#image classification of dataset
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
Image Classification Datasets: The Backbone of Visual AI Solutions

In the era of artificial intelligence (AI), image classification datasets are pivotal in developing intelligent systems capable of recognizing and categorizing visual data. The foundation of these advancements lies in high-quality image classification datasets. At GTS AI, we specialize in providing diverse and precisely annotated datasets tailored to various industries and applications. This blog delves into the importance of image classification datasets, their applications, and why GTS AI is the go-to partner for your dataset needs.
What Is an Image Classification Dataset?
An image classification dataset is a collection of labeled images used to train machine learning models to identify and classify objects, scenes, or patterns. These datasets are meticulously annotated, ensuring each image is tagged with the correct label for accurate model training.
For example, an image classification dataset designed for autonomous vehicles may include labeled images of pedestrians, traffic signs, and vehicles. The diversity and quality of such datasets directly influence the accuracy and reliability of AI models.
Applications of Image Classification Datasets
Image classification datasets are integral to various industries, powering AI-driven solutions across multiple domains. Here are some notable applications:
1. Healthcare
In the medical field, image classification datasets are used to train AI models for disease diagnosis, such as identifying cancerous cells in pathology slides or detecting abnormalities in X-rays and MRIs.
2. Retail and E-commerce
Image classification datasets enable AI models to categorize products, enhance visual search capabilities, and personalized shopping experiences by recommending items based on visual similarity.
3. Autonomous Vehicles
Self-driving cars rely on image classification datasets to identify objects such as pedestrians, traffic lights, and road signs, ensuring safe and efficient navigation.
4. Agriculture
Farmers use AI models trained on image classification datasets to monitor crop health, detect pests, and optimize farming practices, leading to improved productivity.
5. Security and Surveillance
Image classification datasets power facial recognition systems, enabling enhanced security and monitoring in public spaces, workplaces, and homes.
6. Environmental Monitoring
AI models trained on these datasets help identify changes in land use, deforestation, and other environmental factors using satellite imagery.
Why Choose GTS AI for Image Classification Datasets?
At GTS AI, we understand that the success of your AI project hinges on the quality of your dataset. Here’s why we are the preferred choice:
1. Diverse and Comprehensive Datasets
Our image classification datasets cover a wide range of industries and applications, ensuring you get data that aligns with your specific needs.
2. High-Quality Annotations
Our expert annotators use advanced tools to label images accurately, guaranteeing precise and consistent data for your models.
3. Customized Solutions
Every project is unique. We provide tailor-made datasets designed to meet your requirements, whether you need datasets for healthcare, retail, or any other domain.
4. Ethical Data Practices
We prioritize data privacy and adhere to global standards and ethical practices in data collection and annotation.
5. Stringent Quality Assurance
Every dataset undergoes rigorous quality checks to ensure consistency, accuracy, and reliability.
6. Scalability
From small datasets for pilot projects to large-scale datasets for enterprise solutions, we cater to projects of all sizes.
7. Timely Delivery
We understand the importance of deadlines. Our efficient processes ensure that your datasets are delivered on time without compromising quality.
How GTS AI Delivers Image Classification Datasets
Our process is designed to deliver exceptional results efficiently:
Requirement Analysis We collaborate with you to understand your project goals and dataset requirements.
Data Collection We source or collect images aligned with your project’s objectives.
Annotation Our skilled annotators label the images with precision, ensuring the highest level of accuracy.
Quality Assurance Each dataset undergoes multiple quality checks to meet industry standards.
Delivery We deliver the finalized dataset in your preferred format, ready for immediate use in AI model training.
Conclusion
Image classification datasets are the cornerstone of AI-driven visual recognition systems. At GTS AI, we combine expertise, technology, and commitment to deliver high-quality datasets that empower businesses to innovate. Whether you’re developing solutions for healthcare, autonomous vehicles, or e-commerce, our image classification datasets provide the foundation for building intelligent, reliable AI models.
Visit our Image Classification Services page to learn more about how GTS AI can support your AI initiatives. Partner with us to take your AI projects to the next level and stay ahead in the competitive world of artificial intelligence.
