#independent software testing services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
The Importance of Independent Testing Services for Modern Software Delivery
Independent Testing Services: Why They Matter for Reliable Software Delivery
In today’s competitive digital landscape, delivering high-quality, reliable, and secure software is essential for businesses of all sizes. One of the most effective ways to ensure this is by investing in independent testing services. Unlike in-house testing teams, independent testers provide unbiased quality assurance, bringing a fresh perspective and specialized expertise to the software testing process.
In this article, we’ll explore what independent testing services are, their key benefits, and why partnering with a professional independent testing provider can add significant value to your software development lifecycle.
What Are Independent Testing Services?
Independent testing services involve engaging a third-party organization or team to assess, validate, and verify your software applications. These services operate separately from the development team, ensuring an objective evaluation of the product’s functionality, performance, security, and usability.
Independent testers follow industry-standard methodologies, frameworks, and testing tools to identify defects, performance bottlenecks, and security vulnerabilities before the software reaches end-users.
Key Benefits of Independent Testing Services
1️⃣ Unbiased and Objective Assessment
Since independent testing providers work separately from your internal development teams, they offer impartial feedback on software quality. This helps identify issues that might otherwise go unnoticed due to internal familiarity or project biases.
2️⃣ Access to Specialized Expertise
Professional testing service providers bring domain knowledge, testing frameworks, and specialized tools for different types of software applications — including web, mobile, enterprise, and cloud-based solutions.
3️⃣ Faster Time-to-Market
By streamlining testing processes and identifying issues early, independent testing services help businesses speed up their software delivery cycles without compromising on quality.
4️⃣ Enhanced Security Validation
Security is a critical aspect of modern software systems. Independent testers conduct thorough vulnerability assessments, penetration testing, and compliance checks to ensure your software meets security standards.
5️⃣ Cost-Efficient Quality Assurance
Outsourcing testing reduces the overhead costs associated with maintaining a large in-house QA team while ensuring professional-grade quality assurance services tailored to your project needs.
Types of Independent Testing Services Offered
Independent testing providers typically offer a comprehensive range of services, including:
Functional Testing
Performance and Load Testing
Security Testing
Automation Testing
Mobile App Testing
User Acceptance Testing (UAT)
Compatibility Testing
Regression Testing
API Testing
Compliance and Certification Testing
Why Businesses Should Invest in Independent Testing Services
As software applications grow more complex and customer expectations rise, relying solely on internal QA processes can introduce risks. Independent testing services not only enhance product quality but also help mitigate operational, reputational, and financial risks associated with software failures.
By collaborating with an experienced independent testing partner, businesses can:
Ensure product reliability and performance
Meet regulatory and industry compliance standards
Improve customer satisfaction and retention
Optimize internal resources and focus on core competencies
Gain strategic insights for product improvement
Conclusion
Incorporating independent testing services into your software development strategy is a proactive step towards delivering robust, secure, and user-friendly digital solutions. With their unbiased approach, domain expertise, and cost-efficient processes, independent testers can significantly elevate the quality of your applications while accelerating delivery timelines.
If your business is looking to enhance software reliability, reduce operational risks, and achieve faster market readiness, partnering with a trusted independent testing services provider is a smart, future-ready decision
#software testing#independent testing services#automation testing#qa testing#software development company in india
0 notes
Text






