#json rest api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Exposing your API in Drupal
API’s can be great when you want your website to communicate with other third-party sites/apps to give or request any kind of data. Learn how you can expose APIs in Drupal 10 in this brief tutorial.

0 notes
Text
Tugas Rest API
kerjakan soal-soal dibawah ini dalam bentuk deskriptif Mengapa kita perlu mempelajari Rest API? Apakah API dan Rest API itu? jelaskan dan cara kerjanya, boleh membuat alur berbentuk bagan? komponen Web API apa saja dan Bagaimana arsitektur Rest API? Apa saja yang dikelola oleh Rest API sehingga menghasilkan output atau titik akhir? Apa berbedaan antara SOAP dan REST API? Apa dan bagaimana…

View On WordPress
0 notes
Text
Unlocking the Power of WP REST API: A Comprehensive Guide
Why Should You Use the WP REST API? The WP REST API is a powerful tool that allows you to interact with your WordPress site’s data and functionality using the JSON format. Whether you’re a developer, designer, or site owner, understanding and utilizing the capabilities of the WP REST API can greatly enhance your WordPress experience. Here are some key reasons why you should consider using the WP…
#API Integration#development#JSON#plugins#REST API#website development#WordPress#WordPress Development#WordPress REST API
0 notes
Text
Boost Productivity with Databricks CLI: A Comprehensive Guide
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type.
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type. The best part? Windows users can join in on the exhilarating journey and install the new CLI with Homebrew, just like macOS and Linux users. This blog aims to provide comprehensive…

View On WordPress
#API#Authentication#Azure Databricks#Azure Databricks Cluster#Azure SQL Database#Cluster#Command prompt#data#Data Analytics#data engineering#Data management#Database#Databricks#Databricks CLI#Databricks CLI commands#Homebrew#JSON#Linux#MacOS#REST API#SQL#SQL database#Windows
0 notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
This Week in Rust 533
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
crates.io: API status code changes
Foundation
Google Contributes $1M to Rust Foundation to Support C++/Rust "Interop Initiative"
Project/Tooling Updates
Announcing the Tauri v2 Beta Release
Polars — Why we have rewritten the string data type
rust-analyzer changelog #219
Ratatui 0.26.0 - a Rust library for cooking up terminal user interfaces
Observations/Thoughts
Will it block?
Embedded Rust in Production ..?
Let futures be futures
Compiling Rust is testing
Rust web frameworks have subpar error reporting
[video] Proving Performance - FOSDEM 2024 - Rust Dev Room
[video] Stefan Baumgartner - Trials, Traits, and Tribulations
[video] Rainer Stropek - Memory Management in Rust
[video] Shachar Langbeheim - Async & FFI - not exactly a love story
[video] Massimiliano Mantione - Object Oriented Programming, and Rust
[audio] Unlocking Rust's power through mentorship and knowledge spreading, with Tim McNamara
[audio] Asciinema with Marcin Kulik
Non-Affine Types, ManuallyDrop and Invariant Lifetimes in Rust - Part One
Nine Rules for Accessing Cloud Files from Your Rust Code: Practical lessons from upgrading Bed-Reader, a bioinformatics library
Rust Walkthroughs
AsyncWrite and a Tale of Four Implementations
Garbage Collection Without Unsafe Code
Fragment specifiers in Rust Macros
Writing a REST API in Rust
[video] Traits and operators
Write a simple netcat client and server in Rust
Miscellaneous
RustFest 2024 Announcement
Preprocessing trillions of tokens with Rust (case study)
All EuroRust 2023 talks ordered by the view count
Crate of the Week
This week's crate is embedded-cli-rs, a library that makes it easy to create CLIs on embedded devices.
