#json parser editor
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
right now in my video game I suppose you could say I'm procrastinating making my parser, haha. Instead I'm making it so that undefined combinations of runes are still saved when you click "save and quit" on the scroll editor, this will be helpful because I expect that at a certain point I'm going to have to stop defining every single rune myself with a json file and instead using my "second" parser to say that, for example, rune "A" combined with the "Possessive" combined with rune "B" is a valid new rune, which will be useful for obvious reasons I think
2 notes
·
View notes
Text
Ontology in Use: A Deep Dive into Semantic Relationships and Knowledge Management
In the realm of artificial intelligence and data science, ontology plays a pivotal role. It provides a structured framework that enables efficient knowledge management and data analysis. This article aims to shed light on the practical applications of ontology, with a focus on tools that support semantic relationships, such as RDF/RDFS and OWL.
Understanding Ontology
Ontology is a branch of philosophy that deals with the nature of being or reality. In the context of computer science and information technology, ontology refers to a formal representation of knowledge within a domain. It provides a framework for defining and organizing concepts and their relationships, thereby creating a shared understanding of a specific area of interest.
Tools Supporting Semantic Relationships
There are numerous tools available that support semantic relationships, particularly those defined by RDF/RDFS and OWL. RDF (Resource Description Framework) and RDFS (RDF Schema) provide a foundation for processing metadata and represent information on the web. OWL (Web Ontology Language), on the other hand, is designed to represent rich and complex knowledge about things, groups of things, and relations between things.
Some of the notable tools that support RDF/RDFS and OWL include:
Protégé: A free, open-source ontology editor and framework for building intelligent systems. Protégé fully supports the latest OWL 2 Web Ontology Language and RDF specifications from the World Wide Web Consortium.
Apache Jena: A free and open-source Java framework for building Semantic Web and Linked Data applications. It provides an RDF API to interact with the core API to create and read Resource Description Framework (RDF) graphs.
OpenLink Virtuoso: A comprehensive platform that includes a reasoner, triple store, RDFS reasoner, OWL reasoner, RDF generator, SPARQL endpoint, and RDB2RDF.
RDFLib: A Python library for working with RDF. It contains parsers and serializers for RDF/XML, N3, NTriples, N-Quads, Turtle, TriX, Trig, and JSON-LD.
YAGO: A Practical Application of Ontology
YAGO (Yet Another Great Ontology) is a prime example of ontology in use. It's a knowledge base that contains information about the real world, including entities such as movies, people, cities, countries, and relations between these entities. YAGO arranges its entities into classes and these classes are arranged in a taxonomy. For example, Elvis Presley belongs to the class of people, Paris belongs to the class of cities, and so on.
What makes YAGO special is that it combines two great resources: Wikidata and schema.org. Wikidata is the largest general-purpose knowledge base on the Semantic Web, while schema.org is a standard ontology of classes and relations. YAGO combines these two resources, thus getting the best from both worlds: a huge repository of facts, together with an ontology that is simple and used as a standard by a large community.
The Future of Ontology
The future of ontology looks promising. With the rise of artificial intelligence and machine learning, the need for structured and semantically rich data is more critical than ever. Ontology provides a way to structure this data in a meaningful way, enabling machines to understand and reason about the world in a similar way to humans.
In conclusion, ontology plays a crucial role in knowledge management and data analysis. It provides a structured framework for defining and organizing concepts and their relationships, thereby creating a shared understanding of a specific area of interest. The practical applications of ontology, such as YAGO, demonstrate the power and potential of this approach. As we continue to advance in the field of artificial intelligence, the importance and use of ontology will undoubtedly continue to grow.
1 note
·
View note
Text
Making a format
Last week I indulged in a thought
For my Danganronpa style engine, I need a 3d model format. It’s after all not just flat sprites but actual 3d geometry everywhere. Looking over the collection if formats there.. I mean.. FBX is a mammoth closed source proprietary 3d scene interchange format with all kinds of crazy nonsense packed inside I’d have to learn to deal with by hand. Collada is a complicated xml based format with all kinds of crazy scene and object graph nonsense packed in, and deprecated to boot. glTF2 is a great format but then I’m dealing with parsing complicated hyper-related json structures and reading binary blobs, and my brain just doesn’t want to deal with it. You know I did want to deal with? OBJ.
Oh it’s an excellent simple format, and I got excited about it too… until I watched some more footage and noticed… there’s animation in them thar scenes.. not complicated animation mind you, but everything from the pop-up book style scene-transitions, to background elements like calling fans and even as we saw your 3d avatar.. walking/running/sprinting.. ya.. need animation. And guess what obj doesn’t support?
On top of that, all these formats have a big thing in common… none of them are FOR games. They’re for Scenes. The big engines support them not because they’re popular.. But because their editors are essentially scrpted scene assemblers with many of the same tools packed into an fbx.
So I’m over here.. demanding simplicity. Man oh man why couldn’t there be a format as simple as OBJ, but supports skeletal animation, and designed for single models? What if you didn’t need to download some bloated SDK or spend 50 hours writing a parser that only supports a subset of what the format packs in?
That’s when I had an idea.. What if I simply extended OBJ?
Oh, but if I’m gonna take the time to extend obj, why don’t I fix some of the stuff that indeed bugs me about it, like keeping all things 0-indexed, and providing the whole vertex buffer object for each vertex on the same line, neatly arranged? Because at the end of the day, even obj is more interested in data-exchange between 3d suites.
Ok, so if I’m going to do the whole line prefix denotes data type thing complete with a state machine that dictates how to deal with the data found on each line.. we may as well make each line as useful as possible, right? That’s when I came across the tagline for the format “because I respect your time”. I was going to pay extra special attention to make sure the entire format stays the course and is predictably, and disgustingly, easy to read; without the need for anything else. No you don’t need json reader, pikl sdk, fast toml, or speed yaml. No you don’t need to make some kind of tokenizer or look for brackets or line endings, nor are you going to need to worry about quotes.
There’s two primary ways to read this format:
1. Read a line in, scan character by character; detect the unique line prefix and that prefix will explain all there is to know; or
2. Read line in, split it by space char, match the first element to some parsing mode, and use the rest of the elements as needed by index value
This all sounded great to me… But like I said, obj isn’t designed for use in games, in fact the format has its own annoyances to walk through. There’s got to be a bett- I got it. MD5.
You know, Id Software is known for their engines. And their tech is hyper fixated on performance, even at the cost of flexibility. The MD2 format is frustratingly limited, but it’s a very purpose built format that did the job And did it well for usage in a video game. MD5 is their last model format to be open sourced and with luck it also happens to be an ASCII format. But what it also supports is skeletal animation and in such a way that makes a lot of sense too. But I find the format plagued by a weird C-like syntax that I definitely didn’t come here to try and deal with.
So my idea was simply this: what if obj had a baby with md5?
That’s where I’m at right now.
I have the whole thing specced out and now I’m just learning how to write a blender plug-in…
1 note
·
View note
Text
New Dev Tools
Things have gotten complicated. I have enough of a game there to stop faffing about with adding elements higgledy-piggledy to a test level and actually start doing some level design. I want to get this game in front of test players as soon as I can so I can get feedback on, you know, if it's any good, how I can make it better, and so forth; and for that I need real levels even if they're in an early, rough form. The problem I'm confronting now is just how much I suck at level design.
Part of the problem is, that lovely JSON format I devised for level layout makes it difficult to visualize a level. So that brings me to the first new dev tool I'm using.
NA-Builder
NA-Builder is an ongoing effort for a level viewer/editor for NullAwesome. It is written largely in Gambit Scheme, with some bits in C; and structured so that I can start with the simplest bit, a JSON parser, and gradually add components on top of that until I have a full-fledged graphical editor.
But alas, I'm nowhere near building the editor. So instead, I settled for an image generator that uses the JSON parser to read a level file and spits out a map of the level in XPM format. Then I have some Emacs Lisp which allows me to send the current buffer to the map generator and opens the resulting image in a separate buffer -- so at the stroke of a key, I can view the results right within Emacs. This considerably quickens the feedback loop when I'm editing a level by tweaking the JSON directly. It works well enough for now.
NA-Builder is not yet ready for wide release. Maybe someday.
Waydroid
The other dev tool I've been making use of is not of my own authorship, but I got it working well enough for normal use.
See, the problem is, the Android emulators that ship with Android Studio suck. I have added keyboard support to the game so that it is easily playable on PCs, Chromebooks, and other devices. But the Android Studio emulator's keyboard support is... spotty. When you hold down a key, it appears to send key-press/key-release events to the app very rapidly, resulting in herky-jerky character movements and an inability to jump with any precision. But when I tried a commercial PC Android emulator like BlueStacks, everything was hunky-dory.
I noticed that Void Linux had a Waydroid package so I thought I might give it a go. Waydroid is an Android environment in a container that uses the Wayland display protocol to present its user interface. I have not joined many of my Linux-using colleagues in embracing the glorious Wayland future; I'm still on Xorg as my display server. But the Weston compositor has an X11 backend so I start Weston in my X session and have Waydroid display on that. This works out really well, and allows me to test out the game entirely on my PC. When I start Waydroid, an ADB connection is automatically established, and Android Studio picks it up immediately.
0 notes
Text
UPDATE: most of the expression parsing is done. now all that is left is variable and const declaration, code blocks and functions. then i will start on the interpreter, which will be probably the worst part :P
good news is: the parser is currently EXTREMELY flexible. meaning it can distinguish between -x 24; -y 56 and -x 24 -y 56 with zero problems :P
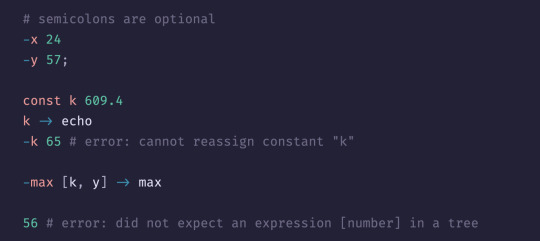
another upside is a sort of relaxed JSON format, Like this:

btw if you were wondering what editor I'm using, It's the one and only zed editor ;)
also i think `did not expect X in a tree` is a really funny way to put it, so i'm just going with that!
stay tuned!
Writing a programming language in C. How is this syntax:
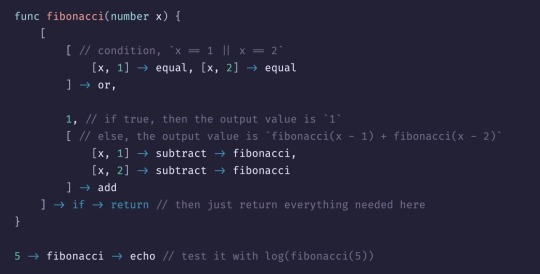
#compblr#codeblr#progblr#programming#programmer#software engineering#code#developer#c#coding#development#programming language
55 notes
·
View notes
Text
Json Parser
Json parser is a type of data used to write in java script .Json is easily readable by humans and computers. It is also used for editing data formats and it is one of the finest way to convert data structure programming languages. Data exchange through XML is now the most popular way for applications to communicate.
JSON is a subset of JavaScript (hence its name). It became popular around the time of web browser scripting languages. The JSON data structures are supported by nearly all popular programming languages, making it completely language-independent.
1 note
·
View note
Text
Everyone who implements a JSON parser should be accepting trailing commas after the last element of a list or a map.
If you must support rejecting the comma, let the user pass that in as an option. And don't call that option something that sounds plausibly justified and general enough to catch good behavior that you might want, like `strict`. Call it something self-revealing like `reject_trailing_comma`, so that there's no question about exactly what behavior you're turning on, probably for no good reason.
What happened to following wisdom like "be liberal in what you accept as input, be conservative in what you produce as output"? That never stopped being wise.
Of course that wisdom needs to be balanced with other wisdom like "don't turn errors into silent misbehavior", "don't go off-standard just because you think you know better", and so on. But this is not some arbitrary deviation from the spec. This is one very specific deviation, which fixes a very common and well-established nuisance, by adding behavior which is extremely idiomatic and is practically a de facto "standard" for languages in general nowadays. And what errors, exactly, are exposed by rejecting JSON which is entirely valid other than having a trailing comma at the end of a list or map?
The only things rejecting trailing commas is good for is
testing if JSON-producing code is strictly conforming to spec,
making JSON parsers a tiny bit easier to thoughtlessly implement (but people who can't make the mental step from "if comma then expect next item, else expect closing brace" to "if comma, expect either closing brace or next item" probably shouldn't be writing production JSON parsers), and
inconveniencing human users whenever JSON needs to be edited by hand.
That last one is very very important, much more important than the other two. Especially because we live in a world where almost everything else already supports trailing commas, so a human is likely to be very used to the pattern of just deleting lines from a list or map literal without having to micro-manage the comma on the prior line in some situations. In most text editors, browser text boxes, and so on, it's also more ergonomic to select and delete one line than it is to select and delete one line and also the last character on the prior line.
If you work with JSON a lot you eventually get desensitized to it, train your brain to work with the abusive no-trailing-comma requirement, and stop noticing that this is an actual problem. But that doesn't mean it isn't a problem. It just means JSON has trained you into making excuses for it. If you want to be the eager supplicating servant of a short-sighted technicality in a formal spec, be my guest I guess, but keep your kinks to yourself.
But if you insist on thinking that it's not a big deal, you should be legally required to be hooked up to receive a small electric shock every time a person anywhere in the world is frustrated by having to delete the trailing comma. Then you'd be qualified to say that it isn't a big deal, but I don't think you'd last even a day.
Anyway, the way formal standards get changed a lot of the time is when every implementation does the right thing on top of or instead of the spec. So if you're in the position to do so, do your part.
P.S. If your JSON parser has crossed the Hyrum's Law threshold so badly that now you can't change default behavior without too many angry users complaining that they were actually relying on the trailing comma rejection (seems unlikely in the typical case but I'm sure there's someone out there who is), at least implement trailing comma tolerance as opt-in behavior, until you're ready to flip the default after a warning period or whatever. But I think almost every JSON parser out there could start accepting trailing commas by default tomorrow, and the vast majority of users would be unaffected or just get small quality-of-life improvements, and the remaining few who really need that trailing comma rejection could be served by an optional flag.
9 notes
·
View notes
Link
JSON Parser Online helps to parse, view, analyze JSON data in Tree View. It's a pretty simple and easy way to parse JSON Data and Share with others.
This Parse JSON Online tool is very powerful.
This will show data in a tree view which supports image viewer on hover.
It also validates your data and shows error in great detail.
It's a wonderful tool crafted for JSON lovers who is looking for to deserialize json online.
This json decode online helps to decode JSON which are unreadable.
1 note
·
View note
Text
top 10 free python programming books pdf online download
link :https://t.co/4a4yPuVZuI?amp=1
python download python dictionary python for loop python snake python tutorial python list python range python coding python programming python array python append python argparse python assert python absolute value python append to list python add to list python anaconda a python keyword a python snake a python keyword quizlet a python interpreter is a python code a python spirit a python eating a human a python ate the president's neighbor python break python basics python bytes to string python boolean python block comment python black python beautifulsoup python built in functions b python regex b python datetime b python to dictionary b python string prefix b' python remove b' python to json b python print b python time python class python certification python compiler python command line arguments python check if file exists python csv python comment c python interface c python extension c python api c python tutor c python.h c python ipc c python download c python difference python datetime python documentation python defaultdict python delete file python data types python decorator d python format d python regex d python meaning d python string formatting d python adalah d python float d python 2 d python date format python enumerate python else if python enum python exit python exception python editor python elif python environment variables e python numpy e python for everyone 3rd edition e python import e python int e python variable e python float python e constant python e-10 python format python function python flask python format string python filter python f string python for beginners f python print f python meaning f python string format f python float f python decimal f python datetime python global python global variables python gui python glob python generator python get current directory python getattr python get current time g python string format g python sleep g python regex g python print g python 3 g python dictionary g python set g python random python hello world python heapq python hash python histogram python http server python hashmap python heap python http request h python string python.h not found python.h' file not found python.h c++ python.h windows python.h download python.h ubuntu python.h not found mac python if python ide python install python input python interview questions python interpreter python isinstance python int to string in python in python 3 in python string in python meaning in python is the exponentiation operator in python list in python what is the result of 2 5 in python what does mean python json python join python join list python jobs python json parser python join list to string python json to dict python json pretty print python j complex python j is not defined python l after number python j imaginary jdoodle python python j-link python j+=1 python j_security_check python kwargs python keyerror python keywords python keyboard python keyword arguments python kafka python keyboard input python kwargs example k python regex python k means python k means clustering python k means example python k nearest neighbor python k fold cross validation python k medoids python k means clustering code python lambda python list comprehension python logging python language python list append python list methods python logo l python number l python array python l-bfgs-b python l.append python l system python l strip python l 1 python map python main python multiprocessing python modules python modulo python max python main function python multithreading m python datetime m python time python m flag python m option python m pip install python m pip python m venv python m http server python not equal python null python not python numpy python namedtuple python next python new line python nan n python 3 n python meaning n python print n python string n python example in python what is the input() feature best described as n python not working in python what is a database cursor most like python online python open python or python open file python online compiler python operator python os python ordereddict no python interpreter configured for the project no python interpreter configured for the module no python at no python 3.8 installation was detected no python frame no python documentation found for no python application found no python at '/usr/bin python.exe' python print python pandas python projects python print format python pickle python pass python print without newline p python re p python datetime p python string while loop in python python p value python p value from z score python p value calculation python p.map python queue python queue example python quit python qt python quiz python questions python quicksort python quantile qpython 3l q python download qpython apk qpython 3l download for pc q python 3 apk qpython ol q python 3 download for pc q python 3 download python random python regex python requests python read file python round python replace python re r python string r python sql r python package r python print r python reticulate r python format r python meaning r python integration python string python set python sort python split python sleep python substring python string replace s python 3 s python string s python regex s python meaning s python format s python sql s python string replacement s python case sensitive python try except python tuple python time python ternary python threading python tutor python throw exception t python 3 t python print .t python numpy t python regex python to_csv t python scipy t python path t python function python unittest python uuid python user input python uppercase python unzip python update python unique python urllib u python string u' python remove u' python json u python3 u python decode u' python unicode u python regex u' python 2 python version python virtualenv python venv python virtual environment python vs java python visualizer python version command python variables vpython download vpython tutorial vpython examples vpython documentation vpython colors vpython vector vpython arrow vpython glowscript python while loop python write to file python with python wait python with open python web scraping python write to text file python write to csv w+ python file w+ python open w+ python write w+ python open file w3 python w pythonie python w vs wb python w r a python xml python xor python xrange python xml parser python xlrd python xml to dict python xlsxwriter python xgboost x python string x-python 2 python.3 x python decode x python 3 x python byte x python remove python x range python yield python yaml python youtube python yaml parser python yield vs return python yfinance python yaml module python yaml load python y axis range python y/n prompt python y limit python y m d python y axis log python y axis label python y axis ticks python y label python zip python zipfile python zip function python zfill python zip two lists python zlib python zeros python zip lists z python regex z python datetime z python strftime python z score python z test python z transform python z score to p value python z table python 0x python 02d python 0 index python 0 is false python 0.2f python 02x python 0 pad number python 0b 0 python meaning 0 python array 0 python list 0 python string 0 python numpy 0 python matrix 0 python index 0 python float python 101 python 1 line if python 1d array python 1 line for loop python 101 pdf python 1.0 python 10 to the power python 101 youtube 1 python path osprey florida 1 python meaning 1 python regex 1 python not found 1 python slicing 1 python 1 cat 1 python list 1 python 3 python 2.7 python 2d array python 2 vs 3 python 2.7 download python 2d list python 2.7 end of life python 2to3 python 2 download 2 python meaning 2 pythons fighting 2 pythons collapse ceiling 2 python versions on windows 2 pythons fall through ceiling 2 python versions on mac 2 pythons australia 2 python list python 3.8 python 3.7 python 3.6 python 3 download python 3.9 python 3.7 download python 3 math module python 3 print 3 python libraries 3 python ide python3 online 3 python functions 3 python matrix 3 python tkinter 3 python dictionary 3 python time python 4.0 python 4 release date python 4k python 4 everyone python 44 mag python 4 loop python 474p remote start instructions python 460hp 4 python colt 4 python automl library python 4 missile python 4 download python 4 roadmap python 4 hours python 5706p python 5e python 50 ft water changer python 5105p python 5305p python 5000 python 5706p manual python 5760p 5 python data types 5 python projects for beginners 5 python libraries 5 python projects 5 python ide with icons 5 python program with output 5 python programs 5 python keywords python 64 bit python 64 bit windows python 64 bit download python 64 bit vs 32 bit python 64 bit integer python 64 bit float python 6 decimal places python 660xp 6 python projects for beginners 6 python holster 6 python modules 6 python 357 python 6 missile python 6 malware encryption python 6 hours python 7zip python 7145p python 7754p python 7756p python 7145p manual python 7145p remote start python 7756p manual python 7154p programming 7 python tricks python3 7 tensorflow python 7 days ago python 7 segment display python 7-zip python2 7 python3 7 ssl certificate_verify_failed python3 7 install pip ubuntu python 8 bit integer python 881xp python 8601 python 80 character limit python 8 ball python 871xp python 837 parser python 8.0.20 8 python iteration skills 8 python street dakabin python3 8 tensorflow python 8 puzzle python 8 download python 8 queens python 95 confidence interval python 95 percentile python 990 python 991 python 99 bottles of beer python 90th percentile python 98-381 python 9mm python 9//2 python 9 to 09 python 3 9 python 9 subplots pythonrdd 9 at rdd at pythonrdd.scala python 9 line neural network python 2.9 killed 9 python

