#generate a JSON Web Token
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
How To Generate JWT Token
Welcome To the Article About How To Generate JWT Token (JSON Web Token)! In this article, we will discuss the concept of the JWT token, the benefits of using it, how to generate it, and the security considerations that come with it. We will also explore how to use JWT token authentication in your applications. By the end of this blog, you will have a better understanding of JWT token and how to…

View On WordPress
#generate a JSON Web Token#Generate jwt Token#How to generate a JSON Web Token#How To Generate jwt Token#how to generate jwt token in python#how to generate jwt token online
0 notes
Text
This Week in Rust 533
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
crates.io: API status code changes
Foundation
Google Contributes $1M to Rust Foundation to Support C++/Rust "Interop Initiative"
Project/Tooling Updates
Announcing the Tauri v2 Beta Release
Polars — Why we have rewritten the string data type
rust-analyzer changelog #219
Ratatui 0.26.0 - a Rust library for cooking up terminal user interfaces
Observations/Thoughts
Will it block?
Embedded Rust in Production ..?
Let futures be futures
Compiling Rust is testing
Rust web frameworks have subpar error reporting
[video] Proving Performance - FOSDEM 2024 - Rust Dev Room
[video] Stefan Baumgartner - Trials, Traits, and Tribulations
[video] Rainer Stropek - Memory Management in Rust
[video] Shachar Langbeheim - Async & FFI - not exactly a love story
[video] Massimiliano Mantione - Object Oriented Programming, and Rust
[audio] Unlocking Rust's power through mentorship and knowledge spreading, with Tim McNamara
[audio] Asciinema with Marcin Kulik
Non-Affine Types, ManuallyDrop and Invariant Lifetimes in Rust - Part One
Nine Rules for Accessing Cloud Files from Your Rust Code: Practical lessons from upgrading Bed-Reader, a bioinformatics library
Rust Walkthroughs
AsyncWrite and a Tale of Four Implementations
Garbage Collection Without Unsafe Code
Fragment specifiers in Rust Macros
Writing a REST API in Rust
[video] Traits and operators
Write a simple netcat client and server in Rust
Miscellaneous
RustFest 2024 Announcement
Preprocessing trillions of tokens with Rust (case study)
All EuroRust 2023 talks ordered by the view count
Crate of the Week
This week's crate is embedded-cli-rs, a library that makes it easy to create CLIs on embedded devices.
Thanks to Sviatoslav Kokurin for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fluvio - Build a new python wrapping for the fluvio client crate
Fluvio - MQTT Connector: Prefix auto generated Client ID to prevent connection drops
Ockam - Implement events in SqlxDatabase
Ockam - Output for both ockam project ticket and ockam project enroll is improved, with support for --output json
Ockam - Output for ockam project ticket is improved and information is not opaque
Hyperswitch - [FEATURE]: Setup code coverage for local tests & CI
Hyperswitch - [FEATURE]: Have get_required_value to use ValidationError in OptionExt
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
RustNL 2024 CFP closes 2024-02-19 | Delft, The Netherlands | Event date: 2024-05-07 & 2024-05-08
NDC Techtown CFP closes 2024-04-14 | Kongsberg, Norway | Event date: 2024-09-09 to 2024-09-12
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
309 pull requests were merged in the last week
add avx512fp16 to x86 target features
riscv only supports split_debuginfo=off for now
target: default to the medium code model on LoongArch targets
#![feature(inline_const_pat)] is no longer incomplete
actually abort in -Zpanic-abort-tests
add missing potential_query_instability for keys and values in hashmap
avoid ICE when is_val_statically_known is not of a supported type
be more careful about interpreting a label/lifetime as a mistyped char literal
check RUST_BOOTSTRAP_CONFIG in profile_user_dist test
correctly check never_type feature gating
coverage: improve handling of function/closure spans
coverage: use normal edition: headers in coverage tests
deduplicate more sized errors on call exprs
pattern_analysis: Gracefully abort on type incompatibility
pattern_analysis: cleanup manual impls
pattern_analysis: cleanup the contexts
fix BufReader unsoundness by adding a check in default_read_buf
fix ICE on field access on a tainted type after const-eval failure
hir: refactor getters for owner nodes
hir: remove the generic type parameter from MaybeOwned
improve the diagnostics for unused generic parameters
introduce support for async bound modifier on Fn* traits
make matching on NaN a hard error, and remove the rest of illegal_floating_point_literal_pattern
make the coroutine def id of an async closure the child of the closure def id
miscellaneous diagnostics cleanups
move UI issue tests to subdirectories
move predicate, region, and const stuff into their own modules in middle
never patterns: It is correct to lower ! to _
normalize region obligation in lexical region resolution with next-gen solver
only suggest removal of as_* and to_ conversion methods on E0308
provide more context on derived obligation error primary label
suggest changing type to const parameters if we encounter a type in the trait bound position
suppress unhelpful diagnostics for unresolved top level attributes
miri: normalize struct tail in ABI compat check
miri: moving out sched_getaffinity interception from linux'shim, FreeBSD su…
miri: switch over to rustc's tracing crate instead of using our own log crate
revert unsound libcore changes
fix some Arc allocator leaks
use <T, U> for array/slice equality impls
improve io::Read::read_buf_exact error case
reject infinitely-sized reads from io::Repeat
thread_local::register_dtor fix proposal for FreeBSD
add LocalWaker and ContextBuilder types to core, and LocalWake trait to alloc
codegen_gcc: improve iterator for files suppression
cargo: Don't panic on empty spans
cargo: Improve map/sequence error message
cargo: apply -Zpanic-abort-tests to doctests too
cargo: don't print rustdoc command lines on failure by default
cargo: stabilize lockfile v4
cargo: fix markdown line break in cargo-add
cargo: use spec id instead of name to match package
rustdoc: fix footnote handling
rustdoc: correctly handle attribute merge if this is a glob reexport
rustdoc: prevent JS injection from localStorage
rustdoc: trait.impl, type.impl: sort impls to make it not depend on serialization order
clippy: redundant_locals: take by-value closure captures into account
clippy: new lint: manual_c_str_literals
clippy: add lint_groups_priority lint
clippy: add new lint: ref_as_ptr
clippy: add configuration for wildcard_imports to ignore certain imports
clippy: avoid deleting labeled blocks
clippy: fixed FP in unused_io_amount for Ok(lit), unrachable! and unwrap de…
rust-analyzer: "Normalize import" assist and utilities for normalizing use trees
rust-analyzer: enable excluding refs search results in test
rust-analyzer: support for GOTO def from inside files included with include! macro
rust-analyzer: emit parser error for missing argument list
rust-analyzer: swap Subtree::token_trees from Vec to boxed slice
Rust Compiler Performance Triage
Rust's CI was down most of the week, leading to a much smaller collection of commits than usual. Results are mostly neutral for the week.
Triage done by @simulacrum. Revision range: 5c9c3c78..0984bec
0 Regressions, 2 Improvements, 1 Mixed; 1 of them in rollups 17 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider principal trait ref's auto-trait super-traits in dyn upcasting
[disposition: merge] remove sub_relations from the InferCtxt
[disposition: merge] Optimize away poison guards when std is built with panic=abort
[disposition: merge] Check normalized call signature for WF in mir typeck
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
Nested function scoped type parameters
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2024-02-07 - 2024-03-06 🦀
Virtual
2024-02-07 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh - How Rust Saved My Eyes
2024-02-08 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-02-08 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-02-10 | Virtual (Krakow, PL) | Stacja IT Kraków
Rust – budowanie narzędzi działających w linii komend
2024-02-10 | Virtual (Wrocław, PL) | Stacja IT Wrocław
Rust – budowanie narzędzi działających w linii komend
2024-02-13 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-02-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack n Learn | Mirror: Rust Hack n Learn
2024-02-15 | Virtual + In person (Praha, CZ) | Rust Czech Republic
Introduction and Rust in production
2024-02-19 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-20 | Virtual | Rust for Lunch
Lunch
2024-02-21 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 2 - Types
2024-02-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-02-22 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
Asia
2024-02-10 | Hyderabad, IN | Rust Language Hyderabad
Rust Language Develope BootCamp
Europe
2024-02-07 | Cologne, DE | Rust Cologne
Embedded Abstractions | Event page
2024-02-07 | London, UK | Rust London User Group
Rust for the Web — Mainmatter x Shuttle Takeover
2024-02-08 | Bern, CH | Rust Bern
Rust Bern Meetup #1 2024 🦀
2024-02-08 | Oslo, NO | Rust Oslo
Rust-based banter
2024-02-13 | Trondheim, NO | Rust Trondheim
Building Games with Rust: Dive into the Bevy Framework
2024-02-15 | Praha, CZ - Virtual + In-person | Rust Czech Republic
Introduction and Rust in production
2024-02-21 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #8
2024-02-22 | Aarhus, DK | Rust Aarhus
Rust and Talk at Partisia
North America
2024-02-07 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Feb 7
2024-02-08 | Lehi, UT, US | Utah Rust
BEAST: Recreating a classic DOS terminal game in Rust
2024-02-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust: Open Source Contrib Hackathon & Happy Hour
2024-02-13 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer
2024-02-13 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-02-15 | Boston, MA, US | Boston Rust Meetup
Back Bay Rust Lunch, Feb 15
2024-02-15 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-02-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-02-22 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-02-28 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-02-19 | Melbourne, VIC, AU + Virtual | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-27 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2024-02-27 | Sydney, NSW, AU | Rust Sydney
🦀 spire ⚡ & Quick
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
My take on this is that you cannot use async Rust correctly and fluently without understanding Arc, Mutex, the mutability of variables/references, and how async and await syntax compiles in the end. Rust forces you to understand how and why things are the way they are. It gives you minimal abstraction to do things that could’ve been tedious to do yourself.
I got a chance to work on two projects that drastically forced me to understand how async/await works. The first one is to transform a library that is completely sync and only requires a sync trait to talk to the outside service. This all sounds fine, right? Well, this becomes a problem when we try to port it into browsers. The browser is single-threaded and cannot block the JavaScript runtime at all! It is arguably the most weird environment for Rust users. It is simply impossible to rewrite the whole library, as it has already been shipped to production on other platforms.
What we did instead was rewrite the network part using async syntax, but using our own generator. The idea is simple: the generator produces a future when called, and the produced future can be awaited. But! The produced future contains an arc pointer to the generator. That means we can feed the generator the value we are waiting for, then the caller who holds the reference to the generator can feed the result back to the function and resume it. For the browser, we use the native browser API to derive the network communications; for other platforms, we just use regular blocking network calls. The external interface remains unchanged for other platforms.
Honestly, I don’t think any other language out there could possibly do this. Maybe C or C++, but which will never have the same development speed and developer experience.
I believe people have already mentioned it, but the current asynchronous model of Rust is the most reasonable choice. It does create pain for developers, but on the other hand, there is no better asynchronous model for Embedded or WebAssembly.
– /u/Top_Outlandishness78 on /r/rust
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
Advanced Techniques in Full-Stack Development