0 notes
Text
Understanding Image Classification Datasets: A Guide to High-Quality Data for AI Training

A basic problem in computer vision is image classification, which entails grouping images into predetermined classifications. To train machine learning models to identify patterns and provide predictions regarding visual input, image classification datasets are important to this process. We'll discuss picture classification datasets, their significance, and how to select the best ones for your machine-learning applications in this blog.
What is an Image Classification Dataset?
An image classification dataset is a collection of images that have been labeled with predefined categories. These labels are crucial because they provide the necessary ground truth data that machine learning models use to learn how to classify new, unseen images. Each image in the dataset is associated with one or more labels, indicating the category it belongs to. For example, a dataset could have images labeled as ‘cat’, ‘dog’, ‘car’, ‘tree’, etc. The goal of using these datasets is to teach an AI model to recognize and differentiate between these categories automatically.
Importance of High-Quality Image Classification Datasets
The quality and size of an image classification dataset play a significant role in the performance of a machine learning model. High-quality datasets, which are diverse and contain a balanced number of examples per class, can significantly improve the model’s accuracy and generalization ability. Here’s why they are important.
Better Model Performance: A well-curated dataset with a broad range of images allows the model to learn a more comprehensive set of features, making it capable of recognizing patterns across different scenarios. For instance, a dataset that includes various lighting conditions, angles, and backgrounds can help the model perform well under different real-world conditions.
Avoids Overfitting: Reduces Overfitting: Overfitting happens when a model is overly tuned to its training data and fails to generalize well to new, unseen data. A diverse dataset helps prevent this by exposing the model to different variations, which improves its ability to generalize to new scenarios.
Ensures Fair Representation: Diverse datasets are essential for building fair and unbiased models. For instance, if a dataset primarily consists of images of a particular demographic or environment, the model might not perform well in diverse scenarios. A balanced dataset helps create models that are more robust and reliable across different conditions.
Choosing the right image classification datasets to Choose the Right Image Classification Dataset
t involves understanding the goals of your project, the types of images it needs to include, and the quality of the dataset. Here are some factors to consider:
Relevance: The dataset should be relevant to the problem at hand. For example, if you are building a model to classify animals, the dataset should contain animal images. If your project is focused on objects, the dataset should include a wide range of those objects.
Size and Scale: The size of the dataset is important. Larger datasets provide more data for training, which can improve model performance. However, they also require more computational resources. Depending on your project, you might need a trade-off between dataset size and computational cost.
Annotation Quality: Ensure that the dataset is well-annotated. The quality of annotations directly affects the model’s learning. Poorly annotated datasets can lead to confusion and errors in the model’s predictions.
Balance and Diversity: A balanced dataset ensures that each class has a similar number of samples, preventing the model from becoming biased towards more frequent classes. Diversity in the dataset helps in training models that can generalize better across different situations.
Popular Image Classification Datasets
Several popular image classification datasets are widely used in the machine learning community. Some of these include
ImageNet: One of the largest and most popular datasets, ImageNet contains over 14 million images across 20,000 categories. It has been instrumental in the development of deep learning models like AlexNet, which significantly advanced the field.
CIFAR-10 and CIFAR-100: These smaller datasets contain 60,000 32x32 pixel color images in 10 and 100 classes, respectively. They are often used as benchmarks for evaluating image classification models.
MNIST: A dataset of 70,000 grayscale images of handwritten digits (0-9). It’s a common starting point for developing and testing image processing algorithms.
Pascal VOC: A dataset specifically designed for object detection and segmentation. It contains images of various objects with detailed annotations.
Conclusion
Building reliable and efficient machine learning models requires careful selection of the image categorization dataset. Your model will perform well on both training and testing data if you prioritize the dataset's quality, relevance, and diversity. With the correct dataset, you may fully utilize picture data and make data-driven decisions by utilizing potent machine learning algorithms.
0 notes
Text
ultimately i do not care about the utility of ai image generation. its true, its a powerful tool, and the genies out of the bottle, so ultimately i would like to see it used in a positive way. but as people whove been aware of machine learning and how it intersects with data rights have been saying from the get go, there is literally no usable ai model, of any kind, not for classification, not for generation, not for moderation, that is trained on primarily consensually given data. besides that, there is a lot of invisible work. there are people being underpaid to look at and sort abhorrent traumatizing images to get moderation algorithms to kinda sorta work. and even still, all of these datasets are poisoned by bias. we all remember how long it took snapchats ai to figure out black faces, dont we? like. i dont care what it can do. i care about the many layers of exploitation that led to this.
