#deterministic vs probabilistic
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Deterministic vs. Probabilistic Matching: What’s the Difference and When to Use Each?
In today's data-driven world, businesses often need to match and merge data from various sources to create a unified view. This process is critical in industries like marketing, healthcare, finance, and more. When it comes to matching algorithms, two primary methods stand out: deterministic and probabilistic matching. But what is the difference between the two, and when should each be used? Let’s dive into the details and explore both approaches.
1. What Is Deterministic Matching?
Deterministic matching refers to a method of matching records based on exact or rule-based criteria. This approach relies on specific identifiers like Social Security numbers, email addresses, or customer IDs to find an exact match between data points.
How It Works: The deterministic matching algorithm looks for fields that perfectly match across different datasets. If all specified criteria are met (e.g., matching IDs or emails), the records are considered a match.
Example: In healthcare, matching a patient’s medical records across systems based on their unique patient ID is a common use case for deterministic matching.
Advantages: High accuracy when exact matches are available; ideal for datasets with consistent, structured, and well-maintained records.
Limitations: Deterministic matching falls short when data is inconsistent, incomplete, or when unique identifiers (such as email or customer IDs) are not present.
2. What Is Probabilistic Matching?
Probabilistic matching is a more flexible approach that evaluates the likelihood that two records represent the same entity based on partial, fuzzy, or uncertain data. It uses statistical algorithms to calculate probabilities and scores to determine the best possible match.
How It Works: A probabilistic matching algorithm compares records on multiple fields (such as names, addresses, birth dates) and assigns a probability score based on how similar the fields are. A match is confirmed if the score exceeds a pre-defined threshold.
Example: In marketing, matching customer records from different databases (which may have variations in how names or addresses are recorded) would benefit from probabilistic matching.
Advantages: It handles discrepancies in data (e.g., misspellings, name changes) well and is effective when exact matches are rare or impossible.
Limitations: While more flexible, probabilistic matching is less precise and may yield false positives or require additional human review for accuracy.
3. Deterministic vs. Probabilistic Matching: Key Differences
Understanding the differences between deterministic vs probabilistic matching is essential to selecting the right approach for your data needs. Here’s a quick comparison:
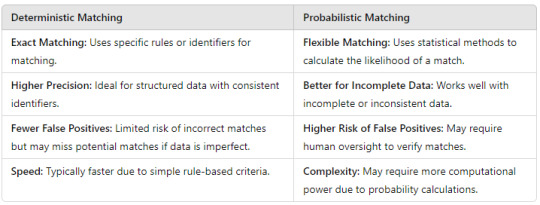
4. Real-World Applications: Deterministic vs. Probabilistic Matching
Deterministic Matching in Action
Finance: Banks often use deterministic matching when reconciling transactions, relying on transaction IDs or account numbers to ensure precision in identifying related records.
Healthcare: Hospitals utilize deterministic matching to link patient records across departments using unique identifiers like medical record numbers.
Probabilistic Matching in Action
Marketing: Marketers often deal with messy customer data that includes inconsistencies in name spelling or address formatting. Here, probabilistic vs deterministic matching comes into play, with probabilistic matching being favored to find the most likely matches.
Insurance: Insurance companies frequently use probabilistic matching to detect fraud by identifying subtle patterns in data that might indicate fraudulent claims across multiple policies.
5. When to Use Deterministic vs. Probabilistic Matching?
The choice between deterministic and probabilistic matching depends on the nature of the data and the goals of the matching process.
Use Deterministic Matching When:
Data is highly structured: If you have clean and complete datasets with consistent identifiers (such as unique customer IDs or social security numbers).
Precision is critical: When the cost of incorrect matches is high (e.g., in financial transactions or healthcare data), deterministic matching is a safer choice.
Speed is a priority: Deterministic matching is faster due to the simplicity of its rule-based algorithm.
Use Probabilistic Matching When:
Data is messy or incomplete: Probabilistic matching is ideal when dealing with datasets that have discrepancies (e.g., variations in names or missing identifiers).
Flexibility is needed: When you want to capture potential matches based on similarities and patterns rather than strict rules.
You’re working with unstructured data: In scenarios where exact matches are rare, probabilistic matching provides a more comprehensive way to link related records.
6. Combining Deterministic and Probabilistic Approaches
In many cases, businesses might benefit from a hybrid approach that combines both deterministic and probabilistic matching methods. This allows for more flexibility by using deterministic matching when exact identifiers are available and probabilistic methods when the data lacks structure or consistency.
Example: In identity resolution, a company may first apply deterministic matching to link accounts using unique identifiers (e.g., email or phone number) and then apply probabilistic matching to resolve any remaining records with partial data or variations in names.
Conclusion
Choosing between deterministic vs probabilistic matching ultimately depends on the specific needs of your data matching process. Deterministic matching provides high precision and works well with structured data, while probabilistic matching algorithms offer flexibility for dealing with unstructured or incomplete data.
By understanding the strengths and limitations of each approach, businesses can make informed decisions about which algorithm to use—or whether a combination of both is necessary—to achieve accurate and efficient data matching. In today’s increasingly complex data landscape, mastering these techniques is key to unlocking the full potential of your data.
0 notes
Text
PSA:
An algorithm is simply a list of instructions used to perform a computation. They've existed for use by mathematicians long prior to the invention of computers. Nearly everything a computer does is algorithmic in some way. It is not inherently a machine-learning concept (though machine learning systems do use algorithms), and websites do not have special algorithms designed just for you. Sentences like "Youtube is making bad recommendations, I guess I messed up my algorithm" simply make no sense. No one at Youtube HQ has written a bespoke algorithm just for you.
Furthermore, people often try to distinguish between more predictable and less predictable software systems (eg tag-based searching vs data-driven search/fuzzy-finding) by referring to the less predictable version as "algorithmic". Deterministic algorithms are still algorithms. Better terms for most of these situations include:
data-driven
fuzzy
probabilistic
machine-learning/ML
Thank you.
#196#r196#r/196#algorithm#algorithmic#search#search engine#recommendation system#machine learning#ai#artificial intelligence
6 notes
·
View notes
Text
0 notes
Text
Choosing Between Software Development and AI Engineering: A Guide for Freshers
Overview of AI vs. Traditional Engineering
As technology evolves, the choice between pursuing a career in Artificial Intelligence (AI) or traditional engineering is becoming increasingly relevant. Both paths offer unique opportunities and challenges, and understanding their distinctions is crucial for making an informed decision.
Key Differences Between AI and Traditional Engineering
Development Methodologies
Traditional Engineering typically follows a linear development model, such as the Waterfall model. This approach emphasizes comprehensive planning, documentation, and a clear sequence of phases: requirements gathering, design, implementation, testing, and maintenance. Each phase must be completed before proceeding to the next, which can lead to rigidity in adapting to change.
AI Development: Often employs iterative and agile methodologies. This flexibility allows for continuous learning and adaptation based on real-world data. AI systems evolve through repeated training, evaluation, and refinement cycles, making them more responsive to changing requirements.
Data Dependency
Traditional Software: Relies on predefined rules and logic. The quality of the software is largely determined by the accuracy of the code and specifications provided at the start of the project.
AI Systems: Heavily dependent on data quality and quantity. The performance of AI models is directly influenced by the data they are trained on; poor data can lead to biased or inaccurate outcomes
Algorithm Complexity
Traditional Engineering: Utilizes straightforward algorithms that follow deterministic logic. This predictability allows for easier tracing of software behavior back to the code.
AI Development: Involves complex algorithms, including machine learning and deep learning models that can learn from data and make decisions based on patterns. This complexity can make AI systems less interpretable compared to traditional software.
Problem-Solving Capabilities
Traditional Systems: Are proficient at solving specific tasks they are programmed for but lack the ability to adapt or learn from new information.