Certainly, let's delve deeper into more advanced techniques and concepts in full-stack development:
1. Server-Side Rendering (SSR) and Static Site Generation (SSG):
SSR: Rendering web pages on the server side to improve performance and SEO by delivering fully rendered pages to the client.
SSG: Generating static HTML files at build time, enhancing speed, and reducing the server load.
2. WebAssembly:
WebAssembly (Wasm): A binary instruction format for a stack-based virtual machine. It allows high-performance execution of code on web browsers, enabling languages like C, C++, and Rust to run in web applications.
3. Progressive Web Apps (PWAs) Enhancements:
Background Sync: Allowing PWAs to sync data in the background even when the app is closed.
Web Push Notifications: Implementing push notifications to engage users even when they are not actively using the application.
4. State Management:
Redux and MobX: Advanced state management libraries in React applications for managing complex application states efficiently.
Reactive Programming: Utilizing RxJS or other reactive programming libraries to handle asynchronous data streams and events in real-time applications.
5. WebSockets and WebRTC:
WebSockets: Enabling real-time, bidirectional communication between clients and servers for applications requiring constant data updates.
WebRTC: Facilitating real-time communication, such as video chat, directly between web browsers without the need for plugins or additional software.
6. Caching Strategies:
Content Delivery Networks (CDN): Leveraging CDNs to cache and distribute content globally, improving website loading speeds for users worldwide.
Service Workers: Using service workers to cache assets and data, providing offline access and improving performance for returning visitors.
7. GraphQL Subscriptions:
GraphQL Subscriptions: Enabling real-time updates in GraphQL APIs by allowing clients to subscribe to specific events and receive push notifications when data changes.
8. Authentication and Authorization:
OAuth 2.0 and OpenID Connect: Implementing secure authentication and authorization protocols for user login and access control.
JSON Web Tokens (JWT): Utilizing JWTs to securely transmit information between parties, ensuring data integrity and authenticity.
9. Content Management Systems (CMS) Integration:
Headless CMS: Integrating headless CMS like Contentful or Strapi, allowing content creators to manage content independently from the application's front end.
10. Automated Performance Optimization:
Lighthouse and Web Vitals: Utilizing tools like Lighthouse and Google's Web Vitals to measure and optimize web performance, focusing on key user-centric metrics like loading speed and interactivity.
11. Machine Learning and AI Integration:
TensorFlow.js and ONNX.js: Integrating machine learning models directly into web applications for tasks like image recognition, language processing, and recommendation systems.
12. Cross-Platform Development with Electron:
Electron: Building cross-platform desktop applications using web technologies (HTML, CSS, JavaScript), allowing developers to create desktop apps for Windows, macOS, and Linux.
13. Advanced Database Techniques:
Database Sharding: Implementing database sharding techniques to distribute large databases across multiple servers, improving scalability and performance.
Full-Text Search and Indexing: Implementing full-text search capabilities and optimized indexing for efficient searching and data retrieval.
14. Chaos Engineering:
Chaos Engineering: Introducing controlled experiments to identify weaknesses and potential failures in the system, ensuring the application's resilience and reliability.
15. Serverless Architectures with AWS Lambda or Azure Functions:
Serverless Architectures: Building applications as a collection of small, single-purpose functions that run in a serverless environment, providing automatic scaling and cost efficiency.
16. Data Pipelines and ETL (Extract, Transform, Load) Processes:
Data Pipelines: Creating automated data pipelines for processing and transforming large volumes of data, integrating various data sources and ensuring data consistency.
17. Responsive Design and Accessibility:
Responsive Design: Implementing advanced responsive design techniques for seamless user experiences across a variety of devices and screen sizes.
Accessibility: Ensuring web applications are accessible to all users, including those with disabilities, by following WCAG guidelines and ARIA practices.
full stack development training in Pune
2 notes
·
View notes
Text
How to archive a Discord channel
I'm going to say this way ahead of time: this is going to be waaaaaaay more of an annoying process than it should be. Discord should allow exporting the channel history to server owners, without the need of doing all this. I won't blame you if you give up.
Get the DiscordChatExporter application to download the chat history
This program has two versions
one that has a graphical interface, but works on Windows only
one that has a command line interface, but works on Windows, Linux and macOS
This guide covers the first. The second one maybe next time, in another post. The second version also makes it easier to download every channel on the server.
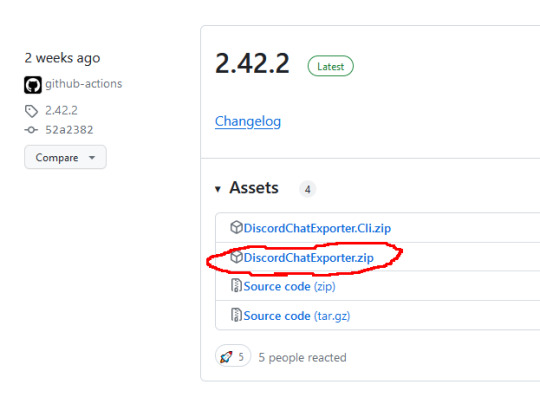
Step 1: Go to here, and download the latest version in the zip file named DiscordChatExporter.zip
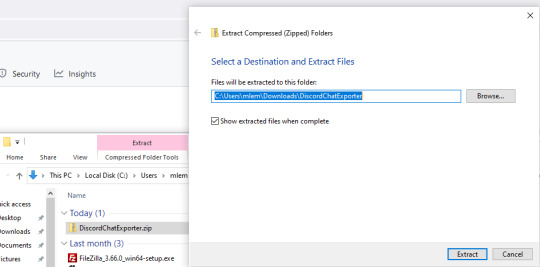
Step 2: Unpack the zip file
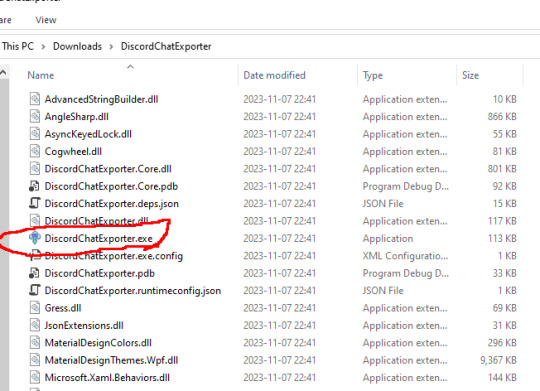
Step 3: Run DiscordChatExporter.exe
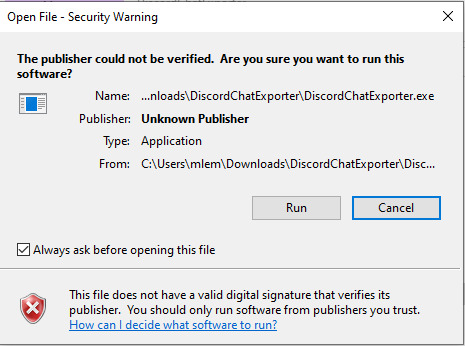
Step 4: Dismiss the scary looking warning as this will show up for any program that which developer can't afford paying $629 a year.
Step 5: Close the welcoming message and you'll see the application interface:
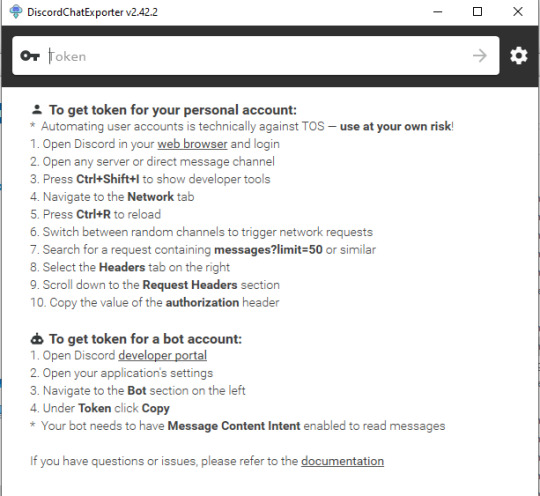
Prepare an access token. Do not share it to anyone else - treat it the same way as you treat your password.
There are two ways to do it:
Approach 1: use your own access token, will work with any channel you're able to access, including Direct Messages, but it is a violation of Discord Terms of Service, and therefore your Discord account could get banned for it. Use at your own risk.
Follow the instructions here, which are fairly detailed step-by-step instructions for Chrome, Firefox, and also the desktop app. I'm gonna expand more on approach 2 as I had to figure it out myself, and the current instructions for approach 2 are not really adequate enough. If you go with approach 1, skip down the entire section below, until the "Paste the token in the Token textbox and click the arrow button" section.
Approach 2: create a bot account, invite it to your server, and use its access token. This process assumes you have enough privileges to invite bots to the server ("Manage Server" permission), and therefore, but is also 100% okay as far as Discord's Terms of Service are concerned. It is also generally safer, as accidental leaking of the token will not risk you losing your user account.
Step 1: Go to the Discord developer portal.
Step 2: Create a new application by clicking the "New Application" button
Step 3: Name it however you want, I personally named it "mlemgrab". Agree to the scary sounding long ass terms of service.
Step 4: Go to the Bot section, scroll down to the "Privileged Gateway Intents"

