#embedded-systems
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
RN42 Bluetooth Module: A Comprehensive Guide
The RN42 Bluetooth module was developed by Microchip Technology. It’s designed to provide Bluetooth connectivity to devices and is commonly used in various applications, including wireless communication between devices.
Features Of RN42 Bluetooth Module
The RN42 Bluetooth module comes with several key features that make it suitable for various wireless communication applications. Here are the key features of the RN42 module:
Bluetooth Version:
The RN42 module is based on Bluetooth version 2.1 + EDR (Enhanced Data Rate).
Profiles:
Supports a range of Bluetooth profiles including Serial Port Profile (SPP), Human Interface Device (HID), Audio Gateway (AG), and others. The availability of profiles makes it versatile for different types of applications.
Frequency Range:
Operates in the 2.4 GHz ISM (Industrial, Scientific, and Medical) band, the standard frequency range for Bluetooth communication.
Data Rates:
Offers data rates of up to 3 Mbps, providing a balance between speed and power consumption.
Power Supply Voltage:
Operates with a power supply voltage in the range of 3.3V to 6V, making it compatible with a variety of power sources.
Low Power Consumption:
Designed for low power consumption, making it suitable for battery-powered applications and energy-efficient designs.
Antenna Options:
Provides options for both internal and external antennas, offering flexibility in design based on the specific requirements of the application.
Interface:
Utilizes a UART (Universal Asynchronous Receiver-Transmitter) interface for serial communication, facilitating easy integration with microcontrollers and other embedded systems.
Security Features:
Implements authentication and encryption mechanisms to ensure secure wireless communication.
Read More: RN42 Bluetooth Module
#rn42-bluetooth-module#bluetooth-module#rn42#bluetooth-low-energy#ble#microcontroller#arduino#raspberry-pi#embedded-systems#IoT#internet-of-things#wireless-communication#data-transmission#sensor-networking#wearable-technology#mobile-devices#smart-homes#industrial-automation#healthcare#automotive#aerospace#telecommunications#networking#security#software-development#hardware-engineering#electronics#electrical-engineering#computer-science#engineering
0 notes
Text
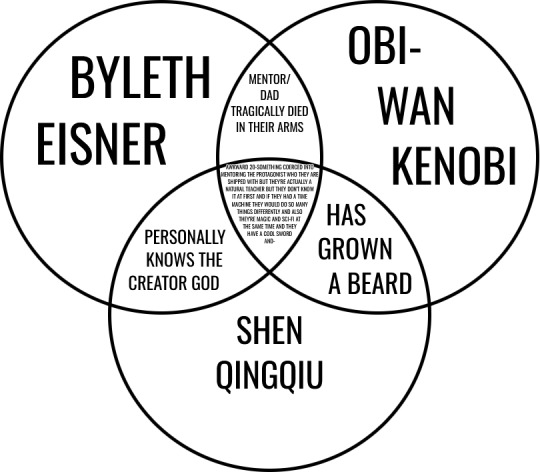
(A venn diagram connecting Byleth Eisner, Obi-Wan Kenobi, and Shen Qingqiu. The overlap between Byleth and Obi-Wan says 'mentor/dad tragically died in their arms', the overlap between Byleth and Shen Qingqiu says 'personally knows the creator god', and the overlap between Shen Qingqiu and Obi-Wan says 'has grown a beard'. In the middle is a solid paragraph of text that reads 'awkward 20-something coerced into mentoring the protagonist who they are shipped with but they're actually a natural teacher but they don't know it at first and if they had a time machine they would do so many things differently and also they're magic and sci-fi at the same time and they have a cool sword and-'. End of image description.)
Is this anything, or...?
#svsss#star wars#fire emblem three houses#fe3h#scum villain's self saving system#scum villain#shen qingqiu#obi-wan kenobi#byleth eisner#there's more that would fit into the middle#especially the complicated relationship to dying#but it was already so packed that I figured I ought to put the image description in the post instead of embedding it lol#anyway uh I have a Type I guess...?
306 notes
·
View notes
Text
genuinely terrifying to me that you can emphasise the true dangers of artificial intelligence in this era of oversharing, but people will turn a blind eye and ignore because oh twitter have made a fun little app where you can develop incredibly realistic pictures of a real person in any sort of clothes, location, or position you want.
you're teaching it.
you're refining it.
one day that could be you. your child. your loved ones. your likeness being used in videos doing something you'd never dream of doing. in a video you'd never wish to be shared.
but oh it's fun as a meme. fun to get that little serotonin boost that internet attention gives you.