AI Systems: Excel in dynamic environments, adapting to unforeseen challenges and generalizing knowledge across diverse problem domains. They often outperform traditional computing in complex scenarios that require nuanced understanding.
Decision-Making Processes
Traditional Computing: Decisions are deterministic, adhering strictly to predefined rules without the capacity for nuance or contextual awareness.
AI Decision-Making: Involves probabilistic reasoning where machine learning models assess probabilities based on data patterns, facilitating a more nuanced decision-making process akin to human cognition.
Career Path Considerations
When choosing between AI engineering and traditional software development, consider the following factors:
Interest in Data vs. Software Applications: If you enjoy working with data, solving complex problems, and utilizing statistical methods, AI engineering may be a suitable path. Conversely, if you prefer building software applications using various programming languages and frameworks, traditional software development might be a better fit.
Job Market Trends: The demand for AI professionals is rapidly increasing as businesses seek to leverage data-driven insights. Traditional engineering roles remain essential but may not offer the same growth potential as AI-related positions in emerging technologies like machine learning and automation.
Skill Set Requirements: AI engineering typically requires knowledge of algorithms, statistics, and programming languages suited for data manipulation (e.g., Python). Traditional engineering focuses more on software design principles, coding practices, and project management skills.
Conclusion
Arya College of Engineering & I.T. has Both AI and traditional engineering paths that offer rewarding careers but cater to different interests and skill sets. As technology continues to advance, hybrid roles that integrate both fields are likely to emerge. Therefore, aspiring professionals should evaluate their interests in problem-solving approaches, data-handling capabilities, and adaptability to choose the path that aligns best with their career aspirations. Understanding the strengths and limitations of each approach will enable individuals to harness their potential effectively in an increasingly complex digital landscape.
0 notes
Text
8 GenAI Concepts Every Investor and Executive Needs to Know

Generative AI (GenAI) has rapidly moved from a theoretical concept to a powerful business tool with practical applications across various industries. However, for investors and executives to leverage the potential of this transformative technology, it is crucial to grasp some foundational concepts that will shape their approach to adopting and integrating GenAI into their companies. In this article, we explore eight key concepts every executive and investor should understand to make informed decisions about GenAI’s role in their organizations.
1. Distinguishing Between GenAI Use Cases and ROI
The world of GenAI is vast, and conversations about it often blend different use cases, making it difficult to assess its value accurately. Each GenAI application has different implications in terms of return on investment (ROI) and technological requirements. To navigate this landscape, it is important to understand the various categories of GenAI use cases—each with its unique value propositions.
Some GenAI applications are focused on automating repetitive tasks, while others aim to enhance creative processes. For example, natural language processing (NLP) tools can automate customer service inquiries, while machine learning models can assist in personalized marketing campaigns. The ROI for each use case can vary dramatically, from improving task efficiency by 10% to creating entirely new revenue streams. Understanding these categories is key to identifying the most promising areas for investment.
2. Deterministic vs. Probabilistic Software
One of the most important concepts when evaluating GenAI is the distinction between deterministic and probabilistic software. Deterministic applications are predictable—inputs lead to the same, fixed outputs every time. In contrast, probabilistic software, which powers GenAI, involves uncertainty and unpredictability. GenAI’s decision-making process is based on probabilities and patterns learned from data, leading to outputs that are not always fixed.
This difference has significant implications for how businesses use GenAI. While deterministic software is often easier to deploy and predict, probabilistic models like those in GenAI offer the potential for much richer, more adaptive capabilities. Businesses must be prepared for this unpredictability and manage it accordingly when using GenAI in decision-making processes.
3. The WINS Framework: A Focused Approach to GenAI Opportunities
When considering how GenAI will affect a specific industry, company, or job, asking broad, sweeping questions like "How will GenAI impact my business?" is often unproductive. These questions lead to vague answers that don’t provide actionable insights. A better approach is to use the "WINS framework, which focuses on Knowledge Work, Innovation, Networking, and Scaling.
The WINS framework narrows the scope and enables a more targeted analysis of how GenAI can either create opportunities or disrupt existing business models. By focusing on knowledge work—the processes that involve handling and analyzing information—executives can identify where GenAI could improve efficiency, reduce costs, or create new business models.
For example, applying GenAI to repetitive tasks like RFP responses or contract analysis can significantly enhance productivity and reduce human error. Focusing on such areas allows companies to measure the true impact of GenAI on their business rather than getting lost in broad, philosophical discussions.
4. GenAI as "Power Tools" for Knowledge Work
One of the most profound ways GenAI can benefit a company is by acting as "power tools" for knowledge work. This metaphor compares GenAI’s capabilities to the electric drills used to replace manual, time-consuming tasks. GenAI automates and accelerates tasks such as brainstorming, analysis, job description creation, and career planning, which traditionally require significant human effort.
Research has shown that integrating GenAI into these tasks can improve performance by as much as 10% to 300%, depending on the task and how it is implemented. This level of productivity improvement is transformative, especially when applied across entire departments or business units. By leveraging GenAI for these types of tasks, companies can enhance operational efficiency, reduce costs, and free up human workers to focus on more strategic activities.
5. Moving Beyond ChatGPT to Unlock True Value
Many people, including investors and executives, associate GenAI primarily with consumer-facing applications like OpenAI's ChatGPT. While ChatGPT is an impressive demonstration of text-based interaction, true value is unlocked when businesses apply GenAI to their own data. By integrating GenAI with proprietary data, companies can create custom applications such as technical product manual chatbots or onboarding tools for new employees.
For instance, a large company could use GenAI to build a chatbot that helps new sales representatives quickly understand product features, company policies, and sales techniques by leveraging company-specific documents. This use of GenAI can help streamline training, reduce onboarding times, and enhance employee performance.
6. The Rise of Multi-Modal GenAI
GenAI is moving beyond simple "text-to-text" interactions, such as those seen in ChatGPT. Multi-modal GenAI expands the range of inputs and outputs, enabling more complex interactions. For example, the ability to convert text into video or audio (text-to-video or text-to-speech) is opening up new possibilities for content creation, customer engagement, and training.
The implications of multi-modal GenAI are vast. It allows businesses to create more immersive and dynamic customer experiences, such as interactive tutorials or personalized marketing campaigns that include text, images, and video. Companies that embrace these capabilities can differentiate themselves in the marketplace by offering more engaging, high-quality content.
7. Slow Adoption but Significant Potential for Digital Transformation
While GenAI is seen as a powerful tool for accelerating digital transformation, it is important to note that many businesses are still in the early stages of adoption. According to recent studies, less than 5% of companies have GenAI applications in production. This slow uptake presents both a challenge and an opportunity for executives looking to gain a competitive advantage.
The companies that successfully integrate GenAI into their operations stand to benefit immensely. GenAI can act as a catalyst for digital transformation, helping companies automate processes, innovate their product offerings, and enhance customer experiences. However, businesses need to be patient and strategic in their implementation, as achieving meaningful transformation can take time.
8. The EAT Framework: Education, Application, and Transformation
Successfully implementing GenAI in a business requires more than just adopting the technology—it requires a comprehensive strategy. The "EAT" framework (Educate, Apply, and Transform) provides a roadmap for companies looking to leverage GenAI. Education should start at the board level and trickle down to all employees. It typically takes six to nine months of education before a company can begin applying GenAI effectively.
The application phase is where businesses start using GenAI to solve specific challenges, and the transformation phase involves fully integrating GenAI into all aspects of the organization. This process often takes three years or more, but it is crucial for achieving lasting, scalable success.
Conclusion
GenAI is not just another technological trend; it is a transformative force that can reshape industries, enhance business operations, and drive innovation. For executives and investors to unlock its full potential, they must understand the key concepts outlined above: from the distinct categories of GenAI use cases to the frameworks that guide its strategic implementation. With careful planning, education, and a commitment to transformation, businesses can harness the power of GenAI to drive long-term success and stay competitive in a rapidly evolving digital landscape.