Step 5: Enable the "Message Content Intent". We don't have to worry about the "if your bot is in more than 100 servers" part because our bot will never be in this many servers.
Step 6: Save changes by pressing the green button "Save Changes"

Step 7: Go to "OAuth2" followed by "URL Generator"
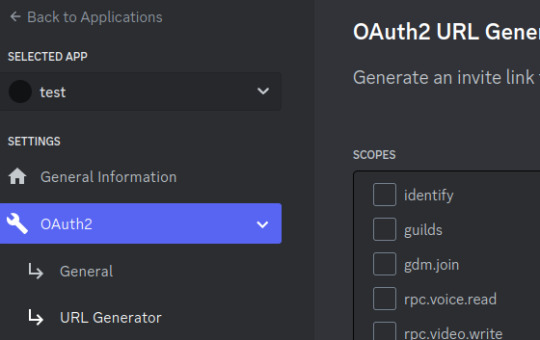
Step 8: Select the "bot" scope and then "Read Messages/View Channels" and "Read Message History" permissions

Step 9: Copy the link at the bottom and visit it:
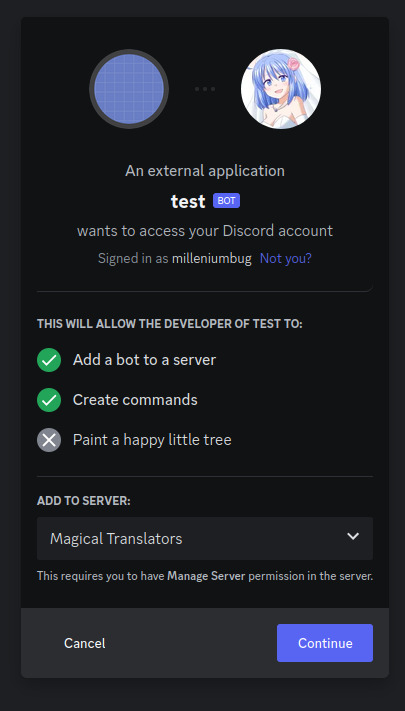
Step 10: Press "Continue", and approve the required permissions by clicking Authorize. Once you do it, the bot account is on the server.
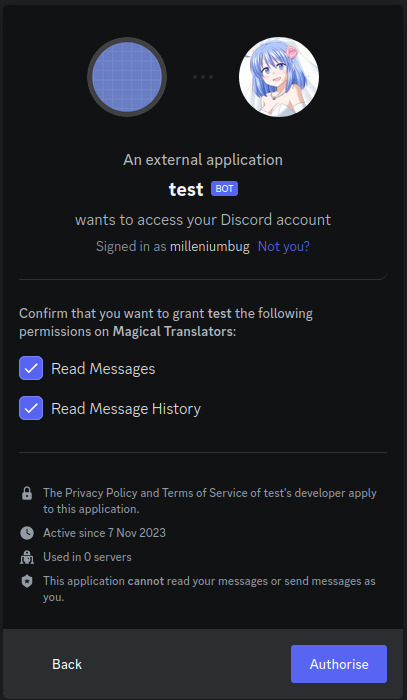
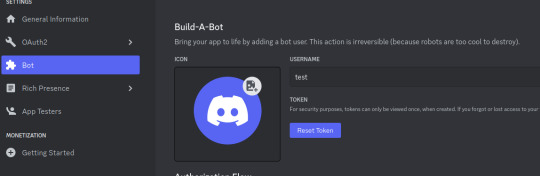
Step 11: Go to "Bot" and click the "Reset Token" button to get the token that will allow you to act (in our case, getting all the messages) using the bot user. If you lose that token, you can click reset again to get a new one.
Paste the token in the Token textbox and click the arrow button

Select the server, and then the channel you want to archive

Click the download button on the bottom right

Select where you want to save it, and the format. HTML is good for easy browsing and preview in a web browser, JSON is good for further processing (let's say someone else later writes a program for importing the conversation elsewhere).
For archivization purposes I recommend saving in both HTML and JSON.
Click "More" for more options.
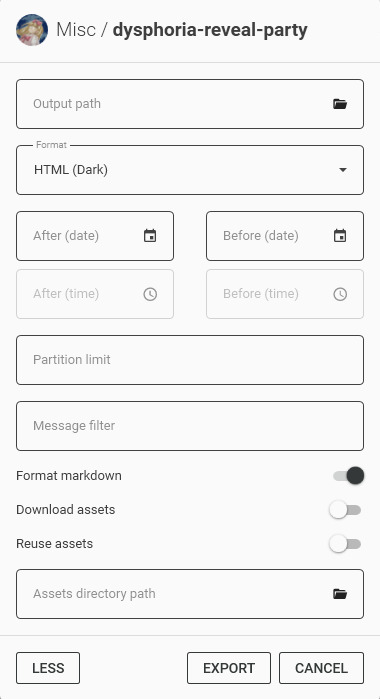
By default the program will not download any message attachments nor avatars or emotes. If you want that, select "Download assets" option. Preferably while also selecting the "Reuse assets" option and selecting a single directory for assets if you want to archive multiple channels.
You can also select the specific time range and using the partition limit - split the archive into several files each containing N messages.
Press Export. Wait. The progress bar will move very slowly.
Once it is done, you should be able to open the HTML file with your web browser.
Treat anything on Discord as media that will be lost
Do not use Discord to host your files. Do not rely on Discord to preserve your text. DO NOT RELY ON DISCORD FOR ANY KIND OF PRESERVATION OR HOSTING!!
It CAN be lost, it WILL be lost! You must consider Discord as a part of the Core Internet, controlled by one company that hosts the servers.
I thought it was impressive at first that it replaced IRC, but now I am horrified. If the company behind Discord went under today, how many friends would you lose?
How many relationships? How much writing?
You may think this won't happen, but I remember when AIM went down and along with it, entire novels worth of interaction with my oldest friend.
IT CAN HAPPEN TO YOU. IT WILL HAPPEN AGAIN. NO COMPANY IS INFALLIBLE.
Back up your files! Download anything you've saved to Discord NOW, before the API changes go into effect! And DO NOT RELY ON THEM FOR HOLDING IMPORTANT FILES!
52K notes
·
View notes
Text
API Vulnerabilities in Symfony: Common Risks & Fixes
Symfony is one of the most robust PHP frameworks used by enterprises and developers to build scalable and secure web applications. However, like any powerful framework, it’s not immune to security issues—especially when it comes to APIs. In this blog, we’ll explore common API vulnerabilities in Symfony, show real coding examples, and explain how to secure them effectively.

