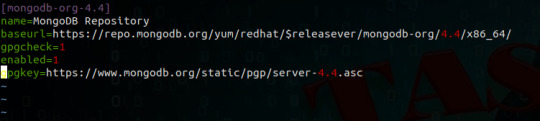
#install MongoDB shell amazon linux
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Install MongoDB on AWS EC2 Instances.
Install MongoDB on AWS EC2 Instances.
We will see how to install MongoDB on AWS ec2 Instances, amazon Linux 2 or we can install MongoDB of any version on the AWS Linux 2 server in this article. The Amazon Linux 2 server is the RPM-based server with the 5 years Long Term Support by AWS. (Amazon Web Services). MongoDB is a No-SQL database which is written in C++, It uses a JSON like structure. MongoDB is a cross-platform and…
View On WordPress
#aws mongodb service#install mongo shell on amazon linux#install mongodb#install mongodb centos 7#install mongodb centos 8#install MongoDB in AWS ec2 instance#install MongoDB in AWS linux.#install MongoDB on amazon ec2#install MongoDB on amazon linux#install MongoDB on amazon linux AMI#install mongodb on aws#install MongoDB on AWS server#install MongoDB shell amazon linux#mongodb install linux
0 notes
Link
MongoDB is a NoSQL database that is designed to store large data amounts in document-oriented storage with a dynamic schema. Install MongoDB centos 7 is the leading NoSQL database used in modern web applications.
0 notes
Text
Migrate an application from using GridFS to using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility)
In many database applications there arises a need to store large objects, such as files, along with application data. A common approach is to store these files inside the database itself, despite the fact that a database isn’t the architecturally best choice for storing large objects. Primarily, because file system APIs are relatively basic (such as list, get, put, and delete), a fully-featured database management system, with its complex query operators, is overkill for this use case. Additionally, large objects compete for resources in an OLTP system, which can negatively impact query workloads. Moreover, purpose-built file systems are often far more cost-effective for this use case than using a database, in terms of storage costs as well as computing costs to support the file system. The natural alternative to storing files in a database is on a purpose-built file system or object store, such as Amazon Simple Storage Service (Amazon S3). You can use Amazon S3 as the location to store files or binary objects (such as PDF files, image files, and large XML documents) that are stored and retrieved as a whole. Amazon S3 provides a serverless service with built-in durability, scalability, and security. You can pair this with a database that stores the metadata for the object along with the Amazon S3 reference. This way, you can query the metadata via the database APIs, and retrieve the file via the Amazon S3 reference stored along with the metadata. Using Amazon S3 and Amazon DocumentDB (with MongoDB compatibility) in this fashion is a common pattern. GridFS is a file system that has been implemented on top of the MongoDB NoSQL database. In this post, I demonstrate how to replace the GridFS file system with Amazon S3. GridFS provides some nonstandard extensions to the typical file system (such as adding searchable metadata for the files) with MongoDB-like APIs, and I further demonstrate how to use Amazon S3 and Amazon DocumentDB to handle these additional use cases. Solution overview For this post, I start with some basic operations against a GridFS file system set up on a MongoDB instance. I demonstrate operations using the Python driver, pymongo, but the same operations exist in other MongoDB client drivers. I use an Amazon Elastic Compute Cloud (Amazon EC2) instance that has MongoDB installed; I log in to this instance and use Python to connect locally. To demonstrate how this can be done with AWS services, I use Amazon S3 and an Amazon DocumentDB cluster for the more advanced use cases. I also use AWS Secrets Manager to store the credentials for logging into Amazon DocumentDB. An AWS CloudFormation template is provided to provision the necessary components. It deploys the following resources: A VPC with three private and one public subnets An Amazon DocumentDB cluster An EC2 instance with the MongoDB tools installed and running A secret in Secrets Manager to store the database credentials Security groups to allow the EC2 instance to communicate with the Amazon DocumentDB cluster The only prerequisite for this template is an EC2 key pair for logging into the EC2 instance. For more information, see Create or import a key pair. The following diagram illustrates the components in the template. This CloudFormation template incurs costs, and you should consult the relevant pricing pages before launching it. Initial setup First, launch the CloudFormation stack using the template. For more information on how to do this via the AWS CloudFormation console or the AWS Command Line Interface (AWS CLI), see Working with stacks. Provide the following inputs for the CloudFormation template: Stack name Instance type for the Amazon DocumentDB cluster (default is db.r5.large) Master username for the Amazon DocumentDB cluster Master password for the Amazon DocumentDB cluster EC2 instance type for the MongoDB database and the machine to use for this example (default: m5.large) EC2 key pair to use to access the EC2 instance SSH location to allow access to the EC2 instance Username to use with MongoDB Password to use with MongoDB After the stack has completed provisioning, I log in to the EC2 instance using my key pair. The hostname for the EC2 instance is reported in the ClientEC2InstancePublicDNS output from the CloudFormation stack. For more information, see Connect to your Linux instance. I use a few simple files for these examples. After I log in to the EC2 instance, I create five sample files as follows: cd /home/ec2-user echo Hello World! > /home/ec2-user/hello.txt echo Bye World! > /home/ec2-user/bye.txt echo Goodbye World! > /home/ec2-user/goodbye.txt echo Bye Bye World! > /home/ec2-user/byebye.txt echo So Long World! > /home/ec2-user/solong.txt Basic operations with GridFS In this section, I walk through some basic operations using GridFS against the MongoDB database running on the EC2 instance. All the following commands for this demonstration are available in a single Python script. Before using it, make sure to replace the username and password to access the MongoDB database with the ones you provided when launching the CloudFormation stack. I use the Python shell. To start the Python shell, run the following code: $ python3 Python 3.7.9 (default, Aug 27 2020, 21:59:41) [GCC 7.3.1 20180712 (Red Hat 7.3.1-9)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> Next, we import a few packages we need: >>> import pymongo >>> import gridfs Next, we connect to the local MongoDB database and create the GridFS object. The CloudFormation template created a MongoDB username and password based on the parameters entered when launching the stack. For this example, I use labdb for the username and labdbpwd for the password, but you should replace those with the parameter values you provided. We use the gridfs database to store the GridFS data and metadata: >>> mongo_client = pymongo.MongoClient(host="localhost") >>> mongo_client["admin"].authenticate(name="labdb", password="labdbpwd") Now that we have connected to MongoDB, we create a few objects. The first, db, represents the MongoDB database we use for our GridFS, namely gridfs. Next, we create a GridFS file system object, fs, that we use to perform GridFS operations. This GridFS object takes as an argument the MongoDB database object that was just created. >>> db = mongo_client.gridfs >>> fs = gridfs.GridFS(db) Now that this setup is complete, list the files in the GridFS file system: >>> print(fs.list()) [] We can see that there are no files in the file system. Next, insert one of the files we created earlier: >>> h = fs.put(open("/home/ec2-user/hello.txt", "rb").read(), filename="hello.txt") This put command returns an ObjectId that identifies the file that was just inserted. I save this ObjectID in the variable h. We can show the value of h as follows: >>> h ObjectId('601b1da5fd4a6815e34d65f5') Now when you list the files, you see the file we just inserted: >>> print(fs.list()) ['hello.txt'] Insert another file that you created earlier and list the files: >>> b = fs.put(open("/home/ec2-user/bye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt', 'hello.txt'] Read the first file you inserted. One way to read the file is by the ObjectId: >>> print(fs.get(h).read()) b'Hello World!n' GridFS also allows searching for files, for example by filename: >>> res = fs.find({"filename": "hello.txt"}) >>> print(res.count()) 1 We can see one file with the name hello.txt. The result is a cursor to iterate over the files that were returned. To get the first file, call the next() method: >>> res0 = res.next() >>> res0.read() b'Hello World!n' Next, delete the hello.txt file. To do this, use the ObjectId of the res0 file object, which is accessible via the _id field: >>> fs.delete(res0._id) >>> print(fs.list()) ['bye.txt'] Only one file is now in the file system. Next, overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = fs.put(open("/home/ec2-user/goodbye.txt", "rb").read(), filename="bye.txt") >>> print(fs.list()) ['bye.txt'] This overwrite doesn’t actually delete the previous version. GridFS is a versioned file system and keeps older versions unless you specifically delete them. So, when we find the files based on the bye.txt, we see two files: >>> res = fs.find({"filename": "bye.txt"}) >>> print(res.count()) 2 GridFS allows us to get specific versions of the file, via the get_version() method. By