#install MongoDB on amazon ec2
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
What Is Amazon EBS? Features Of Amazon EBS And Pricing

Amazon Elastic Block Store: High-performance, user-friendly block storage at any size
What is Amazon EBS?
Amazon Elastic Block Store provides high-performance, scalable block storage with Amazon EC2 instances. AWS Elastic Block Store can create and manage several block storage resources:
Amazon EBS volumes: Amazon EC2 instances can use Amazon EBS volumes. A volume associated to an instance can be used to install software and store files like a local hard disk.
Amazon EBS snapshots: Amazon EBS snapshots are long-lasting backups of Amazon EBS volumes. You can snapshot Amazon EBS volumes to backup data. Afterwards, you can always restore new volumes from those snapshots.
Advantages of the Amazon Elastic Block Store
Quickly scale
For your most demanding, high-performance workloads, including mission-critical programs like Microsoft, SAP, and Oracle, scale quickly.
Outstanding performance
With high availability features like replication within Availability Zones (AZs) and io2 Block Express volumes’ 99.999% durability, you can guard against failures.
Optimize cost and storage
Decide which storage option best suits your workload. From economical dollar-per-GB to high performance with the best IOPS and throughput, volumes vary widely.
Safeguard
You may encrypt your block storage resources without having to create, manage, and safeguard your own key management system. Set locks on data backups and limit public access to prevent unwanted access to your data.
Easy data security
Amazon EBS Snapshots, a point-in-time copy that can be used to allow disaster recovery, move data across regions and accounts, and enhance backup compliance, can be used to protect block data storage both on-site and in the cloud. With its integration with Amazon Data Lifecycle Manager, AWS further streamlines snapshot lifecycle management by enabling you to establish policies that automate various processes, such as snapshot creation, deletion, retention, and sharing.
How it functions
A high-performance, scalable, and user-friendly block storage solution, Amazon Elastic Block Store was created for Amazon Elastic Compute Cloud (Amazon EC2).Image credit to AWS
Use cases
Create your cloud-based, I/O-intensive, mission-critical apps
Switch to the cloud for mid-range, on-premises storage area network (SAN) applications. Attach block storage that is both high-performance and high-availability for applications that are essential to the mission.
Utilize relational or NoSQL databases
Install and expand the databases of your choosing, such as Oracle, Microsoft SQL Server, PostgreSQL, MySQL, Cassandra, MongoDB, and SAP HANA.
Appropriately scale your big data analytics engines
Detach and reattach volumes effortlessly, and scale clusters for big data analytics engines like Hadoop and Spark with ease.
Features of Amazon EBS
It offers the following features:
Several volume kinds: Amazon EBS offers a variety of volume types that let you maximize storage efficiency and affordability for a wide range of uses. There are two main sorts of volume types: HDD-backed storage for workloads requiring high throughput and SSD-backed storage for transactional workloads.
Scalability: You can build Amazon EBS volumes with the performance and capacity requirements you want. You may adjust performance or dynamically expand capacity using Elastic Volumes operations as your needs change, all without any downtime.
Recovery and backup: Back up the data on your disks using Amazon EBS snapshots. Those snapshots can subsequently be used to transfer data between AWS accounts, AWS Regions, or Availability Zones or to restore volumes instantaneously.
Data protection: Encrypt your Amazon EBS volumes and snapshots using Amazon EBS encryption. To secure data-at-rest and data-in-transit between an instance and its connected volume and subsequent snapshots, encryption procedures are carried out on the servers that house Amazon EC2 instances.
Data availability and durability: io2 Block Express volumes have an annual failure rate of 0.001% and a durability of 99.999%. With a 0.1% to 0.2% yearly failure rate, other volume types offer endurance of 99.8% to 99.9%. To further guard against data loss due to a single component failure, volume data is automatically replicated across several servers in an Availability Zone.
Data archiving: EBS Snapshots Archive provides an affordable storage tier for storing full, point-in-time copies of EBS Snapshots, which you must maintain for a minimum of ninety days in order to comply with regulations. and regulatory purposes, or for upcoming project releases.
Related services
These services are compatible with Amazon EBS:
In the AWS Cloud, Amazon Elastic Compute Cloud lets you start and control virtual machines, or EC2 instances. Like hard drives, EBS volumes may store data and install software.
You can produce and maintain cryptographic keys with AWS Key Management Service, a managed service. Data saved on your Amazon EBS volumes and in your Amazon EBS snapshots can be encrypted using AWS KMS cryptographic keys.
EBS snapshots and AMIs supported by EBS are automatically created, stored, and deleted with Amazon Data Lifecycle Manager, a managed service. Backups of your Amazon EC2 instances and Amazon EBS volumes can be automated with Amazon Data Lifecycle Manager.
EBS direct APIs: These services let you take EBS snapshots, write data to them directly, read data from them, and determine how two snapshots differ or change from one another.
Recycle Bin is a data recovery solution that lets you recover EBS-backed AMIs and mistakenly erased EBS snapshots.
Accessing Amazon EBS
The following interfaces are used to build and manage your Amazon EBS resources:
Amazon EC2 console
A web interface for managing and creating snapshots and volumes.
AWS Command Line Interface
A command-line utility that enables you to use commands in your command-line shell to control Amazon EBS resources. Linux, Mac, and Windows are all compatible.
AWS Tools for PowerShell
A set of PowerShell modules for scripting Amazon EBS resource activities from the command line.
Amazon CloudFormation
It’s a fully managed AWS service that allows you describe your AWS resources using reusable JSON or YAML templates, and then it will provision and setup those resources for you.
Amazon EC2 Query API
The HTTP verbs GET or POST and a query parameter called Action are used in HTTP or HTTPS requests made through the Amazon EC2 Query API.
Amazon SDKs
APIs tailored to particular languages that let you create apps that interface with AWS services. Numerous well-known programming languages have AWS SDKs available.
Amazon EBS Pricing
You just pay for what you provision using Amazon EBS. See Amazon EBS pricing for further details.
Read more on Govindhtech.com
#AmazonEBS#ElasticBlockStore#AmazonEC2#EBSvolumes#EC2instances#EBSSnapshots#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Install MongoDB on AWS EC2 Instances.
Install MongoDB on AWS EC2 Instances.
We will see how to install MongoDB on AWS ec2 Instances, amazon Linux 2 or we can install MongoDB of any version on the AWS Linux 2 server in this article. The Amazon Linux 2 server is the RPM-based server with the 5 years Long Term Support by AWS. (Amazon Web Services). MongoDB is a No-SQL database which is written in C++, It uses a JSON like structure. MongoDB is a cross-platform and…
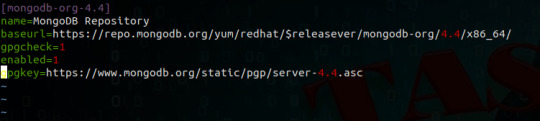
View On WordPress
#aws mongodb service#install mongo shell on amazon linux#install mongodb#install mongodb centos 7#install mongodb centos 8#install MongoDB in AWS ec2 instance#install MongoDB in AWS linux.#install MongoDB on amazon ec2#install MongoDB on amazon linux#install MongoDB on amazon linux AMI#install mongodb on aws#install MongoDB on AWS server#install MongoDB shell amazon linux#mongodb install linux
0 notes
Text
AWS EC2 Instance Setup and Run MongoDB in EC2 | Run MongoDB in EC2 Server
Hello friends, a new #video on #awsec2 #server setup #mongodb installation in #ec2 instance is published on #codeonedigest #youtube channel. Learn #aws #ec2 #mongodb #programming #coding with codeonedigest. #awsec2 #awsec2instance
In this video we will learn amazon EC2 server setup from beginning. Also, install nosql mongo database in EC2 sever. Creating aws linux EC2 instance from AWS management console. Adding firewall rule in the security group to open mongodb port. Login to EC2 instance from local terminal using secret key pair. Download mongo database in EC2 instance. Install Mongo database in EC2…

View On WordPress
0 notes
Text
Big Data Hadoop Training
About Big Data Hadoop Training Certification Training Course
It is an all-inclusive Hadoop Big Data Training Course premeditated by industry specialists considering present industry job necessities to offers exhaustive learning on big data and Hadoop modules. This is an industry recognized Big Data Certification Training course that is known as combination of the training courses in Hadoop developer, Hadoop testing, analytics and Hadoop administrator. This Cloudera Hadoop training will prepare you to clear big data certification.
Big data Hadoop online training program not only prepare applicant with the important and best concepts of Hadoop, but also give the required work experience in Big Data and Hadoop by execution of actual time business projects.
Big Data Hadoop Live Online Classes are being conducted by using professional grade IT Conferencing System from Citrix. All the student canintermingle with the faculty in real-time during the class by having chat and voice. There student need to install a light- weight IT application on their device that could be desktop, laptop, mobile and tablet.