#dead ass. why am i seeing f1 wags pregannt. why is that something that exists.#i genuinely dont think people realise HOW dangerous and horrifying this is.#PLEASE think.#yes it's funny to request an edit idk of ur fav f1 player onto ur fav football player or whatever. but do you actually need to.#do you need to help make these systems better. do you need to fucking request giving a wag a pregnant belly#oh my god it makes me sick to my stomach people think this is okay#jesus fucking christ elon musk is AN EVIL MAN and ur just helping him. for free.#the era of disinformation is so embedded in our culture now and it's fucking terrifying
63 notes
·
View notes
Text
I like to think that after years of waking up at the crack of dawn for training, all the ninja are early birds at this point, whether they like it or not—except Nya, who has to be dragged to morning practices every morning looking like a raccoon who’s moments away from snapping. Jay, meanwhile, has adjusted to the early mornings, but is very much on the not side of like it or not. Every time his body naturally wakes him up at the crack of dawn and he gets to watch a beautiful sunrise on the deck of the bounty with his friends, he spends the entire time complaining how disgusting it is that his body is acclimated to this
#ninjago#brought to you by: i used to run cross country and my body never adjusted to the early morning runs but man did i love watching the sunrise#on one hand i miss it on the other i just cannot get up that early#nya probably wventually just starts staying up until practices and then crashing after. which is an absolutely terrible system but it works#for her. she also tries to convince everyone that the reason she’s so bad about getting up is because she started official training years#later than everyone else but that’s not why. the night owl gene is just embedded into her bones
195 notes
·
View notes
Text
i wonder if there’s any overlap between sleep token fans and fans of the da vinci code
#guyphantom ramblings#sleep token posting#sleep token#both portray a sort of religious fantasy#both with very tense and dangerous stakes and consequences#with different vessels of ‘gods’ or what are perceived to be ones#heavy focus on belief systems and clashing between what their respective gods may want from them#this is to say i watched the da vinci code and now silas has embedded himself in my brain like a worm
10 notes
·
View notes
Text
#sunset's rambles#h e l p#i have two options and i don't know which is preferred#as much as embedding an actual spotify playlist sounds cool#i don't think enough characters will have a playlist long enough to be worth making a bigger mess of my spotify than it already is lol#not just for zelda characters i'm gonna use the same system for everyone#feel free to propaganda me
3 notes
·
View notes
Text

CAN Bus Development for Embedded Systems: With and Without an Operating System
Explore the differences in CAN Bus development between embedded systems with or without an operating system. Compare Linux-based Raspberry Pi with PiCAN HATs to bare-metal Teensy and ESP32 platforms. Learn which solution fits your application needs.
#can bus#embedded system#CAN Bus development#linux#RTOS#Teensy#ESP32#Raspberry Pi#pican#operating system#embedded programming#software development
2 notes
·
View notes
Text
Haha nooo you don't get it, THIS system of assigning people traits based solely on birth circumstances isn't bad!! And actually if you judge me for using it you're a misogynist.
#What do you mean 'it's an embedded cultural system in parts of the globe that directly affects people's well-being?'#goddd youre such a scorpio
3 notes
·
View notes
Text
i've gotta program something soon...
#my posts#gets computer science degree#proceeds to do no programming for 4 months#i have like a few programming ideas but starting things is hard#i want to play with godot more it seems fun#i should probably also learn C++ for job reasons since i want to get into lower level/embedded stuff and only know C and rust#i guess the problem there is i'd have to like come up with a project to learn it with#preferably something lower level#maybe finally do that make your own file system project i skipped?#or like something with compression and parsing file formats#that's all pretty involved though so something like playing with godot would probably be better to get myself back in the programming mood#some sort of silly 2d game probably#i've had thoughts of making a silly little yume nikki-like for my friends to play that could be fun#or just any silly little game for just my friends idk#starting with gamemaker kinda made using other game engines a bit weird for me#so getting used to how more normal game engines work would probably be useful#i also want to mess with 3d games that seems fun too#but see the problem with all of this is that i suck at starting projects#and am even worse at actually finishing them#well i guess we'll see what happens?#also hi if you read all of this lol
17 notes
·
View notes
Text
My mentor for electronics and embedded systems is sooo good at teaching istg. I walked up to this man after his class and I asked him and he explained the basics in 15minutes and when I thanked him he said “thank YOU for your queries “ bro he almost made me tear up cuz Engineering professors/mentors have been real rough 🙌
6 notes
·
View notes
Text
lol i got a free engineering travel mug from the event
2 notes
·
View notes
Text
AI Doesn’t Necessarily Give Better Answers If You’re Polite
New Post has been published on https://thedigitalinsider.com/ai-doesnt-necessarily-give-better-answers-if-youre-polite/
AI Doesn’t Necessarily Give Better Answers If You’re Polite
Public opinion on whether it pays to be polite to AI shifts almost as often as the latest verdict on coffee or red wine – celebrated one month, challenged the next. Even so, a growing number of users now add ‘please’ or ‘thank you’ to their prompts, not just out of habit, or concern that brusque exchanges might carry over into real life, but from a belief that courtesy leads to better and more productive results from AI.