Thanks to Sviatoslav Kokurin for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fluvio - Build a new python wrapping for the fluvio client crate
Fluvio - MQTT Connector: Prefix auto generated Client ID to prevent connection drops
Ockam - Implement events in SqlxDatabase
Ockam - Output for both ockam project ticket and ockam project enroll is improved, with support for --output json
Ockam - Output for ockam project ticket is improved and information is not opaque
Hyperswitch - [FEATURE]: Setup code coverage for local tests & CI
Hyperswitch - [FEATURE]: Have get_required_value to use ValidationError in OptionExt
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
RustNL 2024 CFP closes 2024-02-19 | Delft, The Netherlands | Event date: 2024-05-07 & 2024-05-08
NDC Techtown CFP closes 2024-04-14 | Kongsberg, Norway | Event date: 2024-09-09 to 2024-09-12
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
309 pull requests were merged in the last week
add avx512fp16 to x86 target features
riscv only supports split_debuginfo=off for now
target: default to the medium code model on LoongArch targets
#![feature(inline_const_pat)] is no longer incomplete
actually abort in -Zpanic-abort-tests
add missing potential_query_instability for keys and values in hashmap
avoid ICE when is_val_statically_known is not of a supported type
be more careful about interpreting a label/lifetime as a mistyped char literal
check RUST_BOOTSTRAP_CONFIG in profile_user_dist test
correctly check never_type feature gating
coverage: improve handling of function/closure spans
coverage: use normal edition: headers in coverage tests
deduplicate more sized errors on call exprs
pattern_analysis: Gracefully abort on type incompatibility
pattern_analysis: cleanup manual impls
pattern_analysis: cleanup the contexts
fix BufReader unsoundness by adding a check in default_read_buf
fix ICE on field access on a tainted type after const-eval failure
hir: refactor getters for owner nodes
hir: remove the generic type parameter from MaybeOwned
improve the diagnostics for unused generic parameters
introduce support for async bound modifier on Fn* traits
make matching on NaN a hard error, and remove the rest of illegal_floating_point_literal_pattern
make the coroutine def id of an async closure the child of the closure def id
miscellaneous diagnostics cleanups
move UI issue tests to subdirectories
move predicate, region, and const stuff into their own modules in middle
never patterns: It is correct to lower ! to _
normalize region obligation in lexical region resolution with next-gen solver
only suggest removal of as_* and to_ conversion methods on E0308
provide more context on derived obligation error primary label
suggest changing type to const parameters if we encounter a type in the trait bound position
suppress unhelpful diagnostics for unresolved top level attributes
miri: normalize struct tail in ABI compat check
miri: moving out sched_getaffinity interception from linux'shim, FreeBSD su…
miri: switch over to rustc's tracing crate instead of using our own log crate
revert unsound libcore changes
fix some Arc allocator leaks
use <T, U> for array/slice equality impls
improve io::Read::read_buf_exact error case
reject infinitely-sized reads from io::Repeat
thread_local::register_dtor fix proposal for FreeBSD
add LocalWaker and ContextBuilder types to core, and LocalWake trait to alloc
codegen_gcc: improve iterator for files suppression
cargo: Don't panic on empty spans
cargo: Improve map/sequence error message
cargo: apply -Zpanic-abort-tests to doctests too
cargo: don't print rustdoc command lines on failure by default
cargo: stabilize lockfile v4
cargo: fix markdown line break in cargo-add
cargo: use spec id instead of name to match package
rustdoc: fix footnote handling
rustdoc: correctly handle attribute merge if this is a glob reexport
rustdoc: prevent JS injection from localStorage
rustdoc: trait.impl, type.impl: sort impls to make it not depend on serialization order
clippy: redundant_locals: take by-value closure captures into account
clippy: new lint: manual_c_str_literals
clippy: add lint_groups_priority lint
clippy: add new lint: ref_as_ptr
clippy: add configuration for wildcard_imports to ignore certain imports
clippy: avoid deleting labeled blocks
clippy: fixed FP in unused_io_amount for Ok(lit), unrachable! and unwrap de…
rust-analyzer: "Normalize import" assist and utilities for normalizing use trees
rust-analyzer: enable excluding refs search results in test
rust-analyzer: support for GOTO def from inside files included with include! macro
rust-analyzer: emit parser error for missing argument list
rust-analyzer: swap Subtree::token_trees from Vec to boxed slice
Rust Compiler Performance Triage
Rust's CI was down most of the week, leading to a much smaller collection of commits than usual. Results are mostly neutral for the week.
Triage done by @simulacrum. Revision range: 5c9c3c78..0984bec
0 Regressions, 2 Improvements, 1 Mixed; 1 of them in rollups 17 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider principal trait ref's auto-trait super-traits in dyn upcasting
[disposition: merge] remove sub_relations from the InferCtxt
[disposition: merge] Optimize away poison guards when std is built with panic=abort
[disposition: merge] Check normalized call signature for WF in mir typeck
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
Nested function scoped type parameters
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2024-02-07 - 2024-03-06 🦀
Virtual
2024-02-07 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh - How Rust Saved My Eyes
2024-02-08 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-02-08 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-02-10 | Virtual (Krakow, PL) | Stacja IT Kraków
Rust – budowanie narzędzi działających w linii komend
2024-02-10 | Virtual (Wrocław, PL) | Stacja IT Wrocław
Rust – budowanie narzędzi działających w linii komend
2024-02-13 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-02-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack n Learn | Mirror: Rust Hack n Learn
2024-02-15 | Virtual + In person (Praha, CZ) | Rust Czech Republic
Introduction and Rust in production
2024-02-19 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-20 | Virtual | Rust for Lunch
Lunch
2024-02-21 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 2 - Types
2024-02-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-02-22 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
Asia
2024-02-10 | Hyderabad, IN | Rust Language Hyderabad
Rust Language Develope BootCamp
Europe
2024-02-07 | Cologne, DE | Rust Cologne