🎄💾🗓️ Day 11: Retrocomputing Advent Calendar - The SEL 840A🎄💾🗓️
Systems Engineering Laboratories (SEL) introduced the SEL 840A in 1965. This is a deep cut folks, buckle in. It was designed as a high-performance, 24-bit general-purpose digital computer, particularly well-suited for scientific and industrial real-time applications.
Notable for using silicon monolithic integrated circuits and a modular architecture. Supported advanced computation with features like concurrent floating-point arithmetic via an optional Extended Arithmetic Unit (EAU), which allowed independent arithmetic processing in single or double precision. With a core memory cycle time of 1.75 microseconds and a capacity of up to 32,768 directly addressable words, the SEL 840A had impressive computational speed and versatility for its time.
Its instruction set covered arithmetic operations, branching, and program control. The computer had fairly robust I/O capabilities, supporting up to 128 input/output units and optional block transfer control for high-speed data movement. SEL 840A had real-time applications, such as data acquisition, industrial automation, and control systems, with features like multi-level priority interrupts and a real-time clock with millisecond resolution.
Software support included a FORTRAN IV compiler, mnemonic assembler, and a library of scientific subroutines, making it accessible for scientific and engineering use. The operator’s console provided immediate access to registers, control functions, and user interaction! Designed to be maintained, its modular design had serviceability you do often not see today, with swing-out circuit pages and accessible test points.
And here's a personal… personal computer history from Adafruit team member, Dan…
== The first computer I used was an SEL-840A, PDF:
I learned Fortran on it in eight grade, in 1970. It was at Oak Ridge National Laboratory, where my parents worked, and was used to take data from cyclotron experiments and perform calculations. I later patched the Fortran compiler on it to take single-quoted strings, like 'HELLO', in Fortran FORMAT statements, instead of having to use Hollerith counts, like 5HHELLO.
In 1971-1972, in high school, I used a PDP-10 (model KA10) timesharing system, run by BOCES LIRICS on Long Island, NY, while we were there for one year on an exchange.
This is the front panel of the actual computer I used. I worked at the computer center in the summer. I know the fellow in the picture: he was an older high school student at the time.
The first "personal" computers I used were Xerox Alto, Xerox Dorado, Xerox Dandelion (Xerox Star 8010), Apple Lisa, and Apple Mac, and an original IBM PC. Later I used DEC VAXstations.
Dan kinda wins the first computer contest if there was one… Have first computer memories? Post’em up in the comments, or post yours on socialz’ and tag them #firstcomputer #retrocomputing – See you back here tomorrow!
#retrocomputing#firstcomputer#electronics#sel840a#1960scomputers#fortran#computinghistory#vintagecomputing#realtimecomputing#industrialautomation#siliconcircuits#modulararchitecture#floatingpointarithmetic#computerscience#fortrancode#corememory#oakridgenationallab#cyclotron#pdp10#xeroxalto#computermuseum#historyofcomputing#classiccomputing#nostalgictech#selcomputers#scientificcomputing#digitalhistory#engineeringmarvel#techthroughdecades#console
31 notes
·
View notes
Text
About ThoughtCoders – Leading Software Testing Company ThoughtCoders is a premier Software Testing Company offering comprehensive end-to-end solutions in Quality Assurance, Test Automation, Low-Code and Codeless Automation, Integration Testing, and Offshore QA Services. With a strong track record of delivering high-quality enterprise solutions, we are trusted by clients across industries. Our team comprises industry leaders, expert consultants, and domain-specific SMEs who are passionate about delivering excellence in software quality. Established in June 2021, ThoughtCoders is a government-registered entity, officially recognized under the Startup India Programme by the Ministry of Corporate Affairs (MCA). We operate from a state-of-the-art delivery center in Ballia, Uttar Pradesh, equipped with robust infrastructure to support global delivery models. Our Core Services Quality Assurance Services Test Automation Services Offshore Quality Assurance & Testing Remote QA Team Setup QA Outsourcing Non-Functional Testing (NFR) Visual Testing Solutions Accessibility Testing Services Why Choose ThoughtCoders? At ThoughtCoders, we specialize in independent software testing, TestOps, DevOps integration, and the development of custom QA tools that help accelerate release cycles while maintaining top-tier software quality.
2 notes
·
View notes
Note
How smart are you? You’ve given some hints before but how many degrees do you have? What are you studying? What do you want to do in live professionally and passionately? What’s your purpose career wise?
Also hypothetically would you be open to being your wives employee if she had a really successful company?
I actually don't have any degrees! I'm a nerd and smart but also certainly have my flaws.
For context, I was an honors student all growing up. Always tested in the 99th percentile for state aptitude assessments. I got a 33 on my ACT, did well on a bunch of AP tests and went to a non-ivy-league but prestiguous state school in the top 25% of the incoming class and as a university scholar, in an accelerated chemistry PhD program, and lived in an honors community on campus.
I learned to speak some Chinese, became an instructor for a traditional Korean percussion group, led a bible study, tutored students in organic chemistry, and did excellent in my humanities courses writing on topics like a linguistic study of gender conception in viking-era icelandic society and designing an interventional plan to address youth homelessness in the community.
College was the best 2 years of my life, I adored everything about it but I also completely overloaded myself. Turns out you need more than raw brains for success. I was conflicted between prioritizing my studies vs my faith, and had unadressed adhd and anxiety i wasnt ever aware of and didnt know how to cope with. When my 19 credit hours were drowning me, I couldnt own up to the shame of overwhelm and failure, couldnt look my teachers in the eye and ultimately stopped showing up to class and dropped out.
I'm now back in school with a better understanding of myself, an absense of competing priorities and a lot of experience. Im pursuing working in Radiology doing either CT or MRI. A lot of my friends growing up are finishing their PhD theses and I love discussing them with them, but I myself don't have even an associate's to my name.
Career wise, I originally wanted to be a professor of either Chemistry or Materials Science. I debated majoring in Linguistics or teaching English as a second language but i don't speak anything fluent enough to really do that yet. I've since considered pursuing a career in comedy, as a science communicator and journalist or PIO, as a university student advisor, and taught myself to code to maybe pursue programming.
I love learning. Currently I'm putting the most effort into Chinese classical literature. I've done personal units on nutrition, skincare, fitness, urban planning, economics, and some software like adobe illustrator and game dev with Unity and Godot.
For my professional future, I think I'm for now planning on being a travelling technician in healthcare. It'd give me an opportunity to see lots of different places which is a goal of mine and shouldn't have too many commitments keeping me held in place. Maybe I'll finally get over my fear of casual hookups and become a traveling nurse by day and city-to-city clit servicer by night sampling all sorts of delicious lady bits. Idk. For now I'm just focused on what I'm doing in the moment.
In terms of passions I want time and independence to pursue learning as an autodidact. I'd love to maintain access to university libraries and attend lots of public lectures and symposiums if i could live near enough a big university. I want to read about the things that interest me and someday get over my social anxiety and travel to make friends all over the world with fellow nerds.
In terms of working for my wife of course that would be really sexy I'd love to be my partners doting but slutty assistant 💕 depending on the industry i guess. I think something like insurance or real estate is kind of predatory tbh and wouldnt want to be associated with it. But if I didn't have an issue with it I'd adore being my partners employee. Or even just a supportive house husband or trusted personal assistant ❤️❤️ a role i've always thought I have the potential to be quite good at
8 notes
·
View notes
Text
As Russia has tested every form of attack on Ukraine's civilians over the past decade, both digital and physical, it's often used winter as one of its weapons—launching cyberattacks on electric utilities to trigger December blackouts and ruthlessly bombing heating infrastructure. Now it appears Russia-based hackers last January tried yet another approach to leave Ukrainians in the cold: a specimen of malicious software that, for the first time, allowed hackers to reach directly into a Ukrainian heating utility, switching off heat and hot water to hundreds of buildings in the midst of a winter freeze.
Industrial cybersecurity firm Dragos on Tuesday revealed a newly discovered sample of Russia-linked malware that it believes was used in a cyberattack in late January to target a heating utility in Lviv, Ukraine, disabling service to 600 buildings for around 48 hours. The attack, in which the malware altered temperature readings to trick control systems into cooling the hot water running through buildings' pipes, marks the first confirmed case in which hackers have directly sabotaged a heating utility.
Dragos' report on the malware notes that the attack occurred at a moment when Lviv was experiencing its typical January freeze, close to the coldest time of the year in the region, and that ��the civilian population had to endure sub-zero [Celsius] temperatures.” As Dragos analyst Kyle O'Meara puts it more bluntly: “It's a shitty thing for someone to turn off your heat in the middle of winter.”
The malware, which Dragos is calling FrostyGoop, represents one of less than 10 specimens of code ever discovered in the wild that's designed to interact directly with industrial control-system software with the aim of having physical effects. It's also the first malware ever discovered that attempts to carry out those effects by sending commands via Modbus, a commonly used and relatively insecure protocol designed for communicating with industrial technology.
Dragos first discovered the FrostyGoop malware in April after it was uploaded in several forms to an online malware scanning service—most likely the Google-owned scanning service and malware repository VirusTotal, though Dragos declined to confirm which service—perhaps by the malware's creators, in an attempt to test whether it was detected by antivirus systems. Working with Ukraine's Cyber Security Situation Center, a part of the country's SBU cybersecurity and intelligence agency, Dragos says it then learned that the malware had been used in the cyberattack that targeted a heating utility starting on January 22 in Lviv, the largest city in western Ukraine.
Dragos declined to name the victim utility, and in fact says it hasn't independently confirmed the the utility's name, since it only became aware of the targeting from the Ukrainian government. Dragos' description of the attack, however, closely matches reports of a heating outage at the Lvivteploenergo utility around the same time, which according to local media led to a loss of heating and hot water for close to 100,000 people.
Lviv mayor Andriy Sadovyi at the time called the event a “malfunction" in a post to the messaging service Telegram, but added, “there is a suspicion of external interference in the company's work system, this information is currently being checked.” A Lvivteploenergo statement on January 23 described the outage more conclusively as the “result of a hacker attack.”
Lvivteploenergo didn't respond to WIRED's request for comment, nor did the SBU. Ukraine's cybersecurity agency, the State Services for Special Communication and Information Protection, declined to comment.
In its breakdown of the heating utility attack, Dragos says that the FrostyGoop malware was used to target ENCO control devices—Modbus-enabled industrial monitoring tools sold by the Lithuanian firm Axis Industries—and change their temperature outputs to turn off the flow of hot water. Dragos says that the hackers had actually gained access to the network months before the attack, in April 2023, by exploiting a vulnerable MikroTik router as an entry point. They then set up their own VPN connection into the network, which connected back to IP addresses in Moscow.
Despite that Russia connection, Dragos says it hasn't tied the heating utility intrusion to any known hacker group it tracks. Dragos noted in particular that it hasn't, for instance, tied the hacking to the usual suspects such as Kamacite or Electrum, Dragos' own internal names for groups more widely referred to collectively as Sandworm, a notorious unit of Russia's military intelligence agency, the GRU.
Dragos found that, while the hackers used their breach of the heating utility's network to send FrostyGoop's Modbus commands that targeted the ENCO devices and crippled the utility's service, the malware appears to have been hosted on the hackers' own computer, not on the victim's network. That means simple antivirus alone, rather than network monitoring and segmentation to protect vulnerable Modbus devices, likely won't prevent future use of the tool, warns Dragos analyst Mark “Magpie” Graham. “The fact that it can interact with devices remotely means it doesn't necessarily need to be deployed to a target environment,” Graham says. “You may potentially never see it in the environment, only its effects.”
While the ENCO devices in the Lviv heating utility were targeted from within the network, Dragos also warns that the earlier version of FrostyGoop it found was configured to target an ENCO device that was instead publicly accessible over the open internet. In its own scans, Dragos says it found at least 40 such ENCO devices that were similarly left vulnerable online. The company warns that there may in fact be tens of thousands of other Modbus-enabled devices connected to the internet that could potentially be targeted in the same way. “We think that FrostyGoop would be able to interact with a huge number of these devices, and we're in the process of conducting research to verify which devices would indeed be vulnerable,” Graham says.
While Dragos hasn't officially linked the Lviv attack to the Russian government, Graham himself doesn't shy away from describing the attack as a part of Russia's war against the country—a war that has brutally decimated Ukrainian critical infrastructure with bombs since 2022 and with cyberattacks starting far earlier, since 2014. He argues that the digital targeting of heating infrastructure in the midst of Ukraine's winter may actually be a sign that Ukrainians' increasing ability to shoot down Russian missiles has pushed Russia back to hacking-based sabotage, particularly in western Ukraine. “Cyber may actually be more efficient or likely to be successful towards a city over there, while kinetic weapons are maybe still successful at a closer range," Graham says. “They’re trying to use the full spectrum, the full gamut of available tools in the armory.”
Even as those tools evolve, though, Graham describes the hackers' goals in terms that have changed little in Russia's decade-long history of terrorizing its neighbor: psychological warfare aimed at undermining Ukraine's will to resist. “This is how you chip away at the will of the people,” says Graham. “It wasn’t aimed at disrupting the heating for all of winter. But enough to make people to think, is this the right move? Do we continue to fight?”
9 notes
·
View notes
Text
okay, so- the past three days have been pretty insane, hence no to-do lists. did not know hour-to-hour what in the hell i'd have to do next.
monday morning, there was a company meeting, and it was announced that we were being sold. this was not... the most surprising thing in the world, because about a month ago there was this sudden hasty push by the top to reorganize the business into distinct independent units that didn't depend on shared services. like, what else would the point of doing that be, if not to sell off pieces of the business? sure, they said that wasn't happening, but who the hell was fooled by that?
so i used to do most of my work on these projects for this one specific business unit, building and running a bunch of middleware API integrations for our learning management system. but my boss, who used to be in charge of the dev team generally, got assigned to this totally different unit- and she liked me enough that she pushed really hard to get me reassigned to her unit.
so i was already conflicted about that:
i really like my boss- she's really understanding of my need for flexibility to work on my side projects, she only cares that i get the work done (and even with many side projects, i still consistently exceed expectations and get a full-time workload done ahead of schedule), and she was pushing hard to get me a raise against upper management who'd taken to using covid austerity as an excuse to never give anyone any raises ever. and the team assigned to this unit didn't have any senior devs who could handle a big infrastructure transition, and i'd just become AWS certified, and without someone like me, my coworkers assigned to that unit would be in some hot water. plus, after the transition, maintaining a reduced suite of products would probably be easier day-to-day.
but on the other hand, all my projects in the other business unit, with the LMS- those are pretty vital, and the nature of the contracts with those clients necessitates frequent maintenance and changes. my code for those integrations is bad, for various reasons but mainly that there is no dev environment for testing changes. it's fundamentally about managing production data in databases we don't directly control, so every change has to be done very quickly and carefully, with no room for big refactors to clean things up (and risk breaking stuff). it's a mess, and no one in the other business unit is prepared to take it over. plus- i liked working directly with clients, doing work where if i did the work someone was appreciative of the work. it was motivating!
ultimately, i decided to trust my boss and follow her to the other business unit. we weren't completely splitting from the rest of the business- i'd still be able to train up someone else to take over my projects, we'd still have the shared customer accounts management software, and- crucially- i'd still have the boss who understood my needs and had no interest in squeezing value out of me.
so i went on vacation for a couple weeks right after committing to that decision- and then i came back on monday, and that day they announce we're being sold.

