According to recent surveys, data analytics jobs are among the top high-paying and in-demand roles in India and globally.
Some key reasons to consider a career in data analytics:
High salary packages
Abundant job opportunities in every sector
Scope for international placements
Opportunity to work with cutting-edge tools and technologies
Why GoDigi Infotech for a Data Analyst Course in Kharadi Pune?
GoDigi Infotech is recognized for offering practical, job-ready training in emerging technologies. Here’s why it’s the top choice for learners in Pune:
1. Comprehensive Curriculum
The Data Analyst Course in Kharadi Pune at GoDigi Infotech covers everything from the fundamentals to advanced techniques. The curriculum includes:
Data Cleaning & Preparation
Excel for Data Analysis
SQL for Databases
Data Visualization using Tableau and Power BI
Statistical Analysis
Python for Data Science
Case Studies & Real-Time Projects
2. Industry-Experienced Trainers
Learning from professionals who have hands-on experience in the analytics domain ensures students grasp real-world applications, tools, and workflows effectively.
3. Hands-on Training with Real Projects
This course is not just theory-based. You’ll be working on real-world projects that simulate the challenges data analysts face in the field. By the end of the course, you’ll have a portfolio that showcases your expertise.
4. Placement Assistance & Career Guidance
GoDigi Infotech provides 100% placement assistance. From resume building to mock interviews and direct connections with hiring partners, students are supported throughout their job-hunting journey.
5. Flexible Learning Options
Whether you're a working professional or a fresh graduate, GoDigi offers weekend and weekday batch options to suit your schedule.
Who Can Enroll in This Data Analyst Course?
This course is designed for:
Fresh Graduates (BSc, BCA, BE, BCom, etc.)
Working Professionals looking to upskill
IT Professionals transitioning into data-driven roles
Entrepreneurs wanting to make data-informed decisions
No prior coding experience? No problem. The course begins with foundational concepts and gradually moves to advanced topics.
Course Duration and Certification
Duration: 3 to 6 months (depending on the batch type)
Mode: Online/Offline Hybrid
Certification: Industry-recognized certificate upon successful completion
This certificate validates your data analysis skills and increases your chances of being hired by top MNCs and startups.
Location Advantage – Kharadi, Pune
Kharadi is a prominent IT hub in Pune, home to leading companies like TCS, Zensar, Barclays, and more. Taking your Data Analyst Course in Kharadi Pune means you're learning right in the middle of opportunities. Many GoDigi Infotech students receive internship and placement opportunities from nearby companies even before completing the course.
What Makes GoDigi Infotech Unique?
GoDigi Infotech doesn’t just teach you tools; it shapes you into a data-driven thinker. The approach here focuses on:
Problem-Solving Mindset
Business Intelligence Thinking
Data Storytelling Skills
Agile & Practical Learning
It’s not just a course. It’s a transformation into a professional that companies want to hire
Alumni Success Stories
Many GoDigi Infotech alumni are now working as data analysts, business analysts, and data scientists at renowned firms like Infosys, Accenture, Capgemini, and Tech Mahindra. Their testimonials speak volumes about the quality of training and support the institute provides.
How to Enroll?
Getting started is easy. You can visit the institute directly or connect online through the GoDigi Infotech Google Map Listing and schedule your free counseling session.
Conclusion
If you are serious about entering the field of data analytics and want a structured, practical, and career-oriented program, GoDigi Infotech’s Data Analyst Course in Kharadi Pune is the right choice. With its hands-on learning, expert mentors, and job support, you’re not just learning a skill—you’re investing in a future-proof career.
Take the first step toward your data analytics journey today with GoDigi Infotech. Your career transformation starts here!
0 notes