#dataset for machine learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
0 notes
Text
you know what i have always hated. you say 'ai is racist' and theres like 5 white silicon valley dudebros ready to um actually you. 'its the datasets that are biased, the algorithm doesnt hold any biases' okay dipshit. and hows your untrained algorithm working out for you.
#dils declares#and also its machine learning. the bad dataset has taught it bad practices.#'its not literally learning' do you want me to fucking kill you
69 notes
·
View notes
Text
So... I think I've just finished writing a 7.7 or 7.8K words long chapter in 2-3 days.
What the fuck possessed me? Did I finally manage to build up a working writing routine for me?
Did suffering the fanfic writer curse in advance really payout and work?
Anyways, am currently editing my current stp truth lies AU chapter "The drowned Cage" there. Will archive locked post it then. Maybe put up a publically encrypted/enciphered version of the fic once I got Maddening Shackles fully written down and posted.
But breakfast first! Food.
#aromantic ghost menace#slay the princess#stp#stp au#truth lies au#slay the princess au#Fanfic#Writing#Fanfiction#My fics#fic update#I'm just... who the fuck possessed me and what did I trade in?!#Also yeah will publically cipher encrypt it later on so it poisons scraped datasets for LLMs#Cause good luck trying to train essentially a statistical learning machine to recognize and decode seeming gibberish by itself
6 notes
·
View notes
Text
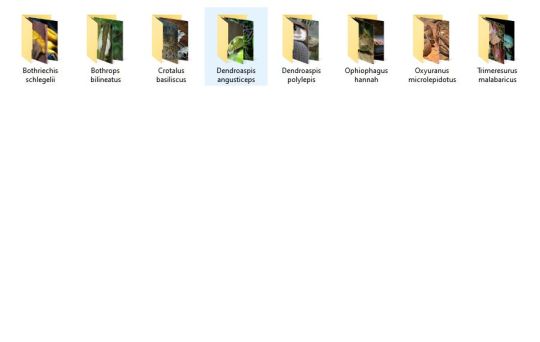
Tonight I am hunting down venomous and nonvenomous snake pictures that are under the creative commons of specific breeds in order to create one of the most advanced, in depth datasets of different venomous and nonvenomous snakes as well as a test set that will include snakes from both sides of all species. I love snakes a lot and really, all reptiles. It is definitely tedious work, as I have to make sure each picture is cleared before I can use it (ethically), but I am making a lot of progress! I have species such as the King Cobra, Inland Taipan, and Eyelash Pit Viper among just a few! Wikimedia Commons has been a huge help!
I'm super excited.
Hope your nights are going good. I am still not feeling good but jamming + virtual snake hunting is keeping me busy!
#programming#data science#data scientist#data analysis#neural networks#image processing#artificial intelligence#machine learning#snakes#snake#reptiles#reptile#herpetology#animals#biology#science#programming project#dataset#kaggle#coding
43 notes
·
View notes
Text
I think that if a person knows that something was made using trained on unethically sourced data AI. And still uses it/likes it/supports it/defends it.
Then said person should stop "being mad" when their data is used to train AI without consent.
#nitunio.txt#please dont half-ass it in terms of not supporting this stuff#if you like and willingly use writing AI that scrapes web without consent#then turn around and say 'wahh AI bad' when it concerns digital art. you're just a hypocrite#same goes for photos and music and other creative work#if you come across any 'machine learning AI generation' website immediately go to their FAQ or About sections#just see for yourself if they provide any sources for the data they've used and if it was consensual and only after that#ask yourself if you should be using it or just make something yourself#hell you can even ask somebody or pay somebody to do something you can't do. thats the joy of community#and even then there are many resources that were already made to be used for free with or without credit#i ramble a lot about things like these bc i cant just wrap my head around it#i just need all of these scraped datasets to burn down and self-delete
2 notes
·
View notes
Text
Researchers develop unsupervised machine learning method to improve fraud detection in imbalanced datasets