#pythonprogramming #pythoncode #pythonlearning #pythons #pythona #pythonadvanceprojects #pythonarms #pythonautomation #pythonanchietae #apython #apythonisforever #apythonpc #apythonskin #apythons #pythonbrasil #bpython #bpythons #bpython8 #bpythonshed #pythoncodesnippets #pythoncowboy #pythoncurtus #cpython #cpythonian #cpythons #cpython3 #pythondjango #pythondev #pythondevelopers #pythondatascience #pythone #pythonexhaust #pythoneğitimi #pythoneggs #pythonessgrp #epython #epythonguru #pythonflask #pythonfordatascience #pythonforbeginners #pythonforkids #pythonfloripa #fpython #fpythons #fpythondeveloper #pythongui #pythongreen #pythongame #pythongang #pythong #gpython #pythonhub #pythonhackers #pythonhacking #pythonhd #hpythonn #hpythonn✔️ #hpython #pythonista #pythoninterview #pythoninterviewquestion #pythoninternship #ipython #ipythonnotebook #ipython_notebook #ipythonblocks #ipythondeveloper #pythonjobs #pythonjokes #pythonjobsupport #pythonjackets #jpython #jpythonreptiles #pythonkivy #pythonkeeper #pythonkz #pythonkodlama #pythonkeywords #pythonlanguage #pythonlipkit #lpython #lpythonlaque #lpythonbags #lpythonbag #lpythonprint #pythonmemes #pythonmolurusbivittatus #pythonmorphs #mpython #mpythonprogramming #mpythonrefftw #mpythontotherescue #mpython09 #pythonnalchik #pythonnotlari #pythonnails #pythonnetworking #pythonnation #pythonopencv #pythonoop #pythononline #pythononlinecourse #pythonprogrammers #ppython #ppythonwallet #ppython😘😘 #ppython3 #pythonquiz #pythonquestions #pythonquizzes #pythonquestion #pythonquizapp #qpython3 #qpython #qpythonconsole #pythonregiusmorphs #rpython #rpythonstudio #rpythonsql #pythonshawl #spython #spythoniade #spythonred #spythonredbackpack #spythonblack #pythontutorial #pythontricks #pythontips #pythontraining #pythontattoo #tpythoncreationz #tpython #pythonukraine #pythonusa #pythonuser #pythonuz #pythonurbex #üpython #upython #upythontf #pythonvl #pythonvert #pythonvertarboricole #pythonvsjava #pythonvideo #vpython #vpythonart #vpythony #pythonworld #pythonwebdevelopment #pythonweb #pythonworkshop #pythonx #pythonxmen #pythonxlanayrct #pythonxmathindo #pythonxmath #xpython #xpython2 #xpythonx #xpythonwarriorx #xpythonshq #pythonyazılım #pythonyellow #pythonyacht #pythony #pythonyerevan #ypython #ypythonproject #pythonz #pythonzena #pythonzucht #pythonzen #pythonzbasketball #python0 #python001 #python079 #python0007 #python08 #python101 #python1 #python1k #python1krc #python129 #1python #python2 #python2020 #python2018 #python2019 #python27 #2python #2pythons #2pythonsescapedfromthezoo #2pythons1gardensnake #2pythons👀 #python357 #python357magnum #python38 #python36 #3pythons #3pythonsinatree #python4kdtiys #python4 #python4climate #python4you #python4life #4python #4pythons #python50 #python5 #python500 #python500contest #python5k #5pythons #5pythonsnow #5pythonprojects #python6 #python6s #python69 #python609 #python6ft #6python #6pythonmassage #python7 #python734 #python72 #python777 #python79 #python8 #python823 #python8s #python823it #python800cc #8python #python99 #python9 #python90 #python90s #python9798
1 note
·
View note
Text
[Second week of 2019.11] White Spirit devlog - Misunderstanding of Manipulator and the struggle with bugs
Hi, there.
This week, the code I started fixing after discovering an issue that did not clean up event callbacks in the editor created a fairly complex bug. I spent quite a lot of time looking for bugs in three days, so I have fewer devlog this week.
As soon as I created the dialog last week, I implemented the selection dialog. However, while implementing this, I found that the usage of the Manipulator is wrong.
The first discovery that the Action event that implemented and registered the dialog event last week was not cleaned up when the event editor was unloaded.
I was thinking that the UnregisterCallbacksFromTarget method would be called when the element was removed from the layout.
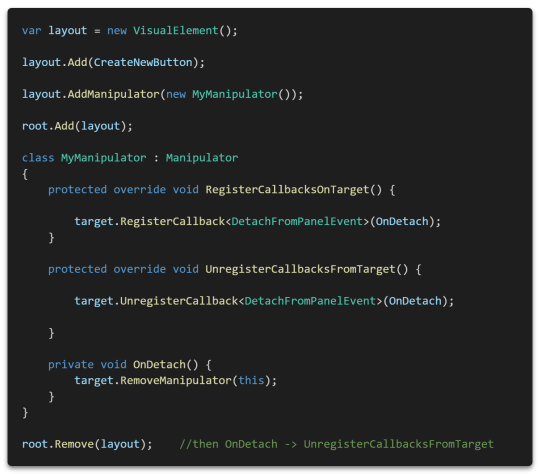
Fortunately, this problem was solved simply by removing the Manipulator from DetachFromPanelEvent.
(If you recycle layout object, this is not recommended. Remove the Manipulator when your layout object are cleaned up.)

