#probabilistic matching
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
The Role of MDM in Enhancing Data Quality
In today’s data-centric business world, organizations rely on accurate and consistent data to drive decision-making. One of the key components to ensuring data quality is Master Data Management (MDM). MDM plays a pivotal role in consolidating, managing, and maintaining high-quality data across an organization’s various systems and processes. As businesses grow and data volumes expand, the need for efficient data quality measures becomes critical. This is where techniques like deterministic matching and probabilistic matching come into play, allowing MDM systems to manage and reconcile records effectively.

Understanding Data Quality and Its Importance
Data quality refers to the reliability, accuracy, and consistency of data used across an organization. Poor data quality can lead to incorrect insights, flawed decision-making, and operational inefficiencies. For example, a customer database with duplicate records or inaccurate information can result in misguided marketing efforts, customer dissatisfaction, and even compliance risks.
MDM addresses these challenges by centralizing an organization’s key data—referred to as "master data"—such as customer, product, and supplier information. With MDM in place, organizations can standardize data, remove duplicates, and resolve inconsistencies. However, achieving high data quality requires sophisticated data matching techniques.
Deterministic Matching in MDM
Deterministic matching is a method used by MDM systems to match records based on exact matches of predefined identifiers, such as email addresses, phone numbers, or customer IDs. In this approach, if two records have the same value for a specific field, such as an identical customer ID, they are considered a match.
Example: Let’s say a retailer uses customer IDs to track purchases. Deterministic matching will easily reconcile records where the same customer ID appears in different systems, ensuring that all transactions are linked to the correct individual.
While deterministic matching is highly accurate when unique identifiers are present, it struggles with inconsistencies. Minor differences, such as a typo in an email address or a missing middle name, can prevent records from being matched correctly. For deterministic matching to be effective, the data must be clean and standardized.
Probabilistic Matching in MDM
In contrast, probabilistic matching offers a more flexible and powerful solution for reconciling records that may not have exact matches. This technique uses algorithms to calculate the likelihood that two records refer to the same entity, even if the data points differ. Probabilistic matching evaluates multiple attributes—such as name, address, and date of birth—and assigns a weight to each attribute based on its reliability.
Example: A bank merging customer data from multiple sources might have a record for "John A. Doe" in one system and "J. Doe" in another. Probabilistic matching will compare not only the names but also other factors, such as addresses and phone numbers, to determine whether these records likely refer to the same person. If the combined data points meet a predefined probability threshold, the records will be merged.
Probabilistic matching is particularly useful in MDM when dealing with large datasets where inconsistencies, misspellings, or missing information are common. It can also handle scenarios where multiple records contain partial data, making it a powerful tool for improving data quality in complex environments.
The Role of Deterministic and Probabilistic Matching in MDM
Both deterministic and probabilistic matching are integral to MDM systems, but their application depends on the specific needs of the organization and the quality of the data.
Use Cases for Deterministic Matching: This technique works best in environments where data is clean and consistent, and where reliable, unique identifiers are available. For example, in industries like healthcare or finance, where Social Security numbers, patient IDs, or account numbers are used, deterministic matching provides quick, highly accurate results.
Use Cases for Probabilistic Matching: Probabilistic matching excels in scenarios where data is prone to errors or where exact matches aren’t always possible. In retail, marketing, or customer relationship management, customer information often varies across platforms, and probabilistic matching is crucial for linking records that may not have consistent data points.
Enhancing Data Quality with MDM
Master Data Management, when coupled with effective matching techniques, significantly enhances data quality by resolving duplicate records, correcting inaccuracies, and ensuring consistency across systems. The combination of deterministic and probabilistic matching allows businesses to achieve a more holistic view of their data, which is essential for:
Accurate Reporting and Analytics: High-quality data ensures that reports and analytics are based on accurate information, leading to better business insights and decision-making.
Improved Customer Experience: Consolidating customer data allows businesses to deliver a more personalized and seamless experience across touchpoints.
Regulatory Compliance: Many industries are subject to stringent data regulations. By maintaining accurate records through MDM, businesses can meet compliance requirements and avoid costly penalties.
Real-World Application of MDM in Enhancing Data Quality
Many industries rely on MDM to enhance data quality, especially in sectors where customer data plays a critical role.
Retail: Retailers use MDM to unify customer data across online and offline channels. With probabilistic matching, they can create comprehensive profiles even when customer names or contact details vary across systems.
Healthcare: In healthcare, ensuring accurate patient records is crucial for treatment and care. Deterministic matching helps link patient IDs, while probabilistic matching can reconcile records with missing or inconsistent data, ensuring no critical information is overlooked.
Financial Services: Banks and financial institutions rely on MDM to manage vast amounts of customer and transaction data. Both deterministic and probabilistic matching help ensure accurate customer records, reducing the risk of errors in financial reporting and regulatory compliance.
Conclusion
Master Data Management plays a crucial role in enhancing data quality across organizations by centralizing, standardizing, and cleaning critical data. Techniques like deterministic and probabilistic matching ensure that MDM systems can effectively reconcile records, even in complex and inconsistent datasets. By improving data quality, businesses can make better decisions, provide enhanced customer experiences, and maintain regulatory compliance.
In today’s competitive market, ensuring data accuracy isn’t just a best practice—it’s a necessity. Through the proper application of MDM and advanced data matching techniques, organizations can unlock the full potential of their data, paving the way for sustainable growth and success.
0 notes
Text
Growing ever more frustrated with the use of the term "AI" and how the latest marketing trend has ensured its already rather vague and highly contextual meaning has now evaporated into complete nonsense. Much like how the only real commonality between animals colloquially referred to as "Fish" is "probably lives in the water", the only real commonality between things currently colloquially referred to as "AI" is "probably happens on a computer"
For example, the "AI" you see in most games wot controls enemies and other non-player actors typically consist primarily of timers, conditionals, and RNG - and are typically designed with the goal of trying to make the game fun and/or interesting rather than to be anything ressembling actually intelligent. By contrast, the thing that the tech sector is currently trying to sell to us as "AI" relates to a completely different field called Machine Learning - specifically the sub-fields of Deep Learning and Neural Networks, specifically specifically the sub-sub-field of Large Language Models, which are an attempt at modelling human languages through large statistical models built on artificial neural networks by way of deep machine learning.
the word "statistical" is load bearing.
Say you want to teach a computer to recognize images of cats. This is actually a pretty difficult thing to do because computers typically operate on fixed patterns whereas visually identifying something as a cat is much more about the loose relationship between various visual identifiers - many of which can be entirely optional: a cat has a tail except when it doesn't either because the tail isn't visible or because it just doesn't have one, a cat has four legs, two eyes and two ears except for when it doesn't, it has five digits per paw except for when it doesn't, it has whiskers except for when it doesn't, all of these can look very different depending on the camera angle and the individual and the situation - and all of these are also true of dogs, despite dogs being a very different thing from a cat.