Embedded Abstractions | Event page
2024-02-07 | London, UK | Rust London User Group
Rust for the Web — Mainmatter x Shuttle Takeover
2024-02-08 | Bern, CH | Rust Bern
Rust Bern Meetup #1 2024 🦀
2024-02-08 | Oslo, NO | Rust Oslo
Rust-based banter
2024-02-13 | Trondheim, NO | Rust Trondheim
Building Games with Rust: Dive into the Bevy Framework
2024-02-15 | Praha, CZ - Virtual + In-person | Rust Czech Republic
Introduction and Rust in production
2024-02-21 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #8
2024-02-22 | Aarhus, DK | Rust Aarhus
Rust and Talk at Partisia
North America
2024-02-07 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Feb 7
2024-02-08 | Lehi, UT, US | Utah Rust
BEAST: Recreating a classic DOS terminal game in Rust
2024-02-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust: Open Source Contrib Hackathon & Happy Hour
2024-02-13 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer
2024-02-13 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-02-15 | Boston, MA, US | Boston Rust Meetup
Back Bay Rust Lunch, Feb 15
2024-02-15 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-02-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-02-22 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-02-28 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-02-19 | Melbourne, VIC, AU + Virtual | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-27 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2024-02-27 | Sydney, NSW, AU | Rust Sydney
🦀 spire ⚡ & Quick
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
My take on this is that you cannot use async Rust correctly and fluently without understanding Arc, Mutex, the mutability of variables/references, and how async and await syntax compiles in the end. Rust forces you to understand how and why things are the way they are. It gives you minimal abstraction to do things that could’ve been tedious to do yourself.
I got a chance to work on two projects that drastically forced me to understand how async/await works. The first one is to transform a library that is completely sync and only requires a sync trait to talk to the outside service. This all sounds fine, right? Well, this becomes a problem when we try to port it into browsers. The browser is single-threaded and cannot block the JavaScript runtime at all! It is arguably the most weird environment for Rust users. It is simply impossible to rewrite the whole library, as it has already been shipped to production on other platforms.
What we did instead was rewrite the network part using async syntax, but using our own generator. The idea is simple: the generator produces a future when called, and the produced future can be awaited. But! The produced future contains an arc pointer to the generator. That means we can feed the generator the value we are waiting for, then the caller who holds the reference to the generator can feed the result back to the function and resume it. For the browser, we use the native browser API to derive the network communications; for other platforms, we just use regular blocking network calls. The external interface remains unchanged for other platforms.
Honestly, I don’t think any other language out there could possibly do this. Maybe C or C++, but which will never have the same development speed and developer experience.
I believe people have already mentioned it, but the current asynchronous model of Rust is the most reasonable choice. It does create pain for developers, but on the other hand, there is no better asynchronous model for Embedded or WebAssembly.
– /u/Top_Outlandishness78 on /r/rust
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
You can learn NodeJS easily, Here's all you need:
1.Introduction to Node.js
• JavaScript Runtime for Server-Side Development
• Non-Blocking I/0
2.Setting Up Node.js
• Installing Node.js and NPM
• Package.json Configuration
• Node Version Manager (NVM)
3.Node.js Modules
• CommonJS Modules (require, module.exports)
• ES6 Modules (import, export)
• Built-in Modules (e.g., fs, http, events)
4.Core Concepts
• Event Loop
• Callbacks and Asynchronous Programming
• Streams and Buffers
5.Core Modules
• fs (File Svstem)
• http and https (HTTP Modules)
• events (Event Emitter)
• util (Utilities)
• os (Operating System)
• path (Path Module)
6.NPM (Node Package Manager)
• Installing Packages
• Creating and Managing package.json
• Semantic Versioning
• NPM Scripts
7.Asynchronous Programming in Node.js
• Callbacks
• Promises
• Async/Await
• Error-First Callbacks
8.Express.js Framework
• Routing
• Middleware
• Templating Engines (Pug, EJS)
• RESTful APIs
• Error Handling Middleware
9.Working with Databases
• Connecting to Databases (MongoDB, MySQL)
• Mongoose (for MongoDB)
• Sequelize (for MySQL)
• Database Migrations and Seeders
10.Authentication and Authorization
• JSON Web Tokens (JWT)
• Passport.js Middleware
• OAuth and OAuth2
11.Security
• Helmet.js (Security Middleware)
• Input Validation and Sanitization
• Secure Headers
• Cross-Origin Resource Sharing (CORS)
12.Testing and Debugging
• Unit Testing (Mocha, Chai)
• Debugging Tools (Node Inspector)
• Load Testing (Artillery, Apache Bench)
13.API Documentation
• Swagger
• API Blueprint
• Postman Documentation
14.Real-Time Applications
• WebSockets (Socket.io)
• Server-Sent Events (SSE)
• WebRTC for Video Calls
15.Performance Optimization
• Caching Strategies (in-memory, Redis)
• Load Balancing (Nginx, HAProxy)
• Profiling and Optimization Tools (Node Clinic, New Relic)
16.Deployment and Hosting
• Deploying Node.js Apps (PM2, Forever)
• Hosting Platforms (AWS, Heroku, DigitalOcean)
• Continuous Integration and Deployment-(Jenkins, Travis CI)
17.RESTful API Design
• Best Practices
• API Versioning
• HATEOAS (Hypermedia as the Engine-of Application State)
18.Middleware and Custom Modules
• Creating Custom Middleware
• Organizing Code into Modules
• Publish and Use Private NPM Packages
19.Logging
• Winston Logger
• Morgan Middleware
• Log Rotation Strategies
20.Streaming and Buffers
• Readable and Writable Streams
• Buffers
• Transform Streams
21.Error Handling and Monitoring
• Sentry and Error Tracking
• Health Checks and Monitoring Endpoints
22.Microservices Architecture
• Principles of Microservices
• Communication Patterns (REST, gRPC)
• Service Discovery and Load Balancing in Microservices
1 note
·
View note
Text
Best API of Horse Racing for Betting Platforms: Live Odds, Data Feeds & Profits Unlocked

Discover the most accurate and profitable API of horse racing with live odds, betting data feeds, and fast integration. Ideal for UK/USA markets and fantasy apps.