default, this returns the most recent version. Versions are numbered in a one-up counted way, starting at 0. So we can access the original version by specifying version 0. We can also access the most recent version by specifying version -1. First, the default, most recent version: >>> x = fs.get_version(filename="bye.txt") >>> print(x.read()) b'Goodbye World!n' Next, the first version: >>> x0 = fs.get_version(filename="bye.txt", version=0) >>> print(x0.read()) b'Bye World!n' The following code is the second version: >>> x1 = fs.get_version(filename="bye.txt", version=1) >>> print(x1.read()) b'Goodbye World!n' The following code is the latest version, which is the same as not providing a version, as we saw earlier: >>> xlatest = fs.get_version(filename="bye.txt", version=-1) >>> print(xlatest.read()) b'Goodbye World!n' An interesting feature of GridFS is the ability to attach metadata to the files. The API allows for adding any keys and values as part of the put() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = fs.put(open("/home/ec2-user/byebye.txt", "rb").read(), filename="bye.txt", somekey="somevalue") >>> c = fs.get_version(filename="bye.txt") >>> print(c.read()) b'Bye Bye World!n' We can access the custom metadata as a field of the file: >>> print(c.somekey) somevalue Now that we have the metadata attached to the file, we can search for files with specific metadata: >>> sk0 = fs.find({"somekey": "somevalue"}).next() We can retrieve the value for the key somekey from the following result: >>> print(sk0.somekey) somevalue We can also return multiple documents via this approach. In the following code, we insert another file with the somekey attribute, and then we can see that two files have the somekey attribute defined: >>> h = fs.put(open("/home/ec2-user/solong.txt", "rb").read(), filename="solong.txt", somekey="someothervalue", key2="value2") >>> print(fs.find({"somekey": {"$exists": True}}).count()) 2 Basic operations with Amazon S3 In this section, I show how to get the equivalent functionality of GridFS using Amazon S3. There are some subtle differences in terms of unique identifiers and the shape of the returned objects, so it’s not a drop-in replacement for GridFS. However, the major functionality of GridFS is covered by the Amazon S3 APIs. I walk through the same operations as in the previous section, except using Amazon S3 instead of GridFs. First, we create an S3 bucket to store the files. For this example, I use the bucket named blog-gridfs. You need to choose a different name for your bucket, because bucket names are globally unique. For this demonstration, we want to also enable versioning for this bucket. This allows Amazon S3 to behave similarly as GridFS with respect to versioning files. As with the previous section, the following commands are included in a single Python script, but I walk through these commands one by one. Before using the script, make sure to replace the secret name with the one created by the CloudFormation stack, as well as the Region you’re using, and the S3 bucket you created. First, we import a few packages we need: >>> import boto3 Next, we connect to Amazon S3 and create the S3 client: session = boto3.Session() s3_client = session.client('s3') It’s convenient to store the name of the bucket we created in a variable. Set the bucket variable appropriately: >>> bucket = "blog-gridfs" Now that this setup is complete, we list the files in the S3 bucket: >>> s3_client.list_objects(Bucket=bucket) {'ResponseMetadata': {'RequestId': '031B62AE7E916762', 'HostId': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'UO/3dOVHYUVYxyrEPfWgVYyc3us4+0NRQICA/mix//ZAshlAwDK5hCnZ+/wA736x5k80gVcyZ/w=', 'x-amz-request-id': '031B62AE7E916762', 'date': 'Wed, 03 Feb 2021 22:37:12 GMT', 'x-amz-bucket-region': 'us-east-1', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'IsTruncated': False, 'Marker': '', 'Name': 'blog-gridfs', 'Prefix': '', 'MaxKeys': 1000, 'EncodingType': 'url'} The output is more verbose, but we’re most interested in the Contents field, which is an array of objects. In this example, it’s absent, denoting an empty bucket. Next, insert one of the files we created earlier: >>> h = s3_client.put_object(Body=open("/home/ec2-user/hello.txt", "rb").read(), Bucket=bucket, Key="hello.txt") This put_object command takes three parameters: Body – The bytes to write Bucket – The name of the bucket to upload to Key – The file name The key can be more than just a file name, but can also include subdirectories, such as subdir/hello.txt. The put_object command returns information acknowledging the successful insertion of the file, including the VersionId: >>> h {'ResponseMetadata': {'RequestId': 'EDFD20568177DD45', 'HostId': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'sg8q9KNxa0J+4eQUMVe6Qg2XsLiTANjcA3ElYeUiJ9KGyjsOe3QWJgTwr7T3GsUHi3jmskbnw9E=', 'x-amz-request-id': 'EDFD20568177DD45', 'date': 'Wed, 03 Feb 2021 22:39:19 GMT', 'x-amz-version-id': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab', 'etag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'ETag': '"8ddd8be4b179a529afa5f2ffae4b9858"', 'VersionId': 'ADuqSQDju6BJHkw86XvBgIPKWalQMDab'} Now if we list the files, we see the file we just inserted: >>> list = s3_client.list_objects(Bucket=bucket) >>> print([i["Key"] for i in list["Contents"]]) ['hello.txt'] Next, insert the other file we created earlier and list the files: >>> b = s3_client.put_object(Body=open("/home/ec2-user/bye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt', 'hello.txt'] Read the first file. In Amazon S3, use the bucket and key to get the object. The Body field is a streaming object that can be read to retrieve the contents of the object: >>> s3_client.get_object(Bucket=bucket, Key="hello.txt")["Body"].read() b'Hello World!n' Similar to GridFS, Amazon S3 also allows you to search for files by file name. In the Amazon S3 API, you can specify a prefix that is used to match against the key for the objects: >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket, Prefix="hello.txt")["Contents"]]) ['hello.txt'] We can see one file with the name hello.txt. Next, delete the hello.txt file. To do this, we use the bucket and file name, or key: >>> s3_client.delete_object(Bucket=bucket, Key="hello.txt") {'ResponseMetadata': {'RequestId': '56C082A6A85F5036', 'HostId': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'HTTPStatusCode': 204, 'HTTPHeaders': {'x-amz-id-2': '3fXy+s1ZP7Slw5LF7oju5dl7NQZ1uXnl2lUo1xHywrhdB3tJhOaPTWNGP+hZq5571c3H02RZ8To=', 'x-amz-request-id': '56C082A6A85F5036', 'date': 'Wed, 03 Feb 2021 22:45:57 GMT', 'x-amz-version-id': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd', 'x-amz-delete-marker': 'true', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'DeleteMarker': True, 'VersionId': 'rVpCtGLillMIc.I1Qz0PC9pomMrhEBGd'} >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] The bucket now only contains one file. Let’s overwrite the bye.txt file with different data, in this case the goodbye.txt file contents: >>> hb = s3_client.put_object(Body=open("/home/ec2-user/goodbye.txt", "rb").read(), Bucket=bucket, Key="bye.txt") >>> print([i["Key"] for i in s3_client.list_objects(Bucket=bucket)["Contents"]]) ['bye.txt'] Similar to GridFS, with versioning turned on in Amazon S3, an overwrite doesn’t actually delete the previous version. Amazon S3 keeps older versions unless you specifically delete them. So, when we list the versions of the bye.txt object, we see two files: >>> y = s3_client.list_object_versions(Bucket=bucket, Prefix="bye.txt") >>> versions = sorted([(i["Key"],i["VersionId"],i["LastModified"]) for i in y["Versions"]], key=lambda y: y[2]) >>> print(len(versions)) 2 As with GridFS, Amazon S3 allows us to get specific versions of the file, via the get_object() method. By default, this returns the most recent version. Unlike GridFS, versions in Amazon S3 are identified with a unique identifier, VersionId, not a counter. We can get the versions of the object and sort them based on their LastModified field. We can access the original version by specifying the VersionId of the first element in the sorted list. We can also access the most recent version by not specifying a VersionId: >>> x0 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[0][1]) >>> print(x0["Body"].read()) b'Bye World!n' >>> x1 = s3_client.get_object(Bucket=bucket, Key="bye.txt", VersionId=versions[1][1]) >>> print(x1["Body"].read()) b'Goodbye World!n' >>> xlatest = s3_client.get_object(Bucket=bucket, Key="bye.txt") >>> print(xlatest["Body"].read()) b'Goodbye World!n' Similar to GridFS, Amazon S3 provides the ability to attach metadata to the files. The API allows for adding any keys and values as part of the Metadata field in the put_object() operation. In the following code, we add a key-value pair with the key somekey and the value somevalue: >>> bb = s3_client.put_object(Body=open("/home/ec2-user/byebye.txt", "rb").read(), Bucket=bucket, Key="bye.txt", Metadata={"somekey": "somevalue"}) >>> c = s3_client.get_object(Bucket=bucket, Key="bye.txt") We can access the custom metadata via the Metadata field: >>> print(c["Metadata"]["somekey"]) somevalue We can also print the contents of the file: >>> print(c["Body"].read()) b'Bye Bye World!n' One limitation with Amazon S3 versus GridFS is that you can’t search for objects based on the metadata. To accomplish this use case, we employ Amazon DocumentDB. Use cases with Amazon S3 and Amazon DocumentDB Some use cases may require you to find objects or files based on the metadata, beyond just the file name. For example, in an asset management use case, we may want to record the author or a list of keywords. To do this, we can use Amazon S3 