So, whether you are planning to start your career, or you need to leap ahead by mastering advanced software, this course covers all things that is expected of expert Big Data professional. Learn skills that will distinguish you instantly from other Big Data Job seekers with exhaustive coverage of Strom, MongoDB, Spark and Cassandra. Quickly join the institution that is well-known worldwide for its course content, hands-on experience, delivery and market- readiness.
Know about the chief points of our Big Data Hadoop Training Online
The Big Data Hadoop Certification course is specially designed to provide you deep knowledge of the Big Data framework by using the Hadoop and Spark, including HDFS, YARN, and MapReduce. You will come to know how to use Pig, Impala to procedure and analyse large datasets stored in the HDFS, and usage Sqoop and Flume for data absorption along with our big Data training.
With our big data course, you will also able to learn the multiple interactive algorithms in Spark and use Spark SQL for creating, transforming and querying data forms. This is guarantee that you will become master real- time data processing by using Spark, including functional programming in Spark, implementing Spark application, using Spark RDD optimization techniques and understanding parallel processing in Spark.
As a part of big data course, you will be needed to produce real- life business- based projects by using CloudLab in the domains of banking, social media, insurance, telecommuting and e-commerce. This big data Hadoop training course will prepare you for the Cloudera CCA1775 big data certification.
What expertise you will learn with this Big Data Hadoop Training?
Big data Hadoop training will permit you to master the perceptions of the Hadoop framework and its deployment in cluster environment. You would learn to:
Let’s understand the dissimilar components/ features of Hadoop ecosystem such as - HBase, Sqoop, MapReduce, Pig, Hadoop 2.7, Yarn, Hive, Impala, Flume and Apache Spark with this Hadoop course.
· Be prepared to clear the Big Data Hadoop certification
· Work with Avro data formats
· Practice real- life projects by using Hadoop and Apache Spark
· Facility to make you learn Spark, Spark RDD, Graphx, MLlib writing Spark applications
· Detailed understanding of Big data analytics
· Master Hadoop administration activities like cluster,monitoring,managing,troubleshooting and administration
· Master HDFS, MapReduce, Hive, Pig, Oozie, Sqoop, Flume, Zookeeper, HBase
Setting up Pseudo node and Multi node cluster on Amazon EC2
Master fundamentals of Hadoop 2.7 and YARN and write applications using them
Configuring ETL tools like Pentaho/Talend to work with MapReduce, Hive, Pig, etc
Hadoop testing applications using MR Unit and other automation tools.

1 note
·
View note
Text
1 and 1 bitnami mean ssl

1 AND 1 BITNAMI MEAN SSL HOW TO
1 AND 1 BITNAMI MEAN SSL INSTALL
1 AND 1 BITNAMI MEAN SSL UPDATE
Im also looking forward to branching out and trying the Wordpress, Ghost, and Magento stacks as well. 0 5 1 /home/bitnami/letsencrypt/letsencrypt-auto renew sudo /opt/bitnami/ctlscript.sh restart.
1 AND 1 BITNAMI MEAN SSL INSTALL
Do you have any favorite stacks/apps So far, Ive had great success with the Bitnami MEAN stack in AWS. Install Letsencrypt SSL to your Lightsail WordPress.
1 AND 1 BITNAMI MEAN SSL UPDATE
When any security threat or update is identified, Bitnami automatically repackages the applications and pushes the latest versions to the cloud marketplaces. The Bitnami MEAN stack came super handy, because it offered a one-stop solution for deploying my app onto Amazon EC2. The respective trademarks mentioned in the offering are owned by the respective companies, and use of them does not imply any affiliation or endorsement.īitnami certified images are always up-to-date, secure, and built to work right out of the box.īitnami packages applications following industry standards, and continuously monitors all components and libraries for vulnerabilities and application updates. 12 5 1 cd /opt/bitnami/letsencrypt & sudo. Trademarks: This software listing is packaged by Bitnami. I have also set up a cron job with the following (based on your article) added to the crontab. Once inside your Compute Engine, click on the SSH button to connect to your WordPress installation. SSLProtocol all -SSLv2 -SSLv3 -TLSv1 -TLSv1.1. i tried to edit this /opt/bitnami/apache2/conf/bitnami/nf. how can i disable TLS v1.0 and v1.1 and force v1.2 and 1.3. Go to your Compute Engine, then to VM instances to access your WordPress installation. Description: we are using canvas bitnami lms ec2 instance version 2020.12.16.47-1. If your application fulfill these requirements you will be able to deploy several instances of your application working behind a LoadBalancer and with a shared filesystem in just a few minutes. Go to your Google Compute homepage and click the hamburger menu in the upper left-hand corner.
1 AND 1 BITNAMI MEAN SSL HOW TO
For deployment issues, reach out our support team at, it will try to answer any question they receive within 24 hours on working days. This application is an example of how to deploy Node.js applications in high availability mode in the Azure cloud. Learn how to install, configure, and manage it at. This solution is free, ready-to-run, and open source software packaged by Bitnami. It also includes common components and libraries that help to develop modern server applications such as Apache web server, PHP, RockMongo, and Git. It includes SSL auto-configuration with Let's Encrypt certificates, and the latest releases of Javascript components: MongoDB, Express, Angular, and Node.js. Steaming your favorite TV shows, movies or sporting events with MyGica excellent. This image is configured for production environments. 1 Beta 1 Crack & Activator SheetCAM TNG 7. According to the Register: 'Apple said: 'Complete support will be removed from Safari in updates to Apple iOS and macOS beginning in March 2020.' Google has said it will remove support for TLS 1.0 and 1.1 in Chrome 81 (expected on March 17). MEAN gives you the abilty to start building dynamic web applications by providing a complete framework to write your app code. Just another reason to make the switch to TLS 1.2 or 1.3, if you haven't already.
1 note
·
View note
Text
Robo 3t free version

#ROBO 3T FREE VERSION INSTALL#
#ROBO 3T FREE VERSION UPDATE#
Run the script to start the installation process: sudo bash studio-3t-linux-圆4.shĪs you run the script, a GUI Setup will open.
#ROBO 3T FREE VERSION INSTALL#
Now, to see whether the downloaded file is there or not use: lsĪs you are confirmed, the Studio 3T free file is there, extract it first: tar -xvf studio-3t-linux-圆4.tar.gzĪfter extracting the Tar archived file we have downloaded, you will have a script to install Studio 3T free on Ubuntu 22.04 system. Because whatever we download using the browser goes into that. Once you have downloaded the Robot 3T now known as a Studio 3T Free, go to the Downloads directory. Therefore, we have to download it manually from its website. Unfortunately, Studio 3T free version is not available to install using the standard repository of Ubuntu 22.04.
#ROBO 3T FREE VERSION UPDATE#
Open your terminal and run: sudo apt update & sudo apt upgrade This will also rebuild the system’s APT package index. Let’s execute the given command to install the latest available security updates for our system. The steps given here can be used for other versions of Ubuntu such as 20.04 or 18.04 including on Linux such as Debian, Linux Mint, and more… Update Ubuntu 22.04 Steps to install Robo 3T or Studio 3T free on Ubuntu 22.04 Studio 3T free Interface on Ubuntu 22.04.Steps to install Robo 3T or Studio 3T free on Ubuntu 22.04.⇒ Supported cloud platforms are MongoDB Atlas, Compose, mLab, ObjectRocket, ScaleGrid, Amazon EC2 ⇒ Support for SCRAM-SHA-256 auth mechanism ⇒ Support for importing from MongoDB SRV connection strings ⇒ Visual tool helping you manage Database ⇒ Native and cross-platform MongoDB manager It allows CSV, JSON, SQL, and BSON import/export, MongoDB task scheduling, data masking for protection, data schema exploration, real-time code auto-completion, and more. On one hand, the Studio 3T is a paid tool, whereas the Studio 3T Free is a free version with users can build queries using drag and drop functionality, generate driver code in seven languages, break down aggregation queries, plus more. It is also a cross-platform MongoDB GUI management tool available for Windows, macOS, and Linux. Formerly, Robo 3T is known as Robomongo, and now Studio 3T Free. Robo 3T offer MongoDB a GUI interface tool that is maintained and provided by the developers of MongoDB client Studio 3T (paid one with 30 days trial). Tutorial to install Robot 3T or Studio 3T free on Ubuntu 22.04 LTS Jammy JellyFish using the command line to get a Graphical user interfaces for managing your Mongo DB server instance.