#dils declares#note that i did not mention intellectual property.#thats because intellectual property is a stopgap for and facsimile of the real issue of exploitation.#dils directs
28 notes
·
View notes
Text
KNN Algorithm | Learn About Artificial Intelligence
The k-Nearest Neighbors (KNN) algorithm is a simple, versatile, and popular machine learning method used for both classification and regression tasks, making predictions based on the proximity of data points to their nearest neighbors in a dataset.
Detect Triangle shape inside image using Java Open CV //Triangle Transform Computer Vision part one

KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions on new, unseen data. KNN relies on a distance metric.
Lazy Learning: It's considered a "lazy learner" because it doesn't have a dedicated training phase; instead, it stores the training data and uses it directly for prediction.
Proximity-Based: KNN relies on the principle that similar data points are located near each other, and it makes predictions based on the classes or values of the nearest neighbors.
Classification: In classification, KNN assigns a new data point to the class that is most common among its k nearest neighbors.
Regression: In regression, KNN predicts a value by averaging the values of the k nearest neighbors.
Parameter k: The parameter 'k' determines the number of nearest neighbors to consider when making a prediction.
#3d printing#machine learning#artificial intelligence#techno facts#techno design#techno fanart#techno music#100 days of productivity#techno image processing#techno ai#ai image generator#ai art#animation#ai image creation#academia#ai image editing#ai generated#3d image process#3d image producing
2 notes
·
View notes
Text
What is artificial intelligence (AI)?

Imagine asking Siri about the weather, receiving a personalized Netflix recommendation, or unlocking your phone with facial recognition. These everyday conveniences are powered by Artificial Intelligence (AI), a transformative technology reshaping our world. This post delves into AI, exploring its definition, history, mechanisms, applications, ethical dilemmas, and future potential.
What is Artificial Intelligence? Definition: AI refers to machines or software designed to mimic human intelligence, performing tasks like learning, problem-solving, and decision-making. Unlike basic automation, AI adapts and improves through experience.
Brief History:
1950: Alan Turing proposes the Turing Test, questioning if machines can think.
1956: The Dartmouth Conference coins the term "Artificial Intelligence," sparking early optimism.
1970s–80s: "AI winters" due to unmet expectations, followed by resurgence in the 2000s with advances in computing and data availability.
21st Century: Breakthroughs in machine learning and neural networks drive AI into mainstream use.
How Does AI Work? AI systems process vast data to identify patterns and make decisions. Key components include:
Machine Learning (ML): A subset where algorithms learn from data.
Supervised Learning: Uses labeled data (e.g., spam detection).
Unsupervised Learning: Finds patterns in unlabeled data (e.g., customer segmentation).
Reinforcement Learning: Learns via trial and error (e.g., AlphaGo).
Neural Networks & Deep Learning: Inspired by the human brain, these layered algorithms excel in tasks like image recognition.
Big Data & GPUs: Massive datasets and powerful processors enable training complex models.
Types of AI
Narrow AI: Specialized in one task (e.g., Alexa, chess engines).
General AI: Hypothetical, human-like adaptability (not yet realized).
Superintelligence: A speculative future AI surpassing human intellect.
Other Classifications:
Reactive Machines: Respond to inputs without memory (e.g., IBM’s Deep Blue).
Limited Memory: Uses past data (e.g., self-driving cars).
Theory of Mind: Understands emotions (in research).
Self-Aware: Conscious AI (purely theoretical).
Applications of AI
Healthcare: Diagnosing diseases via imaging, accelerating drug discovery.
Finance: Detecting fraud, algorithmic trading, and robo-advisors.
Retail: Personalized recommendations, inventory management.
Manufacturing: Predictive maintenance using IoT sensors.
Entertainment: AI-generated music, art, and deepfake technology.
Autonomous Systems: Self-driving cars (Tesla, Waymo), delivery drones.