and Amazon DocumentDB to provide a very similar developer experience, but leveraging the power of a purpose-built document database and a purpose-built object store. In this section, I walk through how to use these two services to cover the additional use case of needing to find files based on the metadata. First, we import a few packages: >>> import json >>> import pymongo >>> import boto3 We use the credentials that we created when we launched the CloudFormation stack. These credentials were stored in Secrets Manager. The name of the secret is the name of the stack that you used to create the stack (for this post, docdb-mongo), with -DocDBSecret appended to docdb-mongo-DocDBSecret. We assign this to a variable. You should use the appropriate Secrets Manager secret name for your stack: >>> secret_name = 'docdb-mongo-DocDBSecret' Next, we create a Secrets Manager client and retrieve the secret. Make sure to set the Region variable with the Region in which you deployed the stack: >>> secret_client = session.client(service_name='secretsmanager', region_name=region) >>> secret = json.loads(secret_client.get_secret_value(SecretId=secret_name)['SecretString']) This secret contains the four pieces of information that we need to connect to the Amazon DocumentDB cluster: Cluster endpoint Port Username Password Next we connect to the Amazon DocumentDB cluster: >>> docdb_client = pymongo.MongoClient(host=secret["host"], port=secret["port"], ssl=True, ssl_ca_certs="/home/ec2-user/rds-combined-ca-bundle.pem", replicaSet='rs0', connect = True) >>> docdb_client["admin"].authenticate(name=secret["username"], password=secret["password"]) True We use the database fs and the collection files to store our file metadata: >>> docdb_db = docdb_client["fs"] >>> docdb_coll = docdb_db["files"] Because we already have data in the S3 bucket, we create entries in the Amazon DocumentDB collection for those files. The information we store is analogous to the information in the GridFS fs.files collection, namely the following: bucket – The S3 bucket filename – The S3 key version – The S3 VersionId length – The file length in bytes uploadDate – The S3 LastModified date Additionally, any metadata that was stored with the objects in Amazon S3 is also added to the document in Amazon DocumentDB: >>> for ver in s3_client.list_object_versions(Bucket=bucket)["Versions"]: ... obj = s3_client.get_object(Bucket=bucket, Key=ver["Key"], VersionId=ver["VersionId"]) ... to_insert = {"bucket": bucket, "filename": ver["Key"], "version": ver["VersionId"], "length": obj["ContentLength"], "uploadDate": obj["LastModified"]} ... to_insert.update(obj["Metadata"]) ... docdb_coll.insert_one(to_insert) ... Now we can find files by their metadata: >>> sk0 = docdb_coll.find({"somekey": "somevalue"}).next() >>> print(sk0["somekey"]) somevalue To read the file itself, we can use the bucket, file name, and version to retrieve the object from Amazon S3: >>> print(s3_client.get_object(Bucket=sk0["bucket"], Key=sk0["filename"], VersionId=sk0["version"])["Body"].read()) b'Bye Bye World!n' Now we can put another file with additional metadata. To do this, we write the file to Amazon S3 and insert the metadata into Amazon DocumentDB: >>> h = s3_client.put_object(Body=open("/home/ec2-user/solong.txt", "rb").read(), Bucket=bucket, Key="solong.txt") >>> docdb_coll.insert_one({"bucket": bucket, "filename": "solong.txt", "version": h["VersionId"], "somekey": "someothervalue", "key2": "value2"}) Finally, we can search for files with somekey defined, as we did with GridFS, and see that two files match: >>> print(docdb_coll.find({"somekey": {"$exists": True}}).count()) 2 Clean up You can delete the resources created in this post by deleting the stack via the AWS CloudFormation console or the AWS CLI. Conclusion Storing large objects inside a database is typically not the best architectural choice. Instead, coupling a distributed object store, such as Amazon S3, with the database provides a more architecturally sound solution. Storing the metadata in the database and a reference to the location of the object in the object store allows for efficient query and retrieval operations, while reducing the strain on the database for serving object storage operations. In this post, I demonstrated how to use Amazon S3 and Amazon DocumentDB in place of MongoDB’s GridFS. I leveraged Amazon S3’s purpose-built object store and Amazon DocumentDB, a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. For more information about recent launches and blog posts, see Amazon DocumentDB (with MongoDB compatibility) resources. About the author Brian Hess is a Senior Solution Architect Specialist for Amazon DocumentDB (with MongoDB compatibility) at AWS. He has been in the data and analytics space for over 20 years and has extensive experience with relational and NoSQL databases. https://aws.amazon.com/blogs/database/migrate-an-application-from-using-gridfs-to-using-amazon-s3-and-amazon-documentdb-with-mongodb-compatibility/
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - cvwing http://cvwing.com/jobs/technology/cloud-dba_i13145
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - LinkHello http://linkhello.com/jobs/technology/cloud-dba_i10223
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - LinkHello http://linkhello.com/jobs/technology/cloud-dba_i10223
0 notes
Text
DevOps Engineer job at Camdy Global Sdn Bhd Malaysia
CAMDY is a market place for personalized gifts. Our mission is to revolutionize the gift industry by providing the widest variety of unique & customize-able products using cutting edge technology.
· Installation, testing the operation server software, hardware and firmware
· Setup of Virtual Private Cloud, Network ACLs, Security Groups and route tables
· Plan, manage, document and perform installations and upgrades of servers
· Configuration and administration of Load Balancers, Network and Auto scaling for high availability
· Design, implement and maintain system security
· Installing and configuring operating systems in adherence to specification
· Develop, review, and modify changes to the schedule of operation to ensure systems, servers, workstations, peripherals, communications devices, and software is on-line, patched and supported.
· Configure and manage system backups and restores
· Provide UNIX-based application support
· Managing Application Security such as creating/managing users’ responsibilities
· Analyze failure trends and provide recommendations on future design
· Ensure policies, procedures, and strategies are optimize and integrated into the installation, configuration, and maintenance of the operating environment
· Operating Systems: UNIX, Linux Ubuntu.
· Cloud technologies: AWS, Docker.
· Database: MySQL,MongoDB.
· Version Control Systems: Git, GitHub
· Languages/Scripting: Various shell flavors ksh, csh, bash, JSON, Amazon Web Services Scripting, PHP, Javascript.
· Development Environments and Tools: Docker, Virtualbox.
· Web/App Servers: Apache, NGINX.
· Monitoring: Nagios, Nagios Log server, Centreon, ELK, Grafana.
Others
· At least 3 to 5 years of experience in the relevant field.
· Good to have CCNP and LPIC-2 certificate
· Knowledge and experience with large-scale systems integration involving private, hybrid, and public cloud platforms.
· Advanced knowledge of large-scale server architecture & database administration and monitoring tools
· Must be willing to be on call especially during emergency
· Excellent communication skills
· Able to work with minimal supervision.
From http://www.startupjobs.asia/job/26400-devops-engineer-it-job-at-camdy-global-sdn-bhd-malaysia
from https://startupjobsasiablog.wordpress.com/2017/03/22/devops-engineer-job-at-camdy-global-sdn-bhd-malaysia/
0 notes
Text
DevOps Engineer job at Camdy Global Sdn Bhd Malaysia
CAMDY is a market place for personalized gifts. Our mission is to revolutionize the gift industry by providing the widest variety of unique & customize-able products using cutting edge technology.
· Installation, testing the operation server software, hardware and firmware
· Setup of Virtual Private Cloud, Network ACLs, Security Groups and route tables
· Plan, manage, document and perform installations and upgrades of servers
· Configuration and administration of Load Balancers, Network and Auto scaling for high availability
· Design, implement and maintain system security
· Installing and configuring operating systems in adherence to specification
· Develop, review, and modify changes to the schedule of operation to ensure systems, servers, workstations, peripherals, communications devices, and software is on-line, patched and supported.
· Configure and manage system backups and restores
· Provide UNIX-based application support
· Managing Application Security such as creating/managing users’ responsibilities
· Analyze failure trends and provide recommendations on future design
· Ensure policies, procedures, and strategies are optimize and integrated into the installation, configuration, and maintenance of the operating environment
· Operating Systems: UNIX, Linux Ubuntu.
· Cloud technologies: AWS, Docker.
· Database: MySQL,MongoDB.
· Version Control Systems: Git, GitHub
· Languages/Scripting: Various shell flavors ksh, csh, bash, JSON, Amazon Web Services Scripting, PHP, Javascript.
· Development Environments and Tools: Docker, Virtualbox.
· Web/App Servers: Apache, NGINX.
· Monitoring: Nagios, Nagios Log server, Centreon, ELK, Grafana.
Others
· At least 3 to 5 years of experience in the relevant field.
· Good to have CCNP and LPIC-2 certificate
· Knowledge and experience with large-scale systems integration involving private, hybrid, and public cloud platforms.