We'll also demonstrate how our Free Website Security Scanner helps identify these vulnerabilities before attackers do.
🚨 Common API Vulnerabilities in Symfony
Let’s dive into the key API vulnerabilities developers often overlook:
1. Improper Input Validation
Failure to sanitize input can lead to injection attacks.
❌ Vulnerable Code:
// src/Controller/ApiController.php public function getUser(Request $request) { $id = $request->query->get('id'); $user = $this->getDoctrine() ->getRepository(User::class) ->find("SELECT * FROM users WHERE id = $id"); return new JsonResponse($user); }
✅ Secure Code with Param Binding:
public function getUser(Request $request) { $id = (int)$request->query->get('id'); $user = $this->getDoctrine() ->getRepository(User::class) ->find($id); return new JsonResponse($user); }
Always validate and sanitize user input, especially IDs and query parameters.
2. Broken Authentication
APIs that don’t properly verify tokens or allow session hijacking are easy targets.
❌ Insecure Token Check:
if ($request->headers->get('Authorization') !== 'Bearer SECRET123') { throw new AccessDeniedHttpException('Unauthorized'); }
✅ Use Symfony’s Built-in Security:
# config/packages/security.yaml firewalls: api: pattern: ^/api/ stateless: true jwt: ~
Implement token validation using LexikJWTAuthenticationBundle to avoid manual and error-prone token checking.
3. Overexposed Data in JSON Responses
Sometimes API responses contain too much information, leading to data leakage.
❌ Unfiltered Response:
return $this->json($user); // Might include password hash or sensitive metadata
✅ Use Serialization Groups:
// src/Entity/User.php use Symfony\Component\Serializer\Annotation\Groups; class User { /** * @Groups("public") */ private $email; /** * @Groups("internal") */ private $password; } // In controller return $this->json($user, 200, [], ['groups' => 'public']);
Serialization groups help you filter sensitive fields based on context.
🛠️ How to Detect Symfony API Vulnerabilities for Free
📸 Screenshot of the Website Vulnerability Scanner tool homepage

Screenshot of the free tools webpage where you can access security assessment tools.
Manual code audits are helpful but time-consuming. You can use our free Website Security Checker to automatically scan for common security flaws including:
Open API endpoints
Broken authentication
Injection flaws
Insecure HTTP headers
🔎 Try it now: https://free.pentesttesting.com/
📸 Screenshot of an actual vulnerability report generated using the tool to check Website Vulnerability

An Example of a vulnerability assessment report generated with our free tool, providing insights into possible vulnerabilities.
✅ Our Web App Penetration Testing Services
For production apps and high-value APIs, we recommend deep testing beyond automated scans.
Our professional Web App Penetration Testing Services at Pentest Testing Corp. include:
Business logic testing
OWASP API Top 10 analysis
Manual exploitation & proof-of-concept
Detailed PDF reports
💼 Learn more: https://www.pentesttesting.com/web-app-penetration-testing-services/
📚 More Articles from Pentest Testing Corp.
For in-depth cybersecurity tips and tutorials, check out our main blog:
🔗 https://www.pentesttesting.com/blog/
Recent articles:
Laravel API Security Best Practices
XSS Mitigation in React Apps
Threat Modeling for SaaS Platforms
📬 Stay Updated: Subscribe to Our Newsletter
Join cybersecurity enthusiasts and professionals who subscribe to our weekly threat updates, tools, and exclusive research:
🔔 Subscribe on LinkedIn: https://www.linkedin.com/build-relation/newsletter-follow?entityUrn=7327563980778995713
💬 Final Thoughts
Symfony is powerful, but with great power comes great responsibility. Developers must understand API security vulnerabilities and patch them proactively. Use automated tools like ours for Website Security check, adopt secure coding practices, and consider penetration testing for maximum protection.
Happy Coding—and stay safe out there!
#cyber security#cybersecurity#data security#pentesting#security#coding#symfony#the security breach show#php#api
1 note
·
View note
Text
Authentication and Authorization in Node.js with JWT