Ethical Considerations
Bias & Fairness: Biased training data can lead to discriminatory outcomes (e.g., facial recognition errors in darker skin tones).
Privacy: Concerns over data collection by smart devices and surveillance systems.
Job Displacement: Automation risks certain roles but may create new industries.
Accountability: Determining liability for AI errors (e.g., autonomous vehicle accidents).
The Future of AI
Integration: Smarter personal assistants, seamless human-AI collaboration.
Advancements: Improved natural language processing (e.g., ChatGPT), climate change solutions (optimizing energy grids).
Regulation: Growing need for ethical guidelines and governance frameworks.
Conclusion AI holds immense potential to revolutionize industries, enhance efficiency, and solve global challenges. However, balancing innovation with ethical stewardship is crucial. By fostering responsible development, society can harness AI’s benefits while mitigating risks.
2 notes
·
View notes
Text
Despite uncovering widespread AI errors in healthcare, Ziad remained optimistic about how algorithms might help to care better for all patients. He felt they could be particularly useful in improving diagnostics that doctors tended to get wrong, but also in improving our current medical knowledge by discovering new patterns in medical data. Most modern healthcare AI is trained on doctors’ diagnoses, which Ziad felt wasn’t enough. ‘If we want AI algorithms to teach us new things,’ he said, ‘that means we can’t train them to learn just from doctors, because then it sets a very low ceiling – they can only teach us what we already know, possibly more cheaply and more efficiently.’ Rather than use AI as an alternative to human doctors – who weren’t as scarce as in rural India – he wanted to use the technology to augment what the best doctors could do.
[….]
To solve the mystery, Ziad had to return to first principles. He wanted to build a software that could predict a patient’s pain levels based on their X-ray scans. But rather than training the machine-learning algorithms to learn from doctors with their own intrinsic biases and blind spots, he trained them on patients’ self-reports. To do this, he acquired a training dataset from the US National Institutes of Health, a set of knee X-rays annotated with patients’ own descriptions of their pain levels, rather than simply a radiologist’s classification. The arthritis pain model he built found correlations between X-ray images and pain descriptions. He then used it to predict how severe a new patient’s knee pain was, from their X-ray. His goal wasn’t to build a commercial app, but to carry out a scientific experiment.
It turned out that the algorithms trained on patients’ own reported pain did a far better job than a human radiologist in predicting which knees were more painful.
The most striking outcome was that Ziad’s pain model outperformed human radiologists at predicting pain in African American patients. ‘The algorithms were seeing signals in the knee X-ray that the radiologist was missing, and those signals were disproportionately present in black patients and not white patients,’ he said. The research was published in 2021, and concluded: ‘Because algorithmic severity measures better capture underserved patients’ pain, and severity measures influence treatment decisions, algorithmic predictions could potentially redress disparities in access to treatments like arthroplasty.’
Meanwhile, Ziad plans to dig deeper to decode what those signals are. He is using machine-learning techniques to investigate what is causing excess pain using MRIs and samples of cartilage or bone in the lab. If he finds explanations, AI may have helped to discover something new about human physiology and neuroscience that would have otherwise been ignored.
— Madhumita Murgia, Code Dependent: Living in the Shadow of AI
2 notes
·
View notes
Text
7 Computer Vision Projects for All Levels - KDnuggets
2 notes
·
View notes
Text
really i think that unless your opinions about AI disentangle
large language models (chatgpt et al; low factual reliability, but can sometimes come up with interesting concepts)
diffusion and similar image generators (stable diffusion et al; varying quality, but can produce some impressive work especially if you lean into the weirdness)
classification models (OCR, text-to-speech; have been in use for over a decade depending on the domain)
the entire rest of the field before 2010 or so
you're going to suffer from confused thinking
expanding on point 3 a bit because it's one i'm familiar with: for speech-to-text, image-to-text, handwriting recognition, and similar things, nobody does any non-ML approaches anymore. ML approaches are fast enough, more reliable, generalize easier to other languages, and don't require as much work to create. something like cursorless, hands-free text editing for people with carpal tunnel or whatever, 100% relies on an ML model these days. this has zero bearing on copyright of gathering datasets (many speech-to-text datasets are gathered in controlled conditions specifically for creating a dataset) or AI "taking jobs" (nobody is going to pay a stenographer to follow them around with a laptop) or whatever
7 notes
·
View notes
Text
youtube
Ever wondered what the datasets used to train AI look like? This video is a subset of ImageNet-1k (18k images) with some other metrics.