also that my boss is fired and being replaced by someone from the new company.

also that we have two months to completely disconnect all our products from shared service infrastructure and rebuild our own.

also no takesies-backsies, the acquisition agreement included terms that the former company not hire back any of the sold-off employees or even discuss the acquisition with them at all. no chance to react to the new information except to sign the new offer letter by close of business on Wednesday.

i was unhappy about this! can you tell???
so my first thought was- okay, this is bullshit. i still want to work for the LMS people, the LMS people still want me to work for them, there has to be a solve here. so i go to the guy in charge of that division, who also wants me to keep working there, and he says okay i'll have our lawyers look into it.
and then... he gets back to me sounding like a robot, "i am unable to discuss this further with you at this time", which is so obviously out of character for the guy that i can tell legal's thrown the book at him. i talk to legal myself- it's a dead end. they can't- they're unable to even talk about why they can't talk about it, because obviously this deal was engineered to prevent me from doing exactly what i'm trying to do here.
so i go at it from the other angle. president of the sold company, now a wholly-owned for-profit subsidiary of a nonprofit organization (is that even allowed???), i explain to him, hey, this is a mistake, i'm only here because my old boss really wanted me to be on her team, surely you can let me go continue doing my actual job?
nope.

so then i start playing hardball.
the salary they're offering me is, adjusted for inflation, less than the salary i was offered two years ago, which had come with the (entirely failed) non-promise that i'd be bumped up to a certain level very quickly after some formalities re: the employment structure. i explain, in detail, how upset i am with the entire state of affairs- and i threaten to walk, which i am allowed to do. i'm not required to sign their new contract- i'd need to go job-hunting, sure, but i have money in the bank, i can afford to do it, and i could definitely get a better deal somewhere else.
this is a tense situation! my old boss knew this team needed me- but they unceremoniously fired her while she was on vacation, so her opinion doesn't mean dirt to them apparently. it's unclear how vital i really am to this- they could maybe train up one of the other devs to handle the AWS stuff.
and on my side- if i walk, that's it. all that horrible messy code for the LMS stuff- i don't get two months to train someone else up and write documentation and do some housecleaning. i'm gone! my horrific dirty laundry (and hours and hours of regular maintenance work) gets handed off to some other dev who's totally unprepared for it, and that person inevitably puts a curse on my entire family line as retribution for me leaving them holding that intolerable bag. i don't actually want to walk, because then i end up the bad guy in the eyes of people i respect and care about.
(also i'd have to do a job hunt and that shit is so god damn annoying you have no idea you probably have some idea.)
so i tell the guy, look- i can do better. i'm basically starting over doing harder work at an unfamiliar company, and if i'm doing that anyway, why not do it for someone who'll pay me? if you don't give me X amount of money, i'm walking out, and now you don't have an infrastructure guy during the two-month window you have to migrate a shit-ton of infrastructure. i am a serious dude and you can't just fuck with me!
(and inside i'm like:

because oh god i am not a serious dude i am so easily fucked with what if i'm pushing my luck too hard)
and he lets me fuckin' stew. 5:00 on wednesday i need to have either signed a contract or not signed a contract, and he hedges and goes to talk with the higher-ups and makes no promises, and i have no idea whether it's because i scared him or if he's trying to work out how to replace me or what. all this negotiation has been eating my brain for the past couple days and it's coming down to the wire-
and then a couple hours before the deadline he gets back to me with a counteroffer. it's less than i was asking, because that's how negotiations work, but it is more than i was making when i was brought on, by a good 10k.

so now it's on to round two. i'm gonna stick around for this two-month period, make this transition work, clean up my mess and take care of things with my now ex-coworkers- and then if they haven't either proven their management is tolerable or given me a crystal-clear path to advancement, we're back to the standoff- except this time, they'll have a good idea of exactly what it is they stand to lose.
haaaaaaaaaaaaaaah. okay. okay. yeah. so that's dealt with for the time being. i can breathe now. we'll see how it goes. fuck.
27 notes
·
View notes
Text
Shinetech Software achieves Cyber Essentials Plus certification
Shinetech Software is proud to announce that it has achieved Cyber Essentials Plus certification proving its dedication to cyber security and protection from cyber-attacks. Cyber Essentials Plus is an official UK Government-backed, industry-supported certification scheme to help organisations demonstrate operational security against the ever-growing threat of cyber-attacks and a commitment to cyber security.
Assessed and verified through an independent external audit it requires compliance and rigorous testing of our business security controls and processes. The certification also acknowledges our strong security management ethos and procedural framework.

Frank Zhang, UK Managing Director at Shinetech Software says “Achieving the Cyber Essentials Plus certification underscores our commitment to ensuring our cyber security is as strong as possible to protect our customers’ data. We take these responsibilities very seriously and this certification complements our existing ISO 27001 Information Security Management System certification.”.
Andy Landsberg, Cyber Security Manager at Frimley Health NHS Foundation Trust says “We have worked with Shinetech Software over many years and are pleased they have achieved the Cyber Essentials Plus certification in recognition of the controls they have in place and the work they undertake to maintain data security, illustrating their adherence to best practice guidelines.”.
Frimley Health, along with other key partners including Barts Health NHS Trust, Lewisham & Greenwich NHS Trust and Queen Mary University of London, collaborated with Shinetech Software on the industry award winning GDPR compliant Class Attendance Tracker QR (CATQR) digital solution for employers and educational institutions to monitor staff and student attendance in real-time.
Apple and Google recently approved the release of the new CATQR mobile app which is compliant with the latest Apple iOS and Google Android mobile app policy and security guidelines.
Shinetech Software is a Microsoft Gold Certified Partner and Gartner Cool Vendor with delivery centres in London, New York and Sydney supported by over 20 software engineering development centres throughout Asia.
Find out more about Shinetech Software bespoke software engineering services on https://www.shinetechsoftware.co.uk and watch the Frimley Health CATQR video on https://www.catqr.com or https://www.youtube.com/watch?v=ONq55EgAA5I
3 notes
·
View notes
Text
Understanding Encryption: How Signal & Telegram Ensure Secure Communication