· Advanced knowledge of large-scale server architecture & database administration and monitoring tools
· Must be willing to be on call especially during emergency
· Excellent communication skills
· Able to work with minimal supervision.
StartUp Jobs Asia - Startup Jobs in Singapore , Malaysia , HongKong ,Thailand from http://www.startupjobs.asia/job/26400-devops-engineer-it-job-at-camdy-global-sdn-bhd-malaysia Startup Jobs Asia https://startupjobsasia.tumblr.com/post/158692489734
0 notes
Text
DevOps Engineer job at Camdy Global Sdn Bhd Malaysia
CAMDY is a market place for personalized gifts. Our mission is to revolutionize the gift industry by providing the widest variety of unique & customize-able products using cutting edge technology.
· Installation, testing the operation server software, hardware and firmware
· Setup of Virtual Private Cloud, Network ACLs, Security Groups and route tables
· Plan, manage, document and perform installations and upgrades of servers
· Configuration and administration of Load Balancers, Network and Auto scaling for high availability
· Design, implement and maintain system security
· Installing and configuring operating systems in adherence to specification
· Develop, review, and modify changes to the schedule of operation to ensure systems, servers, workstations, peripherals, communications devices, and software is on-line, patched and supported.
· Configure and manage system backups and restores
· Provide UNIX-based application support
· Managing Application Security such as creating/managing users’ responsibilities
· Analyze failure trends and provide recommendations on future design
· Ensure policies, procedures, and strategies are optimize and integrated into the installation, configuration, and maintenance of the operating environment
· Operating Systems: UNIX, Linux Ubuntu.
· Cloud technologies: AWS, Docker.
· Database: MySQL,MongoDB.
· Version Control Systems: Git, GitHub
· Languages/Scripting: Various shell flavors ksh, csh, bash, JSON, Amazon Web Services Scripting, PHP, Javascript.
· Development Environments and Tools: Docker, Virtualbox.
· Web/App Servers: Apache, NGINX.
· Monitoring: Nagios, Nagios Log server, Centreon, ELK, Grafana.
Others
· At least 3 to 5 years of experience in the relevant field.
· Good to have CCNP and LPIC-2 certificate
· Knowledge and experience with large-scale systems integration involving private, hybrid, and public cloud platforms.
· Advanced knowledge of large-scale server architecture & database administration and monitoring tools
· Must be willing to be on call especially during emergency
· Excellent communication skills
· Able to work with minimal supervision.
StartUp Jobs Asia - Startup Jobs in Singapore , Malaysia , HongKong ,Thailand from http://www.startupjobs.asia/job/26400-devops-engineer-it-job-at-camdy-global-sdn-bhd-malaysia
0 notes
Text
Whatâs New in MongoDB 3.4, Part 3: Modernized Database Tooling
Welcome to the final post in our 3-part MongoDB 3.4 blog series.
In part 1 we demonstrated the extended multimodel capabilities of MongoDB 3.4, including native graph processing, faceted navigation, rich real-time analytics, and powerful connectors for BI and Apache Spark
In part 2 we covered the enhanced capabilities for running mission-critical applications, including geo-distributed MongoDB zones, elastic clustering, tunable consistency, and enhanced security controls.
We are concluding this series with the modernized DBA and Ops tooling available in MongoDB 3.4. Remember, if you want to get the detail now on everything the new release offers, download the Whatâs New in MongoDB 3.4 white paper .
MongoDB Compass
MongoDB Compass is the easiest way for DBAs to explore and manage MongoDB data. As the GUI for MongoDB, Compass enables users to visually explore their data, and run ad-hoc queries in seconds â all with zero knowledge of MongoDB's query language.
The latest Compass release expands functionality to allow users to manipulate documents directly from the GUI, optimize performance, and create data governance controls.
DBAs can interact with and manipulate MongoDB data from Compass. They can edit, insert, delete, or clone existing documents to fix data quality or schema issues in individual documents identified during data exploration. If a batch of documents need to be updated, the query string generated by Compass can be used in an update command within the mongo shell.
Trying to parse text output can significantly increase the time to resolve query performance issues. Visualization is core to Compass, and has now been extended to generating real-time performance statistics, and presenting indexes and explain plans.
Figure 1: Real-time performance statistics now available from MongoDB Compass
The visualization of the same real-time server statistics generated by the mongotop and mongostat commands directly within the Compass GUI allows DBAs to gain an immediate snapshot of server status and query performance.
If performance issues are identified, DBAs can visualize index coverage, enabling them to determine which specific fields are indexed, their type, size, and how often they are used.
Compass also provides the ability to visualize explain plans, presenting key information on how a query performed â for example the number of documents returned, execution time, index usage, and more. Each stage of the execution pipeline is represented as a node in a tree, making it simple to view explain plans from queries distributed across multiple nodes.
If specific actions, such as adding a new index, need to be taken, DBAs can use MongoDBâs management tools to automate index builds across the cluster.
Figure 2: MongoDB Compass visual query plan for performance optimization across distributed clusters
Document validation allows DBAs to enforce data governance by applying checks on document structure, data types, data ranges, and the presence of mandatory fields. Validation rules can now be managed from the Compass GUI. Rules can be created and modified directly using a simple point and click interface, and any documents violating the rules can be clearly presented. DBAs can then use Compassâs CRUD support to fix data quality issues in individual documents.
MongoDB Compass is included with both MongoDB Professional and MongoDB Enterprise Advanced subscriptions used with your self-managed instances, or hosted MongoDB Atlas instances. MongoDB Compass is free to use for evaluation and in development environments. You can get MongoDB Compass from the download center, and read about it in the documentation.
Operational Management for DevOps Teams
Ops Manager is the simplest way to run MongoDB on your own infrastructure, making it easy for operations teams to deploy, monitor, backup, and scale MongoDB. Ops Manager is available as part of MongoDB Enterprise Advanced, and its capabilities are also available in Cloud Manager, a tool hosted by MongoDB in the cloud. Ops Manager and Cloud Manager provide an integrated suite of applications that manage the complete lifecycle of the database:
Automated deployment and management with a single click and zero-downtime upgrades
Proactive monitoring providing visibility into the performance of MongoDB, history, and automated alerting on 100+ system metrics
Disaster recovery with continuous, incremental backup and point-in-time recovery, including the restoration of complete running clusters from your backup files
Ops Manager has been enhanced as part of the MongoDB 3.4 release, now offering:
Finer-grained monitoring telemetry
Configuration of MongoDB zones and LDAP security
Richer private cloud integration with server pools and Cloud Foundry
Encrypted backups
Support for Amazon S3 as a location for backups
Ops Manager Monitoring
Ops Manager now allows telemetry data to be collected every 10 seconds, up from the previous minimum 60 seconds interval. By default, telemetry data at the 10-second interval is available for 24 hours. 60-second telemetry is retained for 7 days, up from the previous 48-hour period. These retention policies are now fully configurable, so administrators can tune the timelines available for trend analysis, capacity planning, and troubleshooting.
Generating telemetry views synthesized from hardware and software statistics helps administrators gain a complete view of each instance to better monitor and maintain database health. Ops Manager has always displayed hardware monitoring telemetry alongside metrics collected from the database, but required a third party agent to collect the raw hardware data. The agent increased the number of system components to manage, and was only available for Linux hosts. The Ops Manager agent has now been extended to collect hardware statistics, such as disk utilization and CPU usage, alongside existing MongoDB telemetry. In addition, platform support has been extended to include Windows and OS X.
Private Cloud Integration
Many organizations are seeking to replicate benefits of the public cloud into their own infrastructure through the build-out of private clouds. A number of organizations are using MongoDB Enterprise Advanced to deliver an on-premise Database-as-a-Service (DBaaS). This allows them to standardize the way in which internal business units and project teams consume MongoDB, improving business agility, corporate governance, cost allocation, and operational efficiency.
Ops Manager now provides the ability to create pre-provisioned server pools. The Ops Manager agent can be installed across a fleet of servers (physical hardware, VMs, AWS instances, etc.) by a configuration management tool such as Chef, Puppet, or Ansible. The server pool can then be exposed to internal teams, ready for provisioning servers into their local groups, either by the programmatic Ops Manager API or the Ops Manager GUI. When users request an instance, Ops Manager will remove the server from the pool, and then provision and configure it into the local group. It can return the server to the pool when it is no longer required, all without sysadmin intervention. Administrators can track when servers are provisioned from the pool, and receive alerts when available server resources are running low. Pre-provisioned server pools allow administrators to create true, on-demand database resources for private cloud environments. You can learn more about provisioning with Ops Manager server pools from the documentation.
Building upon server pools, Ops Manager now offers certified integration with Cloud Foundry. BOSH, the Cloud Foundry configuration management tool, can install the Ops Manager agent onto the server configuration requested by the user, and then use the Ops Manager API to build the desired MongoDB configuration. Once the deployment has reached goal state, Cloud Foundry will notify the user of the URL of their MongoDB deployment. From this point, users can log in to Ops Manager to monitor, back-up, and automate upgrades of their deployment.