Introduction: Why Accurate Horse Racing APIs Matter in 2025
In the competitive world of sports betting and fantasy gaming, milliseconds and margins matter. When it comes to horse racing, success hinges on real-time, trustworthy data and sharp odds. Whether you run a betting exchange, fantasy app, or affiliate site, using the right horse racing API can mean the difference between profit and failure.
The API of horse racing offered by fantasygameprovider.com is engineered to meet this demand—providing live horse racing odds, race entries, results, and predictive analytics that align perfectly with the betting industry’s needs.
What Is a Horse Racing API?
A horse racing API is a service that delivers structured, real-time horse racing data to apps, websites, and betting platforms. This includes:
Live race updates
Racecard entries & scratchings
Odds feed (fixed & fluctuating)
Final results with payout info
Jockey, trainer, and form data
These are typically delivered in JSON or XML formats, allowing seamless integration with sportsbooks, exchanges, or fantasy game engines.
📊 Who Needs Horse Racing APIs?
Audience
Use Case
Betting Sites
Deliver live odds, matchups, and payouts.
Fantasy Sports Platforms
Use live feeds to auto-update scores & leaderboards.
Betting Tipsters/Affiliates
Showcase predictive models based on fresh data.
Mobile Apps
Enable live race streaming with betting APIs.
Trading Bots
Automate wagers with low-latency horse racing data.
Why Choose FantasyGameProvider’s Horse Racing API?

Unlike basic feeds, our API is tailored for commercial use. Here's why it stands out:
Feature
FantasyGameProvider
Other APIs
Live Odds Feed
✅ Updated in <2s
⚠️ 5–15s delay
Global Racing
✅ UK, USA, AUS, HK
⚠️ Limited coverage
Data Format
✅ JSON + XML
⚠️ JSON only
Accuracy
✅ Enterprise-Grade (99.9%)
⚠️ Variable
Predictive Insights
✅ AI-Driven Models
❌ Not Included
Betting Integration
✅ Easy with Betfair, SBTech
⚠️ Manual setup required
Our horse racing odds API not only mirrors UK and USA live betting markets, but also lets you build automated bet triggers and smart notifications for sharp edge betting.
💸 How Betting Businesses Profit with Horse Racing APIs
If you're running a betting website or fantasy sports app, here's how the API of horse racing can boost your ROI:
Real-time updates = More active users
Faster odds delivery = Better arbitrage potential
Accurate results = Fewer payout disputes
Live data = Higher session times (ideal for monetizing with ads)
Custom alerts = VIP features for paid subscribers
Fantasygameprovider.com also allows white-label API integration to match your brand.
How to Choose the Right Horse Racing API – Checklist ✅
Make sure your API includes the following:
✅ Live odds feed with fast refresh rate (sub-2 seconds ideal)
✅ Coverage of all major race tracks (UK, USA, AUS)
✅ Reliable JSON & XML format
✅ Built-in historical data & form guide
✅ Scalable architecture for high traffic
✅ Supports Betfair, Oddschecker, and other exchanges
✅ Licensed data provider
Our API meets all these criteria and goes further by offering automated betting signals and predictive race modeling—key for next-gen apps.
Betfair API vs FantasyGameProvider: Which Is Better?
Feature
Betfair API
FantasyGameProvider
Odds Feed
Excellent (exchange-based)
Excellent (market + exchange)
Historical Data
Partial
Full form + performance stats
Developer Simplicity
Moderate
Plug-and-play REST endpoints
Support
Community-based
24/7 Support
Customization
Limited
High (webhooks, triggers, filters)
Pricing
Tiered
Affordable & negotiable plans
Conclusion: If you want full access to live odds, race data, and fast integration without the steep learning curve, fantasygameprovider.com offers better developer flexibility and betting UX.