Read more on how I made it and see some extra visualizations.
Okay! I'll split this up by the elements in the video, but first I need to add some context about
The dataset
ImageNet-1k (aka ILSVRC 2012) is an image classification dataset - you have a set number of classes (in this case 1000) and each class has a set of images. This is the most popular version of ImageNet, which usually has 21000 classes.
ImageNet was made using nouns from WordNet, searched online. From 2010 to 2017 yearly competitions were held to determine the best image classification model. It has greatly benefitted computer vision, developing model architectures that you've likely used unknowingly. See the accuracy progression here.
ResNet
Residual Network (or ResNet) is an architecture for image recognition made in 2015, trying to fix "vanishing/exploding gradients" (read the paper here). It managed to achieve an accuracy of 96.43% (that's 96 thousand times better than randomly guessing!), winning first place back in 2015. I'll be using a smaller version of this model (ResNet-50), boasting an accuracy of 95%.
The scatter plot
If you look at the video long enough, you'll realize that similar images (eg. dogs, types of food) will be closer together than unrelated ones. This is achieved using two things: image embeddings and dimensionality reduction.
Image embeddings
In short, image embeddings are points in an n-dimensional space (read this post for more info on higher dimensions), in this case, made from chopping off the last layer from ResNet-50, producing a point in 1024-dimensional space.
The benefit of doing all of that than just comparing pixels between two images is that the model (specifically made for classification) only looks for features that would make the classification easier (preserving semantic information). For instance - you have 3 images of dogs, two of them are the same breed, but the first one looks more similar to the other one (eg. matching background). If you compare the pixels, the first and third images would be closer, but if you use embeddings the first and second ones would be closer because of the matching breeds.
Dimensionality reduction
Now we have all these image embeddings that are grouped by semantic (meaning) similarity and we want to visualize them. But how? You can't possibly display a 1024-dimensional scatter plot to someone and for them to understand it. That's where dimensionality reduction comes into play. In this case, we're reducing 1024 dimensions to 2 using an algorithm called t-SNE. Now the scatter plot will be something we mere mortals can comprehend.
Extra visualizations
Here's the scatter plot in HD:
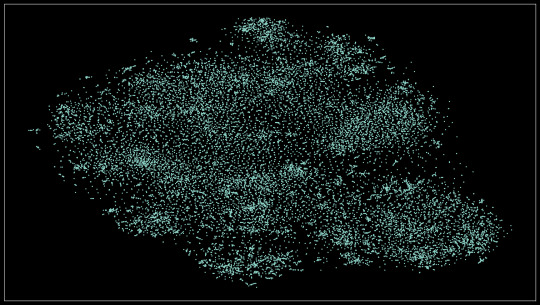
This idea actually comes from an older project where I did this on a smaller dataset (about 8k images). The results were quite promising! You can see how each of the 8 classes is neatly separated, plus how differences in the subject's angle, surroundings, and color.

Find the full-resolution image here
Similar images
I just compared every point to every other point (in the 2d space, It would be too computationally expensive otherwise) and got the 6 closest points to that. You can see when the model incorrectly classifies something if the related images are not similar to the one presented (eg. there's an image of a payphone but all of the similar images are bridges).
Pixel rarity
This one was pretty simple, I used a script to count the occurrences of pixel colors. Again, this idea comes from an older project, where I counted the entirety of the dataset, so I just used that.
Extra visualization
Here are all the colors that appeared in the image, sorted by popularity, left to right, up to down

Some final stuff
MP means Megapixel (one million pixels) - a 1000x1000 image is one megapixel big (it has one million pixels)
That's all, thanks for reading. Feel free to ask questions and I'll try my best to respond to them.
3 notes
·
View notes
Text
Enhancing AI Capabilities with High-Quality Image Classification Datasets

Image classification is a transformative application of artificial intelligence (AI), driving innovation in healthcare and e-commerce. A pivotal component of building an accurate and efficient image classification system is the dataset used for training and testing. At GTS AI, we provide industry-leading image classification datasets designed to elevate your AI projects. In this blog, we’ll explore the significance of image classification datasets, their applications, and how to choose the best dataset for your needs.