0 notes
Text
Migrate an application from using GridFS to using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility)
In many database applications there arises a need to store large objects, such as files, along with application data. A common approach is to store these files inside the database itself, despite the fact that a database isn’t the architecturally best choice for storing large objects. Primarily, because file system APIs are relatively basic (such as list, get, put, and delete), a fully-featured database management system, with its complex query operators, is overkill for this use case. Additionally, large objects compete for resources in an OLTP system, which can negatively impact query workloads. Moreover, purpose-built file systems are often far more cost-effective for this use case than using a database, in terms of storage costs as well as computing costs to support the file system. The natural alternative to storing files in a database is on a purpose-built file system or object store, such as Amazon Simple Storage Service (Amazon S3). You can use Amazon S3 as the location to store files or binary objects (such as PDF files, image files, and large XML documents) that are stored and retrieved as a whole. Amazon S3 provides a serverless service with built-in durability, scalability, and security. You can pair this with a database that stores the metadata for the object along with the Amazon S3 reference. This way, you can query the metadata via the database APIs, and retrieve the file via the Amazon S3 reference stored along with the metadata. Using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility) in this fashion is a common pattern. GridFS is a file system that has been implemented on top of the MongoDB NoSQL database. In this post, I demonstrate how to replace the GridFS file system with Amazon S3. GridFS provides some nonstandard extensions to the typical file system (such as adding searchable metadata for the files) with MongoDB-like APIs, and I further demonstrate how to use Amazon S3 and Amazon DocumentDB to handle these additional use cases. Solution overview For this post, I start with some basic operations against a GridFS file system set up on a MongoDB instance. I demonstrate operations using the Python driver, pymongo, but the same operations exist in other MongoDB client drivers. I use an Amazon Elastic Compute Cloud (Amazon EC2) instance that has MongoDB installed; I log in to this instance and use Python to connect locally. To demonstrate how this can be done with AWS services, I use Amazon S3 and an Amazon DocumentDB cluster for the more advanced use cases. I also use AWS Secrets Manager to store the credentials for logging into Amazon DocumentDB. An AWS CloudFormation template is provided to provision the necessary components. It deploys the following resources: A VPC with three private and one public subnets An Amazon DocumentDB cluster An EC2 instance with the MongoDB tools installed and running A secret in Secrets Manager to store the database credentials Security groups to allow the EC2 instance to communicate with the Amazon DocumentDB cluster The only prerequisite for this template is an EC2 key pair for logging into the EC2 instance. For more information, see Create or import a key pair. The following diagram illustrates the components in the template. This CloudFormation template incurs costs, and you should consult the relevant pricing pages before launching it. Initial setup First, launch the CloudFormation stack using the template. For more information on how to do this via the AWS CloudFormation console or the AWS Command Line Interface (AWS CLI), see Working with stacks. Provide the following inputs for the CloudFormation template: Stack name Instance type for the Amazon DocumentDB cluster (default is db.r5.large) Master username for the Amazon DocumentDB cluster Master password for the Amazon DocumentDB cluster EC2 instance type for the MongoDB database and the machine to use for this example (default: m5.large) EC2 key pair to use to access the EC2 instance SSH location to allow access to the EC2 instance Username to use with MongoDB Password to use with MongoDB After the stack has completed provisioning, I log in to the EC2 instance using my key pair. The hostname for the EC2 instance is reported in the ClientEC2InstancePublicDNS output from the CloudFormation stack. For more information, see Connect to your Linux instance. I use a few simple files for these examples. After I log in to the EC2 instance, I create five sample files as follows: cd /home/ec2-user echo Hello World! > /home/ec2-user/hello.txt echo Bye World! > /home/ec2-user/bye.txt echo Goodbye World! > /home/ec2-user/goodbye.txt echo Bye Bye World! > /home/ec2-user/byebye.txt echo So Long World! > /home/ec2-user/solong.txt Basic operations with GridFS In this section, I walk through some basic operations using GridFS against the MongoDB database running on the EC2 instance. All the following commands for this demonstration are available in a single Python script. Before using it, make sure to replace the username and password to access the MongoDB database with the ones you provided when launching the CloudFormation stack. I use the Python shell. To start the Python shell, run the following code: $ python3 Python 3.7.9 (default, Aug 27 2020, 21:59:41) [GCC 7.3.1 20180712 (Red Hat 7.3.1-9)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> Next, we import a few packages we need: >>> import pymongo >>> import gridfs Next, we connect to the local MongoDB database and create the GridFS object. The CloudFormation template created a MongoDB username and password based on the parameters entered when launching the stack. For this example, I use labdb for the username and labdbpwd for the password, but you should replace those with the parameter values you provided. We use the gridfs database to store the GridFS data and metadata: >>> mongo_client = pymongo.MongoClient(host="localhost") >>> mongo_client["admin"].authenticate(name="labdb", password="labdbpwd") Now that we have connected to MongoDB, we create a few objects. The first, db, represents the MongoDB database we use for our GridFS, namely gridfs. Next, we create a GridFS file system object, fs, that we use to perform GridFS operations. This GridFS object takes as an argument the MongoDB database object that was just created. >>> db = mongo_client.gridfs >>> fs = gridfs.GridFS(db) Now that this setup is complete, list the files in the GridFS file system: >>> print(fs.list()) [] We can see that there are no files in the file system. Next, insert one of the files we created earlier: >>> h = fs.put(open("/home/ec2-user/hello.txt", "rb").read(), filename="hello.txt") This put command returns an ObjectId that identifies the file that was just inserted. I save this ObjectID in the variable h. We can show the value of h as follows: >>> h ObjectId('601b1da5fd4a6815e34d65f5') Now when you list the files, you see the file we just inserted: >>> print(fs.list()) ['hello.txt'] Insert another file that you created earlier and list the files: >>> b = fs.put(open("/home/ec2-user/bye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt', 'hello.txt'] Read the first file you inserted. One way to read the file is by the ObjectId: >>> print(fs.get(h).read()) b'Hello World!n' GridFS also allows searching for files, for example by filename: >>> res = fs.find({"filename": "hello.txt"}) >>> print(res.count()) 1 We can see one file with the name hello.txt. The result is a cursor to iterate over the files that were returned. To get the first file, call the next() method: >>> res0 = res.next() >>> res0.read() b'Hello World!n' Next, delete the hello.txt file. To do this, use the ObjectId of the res0 file object, which is accessible via the _id field: >>> fs.delete(res0._id) >>> print(fs.list()) ['bye.txt'] Only one file is now in the file system. Next, overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = fs.put(open("/home/ec2-user/goodbye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt'] This overwrite doesn’t actually delete the previous version. GridFS is a versioned file system and keeps older versions unless you specifically delete them. So, when we find the files based on the bye.txt, we see two files: >>> res = fs.find({"filename": "bye.txt"}) >>> print(res.count()) 2 GridFS allows us to get specific versions of the file, via the get_version() method. By default, this returns the most recent version. Versions are numbered in a one-up counted way, starting at 0. So we can access the original version by specifying version 0. We can also access the most recent version by specifying version -1. First, the default, most recent version: >>> x = fs.get_version(filename="bye.txt") >>> print(x.read()) b'Goodbye World!n' Next, the first version: >>> x0 = fs.get_version(filename="bye.txt", version=0) >>> print(x0.read()) b'Bye World!n' The following code is the second version: >>> x1 = fs.get_version(filename="bye.txt", version=1) >>> print(x1.read()) b'Goodbye World!n' The following code is the latest version, which is the same as not providing a version, as we saw earlier: >>> xlatest = fs.get_version(filename="bye.txt", version=-1) >>> print(xlatest.read()) b'Goodbye World!n' An interesting feature of GridFS is the ability to attach metadata to the files. The API allows for adding any keys and values as part of the put() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = fs.put(open("/home/ec2-user/byebye.txt", "rb").read(), filename="bye.txt", somekey="somevalue") >>> c = fs.get_version(filename="bye.txt") >>> print(c.read()) b'Bye Bye World!n' We can access the custom metadata as a field of the file: >>> print(c.somekey) somevalue Now that we have the metadata attached to the file, we can search for files with specific metadata: >>> sk0 = fs.find({"somekey": "somevalue"}).next() We can retrieve the value for the key somekey from the following result: >>> print(sk0.somekey) somevalue We can also return multiple documents via this approach. In the following code, we insert another file with the somekey attribute, and then we can see that two files have the somekey attribute defined: >>> h = fs.put(open("/home/ec2-user/solong.txt", "rb").read(), filename="solong.txt", somekey="someothervalue", key2="value2") >>> print(fs.find({"somekey": {"$exists": True}}).count()) 2 Basic operations with Amazon S3 In this section, I show how to get the equivalent functionality of GridFS using Amazon S3. There are some subtle differences in terms of unique identifiers and the shape of the returned objects, so it’s not a drop-in replacement for GridFS. However, the major functionality of GridFS is covered by the Amazon S3 APIs. I walk through the same operations as in the previous section, except using Amazon S3 instead of GridFs. First, we create an S3 bucket to store the files. For this example, I use the bucket named blog-gridfs. You need to choose a different name for your bucket, because bucket names are globally unique. For this demonstration, we want to also enable versioning for this bucket. This allows Amazon S3 to behave similarly as GridFS with respect to versioning files. As with the previous section, the following commands are included in a single Python script, but I walk through these commands one by one. Before using the script, make sure to replace the secret name with the one created by the CloudFormation