1 note
·
View note
Text
AI Uncovered: A Comprehensive Guide

Machine Learning (ML) ML is a subset of AI that specifically focuses on developing algorithms and statistical models that enable machines to learn from data, without being explicitly programmed. ML involves training models on data to make predictions, classify objects, or make decisions. Key characteristics: - Subset of AI - Focuses on learning from data - Involves training models using algorithms and statistical techniques - Can be supervised, unsupervised, or reinforcement learning Artificial Intelligence (AI) AI refers to the broader field of research and development aimed at creating machines that can perform tasks that typically require human intelligence. AI involves a range of techniques, including rule-based systems, decision trees, and optimization methods. Key characteristics: - Encompasses various techniques beyond machine learning - Focuses on solving specific problems or tasks - Can be rule-based, deterministic, or probabilistic Generative AI (Gen AI) Gen AI is a subset of ML that specifically focuses on generating new, synthetic data that resembles existing data. Gen AI models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), learn to create new data samples by capturing patterns and structures in the training data. Key characteristics: - Subset of ML - Focuses on generating new, synthetic data - Involves learning patterns and structures in data - Can be used for data augmentation, synthetic data generation, and creative applications Distinctions - AI vs. ML: AI is a broader field that encompasses various techniques, while ML is a specific subset of AI that focuses on learning from data. - ML vs. Gen AI: ML is a broader field that includes various types of learning, while Gen AI is a specific subset of ML that focuses on generating new, synthetic data. - AI vs. Gen AI: AI is a broader field that encompasses various techniques, while Gen AI is a specific subset of ML that focuses on generating new data. Example Use Cases - AI: Virtual assistants (e.g., Siri, Alexa), expert systems, and decision support systems. - ML: Image classification, natural language processing, recommender systems, and predictive maintenance. - Gen AI: Data augmentation, synthetic data generation, image and video generation, and creative applications (e.g., art, music). AI Terms - ANN (Artificial Neural Network): A computational model inspired by the human brain's neural structure. - API (Application Programming Interface): A set of rules and protocols for building software applications. - Bias: A systematic error or distortion in an AI model's performance. - Chatbot: A computer program that simulates human-like conversation. - Computer Vision: The field of AI that enables computers to interpret and understand visual data. - DL (Deep Learning): A subset of ML that uses neural networks with multiple layers. - Expert System: A computer program that mimics human decision-making in a specific domain. - Human-in-the-Loop (HITL): A design approach where humans are involved in AI decision-making. - Intelligent Agent: A computer program that can perceive, reason, and act autonomously. - Knowledge Graph: A database that stores relationships between entities. - NLP (Natural Language Processing): The field of AI that enables computers to understand human language. - Robotics: The field of AI that deals with the design and development of robots. - Symbolic AI: A type of AI that uses symbols and rules to represent knowledge. ML Terms - Activation Function: A mathematical function used to introduce non-linearity in neural networks. - Backpropagation: An algorithm used to train neural networks. - Batch Normalization: A technique used to normalize input data. - Classification: The process of assigning labels to data points. - Clustering: The process of grouping similar data points. - Convolutional Neural Network (CNN): A type of neural network for image processing. - Data Augmentation: Techniques used to artificially increase the size of a dataset. - Decision Tree: A tree-like model used for classification and regression. - Dimensionality Reduction: Techniques used to reduce the number of features in a dataset. - Ensemble Learning: A method that combines multiple models to improve performance. - Feature Engineering: The process of selecting and transforming data features. - Gradient Boosting: A technique used to combine multiple weak models. - Hyperparameter Tuning: The process of optimizing model parameters. - K-Means Clustering: A type of unsupervised clustering algorithm. - Linear Regression: A type of regression analysis that models the relationship between variables. - Model Selection: The process of choosing the best model for a problem. - Neural Network: A type of ML model inspired by the human brain. - Overfitting: When a model is too complex and performs poorly on new data. - Precision: The ratio of true positives to the sum of true positives and false positives. - Random Forest: A type of ensemble learning algorithm. - Regression: The process of predicting continuous outcomes. - Regularization: Techniques used to prevent overfitting. - Supervised Learning: A type of ML where the model is trained on labeled data. - Support Vector Machine (SVM): A type of supervised learning algorithm. - Unsupervised Learning: A type of ML where the model is trained on unlabeled data. Gen AI Terms - Adversarial Attack: A technique used to manipulate input data to mislead a model. - Autoencoder: A type of neural network used for dimensionality reduction and generative modeling. - Conditional Generative Model: A type of Gen AI model that generates data based on conditions. - Data Imputation: The process of filling missing values in a dataset. - GAN (Generative Adversarial Network): A type of Gen AI model that generates data through competition. - Generative Model: A type of ML model that generates new data samples. - Latent Space: A lower-dimensional representation of data used in Gen AI models. - Reconstruction Loss: A measure of the difference between original and reconstructed data. - VAE (Variational Autoencoder): A type of Gen AI model that generates data through probabilistic encoding. Other Terms - Big Data: Large datasets that require specialized processing techniques. - Cloud Computing: A model of delivering computing services over the internet. - Data Science: An interdisciplinary field that combines data analysis, ML, and domain expertise. - DevOps: A set of practices that combines software development and operations. - Edge AI: The deployment of AI models on edge devices, such as smartphones or smart home devices. - Explainability: The ability to understand and interpret AI model decisions. - Fairness: The absence of bias in AI model decisions. - IoT (Internet of Things): A network of physical devices embedded with sensors and software. - MLOps: A set of practices that combines ML and DevOps. - Transfer Learning: A technique used to adapt pre-trained models to new tasks. This list is not exhaustive, but it covers many common terms and acronyms used in AI, ML, and Gen AI. I hope this helps you learn and navigate the field! Large Language Models (LLMs) Overview LLMs are a type of artificial intelligence (AI) designed to process and generate human-like language. They're a subset of Deep Learning (DL) models, specifically transformer-based neural networks, trained on vast amounts of text data. LLMs aim to understand the structure, syntax, and semantics of language, enabling applications like language translation, text summarization, and chatbots. Key Characteristics - Massive Training Data: LLMs are trained on enormous datasets, often exceeding billions of parameters. - Transformer Architecture: LLMs utilize transformer models, which excel at handling sequential data like text. - Self-Supervised Learning: LLMs learn from unlabeled data, predicting missing words or next tokens. - Contextual Understanding: LLMs capture context, nuances, and relationships within language. How LLMs Work - Tokenization: Text is broken into smaller units (tokens) for processing. - Embeddings: Tokens are converted into numerical representations (embeddings). - Transformer Encoder: Embeddings are fed into the transformer encoder, generating contextualized representations. - Decoder: The decoder generates output text based on the encoder's output. - Training: LLMs are trained using masked language modeling, predicting missing tokens. Types of LLMs - Autoregressive LLMs (e.g., BERT, RoBERTa): Generate text one token at a time. - Masked LLMs (e.g., BERT, DistilBERT): Predict missing tokens in a sequence. - Encoder-Decoder LLMs (e.g., T5, BART): Use separate encoder and decoder components. Applications - Language Translation: LLMs enable accurate machine translation. - Text Summarization: LLMs summarize long documents into concise summaries. - Chatbots: LLMs power conversational AI, responding to user queries. - Language Generation: LLMs create coherent, context-specific text. - Question Answering: LLMs answer questions based on context. Relationship to Other AI Types - NLP: LLMs are a subset of NLP, focusing on language understanding and generation. - DL: LLMs are a type of DL model, utilizing transformer architectures. - ML: LLMs are a type of ML model, trained using self-supervised learning. - Gen AI: LLMs can be used for generative tasks, like text generation. Popular LLMs - BERT (Bidirectional Encoder Representations from Transformers) - RoBERTa (Robustly Optimized BERT Pretraining Approach) - T5 (Text-to-Text Transfer Transformer) - BART (Bidirectional and Auto-Regressive Transformers) - LLaMA (Large Language Model Meta AI) LLMs have revolutionized NLP and continue to advance the field of AI. Their applications are vast, and ongoing research aims to improve their performance, efficiency, and interpretability. Types of Large Language Models (LLMs) Overview LLMs are a class of AI models designed to process and generate human-like language. Different types of LLMs cater to various applications, tasks, and requirements. Key Distinctions 1. Architecture - Transformer-based: Most LLMs use transformer architectures (e.g., BERT, RoBERTa). - Recurrent Neural Network (RNN)-based: Some LLMs use RNNs (e.g., LSTM, GRU). - Hybrid: Combining transformer and RNN architectures. 