What Is an Image Classification Dataset?
An image classification dataset is a curated collection of images labeled according to predefined categories or classes. These datasets are used to train AI models to identify and classify objects, patterns, or scenes in images. Key components of such datasets include:
Images: High-resolution images capturing various objects, scenes, or phenomena.
Labels: Descriptive tags or categories associated with each image to guide the model’s learning process.
High-quality datasets ensure that AI models achieve high accuracy, scalability, and adaptability in real-world applications.
Why Are Image Classification Datasets Important?
Model Training: A robust dataset enables AI models to learn patterns, features, and relationships within images, leading to better predictions.
Accuracy: High-quality datasets with clear and consistent labeling improve the precision of image classification models.
Diversity: Datasets containing diverse images ensure that models generalize well across various use cases and environments.
Innovation: Access to specialized datasets fosters the development of advanced applications, such as automated medical diagnostics and personalized shopping experiences.
Applications of Image Classification
Image classification is a cornerstone technology across multiple sectors, including:
Healthcare: AI models classify medical images to assist in diagnosing diseases, such as cancer detection in X-rays or MRIs.
Retail and E-Commerce: Product recommendation systems rely on image classification to categorize and tag inventory for personalized customer experiences.
Autonomous Vehicles: Image classification identifies road signs, pedestrians, and other objects, ensuring safe navigation.
Environmental Monitoring: Models classify satellite or drone images to track deforestation, urbanization, or wildlife populations.
Content Moderation: Social media platforms use image classification to detect and filter inappropriate content.
Features of a High-Quality Image Classification Dataset
When selecting a dataset, look for these attributes:
Comprehensive Labeling: Datasets should have accurate, detailed, and consistent labels to enhance the model’s learning process.
Diversity: Images should cover various conditions, objects, and scenarios to ensure the model’s robustness.
Scalability: Large datasets provide the volume needed to train complex models effectively.
Relevance: The dataset should align with the specific goals and use cases of your project.
GTS AI’s Image Classification Datasets
At GTS AI, we offer premium image classification datasets tailored to your project’s needs. Here’s why our datasets stand out:
Diverse Categories: Extensive range of labeled images from various domains.
High Resolution: High-quality images for precise feature extraction and model training.
Real-World Scenarios: Includes images capturing different conditions, lighting, and environments.
Customizable: Flexible options to curate datasets specific to your industry or application.
Best Practices for Using Image Classification Datasets
To maximize the potential of your image classification dataset:
Data Augmentation: Enhance the dataset by applying transformations like rotation, scaling, and flipping to improve model performance.
Preprocessing: Normalize and clean images to ensure consistency in training.
Splitting: Divide the dataset into training, validation, and test sets to evaluate model performance effectively.
Model Fine-Tuning: Use transfer learning or iterative optimization to adapt pre-trained models to your dataset.
Conclusion
Image classification datasets are the foundation of successful AI systems, enabling breakthroughs in industries like healthcare, retail, and autonomous technology. By choosing high-quality, diverse, and relevant datasets, you can develop robust AI models that deliver reliable results. Visit GTS AI to explore our cutting-edge image classification datasets and elevate your AI solutions.
0 notes
Text
Image Classification Datasets: Fueling the Future of AI

Within artificial intelligence (AI), the power to classify images precisely is a valuable tool for machines to be able to really get and decode the visual world; later on, they are used thus. From object detection to medicine, the image classification dataset procedure is a key task, which, in turn, facilitates different AI systems to the maximum. The core image classification datasets are meticulously curated collections of labeled images that are essential in the education of these systems, as they allow AI models to learn how to categorize visual data.
What is Image Classification?
Image classification is the assignment of an image to a certain category by taking into account its content. As an example, a dataset containing photos of different animals could be labeled as "dog," "cat," or "elephant." A trained model, whether it is supervised or unsupervised, can thus recognize and later classify objects in new, unseen images using the data of different patterns, textures, and features. A successful image classification method is dependent on good datasets, where the images are appropriately labeled with correct tags and also represent the broadest possible range of conditions.