So, what do you do? Well, this where machine learning comes into the picture - see, machine learning is all about using an initial "training" data set to build a statistical model that can then be used to analyse and identify new data and/or extrapolate from incomplete or missing data. So in this case, we take a machine learning system and feeds it a whole bunch of images - some of which are of cats and thus we mark as "CAT" and some of which are not of cats and we mark as "NOT CAT", and what we get out of that is a statistical model that, upon given a picture, will assign a percentage for how well it matches its internal statistical correlations for the categories of CAT and NOT CAT.
This is, in extremely simplified terms, how pretty much all machine learning works, including whatever latest and greatest GPT model being paraded about - sure, the training methods are much more complicated, the statistical number crunching even more complicated still, and the sheer amount of training data being fed to them is incomprehensively large, but at the end of the day they're still models of statistical probability, and the way they generate their output is pretty much a matter of what appears to be the most statistically likely outcome given prior input data.
This is also why they "hallucinate" - the question of what number you get if you add 512 to 256 or what author wrote the famous novel Lord of the Rings, or how many academy awards has been won by famous movie Goncharov all have specific answers, but LLMs like ChatGPT and other machine learning systems are probabilistic systems and thus can only give probabilistic answers - they neither know nor generally attempt to calculate what the result of 512 + 256 is, nor go find an actual copy of Lord of the Rings and look what author it says on the cover, they just generalise the most statistically likely response given their massive internal models. It is also why machine learning systems tend to be highly biased - their output is entirely based on their training data, they are inevitably biased not only by their training data but also the selection of it - if the majority of english literature considered worthwhile has been written primarily by old white guys then the resulting model is very likely to also primarily align with the opinion of a bunch of old white guys unless specific care and effort is put into trying to prevent it.
It is this probabilistic nature that makes them very good at things like playing chess or potentially noticing early signs of cancer in x-rays or MRI scans or, indeed, mimicking human language - but it also means the answers are always purely probabilistic. Meanwhile as the size and scope of their training data and thus also their data models grow, so does the need for computational power - relatively simple models such as our hypothetical cat identifier should be fine with fairly modest hardware, while the huge LLM chatbots like ChatGPT and its ilk demand warehouse-sized halls full of specialized hardware able to run specific types of matrix multiplications at rapid speed and in massive parallel billions of times per second and requiring obscene amounts of electrical power to do so in order to maintain low response times under load.
36 notes
·
View notes
Note
"majority indistinguishable on the basis of X" doesn't make much sense. Can you figure out which of two people is which gender based on height only? With certainty, no, probabilistically, absolutely yes. And vice versa, given two heights you can guess gender. And if you exclude everyone below some height you'll get more males, if you want to match them you have shorten males or lengthen females, etc. These all follow from "generally more" statements, which is why people make them.
Or, we could be talking about some more binary fixed trait, the kind of trait you either have or do not have, i.e. 1% of people in Group A have Trait X; 2% of people in Group B have Trait X.
The majority of Groups A and B are indistinguishable in regards to trait X; grab a random person from Group A, and a random person from Group B, and the odds are that *neither* one has trait X.
See? We already are in the realm of imprecision where we don't even know what's being asserted, let alone what we should do about the assertion!
20 notes
·
View notes
Text
My boss is far too enamored with chatgpt
We have a chatbot for our customers at work (which does not use genai, it's written in Python) and it works very well. Trouble is, it's only in one language, and it's menu-based, it doesn't parse free text. My boss wants it to be in two languages, and be able to parse the questions that people send to it. So she wants to use a gpt engine trained on our data instead. She insists that this will be faster and easier than adding to the system we already have. (which I think is code for "the person who built it isn't available, and she doesn't want me to spend the time to add to it because there are too many other things she wants me to do")
Multiple examples of wrong or misspelled answers didn't deter her, she just insisted that my instructions to the gpt engine needed to be tweaked. I finally managed to convince her that it wouldn't search the data by going into regular chatgpt and asking it how gpt-4 dealt with partial matching, which got it to admit that it doesn't search its own training data, it just builds a probabilistic model.
Time wasted: 3 hours, plus I had to use chatgpt because my boss wouldn't accept any other source
Boss still wants to use a gpt engine to turn user input into queries to search our database. *headdesk* *headdesk* *headdesk*
Here's hoping I can demonstrate why that's a bad idea after the weekend...
2 notes
·
View notes
Text
On top of that, Wikipedia is even more valuable now as a collection of human-curated knowledge. Nowadays if you type a question into Google (and a bit less so if you just enter a simple topic), at least the first three pages are almost entirely full of random websites with hilariously long, drawn-out, rambling articles that all sound virtually the same—because they were generated to match up with the question, but not to genuinely answer it.
ChatGPT and the like are flooding the web with this regurgitated content, making it harder to find detailed and accurate knowledge. And that makes it all the more necessary to collect and preserve the knowledge of real people with genuine expertise.
And that's in places like Wikipedia, Stackoverflow, Reddit... and even the myriad independent blogs operated by individuals. They're all places where sharing useful information is more important than twisting info into a form that maximizes algorithmic output.
So yeah, in the past, people would be cautious of Wikipedia because anyone with a pulse and Internet access was allowed to edit it; but now we're at the point where machines are probabilistically shoving words together to look like the words often seen together in common literature. Real people with genuine knowledge and public accountability to being accurate will always be more trustworthy than those.
If I may, I must make the gentle request that people consult Wikipedia for basic information about anything.
I’m not entirely sure what’s going on, but more and more people coming to me saying they can’t find info about [noun], when googling it yields its Wikipedia entry on the first page.
I’ve said it before, but I’ll gladly say it again: You can trust Wikipedia for general information. The reason why it’s unreliable for academic citations is because it’s a living, changing document. It’s also written by anonymous authors, and author reputation is critical for research paper integrity.
But for learning the basics of what something is? Wikipedia is your friend. I love Wikipedia. I use it all the time for literally anything and everything, and it’s a huge reason why I know so much about things and stuff.
Please try going there first, and then come to me with questions it doesn’t answer for you.
32K notes
·
View notes
Text
Quantum ML Sheds Quantum black hole information retrieval

Quantum Black Hole
Black hole physics and quantum machine learning intersect in a study on information retrieval constraints.
A recent theoretical work on arXiv relates machine learning's “double descent” phenomenon to black hole mathematical evaporation. The study provides a shared architecture for data recovery in both systems.
The study models the Hawking radiation process as a quantum linear regression problem and finds that the Page time, at which radiation begins to reveal internal Quantum Black Hole information, is the interpolation threshold where test error significantly spikes in overparameterized learning models. Quantum information theory and random matrix analysis make black hole information recovery a high-dimensional learning problem. Importantly, the report makes no new experimental proposals or claims black holes can compute.