2. Training Objectives - Masked Language Modeling (MLM): Predicting masked tokens (e.g., BERT). - Next Sentence Prediction (NSP): Predicting sentence relationships (e.g., BERT). - Causal Language Modeling (CLM): Predicting next tokens (e.g., transformer-XL). 3. Model Size - Small: 100M-500M parameters (e.g., DistilBERT). - Medium: 1B-5B parameters (e.g., BERT). - Large: 10B-50B parameters (e.g., RoBERTa). - Extra Large: 100B+ parameters (e.g., transformer-XL). 4. Training Data - General-purpose: Trained on diverse datasets (e.g., Wikipedia, books). - Domain-specific: Trained on specialized datasets (e.g., medical, financial). - Multilingual: Trained on multiple languages. Notable Models 1. BERT (Bidirectional Encoder Representations from Transformers) - Architecture: Transformer - Training Objective: MLM, NSP - Model Size: Medium - Training Data: General-purpose 2. RoBERTa (Robustly Optimized BERT Pretraining Approach) - Architecture: Transformer - Training Objective: MLM - Model Size: Large - Training Data: General-purpose 3. DistilBERT (Distilled BERT) - Architecture: Transformer - Training Objective: MLM - Model Size: Small - Training Data: General-purpose 4. T5 (Text-to-Text Transfer Transformer) - Architecture: Transformer - Training Objective: CLM - Model Size: Large - Training Data: General-purpose 5. transformer-XL (Extra-Large) - Architecture: Transformer - Training Objective: CLM - Model Size: Extra Large - Training Data: General-purpose 6. LLaMA (Large Language Model Meta AI) - Architecture: Transformer - Training Objective: MLM - Model Size: Large - Training Data: General-purpose Choosing an LLM Selection Criteria - Task Requirements: Consider specific tasks (e.g., sentiment analysis, text generation). - Model Size: Balance model size with computational resources and latency. - Training Data: Choose models trained on relevant datasets. - Language Support: Select models supporting desired languages. - Computational Resources: Consider model computational requirements. - Pre-trained Models: Leverage pre-trained models for faster development. Why Use One Over Another? Key Considerations - Performance: Larger models often perform better, but require more resources. - Efficiency: Smaller models may be more efficient, but sacrifice performance. - Specialization: Domain-specific models excel in specific tasks. - Multilingual Support: Choose models supporting multiple languages. - Development Time: Pre-trained models save development time. LLMs have revolutionized NLP. Understanding their differences and strengths helps developers choose the best model for their specific applications. Parameters in Large Language Models (LLMs) Overview Parameters are the internal variables of an LLM, learned during training, that define its behavior and performance. What are Parameters? Definition Parameters are numerical values that determine the model's: - Weight matrices: Representing connections between neurons. - Bias terms: Influencing neuron activations. - Embeddings: Mapping words or tokens to numerical representations. Types of Parameters 1. Model Parameters Define the model's architecture and behavior: - Weight matrices - Bias terms - Embeddings 2. Hyperparameters Control the training process: - Learning rate - Batch size - Number of epochs Parameter Usage How Parameters are Used - Forward Pass: Parameters compute output probabilities. - Backward Pass: Parameters are updated during training. - Inference: Parameters generate text or predictions. Parameter Count Model Size Parameter count affects: - Model Complexity: Larger models can capture more nuances. - Computational Resources: Larger models require more memory and processing power. - Training Time: Larger models take longer to train. Common Parameter Counts - Model Sizes 1. Small: 100M-500M parameters (e.g., DistilBERT) 2. Medium: 1B-5B parameters (e.g., BERT) 3. Large: 10B-50B parameters (e.g., RoBERTa) 4. Extra Large: 100B+ parameters (e.g., transformer-XL) Parameter Efficiency Optimizing Parameters - Pruning: Removing redundant parameters. - Quantization: Reducing parameter precision. - Knowledge Distillation: Transferring knowledge to smaller models. Parameter Count vs. Performance - Overfitting: Too many parameters can lead to overfitting. - Underfitting: Too few parameters can lead to underfitting. - Optimal Parameter Count: Balancing complexity and generalization. Popular LLMs by Parameter Count 1. BERT (340M parameters) 2. RoBERTa (355M parameters) 3. DistilBERT (66M parameters) 4. T5 (220M parameters) 5. transformer-XL (1.5B parameters) Understanding parameters is crucial for developing and optimizing LLMs. By balancing parameter count, model complexity, and computational resources, developers can create efficient and effective language models. AI Models Overview What are AI Models? AI models are mathematical representations of relationships between inputs and outputs, enabling machines to make predictions, classify data, or generate new information. Models are the core components of AI systems, learned from data through machine learning (ML) or deep learning (DL) algorithms. Types of AI Models 1. Statistical Models Simple models using statistical techniques (e.g., linear regression, decision trees) for prediction and classification. 2. Machine Learning (ML) Models Trained on data to make predictions or classify inputs (e.g., logistic regression, support vector machines). 3. Deep Learning (DL) Models Complex neural networks for tasks like image recognition, natural language processing (NLP), and speech recognition. 4. Neural Network Models Inspired by the human brain, using layers of interconnected nodes (neurons) for complex tasks. 5. Graph Models Representing relationships between objects or entities (e.g., graph neural networks, knowledge graphs). 6. Generative Models Producing new data samples, like images, text, or music (e.g., GANs, VAEs). 7. Reinforcement Learning (RL) Models Learning through trial and error, maximizing rewards or minimizing penalties. Common Use Cases for Different Model Types 1. Regression Models Predicting continuous values (e.g., stock prices, temperatures) - Linear Regression - Decision Trees - Random Forest 2. Classification Models Assigning labels to inputs (e.g., spam vs. non-spam emails) - Logistic Regression - Support Vector Machines (SVMs) - Neural Networks 3. Clustering Models Grouping similar data points (e.g., customer segmentation) - K-Means - Hierarchical Clustering - DBSCAN 4. Dimensionality Reduction Models Reducing feature space (e.g., image compression) - PCA (Principal Component Analysis) - t-SNE (t-Distributed Stochastic Neighbor Embedding) - Autoencoders 5. Generative Models Generating new data samples (e.g., image generation) - GANs (Generative Adversarial Networks) - VAEs (Variational Autoencoders) - Generative Models 6. NLP Models Processing and understanding human language - Language Models (e.g., BERT, RoBERTa) - Sentiment Analysis - Text Classification 7. Computer Vision Models Processing and understanding visual data - Image Classification - Object Detection - Segmentation Model Selection - Problem Definition: Identify the problem type (regression, classification, clustering, etc.). - Data Analysis: Explore data characteristics (size, distribution, features). - Model Complexity: Balance model complexity with data availability and computational resources. - Evaluation Metrics: Choose relevant metrics (accuracy, precision, recall, F1-score, etc.). - Hyperparameter Tuning: Optimize model parameters for best performance. Model Deployment - Model Serving: Deploy models in production environments. - Model Monitoring: Track model performance and data drift. - Model Updating: Re-train or fine-tune models as needed. - Model Interpretability: Understand model decisions and feature importance. AI models are the backbone of AI systems. Understanding the different types of models, their strengths, and weaknesses is crucial for building effective AI solutions. Resources Required to Use Different Types of AI AI Types and Resource Requirements 1. Rule-Based Systems Simple, deterministic AI requiring minimal resources: * Computational Power: Low * Memory: Small * Data: Minimal * Expertise: Domain-specific knowledge 2. Machine Learning (ML) Trained on data, requiring moderate resources: * Computational Power: Medium * Memory: Medium * Data: Moderate (labeled datasets) * Expertise: ML algorithms, data preprocessing 3. Deep Learning (DL) Complex neural networks requiring significant resources: * Computational Power: High * Memory: Large * Data: Massive (labeled datasets) * Expertise: DL architectures, optimization techniques 4. Natural Language Processing (NLP) Specialized AI for text and speech processing: * Computational Power: Medium-High * Memory: Medium-Large * Data: Large (text corpora) * Expertise: NLP techniques, linguistics 5. Computer Vision Specialized AI for image and video processing: * Computational Power: High * Memory: Large * Data: Massive (image datasets) * Expertise: CV techniques, image processing Resources Required to Create AI AI Development Resources 1. Read the full article
0 notes
Text
The Philosophy of Causation
The philosophy of causation delves into the nature of the relationship between cause and effect. This area of philosophy seeks to understand how and why certain events lead to particular outcomes and explores various theories and concepts related to causality. The study of causation is fundamental to numerous fields, including science, metaphysics, and everyday reasoning.