Signal vs. Telegram: A Comparative Analysis

Signal vs Telegram
Security Features Comparison
Signal:
Encryption: Uses the Signal Protocol for strong E2EE across all communications.
Metadata Protection: User privacy is protected because minimum metadata is collected.
Open Source: Code publicly available for scrutiny, anyone can download and inspect the source code to verify the claims.
Telegram:
Encryption: Telegram uses MTProto for encryption, it also uses E2EE but it is limited to Secret Chats only.
Cloud Storage: Stores regular chat data in the cloud, which can be a potential security risk.
Customization: Offers more features and customization options but at the potential cost of security.
Usability and Performance Comparison
Signal:
User Interface: Simple and intuitive, focused on secure communication.
Performance: Privacy is prioritized over performance, the main focus is on minimizing the data collection.
Cross-Platform Support: It is also available on multiple platforms. Like Android, iOS, and desktop.
Telegram:
User Interface: Numerous customization options for its audience, thus making it feature rich for its intended audience.
Performance: Generally fast and responsive, but security features may be less robust.
Cross-Platform Support: It is also available on multiple platforms, with seamless synchronization across devices because all the data is stored on Telegram cloud.
Privacy Policies and Data Handling
Signal:
Privacy Policy: Signal’s privacy policy is straightforward, it focuses on minimal data collection and strong user privacy. Because it's an independent non-profit company.
Data Handling: Signal does not store any message data on its servers and most of the data remains on the user's own device thus user privacy is prioritized over anything.
Telegram:
Privacy Policy: Telegram stores messages on its servers, which raises concerns about privacy, because theoretically the data can be accessed by the service provider.
Data Handling: While Telegram offers secure end to end encrypted options like Secret Chats, its regular chats are still stored on its servers, potentially making them accessible to Telegram or third parties.
Designing a Solution for Secure Communication
Key Components of a Secure Communication System
Designing a secure communication system involves several key components:
Strong Encryption: The system should employ adequate encryption standards (e.g. AES, RSA ) when data is being transmitted or when stored.
End-to-End Encryption: E2EE guarantees that attackers cannot read any of the communication, meaning that the intended recipients are the only ones who have access to it.
Authentication: It is necessary to identify the users using secure means such as Two Factor Authentication (2FA) to restrict unauthorized access.
Key Management: The system should incorporate safe procedures for creating, storing and sharing encryption keys.
Data Integrity: Some standard mechanisms must be followed in order to ensure that the data is not altered during its transmission; For instance : digital signatures or hashing.
User Education: To ensure the best performance and security of the system, users should be informed about security and the appropriate use of the system such practices.
Best Practices for Implementing Encryption
To implement encryption effectively, consider the following best practices:
Use Proven Algorithms: Do not implement proprietary solutions that are untested, because these algorithms are the ones which haven't gone through a number of testing phases by the cryptographic community. On the other hand, use well-established algorithms that are already known and tested for use – such as AES and RSA.
Keep Software Updated: Software and encryption guidelines must be frequently updated because these technologies get out of date quickly and are usually found with newly discovered vulnerabilities.
Implement Perfect Forward Secrecy (PFS): PFS ensures that if one of the encryption keys is compromised then the past communications must remain secure, After every session a new key must be generated.
Data must be Encrypted at All Stages: Ensure that the user data is encrypted every-time, during transit as well as at rest – To protect user data from interception and unauthorized access.
Use Strong Passwords and 2FA: Encourage users to use strong & unique passwords that can not be guessed so easily. Also, motivate users to enable the two-factor authentication option to protect their accounts and have an extra layer of security.
User Experience and Security Trade-offs
While security is important, but it's also important to take care of the user experience when designing a secure communication system. If your security measures are overly complex then users might face difficulties in adopting the system or they might make mistakes in desperation which might compromise security.
To balance security and usability, developers should:

Balancing Security And Usability
Facilitate Key Management: Introduce automated key generation and exchange mechanisms in order to lessen user's overhead
Help Users: Ensure that simple and effective directions are provided in relation to using security aspects.
Provide Control: Let the users say to what degree they want to secure themselves e.g., if they want to make use of E2EE or not.
Track and Change: Always stay alert and hands-on in the system monitoring for security breaches as well as for users, and where there is an issue, do something about it and change
Challenges and Limitations of Encryption Potential Weaknesses in Encryption
Encryption is without a doubt one of the most effective ways of safeguarding that communications are secured. However, it too has its drawbacks and weaknesses that it is prone to:
Key Management: Managing and ensuring the safety of the encryption keys is one of the most painful heads in encryption that one has to bear. When keys get lost or fall into unsafe hands, the encrypted information is also at risk.
Vulnerabilities in Algorithms: As far as encryption is concerned the advanced encryption methods are safe and developed well, but it is not given that vulnerabilities will not pop up over the years. Such vulnerabilities are meant for exploitation by attackers especially where the algorithm in question is not updated as frequently as it should be.
Human Error: The strongest encryption can be undermined by human error. People sometimes use weak usernames and passwords, where they are not supposed to, and or even share their credentials with other persons without considering the consequences.
Backdoors: In some cases, businesses are pressured by Governments or law officials into adding back doors to the encryption software. These backdoors can be exploited by malicious actors if discovered.
Conclusion
Although technology has made it possible to keep in touch with others with minimal effort regardless of their geographical location, the importance of encryption services still persists as it allows us to protect ourselves and our information from external invaders. The development of apps like Signal and Telegram has essentially transformed the aspect of messaging and provided their clients with the best security features covering the use of multiple types of encryption and other means to enhance user privacy. Still, to design a secure communication system, it's not only designing the hardware or software with anti-eavesdropping features, but it factors in the design of systems that relate to the management of keys, communication of the target users, and the trade-off between security and usability.
However, technology will evolve, followed by the issues and the solutions in secure communications. However by keeping up with pace and looking for better ways to protect privacy we can provide people the privacy that they are searching for.
Find Out More
3 notes
·
View notes
Text
Best IT Courses In Bhubaneswar:- seeree services pvt ltd.
Introduction:- seeree is one of the best IT training institute and Software industry, features completely Industrial training on Python , PHP , .NET , C Programming,Java , IOT , AI , GD PI , ORACLE and ALL CERTIFICATION COURSES as well as provides seminar,cultural activity and jobs
Courses we provided:- 1) Java Fullstack 2) Python Fullstack 3) PHP Fullstack 4) Preplacement Training & Sp. Eng 5) .NET Fulstack 6) SEO/Digital Marketing 7) SAP 8) MERN 9) Software Testing 10)Data Analyst 11)Data Science 12)Data Engineering 13)PGDCA 14)Tally 15)Graphics Design
Course1:- Java Fullstack

A Class in Java is where we teach objects how to behave. Education at seeree means way to success. The way of teaching by corporate trainers will bloom your career. We have the best java training classes in Bhubaneswar. 100% Placement Support. Job Support Post Training. This course will give you a firm foundation in Java, commonly used programming language. Java technology is wide used currently. Java is a programming language and it is a platform. Hardware or software environment in which a program runs, known as a platform. Since Java has its own Runtime Environment (JRE) and API, it is called platform. Java programming language is designed to meet the challenges of application development in the context of heterogeneous, network-wide distributed environment. Java is an object-oriented programming (OOP) language that uses many common elements from other OOP languages, such as C++. Java is a complete platform for software development. Java is suitable for enterprise large scale applications.]
Course2:- Python Fullstack

Seeree offers best python course in Bhubaneswar with 100% job assurance and low fee. Learn from real time corporate trainers and experienced faculties. Groom your personality with our faculty. Seeree helps to build confidence in students to give exposure to their skills to the company.
Python is dynamically typed , compiled and interpreted , procedural and object oriented , generalized , general-purpose , platform independent programming language. Python is a high-level, structured, open-source programming language that can be used for a wide variety of programming tasks.
Course3:- PHP Fullstack

seeree is the best training institute which provide PHP Training courses in bhubaneswar and all over odisha We aim the students to learn and grow altogether with the need of IT firms.
PHP is a server scripting language, and a powerful tool for making dynamic and interactive Web pages. PHP is a widely-used, free, and efficient alternative to competitors such as Microsoft's ASP.
Course4:- Preplacement Training & Sp. Eng