stack, as well as the Region you’re using, and the S3 bucket you created. First, we import a few packages we need: >>> import boto3 Next, we connect to Amazon S3 and create the S3 client: session = boto3.Session() s3_client = session.client('s3') It’s convenient to store the name of the bucket we created in a variable. Set the bucket variable appropriately: >>> bucket = "blog-gridfs" Now that this setup is complete, we list the files in the S3 bucket: >>> s3_client.list_objects(Bucket=bucket) {'ResponseMetadata': {'RequestId': '031B62AE7E916762', 'HostId': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'x-amz-request-id': '031B62AE7E916762', 'date': 'Wed, 03 Feb 2021 22:37:12 GMT', 'x-amz-bucket-region': 'us-east-1', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'IsTruncated': False, 'Marker': '', 'Name': 'blog-gridfs', 'Prefix': '', 'MaxKeys': 1000, 'EncodingType': 'url'} The output is more verbose, but we’re most interested in the Contents field, which is an array of objects. In this example, it’s absent, denoting an empty bucket. Next, insert one of the files we created earlier: >>> h = s3_client.put_object(Body=open("/home/ec2-user/hello.txt", "rb").read(), Bucket=bucket, Key="hello.txt") This put_object command takes three parameters: Body – The bytes to write Bucket – The name of the bucket to upload to Key – The file name The key can be more than just a file name, but can also include subdirectories, such as subdir/hello.txt. The put_object command returns information acknowledging the successful insertion of the file, including the VersionId: >>> h {'ResponseMetadata': {'RequestId': 'EDFD20568177DD45', 'HostId': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'x-amz-request-id': 'EDFD20568177DD45', 'date': 'Wed, 03 Feb 2021 22:39:19 GMT', 'x-amz-version-id': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab', 'etag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'ETag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'VersionId': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab'} Now if we list the files, we see the file we just inserted: >>> list = s3_client.list_objects(Bucket=bucket) >>> print([i["Key"] for i in list["Contents"]]) ['hello.txt'] Next, insert the other file we created earlier and list the files: >>> b = s3_client.put_object(Body=open("/home/ec2-user/bye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt', 'hello.txt'] Read the first file. In Amazon S3, use the bucket and key to get the object. The Body field is a streaming object that can be read to retrieve the contents of the object: >>> s3_client.get_object(Bucket=bucket, Key="hello.txt")["Body"].read() b'Hello World!n' Similar to GridFS, Amazon S3 also allows you to search for files by file name. In the Amazon S3 API, you can specify a prefix that is used to match against the key for the objects: >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket, Prefix="hello.txt")["Contents"]]) ['hello.txt'] We can see one file with the name hello.txt. Next, delete the hello.txt file. To do this, we use the bucket and file name, or key: >>> s3_client.delete_object(Bucket=bucket, Key="hello.txt") {'ResponseMetadata': {'RequestId': '56C082A6A85F5036', 'HostId': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'HTTPStatusCode': 204, 'HTTPHeaders': {'x-amz-id-2': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'x-amz-request-id': '56C082A6A85F5036', 'date': 'Wed, 03 Feb 2021 22:45:57 GMT', 'x-amz-version-id': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd', 'x-amz-delete-marker': 'true', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'DeleteMarker': True, 'VersionId': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd'} >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] The bucket now only contains one file. Let’s overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = s3_client.put_object(Body=open("/home/ec2-user/goodbye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] Similar to GridFS, with versioning turned on in Amazon S3, an overwrite doesn’t actually delete the previous version. Amazon S3 keeps older versions unless you specifically delete them. So, when we list the versions of the bye.txt object, we see two files: >>> y = s3_client.list_object_versions(Bucket=bucket, Prefix="bye.txt") >>> versions = sorted([(i["Key"],i["VersionId"],i["LastModified"]) for i in y["Versions"]], key=lambda y: y[2]) >>> print(len(versions)) 2 As with GridFS, Amazon S3 allows us to get specific versions of the file, via the get_object() method. By default, this returns the most recent version. Unlike GridFS, versions in Amazon S3 are identified with a unique identifier, VersionId, not a counter. We can get the versions of the object and sort them based on their LastModified field. We can access the original version by specifying the VersionId of the first element in the sorted list. We can also access the most recent version by not specifying a VersionId: >>> x0 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[0][1]) >>> print(x0["Body"].read()) b'Bye World!n' >>> x1 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[1][1]) >>> print(x1["Body"].read()) b'Goodbye World!n' >>> xlatest = s3_client.get_object(Bucket=bucket, Key="bye.txt") >>> print(xlatest["Body"].read()) b'Goodbye World!n' Similar to GridFS, Amazon S3 provides the ability to attach metadata to the files. The API allows for adding any keys and values as part of the Metadata field in the put_object() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = s3_client.put_object(Body=open("/home/ec2-user/byebye.txt", "rb").read(), Bucket=bucket, Key="bye.txt", Metadata={"somekey": "somevalue"}) >>> c = s3_client.get_object(Bucket=bucket, Key="bye.txt") We can access the custom metadata via the Metadata field: >>> print(c["Metadata"]["somekey"]) somevalue We can also print the contents of the file: >>> print(c["Body"].read()) b'Bye Bye World!n' One limitation with Amazon S3 versus GridFS is that you can’t search for objects based on the metadata. To accomplish this use case, we employ Amazon DocumentDB. Use cases with Amazon S3 and Amazon DocumentDB Some use cases may require you to find objects or files based on the metadata, beyond just the file name. For example, in an asset management use case, we may want to record the author or a list of keywords. To do this, we can use Amazon S3 and Amazon DocumentDB to provide a very similar developer experience, but leveraging the power of a purpose-built document database and a purpose-built object store. In this section, I walk through how to use these two services to cover the additional use case of needing to find files based on the metadata. First, we import a few packages: >>> import json >>> import pymongo >>> import boto3 We use the credentials that we created when we launched the CloudFormation stack. These credentials were stored in Secrets Manager. The name of the secret is the name of the stack that you used to create the stack (for this post, docdb-mongo), with -DocDBSecret appended to docdb-mongo-DocDBSecret. We assign this to a variable. You should use the appropriate Secrets Manager secret name for your stack: >>> secret_name = 'docdb-mongo-DocDBSecret' Next, we create a Secrets Manager client and retrieve the secret. Make sure to set the Region variable with the Region in which you deployed the stack: >>> secret_client = session.client(service_name='secretsmanager', region_name=region) >>> secret = json.loads(secret_client.get_secret_value(SecretId=secret_name)['SecretString']) This secret contains the four pieces of information that we need to connect to the Amazon DocumentDB cluster: Cluster endpoint Port Username Password Next we connect to the Amazon DocumentDB cluster: >>> docdb_client = pymongo.MongoClient(host=secret["host"], port=secret["port"], ssl=True, ssl_ca_certs="/home/ec2-user/rds-combined-ca-bundle.pem", replicaSet='rs0', connect = True) >>> docdb_client["admin"].authenticate(name=secret["username"], password=secret["password"]) True We use the database fs and the collection files to store our file metadata: >>> docdb_db = docdb_client["fs"] >>> docdb_coll = docdb_db["files"] Because we already have data in the S3 bucket, we create entries in the Amazon DocumentDB collection for those files. The information we store is analogous to the information in the GridFS fs.files collection, namely the following: bucket – The S3 bucket filename – The S3 key version – The S3 VersionId length – The file length in bytes uploadDate – The S3 LastModified date Additionally, any metadata that was stored with the objects in Amazon S3 is also added to the document in Amazon DocumentDB: >>> for ver in s3_client.list_object_versions(Bucket=bucket)["Versions"]: ... obj = s3_client.get_object(Bucket=bucket, Key=ver["Key"], VersionId=ver["VersionId"]) ... to_insert = {"bucket": bucket, "filename": ver["Key"], "version": ver["VersionId"], "length": obj["ContentLength"], "uploadDate": obj["LastModified"]} ... to_insert.update(obj["Metadata"]) ... docdb_coll.insert_one(to_insert) ... Now we can find files by their metadata: >>> sk0 = docdb_coll.find({"somekey": "somevalue"}).next() >>> print(sk0["somekey"]) somevalue To read the file itself, we can use the bucket, file name, and version to retrieve the object from Amazon S3: >>> print(s3_client.get_object(Bucket=sk0["bucket"], Key=sk0["filename"], VersionId=sk0["version"])["Body"].read()) b'Bye Bye World!n' Now we can put another file with additional metadata. To do this, we write the file to Amazon S3 and insert the metadata into Amazon DocumentDB: >>> h = s3_client.put_object(Body=open("/home/ec2-user/solong.txt", "rb").read(), Bucket=bucket, Key="solong.txt") >>> docdb_coll.insert_one({"bucket": bucket, "filename": "solong.txt", "version": h["VersionId"], "somekey": "someothervalue", "key2": "value2"}) Finally, we can search for files with somekey defined, as we did with GridFS, and see that two files match: >>> print(docdb_coll.find({"somekey": {"$exists": True}}).count()) 2 Clean up You can delete the resources created in this post by deleting the stack via the AWS CloudFormation console or the AWS CLI. Conclusion Storing large objects inside a database is typically not the best architectural choice. Instead, coupling a distributed object store, such as Amazon S3, with the database provides a more architecturally sound solution. Storing the metadata in the database and a reference to the location of the object in the object store allows for efficient query and retrieval operations, while reducing the strain on the database for serving object storage operations. In this post, I demonstrated how to use Amazon S3 and Amazon DocumentDB in place of MongoDB’s GridFS. I leveraged Amazon S3’s purpose-built object store and Amazon DocumentDB, a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. For more information about recent launches and blog posts, see Amazon DocumentDB (with MongoDB compatibility) resources. About the author Brian Hess is a Senior Solution Architect Specialist for Amazon DocumentDB (with MongoDB compatibility) at AWS. He has been in the data and analytics space for over 20 years and has extensive experience with relational and NoSQL databases. https://aws.amazon.com/blogs/database/migrate-an-application-from-using-gridfs-to-using-amazon-s3-and-amazon-documentdb-with-mongodb-compatibility/
0 notes
Link
Create & Deploy High Performance Node JS Apps on the Cloud and More !