Authentication and authorization are essential for securing modern web applications. In Node.js, using JWT (JSON Web Tokens) has become a trending and efficient way to handle secure access control. JWT allows stateless authentication, making it ideal for RESTful APIs and microservices architecture.
When a user logs in, the server generates a JWT signed with a secret key or a private key (in case of RSA). This token is then sent to the client and stored typically in localStorage or HTTP-only cookies. For each subsequent request, the client sends the token in the header, commonly using the Bearer schema.
The backend uses middleware like jsonwebtoken in combination with Express.js to verify the token and extract user information. If the token is valid, the user gets access to protected routes and resources. Role-based access control (RBAC) can also be implemented to allow specific users access to different parts of the application.
JWTs are widely used in Node.js for API security, real-time applications, and mobile backends due to their lightweight and stateless nature. Key trends include integrating JWT with OAuth2.0, using refresh tokens for long-lived sessions, and enhancing security with HTTPS and token expiration strategies.
Popular npm packages include jsonwebtoken, bcryptjs for password hashing, and dotenv for environment variables. Combining JWT with MongoDB, Mongoose, and Express.js is a common stack for secure backend development in 2025.
0 notes
Text
Enhancing Security in Backend Development: Best Practices for Developers
In today’s rapidly evolving digital environment, security in backend systems is paramount. As the backbone of web applications, the backend handles sensitive data processing, storage, and communication. Any vulnerabilities in this layer can lead to catastrophic breaches, affecting user trust and business integrity. This article highlights essential best practices to ensure your backend development meets the highest security standards.
1. Implement Strong Authentication and Authorization
One of the primary steps in securing backend development services is implementing robust authentication and authorization protocols. Password-based systems alone are no longer sufficient. Modern solutions like OAuth 2.0 and JSON Web Tokens (JWT) offer secure ways to manage user sessions. Multi-factor authentication (MFA) adds another layer of protection, requiring users to verify their identity using multiple methods, such as a password and a one-time code.
Authorization should be handled carefully to ensure users only access resources relevant to their role. By limiting privileges, you reduce the risk of sensitive data falling into the wrong hands. This practice is particularly crucial for applications that involve multiple user roles, such as administrators, managers, and end-users.
2. Encrypt Data in Transit and at Rest
Data encryption is a non-negotiable aspect of backend security. When data travels between servers and clients, it is vulnerable to interception. Implement HTTPS to secure this communication channel using SSL/TLS protocols. For data stored in databases, use encryption techniques that prevent unauthorized access. Even if an attacker gains access to the storage, encrypted data remains unreadable without the decryption keys.
Managing encryption keys securely is equally important. Store keys in hardware security modules (HSMs) or use services like AWS Key Management Service (KMS) to ensure they are well-protected. Regularly rotate keys to further reduce the risk of exposure.
3. Prevent SQL Injection and Other Injection Attacks
Injection attacks, particularly SQL injections, remain one of the most common threats to backend technologies for web development. Attackers exploit poorly sanitized input fields to execute malicious SQL queries. This can lead to unauthorized data access or even complete control of the database.
To mitigate this risk, always validate and sanitize user inputs. Use parameterized queries or prepared statements, which ensure that user-provided data cannot alter the intended database commands. Additionally, educate developers on the risks of injection attacks and implement static code analysis tools to identify vulnerabilities during the development process.
4. Employ Secure API Design
APIs are integral to backend development but can also serve as entry points for attackers if not secured properly. Authentication tokens, input validation, and rate limiting are essential to preventing unauthorized access and abuse. Moreover, all API endpoints should be designed with security-first principles.
For example, avoid exposing sensitive information in API responses. Error messages should be generic and not reveal the backend structure. Consider using tools like API gateways to enforce security policies, including data masking, IP whitelisting, and token validation.
5. Keep Dependencies Updated and Patched
Third-party libraries and frameworks streamline development but can introduce vulnerabilities if not updated regularly. Outdated software components are a common attack vector. Perform routine dependency checks and integrate automated vulnerability scanners like Snyk or Dependabot into your CI/CD pipeline.
Beyond updates, consider using tools to analyze your application for known vulnerabilities. For instance, dependency management tools can identify and notify you of outdated libraries, helping you stay ahead of potential risks.
6. Adopt Role-Based Access Control (RBAC)
Access management is a critical component of secure backend systems. Role-Based Access Control (RBAC) ensures users and applications have access only to what they need. Define roles clearly and assign permissions at a granular level. For example, a customer service representative may only access user profile data, while an admin might have permissions to modify backend configurations.
Implementing RBAC reduces the potential damage of a compromised user account. For added security, monitor access logs for unusual patterns, such as repeated failed login attempts or unauthorized access to restricted resources.
7. Harden Your Database Configurations
Databases are at the heart of backend systems, making them a prime target for attackers. Properly configuring your database is essential. Start by disabling unnecessary services and default accounts that could be exploited. Enforce strong password policies and ensure that sensitive data, such as passwords, is hashed using secure algorithms like bcrypt or Argon2.
Database permissions should also be restricted. Grant the least privilege necessary to applications interacting with the database. Regularly audit these permissions to identify and eliminate unnecessary access.
8. Monitor and Log Backend Activities
Real-time monitoring and logging are critical for detecting and responding to security threats. Implement tools like Logstash, Prometheus, and Kibana to track server activity and identify anomalies. Logs should include information about authentication attempts, database queries, and API usage.
However, ensure that logs themselves are secure. Store them in centralized, access-controlled environments and avoid exposing them to unauthorized users. Use log analysis tools to proactively identify patterns that may indicate an ongoing attack.
9. Mitigate Cross-Site Scripting (XSS) Risks
Cross-site scripting attacks can compromise your backend security through malicious scripts. To prevent XSS attacks, validate and sanitize all inputs received from the client side. Implement Content Security Policies (CSP) that restrict the types of scripts that can run within the application.
Another effective measure is to encode output data before rendering it in the user’s browser. For example, HTML encoding ensures that malicious scripts cannot execute, even if injected.
10. Secure Cloud Infrastructure
As businesses increasingly migrate to the cloud, backend developers must adapt to the unique challenges of cloud security. Use Identity and Access Management (IAM) features provided by cloud platforms like AWS, Google Cloud, and Azure to define precise permissions.
Enable encryption for all data stored in the cloud and use virtual private clouds (VPCs) to isolate your infrastructure from external threats. Regularly audit your cloud configuration to ensure compliance with security best practices.
11. Foster a Culture of Security
Security isn’t a one-time implementation — it’s an ongoing process. Regularly train your development team on emerging threats, secure coding practices, and compliance standards. Encourage developers to follow a security-first approach at every stage of development.
Conduct routine penetration tests and code audits to identify weaknesses. Establish a response plan to quickly address breaches or vulnerabilities. By fostering a security-conscious culture, your organization can stay ahead of evolving threats.
Thus, Backend security is an ongoing effort requiring vigilance, strategic planning, and adherence to best practices. Whether you’re managing APIs, databases, or cloud integrations, securing backend development services ensures the reliability and safety of your application.
0 notes
Text
Understanding Authentication: Cookies, Sessions, and JWT

Understanding Authentication: Cookies, Sessions, and JWT
Authentication is a cornerstone of web security, ensuring that users can access only the resources they are authorized for. Different methods like cookies, sessions, and JSON Web Tokens (JWT) are commonly used to implement authentication. Here’s a breakdown of each method, their key features, and use cases.
1. Cookies
Cookies are small data files stored on a user’s browser and sent with every request to the server. They are often used to persist user authentication data across sessions.
Key Features:
Stored on the client side.
Can include attributes like HttpOnly, Secure, and SameSite to improve security.
Frequently used for tracking user sessions or preferences.
How It Works:
The server creates a cookie when the user logs in.
The cookie is sent to the user’s browser.
With every subsequent request, the browser sends the cookie back to the server.
Example (HTTP):http Set-Cookie: sessionId=abc123; HttpOnly; Secure; Path=/;
Use Case: Persistent login, especially for websites with session-based authentication.
2. Sessions
Sessions store user-specific data on the server. When a user logs in, the server creates a session and assigns a unique session ID. This ID is shared with the client, typically through a cookie.
Key Features:
Data is stored server-side, reducing the risk of client-side tampering.
Session data can include user-specific state, preferences, or permissions.
Requires server resources to manage.
How It Works:
User logs in, and the server creates a session.
A session ID is sent to the client (via a cookie or request).
The server retrieves session data using the session ID.
Example (Python Flask):python from flask import session# Set session data session['user_id'] = user.id# Get session data user_id = session.get('user_id')
Use Case: Suitable for server-rendered web applications requiring state management.
3. JSON Web Tokens (JWT)
JWTs are self-contained, compact tokens encoded in a URL-safe format. They consist of three parts: Header, Payload, and Signature. The payload often contains claims (e.g., user ID, roles, expiration time).
Key Features:
Stateless: No server-side storage needed.
Can be signed and optionally encrypted for security.
Suitable for distributed systems like microservices.
How It Works:
The server generates a JWT upon user login.
The JWT is sent to the client and stored (e.g., in local storage or cookies).
The client sends the JWT with each request (commonly in the Authorization header).
The server validates the JWT using its signature.
Example (Python):pythonimport jwt# Create a token payload = {"user_id": 123, "exp": 1672531199} secret = "my_secret_key" token = jwt.encode(payload, secret, algorithm="HS256")# Decode a token decoded = jwt.decode(token, secret, algorithms=["HS256"])
Use Case: Best for stateless authentication in APIs and microservices.
Choosing the Right Approach
MethodBest ForDrawbackCookiesPersistent client-side state managementVulnerable to client-side risksSessionsServer-side state managementScales with server resourcesJWTStateless, distributed systemsLarger token size
Conclusion
Cookies, sessions, and JWTs each have their strengths and trade-offs. The choice depends on your application’s architecture and requirements:
Cookies and sessions are ideal for traditional server-side web apps.
JWTs excel in stateless, distributed systems like APIs or microservices.
Understanding these mechanisms empowers you to design secure, scalable, and efficient authentication systems for your applications.

0 notes
Text
Next-Generation Web Security Solutions with OAuth 2.0 and JWT
Introduction As the web continues to evolve, security has become a top priority. Next-Generation Web Security: Implementing OAuth 2.0 and JWT is a critical aspect of this, providing a robust and secure way to authenticate and authorize users. In this tutorial, we will explore the implementation of OAuth 2.0 and JSON Web Tokens (JWT) to secure your web applications. What You Will…
0 notes
Text
6 Amazing Tips for Headless WordPress Development | Island Wizards