So, I revamped our abstract Manipulator class for the event editor.
Changed DetachFromPanelEvent to handle internally automatically.
However, while fixing this, I found some difficult bugs.
As the Unity came to 2019, there was even a bug where Unity crashed every time when view a native object in debugger, so I spent quite a bit of time debugging in the editor.
Fortunately it was a simple problem and I fixed a bug that was difficult.

And while checking this, I found out that Json.NET is basically able to parse even if it contains line breaks.

The default parser included in JavaScript, the original owner of JSON, doesn't accept this syntax (...)
Anyway, the fact that line breaks are parseable can be useful when I need a long text.
Anyway, after going through various problems, I added a camera change event, a camera zoom event, and added a feature to assign a unique color to each event.
This work is now beginning to end. I want to make some real parts of game...

See you in next week.
1 note
·
View note
Text
Best json formatter

BEST JSON FORMATTER REGISTRATION
BEST JSON FORMATTER CODE
BEST JSON FORMATTER FREE
The data structure is simple to comprehend.
For most programming languages, a gazillion JSON libraries are available for.
Parsing is simple, particularly in JavaScript.
Unlike XML, it’s lightweight because it doesn’t use a complete markup structure.
It’s readable by humans if it’s formatted correctly.
There are lots of reasons why you would like JSON to be used:
This JSON formatter online can also be used as a JSON lint.
Store data for the last Formatted JSON locally in Browser Local Storage.
It’s the only JSON tool that displays the image in a tree view on the Image URL hover.
It helps to verify JSON via Error Messages online.
BEST JSON FORMATTER CODE
If the JSON is invalid, it will search the correct JSON code for errors and point out the errors. You can paste or upload the data from your computer to JSON Parser Online. It will automatically detect invalid JSON documentation or syntax automatically and get instant results in an easy-to-read format. All you require to do is paste your JSON code into the specified space. JSON formatter is an online application that uses the online JSON schema validator to validate JSON code.
BEST JSON FORMATTER REGISTRATION
No need for installation or registration is necessary! Online JSON Tools JSON Formatter It’s quick and easy with such apps, fill in the editor and click on the desired action button. This can be useful for embedding JSON in code, for instance. Finally, you can also use JSON data to escape/unescape. It’s also possible to minify your JSON (The opposite of pretty JSON, it removes all unnecessary characters). Your JSON data is automatically checked when you fill in the editor, and a message tells you whether or not your JSON is correct. These tools are also a validator and a JSON checker: you can check JSON online without pressing. This tool allows JSON to be read and debugged easily by humans. For a human (without line breaks), JSON strings are not always very readable, mainly if they are bulky. To help debug JSON, the JSON formatter tool was developed. It is a widespread data format with a diverse range of applications, such as serving as a replacement for XML in AJAX systems. It is an open standard file format and data exchange format that uses human-readable text to save and transmit data objects consisting of attribute-value and array data types. JSON is “self-describing” and easy to understand. JSON is often used when information is sent from a server to a webpage. No data will be stored in our server.JSON is a lightweight form for storing and transporting data. Yes, our JSON formatter online tool is privacy friendly and formatting JSON is done locally in your browser. Copy the JSON formatted code by clicking on copy button. To use JSON Formatter online, paste your tidy JSON code inside the input box, then select indent and click on format JSON button. It can be used as JSON validator, editor and viewer tool. JSON Formatter is an online tool that can be used to format JSON.
SQL formatter – SQL formatter beautifies tidy SQL with your desired indentation level.
CSS Formatter – Use this CSS formatter online tool to format/beautify CSS code.
JavaScript Formatter – Online JS formatter helps to format or beautify JavaScript.
It also be used as JSON formatter and validator.
JSON Formatter– Online JSON formatter helps to quickly format JSON.
HTML formatter – Online HTML formatter beautifies ugly/tidy HTML code by making it readable and pretty, with proper indentation level.
Online tools to format JSON, JS, CSS, HTML and SQL
You can use this JSON formatter as JSON validator, JSON viewer or JSON editor.
It allows you to copy formatted JSON data.
It allows you to upload JSON file and format it instantly.
It’s the best JSON formatter online tool to format/beautify your JSON.
Choose indentation level ( 4 spaces by default) as your choice to format your JSON code.
JSON formatter supports 5 indentation levels: 2 spaces, 3 spaces, 4 spaces, 8 spaces and tabs.
This JSON formatter beautifies JSON locally on your device, which means no data is uploaded to the server.
BEST JSON FORMATTER FREE
Free and easy-to-use online JSON formatter tool for developer.If you Want to format or beautify JSON? then simply paste your JSON file in the code editor and let JSON formatter format, validate and print your JSON data into pretty, human-readable format.Step 4: Feel free to use the quick copy button to copy the code.Step 3: If you’ve done it correctly, the formatted JSON code should now appear in the output box (bottom side).Step 2: Click the “Format JSON” button and wait for the JSON formatter tool to finish formatting your code.Step 1: Paste your JSON code inside the input box (top side).
0 notes
Text
Brew swagger editor