Conceptual bridge The Page curve from quantum black hole physics and the twofold descent curve from statistical learning are intimately linked in this study. Both theories explain information accessibility changes. Page time in black holes measures how much information is in the outer radiation relative to the Quantum Black Hole interior. This is significant because Hawking radiation information begins to emerge, like a phase change. Machine learning's interpolation threshold determines if a model can fit training data perfectly. Even when the model is overfit, its performance can improve after this threshold.
Spectral analysis of high-dimensional systems is needed to relate these events. Quantum black hole radiation shape and rank are measured by Marchenko-Pastur distribution. Massive random matrices stretch or compress dimensions. This distribution is needed to understand sparse data-trained machine learning model generalisation. According to their model, radiation dimensionality is like learning model parameters and Quantum Black Hole microstates are proportional to dataset size.
Label Prediction from Features The paper offers a quantum learning problem to learn the black hole's intrinsic states as a model learns labels from features. visible radiation. We consider Hawking radiation information retrieval supervised learning. They demonstrate in their quantum regression model that the test error diverges at the Page time, which is identical to the classical double descent error spike at the interpolation threshold. The test error falling on each side of this peak shows geometric or inversion symmetry in machine learning systems.
When model capacity equals data size, performance is worst; when capacity is significantly smaller or larger, performance increases. Black hole evaporation behaves similarly when the radiation's entropy matches the surviving black hole's, making information the least recoverable at Page time. A “quantum phase transition” in information retrieval occurs when the prediction error variance, which measures model sensitivity, diverges at Page time. The radiation subsystem alone can retrieve all Quantum Black Hole inner information after the Page time, when the radiation space becomes “overcomplete.”
Techniques and Frameworks Density matrices that encode probabilistic quantum states simulate the Quantum Black Hole and its radiation as a quantum system to get their results. Evaporation is linked to supervised learning by evaluating these matrices' regression behaviour. Formulas from random matrix theory and quantum information theory determine significant numbers like prediction error variance.
Even if theoretically and mathematically sound, the study simplifies concepts like the Marchenko Pastur rule, Hawking radiation, and the Page curve into a single analytical framework. Unfeasible assumptions include monitoring or manipulating quantum information at infinitely fine scales, an accurate quantum gravity theory, and complete understanding of quantum black hole microstates. Even though their analogies are mathematically valid, the authors do not claim black holes perform machine learning. Instead, they claim that both systems have similar information-theoretic constraints.
Future Quantum and AI Research Prospects This interdisciplinary approach may allow academics to re-examine quantum gravity problems using AI. Variance and bias may offer new insights into information behaviour under extreme physical restrictions, like entropy and temperature did for black holes.
However, black hole learning dynamics may provide novel models for how quantum machine learning systems generalise in the face of data overcapacity or scarcity. This study adds to studies on enhancing learning algorithms and understanding the universe's most intriguing riddles. A unified mathematical language links physics and machine learning.
Preprint authors: Spinor Media's Zae Young Kim and Jungwon University's Jae-Weon Lee. The arXiv paper lacks peer review, a necessary scientific step.
#QuantumBlackHole#arXiv#machinelearning#highdimensionalsystems#quantumstates#physicalprocess#quantummachinelearning#News#Technews#Technology#TechnologyNews#Technologytrends#Govindhtech
1 note
·
View note
Video
youtube
SmartBet AI Match Analysis: St. Louis vs. LA Galaxy
This document outlines The Gambler's Ruin Project, which utilizes SmartBet AI Technology to generate probabilistic predictions for MLS soccer matches, specifically detailing the upcoming match between Saint Louis City SC and Los Angeles Galaxy. The core of the AI is a hybrid model combining Poisson regression for goal predictions with various machine learning classifiers (Random Forest, XGBoost, MLP NN, LightGBM) to forecast match outcomes. The system incorporates features like Elo ratings, team form, injuries, and market odds, and employs techniques such as bootstrapping, Monte Carlo simulations, and stacked ensembles to refine predictions and assess uncertainty. The document also includes a disclaimer about responsible gambling and clarifies that it provides informational content, not betting services.
0 notes
Text
Enhancing Data Accuracy with Reliable Data Management and Record Linkage Software
In today’s data-driven world, accurate information is the backbone of business decision-making. Whether it’s in healthcare, finance, retail, or government operations, managing vast amounts of data efficiently is essential. Yet, data is often scattered across multiple systems, incomplete, duplicated, or inconsistent. That’s where reliable data management and robust record linkage software come into play — streamlining operations, reducing errors, and enhancing overall productivity.
The Need for Reliable Data Management
Reliable data management isn’t just about storing data; it’s about making data useful, accessible, and trustworthy. Poor data quality leads to flawed analytics, customer dissatisfaction, compliance risks, and financial losses. As organizations grow, the need for a systematic data strategy becomes more critical than ever.
Match Data Pro LLC specializes in offering advanced data solutions that help businesses cleanse, consolidate, and control their data. By implementing cutting-edge data management tools, businesses can:
Eliminate duplicate records
Maintain consistent data across platforms
Comply with data privacy regulations
Enhance customer engagement with accurate profiles
Improve analytics and reporting accuracy
What is Record Linkage?
Record linkage is the process of identifying and linking records across one or more databases that refer to the same entity — such as a person, organization, or product — even if the records do not share a common unique identifier. For example, "John A. Smith" and "J. Smith" with similar contact details might refer to the same person but appear as separate entries in different systems.
Manual data matching is inefficient and prone to error, especially when dealing with large datasets. That’s where automated record linkage software becomes invaluable. It applies algorithms to detect similarities, variations, and relationships between data records, helping businesses recognize and merge duplicates effectively.
Why Use Record Linkage Software?
Match Data Pro LLC offers a powerful record linkage system that automates the process of identifying matches and near-matches across large data sets. Here are some reasons why organizations are turning to these tools:
1. Data Consolidation
Merging data from multiple sources requires accurate identification of duplicates. Record linkage ensures that each entity is represented uniquely.
2. Better Decision-Making
Accurate, deduplicated data gives leadership teams more confidence in their analytics and reporting tools.
3. Improved Customer Experience
By unifying data points into a single customer view, businesses can personalize interactions and support more effectively.
4. Compliance and Governance
Industries like healthcare, banking, and e-commerce are bound by data protection laws. Record linkage tools help maintain compliant and auditable datasets.
5. Scalability
As your data grows, a record linkage system can handle millions of records with minimal manual intervention — allowing you to scale without data chaos.
How Match Data Pro LLC Delivers Record Linkage Excellence
Match Data Pro LLC’s record linkage software is designed to be flexible, secure, and intelligent. It supports both deterministic and probabilistic matching techniques, ensuring high precision and recall.