Headless WordPress development is a new and exciting way to create flexible, fast, and modern websites. By separating WordPress as a content management system (CMS) from the front-end display, you can have total freedom to use powerful frameworks like React, Vue.js, or Next.js. But how do you get the most out of this setup? Here are six amazing tips from Island Wizards to help you succeed!
1. Choose the Right API for Your Needs
Explanation: In headless WordPress, communication happens through APIs. You can use either the REST API or GraphQL to connect your content to the front end.
Tip: GraphQL can be more flexible, allowing you to fetch only the data you need, making your site faster. At Island Wizards, we often use GraphQL for projects with complex data requirements to keep things simple and efficient.
2. Focus on Performance Optimization
Explanation: The speed of your site matters—a lot. Since headless sites depend on API calls, making them fast is crucial.
Tip: Reduce data transfer by optimizing API requests and using caching. Island Wizards recommends static site generation (SSG) whenever possible, which makes pages load lightning-fast by pre-generating content.
3. Structure Your Content Wisely
Explanation: Good content structure is the backbone of headless WordPress development. Think about how your content types, taxonomies, and fields are set up.
Tip: Use plugins like Advanced Custom Fields (ACF) to create flexible data models. This makes it easier to pull the right content for your front end. Island Wizards always starts projects by carefully planning how content should be organized.
4. Use a Reliable Front-End Framework
Explanation: Choosing the right front-end framework can make all the difference. Popular options include React, Vue.js, and Next.js.
Tip: Consider using Next.js for its server-side rendering (SSR) and static generation capabilities, which make your site faster and improve SEO. Island Wizards uses these frameworks to create responsive and user-friendly experiences.
5. Prioritize Security
Explanation: Headless WordPress setups have unique security challenges since the front end and backend are separate.
Tip: Secure API endpoints with robust authentication methods like JSON Web Tokens (JWT). Island Wizards takes security seriously, ensuring every endpoint is protected and regularly tested to prevent breaches.
6. Test and Optimize Your APIs
Explanation: Regular testing ensures that your API calls work smoothly. Slow or broken APIs can frustrate users and hurt your site's performance.
Tip: Use tools like Postman for testing API calls and integrate automated testing into your workflow. Island Wizards suggests continuous testing to catch issues early and keep everything running smoothly.
Why Island Wizards for Your Headless WordPress Development?
At Island Wizards, we specialize in creating modern, high-performance headless WordPress websites. Island Wizards team blends innovative front-end solutions with powerful WordPress backends to deliver unmatched speed, flexibility, and security. By choosing Island Wizards, you can transform your web presence and stand out from the competition.
Explore more about our service… https://islandwizards.com/blogs/difference-between-webflow-and-wordpre.. https://islandwizards.com/blogs/how-shopify-sections-can-help-you-boos..
#white label agency solution#best white label agency in uk#headless wordpress solution#best it company#shopify#wordpress#island wizards#headless wordpress development services#seo#island wizards uk'#shopify partner program#wizards island#white label agency
1 note
·
View note
Text
Watsonx.data Presto C++ With Intel Sapphire Rapids On AWS

Using Watsonx.data Presto C++ with the Intel Sapphire Rapid Processor on AWS to speed up query performance
Over the past 25 years, there have been notable improvements in database speed due to IBM and Intel’s long-standing cooperation. The most recent generation of Intel Xeon Scalable processors, when paired with Intel software, can potentially improve IBM Watsonx.data performance, according to internal research conducted by IBM.
A hybrid, managed data lake house, IBM Watsonx.data is tailored for workloads including data, analytics, and artificial intelligence. Using engines like Presto and Spark to drive corporate analytics is one of the highlights. Watsonx.data also offers a single view of your data across hybrid cloud environments and a customizable approach.
Presto C++
The next edition of Presto, called Presto C++, was released by IBM in June. It was created by open-source community members from Meta, IBM, Uber, and other companies. The Velox, an open-source C++ native acceleration library made to be compatible with various compute engines, was used in the development of this query engine in partnership with Intel. In order to further improve query performance through efficient query rewrite, IBM also accompanied the release of the Presto C++ engine with a query optimizer built on decades of experience.
Summary
A C++ drop-in replacement for Presto workers built on the Velox library, Presto C++ is also known as the development name Prestissimo. It uses the Proxygen C++ HTTP framework to implement the same RESTful endpoints as Java workers. Presto C++ does not use JNI and does not require a JVM on worker nodes because it exclusively uses REST endpoints for communication with the Java coordinator and amongst workers.
Inspiration and Goals
Presto wants to be the best data lake system available. The native Java-based version of the Presto evaluation engine is being replaced by a new C++ implementation using Velox in order to accomplish this goal.
In order to allow the Presto community to concentrate on more features and improved connectivity with table formats and other data warehousing systems, the evaluation engine has been moved to a library.
Accepted Use Cases
The Presto C++ evaluation engine supports just certain connectors.
Reads and writes via the Hive connection, including CTAS, are supported.
Only reads are supported for iceberg tables.
Both V1 and V2 tables, including tables with delete files, are supported by the Iceberg connector.
TPCH.naming=standard catalog property for the TPCH connector.
Features of Presto C++
Task management: Users can monitor and manage tasks using the HTTP endpoints included in Presto C++. This tool facilitates tracking ongoing procedures and improves operational oversight.
Data processing across a network of nodes can be made more effective by enabling the execution of functions on distant nodes, which improves scalability and distributed processing capabilities.
For secure internal communication between nodes, authentication makes use of JSON Web Tokens (JWT), guaranteeing that data is safe and impenetrable while being transmitted.
Asynchronous data caching with prefetching capabilities is implemented. By anticipating data demands and caching it beforehand, this maximizes processing speed and data retrieval.
Performance Tuning: Provides a range of session parameters, such as compression and spill threshold adjustments, for performance tuning. This guarantees optimal performance of data processing operations by enabling users to adjust performance parameters in accordance with their unique requirements.
Limitations of Presto C++
There are some drawbacks to the C++ evaluation engine:
Not every built-in function is available in C++. A query failure occurs when an attempt is made to use unimplemented functions. See Function Coverage for a list of supported functions.
C++ does not implement all built-in types. A query failure will occur if unimplemented types are attempted to be used.
With the exception of CHAR, TIME, and TIME WITH TIMEZONE, all basic and structured types in Data Types are supported. VARCHAR, TIMESTAMP, and TIMESTAMP WITH TIMEZONE are subsumptions of these.
The length n in varchar[n] is not honored by Presto C++; it only supports the limitless length VARCHAR.
IPADDRESS, IPPREFIX, UUID, KHYPERLOGLOG, P4HYPERLOGLOG, QDIGEST, TDIGEST, GEOMETRY, and BINGTILE are among the types that are not supported.
The C++ evaluation engine does not use all of the plugin SPI. Specifically, several plugin types are either fully or partially unsupported, and C++ workers will not load any plugins from the plugins directory.
The C++ evaluation engine does not support PageSourceProvider, RecordSetProvider, or PageSinkProvider.
Block encodings, parametric types, functions, and types specified by the user are not supported.
At the split level, the event listener plugin is not functional.
See Remote Function Execution for information on how user-defined functions differ from one another.
The C++ evaluation engine has a distinct memory management system. Specifically:
There is no support for the OOM killer.
There is no support for the reserved pool.
Generally speaking, queries may utilize more memory than memory arbitration permits. Refer to Memory Management.
Functions
reduce_agg
Reduce_agg is not allowed to return null in the inputFunction or the combineFunction of C++-based Presto. This is acceptable but ill-defined behavior in Presto (Java). See reduce_agg for more details about reduce_agg in Presto.
Amazon Elastic Compute Cloud (EC2) R7iz instances are high-performance CPU instances that are designed for memory. With a sustained all-core turbo frequency of 3.9 GHz, they are the fastest 4th Generation Intel Xeon Scalable-based (Sapphire Rapids) instances available in the cloud. R7iz instances can lower the total cost of ownership (TCO) and provide performance improvements of up to 20% over Z1d instances of the preceding generation. They come with integrated accelerators such as Intel Advanced Matrix Extensions (Intel AMX), which provide a much-needed substitute for clients with increasing demands for AI workloads.
R7iz instances are well-suited for front-end Electronic Design Automation (EDA), relational database workloads with high per-core licensing prices, and workloads including financial, actuarial, and data analytics simulations due to their high CPU performance and large memory footprint.
IBM and Intel have collaborated extensively to offer open-source software optimizations to Watsonx.data, Presto, and Presto C++. In addition to the hardware enhancements, Intel 4th Gen Xeon has produced positive Watsonx.data outcomes.
Based on publicly available 100TB TPC-DS Query benchmarks, IBM Watsonx.data with Presto C++ v0.286 and query optimizer on AWS ROSA, running on Intel processors (4th generation), demonstrated superior price performance over Databrick’s Photon engine, with better query runtime at comparable cost.
Read more on Govindhtech.com
#AWS#PrestoC++#Intel#C++#C++evaluation#R7izinstances#C++engine#Watsonx.data#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
The Evolution of Identity and Access Management: SCIM, SAML vs. OpenID Connect, and Integration Challenges
In the ever-evolving digital landscape, Identity and Access Management (IAM) has become crucial for organizations to ensure security, compliance, and efficiency. The increasing reliance on technology has necessitated the development of sophisticated IAM protocols and standards. This blog will explore a SCIM example, compare SAML vs. OpenID Connect, and discuss the challenges and solutions associated with IAM integration.

Understanding SCIM: An Example
System for Cross-domain Identity Management (SCIM) is a standard protocol designed to simplify the management of user identities in cloud-based applications and services. SCIM automates the exchange of user identity information between identity providers and service providers, ensuring seamless integration and synchronization.
SCIM Example
Consider an organization using multiple cloud services, such as Office 365, Google Workspace, and Salesforce. Managing user identities manually across these platforms can be cumbersome and error-prone. By implementing SCIM, the organization can automate the provisioning and deprovisioning of user accounts.
For instance, when a new employee joins the company, the IAM system can automatically create their user account in all relevant cloud services using SCIM. Similarly, when an employee leaves, their access can be revoked across all platforms in a streamlined manner. This automation enhances security, reduces administrative workload, and ensures consistent identity data across all systems.