Why Are Image Classification Datasets Important?
The method’s success lies deeply in the used datasets for the training purpose of AI model’s. A properly organized image classification dataset enables machine learning systems to differentiate various categories, thus, the system will become smarter and more accurate. Here are some reasons why these datasets are crucial for AI development:
Improved Accuracy
A versatile and full collection of image classification datasets guarantees that the AI model will be able to distinguish among objects, animals, faces, or scenes regardless of the different lighting conditions, environments or viewpoints. The larger and the better the images in the dataset, the higher will be the reliability of the AI's predictions in practical applications.
Reduces Bias
If the dataset has less variety in it, the AI could harbor biases, which, in turn, limit its efficacy. For instance, a facial recognition model taught by a set of pictures containing only one single ethnicity among all images may not be able to capture people from other ethnicities. Facing this limitation, diversity of image classification datasets, including different age groups, genders, places, and settings, is a must to achieve fairness and inclusion.
Enables Efficient Learning
To design a model that is able to capture the general idea of AI, it needs to be trained on different types of data samples from many different categories. Image classification datasets are the ones that make the model understand to classify images by considering important characteristics rather than superficial ones.
Applications of Image Classification Datasets
Datasets designed for image classification are predominantly implemented in many domains and applications. These are some of the main areas where these datasets are critical:
Healthcare
Within medicine, AI-based systems utilizing image classification datasets are expected to become the most advanced approach to diagnosing diseases in the future. An AI model trained on a huge dataset of medical images of different cases can detect abnormalities like cancer, T.B., or heart disease with a very high level of accuracy. These AI-based systems are the tools through which doctors can reach correct medical conclusions faster.
Retail and E-Commerce
Within the retail division, image classification is applied to product categorization. Retailers may easily use AI to automatically sort and categorize products based on the visual representations including stockrooms and customers. By means of a database containing the classification of images, online shops can online platforms Visual Search to enhance their search and recommendation systems by, for example, helping customers to their desired products visually.
Autonomous Vehicles
Autonomous cars use image classification datasets for road signs, pedestrians, traffic lights, and other vehicles, as they recognize objects by comparing them with the datasets. Autonomous vehicles are able to safely drive around thanks to big and wide bodies of unique image data that allows them to understand their surroundings and decide what to do at that moment.
Agriculture
AI is being employed in agriculture as a tool by farmers and researchers to supervise crop health, detect diseases, and evaluate soil conditions. Image classification datasets are very important in the training of AI models that can identify plant species, observe their growth, and even detect early signs of disease or pest infestation, which in turn, allows for more efficient farming practices.
Security and Surveillance
Security systems with AI models supervised on image classification datasets contribute to the identification of deviants and possible security risks in surveillance footage. Image classification systems can make well-timed decisions of these deviations, thus not only catching suspected people in the surveillance videos, but also tracking the unusual tendencies within the crowd.
Social Media
Social media platforms are using image classification datasets for content moderation, auto-tagging, and even facial recognition. These systems measure and classify millions of images by AI which automatically tags them and this draws user interest and gives the platform safety.
Building a Good Image Classification Dataset
Materials in a quality image classification dataset should be carefully thought out with an emphasis on detail. Below are some important aspects of constructing a dataset:
Diversity of Data
One that is deemed to be a successful image classification dataset includes a wide range of categories and conditions. The AI model learns properly to handle the heterogeneous case of the real-world. For example, creating a face image dataset will necessarily contain the annotated faces of different people with varied ages, ethnicities, and facial expressions which will obviate the bias problem and the model will then be able to generalize.
High-Quality, Labeled Images
Every picture will be examined in this dataset and pinned with its relevant tag correctly. The more exact and uniform the tagging of the images, the more efficiently the model will learn. Properly labeling pictures is a lengthy process for sure but it is a critical constituent of high-quality training.
Data Augmentation
In most of the cases, data augmentation techniques like rotating, cropping, or flipping the images, turn out to be the best way of increasing the dataset. This way, the model actually learns to recognize objects or features from the images, or there can be different possible conditions of those.
Data Preprocessing
Preprocessing of data (for example, by means of resizing images, normalizing pixel values, or removing noisy data) guarantees that the AI model can process the images efficiently and consequently the training is faster and more accurate.