#Brew swagger editor code
Provides the support for management of multiple API versions.Enables us to share the APIs privately and publicly.
#Brew swagger editor code
Helps in generation of server side and client side code and pushes it to Git servers.Better collaboration on API definitions with your team.Saves the common API components (such as data models and responses) in domains and references those from API definitions.Hosts all your API definitions in a single location.Defines the APIs in the OpenAPI format.SwaggerHub can help us to do number of tasks: SwaggerHub integrates the core Swagger tools (Codegen, Editor, UI, Validator) into a single platform which helps to coordinate the complete API’s lifecycle. SwaggerHub is built by the same people which are behind the open-source Swagger tools. SwaggerHub is basically a collaborative platform with its help we can define our APIs via OpenAPI specifications and manage APIs throughout their lifecycle. SwaggerHub is a platform for integrated API development that uses all the core features of the open source Swagger framework, along with additional advanced features to document, build, deploy and manage your APIs. Within a few clicks, Swagger Inspector can generate your OpenAPI documentation and save a lot of valuable development time. Swagger Inspector enables you to automatically generate the OpenAPI file from any end point you provide. Swagger Core is basically a Java implementation of the OpenAPI Specifications. Swagger parser parses Swagger specs in JSON or YAML format, its a standalone library for parsing OpenAPI definitions in Java Swagger Core Swagger codegen generates the server stubs and all required client libraries from an OpenAPI specification using OpenAPI specification. It reads OpenAPI specification’s json file and renders the interactive page in the browser. Swagger UI is basically a GUI which consists of HTML, CSS and Javascript assets. Swagger UI renders OpenAPI specifications as an interactive API documentation. You can preview the changes at real-time. Swagger editor lets you edit OpenAPI specifications in YAML format inside the browser. Swagger Editor is a browser-based editor in which you can write OpenAPI specs. Swagger framework consists of multiple tools, few of them are explained below: Swagger Editor
0 notes
Text
alright technically it is on your prof for never teaching you how to do that, but fr, if you put sensitive information (like an API key or, worse, login credentials) in a file that actually gets committed to a public git repo, you are basically asking to get 20 different kinds of hacked. it's like logging onto some MMO or forum or whatever and putting your password in chat.
now about the gitignore file. Super simple. Create a file in the root of your git repo called ".gitignore" exactly. open it with a text editor and put in relative paths to files, one to a line, that you want Git to, well, ignore. For example, say I have two files in my repo that I don't want Joe Random on the internet to be able to look at because I put hardcoded access tokens in them, secrets.json in my repo root and a Java class.
My .gitignore could look like this:
secrets.json
src/com/yourname/yourproject/Secrets.java
For 99% of use cases that's all there is to it! You can use wildcards to match multiple files, and you can find a full list of all features supported by .gitignore files here, but that's the gist. Note that one thing you cannot do is exclude individual lines from a single file -- either the whole file is there or it's not -- so I strongly recommend putting all your secrets in one file. If you're in a language that supports includes, like C++ or Rust, I'd put all of them there, and include that file as needed from your other code. Otherwise, either just have a source file containing constant definitions (like a Java class with no constructors or methods, only public static final attributes) or a YAML file or similar on disk which your program parses on startup. I prefer the first approach since the secrets get compiled into your program and you don't have to rely on that config file being there or waste time parsing it, although if everyone who uses your program is going to have a different version of that secret (e.g. if you're writing a Discord bot for people to use on their own computer with their own API key) a config file with the secret is definitely the way to go. It doesn't have to be anything fancy -- a JSON file will do, or even just a text file with one line containing the access token; people who host their own Discord bots are usually tech savvy enough to figure that out -- although if you can be bothered to figure out how to work your language's YAML parser you'll definitely thank yourself later when you decide you'd like to add config options.
Also keep in mind that no matter which approach you take, when you clone your repo on another computer, those files won't be there, and your program won't work. That's the point of a .gitignore file. You'll have to share those files between computers some other way. My preferred method is SFTP, but Google Drive works if you're using an operating system without SFTP support, like Windows (if you decide you like software development, you'll definitely want to look into Linux at some point). This should go without saying, but don't put it in the same repo under a different name, or in a different git repo on the same GitHub/GitLab account with a name like myproject-secrets. Or if you do, at LEAST make the second repo private. People will figure that out.
Pro tip: check your .gitignore file into Git. This will let other people know which files they'll need to provide for themselves, and, if you yourself clone the repo on another computer, will prevent you from accidentally uploading your secrets file from there.
Need to learn how .gitignore and config files work. Got marked down because I didn’t hide my API key that I used for my weather dashboard homework, inside of a .gitignore file…
But Hon, you never taught us that xoxo
90 notes
·
View notes
Text
MAKER Pi Pico #2 - Sensordaten auf einer SD-Card speichern
In diesem Beitrag möchte ich dir zeigen, wie du Sensordaten am MAKER Pi Pico mit dem SD-Card Adapter auf einer entsprechenden Micro SD-Card speichern kannst. https://youtu.be/HII4YTjos3g Im letzten Beitrag habe ich dir gezeigt wie du Sensordaten an den IoT Service ThingSpeak senden kannst, wenn du aber einmal keine WiFi Verbindung hast oder aber dein eigenes Dashboard erstellen möchtest dann kannst du mit diesem Feature deine Daten sicher zwischenspeichern. Den MAKER Pi Pico selber, habe ich dir bereits im Beitrag Maker Pi Pico von Cytron vorgestellt.

MAKER Pi Pico
Benötigte Ressourcen zum Nachbau
Möchtest du die Beispiele aus dem Beitrag nachbauen, so benötigst du folgende Ressourcen: - MAKER Pi Pico,- Micro USB Datenkabel, - DHT11 Sensor, - SD-Card mit 16 GB, - USB SD-Card Reader für den PC

MAKER Pi Pico mit Micro SD-Card
Schaltung & Aufbau
In diesem Beitrag verwende ich den DHT11 Sensor mit Grove Schnittstelle. Der DHT11 Sensor hat den Vorteil das diese zwei Werte liefert (Temperatur, rel. Luftfeuchtigkeit), jedoch den Nachteil das dieser nicht zuverlässig Werte liefert bzw. das Auslesen nicht zuverlässig funktioniert.

MAKER Pi Pico mit DHT11 Sensor und Micro SD-Karte
Pinout des SD-Card Adapters
Der MAKER Pi Pico hat einen SD-Card Adapter onBoard d.h. wir müssen uns nicht zusätzlich ein Modul besorgen und ggf. umständlich anschließen. Wenn du "nur" den Raspberry Pi Pico verwenden möchtest dann gebe ich dir hier das Pinout des SD-Card Adapters. Raspberry Pi Pico GPIOSD ModeSPI ModeGP10CLKSCKGP11CMDSDI / MOSIGP12DAT0SDO / MISOGP13DAT1XGP14DAT2XGP15CD/DAT3CSnPinout des SD-Card Adapters am MAKER Pi Pico Auf der Seite Maker Pi Pico Datasheet findest du weitere technische Daten zum MAKER Pi Pico.

