#install MongoDB in AWS linux.
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Docker Tutorial for Beginners: Learn Docker Step by Step
What is Docker?
Docker is an open-source platform that enables developers to automate the deployment of applications inside lightweight, portable containers. These containers include everything the application needs to run—code, runtime, system tools, libraries, and settings—so that it can work reliably in any environment.
Before Docker, developers faced the age-old problem: “It works on my machine!” Docker solves this by providing a consistent runtime environment across development, testing, and production.
Why Learn Docker?
Docker is used by organizations of all sizes to simplify software delivery and improve scalability. As more companies shift to microservices, cloud computing, and DevOps practices, Docker has become a must-have skill. Learning Docker helps you:
Package applications quickly and consistently
Deploy apps across different environments with confidence
Reduce system conflicts and configuration issues
Improve collaboration between development and operations teams
Work more effectively with modern cloud platforms like AWS, Azure, and GCP
Who Is This Docker Tutorial For?
This Docker tutorial is designed for absolute beginners. Whether you're a developer, system administrator, QA engineer, or DevOps enthusiast, you’ll find step-by-step instructions to help you:
Understand the basics of Docker
Install Docker on your machine
Create and manage Docker containers
Build custom Docker images
Use Docker commands and best practices
No prior knowledge of containers is required, but basic familiarity with the command line and a programming language (like Python, Java, or Node.js) will be helpful.
What You Will Learn: Step-by-Step Breakdown
1. Introduction to Docker
We start with the fundamentals. You’ll learn:
What Docker is and why it’s useful
The difference between containers and virtual machines
Key Docker components: Docker Engine, Docker Hub, Dockerfile, Docker Compose
2. Installing Docker
Next, we guide you through installing Docker on:
Windows
macOS
Linux
You’ll set up Docker Desktop or Docker CLI and run your first container using the hello-world image.
3. Working with Docker Images and Containers
You’ll explore:
How to pull images from Docker Hub
How to run containers using docker run
Inspecting containers with docker ps, docker inspect, and docker logs
Stopping and removing containers
4. Building Custom Docker Images
You’ll learn how to:
Write a Dockerfile
Use docker build to create a custom image
Add dependencies and environment variables
Optimize Docker images for performance
5. Docker Volumes and Networking
Understand how to:
Use volumes to persist data outside containers
Create custom networks for container communication
Link multiple containers (e.g., a Node.js app with a MongoDB container)
6. Docker Compose (Bonus Section)
Docker Compose lets you define multi-container applications. You’ll learn how to:
Write a docker-compose.yml file
Start multiple services with a single command
Manage application stacks easily
Real-World Examples Included
Throughout the tutorial, we use real-world examples to reinforce each concept. You’ll deploy a simple web application using Docker, connect it to a database, and scale services with Docker Compose.
Example Projects:
Dockerizing a static HTML website
Creating a REST API with Node.js and Express inside a container
Running a MySQL or MongoDB database container
Building a full-stack web app with Docker Compose
Best Practices and Tips
As you progress, you’ll also learn:
Naming conventions for containers and images
How to clean up unused images and containers
Tagging and pushing images to Docker Hub
Security basics when using Docker in production
What’s Next After This Tutorial?
After completing this Docker tutorial, you’ll be well-equipped to:
Use Docker in personal or professional projects
Learn Kubernetes and container orchestration
Apply Docker in CI/CD pipelines
Deploy containers to cloud platforms
Conclusion
Docker is an essential tool in the modern developer's toolbox. By learning Docker step by step in this beginner-friendly tutorial, you’ll gain the skills and confidence to build, deploy, and manage applications efficiently and consistently across different environments.
Whether you’re building simple web apps or complex microservices, Docker provides the flexibility, speed, and scalability needed for success. So dive in, follow along with the hands-on examples, and start your journey to mastering containerization with Docker tpoint-tech!
0 notes
Text
Install MongoDB on AWS EC2 Instances.
Install MongoDB on AWS EC2 Instances.
We will see how to install MongoDB on AWS ec2 Instances, amazon Linux 2 or we can install MongoDB of any version on the AWS Linux 2 server in this article. The Amazon Linux 2 server is the RPM-based server with the 5 years Long Term Support by AWS. (Amazon Web Services). MongoDB is a No-SQL database which is written in C++, It uses a JSON like structure. MongoDB is a cross-platform and…
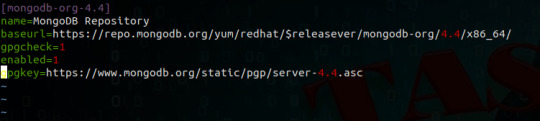
View On WordPress
#aws mongodb service#install mongo shell on amazon linux#install mongodb#install mongodb centos 7#install mongodb centos 8#install MongoDB in AWS ec2 instance#install MongoDB in AWS linux.#install MongoDB on amazon ec2#install MongoDB on amazon linux#install MongoDB on amazon linux AMI#install mongodb on aws#install MongoDB on AWS server#install MongoDB shell amazon linux#mongodb install linux
0 notes
Photo

hydralisk98′s web projects tracker:
Core principles=
Fail faster
‘Learn, Tweak, Make’ loop
This is meant to be a quick reference for tracking progress made over my various projects, organized by their “ultimate target” goal:
(START)
(Website)=
Install Firefox
Install Chrome
Install Microsoft newest browser
Install Lynx
Learn about contemporary web browsers
Install a very basic text editor
Install Notepad++
Install Nano
Install Powershell
Install Bash
Install Git
Learn HTML
Elements and attributes
Commenting (single line comment, multi-line comment)
Head (title, meta, charset, language, link, style, description, keywords, author, viewport, script, base, url-encode, )
Hyperlinks (local, external, link titles, relative filepaths, absolute filepaths)
Headings (h1-h6, horizontal rules)
Paragraphs (pre, line breaks)
Text formatting (bold, italic, deleted, inserted, subscript, superscript, marked)
Quotations (quote, blockquote, abbreviations, address, cite, bidirectional override)
Entities & symbols (&entity_name, &entity_number,  , useful HTML character entities, diacritical marks, mathematical symbols, greek letters, currency symbols, )
Id (bookmarks)
Classes (select elements, multiple classes, different tags can share same class, )
Blocks & Inlines (div, span)
Computercode (kbd, samp, code, var)
Lists (ordered, unordered, description lists, control list counting, nesting)
Tables (colspan, rowspan, caption, colgroup, thead, tbody, tfoot, th)
Images (src, alt, width, height, animated, link, map, area, usenmap, , picture, picture for format support)
old fashioned audio
old fashioned video
Iframes (URL src, name, target)
Forms (input types, action, method, GET, POST, name, fieldset, accept-charset, autocomplete, enctype, novalidate, target, form elements, input attributes)
URL encode (scheme, prefix, domain, port, path, filename, ascii-encodings)
Learn about oldest web browsers onwards
Learn early HTML versions (doctypes & permitted elements for each version)
Make a 90s-like web page compatible with as much early web formats as possible, earliest web browsers’ compatibility is best here
Learn how to teach HTML5 features to most if not all older browsers
Install Adobe XD
Register a account at Figma
Learn Adobe XD basics
Learn Figma basics
Install Microsoft’s VS Code
Install my Microsoft’s VS Code favorite extensions
Learn HTML5
Semantic elements
Layouts
Graphics (SVG, canvas)
Track
Audio
Video
Embed
APIs (geolocation, drag and drop, local storage, application cache, web workers, server-sent events, )
HTMLShiv for teaching older browsers HTML5
HTML5 style guide and coding conventions (doctype, clean tidy well-formed code, lower case element names, close all html elements, close empty html elements, quote attribute values, image attributes, space and equal signs, avoid long code lines, blank lines, indentation, keep html, keep head, keep body, meta data, viewport, comments, stylesheets, loading JS into html, accessing HTML elements with JS, use lowercase file names, file extensions, index/default)
Learn CSS
Selections
Colors
Fonts
Positioning
Box model
Grid
Flexbox
Custom properties
Transitions
Animate
Make a simple modern static site
Learn responsive design
Viewport
Media queries
Fluid widths
rem units over px
Mobile first
Learn SASS
Variables
Nesting
Conditionals
Functions
Learn about CSS frameworks
Learn Bootstrap
Learn Tailwind CSS
Learn JS
Fundamentals
Document Object Model / DOM
JavaScript Object Notation / JSON
Fetch API
Modern JS (ES6+)
Learn Git
Learn Browser Dev Tools
Learn your VS Code extensions
Learn Emmet
Learn NPM
Learn Yarn
Learn Axios
Learn Webpack
Learn Parcel
Learn basic deployment
Domain registration (Namecheap)
Managed hosting (InMotion, Hostgator, Bluehost)
Static hosting (Nertlify, Github Pages)
SSL certificate
FTP
SFTP
SSH
CLI
Make a fancy front end website about
Make a few Tumblr themes
===You are now a basic front end developer!
Learn about XML dialects
Learn XML
Learn about JS frameworks
Learn jQuery
Learn React
Contex API with Hooks
NEXT
Learn Vue.js
Vuex
NUXT
Learn Svelte
NUXT (Vue)
Learn Gatsby
Learn Gridsome
Learn Typescript
Make a epic front end website about
===You are now a front-end wizard!
Learn Node.js
Express
Nest.js
Koa
Learn Python
Django
Flask
Learn GoLang
Revel
Learn PHP
Laravel
Slim
Symfony
Learn Ruby
Ruby on Rails
Sinatra
Learn SQL
PostgreSQL
MySQL
Learn ORM
Learn ODM
Learn NoSQL
MongoDB
RethinkDB
CouchDB
Learn a cloud database
Firebase, Azure Cloud DB, AWS
Learn a lightweight & cache variant
Redis
SQLlite
NeDB
Learn GraphQL
Learn about CMSes
Learn Wordpress
Learn Drupal
Learn Keystone
Learn Enduro
Learn Contentful
Learn Sanity
Learn Jekyll
Learn about DevOps
Learn NGINX
Learn Apache
Learn Linode
Learn Heroku
Learn Azure
Learn Docker
Learn testing
Learn load balancing
===You are now a good full stack developer
Learn about mobile development
Learn Dart
Learn Flutter
Learn React Native
Learn Nativescript
Learn Ionic
Learn progressive web apps
Learn Electron
Learn JAMstack
Learn serverless architecture
Learn API-first design
Learn data science
Learn machine learning
Learn deep learning
Learn speech recognition
Learn web assembly
===You are now a epic full stack developer
Make a web browser
Make a web server
===You are now a legendary full stack developer
[...]
(Computer system)=
Learn to execute and test your code in a command line interface
Learn to use breakpoints and debuggers
Learn Bash
Learn fish
Learn Zsh
Learn Vim
Learn nano
Learn Notepad++
Learn VS Code
Learn Brackets
Learn Atom
Learn Geany
Learn Neovim
Learn Python
Learn Java?