Key Concepts in the Philosophy of Causation
Causal Determinism:
Concept: The idea that every event is necessitated by antecedent events and conditions together with the laws of nature.
Argument: If causal determinism is true, then every event or state of affairs, including human actions, is the result of preceding events in accordance with universal laws.
Causal Relations and Counterfactuals:
Concept: Causal relations can often be understood in terms of counterfactual dependence: if event A had not occurred, event B would not have occurred either.
Argument: David Lewis’s counterfactual theory of causation emphasizes the importance of counterfactuals (what would have happened if things had been different) in understanding causation.
Humean Regularity Theory:
Concept: David Hume proposed that causation is nothing more than the regular succession of events; if A is regularly followed by B, we consider A to be the cause of B.
Argument: This theory suggests that causation is about patterns of events rather than any necessary connection between them.
Mechanistic Theories:
Concept: These theories emphasize the importance of mechanisms—specific processes or systems of parts that produce certain effects.
Argument: Understanding the mechanisms underlying causal relationships is crucial for explaining how causes bring about their effects.
Probabilistic Causation:
Concept: This approach deals with causes that increase the likelihood of their effects rather than deterministically bringing them about.
Argument: Probabilistic causation is essential for understanding phenomena in fields like quantum mechanics and statistics, where outcomes are not strictly determined.
Agent Causation:
Concept: This theory posits that agents (typically human beings) can initiate causal chains through their actions.
Argument: Unlike event causation, where events cause other events, agent causation places the source of causal power in agents themselves, which is significant for discussions of free will and moral responsibility.
Causal Pluralism:
Concept: The view that there are multiple legitimate ways to understand and analyze causation, depending on the context.
Argument: Causal pluralism suggests that different scientific, philosophical, and everyday contexts may require different accounts of causation.
Theoretical Perspectives on Causation
Humean vs. Non-Humean Causation:
Humean: Emphasizes regularity and contiguity in space and time between causes and effects, rejecting the notion of necessary connections.
Non-Humean: Asserts that there are genuine necessary connections in nature that underpin causal relationships.
Reductionism vs. Non-Reductionism:
Reductionism: Seeks to explain causation in terms of more fundamental phenomena, such as laws of nature or physical processes.
Non-Reductionism: Holds that causal relations are fundamental and cannot be fully explained by reducing them to other phenomena.
Causal Realism vs. Causal Anti-Realism:
Causal Realism: The belief that causal relations are objective features of the world.
Causal Anti-Realism: The belief that causal relations are not objective features of the world but rather constructs or useful fictions.
Temporal Asymmetry of Causation:
Concept: Causation is often thought to have a temporal direction, with causes preceding their effects.
Argument: Philosophers debate whether this asymmetry is a fundamental feature of reality or a result of our psychological or epistemic limitations.
The philosophy of causation is a rich and complex field that addresses fundamental questions about how and why events occur. From the deterministic framework of classical mechanics to the probabilistic nature of quantum mechanics, and from the regularity theory of Hume to contemporary mechanistic approaches, causation remains a central topic in understanding the structure of reality.
#philosophy#epistemology#knowledge#learning#education#chatgpt#ontology#metaphysics#Causation#Determinism#Counterfactuals#Humean Theory#Mechanistic Theories#Probabilistic Causation#Agent Causation#Causal Pluralism#Temporal Asymmetry
0 notes
Text
Accurate football prediction,
Accurate football prediction,
Football prediction is an intricate blend of art and science. As one of the world's most beloved sports, football draws immense attention, with millions of fans and analysts attempting to predict match outcomes. Accurate football prediction is not just about luck; it requires a deep understanding of various factors, from player form to team strategy, historical data, and even psychological aspects. This article delves into the methods and tools that can enhance the accuracy of football predictions.
Understanding the Basics At its core, football prediction involves forecasting the results of football matches. This can range from predicting the winner of a single match to forecasting league standings, player performances, and more. Accurate predictions rely on a combination of statistical analysis, historical data, and current trends.
Statistical Analysis Statistics play a crucial role in football prediction. Analysts examine a plethora of data points, such as:
Team Performance: Historical performance of teams in various conditions (home vs. away games, against specific opponents). Player Statistics: Individual player metrics, including goals scored, assists, defensive capabilities, and injury history. Match Outcomes: Outcomes of previous matches between the teams involved. By crunching these numbers, analysts can identify patterns and trends that might influence future performances.
Historical Data Historical data provides context and depth to statistical analysis. For instance, a team’s performance over the past few seasons can indicate its consistency and resilience. Additionally, head-to-head records between teams can reveal psychological advantages or disadvantages.
Current Trends and Form Current form is a critical factor in football prediction. A team or player in good form is more likely to perform well. Factors influencing current form include:
Recent Performance: How the team or player has performed in recent matches. Injuries and Suspensions: Availability of key players. Psychological Factors: Morale and motivation, influenced by recent results or off-field issues. Advanced Techniques in Football Prediction With advancements in technology and data science, football prediction has evolved significantly. Modern techniques incorporate machine learning and artificial intelligence to enhance accuracy.
Machine Learning Models Machine learning models can process vast amounts of data and identify complex patterns that human analysts might miss. These models can be trained on historical match data to predict outcomes based on a variety of inputs, such as team and player statistics, weather conditions, and even social media sentiment.
Simulation Models Simulation models, such as the Monte Carlo simulation, are used to predict the probability of various outcomes. By running thousands of simulations of a match, analysts can estimate the likelihood of different results, helping to provide a probabilistic view rather than a deterministic prediction.
Expert Systems Expert systems leverage the knowledge and experience of football analysts and coaches. These systems use rule-based algorithms to replicate expert decision-making processes, combining statistical data with qualitative insights.
The Role of Human Insight Despite technological advancements, human insight remains invaluable in football prediction. Experienced analysts can interpret data in the context of the sport’s nuances, considering factors like team chemistry, managerial tactics, and unexpected developments that pure data analysis might overlook.
Psychological and Contextual Factors Psychological factors, such as team morale, the impact of a passionate home crowd, or the pressure of a crucial match, can significantly influence outcomes. Understanding the context of a match, including the stakes involved and the motivations of the players and teams, is essential for accurate prediction.
Challenges in Football Prediction Football is inherently unpredictable, with many variables at play. Factors such as unexpected injuries, referee decisions, and even weather conditions can drastically alter the outcome of a match. Therefore, while data and analysis can significantly improve prediction accuracy, the element of uncertainty always remains.