MongoDB Ops Manager is available for evaluation from the download center.
Backups to Amazon S3
Ops Manager can now store backups in the Amazon S3 storage service, with support for deduplication, compression, and encryption. The addition of S3 provides administrators with greater choice in selecting the backup storage architecture that best meets specific organizational requirements for data protection:
MongoDB blockstore backups
Filesystem backups (SAN, NAS, & NFS)
Amazon S3 backups
Whichever architecture is chosen, administrators gain all of the benefits of Ops Manager, including point-in-time recovery of replica sets, cluster-wide snapshots of sharded databases, and data encryption.
You can learn more about Ops Manager backups from the documentation.
MongoDB Atlas: VPC Peering
The MongoDB Atlas database service provides the features of MongoDB, without the operational heavy lifting required for any new application. MongoDB Atlas is available on-demand through a pay-as-you-go model and billed on an hourly basis, letting developers focus on apps, rather than ops.
MongoDB Atlas offers the latest 3.4 release (community edition) as an option. In addition, MongoDB Atlas also now offers AWS Virtual Private Cloud (VPC) peering. Each MongoDB Atlas group is provisioned into its own AWS VPC, thus isolating the customerâs data and underlying systems from other MongoDB Atlas users. With the addition of VPC peering, customers can now connect their application servers deployed to another AWS VPC directly to their MongoDB Atlas cluster using private IP addresses. Whitelisting public IP addresses is not required for servers accessing MongoDB Atlas from a peered VPC. Services such as AWS Elastic Beanstalk or AWS Lambda that use non-deterministic IP addresses can also be connected to MongoDB Atlas without having to open up wide public IP ranges that could compromise security. VPC peering allows users to create an extended, private network connecting their application servers and backend databases.
You can learn more about MongoDB Atlas from the documentation.
Next Steps
As we have seen through this blog series, MongoDB 3.4 is a significant evolution of the industryâs fastest growing database:
Native graph processing, faceted navigation, richer real-time analytics, and powerful connectors for BI and Spark integration bring additional multimodel database support right into MongoDB.
Geo-distributed MongoDB zones, elastic clustering, tunable consistency, and enhanced security controls bring state-of-the-art database technology to your most mission-critical applications.
Enhanced DBA and DevOps tooling for schema management, fine-grained monitoring, and cloud-native integration allow engineering teams to ship applications faster, with less overhead and higher quality.
Remember, you can get the detail now on everything packed into the new release by downloading the Whatâs New in MongoDB 3.4 white paper.
Alternatively, if youâd had enough of reading about it and want to get started now, then:
Download MongoDB 3.4
Alternatively, spin up your own MongoDB 3.4 cluster on the MongoDB Atlas database service
Sign up for our free 3.4 training from the MongoDB University
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs from Latest listings added - JobsAggregation http://jobsaggregation.com/jobs/technology/cloud-dba_i9405
0 notes
Text
Cloud DBA
Role: Cloud DBA Location: Atlanta, GA Type: Contract Job Description: Primary Skills: NoSQL, Oracle and Cloud Spanner. Job Requirements: ? Bachelor?s degree (Computer Science preferred) with 5+ year?s experience as a DBA managing databases (Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore, etc) in Linux environment. ? Experience in a technical database engineering role, such as software development, release management, deployment engineering, site operations, technical operations, etc. ? Production DBA experience with NoSQL databases. ? Actively monitor existing databases to identify performance issues, and give application team?s guidance and oversight to remediate performance issues. ? Excellent troubleshooting/problem solving and communication skills. ? Scripting/Programming (UNIX shell, Python, etc.) experience is highly desirable what will make you stand out? ? Experience with other Big Data technologies is a plus. ? Experience with Oracle, PostgreSQL database administration is a plus. ? Knowledge Continuous Integration/Continuous Delivery. ? Linux system administration. Roles and Responsibilities: ? Responsible for database deployments, and monitor for capacity, performance, and/or solving issues. ? Experience with backup/recovery, sizing and space management, tuning, diagnostics, and proficient with administering multiple databases. ? Enable/Integrate monitoring, auditing, and alert systems for databases with existing monitoring infrastructure. ? Responsible for working with development teams in evaluating new database technologies and provide SME guidance to development teams. ? Responsible for system performance and reliability. ? Occasional off-shift on-call availability to resolve Production issues or assist in Production deployments. ? Thorough knowledge of UNIX operating system and shell scripting. ? Good Experience in databases like, Cassandra, MongoDB, Amazon DynamoDB, Google Cloud Bigtable, Google Cloud Datastore,in Linux environment. ? Perform independent security reviews of critical databases across the organization to ensure the databases are aligned with Equifax Global Security Policies, Access Control Standards and industry standard methodologies. ? Experience with Cloud technologies like AWS, GCP, Azure is required. ? DBA ought to ensure the databases are highly available, have sufficient capacity in place and are fully resilient across multiple data centers and cloud architectures. ? You should be able to uphold high standards, learn and adopt new methodologies and tackle new challenges in everyday work. We want our DBA to be on the state of the art of technologies constantly seeking to improve performance, and uptime of the database systems. ? Handle NoSQL databases in all SDLC environments including installation, configuration, backup, recovery, replication, upgrades, etc. Reference : Cloud DBA jobs Source: http://jobrealtime.com/jobs/technology/cloud-dba_i10119
0 notes
Text
Profiling slow-running queries in Amazon DocumentDB (with MongoDB compatibility)
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without having to worry about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. AWS built Amazon DocumentDB to uniquely solve your challenges around availability, performance, reliability, durability, scalability, backup, and more. In doing so, we built several tools, like the profiler, to help you run analyze your workload on Amazon DocumentDB. The profiler gives you the ability to log the time and details of slow-running operations on your cluster. In this post, we show you how to use the profiler in Amazon DocumentDB to analyze slow-running queries to identify bottlenecks and improve individual query performance and overall cluster performance. Prerequisites To use the Amazon DocumentDB profiler, create an AWS Cloud9 environment and an Amazon DocumentDB cluster. You use the AWS Cloud9 terminal to run queries against the cluster. For instructions on setting up your environment and creating your cluster, see Getting Started with Amazon DocumentDB (with MongoDB compatibility); Part 2 – using AWS Cloud9. Solution overview The solution described in this post includes the following tasks: Turn on the profiler for your cluster to profile slow-running queries Load a dataset and run sample queries Use AWS CloudWatch Logs to analyze logs and identify bottlenecks for slow-running queries Improve performance of slow-running queries by adding a missing index Turning on the profiler To enable the profiler, you must first create a custom cluster parameter group. A cluster parameter group is a group of settings that determine how your cluster is configured. When you provision an Amazon DocumentDB cluster, it’s provisioned with the default cluster parameter group. The default settings are immutable; to make changes to your cluster, you need a custom parameter group. On the Amazon DocumentDB console, choose your parameter group. If you don’t have one, you can create a cluster parameter group. Select the profiler parameter and change its value to enabled. You can also modify profiler_sampling_rate and profiler_threshold_ms parameters based on your preferences. profiler_sampling_rate is a fraction of slow operations that should be profiled or logged. profiler_threshold_ms is a threshold in milliseconds; all commands that take longer than profiler-threshold-ms are logged. For more information about parameters, see Enabling the Amazon DocumentDB Profiler. For this post, I set profiler_sampling_rate to 1 and profiler_threshold_ms to 50. Select the cluster you want to turn on the profiler for, and choose the Configuration Choose Modify. For Cluster parameter group, choose your custom parameter group. If you’re already using a custom parameter group, you can skip this step. For Log exports, select Profiler logs. This enables your cluster to export the logs to CloudWatch. If you have already enabled log exports for profiler logs, you can skip this step. For When to apply modifications, select Apply immediately. Alternatively, you can apply the change during your next scheduled maintenance window. Choose Modify cluster. You now need to reboot your instances to apply the new parameter group. On the Instances page, select your instance. From the Actions drop-down menu, choose Reboot. You have successfully turned on the profiler and turned on log exports to CloudWatch. Loading a dataset For this post, I load a sample dataset on to my Amazon DocumentDB cluster and run some queries. The dataset consists of JSON documents that capture data related to the spread and characteristics, case count, and location info of the novel coronavirus (SARS-CoV-2). Download the dataset with the following code: wget -O cases.json https://raw.githubusercontent.com/aws-samples/amazon-documentdb-samples/master/datasets/cases.json Load the dataset using mongoimport: mongoimport --ssl --host= --collection=daily_cases --db=testdb --file=cases.json --numInsertionWorkers 4 --username= --password= --sslCAFile rds-combined-ca-bundle.pem