Learn R
Learn Swift?
Learn Go-lang?
Learn Common Lisp
Learn Clojure (& ClojureScript)
Learn Scheme
Learn C++
Learn C
Learn B
Learn Mesa
Learn Brainfuck
Learn Assembly
Learn Machine Code
Learn how to manage I/O
Make a keypad
Make a keyboard
Make a mouse
Make a light pen
Make a small LCD display
Make a small LED display
Make a teleprinter terminal
Make a medium raster CRT display
Make a small vector CRT display
Make larger LED displays
Make a few CRT displays
Learn how to manage computer memory
Make datasettes
Make a datasette deck
Make floppy disks
Make a floppy drive
Learn how to control data
Learn binary base
Learn hexadecimal base
Learn octal base
Learn registers
Learn timing information
Learn assembly common mnemonics
Learn arithmetic operations
Learn logic operations (AND, OR, XOR, NOT, NAND, NOR, NXOR, IMPLY)
Learn masking
Learn assembly language basics
Learn stack construct’s operations
Learn calling conventions
Learn to use Application Binary Interface or ABI
Learn to make your own ABIs
Learn to use memory maps
Learn to make memory maps
Make a clock
Make a front panel
Make a calculator
Learn about existing instruction sets (Intel, ARM, RISC-V, PIC, AVR, SPARC, MIPS, Intersil 6120, Z80...)
Design a instruction set
Compose a assembler
Compose a disassembler
Compose a emulator
Write a B-derivative programming language (somewhat similar to C)
Write a IPL-derivative programming language (somewhat similar to Lisp and Scheme)
Write a general markup language (like GML, SGML, HTML, XML...)
Write a Turing tarpit (like Brainfuck)
Write a scripting language (like Bash)
Write a database system (like VisiCalc or SQL)
Write a CLI shell (basic operating system like Unix or CP/M)
Write a single-user GUI operating system (like Xerox Star’s Pilot)
Write a multi-user GUI operating system (like Linux)
Write various software utilities for my various OSes
Write various games for my various OSes
Write various niche applications for my various OSes
Implement a awesome model in very large scale integration, like the Commodore CBM-II
Implement a epic model in integrated circuits, like the DEC PDP-15
Implement a modest model in transistor-transistor logic, similar to the DEC PDP-12
Implement a simple model in diode-transistor logic, like the original DEC PDP-8
Implement a simpler model in later vacuum tubes, like the IBM 700 series
Implement simplest model in early vacuum tubes, like the EDSAC
[...]
(Conlang)=
Choose sounds
Choose phonotactics
[...]
(Animation ‘movie’)=
[...]
(Exploration top-down ’racing game’)=
[...]
(Video dictionary)=
[...]
(Grand strategy game)=
[...]
(Telex system)=
[...]
(Pen&paper tabletop game)=
[...]
(Search engine)=
[...]
(Microlearning system)=
[...]
(Alternate planet)=
[...]
(END)
4 notes
·
View notes
Text
MongoDB backup to S3 on Kubernetes- Alt Digital Technologies

Introduction
Kubernetes CronJob makes it very easy to run Jobs on a time-based schedule. These automated jobs run like Cron tasks on a Linux or UNIX system.
In this post, we’ll make use of Kubernetes CronJob to schedule a recurring backup of the MongoDB database and upload the backup archive to AWS S3.
There are several ways of achieving this, but then again, I had to stick to one using Kubernetes since I already have a Kubernetes cluster running.
Prerequisites:
Docker installed on your machine
Container repository (Docker Hub, Google Container Registry, etc) – I’ve used docker hub
Kubernetes cluster running
Steps to achieve this:
MongoDB installed on the server and running or MongoDB Atlas – I’ve used Atlas
AWS CLI installed in a docker container
A bash script will be run on the server to backup the database
AWS S3 Bucket configured
Build and deploy on Kubernetes
MongoDB Setup:
You can set up a mongo database on your server or use a MongoDB Atlas cluster instead. The Atlas cluster is a great way to set up a mongo database and is free for M0 clusters. You can also use a mongo database on your server or on a Kubernetes cluster.
After creating your MongoDB instance, we will need the Connection String. Please keep it safe somewhere, we will need it later. Choosing a connection string may confuse which one to pick. So we need to select the MongoDB Compass one that looks in the below format. Read more!!
0 notes
Text
AWS EC2 Instance Setup and Run MongoDB in EC2 | Run MongoDB in EC2 Server
Hello friends, a new #video on #awsec2 #server setup #mongodb installation in #ec2 instance is published on #codeonedigest #youtube channel. Learn #aws #ec2 #mongodb #programming #coding with codeonedigest. #awsec2 #awsec2instance
In this video we will learn amazon EC2 server setup from beginning. Also, install nosql mongo database in EC2 sever. Creating aws linux EC2 instance from AWS management console. Adding firewall rule in the security group to open mongodb port. Login to EC2 instance from local terminal using secret key pair. Download mongo database in EC2 instance. Install Mongo database in EC2…

View On WordPress
0 notes
Text
In today’s article we shall look at the steps required to install and configure Pritunl VPN on Debian 11 / Debian 10 / Proxmox VE. Pritunl VPN is an opensource VPN server that you can adopt as an alternative to Aviatrix and Pulse Secure solutions. In Pritunl all configurations are done from a web interface which makes it easy to manage irregardless of the size of an organization or complexity of where it’s deployed. Security is a top priority in Pritunl solution, all traffic between clients and the server is encrypted. You can optionally enable two-step authentication using Google Authenticator. Here are some notable features of Pritunl VPN; It has support for multi-cloud VPN peering It is simple to install, configure and manage You can configure upto five layers of authentication giving it better security. Wireguard and OpenVPN clients are supported Highly scalable for upto thousands of users – both in Cloud and On-prem infrastructures Can be configured for multi-cloud site-to-site links with VPC peering. VPC peering is available for Google Cloud, AWS, Azure and Oracle Cloud. Interconnect AWS VPC networks across AWS regions and provide reliable remote access with automatic failover that can scale horizontally Architecture of Pritunl VPN Pritunl VPN presents a distributed and scalable infrastructure that can be easily scaled to thousands of users. MongoDB clusters can be deployed in HA setup to guarantee availability of VPN system in your environment. Pritunl works on client-server architecture, where user profiles are downloaded on clients, while servers and users are configured on the VPN server. Pritunl is built on MongoDB – a highly scalable, and reliable NoSQL database solution. MongoDB has support for replication that can be done in minutes making a Pritunl cluster deployment fast and easy. Setup Pritunl VPN on Debian 11 / Debian 10 / Proxmox VE In this section we’ll discuss the installation and configurations of Pritunl VPN server on Debian 11 / Debian 10 / Proxmox VE. We recommend you perform this installation on a fresh installation of Debian Linux. Also ensure you access the server as user with sudo privs or as root user. Step 1: Update Debian system Login to your Debian machine and perform an update and optionally upgrade all packages on the system. sudo apt update && sudo apt -y full-upgrade After updates are committed, check if a reboot is required on the system. [ -f /var/run/reboot-required ] && sudo reboot -f Step 2: Add MongoDB and Pritunl repositories Install basic utility packages required for this operation: sudo apt update sudo apt install gpg curl gnupg2 software-properties-common apt-transport-https lsb-release ca-certificates Import MongoDB APT repository keys to your system. curl -fsSL https://www.mongodb.org/static/pgp/server-5.0.asc|sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/mongodb-5.gpg Import Pritunl VPN GPG keys: $ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com --recv 7AE645C0CF8E292A Executing: /tmp/apt-key-gpghome.6ZjhVSgCdC/gpg.1.sh --keyserver hkp://keyserver.ubuntu.com --recv 7AE645C0CF8E292A gpg: key 7AE645C0CF8E292A: public key "Pritunl " imported gpg: Total number processed: 1 gpg: imported: 1 Add Pritunl repository: echo "deb http://repo.pritunl.com/stable/apt $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/pritunl.list Add Mongodb repository by running the commands below: echo "deb http://repo.mongodb.org/apt/debian buster/mongodb-org/5.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list Step 3: Install Pritunl and MongoDB With both repositories added and confirmed to be working let’s proceed to install pritunl and mongo-server packages. sudo apt update sudo apt install mongodb-org pritunl Now start and enable Pritunl and MongoDB as below: sudo systemctl start pritunl mongod sudo systemctl enable pritunl mongod Step 4: Configure Pritunl VPN Server Our Pritunl VPN server is now installed and running.
Next we access its web console on a web browser server’s IP to configure it. http://. You’ll need Setup Key to proceed. Run the command setup-key to generate it: $ sudo pritunl setup-key c76683c87efe4774887a9a223a2f1fd6 Once you enter the setup-key and mongodb url, it will prompt you for username and password. The default username and password are obtained with the below command: $ sudo pritunl default-password [undefined][2022-06-28 15:13:50,043][INFO] Getting default administrator password Administrator default password: username: "pritunl" password: "vzjTDicF92Ol" You’ll land on a page like below where you can change admin user and password, set domain and Let’s Encrypt SSL. Next configure organizations, users and servers. VPN users are added by clicking on ‘Users’. Users are mapped to server in an organization. To create a new organization click on ‘Add organization’ then specify a name and ‘Add’. Create a VPN server by clicking on ‘servers’ then ‘Add server’ Provide server information required then click ‘Add’. Finally attach the server to an organization by clicking on ‘Attach organization’ and choosing your organization. Adding users Click on ‘Add user’ to create a user profile on your VPN server. To add many users at once use the ‘Bulk Add user’ function on the web interface. Step 5: Configure Pritunl Clients Visit the Pritunl VPN clients page and choose one for your Workstation to download and install. Once VPN client has been installed, login to Pritunl VPN server to download user profile. Click on ‘Users’ select the particular user and click on the download icon to get the user profile. Launch your Pritunl VPN client, then choose “Import Profile” Locate user’s profile .tar file downloaded and import it, then you’ll be able to connect to Pritunl VPN server.