Key features include:
Fuzzy matching algorithms that identify similar entries despite typos or name variations
Customizable rules for industry-specific linkage criteria
Automated matching and review workflows
Audit trails and reports for compliance
Real-time integration with your data pipeline or third-party tools
The record linkage system is easy to deploy and integrates with existing databases, CRMs, and cloud platforms, ensuring quick ROI.
Real-World Applications of Record Linkage
Let’s explore a few real-life examples of how businesses benefit from reliable data management and record linkage:
Healthcare
Linking patient records across hospitals, clinics, and insurance providers to ensure cohesive treatment and prevent medical errors.
E-Commerce
Matching customer orders, preferences, and feedback across platforms to enhance personalization and increase customer satisfaction.
Government
Consolidating citizen records across departments for better public services and fraud prevention.
Finance
Ensuring customer KYC (Know Your Customer) compliance by merging data from multiple banking systems.
Final Thoughts
In an era where data is currency, investing in reliable data management and intelligent record linkage software is not a luxury — it's a necessity. With the right tools, companies can clean their data lakes, improve operations, make smarter decisions, and offer a better experience to their customers.
Match Data Pro LLC is at the forefront of data accuracy and linkage innovation. Whether you're struggling with duplicate data, siloed systems, or inaccurate reports, their record linkage system can transform your data landscape.
Ready to streamline your data and unlock its true potential? Connect with Match Data Pro LLC today and experience the power of accurate, unified information.
0 notes
Text
Boost Efficiency with Cutting-Edge Automated Bank Reconciliation Systems

Automated solutions for bank reconciliation are changing how we manage finances. They get rid of the need to manually check bank statements and accounting data. With top-notch software, companies can save time, cut costs, and improve their financial accuracy.
As financial automation keeps changing the industry, it's key for finance experts to know the good points and features of automated bank reconciliation systems.
Key Takeaways
Automated bank reconciliation systems save time and reduce manual errors.
These systems enhance financial accuracy and compliance.
Software for bank reconciliation offers a range of benefits, including cost savings.
Accounting reconciliation software is a key tool for financial automation.
Cutting-edge automated bank reconciliation systems are transforming financial management.
The Hidden Costs and Challenges of Traditional Bank Reconciliation
Traditional bank reconciliation is often slow and risky. The manual process takes a lot of time and can lead to mistakes. This wastes a lot of a financial team's time and effort.
Common Pain Points in Manual Reconciliation Processes
Manual reconciliation has many problems, including:
Time-consuming data entry and verification
High risk of human error
Difficulty in identifying and resolving discrepancies
Limited visibility into the reconciliation process
These issues slow down the process and take away from planning the finances.
Quantifying the Impact of Errors and Delays
Errors and delays in manual reconciliation can cause big problems. Studies show that it can take up to 59% of a financial team's time. Mistakes can lead to financial losses and trouble with rules.
Automating the process can cut this time by up to 80%. This makes things more efficient and lowers the chance of mistakes.
Compliance Risks in Manual Systems
Manual systems also have big risks for following rules. They lack clear records and audit trails. This makes it hard to show you're following financial rules.
Also, mistakes can lead to wrong financial reports. This could mean fines from regulators.
Knowing these problems, finance teams can see why they need automated solutions. These tools can make financial work smoother and safer.
Automated Bank Reconciliation Systems: Transforming Financial Operations
Modern finance is changing fast thanks to automated bank reconciliation systems. These systems use AI and machine learning. They make financial work easier, cut down on mistakes, and give quick insights into money moves.
Core Components and Functionality
Automated bank reconciliation software has key parts that help match and reconcile transactions well. These parts include:
Advanced data ingestion capabilities to handle various financial data formats
Intelligent matching algorithms that use machine learning to identify and match transactions
Real-time processing and reporting for up-to-date financial insights
Integration with existing financial systems, such as ERP and accounting software
Customizable workflows for exception handling and approval processes
How Modern Systems Differ from Legacy Solutions
Modern systems are different from old ones. Old systems use manual work and simple rules. New systems use AI and machine learning for better results. Key differences are:
Enhanced accuracy through machine learning-based matching algorithms
Real-time processing capabilities for timely financial insights
Scalability to handle large volumes of transactions
Flexibility to adapt to changing financial regulations and requirements
The Technology Behind Automated Matching
The tech behind automated matching is advanced. It uses smart algorithms that get better over time. These algorithms can:
Identifying complex transaction patterns
Handling multiple data formats and sources
Providing probabilistic matching to account for uncertainties
Continuously learning and adapting to new data and transaction types
These advanced technologies make automated bank reconciliation systems better. They save time, boost accuracy, and offer deep insights into finance.
Measurable Benefits of Implementing Reconciliation Automation
Automated reconciliation systems are changing how we manage finances. They bring many benefits, like saving money and making financial tasks more accurate.
Time and Resource Optimization
One big plus of using automated reconciliation is saving time and resources. It can cut down reconciliation time by up to 80%. This lets staff do more important work.
Reduced manual labor
Faster reconciliation processes
Improved productivity
Error Reduction and Accuracy Improvements
Automated systems also cut down on errors. Companies can save up to $150,000 a year by avoiding mistakes. This makes financial records more accurate.
Automated matching reduces human error
Improved accuracy in financial reporting
Enhanced reliability of financial data
Enhanced Financial Control and Audit Readiness
Reconciliation automation also helps with financial control and being ready for audits. It keeps financial records current. This ensures companies follow rules and lowers audit risks.
By using reconciliation automation, businesses get many benefits. These include saving money, improving accuracy, and better financial control.
Essential Features to Look for in Reconciliation Software
To get the most out of reconciliation software, finance pros need to know what's key. The best software automates tough tasks and gives instant insights. This boosts financial work by making it more efficient and accurate.
Intelligent Matching Algorithms
At the core of good reconciliation software are smart matching algorithms. These algorithms match transactions across accounts and statements on their own. This cuts down on manual work and errors. Advanced algorithms have:
Complex matching rules
Support for various matching methods (like fuzzy and exact matching)
Machine learning for getting better over time
Exception Management Workflows
Exception management workflows are key for dealing with reconciliation issues. A top-notch software should have:
Auto exception reports
Customizable workflows for checking and fixing issues
Tools for team collaboration on solving problems
Customizable Reporting and Analytics
Customizable reports and analytics help finance teams understand their data better. Look for software with:
Flexible report templates
Live analytics and dashboards
Tools for deep analysis
Integration Capabilities with Banking and ERP Systems
Smooth integration with banking and ERP systems is essential. Make sure the software can:
Link with many banking systems for data
Work well with ERP systems for data sharing
Handle different data types for flexibility
By focusing on these key features, companies can find software that meets their needs now and grows with them. The right software boosts financial control, cuts down on mistakes, and makes work more efficient.