Use mongoimport version 3.6.18 with Amazon DocumentDB. If you don’t have mongoimport, you can install it from the MongoDB download center. To install mongoimport 3.6 on Amazon Linux, run: echo -e "[mongodb-org-3.6] nname=MongoDB Repositorynbaseurl=https://repo.mongodb.org/yum/amazon/2013.03/mongodb-org/3.6/x86_64/ngpgcheck=1 nenabled=1 ngpgkey=https://www.mongodb.org/static/pgp/server-3.6.asc" | sudo tee /etc/yum.repos.d/mongodb-org-3.6.repo sudo yum install mongodb-org-tools-3.6.18 To install mongoimport 3.6 on Ubuntu: echo 'deb https://repo.mongodb.org/apt/ubuntu '$codename'/mongodb-org/3.6 multiverse' | sudo tee /etc/apt/sources.list.d/mongodb-org-3.6.list sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com --recv 2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5 sudo apt-get update sudo apt-get install -y mongodb-org-tools=3.6.18 For more information on using mongoimport, see Dumping, Restoring, Importing, and Exporting Data. To export a log to CloudWatch, I need to run a query that is longer than 50 milliseconds. To do that, I run two queries on my dataset, using the mongo shell on my AWS Cloud9 environment. For installation instructions, see Installing the mongo shell. Run the first query: db.daily_cases.find({"Cases": 1068}) Run the second query: db.daily_cases.aggregate([{ $match: { Cases: { $gte: 100, $lt: 1000 } }}, { $group: { _id: null, count: { $sum: 1 } } } ]); Analyzing slow-running query logs in CloudWatch To view the logs of your slow-running queries, complete the following steps: On the CloudWatch console, under Logs, choose Log groups. Select the log group associated with your cluster. The log group should have the following format: /aws/docdb//profiler. It can take up to 1 hour for the log group to show up after enabling the profiler and turning on log exports. Select the log stream. Typically, every Amazon DocumentDB instance has its own log stream. For this use case, because you only have one instance, you only see one log stream. Set the time period filter to your desired value. For this use case, I filter it to 1 hour; in the following screenshot, you can see the two queries I ran earlier. It typically takes 1–2 minutes for your queries to show up in the log events. You can now analyze the logs. The following two screenshots are EXPLAIN plans for the queries we ran. The plan outlines the stages and times for a query, and helps you discover potential bottlenecks. Looking at the logs, you can see that the first query took 485 milliseconds, and the second query took 559 milliseconds. Because both took longer than 50 milliseconds, they showed up in the profiler logs. Improving performance by adding an index When you analyze the query logs, you can identify bottlenecks. The profiler logged both queries we ran earlier in CloudWatch because the runtime was over 50 milliseconds. From the logs, you can see that both the queries perform a COLLSCAN, which is a full collection sequential scan. COLLSCANs are often slow because you read your entire dataset. To reduce COLLSCANs, you can create indexes on fields that have a high degree of uniqueness and are queried frequently for a certain value or range of values for the field. For this use case, we can reduce COLLSCANS by creating an index on Cases. See the following code: db.daily_cases.createIndex({Cases:1}) For more information about indexes, see Working with Indexes. You can now rerun the queries to observe the new times. Ideally, the queries should run faster because the indexes prevent collection scans. To view the query plan and the amount of time it took to run at runtime, you can add explain("executionStats") to your query. To rerun the first query, enter the following code: db.daily_cases.find({"Cases": 1068}).explain("executionStats") The following screenshot shows the query plan. To run the second query, enter the following code: db.daily_cases.aggregate([{ $match: { Cases: { $gte: 100, $lt: 1000 } }}, { $group: { _id: null, count: { $sum: 1 } } } ]); The following screenshot shows the query plan. Instead of COLLSCANS, the query now uses IXSCANS and IXONLYSCANS. Instead of sequentially scanning the entire collection, the query optimizer uses indexes, which reduces the number of documents that need to be read to answer the query. This improved the runtime for the queries: the first query went from 485 milliseconds to 0.35 milliseconds, and the second query went from 559 milliseconds to 70 milliseconds. Conclusion In this post, you learned how to turn on the profiler in Amazon DocumentDB to analyze slow-running queries to identify performance issues, bottlenecks, and improve individual query performance and overall cluster performance. For more information, see Profiling Amazon DocumentDB Operations and Performance and Resource Utilization. If you have any questions or comments about this post, please use the comments section. If you have any features requests for Amazon DocumentDB, email us at [email protected]. About the Author Meet Bhagdev is a Sr. Product Manager with Amazon Web Services https://aws.amazon.com/blogs/database/profiling-slow-running-queries-in-amazon-documentdb-with-mongodb-compatibility/
0 notes
Text
Ramping up on Amazon DocumentDB (with MongoDB compatibility)
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. Amazon DocumentDB is compatible with MongoDB 3.6 drivers and tools. A vast majority of the applications, drivers, and tools that you already use today with their MongoDB database can be used with Amazon DocumentDB with little or no change. In this blog post, I provide you with a quick summary and set of resources, to the topics that I get asked about the most, so that you can quickly ramp up on Amazon DocumentDB: What is Amazon DocumentDB? How to get started with Amazon DocumentDB? How to build and scale with Amazon DocumentDB? How to migrate to Amazon DocumentDB? Who is using Amazon DocumentDB? How to stay up to date with Amazon DocumentDB? What is Amazon DocumentDB? To learn more about what makes Amazon DocumentDB unique and how its cloud-native architecture leverages the separation of storage and compute to help you scale quickly, visit the following resources: Amazon DocumentDB Deep Dive (from re:Invent 2019) In this talk, I give an overview of why developers choose the document model, common use cases, examples of when you should consider an alternative data store, and how Amazon DocumentDB solves specific customer problems related to managing and scaling document databases. The highlight of the session is how Fulfillment by Amazon (FBA) reduced their database infrastructure footprint from 96 instances of their previous solution to just two Amazon DocumentDB instances. Migrating to Amazon DocumentDB simultaneously increased performance by 66 percent and reduced costs by 45 percent. FBA’s example shows the result of using the right database for the job. FBA also provides a great set of lessons learned for scaling reads and writes, and indexing strategies with Amazon DocumentDB. The talk also includes three live demos where I create a snapshot backup of a 1.5-TB cluster in less than one minute, add a new instance to the same 1.5-TB cluster in five minutes, and query data in Amazon DocumentDB with a SQL interface using the new federated query capabilities in Amazon Athena. Features As a fully managed database service, Amazon DocumentDB provides a number of capabilities and features that enable you to build performant, scalable, secure and compliant, and highly available applications on AWS. FAQs The most frequently asked questions for Amazon DocumentDB. FAQs include What does “MongoDB-compatible” mean?, Does Amazon DocumentDB have an SLA?, How does per-second billing work?, and more. How to get started with Amazon DocumentDB? Interested in getting to “hello world” with Amazon DocumentDB? Visit the following guides and documentation for more information: Getting started guide Go from zero to “Hello World’ with the getting started guide. Learn how to provision an Amazon DocumentDB cluster using the AWS Management Console or AWS CLI and connect and query using the mongo shell. Connecting from AWS Cloud9 For development, test, and management, you can use AWS Cloud9 to connect to and access your Amazon DocumentDB cluster from your web browser. AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code using just a browser. It provides a web-based terminal access (Amazon Linux or Ubuntu) so that you can install mongo shell or any MongoDB SDK and connect to Amazon DocumentDB. Connecting from outside a VPC Amazon DocumentDB clusters are deployed within an Amazon Virtual Private Cloud (Amazon VPC). Clusters can be accessed directly by Amazon EC2 instances or other AWS services that are deployed in the same Amazon VPC. Additionally, clusters can be accessed by EC2 instances or other AWS services in different VPCs in the same AWS Region or other Regions via VPC peering. How to build and scale with Amazon DocumentDB? When you are ready to starting building and scaling on Amazon DocumentDB, below are the key resources that you are going to want to start with. Best practices Learn best practices for working with Amazon DocumentDB. This section is continually updated as new best practices are identified. Monitoring Amazon DocumentDB provides Amazon CloudWatch metrics for your cluster and instances. You can use the AWS Management Console to view over 20 key operational metrics for your cluster, including compute, memory, storage, query throughput, and active connections. Additionally, you can use the profiler in Amazon DocumentDB to log the execution time and details of operations that were performed on your cluster. The profiler is useful for monitoring the slowest operations on your cluster to help you improve individual query performance and overall cluster performance. Read scaling Unlike traditional monolithic database architecture, Amazon DocumentDB separates storage and compute. Given this modern architecture, we encourage you to read scale on replica instances. Reads on replica instances do not block writes being replicated from the primary instance. You can add up to 15 read replica instances in a cluster and scale out to millions of reads per second. Backup and PITR restore Amazon DocumentDB’s backup capability enables point-in-time recovery for your clusters. This allows you to restore your cluster to any