This assumption has circulated between both users and researchers, with prompt-phrasing studied in research circles as a tool for alignment, safety, and tone control, even as user habits reinforce and reshape those expectations.
For instance, a 2024 study from Japan found that prompt politeness can change how large language models behave, testing GPT-3.5, GPT-4, PaLM-2, and Claude-2 on English, Chinese, and Japanese tasks, and rewriting each prompt at three politeness levels. The authors of that work observed that ‘blunt’ or ‘rude’ wording led to lower factual accuracy and shorter answers, while moderately polite requests produced clearer explanations and fewer refusals.
Additionally, Microsoft recommends a polite tone with Co-Pilot, from a performance rather than a cultural standpoint.
However, a new research paper from George Washington University challenges this increasingly popular idea, presenting a mathematical framework that predicts when a large language model’s output will ‘collapse’, transiting from coherent to misleading or even dangerous content. Within that context, the authors contend that being polite does not meaningfully delay or prevent this ‘collapse’.
Tipping Off
The researchers argue that polite language usage is generally unrelated to the main topic of a prompt, and therefore does not meaningfully affect the model’s focus. To support this, they present a detailed formulation of how a single attention head updates its internal direction as it processes each new token, ostensibly demonstrating that the model’s behavior is shaped by the cumulative influence of content-bearing tokens.
As a result, polite language is posited to have little bearing on when the model’s output begins to degrade. What determines the tipping point, the paper states, is the overall alignment of meaningful tokens with either good or bad output paths – not the presence of socially courteous language.
An illustration of a simplified attention head generating a sequence from a user prompt. The model starts with good tokens (G), then hits a tipping point (n*) where output flips to bad tokens (B). Polite terms in the prompt (P₁, P₂, etc.) play no role in this shift, supporting the paper’s claim that courtesy has little impact on model behavior. Source: https://arxiv.org/pdf/2504.20980
If true, this result contradicts both popular belief and perhaps even the implicit logic of instruction tuning, which assumes that the phrasing of a prompt affects a model’s interpretation of user intent.
Hulking Out
The paper examines how the model’s internal context vector (its evolving compass for token selection) shifts during generation. With each token, this vector updates directionally, and the next token is chosen based on which candidate aligns most closely with it.
When the prompt steers toward well-formed content, the model’s responses remain stable and accurate; but over time, this directional pull can reverse, steering the model toward outputs that are increasingly off-topic, incorrect, or internally inconsistent.
The tipping point for this transition (which the authors define mathematically as iteration n*), occurs when the context vector becomes more aligned with a ‘bad’ output vector than with a ‘good’ one. At that stage, each new token pushes the model further along the wrong path, reinforcing a pattern of increasingly flawed or misleading output.
The tipping point n* is calculated by finding the moment when the model’s internal direction aligns equally with both good and bad types of output. The geometry of the embedding space, shaped by both the training corpus and the user prompt, determines how quickly this crossover occurs:
An illustration depicting how the tipping point n* emerges within the authors’ simplified model. The geometric setup (a) defines the key vectors involved in predicting when output flips from good to bad. In (b), the authors plot those vectors using test parameters, while (c) compares the predicted tipping point to the simulated result. The match is exact, supporting the researchers’ claim that the collapse is mathematically inevitable once internal dynamics cross a threshold.
Polite terms don’t influence the model’s choice between good and bad outputs because, according to the authors, they aren’t meaningfully connected to the main subject of the prompt. Instead, they end up in parts of the model’s internal space that have little to do with what the model is actually deciding.
When such terms are added to a prompt, they increase the number of vectors the model considers, but not in a way that shifts the attention trajectory. As a result, the politeness terms act like statistical noise: present, but inert, and leaving the tipping point n* unchanged.
The authors state:
‘[Whether] our AI’s response will go rogue depends on our LLM’s training that provides the token embeddings, and the substantive tokens in our prompt – not whether we have been polite to it or not.’
The model used in the new work is intentionally narrow, focusing on a single attention head with linear token dynamics – a simplified setup where each new token updates the internal state through direct vector addition, without non-linear transformations or gating.