Types of Automated Reconciliation Solutions for Different Business Needs
The market has many automated reconciliation solutions for various business needs. Companies can pick the best one for their operations.
Cloud-Based vs. On-Premise Balance Sheet Reconciliation Software
Choosing between cloud-based or on-premise reconciliation software is key. Cloud-based options are flexible and cost-effective. They're great for businesses with changing needs or looking to save money upfront.
On-premise solutions give more control over data security and customization. They're best for businesses in strict regulations or with complex processes.
Industry-Specific Reconciliation Tools
Each industry has unique reconciliation needs. Industry-specific tools are made to meet these needs. They offer features tailored to each sector's challenges.
Banking and financial services: Solutions for complex transactions and high volumes.
Healthcare: Tools for billing and insurance needs.
Retail: Software that works with point-of-sale systems and manages inventory.
Scalable Solutions for Growing Businesses
As businesses grow, their reconciliation needs change. Scalable solutions adapt to these changes. They help businesses keep up with growth without needing constant system updates.
When picking a reconciliation solution, consider your current and future needs. Think about your industry's specific challenges. This ensures you choose a solution that works well now and in the future.
Strategic Implementation of Bank Reconciliation Automation
To get the most out of bank reconciliation automation, planning is key. A smart plan makes sure the system fits well with current financial work. This boosts efficiency and keeps things running smoothly.
Assessment and Planning Phase
The first step is to check how your finances are doing now. Look for ways to improve. This means:
Checking your current reconciliation methods and finding problems.
Deciding what parts of your finance you want to automate.
Picking the right tools or software for the job.
In the planning stage, set clear goals, a timeline, and resources. This sets up your project for success.
Data Migration and System Integration
Moving your data and making sure systems work together is important. This means:
Getting your data ready, matching it to the new system, and setting up the system to work with your finance tools.
Training and Change Management Strategies
Good training and managing change are key to using the new system well. This includes:
Teaching staff about the new system.
Planning for how to handle any resistance to the new tech.
Keeping an eye on how things are going and making changes if needed.
By focusing on these areas, you can make the switch to automated bank reconciliation smoothly. This leads to better efficiency, accuracy, and control over your finances.
youtube
Success Stories: Organizations Transformed by Automated Reconciliation
Automated reconciliation has changed how many organizations handle their finances. By using automated bank reconciliation software, companies have seen big improvements. They now work more efficiently, make fewer mistakes, and have better control over their money.
Efficient Financial Institution Operations
A top financial institution used reconciliation automation. This cut their processing time by 40% and lowered costs by 25%. The system let them handle more transactions without needing more people.
This shows how automated reconciliation helps in busy financial settings. It brought better accuracy, less manual work, and quicker month-end closings.
Corporate Accounting Department Transformation
A big company's accounting team struggled with manual reconciliation. They spent too much time on it and made many mistakes. But after getting automated reconciliation software, things changed for the better.
Reduced reconciliation time by 60%
Improved accuracy to 99.9%
Enhanced visibility into financial transactions
Small Business Efficiency Gains
A small business with a small accounting team used reconciliation automation. This made their financial work much smoother. They saw fewer errors and better financial reports.
The business could focus on more important tasks. They didn't need to hire more people to handle their finances. This helped them grow without adding too much to their costs.
Conclusion: Embracing the Future of Financial Reconciliation
Financial operations are always changing, and automated bank reconciliation systems are key. They help reduce errors and improve control over finances. This makes audits easier and more reliable.
New technologies like AI and blockchain are changing how we do financial reconciliation. They make transactions faster, more accurate, and secure. This is a big step forward.
Businesses that use automated reconciliation software are ready for the future. They enjoy many benefits. These include:
Improved efficiency and less manual work
More accurate and safer transactions
Better control over finances and audit readiness
Automated bank reconciliation systems are essential for the future of finance. They help businesses stay ahead in a fast-changing world.
Also Read: Reconciliation Software for High-Volume Transactions: What to Look For
#reconciliation#automation#bank reconciliation#recon#automated reconciliation#finance management#Youtube
0 notes
Text
We Need Something Better

Source: Anthropic
I think it is safe to say that we need something better than these benchmarks for evaluating LLMs in the future. These sort of contrived tests that can be trained on are a poor representation of any actual ability to function in the space that is being tested.
The fact that an AI can solve some coding benchmark problems or some math or language puzzles doesn't mean that the model is actually any good at those things. This is especially true given that these companies tend to train their models to do well on these benchmarks. This may not be teaching to the test, but it certainly is a far cry from the kind of programming or math knowledge that a real programmer or mathematician would have.
Remember these tools simply and blindly apply known approaches to the task and solve by constructing solutions from bits constructed probabilistically.
I think there is always going to be the inherent problem that to a certain extent some of these tasks are subjective. Which is the better way to write some function is somewhat subjective depending on what you are measuring. I do think that we see a gaping divide between what model benchmarks tell us and actual real world performance. This is always going to be the case because ultimately what a given model will do well at is going to be based on its training. The less the problem matches the training the worse it will do.
Additional Sources
SWE-bench Verified OpenAI
SWE-bench Verified Anthropic
0 notes
Text
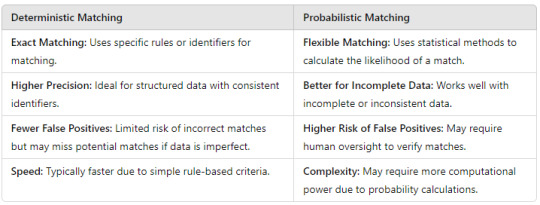
Deterministic vs. Probabilistic Matching: What’s the Difference and When to Use Each?
In today's data-driven world, businesses often need to match and merge data from various sources to create a unified view. This process is critical in industries like marketing, healthcare, finance, and more. When it comes to matching algorithms, two primary methods stand out: deterministic and probabilistic matching. But what is the difference between the two, and when should each be used? Let’s dive into the details and explore both approaches.
1. What Is Deterministic Matching?
Deterministic matching refers to a method of matching records based on exact or rule-based criteria. This approach relies on specific identifiers like Social Security numbers, email addresses, or customer IDs to find an exact match between data points.
How It Works: The deterministic matching algorithm looks for fields that perfectly match across different datasets. If all specified criteria are met (e.g., matching IDs or emails), the records are considered a match.
Example: In healthcare, matching a patient’s medical records across systems based on their unique patient ID is a common use case for deterministic matching.
Advantages: High accuracy when exact matches are available; ideal for datasets with consistent, structured, and well-maintained records.
Limitations: Deterministic matching falls short when data is inconsistent, incomplete, or when unique identifiers (such as email or customer IDs) are not present.