0 notes
Link
Software Engineer - https://www.jovency.com/?p=19884&utm_source=SocialAutoPoster&utm_medium=Social&utm_campaign=Tumblr JOVENCY-job portal Job title: Software Engineer Company: Borders Outsourcing Private Limited Job description: ** We do not post anything to your social profiles or share data with anyone. Continue with Email/Mobile → Account already exists. Please login using your primary number You seem to be our Partner. You seem to be our Employer. You seem to be our Candidate. You seems to have an Agency account with us. Please to login. This link has expired. Kindly enter the credentials to continue. Please contact customer care. More info here: Hi! You seem to be new here. Tell us a few more things to get you started. First Name Last Name Mobile Account already exists. Please login using your primary number Email Email already exists. Password Get application updates via WhatsApp Yes No If you choose ‘Yes’, we’ll only send you updates about your job applications. You can unsubscribe any time by going to Settings. By continuing, you hereby accept our Mobile you entered already exists. Dang, we ran into some issue. Please retry after some time. Hi,You were registered on Waahjobs by Enter Password to account You’re almost done. Enter Password to account Enter Password You have entered an invalid password. Try Again. Dang, we ran into some issue. Please retry after some time. Your account has been deactivated. Please Contact Our Customer Service. OR Welcome back, You previously usedto login ** We do not post anything to your social profiles or share data with anyone. OR Hi,You were registered on Waahjobs by Enter OTP sent on You’re almost done. Enter OTP sent on A Verification email has been sent on. Click on the link to verify. Verify Companies will reach out to you on this number for jobs: OTP Resent Successfully. Enter 5 digit OTP Unable to generate OTP at this time. Please try after some time. OTP you entered is invalid. Please Check again. Maximum Retries Exceeded. OTP Resent Successfully. OR Create Password Forgot Password Verify Email We have sent a ” link to Did not receive the link? link resent successfully. OR ** We do not post anything to your social profiles or share data with anyone. Logging in… × Register Now! Submit your resume or build your profile to get started. Upload Resume* Allowed File types: pdf, doc or docx You seems to already have an account with us. Please to apply. Some Error Occurred, please re-try after some time. Submit or Build Your Profile > > Software Engineer Software EngineerNew 2 Openings Salary INR3Lac 3Lac – 4Lac CTCCTC Experience 4 yrsto5 yrs experience| Resume Required Location Palarivattom, Kochi Software EngineerFULL_TIME Borders Outsourcing Private Limited Not Specified Not Specified 4 yrs 2021-04-12T12:02:49 2021-06-11T12:24:27.162933+05:30 Not Specified Software Developer Job Benefits INR INR3Lac 3Lac – 4Lac CTCCTC Palarivattom, KochiErnakulam KeralaNot SpecifiedIN 9:30 AM – 6:30 PM(day shift) p We are looking for a passionate Software Engineer to design, develop and install software solutions. Software Engineer responsibilities include gathering user requirements, defining system functionality, and writing code in various languages, like Java, Ruby on Rails or .NET programming languages (C, C++, Java, .NET, Python, React, React Native, BEA WebLogic, WebSphere, J2EE, JBoss, ADO, Perl, HTML, JSP, JavaScript, Web services, AWS, GCP, SOAP, XML, ASP, JSP, PHP, MySQL, SQL Server, Oracle, UNIX, Linux, Redhat Linux, STL, XSLT, OWL, AJAX, J2EE, J2ME, J2SE, Sun Solaris) Our ideal candidates are familiar with the software development life cycle (SDLC) from preliminary system analysis to tests and deployment. Ultimately, the role of the Software Engineer is to build high-quality, innovative, and fully performing software that complies with coding standards and technical design. /p p br /p p strong Roles and Responsibilities /strong /p p br /p ul li Proven work experience in software engineering /li li Hands-on experience in designing interactive applications. Ability to develop software in Knowledge of multiple back-end languages (e.g. C#, Java, Python, .Net,PHP, Laravle ) and JavaScript frameworks (e.g. Angular, React, Node.js) Databases (e.g. MySQL, MongoDB), web servers (e.g. Apache) and UI/UX design. AWS & Google Cloud (GCP) ( MUST ) /li li Experience in developing web applications using at least one popular web framework (JSF, Wicket, GWT, Spring MVC) /li li Experience with test-driven development /li li Mastery in software engineering tools /li li Ability to document requirements and specifications /li li Familiarity with software development methodology and release processes /li li BS degree in Computer Science or Engineering /li li Common IT Hardware, Software, Platform and Systems Knowledge: C, C++, Java, .NET, Python, BEA WebLogic, WebSphere, J2EE, JBoss, ADO, Perl, HTML, JSP, JavaScript, Web services, SOAP, XML, ASP, JSP, PHP, MySQL, SQL Server, Oracle, UNIX, Linux, Redhat Linux, STL, XSLT, OWL, AJAX, J2EE, J2ME, J2SE, Sun Solaris /li li Software Engineer top skills & proficiencies: /li li Software Development /li li Analytical & Problem Solving Skills /li li Ability to Learn Quickly /li li Team Player /li li Agile Development Processes and Principles /li li Written and Verbal Communication /li li Customer-Oriented /li li Analysis /li li General Programming Skills /li li Software Debugging /li li Software Documentation /li li Software Testing /li li Software Development Fundamentals & process /li /ul p br /p p strong Desired Candidate Profile /strong /p p br /p ul li High school degree or equivalent /li li Excellent analytical and time-management skills /li li Ability to work independently or as an active member of a team /li /ul Share via Additional Details Job Type Full Time Shift Timings 9:30 AM – 6:30 PM(day shift) Working Days 5 days Job Requirements Education Below 10th allowed Experience 4 yrs to 5 yrs of experience as Software Developer preferred Age 18 – 30 yrs Skills Compulsory Job Description We are looking for a passionate Software Engineer to design, develop and install software solutions. Software Engineer responsibilities include gathering user requirements, defining system functionality, and writing code in various languages, like Java, Ruby on Rails or .NET programming languages (C, C++, Java, .NET, Python, React, React Native, BEA WebLogic, WebSphere, J2EE, JBoss, ADO, Perl, HTML, JSP, JavaScript, Web services, AWS, GCP, SOAP, XML, ASP, JSP, PHP, MySQL, SQL Server, Oracle, UNIX, Linux, Redhat Linux, STL, XSLT, OWL, AJAX, J2EE, J2ME, J2SE, Sun Solaris) Our ideal candidates are familiar with the software development life cycle (SDLC) from preliminary system analysis to tests and deployment. Ultimately, the role of the Software Engineer is to build high-quality, innovative, and fully performing software that complies with coding standards and technical design. Roles and Responsibilities Proven work experience in software engineering Hands-on experience in designing interactive applications. Ability to develop software in Knowledge of multiple back-end languages (e.g. C#, Java, Python, .Net,PHP, Laravle ) and JavaScript frameworks (e.g. Angular, React, Node.js) Databases (e.g. MySQL, MongoDB), web servers (e.g. Apache) and UI/UX design. AWS & Google Cloud (GCP) ( MUST ) Experience in developing web applications using at least one popular web framework (JSF, Wicket, GWT, Spring MVC) Experience with test-driven development Mastery in software engineering tools Ability to document requirements and specifications Familiarity with software development methodology and release processes BS degree in Computer Science or Engineering Common IT Hardware, Software, Platform and Systems Knowledge: C, C++, Java, .NET, Python, BEA WebLogic, WebSphere, J2EE, JBoss, ADO, Perl, HTML, JSP, JavaScript, Web services, SOAP, XML, ASP, JSP, PHP, MySQL, SQL Server, Oracle, UNIX, Linux, Redhat Linux, STL, XSLT, OWL, AJAX, J2EE, J2ME, J2SE, Sun Solaris Software Engineer top skills & proficiencies: Software Development Analytical & Problem Solving Skills Ability to Learn Quickly Team Player Agile Development Processes and Principles Written and Verbal Communication Customer-Oriented Analysis General Programming Skills Software Debugging Software Documentation Software Testing Software Development Fundamentals & process Desired Candidate Profile High school degree or equivalent Excellent analytical and time-management skills Ability to work independently or as an active member of a team Company Details Borders has pioneered IT services in India for 15 years, consistently delivering business value with the latest technology. Software Engineer at Borders Outsourcing Private Limited(Posted by borders outsourcing private limited) 3Lac – 4Lac CTC Palarivattom, Kochi 4 yrsto5 yrs experience Note: Waahjobs does NOT ask money from jobseeker anytime. If a company is asking money from jobseeker, it is most probably a scam. Expected salary: Rs.25000 per month Location: Kochi, Kerala Job date: Tue, 13 Apr 2021 22:51:17 GMT Apply for the job now!
1 note
·
View note
Link

UTILITY STORES CORPORATION OF PAKISTAN (PRIVATE) LIMITED
HEAD OFFICE, ISLAMABAD
CAREER OPPORTUNITY
Utility Stores Corporation is looking for individuals for following positions who are innovative, productive and
enthusiastic with ability to deliver results: -
ProvinciaV
S.No Name of Post
Requisite Qualification
Regional Quota
and Experience
University Degree in Computer Science, Business
Administration or related field equals to 16 years of education
with minimum 10 years practical experience preferably in
Digital Transformation Project Management/Data Science/Big
Data/IT Systems and Architecture in an Industrial /
Project Manager
Merit: 01
Commercial/ FMCG organization.PMP, Agile, and/or other
1 (Market Based Salary)
Project Management-related certification(s).Must have
(01 Post)
experience of managing implementation projects in any Retail
Chain organization. Experience in developing detailed project
schedules and building effective Work Breakdown Structures
(WBS).Proficiency with MS Project, Excel, Visio, PowerPoint
and SharePoint with experience presenting to stakeholders and /
or Senior Leadership.
University Degree in Computer Science or related field equals
to 16 years of education. 7 years of experience with utilizing,
configuring, and installing software for connecting distributed
software and services across heterogeneous platforms.
Experience in securing production workloads in public/private
clouds, Private Cloud Deployment using Open Source
Technologies, like Linux, MaaS - Bare Metal Management
software, Open Stack software bundle and with Linux operating
Manager Systems/
Sindh: 01
systems. Strong understanding across cloud and infrastructure
Information Security
2 (Market Based Salary)
components (server, storage, data, and applications) to deliver
end to end cloud infrastructure architectures and designs. Clear
(01 Post)
understanding of the challenges of information security.
Excellent analytical and problem-solving abilities to identify
and fix security risks.
University Degree in Computer Science or related field equals
to 16 years of education.5 years of relevant work experience
particularly in Software Requirements, Software Architecture,
Software Development Fundamentals, Object-Oriented Design
(OOD), Multimedia Content Development and Software
Software Developer
Punjab: 01
ICT: 01
(Market Based Salary)
Debugging. Work experience as a Python Developer and
expertise in at least one popular Python framework (like
Django, Flask or Pyramid). Knowledge of object-relational
(02 Posts)
mapping (ORM), Odoo framework and front-end technologies
(like JavaScript and HTMLS).
University Degree in Computer Science or related field equals
to 16 years of education with3 years of relevant experience.
Demonstrable portfolio of released applications on the App
store or the Android market. Extensive knowledge of at least
Mobile App Developer
one programming language like Swift, Java etc. Experience
(Market Based Salary) Punjab
(Including ICT)
with third-party libraries and APIs. Superior analytical skills
(01 Post)
: : 01
with a good problem-solving attitude, ability to perform in a
team environment and ability to interpret and follow technical
plan.