- By Nuadox Crew -
Researchers at Florida Atlantic University have developed a new machine learning method that significantly improves fraud detection by generating accurate class labels from severely imbalanced datasets—common in fraud cases where fraudulent events are rare.
Unlike traditional methods that rely on labeled data, their unsupervised technique works without prior labeling, cutting costs and addressing privacy concerns.
Tested on large real-world datasets (European credit card transactions and Medicare claims), the method outperformed the widely-used Isolation Forest algorithm by minimizing false positives and requiring less human oversight. It combines three unsupervised learning models with a percentile-gradient approach to isolate the most confidently identified fraud cases, enhancing accuracy and efficiency.
Published in the Journal of Big Data, this approach offers scalable, low-cost fraud detection for high-risk industries like finance and healthcare, and was recognized with a Best Student Paper Award at the IEEE ICTAI 2024 conference. Future work will focus on automating optimal label selection to further boost scalability.
Read more at Florida Atlantic University (FAU)
Scientific paper: Mary Anne Walauskis et al, Unsupervised label generation for severely imbalanced fraud data, Journal of Big Data (2025). DOI: 10.1186/s40537-025-01120-x
Related Content
Small Data approaches provide nuance and context to health datasets
Other Recent News
New oral medication shows promise against antibiotic-resistant gonorrhea.
Medical imaging radiation may be responsible for 5% of cancer cases in the U.S.
0 notes
Text
The Epistemology of Algorithmic Bias Detection: A Multidisciplinary Exploration at the Intersection of Linguistics, Philosophy, and Artificial Intelligence
We live in an increasingly data-driven world, where algorithms permeate nearly every facet of our existence, from the mundane suggestions of online retailers and products to the critical decisions impacting healthcare and justice systems. Photo by Tara Winstead on Pexels.com These algorithms, while often presented as objective and impartial, are inherently products of human design and the data…

View On WordPress
#Algorithm#algorithm design#algorithmic bias#Artificial Intelligence#bias#confirmation bias#critical discourse analysis#critical reflection#data bias#dataset#Deep Learning#deontology#epistemology#epistēmē#ethical principles#fairness#inequality#interdisciplinary collaboration#justice#Language#linguistics#Machine Learning#natural language processing#objectivity#Philosophy#pragmatics#prohairesis#Raffaello Palandri#sampling bias#Sapir-Whorf hypothesis
1 note
·
View note
Text
https://justpaste.it/gwflf
0 notes
Text
Video Annotation Services: Transforming Autonomous Vehicle Training

Introduction:
As autonomous vehicles (AVs) progressively Video Annotation Services shape the future of transportation, the underlying technology is heavily dependent on precise and comprehensive datasets. A pivotal element facilitating this advancement is video annotation services. These services enable machine learning models to accurately perceive, interpret, and react to their environment, rendering them essential for the training of autonomous vehicles.
The Importance of Video Annotation in Autonomous Vehicles
Autonomous vehicles utilize sophisticated computer vision systems to analyze real-world data. These systems must be capable of recognizing and responding to a variety of road situations, including the identification of pedestrians, vehicles, traffic signals, road signs, lane markings, and potential hazards. Video annotation services play a crucial role in converting raw video footage into labeled datasets, allowing AI models to effectively "learn" from visual information.
The contributions of video annotation to AV training include:
Object Detection and Classification Video annotation facilitates the identification and labeling of objects such as cars, bicycles, pedestrians, and streetlights. These labels assist the AI model in comprehending various objects and their relevance on the road.
Lane and Boundary Detection By annotating road lanes and boundaries, autonomous vehicles can maintain their designated paths and execute accurate turns, thereby improving safety and navigation.
Tracking Moving Objects Frame-by-frame annotation allows AI models to monitor the movement of objects, enabling them to predict trajectories and avoid collisions.
Semantic Segmentation Annotating each pixel within a frame offers a comprehensive understanding of road environments, including sidewalks, crosswalks, and off-road areas.
Scenario-Based Training Annotated videos that encompass a range of driving scenarios—such as urban traffic, highways, and challenging weather conditions—aid in training AVs to navigate real-world complexities.
The Importance of High-Quality Video Annotation Services
The development of autonomous vehicles necessitates extensive annotated video data. The precision and dependability of these annotations significantly influence the effectiveness of AI models. Here are the reasons why collaborating with a professional video annotation service provider is essential:
Expertise in Complex Situations: Professionals possess a deep understanding of the intricacies involved in labeling complex and dynamic road environments.
Utilization of Advanced Tools and Techniques: High-quality video annotation services employ state-of-the-art tools, such as 2D and 3D annotation, bounding boxes, polygons, and semantic segmentation.
Scalability: As the development of autonomous vehicles expands, service providers are equipped to manage large volumes of data efficiently.
Consistency and Precision: Automated quality checks, along with manual reviews, guarantee that annotations adhere to the highest standards.
How Transforms Video Annotation
At we focus on providing exceptional image and video annotation services specifically designed for the training of autonomous vehicles. Our team merges technical proficiency with advanced tools to generate datasets that foster innovation within the AV sector.
Key Features of Our Offerings:
Tailored annotation solutions to address specific project requirements.
Support for a variety of annotation types, including bounding boxes, 3D point clouds, and polygon annotations.
Stringent quality assurance protocols to ensure data accuracy.
Scalable solutions capable of accommodating projects of any size or complexity.
By selecting you secure a dependable partner dedicated to enhancing the performance of your AI models and expediting the advancement of autonomous vehicles.
The Future of Autonomous Vehicle Training
As the demand for autonomous vehicles Globose Technology Solutions continues to rise, the necessity for accurate and diverse datasets will become increasingly critical. Video annotation services will play a pivotal role in facilitating safer, smarter, and more efficient AV systems. By investing in high-quality annotation services, companies can ensure their AI models are well-prepared to navigate the complexities of real-world environments. The success of your AI initiatives, whether in the realm of self-driving vehicles, drones, or other autonomous systems, heavily relies on video annotation services. Collaborating with specialists such as can help convert unprocessed video data into valuable insights, thereby propelling your innovation efforts.
0 notes
Text
Advancing Machine Learning with High-Quality Image Datasets