2. What Is Probabilistic Matching?
Probabilistic matching is a more flexible approach that evaluates the likelihood that two records represent the same entity based on partial, fuzzy, or uncertain data. It uses statistical algorithms to calculate probabilities and scores to determine the best possible match.
How It Works: A probabilistic matching algorithm compares records on multiple fields (such as names, addresses, birth dates) and assigns a probability score based on how similar the fields are. A match is confirmed if the score exceeds a pre-defined threshold.
Example: In marketing, matching customer records from different databases (which may have variations in how names or addresses are recorded) would benefit from probabilistic matching.
Advantages: It handles discrepancies in data (e.g., misspellings, name changes) well and is effective when exact matches are rare or impossible.
Limitations: While more flexible, probabilistic matching is less precise and may yield false positives or require additional human review for accuracy.
3. Deterministic vs. Probabilistic Matching: Key Differences
Understanding the differences between deterministic vs probabilistic matching is essential to selecting the right approach for your data needs. Here’s a quick comparison:
4. Real-World Applications: Deterministic vs. Probabilistic Matching
Deterministic Matching in Action
Finance: Banks often use deterministic matching when reconciling transactions, relying on transaction IDs or account numbers to ensure precision in identifying related records.
Healthcare: Hospitals utilize deterministic matching to link patient records across departments using unique identifiers like medical record numbers.
Probabilistic Matching in Action
Marketing: Marketers often deal with messy customer data that includes inconsistencies in name spelling or address formatting. Here, probabilistic vs deterministic matching comes into play, with probabilistic matching being favored to find the most likely matches.
Insurance: Insurance companies frequently use probabilistic matching to detect fraud by identifying subtle patterns in data that might indicate fraudulent claims across multiple policies.
5. When to Use Deterministic vs. Probabilistic Matching?
The choice between deterministic and probabilistic matching depends on the nature of the data and the goals of the matching process.
Use Deterministic Matching When:
Data is highly structured: If you have clean and complete datasets with consistent identifiers (such as unique customer IDs or social security numbers).
Precision is critical: When the cost of incorrect matches is high (e.g., in financial transactions or healthcare data), deterministic matching is a safer choice.
Speed is a priority: Deterministic matching is faster due to the simplicity of its rule-based algorithm.
Use Probabilistic Matching When:
Data is messy or incomplete: Probabilistic matching is ideal when dealing with datasets that have discrepancies (e.g., variations in names or missing identifiers).
Flexibility is needed: When you want to capture potential matches based on similarities and patterns rather than strict rules.
You’re working with unstructured data: In scenarios where exact matches are rare, probabilistic matching provides a more comprehensive way to link related records.
6. Combining Deterministic and Probabilistic Approaches
In many cases, businesses might benefit from a hybrid approach that combines both deterministic and probabilistic matching methods. This allows for more flexibility by using deterministic matching when exact identifiers are available and probabilistic methods when the data lacks structure or consistency.
Example: In identity resolution, a company may first apply deterministic matching to link accounts using unique identifiers (e.g., email or phone number) and then apply probabilistic matching to resolve any remaining records with partial data or variations in names.
Conclusion
Choosing between deterministic vs probabilistic matching ultimately depends on the specific needs of your data matching process. Deterministic matching provides high precision and works well with structured data, while probabilistic matching algorithms offer flexibility for dealing with unstructured or incomplete data.
By understanding the strengths and limitations of each approach, businesses can make informed decisions about which algorithm to use—or whether a combination of both is necessary—to achieve accurate and efficient data matching. In today’s increasingly complex data landscape, mastering these techniques is key to unlocking the full potential of your data.
0 notes
Text
How to utilize AI for improved data cleaning

Ask any data scientist, analyst, or ML engineer about their biggest time sink, and chances are "data cleaning" will top the list. It's the essential, yet often unglamorous, groundwork required before any meaningful analysis or model building can occur. Traditionally, this involves painstaking manual checks, writing complex rule-based scripts, and battling inconsistencies that seem to multiply with data volume. While crucial, these methods often struggle with scale, nuance, and the sheer variety of errors found in real-world data.
But what if data cleaning could be smarter, faster, and more effective? As we navigate the rapidly evolving tech landscape of 2025, Artificial Intelligence (AI) is stepping up, offering powerful techniques to significantly improve and accelerate this critical process. For organizations across India undergoing digital transformation and harnessing vast amounts of data, leveraging AI for data cleaning isn't just an advantage – it's becoming a necessity.
The Limits of Traditional Cleaning
Traditional approaches often rely on:
Manual Inspection: Spot-checking data, feasible only for small datasets.
Rule-Based Systems: Writing specific rules (e.g., if value < 0, replace with null) which become complex to manage and fail to catch unexpected or subtle errors.
Simple Statistics: Using mean/median/mode for imputation or standard deviations for outlier detection, which can be easily skewed or inappropriate for complex distributions.
Exact Matching: Finding duplicates only if they match perfectly.
These methods are often time-consuming, error-prone, difficult to scale, and struggle with unstructured data like free-form text.
How AI Supercharges Data Cleaning
AI brings learning, context, and probabilistic reasoning to the table, enabling more sophisticated cleaning techniques:
Intelligent Anomaly Detection: Instead of rigid rules, AI algorithms (like Isolation Forests, Clustering methods e.g., DBSCAN, or Autoencoders) can learn the 'normal' patterns in your data and flag outliers or anomalies that deviate significantly, even in high-dimensional spaces. This helps identify potential errors or rare events more effectively.
Context-Aware Imputation: Why fill missing values with a simple average when AI can do better? Predictive models (from simple regressions or k-Nearest Neighbors to more complex models) can learn relationships between features and predict missing values based on other available data points for that record, leading to more accurate and realistic imputations.
Advanced Duplicate Detection (Fuzzy Matching): Finding records like "Tech Solutions Pvt Ltd" and "Tech Solutions Private Limited" is trivial for humans but tricky for exact matching rules. AI, particularly Natural Language Processing (NLP) techniques like string similarity algorithms (Levenshtein distance), vector embeddings, and phonetic matching, excels at identifying these non-exact or 'fuzzy' duplicates across large datasets.
Automated Data Type & Pattern Recognition: AI models can analyze columns and infer the most likely data type or identify entries that don't conform to learned patterns (e.g., spotting inconsistent date formats, invalid email addresses, or wrongly formatted phone numbers within a column).
Probabilistic Record Linkage: When combining datasets without a perfect common key, AI techniques can calculate the probability that records from different sources refer to the same entity based on similarities across multiple fields, enabling more accurate data integration.
Error Spotting in Text Data: Using NLP models, AI can identify potential typos, inconsistencies in categorical labels (e.g., "Mumbai", "Bombay", "Mumbai City"), or even nonsensical entries within free-text fields by understanding context and language patterns.
Standardization Suggestions: AI can recognize different representations of the same information (like addresses or company names) and suggest or automatically apply standardization rules, bringing uniformity to messy categorical or text data.