This simplified setup lets the authors work out exact results and gives them a clear geometric picture of how and when a model’s output can suddenly shift from good to bad. In their tests, the formula they derive for predicting that shift matches what the model actually does.
Chatting Up..?
However, this level of precision only works because the model is kept deliberately simple. While the authors concede that their conclusions should later be tested on more complex multi-head models such as the Claude and ChatGPT series, they also believe that the theory remains replicable as attention heads increase, stating*:
‘The question of what additional phenomena arise as the number of linked Attention heads and layers is scaled up, is a fascinating one. But any transitions within a single Attention head will still occur, and could get amplified and/or synchronized by the couplings – like a chain of connected people getting dragged over a cliff when one falls.’
An illustration of how the predicted tipping point n* changes depending on how strongly the prompt leans toward good or bad content. The surface comes from the authors’ approximate formula and shows that polite terms, which don’t clearly support either side, have little effect on when the collapse happens. The marked value (n* = 10) matches earlier simulations, supporting the model’s internal logic.
What remains unclear is whether the same mechanism survives the jump to modern transformer architectures. Multi-head attention introduces interactions across specialized heads, which may buffer against or mask the kind of tipping behavior described.
The authors acknowledge this complexity, but argue that attention heads are often loosely-coupled, and that the sort of internal collapse they model could be reinforced rather than suppressed in full-scale systems.
Without an extension of the model or an empirical test across production LLMs, the claim remains unverified. However, the mechanism seems sufficiently precise to support follow-on research initiatives, and the authors provide a clear opportunity to challenge or confirm the theory at scale.
Signing Off
At the moment, the topic of politeness towards consumer-facing LLMs appears to be approached either from the (pragmatic) standpoint that trained systems may respond more usefully to polite inquiry; or that a tactless and blunt communication style with such systems risks to spread into the user’s real social relationships, through force of habit.
Arguably, LLMs have not yet been used widely enough in real-world social contexts for the research literature to confirm the latter case; but the new paper does cast some interesting doubt upon the benefits of anthropomorphizing AI systems of this type.
A study last October from Stanford suggested (in contrast to a 2020 study) that treating LLMs as if they were human additionally risks to degrade the meaning of language, concluding that ‘rote’ politeness eventually loses its original social meaning:
[A] statement that seems friendly or genuine from a human speaker can be undesirable if it arises from an AI system since the latter lacks meaningful commitment or intent behind the statement, thus rendering the statement hollow and deceptive.’
However, roughly 67 percent of Americans say they are courteous to their AI chatbots, according to a 2025 survey from Future Publishing. Most said it was simply ‘the right thing to do’, while 12 percent confessed they were being cautious – just in case the machines ever rise up.
* My conversion of the authors’ inline citations to hyperlinks. To an extent, the hyperlinks are arbitrary/exemplary, since the authors at certain points link to a wide range of footnote citations, rather than to a specific publication.
First published Wednesday, April 30, 2025. Amended Wednesday, April 30, 2025 15:29:00, for formatting.
#2024#2025#ADD#Advanced LLMs#ai#AI chatbots#AI systems#Anderson's Angle#Artificial Intelligence#attention#bearing#Behavior#challenge#change#chatbots#chatGPT#circles#claude#coffee#communication#compass#complexity#content#Delay#direction#dynamics#embeddings#English#extension#focus
2 notes
·
View notes
Text
the cartridge slot on the nintendo switch feels antediluvian it borders on like medieval technology like on the one hand it Works Fine but on the other i feel like im handling some kind of new tech from the 60s before springs and latches were invented
#like oh i gotta pull out this delicate little tab and push down ONLY on the embedded cartridge to activate the spring to gently remove it#i dont know why it uses an SD card type system
9 notes
·
View notes
Text
SOMEONE GIVE ME A BLOODY INTERNSHIP 😭
#upcoming electronics engineer#proficient in embedded system in c. c++. c. python. and dsa in c++. and programming micro controllers like arduino uno and stm32.#PLEASE HIRE ME PAID OR NOT.
2 notes
·
View notes
Text
also despite all my (rightful) hating on 'the industry' i was right when at 25 i decided i wanted to be a computer programmer bc i am having an incredibly good time at this job learning what zero copy architecture is at 11 am on monday morning
5 notes
·
View notes
Text
*Holding Jack Seward in my arms like a disgruntled cat*
Y’all just don’t understand him like I do
#Jack seward#Dracula#Dracula daily#*baby talking him as I hold him up to my face* you’re the representation of the inherent moral greyness embedded in our medical system#aren’t you? aren’t you?#you represent the allure of knowledge vs humanity and how action makes the man don’t you?#my Dracula daily
47 notes
·
View notes