Data Feeds You Get with Our Horse Racing API

Racecards & scratchings feed
Real-time results feed
Odds feed (fixed, fluctuating, exchange-compatible)
Form & stats feed
Track conditions feed
Horse/jockey/trainer history feed
Automated alerts for betting patterns
Formats available: JSON horse racing data & horse racing XML feed.
FAQs: Betting-Focused Horse Racing API Questions
Q1. Which is the most accurate horse racing API in 2025?
FantasyGameProvider offers 99.9% accuracy with sub-2-second update latency, ideal for professional and retail bettors alike.
Q2. Can I use this API for UK and USA horse racing?
Yes, our UK racing odds data and USA racing API are both available with full schedule and live result support.
Q3. Is your horse racing API suitable for Betfair automation?
Absolutely. Many of our clients use it to build Betfair trading bots using our odds feed and predictive race data.
Q4. Do you offer free trials or sandbox testing?
Yes. Developers can access a sandbox environment to test endpoints before committing.
Q5. What’s the difference between JSON and XML feeds?
JSON is faster and easier to integrate, while XML is preferred for legacy systems. We offer both to suit all tech stacks.
🚀 Start Winning with the Best API of Horse Racing
If you’re serious about building a winning betting platform, profitable tipster site, or a fantasy sports engine, you need the most accurate and commercial-ready API in the industry.
At fantasygameprovider.com, we give you everything:
✅ Live odds ✅ Fast results ✅ Race cards ✅ Predictive models ✅ Betfair compatibility ✅ Global reach (UK, USA, AUS, more)
👉 Ready to dominate the betting space with live horse racing data? Visit fantasygameprovider.com and request your API demo today.
#live cricket odds api#sports betting#betting#bettingapi#fantasygameprovider#Live odds#API of Horse Racing#UK racing odds data#Betfair#Real-time results feed#Betfair API
0 notes
Text
The Future of Crypto APIs: Why Token Metrics Leads the Pack
In this article, we’ll explore why Token Metrics is the future of crypto APIs, and how it delivers unmatched value for developers, traders, and product teams.
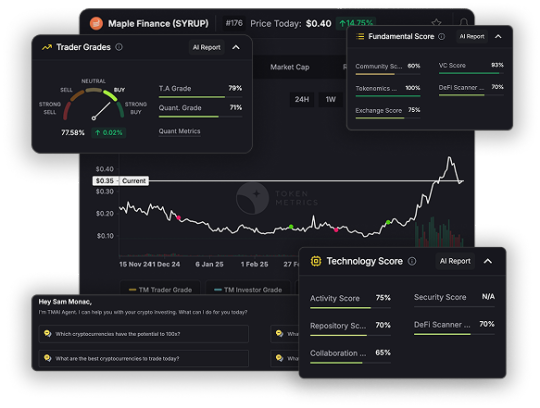
More Than Just Market Data
Most crypto APIs—like CoinGecko, CoinMarketCap, or even exchange-native endpoints—only give you surface-level data: prices, volume, market cap, maybe order book depth crypto trading. That’s helpful… but not enough.
Token Metrics goes deeper:
Trader and Investor Grades (0–100)
Bullish/Bearish market signals
Support/Resistance levels
Real-time sentiment scoring
Sector-based token classification (AI, RWA, Memes, DeFi)
Instead of providing data you have to interpret, it gives you decisions you can act on.
⚡ Instant Intelligence, No Quant Team Required
For most platforms, building actionable insights on top of raw market data requires:
A team of data scientists
Complex modeling infrastructure
Weeks (if not months) of development
With Token Metrics, you skip all of that. You get:
Pre-computed scores and signals
Optimized endpoints for bots, dashboards, and apps
AI-generated insights as JSON responses
Even a solo developer can build powerful trading systems without ever writing a prediction model.
🔄 Real-Time Signals That Evolve With the Market
Crypto moves fast. One minute a token is mooning, the next it’s bleeding.
Token Metrics API offers:
Daily recalculated grades
Real-time trend flips (bullish ↔ bearish)
Sentiment shifts based on news, social, and on-chain data
You’re never working with stale data or lagging indicators.
🧩 Built for Integration, Built for Speed
Unlike many APIs that are bloated or poorly documented, Token Metrics is built for builders.
Highlights:
Simple REST architecture (GET endpoints, API key auth)
Works with Python, JavaScript, Go, etc.
Fast JSON responses for live dashboards
5,000-call free tier to start building instantly
Enterprise scale for large data needs
Whether you're creating a Telegram bot, a DeFi research terminal, or an internal quant dashboard, TM API fits right in.