Anschluss eines SD-Card Adapters an den Raspberry Pi Pico In meinem Fall brauche ich nur den DHT11 Sensor anschließen und das Micro USB Kabel anschließen und bin mit dem Aufbau für diesen Beitrag fertig.
Programmieren des SD-Card Adapters am MAKER Pi Pico
Für die nachfolgenden Beispiele verwende ich das Tutorial "Write Read Data to SD Card Using Maker Pi Pico and CircuitPython" als Basis. Dieses Tutorial ist zwar in Englisch, aber durch die recht einfache Skriptsprache CircuitPython kann man den Quellcode gut lesen und verstehen. Mounten einer SD-Card & schreiben einer Zeile in eine Textdatei Zunächst wollen wir eine SD-Karte mounten quasi einbinden und in eine Datei eine Textzeile schreiben. from board import * from time import * import busio import sdcardio import storage # eine Pause von 1 Sekunde sleep(1) # definieren der Pins der SD-Card spi = busio.SPI(GP10, MOSI=GP11, MISO=GP12) cs = GP15 sd = sdcardio.SDCard(spi, cs) # einbinden der SD Karte vfs = storage.VfsFat(sd) storage.mount(vfs, '/sd') # öffnen der Datei pico.txt zum schreiben # wenn diese Datei nicht existiert dann # wird diese zuvor erstellt with open("/sd/pico.txt", "w") as file: # schreiben einer Zeile in die Datei file.write("Hello, world!") # schreiben eines Zeilenumbruchs file.write("rn") lesen von Dateien einer SD-Card Da wir nun Daten auf die SD-Karte geschrieben haben, möchten wir diese ggf. auch auslesen. Im Beitrag Python #10: Dateiverarbeitung habe ich dir gezeigt wie man mit Dateien & Verzeichnisse in Python arbeitet. Dieses können wir auf die leicht abgewandelte Skriptsprache CircuitPython anwenden. from board import * from time import * import busio import sdcardio import storage # eine Pause von 1 Sekunde sleep(1) # definieren der Pins der SD-Card spi = busio.SPI(GP10, MOSI=GP11, MISO=GP12) cs = GP15 sd = sdcardio.SDCard(spi, cs) # einbinden der SD Karte vfs = storage.VfsFat(sd) storage.mount(vfs, '/sd') # schreiben von 3 Einträgen in die Datei "greeting.txt" # durch den Parameter "a" (a - append / anhängen ) # wird beim nächsten Start des Programmes die Datei # NICHT überschrieben sondern 3 zusätzliche Einträge hinzugefügt for i in range(3): # Datei "greeting.txt" zum schreiben öffnen, die Daten werden # an das Ende der Datei geschrieben with open("/sd/greeting.txt", "a") as file: # schreiben einer Zeile in die Datei file.write("Hello World!") # schreiben eines Zeilenumbruchs file.write("rn") # lesen der zuvor geschriebenen Daten von der SD Karte with open("/sd/greeting.txt", "r") as file: for line in file: print(line)
Ausgabe auf der Konsole
Auf der Konsole werden nun die zuvor geschriebenen Daten angezeigt. code.py Ausgabe: Hello World! Hello World! Hello World! Sollte das Programm jedoch mehrfach gestartet werden, so werden je Start 3 weiteren Datenzeilen hinzugefügt.
Schreiben von Sensordaten auf der SD-Karte
Möchte man Sensordaten schreiben so empfiehlt es sich diese Strukturiert zu schreiben. Man kann hierfür das JSON Format, XML oder auch das recht einfache CSV Format wählen. Da wir lediglich die 4 Werte, - Index, - Zeitstempel, - Temperatur, - rel. Luftfeuchtigkeit schreiben möchten, reicht für diesen Fall das CSV Format aus. (Mit den anderen beiden Formaten werde ich mich gesondert auf meinem Blog befassen.) Was ist das CSV Format? Das CSV Format ist wie erwähnt das einfachste Format. Die Daten werden dabei mit einem definierten Symbol getrennt in einer Zeile gespeichert. Eine Zeile endet immer mit einem Zeilenumbruch "rn". 1;2021-08-22 13:30;13;52 2;2021-08-22 13:31;15;49 Das Symbol zum Trennen von Daten innerhalb einer Zeile ist normalerweise das Semikolon. Aber es kann auch jedes andere Symbol verwendet werden. Ein Problem tritt jedoch auf wenn dieses Symbol innerhalb eines Textes in der Zeile vorkommt, dann kann ein Parser schon an seine grenzen stoßen. Daten im CSV Format schreiben & lesen Wollen wir zunächst ein paar Daten im CSV Format schreiben und lesen. for i in range(3): with open("/sd/date.txt", "a") as file: # schreiben einer CSV Datenzeile in die Datei file.write(str(i)) # Trenner der CSV Datei file.write(";") file.write("2021-08-22 13:3"+str(i)) file.write(";") file.write(str(24)) file.write(";") file.write(str(48)) # schreiben eines Zeilenumbruchs file.write("rn") # lesen der zuvor geschriebenen Daten von der SD Karte with open("/sd/date.txt", "r") as file: for line in file: single_line = line.strip() # entpacken einer Zeile in die Variablen index, timestamp, temp, humi = single_line.split(";") # ausgeben der Daten auf der Konsole print("Index:", str(index)) print("Zeitstempel:", str(timestamp)) print("Temperatur:", str(temp)) print("rel. Luftfeuchtigkeit:", str(humi)) Ausgabe auf der Konsole Auf der Konsole werden nun 3 Blöcke ausgegeben mit den zuvor gespeicherten Daten. code.py Ausgabe: Index: 0 Zeitstempel: 2021-08-22 13:30 Temperatur: 24 rel. Luftfeuchtigkeit: 48 Index: 1 Zeitstempel: 2021-08-22 13:31 Temperatur: 24 rel. Luftfeuchtigkeit: 48 Index: 2 Zeitstempel: 2021-08-22 13:32 Temperatur: 24 rel. Luftfeuchtigkeit: 48 Zeitstempel für die Sensordaten Der MAKER Pi Pico verfügt über ein paar sehr nützliche Features aber eine RealTimeClock ist (bisher) nicht verbaut somit müsste man über die Pins ein solches Modul zusätzlich anschließen oder aber über einen aufgesteckten ESP01 und einer WiFi Verbindung von einem NTP Server die Zeitstempel holen. In diesem Beispiel möchte ich einen Zeitstempel von einem kleinen PHP-Skript auf einer meiner Subdomains lesen (https://zeitstempel.draeger-it.blog/). Der Vorteil ist, dass ich das Format gleich definieren kann und somit der Code im Mu-Editor recht übersichtlich bleibt. Für diese Lösung benötigst du ein aktive WiFi Verbindung zu einem lokalen WLAN Netzwerk. Aufbau einer WiFi Verbindung und laden des Zeitstempels von der Webseite Wie du am MAKER Pi Pico mit dem ESP01 eine WiFi Verbindung zu deinem WLAN Netzwerk aufbaust habe ich dir im Beitrag Maker Pi Pico von Cytron bereits gezeigt. Hier möchte ich dir lediglich das fertige Programm zum lesen eines Zeitstempels zeigen. Dieser Beitrag soll sich hautpsächlich darum drehen wie du nun die Sensordaten mit eben diesem Zeitstempel auf einer SD-Card im CSV Format speicherst. import time import board import adafruit_dht import busio import adafruit_requests as requests import adafruit_espatcontrol.adafruit_espatcontrol_socket as socket from adafruit_espatcontrol import adafruit_espatcontrol secrets = { "ssid" : "FRITZBox7590GI24", "password" : "abc" } timestamp_url = "http://zeitstempel.draeger-it.blog/" RX = board.GP17 TX = board.GP16 uart = busio.UART(TX, RX, receiver_buffer_size=2048) esp = adafruit_espatcontrol.ESP_ATcontrol(uart, 115200, debug=False) requests.set_socket(socket, esp) print("Resetting ESP module") esp.soft_reset() # Aufbau der WiFi Verbindung while not esp.is_connected: print("Connecting...") esp.connect(secrets) print("lesen des Zeitstempels von ", timestamp_url) # Endlosschleife... while True: try: r = requests.get(timestamp_url) print("Zeitstempel:", r.text) time.sleep(2) except: print("Fehler beim lesen des Zeitstempels von", timestamp_url) In diesem kurzen Video zeige ich dir nun die Ausführung des oben gezeigten Programmes. (Das Passwort zu meinem WiFi-Netzwerk habe ich hier mit einem schwarzen Balken unkenntlich gemacht.) Auf der Konsole sieht man den gelesenen Zeitstempel sowie ab und zu das nicht erfolgreich gelesen werden konnte. Ich denke das liegt hier vielmehr an einem Timeout der Verbindung, welcher zu kurz gewählt wurde. Hier kann man sich aber Abhilfe schaffen und ggf. eine kleine Schleife von 10 Durchläufen erzeugen und somit 10-mal probieren einen gültigen Zeitstempel zu laden. Lesen eines Zeitstempels von einer Webseite. schreiben der Sensordaten im CSV Format Da wir nun wissen wie wir Daten auf die SD-Card schreiben und lesen, sowie einen Zeitstempel haben ist der nächste Schritt die Sensordaten auszulesen und diese Daten auf die SD-Card zu schreiben. Damit unser Index (die erste Spalte in der CSV Datei) fortlaufend geschrieben wird, laden wir die CSV Datei beim starten des Mikrocontrollers und speichern und die Anzahl der Zeilen dieser Datei in einer Variable "index". import time import board import adafruit_dht import busio import adafruit_requests as requests import adafruit_espatcontrol.adafruit_espatcontrol_socket as socket from adafruit_espatcontrol import adafruit_espatcontrol import adafruit_dht import sdcardio import storage secrets = { "ssid" : "FRITZBox7590GI24", "password" : "abc" } timestamp_url = "http://zeitstempel.draeger-it.blog/" RX = board.GP17 TX = board.GP16 uart = busio.UART(TX, RX, receiver_buffer_size=2048) esp = adafruit_espatcontrol.ESP_ATcontrol(uart, 115200, debug=False) requests.set_socket(socket, esp) # initialisieren eines DHT11 Sensors am GP27 dhtDevice = adafruit_dht.DHT11(board.GP27) # Zähler für den Index innerhalb der CSV Datei index = 0 # Dateiname für die Sensordaten csv_filename = "/sd/measurements.csv" # definieren der Pins der SD-Card spi = busio.SPI(board.GP10, MOSI=board.GP11, MISO=board.GP12) cs = board.GP15 sd = sdcardio.SDCard(spi, cs) # einbinden der SD Karte vfs = storage.VfsFat(sd) storage.mount(vfs, '/sd') # lesen der Sensorwerte des DHT Sensors def read_dht_values(): result = {} # Schleife von 0 bis 9 for i in range(9): try: # lesen der Sensorwerte result = dhtDevice.temperature result = dhtDevice.humidity # Wenn die Temperatur ODER die rel. Luftfeuchtigkeit nicht vom Typ None ist dann, # soll die aeussere Schleife verlassen werden. if(result is not None or result is not None): break; else: # Wenn die Daten nicht gelesen werden konnten, dann eine kleine # Pause von 2 Sekunden einlegen. time.sleep(2) except RuntimeError as error: print(error.args) except Exception as error: # Im Fall eines Schwerwiegenden Fehlers, so wird das Programm beendet. dhtDevice.exit() raise error return result def setup(): # Zugriff auf die Globale Variable "index" global index print("Setup") # Reset des ESP01 Modules esp.soft_reset() # Aufbau der WiFi Verbindung while not esp.is_connected: print("Verbindung zu", secrets,"wird aufgebaut...") esp.connect(secrets) try: index = sum(1 for line in open(csv_filename)) print("Datei", csv_filename,"enthaelt", str(index), "Zeilen") except: print("Datei wurde nicht gefunden.") index = 0 # lesen des Zeitstempels von der Webseite def read_timestamp(): timestamp = "-undefined-" for i in range(10): try: r = requests.get(timestamp_url) timestamp = r.text # Wenn der Code bis hier funktioniert hat, # dann kann die aeussere Schleife verlassen werden. break; except: pass time.sleep(1) return timestamp def loop(): global index # lesen des Zeitstempels timestamp = read_timestamp() # lesen der Sensordaten dht_values = read_dht_values() # incrementieren des Indexes index = index + 1 # Aufbau der CSV Datenzeile csv_line = str(index) + ";" + timestamp + ";" + str(dht_values) + ";" + str(dht_values) # Ausgeben der CSV Datenzeile auf der Komandozeile print(csv_line) # schreiben der CSV Datenzeile in die Datei with open(csv_filename, "a") as file: file.write(csv_line) # hinzufügen eines Zeilenumbruchs am Zeilenende file.write("rn") # einmaliges Ausführen der Funktion "setup" setup() # Endlosschleife, welche die Funktion "loop" ausführt while True: loop() # eine Pause von 1 Sekunde time.sleep(1) Video - schreiben der DHT11 Sensorwerte in eine CSV Datei auf der SD-Karte Read the full article
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
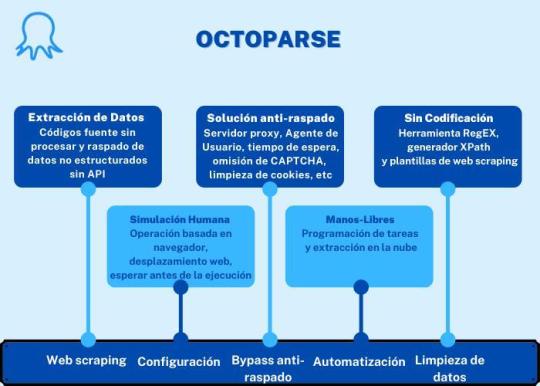
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Text
[Third week of 2019.10] White Spirit devlog - Creating Extended Events in Event Editor v2