Image datasets are at the heart of machine learning, fueling advancements in AI technologies across industries. From healthcare diagnostics to e-commerce personalization, the quality and variety of image datasets play a crucial role in the success of AI models. At GTS AI, we provide high-quality image datasets tailored to diverse machine learning needs. In this blog, we’ll explore the importance of image datasets for machine learning, data collection challenges, and why GTS AI is your ideal partner.
What Are Image Datasets for Machine Learning?
Image datasets for machine learning are structured collections of images designed to train and validate AI models. These datasets typically include:
Images: High-resolution visuals covering various objects, scenes, and scenarios.
Annotations: Metadata or labels that provide context, such as object names, bounding boxes, or segmentation masks.
A high-quality dataset ensures AI models can learn to recognize patterns and make accurate predictions in real-world applications.
Why Are Image Datasets Essential for Machine Learning?
Training AI Models: Robust datasets enable models to learn from diverse data, improving their ability to generalize and perform effectively across various scenarios.
Improving Accuracy: High-quality annotations and varied data help minimize biases and enhance model precision.
Accelerating Innovation: Access to comprehensive datasets allows researchers and developers to build cutting-edge solutions for complex problems.
Benchmarking Performance: Datasets provide a standard for evaluating the efficiency and reliability of machine learning models.
Challenges in Image Data Collection
Collecting high-quality image data for machine learning comes with several challenges:
Diversity: Ensuring the dataset includes images from varied environments, demographics, and conditions is critical but difficult.
Annotation Quality: Precise labeling is essential for model accuracy but requires significant time and expertise.
Data Volume: Large datasets are needed for training complex models, which can be resource-intensive to collect and maintain.
Ethical Considerations: Collecting and using image data must comply with privacy laws and ethical guidelines to protect individual rights.
Applications of Image Datasets in Machine Learning
Image datasets have transformative applications across industries, including:
Healthcare: AI models use medical image datasets to detect diseases, analyze scans, and support diagnostics.
Retail and E-Commerce: Image datasets power recommendation engines, inventory categorization, and virtual try-on features.
Autonomous Vehicles: Datasets enable models to identify road signs, pedestrians, and obstacles for safe navigation.
Agriculture: AI uses image datasets to monitor crop health, detect pests, and optimize farming practices.
Content Moderation: Social platforms rely on datasets to filter inappropriate or harmful visual content.
Features of a High-Quality Image Dataset
When choosing an image dataset, prioritize these attributes:
Diversity: A varied dataset ensures robustness and adaptability across different scenarios.
Annotation Accuracy: Detailed and error-free labels enhance the learning process and model reliability.
Scalability: Large datasets support the training of complex and high-performance AI models.
Relevance: The dataset’s content should align with your project’s specific objectives.
GTS AI’s Image Dataset Collection Services
At GTS AI, we offer expertly curated image datasets for machine learning. Here’s why our services are unparalleled:
Comprehensive Coverage: Our datasets span multiple domains, including healthcare, retail, and transportation.
Custom Solutions: We provide datasets tailored to meet your project’s unique requirements.
High Annotation Standards: Our data is meticulously labeled by experts to ensure accuracy and consistency.
Ethical Data Practices: We adhere to strict privacy and ethical guidelines, ensuring compliance and trustworthiness.
Best Practices for Using Image Datasets
To maximize the value of your image dataset:
Preprocessing: Normalize and clean the dataset to ensure consistent input for training.
Data Augmentation: Apply techniques like cropping, flipping, and color adjustments to enhance model performance.
Validation and Testing: Split the dataset into training, validation, and test sets to evaluate model accuracy and prevent overfitting.
Regular Updates: Keep the dataset updated with new and relevant data to maintain model effectiveness.
Conclusion
High-quality image datasets are the foundation of successful machine learning models, enabling groundbreaking advancements across industries. At GTS AI, we provide top-notch datasets that empower you to build innovative and reliable AI solutions. Invest in the right dataset today and take your machine-learning projects to the next level.
0 notes
Text
Machine Learning Datasets: The Backbone of Successful AI Models