🎯 Use Cases That Actually Matter
Token Metrics API powers:
Signal-based alert systems
Narrative-tracking dashboards
Token portfolio health scanners
Sector rotation tools
On-chain wallets with smart overlays
Crypto AI assistants (RAG, GPT, LangChain agents)
It’s not just a backend feed. It’s the core logic engine for intelligent crypto products.
📈 Proven Performance
Top funds, trading bots, and research apps already rely on Token Metrics API. The AI grades are backtested, the signals are verified, and the ecosystem is growing.
“We plugged TM’s grades into our entry logic and saw a 25% improvement in win rates.” — Quant Bot Developer
“It’s like plugging ChatGPT into our portfolio tools—suddenly it makes decisions.” — Web3 Product Manager
🔐 Secure, Stable, and Scalable
Uptime and reliability matter. Token Metrics delivers:
99.9% uptime
Low-latency endpoints
Strict rate limiting for abuse prevention
Scalable plans with premium SLAs
No surprises. Just clean, trusted data every time you call.
💬 Final Thoughts
Token Metrics isn’t just the best crypto API because it has more data. It’s the best because it delivers intelligence. It replaces complexity with clarity, raw numbers with real signals, and guesswork with action.In an industry that punishes delay and indecision, Token Metrics gives builders and traders the edge they need—faster, smarter, and more efficiently than any other API in crypto.
0 notes
Text
Viability of Designer Brands Dropshipping in 2025
Designer brand dropshipping continues to thrive as a popular and viable business model in the evolving e-commerce landscape. This approach offers numerous advantages, making it an attractive option for both new and seasoned entrepreneurs looking to tap into the luxury market.
Luxury Distribution, a cutting-age designer brands dropshipping solutions remains a lucrative business model in 2025. By leveraging the benefits and navigating the challenges, entrepreneurs can successfully establish their presence in the luxury market. With tools like Luxury Distribution, scaling your dropshipping business will be easier.

Advantages of Designer Brand Dropshipping
Low Initial Investment
One of the primary benefits of dropshipping is the low initial investment. Unlike traditional retail models, entrepreneurs do not need to purchase inventory upfront. This significantly reduces financial barriers, allowing individuals to start their businesses with minimal capital.
No Inventory Management
In the dropshipping model, suppliers handle warehousing, packing, and shipping logistics. This reduces the burden of inventory management, enabling entrepreneurs to focus on marketing and customer acquisition rather than managing stock levels and fulfillment processes.
High Profit Margins
Designer brands often come with higher profit margins compared to mass-market products. This potential for significant profits is particularly appealing for dropshippers, who can capitalize on the prestige associated with well-known brands.
Flexibility and Scalability
Dropshipping provides a flexible business model that allows entrepreneurs to operate from anywhere. As demand grows, businesses can easily scale their operations without the constraints of managing physical inventory. This adaptability is crucial in today’s fast-paced e-commerce scenario.
Leveraging Brand Recognition
By selling established designer brands, entrepreneurs can take advantage of the brand’s reputation and customer loyalty. This recognition can facilitate quicker sales and build trust with potential customers, making it easier to enter competitive markets.
Reduced Risk possibility
The dropshipping model minimizes financial risk since inventory is not purchased in advance. This allows entrepreneurs to test various products and niches without the fear of unsold stock, making it a safer investment strategy.
Why Choose Luxury Distribution?
To scale your presence and streamline sales, consider exploring designer brands dropshipping with Luxury Distribution. This platform offers essential tools to showcase high-end products on popular e-commerce platforms like Shopify and WooCommerce.
Seamless Integrations - Luxury Distribution allows for effortless connections to top e-commerce platforms, providing full API support to keep your store synchronized and efficient.
Flexible Dropshipping Services - Adapting to consumer expectations is crucial. It offers a scalable dropshipping solution that works for both direct-to-consumer and third-party marketplace sales, expanding your audience without additional logistical burdens.
User-Friendly B2B Experience - The Live B2B Catalog is designed for small retailers, boutique stylists, and influencer-led shops. With no minimum orders and real-time availability, browsing is intuitive and efficient.
Integration Methods – It provides multiple integration methods, including REST API, XLSX, JSON, CSV, and XML. This ensures a smooth integration process tailored to your specific needs.
#designerdropshipping#luxurybrandreseller#dropshipdesignergoods#highenddropshipping#brandedfashiondropship#designerlabelstore#luxuryfashiononline#dropshipluxurybrands
0 notes
Text
How can you serialize and deserialize Java objects for frontend-backend communication?

1. What’s Java Serialization and Deserialization All About?
So, how do you handle communication between the frontend and backend in Java? It’s all about turning Java objects into a byte stream (that’s serialization) and then back into objects (deserialization). This makes it easy to exchange data between different parts of your app. The Serializable interface in Java is key for this, as it helps keep the state of objects intact. If you’re taking a Java course in Coimbatore, you’ll get to work on this a lot. Serialization is super important for things like APIs and managing sessions. For Java backend developers, it's a must-know.