What you’ll learn
Build High Performance and Scalable Apps using NodeJS
Learn about ES6 with my free eBook – ECMAScript 6 QuickBytes
Use NodeJS Streams to write a Web Server
Use the Node Package Manager (NPM) for managing dependencies
Use the Express 4 Framework for building NodeJS Apps
Use the EJS templating language
Understand MongoDB as a NoSQL Database
Create & Use MongoDB Databases using services like MongoLab
Create Realtime Apps that use Web Sockets
Upload & Resize Images using NodeJS
Integrate Authentication using Social Media Sites like Facebook
Structure the NodeJS app into modules
Create and Deploy EC2 Cloud Server Instances on Amazon Web Services
Create and Use Amazon’s S3 Storage Service with NodeJS
Use Amazon’s Cloudfront Service
Using Amazon’s Elastic IP
Configure Security Groups, Ports & Forwarding on Amazon EC2
Deploy a NodeJS app on the EC2 Instance
Deploy a NodeJS app on Heroku
Deploy a NodeJS app on Digital Ocean
Install & Deploy NGINX as a Reverse Proxy Server for NodeJS Apps
Configure NGINX as a Load Balancer
Learn about Enterprise Integration
Create an app using the incredible Hapi framework
Learn more about logging using the Hapi framework
Learn to use ES6 with Nodejs
Install & Deploy Apache Apollo MQ with Nodejs and a Python Script
Requirements
Working knowledge of HTML, CSS and Javascript
Basic Working knowledge of an image editing application such as Adobe Photoshop would also help, but is not necessarily needed.
Description
About this Course
NodeJS is a platform that allows developers to write server side high performance and networked applications. And that too using good old Javascript. But wait ! Isn’t Javascript meant to be used for forms and stuff on web pages ?
Well that was 10 years ago. The world has gone from ‘Oops! You’ve not filled up the form properly !’ days to today’s modern web apps and social media sites that rely heavily on Javascript. Google Apps, Facebook, Twitter, Google Plus and LinkedIn, being handful examples of this movement. And to think that this quantum leap would not have been possible without Javascript is not an overstatement. Today, when you socialize with your friends on Facebook, or use your Gmail inbox, you’re running thousands of lines of code written in Javascript, in your browser.
With Node JS, you can take this knowledge back on the server, where usually you would expect to see the likes of PHP, Ruby, ASP dot NET etc. But that’s only a small portion of the reason why NodeJS is so cool. The fact that you can write full blown networked applications (think chat servers, collaborative tools, real-time data visualisation apps) with just a few lines of code is more than reason enough to not only look at NodeJS, but deep dive into it !
But I know PHP ? Why should I learn NodeJS ? Well, for starters, learning something new never hurts. But most importantly, learning NodeJS is great because :
Node allows you to write highly scalable networked apps deployed on the cloud !
You’re working at a different level of application design per se with Node and that means that you’re not writing an app that sits on top of a stack, you design the stack from the server up. And while that may sound daunting, it really is not and you’ll see why.
You code in the same language, both on the server and on the front end ! We’re all polyglots (we use multiple programming languages and syntax in most of our projects), but managing code in the same language on the back-end and the front-end never hurts and in-fact can be a huge time saver when debugging.
NodeJS is used by the likes of LinkedIn, Yahoo and Microsoft to name a few. Its pretty new and consequently you gain advantage from the exponentially growing community of NodeJS & Javascript developers and that’s great fun, really !
If you’ve been coding in Javascript, you can leverage your existing knowledge and skills and take it to a whole new level !
The Real Problem
So, NodeJS sounds pretty interesting so far, but what really hit me in the face when I was learning all about Node was the fact that, with any new platform, framework or technology, you need to take baby steps, all the way through, to making real world examples, if you have to get to the grips of it. And that leads us to why you’re here.
In this course, we’ll go from absolute scratch, all the way up to building and deploying full blown NodeJS app on the Cloud !
Project Oriented Learning
With NodeJS, we will build two full blown apps. We will go all the from concept creation, UI/UX design to coding and deploying our app on the cloud.
A. ChatCAT – One of the fun things that you can do with NodeJS is build realtime apps that allow a high number of concurrent users to interact with each other. Examples of this kind include Chat Servers, Gaming Servers, Collaborative Tools etc. We will build a multi-room chat server that allows users to login via Facebook, Create Chatrooms of their choice and Chat in realtime. We will not only create this app, but also deploy it on Heroku and Digital Ocean !
You will learn all about using Websockets, Structuring your App in an efficient manner, creating and using development & production configurations, Authentication using Facebook, Setting up an App on Facebook, Managing Sessions, Querying & Using a Hosted MongoDB Database, Using Heroku & Digital Ocean’s Cloud Services and lots more…
B. PhotoGRID – The second complete app that we will build in this course is a Photo Gallery app which lets users upload images into a gallery with the ability to vote up the images that they like. This NodeJS app lets users upload files, which are then resized to thumbnails on the server and stored in an Amazon S3 Bucket for optimal delivery to the front end interface. The entire app runs on an Amazon EC2 Cloud Server which we will create from scratch and configure for use.
You will learn about managing file uploads using NodeJS & AJAX, Resizing Images on the Server, Accessing & Storing files in an S3 Bucket, Querying & Using a Hosted MongoDB Database, Using Amazon’s Elastic IP Service & Cloudfront distribution, ensuring your NodeJS app runs automatically even if the server is restarted and lots more…
In the projects above, we leave no stone unturned in terms of execution. This is a complete hands-on course that is not just limited to NodeJS but to the ecosystem that needs attention when a NodeJS app is built and deployed. My intent is hand hold you all the way from writing your first app to deploying production level apps on the cloud.
And I’m always available to personally help you out, should you get stuck.
BONUS :: Here’s the best thing about this course. The curriculum that you see gets you up and running with NodeJS & Cloud Deployment. However, there is so much more that you can do with NodeJS, which is why I will keep adding new lectures and sections to this course on an ongoing basis. There is so much more that you will get with full lifetime access to lectures and all updates !!
So, join in the fun !
Who this course is for:
Understand the inner workings of NodeJS
Web Designers & Front End Developers who wish to extend their knowledge of Javascript for building high performance network applications.
Software Developers who want to build high performance network applications.
Absolute beginners with basic knowledge of HTML, CSS and Javascript, wanting to upgrade to professional Web Development and Building Web Apps.
Anyone who wishes to get hands-on training with setting up an Amazon EC2 Instance with a host of other services like Cloudfront, Elastic IP and S3
Anyone who wishes to get hands-on training with deploying a NodeJS app on the cloud
Computer Engineering students
Tech Entrepreneurs who want to get their hands down and dirty with Web Coding & App Development.
Anyone who wishes to stay on the forefront of technology !
PHP, ASPnet, Perl, Java & Ruby coders wanting to leap onto the NodeJs bandwagon.
Created by Sachin Bhatnagar Last updated 8/2019 English English [Auto-generated]
Size: 2.80 GB
Download Now
https://ift.tt/366Brt1.
The post All about NodeJS appeared first on Free Course Lab.
0 notes
Text
Install MongoDB on EC2( Amazon Linux 2)
Install MongoDB on EC2( Amazon Linux 2)
This tutorial explains, How to Install MongoDB on EC2 (Amazon Linux 2)
MongoDB is an opensource NoSQL database that keeps data as Jason-like structure, unlike SQL database that stores data in table structure.
Also Read: How to install Anaconda on Linux
&& 15 Important PostgreSQL commands you must know
Install MongoDB on Ubuntu using Yum
Step 1– Update Amazon Linux 2
$ yum update -y
Step 2…
View On WordPress
0 notes
Text
Steps to Install MongoDB on Amazon Linux
In this tutorial, we will explain steps to install MongoDB on Amazon Linux. Before starting with the tutorials lets see what are the dependency to install MongoDB on Amazon Linux.
Prerequisites to Install MongoDB on EC2 Amazon Linux
You must have an EC2 instance running with Amazon Linux
Need root/sudo access to this EC2 instance.