Comparing SAML vs. OpenID Connect
When it comes to authentication protocols, SAML (Security Assertion Markup Language) and OpenID Connect are two of the most widely used standards. Both serve the purpose of providing secure authentication, but they do so in different ways and are suited to different use cases.
SAML
SAML is an XML-based framework primarily used for Single Sign-On (SSO) in enterprise environments. It allows users to authenticate once and gain access to multiple applications without re-entering credentials. SAML is commonly used in scenarios where secure, federated access to web applications is required, such as accessing corporate intranets or SaaS applications.
OpenID Connect
OpenID Connect is a modern identity layer built on top of the OAuth 2.0 protocol. It uses JSON-based tokens and is designed for mobile and web applications. OpenID Connect provides a more flexible and user-friendly approach to authentication, making it ideal for consumer-facing applications where user experience is paramount.
SAML vs. OpenID Connect: Key Differences
Protocol Structure: SAML uses XML, whereas OpenID Connect uses JSON.
Use Cases: SAML is suited for enterprise SSO, while OpenID Connect is better for modern web and mobile applications.
Token Types: SAML uses assertions, whereas OpenID Connect uses ID tokens.
User Experience: OpenID Connect generally offers a more seamless and user-friendly experience compared to SAML.
The Challenges of IAM Integration
With the growing reliance on technology, integrating various IAM components and protocols has become increasingly complex. Effective IAM integration is essential for ensuring that different systems work together harmoniously, providing a seamless and secure user experience. However, several challenges can arise during the integration process.
Compatibility Issues
Organizations often use a mix of legacy systems and modern applications, leading to compatibility issues. Ensuring that different IAM solutions can communicate and share identity data effectively is a significant challenge.
Data Consistency
Maintaining consistent identity data across multiple platforms is crucial for security and compliance. Any discrepancies in user data can lead to unauthorized access or account lockouts.
Scalability
As organizations grow, their IAM systems must be able to scale accordingly. Integrating IAM solutions that can handle an increasing number of users and applications without compromising performance is vital.
Security Concerns
Integrating multiple IAM solutions can introduce security vulnerabilities if not done correctly. Ensuring that data is securely transmitted and that all systems adhere to robust security protocols is paramount.
Solutions for Effective IAM Integration
To overcome these challenges, organizations should adopt a strategic approach to IAM integration:
Standardization
Adopting standard protocols such as SCIM, SAML, and OpenID Connect can simplify integration by ensuring compatibility and consistency across different systems.
Centralized Identity Management
Implementing a centralized IAM platform can help streamline identity management processes and ensure consistent data across all applications and services.
Regular Audits
Conducting regular audits of IAM systems and processes can help identify and address potential vulnerabilities and inconsistencies, ensuring that the integration remains secure and effective.
Vendor Support
Working with reputable IAM vendors who offer comprehensive support and integration services can significantly ease the integration process and ensure a successful deployment.
Conclusion
As organizations continue to increase their reliance on technology, the need for robust and effective IAM integration becomes more critical. By understanding the differences between SAML vs. OpenID Connect, leveraging standards like SCIM, and adopting strategic integration practices, organizations can enhance security, streamline operations, and provide a seamless user experience. The right IAM solutions not only protect against cyber threats but also empower businesses to thrive in the digital age.
0 notes
Text
How to Use JWT Authentication in Slimphp Slim Skeleton API
In this tutorial, we’ll explore how to use JWT (JSON Web Tokens) in a Slimphp Slim Skeleton API. We’ll walk through the steps for implementing JWT authentication to secure your API endpoints. Additionally, we’ll cover how to generate and validate tokens efficiently. By the end, you’ll have a comprehensive understanding of how to integrate JWT into your Slimphp Slim Skeleton API to enhance…

View On WordPress
0 notes
Text
Unveiling Kalp Conjurer: Protecting RWAs Through Network Governance

The dynamics and complexities of blockchain technology are evident and often result in creating significant challenges when it comes to creating, deploying, and managing decentralized networks. The complexities of architecture, concerns regarding scalability, and the need for stringent security measures are impeding as roadblocks in adoption and realization of its innovative use cases.
But as blockchain today stands as a game-changer in the world of high-quality asset class investments by bringing Real-World Assets on chain for tokenization, the Kalp Permissioned Cross-chain Ecosystem has introduced Kalp Conjurer, an indispensable tool designed to simplify and streamline the entire lifecycle of blockchain network management.
The Kalp Conjurer:
At its core, Kalp Conjurer is a comprehensive platform that empowers developers to navigate the intricacies of blockchain technology with ease. It addresses several critical challenges that have traditionally impeded blockchain adoption and scalability, offering a suite of powerful features and capabilities to enhance the developer experience.
Features of Kalp Conjurer:
Let’s get down to the scratch and understand Kalp Conjurer frame-by-frame:
Parallel Chaincode Deployment
One of the most groundbreaking features introduced in Kalp Conjurer v3.3 is parallel chaincode deployment within a single parachain. This revolutionary advancement promises unparalleled speed and agility, empowering developers to deploy multiple chaincodes simultaneously with ease. By eliminating the need for sequential deployments, this feature significantly accelerates the development cycle, enabling faster time-to-market for innovative blockchain solutions. This capability is a game-changer for projects that require frequent updates or have complex smart contract ecosystems.
Enhanced Data Management with PostgreSQL
Kalp Conjurer’s integration with PostgreSQL as the primary database solution enhances data management and reliability. By streamlining processes and removing JSON support within operations, the platform achieves enhanced performance and efficiency, further optimizing the developer experience. This shift towards a more robust database solution underscores Kalp Conjurer’s commitment to providing enterprise-grade tools for blockchain development.
The Network Governance Layer
The Kalp network’s lifeblood lies in its Network Governance Layer, a robust system built with microservices. Golang and the Gin web framework empower this architecture to deliver efficient user management and network operations. At its core, the Network Governance Layer dynamically verifies user availability, seamlessly tracking entry and exit points, along with user existence, to provide a real-time picture of user activity within the network. This vital functionality ensures that the ecosystem remains secure and responsive, catering to the ever-changing needs of its users.
User Registration and Compliance
One of the critical features of Kalp Conjurer is its user registration and compliance checking capabilities. By thoroughly vetting user enrollment and generating certificates through the network, it ensures a secure and controlled access environment. This attention to security and compliance is crucial for enterprises operating in regulated industries or dealing with sensitive data.
Key Management
Additionally, Kalp Conjurer streamlines key management, generating private and public keys for authentication of transactions and network interactions, respectively. This centralized approach to key management simplifies the often complex task of managing cryptographic keys, reducing the risk of key loss or compromise.
On-Stage Testing and Future Developments
The latest update on Kalp Conjurer brings exciting news — it has entered the on-stage testing phase. This milestone signifies a significant step towards addressing key challenges faced by blockchain networks, such as complexity in network management, scalability issues, and enhancing security and access control mechanisms. As Kalp Conjurer progresses through this testing phase, developers can look forward to even more robust and refined features in future releases.
Benefits of Kalp Conjurer:
All these features not just make Kalp Conjurer a massive hit amongst blockchain-philes but also escalate the abilities of the technology to build capable applications. Kalp Conjurer brings in a whole lot of benefits for developers and enterprises aiming to upgrade their tech stack.
Scalable Network Creation
One of the key strengths of Kalp Conjurer is its ability to enable scalable network creation. Developers can easily set up networks with customizable numbers of peers and orders, ensuring that their blockchain solutions can scale to meet growing demands without compromising performance or reliability. This flexibility allows projects to start small and expand as needed, adapting to changing business requirements and user demand.
Multi-Chain Management
Kalp Conjurer’s multi-chain management capabilities are a game-changer for developers working on complex, interconnected blockchain ecosystems. With the ability to seamlessly manage multiple blockchain chains, developers can build robust and interconnected solutions that transcend the limitations of siloed networks, unlocking new possibilities for cross-chain interactions and data sharing. This feature is particularly valuable for enterprises looking to create comprehensive blockchain solutions that span multiple departments or business units.
Stateless Chaincode Deployment and Upgradation
The platform’s stateless chaincode deployment and upgradation feature streamlines the process of deploying and upgrading smart contracts (chaincodes) across multiple chains.
This not only reduces manual effort but also mitigates the risk of potential errors, ensuring a smoother and more efficient development lifecycle. By simplifying this critical aspect of blockchain development, Kalp Conjurer enables developers to focus on creating innovative solutions rather than getting bogged down in deployment complexities.
Database Flexibility
Recognizing the diverse needs of developers, Kalp Conjurer offers database flexibility, supporting both SQLite and PostgreSQL for Certificate Authority servers. This flexibility empowers developers to select the database solution that best aligns with their project requirements, enabling seamless integration and optimized performance. Whether a project requires the lightweight nature of SQLite or the robust features of PostgreSQL, Kalp Conjurer has developers covered.
Resource Optimization
Resource optimization is another key aspect of Kalp Conjurer, as it reduces infrastructure costs without compromising performance. By leveraging efficient resource allocation strategies, developers can maximize their return on investment while delivering high-quality blockchain solutions. This cost-effectiveness is particularly important for startups and small to medium-sized enterprises looking to leverage blockchain technology without breaking the bank.
Comprehensive Network Management
Kalp Conjurer’s comprehensive network management capabilities extend to network configuration, node lifecycle management, channel management, and stringent security measures. This holistic approach ensures that developers have complete control over their blockchain networks, enabling them to adapt to changing requirements and maintain a secure and trusted environment for their applications. From initial setup to ongoing maintenance, Kalp Conjurer provides the tools needed to manage blockchain networks effectively.
Impact on the Blockchain Ecosystem
As the Kalp ecosystem continues to evolve, Kalp Conjurer stands as a beacon of innovation, empowering developers to navigate the complexities of blockchain technology with confidence and ease. By addressing key challenges such as complexity in network management, scalability issues, chaincode deployment, and security concerns, Kalp Conjurer paves the way for the rapid adoption and deployment of blockchain solutions across diverse industries and use cases.
The impact of Kalp Conjurer extends beyond just simplifying development processes. It has the potential to accelerate blockchain adoption across industries by lowering the barriers to entry and enabling enterprises to focus on creating value-driven blockchain solutions rather than grappling with technical complexities.
Kalp Conjurer represents a paradigm shift in blockchain development and management. By providing a comprehensive suite of tools and features, it empowers developers to create, deploy, and manage blockchain networks with unprecedented ease and efficiency. From scalable network creation to parallel chaincode deployment, Kalp Conjurer addresses the most pressing challenges faced by blockchain developers today.
As the blockchain landscape continues to evolve, tools like Kalp Conjurer will play a crucial role in shaping the future of decentralized technologies. By simplifying complex processes and enhancing security and scalability, Kalp Conjurer is not just a development tool — it’s a catalyst for innovation in the blockchain space.
The journey of blockchain technology is still in its early stages, and with solutions like Kalp Conjurer leading the way, we can expect to see a new wave of innovative, scalable, and secure blockchain applications emerging across various industries. As developers and enterprises continue to explore the potential of blockchain technology, Kalp Conjurer stands ready to support their journey, unlocking new possibilities and driving the future of decentralized systems.
1 note
·
View note
Text
Implementing Authentication in React Applications: Secure User Management