2. Why Is Serialization Important Nowadays?
When it comes to Java and modern web apps, we often use JSON or XML for serialized data. Libraries like Jackson and Gson make it easy to convert Java objects to JSON and vice versa. These formats are great for frontend and make communication smoother. If you study Java in Coimbatore, you'll learn how serialization fits into REST APIs. Good serialization helps keep your app performing well and your data secure while also supporting setups like microservices.
3. What’s the Serializable Interface?
The Serializable interface is a simple marker in Java telling the system which objects can be serialized. If you get this concept down, it really helps answer how to serialize and deserialize Java objects for frontend-backend communication. By using this interface, you can easily save and send Java objects. Students in a Java Full Stack Developer Course in Coimbatore learn how to manage complex object structures and deal with transient variables to keep things secure and fast.
4. Tools and Libraries for Serialization in Java
To serialize objects well, developers often rely on libraries like Jackson and Gson, along with Java’s ObjectOutputStream. These are essential when you’re trying to serialize Java objects for frontend-backend communication. With these tools, turning Java objects into JSON or XML is a breeze. In Java courses in Coimbatore, learners work with these tools on real projects, and they offer options for customizing how data is serialized and handling errors more smoothly.
5. Deserialization and Keeping Things Secure
Deserialization is about getting objects back from a byte stream, but you've got to do this carefully. To serialize and deserialize Java objects safely, you need to check the source and structure of incoming data. Training in Coimbatore covers secure deserialization practices so you can avoid issues like remote code execution. Sticking to trusted libraries and validating input helps keep your app safe from attacks.
6. Syncing Frontend and Backend
Getting the frontend and backend in sync relies heavily on good serialization methods. For instance, if the Java backend sends data as JSON, the frontend—often built with React or Angular—needs to handle it right. This is a key part of learning how to serialize and deserialize Java objects for frontend-backend communication. In Java Full Stack Developer Courses in Coimbatore, students work on apps that require this skill.
7. Dealing with Complex Objects and Nested Data
A big challenge is when you have to serialize complex or nested objects. When figuring out how to serialize and deserialize Java objects for frontend-backend communication, you need to manage object references and cycles well. Libraries like Jackson can help flatten or deeply serialize data structures. Courses in Coimbatore focus on real-world data models to give you practical experience.
8. Making Serialization Efficient
Efficient serialization cuts down on network delays and boosts app performance. Students in Java training in Coimbatore learn how to make serialization better by skipping unnecessary fields and using binary formats like Protocol Buffers. Balancing speed, readability, and security is the key to good serialization.
9. Real-Life Examples of Java Serialization
Things like login sessions, chat apps, and shopping carts all depend on serialized objects. To really understand how to serialize and deserialize Java objects for frontend-backend communication, you need to know about the real-time data demands. In a Java Full Stack Developer Course in Coimbatore, you’ll get to simulate these kinds of projects for hands-on experience.
10. Wrapping It Up: Getting Good at Serialization
So how should you go about learning how to serialize and deserialize Java objects? The right training, practice, and tools matter. Knowing how to map objects and secure deserialized data is crucial for full-stack devs. If you're keen to master these skills, check out a Java course or a Java Full Stack Developer Course in Coimbatore. With practical training and real projects, Xplore IT Corp can set you on the right path for a career in backend development.
FAQs
1. What’s Java serialization for?
Serialization is for turning objects into a byte stream so they can be stored, shared, or cached.
2. What are the risks with deserialization?
If deserialization is done incorrectly, it can lead to vulnerabilities like remote code execution.
3. Can every Java object be serialized?
Only objects that implement the Serializable interface can be serialized. Certain objects, like threads or sockets, can’t be.
4. Why use JSON for communication between frontend and backend?
JSON is lightweight, easy to read, and can be easily used with JavaScript, making it perfect for web apps.
5. Which course helps with Java serialization skills?
The Java Full Stack Developer Course in Coimbatore at Xplore IT Corp offers great training on serialization and backend integration.
#Java programming#Object-oriented language#Java Virtual Machine (JVM)#Java Development Kit (JDK)#Java Runtime Environment (JRE)#Core Java#Advanced Java#Java frameworks#Spring Boot#Java APIs#Java syntax#Java libraries#Java multithreading#Exception handling in Java#Java for web development#Java IDE (e.g.#Eclipse#IntelliJ)#Java classes and objects
0 notes
Text
Learn Everything with a MERN Full Stack Course – The Future of Web Development

The internet is evolving, and so is the demand for talented developers who can build fast, interactive, and scalable applications. If you're someone looking to make a successful career in web development, then learning the mern stack is a smart choice. A mern full stack course is your complete guide to mastering both the frontend and backend aspects of modern web applications.
In this blog, we’ll cover what the MERN stack is, what you learn in a MERN full stack course, and why it is one of the best investments you can make for your career today.