The Benefits Are Clear
Integrating AI into your data cleaning workflow offers significant advantages:
Speed & Efficiency: Automating complex tasks dramatically reduces cleaning time.
Improved Accuracy: AI catches subtle errors and handles complex cases better than rigid rules.
Scalability: AI techniques handle large and high-dimensional datasets more effectively.
Enhanced Consistency: Leads to more reliable data for analysis and model training.
Reduced Tedium: Frees up data professionals to focus on higher-value analysis and insights.
Getting Started: Tools & Considerations
You don't necessarily need a PhD in AI to start. Many tools and libraries are available:
Python Libraries: Leverage libraries like Pandas for basic operations, Scikit-learn for ML models (outlier detection, imputation), fuzzywuzzy or recordlinkage for duplicate detection, and NLP libraries like spaCy or Hugging Face Transformers for text data.
Data Quality Platforms: Many modern data quality and preparation platforms are incorporating AI features, offering user-friendly interfaces for these advanced techniques.
Cloud Services: Cloud providers often offer AI-powered data preparation services.
Important Considerations:
Human Oversight: AI is a powerful assistant, not a replacement for human judgment. Always review AI-driven cleaning actions.
Interpretability: Understanding why an AI model flagged something as an error can sometimes be challenging.
Bias Potential: Ensure the AI models aren't learning and perpetuating biases present in the original messy data.
Context is Key: Choose the right AI technique for the specific data cleaning problem you're trying to solve.
Conclusion
Data cleaning remains a foundational step in the data lifecycle, but the tools we use are evolving rapidly. AI offers a leap forward, transforming this often-tedious task into a smarter, faster, and more effective process. For businesses and data professionals in India looking to extract maximum value from their data assets, embracing AI for data cleaning is a crucial step towards building more robust analyses, reliable machine learning models, and ultimately, making better data-driven decisions. It’s time to move beyond simple rules and let AI help bring true clarity to your data.
0 notes
Text
Is a Deterministic or Probabilistic Matching Algorithm Right

Data matching is a process used to improve data quality. It involves cleaning up bad data by comparing, identifying, or merging related entities across two or more sets of data. Two main matching techniques used are deterministic matching and probabilistic matching.
Deterministic Matching
Deterministic matching is a technique used to find an exact match between records. It involves dealing with data that comes from various sources such as online purchases, registration forms, and social media platforms, among others. This technique is ideal for situations where the record contains a unique identifier, such as a Social Security Number (SSN), national ID, or other identification number.
Probabilistic Matching
Probabilistic matching involves matching records based on the degree of similarity between two or more datasets. Probability and statistics are usually applied, and various algorithms are used during the matching process to generate matching scores. In probabilistic matching, several field values are compared between two records, and each field is assigned a weight that indicates how closely the two field values match. The sum of the individual field’s weights indicates a possible match between two records. Melissa
Choosing the Right Algorithm
Deterministic Matching: Ideal for situations where data is consistent and contains unique identifiers.
Probabilistic Matching: Better suited for situations where data may be inconsistent or incomplete, and a degree of similarity is acceptable.
Probabilistic algorithms will generate more profile matches compared to deterministic ones. When aiming for broad audience coverage rather than accuracy, probabilistic algorithms have an advantage.
youtube
SITES WE SUPPORT
AVS Mismatch Cards – Wix
0 notes
Text
Advanced Statistical Methods for Data Analysts: Going Beyond the Basics
Introduction
Advanced statistical methods are a crucial toolset for data analysts looking to gain deeper insights from their data. While basic statistical techniques like mean, median, and standard deviation are essential for understanding data, advanced methods allow analysts to uncover more complex patterns and relationships.
Advanced Statistical Methods for Data Analysts
Data analysis has statistical theorems as its foundation. These theorems are stretched beyond basic applications to advanced levels by data analysts and scientists to fully exploit the possibilities of data science technologies. For instance, an entry-level course in any Data Analytics Institute in Delhi would cover the basic theorems of statistics as applied in data analysis while an advanced-level or professional course will teach learners some advanced theorems of statistics and how those theorems can be applied in data science. Some of the statistical theorems that extent beyond the basic ones are:
Regression Analysis: One key advanced method is regression analysis, which helps analysts understand the relationship between variables. For instance, linear regression can be utilised to estimate the value of a response variable using various input variables. This can be particularly useful in areas like demand forecasting and risk management.
Cluster Analysis: Another important method is cluster analysis, in which similar data points are grouped together. This can be handy for identifying patterns in data that may not be readily visible, such as customer segmentation in marketing.
Time Series Analysis: This is another advanced method that is used to analyse data points collected over time. This can be handy for forecasting future trends based on past data, such as predicting sales for the next quarter based on sales data from previous quarters.
Bayesian Inference: Unlike traditional frequentist statistics, Bayesian inference allows for the incorporation of previous knowledge or beliefs about a parameter of interest to make probabilistic inferences. This approach is particularly functional when dealing with small sample sizes or when prior information is available.
Survival Analysis: Survival analysis is used to analyse time-to-event data, such as the time until a patient experiences a particular condition or the time until a mechanical component fails. Techniques like Kaplan-Meier estimation and Cox proportional hazards regression are commonly used in survival analysis.
Spatial Statistics: Spatial statistics deals with data that have a spatial component, such as geographic locations. Techniques like spatial autocorrelation, spatial interpolation, and point pattern analysis are used to analyse spatial relationships and patterns.
Machine Learning: Machine learning involves advanced statistical techniques—such as ensemble methods, dimensionality reduction, and deep learning, that go beyond the fundamental theorems of statistics. These are typically covered in an advanced Data Analytics Course.
Causal Inference: Causal inference is used to identify causal relationships between variables dependent on observational data. Techniques like propensity score matching, instrumental variables, and structural equation modelling are used to estimate causal effects.
Text Mining and Natural Language Processing (NLP): Techniques in text mining and natural language processing are employed to analyse unstructured text data. NLP techniques simplify complex data analytics methods, rendering them comprehensible for non-technical persons. Professional data analysts need to collaborate with business strategists and decision makers who might not be technical experts. Many organisations in commercialised cities where data analytics is used for achieving business objectives require their workforce to gain expertise in NLP. Thus, a professional course from a Data Analytics Institute in Delhi would have many enrolments from both technical and non-technical professionals aspiring to acquire expertise in NLP.
Multilevel Modelling: Multilevel modelling, also known as hierarchical or mixed-effects modelling, helps with analysing nested structured data. This approach allows for the estimation of both within-group and between-group effects.
Summary
Overall, advanced statistical methods are essential for data analysts looking to extract meaningful insights from their data. By going beyond the basics, analysts can uncover hidden patterns and relationships that can lead to more informed decision-making. Statistical theorems are mandatory topics in any Data Analytics Course; only that the more advanced the course level, the more advanced the statistical theorems taught in the course.