Introduction
Authentication is a critical aspect of web development, ensuring that users can securely access and interact with your application. In this guide, we will explore best practices for implementing authentication in React applications, covering techniques for secure user management, user authentication, and authorization to protect sensitive data and provide a seamless user experience.
The Importance of Authentication in React Applications
Authentication is essential for verifying the identity of users and controlling access to protected resources within your application. By implementing robust authentication mechanisms in React applications, you can safeguard user data, prevent unauthorized access, and build trust with your audience.
User Authentication with JWT and Cookies
JSON Web Tokens (JWT) and cookies are commonly used for user authentication in web applications. JWTs provide a secure way to transmit user information between the client and server, while cookies can store session data on the client side for persistent authentication. By combining JWTs with cookies, you can create a reliable and secure authentication flow in your React application.
Implementing Secure User Management
User Registration: Allow users to create accounts securely by implementing a registration form with validation and password hashing to protect sensitive information.
User Login: Enable users to log in to your application using their credentials, verifying their identity and generating authentication tokens for secure access to protected routes.
Password Reset: Implement a password reset mechanism that allows users to securely reset their passwords through email verification or security questions.
Role-Based Access Control: Implement role-based access control (RBAC) to define user roles and permissions, ensuring that users can only access resources based on their assigned roles.
Securing API Requests with Authentication
Protect your API endpoints by implementing authentication mechanisms such as JWT validation, session management, and authorization checks. By securing API requests, you can prevent unauthorized access to sensitive data and ensure the integrity of your application's backend services.
Conclusion
Implementing authentication in React applications is crucial for ensuring the security and integrity of user data and resources. By following best practices for secure user management, user authentication with JWT and cookies, and securing API requests with authentication, you can build robust and trustworthy applications that prioritize user privacy and data protection. Whether you're developing a simple login system or a complex user management platform, mastering authentication in React is key to providing a secure and seamless user experience for your audience.
For businesses looking to enhance their React applications with advanced UI design features, partnering with a reputable React.js development company can provide access to experienced developers who specialize in UI design and front-end development. hire react js developer and businesses can ensure that their applications deliver compelling user experiences and drive user engagement.
0 notes
Text
Man-in-the-Middle (MitM) Attacks in Laravel: Prevention Guide
Man-in-the-middle (MitM) attacks are among the most serious threats web developers face. These attacks allow malicious actors to intercept, alter, or steal sensitive information during communication between two parties. As Laravel is a popular PHP framework for building web applications, securing it against such vulnerabilities is critical.

In this blog, we’ll explore what MitM attacks are, how they can exploit Laravel-based applications, and steps to secure your Laravel projects with examples.
What Are Man-in-the-Middle (MitM) Attacks?
MitM attacks occur when an attacker secretly intercepts and potentially alters communication between two parties without their knowledge. This can lead to:
Data theft: Intercepted credentials, session tokens, or personal data.
Session hijacking: Taking control of a user’s session.
Identity spoofing: Posing as one of the communicating parties.
How MitM Attacks Target Laravel Applications
Laravel, while secure, may be vulnerable if developers overlook:
Unencrypted HTTP requests.
Weak session handling mechanisms.
Misconfigured API endpoints.
Example of a Vulnerable Laravel Application
Imagine a Laravel app that sends sensitive user data over plain HTTP:
Route::post('/login', function(Request $request) { $username = $request->input('username'); $password = $request->input('password'); // Authenticate user logic here });
If the app doesn't enforce HTTPS, this communication can be intercepted, exposing the username and password.
Preventing MitM Attacks in Laravel
1. Enforce HTTPS in Your Application
Laravel makes it easy to enforce HTTPS. Use the AppServiceProvider to redirect HTTP traffic to HTTPS:
public function boot() { if (env('APP_ENV') === 'production') { \URL::forceScheme('https'); } }
2. Secure Session Management
Laravel’s session configuration should prioritize security. Update the config/session.php file:
'secure' => env('SESSION_SECURE_COOKIE', true), // Ensures cookies are only sent over HTTPS. 'same_site' => 'strict', // Prevents cross-site request forgery (CSRF).
3. Utilize SSL/TLS Certificates
Always install and configure an SSL/TLS certificate for your Laravel application. Use tools like Let’s Encrypt for free SSL certificates.
4. Implement Content Security Policy (CSP)
CSP can reduce MitM attack risks by controlling the sources your application trusts. You can use Laravel middleware like spatie/laravel-csp. Example middleware:
public function buildContentSecurityPolicy() { return CSP::addDirective('default-src', 'self') ->addDirective('script-src', 'self cdn.example.com'); }
5. Test Your Website Security
A proactive way to ensure your Laravel application is secure is by using a website security checker tool. Take advantage of our Free Website Security Checker tool.

Screenshot of the tool’s interface to show how easy it is to scan your website.
Use this tool to check vulnerabilities, including issues related to MitM attacks, and get a detailed report.

Example of a vulnerability assessment report generated by the tool.
6. Secure Your API Calls
Use Laravel's built-in encrypt method to secure sensitive data in API responses:
use Illuminate\Support\Facades\Crypt; $data = ['message' => 'Sensitive data']; $encrypted = Crypt::encrypt($data); return response()->json(['data' => $encrypted]);
And on the client side:
$decrypted = Crypt::decrypt($encryptedData);
Conclusion
MitM attacks pose a significant risk to web applications, but with the right practices, Laravel developers can mitigate these threats. From enforcing HTTPS to securing session data and using security tools like ours to test website security free, you can build robust defenses.
Stay vigilant, secure your Laravel apps, and keep user data safe. Happy coding! 🚀
#cyber security#cybersecurity#data security#pentesting#security#the security breach show#laravel#mitm
1 note
·
View note