University Degree in Computer Science or related field equals
to 16 years of education with 5 years of relevant database
administration experience. Hands-on experience in the
Database Administrator
definition, design, creation, and security of a database
5 (Market Based Salary) Punjab: 01
environment and database technologies (MySQL, MS SQL
(01 Post)
PostgreSQL Oracle, MongoDB). Experience with any cloud
services (OpenStack, AWS, and Microsoft Azure. Ability to
work independently with minimal supervision.
University Degree in Computer Science or related field equals
to 16 years of education with 5 years of relevant network
administration experience. Advanced knowledge of system
vulnerabilities and security issues and knowledge of best
practices around management, control, and monitoring of server
Network Administrator
infrastructure. Experience with firewalls, Internet VPN's
(Market Based Salary)
Punjab: 01
remote implementation, VMs, troubleshooting, and problem
(01 Post)
resolution. Ability to set up and configure server hardware.
University Degree in Computer Science or related field equals to
16 years of education with 5 years relevant hands on experience
with automation/DevOps activities. Extensive experience with
automation using scripting languages, such as Python as well as
configuration of infrastructure with code automation, version
control software and job execution tools, preferably Git.
Experience with Application Logging, Monitoring and
7 DevOps Engineers Punjab: 01
performance Management. Strong understanding of continuous
(Market Based Salary)
Sindh: 01 integration/delivery practices and other DevOps concepts.
(02 Posts)
Experience with cloud platforms, virtualization platforms and
containers, such as AWS, Azure, OpenStack, Docker,
VMWare/VSphere, etc. Experience with web application
environments, such as TCP/IP, SSL/TLS, HTTP, DNS, routing,
load balancing, CDNs, etc.
University Degree in Interaction Design, Architecture, or related
field equals to 16 years of education.3 years of relevant
experience with multiple visual design programs such as
Photoshop or Illustrator. Knowledgeable in wire-framing tools,
storyboards, user flows, and site mapping. In-depth
understanding of UI, latest design and technology trends and
UI Graphic Designer
their role in a commercial environment. Measure Human
8
Punjab (Including
(Market Based Salary)
ICT): 01 Computer interaction element of a design. Mathematical aptitude
(01 Posts)
and problem-solving skills to analyze problems and strategize
for better solutions. Able to multitask, prioritize, and manage
time efficiently, work independently and as an active member of
a team. Create visual elements such as logos, original images,
and illustrations to help deliver a message. Design layouts,
including selection of colors, images, and typefaces.
University Degree in Computer Science or related field equals to
16 years of education with minimum one year of relevant work
experience. Experience in Software Requirements, Software
Junior Software Baluchistan: 01
Architecture, Software Development Fundamentals, Object-
Developer
Oriented Design (OOD), Multimedia Content Development,
(Market Based Salary)
KPK: 01
Software Debugging. Work experience as a Python Developer
(02 Posts)
with expertise in at least one popular Python framework (like
Django, Flask or Pyramid). Knowledge of object-relational
mapping (ORM), Odoo framework and Familiarity with front-
end technologies (like JavaScript and HTML5).
1.
2.
3.
4.
5.
6.
Maximum age limit for positions at serial 1 & 2 is 45 years, for positions at serial 3to 8 is 40 years and
for position at serial 9 is 30 years.
• The appointment would be purely on a contract basis for a period of 2 years, extendable subject to
satisfactory performance.
Organization is committed to the principles of equal employment opportunity and to make employment
decision based on merit. Female Candidates are encouraged to apply.
Applicants working in Government, Semi-Government Autonomous Bodies should route their
applications through proper channel duly accompanied with NOC.
Advance copy of the application shall not be entertained.
Applicants sending applications through post courier must indicate the name of position on the top left
corner of the envelope.
Only shortlisted candidates would be called for interview.
Internal candidate meeting the above criteria can also apply.
Applications on the prescribed format (available on USC website www.usc.org.pk) along with CV
should reach through post on the following address within 15 days of the publication of this
advertisement. Applications received after due date will not be entertained.
Office of the General Manager (HR&A)
Utility Stores Corporation of Pakistan (Private) Limited
Head Office, Plot No. 2039, Sector F-7/G-7, Blue Area, Islamabad
Contact No. 051-9245039
7.
8.
9
PID(1) 6155/20
0 notes
Text
Migrate an application from using GridFS to using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility)
In many database applications there arises a need to store large objects, such as files, along with application data. A common approach is to store these files inside the database itself, despite the fact that a database isn’t the architecturally best choice for storing large objects. Primarily, because file system APIs are relatively basic (such as list, get, put, and delete), a fully-featured database management system, with its complex query operators, is overkill for this use case. Additionally, large objects compete for resources in an OLTP system, which can negatively impact query workloads. Moreover, purpose-built file systems are often far more cost-effective for this use case than using a database, in terms of storage costs as well as computing costs to support the file system. The natural alternative to storing files in a database is on a purpose-built file system or object store, such as Amazon Simple Storage Service (Amazon S3). You can use Amazon S3 as the location to store files or binary objects (such as PDF files, image files, and large XML documents) that are stored and retrieved as a whole. Amazon S3 provides a serverless service with built-in durability, scalability, and security. You can pair this with a database that stores the metadata for the object along with the Amazon S3 reference. This way, you can query the metadata via the database APIs, and retrieve the file via the Amazon S3 reference stored along with the metadata. Using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility) in this fashion is a common pattern. GridFS is a file system that has been implemented on top of the MongoDB NoSQL database. In this post, I demonstrate how to replace the GridFS file system with Amazon S3. GridFS provides some nonstandard extensions to the typical file system (such as adding searchable metadata for the files) with MongoDB-like APIs, and I further demonstrate how to use Amazon S3 and Amazon DocumentDB to handle these additional use cases. Solution overview For this post, I start with some basic operations against a GridFS file system set up on a MongoDB instance. I demonstrate operations using the Python driver, pymongo, but the same operations exist in other MongoDB client drivers. I use an Amazon Elastic Compute Cloud (Amazon EC2) instance that has MongoDB installed; I log in to this instance and use Python to connect locally. To demonstrate how this can be done with AWS services, I use Amazon S3 and an Amazon DocumentDB cluster for the more advanced use cases. I also use AWS Secrets Manager to store the credentials for logging into Amazon DocumentDB. An AWS CloudFormation template is provided to provision the necessary components. It deploys the following resources: A VPC with three private and one public subnets An Amazon DocumentDB cluster An EC2 instance with the MongoDB tools installed and running A secret in Secrets Manager to store the database credentials Security groups to allow the EC2 instance to communicate with the Amazon DocumentDB cluster The only prerequisite for this template is an EC2 key pair for logging into the EC2 instance. For more information, see Create or import a key pair. The following diagram illustrates the components in the template. This CloudFormation template incurs costs, and you should consult the relevant pricing pages before launching it. Initial setup First, launch the CloudFormation stack using the template. For more information on how to do this via the AWS CloudFormation console or the AWS Command Line Interface (AWS CLI), see Working with stacks. Provide the following inputs for the CloudFormation template: Stack name Instance type for the Amazon DocumentDB cluster (default is db.r5.large) Master username for the Amazon DocumentDB cluster Master password for the Amazon DocumentDB cluster EC2 instance type for the MongoDB database and the machine to use for this example (default: m5.large) EC2 key pair to use to access the EC2 instance SSH location to allow access to the EC2 instance Username to use with MongoDB Password to use with MongoDB After the stack has completed provisioning, I log in to the EC2 instance using my key pair. The hostname for the EC2 instance is reported in the ClientEC2InstancePublicDNS output from the CloudFormation stack. For more information, see Connect to your Linux instance. I use a few simple files for these examples. After I log in to the EC2 instance, I create five sample files as follows: cd /home/ec2-user echo Hello World! > /home/ec2-user/hello.txt echo Bye World! > /home/ec2-user/bye.txt echo Goodbye World! > /home/ec2-user/goodbye.txt echo Bye Bye World! > /home/ec2-user/byebye.txt echo So Long World! > /home/ec2-user/solong.txt Basic operations with GridFS In this section, I walk through some basic operations using GridFS against the MongoDB database running on the EC2 instance. All the following commands for this demonstration are available in a single Python script. Before using it, make sure to replace the username and password to access the MongoDB database with the ones you provided when launching the CloudFormation stack. I use the Python shell. To start the Python shell, run the following code: $ python3 Python 3.7.9 (default, Aug 27 2020, 21:59:41) [GCC 7.3.1 20180712 (Red Hat 7.3.1-9)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> Next, we import a few packages we need: >>> import pymongo >>> import gridfs Next, we connect to the local MongoDB database and create the GridFS object. The CloudFormation template created a MongoDB username and password based on the parameters entered when launching the stack. For this example, I use labdb for the username and labdbpwd for the password, but you should replace those with the parameter values you provided. We use the gridfs database to store the GridFS data and metadata: >>> mongo_client = pymongo.MongoClient(host="localhost") >>> mongo_client["admin"].authenticate(name="labdb", password="labdbpwd") Now that we have connected to MongoDB, we create a few objects. The first, db, represents the MongoDB database we use for our GridFS, namely gridfs. Next, we create a GridFS file system object, fs, that we use to perform GridFS operations. This GridFS object takes as an argument the MongoDB database object that was just created. >>> db = mongo_client.gridfs >>> fs = gridfs.GridFS(db) Now that this setup is complete, list the files in the GridFS file system: >>> print(fs.list()) [] We can see that there are no files in the file system. Next, insert one of the files we created earlier: >>> h = fs.put(open("/home/ec2-user/hello.txt", "rb").read(), filename="hello.txt") This put command returns an ObjectId that identifies the file that was just inserted. I save this ObjectID in the variable h. We can show the value of h as follows: >>> h ObjectId('601b1da5fd4a6815e34d65f5') Now when you list the files, you see the file we just inserted: >>> print(fs.list()) ['hello.txt'] Insert another file that you created earlier and list the files: >>> b = fs.put(open("/home/ec2-user/bye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt', 'hello.txt'] Read the first file you inserted. One way to read the file is by the ObjectId: >>> print(fs.get(h).read()) b'Hello World!n' GridFS also allows searching for files, for example by filename: >>> res = fs.find({"filename": "hello.txt"}) >>> print(res.count()) 1 We can see one file with the name hello.txt. The result is a cursor to iterate over the files that were returned. To get the first file, call the next() method: >>> res0 = res.next() >>> res0.read() b'Hello World!n' Next, delete the hello.txt file. To do this, use the ObjectId of the res0 file object, which is accessible via the _id field: >>> fs.delete(res0._id) >>> print(fs.list()) ['bye.txt'] Only one file is now in the file system. Next, overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = fs.put(open("/home/ec2-user/goodbye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt'] This overwrite doesn’t actually delete the previous version. GridFS is a versioned file system and keeps older versions unless you specifically delete them. So, when we find the files based on the bye.txt, we see two files: >>> res = fs.find({"filename": "bye.txt"}) >>> print(res.count()) 2 GridFS allows us to get specific versions of the file, via the get_version() method. By default, this returns the most recent version. Versions are numbered in a one-up counted way, starting at 0. So we can access the original version by specifying version 0. We can also access the most recent version by specifying version -1. First, the default, most recent version: >>> x = fs.get_version(filename="bye.txt") >>> print(x.read()) b'Goodbye World!n' Next, the first version: >>> x0 = fs.get_version(filename="bye.txt", version=0) >>> print(x0.read()) b'Bye World!n' The following code is the second version: >>> x1 = fs.get_version(filename="bye.txt", version=1) >>> print(x1.read()) b'Goodbye World!n' The following code is the latest version, which is the same as not providing a version, as we saw earlier: >>> xlatest = fs.get_version(filename="bye.txt", version=-1) >>> print(xlatest.read()) b'Goodbye World!n' An interesting feature of GridFS is the ability to attach metadata to