These below steps support for EC2 Amazon Linux:
Amazon Linux 2
Ama…
View On WordPress
0 notes
Text
Mathew James - Technical Director
Address:
Registered Office, Three Gables, Cornerhall
Hemel Hempstead, Hertfordshire
HP3 9HN
Phone:
0330 113 6457
Business Email:
Url of business:
https://www.iteverywhere.co.uk
Keywords or tags:
IT Everywhere | Web design company and digital marketing agency, providing affordable professional digital services in web design, mobile apps, online marketing, brand development in Hertfordshire, Buckinghamshire, Bedfordshire, Lincolnshire, Warwickshire, London, PHP, WordPress, Drupal, CakePHP, Magento, PrestaShop, oscommerce, opencart, zencart, cubecart, JAVA, J2EE, JSP, JDBC, MVC, C# .Net, VB, XML, XSLT, Webservices, WSDL, SOAP, JSON, RESTful, HTML 5, CSS3, HTML, XHTML, Java Script, JQuery, Adobe Photoshop, Adobe illustrator, Databases: SQL, MySQL, SQL Server 2005/2008, Oracle 11g, Stored procedures, MongoDB, Amazon Aurora, Payment Gateways: Worldpay, Verifone, Sagepay, Stripe, Amazon pay, Go Cardless, Paypal, TNSI, Servers: Apache, Tomcat, JBOSS, Server Management: Server deployments, installing and configuring VPS servers, Centos, Ubuntu, Debian, AWS, EC2, S3, Route53, Email servers, Postifx, DNS Servers, VMWare, Vsphere and Virtual Box
Description:
Web design company and digital marketing agency, providing affordable professional digital services in web design, mobile apps, online marketing, brand development.
Year Found:
2013
Number of Employee:
10-15
0 notes
Link
About Big Data Hadoop Training Certification Training Course
It is an all-inclusive Hadoop Big Data Training Course premeditated by industry specialists considering present industry job necessities to offers exhaustive learning on big data and Hadoop modules. This is an industry recognized Big Data Hadoop Certification Training course that is known as combination of the training courses in Hadoop developer, Hadoop testing, analytics and Hadoop administrator. This Cloud era Hadoop training will prepare you to clear big data certification.
Big data Hadoop online training program not only prepare applicant with the important and best concepts of Hadoop, but also give the required work experience in Big Data and Hadoop by execution of actual time business projects.
Big Data Hadoop Online Classes are being conducted by using professional grade IT Conferencing System from Citrix. All the student can intermingle with the faculty in real-time during the class by having chat and voice. There student need to install a light- weight IT application on their device that could be desktop, laptop, mobile and tablet.
So, whether you are planning to start your career, or you need to leap ahead by mastering advanced software, this course covers all things that is expected of expert Big Data professional. Learn skills that will distinguish you instantly from other Big Data Job seekers with exhaustive coverage of Strom, MongoDB, Spark and Cassandra. Quickly join the institution that is well-known worldwide for its course content, hands-on experience, delivery and market- readiness.
Know about the chief points of our Big Data Hadoop Training Online
The Big Data Hadoop Certification course is specially designed to provide you deep knowledge of the Big Data framework by using the Hadoop and Spark, including HDFS, YARN, and MapReduce. You will come to know how to use Pig, Impala to procedure and analyse large datasets stored in the HDFS, and usage Sqoop and Flume for data absorption along with our big Data training.
With our big data course, you will also able to learn the multiple interactive algorithms in Spark and use Spark SQL for creating, transforming and querying data forms. This is guarantee that you will become master real- time data processing by using Spark, including functional programming in Spark, implementing Spark application, using Spark RDD optimization techniques and understanding parallel processing in Spark.
As a part of big data course, you will be needed to produce real- life business- based projects by using Cloud Lab in the domains of banking, social media, insurance, telecommuting and e-commerce. This big data Hadoop training course will prepare you for the Cloud era CCA1775 big data certification.
What expertise you will learn with this Big Data Hadoop Training?
Big data Hadoop training will permit you to master the perceptions of the Hadoop framework and its deployment in cluster environment. You would learn to:
Let’s understand the dissimilar components/ features of Hadoop ecosystem such as - HBase, Sqoop, MapReduce, Pig, Hadoop 2.7, Yarn, Hive, Impala, Flume and Apache Spark with this Hadoop course.
· Be prepared to clear the Big Data Hadoop certification
· Work with Avro data formats
· Practice real- life projects by using Hadoop and Apache Spark
· Facility to make you learn Spark, Spark RDD, Graphx, MLlib writing Spark applications
· Detailed understanding of Big data analytics
· Master Hadoop administration activities like cluster,monitoring,managing,troubleshooting and administration
· Master HDFS, MapReduce, Hive, Pig, Oozie, Sqoop, Flume, Zookeeper, HBase
Setting up Pseudo node and Multi node cluster on Amazon EC2
Master fundamentals of Hadoop 2.7 and YARN and write applications using them
Configuring ETL tools like Pentaho/Talend to work with MapReduce, Hive, Pig, etc
Hadoop testing applications using MR Unit and other automation tools.
0 notes
Text
@AWS Cloudformation pass parameters from pull down menu to UserData.
Declaring the Ref s and Mapping Findinmap in CloudFormation which can be used in userdata on your EC2 server (maybe others too) Almost 20 hours of learning and making mistakes
I have been working on making a Multi Region Replicated MongoDB with Oneclick installation via AWS Marketplace. I go the script working. Now I need Amazonize it so it can be launched without having to spend 2 weeks…
View On WordPress
0 notes
Photo

Top 5 PaaS Solutions for Developing Java Applications
Platform as a service (PaaS) is a cloud computing model allowing developers to build and deliver applications over the internet without bothering about the complexity of maintaining the infrastructure usually associated with developing and operating them. Developers can easily access and administer PaaS via a web browser but some have IDE plugins to make using them even simpler.
More elaborately, PaaS is like booking an Uber: You get in and choose your destination and the route you want to get there. How to keep the car running and figuring out the details is up to Uber's driver. Infrastructure as a Service (IaaS), on the other hand, is like renting a car: Driving, fueling (setting it up, maintaining software, etc.), is your job but getting it repaired is someone's else problem.
In case you prefer the IaaS model have a look at this article about the top 5 IaaS solutions for hosting Java applications.
Why use PaaS?
PaaS is a cloud application platform that runs on top of IaaS and host software as a service application. PaaS comprises of operating systems, middleware, servers, storage, runtime, virtualization and other software that allows applications to run in the cloud with many of the system administration abstracted away. This allows organizations to focus on two important things, their customers and their code. PaaS takes care of all the system administration details of setting up servers and VMs, installing runtimes, libraries, middleware, configuring build and testing tools. The workflow in PaaS is as simple as coding in the IDE and then pushing the code using tools like Git and seeing the changes live immediately.
By delivering infrastructure as a service, PaaS also offers the same advantages as IaaS but with additional features of development tools.
Better Coding time: As PaaS provides development tools with pre-coded application components, time to code a new app is reduced.
Dynamic allocation: In today's competitive world, most of the IT teams need to have the flexibility of deploying a new feature or a new service of an application for quick testing or to test these on a small section of clients before making them available to the entire world. With PaaS, such tasks have now become possible.
Develop cross-platform apps easily: PaaS service providers give us various development options for different platforms like computers, mobile devices, and tablets, making cross-platform apps easier and quicker to develop.
Support geographically: It is useful in situations where multiple developers are working on a single project but are not located nearby.
Use helpful tools affordable: Pay-as-you-go method allows you to be charged for what you use. Thus one can use necessary software or analytical tools as per their requirement. It provides support for complete web application lifecycle: building, testing, deploying, managing and updating.
Iaas offers storage and infrastructure resources required to deliver to cloud services whereas organizations using PaaS don’t have to worry about infrastructure nor for services like software updates, storage, operating systems, load balancing, etc. IaaS can be used by organizations which need complete control over their high performing applications, startups and small companies with time & energy constraint, growing organizations which do not want to commit to hardware/software resources, applications which see volatile demands – were scaling up or down is critical based on traffic spikes or valleys.
PaaS for Java is well suited as the JVM, the application server, and deployment archives, i.e., WARs or EARs provide natural isolations for Java applications, allowing many developers to deploy applications in the same infrastructure. As a Java developer, we should keep the following points in mind before choosing a PaaS service:
the flexibility of choosing your application server like JBoss, Tomcat, etc
able to control JVM tuning, i.e., GC tuning
able to plug-in your choice of the stack like MongoDB, MySQL, Redis, etc
the proper logging facility
In this article, we are going compare five PaaS service providers; AWS's Elastic Beanstalk, Heroku, IBM's Bluemix, RedHat's OpenShift and Google App Engine from the view of a Java developer.
Amazon's Elastic Beanstalk
Elastic Beanstalk allows users to create, push and manage web applications in the Amazon Web Services (AWS) console. With Elastic Beanstalk, just upload your code and it automatically handles the deployment, provisioning of a load balancer and the deployment of your WAR file to one or more EC2 instances running the Apache Tomcat application server. Also, you continue to have full control over the AWS resources powering your application.