Conclusion Accurate football prediction is a dynamic and complex field, requiring a blend of statistical analysis, historical context, current trends, advanced modeling techniques, and human insight. While no method can guarantee perfect predictions, the integration of these diverse approaches can significantly enhance the accuracy and reliability of forecasts. As technology continues to evolve, the future of football prediction looks promising, offering deeper insights and more sophisticated tools for analysts and fans alike.
0 notes
Text
Japan’s Flaky ID Card Scheme — What Lies at its Root?

“Fujitsu admits it fluffed the fix for Japan’s flaky ID card scheme” https://www.theregister.com/2023/06/30/fujitsu_japan_micjet_id_card_pause/
Being a Japanese identity guy, I feel pressed to say something about these embarrassing developments in identity assurance in Japan.
At the root of all those visible problems lies an invisible structural failure, that is, the overall system was conceived and designed by the people who are not just security-illiterate but science-illiterate.
Those who are indifferent to what is required for identification and for authentication.
Those who are indifferent to what a probabilistic factor means as against deterministic factors.
Those who are indifferent to the difference between two factors deployed in a two-layer/in-series formation and in a two-entrance/in-parallel formation.
In brief, those who adamantly deny the scientific observation that biometrics used with a default/fallback password in a two-entrance/in-parallel formation would only provide the overall identity security lower than a password-only authentication.
Those people are also the believers of a myth of PIN, that is, “PIN must be easier to remember than an alphanumeric password because it is simpler and shorter” — They seem to be just ignorant of ‘Interference of Memory’.
PIN may be easier to remember if we have to manage just one. But, what would happen when we are told to mange 2, 3, 4 and more? — Most citizens would have to rely on practicable, if very unsafe, solutions — “Reuse the same PIN across all the accounts” or “Write all PINs on a memo and carry it around with the cards requiring those PINs”. Or “Get a new PIN issued every time it is needed” to get the help desks overwhelmed.
The Japanese ID card system was conceived, designed, produced and implemented by those science-illiterate people. It would be a miracle if it worked nicely.
Ref: “In-Series’ vs ‘In-Parallel’ and Those Reputed Cybersecurity/Cryptography Professionals? “(6June2023)https://www.linkedin.com/posts/hitoshikokumai_identity-authentication-password-activity-7071783812686385152-6o-4
Well, I did try to help. But my offer of help was responded by the sheer silence of those people who knew that I flatly denied all their misbeliefs. I am now working from UK.

0 notes
Photo

Artificial Intelligence is not only changing the software paradigm (deterministic vs probabilistic), it will contribute on economy growth + $15.7 tn by 2030. #Infographic by @antgrasso source @Accenture @PwC via @raconteur #AI #ML #DigitalTransformation #Business pic.twitter.com/nu5F1Wq7zo
— dbi.srl (@dbi_srl) August 19, 2019
1 note
·
View note
Text
Chaos and order in The Expanse:
Book spoilers below.
Chaos vs. order is textually present as a theme in The Expanse through religious and mythical references, and through dialogue. In the first book, Eros Station is the catalyst for the protomolecule’s spread. Eros, in his earliest Greek forms, was a primordial god born with or from Chaos, depending on the interpretation. The title of the first book, Leviathan Wakes, references a sea monster, Leviathan, defeated by Yahweh in the Tanakh, itself a reflection of an older story.
Such stories are part of a common narrative, sometimes called Chaoskampf, that is found across cultures, in myth, legend, and religion – that of a fight between a deity, usually a storm god, and a chaos monster, usually a sea monster or dragon, interpreted by some as representing the struggle between order and chaos in the cycle of creation. Other examples include the Greek Zeus vs. Typhon, the Vedic Indra vs. Vritra, and the Babylonian Marduk vs. Tiamat.
The title of the upcoming eighth book is Tiamat’s Wrath. There are several recent references to storms, namely among the Laconian ships - the Gathering Storm, the Heart of the Tempest, the Eye of the Typhoon, etc. The struggle between order and chaos is all but stated as a theme by Duarte in his conversation with Holden at the end of Persepolis Rising:
“There was no path where we left the gates alone. No future where we didn’t use the technologies and lessons we learned from them. And there wasn’t likely to be one where we didn’t face the same kind of pushback that killed the ones who came before us. There was only the way forward where we were scattershot and chaotic, or the one where we were organized, regimented, and disciplined."
Tiamat probably refers to the alien killers, the sea monster of the series, and in this scenario, Duarte has positioned himself and humanity as the storm god meant to fight the monster.
However, while the Laconian ships are named after storms, the Heart of the Tempest and the protomolecule-augmented power armor are described as looking like deep sea creatures, placing Laconia thematically closer to the metaphorical sea monster of the series. It’s also probably a nod to the inherent connection between the alien technology and said sea monster.
These are just some general observations, from which I’m going to make two leaps below:
1. The alien killers.
In Greek cosmogony, “chaos” refers to the primordial void that existed before creation, the empty space on which Earth rests, or the gap created by the separation of Earth and Sky. Notably, it is sometimes compared to water. Chaos was considered the first primordial god.
Chaos is also a component of early Greek philosophy, representing the idea of a base, primordial substrate from which all things arise, an idea that has persisted in increasingly complex forms all the way into modern physics. The way that the alien killers and their artifacts and existence are described certainly echo this, as they seem to manifest between and beyond elementary particles. Humans perceive the killers’ artifacts and presence as getting smaller and smaller, down to the basics we know and beyond. It’s described as the “true shape of reality” by Elvi, and “something deep, something profound” by Duarte.
So, if we assume that the alien killers are the chaos monster, then for the purposes of The Expanse: matter is order, and whatever lies beyond the subatomic level is chaos, thematically speaking. This lines up with the divide between relativity and quantum mechanics, two theories of physics that, for now, become incompatible with each other where the smallest facets of reality are concerned. Relativity - concerning gravity and space-time - is deterministic or, in other words, ordered. Quantum mechanics - concerning subatomic interactions - is probabilistic or, in other words, chaotic.
Meanwhile, the ring system seems to be an access point into the material universe for the alien killers. The aliens began destroying parts of their empire in an effort to stop whatever was killing them, then shut the entire ring system down. It ate ships in a way that mirrored what Elvi experienced when she went through the “bullet” that the killers left behind on Ilus, and Marco saw something “dark and sudden” within the cloud of elementary particles while the Pella was being eaten in the ring.
Therefore, we can assume that the alien killers are somehow connected to the slow zone, the ring system, and the rest of the alien technology, including the protomolecule. There are several descriptions of the protomolecule and other alien tech that call to mind sea creatures and the ocean, reinforcing this connection, and remember, Eros emerged with Chaos.
So, the first leap: I think the slow zone, which is described as needing a lot of energy to keep it from collapsing, is simply an aspect of another dimension made manifest. Theories of physics that attempt to unify the fundamental interactions, of which the classical concept of “chaos” is an early shadow, often rely on proposing extra dimensions of existence beyond four (three space, one time) in order to build a bridge between quantum mechanics and relativity. Not necessarily a place (outside of the slow zone) in the colloquial way that “dimension” is often used, but maybe some older state or structure underlying the universe (hence emitting radiation older than the Big Bang), that may provide its very foundation, similar to the Greek conception of chaos as the primordial void/foundation underneath “Earth” and as the basic substrate of reality.
My guess is that the aliens, who were clearly capable of subatomic engineering, somehow tunneled “deep” enough into the subatomic “layers” to utilize properties of this dimension. The slow zone is a manifestation of that, and their technology, like the protomolecule, can probably tap into those properties as well. And in tapping into it, the aliens accidentally invited something existing entirely within that dimension into shallower waters, so to speak. In other words, a situation meant to parallel humans digging too deep on Phoebe and unleashing the protomolecule in a foolish attempt to use it.