the files. The API allows for adding any keys and values as part of the put() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = fs.put(open("/home/ec2-user/byebye.txt", "rb").read(), filename="bye.txt", somekey="somevalue") >>> c = fs.get_version(filename="bye.txt") >>> print(c.read()) b'Bye Bye World!n' We can access the custom metadata as a field of the file: >>> print(c.somekey) somevalue Now that we have the metadata attached to the file, we can search for files with specific metadata: >>> sk0 = fs.find({"somekey": "somevalue"}).next() We can retrieve the value for the key somekey from the following result: >>> print(sk0.somekey) somevalue We can also return multiple documents via this approach. In the following code, we insert another file with the somekey attribute, and then we can see that two files have the somekey attribute defined: >>> h = fs.put(open("/home/ec2-user/solong.txt", "rb").read(), filename="solong.txt", somekey="someothervalue", key2="value2") >>> print(fs.find({"somekey": {"$exists": True}}).count()) 2 Basic operations with Amazon S3 In this section, I show how to get the equivalent functionality of GridFS using Amazon S3. There are some subtle differences in terms of unique identifiers and the shape of the returned objects, so it’s not a drop-in replacement for GridFS. However, the major functionality of GridFS is covered by the Amazon S3 APIs. I walk through the same operations as in the previous section, except using Amazon S3 instead of GridFs. First, we create an S3 bucket to store the files. For this example, I use the bucket named blog-gridfs. You need to choose a different name for your bucket, because bucket names are globally unique. For this demonstration, we want to also enable versioning for this bucket. This allows Amazon S3 to behave similarly as GridFS with respect to versioning files. As with the previous section, the following commands are included in a single Python script, but I walk through these commands one by one. Before using the script, make sure to replace the secret name with the one created by the CloudFormation stack, as well as the Region you’re using, and the S3 bucket you created. First, we import a few packages we need: >>> import boto3 Next, we connect to Amazon S3 and create the S3 client: session = boto3.Session() s3_client = session.client('s3') It’s convenient to store the name of the bucket we created in a variable. Set the bucket variable appropriately: >>> bucket = "blog-gridfs" Now that this setup is complete, we list the files in the S3 bucket: >>> s3_client.list_objects(Bucket=bucket) {'ResponseMetadata': {'RequestId': '031B62AE7E916762', 'HostId': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'x-amz-request-id': '031B62AE7E916762', 'date': 'Wed, 03 Feb 2021 22:37:12 GMT', 'x-amz-bucket-region': 'us-east-1', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'IsTruncated': False, 'Marker': '', 'Name': 'blog-gridfs', 'Prefix': '', 'MaxKeys': 1000, 'EncodingType': 'url'} The output is more verbose, but we’re most interested in the Contents field, which is an array of objects. In this example, it’s absent, denoting an empty bucket. Next, insert one of the files we created earlier: >>> h = s3_client.put_object(Body=open("/home/ec2-user/hello.txt", "rb").read(), Bucket=bucket, Key="hello.txt") This put_object command takes three parameters: Body – The bytes to write Bucket – The name of the bucket to upload to Key – The file name The key can be more than just a file name, but can also include subdirectories, such as subdir/hello.txt. The put_object command returns information acknowledging the successful insertion of the file, including the VersionId: >>> h {'ResponseMetadata': {'RequestId': 'EDFD20568177DD45', 'HostId': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'x-amz-request-id': 'EDFD20568177DD45', 'date': 'Wed, 03 Feb 2021 22:39:19 GMT', 'x-amz-version-id': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab', 'etag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'ETag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'VersionId': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab'} Now if we list the files, we see the file we just inserted: >>> list = s3_client.list_objects(Bucket=bucket) >>> print([i["Key"] for i in list["Contents"]]) ['hello.txt'] Next, insert the other file we created earlier and list the files: >>> b = s3_client.put_object(Body=open("/home/ec2-user/bye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt', 'hello.txt'] Read the first file. In Amazon S3, use the bucket and key to get the object. The Body field is a streaming object that can be read to retrieve the contents of the object: >>> s3_client.get_object(Bucket=bucket, Key="hello.txt")["Body"].read() b'Hello World!n' Similar to GridFS, Amazon S3 also allows you to search for files by file name. In the Amazon S3 API, you can specify a prefix that is used to match against the key for the objects: >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket, Prefix="hello.txt")["Contents"]]) ['hello.txt'] We can see one file with the name hello.txt. Next, delete the hello.txt file. To do this, we use the bucket and file name, or key: >>> s3_client.delete_object(Bucket=bucket, Key="hello.txt") {'ResponseMetadata': {'RequestId': '56C082A6A85F5036', 'HostId': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'HTTPStatusCode': 204, 'HTTPHeaders': {'x-amz-id-2': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'x-amz-request-id': '56C082A6A85F5036', 'date': 'Wed, 03 Feb 2021 22:45:57 GMT', 'x-amz-version-id': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd', 'x-amz-delete-marker': 'true', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'DeleteMarker': True, 'VersionId': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd'} >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] The bucket now only contains one file. Let’s overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = s3_client.put_object(Body=open("/home/ec2-user/goodbye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] Similar to GridFS, with versioning turned on in Amazon S3, an overwrite doesn’t actually delete the previous version. Amazon S3 keeps older versions unless you specifically delete them. So, when we list the versions of the bye.txt object, we see two files: >>> y = s3_client.list_object_versions(Bucket=bucket, Prefix="bye.txt") >>> versions = sorted([(i["Key"],i["VersionId"],i["LastModified"]) for i in y["Versions"]], key=lambda y: y[2]) >>> print(len(versions)) 2 As with GridFS, Amazon S3 allows us to get specific versions of the file, via the get_object() method. By default, this returns the most recent version. Unlike GridFS, versions in Amazon S3 are identified with a unique identifier, VersionId, not a counter. We can get the versions of the object and sort them based on their LastModified field. We can access the original version by specifying the VersionId of the first element in the sorted list. We can also access the most recent version by not specifying a VersionId: >>> x0 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[0][1]) >>> print(x0["Body"].read()) b'Bye World!n' >>> x1 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[1][1]) >>> print(x1["Body"].read()) b'Goodbye World!n' >>> xlatest = s3_client.get_object(Bucket=bucket, Key="bye.txt") >>> print(xlatest["Body"].read()) b'Goodbye World!n' Similar to GridFS, Amazon S3 provides the ability to attach metadata to the files. The API allows for adding any keys and values as part of the Metadata field in the put_object() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = s3_client.put_object(Body=open("/home/ec2-user/byebye.txt", "rb").read(), Bucket=bucket, Key="bye.txt", Metadata={"somekey": "somevalue"}) >>> c = s3_client.get_object(Bucket=bucket, Key="bye.txt") We can access the custom metadata via the Metadata field: >>> print(c["Metadata"]["somekey"]) somevalue We can also print the contents of the file: >>> print(c["Body"].read()) b'Bye Bye World!n' One limitation with Amazon S3 versus GridFS is that you can’t search for objects based on the metadata. To accomplish this use case, we employ Amazon DocumentDB. Use cases with Amazon S3 and Amazon DocumentDB Some use cases may require you to find objects or files based on the metadata, beyond just the file name. For example, in an asset management use case, we may want to record the author or a list of keywords. To do this, we can use Amazon S3 and Amazon DocumentDB to provide a very similar developer experience, but leveraging the power of a purpose-built document database and a purpose-built object store. In this section, I walk through how to use these two services to cover the additional use case of needing to find files based on the metadata. First, we import a few packages: >>> import json >>> import pymongo >>> import boto3 We use the credentials that we created when we launched the CloudFormation stack. These credentials were stored in Secrets Manager. The name of the secret is the name of the stack that you used to create the stack (for this post, docdb-mongo), with -DocDBSecret appended to docdb-mongo-DocDBSecret. We assign this to a variable. You should use the appropriate Secrets Manager secret name for your stack: >>> secret_name = 'docdb-mongo-DocDBSecret' Next, we create a Secrets Manager client and retrieve the secret. Make sure to set the Region variable with the Region in which you deployed the stack: >>> secret_client = session.client(service_name='secretsmanager', region_name=region) >>> secret = json.loads(secret_client.get_secret_value(SecretId=secret_name)['SecretString']) This secret contains the four pieces of information that we need to connect to the Amazon DocumentDB cluster: Cluster endpoint Port Username Password Next we connect to the Amazon DocumentDB cluster: >>> docdb_client = pymongo.MongoClient(host=secret["host"], port=secret["port"], ssl=True, ssl_ca_certs="/home/ec2-user/rds-combined-ca-bundle.pem", replicaSet='rs0', connect = True) >>> docdb_client["admin"].authenticate(name=secret["username"], password=secret["password"]) True We use the database fs and the collection files to store our file metadata: >>> docdb_db = docdb_client["fs"] >>> docdb_coll = docdb_db["files"] Because we already have data in the S3 bucket, we create entries in the Amazon DocumentDB collection for those files. The information we store is analogous to the information in the GridFS fs.files collection, namely the following: bucket – The S3 bucket filename – The S3 key version – The S3 VersionId length – The file length in bytes uploadDate – The S3 LastModified date Additionally, any metadata that was stored with the objects in Amazon S3 is also added to the document in Amazon DocumentDB: >>> for ver in s3_client.list_object_versions(Bucket=bucket)["Versions"]: ... obj = s3_client.get_object(Bucket=bucket, Key=ver["Key"], VersionId=ver["VersionId"]) ... to_insert = {"bucket": bucket, "filename": ver["Key"], "version": ver["VersionId"], "length": obj["ContentLength"], "uploadDate": obj["LastModified"]} ... to_insert.update(obj["Metadata"]) ... docdb_coll.insert_one(to_insert) ... Now we can find files by their metadata: >>> sk0 = docdb_coll.find({"somekey": "somevalue"}).next() >>> print(sk0["somekey"]) somevalue To read the file itself, we can use the bucket, file name, and version to retrieve the object from Amazon S3: >>> print(s3_client.get_object(Bucket=sk0["bucket"], Key=sk0["filename"], VersionId=sk0["version"])["Body"].read()) b'Bye Bye World!n' Now we can put another file with additional metadata. To do this, we write the file to Amazon S3 and insert the metadata into Amazon DocumentDB: >>> h = s3_client.put_object(Body=open("/home/ec2-user/solong.txt", "rb").read(), Bucket=bucket, Key="solong.txt") >>> docdb_coll.insert_one({"bucket": bucket, "filename": "solong.txt", "version": h["VersionId"], "somekey": "someothervalue", "key2": "value2"}) Finally, we can search for files with somekey defined, as we did with GridFS, and see that two files match: >>> print(docdb_coll.find({"somekey": {"$exists": True}}).count()) 2 Clean up You can delete the resources created in this post by deleting the stack via the AWS CloudFormation console or the AWS CLI. Conclusion Storing large objects inside a database is typically not the best architectural choice. Instead, coupling a distributed object store, such as Amazon S3, with the database provides a more architecturally sound solution. Storing the metadata in the database and a reference to the location of the object in the object store allows for efficient query and retrieval operations, while reducing the strain on the database for serving object storage operations. In this post, I demonstrated how to use Amazon S3 and Amazon DocumentDB in place of MongoDB’s GridFS. I leveraged Amazon S3’s purpose-built object store and Amazon DocumentDB, a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. For more information about recent launches and blog posts, see Amazon DocumentDB (with MongoDB compatibility) resources. About the author Brian Hess is a Senior Solution Architect Specialist for Amazon DocumentDB (with MongoDB compatibility) at AWS. He has been in the data and analytics space for over 20 years and has extensive experience with relational and NoSQL databases. https://aws.amazon.com/blogs/database/migrate-an-application-from-using-gridfs-to-using-amazon-s3-and-amazon-documentdb-with-mongodb-compatibility/
0 notes
Text
How to train existing employees on Big Data
It’s very challenging to talk about Big Data without taking about the skills required for big data. At present companies are suffering from Big Data skill gap. According to a CompTIA survey of 500 U.S. business and IT executives, 50 percent of firms that are moving forward on the way to leverage big data, and 71 percent of firms that just started leveraging big data, feel that their staff are not so proficient in data management and analysis skills. Due to the lack of knowledge about big data processing, employees couldn’t give their full effort and it may cause for the project failure. So, the training of existing employees on Big Data should be an integrated part of big data processing.