Welcome to SEEREE Institute, where excellence meets opportunity. At SEEREE, we are dedicated to providing a transformative learning experience that empowers students to achieve their goals and contribute to a brighter future.
Our institute offers cutting-edge courses designed to meet the needs of the ever-evolving global landscape. With a team of highly qualified instructors and state-of-the-art facilities, we ensure a supportive and inspiring environment for learning and growth.
Whether you're here to develop new skills, explore innovative fields, or pursue personal and professional success, SEEREE Institute is the perfect place to begin your journey. Thank you for choosing us, and we look forward to being a part of your success story.
Course5:- .NET Fullstack

Seeree offers best .NET course in Bhubaneswar with 100% job assurance and low fee. Learn from real time corporate trainers and experienced faculties. Groom your personality with our faculty. Seeree helps to build confidence in students to give exposure to their skills to the company.
Course6:- SEO/Digital Marketing

In today's fast-paced digital world, businesses thrive on visibility, engagement, and strategic online presence. At SEEREE, we empower you with the skills and knowledge to master the art of Search Engine Optimization (SEO) and Digital Marketing.
Our comprehensive program is designed for beginners and professionals alike, covering everything from keyword research, on-page and off-page SEO, and content marketing, to social media strategies, PPC campaigns, and analytics.
With hands-on training, real-world projects, and guidance from industry experts, we ensure you're equipped to drive measurable results and excel in this dynamic field.
Join us at SEEREE Institute and take the first step towards becoming a leader in the digital marketing landscape!"
Course7:- SAP

SAP refers to Systems, Applications, and Products in Data Processing. Some of the most common subjects covered in these courses include human resource software administration, database management, and business training. Obtaining SAP certification can be done on a stand-alone basis or as part of a degree program.
Course8:- MERN

Seeree offers the best MERN course in Bhubaneswar with 100% job assurance and low fees. Learn from real-time corporate trainers and experienced faculty. Seeree helps students build confidence and gain skills to excel in company roles.
Are you ready to step into the exciting world of web development? At SEEREE, we bring you a comprehensive MERN Stack course that equips you with the skills to build modern, dynamic, and responsive web applications from start to finish.
The MERN Stack—comprising MongoDB, Express.js, React.js, and Node.js—is one of the most sought-after technologies in the web development industry. Our program is designed to help you master each component of the stack, from creating robust backends and managing databases to crafting dynamic frontends and seamless APIs.
Course9:- Software Testing

Seeree offers best Testing course in Bhubaneswar with 100% job assurance and low fee. Learn from real time corporate trainers and experienced faculties. Groom your personality with our faculty. Seeree helps to build confidence in students to give exposure to their skills to the company.
In the fast-paced world of software development, ensuring the quality and reliability of applications is crucial. At SEEREE, we offer a comprehensive Software Testing course designed to equip you with the skills and techniques needed to excel in this essential field.
Our program covers all aspects of software testing, from manual testing fundamentals to advanced automation tools and frameworks like Selenium, JIRA, and TestNG. You’ll learn to identify bugs, write test cases, execute test scripts, and ensure software meets high-quality standards.
With hands-on training, real-world scenarios, and guidance from experienced industry professionals, you’ll be prepared to take on roles like Quality Assurance Engineer, Test Analyst, and Automation Tester.
Join SEEREE Institute and gain the expertise to become a key player in delivering flawless software solutions. Your journey to a rewarding career in software testing starts here!"
Course10:- Data Analyst

Seeree offers the best Data Analyst course in Bhubaneswar with 100% job assurance and affordable fees. Our comprehensive curriculum is designed to cover all aspects of data analysis, from data collection and cleaning to advanced data visualization techniques. Learn from real-time corporate trainers and experienced faculty members who bring industry insights into the classroom. Enhance your analytical skills and boost your career prospects with hands-on projects and real-world case studies. Our faculty also focuses on grooming your personality and soft skills, ensuring you are well-prepared for interviews and workplace environments. Seeree is dedicated to building confidence in students, providing them with the necessary exposure to showcase their skills to top companies in the industry.
Course11:- Data Science

Seeree offers the best Data Science course in Bhubaneswar with 100% job assurance and affordable fees. Our comprehensive curriculum is designed to cover all aspects of data science, from data collection and cleaning to advanced data visualization techniques. Learn from real-time corporate trainers and experienced faculty members who bring industry insights into the classroom. Enhance your analytical skills and boost your career prospects with hands-on projects and real-world case studies. Our faculty also focuses on grooming your personality and soft skills, ensuring you are well-prepared for interviews and workplace environments. Seeree is dedicated to building confidence in students, providing them with the necessary exposure to showcase their skills to top companies in the industry.
Course12:- Data Engineering

In the era of big data, the ability to design, build, and manage scalable data infrastructure is one of the most in-demand skills in the tech industry. At SEEREE, we are proud to offer a comprehensive Data Engineering course that prepares you for a career at the forefront of data-driven innovation.
Our program covers essential topics such as data modeling, ETL processes, data warehousing, cloud platforms, and tools like Apache Spark, Kafka, and Hadoop. You’ll learn how to collect, organize, and transform raw data into actionable insights, enabling businesses to make smarter decisions.
With real-world projects, expert mentorship, and hands-on experience with the latest technologies, we ensure that you are industry-ready. Whether you’re starting fresh or upskilling, this program will empower you to unlock opportunities in the rapidly growing field of data engineering.
Join SEEREE Institute and take the first step toward building the data pipelines that power tomorrow’s technology!"
Course13:- PGDCA

Seeree offers the best MERN course in Bhubaneswar with 100% job assurance and low fees. Learn from real-time corporate trainers and experienced faculty. Seeree helps students build confidence and gain skills to excel in company roles.
In today’s digital age, computer applications are at the heart of every industry, driving innovation and efficiency. At SEEREE Institute, our Post Graduate Diploma in Computer Applications (PGDCA) program is designed to provide you with in-depth knowledge and hands-on skills to excel in the IT world.
This program offers a comprehensive curriculum covering programming languages, database management, web development, software engineering, networking, and more. Whether you aim to enhance your technical expertise or step into a rewarding career in IT, PGDCA at SEEREE equips you with the tools to succeed.
With expert faculty, state-of-the-art labs, and real-world projects, we ensure that you gain practical experience and a strong theoretical foundation. By the end of the program, you’ll be prepared for roles such as software developer, system analyst, IT manager, or database administrator.
Course14:- Tally

Seeree offers the best Tally course in Bhubaneswar with 100% job assurance and low fees. Learn from real-time corporate trainers and experienced faculty. Seeree helps students build confidence and gain skills to excel in company roles.
In today’s business world, efficient financial management is key to success, and Tally is one of the most trusted tools for accounting and financial operations. At SEEREE Institute, we offer a comprehensive Tally course designed to equip you with the skills needed to manage business finances effortlessly.
Our program covers everything from the basics of accounting and bookkeeping to advanced features like GST compliance, inventory management, payroll processing, and generating financial reports. With hands-on training and real-world applications, you’ll gain practical expertise in using Tally effectively for businesses of any scale.
Whether you're a student, a professional, or a business owner, our Tally program is tailored to meet your needs and enhance your career prospects in the fields of accounting and finance.
Course15:- Graphics Design