The investigator describes physical existence as the “fallen world,” implying that the aliens saw matter as a lesser form of being. It appears that they were reaching beyond the boundaries of matter. If they reached too high - or dug too deep - to touch some primal existence beyond even the elementary particles that we know, then maybe the “gods” of that dimension reached back to strike them down. Hubris punished by Nemesis, another very Greek thing.
(It should also be noted that the show takes the idea of going “deeper” into some metaphorical cosmic ocean even further, visually speaking. The design of the slow zone and the ring system gives the impression of going underwater, and the slow zone looks like a bubble of air. It’s easy to imagine the shadow of some dark sea monster swimming just beyond its borders.)
2. Juliette Andromeda Mao.
Andromeda was a figure in Greek myth, meant as a sacrifice to a sea monster because of her mother’s hubris. With Leviathan and Tiamat used as titles, and with Chaoskampf references and themes present in the series, an oblique reference to another sea monster might be something to pay attention to. What’s interesting is that, while Julie died because of the protomolecule, and we are made to think that the protomolecule is the sea monster in the first book, it becomes apparent later that it isn’t - at least, not the biggest monster around and not the one to be afraid of.
Duarte is obviously destined to be eaten by his own hubris, but he’s right about one thing, and it’s that the protomolecule is probably going to be crucial to humanity not being utterly destroyed when the hornet’s nest gets kicked.
While I’ve only talked about things in terms of chaos vs. order, I think the ultimate solution is one of balance. Duarte’s idea of “order” is wrong and impossible, and the alien killers, the metaphorical chaos, are an embodiment of cosmic horror and not something to sit down to a conversation with. They are extremes of nature and of humanity, and the solution is somewhere in between them.
The alien technology can obviously tap into that “deep and profound” layer where the alien killers exist, which means that it’s an extension of that chaos, but it was built on a framework of organic material, which means that it’s an extension of the ordered reality of matter as well. The protomolecule is an aspect of that technology; it already is balance.
And the established pattern of the series where alien things are concerned is human beings - Miller, Holden, Elvi - communicating with the protomolecule and the souls within - Julie, Miller - and saving the day through that, a balance and compromise between human and alien. But the protomolecule needs a voice for that.
I don’t think the investigator will come back in a big way. I wouldn’t complain if he did, but Miller’s second death felt final and may have planted the seeds of enabling the protomolecule to, as was often repeated, exceed boundary conditions at a later point.
So, the second leap: if the protomolecule is seeking to defend against an enemy and to reach out to humanity in order to do so, it wouldn’t need an investigator this time. It would need a fighter.
Who was repeatedly described as a fighter, one who exceeded the boundary conditions of her role as a rich man’s daughter? Who was Eros, the seed crystal for the protomolecule’s evolution, whose essence would presumably still exist in its collective “consciousness”? Who would make the beginning and end mirrored and symmetrical, Andromeda not a victim left to be devoured by a sea monster because of a parent’s hubris this time, but a metaphorical god facing the true monster?
The cosmic fight is always between divine beings, and Andromeda doesn’t actually die, after all.
I don’t know if we will see a proto-Julie construct by the end, but I wouldn’t be surprised, because this:
“If you want to create a lasting, stable social order,” Duarte said, “only one person can ever be immortal.”
is just begging to be contradicted, one way or another. It makes sense, it’s symmetrical, it ties back to the chaos vs. order theme of the series, and it was even teased in Abbadon’s Gate. Why introduce the possibility of something happening, if not to explore it eventually? And, of course, there’s Miller’s prophetic line from the first book:
“And if we don’t die, then... well, that’ll be interesting.”
#the expanse#proto julie WHEN and not just because i miss her. i have receipts#expanse spoilers#expanse book spoilers#f: the expanse#*posts
6 notes
·
View notes
Text
View of the Future
Overall, a barbell world, rainforest world with a hollow middle.
Blue-collar manual on the left, super-powered intellectuals on the right
Individuals and small business networks leveraging AI and crypto on the left, giant corporations/platforms with strong government ties on the right and peddling the trust premium. (driven by a more fluid and composable workforce on both sides)
Total liquidity and freedom of the internet and digital world on the left, total rigidity of institutions and regulation of the physical world on the right.
Global bifurcation - Woke capital, commie capital, crypto capital
Video games becoming more like real-life; Real-life becoming more like a game
AI will trigger this entire paradigm shift:
Probabilistic vs deterministic computing - uncovering capabilities that are some parts superpower, genie, and guru (like maps and uber before)
Product design is shifting from user-centric to AI-centric. e.g. Tiktok FY feed
Rise of GPT-optimization specialists, much like SEO, to game and increase discoverability by the algorithm, what the models see
But also... proof-of-human and markers of realism will increase (e.g. putting a timestamp and location on the image taken, blurry onlyfans vids) along with verified-by-human. Human touch will be premium overall. AI and trust go hand-in-hand (though models are blackboxes)
Product people will be either the least or most important , knowing why and what to build (since the building takes care of itself)
Every app will get an AI copilot, until the nature of the app changes (a week where decades happen in ai - shift from assistant to copilot)
Digital production commoditized - bye wordcels, hi wordchads
Tiers of AI - learning from the world (global), my organization (local), and the self (personal)
Entire corpus of human knowledge so far was just a bootloader for AI
Brute-force via GPUs go brr and uncovering the 'shape' of language
But easy things look hard and hard things look easy
A total sea change to how people learn and what they learn - skills change, disruptive to education - at the very least content and ways of assessment should change (like the introduction of calculators but way more powerful)
Act of thinking will still have value by itself - going through the motions of writing and coding will reinforce ideas
Opportunities around AI: 1. Graphics chips 2. productivity apps with in-built distribution 3. fact checkers 4. prompt engineering and algo optimization 5. digital detox - ai fatigue will spur a return to real-world stuff
But where economic value will accrue still unknown - we just know that the big will get biggeer
Still no good AI sci-fi novel... an opportunity?
On the macro side:
Inflation driven by ballooning debt, national conflicts and higher supply chain redundancy, pensions (heavy weight dropped on an already leaky ship -> nationalization of the financial system?)
Deflation driven by technology longer-term - marginal cost of power and compute go to zero
Plus macro forces like aging and sustainability
0 notes
Text
As the pharmaceutical industry advances, ensuring packaging integrity has become increasingly important. While probabilistic CCIT methods have been widely used in the past, their limitations in accuracy, repeatability, and regulatory compliance have led to the growing adoption of deterministic techniques. Deterministic CCIT methods provide higher sensitivity, objective results, and improved regulatory acceptance, making them the preferred choice for pharmaceutical manufacturers. As regulatory bodies continue to push for more robust integrity testing, transitioning to deterministic CCIT methods ensures better product quality, enhances patient safety, and supports compliance with industry standards.
0 notes
Text
3d cellular automaton

3d cellular automaton full#
An alternative class of models which take into account the distribution of toughness is cellular automata finite element models (CAFE). This is because there is no information on the microstructure such as grain size and morphology, texture, and other important features considered in them. While the probabilistic approaches provide a sound scientific basis for capturing the scatter in the fracture data through assuming a probability for the presence of fracture initiators, their microstructurally agnostic assumptions can limit their predictive capability. More suitable probabilistic methods have been devised to describe the scatter associated with fracture.