Now, if you are a caretaker of a company you may have a question that “How”? How to train your employees on big data?
Let us try to find answer for these questions and to make your current team more big data ready.
If you are a company having a base of developers in java, python or Ruby then you may further proceed towards their training on big data because these are some of the language useful for big data processing. So, overall you first need to train your employee on these languages i.e. java, python, ruby, etc.
You also need to train them on database development side with NoSQL Big Data systems like HBASE, MongoDB, Cassandra etc. You may choose database developer with good SQL knowledge to train on database part.
For the installation or setup big data lab you may need to train some people as Linux admin so that they make you big data lab ready for Hadoop or AWS. For this you may choose people with Linux knowledge.
After all these theoretical training you may need to go for some practical work on big data processing. For this use Hortonworks or Cloudera services to give practical training to your employees.
There are many free and paid online courses available for big data training. Can start with free course and can move to paid ones, if anything specific required. You may provide these materials to your employee where they will get online study material as well as practical works on big data processing.
For the analyst work, first you need to find employees with good analytical and reasoning skills. Train them to use different big data analysing tools.
With the help of these ways you may train your existing employees on big data and make them ready to start. The McKinsey Global Institute estimates that by 2018, there will be a shortage of 1.7 million workers with big data skills in the U.S. alone—140,000 to 190,000 workers with deep technical and analytical expertise and 1.5 million managers and analysts with the skills to work with big data outputs. It is a truth that big data processing and most of its components are new but you can easily cross train your employees on big data if you really want to get in this field. You just need to take existing developers, analyst and admins and cross train them.
0 notes
Text
List Of Free Courses To Do In 2021
ASSLAMOALAIKUM !!
As I promised you guys for free courses in my last post and I noticed so many people want to learn something but they can’t afford expensive courses or they don’t know where to start. There shouldn’t be any compromise on getting yourself educated. So, here is the list of free courses for your Self Learning.
Disclaimer : These courses are for educational purpose only. It is illegal to sell someone’s courses or content without there permission. I’m not the owner of any of these courses. I’m only willing to help you and I don’t earn from this blog or any links.
All courses are in English Language.
How to Download
Download & Install uTorrent app in your Laptop or Mobile
Choose your course from the list below
Click the course title & it will download a (.torrent) file
Launch (.torrent) file and click OK
Now download will start & it’ll take time depending on your internet speed
Islam
Basics of Islamic Finance [download] [info]
Arabic of the Quran from Beginner to Advanced [download] [info]
How to read Quran in Tajweed, Quranic Arabic Course [download] [info]
Draw Islamic Geometric Patterns With A Compass And Ruler [download] [info]
Digital Marketing
The Complete Digital Marketing Course — 12 Courses in 1 [download] [info]
Ultimate Google Ads Training 2020: Profit with Pay Per Click [download] [info]
Digital Marketing Masterclass — 23 Courses in 1 [download] [info]
Mega Digital Marketing Course A-Z: 12 Courses in 1 + Updates [download] [info]
Digital Marketing Strategies Top Ad Agencies Use For Clients [download] [info]
Social Media Marketing + Agency
Social Media Marketing MASTERY | Learn Ads on 10+ Platforms [download] [info]
Social Media Marketing Agency : Digital Marketing + Business [download] [info]
Facebook Ads & Facebook Marketing MASTERY 2021 [download] [info]
Social Media Management — The Complete 2019 Manager Bootcamp [download] [info]
Instagram Marketing 2021: Complete Guide To Instagram Growth [download] [info]
How Retargeting Works–The Complete Guide To Retargeting Ads! [download] [info]
YouTube Marketing & YouTube SEO To Get 1,000,000+ Views [download] [info]
YouTube Masterclass — Your Complete Guide to YouTube [download] [info]
Video Editing + Animation
Premiere Pro CC for Beginners: Video Editing in Premiere [download] [info]
Video Editing complete course | Adobe Premiere Pro CC 2020 [download] [info]
Learn Video Editing with Premiere Pro CC for beginners [download] [info]
2D Animation With No Drawing Skills in AE [download] [info]
Maya for Beginners: Complete Guide to 3D Animation in Maya [download] [info]
After Effects — Motion Graphics & Data Visualization [download] [info]
After Effects CC 2020: Complete Course from Novice to Expert [download] [info]
Graphic Designing
Adobe Photoshop CC — Essentials Training Course [download] [info]
Photoshop CC Retouching and Effects Masterclass [download] [info]
Graphic Design Masterclass — Learn GREAT Design [download] [info]
Graphic Design Bootcamp: Photoshop, Illustrator, InDesign [download] [info]
Canva 2019 Master Course | Use Canva to Grow your Business [download] [info]
CorelDRAW for Beginners: Graphic Design in Corel Draw [download] [info]
Learn Corel DRAW |Vector Graphic Design From Scratch | 2020 [download] [info]
Digital Painting: From Sketch to Finished Product [download] [info]
The Ultimate Digital Painting Course — Beginner to Advanced [download] [info]
Graphic Design Masterclass Intermediate: The NEXT Level [download] [info]
Amazon & Dropshipping
How to Start an Amazon FBA Store on a Tight Budget [download] [info]
The Last Amazon FBA Course — [ 2020 ] Private Label Guide [download] [info]
Amazon Affiliate Marketing Using Authority Site (Beginners) [download] [info]
Amazon Affiliates Mastermind: Build Authority Sites [download] [info]
Amazon FBA Course — How to Sell on Amazon MASTERY Course [download] [info]
The Complete Shopify Aliexpress Dropship course [download] [info]
Virtual Assistant
New Virtual Assistant Business — Your Blueprint to Launch [download] [info]
Must-Have Tools for Virtual Assistants [download] [info]
Learn How To Hire and Manage Your Virtual Assistants [download] [info]
Common Virtual Assistant Interview Questions (and Answers) [download] [info]
WordPress
Wordpress for Beginners — Master Wordpress Quickly [download] [info]
Become a WordPress Developer: Unlocking Power With Code [download] [info]
How To Make a Wordpress Website -Elementor Page Builder [download] [info]
The Complete WordPress Website & SEO Training Masterclass [download] [info]
Complete WordPress Theme & Plugin Development Course [2020] [download] [info]
How to build an ecommerce store with wordpress & woocommerce [download] [info]
Website Development for Beginners in Wordpress [download] [info]
Web Design with WordPress: Design and Build Great Websites [download] [info]
Web Development + SEO
The Complete Web Developer Course 2.0 [download] [info]
Build Websites from Scratch with HTML & CSS [download] [info]
Django 3 — Full Stack Websites with Python Web Development [download] [info]
Web Development: Make A Website That Will Sell For Thousands [download] [info]
Set up a localhost Web Server for Faster Website Development [download] [info]
Website Design With HTML, CSS And JavaScript For Beginners [download] [info]
Adobe Muse CC Course — Design and Launch Websites [download] [info]
SEO 2020: Complete SEO Training + SEO for WordPress Websites [download] [info]
Complete SEO Training With Top SEO Expert Peter Kent! [download] [info]
SEO AUDIT MASTERCLASS: How to do a Manual SEO Audit in 2020 [download] [info]
Freelancing
Seth Godin’s Freelancer Course [download] [info]
Fiverr Freelancing 2021: Sell Fiverr Gigs Like The Top 1% [download] [info]
Complete Web Design: from Figma to Webflow to Freelancing [download] [info]
Freelance Bootcamp — The Comprehensive Guide to Freelancing [download] [info]
Learn Photoshop, Web Design & Profitable Freelancing [download] [info]
Start a Freelance Business: Take Back Your Freedom Now! [download] [info]
How to Dominate Freelancing on Upwork [download] [info]
Copywriting — Become a Freelance Copywriter, your own boss [download] [info]
The Freelance Masterclass: For Creatives [download] [info]
Freelance Article Writing: Start a Freelance Writing Career! [download] [info]
Copywriting: Master Copywriting A — Z | Content Writing[download] [info]
Computer Science
Computer Science 101: Master the Theory Behind Programming [download] [info]
SQL — MySQL for Data Analytics and Business Intelligence [download] [info]
Spark and Python for Big Data with PySpark [download] [info]
Learn SAP ABAP Objects — Online Training Course [download] [info]
Build Responsive Real World Websites with HTML5 and CSS3 [download] [info]
Modern HTML & CSS From The Beginning (Including Sass) [download] [info]
Java Programming Masterclass for Software Developers [download] [info]
Java In-Depth: Become a Complete Java Engineer! [download] [info]
MongoDB — The Complete Developer’s Guide 2020 [download] [info]
Complete Whiteboard Animation in VideoScribe — 5 Animations [download] [info]
The Complete React Native + Hooks Course [2020 Edition] [download] [info]
Flutter & Dart — The Complete Guide [2021 Edition] [download] [info]
Ultimate AWS Certified Solutions Architect Associate 2021 [download] [info]
Cisco CCNA 200–301 — The Complete Guide to Getting Certified [download] [info]
App Development
Mobile App Development with PhoneGap [download] [info]
Desktop Application Development Windows Forms C# [download] [info]
Python Desktop Application Development with PyQt [download] [info]
GUI Development with Python and Tkinter [download] [info]
Cross-platform Desktop App Development for Windows Mac Linux [download] [info]
The Complete Android Oreo Developer Course — Build 23 Apps! [download] [info]
The Complete Android App Development [download] [info]
Complete VB.Net Course,Beginners to Visual Basic Apps-7 in 1 [download] [info]
Learning Visual Basic .NET — A Guide To VB.NET Programming [download] [info]
Game Development
Lua Programming and Game Development with LÖVE [download] [info]