Hi, there!
From today, I decided to get into the habit of filling in the write in post of what I worked every day.
I thought that this would allow me to be able to fill in the text in detail with what I learned and what I did at the time.
Leisurely is an important point because I can only use less time on weekdays.
Anyway, from the results of this habit, yes, it works!
On the day I worked, I realized that the method of pre-filling would improve the content and quality of the devlog.
Now let's get to the devlog!
Event Editor v2 Development

I've finished porting conditional events to the event editor v2.
And the reason why it took time to create this event is because of the nature of the event variables managed within the event.
Event variables took time to implement the editor for conditional events because of their ability to freely cast and compare between bool, int, float, and string types.
All of this editor's work is focused on migrating past editors, so you can check the specifics of event variables in last year August's devlog.
https://creta5164.tumblr.com/post/177408351156
https://creta5164.tumblr.com/post/177653185311
And one more thing, the Event Editor uses Json for data polymorphism and transformation tracking, and uses Json.NET's JsonConvert.PopulateObject method as its main element.

But this time, when I created the editor for conditional events, I learned about the new features of JsonConvert.PopulateObject. The default parsing option for the PopulateObject method was to add a set of data (arrays, lists, etc.) after the data, rather than overwriting it. This problem was noticed while testing the Conditional Event Editor, when I found Undo (Ctrl + Z) to increase the conditional element.
The following example will show you what it is.
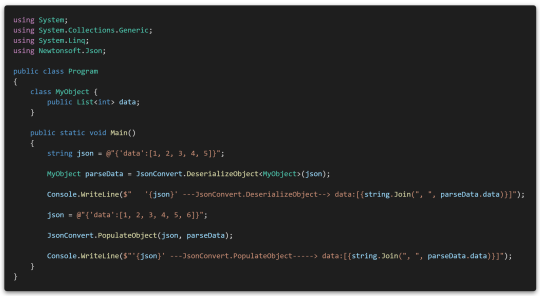

This code parses a JSON string into a MyObject object, then redefines it to JSON with one more number appended to the JSON string, and then updates the data through PopuateObject using JSON characters in the instanced object.
Of course, as mentioned above, elements like arrays are appended after the data. The desired behavior should be to update the data, so I'll should solve the problem.


This problem can fix this by creating a parsing rule via JsonSerializerSettings to force the parser to overwrite new data.
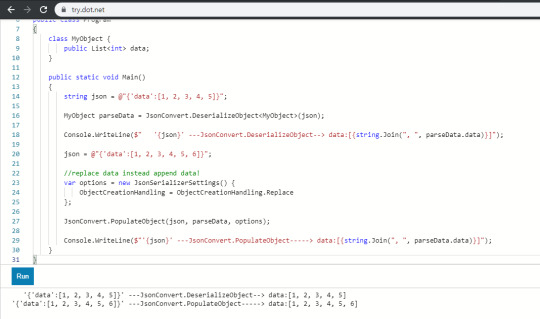
Again, try.dot.net helped to me test our C# code right on the web, so I can able to solve the problem quickly.
Thank you Microsoft!
You can try C# code at here : https://try.dot.net
In addition, this time I noticed an issue where the 'Add Event' button is misplaced in sub-events when the event description gets longer.
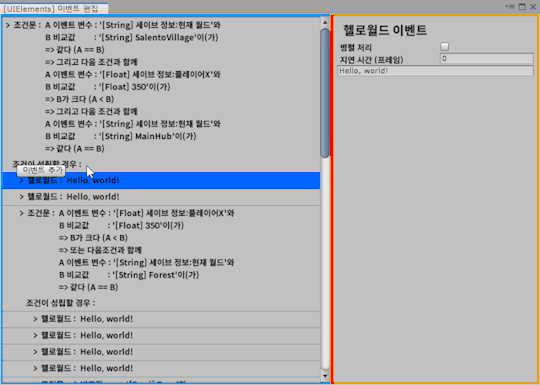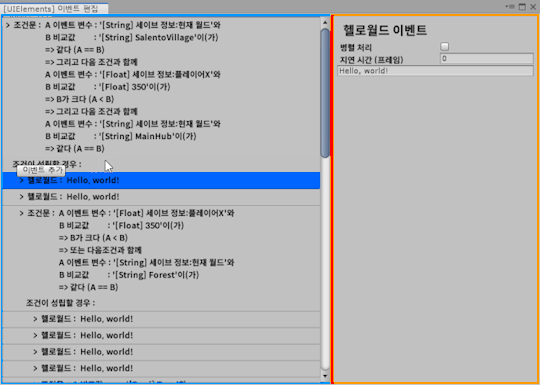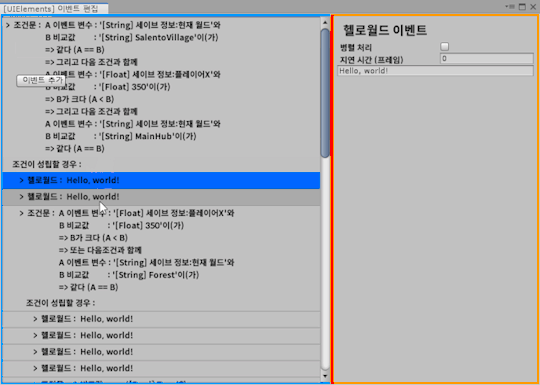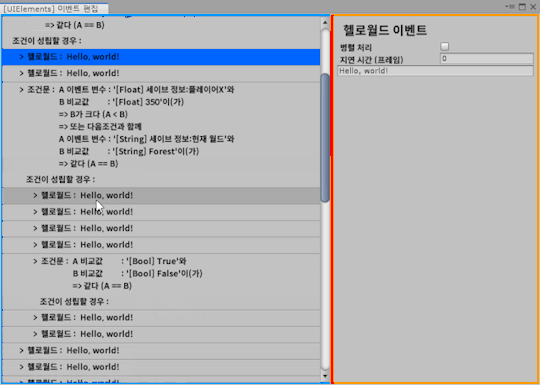
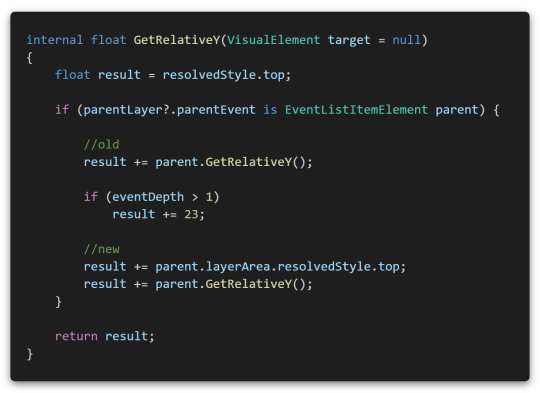
This was a logic error caused by adding only a fixed height in consideration of a situation where there was only one line of event description in a method that could infer where the add event button would be placed. (old) Fixed the event description field to be longer, adding the height of the layer group element. (new)