In the world of creativity and communication, graphic design plays a vital role in bringing ideas to life. At SEEREE Institute, our Graphic Design course is tailored to help you unlock your creative potential and master the art of visual storytelling.
Our program covers a wide range of topics, including design principles, color theory, typography, branding, and user interface design. You’ll gain hands-on experience with industry-standard tools like Adobe Photoshop, Illustrator, and InDesign, enabling you to create stunning visuals for print, digital media, and beyond.
Whether you're an aspiring designer or a professional looking to sharpen your skills, our expert trainers and real-world projects will provide you with the knowledge and confidence to excel in this competitive field.
Join SEEREE Institute and start your journey toward becoming a skilled graphic designer. Let’s design your future together!"
2 notes
·
View notes
Text
Cloud-Native Development in the USA: A Comprehensive Guide
Introduction
Cloud-native development is transforming how businesses in the USA build, deploy, and scale applications. By leveraging cloud infrastructure, microservices, containers, and DevOps, organizations can enhance agility, improve scalability, and drive innovation.
As cloud computing adoption grows, cloud-native development has become a crucial strategy for enterprises looking to optimize performance and reduce infrastructure costs. In this guide, we’ll explore the fundamentals, benefits, key technologies, best practices, top service providers, industry impact, and future trends of cloud-native development in the USA.
What is Cloud-Native Development?
Cloud-native development refers to designing, building, and deploying applications optimized for cloud environments. Unlike traditional monolithic applications, cloud-native solutions utilize a microservices architecture, containerization, and continuous integration/continuous deployment (CI/CD) pipelines for faster and more efficient software delivery.
Key Benefits of Cloud-Native Development
1. Scalability
Cloud-native applications can dynamically scale based on demand, ensuring optimal performance without unnecessary resource consumption.
2. Agility & Faster Deployment
By leveraging DevOps and CI/CD pipelines, cloud-native development accelerates application releases, reducing time-to-market.
3. Cost Efficiency
Organizations only pay for the cloud resources they use, eliminating the need for expensive on-premise infrastructure.
4. Resilience & High Availability
Cloud-native applications are designed for fault tolerance, ensuring minimal downtime and automatic recovery.
5. Improved Security
Built-in cloud security features, automated compliance checks, and container isolation enhance application security.
Key Technologies in Cloud-Native Development
1. Microservices Architecture
Microservices break applications into smaller, independent services that communicate via APIs, improving maintainability and scalability.
2. Containers & Kubernetes
Technologies like Docker and Kubernetes allow for efficient container orchestration, making application deployment seamless across cloud environments.
3. Serverless Computing
Platforms like AWS Lambda, Azure Functions, and Google Cloud Functions eliminate the need for managing infrastructure by running code in response to events.
4. DevOps & CI/CD
Automated build, test, and deployment processes streamline software development, ensuring rapid and reliable releases.
5. API-First Development
APIs enable seamless integration between services, facilitating interoperability across cloud environments.
Best Practices for Cloud-Native Development
1. Adopt a DevOps Culture
Encourage collaboration between development and operations teams to ensure efficient workflows.
2. Implement Infrastructure as Code (IaC)
Tools like Terraform and AWS CloudFormation help automate infrastructure provisioning and management.
3. Use Observability & Monitoring
Employ logging, monitoring, and tracing solutions like Prometheus, Grafana, and ELK Stack to gain insights into application performance.
4. Optimize for Security
Embed security best practices in the development lifecycle, using tools like Snyk, Aqua Security, and Prisma Cloud.
5. Focus on Automation
Automate testing, deployments, and scaling to improve efficiency and reduce human error.
Top Cloud-Native Development Service Providers in the USA
1. AWS Cloud-Native Services
Amazon Web Services offers a comprehensive suite of cloud-native tools, including AWS Lambda, ECS, EKS, and API Gateway.
2. Microsoft Azure
Azure’s cloud-native services include Azure Kubernetes Service (AKS), Azure Functions, and DevOps tools.
3. Google Cloud Platform (GCP)
GCP provides Kubernetes Engine (GKE), Cloud Run, and Anthos for cloud-native development.
4. IBM Cloud & Red Hat OpenShift
IBM Cloud and OpenShift focus on hybrid cloud-native solutions for enterprises.
5. Accenture Cloud-First
Accenture helps businesses adopt cloud-native strategies with AI-driven automation.
6. ThoughtWorks
ThoughtWorks specializes in agile cloud-native transformation and DevOps consulting.
Industry Impact of Cloud-Native Development in the USA
1. Financial Services
Banks and fintech companies use cloud-native applications to enhance security, compliance, and real-time data processing.
2. Healthcare
Cloud-native solutions improve patient data accessibility, enable telemedicine, and support AI-driven diagnostics.
3. E-commerce & Retail
Retailers leverage cloud-native technologies to optimize supply chain management and enhance customer experiences.
4. Media & Entertainment
Streaming services utilize cloud-native development for scalable content delivery and personalization.
Future Trends in Cloud-Native Development
1. Multi-Cloud & Hybrid Cloud Adoption
Businesses will increasingly adopt multi-cloud and hybrid cloud strategies for flexibility and risk mitigation.
2. AI & Machine Learning Integration
AI-driven automation will enhance DevOps workflows and predictive analytics in cloud-native applications.
3. Edge Computing
Processing data closer to the source will improve performance and reduce latency for cloud-native applications.
4. Enhanced Security Measures
Zero-trust security models and AI-driven threat detection will become integral to cloud-native architectures.
Conclusion
Cloud-native development is reshaping how businesses in the USA innovate, scale, and optimize operations. By leveraging microservices, containers, DevOps, and automation, organizations can achieve agility, cost-efficiency, and resilience. As the cloud-native ecosystem continues to evolve, staying ahead of trends and adopting best practices will be essential for businesses aiming to thrive in the digital era.
1 note
·
View note
Text
CrowdStrike Outage: Customers Independent Cybersecurity Firm