0 notes
Text
The security industry functions within a multi-disciplines and diverse base, having risk management as an essential domain of knowledge within security. Similar to other management subjects, security has embraced the application and principles of risk management, especially a probabilistic threat approach to gauge risk and help in decision making. This approach has received support from many individuals, who see probabilistic risk as an instrument that generated informed, rational and objective options from which sound decision might be made. Based upon qualitative, semi-qualitative and quantitative evaluation of probability and outcomes of future incidents, probabilistic risk intends to offer security professionals with the computation of such threats. The measurements are then utilized in the formulation of cost-effective resolutions which then shape a future that tries to lessen probable harm, while exploiting on probable opportunities. Nevertheless, several individuals claim that probabilistic risk is not enough to deliver anticipated coherent computations of security risks in an increasingly changing and uncertain environment. It is thus disputed that probabilistic approach is not effective for security, because security risk management takes a more heuristic approach (Brooks, 2011). The concept of security risk management Over the last two decades, risk management concept as a recognized discipline has come forward through the public and private sectors. Risk management is presently a well-founded discipline, having its own domain practitioners, as well as body of knowhow. According to Brooks (2011) nations all over the globe possess their own standards of risk management and in majority of these states, the senior organizational executives have the obligation of making sure that suitable practices of risk management match the external and interior compliance requirements. However, majority of these compliance requirements and standards only take into consideration risk management, and does not consider a security risk management. Safety or security risk management might be regarded as distinctive from other types of risk management because majority of the more common risk models do not have the essential key concept for efficient design, alleviation, and application of security threats (Aven, 2008). Generally, security might be regarded guaranteed liberty from want or poverty, safety measures taken to prevent theft or intelligence Green and Fischer (2012) note that security means a stable, comparatively predictable atmosphere whereby a group or an individual might pursue their activities in the absence of harm or interruption and with lack of fear of injury or disturbance. Areas of security practices might be regarded civic security, national security or private security, but merging of these fields are increasing within the present political and social environment. The development of security risk management The exposure of the world to rebel attacks has increased societal concern over the capability of state and national governments to protect their citizens. These attacks and other security issues have increased both global and national need for defense that can efficiently safeguard the nationals at a rational cost, attained to some extent via the utilization of security risk management. Security is usually considered in a private, organizational or commercial context for the safeguarding of assets, information, and people. Disrupting and preventing terrorist attacks, safeguarding citizens, vital infrastructure, and major resources, as well responding to incidents are key components in ensuring the safety of a nation. To be able to keep a country, Read the full article
0 notes
Text
Balancing Game Difficulty: How to Keep Players Challenged but Not Frustrated in AR Game Design
Introduction: The Delicate Dance of Game Difficulty
Every game developer faces a crucial challenge: creating an experience that's tough enough to be exciting, but not so hard that players throw their devices in frustration. This balance is even more complex in augmented reality (AR) games, where real-world interactions add an extra layer of complexity to game design.

Understanding the Psychology of Game Difficulty
Why Difficulty Matters
Game difficulty is more than just making things hard. It's about creating a psychological journey that:
Provides a sense of accomplishment
Maintains player motivation
Creates memorable gaming experiences
Balances challenge with enjoyment
The Unique Challenges of AR Game Difficulty
AR-Specific Difficulty Considerations
Augmented reality games face unique challenges in difficulty balancing:
Unpredictable real-world environments
Varying player physical capabilities
Device and space limitations
Diverse player skill levels
Key Principles of Effective Difficulty Design
1. Dynamic Difficulty Adjustment
Implement intelligent systems that:
Adapt to player performance in real-time
Provide personalized challenge levels
Prevent player burnout
Maintain engagement across different skill levels
2. Layered Challenge Structures
Create multiple challenge layers:
Basic objectives for casual players
Advanced challenges for skilled gamers
Hidden complexity for expert players
Seamless difficulty progression
Practical Strategies for AR Game Difficulty Balancing
Adaptive Learning Mechanisms
Use machine learning algorithms to analyze player behavior
Dynamically adjust game challenges
Provide personalized gaming experiences
Create intelligent difficulty scaling
Skill-Based Progression Systems
Design progression that:
Rewards player improvement
Introduces complexity gradually
Provides clear skill development paths
Maintains player motivation
Technical Implementation Techniques
1. Difficulty Adjustment Algorithms
Create flexible difficulty scaling models
Use probabilistic challenge generation
Implement context-aware difficulty settings
Balance randomness with predictability
2. Player Performance Tracking
Track and analyze:
Player movement patterns
Interaction accuracy
Time spent on challenges
Success and failure rates
AR-Specific Difficulty Balancing Approaches
Environment-Aware Challenges
Design challenges that:
Adapt to physical space constraints
Use real-world obstacles creatively
Provide unique interaction opportunities
Leverage device sensor capabilities
Inclusive Design Considerations
Ensure difficulty balancing:
Accommodates different physical abilities
Provides accessibility options
Supports various device capabilities
Creates enjoyable experiences for all players
Common Pitfalls to Avoid
Difficulty Design Mistakes
Overwhelming players with complex mechanics
Creating artificially difficult challenges
Ignoring player feedback
Failing to provide clear progression paths
Case Studies in Successful Difficulty Balancing
Pokémon GO
Adaptive challenge levels
Accessible for beginners
Deep mechanics for advanced players
Continuous engagement through events
Minecraft Earth
Scalable building challenges
Multiple difficulty modes
Creative problem-solving opportunities
Tools and Frameworks for Difficulty Management
Recommended Development Tools
Unity's adaptive difficulty systems
Unreal Engine's player tracking
Custom machine learning models
Advanced analytics platforms
Psychological Principles of Player Engagement
The Flow State
Create experiences that:
Provide consistent challenges
Match player skill levels
Create a sense of continuous improvement
Maintain optimal engagement
Future of Difficulty Design in AR Gaming
Emerging Technologies
AI-driven difficulty adaptation
Advanced player behavior analysis
Personalized gaming experiences
Enhanced machine learning models
Practical Implementation Tips
Start with Player Empathy
Understand your target audience
Playtest extensively
Gather continuous feedback
Embrace Flexibility
Design modular difficulty systems
Allow player customization
Provide multiple challenge paths
Monitor and Iterate
Collect performance data
Analyze player engagement
Continuously refine difficulty mechanics
Conclusion: The Art of Engaging Challenges
Balancing game difficulty is a nuanced craft that combines technical skill, psychological understanding, and creative design. In AR game development, this challenge becomes even more exciting, offering unprecedented opportunities for creating memorable experiences.
#game#vr games#multiplayer games#metaverse#mobile game development#nft#unity game development#gaming#AR
0 notes