What is the MERN Stack?
MERN stands for:
MongoDB – A flexible NoSQL database that stores data in JSON-like format.
Express.js – A web application framework for Node.js, used to build backend services and APIs.
React.js – A powerful frontend JavaScript library developed by Facebook for building user interfaces.
Node.js – A JavaScript runtime that allows developers to run JavaScript on the server side.
These four technologies together form a powerful tech stack that allows you to build everything from single-page websites to complex enterprise-level applications.
Why Take a MERN Full Stack Course?
In a world full of frameworks and languages, the MERN stack offers a unified development experience because everything is built on JavaScript. Here’s why a MERN Full Stack Course is valuable:
1. All-in-One Learning Package
A MERN full stack course teaches both frontend and backend development, which means you won’t need to take separate courses for different parts of web development.
You’ll learn:
React for building interactive UI components
Node and Express for server-side programming
MongoDB for managing the database
2. High Salary Packages
Full stack developers with MERN expertise are highly paid in both startups and MNCs. According to market research, the average salary of a MERN stack developer in India ranges between ₹6 LPA to ₹15 LPA, depending on experience.
3. Multiple Career Opportunities
After completing a MERN full stack course, you can work in various roles such as:
Full Stack Developer
Frontend Developer (React)
Backend Developer (Node & Express)
JavaScript Developer
Freelance Web Developer
What’s Included in a MERN Full Stack Course?
A professional MERN course will cover all major tools, concepts, and real-world projects. Here's a breakdown of typical modules:
Frontend Development:
HTML5, CSS3, Bootstrap
JavaScript & ES6+
React.js with Hooks, State, Props, and Routing
Redux for state management
Backend Development:
Node.js fundamentals
Express.js for server creation
RESTful APIs and middleware
JWT Authentication and security
Database Management:
MongoDB queries and models
Mongoose ORM
Data validation and schema design
DevOps & Deployment:
Using Git and GitHub
Deploying on Heroku, Vercel, or Netlify
Environment variables and production-ready builds
Capstone Projects:
E-commerce Website
Job Portal
Chat App
Blog CMS
These projects help students understand real-world workflows and strengthen their portfolios.
Who Should Join a MERN Full Stack Course?
This course is suitable for:
College students looking for skill development
Job seekers who want to start a tech career
Working professionals who wish to switch careers
Freelancers who want to offer web development services
Entrepreneurs who want to build their own web apps
Certificate and Placement Support
Many institutes offering mern full stack courses provide completion certificates and placement assistance. This not only adds value to your resume but also helps you get your first job faster.
Some courses also include an internship program, giving you industry exposure and hands-on experience with live projects.
Final Words
The demand for MERN stack developers is growing every year, and companies are constantly hiring professionals who understand how to build full-stack applications. A mern full stack courses is the perfect way to gain these skills in a structured and effective manner.
Whether you want to get a job, work as a freelancer, or build your own startup – the MERN stack will empower you to do it all.
0 notes
Text
Developer-Centric KYC API with Full Documentation
SprintVerify provides developers with everything they need to integrate KYC smoothly—REST APIs, test credentials, sample payloads, response structures, error logs, and retry logic. With simple JSON-based calls and scalable endpoints, your dev team can get started immediately and go live faster, reducing engineering overhead by weeks.
0 notes
Text
Expanding Career Opportunities in Software Development
The tech industry is rapidly evolving, creating high demand for professionals skilled in both frontend and backend development. Roles such as PHP Developer, Full Stack Developer, and Backend Developer are especially sought after for their ability to build scalable, secure, and high-performing applications Coding Bit. Developers are expected to work with programming languages like PHP, JavaScript, and Python, and utilize frameworks such as Laravel, React.js, and Node.js. A typical development stack includes working with RESTful APIs, managing SQL or NoSQL databases (like MySQL, MongoDB), and using Git for version control. Knowledge of HTML5, CSS3, and JavaScript ES6 is essential for frontend development, while backend tasks often involve writing server-side logic, handling JSON data, and securing endpoints using JWT authentication. Familiarity with CI/CD pipelines (e.g., GitHub Actions, Jenkins), Docker containers, and automated testing tools like PHP Unit or Postman can significantly enhance a developer’s productivity and employability. As companies prioritize robust, testable, and maintainable code, developers who understand both software construction and software testing fundamentals are more competitive in the Coding Bit.
Full Stack PHP Developer
Combines frontend and backend skills using PHP for server-side logic and JavaScript, HTML, and CSS for UI/UX.
Works with frameworks like Laravel, Symfony, or CodeIgniter.
May handle API integration, database design (MySQL/PostgreSQL), and deployment using tools like Docker or Git. Email Address: [email protected]

#SoftwareDeveloper#WebDeveloper#FullStackDeveloper#BackendDeveloper#PHPDeveloper#TechJobs#CareerInTech#RemoteTechJobs
0 notes