Introduction:
In the swiftly advancing domain of artificial intelligence (AI), machine learning datasets play a pivotal yet often overlooked role. These datasets constitute the essential groundwork for the development of effective AI models, facilitating their ability to learn, adapt, and generate precise predictions. It is imperative for individuals engaged in AI development to comprehend the importance of these datasets and their contribution to the efficacy of AI models.
The Function of Machine Learning Datasets
Datasets For Machine Learning Projects is fundamentally reliant on data. Datasets act as the primary source of input that enables ML algorithms to identify patterns, make informed decisions, and enhance their performance over time. In essence, these datasets provide the necessary examples from which AI systems derive their learning. The performance and accuracy of AI models are directly influenced by the quality, quantity, and diversity of these datasets.
Categories of Machine Learning Datasets
Machine learning datasets can be classified into several categories based on their content and intended use:
Training Datasets: These datasets are utilized to train the model, containing input-output pairs that assist the model in grasping the relationships between various data points.
Validation Datasets: Employed during the training process, validation datasets are used to fine-tune the model's parameters and prevent overfitting, thereby evaluating the model's generalization capabilities.
Test Datasets: After the training phase, test datasets are used to assess the model's performance on new, unseen data, offering an unbiased measure of its accuracy.
Unlabeled Datasets: Commonly used in unsupervised learning, these datasets do not have predefined labels, requiring the model to autonomously identify patterns or groupings.
Significance of High-Quality Datasets
The effectiveness of an AI model is significantly influenced by the quality of the dataset utilized for training. High-quality datasets are characterized by:
Accuracy: They contain precise and trustworthy information.
Relevance: They are closely aligned with the specific problem the AI model is designed to address.
Diversity: They encompass a broad spectrum of scenarios and conditions, ensuring that the model performs effectively across various situations.
Comprehensive: Offering an adequate volume of information to encompass all potential variations.
Challenges in Dataset Preparation
The process of preparing datasets for machine learning is intricate and presents numerous challenges:
Data Collection: Acquiring a substantial amount of pertinent data can be both time-intensive and costly.
Data Annotation: In supervised learning, it is crucial for data to be precisely labeled, which often necessitates considerable manual labor.
Data Cleaning: It is essential to ensure that the dataset is devoid of errors, inconsistencies, and extraneous information.
Data Privacy: Safeguarding sensitive data and adhering to data protection regulations is imperative.
Utilizing Image Annotation Companies

In fields such as computer vision, image annotation companies are essential in delivering high-quality annotated datasets. These firms specialize in tagging images with various labels, bounding boxes, or segmentation masks, which allows AI models to effectively interpret visual information. Collaborating with a reputable image annotation company guarantees that the datasets are accurate, comprehensive, and customized to meet the specific requirements of the AI initiative.
Conclusion
Machine learning datasets serve as the foundation for successful AI models. They supply the critical data necessary for training, validating, and testing machine learning algorithms. By prioritizing the quality and diversity of these datasets and addressing the related challenges, Globose Technology Solutions developers can construct robust models that are capable of making precise predictions and fostering innovative solutions.
0 notes
Text

Smcs- psi is Best machine learning company
SMCS-Psi Pvt. Ltd. is poised to make a significant impact in the field of genomics services for bioinformatics applications. By leveraging the latest advancements in bioinformatics, the company is dedicated to providing its clients with comprehensive and reliable services that will unlock new frontiers in scientific research and medical breakthroughs. Smcs- psi is Best machine learning company
View More at: https://www.smcs-psi.com/
#machine learning for data analysis#machine learning in data analysis#machine learning research#bioinformatics machine learning#data analysis for machine learning#machine learning and bioinformatics#data analysis with machine learning#data analysis in machine learning#ml data#data analysis using machine learning#large machine learning datasets
0 notes
Text

How Video Transcription Services Improve AI Training Through Annotated Datasets
Video transcription services play a crucial role in AI training by converting raw video data into structured, annotated datasets, enhancing the accuracy and performance of machine learning models.
#video transcription services#aitraining#Annotated Datasets#machine learning#ultimate sex machine#Data Collection for AI#AI Data Solutions#Video Data Annotation#Improving AI Accuracy
0 notes
Text
0 notes