Supporting customers during the CrowdStrike outage Independent cybersecurity firm. CrowdStrike launched a software upgrade that started affecting IT systems all across the world. They would like to provide an update on the efforts that were made with CrowdStrike and others to remedy and help consumers, even though this was not a Microsoft issue and it affects the entire ecosystem.
CrowdStrike outage
Everyone have been in constant contact with customers, CrowdStrike outage, and outside developers since the start of this incident in order to gather data and hasten resolutions. It are aware of the impact this issue has brought to many people’s everyday routines as well as companies. The primary objective is to help customers safely restore interrupted systems back online by offering technical advice and support. Among the actions made are:
Using CrowdStrike to automate their solution development process.
In addition to providing a workaround recommendation, CrowdStrike has made a public statement on this vulnerability.
The Windows Message Centre contained instructions on how to fix the issue on Windows endpoints.
Deploying hundreds of engineers and specialists from Microsoft to collaborate directly with clients in order to restore services.
In order to inform ongoing discussions with CrowdStrike and customers, us are working together with other cloud providers and stakeholders, such as Google Cloud Platform (GCP) and Amazon Web Services (AWS), to share awareness on the state of effect they are each witnessing throughout the sector.
publishing the scripts and documentation for manual cleanup as soon as possible.
Customers will be updated on the incident’s status via the Azure Status Dashboard, available here.
They are constantly updating and supporting customers while working around the clock.
CrowdStrike has also assisted us in creating a scalable solution that would speed up Microsoft’s Azure infrastructure’s correction of CrowdStrike’s flawed update.
They have also collaborated on the most efficient methods with AWS and GCP.
CrowdStrike update
Software changes might occasionally create disruptions, but major events like the CrowdStrike event don’t happen often. As of right now, researchers calculate that 8.5 million Windows devices less than 1% of all Windows computers were impacted by CrowdStrike’s update. Even though the percentage was low, the usage of CrowdStrike by businesses that manage numerous vital services has a significant influence on the economy and society.
This event highlights how intertwined the large ecosystem consisting of consumers, software platforms, security and other software vendors, and worldwide cloud providers is. It serves as a reminder of how critical it is that everyone in the tech ecosystem prioritizes disaster recovery utilising existing channels and safe deployment practices.
As the past two days have demonstrated, cooperation and teamwork are the keys to learning, healing, and forward motion. They value the cooperation and teamwork of everyone in this sector, and will continue to keep you informed about the results and future plans.
Overview
An CrowdStrike outage can be a difficult occurrence for any organisation in the ever-changing field cybersecurity . Their resilience and readiness were put to the test recently when a significant CrowdStrike outage affected customers. This post seeks to give a thorough explanation of how they supported the clients at this crucial time, making sure their cybersecurity requirements were satisfied with the highest effectiveness and consideration.
Comprehending the CrowdStrike Incident
One of the top cybersecurity companies’ services experienced problems due to the unanticipated CrowdStrike outage. Many organizations were affected by the outage, which made them susceptible to possible cyberattacks. The primary objective was to minimize the effects of this outage on customers while maintaining security services for them.
Quick Reaction to the Outage
Upon detecting the outage, the dedicated employees moved quickly to resolve it. They prioritized communicating with clients due to recognized the seriousness of the matter. Below is a thorough explanation of the prompt response:
Notification and Communication: Everyone immediately sent out a notification of the outage by email, phone calls, and through own support portal to all impacted clients. Having open and honest communication was essential to reassuring and informing those who hired us.
Activation of the Incident Response Team: They promptly activated the incident response team, which is made up of support engineers and cybersecurity specialists. To evaluate the effects of the outage and create a tactical reaction strategy, this team worked nonstop.
Providing Differential Approaches to Security
Ensuring customers have strong security was the initial focus during the downtime. To guarantee ongoing protection, having put in place a number of other security measures, including:
Temporary Security Solutions: In order to cover for the CrowdStrike outage, they implemented temporary security solutions. Advanced threat intelligence tools, more intrusion detection systems, and improved firewall setups were some of these answers.
Alerts and Manual Monitoring: They increased the manual monitoring efforts at its Security Operations Centre (SOC). In order to ensure prompt action in the event of an incident, having installed extra alarm mechanisms to identify any unusual activity that would point to possible cyber attacks.
Improving Customer Service
It strengthened the support infrastructure in order to reply to the worries and questions of the clients:
24/7 Support Availability: They have extended support service hours to offer assistance whenever you need it. Clients could get in touch with the support team whenever they needed assistance, so they could get it quickly.
Specialised Support Channels: Everyone set up special support channels for problems relating to outages. This made it possible for us to concentrate on helping the impacted clients and to expedite the support process.
Constant Observation and Updates
They continued to provide updates throughout the interruption due to the were committed to being open and satisfying those who trust us:
Regular Status Updates: Having kept you informed on the status of the issue resolution process on a regular basis. The actions being taken to resume regular services and the anticipated time frames for resolution were noted in these updates.
Integration of Customer comments: In order to better understand the client’s unique wants and concerns, and actively sought out their comments. This input was really helpful to us because it adjusted the way to replied and enhanced the assistance offerings.
Acquiring Knowledge and Developing from Experience
They carried out a comprehensive investigation following the CrowdStrike outage in order to pinpoint problem areas and guarantee enhanced readiness for upcoming incidents:
Root Cause Analysis: To identify the causes of the CrowdStrike outage, their team conducted a thorough root cause analysis. They were able to pinpoint areas that required improvement and weaknesses thanks to their investigation.
Process Improvements: Having carried out a number of process enhancements in light of the new information. These included modernizing the security architecture, strengthening communication tactics, and refining the incident response procedures.
Enhancing Their Collaboration with CrowdStrike
Nous collaborated closely with CrowdStrike outage to quickly resolve the issue due to recognized their crucial position in the cybersecurity ecosystem:
Cooperation and Support: In order to guarantee a prompt resolution, they worked in tandem with CrowdStrike’s engineering and technical support teams. They were able to efficiently utilize CrowdStrike’s resources and experience thanks to working together with them.
Post-Outage Review: To assess the CrowdStrike outage and its effects, they jointly reviewed with CrowdStrike once services had fully recovered. This review was crucial to strengthening cooperation and improving the capacity to respond as a team.
In summary
Although the CrowdStrike outage was a difficult occurrence, all proactive and customer-focused strategy made sure that customers got the assistance and security they required. It lies in the unwavering commitment to enhancing its infrastructure and services to deliver the best possible cybersecurity. The desire to remain a dependable and trustworthy partner for their clients, protecting their digital assets from any danger, has been reinforced by what happened during this CrowdStrike outage
Read more on govindhtech.com
#crowdstrikeoutage#CrowdStrike#cybersecurity#Microsoft#MicrosoftAzure#securityoperationscentre#AWS#news#technews#technology#technologynews#technologytrends#govindhtech
2 notes
·
View notes
Photo
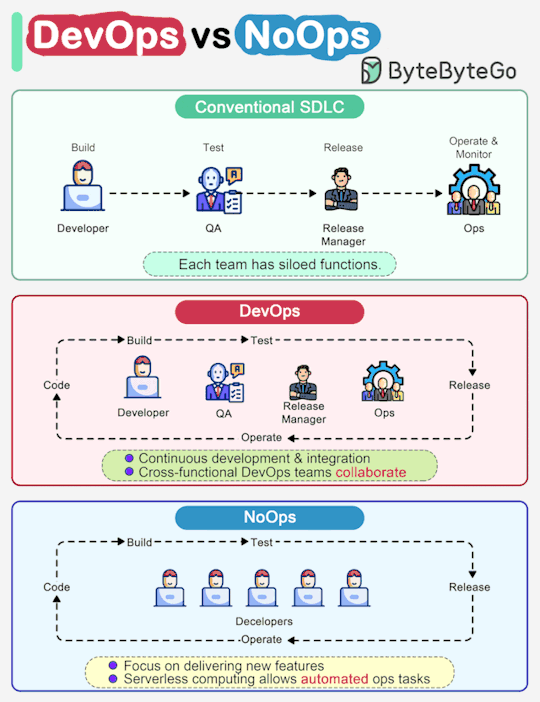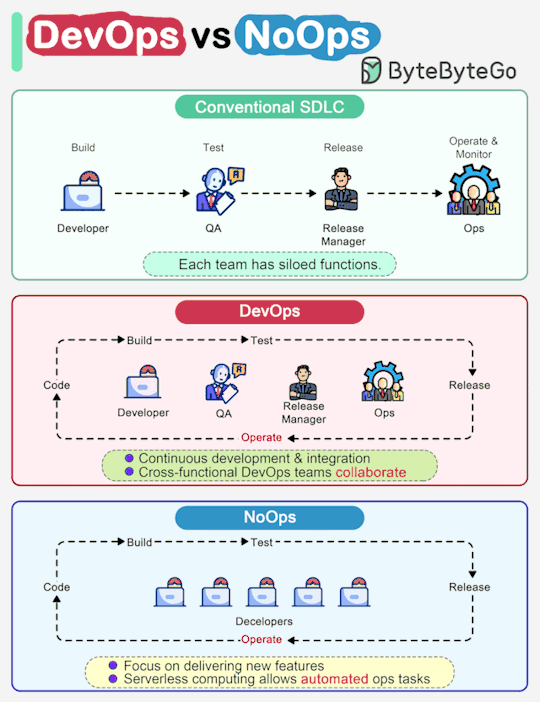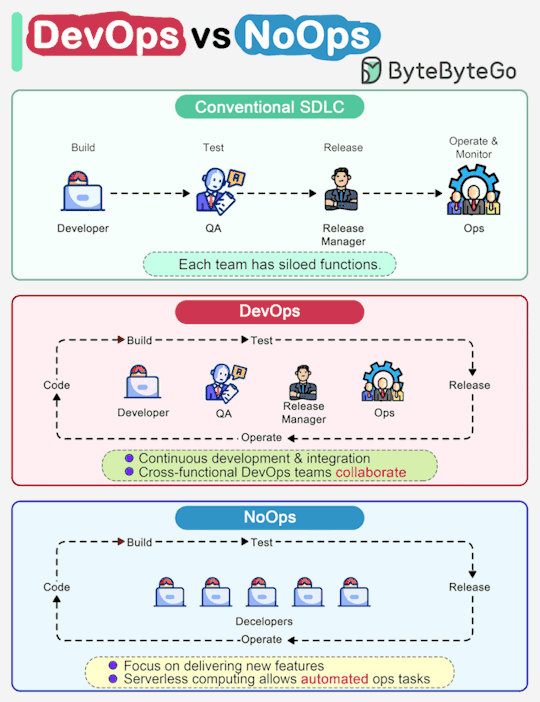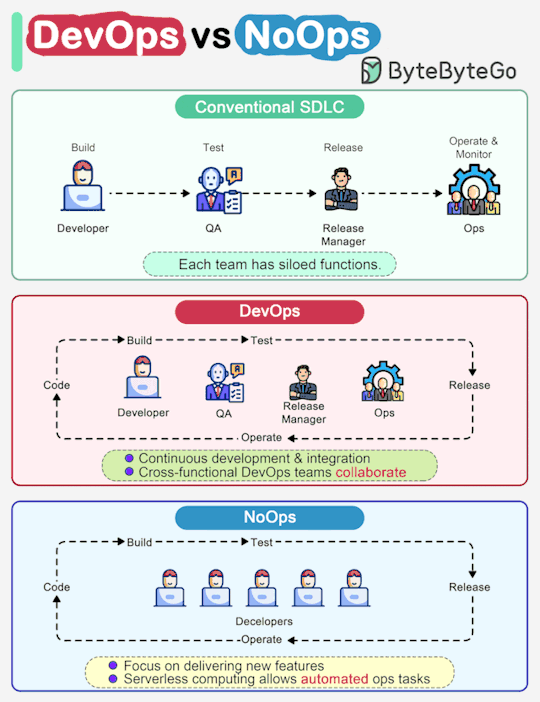
ByteByteGo nails another "a picture is worth a thousand words" infographic. This one highlights some key differences between traditional SDLC, DevOps and emerging NoOps.
In a traditional software development, code, build, test, release and monitoring are siloed functions. Each stage works independently and hands over to the next stage.