There is no additional charge for Elastic Beanstalk. It follows Pay-as-you-go model for the AWS resources needed to store and run your applications. Users who are eligible for AWS free usage tier can use it for free.
Here you can get started with Java application on AWS. Once you package your code into a standard Java Web Application Archive (WAR file), you can upload it to Elastic Beanstalk using the AWS Management Console, the AWS Toolkit for Eclipse or any other command line tools. This toolkit is an open source plug-in and offers you to manage AWS resources with your applications and environments from within Eclipse. It has built-in CloudWatch monitoring metrics such as average CPU utilization, request count, and average latency that you can measure once the application is running. Through its Amazon Simple Notification Service, you can receive emails whenever there is any change in the application.
A downside of Elastic Beanstalk can be the lack of clear documentation. There are no release notes, blogs, or forum posts for new stack upgrades.
A Few users of Elastic Beanstalk are Amazon Corporate LLC, RetailMeNot Inc, Vevo LLC, Credible Labs Inc., and Geofeedia Inc..
Heroku
Continue reading %Top 5 PaaS Solutions for Developing Java Applications%
by Ipseeta via SitePoint http://ift.tt/2plC5At
0 notes
Text
Amazon DocumentDB (with MongoDB compatibility) read autoscaling
Amazon Document DB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. Its architecture supports up to 15 read replicas, so applications that connect as a replica set can use driver read preference settings to direct reads to replicas for horizontal read scaling. Moreover, as read replicas are added or removed, the drivers adjust to automatically spread the load over the current read replicas, allowing for seamless scaling. Amazon DocumentDB separates storage and compute, so adding and removing read replicas is fast and easy regardless of how much data is stored in the cluster. Unlike other distributed databases, you don’t need to copy data to new read replicas. Although you can use the Amazon DocumentDB console, API, or AWS Command Line Interface (AWS CLI) to add and remove read replicas manually, it’s possible to automatically change the number of read replicas to adapt to changing workloads. In this post, I describe how to use Application Auto Scaling to automatically add or remove read replicas based on cluster load. I also demonstrate how this system works by modifying the load on a cluster and observing how the number of read replicas change. The process includes three steps: Deploy an Amazon DocumentDB cluster and required autoscaling resources. Generate load on the Amazon DocumentDB cluster to trigger a scaling event. Monitor cluster performance as read scaling occurs. Solution overview Application Auto Scaling allows you to automatically scale AWS resources based on the value of an Amazon CloudWatch metric, using an approach called target tracking scaling. Target tracking scaling uses a scaling policy to define which CloudWatch metric to track, and the AWS resource to scale, called the scalable target. When you register a target tracking scaling policy, Application Auto Scaling automatically creates the required CloudWatch metric alarms and manages the scalable target according to the policy definition. The following diagram illustrates this architecture. Application Auto Scaling manages many different AWS services natively, but as of this writing, Amazon DocumentDB is not included among these. However, you can still define an Amazon DocumentDB cluster as a scalable target by creating an Auto Scaling custom resource, which allows our target tracking policy to manage an Amazon DocumentDB cluster’s configuration through a custom HTTP API. This API enables the Application Auto Scaling service to query and modify a resource. The following diagram illustrates this architecture. We create the custom HTTP API with two AWS services: Amazon API Gateway and AWS Lambda. API Gateway provides the HTTP endpoint, and two Lambda functions enable Application Auto Scaling to discover the current number of read replicas, and increase or decrease the number of read replicas. One Lambda function handles the status query (a GET operation), and the other handles adjusting the number of replicas (a PATCH operation). Our complete architecture looks like the following diagram. Required infrastructure Before we try out Amazon DocumentDB read autoscaling, we create an AWS CloudFormation stack that deploys the following infrastructure: An Amazon Virtual Private Cloud (VPC) with two public and two private subnets to host our Amazon DocumentDB cluster and other resources. An Amazon DocumentDB cluster consisting of one write and two read replicas, all of size db.r5.large. A jump host (Amazon Elastic Compute Cloud (Amazon EC2)) that we use to run the load test. It lives in a private subnet and we access it via AWS Systems Manager Session Manager, so we don’t need to manage SSH keys or security groups to connect. The autoscaler, which consists of a REST API backed by two Lambda functions. A preconfigured CloudWatch dashboard with a set of useful charts for monitoring the Amazon DocumentDB write and read replicas. Start by cloning the autoscaler code from its Git repository. Navigate to that directory. Although you can create the stack on the AWS CloudFormation console, I’ve provided a script in the repository to make the creation process easier. Create an Amazon Simple Storage Service (Amazon S3) bucket to hold the CloudFormation templates: aws s3 mb s3:// On the Amazon S3 console, enable versioning for the bucket. We use versions to help distinguish new versions of the Lambda deployment packages. Run a script to create deployment packages for our Lambda functions: ./scripts/zip-lambda.sh Invoke the create.sh script, passing in several parameters. The template prefix is the folder in the S3 bucket where we store the Cloud Formation templates. ./scripts/create.sh For example, see the following code: ./scripts/create.sh cfn PrimaryPassword docdbautoscale us-east-1 The Region should be the same Region in which the S3 bucket was created. If you need to update the stack, pass in –update as the last argument. Now you wait for the stack to create. When the stack is complete, on the AWS CloudFormation console, note the following values on the stack Outputs tab: DBClusterIdentifier DashboardName DbEndpoint DbUser JumpHost VpcId ApiEndpoint When we refer to these later on, they appear in brackets, like Also note your AWS Region and account number. Register the autoscaler: cd scripts python register.py Autoscaler design The autoscaler implements the custom resource scaling pattern from the Application Auto Scaling service. In this pattern, we have a REST API that offers a GET method to obtain the status of the resource we want to scale, and a PATCH method that updates the resource. The GET method The Lambda function that implements the GET method takes an Amazon DocumentDB cluster identifier as input and returns information about the desired and actual number of read replicas. The function first retrieves the current value of the desired replica count, which we store in the Systems Manager Parameter Store: param_name = "DesiredSize-" + cluster_id r = ssm.get_parameter( Name= param_name) desired_count = int(r['Parameter']['Value']) Next, the function queries Amazon DocumentDB for information about the read replicas in the cluster: r = docdb.describe_db_clusters( DBClusterIdentifier=cluster_id) cluster_info = r['DBClusters'][0] readers = [] for member in cluster_info['DBClusterMembers']: member_id = member['DBInstanceIdentifier'] member_type = member['IsClusterWriter'] if member_type == False: readers.append(member_id) It interrogates Amazon DocumentDB for information about the status of each of the replicas. That lets us know if a scaling action is ongoing (a new read replica is creating). See the following code: r = docdb.describe_db_instances(Filters=[{'Name':'db-cluster-id','Values': [cluster_id]}]) instances = r['DBInstances'] desired_count = len(instances) - 1 num_available = 0 num_pending = 0 num_failed = 0 for i in instances: instance_id = i['DBInstanceIdentifier'] if instance_id in readers: instance_status = i['DBInstanceStatus'] if instance_status == 'available': num_available = num_available + 1 if instance_status in ['creating', 'deleting', 'starting', 'stopping']: num_pending = num_pending + 1 if instance_status == 'failed': num_failed = num_failed + 1 Finally, it returns information about the current and desired number of replicas: responseBody = { "actualCapacity": float(num_available), "desiredCapacity": float(desired_count), "dimensionName": cluster_id, "resourceName": cluster_id, "scalableTargetDimensionId": cluster_id, "scalingStatus": scalingStatus, "version": "1.0" } response = { 'statusCode': 200, 'body': json.dumps(responseBody) } return response The PATCH method The Lambda function that handles a PATCH request takes the desired number of read replicas as input: {"desiredCapacity":2.0} The function uses the Amazon DocumentDB Python API to gather information about the current state of the cluster, and if a scaling action is required, it adds or removes a replica. When adding a replica, it uses the same settings as the other replicas in the cluster and lets Amazon DocumentDB choose an Availability Zone automatically. When removing replicas, it chooses the Availability Zone that has the most replicas available. See the following code: # readers variable was initialized earlier to a list of the read # replicas. reader_type and reader_engine were copied from # another replica. desired_count is essentially the same as # desiredCapacity. if scalingStatus == 'Pending': print("Initiating scaling actions on cluster {0} since actual count {1} does not equal desired count {2}".format(cluster_id, str(num_available), str(desired_count))) if num_available < desired_count: num_to_create = desired_count - num_available for idx in range(num_to_create): docdb.create_db_instance( DBInstanceIdentifier=readers[0] + '-' + str(idx) + '-' + str(int(time.time())), DBInstanceClass=reader_type, Engine=reader_engine, DBClusterIdentifier=cluster_id ) else: num_to_remove = num_available - desired_count for idx in range(num_to_remove): # get the AZ with the most replicas az_with_max = max(reader_az_cnt.items(), key=operator.itemgetter(1))[0] LOGGER.info(f"Removing read replica from AZ {az_with_max}, which has {reader_az_cnt[az_with_max]} replicas") # get one of the replicas from that AZ reader_list = reader_az_map[az_with_max] reader_to_delete = reader_list[0] LOGGER.info(f"Removing read replica {reader_to_delete}") docdb.delete_db_instance( DBInstanceIdentifier=reader_to_delete) reader_az_map[az_with_max].remove(reader_to_delete) reader_az_cnt[az_with_max] -= 1 We also store the latest desired replica count in the Parameter Store: r = ssm.put_parameter( Name=param_name, Value=str(desired_count), Type='String', Overwrite=True, AllowedPattern='^d+$' ) Defining the scaling target and scaling policy We use the boto3 API to register the scaling target. The MinCapacity and MaxCapacity are set to 2 and 15 in the scaling target, because we always want at least two read replicas, and 15 is the maximum number of read replicas. The following is the relevant snippet from the registration script: # client is the docdb boto3 client response = client.register_scalable_target( ServiceNamespace='custom-resource', ResourceId='https://' + ApiEndpoint + '.execute-api.' + Region + '.amazonaws.com/prod/scalableTargetDimensions/' + DBClusterIdentifier, ScalableDimension='custom-resource:ResourceType:Property', MinCapacity=2, MaxCapacity=15, RoleARN='arn:aws:iam::' + Account + ':role/aws-service-role/custom-resource.application-autoscaling.amazonaws.com/AWSServiceRoleForApplicationAutoScaling_CustomResource' ) The script also creates the autoscaling policy. There are several important configuration parameters in this policy. I selected CPU utilization on the read replicas as the target metric (CPU utilization is not necessarily the best metric for your workload’s scaling trigger; other options such as BufferCacheHitRatio may provide better behavior). I set the target value at an artificially low value of 5% to more easily trigger a scaling event (a more realistic value for a production workload is 70–80%). I also set a long cooldown period of 10 minutes for both scale-in and scale-out to avoid having replicas added or removed too frequently. You need to determine the cooldown periods that are most appropriate for your production workload. The following is the relevant snippet from the script: response = client.put_scaling_policy( PolicyName='docdbscalingpolicy', ServiceNamespace='custom-resource', ResourceId='https://' + ApiEndpoint + '.execute-api.' + Region + '.amazonaws.com/prod/scalableTargetDimensions/' + DBClusterIdentifier, ScalableDimension='custom-resource:ResourceType:Property', PolicyType='TargetTrackingScaling', TargetTrackingScalingPolicyConfiguration={ 'TargetValue': 5.0, 'CustomizedMetricSpecification': { 'MetricName': 'CPUUtilization', 'Namespace': 'AWS/DocDB', 'Dimensions': [ { 'Name': 'Role', 'Value': 'READER' }, { 'Name': 'DBClusterIdentifier', 'Value': DBClusterIdentifier } ], 'Statistic': 'Average', 'Unit': 'Percent' }, 'ScaleOutCooldown': 600, 'ScaleInCooldown': 600, 'DisableScaleIn': False } ) Generating load I use the YCSB framework to generate load. Complete the following steps: Connect to the jump host using Session Manager: aws ssm start-session --target Install YCSB: sudo su - ec2-user sudo yum -y install java curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz tar xfvz ycsb-0.17.0.tar.gz cd ycsb-0.17.0 Run the load tester. We use workloadb, which is a read-heavy workload: ./bin/ycsb load mongodb -s -P workloads/workloadb -p recordcount=10000000 -p mongodb.url=”mongodb://:@:27017/?replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false” > load.dat ./bin/ycsb run mongodb -threads 10 -target 100 -s -P workloads/workloadb -p recordcount=10000000 -p mongodb.url=”mongodb://< PrimaryUser>:@:27017/?replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false” > run.dat These two commands load data in the Amazon DocumentDB database and run a read-heavy workload using that data. Monitoring scaling activity and cluster performance The CloudFormation stack created a CloudWatch dashboard that shows several metrics. The following screenshot shows the dashboard for the writer node. The following screenshot shows the dashboard for the read replicas. As YCSB runs, watch the dashboard to see the load increase. When the CPU load on the readers exceeds our 5% target, the autoscaler should add a read replica. We can verify that by checking the Amazon DocumentDB console and observing the number of instances in the cluster. Cleaning up If you deployed the CloudFormation templates used in this post, consider deleting the stack if you don’t want to keep the resources. Conclusion In this post, I showed you how to use a custom Application Auto Scaling resource to automatically add or remove read replicas to an Amazon DocumentDB cluster, based on a specific performance metric and scaling policy. Before using this approach in a production setting, you should decide which Amazon DocumentDB performance metric best reflects when your workload needs to scale in or scale out, determine the target value for that metric, and settle on a cooldown period that lets you respond to cluster load without adding or removing replicas too frequently. As a baseline, you could try a scaling policy that triggers a scale-up when CPUUtilization is over 70% or FreeableMemory is under 10%. About the Author Randy DeFauw is a principal solutions architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. https://aws.amazon.com/blogs/database/amazon-documentdb-with-mongodb-compatibility-read-autoscaling/
0 notes
Text
75% off #Learn Node.js API’s Fast and Simple – $10
Learn to create Node.js API backend services REST/JSON for mobile/web, host on your own Linux server
Beginner Level, – Video: 2 hours, 13 lectures
Average rating 4.6/5 (4.6)
Course requirements:
Students need access to an Computer with Node.js, NPM 4 and MongoDB installed.
Course description:
Learn the basic concepts of API’s to include HTTP based REST with JSON payloads. Learn how to create a working system with Node.js using the Express.js framework. Learn how to create an API that connects to MongoDB. We walk thru creating some simple API’s and follow thru with deployment onto a server. This development is presented on a Mac OSX with Node.js 4 and deployed on a Linux server in a cloud environment (Amazon EC2).
Build a strong foundation in API development with Node.js. This course helps you understand and implement API’s using Node.js, Express.js and MongoDB technologies to allow you to create your own back end server with the latest technologies.
Javascript Node.js 4.x NPM Express MongoDB Linux
Professional skills and experience from an iOS / Node.js Architect with over 8 years experience.
Learn the fundamentals but also tips and tricks of the experts. Learn about the different type of API end points and how to create a full end to end solution.
We will walk thru the project setup and all required elements to create a full end to end API server.
Content and Overview
This course explains key technology concepts of API’s with REST and JSON technology in a Node.js system. We show development from start to finish to include deployment on a live production server not just a test machine.
What am I going to get from this course?
Detailed knowledge of how to create Node.js / Express.js based REST/JSON API’s Learn how to use MongoDB as the back end for API’s. Teaching by example showing every detail to the smallest degree from starting a new application to deploying it in production. Access to Instructors GitHub account with many extras and examples.
If you don’t have a a production server device don’t worry, we show you how to test everything on your local computer.
Note: Development is all described on a Mac OSX notebook, Windows is not address. Node.js using JavaScript is a portable language and all the tools described in this class are available on other systems as well but no intention is made to describe how to setup them up of use the Windows or Linux versions.
Full details Students will be able to create a Node.js based API end point. Students will understand technology for API’s, REST, JSON and how to integrate into a Node.js server. Students will understand how to create an API that connects with MongoDB Students will understand how to create an API that connects with MongoDB This course is focused at mobile app developers that need a backend service that provides custom processing and can becom epart of a set of IP for a startup company This course is for anyone who wants to learn how to build a high performance API Fast and Simply
Reviews:
“good basic introduction�� (Mohd Syafiq (Dr Syafiq))
“Great content. All the node api secrets revealed” (Tom Littleton)
“” ()
About Instructor:
Tom Jay
I’ve been developing mobile applications for over 8 years with focus on iOS. I have taught in-class paid course for a major training company in San Francisco.
I have over 20 years of Enterprise Server development with Java/J2EE, Oracle, MySQL, XML/JSON Web Services, API development and location based systems using MongoDB.
I have created dozens of mobile apps form Banking, Social Messaging, Event Discover and Medical device interfaces. I like mobile payments and iBeacon integration. I mainly focus on IoT development (BLE) for IoT and iBeacon technologies. Please watch my courses on Mobile development.
Instructor Other Courses:
Learn iOS 9 Push Notifications Arduino 101 – Intel Curie iOS 9 NSNotificationCenter in Swift (Not Push Notifications) …………………………………………………………… Tom Jay coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon Learn Node.js API’s Fast and Simple Learn Node.js API’s Fast and Simple course coupon Learn Node.js API’s Fast and Simple coupon coupons
The post 75% off #Learn Node.js API’s Fast and Simple – $10 appeared first on Udemy Cupón.
from Udemy Cupón http://www.xpresslearn.com/udemy/coupon/75-off-learn-node-js-apis-fast-and-simple-10/
from https://xpresslearn.wordpress.com/2017/02/26/75-off-learn-node-js-apis-fast-and-simple-10/
0 notes