second during your retention period, up until the last five minutes. Your automatic backup retention period can be configured up to thirty-five days. Automated backups are stored in Amazon S3, which is designed for 99.999999999% durability. Amazon DocumentDB backups are automatic, incremental, and continuous and have no impact on cluster performance. Security Amazon DocumentDB allows you to encrypt your databases using keys you create and control through AWS Key Management Service (KMS). On a cluster running with Amazon DocumentDB encryption, data stored at rest in the underlying storage is encrypted, as are the automated backups, snapshots, and replicas in the same cluster. By default, connections between a client and Amazon DocumentDB are encrypted-in-transit with TLS. Pricing and the Pricing Calculator There are no upfront investments required to use Amazon DocumentDB, and you only pay for the capacity they use. Amazon DocumentDB charges on four dimensions: instance, storage, IOPS, and backup storage. High Availability and Replication You can achieve high availability and read scaling in Amazon DocumentDB by using replica instances. The health of your Amazon DocumentDB cluster and its instances are continuously monitored. On instance failure, Amazon DocumentDB automates failover to a replica. Amazon DocumentDB recovery does not require the potentially lengthy replay of database redo logs, so your instance restart times are typically 30 seconds or less. It also isolates the database cache from database processes, allowing the cache to survive a database restart. How to migrate to Amazon DocumentDB? Many developers are looking to get out of the business of investing in undifferentiated heavy lifting and self-managing their databases. You migrate your MongoDB databases on-premises or on Amazon EC2 to Amazon DocumentDB for free (for six months per instance) with virtually no downtime using the AWS Database Migration Service (DMS). With DMS, you can migrate from a MongoDB replica set or from a sharded cluster to Amazon DocumentDB. In the three-minute video below, learn how to perform a live migration from MongoDB to Amazon DocumentDB using the AWS DMS. In this video, I set up two identical applications running against MongoDB (source) and Amazon DocumentDB (target), create a DMS task for a live migration, make changes to the source application, and then verify the live migration with the target application. To perform migrations, you typically us the AWS DMS to perform online, hybrid, or offline migrations. To learn more about migrations, visit the following: Migration guide The Amazon DocumentDB migration guide walks you through all the phases – discovery, planning, testing, failover – that you need to consider for a migration. The guide also discusses different approaches (online, hybrid, offline) and tools like DMS that help you migrate to Amazon DocumentDB. Migration overview (from re:Invent 2019) Jeff Duffy, the senior specialist solutions architect for Amazon DocumentDB, provides an overview of customers’ strategies and considerations when migrating to Amazon DocumentDB. The session includes discussions about relational and nonrelational sources, migration phases of discovery/planning/testing/execution, cluster sizing, and migration tooling. The highlight of the session is FINRA’s story of how they migrated from a relational database using XML to Amazon DocumentDB. With Amazon DocumentDB, FINRA can move faster using JSON natively in their database because there is no transformation layer needed from the application. FINRA also discusses how Amazon DocumentDB met their high SLA and security requirements. Migration tutorial Use the Amazon DocumentDB migration tutorial to guide you through the process of migrating from self-hosted MongoDB to Amazon DocumentDB using AWS DMS. Migration Workshop: Migrating your MongoDB Database to Amazon DocumentDB In this Workshop, practice how to migrate your MongoDB databases to Amazon DocumentDB using different strategies. Who is using Amazon DocumentDB? Customers like Capital One, OnDeck, Freshop, Woot!, Amazon and many more are using Amazon DocumentDB to build and scale their applications on AWS. To learn more about customers using Amazon DocumentDB, visit the following: Learn how Fulfillment by Amazon uses Amazon DocumentDB Learn how Fulfillment by Amazon (FBA) reduced their database infrastructure footprint from 96 instances of their previous solution to just two Amazon DocumentDB instances. Migrating to Amazon DocumentDB simultaneously increased performance by 66 percent and reduced costs by 45 percent. FBA’s example shows the result of using the right database for the job. FBA also provides a great set of lessons learned for scaling reads and writes, and indexing strategies with Amazon DocumentDB. Learn how FINRA migrated from Oracle to Amazon DocumentDB Learn how FINRA migrated from a relational database using XML to Amazon DocumentDB. With Amazon DocumentDB, FINRA can move faster using JSON natively in their database because there is no transformation layer needed from the application. FINRA also discusses how Amazon DocumentDB met their high SLA and security requirements. Deutsche Fußball Liga GmbH (DFL) uses AWS and Amazon DocumentDB their publishing platform “We, the Deutsche Fußball Liga GmbH (DFL) use AWS to power our publishing platform, delivering the latest news from the league to millions of fans worldwide. As our content and user base grew, we had a focus on maintaining our relational database’s performance. We migrated to Amazon DocumentDB (with MongoDB compatibility) because of its flexible schema, native JSON support that enables our developers to deploy faster, and its decoupled architecture can scale our read throughput in minutes. We prototyped the application locally using the MongoDB Community Edition, and quickly deployed to production on Amazon DocumentDB. Everything worked just as we expected and we have successfully scaled our database performance.” -Andreas Heyden, CEO DFL Digital Sports, EVP Digital Innovations – DFL Group How to stay up to date with Amazon DocumentDB? Amazon DocumentDB launches, blogs, and videos Find the latest Amazon DocumentDB launches, blogs, and webinars. Amazon DocumentDB Documentation We are constantly updating our technical documentation and best practices based on your feedback. MongoDB API compatibility and functional difference You can find the most up-to-date list of supported MongoDB APIs and functional differences. We are constantly listening and working backwards from our customers to deliver the capabilities that they want the most Ask a question on the Amazon DocumentDB forum Use the Amazon DocumentDB AWS Forums to learn, share knowledge, and get answers from a community of developers and the service team. About the Authors Joseph Idziorek is a Principal Product Manager at Amazon Web Services. Sameer Kumar is a Senior Specialist Technical Account Manager at Amazon Web Services. He focuses on Amazon RDS PostgreSQL, Aurora PostgreSQL and DocumentDB. He works with enterprise customers providing technical assistance on database operational performance and sharing database best practices. https://probdm.com/site/MTk0OTg
0 notes
Text
Getting started with Amazon DocumentDB (with MongoDB compatibility); Part 1 – using Amazon EC2
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without having to worry about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. In part 1 of this series, this post shows you how to get started with Amazon DocumentDB. To do that, you are going to create an Amazon EC2 instance in your default Amazon VPC. For instructions on creating a default VPC, see Getting Started with Amazon VPC. You also provision a 1-instance Amazon DocumentDB cluster in the same default VPC. This post demonstrates how to SSH to the EC2 instance from your local computer and connect to your cluster from the EC2 instance with a mongo shell. Lastly, you learn how to run queries against your Amazon DocumentDB cluster. This walkthrough costs less than $0.30 to complete. When creating AWS resources, we recommend that you follow the AWS IAM best practices. The following diagram shows the final architecture of this walkthrough. For this walkthrough, use the default VPC in a given Region. For more information, see Creating a Virtual Private Cloud (VPC). Creating two security groups The first step is to create two new security groups in your default VPC. The first security group (demoEC2) allows you to SSH into your EC2 instance from your local machine (client). The second security group (demoDocDB) enables you to connect to your Amazon DocumentDB cluster on port 27017 (the default port for Amazon DocumentDB) from your EC2 instance. Complete the following steps: On the Amazon EC2 console, choose Network & Security. Choose Security Groups. Choose Create Security Group. The page prompts you to supply a security group name and description. For the first security group, for Security group name, enter demoEC2. Optionally, enter a description. Choose Add Rule. For Type, choose SSH. The Port Range will automatically default to 22. For Source, choose MY IP. You can only access the demoEC2 security group from your current IP address. If your IP address changes, you must update the security group. Choose Create. Next, create a second security group for your Amazon DocumentDB cluster called demoDocDB. Repeat the previous steps, with the following changes: For Type, choose Custom TCP. For Port Range, enter 27017. For Source, choose demoEC2.You may need to refresh your browser for the Amazon EC2 console to auto-populate the demoEC2 source name. Choose Create. Creating an EC2 instance The next step is to create an EC2 instance in the same Region and VPC that you use to provision your Amazon DocumentDB cluster. Create your Amazon DocumentDB cluster in your default VCP. Because Amazon DocumentDB is a VPC-only service, this post demonstrates how to SSH into the EC2 instance and use the EC2 instance to connect to your Amazon DocumentDB cluster. Complete the following steps: On the Amazon EC2 console, choose Launch instance. Locate Amazon Linux 2 AMI and choose Select. Select the t2.micro instance type. Choose Review and Launch. On the Step 7: Review Instance Launch page, review your final configuration. You also have to specify that you want to use the