3d cellular automaton full#
Therefore, deterministic approaches do not give full picture of scatter in fracture behaviour. This is evidenced by scatter in the toughness of seemingly identical specimens. The relative error of grain size before and after heat preservation is in the range of 0.1–0.6 μm, which indicates that the 3D cellular automata can accurately simulate the heat preservation process of AZ31 magnesium alloy.įracture is an inherently statistical phenomenon as it is a function of micro-structural heterogeneities such as distributed defects and inclusions. The angle between the two-dimensional slices of three-dimensional grains is approximately 120°, which is consistent with that of the traditional two-dimensional cellular automata. The grain of AZ31 magnesium alloy increases in size with the increase of temperature, and the number of grains decreases with the increase in time. Grains of different sizes are distributed normally at different times, most of which are grains with the ratio of grain diameter to average grain diameter R/Rm ≈ 1.0, which meets the minimum energy criterion of grain evolution. The results show that the normal growth of three-dimensional grains satisfies the Aboav-weaire equation, the average number of grain planes is between 12 and 14 at 420☌ and 2000 CAS, and the maximum number of grain planes is more than 40. Also, the effect of temperature on the three-dimensional grain growth process of AZ31 magnesium alloy is analyzed. However, further coarray optimi-sation is needed to narrow the performance gap between coarrays and MPI.īased on the thermodynamic conversion mechanism and energy transition principle, a three-dimensional cellular automata model of grain growth is established from the aspects of grain orientation, grain size distribution, grain growth kinetics, and grain topology. Overall, the results look promising for coarray use beyond 100k cores. The sampling and tracing analysis shows good load balancing in compute in all miniapps, but imbalance in communication, indicating that the difference in performance between MPI and coarrays is likely due to parallel libraries (MPICH2 vs libpgas) and the Cray hardware specific libraries (uGNI vs DMAPP). This is further evi-denced by the fact that very aggressive cache and inter-procedural optimisations lead to no performance gain. This is likely because the CA algorithm is network bound at scale. Adding OpenMP to MPI or to coarrays resulted in worse L2 cache hit ratio, and lower performance in all cases, even though the NUMA effects were ruled out. MPI halo exchange (HX) scaled better than coarray HX, which is surprising because both algorithms use pair-wise communications: MPI IRECV/ISEND/WAITALL vs Fortran sync images. Ping-pong latency and bandwidth results are very similar with MPI and with coarrays for message sizes from 1B to several MB. The work was done on ARCHER (Cray XC30) up to the full machine capacity: 109,056 cores. Ising energy and magnetisation were calculated with MPI_ALLREDUCE and Fortran 2018 co_sum collectives. Scaling of coarrays is compared in this work to MPI, using cellular automata (CA) 3D Ising magnetisation miniapps, built with the CASUP CA library,, developed by the authors. Fortran coarrays are an attractive alternative to MPI due to a familiar Fortran syntax, single sided communications and implementation in the compiler.
0 notes
Text
Accurate football prediction,
Accurate football prediction,
Football prediction is an intricate blend of art and science. As one of the world's most beloved sports, football draws immense attention, with millions of fans and analysts attempting to predict match outcomes. Accurate football prediction is not just about luck; it requires a deep understanding of various factors, from player form to team strategy, historical data, and even psychological aspects. This article delves into the methods and tools that can enhance the accuracy of football predictions.
Understanding the Basics At its core, football prediction involves forecasting the results of football matches. This can range from predicting the winner of a single match to forecasting league standings, player performances, and more. Accurate predictions rely on a combination of statistical analysis, historical data, and current trends.
Statistical Analysis Statistics play a crucial role in football prediction. Analysts examine a plethora of data points, such as:
Team Performance: Historical performance of teams in various conditions (home vs. away games, against specific opponents). Player Statistics: Individual player metrics, including goals scored, assists, defensive capabilities, and injury history. Match Outcomes: Outcomes of previous matches between the teams involved. By crunching these numbers, analysts can identify patterns and trends that might influence future performances.
Historical Data Historical data provides context and depth to statistical analysis. For instance, a team’s performance over the past few seasons can indicate its consistency and resilience. Additionally, head-to-head records between teams can reveal psychological advantages or disadvantages.
Current Trends and Form Current form is a critical factor in football prediction. A team or player in good form is more likely to perform well. Factors influencing current form include:
Recent Performance: How the team or player has performed in recent matches. Injuries and Suspensions: Availability of key players. Psychological Factors: Morale and motivation, influenced by recent results or off-field issues. Advanced Techniques in Football Prediction With advancements in technology and data science, football prediction has evolved significantly. Modern techniques incorporate machine learning and artificial intelligence to enhance accuracy.
Machine Learning Models Machine learning models can process vast amounts of data and identify complex patterns that human analysts might miss. These models can be trained on historical match data to predict outcomes based on a variety of inputs, such as team and player statistics, weather conditions, and even social media sentiment.
Simulation Models Simulation models, such as the Monte Carlo simulation, are used to predict the probability of various outcomes. By running thousands of simulations of a match, analysts can estimate the likelihood of different results, helping to provide a probabilistic view rather than a deterministic prediction.
Expert Systems Expert systems leverage the knowledge and experience of football analysts and coaches. These systems use rule-based algorithms to replicate expert decision-making processes, combining statistical data with qualitative insights.
The Role of Human Insight Despite technological advancements, human insight remains invaluable in football prediction. Experienced analysts can interpret data in the context of the sport’s nuances, considering factors like team chemistry, managerial tactics, and unexpected developments that pure data analysis might overlook.
Psychological and Contextual Factors Psychological factors, such as team morale, the impact of a passionate home crowd, or the pressure of a crucial match, can significantly influence outcomes. Understanding the context of a match, including the stakes involved and the motivations of the players and teams, is essential for accurate prediction.
Challenges in Football Prediction Football is inherently unpredictable, with many variables at play. Factors such as unexpected injuries, referee decisions, and even weather conditions can drastically alter the outcome of a match. Therefore, while data and analysis can significantly improve prediction accuracy, the element of uncertainty always remains.
Conclusion Accurate football prediction is a dynamic and complex field, requiring a blend of statistical analysis, historical context, current trends, advanced modeling techniques, and human insight. While no method can guarantee perfect predictions, the integration of these diverse approaches can significantly enhance the accuracy and reliability of forecasts. As technology continues to evolve, the future of football prediction looks promising, offering deeper insights and more sophisticated tools for analysts and fans alike.
0 notes
Note
Oooh, I wanna tack my two bits on as a certified physicist and uncertified world-builder: You're never gonna build a world that's entirely self-consistent, let alone accurate to the real world, and that's okay. Let me explain:
When you tell a story, generally you generally set out some rules, whether intentionally or not, like: "Trees are a thing, they look like this", "Things fall down and we call that gravity", "Water is wet and flows downhill". Lots of general "This is how the world works" sorts of rules. A lot of what one might call "setting the scene" in storytelling is also establishing the rules in your world (and subverting those rules later/showing that those rules didn't actually make sense can be a powerful tool in telling a story)
Now, here's the thing: That's exactly what science is. You set out some rules, you tell a story with them, and see where those rules get broken. The big difference is that the stage for the story is the real world, so the story you tell is the one that reality writes. And every single time (and I do mean every time) the real world will break your rules, sometimes just a little bit, sometimes a lot, because your rules aren't a perfect reflection of reality. So you adjust your rules a bit and you tell a new story. And another, and another...
To put it another way, people have been doing science for a while now. We've worked really hard to figure out the rules of reality but we're still not done (and maybe never will be). A lot of the rules we've figured out are, at least on the surface, contradictory: just look at the ongoing attempts to reconcile general relativity (how big things work) with quantum mechanics (how little things work). Two different systems, based on two kinds of incompatible mathematics (deterministic vs. probabilistic) that work on two different scales, both attempting to describe the same thing: everything that exists. If you were put that in a story, the same kind of people who would get up in arms about "inconsistencies/things not adding up" would be all over you for it. But that's just how things are! Those are the rules of existence to best degree we currently know them!
To summarize: We've been working for many years to tell the story of the universe. We still haven't figured out *the rules*, we probably never will, and the one's we've figured out aren't as clean and self-consistent as we'd like. When you build a world, you're creating your own version of our messy, inconsistent universe, creating your own rules and telling a story with them. And just like in the real world, they're going to be just a little wrong. Embrace that, tell the story you want to, and the universe will be better for it.
Do you have any advice for sci-fi stories?
Chase the ideas that make the most interesting story. Worry about whether the science adds up or not later.
17 notes
·
View notes