DevOps, on the other hand, encourages continuous development and collaboration between developers and operations. This shortens the overall life cycle and provides continuous software delivery.
NoOps is a newer concept with the development of serverless computing. Since we can architect the system using FaaS (Function-as-a-Service) and BaaS (Backend-as-a-Service), the cloud service providers can take care of most operations tasks. The developers can focus on feature development and automate operations tasks.
NoOps is a pragmatic and effective methodology for startups or smaller-scale applications, which moves shortens the SDLC even more than DevOps.
(via EP90: How do SQL Joins Work? - ByteByteGo Newsletter)
5 notes
·
View notes
Text
What Happens To Old War Gear? (Final Effect)
When military-grade weaponry becomes obsolete or is replaced, it is not uncommon to sell it to civilians at a reduced price for defensive purposes. For example, it is not at all unusual to see old war mechs on the frontier being piloted by minors and settlers in outlying colonies. You can even find war mechs whose piloting systems have been replaced by simple AI.
Due to the ever-present threat of the Grimm, and the myriad natural dangers that can be found on planets and in star systems all over the galaxy, civilians need ways to defend themselves. Old war gear offers an affordable solution to that problem since even centuries-old weaponry is still highly effective against most threats.
For example, there are mining colonies where the same war mechs have served as guardians for almost a thousand years. It turns out that being huge, heavily armoured, and armed to the absolute teeth prevents them from becoming completely obsolete despite their age.
One of the oldest such war mechs, an ancient LR-21 model has been in service for roughly fifteen hundred years. Originally designed to offer mobile heavy fire support on the field, the LR-21 is operated by a simple AI. Upgrades to its software and its hardware over the years mean that it has greatly changed from its original load out, but it has also remained an imposing and deadly presence on the battlefield.
For civilians, old war gear is an affordable way of acquiring equipment that is battle tested and ready for use. It's true that there are ample standard options for weaponry and war gear for civilians, but the law places strict limits on what can and cannot be purchased freely. These laws are relaxed somewhat for old war gear although the process of acquiring it does mean more background checks and the like.
You can also find old war gear in the service of the various smaller nations that exist in the galaxy. For instance, many older starships are sold to independent star systems or small factions rather than simply destroyed. These ships are, of course, inferior to those in service with the Empire or the Alliance, but they are nevertheless usually greatly superior to what these other factions could create on their own. They are also cheaper to buy than to construct.
As an aside, this makes coordination with these independent factions easier when Grimm incursions occur since the Empire and Alliance are also familiar with their vessels. This has led to some amusing incidents like two thousand year old ships still seeing combat after a bit of upgrading.
Due to the constant warfare against the Grimm, equipment is generally built to last and to be used as many times as possible before being replaced. At which point, it can then be used as reserve weaponry. Although disposable weapons certainly do exist, the sheer scale of the conflict against the Grimm means that efficient use of resources is key.
The regular sales of old war gear held by the Empire are often likened to yard sales with the Dia-Farron presiding and hawking their wares.
"Hey, you there! You look like you could use an old frigate! It might be three generations old, but it can still dump a thousand missiles on target in less than a minute! I'll even throw in a couple of old war mechs. Anything manages to get past the frigate and make landfall, the war mechs will turn it to ash! Don't think too hard about it. I've got plenty of other people interested, and I've only got four more of these frigates left!"
5 notes
·
View notes
Text
Independent Software Testing Services | Reliable QA by Testers Hub
As an independent software testing company, we help businesses validate their digital products with complete transparency and integrity. Our QA team provides real-time feedback on issues like performance lag, data handling, and integration bugs. With offshore software testing services, we reduce testing costs while maintaining top-tier standards. If you're ready to outsource software testing services, our team is available around the clock to help you detect and resolve problems quickly before your users do.
0 notes
Text
Is Outsourcing the Secret to Reducing Overhead and Increasing Efficiency?
In the relentless pursuit of operational efficiency, companies worldwide are turning to outsourcing as a proven strategy to Reduce Costs while maintaining or enhancing service quality. Outsourcing enables businesses to delegate non-core functions to specialized providers who can perform these tasks more cost-effectively, allowing internal resources to focus on strategic initiatives.
Key Ways Outsourcing Reduces Costs
1. Labor Cost Arbitrage
One of the most significant cost-saving drivers is labor arbitrage. By outsourcing to regions with lower wage rates, companies can access skilled talent at a fraction of the cost compared to their home countries. For example, many Western companies outsource IT support, customer service, and back-office functions to countries like India, the Philippines, or Eastern Europe, achieving substantial savings without compromising quality.
2. Reduced Overhead Expenses
Outsourcing eliminates the need for companies to invest heavily in infrastructure, such as office space, hardware, software licenses, and utilities. Vendors typically have established facilities and technology stacks, spreading these fixed costs across multiple clients, which translates into lower prices for each customer.
3. Conversion of Fixed Costs to Variable Costs
By outsourcing, companies shift from fixed expenses (e.g., salaries, benefits, equipment depreciation) to variable costs that fluctuate with business volume. This flexibility is especially valuable for handling seasonal demand spikes or project-based workloads without the risk of underutilized resources.
4. Increased Efficiency and Productivity
Specialized outsourcing providers bring domain expertise, process optimization, and advanced technologies that improve operational efficiency. Streamlined workflows, automation, and continuous improvement initiatives reduce errors and turnaround times, leading to cost savings.
5. Lower Recruitment and Training Costs
Recruiting, onboarding, and training employees require significant time and financial investment. Outsourcing vendors manage these processes internally, absorbing associated costs and risks. This is particularly beneficial in industries with high turnover or specialized skill requirements.
6. Access to Innovation and Best Practices
Outsourcing partners often serve multiple clients across industries, enabling them to develop and apply best practices, innovative tools, and methodologies that individual companies may find costly to implement independently.
Real-World Examples
A retail company outsourced its customer service operations to a nearshore provider, reducing labor costs by 40% while improving customer satisfaction through multilingual support.
An IT firm delegated software testing to an offshore team, cutting project expenses by 30% and accelerating time-to-market due to round-the-clock development cycles.
A financial services company outsourced back-office processing, eliminating the need for costly infrastructure upgrades and reducing processing errors through vendor expertise.
Considerations to Maximize Cost Reduction
While outsourcing offers clear cost advantages, success depends on effective management:
Vendor Selection: Choose partners with proven track records, transparent pricing, and aligned incentives.
Clear Contracts: Define scope, service levels, and penalties to avoid hidden costs.
Governance: Maintain oversight through regular performance reviews and open communication.
Cultural Fit: Ensure compatibility to minimize misunderstandings and rework.
Continuous Improvement: Collaborate with vendors to identify further efficiency gains.
Potential Pitfalls
Cost savings should not come at the expense of quality or customer experience. Poorly managed outsourcing can lead to:
Hidden costs from scope creep or contract amendments.
Increased rework due to communication gaps.
Damage to brand reputation if customer service suffers.
Balancing cost reduction with quality assurance is critical.
Conclusion
Outsourcing is a powerful lever to Reduce Costs across multiple dimensions, from labor and overhead to process efficiency. When executed strategically, it enables businesses to optimize expenditures, improve agility, and focus on core competencies.
For a comprehensive guide on how outsourcing helps businesses save money and improve operations, explore this insightful article on Reducing Costs.
0 notes