Unreal Engine C++ Developer: Learn C++ and Make Video Games [download] [info]
Complete C# Unity Game Developer 2D [download] [info]
Complete C# Unity Game Developer 3D [download] [info]
Python Bootcamp 2020 Build 15 working Applications and Games [download] [info]
RPG Core Combat Creator: Learn Intermediate Unity C# Coding [download] [info]
Make a fighting game in Unity [download] [info]
Coding
Ultimate Rust Crash Course [download] [info]
C Programming For Beginners — Master the C Language [download] [info]
Mastering Data Structures & Algorithms using C and C++ [download] [info]
C++: From Beginner to Expert [download] [info]
Lua Scripting: Master complete Lua Programming from scratch [download] [info]
PHP for Beginners — Become a PHP Master — CMS Project [download] [info]
Learn Object Oriented PHP By Building a Complete Website [download] [info]
PHP with Laravel for beginners — Become a Master in Laravel [download] [info]
Learn Python Programming Masterclass [download] [info]
Python Beyond the Basics — Object-Oriented Programming [download] [info]
Node.js, Express, MongoDB & More: The Complete Bootcamp 2021 [download] [info]
Node.js API Masterclass With Express & MongoDB [download] [info]
Engineering & Technology
Arduino Step by Step: Getting Started [download] [info]
Arduino Programming and Hardware Fundamentals with Hackster [download] [info]
Arduino Step by Step Getting Serious [download] [info]
Complete Guide to Build IOT Things from Scratch to Market [download] [info]
Introduction to Internet of Things(IoT) using Raspberry Pi 2 [download] [info]
Internet of Things (IoT) — The Mega Course [download] [info]
Automobile Engineering: Vehicle dynamics for Beginners [download] [info]
Automotive 101: A Beginners Guide To Automotive Repair [download] [info]
Mechanical Engineering and Electrical Engineering Explained [download] [info]
Basics Of PLC Programming From Zero Using LogixPro Simulator [download] [info]
Internal Combustion Engine Basics (Mechanical Engineering) [download] [info]
Deep Learning A-Z: Hands-On Artificial Neural Networks [download] [info]
Artificial Intelligence A-Z™: Learn How To Build An AI [download] [info]
Tensorflow 2.0: Deep Learning and Artificial Intelligence [download] [info]
Business & Management
Business Continuity Management System. ISO 22301 [download] [info]
The Data Science Course 2020: Complete Data Science Bootcamp [download] [info]
An Entire MBA in 1 Course:Award Winning Business School Prof [download] [info]
Brand Management: Build Successful Long Lasting Brands [download] [info]
IT Help Desk Professional [download] [info]
Ethics and Attitude in the Office [download] [info]
The Ultimate Microsoft Office 2016 Training Bundle [download] [info]
How to Sell Anything to Anyone [download] [info]
The Complete Communication Skills Master Class for Life [download] [info]
Business Ethics: How to Create an Ethical Organization [download] [info]
Others Mixed
Blogging Masterclass: How To Build A Successful Blog In 2021 [download] [info]
Blogging for a Living — Perfect Small Budget Project [download] [info]
The Complete JavaScript Course 2021: From Zero to Expert! [download] [info]
The Complete Foundation Stock Trading Course [download] [info]
Lead Generation MASTERY with Facebook Lead & Messenger Ads [download] [info]
Data Entry Course for Beginners [download] [info]
SAP WM Course on RF/Mobile Data Entry [download] [info]
The complete AutoCAD 2018–21 course [download] [info]
Complete course in AutoCAD 2020 : 2D and 3D [download] [info]
The Complete Foundation FOREX Trading Course [download] [info]
Complete Fitness Trainer Certification: Beginner To Advanced [download] [info]
Health Coaching Certification Holistic Wellness Health Coach [download] [info]
Chinese language for beginners : Mandarin Chinese [download] [info]
Learn Italian Language: Complete Italian Course — Beginners [download] [info]
Emotional Intelligence: Master Anxiety, Fear, & Emotions [download] [info]
Accounting & Financial Statement Analysis: Complete Training [download] [info]
Accounting in 60 Minutes — A Brief Introduction [download] [info]
The Complete Cyber Security Course : Hackers Exposed! [download] [info]
How To Be Successful in Network Marketing [download] [info]
Create and Sell Online Courses in Website with WordPress CMS [download] [info]
Teacher Training — How to Teach Online — Remote Teaching 1Hr [download] [info]
Sell Your Art Masterclass [download] [info]
The Ultimate Guide To Food Photography [download] [info]
Fundamentals of Analyzing Real Estate Investments [download] [info]
1 note
·
View note
Text
10 Top Mongodb GUI tools to manage databases graphically

MongoDB open source database program is available in Community, Enterprise MongoDB Atlas Editions. The community server edition is free to use while for the MongoDB Enterprise Server which is commercial edition one has to buy its subscription. It is available for Windows, Linux, and OS X. The MongoDB Atlas is meant to run on cloud platforms such as AWS, Microsoft Azure, and Google Cloud Platform. The MongoDB is a document-oriented database program fall under the NoSQL database program category and uses JSON-like documents with schemata. The default interface of the MongoDB is a (CLI) command line and become difficult for new users to handle the databases like a pro. So, here we come up with some of the best available MongoDB management tools to provide a GUI interface in order to improve productivity. Just like phpmyadmin to provide HTTP web-based GUI interface for MySQL/MariaDB databases. However, all tools comprised here are not HTTP based and only a few of them provide a web interface to MongoDB. Before moving to MongoDB GUI tools see: How to download & install Mongodb on Ubuntu 19.04 via command terminal Here is the list of most popular MongoDB management tools with GUI Interface:
Read the full article
#bestmongodbgui#database#developers#mongobooster#mongodb#mongodbdatabase#mongodbguimac#mongodbguiubuntu#mongodbtools#nosqlboosterformongodb
0 notes
Text
10 Basic Strides for Planning Another Laborer
By Tres Logics
That is a respectable new Linux laborer you showed up at… it would be a shame if something some way or another figured out how to happen to it. It might drive okay to leave the holder, yet before you put it in progress, there are 10 phases you need to take to guarantee it's planned securely. The nuances of these methods may change starting with one scattering then onto the next, yet sensibly they apply to any sort of Linux. By affirming these methods on new specialists, you can ensure that they have in any occasion fundamental protection from the most broadly perceived attacks.
What Why
Customer configuration Secure your accreditations
Association configuration Build up correspondences
Pack management Add what you need, wipe out what you don't
Update installation Fix your shortcomings
NTP configuration Forestall clock drift
Firewalls and Iptables Limit your external impression
Getting SSH Solidify far away gatherings
Daemon configuration Minimize your attack surface
SELinux and further hardening Protect the piece and applications
Logging Know what's happening
1 - Customer Game plan
Indisputably the main thing you should do if it wasn't fundamental for your working framework game plan, is to change the root secret key. This should act normally obvious anyway can be incredibly overlooked during an ordinary laborer course of action. The mysterious word should be at any rate 8 characters, using a blend of upper and lowercase letters, numbers, and pictures. You should in like manner set up a mysterious key procedure that decides developing, locking, history, and unpredictability necessities if you will use close by records. A large part of the time, you ought to debilitate the root customer through and through and make non-supported customer accounts with sudo access for the people who require raised rights.
2 - Association Plan
Maybe the most fundamental arrangements you'll need to make is to engage network accessibility by distributing the specialist an IP address and hostname. For most laborers, you'll need to use a static IP so clients can by and large find the resource at a comparative area. If your association uses VLANs, consider how disconnected the specialist's section is and where it would best fit. In case you don't use IPv6, turn it off. Set the hostname, region, and DNS specialist information. At any rate two DNS laborers should be used for overabundance and you should test ns-lookup to guarantee the name objective is working adequately.
3 - Pack The chiefs
Presumably, you're setting up your new specialist for a specific explanation, so guarantee you present whatever groups you may need if they aren't fundamental for the scattering you're using. These could be application packs like PHP, MongoDB, Nginx or supporting groups like a pear. Essentially, any coincidental groups that are acquainted on your structure should with be taken out to wither the specialist impression. The whole of this should be done through your movement's pack the board game plan, for instance, yum or capable for less complex organization so to speak.
4 - Update Foundation and Plan
At the point when you have the right packages presented on your laborer, you ought to guarantee everything is revived. The groups you presented, yet the part and default packages as well. But in the event that you have a need for a specific structure, you should reliably use the latest creation conveyance to keep your system secure. Ordinarily, your pack the chief's plan will pass on the most state-of-the-art maintained variation. You should in like manner consider setting up modified revives inside the group the board instrument if doing so works for the service(s) you're working with on this laborer
5 - NTP Game plan
Mastermind your specialist to synchronize its chance with NTP laborers. These could be inside NTP laborers if your present condition has those or outside miscreants that are open for anyone. What's critical is to prevent clock skim, where the laborer's clock inclines from the constant. This can cause a huge load of issues, including approval issues where the time incline between the laborer and the affirming establishment is assessed before surrendering access. This should be a fundamental change, yet it's an essential piece of a strong system.