Ok, works well now!
I have just completed the conditional event, but there are still a lot of events left in the Event Editor v1.

From here, there are events that are specific to this game, so I decided to create a folder to organize those events separately.
I worked to make Unity form elements more readable before starting again.
UIElements has something called uss, which is similar to css, the design markup language for HTML.
I used this to change the text and size of all the basic elements.

First of all, Unity has a menu at the top right of every tab. ([▼三] icon)
If you expand it, there is a UIElements Debugger item, which will bring up a tool similar to the web browser's developer console.
(Or you can do it by pressing Ctrl + F5, but somehow I had a habit of constantly pressing F12 and then realizing that it wasn't the web...lol)

The window on the left is the debugger tool for UIElements.
Within the debugger tool there is a layout tree view on the left and element information on the right.
If you're a front-end web developer, you're pretty familiar with it.
1. Layout tree view
Hierarchy's version of UIElements. This shows the UIElements layout structure that the debugger is viewing (dropdown at the top right). From there, you can unfold the layout yourself and visually see how the layout is for each element. I already hovered over the TextInput element on the left, so the text in my layout is highlighted.
2. Element's Information (Properties)
Similarly, this is the UIElements version of the Inspector. This shows the information for the element selected in the layout tree view. You can see what the uss style class is applied to that element, or inline styles to see what values it contains. If you directly modify the value of an inline style here, it will temporarily affect the appearance of that element. In other words, You can try with your wonder "How can I give style values to look pretty?" or "What happens if this stretches a lot?" and can see the same thing in advance and experiment. In particular, the values at the top of the rectangle represent the margin, border, padding, and actual element size information of the applied style, which can be very useful when working with layout design.
As you can see from the layout tree view, that the Unity UIElements main form control does not consist of one or more elements. (for example, if it's Toggle, then the Label element is also included.) Looking at these elements, you can see that there is a uss class that starts with 'unity'.

Unity's default stylesheets are applied first in order, so if you write style information with the same class name, it will be applied later, giving you the freedom to customize Unity's controls.
So, I used this to improve readability.
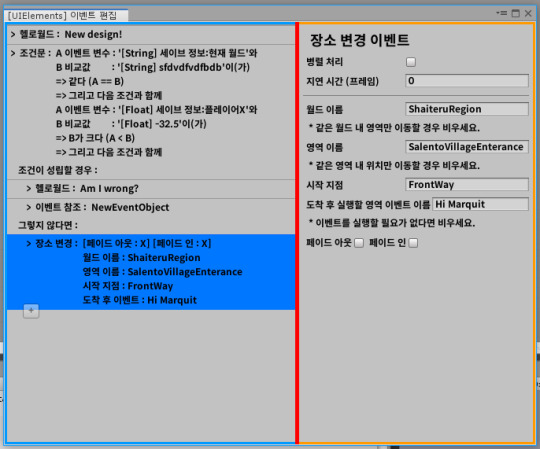
Anyway, I ported the change place event that was in v1.

Then I compared the event editor v1 to the v2 I working currently. It's changed a lot... and also readability changed a lot.
In fact, the readability is definitely different when viewed on high resolution and small screens.
(Dear Unity dev, please change Unity editor's font for CJK... please...)
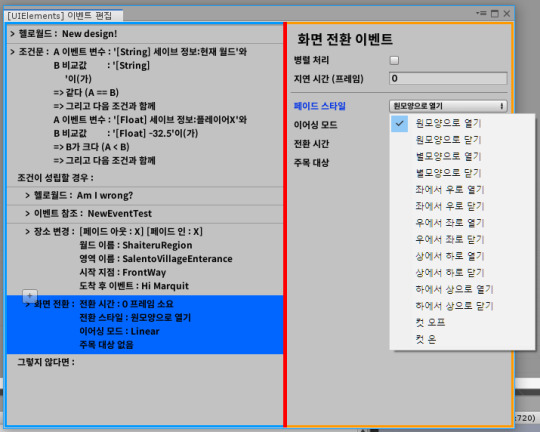
And I keep worked on porting the events.
(This is screen fade event)

Then, as I worked on the screen fade event, I started to get confused as I worked on the unusual structure design I envisioned.
For events that refer to Unity objects, I've summarized where and how to reference them in comments.
Comment’s content
TODO : This event is a good example of an event that refers to a UnityObject. For events that do not use a UnityObject reference, take a look at HelloworldEvent. Reference data is based on SerializedProperty. ------------------------------------------------------------------------- References in the editor can be accessed through Editor_references, and both the editor and runtime can inherit the Editor_PreserveData and PreserveData methods to handle the data they reference. Reference data is an array.
26L-27L: The required number of reference data and the location of the data to be referenced have been explicitly declared. This can reduce the risk of hardcoding by modifying numbers even if the array's specifications change or the data structure changes.
143L: Fields that inherit from UnityObject are safe to get from PreserveData, so add a JsonIgnore attribute to avoid storing data explicitly.
146L-155L: At runtime you can get the reference target here.
You can check it how unusual my structure is in last month's devlog.
https://creta5164.tumblr.com/post/187730990776
Then, while testing the screen fade event, I found a bug.
I decided to set the center point of the screen fade through the transform used in the screen fade event.
But as soon as I added the event to event list in event editor, the object value of the previous reference event entered first.
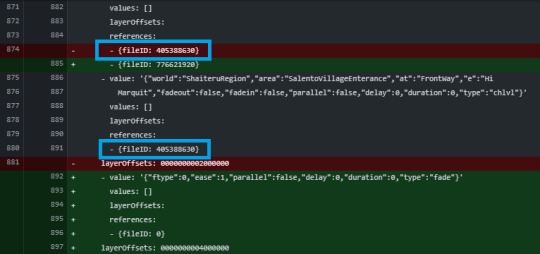
As a result, Unity Serializer brought the data of the newly added element as it was before the data was added, so that the data entering the center target was getting the value of the reference event above it.
(I've only modified and checked it now, but as you can see, the data in the place change event was intact as well.)
Because this is not the desired behavior, we used the ClearArray() method of SerializedProperty for the newly added data.

The text of my devlog is really the longest devlog in a while!
I want to thank you for reading so far...
I'll continue to do this next week.
As mentioned at the outset, future devlog will be written ahead of time after work, which is likely to increase the amount of development journals in each state.
When I'm done with the event system and the editor, I want to start by laying out the decorations in the room and making progress.
Until then, see you in next week!
1 note
·
View note