Conclusion: The Future of Image Classification with AI
With AI evolving, accuracy and image classification datasets will be demanded increasingly. These connotations are the triggers of tons of AI applications, from healthcare to retail, and security followed by autonomous driving. The variety and quality of the data-set will seriously determine the AI model to identify proper images, thus, image classification is a core part of successful AI projects.
One of the best approaches to develop a genuine, efficient, and inclusive AI system is by creating different kinds of good quality and labeled image classification datasets. If you've exponentially boosted your skills in the fields like healthcare, retail, or agriculture then choosing the correct data sources is the key step toward the successful AI and ML implementation.
0 notes
Text
KNN Algorithm | Learn About Artificial Intelligence
The k-Nearest Neighbors (KNN) algorithm is a simple, versatile, and popular machine learning method used for both classification and regression tasks, making predictions based on the proximity of data points to their nearest neighbors in a dataset.
Detect Triangle shape inside image using Java Open CV //Triangle Transform Computer Vision part one

KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions on new, unseen data. KNN relies on a distance metric.
Lazy Learning: It's considered a "lazy learner" because it doesn't have a dedicated training phase; instead, it stores the training data and uses it directly for prediction.
Proximity-Based: KNN relies on the principle that similar data points are located near each other, and it makes predictions based on the classes or values of the nearest neighbors.
Classification: In classification, KNN assigns a new data point to the class that is most common among its k nearest neighbors.
Regression: In regression, KNN predicts a value by averaging the values of the k nearest neighbors.
Parameter k: The parameter 'k' determines the number of nearest neighbors to consider when making a prediction.
#machine learning#artificial image#artificial intelligence#knn algorithm#opencv#image processing#ai image#ai image generator#animation#animation practice#animation design#3d printing#3d image producing#3d image process
5 notes
·
View notes
Text
Also, people need to understand that without original material to train on, AI is absolutely useless. The potential accuracy of any model is based on the quality of the dataset it trains on.
Guess what that means. That if there are no original writers anymore, there will be no more original content to train on, the models will regurgitate their own outputs of questionable quality, and the overall quality of the model drops because the model can only know if its output is accurate only based on its input, so basically Garbage In Garbage Out.
I am a programmer, I really like AI, my undergraduate thesis was on classification of emotions by biometric signals.
And I really like the image generation models, it's always interesting to see how models perceive weird or abstract prompts, or how different models perceive the same prompt, but the essence is, none of these models would exist if not for the original work, that real actual humans produced.
AI can't think of imagine, these are human traits. It can't replace artists cause the quality of its work will never be on par, there will never be a new idea.
AI, however can analyse, compare, and optimise better and faster than humans, so coding work is probably at risk the next few years. Fun!
Anyway, as with any tool, AI is not the devil, the corporations that exploit it for cheap labour at the expense of people. There's AI that can monitor how many coffees a barista has made on their shift and how much time the patron have spent in the shop for the sake of efficiency for fucks sake. That right there is the devil.
49K notes
·
View notes
Text
🎣 Classify Fish Images Using MobileNetV2 & TensorFlow 🧠
In this hands-on video, I’ll show you how I built a deep learning model that can classify 9 different species of fish using MobileNetV2 and TensorFlow 2.10 — all trained on a real Kaggle dataset! From dataset splitting to live predictions with OpenCV, this tutorial covers the entire image classification pipeline step-by-step.
🚀 What you’ll learn:
How to preprocess & split image datasets
How to use ImageDataGenerator for clean input pipelines
How to customize MobileNetV2 for your own dataset
How to freeze layers, fine-tune, and save your model
How to run predictions with OpenCV overlays!
You can find link for the code in the blog: https://eranfeit.net/how-to-actually-fine-tune-mobilenetv2-classify-9-fish-species/
You can find more tutorials, and join my newsletter here : https://eranfeit.net/
👉 Watch the full tutorial here: https://youtu.be/9FMVlhOGDoo
Enjoy
Eran
#Python #ImageClassification #MobileNetV2
#artificial intelligence#convolutional neural network#deep learning#tensorflow#python#machine learning
0 notes