6 - Firewalls and iptables
Dependent upon your movement, iptables may as of now be completely gotten and anticipate that you should open what you need, anyway paying little psyche to the default config, you should reliably explore it and guarantee it's set up the way where you need. Try to reliably use the norm of least benefit and simply open those ports you thoroughly need for the organizations on that laborer. If your specialist is behind a submitted firewall or something to that effect, make sure to deny everything aside from what's significant there as well. Tolerating your iptables/firewall IS restrictive as per usual, make sure to open up what you need for your specialist to handle its work!
7 - Getting SSH
SSH is the rule far away access method for Linux courses and as such should be fittingly gotten. You ought to incapacitate the root's ability to SSH in indirectly, whether or not you injured the record with the objective that just in case of root gets enabled on the specialist for no good reason it really will not be exploitable remotely. You can similarly restrict SSH to certain IP ranges if you have a fixed course of action of client IPs that will interface. On the other hand, you can change the default SSH port to "dull" it, yet really, a fundamental yield will uncover the new open port to any person who needs to find it. Finally, you can disable mystery express check completely and use confirmation based affirmation to decrease extensively further the chances of SSH misuse.
8 - Daemon Arrangement
You've cleaned up your packs, and yet, it's basic to set the right applications to AutoStart on reboot. Make sure to execute any daemons you needn't mess with. One key to a protected specialist is decreasing the unique impression whatever amount as could be anticipated so the solitary surface districts available for attack are those required by the application(s). At whatever point this is done, lingering organizations should be cemented whatever amount as could be required to ensure strength.
9 - SELinux and Further Cementing
In case you've anytime used a Red Cap distro, you might be familiar with SELinux, the bit setting gadget that safeguards the system from various errands. SELinux is unprecedented at getting against unapproved use and access of structure resources. It's in like manner inconceivable at breaking applications, so guarantee you test your plan out with SELinux enabled and use the logs to guarantee nothing certifiable is being obstructed. Past this, you need to explore setting any applications like MySQL or Apache, as everybody will have a set-up of best practices to follow.
10 - Logging
Finally, you ought to guarantee that the level of logging you need is enabled and that you have sufficient resources for it. You will end up examining this specialist, so assist yourself with excursion and collect the logging structure you'll need to deal with issues quickly. Most programming has configurable logging, nonetheless, you'll require some experimentation to find the right concordance between inadequate information and to a limit. There are a huge gathering of pariah logging instruments that can help including combination to portrayal, yet every environment ought to be considered for its necessities first. By then, you can find the tool(s) that will help you fill them.
Each and every one of these methods can save some push to complete, especially the initial go through around. In any case, by setting up an ordinary act of starting laborer course of action, you can ensure that new machines in your present situation will be adaptable. Failure to take any of these steps can incite truly real results if your laborer is ever the target of an attack. Following them won't guarantee prosperity - data infiltrates happen - yet it makes it certainly harder for malignant performers and will require some degree of capacity to endure.
Worker Setup By Tres Logics
We have a solid group of specialists in the field of various Worker solidifying Establishment/setup, the board, and support.
We offer types of assistance in the accompanying regions:
Cloud Worker Establishments/Arrangement, The executives, support, and organizations. (MS Sky blue, AWS, and so forth)
Linux Worker Establishment, The board, and Support (Ubuntu, RedHat, CentOS, and so forth)
Window Workers (2016 ,2012 ,2008)
Linux, Apache, MySQL, and PHP (Light) Arrangement and Upkeep
Control Board Establishment/arrangement, the executives, and support (cPanel, Plesk, CentOS Web Board).
Java Worker Climate arrangement (Apache Tomcat, JBoss EAP, Uncontrollably, and so forth)
Data set worker establishment/setup, replication, and the board (SQL Worker, MongoDB, Redis, MySQL, and so forth)
Worker Information Movement
Mail Worker Arrangement/Setup and the board
Worker Security and checking
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - cvwing http://cvwing.com/jobs/technology/cloud-dba_i13145
0 notes
Text
All applications generate information when running, this information is stored as logs. As a system administrator, you need to monitor these logs to ensure the proper functioning of the system and therefore prevent risks and errors. These logs are normally scattered over servers and management becomes harder as the data volume increases. Graylog is a free and open-source log management tool that can be used to capture, centralize and view real-time logs from several devices across a network. It can be used to analyze both structured and unstructured logs. The Graylog setup consists of MongoDB, Elasticsearch, and the Graylog server. The server receives data from the clients installed on several servers and displays it on the web interface. Below is a diagram illustrating the Graylog architecture Graylog offers the following features: Log Collection – Graylog’s modern log-focused architecture can accept nearly any type of structured data, including log messages and network traffic from; syslog (TCP, UDP, AMQP, Kafka), AWS (AWS Logs, FlowLogs, CloudTrail), JSON Path from HTTP API, Beats/Logstash, Plain/Raw Text (TCP, UDP, AMQP, Kafka) e.t.c Log analysis – Graylog really shines when exploring data to understand what is happening in your environment. It uses; enhanced search, search workflow and dashboards. Extracting data – whenever log management system is in operations, there will be summary data that needs to be passed to somewhere else in your Operations Center. Graylog offers several options that include; scheduled reports, correlation engine, REST API and data fowarder. Enhanced security and performance – Graylog often contains sensitive, regulated data so it is critical that the system itself is secure, accessible, and speedy. This is achieved using role-based access control, archiving, fault tolerance e.t.c Extendable – with the phenomenal Open Source Community, extensions are built and made available in the market to improve the funmctionality of Graylog This guide will walk you through how to run the Graylog Server in Docker Containers. This method is preferred since you can run and configure Graylog with all the dependencies, Elasticsearch and MongoDB already bundled. Setup Prerequisites. Before we begin, you need to update the system and install the required packages. ## On Debian/Ubuntu sudo apt update && sudo apt upgrade sudo apt install curl vim git ## On RHEL/CentOS/RockyLinux 8 sudo yum -y update sudo yum -y install curl vim git ## On Fedora sudo dnf update sudo dnf -y install curl vim git 1. Install Docker and Docker-Compose on Linux Of course, you need the docker engine to run the docker containers. To install the docker engine, use the dedicated guide below: How To Install Docker CE on Linux Systems Once installed, check the installed version. $ docker -v Docker version 20.10.13, build a224086 You also need to add your system user to the docker group. This will allow you to run docker commands without using sudo sudo usermod -aG docker $USER newgrp docker With docker installed, proceed and install docker-compose using the guide below: How To Install Docker Compose on Linux Verify the installation. $ docker-compose version Docker Compose version v2.3.3 Now start and enable docker to run automatically on system boot. sudo systemctl start docker && sudo systemctl enable docker 2. Provision the Graylog Container The Graylog container will consist of the Graylog server, Elasticsearch, and MongoDB. To be able to achieve this, we will capture the information and settings in a YAML file. Create the YAML file as below: vim docker-compose.yml In the file, add the below lines: version: '2' services: # MongoDB: https://hub.docker.com/_/mongo/ mongodb: image: mongo:4.2 networks: - graylog #DB in share for persistence volumes: - /mongo_data:/data/db # Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/docker.html
elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2 #data folder in share for persistence volumes: - /es_data:/usr/share/elasticsearch/data environment: - http.host=0.0.0.0 - transport.host=localhost - network.host=0.0.0.0 - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 mem_limit: 1g networks: - graylog # Graylog: https://hub.docker.com/r/graylog/graylog/ graylog: image: graylog/graylog:4.2 #journal and config directories in local NFS share for persistence volumes: - /graylog_journal:/usr/share/graylog/data/journal environment: # CHANGE ME (must be at least 16 characters)! - GRAYLOG_PASSWORD_SECRET=somepasswordpepper # Password: admin - GRAYLOG_ROOT_PASSWORD_SHA2=e1b24204830484d635d744e849441b793a6f7e1032ea1eef40747d95d30da592 - GRAYLOG_HTTP_EXTERNAL_URI=http://192.168.205.4:9000/ entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh networks: - graylog links: - mongodb:mongo - elasticsearch restart: always depends_on: - mongodb - elasticsearch ports: # Graylog web interface and REST API - 9000:9000 # Syslog TCP - 1514:1514 # Syslog UDP - 1514:1514/udp # GELF TCP - 12201:12201 # GELF UDP - 12201:12201/udp # Volumes for persisting data, see https://docs.docker.com/engine/admin/volumes/volumes/ volumes: mongo_data: driver: local es_data: driver: local graylog_journal: driver: local networks: graylog: driver: bridge In the file, replace: GRAYLOG_PASSWORD_SECRET with your own password which must be at least 16 characters GRAYLOG_ROOT_PASSWORD_SHA2 with a SHA2 password obtained using the command: echo -n "Enter Password: " && head -1 1514/tcp, :::1514->1514/tcp, 0.0.0.0:9000->9000/tcp, 0.0.0.0:1514->1514/udp, :::9000->9000/tcp, :::1514->1514/udp, 0.0.0.0:12201->12201/tcp, 0.0.0.0:12201->12201/udp, :::12201->12201/tcp, :::12201->12201/udp thor-graylog-1 1a21d2de4439 docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2 "/tini -- /usr/local…" 31 seconds ago Up 28 seconds 9200/tcp, 9300/tcp thor-elasticsearch-1 1b187f47d77e mongo:4.2 "docker-entrypoint.s…" 31 seconds ago Up 28 seconds 27017/tcp thor-mongodb-1 If you have a firewall enabled, allow the Graylog service port through it. ##For Firewalld sudo firewall-cmd --zone=public --add-port=9000/tcp --permanent sudo firewall-cmd --reload ##For UFW sudo ufw allow 9000/tcp 5. Access the Graylog Web UI Now open the Graylog web interface using the URL http://IP_address:9000. Log in using the username admin and SHA2 password(StrongPassw0rd) set in the YAML. On the dashboard, let’s create the first input to get logs by navigating to the systems tab and selecting input. Now search for Raw/Plaintext TCP and click launch new input Once launched, a pop-up window will appear as below. You only need to change the name for the input, port(1514), and select the node, or “Global” for the location for the input. Leave the other details as they are. Save the file and try sending a plain text message to the Graylog Raw/Plaintext TCP input on port 1514. echo 'First log message' | nc localhost 1514 ##OR from another server##
echo 'First log message' | nc 192.168.205.4 1514 On the running Raw/Plaintext Input, show received messages The received message should be displayed as below. You can as well export this to a dashboard as below. Create the dashboard by providing the required information. You will have the dashboard appear under the dashboards tab. Conclusion That is it! We have triumphantly walked through how to run the Graylog Server in Docker Containers. Now you can monitor and access logs on several servers with ease. I hope this was significant to you.
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - JobsAggregation http://jobsaggregation.com/jobs/technology/cloud-dba_i9405
0 notes