demoEC2 security group that you just created. Choose Edit security groups. Choose Select an existing security group. Select your demoEC2 group. Choose Review and Launch. If you selected the demoEC2 security group, you see the rules that you added at the bottom of the section. See the following screenshot. Verify the information and choose Launch. On the Select an existing key pair or create a new key pair section, you must provide an Amazon EC2 key pair. If you don’t have an EC2 key pair, choose Create a new key pair and follow the instructions. You have to download a private key file (.pem file). You need this file later when you log in to your EC2 instance. . If you have an EC2 key pair, under Select a key pair, choose your key pair from the list. You must already have the private key file (.pem file) available to log in to your EC2 instance. Choose Launch Instances. Creating an Amazon DocumentDB cluster While the EC2 instance is being provisioned, launch your Amazon DocumentDB cluster. Complete the following steps: On the Amazon DocumentDB console, under Clusters, choose Create. On the Create Amazon DocumentDB cluster page, for Number of instances, choose 1. This helps minimize costs. Leave other settings at their default. In the Authentication section, enter a username and password. You use this username and password to authenticate your cluster in a later step. Turn on Show advanced settings. In the Network settings section, for VPC security groups, choose demoDocDB. Choose Create cluster. Amazon DocumentDB is now provisioning your cluster, which can take up to a few minutes to finish. You can connect to your cluster when both the cluster and instance status show as Available. While Amazon DocumentDB provisions the cluster, complete the remaining steps to connect to your Amazon DocumentDB cluster. Connecting to your EC2 instance To install the mongo shell, you must first connect to your EC2 instance. Installing the mongo shell enables you to connect to and query your Amazon DocumentDB cluster. Complete the following steps: On the Amazon EC2 console, choose the instance you created. If the instance status is running, you can now connect to it and install the mongo shell. Choose Connect. You have three options for your connection method: A standalone SSH client Session Manager EC2 Instance Connect (browser-based SSH connection) This post covers EC2 Instance Connect and a standalone SSH client. EC2 Instance Connect is the quickest and often the most straightforward option because you connect to your EC2 instance with a click of the button with a browser-based SSH connection. A standalone SSH client is a good option if you want to connect to your cluster using an SSH client like Terminal or PuTTY on your local machine. If your IP address changed after you started this walkthrough, or you are coming back to your environment at a later time, you must update your demoEC2 security group inbound rule to enable inbound traffic from your new API address. EC2 Instance Connect To connect to your EC2 instance using a browser-based SSH connection, complete the following steps: In the Connect to your instance section, for Connection method, select EC2 Instance Connect (browser-based SSH connection). The user name will default to “ec2-user.” Choose Connect. A command-line prompt opens, from which you can run commands. See the following screenshot. Proceed to the step Installing the mongo shell. Standalone SSH client To connect to the default connection method of a standalone SSH client, complete the following steps: In the Connect to your instance section, for Connection method, select A standalone SSH client. Choose Connect. In the Connect to your instance section, copy the example connection string. If you are using a macOS as your local machine, open the terminal and use the example connection string to connect to your EC2 instance. This step varies depending on what you are using as your local machine. For more information, see Connecting to Your Linux Instance Using SSH.When you choose Connect, you must make sure that the .pem file you downloaded or chose earlier has the correct permissions. For this walkthrough, name the .pem file documentdb.pem. The following screenshot shows you the .pem for your EC2 instance and how to set the correct permissions on your EC2 instance. When you connect to your EC2 instance for the first time, you must verify the authenticity of the host. If everything is correct, enter yes. You should now be connected to your EC2 instance that is in the same Region and VPC as your Amazon DocumentDB cluster. See the following screenshot. Proceed to the next step. Installing the mongo shell You can now install the mongo shell, which is a command-line utility that you use to connect and query your Amazon DocumentDB cluster. To install the mongo shell on Amazon Linux, complete the following steps. Create the repository file. At the command line of your EC2 instance, execute the follow command: echo -e "[mongodb-org-3.6] nname=MongoDB Repositorynbaseurl=https://repo.mongodb.org/yum/amazon/2013.03/mongodb-org/3.6/x86_64/ngpgcheck=1 nenabled=1 ngpgkey=https://www.mongodb.org/static/pgp/server-3.6.asc" | sudo tee /etc/yum.repos.d/mongodb-org-3.6.repo When it is complete, install the mongo shell by executing the following command: sudo yum install -y mongodb-org-shell Transport Layer Security (TLS) is enabled by default for any new Amazon DocumentDB clusters. For more information, see Managing Amazon DocumentDB Cluster TLS Settings. To encrypt data in transit, download the CA certificate for Amazon DocumentDB. See the following code: wget https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem You are now ready to connect to your Amazon DocumentDB cluster. Connecting to your Amazon DocumentDB cluster On the Amazon Document DB console, under Clusters, locate your cluster. This post uses the cluster docdb-2020-02-08-14-15-11. Choose the cluster you created. Copy the connection string provided. Omit so that you are prompted for the password by the mongo shell when you connect. This way, you don’t have to type your password in cleartext. Your connection string should look like the following code: mongo --ssl host docdb-2020-02-08-14-15-11.<cluster>.<region>.docdb.amazonaws.com:27107 --sslCAFile rds-combined-ca-bundle.pem --username demoUser --password When you enter your password and can see the rs0:PRIMARY> prompt, you are successfully connected to your Amazon DocumentDB cluster. For information about troubleshooting, see Troubleshooting Amazon DocumentDB. Inserting and querying data Now that you are connected to your cluster, you can run a few queries to get familiar with using a document database. To insert a single document, enter the following code: db.collection.insert({"hello":"DocumentDB"}) You get the following output: WriteResult({ "nInserted" : 1 }) You can read the document that you wrote with the findOne() command (because it only returns a single document). See the following code: db.collection.findOne() You get the following output: { "_id" : ObjectId("5e401fe56056fda7321fbd67"), "hello" : "DocumentDB" } To perform a few more queries, consider a gaming profiles use case. First, insert a few entries into a collection called profiles. See the following code: db.profiles.insertMany([ { "_id" : 1, "name" : "Tim", "status": "active", "level": 12, "score":202}, { "_id" : 2, "name" : "Justin", "status": "inactive", "level": 2, "score":9}, { "_id" : 3, "name" : "Beth", "status": "active", "level": 7, "score":87}, { "_id" : 4, "name" : "Jesse", "status": "active", "level": 3, "score":27} ]) You get the following output: { "acknowledged" : true, "insertedIds" : [ 1, 2, 3, 4 ] } Use the find() command to return all the documents in the profiles collection. See the following code: db.profiles.find() You get the following output: { "_id" : 1, "name" : "Tim", "status" : "active", "level" : 12, "score" : 202 } { "_id" : 2, "name" : "Justin", "status" : "inactive", "level" : 2, "score" : 9 } { "_id" : 3, "name" : "Beth", "status" : "active", "level" : 7, "score" : 87 } { "_id" : 4, "name" : "Jesse", "status" : "active", "level" : 3, "score" : 27 } Use a query for a single document using a filter. See the following code: db.profiles.find({name: "Jesse"}) You get the following output: { "_id" : 4, "name" : "Jesse", "status" : "active", "level" : 3, "score" : 27 } A common use case in gaming is finding a profile for a given user and incrementing a value in the user’s profile. In this scenario, you want to run a promotion for the top active gamers. If the gamer fills out a survey, you increase their score by +10. To do that, use the findAndModify command. In this use case, the user Tim received and completed a survey. To give Tim the credit to their score, enter the following code: db.profiles.findAndModify({ query: { name: "Tim", status: "active"}, update: { $inc: { score: 10 } } }) You get the following output: { "_id" : 1, "name" : "Tim", "status" : "active", "level" : 12, "score" : 202 } You can verify the result with the following query: db.profiles.find({name: "Tim"}) You get the following output: { "_id" : 1, "name" : "Tim", "status" : "active", "level" : 12, "score" : 212 } You can now continue to insert and query your data. Cleaning up When you complete the walkthrough, you can either stop your Amazon DocumentDB cluster and stop your EC2 instance to reduce costs, or delete the resources. For more information, see Deleting an Amazon DocumentDB Cluster and Terminate Your Instance. Summary This post showed you how to get started with Amazon DocumentDB by creating an EC2 instance, installing the mongo shell, creating an Amazon DocumentDB cluster, connecting to your cluster, and performing a few queries to see how easy it is to insert and query JSON documents within Amazon DocumentDB. For more information, see Ramping up on Amazon DocumentDB (with MongoDB compatibility). For more information about recent launches and blog posts, see Amazon DocumentDB (with MongoDB compatibility) resources. Stay tuned for the next blog post in this series, which shows you how to get started with Amazon DocumentDB using AWS Cloud9. About the Authors Joseph Idziorek is a Principal Product Manager at Amazon Web Services. Randy DeFauw is a Principal Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. https://probdm.com/site/MTg5NjU
0 notes